postgresql 配置文件详解
 如果要查看配置文件(postgresql.conf)中的一些选项,则可以登录psql后使用命令来查看
如果要查看配置文件(postgresql.conf)中的一些选项,则可以登录psql后使用命令来查看show 选项名;
show all; #查看所有数据库参数的值
主要选项:
| 选项 | 默认值 | 说明 | 是否优化 | 原因 |
| max_connections | 100 | 允许客户端的最大并发连接数目 | 否 | 因为在测试的过程中,100个连接已经足够 |
| fsync | on | 强制把数据同步更新到磁盘 | 是 | 因为系统的IO压力很大,为了更好的测试其他配置的影响,把改参数改为off |
| shared_buffers | 24MB | 决定有多少内存可以被PostgreSQL用于缓存数据(推荐内存的1/4) | 是 | 在IO压力很大的情况下,提高该值可以减少IO |
| work_mem | 1MB | 使内部排序和一些复杂的查询都在这个buffer中完成 | 是 | 有助提高排序等操作的速度,并且减低IO |
| effective_cache_size | 128MB | 优化器假设一个查询可以用的最大内存,和shared_buffers无关(推荐内存的1/2) | 是 | 设置稍大,优化器更倾向使用索引扫描而不是顺序扫描 |
| maintenance_work_mem | 16MB | 这里定义的内存只是被VACUUM等耗费资源较多的命令调用时使用 | 是 | 把该值调大,能加快命令的执行 |
| wal_buffer | 768kB | 日志缓存区的大小 | 是 | 可以降低IO,如果遇上比较多的并发短事务,应该和commit_delay一起用 |
| checkpoint_segments | 3 | 设置wal log的最大数量数(一个log的大小为16M) | 是 | 默认的48M的缓存是一个严重的瓶颈,基本上都要设置为10以上 |
| checkpoint_completion_target | 0.5 | 表示checkpoint的完成时间要在两个checkpoint间隔时间的N%内完成 | 是 | 能降低平均写入的开销 |
| commit_delay | 0 | 事务提交后,日志写到wal log上到wal_buffer写入到磁盘的时间间隔。需要配合commit_sibling | 是 | 能够一次写入多个事务,减少IO,提高性能 |
| commit_siblings | 5 | 设置触发commit_delay的并发事务数,根据并发事务多少来配置 | 是 | 减少IO,提高性能 |
| superuser_reserved_connections | 3 | 预留给超级用户的数据库连接数目,该值必须小于max_connections。 | 是 | 减少IO,提高性能 |
一、连接配置与安全认证
1、连接Connection Settings
listen_addresses (string)
这个参数只有在启动数据库时,才能被设置。它指定数据库用来监听客户端连接的TCP/IP地址。默认是值是* ,表示数据库在启动以后将在运行数据的机器上的所有的IP地址上监听用户请求(如果机器只有一个网卡,只有一个IP地址,有多个网卡的机器有多个 IP地址)。可以写成机器的名字,也可以写成IP地址,不同的值用逗号分开,例如,’server01’, ’140.87.171.49, 140.87.171.21’。如果被设成localhost,表示数据库只能接受本地的客户端连接请求,不能接受远程的客户端连接请求。
port (integer)
这个参数只有在启动数据库时,才能被设置。它指定数据库监听户端连接的TCP端口。默认值是5432。
max_connections (integer)
这个参数只有在启动数据库时,才能被设置。它决定数据库可以同时建立的最大的客户端连接的数目。默认值是100。每个连接占用 400字节共享内存。Note: Increasing max_connections costs ~400 bytes of shared memory per connection slot, plus lock space (see max_locks_per_transaction).
superuser_reserved_connections (integer)
这个参数只有在启动数据库时,才能被设置。它表示预留给超级用户的数据库连接数目。它的值必须小于max_connections。 普通用户可以在数据库中建立的最大的并发连接的数目是max_connections 默认值是3。
unix_socket_group (string)
这个参数只有在启动数据库时,才能被设置。设置Unix-domain socket所在的操作系统用户组。默认值是空串,用启动数据库的操作系统用户所在的组作为Unix-domain socket的用户组。
unix_socket_permissions (integer)
这个参数只有在启动数据库时,才能被设置。它设置Unix-domain socket的访问权限,格式与操作系统的文件访问权限是一样的。默认值是0770,表示任何操作系统用户都能访问Unix-domain socket。可以设为0770(所有Unix-domain socket文件的所有者所在的组包含的用户都能访问)和0700(只有Unix-domain socket文件的所有者才能访问)。对于Unix-domain socket,只有写权限才有意义,读和执行权限是没有意义的。
#unix_socket_directories = '/tmp' # comma-separated list of directories(change requires restart)
#bonjour = off # advertise server via Bonjour(change requires restart)
#bonjour_name = '' # defaults to the computer name(change requires restart)
2、安全认证Security and Authentication
authentication_timeout (integer)
这个参数只能在postgresql.conf文件中被设置,它指定一个时间长度,在这个时间长度内,必须完成客户端认证操作,否则客户端连接请求将被拒绝。它可以阻止某些客户端进行认证时长时间占用数据库连接。单位是秒,默认值是60。
ssl (boolean)
这个参数只有在启动数据库时,才能被设置。决定数据库是否接受SSL连接。默认值是off。
ssl_ciphers (string)
指定可以使用的SSL加密算法。查看操作系统关于openssl的用户手册可以得到完整的加密算法列表(执行命令openssl ciphers –v也可以得到)。
#ssl_prefer_server_ciphers = on # (change requires restart)
#ssl_ecdh_curve = 'prime256v1' # (change requires restart)
#ssl_renegotiation_limit = 0 # amount of data between renegotiations
#ssl_cert_file = 'server.crt' # (change requires restart)
#ssl_key_file = 'server.key' # (change requires restart)
#ssl_ca_file = '' # (change requires restart)
#ssl_crl_file = '' # (change requires restart)
#password_encryption = on
#db_user_namespace = off
# GSSAPI using Kerberos
#krb_server_keyfile = ''
#krb_caseins_users = off
# - TCP Keepalives -
tcp_keepalives_idle (integer)
这个参数可以在任何时候被设置。默认值是0,意思是使用操作系统的默认值。它设置TCP套接字的TCP_KEEPIDLE属性。这个参数对于通过Unix-domain socket建立的数据库连接没有任何影响。即 间歇性发送TCP心跳包,房子连接被网络设备中断。
tcp_keepalives_interval (integer)
这个参数可以在任何时候被设置。默认值是0,意思是使用操作系统的默认值。它设置TCP套接字的TCP_KEEPINTVL属性。这个参数对于通过Unix-domain socket建立的数据库连接没有任何影响。
tcp_keepalives_count (integer)
这个参数可以在任何时候被设置。默认值是0,意思是使用操作系统的默认值。它设置TCP套接字的TCP_KEEPCNT属性。这个参数对于通过Unix-domain socket建立的数据库连接没有任何影响。
二、文件配置FILE LOCATIONS
# The default values of these variables are driven from the -D command-line
# option or PGDATA environment variable, represented here as ConfigDir.
#data_directory = 'ConfigDir' # use data in another directory(change requires restart)
#hba_file = 'ConfigDir/pg_hba.conf' # host-based authentication file(change requires restart)
#ident_file = 'ConfigDir/pg_ident.conf' # ident configuration file(change requires restart)
# If external_pid_file is not explicitly set, no extra PID file is written.
#external_pid_file = '' # write an extra PID file(change requires restart)
三、内存 Memory
shared_buffers (integer)
这个参数只有在启动数据库时,才能被设置。它表示数据缓冲区中的数据块的个数,每个数据块的大小是8KB。数据缓冲区位于数据库的共享内存中,它越大越好,不能小于128KB。默认值是128MB。
temp_buffers (integer)
这个参数可以在任何时候被设置。默认值是8MB。它决定存放临时表的数据缓冲区中的数据块的个数,每个数据块的大小是8KB。临时表缓冲区存放在每个数据库进程的私有内存中,而不是存放在数据库的共享内存中。最小值800KB
max_prepared_transactions (integer)
这个参数只有在启动数据库时,才能被设置。它决定能够同时处于prepared状态的事务的最大数目(参考PREPARE TRANSACTION命令)。如果它的值被设为0。则将数据库将关闭prepared事务的特性。它的值通常应该和max_connections的值一样大。每个事务消耗600字节(b)共享内存。
work_mem (integer)
这个参数可以在任何时候被设置。它决定数据库的排序操作和哈希表使用的内存缓冲区的大小。如果work_mem指定的内存被耗尽,数据库将使用磁盘文件进行完成操作,速度会慢很多。ORDER BY、DISTINCT和merge连接会使用排序操作。哈希表在Hash连接、hash聚集函数和用哈希表来处理IN谓词中的子查询中被使用。单位是KB,默认值是4MB。
maintenance_work_mem (integer)
这个参数可以在任何时候被设置。它决定数据库的维护操作使用的内存空间的大小。数据库的维护操作包括VACUUM、CREATE INDEX和ALTER TABLE ADD FOREIGN KEY等操作。maintenance_work_mem的值如果比较大,通常可以缩短VACUUM数据库和从dump文件中恢复数据库需要的时间。maintenance_work_mem存放在每个数据库进程的私有内存中,而不是存放在数据库的共享内存中。单位是KB,默认值是64MB。
max_stack_depth (integer)
这个参数可以在任何时候被设置,但只有数据库超级用户才能修改它。它决定一个数据库进程在运行时的STACK所占的空间的最大值。数据库进程在运行时,会自动检查自己的STACK大小是否超过max_stack_depth,如果超过,会自动终止当前事务。这个值应该比操作系统设置的进程STACK的大小的上限小1MB。使用操作系统命令“ulimit –s“可以得到操作系统设置的进程STACK的最大值。单位是KB,默认值是2MB。
#huge_pages = try # on, off, or try (change requires restart)
#尽量使用大页,需要操作系统的支持,配置vm.nr_hugepages*2MB大于 shared_buffers.
