数据压缩算法-LZ77
 LZ77与LZ78是Abraham Lempel与Jacob Ziv在1977年以及1978年发表的论文中的两个无损数据压缩算法。这两个算法是大多数LZ算法变体如LZW、LZSS以及其它一些压缩算法的基础。与最小冗余编码器或者行程长度编码器不同,这两个都是基于字典的编码器。LZ77是“滑动窗”压缩算法,这个算法后来被证明等同于LZ78中首次出现的显式字典编码技术。
LZ77与LZ78是Abraham Lempel与Jacob Ziv在1977年以及1978年发表的论文中的两个无损数据压缩算法。这两个算法是大多数LZ算法变体如LZW、LZSS以及其它一些压缩算法的基础。与最小冗余编码器或者行程长度编码器不同,这两个都是基于字典的编码器。LZ77是“滑动窗”压缩算法,这个算法后来被证明等同于LZ78中首次出现的显式字典编码技术。 其所使用的算法是采用字典做数据压缩的算法,由以色列的两位大神Jacob Ziv与Abraham Lempel在1977年发表的论文《A Universal Algorithm for Sequential Data Compression》中提出。基于统计的数据压缩编码,比如Huffman编码,需要得到先验知识——信源的字符频率,然后进行压缩。但是在大多数情况下,这种先验知识是很难预先获得。因此,设计一种更为通用的数据压缩编码显得尤为重要。LZ77数据压缩算法应运而生,其核心思想:利用数据的重复结构信息来进行数据压缩。
LZ77
LZ77算法通过使用编码器或者解码器中已经出现过的相应匹配数据信息替换当前数据从而实现压缩功能。这个匹配信息使用称为长度-距离对的一对数据进行编码,它等同于“每个给定长度个字符都等于后面特定距离字符位置上的未压缩数据流。”(“距离”有时也称作“偏移”。)
编码器和解码器都必须保存一定数量的最近的数据,如最近2 KB、4 KB或者32 KB的数据。保存这些数据的结构叫作滑动窗口,因为这样所以LZ77有时也称作滑动窗口压缩。编码器需要保存这个数据查找匹配数据,解码器保存这个数据解释编码器所指代的匹配数据。所以编码器可以使用一个比解码器更小的滑动窗口,但是反过来却不行。
许多关于LZ77算法的文档都将长度距离对描述为从滑动窗“复制”数据的命令:“在缓冲区中回退距离个字符然后从那点开始复制长度个字符。”尽管对于习惯于指令式编程的人们来说很直观,但是它仍然使得人们很难理解LZ77编码的一个特点:也就是说,长度距离对中的长度超过距离这样一种情况不仅是可接受的而且还是经常出现的情况。作为一个复制命令,就会让人费解:“回退一个字符然后从那点开始复制七个字符。”但是如果缓冲区中只有一个字符的话那该如何复制七个字符呢?然而将长度距离对看作对于特性的描述就可以避免这种混淆:后面的七个字符与前面的七个完全相同。这就意味着每个字符都可以通过在缓冲区找到确定下来:即使在当前数据对解码开始的时候所要查找的字符并不在缓冲区中也可以。通过这个定义,这样的数据对将是距离字符序列的多次重复,也就是说LZ77成了一个灵活容易的行程长度编码形式。
尽管所有的LZ77算法都是根据同样的基本原理工作,但是如何输出编码后的数据可能会大不一样,例如长度与距离的取值范围是多少以及如何区分长度距离对和字面符号(即直接用字符本身,而不是用长度距离对表示)。下面是一些实例:
1、在Lempel与Ziv最初1977年论文中描述的算法每次将数据输出成三个数值:在缓冲区中找到的最大匹配长度与位置以及紧随这个匹配的字面符号。如果输入流中的两个相邻字符只能编码成字面符号的话,那么长度就是0。
2、在PalmDoc格式中,长度距离对经常用两字节序列进行编码,在这两字节的16位中,11位表示距离,3位表示长度,剩余的两位用来表示第一个字节是这样一个两个字节序列的开头。
3、直到2004年,最流行的基于LZ77的压缩方法是同时使用了LZ77与哈夫曼编码的DEFLATE。字面符号、长度以及用于指示当前数据块结束的符号都放到一个字母表中。距离可以安全地放到一个单独的字母表中,由于距离只会出现在一个长度后面,所以它不可能与其它类型的符号混淆。
LZ78
LZ77算法针对过去的数据进行处理,而LZ78算法却是针对后来的数据进行处理。LZ78通过对输入缓存数据进行预先扫描与它维护的字典中的数据进行匹配来实现这个功能,在找到字典中不能匹配的数据之前它扫描进所有的数据,这时它将输出数据在字典中的位置、匹配的长度以及找不到匹配的数据,并且将结果数据添加到字典中。
尽管在最初得到流行,但是后来LZ78的普及逐渐衰减,这可能是由于在刚LZ78出现的一些年份,一部分LZ78算法获得了美国专利保护。最流行的LZ78压缩形式是LZW算法,这个算法是Terry Welch所开发的一个LZ78变体。
2021年1月18日,IEEE 终身研究员 Jacob Ziv 将获得今年的 IEEE 荣誉勋章,主要原因是他对信息论和数据压缩技术的重要贡献以及杰出的研究领导能力。 Jacob Ziv 被称为数据压缩先驱是因为他和 Abraham Lempel 在 1977 年发布的 Lempel-Ziv 算法(LZ77)及之后的系列贡献。
LZ77 是许多无损压缩算法的基础,是第一个使用字典来压缩数据的算法。LZ77 管理一个叫做 slidingwindow 的动态字典,算法的工作原理是将一串字符替换为单个代码,并标记为“tokens”。当算法识别出一个新的字符串时,它就输出这个字符串,然后将其添加到字典中,下次再遇到这个字符串时,输出单个代码,这意味着数据被“压缩”了,以便更有效地传输。
一个简单的例子:
"I am an engineer therefore I am an engineer, and only if I am an engineer"
变成
"I am an engineer* there&fo& *, and only if *.
