mysql json 使用入门
 1、json 对象的介绍
1、json 对象的介绍在 mysql 未支持 json 数据类型时,通常使用 varchar、blob 或 text 的数据类型存储 json 字符串,对 mysql 来说,用户插入的数据只是序列化后的一个普通的字符串,不会对 JSON 文档本身的语法合法性做检查,文档的合法性需要用户自己保证。在使用时需要先将整个 json 对象从数据库读取出来,在内存中完成解析及相应的计算处理,这种方式增加了数据库的网络开销并降低处理效率。
从 MySQL 5.7.8 开始,MySQL 支持 RFC 7159 定义的全部 json 数据类型,具体的包含四种基本类型(strings, numbers, booleans,and null)和两种结构化类型(objects and arrays)。可以有效地访问 JSON 文档中的数据。与将 JSON 格式的字符串存储在字符串列中相比,该数据类型具有以下优势:
1).自动验证存储在 JSON 列中的 JSON 文档。无效的文档会产生错误。
2).优化的存储格式。存储在列中的 JSON 文档被转换为允许快速读取文档元素的内部格式。当读取 JSON 值时,不需要从文本表示中解析该值,使服务器能够直接通过键或数组索引查找子对象或嵌套值,而无需读取文档中它们之前或之后的所有值。
2、json 类型的存储结构
mysql 为了提供对 json 对象的支持,提供了一套将 json 字符串转为结构化二进制对象的存储方式。json 会被转为二进制的 doc 对象存储于磁盘中(在处理 JSON 时 MySQL 使用的 utf8mb4 字符集,utf8mb4 是 utf8 和 ascii 的超集)。
doc 对象包含两个部分,type 和 value 部分。其中 type 占 1 字节,可以表示 16 种类型:大的和小的 json object 类型、大的和小的 json array 类型、literal 类型(true、false、null 三个值)、number 类型(int6、uint16、int32、uint32、int64、uint64、double 类型、utf8mb4 string 类型和 custom data(mysql 自定义类型),具体可以参考源码 json_binary.cc 和 json_binary.h 进行学习。
下面进行简单介绍:
type ::=
0x00 | // small JSON object
0x01 | // large JSON object
0x02 | // small JSON array
0x03 | // large JSON array
0x04 | // literal (true/false/null)
0x05 | // int16
0x06 | // uint16
0x07 | // int32
0x08 | // uint32
0x09 | // int64
0x0a | // uint64
0x0b | // double
0x0c | // utf8mb4 string
0x0f // custom data (any MySQL data type)
1).value 包含 object、array、literal、number、string 和 custom-data 六种类型,与 type 的 16 种类型对应。
2).object 表示 json 对象类型,由 6 部分组成:
3).object ::= element-count size key-entry value-entry key value
其中:
element-count 表示对象中包含的成员(key)个数,在 array 类型中表示数组元素个数。
size 表示整个 json 对象的二进制占用空间大小。小对象用 2Bytes 空间表示(最大 64K),大对象用 4Bytes 表示(最大 4G)
key-entry 可以理解为一个用于指向真实 key 值的数组。本身用于二分查找,加速 json 字段的定位。
key-entry 由两个部分组成:
key-entry ::= key-offset key-length
其中:
key-offset:表示 key 值存储的偏移量,便于快速定位 key 的真实值。
key-length:表示 key 值的长度,用于分割不同 key 值的边界。长度为 2Bytes,这说明,key 值的长度最长不能超过 64kb。
4).value-entry 与 key-enter 功能类似,不同之处在于,value-entry 可能存储真实的 value 值。
value-entry 由两部分组成:
value-entry ::= type offset-or-inlined-value
其中:
type 表示 value 类型,如上文所示,支持 16 种基本类型,从而可以表示各种类型的嵌套。
5).offset-or-inlined-value:有两层含义,如果 value 值足够小,可以存储于此,那么就存储数据本身,如果数据本身较大,则存储真实值的偏移用于快速定位。
