理解Perl作用域和回调与闭包
将以前一直只限于知道,却不能清晰理解的这几个概念完完整整地梳理了一番。内容参考自骏马金龙的博客空间,感谢原作者。
词法作用域和动态作用域
不管什么语言总要学习作用域(或生命周期)的概念,比如常见的称呼:全局变量、包变量、模块变量、本地变量、局部变量等等。不管如何称呼这些作用域的范围,实现它们的目的都一样:
(1)为了避免名称冲突;
(2)为了限定变量的生命周期(本文以变量名说事,其它的名称在规则上是一样的)。
但是不同语言的作用域规则不一样,虽然学个简单的基础就足够应用,因为我们有编程规范:
(1)尽量避免名称冲突;
(2)加上类似于local的修饰符尽量缩小生效范围;
(3)放进代码块,等等。
但是真正去细心验证作用域的生效机制却并非易事(我学Python的时候,花了很长时间细细验证,学Perl的时候又花了很长时间细细验证),但可以肯定的是,理解本文的词法作用域规则(Lexical scoping)和动态作用域规则(dynamic scoping),对学习任何语言的作用域规则都有很大帮助,这两个规则是各种语言都宏观通用的。
很简单的一段bash下的代码:
x=1
function g(){ echo "g: $x" ; x=2; }
function f(){ local x=3 ; g; echo "f: $x"; } # 输出2还是3
f # 输出1还是3?
echo $x # 输出1还是2?
对于bash来说,上面输出的分别是3(g函数中echo)、2(f函数中的echo)和1(最后一行echo)。但是同样语义的代码在其它语言下得到的结果可能就不一样(分别输出1、3和2,例如perl中将local替换为my)。
这牵扯到两种贯穿所有程序语言的作用域概念:词法作用域(类似于C语言中static)和动态作用域。词法作用域和"词法"这个词真的没什么关系,反而更应该称之为"文本段作用域"。要区别它们,只需要回答"函数out_func中嵌套的内层函数in_func能否看见out_func中的环境"。
对于上面的bash代码来说,假如这段代码是适用于所有语言的伪代码:
1.对于词法作用域的语言,执行f时会调用g,g将无法访问f文本段的变量,词法作用域认为g并不是f的一部分,而是跳出f的,因为g的定义文本段是在全局范围内的,所以它是全局文本段的一部分。如果函数g的定义文本段是在f内部,则g属于f文本段的一部分。
1.1.所以g不知道f文本段中local x=3的设置,于是g的echo会输出全局变量x=1,然后设置x=2,因为它没有加上作用域修饰符,而g又是全局内的函数,所以x将修改全局作用域的x值,使得最后的echo输出2,而f中的echo则输出它自己文本段中的local x=3。所以整个流程输出1 3 2
2.对于动态作用域的语言,执行f时会调用g,g将可以访问f文本中的变量,动态作用域认为g是f文本段的一部分,是f中的嵌套函数。
2.1.所以g能看到local x=3的设置,所以g的echo会输出3。g中设置x=2后,仅仅只是在f的内层嵌套函数中设置,所以x=2对g文本段和f文本段(因为g是f的一部分)都可见,但对f文本段外部不可见,所以f中的echo输出2,最后一行的echo输出1。所以整个流程输出3 2 1
3.总结来说:
3.1.词法作用域是关联在编译期间的,对于函数来说就是函数的定义文本段的位置决定这个函数所属的范围;
3.2.动态作用域是关联在程序执行期间的,对于函数来说就是函数执行的位置决定这个函数所属的范围。
由于bash实现的是动态作用域规则。所以输出的是3 2 1。对于perl来说,my修饰符实现词法作用域规则,local修饰符实现动态作用域规则。
例如使用my修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { my $x=3; g(); print "f: $x\n"; } # 词法作用域
f();
print "$x\n";
执行结果:$ perl scope2.pl
g: 1
f: 3
2
使用local修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { local $x=3; g(); print "f: $x\n"; } # 动态作用域
f();
print "$x\n";
执行结果:$ perl scope2.pl
g: 3
f: 2
1
有些语言只支持一种作用域规则,特别是那些比较现代化的语言,而有些语言支持两种作用域规则(正如perl语言,my实现词法变量作用域规则,local实现动态作用域规则)。相对来说,词法作用域规则比较好控制整个流程,还能借此实现更丰富的功能(如最典型的"闭包"以及高阶函数),而动态作用域由于让变量生命周期"没有任何深度"(回想一下shell脚本对函数和作用域的控制,非常傻瓜化),比较少应用上,甚至有些语言根本不支持动态作用域。
闭包和回调函数
理解闭包、回调函数不可不知的术语
1.引用(reference):数据对象和它们的名称
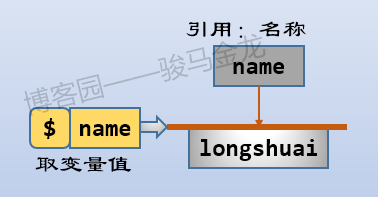
前文所说的可见、不可见、变量是否存在等概念,都是针对变量名(或其它名称,如函数名、列表名、hash名)而言的,和变量的值无关。名称和值的关系是引用(或指向)关系,赋值的行为就是将值所在的数据对象的引用(指针)交给名称,让名称指向这个内存中的这个数据值对象。如下图:
2.一级函数(first-class functions)和高阶函数(high-order functions)
有些语言认为函数就是一种类型,称之为函数类型,就像变量一样。这种类型的语言可以:
1).将函数赋值给某个变量,那么这个变量就是这个函数体的另一个引用,就像是第二个函数名称一样。通过这个函数引用变量,可以找到函数体,然后调用执行。
1.1).例如perl中$ref_func=\&myfunc表示将函数myfunc的引用赋值给$ref_func,那么$ref_func也指向这个函数。
2).将函数作为另一个函数的参数。例如两个函数名为myfunc和func1,那么myfunc(func1)就将func1作为myfunc的参数。
2.1).这种行为一般用于myfunc函数中对满足某些逻辑的东西执行func1函数。
2.2).举个简单的例子,unix下的find命令,将find看作是一个函数,它用于查找指定路径下符合条件的文件名,将-print、-exec {}\;选项实现的功能看作是其它的函数(请无视它是否真的是函数),这些选项对应的函数是find函数的参数,每当find函数找到符合条件的文件名时,就执行-print函数输出这个文件名。
3).函数的返回值也可以是另一个函数。例如myfunc函数的定义语句为function myfunc(){ ...return func1 }。
其实,实现上面三种功能的函数称之为一级函数或高阶函数,其中高阶函数至少要实现上面的2和3。一级函数和高阶函数并没有区分的必要,但如果一定要区分,那么:
3.1).一级函数更像是一种术语概念,它将函数当作一种值看待,可以将其赋值出去、作为参数传递出去以及作为返回值,对于计算机程序语言而言,它更多的是用来描述某种语言是否支持一级函数;
3.2).高阶函数是一种函数类型,就像回调函数一样,当某个函数符合高阶函数的特性,就可以将其称之为这是一个高阶函数。
3.自由变量(free variable)和约束变量(bound variable)
这是一组数学界的术语。
在计算机程序语言中,自由变量是指函数中的一种特殊变量,这种变量既不在本函数中定义,也不是本函数的参数。换句话说,可能是外层函数中定义的但却在内层函数中使用的,所以自由变量常常和"非本地变量"(non-local variable,熟悉Python的人肯定知道)互用。例如:
function func1(x){
var z;