第一次出现"I am an engineer"后,指定了"*"值,之后再出现该短语由"*"表示。同样,& 是已被指定了"re"值。
1978 年,二人又发布了通过解析输入数据生成静态字典的 LZ78 算法。这两个算法能够从压缩数据中完美实现数据解压重构,并且比以往的算法效率更高,它们也可以用在 GIF,PNG,ZIP 文件的压缩中。
"LZ 算法是第一个成功的通用压缩算法",一位支持 Jacob Ziv 获奖的工程师说道,"这些算算法以及 Jacob Ziv 对它们的分析已经构成了后续大多数通用算法的基础。"
此外,Jacob Ziv 还有很多成就,并获得多项殊荣,包括 1995 年的 Marconi Prize,2008 年的 BBVA Foundation Frontiers of Knowledge Award,2017 年的 EMET Prize。
Jacob Ziv 出生在以色列,1955 年开始其工程师生涯,在以色列国防部任职,负责通信系统的开发。1962 年获得麻省理工学院的电气工程博士学位,后重新加入以色列国防部领导通信系统部门。自 1970 年以来,他一直任以色列理工学院电气工程教授,并在 1974 年至 1976 年担任电气工程学院院长,1978 年至 1982 年担任学院教务处副院长。
无损压缩鼻祖Abraham Lempel离世,享年86岁
来自以色列的科学家的他正是因为他和同事发明的LZ77/LZ78压缩算法,才有了Zip、GIF、PNG、TIFF、MP3、PDF等直到今天还在流行的文件格式。他生前曾就职的的以色列理工学院评价他为“学院成立100年来最伟大的研究员之一”,并称很少有科学家“像他一样在技术发展以及我们的日常生活领域中都产生了如此大的影响”。

无数网友为他的离世哀悼。有人还表示:我的研究生论文主题是HTML压缩,里面都还写有他的名字呢。
共同发明LZ77/LZ78,彻底改写数据压缩领域
Lempel教授于1936年出生于波兰。23岁的时候他进入以色列理工学院,经过八年的学习,拿到博士学位。在毕业十年之际,41岁的他成为母校的全职教授,负责电气工程和计算机科学专业的教学(随后又担任了三年计算机学院院长)。这一年他和同事Jacob Ziv发明LZ77算法的那一年,也就是1977年(下图左为Ziv,右为Lempel)。

正如其名,“LZ77”中的“L”代表Lempel教授,“Z”代表他的同事Ziv教授,“77”则是发明年份。
如果你是计算机专业的学生,LZ77算法一定出现过你的课本之上。其特点包括简单、易于实现,可以针对任何数据格式进行无损压缩,完全区别于此前已经诞生的各种有损压缩算法。它主要采用的是基于字典的方式进行压缩。简单来说,就是把数据中可以组成“短语”的一串字符加入“字典”,然后再有匹配的字符出现就采用标记来代替,由此就能实现压缩的目的。
在具体操作中,该算法会将数据分为“滑动窗口”和“数据缓冲区”。每次处理数据的时候,先把一部分数据预载入缓冲区,然后依次载入滑动窗口区(有长度限制)。如果后进入的字符在滑动窗口里面出现匹配的时候,就记进当前的短语字典中。随着滑动窗口的不断向前,字典会不断变化,不停地滑动字符向前,寻找到更多与字典中的短语匹配的选项,然后用带有含义的标记符进行标记,最终就可以得到一段压缩好的表示结果。
例子如下图所示,粉色为滑动窗口区,蓝色为缓冲区。
