 各版本的常用命令差异示例:
各版本的常用命令差异示例:show innodb status\G mysql-5.1
show engines innodb status\G mysql-5.5
mysql-server-5.0
增加了Stored procedures、Views、Cursors、Triggers、XA transactions的支持,增加了INFORATION_SCHEMA系统数据库。
mysql-server-5.1
增加了Event scheduler,Partitioning,Pluggable storage engine API ,Row-based replication、Global级别动态修改general query log和slow query log的支持。
小版本的重要特性:
5.1.2 开始支持微秒级的慢查询。关于慢查询相关信息请参考 http://linuxguest.blog.51cto.com/195664/721042
mysql-server-5.5
1)默认存储引擎更改为InnoDB
2)提高性能和可扩展性
a. 提高了默认线程并发数(innodb_thread_concurrency)
b. 后台输入/输出线程控制(innodb_read_io_threads、innodb_write_io_threads)
c. 主线程输入/输出速率控制(innodb_io_capacity)
d. 操作系统内存分配程序使用控制(innodb_use_sys_malloc)
e. 适应性散列索引(Hash Index)控制,用户可以关闭适应性散列功能。
f. 插入缓冲(Insert Buffering)控制,用户可以关闭innodb的插入缓冲功能。
g. 通过快速加锁算法提高可扩展性,innodb不在使用代理(posix)线程,而是使用原生的独立操作来完成互斥和读写锁定。
h. 恢复组提交(Restored Group Commit)
i. 提高恢复性能
j. 多缓冲池实例
k. 多个回滚段(Multiple Rollback Segments),之前的innodb版本最大能处理1023个并发处理操作,现在mysql5.5可以处理高达128K的并发事物,
l. Linux系统固有的异步输入/输出,mysql5.5数据库系统也提高了linux系统的输入输出请求的并发数。
m. 扩展变化缓冲:添加了删除缓冲和清除缓冲
n. 改善了日志系统互斥和单独刷新(Flush)列表互斥
o. 改善清除程序进度,在mysql5.5中清楚操作线程是独立的线程,并支持并发,可以使用innodb_purge_treads配置。
p. 改善事务处理中的元数据锁定。例如,事物中一个语句需要锁一个表,会在事物结束时释放这个表,而不是像以前在语句结束时释放表。
3)提高实用性
a. 半同步复制(Semi-synchronous Replication)
b. 复制Heartbeat
c. 中继日志自动恢复(Automatic Relay Log Recovery)
d. 根据服务器过滤项复制(Replication Per Server Filtering)
e. 从服务器复制支持的数据类型转换(Replication Slave Side Data Type Conversions)
4)提高易管理性和效率
a. 建立快速索引(Faster Index Creation)
b. 高效的数据压缩(Efficient Data Compression)
c. 为大物件和可变长度列提供高效存储
d. 增加了INFORMATION_SCHEMA表,新的表提供了与InnoDB压缩和事务处理锁定有关的具体信息。
5)提高可用性
a. 针对SIGNAL/RESIGNAL的新SQL语法
b. 新的表/索引分区选项。MySQL5.5将表和索引RANG和LIST分区范围扩展到了非整数列和日期,并增加了在多个列上分区的能力。
6)改善检测和诊断
Mysql5.5引入了一种新的性能架构(performancn_shema,P_S),用于监控mysql监控服务器运行时的性能。
小版本的重要特性:
percona-server-5.5.18.23支持group commit
mysql-server-5.6
1)InnoDB现在可以限制大量表打开的时候内存占用过多的问题(比如这里提到的)(第三方已有补丁)
2)InnoDB性能加强。如分拆kernel mutex;flush操作从主线程分离;多个perge线程;大内存优化等
3)InnoDB死锁信息可以记录到 error 日志,方便分析
4)MySQL5.6支持延时复制,可以让slave跟master之间控制一个时间间隔,方便特殊情况下的数据恢复。
5)表分区功能增强
