
1.4.1 标准 (ANSI C, POSIX, SVID, XPG, …)
ANSI C:这一标准是 ANSI(美国国家标准局)于 1989 年制定的 C 语言标准。 后来被 ISO(国际标准化组织)接受为标准,因此也称为 ISO C。
ANSI C 的目标是为各种操作系统上的 C 程序提供可移植性保证,而不仅仅限于 UNIX。 该标准不仅定义了 C 编程语言的语发和语义,而且还定义了一个标准库。这个库可以根据 头文件划分为 15 个部分,其中包括:字符类型 ()、错误码 ()、 浮点常数 ()、数学常数 ()、标准定义 ()、 标准 I/O ()、工具函数 ()、字符串操作 ()、 时间和日期 ()、可变参数表 ()、信号 ()、 非局部跳转 ()、本地信息 ()、程序断言 () 等等。
POSIX:该标准最初由 IEEE 开发的标准族,部分已经被 ISO 接受为国际标准。该标准的具体内容 见 1.1.3。POSIX.1 和 POSIX.2 分别定义了 POSIX 兼容操作系统的 C 语言系统接口 以及 shell 和工具标准。这两个标准是通常提到的标准。
SVID:System V 的接口描述。System V 接口描述(SVID)是描述 AT&&;T Unix System V 操作 系统的文档,是对 POSIX 标准的扩展超集。
XPG:X/Open 可移植性指南。X/Open 可移植性指南(由 X/Open Company, Ltd.出版), 是比 POSIX 更为一般的标准。X/Open 拥有 Unix 的版权,而 XPG 则指定成为 Unix 操作系统必须满足的要求。
1.4.2 函数库和系统调用
1). glibc
众所周知,C 语言并没有为常见的操作,例如输入/输出、内存管理,字符串操作等提供内置的支持。相反,这些功能一般由标准的“函数库”来提供。GNU 的 C 函数库,即 glibc,是 Linux 上最重要的函数库,它定义了 ISO C 标准指定的所有的库函数,以及由 POSIX 或其他 UNIX 操作系统统变种指定的附加特色,还包括有与 GNU 系统相关的扩展。目前,流行的 Linux 系统使用 glibc 2.0 以上的版本。glibc 基于如下标准:
ISO C: C 编程语言的国际标准,即 ANSI C。
POSIX:GNU C 函数库实现了 ISO/IEC 9945-1:1996 (POSIX 系统应用程序编程接口, 即 POSIX.1)指定的所有函数。该标准是对 ISO C 的扩展,包括文件系统接口原 语、设备相关的终端控制函数以及进程控制函数。同时,GUN C 函数库还支持部分由 ISO/IEC 9945-2:1993(POSIX Shell 和 工具标准,即 POSIX.2)指定的函数, 其中包括用于处理正则表达式和模式匹配的函数。
Berkeley Unix:BSD 和 SunOS。GNU C 函数库定义了某些 UNIX 版本中尚未标准化的函数,尤其是 4.2 BSD, 4.3 BSD, 4.4 BSD Unix 系统(即“Berkeley Unix”)以及“SunOS” (流行的 4.2 BSD 变种,其中包含有某些 Unix System V 的功能)。BSD 函数包括 符号链接、select 函数、BSD 信号处理函数以及套接字等等。
SVID:System V 的接口描述。GNU C 函数库定义了大多数由 SVID 指定而未被 ISO C 和 POSIX 标准指定的函数。来自 System V 的支持函数包括进程间通信和共享内存、 hsearch 和 drand48 函数族、fmtmsg 以及一些数学函数。
XPG:X/Open 可移植性指南。GNU C 函数库遵循 X/Open 可移植性指南(Issue 4.2) 以及所有的 XSI(X/Open 系统接口)兼容系统的扩展,同时也遵循所有的 X/Open Unix 扩展。
2). 其他重要函数库
除 glibc 之外,流行的 Linux 发行版中还包含有一些其他的函数库,这些函数库具有重要地位,例如:
GNU Libtool:GNU Libtool 实际是一个脚本生成工具,它可以为软件包开发者提供一般性 的共享库支持。