dynamic_shared_memory_type = posix # the default is the first optionsupported by the operating system:posix sysv windows mmap
#use none to disable dynamic shared memory
#autovacuum_work_mem = -1
# min 1MB, or -1 to use
maintenance_work_mem
四、资源(空闲空间映射)
Free Space Map
数据库的所有可用空间信息都存放在一个叫free space map (FSM)的结构中,它记载数据文件中每个数据块的可用空间的大小。FSM中没有记录的数据块,即使有可用空间,也不会系统使用。系统如果需要新的物理存储空间,会首先在FSM中查找,如果FSM中没有一个数据页有足够的可用空间,系统就会自动扩展数据文件。所以,FSM如果太小,会导致系统频繁地扩展数据文件,浪费物理存储空间。命令VACUUM VERBOSE在执行结束以后,会提示当前的FSM设置是否满足需要,如果FSM的参数值太小,它会提示增大参数。
FSM存放在数据库的共享内存中,由于物理内存的限制,FSM不可能跟踪数据库的所有的数据文件的所有数据块的可用空间信息,只能跟踪一部分数据块的可用空间信息。
max_fsm_relations (integer)
这个参数只有在启动数据库时,才能被设置。默认值是1000。它决定FSM跟踪的表和索引的个数的上限。每个表和索引在FSM中占7个字节的存储空间。
max_fsm_pages (integer)
这个参数只有在启动数据库时,才能被设置。它决定FSM中跟踪的数据块的个数的上限。initdb在创建数据库集群时会根据物理内存的大小决定它的值。每个数据块在fsm中占6个字节的存储空间。它的大小不能小于16 * max_fsm_relations。默认值是20000。
五、内核资源Kernel Resource Usage
max_files_per_process (integer)
这个参数只有在启动数据库时,才能被设置。他设定每个数据库进程能够打开的文件的数目。默认值是1000。
shared_preload_libraries (string)
这个参数只有在启动数据库时,才能被设置。它设置数据库在启动时要加载的操作系统共享库文件。如果有多个库文件,名字用逗号分开。如果数据库在启动时未找到shared_preload_libraries指定的某个库文件,数据库将无法启动。默认值为空串。
六、垃圾资源回收Cost-Based Vacuum Delay
执行VACUUM 和ANALYZE命令时,因为它们会消耗大量的CPU与IO资源,而且执行一次要花很长时间,这样会干扰系统执行应用程序发出的SQL命令。为了解决这个问题,VACUUM 和ANALYZE命令执行一段时间后,系统会暂时终止它们的运行,过一段时间后再继续执行这两个命令。这个特性在默认的情况下是关闭的。将参数vacuum_cost_delay设为一个非零的正整数就可以打开这个特性。
用户通常只需要设置参数vacuum_cost_delay和vacuum_cost_limit,其它的参数使用默认值即可。VACUUM 和ANALYZE命令在执行过程中,系统会计算它们执行消耗的资源,资源的数量用一个正整数表示,如果资源的数量超过vacuum_cost_limit,则执行命令的进程会进入睡眠状态,睡眠的时间长度是是vacuum_cost_delay。vacuum_cost_limit的值越大,VACUUM 和ANALYZE命令在执行的过程中,睡眠的次数就越少,反之,vacuum_cost_limit的值越小,VACUUM 和ANALYZE命令在执行的过程中,睡眠的次数就越多。
vacuum_cost_delay (integer)
这个参数可以在任何时候被设置。默认值是0。它决定执行VACUUM 和ANALYZE命令的进程的睡眠时间。单位是毫秒。它的值最好是10的整数,如果不是10的整数,系统会自动将它设为比该值大的并且最接近该值的是10的倍数的整数。如果值是0,VACUUM 和ANALYZE命令在执行过程中不会主动进入睡眠状态,会一直执行下去直到结束。
vacuum_cost_page_hit (integer)
这个参数可以在任何时候被设置。默认值是1。锁住缓冲池,查找共享的散列表以及扫描页面的内容的开销(credits)。
vacuum_cost_page_miss (integer)
这个参数可以在任何时候被设置。默认值是10。表示锁住缓冲池,查找共享散列表,从磁盘读取需要的数据块以及扫描它的内容的开销。
vacuum_cost_page_dirty (integer)
这个参数可以在任何时候被设置。默认值是20。如果清理修改一个原先是干净的块的预计开销。它需要一个把脏的磁盘块再次冲刷到磁盘上的额外开销。
vacuum_cost_limit (integer)
这个参数可以在任何时候被设置。默认值是200。导致清理进程休眠的积累开销。
七、后台写数据库进程Background Writer
后台写数据库进程负责将数据缓冲区中的被修改的数据块(又叫脏数据块)写回到数据库物理文件中。
bgwriter_delay (integer)
这个参数只能在文件postgresql.conf中设置。它决定后台写数据库进程的睡眠时间。后台写数据库进程每次完成写数据到物理文件中的任务以后,就会睡眠bgwriter_delay指定的时间。 bgwriter_delay的值应该是10的倍数,如果用户设定的值不是10的倍数,数据库会自动将参数的值设为比用户指定的值大的最接近用户指定的值的同时是10的倍数的值。单位是毫秒,默认值是200。即 后端写进程每隔多少毫秒重复一次动作。
bgwriter_lru_maxpages (integer)
这个参数只能在文件postgresql.conf中设置。默认值是100。后台写数据库进程每次写脏数据块时,写到外部文件中的脏数据块的个数不能超过bgwriter_lru_maxpages指定的值。例如,如果它的值是500,则后台写数据库进程每次写到物理文件的数据页的个数不能超过500,若超过,进程将进入睡眠状态,等下次醒来再执行写物理文件的任务。如果它的值被设为0, 后台写数据库进程将不会写任何物理文件(但还会执行检查点操作)。
即 一个周期最多写多少脏页。
bgwriter_lru_multiplier (floating point)
这个参数只能在文件postgresql.conf中设置。默认值是2.0。它决定后台写数据库进程每次写物理文件时,写到外部文件中的脏数据块的个数(不能超过bgwriter_lru_maxpages指定的值)。一般使用默认值即可,不需要修改这个参数。这个参数的值越大,后台写数据库进程每次写的脏数据块的个数就越多
----Asynchronous Behavior----
#effective_io_concurrency = 1 # 1-1000; 0 disables prefetching
#max_worker_processes = 8
如果要使用 worker process,最多可以允许 fork多少个 worker进程
八、事务日志预写
full_page_writes (boolean)
这个参数只能在postgresql.conf文件中被设置。默认值是on。打开这个参数,可以提高数据库的可靠性,减少数据丢失的概率,但是会产生过多的事务日志,降低数据库的性能。 即 服务器在checkpoint之后在对页面的第一次写时将整个页面写到wal里面。
wal_buffers (integer)
这个参数只有在启动数据库时,才能被设置。默认值是8。它指定事务日志缓冲区中包含的数据块的个数,每个数据块的大小是8KB,所以默认的事务日志缓冲区的大小是8*8=64KB。事务日志缓冲区位于数据库的共享内存中。即 放在共享内存里用于wal 数据的磁盘页面缓冲区的数目,最小32kb,-1表示基于share buffer的设置。
wal_writer_delay (integer)
这个参数只能在postgresql.conf文件中被设置。它决定写事务日志进程的睡眠时间。WAL进程每次在完成写事务日志的任务后,就会睡眠wal_writer_delay指定的时间,然后醒来,继续将新产生的事务日志从缓冲区写到WAL文件中。单位是毫秒(millisecond),默认值是200。 即 每隔多长时间进行一次写操作。
commit_delay (integer)
这个参数可以在任何时候被设置。它设定事务在发出提交命令以后的睡眠时间,只有在睡眠了commit_delay指定的时间以后,事务产生的事务日志才会被写到事务日志文件中,事务才能真正地提交。增大这个参数会增加用户的等待时间,但是可以让多个事务被同时提交,提高系统的性能。如果数据库中的负载比较高,而且大部分事务都是更新类型的事务,可以考虑增大这个参数的值。下面的参数commit_siblings会影响commit_delay是否生效。默认值是0,单位是微秒(microsecond)。0表示无延迟。即 向WAL缓冲区写入记录和将缓冲区刷新到磁盘上之间的时间延迟。
commit_siblings (integer)
这个参数可以在任何时候被设置。这个参数的值决定参数commit_delay是否生效。假设commit_siblings的值是5,如果一个事务发出一个提交请求,此时,如果数据库中正在执行的事务的个数大于或等于5,那么该事务将睡眠commit_delay指定的时间。如果数据库中正在执行的事务的个数小于5,这个事务将直接提交。默认值是5。即 在commit_delay时间内,最少打开的并发事务数(1-1000);
#wal_level = minimal 预写日志模式
# minimal, archive, hot_standby, or logical(change requires restart)
#fsync = on 设置同步方式
# turns forced synchronization on or off
#synchronous_commit = on 如果磁盘的IOPS一般,建议使用异步提交来提高性能,但是数据库crash或操作系统crash时,最多可能丢失2*wal_writer_delay时间段产生的事务日志(在wal buffer中)
# synchronization level;off, local, remote_write, or on
#wal_sync_method = fsync 用来向磁盘强制更新wal数据的方法。如果fsync 是关闭的,那这个设置就是无关无效的。
# the default is the first option
# supported by the operating system:
# open_datasync(用O_DSYNC选项的open()打开WAL文件)
# fdatasync (default on Linux) 每次提交的时候都调用fdatasync()
# fsync 每次提交的时候都调用fsync
# fsync_writethrough每次提交的时候都调用fsync(),强制写出任何磁盘写缓冲区
# open_sync 用O_DSYNC选项的open()打开WAL文件
#wal_log_hints = off
# also do full page writes of non-critical updates (change requires restart)
九、
十、检查点Checkpoints