function func2(y){
return x+y+z # x和z既不是func2内部定义的,也不是func2的参数,所以x和z都是自由变量
}
return func1
}
自由变量和约束变量对应。所谓约束变量,是指这个变量之前是自由变量,但之后会对它进行赋值,将自由变量绑定到一个值上之后,这个变量就成为约束变量或者称为绑定变量。例如:
function func1(x){
var m=20 # 对func2来说,这是自由变量,对其赋值,所以m变成了bound variable
var z
function func2(y){
z=10 # 对自由变量z赋值,z变成bound variable
return m+x+y+z # m、x和z都是自由变量
}
return func1
}
ref_func=func1(3) # 对x赋值,x变成bound variable
回调函数
回调函数一开始是C里面的概念,它表示的是一个函数:
1.可以访问另一个函数
2.当这个函数执行完了,会执行另一个函数
也就是说,将一个函数(B)作为参数传递给另一个函数(A),但A执行完后,再自动调用B。所以这种回调函数的概念也称为"call after"。
但是现在回调函数已经足够通用化了。通用化的回调函数定义为:将函数B作为另一个函数A的参数,执行到函数A中某个地方的时候去调用B。和原来的概念相比,不再是函数A结束后再调用,而是我们自己定义在哪个地方调用。
例如,Perl中的File::Find模块中的find函数,通过这个函数加上回调函数,可以实现和unix find命令相同的功能。例如搜索某个目录下的文件,然后print输出这个文件名,即find /path xxx -print。
#!/usr/bin/perl
use File::Find;
sub print_path {# 定义一个函数,用于输出路径名称
print "$File::Find::name\n";
}
$callback = \&print_path; # 创建一个函数引用,名为$callback,所以perl是一种支持一级函数的语言
find( $callback,"/tmp" ); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
这里传递给find函数的$callback就是一个回调函数,几个关键点:
1.$callback作为参数传递给另一个find()函数(所以find()函数是一个高阶函数);
2.在find()函数中,每查找到一个文件,就调用一次这个$callback函数。当然,如果find是我们自己写的程序,就可以由我们自己定义在什么地方去调用$callback;
3.$callback不是我们主动调用的,而是由find()函数在某些情况下(每查找到一个文件)去调用的。
回调就像对函数进行填空答题一样,根据我们填入的内容去复用填入的函数从而实现某一方面的细节,而普通函数则是定义了就只能机械式地复用函数本身。
之所以称为回调函数,是因为这个函数并非由我们主观地、直接地去调用,而是将函数作为一个参数,通过被调用者间接去调用这个函数参数。本质上,回调函数和一般的函数没有什么区别,可能只是因为我们定义一个函数,却从来没有直接调用它,这一点感觉上有点奇怪,所以有人称之为"回调函数",用来统称这种间接的调用关系。
回调函数可以被多线程异步执行。
彻底搞懂闭包
计算机中的闭包概念是从数学世界引入的,在计算机程序语言中,它也称为词法闭包、函数闭包。
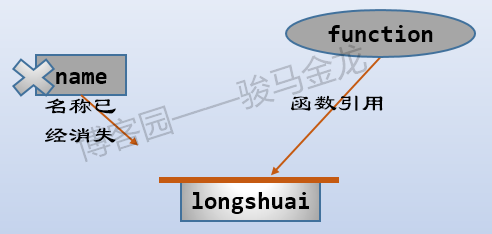
闭包简单的、通用的定义是指:函数引用一个词法变量,在函数或语句块结束后(变量的名称消失),词法变量仍然对引用它的函数有效。在下一节还有关于闭包更严格的定义(来自wiki)。
看一个python示例:函数f中嵌套了函数g,并返回函数g
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数(高阶函数的特性)
# 将执行函数时返回的闭包函数赋值给变量(高阶函数的特性)
a = f(1)
# 调用存储在变量中闭包函数
print (a(5))
# 无需将闭包存储进临时变量,直接一次性调用闭包函数
print( f(1)(5) ) # f(1)是闭包函数,因为没有将其赋值给变量,所以f(1)称为"匿名闭包"
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,在f()返回g函数后,f()就退出了,随之消失的是变量名x(注意是变量名称x,变量的值在这里还不一定会消失)。当将闭包f(1)赋值给a后,原来x指向的数据对象(即数值1)仍被a指向的闭包函数引用着,所以x对应的值1在x消失后仍保存在内存中,只有当名为a的闭包被消除后,原来x指向的数值1才会消失。
闭包特性1:对于返回的每个闭包g()来说,不同的g()引用不同的x对应的数据对象。换句话说,变量x对应的数据对象对每个闭包来说都是相互独立的。
例如下面得到两个闭包,这两个闭包中持有的自由变量虽然都引用相等的数值1,但两个数值是不同数据对象,这两个闭包也是相互独立的:
a=f(1)
b=f(1)
闭包特性2:对于某个闭包函数来说,只要这不是一个匿名闭包,那么闭包函数可以一直访问x对应的数据对象,即使名称x已经消失。
但是:
a=f(1) # 有名称的闭包a,将一直引用数值对象1
a(3) # 调用闭包函数a,将返回1+3=4,其中1是被a引用着的对象,即使a(3)执行完了也不放开
a(3) # 再次调用函数a,将返回4,其中1和上面一条语句的1是同一个数据对象
f(1)(3) # 调用匿名的闭包函数,数据对象1在f(1)(3)执行完就消失
f(1)(3) # 调用匿名的闭包函数,和上面的匿名闭包是相互独立的
最重要的特性就在于上面执行的两次a(3):将词法变量的生命周期延长,但却足够安全。看下面perl程序中的闭包函数,可以更直观地看到结果。
sub how_many {# 定义函数
my $count=2; # 词法变量$count
return sub {print ++$count,"\n"}; # 返回一个匿名函数,这是一个匿名闭包
}
$ref=how_many(); # 将闭包赋值给变量$ref
how_many()->(); # (1)调用匿名闭包:输出3
how_many()->(); # (2)调用匿名闭包:输出3
$ref->(); # (3)调用命名闭包:输出3
$ref->(); # (4)再次调用命名闭包:输出4
&$ref();
&{$ref}();
上面将闭包赋值给$ref,通过$ref去调用这个闭包,则即使how_many中的$count在how_many()执行完就消失了,但$ref指向的闭包函数仍然在引用这个变量,所以多次调用$ref会不断修改$count的值,所以上面(3)和(4)先输出3,然后输出改变后的4。而上面(1)和(2)的输出都是3,因为两个how_many()函数返回的是独立的匿名闭包,在语句执行完后数据对象3就消失了。
闭包更严格的定义
注意,严格定义的闭包和前面通俗定义的闭包结果上是不一样的,通俗意义上的闭包并不一定符合严格意义上的闭包。
关于闭包更严格的定义,是一段谁都看不懂的说明。如下几个关键词我加粗显示了,因为重要。
闭包是一种在支持一级函数的编程语言中能够将词法作用域中的变量名称进行绑定的技术。在操作上,闭包是一种用于保存函数和环境的记录。这个环境记录了一些关联性的映射,将函数的每个自由变量与创建闭包时所绑定名称的值或引用相关联。通过闭包,就算是在作用域外部调用函数,也允许函数通过闭包拷贝他们的值或通过引用的方式去访问那些已经被捕获的变量。
我知道这段话谁都看不懂,所以简而言之一下:一个函数实例和一个环境结合起来就是闭包。这个所谓的环境,决定了这个函数的特殊性,决定了闭包的特性。