以前,如果源代码包的开发者要利用共享库的优点,则必须为每个软件包可支持的平台编写 定制的支持代码。并且还需要设计配置接口,以便软件包的安装程序能够正确选择要建立的 库类型。利用 GNU Libtool,则可以简化开发者的这一工作。它在一个单独的脚本中同时封装了与平台相关的依赖性以及用户界面。GNU Libtool 可使每个宿主类型的完整功能可通过 一般性的接口获得,同时为程序员隐藏了宿主的特殊性。GNU Libtool 一致性接口是可靠的, 用户不必阅读那些晦涩的文档,以便在每个平台上建立共享库。他们只需运行软件包的配置脚本,而由 libtool 完成繁复的工作。
CrackLib:CrackLib 为用户提供了一个 C 语言函数接口,利用这一函数,可避免用户选择 容易破解的密码。该函数库可在类似 passwd 的程序中使用。
LibGTop:LibGTop 是一个能够获取进程信息以及系统运行信息的函数库,这些信息包括: 系统的一般信息、SYS V IPC 限制、进程列表、进程信息、进程映射、文件系统使用信息等。
图形文件操作函数库:包括 libungif、libtiff、libpng、Imlib, libjpeg 等,可分别用来操作 GIF、TIFF、PNG、JPEG 以及其他一些格式图形文件。
3). 系统调用
系统调用是操作系统提供给外部程序的接口。在 C 语言中,操作系统的系统调用通常通过函数调用的形式完成,这是因为这些函数封装了系统调用的细节,将系统调用的入口、参数以及返回值用 C 语言的函数调用过程实现。在 Linux 系统中,系统调用函数定义在 glibc 中。
谈到系统调用时,需要注意如下几点:
系统调用函数通常在成功时返回 0 值,不成功时返回非零值。如果要检查失败原因,则要判断 errno 这个全局变量的值,errno 中包含有错误代码。
许多系统调用的返回数据通常通过引用参数传递。这时,需要在函数参数中传递一个 缓冲区地址,而返回的数据就保存在该缓冲区中。
不能认为系统调用函数就要比其他函数的执行效率高。要注意,系统调用是一个非常耗时 的过程。 有关系统调用我们将在以后详细讲述。
1.4.3 在线文档 (man, info, HOW-TO, ...)
1). man
man,即 manunal,是 UNIX 系统手册的电子版本。根据习惯,UNIX 系统手册通常分为不同的部分(或小节,即 section),每个小节阐述不同的系统内容。目前的小节划分如下:
命令:普通用户命令
系统调用:内核接口
函数库调用:普通函数库中的函数
特殊文件:/dev 目录中的特殊文件
文件格式和约定:/etc/passwd 等文件的格式
游戏。
杂项和约定:标准文件系统布局、手册页结构等杂项内容
系统管理命令。
内核例程:非标准的手册小节。便于 Linux 内核的开发而包含
其他手册小节:
手册页一般保存在 /usr/man 目录下,其中每个子目录(如 man1, man2, ..., manl, mann)包含不同的手册小节。使用 man 命令查看手册页。
man 命令行:
man [-acdfFhkKtwW] [-m system] [-p string] [-C config_file] [-M path] [-P pager] [-S section_list] [section] name
常用命令行:
$ man open
$ man 7 man
$ man ./myman.3
2). info
Linux 中的大多数软件开发工具都是来自自由软件基金会的 GNU 项目,这些工具软件件的在线文档都以 info 文件的形式存在。info 程序是 GNU 的超文本帮助系统。
info 文档一般保存在 /usr/info 目录下,使用 info 命令查看 info 文档。
要运行 info,可以在 shell 提示符后输入 info,也可以在 GNU 的 emacs 中键入 Esc-x 后跟 info。
info 帮助系统的初始屏幕显示了一个主题目录,你可以将光标移动到带有 * 的主题菜单上面,然后按回车键进入该主题,也可以键入 m,后跟主题菜单的名称而进入该主题。例如,可以键入 m,然后再键入 gcc 而进进入 gcc 主题中。如果要在主题之间跳转,则必须记住如下的几个命令键:
* n:跳转到该节点的下一个节点;
* p:跳转到该节点的上一个节点;
* m: 指定菜单名而选择另外一个节点;
* f:进入交叉引用主题;
* l:进入该窗口中的最后一个节点;
* TAB:跳转到该窗口的下一个超文本链接;
* RET:进入光标处的超文本链接;
* u:转到上一级主题;
* d:回到 info 的初始节点目录;
* h:调出 info 教程;
* q:退出 info。
3). HOW-TO