从上面的原理我们可以看出,LZ77的压缩比比较高,但由于要不停地找匹配选项,压缩过程有一些耗时,但又由于解压速度又非常快(标记会说明匹配项的明确位置),总体还是算得上非常高效的。
两位教授就以论文的形式将他们这一成果公布了出来。很快在1978年,他们又对77算法进行了更新,诞生了同样著名的LZ78,也就是LZ77的第二个版本。
不管后来大家如何“修修补补”,衍生出更加高效和完善的LZSS、LZW、LZH等新算法,它们的原理都和Lempel教授和Ziv教授的思想没有什么差别。因此在这些算法上诞生的TIFF、PNG、ZIP、MP3等广为流传的压缩文件格式,都得感谢这两位老爷子的贡献。
2004年,IEEE就宣布LZ77和LZ78算法成为电气和电子工程的“历史里程碑”。
Lempel教授也因为所作贡献,拿了不少奖项,包括IEEE信息理论学会技术创新金禧奖和2007年的IEEE Richard W. Hamming奖章,后者主要表彰他在“数据压缩方面的开创性工作”。
57岁被惠普聘用,贡献了8项专利
在改写数据压缩领域之后,Lempel教授并没有“闲着”。1993年,已经57岁的他被惠普公司聘用。仅过了一年,他就出来创立了惠普以色列实验室(HP Labs Israel),并担任其董事长直到71岁。在此期间,惠普以Lempel教授的名义注册了8项专利。如今,Lempel教授已于2023年2月5日辞世,离87岁生日就还差一周时间。
讣告地址。
实践证明,通过数据压缩技术可以非常有效地节省客户的存储空间,IBM曾经基于其存储系统统计过常见企业应用空间节省情况,其中数据库业务采用数据压缩技术后可以节省80%的存储空间,桌面虚拟化业务采用数据压缩技术后可以节省71%的存储空间。可见,数据压缩技术可以非常有效的帮助可以节省存储空间,换而言之,压缩技术可以非常有效的帮存储系统使用者节省成本。存储系统中,逻辑卷是被划分为一个一个的数据块,存储系统中的数据压缩则是数据块粒度的。通常在存储系统中以数据块为粒度进行数据压缩,比如ZFS默认以128KB为粒度进行数据压缩。
压缩算法分为无损压缩和有损压缩两类。所谓无损压缩是指数据解压后与原始数据完全一样,而有损压缩则是通过牺牲一定的信息来提升压缩率的方法。有损压缩应用非常广泛,比如我们通过微信发送图片时默认会采用有损压缩算法。由于有损压缩会丢失一部分信息,所以在数据存储领域提到的压缩算法通常是指无损压缩。
压缩算法的原理其实非常简单,它是通过减少数据块中的冗余信息来实现的。提到减少冗余信息,很多读者马上会想到我们上一节介绍的重复数据删除技术。是的,压缩算法本质上也是一种重复数据删除技术,与前者的差异是数据的粒度和检测重复数据的范围不同。
重复数据删除技术通常以数据块或文件为粒度检测是否存储重复的数据,而检测的范围通常是整个存储系统。数据压缩则是以数个字节的粒度,在数据块分为内检测重复的数据。因此在存储系统中通过数据压缩技术解决了重复数据删除技术中数据粒度不能太小的问题。可以通过下图描述一下数据压缩与重复数据删除技术的关系。
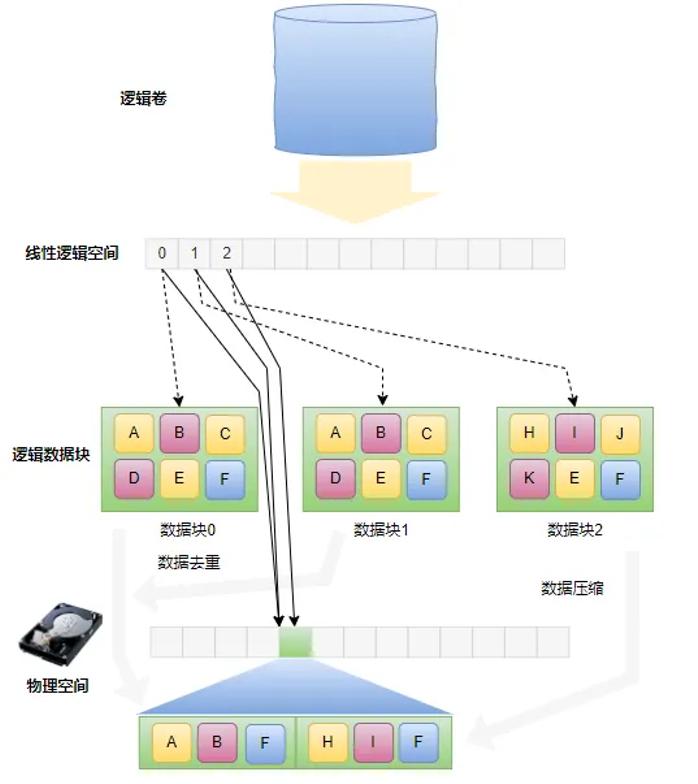
存储引擎数据压缩与去重全景
在存储系统中逻辑卷是一个线性逻辑空间,假设写入了3个连续的数据块,其内容如上图绿色底色所示,分别为数据块0、数据块1和数据块2。上述数据块我们称为逻辑数据块,因为这些数据是呈现给用户的状态,而非真正持久化后的数据。如数据块0包含A、B、C、D、E和F 6个更小的数据块,相同底色的内容是一样的,其它逻辑卷数据块类似。由于数据块0和数据块1包含相同的内容,基于数据去重技术,只有一个逻辑数据块会被存储在物理空间。