还是上面的python示例:函数f中嵌套了函数g,并返回函数g:
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,对于g()来说,这个x不是g()内部定义的,也不是g()的参数,所以这个x对于g来说是一个自由变量(free variable)。虽然g()中持有了自由变量,但是g()函数自身不是闭包函数,只有在g持有的自由变量x和传递给f()函数的x的值(即f(1)中的1)进行绑定的时候,才会从g()创建一个闭包函数,这表示闭包函数开始引用这个自由变量,并且这个闭包一直持有这个变量的引用,即使f()已经执行完毕了。然后在f()中return这个闭包函数,因为这个闭包函数绑定了(引用)自由变量x,这就是闭包函数所在的环境。
环境对闭包来说非常重要,是区别普通函数和闭包的关键。如果返回的每个闭包不是独立持有属于自己的自由变量,而是所有闭包都持有完全相同的自由变量,那么闭包虽然仍可称为闭包,但和普通函数却没有区别了。例如:
def f(x):
x=3
def g(y):
return x + y
return g
a = f(1)
b = f(3)
在上面的示例中,x虽然是自由变量,但却在g()的定义之前就绑定了值(前文介绍过,它称为bound variable),使得闭包a和闭包b持有的不再是自由变量,而是值对象完全相同的绑定变量,其值对象为3,a和b这个时候其实没有任何区别(虽然它们是不同对象)。换句话说,有了闭包a就完全没有必要再定义另一个功能上完全相同的闭包b。
在函数复用性的角度上来说,这里的a和普通函数没有任何区别,都只是简单地复用了函数体。而真正严格意义上的闭包,除了复用函数体,还复用它所在的环境。
但是这样一种情况,对于通俗定义的闭包来说,返回的g()也是一个闭包,但在严格定义的闭包中,这已经不算是闭包。再看一个示例:将自由变量x放在g()函数定义文本段的后面。
def f(y):
return x+y
x=1
def g(z):
x=3
return f(z)
print(g(1)) # 输出2,而不是4
首先要说明的是,python在没有给任何作用域修饰符的时候实现的词法作用域规则,所以上面return f(z)中的f()看见的是全局变量x(因为f()定义在全局文本段中),而不是g()中的x=3。
回到闭包问题上。上面f()持有一个自由变量x,这个f(z)的文本定义段是在全局文本段中,它绑定的自由变量x是全局变量(声明并初始化为空或0),但是这个变量之后赋值为1了。对于g()中返回的每个f()所在的环境来说,它持有的自由变量x一开始都是不确定的,但是后来都确定为1了。这种情况也不能称之为闭包,因为闭包是在f()对自由变量进行绑定时创建的,而这个时候x已经是固定的值对象了。
回调函数、闭包和匿名函数
回调函数、闭包和匿名函数其实没有必然的关系,但因为很多书上都将匿名函数和回调函数、闭包放在一起解释,让人误以为回调函数、闭包需要通过匿名函数实现。实际上,匿名函数只是一个有函数定义文本段,却没有名称的函数,而闭包则是一个函数的实例加上一个环境(严格意义上的定义)。
对于闭包和匿名函数来说,仍然以python为例:
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
def h(x):
return lambda y: x + y # 返回一个闭包:匿名函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
b = h(1)
# 调用存储在变量中闭包函数
print (a(5))
print (b(5))
对于回调函数和匿名函数来说,仍然以perl的find函数为例:
#!/usr/bin/perl
use File::Find;
$callback = sub {
print "$File::Find::name\n";
}; # 创建一个匿名函数以及它的引用
find($callback,"/tmp"); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
匿名函数让闭包的实现更简洁,所以很多时候返回的闭包函数就是一个匿名函数实例。
小结
在Perl中,子程序的引用常用来做回调函数(callback)、闭包(closure),特别是匿名子程序。
再以File::Find模块的find函数为例,它用来搜索给定目录下的文件,然后对每个搜索到的文件执行一些操作(通过定义子程序),这些操作对应的函数要传递给find函数,它们就是回调函数。就像unix下的find命令一样,找到文件,然后print、ls、exec CMD操作一样,这几个操作就是find命令的回调函数。
use File::Find;
sub cmd {
print "$File::Find::name\n";
};
find(\&cmd,qw(/perlapp /tmp/pyapp));
其中$File::Find::name代表的是find搜索到的从起始路径(/perlapp /tmp/pyapp)开始的全路径名,此外find每搜索到一个文件,就会赋值给默认变量$_。它代表的是文件的basename,和$File::Find::name全路径不一样。例如:
起始路径 $File::Find::name $_
-------------------------------------------
/perlapp /perlapp/1.pl 1.pl
. ./a.log a.log
perlapp perlapp/2.pl 2.pl
回到回调函数的问题上。上面的示例中,定义好了一个名为cmd的子程序,但一直都没有主动地去执行这个子程序,而是将它的引用放进find函数中,由find函数每次去调用它。这就像是unix的find命令的"-print"选项一样,其中"-print"选项对应的函数就是一个回调函数。
上面的子程序只调用了一次,没必要花脑细胞去设计它的名称,完全可以将其设计为匿名子程序,放进find函数中。
use File::Find;
find(
sub {
print "$File::Find::name\n";
},
qw(/perlapp /tmp/pyapp)
);
Perl闭包(closure)简单介绍
从Perl语言的角度来简单描述下闭包:子程序1中返回另一个子程序2,这个子程序2访问子程序1中的变量x,当子程序1执行结束,外界无法再访问x,但子程序2因为还引用着变量x所指向的数据对象,使得子程序2在子程序1结束后可以继续访问这个数据对象。所以子程序1中的变量x必须是词法变量,否则子程序1执行完后,变量x可能仍可以被外界访问、修改,如果这样,闭包和普通函数就没有意义了。
一个简单的闭包结构:
sub sub1 {
my $var1=N;
$sub2 =sub {
do something about $var1
}
return $sub2 # 返回一个闭包
}
$my_closure = sub1(); # 将闭包函数存储到子程序引用变量
主要目的是为了让子程序sub1内部嵌套的子程序$sub2可以访问属于子程序sub1但不属于子程序$sub2的变量,这样一来,只要把sub1返回的闭包赋值给$my_closure,就可以让这个闭包函数一直引用$var1变量对应的数值对象,但是sub1执行完毕后,外界就无法再通过$var1去访问这个数据对象(因为是词法变量)。也就是说,sub1执行完后,$var1指向的数据对象只有闭包$my_closure可以访问。
Perl语言有自己的特殊性,特别是它支持只执行一次的语句块(即用大括号{}包围),这使得Perl要创建一个闭包并不一定需要函数嵌套,只需将一个函数放进语句块即可:
my $closure;
{
my $count=1; # 随语句块消失的词法变量
$closure = sub {print ++$count,"\n"}; # 闭包函数