checkpoint_segments (integer) in logfile segments, min 1, 16MB each
这个参数只能在postgresql.conf文件中被设置。默认值是3。它影响系统何时启动一个检查点操作。如果上次检查点操作结束以后,系统产生的事务日志文件的个数超过checkpoint_segments的值,系统就会自动启动一个检查点操作。增大这个参数会增加数据库崩溃以后恢复操作需要的时间。即 最大多少大小的段发生一次checkpoint,等于shared_buffers除以单个wal segment的大小。
checkpoint_timeout (integer) range 30s-1h
这个参数只能在postgresql.conf文件中被设置。单位是秒,默认值是300。它影响系统何时启动一个检查点操作。如果现在的时间减去上次检查点操作结束的时间超过了checkpoint_timeout的值,系统就会自动启动一个检查点操作。增大这个参数会增加数据库崩溃以后恢复操作需要的时间。即 最大多长时间发生一次checkpoint
checkpoint_completion_target (floating point)
这个参数控制检查点操作的执行时间。合法的取值在0到1之间,默认值是0.5。不要轻易地改变这个参数的值,使用默认值即可。 这个参数只能在postgresql.conf文件中被设置。
#checkpoint_warning = 30s
十一、磁盘 Disk
#temp_file_limit = -1 # limits per-session temp file space in kB, or -1 for no limit
每个会话的临时文件空间(kb),-1 表示无限制
十二、归档模式Archiving
archive_mode (boolean)
这个参数只有在启动数据库时,才能被设置。默认值是off。它决定数据库是否打开归档模式。
archive_dir (string)
这个参数只有在启动数据库时,才能被设置。默认值是空串。它设定存放归档事务日志文件的目录。
archive_timeout (integer)
这个参数只能在postgresql.conf文件中被设置。默认值是0。单位是秒。如果archive_timeout的值不是0,而且当前时间减去数据库上次进行事务日志文件切换的时间大于archive_timeout的值,数据库将进行一次事务日志文件切换。一般情况下,数据库只有在一个事务日志文件写满以后,才会切换到下一个事务日志文件,设定这个参数可以让数据库在一个事务日志文件尚未写满的情况下切换到下一个事务日志文件。
十三、优化器参数QUERY TUNING
1、存取方法参数 Planner Method Configuration
下列参数控制查询优化器是否使用特定的存取方法。除非对优化器特别了解,一般情况下,使用它们默认值即可。
enable_bitmapscan (boolean)
打开或者关闭规划器对位图扫描规划类型的使用 。默认值是 on。
enable_hashagg (boolean)
打开或者关闭查询规划器对散列聚集规划类型的使用。默认值是 on。
enable_hashjoin (boolean)
打开或者关闭查询规划器对散列连接规划类型的使用。默认值是 on。
enable_indexscan (boolean)
打开或者关闭查询规划器对索引扫描规划类型的使用。默认值是 on。
enable_mergejoin (boolean)
打开或者关闭查询规划器对合并连接规划类型的使用。默认值是 on。
enable_nestloop (boolean)
打开或者关闭查询规划器对嵌套循环连接规划类型的使用。默认值是 on。
enable_seqscan (boolean)
打开或者关闭查询规划器对顺序扫描规划类型的使用。默认值是 on。
enable_sort (boolean)
打开或者关闭查询规划器使用明确的排序步骤。默认值是 on。
enable_tidscan (boolean)
打开或者关闭查询规划器对TID扫描规划类型的使用。默认值是 on。
2、 优化器成本常量 Planner Cost Constants
优化器用一个正的浮点数来表示不同的查询计划的执行成本,每个基本的数据库操作都会被赋给一个确定的成本常量,优化器根据每个基本操作的执行成本来计算每个查询计划的执行成本。不要轻易地改变下面的参数的值,使用它们的默认值即可。
seq_page_cost (floating point)
设置从数据文件上顺序读取一个数据块的执行成本。默认值是1.0。
random_page_cost (floating point)
设置从数据文件上随机读取一个数据块的执行成本。默认值是4.0。
cpu_tuple_cost (floating point)
设置处理每一个数据行的执行成本。默认值是0.01。
cpu_index_tuple_cost (floating point)
设置在扫描索引的过程中处理每一个索引项的执行成本。默认值是0.005。
cpu_operator_cost (floating point)
设置处理每一个运算符或函数的执行成本。默认值是0.0025。
effective_cache_size (integer)
设置单个查询可以使用的数据缓冲区的大小。默认值是128MB。
3、查询优化 Genetic Query Optimizer
下列参数控制优化器使用的遗传算法。除非对遗传算法特别了解,一般情况下使用它们默认值即可。
geqo (boolean)
打开或者关闭遗传优化器。默认值是on。
geqo_threshold (integer)
确定使用遗传优化器的查询类型。默认值是12。如果FROM子句中引用的的表的数目超过geqo_threshold的值,就会使用遗传优化器。对于简单的查询使用穷举优化器。
geqo_effort (integer)
控制遗传优化器在生成查询计划需要的时间和查询计划的有效性之间做一个折中。有效的取值范围是1到 10。默认值是5。值越大,优化器花在选择查询计划的上的时间越长,同时找到一个最优的查询计划的可能性就越大。系统通常不直接使用geqo_effort的值,而是使用它的值来计算参数geqo_pool_size和geqo_generations的默认。
geqo_pool_size (integer)
控制遗传优化器的池(pool)大小。默认值是0。池大小是遗传群体中的个体数目。至少是2,典型的取值在10和1000之间。如果参数的值是0,系统会自动根据geqo_effort的值和查询中引用的表的个数选择一个默认值。
geqo_generations (integer)
控制遗传优化器的代(generation)的大小。默认值是0。代是遗传算法的迭代次数。至少是1,典型的取值范围与池的取值范围相同。如果参数的值是0,系统会自动根据geqo_pool_size的值和选择一个默认值。
geqo_selection_bias (floating point)
控制遗传优化器的代选择偏差(selection bias)的大小。默认值是2。取值范围在1.50到2.00之间。
4、其它优化器参数 Other Planner Options
default_statistics_target (integer)
设置默认的收集优化器统计数据的目标值。它的值越大,ANALYZE操作的执行的时间越长,扫描的数据行的个数也就越多,得到的优化器统计数据就越准确。也可以使用命令ALTER TABLE ... ALTER COLUMN ... SET STATISTICS来为表的每个列设置一个单独的统计数据目标值,这个值的作用与参数default_statistics_target是一样,它只影响相关的列的统计数据收集过程。默认值是10。
constraint_exclusion (boolean)
如果该参数的值是on,查询优化器将使用表上的约束条件来优化查询。如果它的值是off,查询优化器不会使用表上的约束条件来优化查询。默认值是off。
#cursor_tuple_fraction = 0.1 # range 0.0-1.0
#from_collapse_limit = 8
#join_collapse_limit = 8 # 1 disables collapsing of explicit
# JOIN clauses
十四、数据库运行日志配置参数
1、Where to Log
log_destination = 'stderr' # Valid values are combinations of stderr, csvlog, syslog, and eventlog, depending on platform. csvlog requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on # Enable capturing of stderr and csvlog into log files. Required to be on for csvlogs. (change requires restart)
# These are only used if logging_collector is on:
log_directory (string)
这个参数只能在postgresql.conf文件中被设置。它决定存放数据库运行日志文件的目录。默认值是pg_log。可以是绝对路径,也可是相对路径(相对于数据库文件所在的路径)。
log_filename (string)
它决定数据库运行日志文件的名称。默认值是postgresql-%Y-%m-%d_%H%M%S.log。它的值可以包含%Y、%m、%d、%H、%M和%S这样的字符串,分别表示年、月、日、小时、分和秒。如果参数的值中没有指定时间信息(没有出现%Y、%m、%d、%H、%M和%S中的任何一个),系统会自动在log_filename值的末尾加上文件创建的时间作为文件名,例如,如果log_filename的值是 server_log,那么在Sun Aug 29 19:02:33 2004 MST被创建的日志文件的名称将是server_log.1093827753,1093827753是Sun Aug 29 19:02:33 2004 MST在数据库内部的表示形式。这个参数只能在postgresql.conf文件中被设置。
log_rotation_age (integer)
它决定何时创建一个新的数据库日志文件。单位是分钟。默认值是0。如果现在的时间减去上次创建一个数据库运行日志的时间超过了log_rotation_age的值,数据库将自动创建一个新的运行日志文件。如果它的值是0,该参数将不起任何作用。这个参数只能在postgresql.conf文件中被设置。
log_rotation_size (integer)
这个参数只能在postgresql.conf文件中被设置。它决定何时创建一个新的数据库日志文件。单位是KB。默认值是10240。如果一个日志文件写入的数据量超过log_rotation_size的值,数据库将创建一个新的日志文件。如果它的值被设为0,该参数将不起任何作用。
log_truncate_on_rotation (boolean)
