容器技术的发展史之从虚拟化到云原生
 本文转自编辑部的故事的博客,感谢原作者。
本文转自编辑部的故事的博客,感谢原作者。近年来,云原生 (Cloud Native)可谓是 IT 界最火的概念之一,众多互联网巨头都已经开始积极拥抱云原生。而说到云原生,我们就不得不了解本文的主角 —— 容器(container)。容器技术可谓是撑起了云原生生态的半壁江山。容器作为一种先进的虚拟化技术,已然成为了云原生时代软件开发和运维的标准基础设施,在了解它之前,我们不妨从虚拟化技术说起。
何为虚拟化技术
1961 年 —— IBM709 机实现了分时系统。
计算机历史上首个虚拟化技术实现于 1961 年,IBM709 计算机首次将 CPU 占用切分为多个极短 (1/100sec) 时间片,每一个时间片都用来执行着不同的任务。通过对这些时间片的轮询,这样就可以将一个 CPU 虚拟化或者伪装成为多个 CPU,并且让每一颗虚拟 CPU 看起来都是在同时运行的。这就是虚拟机的雏形。
容器的功能其实和虚拟机类似,无论容器还是虚拟机,其实都是在计算机不同的层面进行虚拟化,即使用逻辑来表示资源,从而摆脱物理限制的约束,提高物理资源的利用率。虚拟化技术是一个抽象又内涵丰富的概念,在不同的领域或层面有着不同的含义。
这里我们首先来粗略地讲讲计算机的层级结构。计算机系统对于大部分软件开发者来说可以分为以下层级结构:
应用程序层
函数库层
操作系统层
硬件层
各层级自底向上,每一层都向上提供了接口,同时每一层也只需要知道下一层的接口即可调用底层功能来实现上层操作(不需要知道底层的具体运作机制)。
但由于早期计算机厂商生产出来的硬件遵循各自的标准和规范,使得操作系统在不同计算机硬件之间的兼容性很差;同理,不同的软件在不同的操作系统下的兼容性也很差。于是,就有开发者人为地在层与层之间创造了抽象层:
应用层
函数库层
API抽象层
操作系统层
硬件抽象层
硬件层
就我们探讨的层面来说,所谓虚拟化就是在上下两层之间,人为地创造出一个新的抽象层,使得上层软件可以直接运行在新的虚拟环境上。简单来说,虚拟化就是通过模访下层原有的功能模块创造接口,来“欺骗”上层,从而达到跨平台开发的目的。
综合上述理念,我们就可以重新认识如今几大广为人知的虚拟化技术:
虚拟机:存在于硬件层和操作系统层间的虚拟化技术。
虚拟机通过“伪造”一个硬件抽象接口,将一个操作系统以及操作系统层以上的层嫁接到硬件上,实现和真实物理机几乎一样的功能。比如我们在一台 Windows 系统的电脑上使用 Android 虚拟机,就能够用这台电脑打开 Android 系统上的应用。
容器:存在于操作系统层和函数库层之间的虚拟化技术。
容器通过“伪造”操作系统的接口,将函数库层以上的功能置于操作系统上。以 Docker 为例,其就是一个基于 Linux 操作系统的 Namespace 和 Cgroup 功能实现的隔离容器,可以模拟操作系统的功能。简单来说,如果虚拟机是把整个操作系统封装隔离,从而实现跨平台应用的话,那么容器则是把一个个应用单独封装隔离,从而实现跨平台应用。所以容器体积比虚拟机小很多,理论上占用资源更少。
JVM:存在于函数库层和应用程序之间的虚拟化技术。
Java 虚拟机同样具有跨平台特性,所谓跨平台特性实际上也就是虚拟化的功劳。我们知道 Java 语言是调用操作系统函数库的,JVM 就是在应用层与函数库层之间建立一个抽象层,对下通过不同的版本适应不同的操作系统函数库,对上提供统一的运行环境交给程序和开发者,使开发者能够调用不同操作系统的函数库。
在大致理解了虚拟化技术之后,接下来我们就可以来了解容器的诞生历史。虽然容器概念是在 Docker 出现以后才开始在全球范围内火起来的,但在 Docker 之前,就已经有无数先驱在探索这一极具前瞻性的虚拟化技术。
容器的前身 “Jail”
1979 年 —— 贝尔实验室发明 chroot
容器主要的特性之一就是进程隔离。早在 1979 年,贝尔实验室在 Unix V7 的开发过程中,发现当一个系统软件编译和安装完成后,整个测试环境的变量就会发生改变,如果要进行下一次构建、安装和测试,就必须重新搭建和配置测试环境。要知道在那个年代,一块 64K 的内存条就要卖 419 美元,“快速销毁和重建基础设施”的成本实在是太高了。
开发者们开始思考,能否在现有的操作系统环境下,隔离出一个用来重构和测试软件的独立环境?于是,一个叫做 chroot(Change Root)的系统调用功能就此诞生。