key 表示 key 值的真实值,类型为:key ::= utf8mb4-data, 这里无需指定 key 值长度,因为 key-entry 中已经声明了 key 的存储长度。同时,在同一个 json 对象中,key 值的长度总是一样的。
array 表示 json 数组,array 类型主要包含 4 部分:
array ::= element-count size value-entry value
来使用示意图更清晰的展示它的结构:
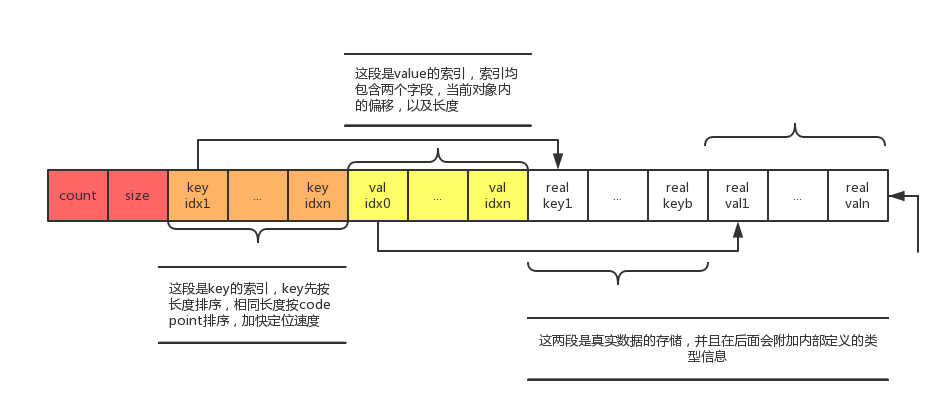
举例说明:


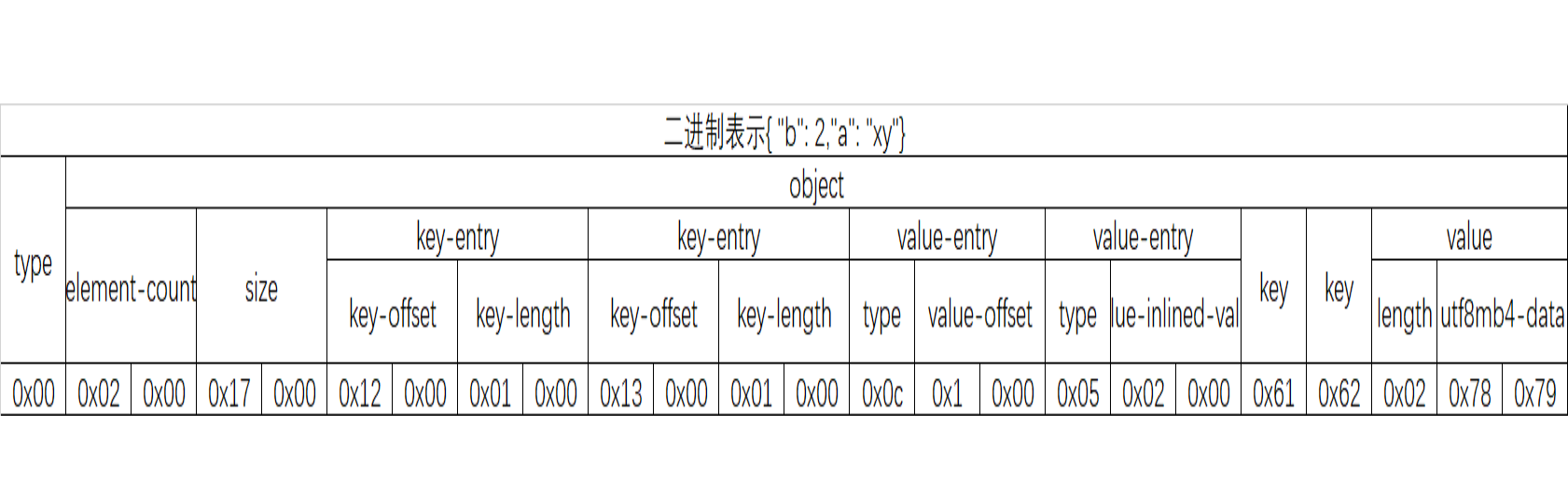

需要注意的是:
1).JSON 对象的 Key 索引(图中橙色部分)都是排序好的,先按长度排序,长度相同的按照 code point 排序;Value 索引(图中黄色部分)根据对应的 Key 的位置依次排列,最后面真实的数据存储(图中白色部分)也是如此
2).Key 和 Value 的索引对存储了对象内的偏移和大小,单个索引的大小固定,可以通过简单的算术跳转到距离为 N 的索引
3).通过 MySQL5.7.16 源代码可以看到,在序列化 JSON 文档时,MySQL 会动态检测单个对象的大小,如果小于 64KB 使用两个字节的偏移量,否则使用四个字节的偏移量,以节省空间。同时,动态检查单个对象是否是大对象,会造成对大对象进行两次解析,源代码中也指出这是以后需要优化的点
4).现在受索引中偏移量和存储大小四个字节大小的限制,单个 JSON 文档的大小不能超过 4G;单个 KEY 的大小不能超过两个字节,即 64K
5).索引存储对象内的偏移是为了方便移动,如果某个键值被改动,只用修改受影响对象整体的偏移量
6).索引的大小现在是冗余信息,因为通过相邻偏移可以简单的得到存储大小,主要是为了应对变长 JSON 对象值更新,如果长度变小,JSON 文档整体都不用移动,只需要当前对象修改大小
7).现在 MySQL 对于变长大小的值没有预留额外的空间,也就是说如果该值的长度变大,后面的存储都要受到影响
8).结合 JSON 的路径表达式可以知道,JSON 的搜索操作只用反序列化路径上涉及到的元素,速度非常快,实现了读操作的高性能
9).MySQL 对于大型文档的变长键值的更新操作可能会变慢,可能并不适合写密集的需求
3、json 类型基本操作
3.1 json 数据插入
json 类型数据插入时有两种方式,一种是基于字符串格式插入,另一种是基于 json_object () 函数,在使用 json_object () 函数只需按 k-v 顺序,以,符号隔开顺序插入即可,MYSQL 会自动验证 JSON 文档,无效的文档会产生错误。
mysql> CREATE TABLE t1 (jdoc JSON);
Query OK, 0 rows affected (0.20 sec)
mysql> INSERT INTO t1 VALUES('{"key1": "value1", "key2": "value2"}');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t1 VALUES('[1, 2,');
ERROR 3140 (22032) at line 2: Invalid JSON text:
"Invalid value." at position 6 in value (or column) '[1, 2,'.
当一个字符串被解析并发现是一个有效的 JSON 文档时,它也会被规范化:具有与文档中先前找到的键重复的键的成员被丢弃(即使值不同)。以下第一个 sql 中通过 JSON_OBJECT () 调用生成的对象值不包括第二个 key1 元素,因为该键名出现在值的前面;第二个 sql 中只保留了 x 第一次出现的值:
mysql> SELECT JSON_OBJECT('key1', 1, 'key2', 'abc', 'key1', 'def');
+------------------------------------------------------+
| JSON_OBJECT('key1', 1, 'key2', 'abc', 'key1', 'def') |
+------------------------------------------------------+
| {"key1": 1, "key2": "abc"} |
+------------------------------------------------------+
mysql> INSERT INTO t1 VALUES
> ('{"x": 17, "x": "red"}'),
> ('{"x": 17, "x": "red", "x": [3, 5, 7]}');
mysql> SELECT c1 FROM t1;
+-----------+
| c1 |
+-----------+