6)MySQL行级复制功能加强,可以降低磁盘、内存、网络等资源开销(只记录能确定行记录的字段即可)
7)Binlog实现 crash-safe
8)复制事件采用crc32校验,增强master/slave 复制数据一致性
9)新增 log_bin_basename (以前variables里面没有binlog位置信息,对数据库的监管很不方便)
从官方手册中可以总结如下:
1、权限认证,不用输入用户名和密码
2、用户密码有效期设置
3、Innodb全文检索
4、Innodb在线DDL功能增强,修改列名等不用复制数据
5、Innodb使用独享表空间时,可自定义表的数据文件存放的位置,繁忙的放SSD,支持单表在不同实例之间的转移
6、Innodb支持页大小的自定义,innodb_page_size
7、Innodb和Memcache接口的整合
8、Innodb统计信息收集更加精准,执行计划更加精准
9、Innodb Undo数据从系统表空间独立出来为单独的表空间,SSD
10、Innodb Redo日志文件大小调整为512G,以前最大为4G
11、Innodb减少内部争用,Flush操作从主线程独立出来为Flush线程,多Purge线程
12、Innodb死锁检测新方法,信息记录在Error Log中
13、Innodb Buffer Pool信息导出导入,Restart Database with Large Buffer Pool
14、Partition 支持分区和表Exchange
15、Partition 支持显示定义操作(Select、Delete、Insert、Replace等)的分区
16、Performance Schema功能增强
17、复制支持基于Transaction的复制Gtids,提高Master和Slave的一致性
18、复制Row复制只保存改变的列,大大节省Disk Space,Newwork resources和Memory usage
19、复制支持把Master 和Slave的相关信息记录在Table中
20、复制支持延迟复制
21、复制执行多线程并行复制,降低Slave与Master的延迟
22、MRR Join操作时候使用范围扫描代替单点循环提高查询效率
23、ICP Index Condition Pushdown
24、Explain支持Delete、Insert、Replace、Update等DML操作
25、子查询优化,老大难的问题终于改进了
26、时间类型字段Time、Datetime、Timestamp支持的粒度由秒扩展到微秒
v5.6正式版发布
在 MySQL 5.5 发布两年后,Oracle 于2013年3月宣布 MySQL 5.6 正式版发布,首个正式版版本号为 5.6.10。在 MySQL 5.5 中使用的是 InnoDB 作为默认的存储引擎,而 5.6 则对 InnoDB 引擎进行了改造,提供全文索引能力,使 InnoDB 适合各种应用场景。
此外,子查询的性能提升也是 MySQL 5.6 的主要任务之一,5.6 中使用一种半连接(semi-joins) 和物化处理来提升子查询的执行速度,这意味着你不需要手工将包含子查询的 SQL 语句用 join 操作来替代。此外,多数修改数据结构的操作 (如 ALTER TABLE) 可在线执行,避免了数据库长时间的挂起。EXPLAIN 语句支持 UPDATE/DELETE/INSERT 语句的执行计划信息。其他关于查询的优化还包括消除在使用很小的 LIMIT 值时的表扫描。
在复制方面,MySQL 面向行的复制支持新的 "row image control" ,只记录修改的列而不是行中所有的列,这对一些包含 BLOGs 字段的数据来说可以节省很大的处理能力,因此此项改进不仅节省了磁盘空间,同时也提升了性能。另外, "Index Condition Pushdown" 是一项新的优化措施使得查询尝试优先使用索引的字段,然后再是 WHERE 条件。
MySQL 5.6 同时引入了 NoSQL 接口,提供了兼容 memcached 的 API,该特性让应用可直接访问 InnoDB 存储引擎。底层上保持着跟关系数据库引擎在维护上的统一。同时底层的 InnoDB 引擎也增强在持久化优化统计、多线程消除以及提供更多的系统表和监控数据。
MySQL 的产品经理 Tomas Ulin 解释了开源社区对 Oracle 关于补丁政策的批评,他说:这是一个不断求证的过程,我们每三个月提供安全补丁,但其实大多数用户并不会这么频繁的更新。而使用社区版的用户抱怨 Oracle 没有提供发行说明中 CVE 号的详细说明,它们只是简单的指向 Oracle 内部的错误码。公司将不会发布这些详情信息。
更多关于 MySQL 5.6 的改进请看 release notes.
