 java程序内存泄漏排查
java程序内存泄漏排查一个java应用越跑越慢,如何排查?
首先通过jps找到java进程ID。然后top -p [pid]发现内存占用是否达到了最大值(-Xmx)。开始怀疑是由于频繁Full GC导致的,于是通过:
jstat -gcutil [pid] 6000
查看GC的情况,其中6000表示每隔60秒钟输出一次。果然是Full GC次数太多,JVM大部分时间都进行Full GC,而此时JVM会暂停其他一切工作,所以程序会运行得非常慢。
那到底的程序的哪一部分导致消耗了这么多的内存呢?
jmap -histo:live [pid]
查看进程中各种类型的对象创建了多少个,以及每种类型的对象占多少内存。当看到有个对象被创建了1千多万个实例时就能定位到是哪里的问题了。
另外说一下,通过jmap还可以生成JVM的内存dump文件,命令为:
jmap -dump:format=b,file=文件名 [pid],
然后通过jhat命令在浏览器中查看,或者通过jvisualvm、eclipse memory analyzer等工具进行查看。使用jhat命令查看的方式为:
jhat -J-Xmx4096M [file]
这个内存用量可以跟据实际情况调整,等控制台输出:Started HTTP server on port 7000. Server is ready,后在浏览器中输入ip:7000就可以查看各上类中各种实例被创建了多少个。
jinfo:可以输出并修改运行时的java 进程的opts。
jps:与unix上的ps类似,用来显示本地的java进程,可以查看本地运行着几个java程序,并显示他们的进程号。
jstat:一个极强的监视VM内存工具。可以用来监视VM内存内的各种堆和非堆的大小及其内存使用量。
jmap:打印出某个java进程(使用pid)内存内的所有'对象'的情况(如:产生那些对象,及其数量)。
jconsole:一个java GUI监视工具,可以以图表化的形式显示各种数据,并可通过远程连接监视远程的服务器VM。
详细用法:在使用这些工具前,先用jps命令获取当前的每个JVM进程号,然后选择要查看的JVM。
查看java进程内存使用情况的常用命令:jstat、jmap。
java程序占用CPU过高排查
查看进程占多少CPU
#top -p 28296
查看进程里各个线程占多少CPU
#top -p 28296 -H
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9731 web 20 0 18.9g 2.6g 13m S 0.3 2.8 0:40.64 /usr/local/jdk1.8.0_11/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat7/208
17228 web 20 0 18.9g 2.6g 13m S 0.3 2.8 0:10.90 /usr/local/jdk1.8.0_11/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat7/208
...
19628 web 20 0 18.9g 2.6g 13m S 0.3 2.8 0:03.98 /usr/local/jdk1.8.0_11/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat7/208
查看线程的执行栈信息
先把线程号转换为16进制。
#printf '%0x\n' 17228
434c
再通过jstack命令看看这个线程在做什么:
$jstack 28296 | grep -A 10 434c
持续执行上述jstack命令多次,不出意料你会发现代码总是停留在某一行或某一个循环块内,如果是停留在某一行说明该行代码执行起来非常耗CPU,如果是停留在某一个循环块内说明这很可能是个死循环。
盘点一些java性能监控及工具
Sun JDK自带监控和故障处理工具 | |
jps | 显示Hotspot虚拟机继承 |
jstat | 收集Hotspot虚拟机的运行数据 |
jinfo | 显示虚拟机配置信息 |
jmap | 生成虚拟机的内存转储快照(文件) |
jhat | 用于分析heapdump文件,建立HTTP server用于浏览器访问。 |
jstack | 显示虚拟机的线程快照 |
在JDK1.5中需要手动来设置“-Dcom.sun.management.jmxremote”开启JMX管理功能,部分工具是基于JMX的,在JDK1.6后该功能默认是开启的。
JVM监控和查看与调优思路一览
jps [options] [hostid]
jps和Linux的ps命令类似,查询的是虚拟机的进程。可以显示执行主类、LVMID(本地虚拟机唯一ID)等,LVMID和系统的PID是一致的。
如 >jps -l
6632 sun.tools.jps.Jps
6640 org.jetbrains.idea.maven.server.RemoteMavenServer
jps工具主要选项
-q:只输出LVMID,省略主类名称
-m:输出虚拟机进程启动时传递给main()函数的参数,如果是内嵌的JVM则使出为null
-l:输出应用程序主类的完整包名,或者是应用程序JAR文件的完整路径
-v:输出虚拟机进程启动时JVM参数
jstat [ option vmid [interval [s|ms] [count] ] ]
jstat用于监视虚拟机各种运行状态信息。可以显示类装载、内存、垃圾收集、JIT编译等运行数据。对于本地虚拟机,VMID和LVMID是一样的,如果是远程的则VMID变成远程的格式。jstat是JDK自带的一个轻量级小工具。全称"Java VirtualMachine statistics monitoring tool",它位于Java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
interval和count表示查询间隔和次数。
如> jstat -gc 632 250 20
每250毫秒查询一次垃圾收集,共20次
