数据压缩算法-LZ4
 LZ4是近年来出现的一种高压缩的无损数据压缩算法,着重于压缩和解压缩速度,由 Yann Collet 主导开发。采用C语言开发并在三类的BSD协议下授权使用,另外它提供了多种语言开发接口。它属于面向字节的 LZ77 压缩方案家族,该算法提供一个比 LZO 算法稍差的压缩率 —— 这逊于 gzip 等算法。但其压缩速度类似 LZO —— 比 gzip 快几倍;而解压速度显著高于 LZO。
LZ4是近年来出现的一种高压缩的无损数据压缩算法,着重于压缩和解压缩速度,由 Yann Collet 主导开发。采用C语言开发并在三类的BSD协议下授权使用,另外它提供了多种语言开发接口。它属于面向字节的 LZ77 压缩方案家族,该算法提供一个比 LZO 算法稍差的压缩率 —— 这逊于 gzip 等算法。但其压缩速度类似 LZO —— 比 gzip 快几倍;而解压速度显著高于 LZO。lz4: Extremely Fast Compression algorithm.
LZ4 is a very fast lossless compression algorithm, providing compression speed at 300 MB/s per core, scalable with multi-cores CPU. It also features an extremely fast decoder, with speeds up and beyond 1GB/s per core, typically reaching RAM speed limits on multi-core systems.
对于需要大吞吐量的压缩场合非常有用,以很小的CPU代价换来更大的存储密度。LZ4凭借其高速的压缩解压缩性能、合理的压缩比以及广泛的适用性,在数据处理领域展现出了巨大的潜力和价值。无论是在数据存储、网络传输还是实时数据处理等场景中,它都能够提供高效、可靠的解决方案。随着技术的不断发展和应用场景的不断拓展,LZ4必将在未来的数据处理领域发挥更加重要的作用。关于它的资料目前较少,这里有一篇文章对它有介绍。
特点
压缩速度极快:LZ4 以其卓越的压缩速度而闻名。在许多实际应用场景中,它的压缩速度远远超过其他常见的压缩算法,如 gzip 等。这使得它非常适合对实时性要求较高的场景,能够在短时间内完成大量数据的压缩。
解压速度快:不仅压缩速度快,其解压速度同样出色。解压过程几乎不消耗太多时间,能够快速将压缩数据恢复到原始状态,保证数据的快速可用性。
压缩比适中:虽然 LZ4 的压缩比不是所有压缩算法中最高的,但它在压缩速度和压缩比之间取得了较好的平衡。对于一些对压缩比要求不是特别苛刻,但对处理速度有较高要求的场景,LZ4 是一个不错的选择。
内存占用低:该算法在运行过程中对内存的需求量相对较少,这使得它在资源受限的环境中也能稳定运行,例如嵌入式系统或内存较小的设备。
它还有个高压缩率的版本:
LZ4 HC -- High Compression Mode of LZ4