v5.5与v5.6默认参数值的差异
这里讲些最重要的也是影响最大的部分:
performance_schema 在 MySQL 5.6 中默认是开启的,但相关的很多参数相比 MySQL 5.5 却是降低了,例如 performance_schema 自动调整到 445 个表和 224 线程,比 MySQL 5.5 低。默认 max_connections 只有150 ,比 200 还小。
innodb_stats_on_metadata 在 MySQL 5.6 默认关闭,使得 information_schema 的查询速度快很多。
innodb_log_file_size – 默认值从 5MB 提升到 50MB,这是一个好的改变,虽然我觉得这个默认数值还可以再大些。对于写负载高的情况下,默认配置的 MySQL 5.6 性能更好。
back_log 改动比较小,从 50 改为 80。如果系统每秒处理的连接数很高,还需要继续提高这个配置的值。
open_files_limit 由原来的 1024 改为 5000
innodb_auto_extend_increment 由 8MB 改为 64MB,可帮助降低碎片。
max_connect_errors 从 10 改为 100,可降低潜在的连接堵塞,但还可以更高些。
sort_buffer_size 从 2M 将为 256K,这可避免小排序导致的资源浪费,但是对大的排序有负面的影响。
max_allowed_packet 从 1MB 改为 4MB 让 MySQL 可处理更大的查询。
join_buffer_size 从 128K 改为 256K,我觉得这个改动影响不大。
table_open_cache 从 400 提高到 2000,挺好!
innodb_buffer_pool_instances 从 1 改为 8,用于优化更高并发的负载。
query_cache_type 和 query_cache_size. The behavior is “no cache” by default still but it is achieved differently now. The query_cache_type is now off by default with default size of 1MB while in MySQL 5.5 and before it was “ON” by default with query cache size of 0 which makes it disabled. I wish query_cache_size though would be larger by default as value of 1M is too small to be practical if someone tries to enable it.
sql_mode has NO_ENGINE_SUBSTITUTION value by default which is good change as trying to create Innodb table but getting MyISAM because Innodb was disabled for some reason was very error prone gotcha. Note this is as far as MySQL 5.6 goes - STRICT_MODE and other safer behaviors are not enabled by default.
innodb_old_blocks_time 设置为 1000,很好的改变,默认扫描 InnoDB 缓冲池大小。
thread_cache_size 默认启用,对很多连接和断开连接操作的情况下有帮助。
sync_relay_log_info and sync_master_info 默认值有原来的 0 改为 10000. 该改动几乎不会影响负载。
secure_auth 默认开启,要求新的密码握手,特别是阻止老的不安全的做法。
innodb_concurrency_tickets has been increased from 500 to 5000. If you’re using innodb_thread_concurrency this will reduce overhead associated with grabbing and releasing innodb_thread_concurrency slot but will increase potential starvation of queued threads especially for IO bound workloads. Most users will not be affected though as innodb_thread_concurrency is 0 by default so this queuing feature is disabled.
innodb_purge_threads 默认为 1 ,使用专用的后台 purge 线程。
innodb_open_files 由 300 改为 2000。
innodb_data_file_path got a small change with starting ibdata1 size raised from 10M to 12M. I’m not sure what is the purpose of this change but it is unlikely to have any practical meaning for users. Considering the default innodb_auto_extend_increment is 64 starting with 64M might have made more sense.