jstat工具主要选项
-class
监视类装载、卸载数量、总空间及类装载所耗费的时间
-gc
监视Java堆状况,Eden区、2个survivor区、老年代、永久代等
-gccapacity
和-gc类似,主要关注各区域最大最小空间
-gcutil
和-gc类似,主要关注已使用空间的百分比
-gccause
和-gcutil一样,会输出上一次gc的原因
-gcnew
监视新生代GC状况
-gcnewcapacity
和-gcnew类似,主要关注最大最小空间
-gcold
监视老年代GC状况
-gcoldcapacity
同上
-gcpermcapacity
永久代的最大最小空间
-compiler
输出JIT编译器编译过的方法,耗时等信息
-printcompilation
输出已被JIT编译的方法
jstat工具特别强大,有众多的可选项,详细查看堆内各个部分的使用量,以及加载类的数量。使用时需加上查看进程的进程id和所选参数。以下详细介绍各个参数的意义。
jstat -class pid:显示加载class的数量,及所占空间等信息。
jstat -compiler pid:显示VM实时编译的数量等信息。
jstat -gc pid:可以显示gc的信息,查看gc的次数,及时间。其中最后五项,分别是young gc的次数,young gc的时间,full gc的次数,full gc的时间,gc的总时间。
jstat -gccapacity:可以显示,VM内存中三代(young,old,perm)对象的使用和占用大小,如:PGCMN显示的是最小perm的内存使用量,PGCMX显示的是perm的内存最大使用量,PGC是当前新生成的perm内存占用量,PC是但前perm内存占用量。其他的可以根据这个类推, OC是old内纯的占用量。
jstat -gcnew pid:new对象的信息。
jstat -gcnewcapacity pid:new对象的信息及其占用量。
jstat -gcold pid:old对象的信息。
jstat -gcoldcapacity pid:old对象的信息及其占用量。
jstat -gcpermcapacity pid: perm对象的信息及其占用量。
jstat -util pid:统计gc信息统计。
jstat -printcompilation pid:当前VM执行的信息。
除了以上一个参数外,还可以同时加上 两个数字,如:jstat -printcompilation 3024 250 6 是每250毫秒打印一次,一共打印6次,还可以加上-h3每三行显示一下标题。
jinfo [ option ] pid
jinfo能实时查看和调整虚拟机的各项参数。用法比较简单,就是能输出并修改运行时的java进程的运行参数。用法是jinfo -opt pid 如:查看2758的MaxPerm大小可以用:jinfo -flag MaxPermSize 2758。
如> jinfo -flag CMSInitiatingOccupancyFraction 6632
jmap [ option ] vmid
jmap用于生成转储快照(heapdump)、查询堆和永久代详细信息等。jmap是一个可以输出所有内存中对象的工具,可以将VM 中的heap,以二进制输出成文本。使用方法 jmap -histo pid。可采用jmap -histo pid>a.log日志将其保存到文件中,间隔一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。jmap-dump:format=b,file=outfile <pid>可以将进程号为<pid>进程的内存heap输出到outfile文件中,然后再配合MAT(内存分析工具)进行分析。
命令:jmap -dump:format=b,file=heap.bin <pid>
file:保存路径及文件名
pid:进程编号
jmap -histo:live pid| less :堆中活动的对象以及大小
jmap -heap pid : 查看堆的使用状况信息
命令格式:
jmap [ option ] pid
jmap工具主要选项
-dump
生成heap文件。-dump:[live,]format-b,file=<filename> 其中live说明只dump出存活的对象
-finalizerinfo
显示F-Queue中等待Finalizer线程执行finalize方法的对象(Linux/Solaris有效)
-heap
显示堆详细信息(Linux/Solaris有效)
-histo
显示堆中对象统计信息,包括类、实例数量和合计容量
-permstat
显示永久代内存状态(Linux/Solaris有效)
-F
-dump没有响应时,可使用这个选项强制生成dump文件(Linux/Solaris有效)。
如> jmap -dump:format=b,file=dumpfile.log 6632
基本参数:
1、-dump:[live,]format=b,file=<filename> 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
$jmap–dump:live,format=b,file=aaa.bin 3772
2、-finalizerinfo 打印正等候回收的对象的信息
$jmap -finalizerinfo 3772
Attaching to process ID 3772, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 20.0-b11
Number of objects pending for finalization: 0 (等候回收的对象为0个)
3、-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
$jmap –heap 3772
using parallel threads in the new generation. ##新生代采用的是并行线程处理方式
using thread-local object allocation.
