Linux下编译器使用参考
 GNU C 与 ANSI C的区别
GNU C 与 ANSI C的区别checking for C compiler default output file
g++: command not found
/usr/bin/ld: cannot find -lc
linux开发调试工具之gdb的使用入门
在CentOS 和 Debian 上安装Build Essentials
linux下制作静态库和动态链接库的方法
查看和修改gcc、g++默认include路径
GCC 编译器使用参数详解
GNU C 编译器使用入门指南
C/C++编译器盘点
GNU C 与 ANSI C的区别
原作者总结了8点,感谢作者。
1.零长度数组
GNU C允许使用零长度数组,定义变长度对象时比较方便
struct var_data {
int len;
char data[0];
};
var_data的大小仅为一个int型,data是常量地址,data[index]是访问其后的内存空间。
struct var_data *s = malloc(sizeof(var_data) + len);
释放内存的时候free(s)只释放int,所以还要认为地释放data空间,这会带来不便。另外只有GNU C支持,c/c++编译永远通不过。
2.case范围
GNU C支持case x...y这样的语法,区间[x ,y]都满足这个条件。例如:
case 0...5 ==> case 0 : case 1: case 2: case 3: case 4: case 5:
3.语句表达式
GNU C可以把括号中的复合语句看成是语句表达式, a=( ; ; ),于是就有了以下应用
#define min_t(type, x, y) ((type __x = (x); typ __y = (y); __x < __y ? __x : __y;))
float minf = min_t(float, f1, f2);
int mini = min_t(int, i1, i2);
4.typeof关键字
typeof(x)语句可以获得x的类型
5.可变参数的宏
标准C只支持可变参数的函数
int printf(const char *format [, argument]...);
而GNU C也支持可变参数的宏
#define pr_debug(fmt, arg...) printfk(fmt, ##arg)
6.标号元素
标准C要求数组或结构体的初始值必须以固定顺序出现,而GNU C可以通过指定索引和结构体成员允许初始化值以任意顺序出现([index] = ),当然也可以如下运用
unsigned char data[MAX] = {[0...MAX - 1] = 0};
下面是借助结构体成员名初始化值
struct file_operations ext2_file_operation = {
llseek: generic_file_llseek,
read: generic_file_read,
write:generic_file_write,
ioctl:ext2_ioctl,
mmap:generic_file_mmap,
open:generic_file_open,
release:ext2_release_file,
fsync:ext2_sync_file,
};
但是linux2.6推荐类似的代码应该尽量采用标准C的语法
struct file_operations ext2_file_operation = {
.llseek = generic_file_llseek,
.read = generic_file_read,
.write = generic_file_write,
.ioctl = ext2_ioctl,
.mmap = generic_file_mmap,
.open =generic_file_open,
.release = ext2_release_file,
.fsync = ext2_sync_file,
};
7.当前函数名
GNU C预定义了两个标识符保存当前函数的名字,__FUNCTION__保存函数在源码中的名字,__PRETTY_FUNCTION__保存带语言特色的名字,而标注C两者是一样的。
void exampe(){
printf("This is function %s\n", __FUNCTION__);
}
8.特殊属性声明
GNU C允许声明函数,变量和类型的特殊属性,以便进行手工优化和定制代码检查的方法。指定一个属性只需在其声明后添加__attribute__((ATTRIBUTE)).
noreturn 属性作用于函数,表示该函数从不反悔。这回让编译器优化代码,并消除不必要的警告信息。
例如:void do_exit(int n) __attribute__((noreturn));
format属性也用于函数,该函数使用printf、scanf或strftime风格的参数,指定format属性可以让编译器根据格式串检查参数类型。
unused属性作用于函数和变量,表示该函数或变量可能不会被用到,这个属性可以避免编译器产生警告信息。
aligned属性用于变量、结构体或联合体,指定变量、结构体或联合体的对齐方式,以字节为单位。
例如:struct example_struct{
char a;
int b;
long c;
} __attribute__((aligned(4)));表示该结构类型的变量以4字节对齐。
packed属性作用于变量和类型,用于变量和结构体成员时表示使用最小可能的对齐,用于枚举、结构体或联合体类型时表示该类型使用最小的内存。
例如:struct example_struct{
char a;
int b;
long c __attribute__((packed));
} ;
9.内建函数
GNU C除了标准C提供的内建函数(memcpy)外,还提供了许多其他的内建函数,通常命名以__builtin开始。
__builtin_return_address(LEVEL)返回当前函数或调用这的返回地址,参数LEVEL指定调用栈的级数,如0表示当前函数的返回地址,1表示当前函数的调用者的返回地址。
__builtin_constant_p(EXP)用于判断一个值是否为编译时常数,是返回1,否则返回0.例如下面的代码检测第一个参数是否为常数以确定采用参数版本还是非参数版本
#define test_bit(nr, addr) (__builtin_constant_p(nr) ? constant_test_bit((nr), (addr)) : variable_test_bit((nr), (addr))
——记《linux设备驱动开发详解》宋宝华
checking for C compiler default output file
checking for C compiler default output file name... configure: error: C compiler cannot create executables这个问题的吧.
我是在编译软件的时候遇见的这个问题.当时我运行./cofugure时候就提示出错,错误就是checking for C compiler default output file name... configure: error: C compiler cannot create executables.
"checking for C compiler default output file name... configure: error: C compiler cannot create executables
See `config.log' for more details.