innodb_purge_patch_size 从 20 改为 300。
innodb_file_per_table 默认启用,这个改变很大,而且很棒,特别是当你的表非常大的时候。
optimizer_switch is the catch all variable for a lot of optimizer options. I wonder why was not it implemented as number of different variables which would make more sense in my opinion. MySQL 5.6 adds a lot more optimizer switches which you can play with: 01 mysql [localhost] {msandbox} (test) > select * from var55 where variable_name='OPTIMIZER_SWITCH' \G
*************************** 1. row ***************************
VARIABLE_NAME: OPTIMIZER_SWITCH
VARIABLE_VALUE: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on
1 row in set (0.00 sec)
mysql [localhost] {msandbox} (test) > select * from var56 where variable_name='OPTIMIZER_SWITCH' \G
*************************** 1. row ***************************
VARIABLE_NAME: OPTIMIZER_SWITCH
VARIABLE_VALUE: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,
index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,
semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
1 row in set (0.00 sec)
MySQL 5.6 中关于密码方面有很多更改的地方,在无需任何配置下还是对安全进行了提升。包括:
全新的密码哈希算法 (SHA-256)
.mylogin 文件对密码进行混淆
可选择在数据库表中存储 Slave 节点密码
可在 START SLAVE 中指定密码
它可以自动的在你的日志文件中隐藏密码。这不只是混淆,然后将单向哈希值存放在日志文件中。通过设定 log-raw=OFF 你可以禁用日志文件的密码隐藏功能。log-raw 设置只影响一般的日志,而慢查询日志和二进制日志中依然会对密码进行隐藏。
在 MySQL 5.5 中这个需要在首次将哈希存储在变量时手工处理,但多数场景下这已经没什么用处了。
另据 mysql 命令的手册,mysql 命令将不会记录匹配到 "*IDENTIFIED*:*PASSWORD*" 的语句。尽管如此,还是别忘记给 MySQL 服务器和客户端日志文件予以核实的权限保护,包括其他的一些如 master.info 的文件。此外,如果你在数据库中存储从节点的凭证时需要使用 MySQL 的特权系统进行保护,如果 master.info 使得某人具有太多的数据库权限,并可使用 LOAD DATA INFILE 加载内容时也应该这么做。
当然我们可以轻松的启用安全连接,这将更好。MySQL 和很多其他应用使用 TLS,但有一些性能的问题,而且设置起来不容易。此外 MySQL 默认是不安全的,只为简单。
ICP(index condition pushdown)是mysql利用索引(二级索引)元组和筛字段在索引中的where条件从表中提取数据记录的一种优化操作。ICP的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的where条件(pushed index condition,推送的索引条件),如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。ICP(优化器)尽可能的把index condition的处理从server层下推到storage engine层。storage engine使用索引过过滤不相关的数据,仅返回符合index condition条件的数据给server层。也是说数据过滤尽可能在storage engine层进行,而不是返回所有数据给server层,然后后再根据where条件进行过滤。使用ICP(mysql 5.6版本以前)和没有使用ICP的数据访问和提取过程如下(插图来在MariaDB Blog):
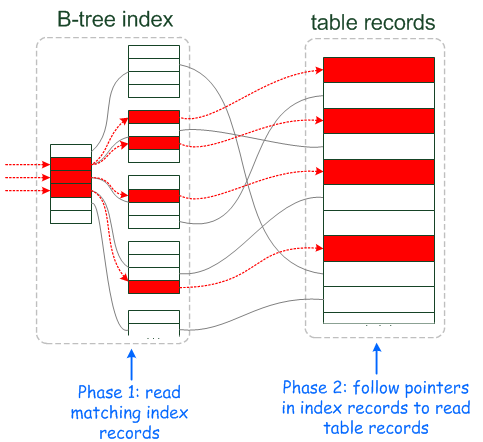
优化器没有使用ICP时,数据访问和提取的过程如下:
1)、当storage engine读取下一行时,首先读取索引元组(index tuple),然后使用索引元组在基表中(base table)定位和读取整行数据。