Concurrent Mark-Sweep GC ##同步并行垃圾回收
Heap Configuration: ##堆配置情况
MinHeapFreeRatio = 40 ##最小堆使用比例
MaxHeapFreeRatio = 70 ##最大堆可用比例
MaxHeapSize = 2147483648 (2048.0MB) ##最大堆空间大小
NewSize = 268435456 (256.0MB) ##新生代分配大小
MaxNewSize = 268435456 (256.0MB) ##最大可新生代分配大小
OldSize = 5439488 (5.1875MB) ##老生代大小
NewRatio = 2 ##新生代比例
SurvivorRatio = 8 ##新生代与suvivor的比例
PermSize = 134217728 (128.0MB) ##perm区大小
MaxPermSize = 134217728 (128.0MB) ##最大可分配perm区大小
Heap Usage: ##堆使用情况
New Generation (Eden + 1 Survivor Space): ##新生代(伊甸区 + survior空间)
capacity = 241631232 (230.4375MB) ##伊甸区容量
used = 77776272 (74.17323303222656MB) ##已经使用大小
free = 163854960 (156.26426696777344MB) ##剩余容量
32.188004570534986% used ##使用比例
Eden Space: ##伊甸区
capacity = 214827008 (204.875MB) ##伊甸区容量
used = 74442288 (70.99369812011719MB) ##伊甸区使用
free = 140384720 (133.8813018798828MB) ##伊甸区当前剩余容量
34.65220164496263% used ##伊甸区使用情况
From Space: ##survior1区
capacity = 26804224 (25.5625MB) ##survior1区容量
used = 3333984 (3.179534912109375MB) ##surviror1区已使用情况
free = 23470240 (22.382965087890625MB) ##surviror1区剩余容量
12.43827838477995% used ##survior1区使用比例
To Space: ##survior2 区
capacity = 26804224 (25.5625MB) ##survior2区容量
used = 0 (0.0MB) ##survior2区已使用情况
free = 26804224 (25.5625MB) ##survior2区剩余容量
0.0% used ## survior2区使用比例
concurrent mark-sweep generation: ##老生代使用情况
capacity = 1879048192 (1792.0MB) ##老生代容量
used = 30847928 (29.41887664794922MB) ##老生代已使用容量
free = 1848200264 (1762.5811233520508MB) ##老生代剩余容量
1.6416783843721663% used ##老生代使用比例
Perm Generation: ##perm区使用情况
capacity = 134217728 (128.0MB) ##perm区容量
used = 47303016 (45.111671447753906MB) ##perm区已使用容量
free = 86914712 (82.8883285522461MB) ##perm区剩余容量
35.24349331855774% used ##perm区使用比例
4、-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量。
$jmap–histo:live 3772
num #instances #bytes class name
----------------------------------------------
1: 65220 9755240 <constMethodKlass>
2: 65220 8880384 <methodKlass>
3: 11721 8252112 [B
4: 6300 6784040 <constantPoolKlass>
5: 75224 6218208 [C
6: 93969 5163280 <symbolKlass>
7: 6300 4854440 <instanceKlassKlass>
8: 5482 4203152 <constantPoolCacheKlass>
9: 72097 2307104 java.lang.String
10: 15102 2289912 [I
11: 4089 2227728 <methodDataKlass>
12: 28887 1386576 org.apache.velocity.runtime.parser.Token
classname是对象类型,说明如下:
B byte
C char
D double
F float
I int
J long
Z boolean
[ 数组,如[I表示int[]
[L+类名其他对象
5、-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
$jmap -permstat 3772
class_loader classes bytes parent_loader alive? type
<bootstrap> 2172 13144040 null live <internal>
0x00000007882d7ab8 0 0 0x0000000788106c00 dead java/util/ResourceBundle$RBClassLoader@0x00000007f83b0388
0x0000000788c15ca8 1 3136 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788fb1718 1 1968 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x00000007882d0f08 1 2008 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788176c60 1 3112 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788a7e018 1 3144 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788f515d0 1 1984 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x000000078829a2c8 1 3112 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788fab478 1 3128 null dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788030fd8 1 3112 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788d46048 1 3144 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x000000078816f6f0 1 3144 null dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
0x0000000788c18850 1 3112 0x00000007880213d8 dead sun/reflect/DelegatingClassLoader@0x00000007f80686e0
6、-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
7、-h | -help 打印辅助信息
8、-J 传递参数给jmap启动的jvm.
9、内存分析简单使用
1.查看堆内存总体概况
jmap -heap 进程ID
2.查看堆中对象的数量以及大小
jmap -histo 进程ID
加上live参数则是过滤出活动的对象信息
jmap -histo:live 进程ID
3.统计gc信息
jmap -gcutil 进程ID 时间间隔(ms)
4.使用界面工具分析内存泄漏情况
1)以二进制形式输出堆内存信息;
jmap -dump:format=b,file=heap.bin 进程ID
2)下载生成的文件heap.bin至本地电脑,利用MemoryAnalyzer等图形化工具可以直观的分析出内存泄漏情况,内存对象查看工具MemoryAnalyzer,可以查看dump时对象数量,内存占用,线程情况等。
jhat <heapdumpfile>
jhat和jmap配合使用。来分析jmap生成的转储快照文件,内置了一个微型的HTTP服务器,供用户在浏览器来访问分析接口。除了这个,还有VisualVM、Eclipse Memory Analyzer、IBM HeapAnalyzer等都能更专业的分析heap文件。
jstack [ option ] vmid
Java堆栈跟踪工具,用于生成虚拟机当前时刻的线程快照(threaddump文件)。打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",可查看jvm线程运行状态,是否有死锁现象等等信息 : jstack pid : thread dump
示例:jstat -gcutil pid 1000 100 :1000ms统计一次gc情况统计100次;
jstack工具主要选项
-F:正常输出请求不响应时,强制输出线程堆栈
-l:除堆栈外,显示关于锁的附加信息
-m:调用本地方法的话,可以显示C/C++堆栈
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息,如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
jstack [ option ] pid
jstack [ option ] executable core
jstack [ option ] [server-id@]remote-hostname-or-IP
1)、options:
executable Java executable from which the core dump was produced.