可供用户参考的联机文档的另一种形式是 HOWTO 文件,这些文件位于系统的 /usr/doc/HOWTO 目录下。 HOWTO 文件的文件名都有一个 -HOWTO 后缀,并且都是文本文件。
每一个 HOWTO 文件包含 Linux 某一方面的信息,例如它支持的硬件或如何建立一个引导盘。 要想查看这些文件,进入 /usr/doc/HOWTO 目录,使用 more 命令,具体形式如下:
$ cd /usr/doc/HOWTO; more topic-name-HOWTO
另外,HOWTO 文档还有其他格式的文件,例如 HTML 和 PS 等,保存在 /usr/doc/HOWTO/other-formats 下。
4). 其他
Linux 的内核文档一般包含在内核源代码中,目录如下:/usr/src/linux-2.x.x/Documentation
/usr/doc 目录下包含有大量与特定软件或函数库相关的说明性文档。
1.4.4 C 语言编程风格
编写这一小节的目的是提醒大家在编程过程中注意编程风格。如果你只是在编写一些小的练习程序,程序只有一两百行长的话,编程风格可能并不重要。然而,如果你和许多人一起进行开发工作,或者,你希望在过一段时间之后,还能够正确理解自己的程序的话,就必须养成良好的编程习惯。在诸多编程习惯当中,编程风格是最重要的一项内容。
良好的编程风格可以在许多方面帮助开发人员。如果你阅读过 Linux 内核源代码的话,可能会对程序的优美编排所倾倒。良好的编程风格可以增加代码的可读性,并帮助你理清头绪。如果程序非常杂乱,大概看一眼就该让你晕头转向了。编程风格最能体现一个程序员的综合素质。
许多读者可能对 Windows 所推崇的匈牙利命名法很熟悉。这种方法定义了非常复杂的函数、变量、类型等的命名方法,典型的命名方法是采用大小写混写的方式,对于变量名称,则采用添加前缀的办法来表示其类型,例如:
char szBuffer[20];
int nCount;
利用 sz 和 n 分别代表字符串和整数。为了表示一个变量名称,采用如下的变量名称是可能的:
int iThisIsAVeryLongVariable;
在 Linux 中,我们经常看到的是定义非常简单的函数接口和变量名称。在 Linux 内核的源代码中,可以看到 Linux 内核源代码的编码风格说(/Documentation/CodingStyle)。UNIX 系统的一个特点是设计精巧,并遵守积木式原则。C 语言最初来自 UNIX 操作系统,与 UNIX 的设计原则一样, C 语言被广泛认可和使用的一个重要原因是它的灵活性以及简洁性。因此,在利用 C 语言编写程序时,始终应当符合其简洁的设计原则,而不应当使用非常复杂的变量命名方法。Linus 为 Linux 内核定义的 C 语言编码风格要点如下:
缩进时,使用长度为 8 个字符宽的 Tab 键。如果程序的缩进超过 3 级,则应考虑重新设计程序。
大括号的位置。除函数的定义体外,应当将左大括号放在行尾,而将右大括号放在行首,函数的定义体应将左右大括号放在行首。如下所示:
int function(int x, int y){
if (x == y) {
...
} else if (x > y) {
...
} else {
...
}
return 0;
}
应采用简洁的命名方法。对变量名,不赞成使用大小写混写的形式,但鼓励使用描述性的名称;尽可能不使用全局变量;不采用匈牙利命名法表示变量的类型;采用短小精悍的名称表示局部变量;保持函数短小,从而避免使用过多的局部变量。
保持函数短小精悍。不应过分强调注释的作用,应尽量采用好的编码风格而不是添加过多的注释。
1.4.5 库和头文件的保存位置
1). 函数库
/lib:系统必备共享库
/usr/lib:标准共享库和静态库
/usr/i486-linux-libc5/lib:libc5 兼容性函数库
/usr/X11R6/lib:X11R6 的函数库
/usr/local/lib:本地函数库
2). 头文件
/usr/include:系统头文件
/usr/local/include:本地头文件
1.4.6 共享库及其相关配置
/etc/ld.so.conf:包含共享库的搜索位置
ldconfig:共享库管理工具,一般在更新了共享库之后要运行该命令
ldd:可查看可执行文件所使用的共享库
一些实用的C语言小技巧
目录:
1. 位相关的运算符
2. 位相关的用法
3. 位字段 (bit field)
4. 怎样判断机器的字节顺序?