| {"x": 17} |
| {"x": 17} |
+-----------+
3.2 json 合并
MySQL 5.7 支持 JSON_MERGE()的合并算法,多个对象合并时产生一个对象。可将多个数组合并为一个数组:
mysql> SELECT JSON_MERGE('[1, 2]', '["a", "b"]', '[true, false]');
+-----------------------------------------------------+
| JSON_MERGE('[1, 2]', '["a", "b"]', '[true, false]') |
+-----------------------------------------------------+
| [1, 2, "a", "b", true, false] |
+-----------------------------------------------------+
当合并数组与对象时,会将对象转换为新数组进行合并:
mysql> SELECT JSON_MERGE('[10, 20]', '{"a": "x", "b": "y"}');
+------------------------------------------------+
| JSON_MERGE('[10, 20]', '{"a": "x", "b": "y"}') |
+------------------------------------------------+
| [10, 20, {"a": "x", "b": "y"}] |
+------------------------------------------------+
如果多个对象具有相同的键,则生成的合并对象中该键的值是包含键值的数组:
mysql> SELECT JSON_MERGE('{"a": 1, "b": 2}', '{"c": 3, "a": 4}');
+----------------------------------------------------+
| JSON_MERGE('{"a": 1, "b": 2}', '{"c": 3, "a": 4}') |
+----------------------------------------------------+
| {"a": [1, 4], "b": 2, "c": 3} |
+----------------------------------------------------+
MySQL 8.0.3(及更高版本)支持两种合并算法,由函数 JSON_MERGE_PRESERVE () 和 JSON_MERGE_PATCH (). 它们在处理重复键的方式上有所不同:JSON_MERGE_PRESERVE () 保留重复键的值(与 5.7 版本的 JSON_MERGE()相同),而 JSON_MERGE_PATCH () 丢弃除最后一个值之外的所有值。具体的:
1).JSON_MERGE_PRESERVE () 函数接受两个或多个 JSON 文档并返回组合结果。如果参数为两个 object, 相同的 key 将会把 value 合并为 array (即使 value 也相同,也会合并为 array), 不同的 key 则直接合并。如果其中一个参数为 json array,则另一个 json object 整体作为一个元素,加入 array 结果。
2).JSON_MERGE_PATCH () 函数接受两个或多个 JSON 文档并返回组合结果。如果参数为两个 object, 相同的 key 的 value 将会被后面参数的 value 覆盖,不同的 key 则直接合并。如果合并的是数组,将按照 “最后一个重复键获胜” 逻辑仅保留最后一个参数。
mysql> SELECT JSON_MERGE_PRESERVE('{"a":1,"b":2}', '{"a":3,"c":3}');
+-------------------------------------------------------+
| JSON_MERGE_PRESERVE('{"a":1,"b":2}', '{"a":3,"c":3}') |
+-------------------------------------------------------+
| {"a": [1, 3], "b": 2, "c": 3} |
+-------------------------------------------------------+
1 row in set (0.01 sec)
mysql> SELECT JSON_MERGE_PATCH('{"a":1,"b":2}', '{"a":3,"c":3}');
+----------------------------------------------------+
| JSON_MERGE_PATCH('{"a":1,"b":2}', '{"a":3,"c":3}') |