make: *** [configure-stamp] Error 77"
原来只装gcc这个包,没有g++这个包。
# apt-get install g++
g++: command not found
g++没有装或却没有更新
以下方法都可以:
centos:
yum -y update gcc
yum -y install gcc+ gcc-c++
ubuntu:
apt-get update gcc
apt-get install g++
linux开发调试工具之gdb的使用入门
编译
gcc -g xxx.c -o xxxgdb
gdb xxxgdb
进入gdb调试界面
查看代码
list ==> l
设置断点 可以以函数为断点 / 行数
break function/lines
查看断点
info breakpoints
执行代码
run ==> 也可以直接输入 r
start ==> 也可以直接输入s
单步调试 下一步
next ==>也可以直接输入 n
执行到下一个断点
continue ==> 也可以直接输入c
print expression 打印一条表达式的值
p expression
edit 编辑 ==> visual 进入vim状态编辑
退出
quit exit
在CentOS 和 Debian 上安装Build Essentials
Linux操作系统上面开发程序, 光有了gcc 是不行的,它还需要一个 build-essential 软件包。其作用是提供编译程序必须软件包的列表信息,也就是说编译程序有了这个软件包它才知道头文件在哪,这样才知道库函数在哪里,最后才组成一个开发环境。当然 build-essential包安装时 需要的依赖包,有些不一定能用的上,它们因依赖而存在。
apt-get install -y build-essential
在Centos上安装build essentials,没有直接的安装指令,需要调用组命令来安装:
yum groupinstall "Development Tools"
安装 "开发工具":
autoconf
automake
bison
byacc
cscope
ctags
diffstat
doxygen
elfutils
flex
gcc
gcc-c++
gcc-gfortran
gettext
git
indent
intltool
libtool
make
patch
patchutils
rcs
redhat-rpm-config
rpm-build
rpm-sign
subversion
swig
systemtap
其余基本为依赖包。
'yum install gcc gcc-c++ make'这个安装指令与上面的组安装相类似。
yum install \
autoconf automake binutils \
bison flex gcc gcc-c++ gettext \
libtool make patch pkgconfig \
redhat-rpm-config rpm-build rpm-sign \
ctags elfutils indent patchutils
linux下制作静态库和动态链接库的方法
静态库.o文件的集合
制作:ar -cr libxxx.a xxx1.o xxx2.o xxx3.o ...
编译:gcc main.c -l xxx [-L 库路径] (如果不加-L则在标准库路径下查找)
运行:./a.out
基本概念:
静态库又称为文档文件Archive File,它是多个.o文件的集合。Linux中静态库文件的后缀为"a"。
静态库的代码在编译时就已经链接到应用程序中,静态库中的各个成员.o文件没有特殊的存在格式,仅仅是一个.o文件的集合。
使用"ar"工具维护和管理静态库
ar的三个参数中:r代表将文件插入归档文件中,c代表建立归档文件,s代表若归档文件中包含了对象模式,可利用此参数建立备存文件的符号表。lib和.a都是系统指定的静态库文件的固定格式,mylib才是静态库的名称,编译时,链接器会在标准路径/usr/lib;/lib或者用户指定的路径下去找.a的文件。
gcc -o main main.c -static -L. –lmylib
-static指定编译器链接静态库,-L.指定静态库的路径为当前路径,在gcc编译器中引用可搜索到的目录和库文件时需用-l+库名,如在gcc中加入-lm可以在程序汇中链接标准算术库,加上-lpthread可以链接到linux标准线程库
小结:使用静态库可以使程序不依赖于任何其他库而独立运行,但是会占用很多内存空间以及磁盘空间,而且如果库文件更新,则需重新编译源代码,使用起来不够灵活.其实,编译的时候不需要加-static,直接用gcc -o main main.c -L. –lmylib,连接器会为我们链接指定的静态库以及标准C的共享库。
动态库并不包含在可执行文件中,在执行时才加载动态库。
制作:gcc -shared -fPIC xxx.c -o libxxx.so
编译:gcc main.c -l xxx [-L 编译时库路径]
临时指定运行时的库查找路径 [LD_LIBRARY_PATH=(运行时库路径)] ./a.out
如果不指定则在标准路径下找,当你发布库要标准路径"/usr/lib 或 /lib"就不需要其它操作,但 gcc 时一定要加'-l'指定的库名。
永久修改运行时的库查找路径
/etc/ld.so.conf 修改连接器的配置文件
ldconfig 使配置文件生效
编译参数解析,最主要的是GCC命令行的一个选项:
-shared 该选项指定生成动态连接库让连接器生成T类型的导出符号表,有时候也生成弱连接W类型的导出符号,不用该标志外部程序无法连接。相当于一个可执行文件
-fPIC:表示编译为位置独立的代码,不用此选项的话编译后的代码是位置相关的所以动态载入时是通过代码拷贝的方式来满足不同进程的需要,而不能达到真正代码段共享的目的。
-L.:表示要连接的库在当前目录中
-ltest:编译器查找动态连接库时有隐含的命名规则,即在给出的名字前面加上lib,后面加上.so来确定库的名称
LD_LIBRARY_PATH:这个环境变量指示动态连接器可以装载动态库的路径。
当然如果有root权限的话,可以修改/etc/ld.so.conf文件,然后调用/sbin/ldconfig来达到同样的目的,不过如果没有root权限,那么只能采用输出LD_LIBRARY_PATH的方法了。
/usr/bin/ld: cannot find -lc
在编译chkrootkit时报
# make sense
cc -static -o strings-static strings.c
/usr/bin/ld: cannot find -lc
collect2: error: ld returned 1 exit status
make: *** [strings-static] Error 1
/usr/bin/ld: 找不到 -lc
collect2: 错误:ld 返回 1
make: *** [strings-static] 错误 1
新版本的Linux操作系统下安装 glibc-devel、glibc和gcc-c++时,都不会安装libc.a. 只安装libc.so.
所以当使用-static选项时,libc.a不能使用,只能报找不到libc了(即软件使用了静态编译,没有使用动态编译方法;在使用静态选项编译时会报找到静态包,因为默认没有安装)。
解决方法
安装glibc-static
yum install glibc-static glibc-utils
# rpm -aq|grep glibc
glibc-common-2.17-326.el7_9.x86_64
glibc-headers-2.17-326.el7_9.x86_64
glibc-2.17-326.el7_9.x86_64
glibc-devel-2.17-326.el7_9.x86_64
# yum install glibc-static glibc-utils
再进行编译就应该没有问题了。
# make clean
# make sense
查看和修改gcc、g++默认include路径
注意:"`"是Tab上面的那个符号。
#gcc
`gcc -print-prog-name=cc1plus` -v
#g++
`g++ -print-prog-name=cc1plus` -v
在编译的预处理阶段, 编译器会展开所有的#include<...>和#include"..."文件,那么编译器是按照什么顺序来查找头文件的呢?