}
$closure->(); # 调用一次闭包函数,输出2
$closure->(); # 再调用一次闭包函数,输出3
&{$closure}(); # 再调用,输出4
在上面的代码中,$count引用数在赋值时为1,在sub中使用并赋值给$closure时引用数为2,当退出代码块的时候,count引用数减为1,由于这是个词法变量,退出代码块后外界就无法通过$count来访问了,但是闭包$closure却一直可以继续访问。
闭包的形式其实多种多样。通俗意义上来说,只要一个子程序1可以访问另一个子程序2中的变量,且子程序1不会随子程序2执行结束就丢失变量,就属于闭包。当然,对于Perl来说,可能子程序2并非是必要的,正如上面的例子。
例如下面的代码段就不属于闭包:
$y=3;
sub mysub1 {
$x=shift;
$x+$y;
}
$nested_ref=\&mysub1;
sub mysub2 {
$x=1;
$z=shift;
return $nested_ref->($z);
}
print mysub2(2);
为mysub2中返回的$nested_ref是一个子程序mysub1的一个实例,但mysub1中使用的$y来自于全局变量,而非mysub2,且mysub2执行完后,$y也不会消失,对于闭包来说这看上去没什么必要。
Perl闭包的应用
再通过File::Find模块的find函数,计算出给定目录下的文件数量:
use File::Find;
my $callback;
{
my $count = 0;
$callback = sub { print ++$count, ": $File::Find::name\n" };
}
find($callback, '.'); # 返回数量和文件名
find($callback, '.'); # 再次执行,数量将在上一个find的基础上递增
Perl的语法强大,可以一次性返回多个闭包:
use File::Find;
sub sub1 {
my $total_size = 0;
return(sub { $total_size += -s if -f }, sub { return $total_size });
}
my ($count_em, $get_results) = sub1();
find($count_em, '/opt');
find($count_em, '/boot');
my $total_size = &$get_results();
print "total size of /opt and /boot: $total_size\n";
上面两个闭包,因为同时引用同一个对象,所以闭包$count_em修改的词法变量,$get_results也可以访问。或者:
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
one_count();
one_count();
print get_count();
由于代码块中的子程序有名称,所以这两个子程序在代码块结束后仍然有效(代码块结束后变量无效是因为加了my修饰符)。
但如果将调用语句放在代码块前面呢?
one_count(); # 1
one_count(); # 2
print get_count(); # 输出:2
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
上面输出2,也就是说$count=10的赋值10行为失效。这是因为词法变量的声明和初始化(初始化为undef)是在编译期间完成的,而赋值操作是在执行到它的时候执行的。所以,编译完成后执行到one_count()这条语句时,将调用已编译好的子程序one_count,但这时还没有执行到语句块,所以$count的赋值还没有执行。
可以将上面的语句块加入到BEGIN块中:
one_count(); # 11
one_count(); # 12
print get_count(); # 输出:12
BEGIN{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
state修饰符替代简单的闭包
前面闭包的作用已经非常明显,就是为了让词法变量不能被外部访问,但却让子程序持续访问它。
Perl从5.10提供了一个state修饰符,它和my完全一样,都是词法变量,唯一的区别在于state修饰符使得变量持久化,但对于外界来说却不可访问(因为是词法变量),而且state修饰的变量只会初始化赋值一次。注意:
1.state修饰符不仅仅只能用于子程序中,在任何语句块中都可以使用,例如find、grep、map中的语句块。
2.只要没有东西在引用state变量,它就会被回收。
3.目前state只能修饰标量,修饰数组、hash时将会报错。但可以修饰数组、hash的引用变量,因为引用就是个标量
例如将state修饰的变量从外层子程序移到内层自层序中,下面两个子程序等价:
use 5.010; # for state
sub how_many1 {
my $count=2;
return sub {print ++$count,"\n"};
}
sub how_many2 {
return sub {state $count=2;print ++$count,"\n"};
}
$ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
需要注意的是,虽然state $count=2,但同一个闭包多次执行时不会重新赋值为2,而是在初始化时赋值一次。而且将子程序调用语句放在子程序定义语句前面是可以如期运行的(前面分析过一般的闭包不会如期运行):
$ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
sub how_many2 {
return sub {state $count=2;print ++$count,"\n"};
}
这是因为state $count=2是子程序中的一部分,无论在哪里调用到它,都会执行这一句赋值语句。再例如,state用于while循环的语句块内部,使得每次迭代过程中都持续访问这个变量,而不会每次迭代都初始化:
#!/usr/bin/perl
use v5.10; # for state
while($i<10){
state $count;
$count += $i;
say $count; # 输出:0 1 3 6 10 15 21 28 36 45
$i++;
}
say $count; # 输出空
词法作用域和动态作用域
不管什么语言总要学习作用域(或生命周期)的概念,比如常见的称呼:全局变量、包变量、模块变量、本地变量、局部变量等等。不管如何称呼这些作用域的范围,实现它们的目的都一样:
(1)为了避免名称冲突;
(2)为了限定变量的生命周期(本文以变量名说事,其它的名称在规则上是一样的)。
但是不同语言的作用域规则不一样,虽然学个简单的基础就足够应用,因为我们有编程规范:
(1)尽量避免名称冲突;
(2)加上类似于local的修饰符尽量缩小生效范围;
(3)放进代码块,等等。
但是真正去细心验证作用域的生效机制却并非易事(我学Python的时候,花了很长时间细细验证,学Perl的时候又花了很长时间细细验证),但可以肯定的是,理解本文的词法作用域规则(Lexical scoping)和动态作用域规则(dynamic scoping),对学习任何语言的作用域规则都有很大帮助,这两个规则是各种语言都宏观通用的。
很简单的一段bash下的代码:
x=1
function g(){ echo "g: $x" ; x=2; }
function f(){ local x=3 ; g; echo "f: $x"; } # 输出2还是3
f # 输出1还是3?