chroot 可以重定向进程及其子进程的 root 目录到文件系统上的新位置,也就是说使用它可以分离每个进程的文件访问权限,使得该进程无法接触到外面的文件,因此这个被隔离出来的新环境也得到了一个非常形象的命名,叫做 Chroot Jail (监狱)。之后只要把需要的系统文件一并拷贝到 Chroot Jail 中,就能够实现软件重构和测试。这项进步开启了进程隔离的大门,为 Unix 提供了一种简单的系统隔离功能,尤其是 jail 的思路为容器技术的发展奠定了基础。但是此时 chroot 的隔离功能仅限于文件系统,进程和网络空间并没有得到相应的处理。
进入21世纪,此时的虚拟机(VM)技术已经相对成熟,人们可以通过虚拟机技术实现跨操作系统的开发。但由于 VM 需要对整个操作系统进行封装隔离,占用资源很大,在生产环境中显得太过于笨重。于是人们开始追求一种更加轻便的虚拟化技术,众多基于 chroot 扩展实现的进程隔离技术陆续诞生。
2000 年 —— FreeBSD 推出 FreeBSD Jail
在 chroot 诞生 21 年后,FreeBSD 4.0 版本推出了一套微型主机环境共享系统 FreeBSD Jail,将 chroot 已有的机制进行了扩展。在 FreeBSD Jail 中,程序除了有自己的文件系统以外,还有独立的进程和网络空间,Jail 中的进程既不能访问也不能看到 Jail 之外的文件、进程和网络资源。
2001 年 —— Linux VServer 诞生
2001年,Linux 内核新增 Linux VServer(虚拟服务器),为 Linux 系统提供虚拟化功能。Linux VServer 采取的也是一种 jail 机制,它能够划分计算机系统上的文件系统、网络地址和内存,并允许一次运行多个虚拟单元。
2004 年 —— SUN 发布 Solaris Containers
该技术同样由 chroot 进一步发展而来。2004 年 2 月,SUN 发布类 Unix 系统 Solaris 的 10 beta 版,新增操作系统虚拟化功能 Container,并在之后的 Solaris 10 正式版中完善。Solaris Containers 支持 x86 和 SPARC 系统,SUN 创造了一个 zone 功能与 Container 配合使用,前者是一个单一操作系统中完全隔离的虚拟服务器,由系统资源控制和 zones 提供的边界分离实现进程隔离。
2005 年 —— OpenVZ 诞生
类似于 Solaris Containers,它通过对 Linux 内核进行补丁来提供虚拟化、隔离、资源管理和状态检查 checkpointing。每个 OpenVZ 容器都有一套隔离的文件系统、用户及用户组、进程树、网络、设备和 IPC 对象。
这个时期的进程隔离技术大多以 Jail 模式为核心,基本实现了进程相关资源的隔离操作,但由于此时的生产开发仍未有相应的使用场景,这一技术始终被局限在了小众而有限的世界里。就在此时,一种名为“云”的新技术正悄然萌发……
“云” 的诞生
2003 年至 2006 年间,Google 公司陆续发布了 3 篇产品设计论文,从计算方式到存储方式,开创性地提出了分布式计算架构,奠定了大数据计算技术的基础。在此基础上,Google 颠覆性地提出“Google 101”计划,并正式创造“云”的概念。一时间,“云计算”、“云存储”等全新词汇轰动全球。随后,亚马逊、IBM 等行业巨头也陆续宣布各自的“云”计划,宣告“云”技术时代的来临。
也是从这时期开始,进程隔离技术进入了一个更高级的阶段。在 Google 提出的云计算框架下,被隔离的进程不仅仅是一个与外界隔绝但本身却巍然不动的 Jail,它们更需要像一个个轻便的容器,除了能够与外界隔离之外,还要能够被控制与调配,从而实现分布式应用场景下的跨平台、高可用、可扩展等特性。
2006 年 —— Google 推出 Process Containers,后更名为 Cgroups
Process Container 是 Google 工程师眼中“容器”技术的雏形,用来对一组进程进行限制、记账、隔离资源(CPU、内存、磁盘 I/O、网络等)。这与前面提到的进程隔离技术的目标其实是一致的。由于技术更加成熟,Process Container 在 2006 年正式推出后,第二年就进入了 Linux 内核主干,并正式更名为 Cgroups,标志着 Linux 阵营中“容器”的概念开始被重新审视和实现。
2008 年 —— Linux 容器工具 LXC 诞生