(可能是产生core dump的java可执行程序)
core 将被打印信息的core dump文件
remote-hostname-or-IP 远程debug服务的主机名或ip
server-id 唯一id,假如一台主机上多个远程debug服务
2)、基本参数:
-F当’jstack [-l] pid’没有相应的时候强制打印栈信息
-l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
-m打印java和native c/c++框架的所有栈信息.
-h | -help打印帮助信息
pid 需要被打印配置信息的java进程id,可以用jps查询.
可视化工具
JDK默认提供了两个可视化工具:Jconsole和VisualVM。Jconsole是JDK1.5提供的虚拟机监控工具,1.6后又推出了更强大的VisualVM。其中VisualVM除了能提供基本的监控功能外,最强大的是它的插件机制,基于它能扩展各种各样的插件用于监控调试。
jconsole是一个用java写的GUI程序,用来监控VM,并可监控远程的VM,易用且功能强。使用方法:命令行里输入 jconsole,选则进程就可以了。JConsole中关于内存分区的说明:
Eden Space (heap): 内存最初从这个线程池分配给大部分对象。
Survivor Space (heap):用于保存在eden space内存池中经过垃圾回收后没有被回收的对象。
Tenured Generation (heap):用于保持已经在 survivor space内存池中存在了一段时间的对象。
Permanent Generation (non-heap):保存虚拟机自己的静态(refective)数据,例如类(class)和方法(method)对象。Java虚拟机共享这些类数据。这个区域被分割为只读的和只写的。
Code Cache (non-heap):HotSpot Java虚拟机包括一个用于编译和保存本地代码(native code)的内存,叫做“代码缓存区”(code cache)。
另附JVM常用参数
参数 | 说明 | 备注 |
-Xms | 最小堆容量,新生代旧生代的初始化容量 | 默认物理内存1/64(新生代+旧生代)-Xms512m |
-Xmx | 最大堆容量,包括新生代和旧生代 | 默认物理内存1/4(新生代+旧生代)-Xmx1024m |
-Xmn | 新生代容量,包括Eden,S1,S0 | 新生代增大对导致旧生代减小,对系统会有较大影响。Sun推荐比例是新生代为整个堆的3/8 |
-XX:NewSize | 新生代容量 | For 1.3/1.4 |
-XX:MaxNewSize | 新生代最大容量 | For 1.3/1.4 |
-XX:PermSize | 持久代的初始值 | 默认物理内存1/64(-XX:PermSize=256m) |
-XX:MaxPermSize | 持久代最大值 | 默认物理内存1/4() |
-Xss | 每个线程的堆栈大小 | JDK5.0以后默认为1M |
-XX:SurvivorRatio | 堆中新生代对比例(Eden对Survivor的倍数,如值为5,即Eden占5/7,S1和S0各占1/7) | |
-XX:+DisableExplicitGC | 关闭System.gc() | |
-XX:MaxTenuringThreshold | 垃圾最大年龄 | 在新生代中,Eden、S0、S1之间存活的周期(复制的次数),默认15 |
-XX:PretenureSizeThreshold | 对象大于这个值则直接分配到老年代(对Serial和ParNew有效) | |
-XX:+UseParallelGC | ||
-XX:+UseParNewGC | 新生代使用ParNew进行收集(并行) | 可与CMS收集同时使用 JDK5.0以上会根据系统配置自行设置 |
-XX:ParallelGCThreads | 并行收集的线程数 | 最好与处理器数相等 |
-XX:+UseParallelOldGC | 旧生代使用Parallel进行收集(并行收集) | |
-XX:GCTimeRatio | 垃圾回收时间占程序运行时间的百分比 | 1(1+n) |
-XX:+UseConcMarkSweepGC | 使用CMS收集 | |
-XX:+PrintGC | 每次GC时打印日志 | |
-XX:+PrintGCDetails | 打印详细日志 | |
-XX:+PrintGCTimeStamps | 打印时间戳 | |
-XX:+PrintGC:PrintGCTimeStamps | ||
-XX:+PrintGCApplicationStoppedTime | 打印出垃圾回收期间程序暂停的时间 | |
-Xloggc:filename | 相关日志输出到文件 |
Java常用性能调优工具的底层实现原理
当Java虚拟机出现故障和性能问题时,通常会借助一些业界知名的工具来辅助排查问题。为了能更好的利用这些工具,需要对这些工具的实现原理有所了解,现有资料在介绍一些性能排查和故障诊断工具时,通常只会围绕这个工具的实现原理展开,例如Eclipse的MAT插件,主要是解读虚拟机的Dump文件。本节将从虚拟机的角度展开,看看虚拟机到底能提供什么样的静态或运行时数据。对于HotSpot这款虚拟机来说,能提供的主要数据如下图所示。