首先会根据gcc 、g++ -I 选项,在预处理的时候去当前路径下寻找.h文件:
g++ -c ttcp_blocking.c -I /home/freeoa/code/pro-master/
然后查找gcc、g++环境变量:
#gcc
export C_INCLUDE_PATH=XXXX:$C_INCLUDE_PATH
#g++
export CPLUS_INCLUDE_PATH=XXX:$CPLUS_INCLUDE_PATH
以上修改可以直接命令行输入(一次性),可以在/etc/profile中完成(对所有用户生效),也可以在用户home目录下的.bashrc或.bash_profile中添加(针对某个用户生效),修改完后重新登录即生效(当然也可以调用source指令,因为重启的意义也是把这个文件刷新一遍,一般修改的是.bashrc)。之后再找下面的默认目录,是有先后顺序的,当找到了就不会再继续查找了。
#当前用户的include路径,一般自己安装的库放这里。比如PCL库,一般推荐放在这里
/usr/local/include
#整个系统的include路径,大家都会用的放这里,比如yum自动安装C++的时候,它的头文件就在/usr/include这里
如何修改gcc、g++默认include路径
方法一:通过命令行添加
g++ -I/home --I/tmp main.cpp #/home的优先级高于/tmp
方法二:通过环境变量添加
#配置文件.bashrc是在/home/zss/,当前用户下,~就表示当前目录,你也可以通过指令
locate .bashrc
vim ~/.bashrc
export CPLUS_INCLUDE_PATH = $CPLUS_INCLUDE_PATH:/Apollo
source ~/.bashrc
#最后需要让修改生效
方法三:添加到/usr/local/include或者/usr/include路径下
注意:优先级排序:通过编译指定的include > 环境变量 > /usr/local/include > /usr/include
GCC 编译器使用参数详解
gcc 与 g++ 分别是 gnu 的 c & c++ 编译器 gcc/g++ 在执行编译工作的时候,总共需要4步:
1、预处理,生成 .i 的文件[预处理器cpp]
2、将预处理后的文件转换成汇编语言, 生成文件 .s [编译器egcs]
3、有汇编变为目标代码(机器代码)生成 .o 的文件[汇编器as]
4、连接目标代码, 生成可执行程序 [链接器ld]
-x language filename
设定文件所使用的语言, 使后缀名无效, 对以后的多个有效。也就是根据约定 C 语言的后缀名称是 .c 的,而 C++ 的后缀名是 .C 或者 .cpp;这个参数对他后面的文件名都起作用,除非到了下一个参数的使用。可以使用的参数吗有下面的这些:'c', 'objective-c', 'c-header', 'c++', 'cpp-output', 'assembler', 与 'assembler-with-cpp'。
用法:
gcc -x c hello.pig
-x none filename
关掉上一个选项,也就是让gcc根据文件名后缀,自动识别文件类型 。
用法:
gcc -x c hello.pig -x none hello2.c
-c
只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
用法:
gcc -c hello.c
将生成 .o 的 obj 文件
-S
只激活预处理和编译,就是指把文件编译成为汇编代码。
用法:
gcc -S hello.c
将生成 .s 的汇编代码,你可以用文本编辑器察看。
-E
只激活预处理,这个不生成文件, 你需要把它重定向到一个输出文件里面。
用法:
gcc -E hello.c > pianoapan.txt
gcc -E hello.c | more
慢慢看吧, 一个 hello word 也要与处理成800行的代码。
-o
制定目标名称, 默认的时候, gcc 编译出来的文件是 a.out, 很难听, 如果你和我有同感,改掉它, 哈哈。
用法:
gcc -o hello.exe hello.c (哦,windows用习惯了)
gcc -o hello.asm -S hello.c
-pipe
使用管道代替编译中临时文件, 在使用非 gnu 汇编工具的时候, 可能有些问题。
gcc -pipe -o hello.exe hello.c
-ansi
关闭 gnu c中与 ansi c 不兼容的特性, 激活 ansi c 的专有特性(包括禁止一些 asm inline typeof 关键字, 以及 UNIX,vax 等预处理宏)。
-fno-asm
此选项实现 ansi 选项的功能的一部分,它禁止将 asm, inline 和 typeof 用作关键字。
-fno-strict-prototype
只对 g++ 起作用, 使用这个选项, g++ 将对不带参数的函数,都认为是没有显式的对参数的个数和类型说明,而不是没有参数。
而 gcc 无论是否使用这个参数, 都将对没有带参数的函数, 认为城没有显式说明的类型。
-fthis-is-varialble
就是向传统 c++ 看齐, 可以使用 this 当一般变量使用。
-fcond-mismatch
允许条件表达式的第二和第三参数类型不匹配, 表达式的值将为 void 类型。
-funsigned-char 、-fno-signed-char、-fsigned-char 、-fno-unsigned-char
这四个参数是对 char 类型进行设置, 决定将 char 类型设置成 unsigned char(前两个参数)或者 signed char(后两个参数)。
-include file
包含某个代码,简单来说,就是便以某个文件,需要另一个文件的时候,就可以用它设定,功能就相当于在代码中使用 #include<filename>。
用法:
gcc hello.c -include /root/pianopan.h
-imacros file
将 file 文件的宏, 扩展到 gcc/g++ 的输入文件, 宏定义本身并不出现在输入文件中。
-Dmacro
相当于 C 语言中的 #define macro
-Dmacro=defn
相当于 C 语言中的 #define macro=defn
-Umacro
相当于 C 语言中的 #undef macro
-undef
取消对任何非标准宏的定义
-Idir
在你是用 #include "file" 的时候, gcc/g++ 会先在当前目录查找你所制定的头文件, 如果没有找到, 他回到默认的头文件目录找, 如果使用 -I 制定了目录,他会先在你所制定的目录查找, 然后再按常规的顺序去找。
对于 #include<file>, gcc/g++ 会到 -I 制定的目录查找, 查找不到, 然后将到系统的默认的头文件目录查找 。
-I-
就是取消前一个参数的功能, 所以一般在 -Idir 之后使用。
-idirafter dir
在 -I 的目录里面查找失败, 讲到这个目录里面查找。
-iprefix prefix 、-iwithprefix dir
一般一起使用, 当 -I 的目录查找失败, 会到 prefix+dir 下查找
-nostdinc
使编译器不再系统默认的头文件目录里面找头文件, 一般和 -I 联合使用,明确限定头文件的位置。
-nostdin C++
规定不在 g++ 指定的标准路经中搜索, 但仍在其他路径中搜索, 此选项在创 libg++ 库使用 。
-C
在预处理的时候, 不删除注释信息, 一般和-E使用, 有时候分析程序,用这个很方便的。
-M
生成文件关联的信息。包含目标文件所依赖的所有源代码你可以用 gcc -M hello.c 来测试一下,很简单。
-MM