在 2008 年,通过将 Cgroups 的资源管理能力和 Linux Namespace(命名空间)的视图隔离能力组合在一起,一项完整的容器技术 LXC(Linux Container)出现在了 Linux 内核中,这就是如今被广泛应用的容器技术的实现基础。我们知道,一个进程可以调用它所在物理机上的所有资源,这样一来就会挤占其它进程的可用资源,为了限制这样的情况,Linux 内核开发者提供了一种特性,进程在一个 Cgroup 中运行的情况与在一个命名空间中类似,但是 Cgroup 可以限制该进程可用的资源。尽管 LXC 提供给用户的能力跟前面提到的各种 Jails 以及 OpenVZ 等早期 Linux 沙箱技术是非常相似的,但伴随着各种 Linux 发行版开始迅速占领商用服务器市场,包括 Google 在内的众多云计算先锋厂商得以充分活用这一早期容器技术,让 LXC 在云计算领域获得了远超前辈的发展空间 。
同年,Google 基于 LXC 推出首款应用托管平台 GAE (Google App Engine),首次把开发平台当做一种服务来提供。GAE 是一种分布式平台服务,Google 通过虚拟化技术为用户提供开发环境、服务器平台、硬件资源等服务,用户可以在平台基础上定制开发自己的应用程序并通过 Google 的服务器和互联网资源进行分发,大大降低了用户自身的硬件要求。
值得一提的是,Google 在 GAE 中使用了一个能够对 LXC 进行编排和调度的工具 —— Borg (Kubernetes 的前身)。Borg 是 Google 内部使用的大规模集群管理系统,可以承载十万级的任务、数千个不同的应用、同时管理数万台机器。Borg 通过权限管理、资源共享、性能隔离等来达到高资源利用率。它能够支持高可用应用,并通过调度策略减少出现故障的概率,提供了任务描述语言、实时任务监控、分析工具等。如果说一个个隔离的容器是集装箱,那么 Borg 可以说是最早的港口系统,而 LXC + Borg 就是最早的容器编排框架。此时,容器已经不再是一种单纯的进程隔离功能,而是一种灵活、轻便的程序封装模式。
2011 年 —— Cloud Foundry 推出 Warden
Cloud Foundry 是知名云服务供应商 VMware 在 2009 年推出的一个云平台,也是业内首个正式定义 PaaS (平台即服务)模式的项目,“PaaS 项目通过对应用的直接管理、编排和调度让开发者专注于业务逻辑而非基础设施”,以及“PaaS 项目通过容器技术来封装和启动应用”等理念都出自 Cloud Foundry。Warden 是 Cloud Foundry 核心部分的资源管理容器,它最开始是一个 LXC 的封装,后来重构成了直接对 Cgroups 以及 Linux Namespace 操作的架构。
随着“云”服务市场的不断开拓,各种 PaaS 项目陆续出现,容器技术也迎来了一个爆发式增长的时代,一大批围绕容器技术进行的创业项目陆续涌现。当然,后来的故事很多人都知道了,一家叫 Docker 的创业公司横空出世,让 Docker 几乎成为了“容器”的代名词。
Docker 横空出世
2013 年 —— Docker 诞生
Docker 最初是一个叫做 dotCloud 的 PaaS 服务公司的内部项目,后来该公司改名为 Docker。Docker 在初期与 Warden 类似,使用的也是 LXC ,之后才开始采用自己开发的 libcontainer 来替代 LXC 。与其他只做容器的项目不同的是,Docker 引入了一整套管理容器的生态系统,这包括高效、分层的容器镜像模型、全局和本地的容器注册库、清晰的 REST API、命令行等等。
Docker 本身其实也是属于 LXC 的一种封装,提供简单易用的容器使用接口。它最大的特性就是引入了容器镜像。Docker 通过容器镜像,将应用程序与运行该程序需要的环境,打包放在一个文件里面。运行这个文件,就会生成一个虚拟容器。
更为重要的是,Docker 项目还采用了 Git 的思路 —— 在容器镜像的制作上引入了“层”的概念。基于不同的“层”,容器可以加入不同的信息,使其可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。通过制作 Docker 镜像,开发者可以通过 DockerHub 这样的镜像托管仓库,把软件直接进行分发。
也就是说,Docker 的诞生不仅解决了软件开发层面的容器化问题,还一并解决了软件分发环节的问题,为“云”时代的软件生命周期流程提供了一套完整的解决方案。
很快,Docker 在业内名声大噪,被很多公司选为云计算基础设施建设的标准,容器化技术也成为业内最炙手可热的前沿技术,围绕容器的生态建设风风火火地开始了。
容器江湖之争
一项新技术的兴起同时也带来了一片新的市场,一场关于容器的蓝海之争也在所难免。
2013 年 —— CoreOS 发布
在 Docker 爆火后,同年年末,CoreOS 应运而生。CoreOS 是一个基于 Linux 内核的轻量级操作系统,专为云计算时代计算机集群的基础设施建设而设计,拥有自动化、易部署、安全可靠、规模化等特性。其在当时有一个非常显眼的标签:专为容器设计的操作系统。
