协程
 协程(英语:coroutine)是计算机程序的一类组件,推广了协作式多任务的子例程,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
协程(英语:coroutine)是计算机程序的一类组件,推广了协作式多任务的子例程,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。根据高德纳的说法,马尔文·康威于1958年发明了术语“coroutine”并用于构建汇编程序,关于协程的最初解说在1963年发表。又称微线程,纤程。协程不是系统级线程,很多时候协程被称为“轻量级线程”、“微线程”、“纤程(fiber)”等。简单来说可以认为协程是线程里不同的函数,这些函数之间可以相互快速切换。它和用户态线程非常接近,用户态线程之间的切换不需要陷入内核,但部分操作系统中用户态线程的切换需要内核态线程的辅助。是编程语言(或者 Lib)提供的特性(协程之间的切换方式与过程可以由编程人员确定),是用户态操作。常用于异步编程,适用于 IO 密集型的任务。
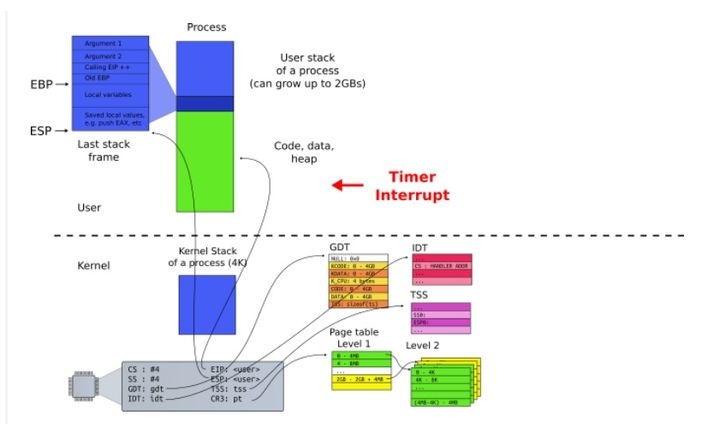
进程、线程上下文切换
它们是操作系统相关知识,下图展示了进程/线程在运行过程 CPU 需要的一些信息(CPU Context,CPU 上下文),比如通用寄存器、栈信息(EBP/ESP)等。进程/线程切换时需要保存与恢复这些信息。
进程/内核态线程切换的时候需要与OS内核进行交互,保存/读取 CPU 上下文信息。内核态(Kernel)的一些数据是共享的,读写时需要同步机制,所以操作一旦陷入内核态就会消耗更多的时间。
进程需要与操作系统中所有其他进程进行资源争抢,且操作系统中资源的锁是全局的;线程之间的数据一般在进程内共享,所以线程间资源共享相比如进程而言要轻一些。虽然很多操作系统(比如 Linux)进程与线程区别不是非常明显,但线程还是比进程要轻。
协程可以通过yield(取其“让步”之义而非“出产”)来调用其它协程,接下来的每次协程被调用时,从协程上次yield返回的位置接着执行,通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的。由于协程不如子例程那样被普遍所知,下面对它们作简要比较:
1.子例程可以调用其他子例程,调用者等待被调用者结束后继续执行,故而子例程的生命期遵循后进先出,即最后一个被调用的子例程最先结束返回。协程的生命期完全由对它们的使用需要来决定。
2.子例程的起始处是惟一的入口点,每当子例程被调用时,执行都从被调用子例程的起始处开始。协程可以有多个入口点,协程的起始处是第一个入口点,每个yield返回出口点都是再次被调用执行时的入口点。
3.子例程只在结束时一次性的返回全部结果值。协程可以在yield时不调用其他协程,而是每次返回一部份的结果值,这种协程常称为生成器或迭代器。
4.现代的指令集架构通常提供对调用栈的指令支持,便于实现可递归调用的子例程。在以Scheme为代表的提供续体的语言环境下,恰好可用此控制状态抽象表示来实现协程。
协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。其次就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
协程的特点
1.可以自动让出 CPU 时间片。注意,不是当前线程让出 CPU 时间片,而是线程内的某个协程让出时间片供同线程内其他协程运行;
2.可以恢复 CPU 上下文。当另一个协程继续执行时,其需要恢复 CPU 上下文环境;
3.协程管理者可以选择一个协程来运行,其他协程要么阻塞,要么ready,或者died;
4.运行中的协程将占有当前线程的所有计算资源;
5.协程天生有栈属性,而且是 lock free。
Linux 2.6 之后的多线程性能提高了很多,大部分场景下线程切换耗时在 2us 左右。正常情况下线程有用的 CPU 时间片都在数十毫秒级别,线程切换占总耗时的千分之几以内。协程的使用可以将这个损耗进一步降低(主要是去除了其他操作,比如 futex 等)