+----------------------------------------------------+
| {"a": 3, "b": 2, "c": 3} |
+----------------------------------------------------+
1 row in set (0.02 sec)
mysql> SELECT JSON_MERGE_PRESERVE('["a", 1]', '"a"','{"key": "value"}');
+-----------------------------------------------------------+
| JSON_MERGE_PRESERVE('["a", 1]', '"a"','{"key": "value"}') |
+-----------------------------------------------------------+
| ["a", 1, "a", {"key": "value"}] |
+-----------------------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT JSON_MERGE_PATCH('["a", 1]', '"a"','{"key": "value"}') ;
+--------------------------------------------------------+
| JSON_MERGE_PATCH('["a", 1]', '"a"','{"key": "value"}') |
+--------------------------------------------------------+
| {"key": "value"} |
+--------------------------------------------------------+
1 row in set (0.01 sec)
3.3 json 数据查询
MySQL 5.7.7 + 本身提供了很多原生的函数以及路径表达式来方便用户访问 JSON 数据。JSON_EXTRACT () 函数用于解析 json 对象,-> 符号是就一种 JSON_EXTRACT () 函数的等价模式。例如查询上面 t1 表中 jdoc 字段中 key 值为 x 的值:
SELECT jdoc->'$.x' FROM t1;
SELECT JSON_EXTRACT(jdoc,'$.x') FROM t1;
JSON_EXTRACT 返回值会带有” “, 如果想获取原本的值可以使用 JSON_UNQUOTE
mysql> SELECT JSON_EXTRACT('{"id": 14, "name": "Aztalan"}', '$.name');
+---------------------------------------------------------+
| JSON_EXTRACT('{"id": 14, "name": "Aztalan"}', '$.name') |
+---------------------------------------------------------+
| "Aztalan" |
+---------------------------------------------------------+
mysql> SELECT JSON_UNQUOTE(json_extract('{"id": 14, "name": "Aztalan"}', '$.name'));;
+-----------------------------------------------------------------------+
| JSON_UNQUOTE(json_extract('{"id": 14, "name": "Aztalan"}', '$.name')) |
+-----------------------------------------------------------------------+
| Aztalan |
+-----------------------------------------------------------------------+
json 路径的语法:
pathExpression:
scope[(pathLeg)*]
pathLeg:
member | arrayLocation | doubleAsterisk
member:
period ( keyName | asterisk )
arrayLocation:
leftBracket ( nonNegativeInteger | asterisk ) rightBracket
keyName:
ESIdentifier | doubleQuotedString
doubleAsterisk:
'**'
period:
'.'