借着 Docker 的东风,CoreOS 迅速在云计算领域蹿红,一时间,Docker + CoreOS 成为业内容器部署的黄金搭档。同时,CoreOS 也为 Docker 的推广与社区建设做出了巨大的贡献。
然而,日渐壮大的 Docker 似乎有着更大的“野心”。不甘于只做“一种简单的基础单元”的 Docker,自行开发了一系列相关的容器组件,同时收购了一些容器化技术的公司,开始打造属于自己的容器生态平台。显然,这对于 CoreOS 来说形成了直接的竞争关系。
2014 年 —— CoreOS 发布开源容器引擎 Rocket
2014 年末,CoreOS 推出了自己的容器引擎 Rocket (简称 rkt),试图与 Docker 分庭抗礼。rkt 和 Docker 类似,都能帮助开发者打包应用和依赖包到可移植容器中,简化搭环境等部署工作。rkt 和 Docker 不同的地方在于,rkt 没有 Docker 那些为企业用户提供的“友好功能”,比如云服务加速工具、集群系统等。反过来说,rkt 想做的,是一个更纯粹的业界标准。
2014 年 —— Google 推出开源的容器编排引擎 Kubernetes
为了适应混合云场景下大规模集群的容器部署、管理等问题,Google 在 2014 年 6 月推出了容器集群管理系统 Kubernetes (简称 K8S)。K8S 来源于我们前面提到的 Borg,拥有在混合云场景的生产环境下对容器进行管理、编排的功能。Kubernetes 在容器的基础上引入了 Pod 功能,这个功能可以让不同容器之间互相通信,实现容器的分组调配。
得益于 Google 在大规模集群基础设施建设的强大积累,脱胎于 Borg 的 K8S 很快成为了行业的标准应用,堪称容器编排的必备工具。而作为容器生态圈举足轻重的一员,Google 在 Docker 与 rkt 的容器之争中站在了 CoreOS 一边,并将 K8S 支持 rkt 作为一个重要里程碑。
2015 年 —— Docker 推出容器集群管理工具 Docker Swarm
作为回应,Docker 公司在 2015 年发布的 Docker 1.12 版本中也开始加入了一个容器集群管理工具 Docker swarm 。
随后,Google 于 2015 年 4 月领投 CoreOS 1200 万美元, 并与 CoreOS 合作发布了首个企业发行版的 Kubernetes —— Tectonic 。从此,容器江湖分为两大阵营,Google 派系和 Docker 派系。
两大派系的竞争愈演愈烈,逐渐延伸到行业标准的建立之争。
2015 年 6 月 —— Docker 带头成立 OCI
Docker 联合 Linux 基金会成立 OCI (Open Container Initiative)组织,旨在“制定并维护容器镜像格式和容器运行时的正式规范(“OCI Specifications”),围绕容器格式和运行时制定一个开放的工业化标准。
2015 年 7 月 —— Google 带头成立 CNCF
而战略目标聚焦于“云”的 Google 在同年 7 月也联合 Linux 基金会成立 CNCF (Cloud Native Computing Foundation)云原生计算基金会,并将 Kubernetes 作为首个编入 CNCF 管理体系的开源项目,旨在“构建云原生计算 —— 一种围绕着微服务、容器和应用动态调度的、以基础设施为中心的架构,并促进其广泛使用”。
这两大围绕容器相关开源项目建立的开源基金会为推动日后的云原生发展发挥了重要的作用,二者相辅相成,制定了一系列行业事实标准,成为当下最为活跃的开源组织。
Kubernetes 生态一统江湖
虽然这些年来 Docker 一直力压 rkt,成为当之无愧的容器一哥,但作为一个庞大的容器技术生态来说,Docker 生态还是在后来的容器编排之争中败给了 Google 的 Kubernetes 。
随着越来越多的开发者使用 Docker 来部署容器,编排平台的重要性日益突出。在 Docker 流行之后,一大批开源项目和专有平台陆续出现,以解决容器编排的问题。Mesos、Docker Swarm 和 Kubernetes 等均提供了不同的抽象来管理容器。这一时期,对于软件开发者来说,选择容器编排平台就像是一场豪赌,因为一旦选择的平台在以后的竞争中败下阵来,就意味着接下来开发的东西在未来将失去市场。就像当初 Android、iOS 和 WP 的手机系统之争一样,只有胜利者才能获得更大的市场前景,失败者甚至会销声匿迹。容器编排平台之争就此拉开帷幕。
2016 年 —— CRI-O 诞生