5. 怎样将整数转换到二进制或十六进制?
6. 怎样高效地统计整数中为1的位的个数?
7. 相关参考
写作目的:记录一些 C 语言中位和字节相关的操作。
测试环境:Ubuntu 16.04 with gcc version 5.4.0
1. 位相关的运算符
1) 取反:~
~(10011010) = (01100101)
运算符 ~ 把 1 变为 0,把 0 变为 1。
2) 按位与:&
(10010011) & (00111101) = (00010001)
运算符 & 通过逐位比较两个运算对象,生成一个新值。对于每个位,只有两个运算对象中相应的位都为 1,结果才为 1。
3) 按位或:|
(10010011) | (00111101) = (10111111)
运算符 | 通过逐位比较两个运算对象,生成一个新值。对于每个位,如果两个运算对象中有 >=1 的位为 1,结果就为 1。
4) 按位异或:^
(10010011) ^ (00111101) = (10101110)
运算符 ^ 逐位比较两个运算对象。对于每个位,如果两个运算对象中有且只有 1 位 为 1, 结果为 1。
5) 左移:<<
(10001010) << 2 = (00101000)
运算符 << 将其左侧运算对象每一位的值向左移动其右侧运算对象指定的位数。左侧运算对象移出左末端位的值会被丢弃,用 0 填充空出的位置。
6) 右移:>>
(10001010) >> 2 = (00100010) // 情况1
(10001010) >> 2 = (11100010) // 情况2
运算符 >> 将其左侧运算对象每一位的值向右移动其右侧运算对象指定的位数。左侧运算对象移出右末端位的值丢。
对于无符号类型,用 0 填充空出的位置。对于有符号类型,其结果取决于机器。空出的位置可能用 0 填充,也可能用符号位填充。
2. 位相关的用法
1) 什么是掩码?
所谓掩码指的是一些设置为开 (1) 或关 (0) 的位组合。
为什么叫掩码?看下面这个例子:
#define MASK (1<<1)
flags = flags & MASK;
上面这个例子中,只有 MASK 中 为1的位才可见,掩码中的 0 隐藏 (掩盖) 了 flags 中相应的位。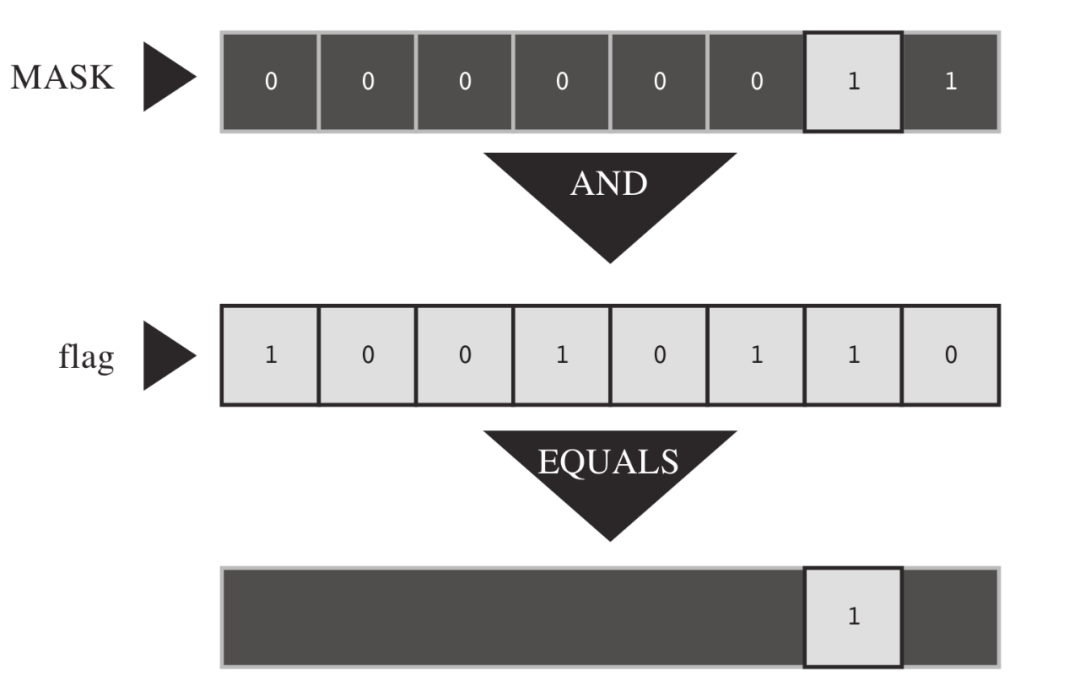
2) 打开 (设置) 位
有时,比如在操作硬件寄存器的情况下,需要打开一个值中的特定位,同时保持其他位不变。这种情况可以使用按位或运算符 | 和一个掩码进行配合:
#define MASK (1<<1)
flags |= MASK;
3) 关闭 (清空) 位
在不影响其他位的情况下关闭指定的位:
#define MASK (1<<1)
flags &= ~MASK;
4) 切换位
切换位指的是打开已关闭的位,或关闭已打开的位:
#define MASK (1<<1)
flags ^= MASK;
5) 检查位
检查某位的值是否为 1:
#define MASK (1<<1)
(flags & MASK) == MASK
注意,掩码至少要与其覆盖的值的宽度相同,要避免符号位带来的意外,最好在代码中使用 unsigned int 操作位和字节。
6) 提取位
移位运算符可用于从较大单元中提取一些位,例如提取 RBG 颜色值:
#define BYTE_MASK 0xff
unsigned long color = 0x123456;
unsigned char blue, green, red;
red = color & BYTE_MASK;
green = (color >> 8) & BYTE_MASK;
blue = (color >> 16) & BYTE_MASK;
3. 位字段 (bit field)
位字段通过一个结构声明来建立,该结构声明为每个字段提供标签,并确定该字段的宽度,在 Linux 驱动中,某些代码使用了位字段:
struct ap_queue_status {
unsigned int queue_empty : 1;
...
unsigned int response_code : 8;
unsigned int pad2 : 16;
} aqs;
给字段赋值:
aqs.queue_empty = 0;
aqs.response_code = 0xff;
所赋的值不能超出字段可容纳的范围。
位字段占用的空间:
struct {
unsigned int autfd : 1;
unsigned int bldfc : 1;
unsigned int undln : 1;
unsigned int itals : 1;
} prnt;
struct {
unsigned int code1 : 2;
unsigned int code2 : 2;
unsigned int code3 : 6;
unsigned int code4 : 8;
#if TEST
unsigned int code5 : 10;
unsigned int code6 : 12;
unsigned int code7 : 24;
#endif
} prcode;
int main(void){
printf("%ld %ld\n", sizeof(prnt), sizeof(prcode));
}
测试结果:
4 4 // without TEST
4 12 // with TEST
系统会自动判断出需要几个 byte 的空间来存储数据,在我的机器上测试,一个成员最起码占用 1 个 byte。
位字段的储存顺序:取决于机器。在有些机器上,存储的顺序是从左往右,而在另一些机器上,是从右往左。另外,不同的机器中两个字段边界的位置也有区别。由于这些原因,位字段通常都不容易移植,我不要求自己写,但是要求自己会看。
4. 怎样判断机器的字节顺序?
演示 demo:
int main(void){
int x = 1;
if (*((char *)&x) == 1)
printf("little - endian\n");
else
printf("big - endian\n");
return 0;
}
运行效果:
$ gcc byte_order.c -o byte_order
$ ./byte_order
little - endian
代码解析:
先初始化在内存中占用 4 个字节的 int 变量。
然后获取int 变量中第 1 个字节的地址,等效代码是:char *px = (char *)&x。
最后获取第 1 个字节的值:*px,观察 *px 是否为 1 就可以知道大小端了。
5. 怎样将整数转换到二进制或十六进制?