系统在创建一个新的数据库运行日志文件时,如果发现存在一个同名的文件,当log_truncate_on_rotation的值是on时,系统覆盖这个同名文件。当log_truncate_on_rotation的值是off时,系统将重用这个同名文件,在它的末尾添加新的日志信息。另外要注意的是,只有在因为参数log_rotation_age起作用系统才创建新的日志文件的情况下,才会覆盖同名的日志文件。因为数据库重新启动或者因为参数log_rotation_size起作用而创建新的日志文件,不会覆盖同名的日志文件,而是在同名的日志文件末尾添加新的日志信息。这个参数只能在postgresql.conf文件中被设置。默认值是off。
例如,将这个参数设为on,将log_rotation_age设为60,将同时将log_filename设为postgresql-%H.log,系统中一共将只有24个日志文件,它们会被不断地重用,任何时刻,系统中最多只有最近24小时的日志信息。
# These are relevant when logging to syslog:
#syslog_facility = 'LOCAL0'
#syslog_ident = 'postgres'
# This is only relevant when logging to eventlog (win32):
#event_source = 'PostgreSQL
2、When to Log
client_min_messages (string)
控制发送给客户端的消息级别。合法的取值是DEBUG5、DEBUG4、DEBUG3、DEBUG2、DEBUG1、LOG、NOTICE、WARNING、ERROR、FATAL和PANIC,每个级别都包含排在它后面的所有级别中的信息。级别越低,发送给客户端的消息就越少。 默认值是NOTICE。这个参数可以在任何时候被设置。
log_min_messages (string)
控制写到数据库日志文件中的消息的级别。合法的取值是DEBUG5、DEBUG4、DEBUG3、DEBUG2、DEBUG1、INFO、NOTICE、WARNING、ERROR、 LOG、FATAL和PANIC,每个级别都包含排在它后面的所有级别中的信息。级别越低,数据库运行日志中记录的消息就越少。默认值是NOTICE。只有超级用户才能修改这个参数。只有超级用户才能设置这个参数。
log_error_verbosity (string)
控制每条日志信息的详细程度。合法的取值是TERSE、DEFAULT和VERBOSE(每个取值都比它前面的取值提供更详细的信息)。只有超级用户才能修改这个参数。默认值是DEFAULT。
log_min_error_statement (string)
控制日志中是否记录导致数据库出现错误的SQL语句。合法的取值是DEBUG5、DEBUG4、DEBUG3、DEBUG2、DEBUG1、INFO、NOTICE、WARNING、ERROR、 LOG、FATAL和PANIC,每个级别都包含排在它后面的所有级别。默认值是ERROR。只有超级用户才能修改这个参数。
消息严重级别
严重级别:用法
DEBUG1..DEBUG5:报告详细的调试信息。
INFO:报告用户可能需要的信息。
NOTICE:报告对用户有用的信息。
WARNING:报告警告信息。
ERROR:报告错误信息。
LOG:报告对数据库管理员有用的信息, 例如,检查点操作统计信息。
FATAL:报告导致当前会话被终止的错误信息。
PANIC:报告导致整个数据库被关闭的错误信息。
3、What to Log
debug_print_parse (boolean)
debug_print_rewritten (boolean)
debug_print_plan (boolean)
debug_pretty_print (boolean)
这些参数控制数据库是否输出运行时的调试信息。这些参数的默认值是off。这些参数可以被任何用户设置。
log_checkpoints (boolean)
控制是否及记录检查点操作信息。默认值是off。这个参数只能在postgresql.conf文件中被设置。必须重启数据库才能生效。
log_connections (boolean)
控制是否及记录客户端连接请求信息。默认值是off。这个参数只能在postgresql.conf文件中被设置。必须重启数据库才能生效。
log_disconnections (boolean)
控制是否记录客户端结束连接信息。默认值是off。这个参数只能在postgresql.conf文件中被设置。
log_duration (boolean)
控制是否记录每个完成的SQL语句的执行时间。只有超级用户才能修改这个参数。默认值是off。对于使用扩展协议与数据库通信的客户端,会记载Parse、Bind和Execute的执行时间。
log_hostname (boolean)
控制是否及记录客户端的主机名。默认值是off。如果设为on,可能会影响数据库的性能,因为解析主机名可能需要一定的时间。这个参数只能在postgresql.conf文件中被设置。这个参数只能在postgresql.conf文件中被设置。
log_line_prefix (string)
控制每条日志信息的前缀格式。默认值是空串,它的格式类似c语言中printf函数的format字符串。这个参数只能在postgresql.conf文件中被设置。
log_line_prefix = '< %m >' # special values:
转义序列
# %a = application name
# %u = user name 用户名
# %d = database name 数据库名
# %r = remote host and port 客户端机器名或IP地址,还有客户端端口
# %h = remote host 客户端机器名或IP地址
# %p = process ID 进程ID
# %t = timestamp without milliseconds 带微秒的时间
# %m = timestamp with milliseconds 不带微秒的时间
# %i = command tag 命令标签: 会话当前执行的命令类型
# %e = SQL state
# %c = session ID 会话ID
# %l = session line number 每个会话的日志编号,从1开始
# %s = session start timestamp 进程启动时间
# %v = virtual transaction ID 虚拟事务ID (backendID/localXID)
# %x = transaction ID (0 if none) 事务ID (0表示没有分配事务ID)
# %q = stop here in non-session 不产生任何输出。如果当前进程是backend进程,忽略这个转义序列,继续处理后面的转义序列。如果当前进程不是backend进程,忽略这个转义序列和它后面的所有转义序列。
# processes
# %% '%' 字符%
log_lock_waits (boolean)
如果一个会话等待某个类型的锁的时间超过deadlock_timeout的值,该参数决定是否在数据库日志中记录这个信息。默认值是off。只有超级用户才能修改这个参数。
log_statement (string)
控制记录哪种SQL语句的执行信息。有效的取值是none、ddl、mod和all。默认值是none。ddl包括所有数据定义语句,如CREATE、ALTER和DROP语句。mod包括所有ddl语句和更新数据的语句,例如INSERT、UPDATE、DELETE、TRUNCATE、 COPY FROM、PREPARE和 EXECUTE。All包括所有的语句。只有超级用户才能修改这个参数。
log_temp_files (integer)
控制是否记录临时文件的删除信息。单位是KB。0表示记录所有临时文件的删除信息。正整数表示只记录大小比log_temp_files的值大的临时文件的删除信息。-1表示不记录任何临时文件删除信息。默认值是-1。这个参数可以在任何时候被设置。
log_timezone (string)
设置数据库日志文件在写日志文件时使用的时区。默认值是unknown,意识是使用操作系统的时区。这个参数只能在postgresql.conf文件中被设置
十五、数据库运行统计相关参数RUNTIME STATISTICS
下面的参数控制是否搜集特定的数据库运行统计数据:
---Query/Index Statistics Collector----
track_activities (boolean)
是否收集每个会话的当前正在执行的命令的统计数据,包括命令开始执行的时间。默认值是on。只有超级用户才能修改这个参数。
track_counts (boolean)
是否收集数据库活动的统计数据。默认值是on。只有超级用户才能修改这个参数。
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#update_process_title = on
#stats_temp_directory = 'pg_stat_tmp'
---统计监测Statistics Monitoring--
log_statement_stats (boolean)
log_parser_stats (boolean)
log_planner_stats (boolean)
log_executor_stats (boolean)
这些参数决定是否在数据库的运行日志里记载每个SQL语句执行的统计数据。如果log_statement_stats的值是on,其它的三个参数的值必须是off。所有的这些参数的默认值都是off。log_statement_stats报告整个语句的统计数据,log_parser_stats记载数据库解析器的统计数据,log_planner_stats报告数据库查询优化器的统计数据,log_executor_stats报告数据库执行器的统计数据。只有超级用户才能修改这些参数。
十六、自动垃圾收集相关参数AUTOVACUUM PARAMETERS
下面的参数控制自动垃圾收集的行为:
autovacuum (boolean)
控制是够打开数据库的自动垃圾收集功能。默认值是on。如果autovacuum被设为on,参数track_counts(参考本章10.9)也要被设为on,自动垃圾收集才能正常工作。注意,即使这个参数被设为off,如果事务ID回绕即将发生,数据库会自动启动一个垃圾收集操作。这个参数只能在文件postgresql.conf中被设置。
log_autovacuum_min_duration (integer)
单位是毫秒。如果它的值为0,所有的垃圾搜集操作都会被记录在数据库运行日志中,如果它的值是-1,所有的垃圾收集操作都不会被记录在数据库运行日志中。如果把它的值设为250毫秒,只要自动垃圾搜集发出的VACUUM和ANALYZE命令的执行时间超过250毫秒,VACUUM和ANALYZE命令的相关信息就会被记录在数据库运行日志中。默认值是-1。这个参数只能在 postgresql.conf中被设置。
autovacuum_max_workers (integer)
设置能同时运行的最大的自动垃圾收集工作进程的数目。默认值是3。这个参数只能在文件postgresql.conf中被设置。
autovacuum_naptime (integer)
设置自动垃圾收集控制进程的睡眠时间。单位是秒,默认值是60。这个参数只能在文件postgresql.conf中被设置。
autovacuum_vacuum_threshold (integer)
设置触发垃圾收集操作的阈值。默认值是50。这个参数只能在文件postgresql.conf中被设置。只有一个表上被删除或更新的记录的数目超过了autovacuum_vacuum_threshold的值,才会对这个表执行垃圾收集操作。