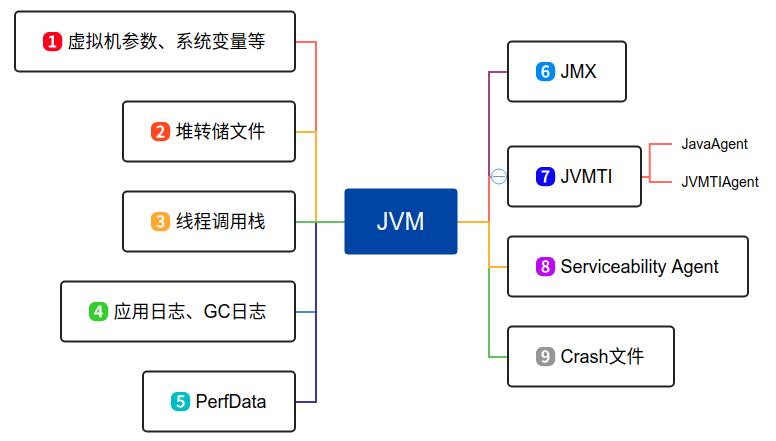
下面就来简单介绍一下上图中9个部分的数据以及围绕这9部分数据做出来的调优工具。
1、虚拟机参数、系统变量等
如果要查看虚拟机参数或系统变量,可通过如下命令:
// 查看系统配置选项
jcmd 5617 VM.flags
// 查看虚拟机启动参数
jcmd 5617 VM.command_line
// 查看系统配置信息
jcmd 5617 VM.system_properties
许多的虚拟机故障和调优都可通过调整虚拟机参数来达到目地,不过对于一般的Java开发人员来说,这并不是一项简单的工作,需要对虚拟机相关的运行原理有所了解。针对虚拟机参数、系统变量等的调优工具有:
(1)VM Options Explorer
(2)HeapDump社区的XXFox
2、堆转储文件
堆转储文件可用来检索整个堆的快照,能够从这个文件中获取到活跃集合、对象的类型和数量,以及对象图的形状和结构等等,堆导出常用的2种方式如下:
(1)通过命令,在发生OOM时导出,可配置参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=堆转储文件名
(2)Attach到目标进程后发送dump命令,jmap工具就是这样做的,通过命令jmap -dump:format=b,file=堆转储文件名 pid导出文件。如文件较大时,可通过添加live参数来有效缩小大小,如果要将堆转储文件转移到其它地方,最好压缩一下,堆转储文件的压缩比例相对较高。
分析堆转储文件的工具通常都能够给出类实例的数量、类实例的大小等,方便进行堆溢出、频繁GC等问题的排查。尤其是更多要关注类实例的数量和大小。假设GC频繁,那么需要重点关注那些类实例占用内存相对较大的;假设GC时间长,需要重点关注实例数量较多的,因为可能活跃的实例较多,标注的时间就会长一些。
分析堆转储文件的工具有:
(1)Eclipse MAT
(2)HeapDump社区的XElephant
(3)HeapHero
3、线程调用栈
通过JDK自带的工具jstack可以导出HotSpot VM的线程栈,这些线程栈对于排查问题非常有帮助,不过导出的线程栈比较原始,拿到这些线程栈后可以做许多的事情,如:
从一次的堆栈信息中,我们可以直接获取以下信息:
是否有很多线程都在等待同一个锁,说明这个系统存在性能瓶颈,导致了锁竞争;
当前线程的总数量,如果线程的总数量有几千上万个,那么大概率是线程泄漏;
每一个线程的调用关系,当前线程在调用哪些函数,从而可看出一些性能比较影响大的一些方法;
每个线程的当前状态,持有哪些锁,在等待哪些锁,是否产生了死锁,当某个锁的等待线程数很多时,很明显这就是系统瓶颈;
大多数线程在干什么,在执行什么代码?
如果指定采样,则从多次采样的堆栈信息中,可以得到以下信息:
线程数不断上涨,可能是线程泄漏;
是否总是存在同一个锁总是有等待的线程,如果有则说明锁是一个性能瓶颈;
一个线程是否长期执行,如果每次打印堆栈某个线程一直处于同样的调用上下文中,那么说明这个线程一直执行这段代码,此时要根据代码逻辑检查,是否合理;
通过多次堆栈信息,结合上火焰图能更容易定位出慢方法;
网络上最常见的通过线程调用栈分析的问题就是CPU使用率高的问题,通过top命令找到占用CPU最高的线程id,然后通过jstack来查看对应线程id的调用栈,不过有些工具可一步到位,例如usefulscripts的show-busy-java-threads脚本,还有Arthas的thread命令等。
分析线程调用栈的工具有:
(1)HeapDump社区的XSheepdog
(2)fastThread
(3)生成火焰图的async-profiler
async-profiler直接抓取的是C/C++栈的调用栈,如果要生成Java调用栈的火焰图,可通过jstack工具导出Java调用栈,然后整理成collapsed格式,利用async-profiler生成火焰图即可。
4、日志
日志是出了系统问题第一手的排查资料,尤其是开发人员自己记录的应用日志。
(1)业务日志
一般是应用的开发者根据不同的业务需求落日志,最终会通过大数据采集后进行存储,方便以报表的方式展现,也能辅助运营人员对业务做出优化。这一类数据对系统问题排查的帮助不大,可直接忽略。
(2)应用日志
应用可能会采集起来进行人工排查或监控。大多数开发人员在查找系统问题时,也应该重点关注这些系统日志,因为它包含应用程序编写的各种错误消息,警告或其他事件。这些消息可以提供与特定用例相关的详细信息。如用例中发生的异常的堆栈跟踪。有关外部系统响应时间较慢的警告消息。用例被触发或完成的信息。
(3)系统日志
GC日志、Crash文件等属于JVM相关的系统日志。这里只介绍一下GC日志,因为它比较重要,记录的信息比较全面。需要配置GC参数来开启,如下:
Java 8版本:-XX:+PrintGC(或-verbose:gc) -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:日志名称
Java 9及9+版本:-Xlog:gc*:file=日志名称