虽然线程切换对于常见业务而言并不重要,但不是所有语言或者系统都支持一次创建很多线程。32 位系统即使使用了虚内存空间,因为进程能访问的虚内存空间大概是 3GB,所以单进程最多创建 300 多条线程(假设系统为每条线程分配 10M 栈空间)。太多线程也有线程切换触发了缺页中断的风险。默认情况下 Linux 系统给每条线程分配的栈空间最大是 6~8MB,这个大小是上限,也是虚内存空间,并不是每条线程真实的栈使用情况。线程真实栈内存使用会随着线程执行而变化,如果线程只使用了少量局部变量,那么真实线程栈可能只有几十个字节的大小。系统在维护线程时需要分配额外的空间,所以线程数的增加还是会提高内存资源的消耗。
这里是一个简单的例子证明协程的实用性。假设你有一个生产者-消费者的关系,这里一个协程生产产品并将它们加入队列,另一个协程从队列中取出产品并使用它。为了提高效率,你想一次增加或删除多个产品。代码可能是这样的:
var q:= new queue
生产者协程
loop
while q is not full
create some new items
add the items to q
yield to consume
消费者协程
loop
while q is not empty
remove some items from q
use the items
yield to produce
每个协程在用yield命令向另一个协程交出控制时都尽可能做了更多的工作。放弃控制使得另一个例程从这个例程停止的地方开始,但因为现在队列被修改了所以他可以做更多事情。尽管这个例子常用来介绍多线程,实际没有必要用多线程实现这种动态:yield语句可以通过由一个协程向另一个协程直接分支的方式实现。
因为相对于子例程,协程可以有多个入口和出口点,可以用协程来实现任何的子例程。事实上,正如Knuth所说:“子例程是协程的特例。”
每当子例程被调用时,执行从被调用子例程的起始处开始;然而,接下来的每次协程被调用时,从协程返回(或yield)的位置接着执行。因为子例程只返回一次,要返回多个值就要通过集合的形式。这在有些语言,如Forth里很方便;而其他语言,如C只允许单一的返回值,所以就需要引用一个集合。相反地,因为协程可以返回多次,返回多个值只需要在后继的协程调用中返回附加的值即可。在后继调用中返回附加值的协程常被称为产生器。
子例程容易实现于堆栈之上,因为子例程将调用的其他子例程作为下级。相反地,协程对等地调用其他协程,最好的实现是用continuations(由有垃圾回收的堆实现)以跟踪控制流程。
网络编程的发展模式大概有下面几种:
1.每个请求一个线程/进程,阻塞式 IO
2.阻塞式 IO,线程池
3.非阻塞式 IO && IO 复用,类似于 Reactor
4.Leader/Folloer 等模式
Reactor 编程模式是事件驱动的,并以回调(handle)的方式完成具体业务,Reactor 的两个基本概念:
1.nonblockingIO+IOmultiplexing,请参考 epoll
2.Event loop,一个监控事件源(epoll fd)的“死循环”
优点:线程数目基本固定,可以在程序启动的时候设置,不会频繁创建与销毁;可以很方便地在线程间调配负载;IO 事件发生的线程是固定的,同一个 TCP 连接不必考虑事件并发。
缺点:基于事件的模型有个非常明显的缺陷,回调函数(handle)不能阻塞(非抢占式调度),否则线程或者进程有耗尽的风险,即使不耗尽,也会给系统带来负担。创建大量进程/线程是不合理的。
子例程可以看作是特定状况的协程,任何子例程都可转写为不调用yield的协程。子程序调用总是一个入口,一次返回,调用顺序是明确的;而协程的调用和子程序不同。协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
这里是一个简单的例子证明协程的实用性。假设这样一种生产者-消费者的关系,一个协程生产产品并将它们加入队列,另一个协程从队列中取出产品并消费它们。伪码表示如下:
var q := 新建队列
coroutine 生产者
loop
while q 不满载
建立某些新产品
向 q 增加这些产品
yield 消费者
coroutine 消费者