2016 年,Kubernetes 项目推出了 CRI (容器运行时接口),这个插件接口让 kubelet(一种用来创建 pod、启动容器的集群节点代理)能够使用不同的、符合 OCI 的容器运行时环境,而不需要重新编译 Kubernetes。基于 CRI ,一个名为 CRI-O 的开源项目诞生,旨在为 Kubernetes 提供一种轻量级运行时环境。
CRI-O 可以让开发者直接从 Kubernetes 来运行容器,这意味着 Kubernetes 可以不依赖于传统的容器引擎(比如 Docker ),也能够管理容器化工作负载。这样一来,在 Kubernetes 平台上,只要容器符合 OCI 标准(不一定得是 Docker),CRI-O 就可以运行它,让容器回归其最基本的功能 —— 能够封装并运行云原生程序即可。
同时,CRI-O 的出现让使用容器技术进行软件管理和运维的人们发现,相对于 Docker 本身的标准容器引擎, Kubernetes 技术栈(比如编排系统、 CRI 和 CRI-O )更适合用来管理复杂的生产环境。可以说,CRI-O 将容器编排工具放在了容器技术栈的重要位置,从而降低了容器引擎的重要性。
在 K8S 顺利抢占先机的情况下,Docker 在推广自己的容器编排平台 Docker Swarm 时反而犯下了错误。2016 年底,业内曝出 Docker 为了更好地适配 Swarm,将有可能改变 Docker 标准的传言。这让许多开发者在平台的选择上更倾向于与市场兼容性更强的 Kubernetes 。
因此,在进入 2017 年之后,更多的厂商愿意把宝压在 K8S 上,投入到 K8S 相关生态的建设中来。容器编排之争以 Google 阵营的胜利告一段落。与此同时,以 K8S 为核心的 CNCF 也开始迅猛发展,成为当下最火的开源项目基金会。这两年包括阿里云、腾讯、百度等中国科技企业也陆续加入 CNCF ,全面拥抱容器技术与云原生。
结语
从数十年前在实验室里对进程隔离功能的探索,再到如今遍布生产环境的云原生基础设施建设,可以说容器技术凝聚了几代开发者的心血,才从一个小小的集装箱发展到一个大型的现代化港口。可以预见的是,从现在到未来很长一段时间里,容器技术都将是软件开发和运维的重要基础设施。
刚哥说关于容器那些事
容器技术是一种虚拟化技术,也就是我们常常说的“软件定义XXX”。在容器之前被广泛应用的是虚拟机技术,也就是软件定义的硬件。代表产品就是VMWare。我早年在EMC工作的时候,公司常常提起收购VMWare是多么多么英明的一项决策,那个时候虚拟机技术真的很火。例如软件模拟硬件,用户可以很方便的在自己的主机上运行不用的硬件和操作系统,并且可以方便的把整个系统的快照作为文件迁移,真的非常方便。
但是虚拟机需要模拟整个的硬件,它的开销是非常大的。内存,CPU和磁盘空间都是独占的。在系统架构的层面,虚拟机技术仍然非常有用,但是对日常的开发工作来说,虚拟机技术就太重了。
从软件开发和部署的角度来看,我们希望有一个这样的虚拟化技术:
能够隔离CPU,内存,磁盘,网络等资源
能够控制资源使用的量和优先级
能够运行独立的操作系统
比较轻量级的系统开销
比较方便的管理功能
在Unix/Linux世界,我们第一个想到的类似的东西是Chroot。
Chroot
chroot是在unix系统的一个操作,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以 `/`,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 `/` 位置。由chroot创造出的那个根目录,叫做“chroot jail”(chroot jail,或chroot prison)。
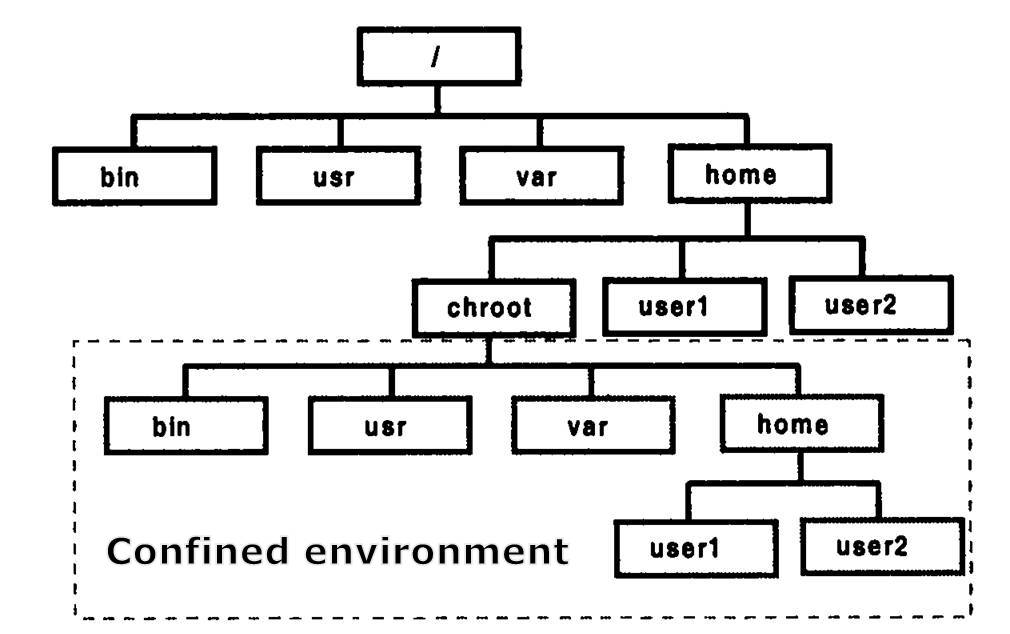
Changing Working Root Directory – Alberto Matus
只有root用户可以执行chroot。大多数Unix系统都没有以完全文件系统为导向,以即给可能通过网络和过程控制,通过系统调用接口来提供一个破坏chroot的程序。
在经过 chroot 之后,系统读取到的目录和文件将不在是旧系统根下的而是新根下(即被指定的新的位置)的目录结构和文件,因此它带来的好处大致有以下3个:
增加了系统的安全性,限制了用户的权力;在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。这个一般是在登录 (login) 前使用 chroot,以此达到用户不能访问一些特定的文件。
建立一个与原系统隔离的系统目录结构,方便用户的开发;使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。