和上面的那个一样,但是它将忽略由 #include<file> 造成的依赖关系。
-MD
和-M相同,但是输出将导入到.d的文件里面
-MMD
和 -MM 相同,但是输出将导入到 .d 的文件里面。
-Wa,option
此选项传递 option 给汇编程序; 如果 option 中间有逗号, 就将 option 分成多个选项, 然 后传递给会汇编程序。
-Wl.option
此选项传递 option 给连接程序; 如果 option 中间有逗号, 就将 option 分成多个选项, 然 后传递给会连接程序。
-llibrary
制定编译的时候使用的库
用法:
gcc -lcurses hello.c
使用 ncurses 库编译程序
-Ldir
制定编译的时候,搜索库的路径。比如你自己的库,可以用它制定目录,不然编译器将只在标准库的目录找。这个dir就是目录的名称。
-O0 、-O1 、-O2 、-O3
编译器的优化选项的 4 个级别,-O0 表示没有优化, -O1 为默认值,-O3 优化级别最高。
-g
只是编译器,在编译的时候,产生调试信息。
-gstabs
此选项以 stabs 格式声称调试信息, 但是不包括 gdb 调试信息。
-gstabs+
此选项以 stabs 格式声称调试信息, 并且包含仅供 gdb 使用的额外调试信息。
-ggdb
此选项将尽可能的生成 gdb 的可以使用的调试信息。
-static
此选项将禁止使用动态库,所以,编译出来的东西,一般都很大,也不需要什么动态连接库,就可以运行。
-share
此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库。
-traditional
试图让编译器支持传统的C语言特性。
GCC 是 GNU 的 C 和 C++ 编译器。实际上,GCC 能够编译三种语言:C、C++ 和 Object C(C 语言的一种面向对象扩展)。利用 gcc 命令可同时编译并连接 C 和 C++ 源程序。
如果有两个或少数几个 C 源文件,也可以方便地利用 GCC 编译、连接并生成可执行文件。假设有两个源文件 main.c 和 factorial.c 两个源文件,现在要编 译生成一个计算阶乘的程序。
factorial.c 文件代码
int factorial (int n){
if (n <= 1)
return 1;
else
return factorial (n - 1) * n;
}
main.c 文件代码
#include <stdio.h>
#include <unistd.h>
int factorial (int n);
int main (int argc, char **argv){
int n;
if (argc < 2){
printf ("Usage: %s n\n", argv [0]);
return -1;
}else{
n = atoi (argv[1]);
printf ("Factorial of %d is %d.\n", n, factorial (n));
}
return 0;
}
利用如下的命令可编译生成可执行文件,并执行程序:
$ gcc -o factorial main.c factorial.c
$ ./factorial 5
Factorial of 5 is 120.
GCC 可同时用来编译 C 程序和 C++ 程序。一般来说,C 编译器通过源文件的后缀名来判断是 C 程序还是 C++ 程序。在 Linux 中,C 源文件的后缀名为 .c,而 C++ 源文件的后缀名为 .C 或 .cpp。但是gcc命令只能编译 C++ 源文件,而不能自动和 C++ 程序使用的库连接。因此,通常使用 g++ 命令来完成 C++ 程序的编译和连接,该程序会自动调用 gcc 实现编译。假设我们有一个如下的 C++ 源文件(hello.c):
hello.c 文件代码
#include <iostream>
void main (void){
cout << "Hello, world!" << endl;
}
则可以如下调用 g++ 命令编译、连接并生成可执行文件:
$ g++ -o hello hello.c
$ ./hello
Hello, world!
gcc 命令的常用选项
| 选项 | 解释 |
|---|---|
| -ansi | 只支持 ANSI 标准的 C 语法。这一选项将禁止 GNU C 的某些特色, 例如 asm 或 typeof 关键词。 |
| -c | 只编译并生成目标文件。 |
| -DMACRO | 以字符串"1"定义 MACRO 宏。 |
| -DMACRO=DEFN | 以字符串"DEFN"定义 MACRO 宏。 |
| -E | 只运行 C 预编译器。 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -IDIRECTORY | 指定额外的头文件搜索路径DIRECTORY。 |
| -LDIRECTORY | 指定额外的函数库搜索路径DIRECTORY。 |
| -lLIBRARY | 连接时搜索指定的函数库LIBRARY。 |
| -m486 | 针对 486 进行代码优化。 |
| -o FILE | 生成指定的输出文件。用在生成可执行文件时。 |
| -O0 | 不进行优化处理。 |
| -O 或 -O1 | 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -shared | 生成共享目标文件。通常用在建立共享库时。 |
| -static | 禁止使用共享连接。 |
| -UMACRO | 取消对 MACRO 宏的定义。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
GNU C 编译器使用入门指南
使用 C 语言编写的源文件代码,使用了标准的英语术语,因而人们可以方便阅读。然而计算机只能理解二进制代码,为将代码转换为机器语言,需要使用一种被称为编译器的工具。Linux下最常见的编译器是 GCC(GNU 编译器集),编译过程涉及到一系列的中间步骤及相关工具,下文就简述了这些中间过程。
准备 GCC(上文有提及,在此简述)
为验证在系统上是否已经安装了 GCC,使用 gcc 命令:
$ gcc --version
如有必要,使用软件包管理器来安装 GCC。在基于 Fedora 的系统上使用 dnf:
$ sudo dnf install gcc libgcc
在基于 Debian 的系统上使用 apt:
$ sudo apt install build-essential
在安装后查看 GCC 的安装位置可以使用:
$ whereis gcc
使用 GCC 来编译一个简单的 C 程序
这里有一个简单的 C 程序,用于演示如何使用 GCC 来编译,在文本编辑器中粘贴这段代码:
// hellogcc.c
#include <stdio.h>
int main() {
printf("Hello, FreeOA!\n");
return 0;
}
保存文件为 hellogcc.c ,接下来编译它:
$ ls
hellogcc.c
$ gcc hellogcc.c
$ ls -1
a.out
hellogcc.c
a.out 是编译后默认生成的二进制文件。为查看新编译的应用程序的输出,只需要运行它,就像运行任意本地二进制文件一样:
$ ./a.out
Hello, FreeOA!
命名输出的文件
文件名称 a.out 是一个约定的结果文件名,如果想具体指定可执行文件的名称,可以使用 -o 选项来指定文件名。
注:和最近 Linux 内核废弃的 a.out 格式无关,只是名字相同,这里生成的 a.out 是 ELF 格式的。
$ gcc -o hellogcc hellogcc.c
$ ls
a.out hellogcc hellogcc.c
$ ./hellogcc
Hello, FreeOA!