它被用于Hadoop等数据库使用此算法进行快速压缩,在Linux内核 v3.11中被原生实现。ZFS文件系统的FreeBSD、Illumos、ZFS on Linux,以及ZFS-OSX实现都支持LZ4算法进行即时压缩,Linux从3.19-rc1开始在SquashFS中支持LZ4。Yann Collet也在较新版的Zstd压缩软件中实现了LZ4。LZ4是开源项目,用户可以自由使用、修改和分发。同时,LZ4得到了活跃的开源社区支持,用户可以在社区中获取帮助和反馈,这为LZ4的持续发展和优化提供了有力保障。
原理
LZ4 采用了基于字典的压缩方法,其核心思想是利用数据中重复出现的模式来减少数据的存储空间。具体来说,它会在输入数据中寻找已经出现过的字符串,并使用对这些字符串的引用来替代重复部分。在压缩过程中,LZ4 会构建一个滑动窗口,用于记录最近处理过的数据。当遇到重复的字符串时,它会记录该字符串在窗口中的位置和长度,而不是再次存储整个字符串。这种方式有效地减少了数据的冗余,从而实现了数据的压缩。
压缩算法简介
该算法是由Yann Collet在2011年设计实现的,lz4属于lz77系列的压缩算法。lz77严格意义上来说不是一种算法,而是一种编码理论,它只定义了原理,并没有定义如何实现。基于lz77理论衍生的算法除lz4以外,还有lzss、lzb、lzh等。它是目前基于综合来看效率最高的压缩算法,更加侧重于压缩解压缩速度,压缩比并不突出,本质上就是时间换空间。对于github上给出的lz4性能介绍:每核压缩速度大于500MB/s,多核CPU可叠加;它所提供的解码器也是极其快速的,每核可达GB/s量级。
功能与性能
LZ4的功能主要体现在其高速的数据压缩和解压缩能力上。根据官方给出的性能数据,LZ4的每核压缩速度大于500MB/s,多核CPU可叠加,其解码器的速度更是达到了每核GB/s量级。这种高速的压缩解压缩性能使得LZ4在需要快速处理大量数据的场景中极具优势,例如在大数据处理、实时数据传输等领域。
算法思想
Lz77编码思想:它是一种基于字典的算法,它将长字符串(也可以称为匹配项或者短语)编码成短小的标记,用小标记代替字典中的短语,也就是说,它通过用小的标记来代替数据中多次重复出现的长字符串来达到数据压缩的目的。其处理的符号不一定是文本字符,也可以是其他任意大小的符号。
短语字典维护:Lz77使用的是一个前向缓冲区和一个滑动窗口。它首先将数据载入到前向缓冲区,形成一批短语,再由滑动窗口滑动时,变成字典的一部分。通过这种方式,LZ4能够高效地识别并替换数据中多次重复出现的长字符串,从而达到压缩的目的。这里从压缩算法对比、LZ算法系列简述、LZ4数据格式、LZ4压缩、LZ4解压、LZ4核心点等方面逐一阐述。
LZ算法系列
“LZ”是Lempel-Ziv的首字母缩写,指的是算法的开发者Abraham Lempel和Jacob Ziv。数字77、78代表是的是论文发表的年份,4是算法的版本号。LZ压缩算法系列包括以下几种:
LZ77:这是LZ压缩算法的早期版本,它是一种无损数据压缩算法,通过在原始数据中寻找重复的子字符串,并将它们替换为较短的引用来实现压缩。