GC日志能够给出回收前后堆中各个代的大小、总堆的大小、GC发生的原因及GC所花费的时间等,连续监控GC日志能够得到GC发生的频次及内存分配率等。好多人有的问题就是,想要知道GC触发的原因,目前只能通过GC日志来查看,所以建议配置GC日志。GC日志可视化分析工具有GCeasy和GCViewer。
通过GC日志可视化分析工具可以很方便的看到JVM各个分代的内存使用情况、垃圾回收次数、垃圾回收的原因、垃圾回收占用的时间、吞吐量等,这些指标在进行JVM调优的时候是很有用的。
GCeasy是一款在线的GC日志分析器,可以通过GC日志分析进行内存泄露检测、GC暂停原因分析、JVM配置建议优化等功能,而且是可以免费使用的(有一些服务是收费的)。在GCeasy的官网上传GC日志(这里用的Parallel收集器),点击Analyze进行分析即可得到报告,得到的报告可以进行下载。由于报告内容比较多,就捡几个主要的截个图简单说明一下,其他的可以自行查看,而且可以自己试试不同的垃圾收集器的GC日志的分析报告有什么区别,有如下的信息:
JVM的各个分代区域分配的内存及使用峰值的内存
关键性能指标:吞吐量及GC暂停平均时间、最大时间、各个时间段的比例
GC发生的原因、次数、时间等
上面介绍了一款在线的GC日志分析器,下面介绍一个离线版的GCViewer,新版本为1.36,需要jdk1.8才可以使用,可从Github下载,下载之后执行 mvn clean install -Dmaven.test.skip=true 命令进行编译,编译完成后在target目录下会看到jar包,双击打开即可。打开之后,点击File->Open File打开我们的GC日志,可以看到图示,图标是可以放大缩小的,主要内容就是红线圈住的部分,里面的内容跟上面的GCeasy的比较类似。
由于GC日志含有的数据指标多,而且日志没有一个标准的格式,所以要借助一些专业的日志解析工具查看,典型的分析工具如下:
(1)开源GCViewer
(2)GCeasy
(3)商用工具Censum
5、PerfData
对于HotSpot VM来说,会将一些统计信息写到一个叫PerfData的共享文件中,默认路径为/tmp/hsperfdata_<user>/。在本机上看一下/tmp/hsperfdata_<user>/目录下。
其中的名称文件是pid, 可以从/tmp/hsperfdata_<user>/<pid>这个特定的文件中获取相关数据。
JDK自带的工具jps就是直接读取这个目录下的文件名来列出所有的Java进程号。正常情况下当JVM进程退出的时候会自动删除,但是当执行kill -9命令时,由于JVM不能捕获这种信号,虽然JVM进程不存在了,但是这个文件还是存在的。这个文件不是一直存在的,当再次有JVM进程启动时会自动删除这些无用的文件。jps在读取/tmp/hsperfdata_<user>/路径下的文件名称时,也会通过attach的方式判断这个进程是否存活,这样就能保证读取出的是存活的进程。
JDK自带的工具jstat也是通过读取PerfData中特定的文件内容来实现的。由于PerfData文件是通过mmap的方式映射到了内存里,而jstat是直接通过DirectByteBuffer的方式从PerfData里读取的,所以只要内存里的值变了,那我们从jstat看到的值就会发生变化,内存里的值什么时候变,取决于-XX:PerfDataSamplingInterval这个参数,默认是50ms,也就是说50ms更新一次值,基本上可以认为是实时的了。基于PerfData实现的jstat,因为垃圾回收器会主动将jstat所需要的摘要数据保存至固定位置之中,所以只需直接读取即可。
jstat在读取相关内容时,需要知道键值对,查看键值对的方式如下:
jstat -J-Djstat.showUnsupported=true -snap 4726
或者直接查看jdk/src/share/classes/sun/tools/jstat/resources/jstat_options文件,其中给出了timestamp、class、compiler、gc、gccapacity、gccause、gcnew、gcnewcapacity、gcold、gcoldcapacity、gcmetacapacity、gcutil、printcompilation这几个大类中的相关信息。
相关工具有:
(1)JDK自带的jps、jstat
(2)vjtools中的vjtop
6、JMX
JVM是一个成熟的执行平台,它为运行中的应用程序注入、监控和可观测性提供了很多技术选择,而JMX(Java Management Extensions)就是一种,通过JMX可以实现对类加载监控、内存监控、线程监控,以及获取Java应用本地JVM内存、GC、线程、Class、堆栈、系统数据等。另外,还可以用作日志级别的动态修改,比如 log4j 就支持 JMX 方式动态修改线上服务的日志级别。最主要的还是被用来做各种监控工具,比如Spring Boot Actuator、JConsole、VisualVM 等。
JMX通过各种 MBean(Managed Bean) 来传递消息。外界可以获取被管理的资源的状态和操纵MBean的行为,常见的MBean如下表所示。
| 名称 | 解释 |