2)、sever层评估where条件,如果该行数据满足where条件则使用,否则丢弃。
3)、执行1),直到最后一行数据。
优化器使用ICP时,server层将会把能够通过使用索引进行评估的where条件下推到storage engine层。数据访问和提取过程如下:
1)、storage engine从索引中读取下一条索引元组。
2)、storage engine使用索引元组评估下推的索引条件。如果没有满足wehere条件,storage engine将会处理下一条索引元组(回到上一步)。只有当索引元组满足下推的索引条件的时候,才会继续去基表中读取数据。
3)、如果满足下推的索引条件,storage engine通过索引元组定位基表的行和读取整行数据并返回给server层。
4)、server层评估没有被下推到storage engine层的where条件,如果该行数据满足where条件则使用,否则丢弃。
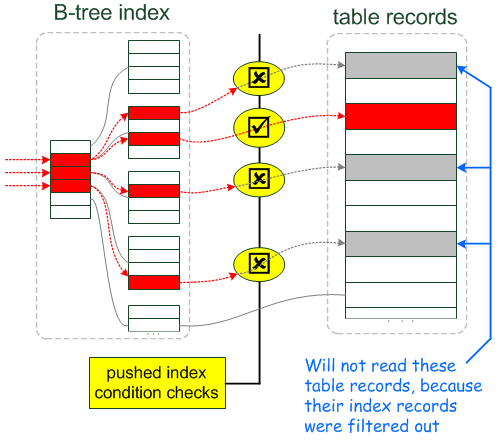
而使用ICP时,如果where条件的一部分能够通过使用索引中的字段进行评估,那么mysql server把这部分where条件下推到storage engine(存储引擎层)。存储引擎通过索引元组的索引列数据过滤不满足下推索引条件的数据行。
索引条件下推的意思就是筛选字段在索引中的where条件从server层下推到storage engine层,这样可以在存储引擎层过滤数据。由此可见,ICP可以减少存储引擎访问基表的次数和mysql server访问存储引擎的次数。
注意一下ICP的使用条件:
只能用于二级索引(secondary index)。
explain显示的执行计划中type值(join 类型)为range、ref、eq_ref或者ref_or_null。且查询需要访问表的整行数据,即不能直接通过二级索引的元组数据获得查询结果(索引覆盖)。
ICP可以用于MyISAM和InnnoDB存储引擎,不支持分区表(5.7将会解决这个问题)。
ICP的开启优化功能与关闭
MySQL5.6可以通过设置optimizer_switch([global|session],dynamic)变量开启或者关闭index_condition_push优化功能,默认开启。
mysql > set optimizer_switch=’index_condition_pushdown=on|off’
用explain查看执行计划时,如果执行计划中的Extra信息为“using index condition”,表示优化器使用的index condition pushdown。
在mysql5.6以前,还没有采用ICP这种查询优化,where查询条件中的索引条件在某些情况下没有充分利用索引过滤数据。假设一个组合索引(多列索引)K包含(c1,c2,…,cn)n个列,如果在c1上存在范围扫描的where条件,那么剩余的c2,…,cn这n-1个上索引都无法用来提取和过滤数据(不管不管是唯一查找还是范围查找),索引记录没有被充分利用。即组合索引前面字段上存在范围查询,那么后面的部分的索引将不能被使用,因为后面部分的索引数据是无序。比如,索引key(a,b)中的元组数据为(0,100)、(1,50)、(1,100) ,where查询条件为 a < 2 and b = 100。由于b上得索引数据并不是连续区间,因为在读取(1,50)之后不再会读取(1,100),mysql优化器在执行索引区间扫描之后也不再扫描组合索引其后面的部分。
表结构定义如下:
CREATE TABLE `person` (
`person_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`postadlcode` int(11) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`person_id`),
KEY `idx_p_a` (`postadlcode`,`age`),
KEY `idx_f_l` (`first_name`,`last_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
关闭ICP优化,Extra信息为“Using Where”。
mysql> set optimizer_switch = "index_condition_pushdown=off";
mysql> explain select * from person where postadlcode between 300000 and 400000 and age > 40;
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key、 | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE、 | person | range | idx_p_a、 | idx_p_a | 7、 | NULL | 21 | Using where |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
开启ICP之后,Extra信息为“Using Index Condition”。
mysql> set optimizer_switch = "index_condition_pushdown=on";