LZ78:这是LZ77的改进版,由Jacob Ziv在1978年提出。它引入了字典的概念,将重复出现的字符串存储在字典中,并使用较短的引用来表示它们,从而实现更高的压缩比。
LZW(Lempel-Ziv-Welch):这是一种无损数据压缩算法,由Abraham Lempel、Jacob Ziv和Gary Welch在1984年提出。它使用了一个类似于LZ78的字典,但使用不同的方法来构建字典和生成引用。LZW算法在许多应用中都得到了广泛使用,例如GIF图像格式和UNIX的compress工具。
LZMA(Lempel-Ziv-Markov chain Algorithm):这是LZ78的改进版,由Markov链蒙特卡罗模型所启发。相比于之前的版本,LZMA使用了更复杂的字典和引用生成方法,从而实现了更高的压缩比。它主要用于7-Zip压缩工具中。
LZSS(Lempel-Ziv-Storer-Szymanski):这是LZ77的另一个改进版,由Storer和Szymanski在1982年提出。它在字典中引入了更多的引用来提高压缩比,同时使用了一个类似于LZ78的方法来构建字典。
LZ2和LZ3:这两种算法是LZ78的简化版,分别由Gunter Bresch和Hans-Arno Jacobsen在1980年代中期和晚期提出。它们的特点是使用较短的引用来提高压缩比。
LZ4:这是一种非常快速的压缩算法,它使用了一个类似于LZ77的字典,但通过一些优化方法来提高压缩和解压缩速度。LZ4被广泛用于需要高性能的数据压缩场景,例如实时传输和存储。
应用场景
1. 数据存储
在数据存储领域,LZ4可以有效减少存储空间的占用。对于一些需要长期存储大量数据的应用,如数据库备份、日志文件存储等,使用LZ4进行数据压缩可以在保证数据完整性的前提下,显著降低存储成本。
2. 网络传输
在网络传输方面,LZ4能够快速压缩数据,减少传输过程中的数据量,从而提高传输效率,降低网络延迟。这对于一些对实时性要求较高的应用,如在线视频直播、实时通信系统等,具有重要的意义。
3. 实时数据处理
在实时数据处理场景中,如金融交易系统、工业自动化控制系统等,数据需要在极短的时间内完成压缩和解压缩操作。LZ4的高速性能使其能够满足这些场景对数据处理速度的严格要求,确保系统的高效运行。
LZ4数据格式
LZ4实现了两种格式:lz4_block_format和lz4_frame_format
lz4_frame_format用于特殊场景,如file/pipe/流式压缩
lz4_block_format:一般场景使用格式,文章只介绍该格式
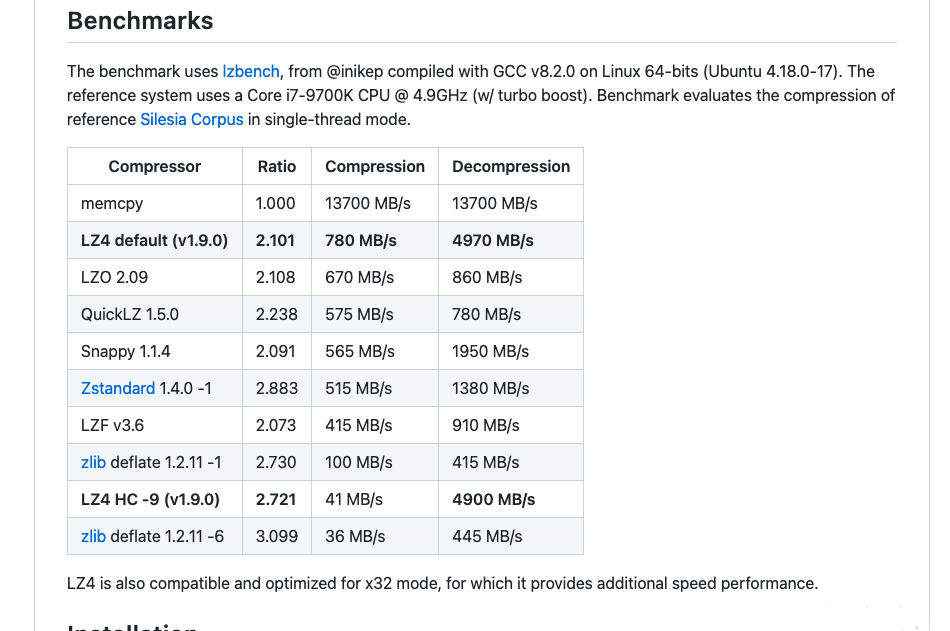
压缩块有多个序列组成,一个序列是由一组字面量(非压缩字节),后跟一个匹配副本:
1.每个序列以token开始,字面量和匹配副本的长度是有token以及offset决定的;
2.literals指没有重复、首次出现的字节流,即不可压缩的部分;
3.literals length指不可压缩部分的长度;
4.match length指重复项(可以压缩的部分)长度。