loop
while q 不空载
从 q 移除某些产品
使用这些产品
yield 生产者
队列用来存放产品的空间有限,同时制约生产者和消费者:为了提高效率,生产者协程要在一次执行中尽量向队列多增加产品,然后再放弃控制使得消费者协程开始运行;同样消费者协程也要在一次执行中尽量从队列多取出产品,从而腾出更多的存放产品空间,然后再放弃控制使得生产者协程开始运行。尽管这个例子常用来介绍多线程,实际上简单明了的使用协程的yield即可实现这种协作关系。
同线程的比较
协程非常类似于线程。但是协程是协作式多任务的,而线程典型是抢占式多任务的。这意味着协程提供并发性而非并行性。协程超过线程的好处是它们可以用于硬性实时的语境(在协程之间的切换不需要涉及任何系统调用或任何阻塞调用),这里不需要用来守卫关键区段的同步性原语(primitive)比如互斥锁、信号量等,并且不需要来自操作系统的支持。有可能以一种对调用代码透明的方式,使用抢占式调度的线程实现协程,但是会失去某些便利(特别是对硬性实时操作的适合性和相对廉价的相互之间切换),主要如下:
1.调度方式:协程由编程者控制,协程之间可以有优先级;线程由系统控制,一般没有优先级。
2.调度速度:协程几乎比线程快一个数量级。协程调用由编码者控制,可以减少无效的调度。
3.资源占用:协程可以控制内存占用量,灵活性更好;线程由系统控制。
4.创建数量:协程的使用更灵活(有优先级控制、资源使用可控),调度速度更快,相比于线程而言调度损耗更小,所以真实可创建且有效的协程数量可以比线程多很多,这是使用协程实现异步编程的重要基础。同样因为调度与资源的限制,有效协程的数量也是有上限的。
线程是协作式多任务的轻量级线程,本质上描述了同协程一样的概念。其区别一定要说有的话,就是协程是语言层级的构造,可看作一种形式的控制流,而线程是系统层级的构造,可看作恰巧没有并行运行的线程。这两个概念谁有优先权是争议性的:线程可看作为协程的一种实现,也可看作实现协程的基底。
协程有助于实现:
1.状态机:在一个子例程里实现状态机,这里状态由该过程当前的出口/入口点确定;这可以产生可读性更高的代码。
2.角色模型:并发的角色模型,例如计算机游戏。每个角色有自己的过程(这又在逻辑上分离了代码),但他们自愿地向顺序执行各角色过程的中央调度器交出控制(这是合作式多任务的一种形式)。
3.生成器:可用于串流,特别是输入/输出流,和对数据结构的通用遍历。
4.通信顺序进程:这里每个子进程都是协程。通道输入/输出和阻塞操作会yield协程,并由调度器在有完成事件时对其解除阻塞(unblock)。可作为替代的方式是,每个子进程可以是在数据管道中位于其后的子进程的父进程(或是位于其前者之父,这种情况下此模式可以表达为嵌套的生成器)。
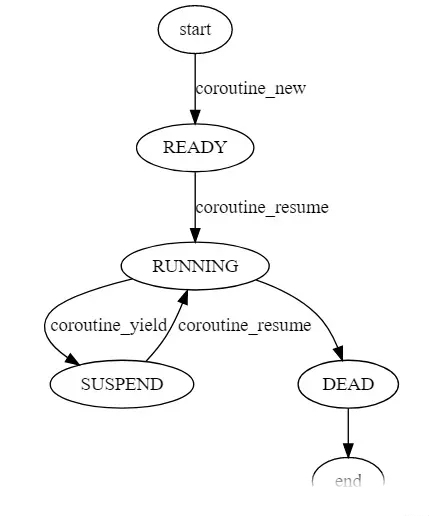
协程的调度
协程的调度与 OS 线程调度十分相似,如下图协程调度示例所示。
系统级线程有锁(mutex)、条件变量(condition)等工具,协程也有对应的工具。比如 libgo 提供了协程之间使用的锁 Co_mutex/Co_rwmutex。不同协程框架对工具的支持程度不同,实现方式也不尽相同。
支持协程的编程语言
协程起源于一种汇编语言方法,但有一些高级编程语言支持它。早期的例子包括Simula、Smalltalk和Modula-2,新近的例子是Ruby、Lua、Julia和Go。
2003年很多最流行的编程语言,包括C语言和它的后继者,都未在语言内或其标准库中直接支持协程(这在很大程度上是受基于堆栈的子例程实现的限制)。C++的Boost.Context库是个例外,它是Boost C++ Libraries的一部分,它在POSIX、Mac OS X和Windows上支持ARM、MIPS、PowerPC、SPAR和x86的上下文切换。可以在Boost.Context之上建造协程。
在协程是某种机制的最自然的实现方式,却不能获得可用协程的情况下,典型的解决方法是使用闭包,它是用状态变量(静态变量常为布尔标志值)来在调用之间维持内部状态,并转移控制权至正确地点的子例程。基于这些状态变量的值,在代码中的条件语句导致在后续调用时有着不同代码路径的执行。另一种典型的解决方法实现一个显式状态机,采用某种形式的大量而复杂的switch语句或goto语句特别是“计算goto”。这种实现被认为难于理解和维护,更是想要有协程支持的动机。
