Base64
 Base64是一种基于64个可打印字符来表示二进制数据的表示方法。每6个比特为一个单元,对应某个可打印字符;3个字节相当于24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。每6个比特为一个单元,对应某个可打印字符;3个字节相当于24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
Base64索引表:
| 数值 | 字符 | 数值 | 字符 | 数值 | 字符 | 数值 | 字符 | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w | |||
| 1 | B | 17 | R | 33 | h | 49 | x | |||
| 2 | C | 18 | S | 34 | i | 50 | y | |||
| 3 | D | 19 | T | 35 | j | 51 | z | |||
| 4 | E | 20 | U | 36 | k | 52 | 0 | |||
| 5 | F | 21 | V | 37 | l | 53 | 1 | |||
| 6 | G | 22 | W | 38 | m | 54 | 2 | |||
| 7 | H | 23 | X | 39 | n | 55 | 3 | |||
| 8 | I | 24 | Y | 40 | o | 56 | 4 | |||
| 9 | J | 25 | Z | 41 | p | 57 | 5 | |||
| 10 | K | 26 | a | 42 | q | 58 | 6 | |||
| 11 | L | 27 | b | 43 | r | 59 | 7 | |||
| 12 | M | 28 | c | 44 | s | 60 | 8 | |||
| 13 | N | 29 | d | 45 | t | 61 | 9 | |||
| 14 | O | 30 | e | 46 | u | 62 | + | |||
| 15 | P | 31 | f | 47 | v | 63 | / |
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个=号,代表补足的字节数。也就是说,当最后剩余两个八位(待补足)字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位(待补足)字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。参考下表:
| 文本(1 Byte) | A | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base64编码 | Q | Q | = | = | ||||||||||||||||||||
| 文本(2 Byte) | B | C | ||||||||||||||||||||||
| 二进制位 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 二进制位(补0) | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Base64编码 | Q | k | M | = | ||||||||||||||||||||
Base64 是一组相似的二进制到文本(binary-to-text)的编码规则,使得二进制数据在解释成 radix-64 的表现形式后能够用 ASCII 字符串的格式表示出来。Base64 这个词出自一种 MIME 数据传输编码。
Base64编码普遍应用于需要通过被设计为处理文本数据的媒介上储存和传输二进制数据而需要编码该二进制数据的场景。这样是为了保证数据的完整并且不用在传输过程中修改这些数据。Base64 也被一些应用(包括使用 MIME 的电子邮件)和在 XML (en-US) 中储存复杂数据时使用。 在 JavaScript 中,有两个函数被分别用来处理解码和编码 base64 字符串:
atob(),btoa()
atob()函数能够解码通过base-64编码的字符串数据。相反地,btoa()函数能够从二进制数据“字符串”创建一个base-64编码的ASCII字符串。atob() 和 btoa() 均使用字符串。
每一个Base64字符实际上代表着6比特位。因此3字节(一字节是8比特,3字节也就是24比特)的字符串/二进制文件可以转换成4个Base64字符(4x6=24比特)。这意味着Base64格式的字符串或文件的尺寸约是原始尺寸的133%(增加了大约33%)。如果编码的数据很少,增加的比例可能会更高。
编码原理:其原理非常的简单,就是将编码表的顺序进行打乱,再进行编码。
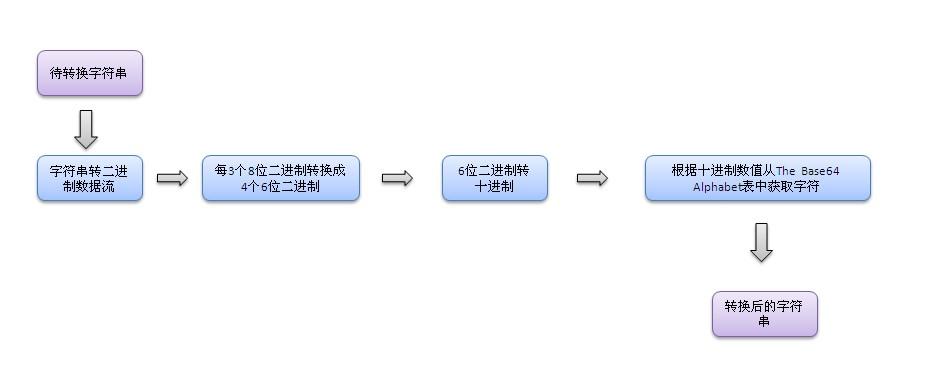
都是按字符串长度,以每 3 个 字符(1Byte=8bit)为一组,然后针对每组,首先获取每个字符的 ASCII 编码(字符'a'=97=01100001),然后将 ASCII 编码转换成 8 bit 的二进制,得到一组 3 * 8=24 bit 的字节。然后再将这 24 bit 划分为 4 个 6 bit 的字节,并在每个 6 bit 的字节前面都填两个高位 0,得到 4 个 8 bit 的字节,然后将这 4 个 8 bit 的字节转换成十进制,对照 BASE64 编码表得到对应编码后的字符。
其本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续6比特(2的6次方=64)计算其十进制值,根据该值在A-Z,a-z,0-9,+,/这64个字符中找到对应的字符,最终得到一个文本字符串。基本规则如下几点:
1.标准Base64只有64个字符(英文大小写、数字和+、/)以及用作后缀的等号符(实际上是65个字符);
2.Base64是把3个字节变成4个可打印字符,所以Base64编码后的字符串一定能被4整除(不算用作后缀的等号);
3.等号一定用作后缀,且数目一定是0个、1个或2个。这是因为如果原文长度不能被3整除,Base64要在后面添加\0凑齐3n位。为了正确还原,添加了几个\0就加上几个等号。显然添加等号的数目只能是0、1或2;
4.严格来说Base64不能算是一种加密,只能说是编码转换。它可以实现可见字符的传输,适用于安全要求不高,对密文要求可见,且密文长度受限的场景。
具体来说,转换方式可以分为四步:
1.将每三个字节作为一组,一共是24个二进制位。
2.将这24个二进制位分为四组,每个组有6个二进制位。
3.在每组前面加两个00,扩展成32个二进制位,即四个字节。
4.根据下表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
注意:
1. 要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
2. 如果被编码字符长度不是3的倍数的时候,则都用0代替,对应的输出字符为"="。
Hex、Base32与Base64
Hex(十六进制)和Base64类似,并不是一种加、解密算法,而是一种编码的手段,重新编码之后的数据很容易还原。编码之后的数据,不会发生中文乱码,也不会出现非法字符和空白字符,更方便程序和人类对数据的读取。字符可分为二种:一种是可见字符,另一种是不可见字符。除了Base64、Hex,还有Unicode、Url等编码,不同的编码,有着不同的特征,根据特征可以应用到不同的场景。
Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,可以查看RFC2045~RFC2049,上面有MIME的详细规范。Base64要求把每三个8Bit的字节转换为四个6Bit的字节(3*8 = 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
编码规则:
把3个字符变成4个字符..