|---|---|
ClassLoadingMXBean | 获取类装载信息,已装载、已卸载量 |
CompilationMXBean | 获取编译器信息 |
GarbageCollectionMXBean | 获取GC信息,但他仅仅提供了GC的次数和GC花费总时间 |
MemoryManagerMXBean | 提供了内存管理和内存池的名字信息 |
MemoryMXBean | 提供整个虚拟机中内存的使用情况 |
MemoryPoolMXBean | 提供获取各个内存池的使用信息 |
OperatingSystemMXBean | 提供操作系统的简单信息 |
RuntimeMXBean | 提供运行时当前JVM的详细信息 |
ThreadMXBean | 提供对线程使用的状态信息 |
一般监控系统用的比较多,也就是和JavaAgent方式结合以后,就能在指定了监控的目标Java进程后,打印目标Java进程的一些系统信息,如堆和非堆的参数。Arthas中dashboard命令中显示的堆外内存大小就是通过JavaAgent加上JMX来实现的。
相关的工具有:
(1)JDK自带的jconsole或VisualVM
(2)监控系统Spring Boot Actuator
(3)vjtools中的vjmxcli
7、JVMTI
JVMTI 本质上是对JVM内部的许多事件进行了埋点。通过这些埋点可以给外部提供当前上下文的一些信息。甚至可以接受外部的命令来改变下一步的动作。外部程序一般利用C/C++实现一个JVMTIAgent,在JVMTIAgent里面注册一些JVM事件的回调。当事件发生时JVMTI调用这些回调方法。JVMTIAgent可以在回调方法里面实现自己的逻辑。通过JVMTI,可以实现对JVM的多种操作,它通过接口注册各种事件勾子,在JVM事件触发时,同时触发预定义的勾子,以实现对各个JVM事件的响应,事件包括类文件加载、异常产生与捕获、线程启动和结束、进入和退出临界区、成员变量修改、GC开始和结束、方法调用进入和退出、临界区竞争与等待、VM启动与退出等等。
另外还有一种是JavaAgent,其底层的实现就是利用了JVMTI,不过可以使用Java语言来实现,但是功能没有JVMTIAgent强大。现在假设有一个需求,监控应用抛出的异常,如果出现异常,就在监控系统中提醒,这时候就需要JVMTI来实现了。
通过JavaAgent对原有的Test类生成的字节码程序进行了增强,这就让想像空间变的非常大,因为可以更改任何方法体中的字节码,甚至替换整个类。例如,可以在字节码前后打印时间,这样就能输出调用方法的耗时;可以给整个方法体增加异常捕获的try-catch,在不修改、不重新部署应用程序的情况下修复某些Bug等等。
有些资料总结了Agent可以实现的功能,如下:
1.使用JVMTI对Class文件加密
有时一些涉及到关键技术的Class文件或者jar包不希望对外暴露,所以需要加密。使用一些常规的手段(例如使用混淆器或者自定义类加载器)来对Class文件进行加密很容易被反编译。反编译后的代码虽然增加了阅读的难度,但花费一些功夫也是可以读懂的。使用JVMTI可以将解密的代码封装成.dll或.so 文件。这些文件想要反编译就很麻烦了。不过个人认为,这样并不能完全避免代码泄漏,不要忘记Agent中提供的一些API,这些API能够将加载到虚拟机中的Class文件的内容Dump出来。
2.使用JVMTI实现应用性能监控(APM)
在微服务大行其道的环境下,分布式系统的逻辑结构变得越来越复杂。这给系统性能分析和问题定位带来了非常大的挑战。基于JVMTI的APM能够解决分布式架构和微服务带来的监控和运维上的挑战。APM通过汇聚业务系统各处理环节的实时数据,分析业务系统各事务处理的交易路径和处理时间,实现对应用的全链路性能监测。
相关的工具有:
(1)开源的Pinpoint、ZipKin、Hawkular
(2)商业的AppDynamics、OneAPM、Google Dapper等都是个中好手。
3.产品运行时错误监测及调试
想要看生产环境的异常,最原始的方式是登录到生产环境的机器查看日志。稍微高级一点的方式是通过日志监控或者APM等工具将异常采集上来。但是这些手段都有许多明显的缺点。首先,不是所有的异常都会被打印到日志中,有些异常可能被代码吃掉了;其次,打印异常的时候通常只有异常堆栈信息,异常发生时上下文的变量值很难获取到(除非有经验的程序员将其打印出来了),而这些信息对定位异常的原因至关重要。基于JVMTI可以开发出一款工具来时事监控生产环境的异常。其基本的原理和如上实例的原理相同。
相关的工具:商业软件OverOps
4.JAVA程序的调试(debug)。
一般JAVA的IDE都自带了调试工具。例如Eclipse的调试器相信大部分人都使用过。它的调试器org.eclipse.jdt.debug插件底层就是调用的JVMTI来实现的。经常使用eclipse等工具对java代码做调试,其实就利用了jre自带的jdwp agent来实现的,只是由于eclipse等工具在没让你察觉的情况下将相关参数(类似-agentlib:jdwp=transport=dt_socket,suspend=y,address=localhost:61349)给自动加到程序启动参数列表里了,其中agentlib参数就是用来跟要加载的agent的名字,比如这里的jdwp(不过这不是动态库的名字,而JVM是会做一些名称上的扩展,比如在linux下会去找libjdwp.so的动态库进行加载,也就是在名字的基础上加前缀lib,再加后缀.so),接下来会跟一堆相关的参数,会将这些参数传给Agent_OnLoad或者Agent_OnAttach函数里对应的options参数。