下图为单个序列的数据格式,一个完整的LZ4压缩块由多个序列组成
LZ4压缩
LZ4遵循上面说到的LZ77思想理论,通过滑动窗口、hash表、数据编码等操作实现数据压缩。压缩过程以至少4字节为扫描窗口查找匹配,每次移动1字节进行扫描,遇到重复的就进行压缩。
样例
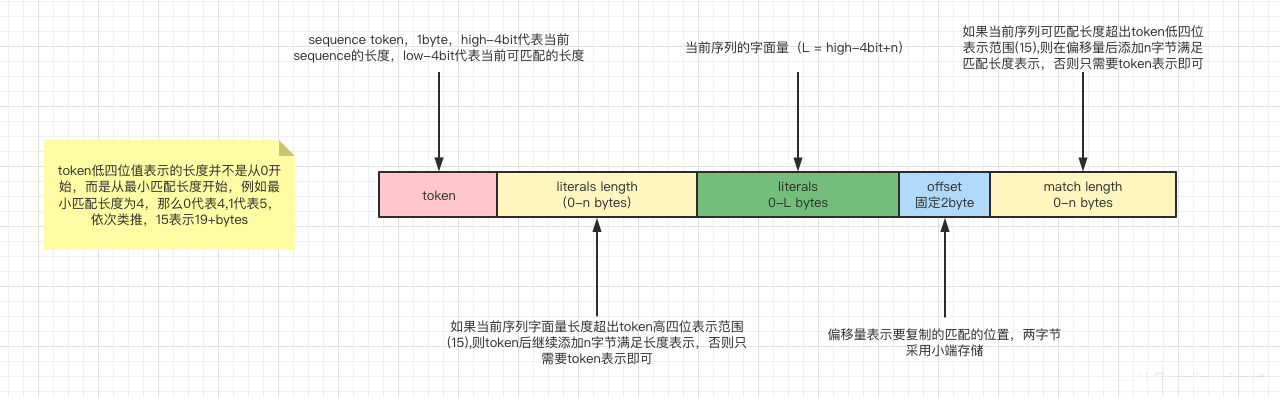
字符串: abcde_fghabcde_ghxxahcde,描述出此字符串的压缩过程;按照6字节扫描窗口,每次1字节来进行扫描。
1.假设lz4的滑动窗口大小为6字节,扫描窗口为1字节;
2.lz4开始扫描,首先对0-5位置做hash,hash表中无该值,所以存入hash表;
3.计算1-6位置hash值,hash表中无此值,继续将hash值存入hash表;
4.依次类推,在计算9-15位置的hash值时,发现hash表中已经存在,则进行压缩,偏移量offset值置为9,重复长度为6,该值存入token值的低4位中;
5.匹配压缩项后开始尝试扩大匹配,当窗口扫描到10-16时,发现并没有匹配到,则将此值存入hash表;如果发现hash表中有值,如果符合匹配条件(例如10-15符合1-6)则扩大匹配项,重复长度设为7,调整相应的token值;
6.这样滑动窗口扫描完所有的字符串之后,结束操作。
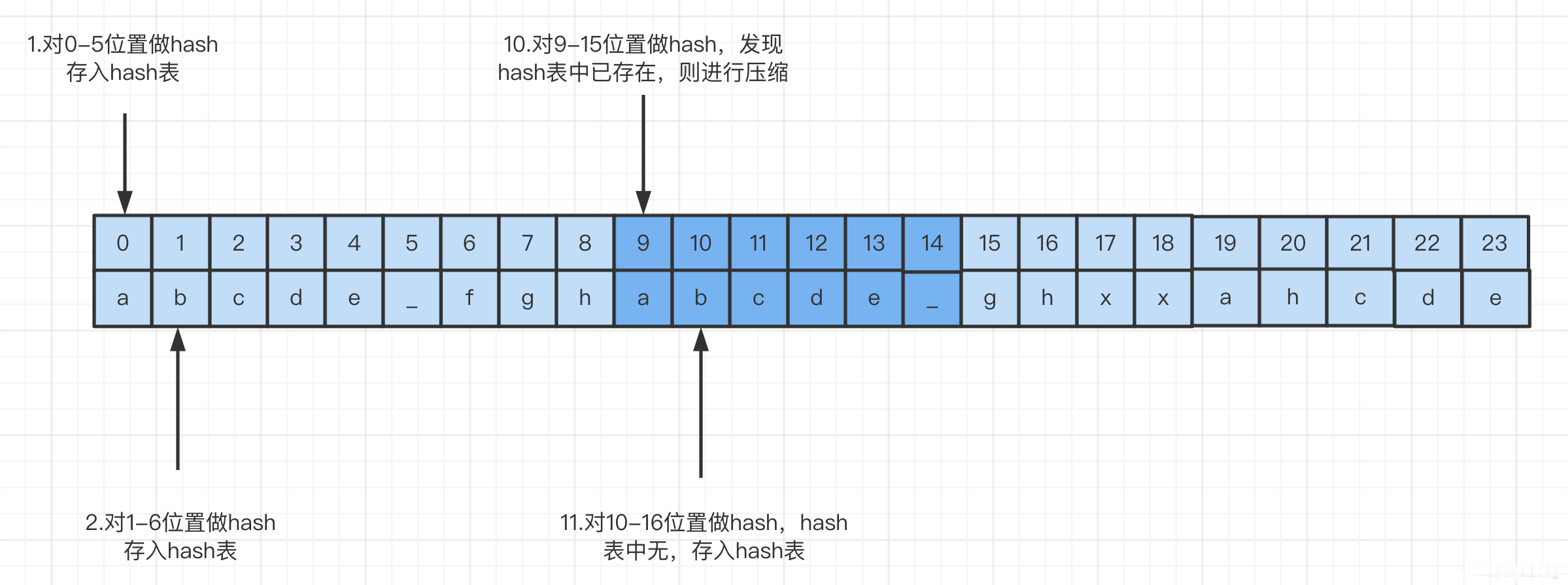
最终,这样压缩过程就结束了,得到这样一个字节串[-110, 97, 98, 99, 100, 101, 95, 102, 103, 104, 9, 0, -112, 103, 104, 120, 120, 97, 104, 99, 100, 101]
LZ4解压
对上述字节串进行解压
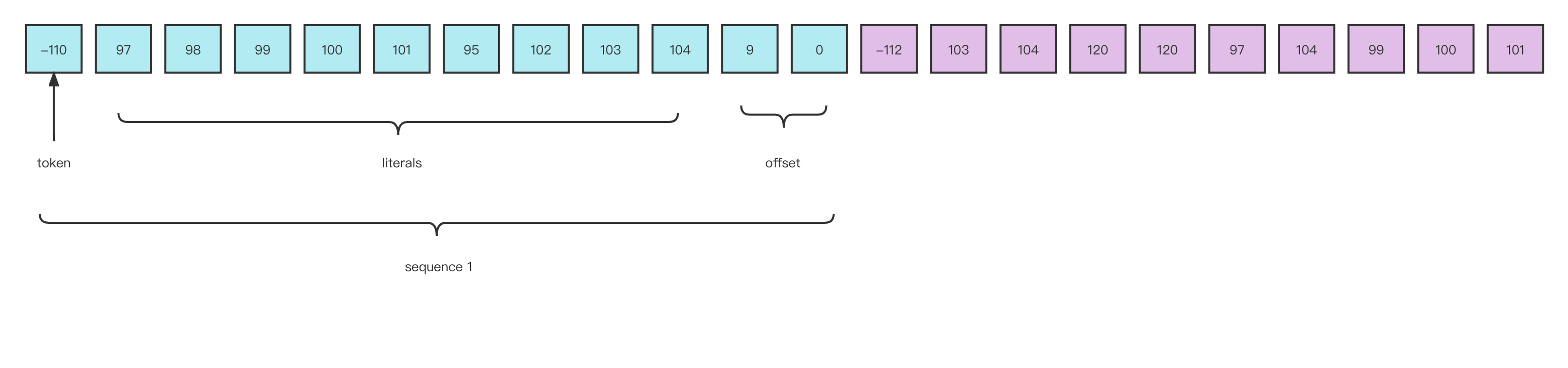
解压过程:
1.当LZ4解压从0开始遍历时,先判断token值(-110),-110转换为计算机二进制为10010010,高四位1001代表字面量长度为9,低四位0010代表重复项匹配的长度2+4(minimum repeated bytes)
2.向后遍历9位,得到长度为9的字符串(abcde_fgh),偏移量为9,从当前位置向前移动9位则是重复位起始位置,低四位说明重复项长度为6字节,则继续生成长度为6的字符串(abcde_)
3.此时生成(abcde_fghabcde_),接着开始判断下一sequence token起始位,最终生成abcde_fghabcde_ghxxahcde(压缩前的字符串)
LZ4的两点核心
相比于LZ77等算法,LZ4压缩与解压之所以会大幅提升,主要得益于两点:
1.采用动态规划的思想,空间换时间,将遍历查找匹配的过程变为hash存储,单次的查询和增改均是O(1)的时间复杂度,使得LZ4总体的时间复杂度为O(n);
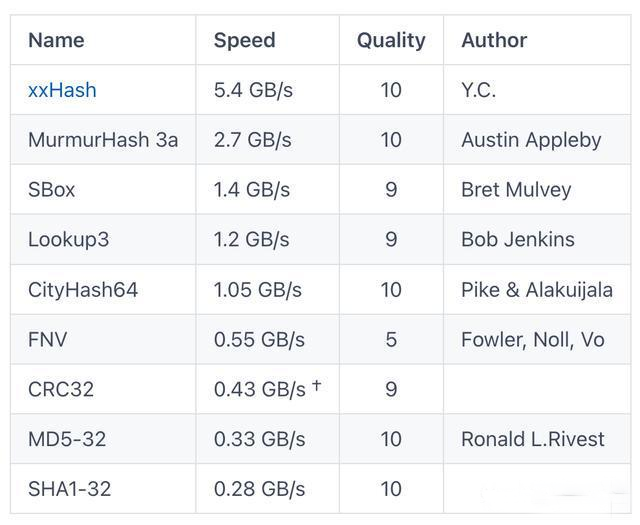
2.hash方式选择xxhash,该算法xxHash是一种非常快速的哈希算法,在RAM速度限制下运行。