演示 demo:
进行任意进制数转换的小函数:
#define BUF_SIZE (33)
char *baseconv(unsigned int num,int base){
static char retbuf[BUF_SIZE];
char *p;
...
p = &retbuf[sizeof(retbuf)-1];
*p='\0';
do {
*--p="0123456789abcdef"[num % base];
num /=base;
} while(num !=0);
return p;
}
在 main() 中进行测试:
int main(void){
int a = 20;
printf("%s\n", baseconv(a, 2));
printf("%s\n", baseconv(a, 16));
return 0;
}
运行效果:
$ gcc int_conv.c -o int_conv
$ ./int_conv
10100
14
代码解析:
首先需要明确的是:整数本来就是以二进制存储的,这里说的转换只是指打印的形式。
在baseconv() 中的缓冲是 static 的,这有2 个作用:1) 将缓冲清 0,2) 只有是 static 的缓冲才能在函数外部被使用。
注意:char *p = &retbuf[sizeof(retbuf)-1] = '\0' 这个操作,这里将缓冲的最高位设置为字符串结束符,同时表明了字符串是从高地址向底地址构造的,函数返回缓冲中有效数据的起始地址。
如果你这样打印:printf("%d %s %s\n", a, baseconv(a, 2), baseconv(a, 16));
会得到这样的结果:10100 00。
这是因为baseconv()中的缓冲是 static 的, baseconv(a, 2) 将 baseconv(a, 16) 冲刷掉了。
6. 怎样高效地统计整数中为1的位的个数?
演示 demo:
统计整数中为1的位的个数的小函数:
static int bitcounts[] = {0,1,1,2,1,2,2,3,1,2,2,3,2,3,3,4};
int bitcount(unsigned int u){
int n=0;
for(; u!=0; u>>=4)
n += bitcounts[u & 0x0f];
return n;
}
在 main() 中进行测试:
int main(void){
int i = 0;
for (i=0; i<=0x0f; i++)
printf("%d\n", bitcount(i));
return 0;
}
运行效果:
$ gcc bit_counts.c -o bit_counts
$ ./bit_counts
0
1
1
2
1
2
2
3
1
2
2
3
2
3
3
4
代码解析:许多像这样的位问题可以使用查找表格来提高效率和速度。这段代码是以每次 4 位的方式计算数值中为1的位的个数。
7. 相关参考
《C Primer Plus 6th》, 15
《你必须知道的 495 个 C语言问题》, 20.7
《C 和指针》, 5.1.3
《C 专家》, NULL
《C 和 C++ 程序员面试秘籍》, 5
《C 语言解惑》, NULL
C语言的设计模式
单一职责
单一职责原则:通常的定义是只专注于做一件事和仅有一个引起它变化的原因。对于接口、实现、函数级别往往我们比较容易关注单一职责,大家谈的也比较多,但对于返回值、参数可能不会有太多的人关注。但往往就是这些不符合单一职责原则的设计可能导致一些很难发现的BUG。看看下面这段代码:
pBuf = (byte*)realloc( pBuf, size);
if( pbBuf != NULL ){
TODO...
}
可能很多人一眼看上去并没有什么问题,先让我们看看这个库函数的定义:
函数简介
原型
extern void *realloc(void *mem_address, unsigned int newsize);
语法:指针名=(数据类型*)realloc(要改变内存大小的指针名,新的大小)。
功能
先判断当前的指针是否有足够的连续空间,如果有,扩大mem_address指向的地址,并且将mem_address返回,如果空间不够,先按照newsize指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来mem_address所指内存区域,同时返回新分配的内存区域的首地址。即重新分配存储器块的地址。
返回值
如果重新分配成功则返回指向被分配内存的指针,否则返回空指针NULL。正常情况下pBuf是新空间的地址没有任何问题,但我们考虑下如果分配失败了呢,pBuf会被赋值成NULL,pBuf原指向的地址空间就没有指针指向了,造成了内存泄露。这种问题往往很难定位。熟悉realloc机制的人可能对这个问题很不屑,认为高手不会犯这些错误。但我们可以想下有没有办法设计一个好的接口让菜鸟也写出不会出错的代码呢。假设这个库函数的接口是这样的呢:
函数简介
原型
extern flag realloc(void **ppMem_address, unsigned int newsize);
语法
返回值 =(数据类型*)realloc(要改变内存大小的指针名,新的大小)。
返回值
如果重新分配成功则返回指True(ppMem_address保存新分配空间地址),否则返回False(ppMem_address保存老空间地址)。
相信任何一个使用这个接口的人都会写出下面的代码:
if( True == realloc( &pBuf, size)){
TODO...