echo $x # 输出1还是2?
对于bash来说,上面输出的分别是3(g函数中echo)、2(f函数中的echo)和1(最后一行echo)。但是同样语义的代码在其它语言下得到的结果可能就不一样(分别输出1、3和2,例如perl中将local替换为my)。
这牵扯到两种贯穿所有程序语言的作用域概念:词法作用域(类似于C语言中static)和动态作用域。词法作用域和"词法"这个词真的没什么关系,反而更应该称之为"文本段作用域"。要区别它们,只需要回答"函数out_func中嵌套的内层函数in_func能否看见out_func中的环境"。
对于上面的bash代码来说,假如这段代码是适用于所有语言的伪代码:
1.对于词法作用域的语言,执行f时会调用g,g将无法访问f文本段的变量,词法作用域认为g并不是f的一部分,而是跳出f的,因为g的定义文本段是在全局范围内的,所以它是全局文本段的一部分。如果函数g的定义文本段是在f内部,则g属于f文本段的一部分。
1.1.所以g不知道f文本段中local x=3的设置,于是g的echo会输出全局变量x=1,然后设置x=2,因为它没有加上作用域修饰符,而g又是全局内的函数,所以x将修改全局作用域的x值,使得最后的echo输出2,而f中的echo则输出它自己文本段中的local x=3。所以整个流程输出1 3 2
2.对于动态作用域的语言,执行f时会调用g,g将可以访问f文本中的变量,动态作用域认为g是f文本段的一部分,是f中的嵌套函数。
2.1.所以g能看到local x=3的设置,所以g的echo会输出3。g中设置x=2后,仅仅只是在f的内层嵌套函数中设置,所以x=2对g文本段和f文本段(因为g是f的一部分)都可见,但对f文本段外部不可见,所以f中的echo输出2,最后一行的echo输出1。所以整个流程输出3 2 1
3.总结来说:
3.1.词法作用域是关联在编译期间的,对于函数来说就是函数的定义文本段的位置决定这个函数所属的范围;
3.2.动态作用域是关联在程序执行期间的,对于函数来说就是函数执行的位置决定这个函数所属的范围。
由于bash实现的是动态作用域规则。所以输出的是3 2 1。对于perl来说,my修饰符实现词法作用域规则,local修饰符实现动态作用域规则。
例如使用my修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { my $x=3; g(); print "f: $x\n"; } # 词法作用域
f();
print "$x\n";
执行结果:$ perl scope2.pl
g: 1
f: 3
2
使用local修饰符的perl程序:
#!/usr/bin/perl
$x=1;
sub g { print "g: $x\n"; $x=2; }
sub f { local $x=3; g(); print "f: $x\n"; } # 动态作用域
f();
print "$x\n";
执行结果:$ perl scope2.pl
g: 3
f: 2
1
有些语言只支持一种作用域规则,特别是那些比较现代化的语言,而有些语言支持两种作用域规则(正如perl语言,my实现词法变量作用域规则,local实现动态作用域规则)。相对来说,词法作用域规则比较好控制整个流程,还能借此实现更丰富的功能(如最典型的"闭包"以及高阶函数),而动态作用域由于让变量生命周期"没有任何深度"(回想一下shell脚本对函数和作用域的控制,非常傻瓜化),比较少应用上,甚至有些语言根本不支持动态作用域。
闭包和回调函数
理解闭包、回调函数不可不知的术语
1.引用(reference):数据对象和它们的名称
前文所说的可见、不可见、变量是否存在等概念,都是针对变量名(或其它名称,如函数名、列表名、hash名)而言的,和变量的值无关。名称和值的关系是引用(或指向)关系,赋值的行为就是将值所在的数据对象的引用(指针)交给名称,让名称指向这个内存中的这个数据值对象。如下图:
2.一级函数(first-class functions)和高阶函数(high-order functions)
有些语言认为函数就是一种类型,称之为函数类型,就像变量一样。这种类型的语言可以:
1).将函数赋值给某个变量,那么这个变量就是这个函数体的另一个引用,就像是第二个函数名称一样。通过这个函数引用变量,可以找到函数体,然后调用执行。
1.1).例如perl中$ref_func=\&myfunc表示将函数myfunc的引用赋值给$ref_func,那么$ref_func也指向这个函数。
2).将函数作为另一个函数的参数。例如两个函数名为myfunc和func1,那么myfunc(func1)就将func1作为myfunc的参数。
2.1).这种行为一般用于myfunc函数中对满足某些逻辑的东西执行func1函数。
2.2).举个简单的例子,unix下的find命令,将find看作是一个函数,它用于查找指定路径下符合条件的文件名,将-print、-exec {}\;选项实现的功能看作是其它的函数(请无视它是否真的是函数),这些选项对应的函数是find函数的参数,每当find函数找到符合条件的文件名时,就执行-print函数输出这个文件名。
3).函数的返回值也可以是另一个函数。例如myfunc函数的定义语句为function myfunc(){ ...return func1 }。
其实,实现上面三种功能的函数称之为一级函数或高阶函数,其中高阶函数至少要实现上面的2和3。一级函数和高阶函数并没有区分的必要,但如果一定要区分,那么:
3.1).一级函数更像是一种术语概念,它将函数当作一种值看待,可以将其赋值出去、作为参数传递出去以及作为返回值,对于计算机程序语言而言,它更多的是用来描述某种语言是否支持一级函数;
3.2).高阶函数是一种函数类型,就像回调函数一样,当某个函数符合高阶函数的特性,就可以将其称之为这是一个高阶函数。
3.自由变量(free variable)和约束变量(bound variable)
这是一组数学界的术语。
在计算机程序语言中,自由变量是指函数中的一种特殊变量,这种变量既不在本函数中定义,也不是本函数的参数。换句话说,可能是外层函数中定义的但却在内层函数中使用的,所以自由变量常常和"非本地变量"(non-local variable,熟悉Python的人肯定知道)互用。例如:
function func1(x){
var z;
function func2(y){
return x+y+z # x和z既不是func2内部定义的,也不是func2的参数,所以x和z都是自由变量
}
return func1
}
自由变量和约束变量对应。所谓约束变量,是指这个变量之前是自由变量,但之后会对它进行赋值,将自由变量绑定到一个值上之后,这个变量就成为约束变量或者称为绑定变量。例如:
function func1(x){
var m=20 # 对func2来说,这是自由变量,对其赋值,所以m变成了bound variable
var z
function func2(y){
z=10 # 对自由变量z赋值,z变成bound variable
return m+x+y+z # m、x和z都是自由变量
}
return func1