随着服务云化的发展,google甚至推出了云端调试工具cloud debugger。它时一个web应用,可以直接对生产环境进行远程调试,不需要重启或者中断服务。阿里也有类似的工具Zdebugger。
5.JAVA程序的诊断(profile)。
当出现CPU使用率过高、线程死锁等问题时,需要使用一些JAVA性能剖析或者诊断工具来分析具体的原因。例如Alibaba开源的Java诊断工具Arthas,深受开发者喜爱。Arthas的功能十分强大,它可以查看或者动态修改某个变量的值、统计某个方法调用链上的耗时、拦截方法前后,打印参数值和返回值,以及异常信息等。
6.热加载
热加载指的是在不重启虚拟机的情况下重新加载一些class。热加载可以在本地调试代码或线上修改代码时不用频繁重启。如spring-loaded,还有商业产品JRebel等。相关工具:
(1)spring-loaded
(2)JRebel
8、Serviceability Agent
SA是JDK提供的一个强大的调试工具集,可以用来调试运行着的Java进程、core文件和虚拟机crash以后的dump文件。所以在遇到CPU飙高、内存泄漏、应用奔溃等问题时,可以借助SA技术实现的工具来查找问题。在JDK自带的工具中,jmap、jstack、jinfo、HSDB等工具都在使用着SA。SA 机制不需要与进程互动,通过直接分析目标进程的内存布局获取目标 JVM 进程的运行时数据,如呈现出类对象、能够识别出Java堆、堆边界、堆内对象、载入的类描述、栈内存、线程状态等信息,是不是感觉黑科技?其实原理也并没那么难,我们平时所说的Java堆栈等内存模型都是虚拟机层面概念,虚拟机最终还是跑在操作系统上的,所以可以使用SA直接读取目标进程的操作系统层面的内存数据。
一般在使用jmap、jstack工具时,使用的是attach方式(之前介绍的JavaAgent和JVMTIAgent同样也使用了attach),这种方式就是与目标进程建立 socket 连接,目标进程处理后回传客户端,所以需要虚拟机本身代码的支持,但是SA不需要在目标 VM 中运行任何代码,SA 使用操作系统提供的符号查找和进程内存读取等原语实现。所以当jmap、jstack等导不出堆栈数据时,可以采用SA的方式获取数据,例如jstack加上-F选项来解决。有时候我们在运行这些工具时,会报如下错误:
Error attaching to process: sun.jvm.hotspot.debugger.DebuggerException: Can't attach to the process: ptrace(PTRACE_ATTACH, ..) failed for 6: Operation not permitted
SA的操作最主要是通过系统调用ptrace实现。ptrace会使内核暂停目标进程并将控制权交给跟踪进程,使跟踪进程得以察看目标进程的内存。这是一个很危险的操作,会造成机密数据泄漏,所以ptrace-scope为了防止用户访问当前正在运行的进程的内存和状态,默认情况下不允许再访问了,可以使用sudo赋于权限来解决这个问题。
常用工具:
(1)JDK自带的 jmap、jstack、jinfo、HSDB等工具
(2)vjmap是分代版的jmap(新生代,存活区,老生代),是排查内存缓慢泄露,老生代增长过快原因的利器,也是利用了SA的原理
注意,当SA 开始分析时,整个目标JVM是停顿下来不工作的,让SA可以从容读取进程内存中的数据,直到断开后才会恢复。所以在生产环境上使用有SA技术的工具时,必须先摘除流量。
9、Crash文件
造成严重错误的原因有多种可能性。Java虚拟机自身的Bug是原因之一,但是这种可能不是很大。在绝大多数情况下,是由于系统的库文件、API或第三方的库文件造成的;系统资源的短缺也有可能造成这种严重的错误。
当JVM发生致命错误导致崩溃时,会生成一个hs_err_pid_xxx.log这样的文件,该文件包含了导致 JVM crash 的重要信息,可以通过分析该文件定位到导致 JVM Crash 的原因,从而修复保证系统稳定。
默认情况下,该文件是生成在工作目录下的,当然也可以通过 JVM 参数指定生成路径:
java -XX:ErrorFile=/var/log/hs_err_pid<pid>.log
这个文件主要包含如下内容:
日志头文件
导致 crash 的线程信息
所有线程信息
安全点和锁信息
堆信息
本地代码缓存
编译事件
gc 相关记录
jvm 内存映射与启动参数
服务器信息
内容还是相对来说比较全的,但是显示过于专业,一般虚拟机开发人员可能参考的比较多一些。分析Crash文件的工具有:CrashAnalysis。
相关参考:
jvm常用命令工具之jps
jvm常用命令工具之jstat
jvm常用命令工具之jmap
jvm常用命令工具之jstack
JVM监控和查看