asterisk:
'*'
leftBracket:
'['
rightBracket:
']'
以 json {“a”: [ [ 3, 2 ], [ { “c” : “d” }, 1 ] ], “b”: { “c” : 6 }, “one potato”: 7, “b.c” : 8 } 为例:
$.a [1] 获取的值为 [ { “c” : “d” }, 1 ]
$.b.c 获取的值为 6
$.”b.c” 获取的值为 8(因为键名包含不合法的表达式所以需要使用引号)
mysql> select json_extract('{ "a": [ [ 3, 2 ], [ { "c" : "d" }, 1 ] ], "b": { "c" : 6 }, "one potato": 7, "b.c" : 8 }','$**.c');
+-------------------------------------------------------------------------------------------------------------------+
| JSON_EXTRACT('{ "a": [ [ 3, 2 ], [ { "c" : "d" }, 1 ] ], "b": { "c" : 6 }, "one potato": 7, "b.c" : 8 }','$**.c') |
+-------------------------------------------------------------------------------------------------------------------+
| ["d", 6] |
+-------------------------------------------------------------------------------------------------------------------+
$**.c 匹配到了两个路径 :
$.a [1].c 获取的值是”d”
$.b.c 获取的值为 6
3.4 json 数据更新
一些函数采用现有的 JSON 文档,以某种方式对其进行修改,然后返回结果修改后的文档。路径表达式指示在文档中进行更改的位置。例如JSON_SET ()、 JSON_INSERT () 和 JSON_REPLACE () 函数各自采用现有的 JSON 文档,加上一个或多个路径和值对,来描述修改文档和要更新的值。这些函数在处理文档中现有值和不存在值的方式上有所不同。具体如下:
mysql> SET @j = '["a", {"b": [true, false]}, [10, 20]]';
JSON_SET () 替换存在的路径的值并添加不存在的路径的值:
mysql> SELECT JSON_SET(@j, '$[1].b[0]', 1, '$[2][2]', 2);
+--------------------------------------------+
| JSON_SET(@j, '$[1].b[0]', 1, '$[2][2]', 2) |
+--------------------------------------------+
| ["a", {"b": [1, false]}, [10, 20, 2]] |
+--------------------------------------------+
在这种情况下,路径 $[1].b [0] 选择一个现有值 (true),该值将替换为路径参数 (1) 后面的值。该路径 $[2][2] 不存在,因此将相应的值 (2) 添加到 选择的值中 $[2]。
JSON_INSERT() 添加新值但不替换现有值:
mysql> SELECT JSON_INSERT(@j, '$[1].b[0]', 1, '$[2][2]', 2);
+-----------------------------------------------+
| JSON_INSERT(@j, '$[1].b[0]', 1, '$[2][2]', 2) |
+-----------------------------------------------+
| ["a", {"b": [true, false]}, [10, 20, 2]] |
+-----------------------------------------------+
JSON_REPLACE() 替换现有值并忽略新值:
mysql> SELECT JSON_REPLACE(@j, '$[1].b[0]', 1, '$[2][2]', 2);
+------------------------------------------------+
| JSON_REPLACE(@j, '$[1].b[0]', 1, '$[2][2]', 2) |
+------------------------------------------------+
| ["a", {"b": [1, false]}, [10, 20]] |
+------------------------------------------------+