而在数据块0和1内部,更小的数据块A、B、C、D、E和F,以及数据块2内部的H、I、J、K、E和F则可以通过压缩计数做进一步的处理。比如数据块0中,可以被压缩为A、B和F,这是因为C、E与A的内容一样,D与B的内容一样,所以完全可以通过A、B和F表示整个数据块0。
在互联网发展的初期,由于带宽非常宝贵,压缩算法得到了极大的发展。目前压缩算法有很多种,常用的如deflate和lz4等,上述压缩算法都是对原有哈夫曼编码和LZ77压缩算法的改进。除了常用的压缩算法,一些互联网大厂也开发了自己的压缩算法,如Google 开发的 Snappy和是Facebook 的Zstandard 等。
1、压缩算法举例
接下来就通过几个实例来了解一下压缩算法是如何工作,通过介绍,我们就能明白为什么说数据压缩也是重复数据删除。LZ77可谓是基于字典压缩算法的鼻祖,我们就先介绍一下LZ77算法的相关内容。虽然LZ77已经很少被使用了,但是其它很多算法都是这个算法的变种,理解了LZ77后,理解其它相关算法也就容易很多。
LZ77压缩算法的原理其实很简单,就是找到重复的字符串(或者二进制数值)并用简单数据代替字符串的过程。后续字符串如果在前面已有相同的字符,那么就有一个简化的方式表示(其实就是一个索引)。由于简化的方式比实际字符串小很多,从整体就实现了数据压缩的目的。
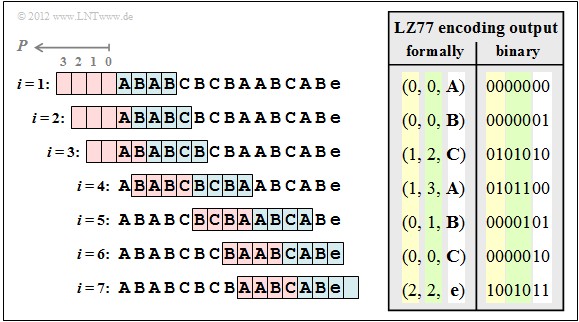
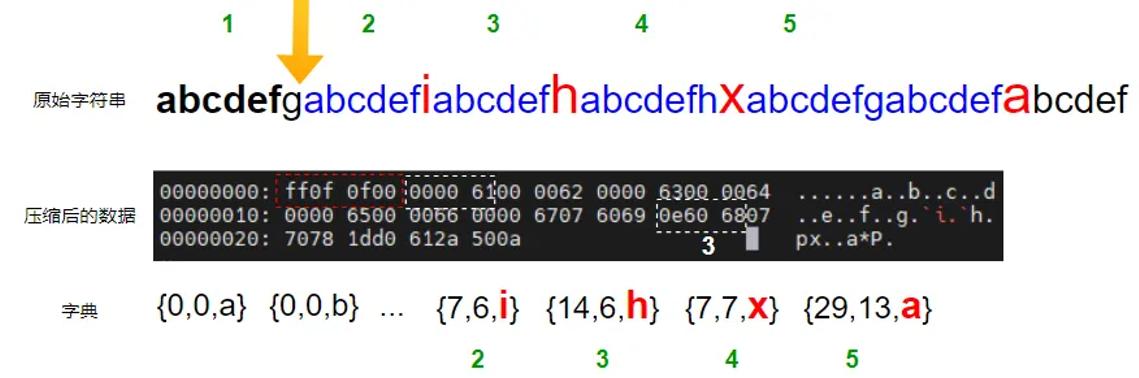
可通过一个简单的例子来说明一下压缩算法的原理。如下图所示是原始字符串与基于LZ77算法压缩后数据的对比图(基于https://github.com/cstdvd/lz77.git中的代码实现生成)。图中字符串,蓝色的部分是与前面有重复的字符串,绿色的数字是子字符串的编号,红色的字符是差异字符。
数据压缩举例
图中黑色底色的是压缩后的二进制数据,通过对比可以看出,二进制数据通过3个字节表示原始字符串中的1个子字符串。最下面的字典是作者对二进制压缩数据的解释,这也是LZ77算法基于字典的原理。以字符串3为例,其二进制数据如黑色背景中标号3所示的数据,翻译为字典则为{14,6,h}。对比一下很容易发现,原始字符串有7个字符(字节),而通过字典表示后就只剩下3个字节。字符串5的长度是13个字节,也可以通过3个字节表示。
通过上面的描述,估计大多数人不清楚上述字典表示什么含义。但是通过上面内容的分析,我们可以看到的是基于重复字符串的原理,可以通过比较小的空间表示一个比较长的字符串,从而实现数据压缩的功能。
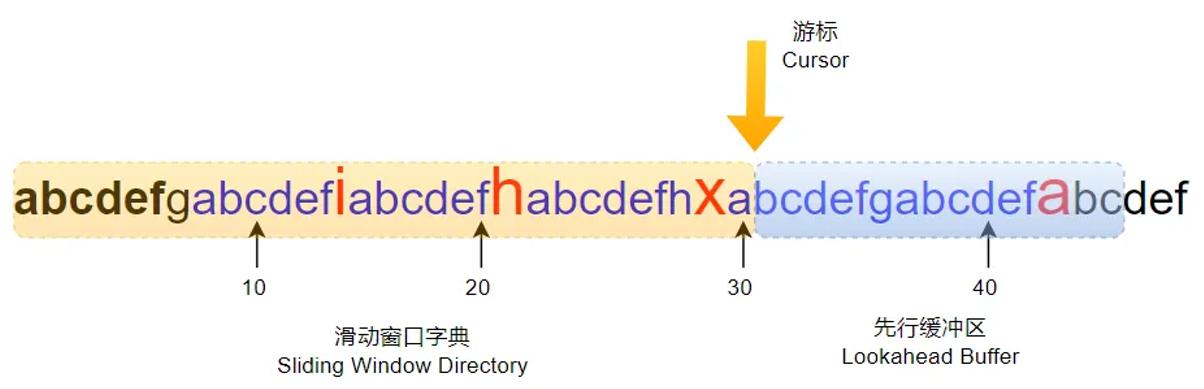
接下来我们就进一步详细LZ77算法的更多细节。首先,LZ77算法是通过一个一个字典来表示原始的数据的。为了生成这些字典,LZ77算法在具体计算的过程中涉及如下一些概念,我们可以用下图表示。
LZ77算法
先行缓冲区:先行缓冲区存储的是待压缩的数据,在本书所使用的代码中该缓冲区的大小是15字节。
滑动窗口字典: 滑动窗口字典中存储的是历史数据。进行数据压缩的时候会从该区域查找与先行缓冲区中字符串重复的字符串。所以滑动窗口中的内容称为字典信息。需要注意的是,滑动窗口虽然是历史数据,但是也不能太大,否则会影响压缩性能,本书中使用代码滑动窗口大小为4095字节。