mysql> explain select * from person where postadlcode between 300000 and 400000 and age > 40;
+----+-------------+--------+-------+---------------+---------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key、 | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-----------------------+
| 1 | SIMPLE、 | person | range | idx_p_a、 | idx_p_a | 7、 | NULL | 21 | Using index condition |
+----+-------------+--------+-------+---------------+---------+---------+------+------+-----------------------+
参考资料:
原文链接
Index Condition Pushdown Optimization
v5.7 重要记事
半同步复制技术介绍
复制架构衍生史
在谈这个特性之前先来看看MySQL的复制架构衍生史。MySQL的复制分为四种:
普通的replication,异步同步。搭建简单,使用非常广泛,从mysql诞生之初,就产生了这种架构,性能非常好,可谓非常成熟。 但是这种架构数据是异步的,所以有丢失数据库的风险。
semi-sync replication,半同步。性能,功能都介于异步和全同步中间。从v5.5开始诞生,目的是为了折中上述两种架构的性能以及优缺点。
sync replication,全同步。目前官方5.7基于Group replication的全同步技术处在labs版本,离正式集成已经不远。全同步技术带来了更多的数据一致性保障。相信是未来同步技术一个重要方向,值得期待。
mysql cluster,基于NDB引擎,搭建也简单,本身也比较稳定,是mysql里面对数据保护最靠谱的架构,也是目前唯一一个数据完全同步的架构,数据零丢失。不过对业务比较挑剔,限制也较多。
半同步复制
在此谈论第二种架构。我们知道,普通的replication,即mysql的异步复制,依靠mysql二进制日志也即binary log进行数据复制。比如两台机器,一台主机(master),另外一台是从机(slave)。
正常的复制为:事务一(t1)写入binlog buffer;dumper 线程通知slave有新的事务t1;binlog buffer 进行checkpoint;slave的io线程接收到t1并写入到自己的的relay log;slave的sql线程写入到本地数据库。 这时,master和slave都能看到这条新的事务,即使master挂了,slave可以提升为新的master。
异常的复制为:事务一(t1)写入binlog buffer;dumper 线程通知slave有新的事务t1;binlog buffer 进行checkpoint;slave因为网络不稳定,一直没有收到t1;master 挂掉,slave提升为新的master,t1丢失。
很大的问题是:主机和从机事务更新的不同步,就算是没有网络或者其他系统的异常,当业务并发上来时,slave因为要顺序执行master批量事务,导致很大的延迟。
为了弥补以上几种场景的不足,mysql从5.5开始推出了半同步。即在master的dumper线程通知slave后,增加了一个ack,即是否成功收到t1的标志码。也就是dumper线程除了发送t1到slave,还承担了接收slave的ack工作。如果出现异常,没有收到ack,那么将自动降级为普通的复制,直到异常修复。 我们可以看到半同步带来的新问题:
如果异常发生,会降级为普通的复制。 那么从机出现数据不一致的几率会减少,并不是完全消失。
主机dumper线程承担的工作变多了,这样显然会降低整个数据库的性能。
在v5.5和v5.6使用after_commit的模式下, 即如果slave 没有收到事务,也就是还没有写入到relay log 之前,网络出现异常或者不稳定,此时刚好master挂了,系统切换到从机,两边的数据就会出现不一致。 在此情况下,slave会少一个事务的数据。
随着v5.7版本的发布,半同步复制技术升级为全新的Loss-less Semi-Synchronous Replication架构,其成熟度、数据一致性与执行效率得到显著的提升。
v5.7 数据复制效率的改进
主从一致性加强, 支持在事务commit前等待ACK。新版本的semi sync 增加了rpl_semi_sync_master_wait_point参数, 来控制半同步模式下主库在返回给会话事务成功之前提交事务的方式。 该参数有两个值:
AFTER_COMMIT(5.6默认值)master将每个事务写入binlog ,传递到slave 刷新到磁盘(relay log),同时主库提交事务。master等待slave 反馈收到relay log,只有收到ACK后master才将commit OK结果反馈给客户端。
AFTER_SYNC(5.7默认值,但5.6中无此模式)master 将每个事务写入binlog , 传递到slave 刷新到磁盘(relay log)。master等待slave 反馈接收到relay log的ack之后,再提交事务并且返回commit OK结果给客户端。 即使主库crash,所有在主库上已经提交的事务都能保证已经同步到slave的relay log中。因此5.7引入了after_sync模式,带来的主要收益是解决after_commit导致的master crash主从间数据不一致问题,因此在引入after_sync模式后,所有提交的数据已经都被复制,故障切换时数据一致性将得到提升。