autovacuum_analyze_threshold (integer)
设置触发ANALYZE操作的阈值。默认值是50。这个参数只能在文件postgresql.conf中被设置。只有一个表上被删除、插入或更新的记录的数目超过了autovacuum_analyze_threshold的值,才会对这个表执行ANALYZE操作。
autovacuum_vacuum_scale_factor (floating point)
这个参数与何时对一个表进行垃圾收集操作相关。默认值是0.2。这个参数只能在文件postgresql.conf中被设置。
autovacuum_analyze_scale_factor (floating point)
这个参数与何时对一个表进行ANALYZE操作相关。默认值是0.1。这个参数只能在文件postgresql.conf中被设置。
autovacuum_freeze_max_age = 200000000
# maximum XID age before forced vacuum # (change requires restart)
指定表上事务的最大年龄,默认2亿,达到这个阀值将触发 autovacuum进程,从而避免 wraparound. 表上的事务年龄可通过 pg_class.relfrozenxid查询
autovacuum_multixact_freeze_max_age = 400000000
# maximum multixact age
# before forced vacuum
# (change requires restart)
autovacuum_vacuum_cost_delay = 20ms
# default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
当 autovacuum进程即将执行时,对vacuum执行cost进行评估,如果超过 autovacuum_vacuum_cost_limit的值时,则延迟,这个延迟的时间值即为改成的值.
autovacuum_vacuum_cost_limit = -1
# default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
这个值 为 autovacuum进程的评估阀值,默认值为-1,表使用 vacuum_cost_limit值,如果在执行 autovacuum进程期间评估的 cost 超过 autovacuum_vacuum_cost_limit,则 autovacuum进程则会休眠
十七、锁管理LOCK MANAGEMENT
deadlock_timeout(integer)
设置死锁超时检测时间。单位是微秒,默认值是1000。死锁检测是一个消耗许多 CPU资源的操作。这个参数的值不能太小。在数据库负载比较大的情况下,应当增大这个参数的值。
max_locks_per_transaction(integer)
这个参数控制每个事务能够得到的平均的对象锁的个数。默认值是64。数据库在启动以后创建的共享锁表的最大可以保存max_locks_per_transaction * (max_connections + max_prepared_transactions)个对象锁。单个事务可以同时获得的对象锁的数目可以超过max_locks_per_transaction的值,只要共享锁表中还有剩余空间。每个锁占用270个字节的共享内存
# lock table slots.
#max_pred_locks_per_transaction = 64 # min 10
# (change requires restart)
十八、客户端连接管理CLIENT CONNECTION DEFAULTS
# - Statement Behavior -
#search_path = '"$user",public' # schema names
#default_tablespace = '' # a tablespace name, '' uses the default
#temp_tablespaces = '' # a list of tablespace names, '' uses
# only default tablespace
#check_function_bodies = on
#default_transaction_isolation = 'read committed'
#default_transaction_read_only = off
#default_transaction_deferrable = off
#session_replication_role = 'origin'
#statement_timeout = 0 # in milliseconds, 0 is disabled
#lock_timeout = 0 # in milliseconds, 0 is disabled
#vacuum_freeze_min_age = 50000000
#vacuum_freeze_table_age = 150000000
#vacuum_multixact_freeze_min_age = 5000000
#vacuum_multixact_freeze_table_age = 150000000
#bytea_output = 'hex' # hex, escape
#xmlbinary = 'base64'
#xmloption = 'content'
#gin_fuzzy_search_limit = 0
# - Locale and Formatting -
datestyle = 'iso, mdy'
#intervalstyle = 'postgres'
timezone = 'PRC'
#timezone_abbreviations = 'Default' # Select the set of available time zone
# abbreviations. Currently, there are
# Default
# Australia (historical usage)
# India
# You can create your own file in
# share/timezonesets/.
#extra_float_digits = 0 # min -15, max 3
#client_encoding = sql_ascii # actually, defaults to database encoding
# These settings are initialized by initdb, but they can be changed.
lc_messages = 'en_US.UTF-8' # locale for system error message strings
lc_monetary = 'en_US.UTF-8' # locale for monetary formatting
lc_numeric = 'en_US.UTF-8' # locale for number formatting
lc_time = 'en_US.UTF-8' # locale for time formatting
# default configuration for text search
default_text_search_config = 'pg_catalog.english'
# - Other Defaults -
#dynamic_library_path = '$libdir'
#local_preload_libraries = ''
#session_preload_libraries = ''
十九、错误处理ERROR HANDLING
#exit_on_error = off # terminate session on any error?
#restart_after_crash = on # reinitialize after backend crash?
二十、配置文件包括 CONFIG FILE INCLUDES
一个配置文件也可以包含其他配置文件,使用include 指令能够达到这个目的。比如在postgresql.conf文件中有如下一行:
include 'my.confg'
这样的话 my.confg文件中的配置信息也会被数据库读入。
include 指令指定的配置文件也可以用include指令再包含其他配置文件。如果include指令中指定的文件名不是绝对路径,数据库会在postgresql.conf文件所在的目录下查找这个文件。
#include_dir = 'conf.d' # include files ending in '.conf' from directory 'conf.d'
#include_if_exists = 'exists.conf' # include file only if it exists
#include = 'special.conf' # include file
二十一、版本\平台兼容VERSION/PLATFORM COMPATIBILITY
# - Previous PostgreSQL Versions -
#array_nulls = on
#backslash_quote = safe_encoding # on, off, or safe_encoding
#default_with_oids = off
#escape_string_warning = on
#lo_compat_privileges = off
#quote_all_identifiers = off
#sql_inheritance = on
#standard_conforming_strings = on
#synchronize_seqscans = on
# - Other Platforms and Clients -
#transform_null_equals = off
二十二、复制REPLICATION
# - Sending Server(s) -
# Set these on the master and on any standby that will send replication data.
#max_wal_senders = 0 # max number of walsender processes(change requires restart)
#wal_keep_segments = 0 # in logfile segments, 16MB each; 0 disables
#wal_sender_timeout = 60s # in milliseconds; 0 disables
#max_replication_slots = 0 # max number of replication slots(change requires restart)
# - Master Server -
# These settings are ignored on a standby server.
#synchronous_standby_names = '' # standby servers that provide sync rep comma-separated list of application_name from standby(s); '*' = all
#vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed
# - Standby Servers -
# These settings are ignored on a master server.
#hot_standby = off # "on" allows queries during recovery(change requires restart)
#max_standby_archive_delay = 30s # max delay before canceling queries when reading WAL from archive; -1 allows indefinite delay
#max_standby_streaming_delay = 30s # max delay before canceling queries when reading streaming WAL; -1 allows indefinite delay
#wal_receiver_status_interval = 10s # send replies at least this often 0 disables
#hot_standby_feedback = off # send info from standby to prevent query conflicts
#wal_receiver_timeout = 60s # time that receiver waits for communication from master in milliseconds; 0 disables
上文源自:Postgresql 配置文件详解
postgresql.conf与postgresql.auto.conf
对于PostgreSQL 9.4或之后的版本,当使用initdb程序命令初始化数据库集簇之后,会在PG_DATA目录下同时存在两个与PostgreSQL服务相关的配置文件。它们分别是postgresql.auto.conf和postgresql.conf。对于postgresql.conf文件,我们比较熟悉,该文件中存储着与PostgreSQL服务相关的所有默认参数。在PostgreSQL 9.4版本之前,如果需要对PostgreSQL服务的某些功能进行优化、或是调整默认配置参数,则修改postgresql.conf配置文件,然后重启PostgreSQL(对于大多数配置参数的修改,均需要重启以生效)服务。
但是从PostgreSQL 9.4版本开始,新引入了postgresql.auto.conf配置文件,它作为postgresql.conf文件的补充,在参数配置格式上,它和postgresql.conf保持一致。即:
configuration_parameter = value 或 configuration_parameter = 'value'
附:postgresql.auto.conf是在PostgreSQL 9.4版本中引入。
但是两个文件之间仍然有着许多的区别,下面将分别一一详细介绍说明。
1、文件默认内容不同
postgresql.conf文件创建成功之后,里面有PostgreSQL依赖的默认配置文件参数,比如“最大连接数、共享缓冲区、时区等等”,如下:
/* defaults */
static int n_connections = 10;
static int n_buffers = 50;
static const char *dynamic_shared_memory_type = NULL;
static const char *default_timezone = NULL;
. . . . . . //省略若干配置参数
而对于postgresql.auto.conf配置文件,一开始除了两行文本注释说明之外,没有其他的配置参数。
1.1、postgresql.auto.conf创建原理
对于postgresql.conf、postgresql.auto.conf两个配置文件,它们均由位于src/bin/initdb/initdb.c文件中的setup_config()函数内部完成。首先创建postgres.conf文件,创建成功之后,再创建postgresql.auto.conf文件。对于postgresql.auto.conf文件的创建过程,整体流程图如下所示:
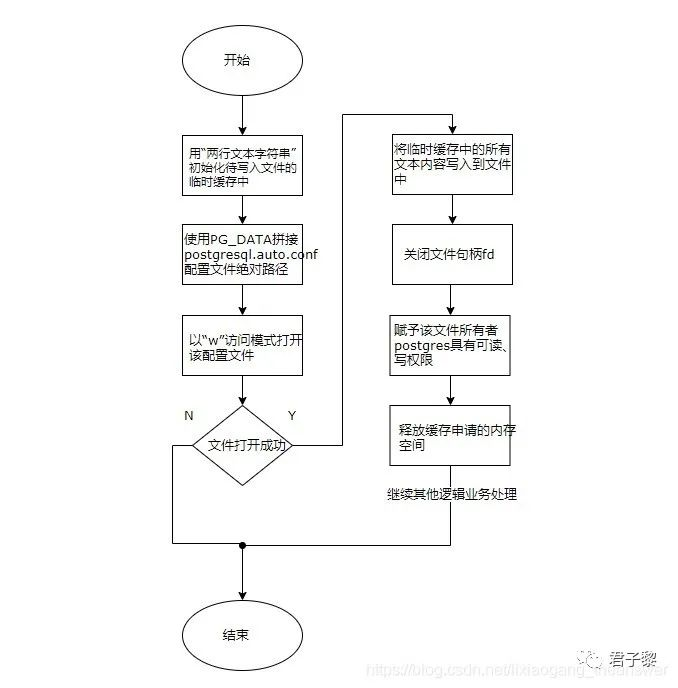
首先使用默认的两行文本字符串初始化缓存变量。然后根据PG_DATA数据蔟目录路径来构建postgresql.auto.conf配置文件的绝对路径名,然后以"w(若文件已存在,则删除已有文件内容,文件被视为一个空文件)"访问模式打开该文件。之后将换取变量中的所有文本内容写入该文件中。接下来关闭该文件描述符,同时赋予该文件的所有者(postgres)具有可读写的权限,最后释放临时缓存变量申请的内存空间。
2、文件修改方式不同
正如postgresql.auto.conf配置文件中初始化时的文本字符串提示一样:
不要手动修改此文件, 因为它会被 ALTER SYSTEM命令给覆盖。
该文件主要用于存储有 ALTER SYSTEM 命令设置的参数值。所以它不需要像postgresql.conf文件一样,每当调整配置参数时,都手动去打开修改、保存。
2.1、ALTER SYSTEM 语句
ALTER SYSTEM语句是PostgreSQL数据库的一个扩展,它用于在PostgreSQL数据库集群中修改服务器的配置参数。然后修改后的参数将保存在postgresql.auto.conf配置文件中。
ALTER SYSTEM的使用格式如下:
ALTER SYSTEM SET configuration_parameter { TO | = } { value | ‘value’ | DEFAULT }
ALTER SYSTEM RESET configuration_parameter
ALTER SYSTEM RESET ALL
当使用ALTER SYSTEM语句修改了某配置参数之后,该文件中存在的这个参数将覆盖解析该文件之前存在的参数值 。通俗点说,就是该文件中的这个参数将覆盖掉postgresql.conf文件中的该参数(但是postgresql.conf文件中这个参数值不会被修改,只是对于PostgreSQL服务,postgresql.auto.conf文件中的该参数具有更高的优先级)。
2.1.1、ALTER SYSTEM 使用方法
对于ALTER SYSTEM语句的语法格式,已经在2.2.1节中进行了介绍,这里使用修改端口“port”参数进行示例说明。
(1) show命令查看当前该配置参数的值。
test=# show port;
port
------
5566
(2) 执行alter system命令修改该port端口为6789。如果待修改的参数值是字符串,则使用单引号将其括起来。
test=# alter system set port = 6789;
ALTER SYSTEM
(3) 通过pg_settings视图查看当前修改的值。
test=# select * from pg_settings where name like 'port';
name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals |
boot_val | reset_val | sourcefile | sourceline | pending_restart
------+---------+------+------------------------------------------------------+------------------------------------------+------------+------------+---------+--------------------+---------+---------+----------+
----------+-----------+------------------------------------+------------+-----------------
port | 5566 | | Connections and Authentication / Connection Settings | Sets the TCP port the server listens on. | | postmaster | integer | configuration file | 1 | 65535 | |
5432 | 5566 | /home/ssd/PGSQL132/postgresql.conf | 63 | f
从终端的显示结果看到,当前的port端口值仍然为postgresql.conf配置文件中的5566,并没有生效。
(4) 尝试使用pg_reload_conf()函数来使服务器进程重新装载它们的配置文件。
test=# select pg_reload_conf();
pg_reload_conf
----------------
t
(5) 通过pg_settings视图查看当前修改的值。
test=# select * from pg_settings where name like 'port';
name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals |
boot_val | reset_val | sourcefile | sourceline | pending_restart
------+---------+------+------------------------------------------------------+------------------------------------------+------------+------------+---------+--------------------+---------+---------+----------+
----------+-----------+------------------------------------+------------+-----------------
port | 5566 | | Connections and Authentication / Connection Settings | Sets the TCP port the server listens on. | | postmaster | integer | configuration file | 1 | 65535 | |
5432 | 5566 | /home/ssd/PGSQL132/postgresql.conf | 63 | t