当开发一个需要编译多个 C 源文件文件的大型应用程序时,这种选项是很有用的。
在 GCC 编译中的中间步骤
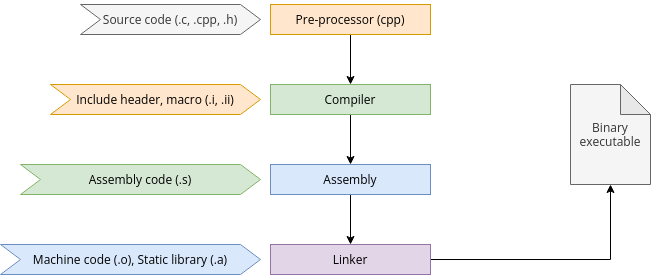
编译实际上有四个步骤,即使在简单的用例中 GCC 自动执行了这些步骤:
预处理:GNU 的 C 预处理器(cpp)解析头文件(#include 语句),展开 宏 定义(#define 语句),并使用展开的源文件代码来生成一个中间文件,如 hellogcc.i。
编译:在这个期间中,编译器将预处理的源文件代码转换为指定 CPU 架构的汇编代码。由此生成是汇编文件使用一个 .s 扩展名来命名,如在这个示例中的 hellogcc.s。
汇编:汇编程序(as)将汇编代码转换为目标机器代码,放在目标文件中,例如 hellogcc.o。
链接:链接器(ld)将目标代码和库代码链接起来生成一个可执行文件,例如 hellogcc。
在运行 GCC 时,可以使用 -v 选项来查看每一步的细节:
$ gcc -v -o hellogcc hellogcc.c
编译器流程图
手动编译代码
体验编译的每个步骤可能是很有用的,因此在一些情况下不需要 GCC 完成所有的步骤。
除源文件文件以外,删除在当前文件夹下生成的文件。
$ rm a.out hellogcc.o
$ ls
hellogcc.c
预处理器
启动预处理器,将其输出重定向为 hellogcc.i :
$ cpp hellogcc.c > hellogcc.i
$ ls
hellogcc.c hellogcc.i
查看输出文件,并注意一下预处理器是如何包含头文件和扩展宏中的源文件代码的。
编译器
现在可以编译代码为汇编代码,使用 -S 选项来设置 GCC 只生成汇编代码:
$ gcc -S hellogcc.i
$ ls
hellogcc.c hellogcc.i hellogcc.s
$ cat hellogcc.s
查看汇编代码,来看看生成了什么。
汇编
使用刚刚所生成的汇编代码来创建一个目标文件:
$ as -o hellogcc.o hellogcc.s
$ ls
hellogcc.c hellogcc.i hellogcc.o hellogcc.s
链接
要生成一个可执行文件,必须将对象文件链接到它所依赖的库。这并不像前面的步骤那么简单,但它却是有教育意义的:
$ ld -o hellogcc hellogcc.o
ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
ld: hellogcc.o: in function `main`:
hellogcc.c:(.text+0xa): undefined reference to `puts'
在链接器查找完 libc.so 库后,出现一个引用 undefined puts 错误。必须找出适合的链接器选项来链接必要的库以解决这个问题。这不是一个小技巧,它取决于所使用的系统布局。
在链接时,必须链接代码到核心运行时(CRT)目标,这是一组帮助二进制可执行文件启动的子例程。链接器也需要知道在哪里可以找到重要的系统库,包括 libc 和 libgcc,尤其是其中的特殊的开始和结束指令。这些指令可以通过 --start-group 和 --end-group 选项来分隔,或者使用指向 crtbegin.o 和 crtend.o 的路径。
这个示例使用了 RHEL 8 上的路径,因此可能需要依据所使用的系统调整路径。
$ ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 \
-o hello \
/usr/lib64/crt1.o /usr/lib64/crti.o \
--start-group \
-L/usr/lib/gcc/x86_64-redhat-linux/8 \
-L/usr/lib64 -L/lib64 hello.o \
-lgcc \
--as-needed -lgcc_s \
--no-as-needed -lc -lgcc \
--end-group \
/usr/lib64/crtn.o
在 Slackware 上,同样的链接过程会使用一组不同的路径,但是可以看到这其中的相似之处:
$ ld -static -o hello \
-L/usr/lib64/gcc/x86_64-slackware-linux/11.2.0/ \
/usr/lib64/crt1.o /usr/lib64/crti.o hello.o /usr/lib64/crtn.o \
--start-group \
-lc -lgcc -lgcc_eh \
--end-group
现在,运行由此生成的可执行文件:
$ ./hello
Hello, FreeOA!
一些有用的实用程序
下面是一些帮助检查文件类型、符号表 和链接到可执行文件的库的实用程序。使用 file 实用程序可以确定文件的类型:
$ file hellogcc.c
hellogcc.c: C source, ASCII text
$ file hellogcc.o
hellogcc.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
$ file hellogcc
hellogcc: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=bb76b241d7d00871806e9fa5e814fee276d5bd1a, for GNU/Linux 3.2.0, not stripped
对目标文件使用 nm 实用程序可以列出 符号表 :
$ nm hellogcc.o
0000000000000000 T main
U puts
使用 ldd 实用程序来列出(所依赖的)动态链接库:
$ ldd hellogcc
linux-vdso.so.1 (0x00007ffe3bdd7000)
libc.so.6 => /lib64/libc.so.6 (0x00007f223395e000)
/lib64/ld-linux-x86-64.so.2 (0x00007f2233b7e000)
小结
在本节中了解到了 GCC 编译中的各种中间步骤,和检查文件类型、符号表和链接到可执行文件的库的实用程序。在使用 GCC 时,将会明白它生成一个二进制文件所要做的步骤,并且当出现一些错误时会知道如何逐步处理解决问题。
C/C++编译器盘点
首先是业界主流知名的几位:MSVC、GCC、Clang、TCC、Digital Mars、Cygwin、MingW(Cygwin和MingW的英文发音),另外还有些新秀,像ICC(Intel C/C++ Compiler)、BCC(Borland C/C++ Compiler,近年鲜有消息)、RVCT(ARM的汇编/C/C++编译器,内置在ARM的IDE——RVDS中)、Pgi编译器……其实真有不少,我们只要熟悉常用的最强大的几款编译器|编译环境就可以了。
MSVC