每76个字符加一个换行符..
最后的结束符也要处理..
示例:
转换前:10101101 10111010 01110110
转换后:00101011 00011011 00101001 00110110
十进制:43 27 41 54
对应码表中的值:r b p 2
所以上面的24位编码,编码后的Base64值为rbp2。
hex也称为base16,意思是使用16个可见字符来表示一个二进制数组,编码后数据大小将翻倍,因为1个字符需要用2个可见字符来表示。
base32,意思是使用32个可见字符来表示一个二进制数组,编码后数据大小变成原来的8/5,也即5个字符用8个可见字符表示,但是最后如果不足8个字符,将用=来补充。
base64,意思是使用64个可见字符来表示一个二进制数组,编码后数据大小变成原来的4/3,也即3个字符用4个可见字符来表示。
三种编码的区别与联系
三种编码的区别
主要就是空间效率的区别,base64是具有比较高的空间效率的。当然hex编码不区分大小写,但是base32与base64是区分的。
三种编码联系
就是大家都是一种稳定的把二进制数组变成可见字符的编码方式。
为什么有的场合必须要使用可见字符
比如在网络中传输数据时,不同路由器对于不可见字符的处理是不同的,因此可能出现数据错误,因此还必须使用可见字符。
应用
MIME
在MIME格式的电子邮件中,Base64可以用来将binary的字节序列数据编码成ASCII字符序列构成的文本。使用时,在传输编码方式中指定Base64。使用的字符包括大小写拉丁字母各26个、数字10个、加号+和斜杠/,共64个字符,等号=用来作为后缀用途。
完整的Base64定义可见RFC 1421和RFC 2045。编码后的数据比原始数据略长,为原来的 4/3。在电子邮件中,根据RFC 822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。转换的时候,将3字节的数据,先后放入一个24位的缓冲区中,先来的字节占高位。数据不足3字节的话,于缓冲器中剩下的比特用0补足。每次取出6比特(因为2^6=64),按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出,直到全部输入数据转换完成。
若原数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。
UTF-7
UTF-7是一个修改版Base64(Modified Base64)。主要是将UTF-16的数据,用Base64的方法编码为可打印的ASCII字符序列。目的是传输Unicode数据。主要的区别在于不用等号=补余,因为该字符通常需要大量的转译。
标准可见 RFC 2152,《A Mail-Safe Transformation Format of Unicode》。
URL
Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java持久化系统Hibernate中,就采用了Base64来将一个较长的唯一标识符(一般为128-bit的UUID)编码为一个字符串,用作HTTP表单和HTTP GET URL中的参数。在其他应用程序中,也常常需要把二进制数据编码为适合放在URL(包括隐藏表单域)中的形式。此时,采用Base64编码不仅比较简短,同时也具有不可读性,即所编码的数据不会被人用肉眼所直接看到。
然而,标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的/和+字符变为形如%XX的形式,而这些%号在存入数据库时还需要再进行转换,因为ANSI SQL中已将%号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它不在末尾填充=号,并将标准Base64中的+和/分别改成了-和_,这样就免去了在URL编解码和数据库存储时所要做的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进Base64变种,它将+和/改成了!和-,因为+,*以及前面在IRCu中用到的[和]在正则表达式中都可能具有特殊含义。此外还有一些变种,它们将+/改为_-或._(用作编程语言中的标识符名称)或.-(用于XML中的Nmtoken)甚至_:(用于XML中的Name)。
其它
垃圾消息传播者用Base64来避过反垃圾邮件工具,因为那些工具通常都不会翻译Base64的消息。某些场景下,以上经由 UTF-8 转换到 Base64 的实现在空间利用上不一定高效。当处理包含大量 U+0800-U+FFFF 区域间字符的文本时, UTF-8 输出结果长于 UTF-16 的,因为这些字符在 UTF-8 下占用三个字节而 UTF-16 是两个。在处理均匀分布 UTF-16 码点的 JavaScript 字符串时应考虑采用 UTF-16 替代 UTF-8 作为 Base64 结果的中间编码格式,这将减少 40% 尺寸。
本文总结自:互联网