切换系统的根目录位置,引导 Linux 系统启动以及急救系统等。chroot 的作用就是切换系统的根位置,而这个作用最为明显的是在系统初始引导磁盘的处理过程中使用,从初始 RAM 磁盘 (initrd) 切换系统的根位置并执行真正的 init。另外,当系统出现一些问题时,我们也可以使用 chroot 来切换到一个临时的系统。
但是Chroot并不能满足我们之前提到的哪些需求,chroot的隔离功能非常有限,chroot的机制本身不是为限制资源的使用而设计,如I/O,带宽,磁盘空间或CPU时间。
为了实现我们之前提到的那些需求,我们需要一种更为强大的虚拟化技术,容器也就随之发展起来。
容器 VS. 虚机
Linux的容器和虚拟机的差比我想大家都比较了解了,我这里再简单叙述一下:
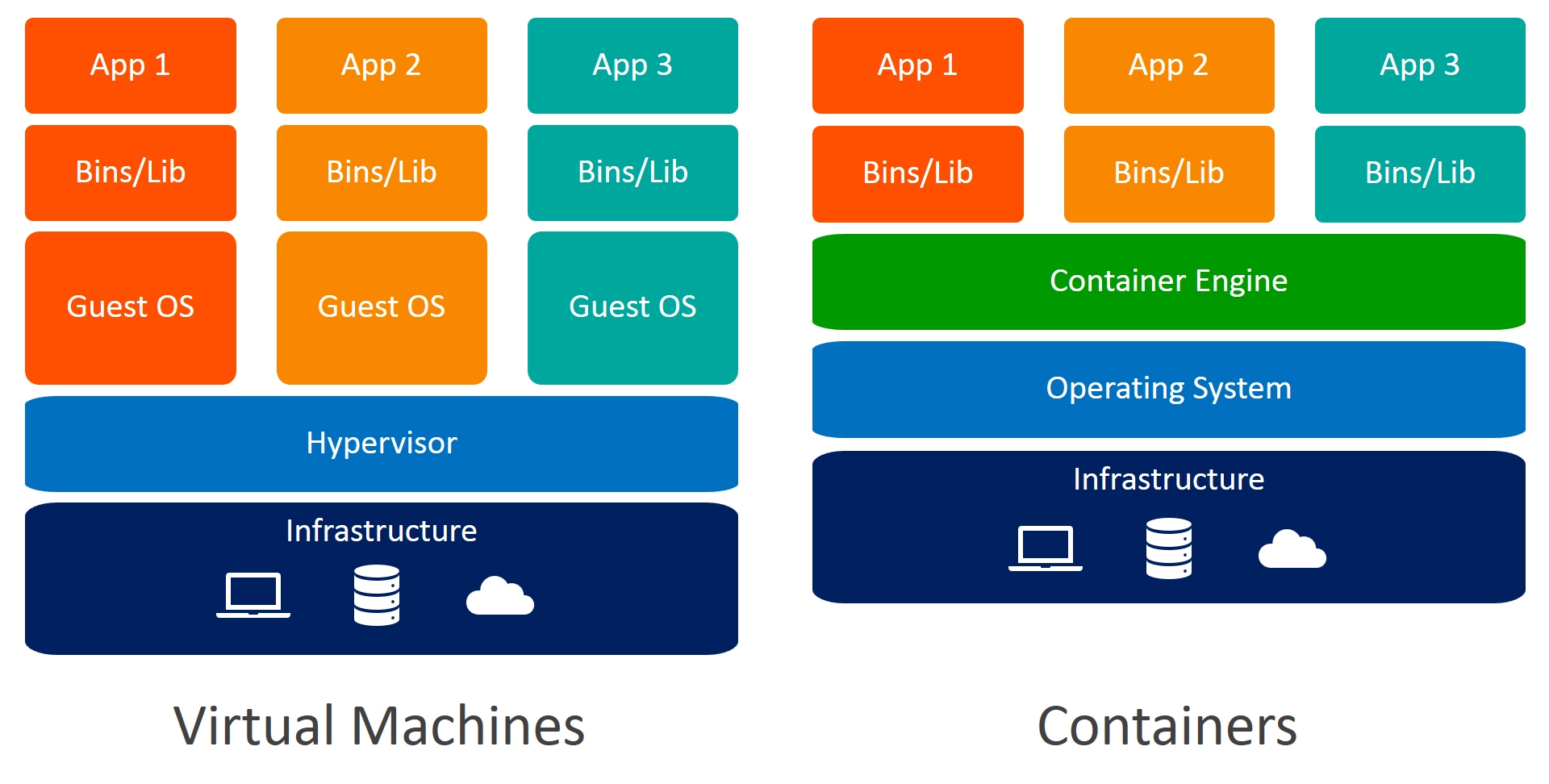
A Practical Guide to Choosing between Docker Containers and VMs
对于使用虚拟机的传统虚拟化,每个虚拟机都有自己的完整操作系统,因此在运行内置于虚拟机的应用程序时,内存使用量可能会高于必要值,虚拟机可能会开始耗尽主机所需的资源。容器共享操作系统环境(内核),因此它们比完整虚拟机使用更少的资源,并减轻主机内存的压力。
传统虚拟机可占用大量磁盘空间:除了虚拟机托管的任何应用程序外,它们还包含完整的操作系统和相关工具。容器相对较轻:它们仅包含使容器化应用程序运行所需的库和工具,因此它们比虚拟机更紧凑,并且启动速度更快。
在更新或修补操作系统时,必须逐个更新传统计算机:必须单独修补每个客户操作系统。对于容器,只需更新容器主机(托管容器的机器)的操作系统。这显著简化了维护。
利用这些优势容器在软件开发领域里迅速发展,我已经很习惯用容器去安装各种软件应用,因为它开销很小,而且隔离性很好,我可以很方便的使用同一个软件的多个版本而不用担心冲突问题。
Linux的的容器技术是如何做到这些的呢?我们来看看构建容器技术的两个核心功能命名空间Namespace和控制组CGroup。
命名空间 Namespace
命名空间是Linux内核的一项功能,该功能对内核资源进行分区。控制进程可以访问的资源,以使一组进程看到一组资源,而另一组进程看到另一组资源。资源可能存在于多个空间中。Linux系统以每种类型的单个名称空间开始,供所有进程使用。进程可以创建其他名称空间,并加入不同的名称空间。
Linux下常见的命名空间有:
挂载Mount mnt
进程Id pid
网络 net
进程间通信 ipc
用户Id user
UTS
简单的讲,利用Namespace可以实现我们想要的资源隔离,控制哪些资源可以使用。
控制组 CGroup
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物理资源 (如 cpu memory i/o 等等) 的机制。2007 年进入 Linux 2.6.24 内核,CGroups 不是全新创造的,它将进程管理从 cpuset 中剥离出来,作者是 Google 的 Paul Menage。CGroups 也是 LXC 为实现虚拟化所使用的资源管理手段。
CGroup 是将任意进程进行分组化管理的 Linux 内核功能。CGroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 CGroup 子系统或控制器。CGroup 子系统有控制内存的 Memory 控制器、控制进程调度的 CPU 控制器等。运行中的内核可以使用的 Cgroup 子系统由/proc/cgroup 来确认。
CGroup的主要功能:
资源限制,可以将组设置为不超过配置的内存限制,其中还包括文件系统缓存[8] [9]
优先次序,一些组可能会在CPU利用率或磁盘I / O吞吐量中获得更大份额。
会计,衡量组的资源使用情况,例如可用于计费目的
控制,冻结进程组,记录检查点并重新启动
CGroup常见的子系统包括:
blkio 对块设备(比如硬盘)的IO进行访问限制
cpu 设置进程的CPU调度的策略,比如CPU时间片的分配
memory 用于控制cgroup中进程的占用以及生成内存占用报告
net_cls 使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器 tc (traffic controller) 可以识别来自特定 cgroup 的包并做限流或监控
net_prio 设置cgroup中进程产生的网络流量的优先级
hugetlb 限制使用的内存页数量
pids 限制任务的数量
ns 可以使不同cgroups下面的进程使用不同的namespace.