在当今的主流编程环境里,协程的合适的替代者是线程和适用范围较小的线程。线程提供了用来管理“同时”执行的代码段实时协作交互的功能,在支持C语言的环境中,线程是广泛有效的,POSIX.1c(IEEE Std 1003.1c-1995)规定了被称为pthreads的一个标准线程API,它在类Unix系统中被普遍实现。线程被很好地实现、文档化和支持,很多程序员对其也比较熟悉。但线程包括了许多强大和复杂的功能用以解决大量困难的问题,这导致了困难的学习曲线,当任务仅需要协程就可完成时,使用线程似乎就是用力过猛了。GNU Pth可被视为类Unix系统上线程的代表,有人尝试过用Windows的线程机制实现协程。
C语言实现
C标准库里有“非局部跳转”函数setjmp和longjmp,它们分别保存和恢复:栈指针、程序计数器、被调用者保存的寄存器和ABI要求的任何其他内部状态。在C99标准中,跳转到已经用return或longjmp终止的函数是未定义的[27],但是大多数longjmp实现在跳转时不专门销毁调用栈中的局部变量,在被后续的函数调用等覆写之前跳转回来恢复时仍是原样,这允许在实现协程时谨慎的用到它们。
POSIX.1-2001/SUSv3和此前的SUSv2进一步提供了操纵上下文的强力设施:setcontext、getcontext、makecontext和swapcontext,可方便地用来实现协程,但是由于makecontext的参数定义不符合C99标准要求,这些函数在POSIX.1-2004中被废弃,并在POSIX.1-2008中被删除。POSIX.1-2001/SUSv3和此前的SUSv2定义了sigaltstack,可用来在不能获得makecontext的情况下稍微迂回的实现协程。极简实现不采用有关的标准API函数进行上下文交换,而是写一小块内联汇编只对换栈指针和程序计数器故而速度明显的要更快。
由于缺乏直接的语言支持,很多作者写了自己的含藏上述技术细节的协程库,以Russ Cox的libtask协程库为代表,它自称能够“写事件驱动程序而没有麻烦的事件”,并可用在FreeBSD、Linux、Mac OS X和SunOS之上。知名的实现还有:libpcl、lthread、libCoroutine、libconcurrency、libcoro、ribs2、libdill、libaco、libco等等。
此外人们做了用C语言的子例程和宏实现协程的大量尝试,并取得了不同程度的成功。Simon Tatham作出的贡献是这一方法的很好示例,它受到了达夫设备利用swtich语句“掉落”特性的启发,并且是Protothreads和类似实现的基础。这种方法的确可以提高代码段的可写性、可读性,但可维护性是存在争议的。这种不为每个协程维护独立的栈帧的实现方式主要缺点是,局部变量在经过从函数yield之后是不保存的,控制权只能从顶层例程yield。
Python实现
Python 2.5基于增强的生成器实现对类似协程功能的更好支持。Python 3.3通过支持委托给子生成器增进了这个能力。Python 3.4介入了综合性的异步I/O框架标准化,在其中扩展了利用子生成器委托的协程,这个扩展在Python 3.8中被弃用。Python 3.5通过async/await语法介入了对协程的显式支持。从Python 3.7开始async/await成为保留关键字。
Perl实现
Coro是Perl5中的一种协程实现,使用C作为底层,所以具有良好的执行性能,而且可以配合AnyEvent共同使用,极大的弥补了Perl在线程上劣势。
Scheme实现
Scheme提供了对续体的完全支持,实现协程是很轻易的,只需维护一个续体的队列。在续体条目中有使用续体将协程实现为独立线程的一个用例。
Smalltalk实现
在大多数Smalltalk环境中,执行堆栈是头等公民,实现协程不需要额外的库或VM支持。
Tcl实现
从 Tcl 8.6 开始,Tcl 核心内置协程支持,成为了继事件循环、线程后的另一种内置的强大功能。