游标:游标是滑动窗口区域与先行缓冲区的分界线,也就是已处理数据与待处理数据的分界线。
字符串表示: 压缩后de 字符串通过一个三元组{p, l, c}表示。其中p表示最长匹配时字典中字符开始的位置,这个位置时相对游标的位置(理解这个很重要)。l是匹配的最大字符串的长度。c是在先行缓冲区中匹配的最大字符串的下一个字符,也就是不匹配的字符。
2、数据压缩过程
接下来我们以上文中的字符串为例介绍一下基于LZ77算法是如何实现数据压缩的。第1步,光标处于字符串开始的地方,此时字典位于字符串的左侧,其中没有任何内容,自然也就找不到匹配的字符串,因此生成{0, 0, a}。
第2步,游标向右移动一个字符,此时字典中的内容及先行缓冲区中的内容如下图所示。虽然字典中已经有内容(a),但先行缓冲区中的字符b无法与其匹配,因此生成{0, 0, b}。
第3步,游标向右移动一个字符,此时字典中的内容及先行缓冲区中的内容如下图所示。虽然字典中已经有内容(ab),但先行缓冲区中的字符c无法与其匹配,因此生成{0, 0, c}。以此类推,一直到第7步,都无法从字典中找到匹配的内容。所以,前面7步分别生成了了{0, 0, a}、{0, 0, b}、{0, 0, c}、{0, 0, d}、{0, 0, e}、{0, 0, f}和{0, 0, g}。

数据压缩过程示意图
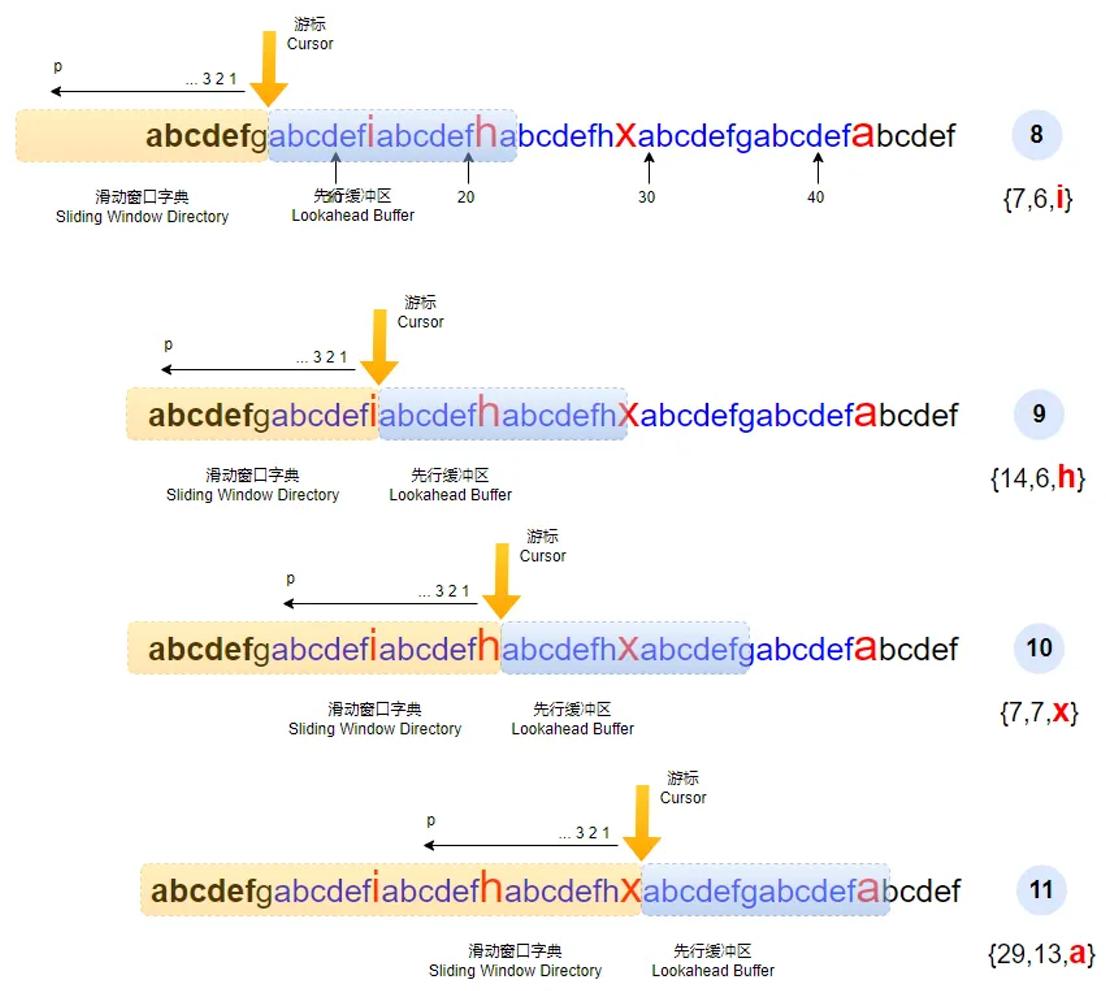
接下来发生了质的转变,第8步,此时先行缓冲区中的第一个abcdef子字符串与字典中的字符串匹配。此时会按照{p, l, c}的格式生成为{7, 6, i},其中位置7是指字典中字符串的第一个字符相对于游标的位置。所谓相对于游标,是指从游标的位置向左计算,如下图中步骤8中左侧箭头所示,字符g的位置为1,字符f的位置为2,以此类推。
需要注意的是,本书所涉及代码是以1作为第一个偏移地址的,而有些实现则以0作为第一个偏移地址。上述细微的差异并不会影响数据压缩的结果,但是在解压的时候则需要保持一致。
由于在字典中有匹配的字符串,接下来游标直接向右移动7个字符,具体如下图中的第9步所示。在第9步中,同样会发现在字典中有匹配的字符串,也就是字典中的第一个abcdef,因此会生成{14, 6, h}。需要注意的是,在字典中有两个abcdef字符串,本算法从左往右搜索,所以优先使用第一个字符串。这个字符串中字母a相对于游标的位置是14,也就是上述结果的原因了。
第10步,游标继续向右滑动7个字符,具体位置如下图所示。此时在滑动窗口字典中有3个abcdef字符串,而第3个后面加上字母h后的字符串正好与先行缓冲区中的abcdefh匹配,于是这里得到的结果是{7, 7, x}。由于多匹配了一个字母h,所以这里的长度变成了7,而非前面的6。
数据压缩过程示意图
第11步,游标继续向右滑动8个字符,具体位置如上图所示。此时我们可以发现先行缓冲区中的字符串abcdefgabcdef与字典一开始的字符串匹配,也就是第一个abcdef字符串的位置,于是得到了{29, 13, a}。至此, 我们解释了几个关键的场景,但是需要注意的是整个字符串并没有压缩完成。
3、数据解压过程
接下来看看压缩的数据是如何被解压的。首先先简单介绍一下解压的基本规则,所有压缩后的数据必然满足下述规则中的某一个,具体包含一下3个规则。
1) p==0并且l==0,此时表示初始情况,字符c被直接解压。换而言之,c就是解压后的字符。