每个subsystem会关联到定义的cgroup上,并对这个cgroup中的进程做相应的限制和控制。
简单的讲,利用CGroup,可以控制能使用的资源的量。
有了Namespace和CGroup这两个特性,容器做到了控制资源隔离和访问的量。但是我们还是需要方便的管理功能和接口,Docker在容器的基本功能的基础上提供了出色的管理功能和接口,成为了容器领域里的事实标准,我们一般说容器,默认的是用Docker的技术。
Docker
Docker 是一个开放源代码软件,是一个开放平台,用于开发应用、交付应用、运行应用。 Docker允许用户将基础设施中的应用单独分割出来,形成更小的颗粒,从而提高交付软件的速度。 Docker容器 与虚拟机类似,但原理上,容器是将操作系统层虚拟化,虚拟机则是虚拟化硬件,因此容器更具有便携性、高效地利用服务器。
Docker的主要特性有:
分层容器
Docker使用AUFS / devicemapper / btrfs使用文件系统的只读层来构建容器。容器由只读层组成,这些只读层在提交后将成为容器映像。镜像是一个包含用于构建应用程序的图层的容器。当docker容器运行时,只有顶层是可读写的,下面的所有层都是只读的,顶层是临时数据,直到将其提交到新层为止。使用只读文件系统的覆盖层会带来固有的复杂性和性能损失。
单一应用容器
Docker将容器限制为仅一个进程。默认的docker baseimage OS模板并非旨在支持多个应用程序,进程或服务,如init,cron,syslog,ssh等。您可以想象这会引入一定的复杂性,并且对日常使用场景具有巨大的影响。由于当前的体系结构,应用程序和服务旨在在正常的多进程OS环境中运行,因此您需要找到一种Docker方式来做事或使用支持Docker的工具。对于LAMP容器的应用程序,需要构建3个相互使用服务的容器,一个PHP容器,一个Apache容器和一个MySQL容器。能在一个容器中建造所有3个容器吗?可以,但无法在同一容器中运行php-fpm,apache和mysqld,也无法安装单独的进程管理器(如runit或supervisor)。
状态分离
Docker将容器存储与应用程序分开,可以在数据卷容器中将持久性数据安装在主机中的容器外部。除非用例只是具有非持久性数据的容器,否则有可能使Docker容器的可移植性降低。这也是容器编排更容易支持无状态应用的根本原因。
镜像注册