多种hash方式的速度对比如下:
使用教程
1. 安装LZ4库
在Linux系统中可以使用包管理工具安装LZ4库,命令如下:apt-get install liblz4-dev
在Windows系统中,可以从LZ4官方网站下载并安装相应的库文件。
2. 包含头文件
在C语言程序中,需要包含LZ4的头文件:
#include <lz4.h>
3. 压缩数据
使用 LZ4_compress_default 函数进行数据压缩,示例代码如下:
int main() {
const char *data = "This is the data to be compressed.";
size_t dataSize = strlen(data) + 1; // Include the null terminator
size_t compressedSize = LZ4_compressBound(dataSize);
char *compressedData = (char *)malloc(compressedSize);
int result = LZ4_compress_default(data, compressedData, dataSize, compressedSize);
if (result <= 0) {
fprintf(stderr, "Compression failed\n");
free(compressedData);
return 1;
}
printf("Compression successful. Compressed size: %d\n", result);
free(compressedData);
return 0;
}
4. 解压缩数据
使用 LZ4_decompress_safe 函数进行数据解压缩,示例代码如下:
void decompressData(const char *compressedData, size_t compressedSize, char *decompressedData, size_t decompressedSize) {
if (LZ4_decompress_safe(compressedData, decompressedData, compressedSize, decompressedSize) <= 0) {
fprintf(stderr, "Failed to decompress data\n");
exit(1);
}
}
int main() {
const char *compressedData = ...; // 假设这是压缩后的数据
size_t compressedSize = ...; // 压缩后数据的大小
size_t decompressedSize = ...; // 解压缩后数据的大小
char *decompressedData = (char *)malloc(decompressedSize);