2) 如果p≥l, 此时将字典[p:p+l]中的数据加c作为解压后的数据,这里所谓的字典中的数据就是前面已经解压的数据。
3) 如果p<l, 此时表示一个循环的过程。怎么理解这个循环的过程呢?由于本例中没有这种场景,我们在后面将举例介绍。
对于压缩文件而言,文件中的数据不仅仅包含压缩的数据,还包含一些其它方面的元数据,比如滑动窗口大小和先行缓冲区大小等等。本例中前4个字节为文件元数据,具体如下图所示。
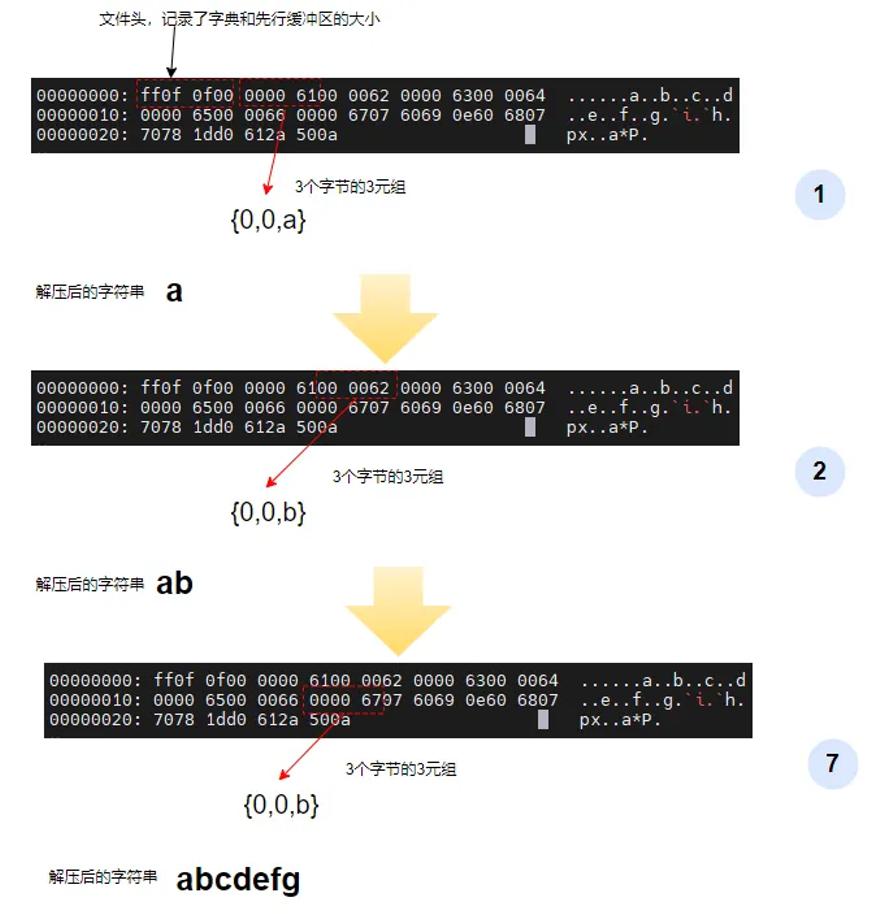
数据解压过程
第一个压缩数据是000061,翻译为{p,l,c}格式为{0, 0, a},所以解压以后的数据就是字符a。以此类推,第2个、第3个一直到第7个字符,都是这种格式,因此直接可以获得解压后的字符。最后得到解压后的字符串如上图第7步的样子。
第8个压缩数据发生了变化,其内容为{7, 6, i},此时光标位于下图第8步所示的位置。按照前面的规则2,解压后的数据应该为字典数据(光标前的数据)[7: 7+6]加上差异字符i,该表达式表示起始位置相对光标为7,长度为6,也就是图中下划线的字符串。
第9个压缩的数据大致类似,其内容为{14, 6, h},于是解压后的数据为图中下划线的字符串加上差异字符h,于是解压后可以得到如下图第9步所示的字符串。
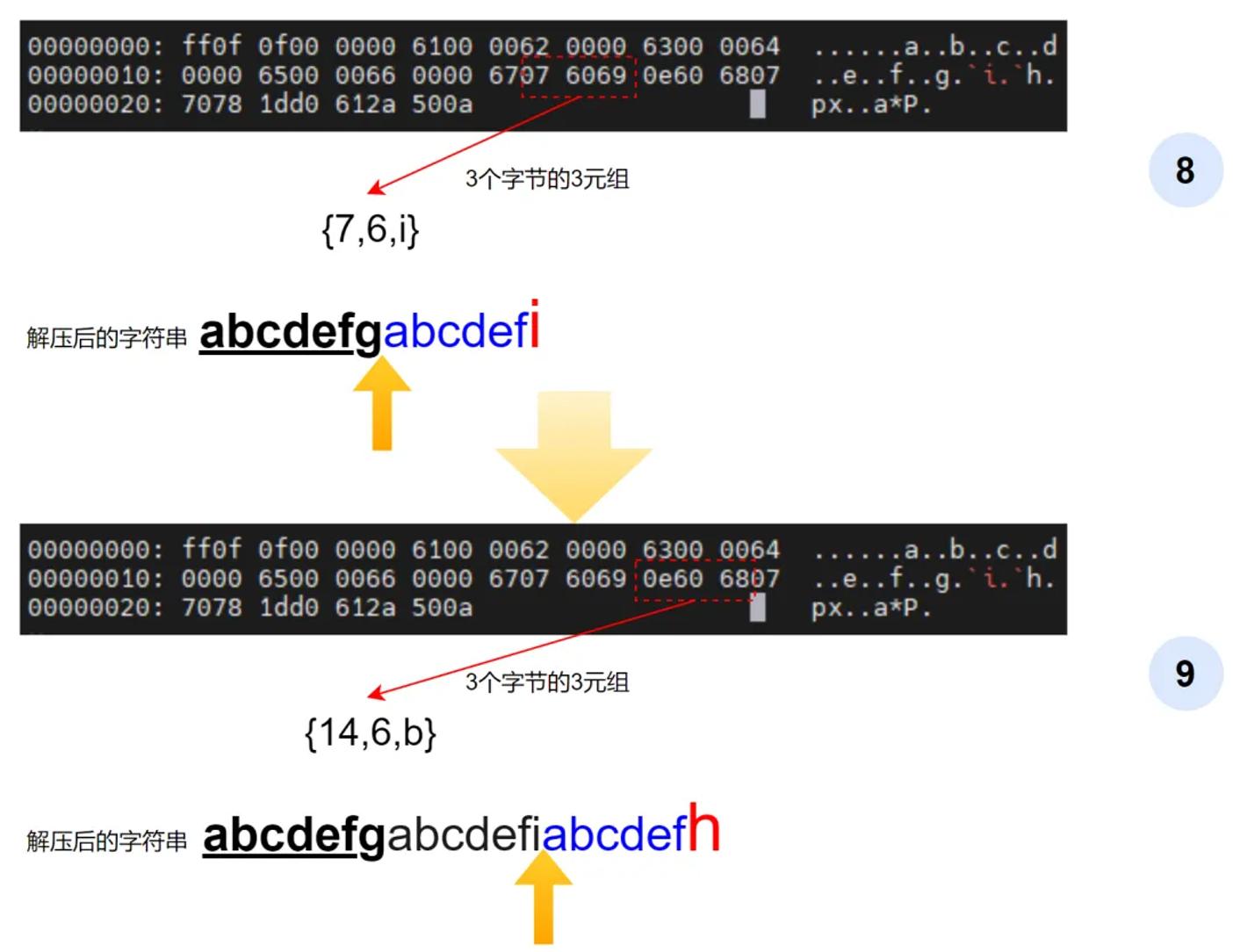
数据解压过程示意图
最后再介绍一下解压原则中的第3个原则,也就是p<l的场景。我们使用另外一个字符串,整个压缩过程如下图上半部分所示,可以看到第3步出现了上述场景。这个时候字典只有ab两个字符,但是匹配上的字符串的最大长度却是6。其原因在查找匹配字符的时候是逐个字符对比的,此时会出现借用先行缓冲区数据的情况,最终会出现如图第3步所示的两个大括号匹配的场景。
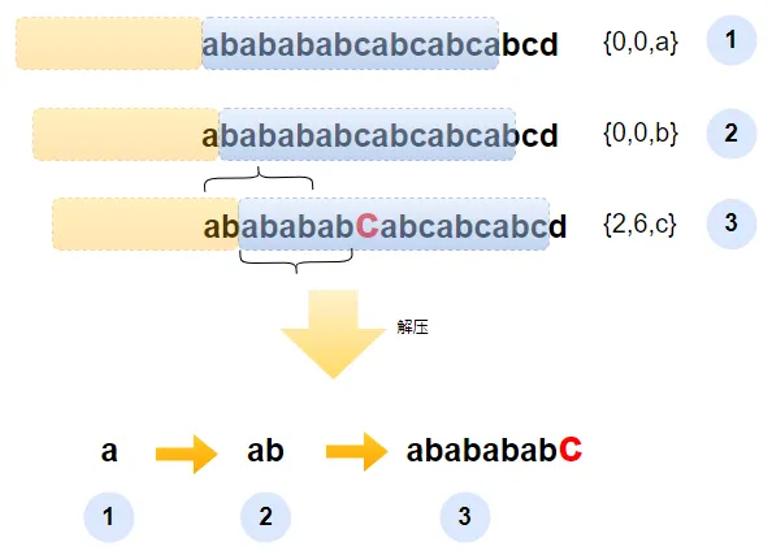
重复数据压缩与解压示意图
解压过程如上图下半部分所示,第1步和第2步是两个独立的字符,解压过程与前面介绍的完全一致,没有什么差异。第3步,从字典的位置来看,只能利用其中的2个字符,此时这个两个字符会首先被解压出来。由于没有达到预定的长度,此时会继续往后借用先行缓冲区中的内容进行解压。由于先行缓冲区前面的内容就是字典中的字符串,因此就出现了多次循环的场景。
4、存储系统中的数据压缩
介绍完数据压缩和解压的原理,我们再看看存储系统是如何实现的。由前面存储引擎相关的内容,我们知道逻辑卷的数据通常是被划分逻辑块来管理的。存储系统中的数据压缩通常以数据块为粒度进行压缩,并将压缩后的数据存储在持久化介质的。
在前面文章中我们曾经介绍过逻辑卷中逻辑块的管理方式,知道逻辑卷的元数据中包含逻辑块对应的物理块的地址信息。在没有压缩技术的情况下,逻辑块的大小与物理块一致,因此我们只需要知道地址就可以读取数据。但是,在引入压缩技术后,逻辑块的数据可能会被压缩的比较小,也就是物理块的边界变得不确定。换而言之,在读取数据的时候,需要知道一个逻辑块对应的数据的物理块地址及大小,这样在解压的时候才能正确解压数据。
以ZFS为例,其IB中除了保存着数据的地址信息外,还有另外两个字段保存着物理块的大小(PSIZE)和逻辑块的大小(LSIZE)等信息。这样当读取逻辑块的数据的时候,ZFS就知道其对应的压缩数据的大小,然后能够解压出正确的数据。