可看到修改的端口配置参数,仍然没有生效。它和postgresql.conf的规则相同,某些参数修改之后必须重启才会生效。postgresql.conf文件中对端口配置参数有明确指示说明,必须重启生效。
port = 5566 # (change requires restart)
因此重启PostgreSQL服务,然后再次通过pg_settings试图参考修改的端口参数情况。可看到已经生效了。
test=# select * from pg_settings where name like 'port';
name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals |
boot_val | reset_val | sourcefile | sourceline | pending_restart
------+---------+------+------------------------------------------------------+------------------------------------------+------------+------------+---------+--------------------+---------+---------+----------+
----------+-----------+-----------------------------------------+------------+-----------------
port | 6789 | | Connections and Authentication / Connection Settings | Sets the TCP port the server listens on. | | postmaster | integer | configuration file | 1 | 65535 | |
5432 | 6789 | /home/ssd/PGSQL132/postgresql.auto.conf | 3 | f
同时postgresql.auto.conf配置文件中也新增了一行文本内容。
2.1.2、ALTER SYSTEM并非所有参数都能修改
并非所有postgresql.conf文件中的配置选项参数都能够使用ALTER SYSTEM命令进行修改,比如data_directory相关系列的配置参数就不能使用该命令进行修改:config_file、hba_file、ident_file、external_pid_file等,更多关于data_directory的配置参数请阅读 GUC-DATA-DIRECTORY。此外一些预配置选项也不能使用此命令修改。比如:block_size、data_checksums、lc_collate等,更多关于预配置选项的配置参数请阅读 Options preconfigurees 。
日志管理
使用pg_ctl命令启动PostgreSQL服务,默认情况下PostgreSQL是不会将系统日志信息输入到设备文件中的。这无疑对PostgreSQL服务的管理和状态监测、性能排查等维护带来了巨大的问题与考验,特别是对于一个现场使用中的数据库而言,若出现了问题而没有日志记录,那将是多么棘手的一件事。
开启PostgreSQL服务日志两种方式
1、pg_ctl的可选参数-l指定日志文件
对于PostgreSQL数据库,可以有两种方式来进行日志配置和打印。第一种是使用pg_ctl启动数据库服务时候,通过使用可选参数-l来配置PostgreSQL将日志信息打印到对应目录。
可通过'--log=/home/xx/xx/freeoa.pg.log'来指定将日志打印到/home/xx/xx/目录下的1.log文件中,注意这里1.log文件已存在该目录,且文件权限用户需要是:postgres,如果是root,则会失败;日志文件中已经有PostgreSQL日志信息。如下:
2021-02-24 19:39:08.697 CST [17377] LOG: starting PostgreSQL 13.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
2021-02-24 19:39:08.698 CST [17377] LOG: listening on IPv6 address "::1", port 5566
2021-02-24 19:39:08.698 CST [17377] LOG: listening on IPv4 address "127.0.0.1", port 5566
2021-02-24 19:39:08.720 CST [17377] LOG: listening on Unix socket "/tmp/.s.PGSQL.5566"
2021-02-24 19:39:08.744 CST [17378] LOG: database system was interrupted; last known up at 2021-02-24 19:36:30 CST
2021-02-24 19:39:08.801 CST [17378] LOG: database system was not properly shut down; automatic recovery in progress
2021-02-24 19:39:08.813 CST [17378] LOG: redo starts at 0/160E738
2021-02-24 19:39:08.813 CST [17378] LOG: invalid record length at 0/160E770: wanted 24, got 0
2021-02-24 19:39:08.813 CST [17378] LOG: redo done at 0/160E738
2021-02-24 19:39:08.878 CST [17377] LOG: database system is ready to accept connections
2、通过postgresql.conf配置文件来指定log日志目录
当使用initdb命令初始化数据库蔟之后,会在指定的目录下生成一个postgresql.conf配置文件,里面是该数据库服务对应的所有完整配置信息,包括辅助进程:logger(系统日志进程)、background writer(后台写进程)、walwriter(预写式日志写进程)、autovacuum launcher(系统自动清理进程)、archiver(日志归档进程)。因此我们在postgresql.conf配置文件中通过修改有关log日志相关的选项,即可达到记录PostgreSQL服务的日志信息目的。
postgresql.conf配置文件中和log日志相关的部分选项参数,如下:
#------------------------------------------------------------------------------
# REPORTING AND LOGGING
#------------------------------------------------------------------------------
# - Where to Log -
# 配置日志输出目录,类unix默认是stderr。根据平台不同,有效值是stderr、csvlog、syslog和eventlog的组合,
# cslog要求logging_collector是on状态。当log日志输出到stderr时使用。
#log_destination = 'stderr'
# 日志收集器(off不开启,on开启)。当开启(on)后,将系统产生的日志信息输出到指定的目录下。
#logging_collector = off
# 配置log日志输出目录
#log_directory = '/home/ssd/psql13_2/LOG_SELF/'
# 配置log日志文件名称的命名规则,如果修改或打开,则使用默认规则
#log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
# log文件权限
#log_file_mode = 0600
# 如果启用,则与新日志文件同名的现有日志文件将被截断,而不是附加到新日志文件。默认值为off,表示在所有情况下都附加到现有文件。
#log_truncate_on_rotation = off
# 保留单个文件的最长时间,默认是1d,也可以是1min,1s。0-则禁用此功能
#log_rotation_age = 1d
# 保留单个文件的最大字节,默认是10MB
#log_rotation_size = 10MB
. . . . . .
log_timezone = 'Asia/Shanghai'
备注:log_rotation_size是配置日志文件大小,当日志文件达到这个大小时候,会被关闭掉,然后重新创建一个新的log文件。
logging_collector配置决定是否开启logger辅助进程
对于PostgreSQL数据库的配置文件postgresql.conf中,logging_collector(日志收集器辅助进程)选项的默认值是off,即关闭的。这时候,当开启(su postgres -c '/usr/local/postgresql13_2/bin/pg_ctl -D /home/ssd/psql13_2/ -m fast start')PostgreSQL服务时候,是看不到logger守护进程的。
现在修改logging_collector的值为on,重启服务,再次查看(ps -eLf|grep postgres),则可看到次数的logger日志搜集辅助进程已经开启。
结论:为了让PostgreSQL数据库记录任何的日志记录消息,必须将loggin_collector参数置为on。当修改次参数时候,必须重新启动PostgreSQL数据库服务。
postgresql.conf文件中与log相关配置的建议
· log_min_duration_statement(通常建议禁用)
用于设置时间阈值:凡是运行时间超过此阈值的查询均应该记录下来(作为“慢速查询”)。设为0:将记录数据库中的运行的每个语句,而设置为-1将禁用日志记录。该参数可以为min、s、ms、h等,比如:1h、1min、1s、1ms。修改此参数不需要重新启动PostgreSQL服务器。eg: log_min_duration_statement = 3s, 则表示记录每个运行超过3s或大于3s的语句。
· log_line_prefix
自定义PostgreSQL数据库日志文件中的每个日志行的格式规则,默认日志行打印规则是:
日期 时区 行号 打印级别 函数名 .... 等等
2021-02-25 14:15:59.221 CST [1340] DEBUG: pg_amproc: vac: 0 (threshold 147), ins: 0 (threshold 1097), anl: 0 (threshold 98)