decompressData(compressedData, compressedSize, decompressedData, decompressedSize);
printf("Decompressed data: %s\n", decompressedData);
free(decompressedData);
return 0;
}
代码示例
以下是一个简单的使用 LZ4 库进行数据压缩和解压的 C 代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "lz4.h"
#define INPUT_SIZE 1024
#define MAX_COMPRESSED_SIZE LZ4_compressBound(INPUT_SIZE)
int main() {
// 初始化输入数据
char input[INPUT_SIZE];
for (int i = 0; i < INPUT_SIZE; i++) {
input[i] = 'a' + (i % 26);
}
// 压缩数据
char compressed[MAX_COMPRESSED_SIZE];
int compressedSize = LZ4_compress_default(input, compressed, INPUT_SIZE, MAX_COMPRESSED_SIZE);
if (compressedSize <= 0) {
fprintf(stderr, "Compression failed.\n");
return 1;
}
// 解压数据
char decompressed[INPUT_SIZE];
int decompressedSize = LZ4_decompress_safe(compressed, decompressed, compressedSize, INPUT_SIZE);
if (decompressedSize != INPUT_SIZE) {
fprintf(stderr, "Decompression failed.\n");
return 1;
}
// 验证解压结果
if (memcmp(input, decompressed, INPUT_SIZE) == 0) {
printf("Compression and decompression successful.\n");
} else {
printf("Decompression result does not match the original input.\n");
}
return 0;
}
编译和运行
假设上述代码保存为 test.c,LZ4 库已经正确安装,并且头文件和库文件的路径已经正确配置。可以使用以下命令进行编译:
gcc -o test test.c -llz4
然后运行生成的可执行文件:./test
如果一切正常,程序将输出 Compression and decompression successful.,表示压缩和解压操作成功。
与其他压缩算法的对比
1. 与Snappy对比