对于存储系统而言,具有压缩特性的数据读写逻辑如下图所示。当写入数据的时候,存储系统会进行数据压缩,然后将压缩后的数据写入持久化层,同时更新逻辑卷中的元数据信息,也就是数据位置和大小的等信息。
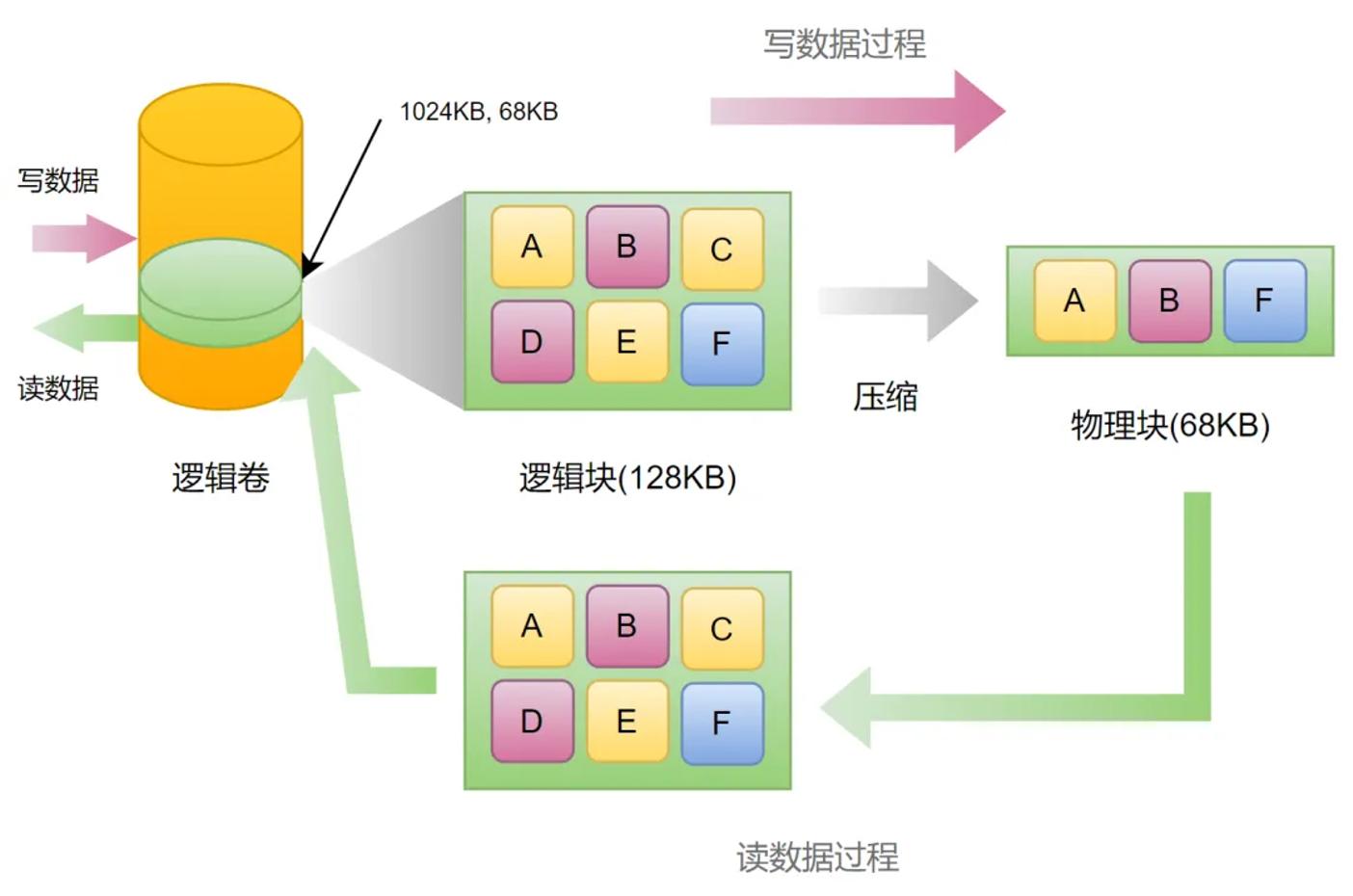
存储系统中的数据压缩与解压
当读取该逻辑块数据的时候,根据元数据中记录的位置和大小信息,首先从持久化层读取压缩数据,然后根据系统中设定的压缩算法等设置进行数据解压,最后得到解压后的数据,存储系统将这个数据返回给主机。
如上所述,存储系统压缩和管理数据是以逻辑块为粒度的,但读写请求大小未必正好等于逻辑块的大小。比如,读请求可能比逻辑块小,此时存储系统也会解压出整个逻辑块,然后将请求需要的数据返回给主机。比如,覆盖写请求的大小比逻辑块小,此时存储系统会先解压数据,然后将新数据覆盖部分老数据,然后再重新压缩。整体而言,存储系统中的压缩技术并不复杂,主要是需要存储系统真多各种IO进行不同的边界处理,确保主机的数据能够被正确存储和读取。本节于2025年6月节选自SunnyZhang的《文件系统技术内幕》,感谢原作者。
为了节省带宽提供网速,Web服务器把内容用gzip做了压缩,浏览器得解压缩一下才能看到并使用。在HTTP压缩中,除了gzip之外,还有compress、deflate、br等算法,让人眼花缭乱。但这些压缩算法,都有一个来源:LZ算法。

LZ来自两个人的名称:Abraham Lempel,Jacob Ziv。
两个人于2023年相继去世,都很长寿,Lempel活了86岁,Ziv一个活了91岁。
数据压缩分为两种,一种是有损压缩,如MP3、JPEG,一些不重要的数据在压缩时会被删除。另外一种是无损压缩,二进制位神奇的“消失”,文件显著变小,方便存储和传输。
1948年,香农创立了信息论以后,大家一直在折腾一件事情:如何找到最优编码,压缩一段信息。香农和法诺率先出手,提出了香农-法诺编码。

它通过符号分组的方式,自顶向下构建了一个二叉树。
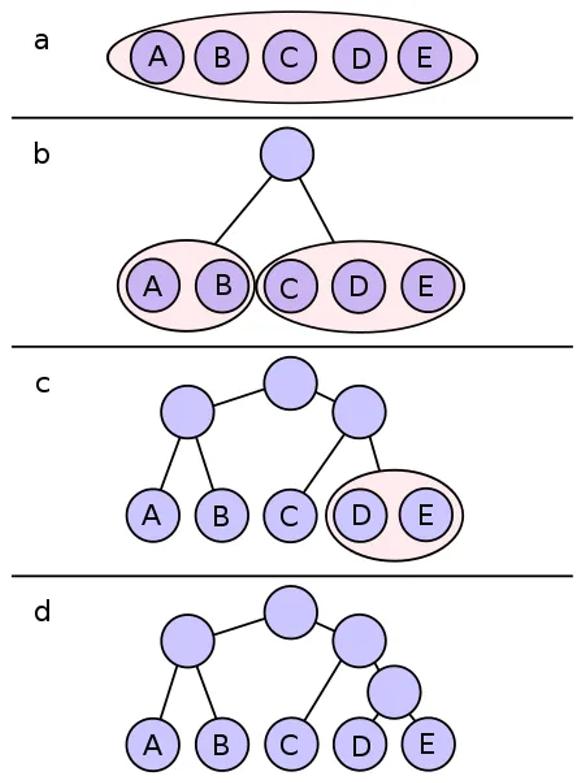
但是这种方式不是最优解,并且编码不是前缀码,容易产生歧义。
法诺后来在麻省理工教信息论时,给学生们提出了一个挑战:要么参加期末考试,要么改进现有的数据压缩算法。一个叫霍夫曼的研究生不喜欢考试,决定走后一条路。
霍夫曼并不知道,就连大名鼎鼎的香农也在这个问题上苦苦挣扎。他研究了几个月并计划了多种方法,都没有用。就在他要放弃,把笔记扔到垃圾桶的那一刻,一个美妙而优雅的算法划过了他的脑海:按照字符出现的频率,从下往上构建二叉树,这就是著名的霍夫曼算法。
霍夫曼的算法被称为“最佳编码”,实现了两个目标:
(1) 任何一个字符编码,都不是其他字符编码的前缀。
(2) 信息编码的总长度最小。
霍夫曼算法虽然很好,但有个巨大的限制:需要先获得所有字符出现的概率,然后才能编码压缩,这在很多情况下是做不到的。
上世纪70年代,互联网出现以后,这个问题变得更为突出。能不能实现一边读取数据,一边压缩?
以色列理工学院的Ziv和Lempel一起向这一问题发起了挑战。
两人是很好的搭档,Ziv擅长统计学和信息论,Lempel则擅长布尔代数和计算机科学。
1977年,他们俩都来到了贝尔实验室做学术休假。
学术休假又称为“知识人才休假”,每工作几年就有一段很长的假期(比如半年),这段假期里想干什么就干什么,还是带薪的。