可以根据自己的需求爱好进行修改,由于该选项参数众多,因此阅读 PostgreSQL日志文档 以进行定制。
· log_duration(建议禁用, off)
该参数默认off的,若打开此参数选项,则会记录PostgreSQL日志中每个已完成语句的持续时间,与log_min_duration_statement无关。启用该参数可能会增加日志文件的使用率,并且增加对服务器性能的影响。
· log_rotation_size
单个日志文件的大小限制,默认是10MB,当log文件超过这个限制后,将重新创建一个log文件。
· log_rotation_age
控制log文件的寿命,默认是1天。一旦log文件的时间达到这个阈值,则将强行进行轮换(即新建一个log文件),通常单位可以是:h、d、min,最小粒度是一分钟。当然,若log_rotation_size先达到,则无论时间是否达到,都将创建一个新的log文件。
比如:log_rotation_age = 5min;log_rotation_size = 1MB,在5min时间后,若单个log文件没有到达1MB,则也会重新创建一个新的log文件。
· log_statement
控制记录什么类型的SQL操作,通常SQL语言包括4中类型的的语言类别语句:DDL(数据定义语言)、DML(数据操作语言)、DCL(数据控制语言)和TCL(事务控制语言)。常见的DDL包括:创建数据库、创建表、修改表、删除表、创建查询命令、修改查询命令和删除数据表等。推荐的设置是DDL,它将记录所有已执行的DDL。其他可能值:none、mod(包括DDL和DML)以及all。
· log_temp_files
记录与临时表有关的日志信息。
logger日志辅助进程的原理
PostgreSQL V8.0引入logger系统日志记录器
syslogger系统日志记录器是在PostgreSQL V8.0版本中引入的。它通过重定向到管道来捕获来自postmaster、backends和其他子进程的所有stderr输出,并将其写入一组日志文件。可以在配置文件(postgresql.conf)中的设置日志文件的大小和保留时间限制。如果达到或是超过了这些限制,则关闭掉当前的日志文件,并且创建一个新的日志文件。这些日志文件存储在一个子目录中(根据postgresql.conf中的log_directory选项)。同时用户可以设置自己的日志文件命名规则方案(即log_filename),如果默认,则log文件名为:'postgresql-%Y-%m-%d_%H%M%S.log'。
在V9.6之前,默认情况下,PostgreSQL是将所有日志文件存储于pg_log目录(PostgreSQL数据库蔟目录,log_directory = ‘pg_log’)中,从PostgreSQL 10开始,pg_log已经重命名为简单日志。比如对于9.6.7版本的PostgreSQL当使用initdb命令初始化数据库蔟之后(目录:/home/ssd/pgsql/data),会在该目录下默认创建一个名为:pg_log 的目录文件,该pg_log目录下是所有与PostgreSQL相关的日志文件信息。
log文件其命名规则默认是13.2的log文件命令规则相同,但是PostgreSQL13.2版本安装的数据库蔟下面已经没有了pg_log目录。当然可以通过修改参数log_directory将log文件存储到指定的目录位置。
SysLogger日志收集器工作原理
SysLogger启动入口
PostgreSQL是一个客户端/服务器模式(C/S)架构,整个服务的初始化代码入口是main.c(/src/backend/main)文件中的main函数。在main函数中会根据启动参数选项来进行判断,并走不同的分支。然后进行postmaster守护进程初始化操作,这一初始化过程主要在postmaster.c文件中实现(位于/src/backend/postmaster/目录)。守护进程postmaster负责整个系统的启动和关闭,它监听并接受来自客户端的连接请求,并未其每一个请求分配一个postgres服务。之后该客户端连接上面的所有请求操作都直接与postgres进程进行交互,而不再经由postmaster守护进程参与。
SysLogger日志收集器的初始化入口是SysLogger_Start函数(/src/backend/postmaster/syslogger.c)。在初始化日志收集器前,会对GNC全局变量参数Logging_collector进行判断(对应postgresql.conf配置文件中的logging_collector,更多细节阅读 PostgreSQL配置管理日志消息 ),若该参数值为true,则表示开启日志收集器进程logger,反之则退出,不开启logger进程。
SysLogger日志收集器的守护进程名是logger,在初始化SysLogger进程的时候,会对全局变量 MyBackendType (BackendType MyBackendType;)进程初始化为:B_LOGGER 的操作(MyBackendType = B_LOGGER;),后面在创建守护进程时候,根据GetBackendTypeDesc()函数获取对应的守护进程名。在PostgreSQL 13.2版本中,共支持以下几种类型的后台守护进程,如下所示枚举值:
typedef enum BackendType{
B_INVALID = 0,
B_AUTOVAC_LAUNCHER,
B_AUTOVAC_WORKER,
B_BACKEND,
B_BG_WORKER,
B_BG_WRITER,
B_CHECKPOINTER,
B_STARTUP,
B_WAL_RECEIVER,
B_WAL_SENDER,
B_WAL_WRITER,
B_ARCHIVER,
B_STATS_COLLECTOR,
B_LOGGER,
} BackendType;
以下是各守护进程(枚举值)对应的进程名字:
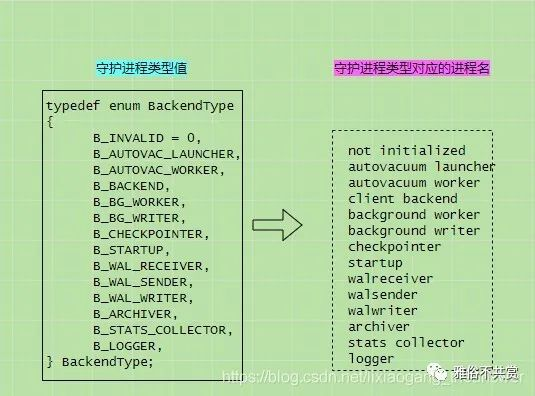
PostgreSQL默认开启的守护进程
并非所有的守护进程都会默认开启,有些是需要在postgresql.conf配置文件中进手动配置启动,比如日志收集器,就需要置参数logging_collector为on。默认情况下,PostgreSQL仅开启了 checkpointer、background write、walwriter、autovacuum launcher、stats collector、logical replication launcher 这几个后台守护进程。
SysLogger日志收集器启动流程
SysLogger日志收集器的整体初始化过程如下流程图所示:
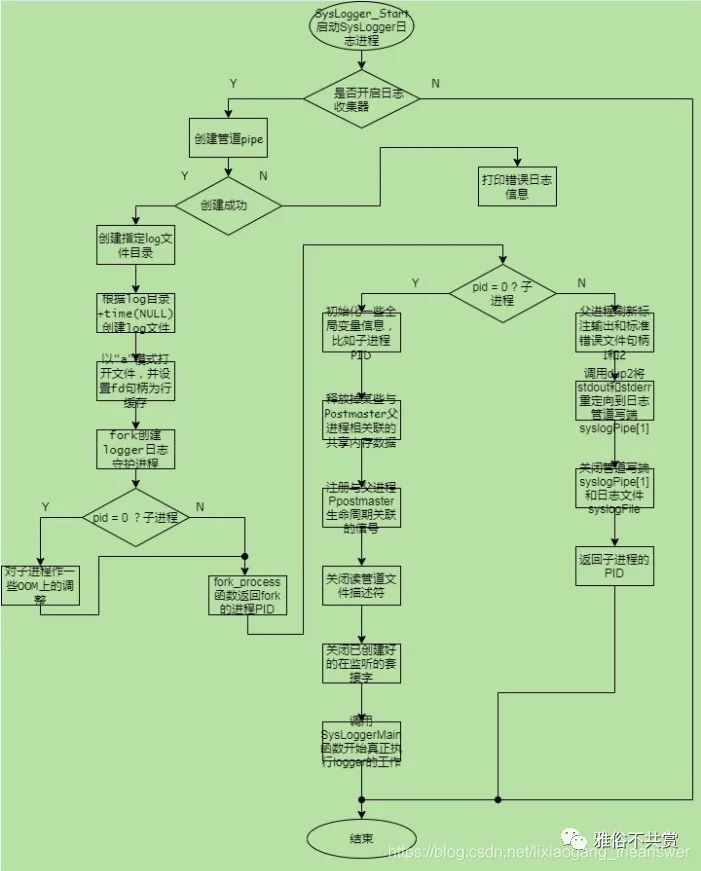
在初始化日志收集器时候,先根据postgres.conf配置文件中的参数(log_directory)来创建对应的log日志目录,默认log日志目录权限为文件拥有者具有读、写和执行权限。如下:
#ifndef S_IRWXU
#define S_IRWXU (S_IRUSR | S_IWUSR | S_IXUSR)
#endif
int MakePGDirectory(const char *directoryName){
return mkdir(directoryName, pg_dir_create_mode);
}
目录创建好之后,再获取当前系统时间,然后将时间按照postgresql.conf配置文件中的log_filename参数的值进行对应的格式化,生成一个新log文件。然后以文件访问模式“+a”的方式打开log文件,若不存在则新建,并且对该log文件的属性进行调整,同时设置该log文件的文件流缓冲区为行缓存(_IOLBF)形式。在log文件创建成功之后,并调用函数fork_process()创建logger子进程(fork_process函数是fork函数的封装,包括返回值都匹配fork),并在子进程中对内存相关的参数(OOM)进行一些内部设置。之后该函数返回进程的PID。
根据PID的值进行对应的其他工作处理,若PID为0,则表示为子进程中,在子进程中会初始化一些与子进程状态相关的全局变量、注册父进程状态信号、关闭读管道、关闭postmaster父进程中的监听套接字和与父进程postmaster相关的内存数据等。然后进入SysLoggerMain()函数真正开始logger日志收集器进程的相关处理操作。而在父进程中,则会先刷新stout、stderr等文件描述符的缓冲区数据,然后在将stdout、stderr文件描述符重定向到管道syslogPiped 写端,接着关闭管道写端和日志文件描述符句柄syslogFile。因为postmaster父进程将永远不会向该log文件中写数据。
之后父进程postmaster中将返回logger日志收集器的子进程PID。该子进程PID将用于postmaster父进程的ServerLoop()函数中。ServerLoop()函数是守护进程postmaster(父进程)的主要空循环处理函数。该函数为一个死循环函数(for( ; ; )), 该函数内部主要负责对 checkpointer(检查点进程)、background write(后台写进程)、walwriter(预写式日志写进程)、autovacuum launcher(系统自动清理进程)、stats collector(统计数据搜集进程)、logger(系统日志进程)、archiver(预写式日志归档进程)等 辅助守护进程的状态管理维护,若发现其中某个进程PID丢失,则立刻重新创建一个新的对应守护进程。
比如对于下图中的几个辅助进程logger、background writer、walwriter、autovacuum launcher、stats collector、logical replication launcher,若其中一个被手动人为kill掉,则postmaster守护进程将会检查到对应辅助子进程被kill掉的状态和对应信号(若开启了最高等级(debug5)日志,则会打印出对应信号值)。然后立刻重新fork()一个对应的子进程。备注:结合代码逻辑测试过,实际情况与逻辑是相吻合的。
此外,ServerLoop()函数还负责监听用户的连接请求,对于用户下发的每个请求,postmaster都会fork一个子进程(postgres)来进行处理,之后的该用户的所有请求操作,包括数据库、表、索引等的增删改查等操作都交由该postgres进程处理响应。因此PostgreSQL是一个多进程的客户端/服务器模型。在接收到用户的连接请求后,ServerLoop()函数将首先创建一个与该请求对应的本地连接ConnCreate()。之后的fork子进程等工作则交给BackendStartup()函数中去处理。当fork进程成功后,父进程中将会把本次创建的子进程的PID放入到后端活动的进程PID链表中,该工作由dlist_push_head()函数负责完成。