性能提升, 支持发送binlog和接受ack的异步化
旧版本的semi sync 受限于dump thread ,原因是dump thread 承担了两份不同且又十分频繁的任务:传送binlog 给slave ,还需要等待slave反馈信息,而且这两个任务是串行的,dump thread 必须等待 slave 返回之后才会传送下一个 events 事务。dump thread 已然成为整个半同步提高性能的瓶颈。在高并发业务场景下,这样的机制会影响数据库整体的TPS 。
为了解决上述问题,在5.7版本的semi sync 框架中,独立出一个 ack collector thread ,专门用于接收slave 的反馈信息。这样master 上有两个线程独立工作,可以同时发送binlog 到slave ,和接收slave的反馈。
性能提升, 控制主库接收slave 写事务成功反馈数量
MySQL 5.7 新增了rpl_semi_sync_master_wait_slave_count参数,可以用来控制主库接受多少个slave写事务成功反馈,给高可用架构切换提供了灵活性。如图所示,当count值为2时,master需等待两个slave的ack。
性能提升, Binlog 互斥锁改进
旧版本半同步复制在主提交binlog的写会话和dump thread读binlog的操作都会对binlog添加互斥锁,导致binlog文件的读写是串行化的,存在并发度的问题。
MySQL 5.7 对binlog lock进行了以下两方面优化: 1. 移除了dump thread对binlog的互斥锁 2. 加入了安全边际保证binlog的读安全
性能提升, 组提交
MySQL 5.7 引入了新的变量slave-parallel-type,其可以配置的值有:1. DATABASE(5.7之前默认值),基于库的并行复制方式; 2. LOGICAL_CLOCK (5.7新增值),基于组提交的并行复制方式;MySQL 5.6版本也支持所谓的并行复制,但是其并行只是基于DATABASE的,也就是基于库的。如果用户的MySQL数据库实例中存在多个DATABASE ,对于从机复制的速度的确可以有比较大的帮助,如果用户实例仅有一个库,那么就无法实现并行回放,甚至性能会比原来的单线程更差。
MySQL5.7中增加了一种新的并行模式:为同时进入COMMIT阶段的事务分配相同的序列号,这些拥有相同序列号的事务在备库是可以并发执行的。MySQL 5.7真正实现的并行复制,这其中最为主要的原因就是slave服务器的回放与主机是一致的即master服务器上是怎么并行执行的slave上就怎样进行并行回放。不再有库的并行复制限制,对于二进制日志格式也无特殊的要求(基于库的并行复制也没有要求)。因此下面的序列中可以并发的序列为(其中前面一个数字为last_committed ,后面一个数字为sequence_number):
trx1 1…..2
trx2 1………….3
trx3 1…………………….4
trx4 2……………………….5
trx5 3…………………………..6
trx6 3………………………………7
trx7 6………………………………..8
备库并行规则:当分发一个事务时,其last_committed 序列号比当前正在执行的事务的最小sequence_number要小时,则允许执行。因此: 1. trx1执行,last_commit<2的可并发,trx2, trx3可继续分发执行 2. trx1执行完成后,last_commit < 3的可以执行, trx4可分发 3. trx2执行完成后,last_commit < 4的可以执行, trx5, trx6可分发 4. trx3、trx4、trx5完成后,last_commit < 7的可以执行,trx7可分发
综述
我们认为MySQL 5.7版对半同步复制技术的优化,使得其成熟度和执行效率都得到了质的提高。我们建议在使用MySQL 5.7作为生产环境的部署时,可以使用半同步技术作为高可用与读写分离方案的数据复制方案。
本文转自:MySQL 5.7 深度解析: 半同步复制技术,感谢原作者。
v5.7 停服
2023年9月,信通院下属的云计算开源产业联盟发布了一个关于 MySQL 数据库开源生态的研究报告《开源数据库生态发展研究报告 - MySQL 开源数据库》,其中提到了在 10 月份 MySQL 社区将会发生一件大事 --MySQL 5.7 将会于 2023 年 10 月 21 日结束服务期(EOL)。MySQL 目前已经成为中国用户使用最广泛的开源数据库,其中 5.7 版本的用户的比重又是最高的,因此 MySQL 5.7 EOL 事件会影响到很多 MySQL 用户。
根据报告中的统计数字,MySQL 5.7 用户占比在国内高达 47%。届时这些用户将会面临选择,如何应对 EOL 事件。实际上 2020 年的时候就有一些机构提醒用户,MySQL 5.7 按照生命周期将于 2023 年到达服务期限,当时这件事还在 MySQL 社区和 DBA 圈子里引发过一些关于开源项目安全性的讨论。3 年后,这个狼来了的问题,终于正式要面对我们了。实际上数据库 EOL 的问题并不是在 MySQL 5.7 上第一次出现,Oracle 用户都很清楚每个版本 EOL 的时间表。只不过 Oracle 官方依然会对付费用户提供延长期服务,还会在数年时间里继续为这些用户发布安全补丁包,因此 EOL 的 Oracle 版本依然可以通过各种渠道找到安全补丁包。而作为开源数据库的 MySQL,EOL 就意味着开源社区不再提供安全与功能方面的补丁升级了。