MSVC(Microsoft Visual C++ Compiler)是微软公司为Windows平台开发的一个C++编译器系列,是Visual Studio集成开发环境的一部分。MSVC不仅支持C++,也支持C语言的编译。以下是关于MSVC系列的详细介绍:
MSVC与Visual Studio的关系:MSVC作为Visual Studio的核心组件之一,负责C和C++代码的编译工作。虽然随Visual Studio一同发布,但它有自己的版本控制系统,与Visual Studio的版本并不完全对应。
ABI兼容性:MSVC的主要版本号表示ABI(应用二进制接口)兼容性,意味着使用相同主要版本号的MSVC编译的代码可以在不同项目间链接,只要这些项目也是用相同主版本号的MSVC编译的。这一特性有助于保持二进制的兼容性,减少依赖问题。
功能特性
标准支持:MSVC持续更新以支持最新的C++标准,包括C++11、14、17、20等,尽管支持程度和具体实现细节可能晚于GCC或Clang。
优化与诊断:提供多种级别的代码优化,包括针对性能和大小的优化选项。同时,它还具有丰富的警告和错误诊断功能,帮助开发者提高代码质量。
链接器与库:与MSVC编译器配套的还有link.exe链接器,它负责将编译生成的对象文件链接成可执行文件或动态链接库。MSVC也提供了丰富的库支持,包括CRT(C运行时库)、STL(标准模板库)等。
开发与集成
集成开发环境:MSVC深度集成于Visual Studio,提供图形界面进行项目管理、代码编写、编译配置、调试等功能。
命令行工具:除了图形界面外,MSVC也提供了命令行工具(如cl.exe),允许开发者通过脚本或终端直接编译代码,适用于自动化构建和持续集成环境。
第三方工具和IDE兼容:尽管MSVC主要与Visual Studio一起使用,它也可以与其它IDE(如Qt Creator)集成,只需正确配置工具链即可。
优点:对Windows平台支持好,编译快。
缺点:对C++的新标准支持得少。
GCC
GCC全称为GNU Compiler Collection(GNU编译器套装),后来逐渐支持更多的语言编译(C++、Fortran、Pascal、Objective-C、Java、Ada、Go等),所以变成了GNU Compiler Collection(GNU编译器套装),是一套由GNU工程开发的支持多种编程语言的编译器。它是自由软件发展过程中的著名例子,由自由软件基金会以GPL协议发布,是大多数类Unix(如Linux、BSD、Mac OS X等)的标准编译器,而且适用于Windows(借助其他移植项目实现的,比如MingW、Cygwin等)。GCC支持多种计算机体系芯片,如x86、ARM,并已移植到其他多种硬件平台。
GCC 是自由软件基金会(Free Software Foundation, FSF)的GNU项目下的一个核心组件。它是一个开源的、跨平台的编译器系统,支持多种编程语言,包括但不限于C、C++、Objective-C、Objective-C++、Fortran、Ada、Go、D和Rust等。GCC不仅能够编译源代码,在命令行中可以使用gcc来编译C代码,使用g++来编译C++代码,还能够进行预处理、汇编和链接,最终生成可执行文件或库文件。
主要特点
跨平台:GCC可以在多种硬件架构和操作系统上运行,包括但不限于x86、ARM、MIPS、PowerPC以及各种Unix-like系统(如Linux、BSD、Solaris)和Windows(通过MinGW或Cygwin)。
多语言支持:GCC不仅仅是一个C编译器,它通过不同的前端支持多种编程语言,每种语言都有专门的编译器前端处理语法解析和语义分析,然后共同使用后端进行代码生成和优化。
高度优化:GCC提供了多种级别的优化选项,从基本的代码优化到高级的机器特定优化,旨在提高生成代码的执行效率。
标准遵循:GCC支持最新的C/C++标准(如C11、C++11、14、17、20等),同时也支持老版本的标准,确保代码的兼容性。
开源自由:作为自由软件,GCC遵循GPL(GNU General Public License)许可协议,用户可以自由地使用、修改和分发GCC。
使用GCC的基本步骤
预处理 (gcc -E): 这个阶段会处理源代码中的预处理指令,如#include、#define等。
编译 (gcc -c): 将预处理后的源代码转换为汇编代码。
汇编 (gcc -S): 将汇编代码转换为目标代码(机器代码)。
链接 (gcc): 将一个或多个目标文件和所需的库链接起来,生成可执行文件。
优点:类Unix下的标准编译器,支持众多语言,支持交叉编译。
缺点:默认不支持Windows,需要第三方移植才可用于Windows。
LLVM+Clang
LLVM(Low Level Virtual Machine)是一个开源的编译器框架项目,它不仅是一个虚拟机,更是一个现代化的、模块化且可重用的编译器基础设施。自2000年起源于伊利诺伊大学厄巴纳-香槟分校的一个研究项目以来,LLVM已发展成为支持多语言、跨平台的编译技术的基石。以下是关于LLVM的详细介绍:
Clang官方网站
核心特性与设计哲学
中间表示(Intermediate Representation, IR):LLVM的核心是其高度优化的、基于静态单赋值(Static Single Assignment, SSA)形式的中间表示。这种IR使得编译器能够以一种语言无关的方式表示代码,便于进行高级优化。
模块化设计:LLVM采用高度模块化的设计,将编译器分为前端、优化器、后端等多个独立的部分。这样的设计允许编译器组件复用,支持多种语言的编译,并且易于添加新的语言前端或目标架构后端。
优化器:LLVM包含了一个强大的优化器,能够在编译时、链接时、运行时甚至是程序空闲时对代码进行优化。这些优化包括但不限于死代码消除、循环优化、向量化、内联函数展开等。
可移植性和跨平台:由于其设计上的灵活性,LLVM能够生成针对多种CPU架构的机器代码,包括x86、ARM、MIPS、PowerPC等,从而支持在不同操作系统和硬件平台上运行。
开源和社区驱动:作为开源软件,LLVM遵循Apache 2.0许可证,拥有活跃的开发者社区,这促进了技术的快速发展和广泛的应用。
主要组成部分
前端(Frontend):负责将源代码转换为LLVM IR,如Clang是C、C++、Objective-C等语言的前端。
优化器(Optimizer):对IR进行一系列的分析和转换,以提高代码的执行效率。
后端(Backend):将优化后的IR转换为目标机器代码,包括汇编代码生成器和链接器支持。
库和工具:除了核心编译器组件,LLVM项目还包括了一系列库和工具,如LLD(LLVM链接器)、Polly(自适应优化)、Sanitizer工具集(用于内存错误检测等)以及Clang工具套件(如Clang Static Analyzer)。
TCC
Tiny C Compiler(TCC),也被称为Small C Compiler(SCC),是由Fabrice Bellard开发的一款小型、快速的C语言编译器。TCC以其小巧的体积、快速的编译速度和直接执行编译结果的能力而著称。以下是关于它的详细介绍:
轻量级与快速:TCC的设计目标是小巧和快速。它的可执行文件体积远小于GCC等传统编译器,且编译速度极快,适合快速编译和测试C语言代码片段。
直接执行模式:一个独特的特点是TCC可以在没有链接步骤的情况下直接执行C程序。它通过内存映射技术将编译后的代码直接加载到内存中执行,这对于快速原型设计和学习C语言非常有用。
跨平台:TCC支持多种操作系统,包括Linux、Windows、Mac OS X等,同时也支持多种处理器架构,如x86、ARM、MIPS等。
静态与动态链接:尽管TCC擅长直接执行代码,但它也支持传统的编译链路流程,能够生成可执行文件、共享库或目标文件,并支持与其他库的链接。
基本的C99支持:TCC实现了大部分C99标准,包括一些C11特性,但并不完全符合最新的C语言标准。它支持指针算术、结构体、联合、枚举、标准库函数等。
内置JIT编译器:TCC还可以作为一个简单的即时(Just-In-Time)编译器使用,这在某些特定应用场景下非常有用,比如动态生成和执行代码。
可嵌入性:因为其小体积和简单接口,TCC很容易被嵌入到其他应用程序中,作为脚本语言的编译器或者用于实时代码生成和执行。
限制
尽管TCC提供了很多便利和高效的功能,但它也有一些局限性:
优化程度有限:相比大型编译器如GCC或Clang,TCC的代码优化程度较低,可能产生的可执行文件较大或运行效率稍逊。
标准支持不完全:虽然支持C99的大部分特性,但对于最新的C语言标准(如C17、C2x)的支持不够全面。
调试信息有限:生成的调试信息不如GCC或Clang丰富,对于复杂项目的调试可能不太友好。
应用场景
使用TCC编译
tcc hello.c -o hello
TCC因其快速编译和直接执行的特性,非常适合于快速原型开发、教学演示、嵌入式系统开发以及需要即时编译能力的场合。它也是那些追求最小化工具链体积和快速迭代开发环境的理想选择。
Digital Mars
Digital Mars是一个历史悠久的编译器套件,专注于提供C和C++的编译解决方案。这个编译器由编程语言设计师沃德·布洛克(Walter Bright)开发,以其小巧、快速和高效的特点著称。以下是有关它的详细介绍:
主要特点
轻量级与便捷性:Digital Mars C/C++编译器(通常称为DMC)以压缩包形式提供,无需安装,解压即用,非常适合追求简洁高效开发环境的用户。与大型IDE相比,它的体积小,启动和编译速度快。
跨平台能力:虽然Digital Mars编译器最知名的是其在Windows平台上的表现,但实际上它也支持Linux和MacOS等操作系统,为跨平台开发提供了便利。
标准支持:DMC支持C89标准和部分C++标准,尽管在某些高级特性和最新标准的支持上可能不如GCC或Clang等其他主流编译器全面。
优化技术:DMC包含强大的优化技术,如先进的寄存器分配和指令调度,有助于生成高效运行的代码。
设计特色:在C++方面,Digital Mars引入了“Design by Contract”概念,这是一种通过编译时检查来增强软件可靠性的方法。
配套工具与库:除了编译器外,Digital Mars还提供了包括标准库函数、反汇编程序、资源编译器等在内的完整开发工具链,以及HTML文档支持,便于开发者查阅和学习。
应用场景
使用 Digital Mars 的 C++ 编译器 dmc 来编译源代码
dmc hello.cpp
快速原型开发:由于其轻便快捷的特性,DMC适合快速创建和测试C/C++代码原型。
教育与学习:开源的性质和简洁的结构使其成为学习C/C++语言及编译原理的良好工具。
特定平台开发:对于需要在Windows平台上进行低级别系统编程或者维护遗留代码的开发者来说,DMC仍然是一个不错的选择。
Cygwin
Cygwin是一个Windows下Unix-like模拟环境,具体说就是Unix-like接口(OS API,命令行)重定向层,其目的是不修改软件源码仅重新编译就可以将Unix-like系统上的软件移植到Windows上(这个移植也许还算不上严格意义上的无缝移植)。始于1995年,最初作为Cygnus软件公司工程师Steve Chamberlain的一个项目。
和GCC的关系:Cygwin是让Windows拥有Unix-like环境的软件而不是编译器,GCC是安装在Cygwin上的编译器。
优点:可以比MingW移植更多的软件到Windows上,对Linux接口模拟比MingW全面。
缺点:软件运行依赖cygwin1.dll,速度受点影响。
注意:Unix-like模拟环境不是Unix虚拟环境,很多论述中都声称Cygwin是在Windows上尽可能模拟类Unix环境,这容易造成误解,好像类Unix的elf程序可以直接运行在安装了Cygwin的Windows上一样。Cygwin和Wine的思路是不同的。在Windows+Cygwin上你可以像类Unix那样使用命令行和编程,但elf等非exe格式的程序是不能被Cygwin运行的,所以Cygwin和Unix虚拟机、Wine是完全不同的,叫Unix-like环境,模拟非虚拟,是有限的选择性的模拟,请不要误解。
MingW
MingW(Minimalist GNU on Windows)是一个Linux/Windows下的可以把软件源码中Unix-like OS API调用通过头文件翻译替换成相应的Windows API调用的编译环境,其目的和Cygwin相同。从而把Linux上的软件在不修改源码的情况下编译为可直接在Win下执行的exe。
和GCC的关系:MingW是编译环境,不是编译器,GCC是MingW中的核心组成。
优点:在Windows下可以和Linux一样的方式编译C/C++源码,可以说是Win版的GCC,其生产的Windows PE程序相比Cygwin不依赖任何第三方库,比Cygwin纯粹,理论上也更快速。
缺点:编译速度、编译出的程序在算法上可能都比MSVC慢。
注意:与Windows下其它编译器不同的是,MinGW与Linux下广泛使用的GNU近乎完全兼容,这意味着,在Linux下如何编译源代码,在MinGW中也可以以完全相同的方式编译。有些Linux下的开发人员(比如开源阵营)发布的源代码通常只提供Linux下的编译方式,而不提供Windows下的编译方式(这可能与其不熟悉windows操作系统有关),但确实有不少用户需要在在Windows下编译使用此源代码。这在种情况下,如果Windows用户想用VC、BC等编译器编译该源代码,必须重写Makefile(各种编译器所支持的Makefile不尽相同),工作量比较大不说,还很难保证不出错。MinGW的出现提供了两个平台下的“跨平台编译方案”。MinGW与MSYS相配合,连./configure都有了。与GNU不同的是,MinGW编译生成的是Windows下的可执行文件(.exe)或库文件(.dll,.lib)——不过编译过程中的的中间文件仍然是.o文件,而不是.obj文件(这当然无所谓了,中间文件嘛,编译完成后就没有用了)。
在对比Cygwin和MingW之前,请先理清一件事,那就是:如何从Unix-like系统向Windows系统移植软件?