Snappy是由Google基于LZ77思路编写的快速数据压缩与解压程序库,其目标也是追求非常高的速度和合理的压缩率。在压缩解压性能方面,Snappy的压缩速度为250MB/s,解压速度为500MB/s,而LZ4的压缩速度更快,每核可达500MB/s以上,解压速度更是达到了GB/s量级。在压缩比方面,Snappy的压缩比一般比LZ4高20-100%,但LZ4在速度上的优势使其在一些对速度要求更高的场景中更具竞争力。
2. 与QuickLZ对比
QuickLZ自称是世界上最快的压缩算法,其压缩速度可达308MB/s每核。然而与LZ4相比,其在解压速度上存在明显差距,LZ4的解压速度通常能够达到内存速度的极限,特别是在多核系统上,LZ4的多线程支持使其能够获得更高的压缩和解压缩速度。
六大压缩算法横评-Ubuntu 19.10 最终选择 LZ4
在2019年9月发布的 Canonical 官方博文中,来自内核团队的 Ubuntu 工程师 Colin Ian King 介绍了 Ubuntu 19.10 操作系统启动方面的一些改进。Ubuntu 19.10(Eoan Ermine)操作系统计划于10月17日正式发布,工程师在文章中表示通过过去数月的努力已经找到了更快的压缩/解压缩算法。
Ubuntu Kernel 团队对 initramfs 的六种压缩方法进行了基准测试,包括 BZIP2,GZIP,LZ4,LZMA,LZMO 和 XZ,以测量 Linux 内核的加载时间以及解压缩时间。主要使用 x86 TSC(Time Stamp Counter)在 x86 设备上进行基准测试。根据测试结果,团队发现 LZ4 是 Ubuntu 19.10(Eoan Ermine)的最佳压缩/解压缩方法,这是因为 BZIP2,LZMA 和 XZ 的解压缩速度很慢,因此在进一步的测试中很快就被排除了。在压缩大小方面,GZIP 效果最好,能将文件压缩至最小,其次是 LZO(大约比 GZIP 大 16%)和LZ4(大约比 GZIP 大 25%),而在压缩时间方面,LZ4 比 GZIP 快 7 倍,LZO 比 GZIP 快约 1.25 倍,因此可以看到 GZIP 的速度不够快。



Colin Ian King 表示:“即使在慢速运行的传输媒介和慢速 CPU 上,LZ4 内核的更长加载时间也会带来更快的压缩时间。不过伴随着媒介传输速度的提升,GZIP,LZ4 和 LZO 之间的加载时间差减小,压缩时间变化来看 LZ4 是最大的赢家”。
自 Ubuntu 18.10(Cosmic Cuttlefish)发布以来,LZ4 已经在 Ubuntu 中默认使用,但看起来 Canonical 将保留 Ubuntu 19.10(Eoan Ermine)操作系统中内核和 initramfs 的默认压缩/解压缩方法。LZ4 是一种无损数据压缩算法,可提供极快的压缩和解压缩速度。在 Ubuntu 19.10(Eoan Ermine)中,LZ4 将用于x86(64位)、PPC64le(PowerPC 64位Little Endian)和 s390(IBM System z)内核。
最新版本:1.9