}
ref_func=func1(3) # 对x赋值,x变成bound variable
回调函数
回调函数一开始是C里面的概念,它表示的是一个函数:
1.可以访问另一个函数
2.当这个函数执行完了,会执行另一个函数
也就是说,将一个函数(B)作为参数传递给另一个函数(A),但A执行完后,再自动调用B。所以这种回调函数的概念也称为"call after"。
但是现在回调函数已经足够通用化了。通用化的回调函数定义为:将函数B作为另一个函数A的参数,执行到函数A中某个地方的时候去调用B。和原来的概念相比,不再是函数A结束后再调用,而是我们自己定义在哪个地方调用。
例如,Perl中的File::Find模块中的find函数,通过这个函数加上回调函数,可以实现和unix find命令相同的功能。例如搜索某个目录下的文件,然后print输出这个文件名,即find /path xxx -print。
#!/usr/bin/perl
use File::Find;
sub print_path {# 定义一个函数,用于输出路径名称
print "$File::Find::name\n";
}
$callback = \&print_path; # 创建一个函数引用,名为$callback,所以perl是一种支持一级函数的语言
find( $callback,"/tmp" ); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
这里传递给find函数的$callback就是一个回调函数,几个关键点:
1.$callback作为参数传递给另一个find()函数(所以find()函数是一个高阶函数);
2.在find()函数中,每查找到一个文件,就调用一次这个$callback函数。当然,如果find是我们自己写的程序,就可以由我们自己定义在什么地方去调用$callback;
3.$callback不是我们主动调用的,而是由find()函数在某些情况下(每查找到一个文件)去调用的。
回调就像对函数进行填空答题一样,根据我们填入的内容去复用填入的函数从而实现某一方面的细节,而普通函数则是定义了就只能机械式地复用函数本身。
之所以称为回调函数,是因为这个函数并非由我们主观地、直接地去调用,而是将函数作为一个参数,通过被调用者间接去调用这个函数参数。本质上,回调函数和一般的函数没有什么区别,可能只是因为我们定义一个函数,却从来没有直接调用它,这一点感觉上有点奇怪,所以有人称之为"回调函数",用来统称这种间接的调用关系。
回调函数可以被多线程异步执行。
彻底搞懂闭包
计算机中的闭包概念是从数学世界引入的,在计算机程序语言中,它也称为词法闭包、函数闭包。
闭包简单的、通用的定义是指:函数引用一个词法变量,在函数或语句块结束后(变量的名称消失),词法变量仍然对引用它的函数有效。在下一节还有关于闭包更严格的定义(来自wiki)。
看一个python示例:函数f中嵌套了函数g,并返回函数g
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数(高阶函数的特性)
# 将执行函数时返回的闭包函数赋值给变量(高阶函数的特性)
a = f(1)
# 调用存储在变量中闭包函数
print (a(5))
# 无需将闭包存储进临时变量,直接一次性调用闭包函数
print( f(1)(5) ) # f(1)是闭包函数,因为没有将其赋值给变量,所以f(1)称为"匿名闭包"
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,在f()返回g函数后,f()就退出了,随之消失的是变量名x(注意是变量名称x,变量的值在这里还不一定会消失)。当将闭包f(1)赋值给a后,原来x指向的数据对象(即数值1)仍被a指向的闭包函数引用着,所以x对应的值1在x消失后仍保存在内存中,只有当名为a的闭包被消除后,原来x指向的数值1才会消失。
闭包特性1:对于返回的每个闭包g()来说,不同的g()引用不同的x对应的数据对象。换句话说,变量x对应的数据对象对每个闭包来说都是相互独立的。
例如下面得到两个闭包,这两个闭包中持有的自由变量虽然都引用相等的数值1,但两个数值是不同数据对象,这两个闭包也是相互独立的:
a=f(1)
b=f(1)
闭包特性2:对于某个闭包函数来说,只要这不是一个匿名闭包,那么闭包函数可以一直访问x对应的数据对象,即使名称x已经消失。
但是:
a=f(1) # 有名称的闭包a,将一直引用数值对象1
a(3) # 调用闭包函数a,将返回1+3=4,其中1是被a引用着的对象,即使a(3)执行完了也不放开
a(3) # 再次调用函数a,将返回4,其中1和上面一条语句的1是同一个数据对象
f(1)(3) # 调用匿名的闭包函数,数据对象1在f(1)(3)执行完就消失
f(1)(3) # 调用匿名的闭包函数,和上面的匿名闭包是相互独立的
最重要的特性就在于上面执行的两次a(3):将词法变量的生命周期延长,但却足够安全。看下面perl程序中的闭包函数,可以更直观地看到结果。
sub how_many {# 定义函数
my $count=2; # 词法变量$count
return sub {print ++$count,"\n"}; # 返回一个匿名函数,这是一个匿名闭包
}
$ref=how_many(); # 将闭包赋值给变量$ref
how_many()->(); # (1)调用匿名闭包:输出3
how_many()->(); # (2)调用匿名闭包:输出3
$ref->(); # (3)调用命名闭包:输出3
$ref->(); # (4)再次调用命名闭包:输出4
&$ref();
&{$ref}();
上面将闭包赋值给$ref,通过$ref去调用这个闭包,则即使how_many中的$count在how_many()执行完就消失了,但$ref指向的闭包函数仍然在引用这个变量,所以多次调用$ref会不断修改$count的值,所以上面(3)和(4)先输出3,然后输出改变后的4。而上面(1)和(2)的输出都是3,因为两个how_many()函数返回的是独立的匿名闭包,在语句执行完后数据对象3就消失了。
闭包更严格的定义
注意,严格定义的闭包和前面通俗定义的闭包结果上是不一样的,通俗意义上的闭包并不一定符合严格意义上的闭包。
关于闭包更严格的定义,是一段谁都看不懂的说明。如下几个关键词我加粗显示了,因为重要。
闭包是一种在支持一级函数的编程语言中能够将词法作用域中的变量名称进行绑定的技术。在操作上,闭包是一种用于保存函数和环境的记录。这个环境记录了一些关联性的映射,将函数的每个自由变量与创建闭包时所绑定名称的值或引用相关联。通过闭包,就算是在作用域外部调用函数,也允许函数通过闭包拷贝他们的值或通过引用的方式去访问那些已经被捕获的变量。
我知道这段话谁都看不懂,所以简而言之一下:一个函数实例和一个环境结合起来就是闭包。这个所谓的环境,决定了这个函数的特殊性,决定了闭包的特性。
还是上面的python示例:函数f中嵌套了函数g,并返回函数g:
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