}
else{
TODO...
}
为什么有人会犯pBuf = (byte*)realloc( pBuf, size);这种错误?因为他只关注了realloc返回值是一个地址,没有关注该返回值还有错误识别的功能,换句话来说这个库函数的返回值不具备单一职责,导致了可能的错误使用。如果使用改进后的接口,因为返回值只有一个判断分配成功与否的功能,相信没有人还会用错。
我们再仔细看看我们新的接口,总觉得似乎有什么地方还是不对,看到void **ppMem_address可能要想一下明白,这个参数既是入参又是出参,它承担了原始地址的输入和新地址的输出,这不又违反了单一职责吗?好吧我们再改进一下:
函数简介
原型
extern flag realloc(void *pIn_Mem_address,void **ppOut_Mem_address, unsigned int newsize);
语法 返回值 =(数据类型*)realloc(要改变内存大小的指针名,新的内存指针名,新的大小)。
返回值 如果重新分配成功则返回指True,否则返回False。
现在这个接口就算一个初次看到的人也应该大概知道什么意思,相信也不会写出什么带BUG的代码,因为函数的参数、返回值都具有单一的功能,通过返回值来判断分配成功与否,通过出参来获取地址。一切看起来都很清晰。
在C库中还有很多类似的函数,如果当初的设计人员能多考虑单一职责,也许现在的系统中就会少了很多隐藏的BUG,接口永远是给别人使用的,一定要把使用者当成傻瓜,也许才能设计出好的接口。
面向对象机制的实现
为什么要用C来模拟面向对象的机制,在实际的工作中我们往往在感慨一些面向对象的经典设计模式由于C语言的限制无法使用,其实通过简单的模拟面向对象的行为,在C语言中也可以使用这些模式。
1:类的构建
类描述了所创建的对象共同的属性和方法。我们在一个源文件中通过把数据和操作进行适当的组织来完成类的模拟。
/*类的数据*/
typedef struct SQUARE_S SQUARE_T;
struct SQUARE_S{
void (*draw)(void*);
int sideLen;
};
/*类的方法*/
static void draw(void* pObj){
SQUARE_T* pSqr = (SQUARE_T*)pObj;
printf("Draw Square len is %d\n",pSqr->sideLen);
}
如上所示,一个正方形的类我们用一个结构体SQUARE_T来表示正方形的属性,draw是其中的一个方法。
2:类的封装性
类的封装一般要求对细节的隐藏并且提供指定的方法供调用者使用,在SQUARE这个类中,sideLen是图形的细节,只需要提供一个draw接口给调用者。因此在提供给外部调用的接口头文件中构建如下的接口。
typedef struct SHAPE_S SHAPE;
struct SHAPE_S{
void (*draw)(void*);
};
通过定义不同的数据结构来达到数据隐藏的目的,如下图所示,对外接口中只能看到draw,内部实现中可以看到draw和sideLen。
3:多态的模拟
多态无疑是面向对象语言的很重要的一个机制,很多面向对象的设计模式都是以多态为基础,C语言并不支持多态,导致很多设计模式都无法直接使用。一个典型的多态例子,通过声明一个SHAPE接口,根据实例化对象类型的不同,pShape在运行时动态的表现不同的行为。
SHAPE* pShape = NULL; //一个形状接口
pShape = (SHAPE*)Ins(SQUARE,2); //实例化为一个正方形
pShape->draw(pShape); //pShape表现为正方形的行为
多态机制的实现依赖函数指针,在每个类的构造函数中把相关接口用具体的函数地址填充,这样在实例化一个对象的时候我们才绑定了其具体的操作,也就是所谓的动态绑定。
/*每个类的构造函数*/
static void* Constructor(void* pObj,va_list* pData){
SQUARE_T* pSquare = (SQUARE_T*)pObj;
pSquare->draw = draw; //具体行为的填充
pSquare->sideLen = va_arg(*pData,int);
return pObj;
}
4:对象的创建
有了类,我们需要实例化为可以运行的对象,实例化主要的工作是分配内存、动态绑定、数据初始化等工作。
void* Ins(const void* pClass,...){
CLASS* pCls = NULL;
void* pObj = NULL;
va_list vaList = NULL;
pCls = (CLASS* )pClass;
pObj = malloc(pCls->classSize);
memset(pObj,0,pCls->classSize);
va_start(vaList,pClass);
pObj = pCls->Constructor(pObj,&vaList);
return pObj;
}
接口隔离
定义为客户端不应该依赖它不需用的接口,在C语言中我们可以把头文件看成一个模块的接口,根据接口隔离原则也就是说这个头文件中只能包含外部需要的接口,但在实际的项目中往往头文件都不符合接口隔离原则。
1:内、外部接口的隔离
头文件中通常包含了模块内部接口(内部类型定义、内部接口声明)和外部接口(外部接口声明)
假设moudle模块对外提供一个fun1接口,模块内部实现需要定义一个结构类型,一般的实现如下:
/*moudle.h*/
typedef struct str_s str_t;
struct str_s{
int a;
int b;
};
void fun1();
/*moudle.c*/
#include "moudle.h"
void fun1(){
str_t s = {0};
TODO...