JSON_REMOVE() 接受一个 JSON 文档和一个或多个路径,这些路径指定要从文档中删除的值。返回值是原始文档减去文档中存在的路径选择的值:
mysql> SELECT JSON_REMOVE(@j, '$[2]', '$[1].b[1]', '$[1].b[1]');
+---------------------------------------------------+
| JSON_REMOVE(@j, '$[2]', '$[1].b[1]', '$[1].b[1]') |
+---------------------------------------------------+
| ["a", {"b": [true]}] |
+---------------------------------------------------+
$[2] 匹配 [10, 20] 并删除它。
$[1].b [1] 匹配 元素 false 中 的第一个实例 b 并将其删除。
不匹配的第二个实例 $[1].b [1]:该元素已被删除,路径不再存在,并且没有效果。
3.5 json 比较与排序
JSON 值可以使用 =, <, <=,>, >=, <>, !=, <=> 等操作符,BETWEEN, IN,GREATEST, LEAST 等操作符现在还不支持。JSON 值使用的两级排序规则,第一级基于 JSON 的类型,类型不同的使用每个类型特有的排序规则。其类型按照优先级从高到低为:
BLOB
BIT
OPAQUE
DATETIME
TIME
DATE
BOOLEAN
ARRAY
OBJECT
STRING
INTEGER, DOUBLE
NULL
优先级高的类型大,不用再进行其他的比较操作;如果类型相同,每个类型按自己的规则排序。具体的规则如下:
1).BLOB/BIT/OPAQUE: 比较两个值前 N 个字节,如果前 N 个字节相同,短的值小
2).DATETIME/TIME/DATE: 按照所表示的时间点排序
3).BOOLEAN: false 小于 true
ARRAY: 两个数组如果长度和在每个位置的值相同时相等,如果不想等,取第一个不相同元素的排序结果,空元素最小。例:[] < [“a”] < [“ab”] < [“ab”, “cd”, “ef”] < [“ab”, “ef”]
4).OBJECT: 如果两个对象有相同的 KEY,并且 KEY 对应的 VALUE 也都相同,两者相等。否则,两者大小不等,但相对大小未规定。例:{“a”: 1, “b”: 2} = {“b”: 2, “a”: 1}
5).STRING: 取两个 STRING 较短的那个长度为 N,比较两个值 utf8mb4 编码的前 N 个字节,较短的小,空值最小。例:”a” <“ab” < “b” < “bc”;此排序等同于使用 collation 对 SQL 字符串进行排序 utf8mb4_bin。因为 utf8mb4_bin 是二进制排序规则,所以 JSON 值的比较区分大小写:”A” < “a”
6).INTEGER/DOUBLE: 包括精确值和近似值的比较
4、JSON 的索引
现在 MySQL 不支持对 JSON 列进行索引,官网文档的说明是:
JSON columns cannot be indexed. You can work around this restriction by creating an index on a generated column that extracts a scalar value from the JSON column.
虽然不支持直接在 JSON 列上建索引,但 MySQL 规定,可以首先使用路径表达式对 JSON 文档中的标量值建立虚拟列,然后在虚拟列上建立索引。这样用户可以使用表达式对自己感兴趣的键值建立索引。举个具体的例子来说明:
ALTER TABLE features ADD feature_street VARCHAR(30) AS (JSON_UNQUOTE(feature->"$.properties.STREET"));
ALTER TABLE features ADD INDEX (feature_street);
两个步骤,可以对 feature 列中 properties 键值下的 STREET 键 (feature->”$.properties.STREET”) 创建索引。
其中,feature_street 列就是新添加的虚拟列。之所以取名虚拟列,是因为与它对应的还有一个存储列 (stored column)。它们最大的区别为虚拟列只修改数据库的 metadata,并不会存储真实的数据在硬盘上,读取过程也是实时计算的方式;而存储列会把表达式的列存储在硬盘上。两者使用的场景不一样,默认情况下通过表达式生成的列为虚拟列。
这样虚拟列的添加和删除都会非常快,而在虚拟列上建立索引跟传统的建立索引的方式并没有区别,会提高虚拟列读取的性能,减慢整体插入的性能。虚拟列的特性结合 JSON 的路径表达式,可以方便的为用户提供高效的键值索引功能。
5、小结
JSON 类型无须预定义字段,适合拓展信息的存储
单个 JSON 文档的大小不能超过 4G;单个 KEY 的大小不能超过两个字节,即 64K
JSON 类型适合应用于不常更新的静态数据
对搜索较频繁的数据建议增加虚拟列并建立索引
上文来源:京东云开发者社区