面对 MySQL 5.7 EOL 这个事件,percona 官方宣布了付费支持的计划,在 EOL 之后的三年内,percona 会为需要服务的客户提供收费服务支持。不过支持的力度如何,是否承诺对安全问题发布补丁不得而知。MariaDB 一贯的对 MySQL 持有敌意,他们希望 MySQL 5.7 用户不要升级 MySQL 8 了,而是通过 11 条简单的命令迁移到 MariaDB 上去。除此之外,一些云厂商也纷纷提出了解决方案。云厂商则纷纷发布了延长服务的声明,微软 Azure 将会在 MySQL 5.7 EOL 之后,为其公有云用户提供延长的服务,由 Azure 官方提供支持,最晚到 2025 年。类似情况,亚马逊也将为其公有云用户提供一年期的支持。不论是亚马逊还是微软,当延长服务期结束后,MySQL 5.7 用户将必须强制升级到 MySQL 8 或者迁移到其他数据库上。
面对这个问题,国内的 MySQL 生态的数据库厂商也纷纷给出了自己的迁移方案,希望吸引这部分用户到自己的产品上来。和一些 MySQL 5.7 用户做了一些交流,根据他们反馈的情况,以及业内对此问题的应对措施,再结合报告中反馈的四种情况,我总结了一下,大致有六种应对措施。
第一条路径:直接升级到 8.0
做出此选择的 MySQL5.7 用户占比较高,此类用户对此问题早已了解,并且在半年前就已经开始应对工作。MySQL 5.7 升级到 8.0 不仅仅是更换一个数据库版本而已,因为 8.0 与 5.7 在技术上有较大的差异,CBO 优化器与 SQL 引擎都有一定的不同,因此数据库升级后应用需要做全面的测试,对于不够兼容的部分代码做一定的修改才能确保顺利迁移。因此采用第一种路径的用户,需要做一定的提前准备。
第二条路径:直接迁 移到 MySQL 兼容的国产数据库
有一部分客户考虑到信创的问题,原本就已经计划对数据库进行国产化替代,准备一次性到位。如果用国产数据库替代,那么可以选择的路径也很多,很多国产数据库产品就是 MySQL 生态产品,比如腾讯 TDSQL、万里 GreatSQL、中兴通讯 GoldenDB、Oceanbase、阿里 PolarDB-x 等。如果不需要使用存储过程,还可以考虑 TiDB。很多国产数据库也有 MySQL 兼容模式,虽然不能完全兼容 MySQL,应用做少量的修改也可以迁移过去。达梦、人大金仓、GaussDB 等数据库都有 MySQL 兼容模式。直接迁移到国产数据库的优点是从根本上完成数据库国产化替代,不过缺点也很明显,一方面是迁移需要一定的资金,也需要一定的时间,另外一方面是国产数据库许可证采购的总体成本不低。
第三条路径:迁移到其他 MySQL 生态的开源产品
比如 MariaDB 和国内的 GreatSQL。 向 MariaDB 迁移的用户主要考虑的是摆脱 Oracle 生态,选择一个相对更加安全的开源项目,不过 MariaDB 社区是否足够安全,也是仁者见仁智者见智。GreatSQL 是 Percona Server 的一个开源分支,也基于 GPLv2 协议,代码托管在国内的 gitee 上。在保持与 Percona Server 兼容的基础上,会更快速地修复漏洞,保障用户的数据安全。随后 GreatSQL 开源社区将会在官网上开设一个 MySQL5.7 停服专区,帮助 MySQL 5.7 的用户解决一些停服带来的问题,为某些暂时无法升级的用户提供支撑。随着软件供应链安全方面的需求的不断加强,国内开源项目分支的发展将会迎来高速发展。这条路径的迁移成本较低,缺点是用户目前对国内的开源分支的认可度还存在一定问题。
第四条路径:对于公有云用户,依托云平台再多撑一两年,在一两年中再选择方向。公有云厂商还会对 MySQL 5.7 提供一定时间的延长支持。公有云用户先观望一年再选择稳妥的技术路线的比例是比较高的。这条路线获得了一定时间的缓冲区,以便于做出更为科学的决策,不过仅仅是过渡期的临时做法。
第五条路径:换门
从 MySQL 直接更换数据库种类,转投另外一个开源数据库 PG 阵营。和摄影界换门一样,采取这条路径是要下大决心的。因为以往的应用都要修改,数据都要迁移,以往积累的应用开发与运维经验也都要放弃。
第六条路径:不变应万变
数据库都是在内部使用的,因此把网络的安全边界扎牢,哪怕有安全漏洞,也不升级,不改变,等到应用系统升级的时候再考虑升级或者更换数据库。选择这条路线的用户比例不低,这条路径成本最低,不过要承担一定的安全风险。采用这条路线的用户把安全依托在网络安全和边界安全上,通过扎紧篱笆来防止安全事故。
最后要表达的观点是,EOL 是很多产品都会面临的事件,无需过度担心。不过数据库产品的 EOL 影响面更广一些,处理起来也更麻烦一些,特别是 MySQL 5.7,对于一些复杂一些的系统,直接升级到 8.0 还是需要做一些验证工作的。作为一个核心的数据资产承载体,没有安全补丁处于裸奔状态的数据库也是一个比较大的隐患。从软件供应链安全上看,商用数据库 Oracle 在代码上的安全性要高于 MySQL 这样的开源数据库,再加上 Oracle 延长期服务依然在出安全补丁,用户也可以通过一些特殊渠道获得安全补丁。因此相对于 Oracle 数据库的版本 EOL,MySQL 的 EOL 问题更受企业级用户的重视。面对即将到来的 MySQL 5.7 EOL,IT 部门的领导和 DBA 哪怕没有做什么动作,多思考一下也是好的。