LZ4 v1.9.4 已于2022年8月中旬发布,这是一个维护版本,包含大约 350 个提交,也是近两年来发布的首个点版本更新,显著提升解压速度。发布公告中称,liblz4 API 的稳定部分没有变更,使得这个版本可以直接替换现有的功能。开发团队也推荐用户升级到新版本。对性能进行了不少优化,比如提升了解压速度:
针对 ARM64 平台,将解压速度提升了大约 20%。例如苹果 M1/M2 设备、现代 ARM64 服务器和其他较新的 64 位 Arm SoC 上均可以看到两位数的解压速度优化;
对于部分涉及小数据块和其他因素的数据压缩的特定场景,解压速度大约提升了 70%;
此外,使用lz4frame 格式压缩数据的解压缩速度提升了大约 40%,因为现在可以忽略解压缩期间的校验和验证。
还为 LZ4 工具库添加了实验性功能 liblz4、修复和更新 Makefile 构建,以及改进文档等。甚至为 LZ4 构建系统代码添加了 Solaris 10 兼容性。更多详情查看发行说明。
最新版本:1.10
2024年7月发布的 v1.10 版本带来了许多显著增强,特别是多线程支持,使其在高吞吐量环境中的表现更加出色。
多线程支持:压缩效率大幅提升
v1.10版本最突出的新功能是多线程支持。这一改进利用现代多核处理器,使多个线程能够同时处理数据,大大减少了压缩和解压大文件所需的时间。尤其是在高压缩模式下,多线程支持表现尤为出色,因为这些模式通常对 CPU 的需求较高。
基准测试结果
以下是最新基准测试在不同操作系统上的性能改进:
在 Windows 11 上,使用 Intel 7840HS CPU,压缩时间从 13.4 秒减少到仅 1.8 秒,速度提高了 7.4 倍。
使用 M1 Pro 芯片的 macOS 用户将看到压缩时间从 16.6 秒减少到 2.55 秒,性能提高了 6.5 倍。
对于使用 i7-9700k 的 Linux 用户,压缩时间从 16.2 秒减少到 3.05 秒,实现了 5.4 倍的速度提升。
这些改进不仅限于压缩,解压过程也受益于多线程支持,虽然程度较小,但通过将 I/O 操作与解压过程重叠,进一步提高了性能。
增强的字典压缩:v1.10 版本还正式支持字典压缩和解压,从实验阶段过渡到完全支持。这使得开发人员可以更可靠地在需要字典技术的应用程序中使用 LZ4,例如在小数据传输中初始化可能成为瓶颈的情况。
新的压缩级别和其他改进:v1.10 引入了一个新的“Level 2”压缩选项,它在性能和压缩率之间提供了最佳平衡,适用于许多应用程序。此外本次更新还包括许多增强功能,如更好的平台支持、改进的错误处理和通过环境变量更灵活的配置。
支持多种架构:增加了对较少知名架构的支持,如 LoongArch 和 RISC-V,确保 LZ4 在各种平台上的可移植性。
LZ4 v1.10 版本通过引入多线程支持和其他多项改进,大幅提升了压缩和解压效率,特别适用于高吞吐量和实时应用场景,增强的字典压缩和新的压缩级别进一步扩展了其应用范围。有关该版本中所有新功能的详细信息,请参阅完整的更新日志。
项目主页:http://lz4.github.io/lz4/