现代操作系统包括Windows和Linux的基本设计概念,像进程线程地址空间虚拟内存这些都大同小异,二者之上的程序之所以不兼容,主要是它们对这些功能具体实现上的差异:
首先,是可执行文件的格式,Window使用PE的格式,并且要求以.EXE为后缀名,Linux则使用Elf。
其次,操作系统API也同,比如Windows用CreateProcess()创建进程,而Unix-like系统则使用fork(),其他还有很多诸如spawn、signals、select、sockets等。
分析之后可知,要把Unix-like系统上的软件移植到Windows上,有几种思路:
第一种:修改软件源码并重新编译,这个方法最笨,类Unix下大量的软件要修改工作量很大,编译生成目标平台可执行文件格式。
第二种:不修改软件源码但把类Unix接口调用悄悄替换为WinAPI,还是需要重新编译,编译生成目标平台可执行文件格式。
第三种,无缝移植的运行环境,无需重新编译,在一种OS上建立另一中OS的应用软件虚拟环境(和虚拟机不一样),比如Wine(把Windows上的可执行程序直接原样移植到Linux上)。
Cygwin和MingW的对比
作为编译环境时,都依赖于GCC
用它们作编译环境、交叉编译,根本上都是因为GCC编译器的支持,它们做的工作是为GCC的编译扫除Unix-like、Windows间OS API的差异这个障碍。
两者都必须重新编译后实现移植,生成的程序都是PE格式。都不能让Linux下的程序直接运行在Windows上(无缝移植),必须通过源代码重新编译。有些人声称cygwin支持rpm的压缩包,注意,rpm压缩包其实是src.rpm,内部还是源码而非elf格式,cygwin不支持常规rpm包的安装。
Cygwin运行在Windows上,MingW运行在Linux或者Windows上
Cygwin是Windows上运行的Unix-like环境,MingW是运行在Linux或者Windows上的Windows PE编译环境。
MingW中的子项目MSys和Cygwin更像
Cygwin除了全面模拟Linux的接口(命令行,OS API),提供给运行在它上面的的Windows程序使用,并提供了大量现成的软件,更像是一个平台。MingW也有一个叫MSys(Minimal SYStem)的子项目,主要是提供了一个模拟Linux的Shell和一些基本的Linux工具。因为编译一个大型程序,光靠一个GCC是不够的,还需要有Autoconf等工具来配置项目,所以一般在Windows下编译ffmpeg等Linux下的大型项目都是通过Msys来完成的,当然Msys只是一个辅助环境,根本的工作还是MingW来做的。
实现思路有同有异
Cygwin和MingW都是第二种软件移植思路,当然二者还是有区别,区别就在于“替换”方式,Cygwin编译时,程序依然以Linux的方式调用系统API,只不过把Unix-like接口link到自己的cygwin1.dll上,然后在cygwin1.dll中重新调用Windows API,cygwin1.dll再调用Windows对应的实现,来把结果返回给程序。也就是说,他们基于Win32 API中写了一个Unix系统API的重定向层,所以用它移植的软件都依赖于cygwin1.dll,MingW编译时通过特有的WinAPI头文件把类Unix-like调用替换为WinAPI,用它移植的软件无需依赖第三方库,可直接运行在Windows平台。为了达到类Unix软件仅通过重新编译移植到Win的目的,Cygwin在运行时偷梁换柱,MingW在编译时偷梁换柱。
用一个PE格式查看工具检查一下就能发现,Cygwin生成的程序依然有fork()这样的Linux系统调用,但目标库是cygwin1;而MingW生成的程序,则全部使用从KERNEL32导出的标准Windows系统API。
使用方式有同有异
把类Unix上的软件移植到Windows是二者的主要目标,除此之外,MingW和Cygwin都可以用来跨平台开发等等其他事情。
Windows + Cygwin:可以在Windows上学习Linux命令,还可以在Windows上做Linux软件的开发,包括用GCC编译elf(交叉编译)。
Linux + MingW:可以在Linux上做Windows软件的开发,包括用GCC编译exe(交叉编译)。
Windows/Linux + MingW:可以摆脱MSVC的“束缚”,用GNU的自由软件来编译生成不依赖第三方库的纯粹Windows PE格式(exe)二进制程序。
Cygwin重量级,MingW轻量级
与MingW思路一致的,两者相比,Cygwin是重量级的(需下载50M以上直至数百兆不等,安装后占用空间可达1G),MinGW是轻量级的(需下载的文件只有20M,安装后70M左右),这是单纯从体积上说的,另外Cygwin现在据说也不是完全免费的了。
网络上的对比列表(UnxUtils自行无视,仅供参考)
| 功能 | UnxUtils | MinGW | Cygwin |
| 设计原理 | 原生 | 原生 | 模拟 |
| 运行依赖 | 无依赖 | 依赖msys.dll(一定依赖它吗?值得验证) | 依赖cygwin.dll |
| 运行性能(比较) | 最快 | 中等 | 慢 |
| DOS执行 | 可以 | 可以 | 不可以 |
| 更新速度 | 完善停止更新 | 较慢 | 基本同步gcc |
| shell命令 | 较多 | 较少 | 较多 |
| uname | WindowsNT | MINGW32_NT-5.1 | CYGWIN_NT-5.1 |
| env | 同Windows | 同Windows | 不完全同Windows |
| root | C:/ | C:/ | / |
| home | C:/Documents and Settings/test | /home/test: No such file or directory | /home/test |
| pwd | C:/bin | /usr/bin | /home/test |
| df | cannot read table of mounted filesystems | 无 | /cygdrive/c |
| vi | 无 | 无 | 有 |
| gcc套件 | 无 | 有 | 有 |
| 开发库 | 无 | WinAPI | POSIX |
| 图形库 | 无 | GTK/QT | GTK/QT |
| 可移植性 | 无 | Win32API不可移植 | 无缝移植 |
| 程序运行 | 无 | 原生 | 模拟 |
| 程序依赖 | 无 | 无 | cygwin.dll |
| 程序性能(比较) | 无 | 较快(慢于VC和Linux下的gcc) | 较慢(快于java) |