上面的a是一个闭包,它是函数g()的一个实例。f()的参数x可以被g访问,对于g()来说,这个x不是g()内部定义的,也不是g()的参数,所以这个x对于g来说是一个自由变量(free variable)。虽然g()中持有了自由变量,但是g()函数自身不是闭包函数,只有在g持有的自由变量x和传递给f()函数的x的值(即f(1)中的1)进行绑定的时候,才会从g()创建一个闭包函数,这表示闭包函数开始引用这个自由变量,并且这个闭包一直持有这个变量的引用,即使f()已经执行完毕了。然后在f()中return这个闭包函数,因为这个闭包函数绑定了(引用)自由变量x,这就是闭包函数所在的环境。
环境对闭包来说非常重要,是区别普通函数和闭包的关键。如果返回的每个闭包不是独立持有属于自己的自由变量,而是所有闭包都持有完全相同的自由变量,那么闭包虽然仍可称为闭包,但和普通函数却没有区别了。例如:
def f(x):
x=3
def g(y):
return x + y
return g
a = f(1)
b = f(3)
在上面的示例中,x虽然是自由变量,但却在g()的定义之前就绑定了值(前文介绍过,它称为bound variable),使得闭包a和闭包b持有的不再是自由变量,而是值对象完全相同的绑定变量,其值对象为3,a和b这个时候其实没有任何区别(虽然它们是不同对象)。换句话说,有了闭包a就完全没有必要再定义另一个功能上完全相同的闭包b。
在函数复用性的角度上来说,这里的a和普通函数没有任何区别,都只是简单地复用了函数体。而真正严格意义上的闭包,除了复用函数体,还复用它所在的环境。
但是这样一种情况,对于通俗定义的闭包来说,返回的g()也是一个闭包,但在严格定义的闭包中,这已经不算是闭包。再看一个示例:将自由变量x放在g()函数定义文本段的后面。
def f(y):
return x+y
x=1
def g(z):
x=3
return f(z)
print(g(1)) # 输出2,而不是4
首先要说明的是,python在没有给任何作用域修饰符的时候实现的词法作用域规则,所以上面return f(z)中的f()看见的是全局变量x(因为f()定义在全局文本段中),而不是g()中的x=3。
回到闭包问题上。上面f()持有一个自由变量x,这个f(z)的文本定义段是在全局文本段中,它绑定的自由变量x是全局变量(声明并初始化为空或0),但是这个变量之后赋值为1了。对于g()中返回的每个f()所在的环境来说,它持有的自由变量x一开始都是不确定的,但是后来都确定为1了。这种情况也不能称之为闭包,因为闭包是在f()对自由变量进行绑定时创建的,而这个时候x已经是固定的值对象了。
回调函数、闭包和匿名函数
回调函数、闭包和匿名函数其实没有必然的关系,但因为很多书上都将匿名函数和回调函数、闭包放在一起解释,让人误以为回调函数、闭包需要通过匿名函数实现。实际上,匿名函数只是一个有函数定义文本段,却没有名称的函数,而闭包则是一个函数的实例加上一个环境(严格意义上的定义)。
对于闭包和匿名函数来说,仍然以python为例:
def f(x):
def g(y):
return x + y
return g # 返回一个闭包:有名称的函数
def h(x):
return lambda y: x + y # 返回一个闭包:匿名函数
# 将执行函数时返回的闭包函数赋值给变量
a = f(1)
b = h(1)
# 调用存储在变量中闭包函数
print (a(5))
print (b(5))
对于回调函数和匿名函数来说,仍然以perl的find函数为例:
#!/usr/bin/perl
use File::Find;
$callback = sub {
print "$File::Find::name\n";
}; # 创建一个匿名函数以及它的引用
find($callback,"/tmp"); # 查找/tmp下的文件,每查找到一个文件,就执行一次$callback函数
匿名函数让闭包的实现更简洁,所以很多时候返回的闭包函数就是一个匿名函数实例。
小结
在Perl中,子程序的引用常用来做回调函数(callback)、闭包(closure),特别是匿名子程序。
再以File::Find模块的find函数为例,它用来搜索给定目录下的文件,然后对每个搜索到的文件执行一些操作(通过定义子程序),这些操作对应的函数要传递给find函数,它们就是回调函数。就像unix下的find命令一样,找到文件,然后print、ls、exec CMD操作一样,这几个操作就是find命令的回调函数。
use File::Find;
sub cmd {
print "$File::Find::name\n";
};
find(\&cmd,qw(/perlapp /tmp/pyapp));
其中$File::Find::name代表的是find搜索到的从起始路径(/perlapp /tmp/pyapp)开始的全路径名,此外find每搜索到一个文件,就会赋值给默认变量$_。它代表的是文件的basename,和$File::Find::name全路径不一样。例如:
起始路径 $File::Find::name $_
-------------------------------------------
/perlapp /perlapp/1.pl 1.pl
. ./a.log a.log
perlapp perlapp/2.pl 2.pl
回到回调函数的问题上。上面的示例中,定义好了一个名为cmd的子程序,但一直都没有主动地去执行这个子程序,而是将它的引用放进find函数中,由find函数每次去调用它。这就像是unix的find命令的"-print"选项一样,其中"-print"选项对应的函数就是一个回调函数。
上面的子程序只调用了一次,没必要花脑细胞去设计它的名称,完全可以将其设计为匿名子程序,放进find函数中。
use File::Find;
find(
sub {
print "$File::Find::name\n";
},
qw(/perlapp /tmp/pyapp)
);
Perl闭包(closure)简单介绍
从Perl语言的角度来简单描述下闭包:子程序1中返回另一个子程序2,这个子程序2访问子程序1中的变量x,当子程序1执行结束,外界无法再访问x,但子程序2因为还引用着变量x所指向的数据对象,使得子程序2在子程序1结束后可以继续访问这个数据对象。所以子程序1中的变量x必须是词法变量,否则子程序1执行完后,变量x可能仍可以被外界访问、修改,如果这样,闭包和普通函数就没有意义了。
一个简单的闭包结构:
sub sub1 {
my $var1=N;
$sub2 =sub {
do something about $var1
}
return $sub2 # 返回一个闭包
}
$my_closure = sub1(); # 将闭包函数存储到子程序引用变量
主要目的是为了让子程序sub1内部嵌套的子程序$sub2可以访问属于子程序sub1但不属于子程序$sub2的变量,这样一来,只要把sub1返回的闭包赋值给$my_closure,就可以让这个闭包函数一直引用$var1变量对应的数值对象,但是sub1执行完毕后,外界就无法再通过$var1去访问这个数据对象(因为是词法变量)。也就是说,sub1执行完后,$var1指向的数据对象只有闭包$my_closure可以访问。