}
客户端在使用接口的时候需要包含moudle.h文件,而该接口并不符合接口的隔离,其内部包含了客户并不需要的一些定义。为了解决这个问题我们可以通过定义不同的头文件来隔离接口,moudle.h定义外部的接口,moudle.inc定义内部接口
/*moudle.h*/
void fun1();
/*moudle.inc*/
typedef struct str_s str_t;
struct str_s{
int a;
int b;
};
/*moudle.c*/
#include "moudle.inc"
void fun1(){
str_t s = {0};
TODO...
};
moudle.h包含外部模块需要的接口,外部模块包含moudle.h,moudle.inc包含内部模块需要的接口,在模块内部包含moudle.inc。通过查看模块的.inc和.h文件,我们就可以清晰的理解模块对外和对内提供了什么接口。
2:避免万能头文件的使用
在实际项目中我们经常可以看到一些头文件包含了所有模块的接口声明,客户端只需要包含这个头文件就可以使用任何接口了。
/*global.h*/
#inlcude "moudle1.h"
#inlcude "moudle2.h"
#inlcude "moudle3.h"
....
#inlcude "moudlen.h"
可能带来如下问题:
会显著的增加编译时间,如果项目大,可能大部分的编译时间都花在展开头文件(笔者一个项目测试80%左右的时间)。
不利于代码的框架的理解,客户端无法从包含的头文件中清晰的看到依赖什么外部模块。
3:如果没有隔离接口可能会导致一些误操作:
一个数据获取模块提供两个接口分别从网络和本地缓存获取数据,后台管理模块使用网络接口定时获取数据更新缓存,前台模块使用缓存接口快速获取数据显示,由于没有对接口隔离,后期的维护人员可能并不清楚开始的设计,在前台模块中直接使用网络接口来获取数据显示,导致界面延迟严重。如果一开始就把接口分离,给前台模块提供本地缓存接口,给后台模块提供网络接口,就不会导致问题的出现。
4:Linux系统编程之
——理解文件IO操作
• 核心技能:掌握系统IO和标准IO的文件操作
• 关键API:open()/read()/write()/close(),fopen()/fread()/fwrite()
• 实战价值:实现数据持久化存储和配置管理
• 典型应用:保存用户设置、记录运行日志
——理解进程管理与应用
• 核心技能:创建和管理多个并发进程
• 关键API:fork()、exec()、wait()、exit()
• 实战价值:构建模块化、高可用的系统架构
• 典型应用:进程保活系统、功能模块分离
——理解进程间通信(IPC)技术
• 核心技能:实现进程间的数据交换和同步
• 关键技术:管道、消息队列、共享内存、信号量
• 实战价值:构建协作式多进程应用
• 典型应用:生产者-消费者模型、任务分发系统
——理解多线程编程
• 核心技能:创建和管理线程,实现线程同步
• 关键技术:pthread库、互斥锁、条件变量
• 实战价值:提高程序并发性能和响应速度
• 典型应用:GUI应用、高并发服务器
——理解Socket网络通信
• 核心技能:实现网络数据传输和通信
• 关键API:socket()、bind()、listen()、accept()、connect()
• 实战价值:构建客户端-服务器架构应用
• 典型应用:网络服务、远程控制、数据传输