大佬们的学术休假很有意思,比如Unix发明人Ken Thomson在休假时就回到了母校伯克利,把Unix传播到了那里,启发Bill Joy等人开发了BSD。
Ziv和Lempel也是这样到美国贝尔实验室去学术休假,在“休假”期间合作发表了一篇论文:《顺序数据压缩的通用算法》,提出了基于“滑动窗口”的算法,它不直接考虑字符频率,而是寻找重复的数据块(如字符串、字节序列等)并引用这些数据块之前出现的位置。
这算法就是LZ77,它适用于任何类型的数据,不需要做预处理(统计字符出现的概率),只需要一次遍历就可以实现极高的压缩比。
第二年他们再接再厉,改进了LZ77变成了LZ78,能够从压缩数据中完美实现数据解压重构,并且比以往的算法效率更高。LZ算法居然停留在理论界好几年,没有大规模使用。
直到1984年,DEC公司的Terry Welch在LZ基础上,创造了LZW算法,用到了Unix的compress程序中。伴随着Unix的广泛传播,LZ算法开始进入飞速发展的快车道。但也进入了群雄并启的乱战时代。
1985年,Thom Henderson在BBS下载文件时,发现总得一个一个地下载,拨号上网太慢了,于是他写了一个叫做ARC的软件,可以将多个文件压缩成一个,这就方便多了。

1986年,Phillip Katz发现了ARC,喜欢的同时又觉得这玩意儿压缩速度太慢,于是就卷起袖子把关键的压缩和解压缩用汇编重写,形成了PKARC,开始卖钱。

Thom Henderson看到自己的生意被抢,一气之下把Phillip Katz告上法庭,理由很充分:你PKARC中的注释、拼写错误都和我的ARC一样,你这是在抄袭!还有,我的ARC虽然是开源的,但是协议规定只能看,不能改!
最终ARC胜诉,Phillip Katz赔了几万美元。天才Phillip Katz当然不服,他研究了LZ77算法和Huffman算法,将二者结合,创造了新的压缩算法(deflate)和新的文件格式(zip),以及新软件PKZIP。

PKZIP无论是在压缩比,还是在解压缩速度上都把ARC打得找不着北,迅速统治了DOS时代。
由于ZIP格式是公开的,开源界info-zip小组也发布了开源、免费的unzip和zip,实现了deflate算法。
随后,Jean-loup Gailly和 Mark Adler基于deflate又开发了著名的gzip(文件格式+实用程序),替换了Unix上的compress。

gzip就是在文章开头看到的那个HTTP压缩格式。
1991年,Nico Mak 觉得PKZIP的命令行实在是不爽,他就基于PKZIP开发了一个Winodws3.1的前端(后来用开源的info-zip替换了PKZIP),让大家可以用图形界面的方式来压缩文件,这就是著名的WinZip。
用户发现WinZip界面精美,操作友好,根本不用记忆那些烦人的参数,点几下鼠标就完成压缩了。
WinZip迅速占据了所有的PC,成为成为90年代最流行的共享软件之一。
不过WinZip再辉煌,毕竟是“寄生”在Windows平台上;Windows出手,干脆把Zip的功能内置到了操作系统中。。
从LZ77开始,到LZW,compress,Deflate,gzip ...... 无损压缩算法不断地修修补补,逐渐形成了一个庞大的家族,但是无论怎么改,它们的原理和思想都和最早的LZ算法没什么差别。这些算法帮助我们压缩图像,压缩文本,压缩互联网传输的内容,成为我们日常生活中不可或缺的一部分。毫不夸张地说,LZ算法和它的派生者们已经统治了全世界。