Perl语言有自己的特殊性,特别是它支持只执行一次的语句块(即用大括号{}包围),这使得Perl要创建一个闭包并不一定需要函数嵌套,只需将一个函数放进语句块即可:
my $closure;
{
my $count=1; # 随语句块消失的词法变量
$closure = sub {print ++$count,"\n"}; # 闭包函数
}
$closure->(); # 调用一次闭包函数,输出2
$closure->(); # 再调用一次闭包函数,输出3
&{$closure}(); # 再调用,输出4
在上面的代码中,$count引用数在赋值时为1,在sub中使用并赋值给$closure时引用数为2,当退出代码块的时候,count引用数减为1,由于这是个词法变量,退出代码块后外界就无法通过$count来访问了,但是闭包$closure却一直可以继续访问。
闭包的形式其实多种多样。通俗意义上来说,只要一个子程序1可以访问另一个子程序2中的变量,且子程序1不会随子程序2执行结束就丢失变量,就属于闭包。当然,对于Perl来说,可能子程序2并非是必要的,正如上面的例子。
例如下面的代码段就不属于闭包:
$y=3;
sub mysub1 {
$x=shift;
$x+$y;
}
$nested_ref=\&mysub1;
sub mysub2 {
$x=1;
$z=shift;
return $nested_ref->($z);
}
print mysub2(2);
为mysub2中返回的$nested_ref是一个子程序mysub1的一个实例,但mysub1中使用的$y来自于全局变量,而非mysub2,且mysub2执行完后,$y也不会消失,对于闭包来说这看上去没什么必要。
Perl闭包的应用
再通过File::Find模块的find函数,计算出给定目录下的文件数量:
use File::Find;
my $callback;
{
my $count = 0;
$callback = sub { print ++$count, ": $File::Find::name\n" };
}
find($callback, '.'); # 返回数量和文件名
find($callback, '.'); # 再次执行,数量将在上一个find的基础上递增
Perl的语法强大,可以一次性返回多个闭包:
use File::Find;
sub sub1 {
my $total_size = 0;
return(sub { $total_size += -s if -f }, sub { return $total_size });
}
my ($count_em, $get_results) = sub1();
find($count_em, '/opt');
find($count_em, '/boot');
my $total_size = &$get_results();
print "total size of /opt and /boot: $total_size\n";
上面两个闭包,因为同时引用同一个对象,所以闭包$count_em修改的词法变量,$get_results也可以访问。或者:
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
one_count();
one_count();
print get_count();
由于代码块中的子程序有名称,所以这两个子程序在代码块结束后仍然有效(代码块结束后变量无效是因为加了my修饰符)。
但如果将调用语句放在代码块前面呢?
one_count(); # 1
one_count(); # 2
print get_count(); # 输出:2
{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
上面输出2,也就是说$count=10的赋值10行为失效。这是因为词法变量的声明和初始化(初始化为undef)是在编译期间完成的,而赋值操作是在执行到它的时候执行的。所以,编译完成后执行到one_count()这条语句时,将调用已编译好的子程序one_count,但这时还没有执行到语句块,所以$count的赋值还没有执行。
可以将上面的语句块加入到BEGIN块中:
one_count(); # 11
one_count(); # 12
print get_count(); # 输出:12
BEGIN{
my $count=10;
sub one_count{ ++$count; }
sub get_count{ $count; }
}
state修饰符替代简单的闭包
前面闭包的作用已经非常明显,就是为了让词法变量不能被外部访问,但却让子程序持续访问它。
Perl从5.10提供了一个state修饰符,它和my完全一样,都是词法变量,唯一的区别在于state修饰符使得变量持久化,但对于外界来说却不可访问(因为是词法变量),而且state修饰的变量只会初始化赋值一次。注意:
1.state修饰符不仅仅只能用于子程序中,在任何语句块中都可以使用,例如find、grep、map中的语句块。
2.只要没有东西在引用state变量,它就会被回收。
3.目前state只能修饰标量,修饰数组、hash时将会报错。但可以修饰数组、hash的引用变量,因为引用就是个标量
例如将state修饰的变量从外层子程序移到内层自层序中,下面两个子程序等价:
use 5.010; # for state
sub how_many1 {
my $count=2;
return sub {print ++$count,"\n"};
}
sub how_many2 {
return sub {state $count=2;print ++$count,"\n"};
}
$ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
需要注意的是,虽然state $count=2,但同一个闭包多次执行时不会重新赋值为2,而是在初始化时赋值一次。而且将子程序调用语句放在子程序定义语句前面是可以如期运行的(前面分析过一般的闭包不会如期运行):
$ref=how_many2(); # 将闭包赋值给变量$ref
$ref->(); # (1)调用命名闭包:输出3
$ref->(); # (2)再次调用命名闭包:输出4
sub how_many2 {
return sub {state $count=2;print ++$count,"\n"};
}
这是因为state $count=2是子程序中的一部分,无论在哪里调用到它,都会执行这一句赋值语句。再例如,state用于while循环的语句块内部,使得每次迭代过程中都持续访问这个变量,而不会每次迭代都初始化:
#!/usr/bin/perl
use v5.10; # for state
while($i<10){
state $count;
$count += $i;
say $count; # 输出:0 1 3 6 10 15 21 28 36 45
$i++;
}
say $count; # 输出空