Docker提供了一个公共和私有镜像注册,用户可以在其中推送和提取镜像。镜像用于组成应用程序的只读层。这使用户可以轻松共享和分发应用程序。
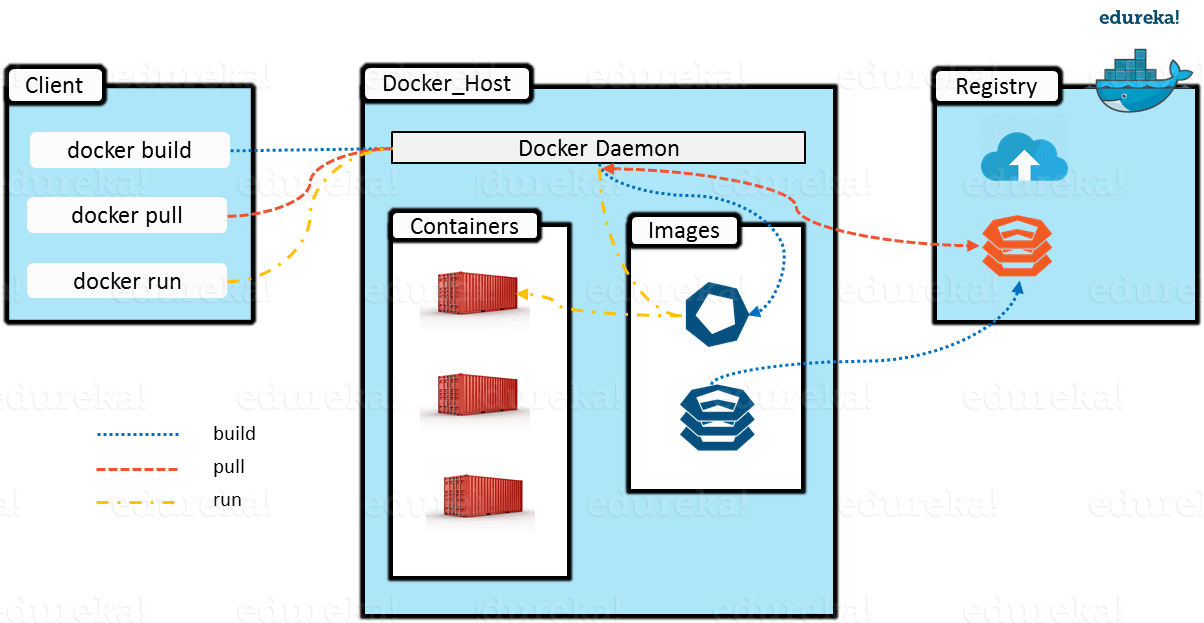
What Is Docker & Docker Container | A Deep Dive Into Docker | Edureka
上图是Docker的架构图,我们看到Docker是如何提供容器的管理功能的。
Docker 守护进程负责容器声明周期的管理
Registry 提供容器镜像仓库的功能
Docker 守护进程负责从镜像仓库推/拉取容器的镜像
客户端程序负责和守护进程通信,发送相关的容器管理的命令
在Docker 1.11版之前,Docker Engine守护进程下载容器映像,启动容器进程,公开远程API并充当日志收集守护进程,所有这些都以集中化进程的身份以root身份运行。尽管这样的集中式体系结构便于部署,但是它没有遵循Unix进程和特权分离的最佳实践;此外,这使得Docker难以与Linux初始系统(如upstart和systemd)正确集成。
如下图所示,从1.11版开始,Docker守护程序不再处理容器本身的执行。而是现在由containerd处理。更准确地说,Docker守护程序将映像准备为开放容器镜像(OCI)捆绑包,并对容器进行API调用以启动OCI捆绑包。然后使用runC启动容器化容器。
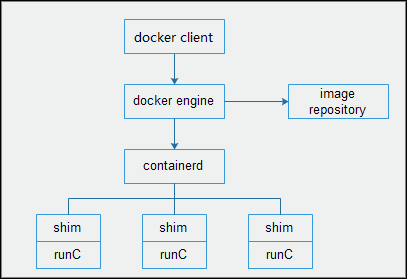
docker概述
那么ContainerD和RunC又分别是神马东东呢?我们继续探索。
ContainerD
Containerd是行业标准的容器运行时,重点是简单性,健壮性和可移植性。containerd可用作Linux和Windows的守护程序。它管理着主机系统的容器的整个生命周期,从镜像传输和存储到容器执行和监督,再到低级存储再到网络附件等等。containerd旨在嵌入到更大的系统中,而不是由开发人员或最终用户直接使用。
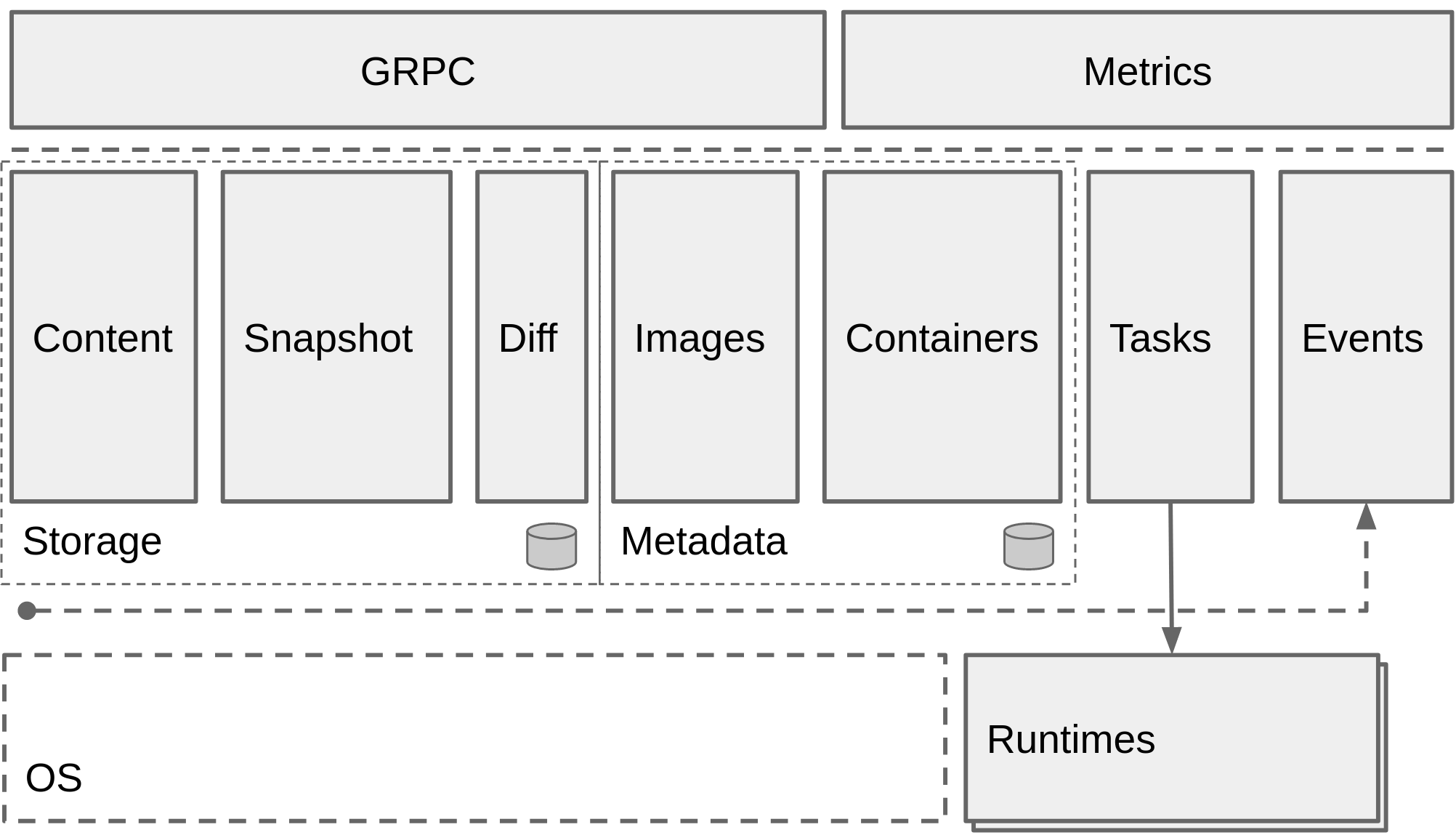
上图是containerD的架构图。
containerD是用Go语言构建的,有兴趣的可以去看它的代码。
runC
RunC 是一个轻量级的工具,它是用来运行容器的,只用来做这一件事,并且这一件事要做好。我们可以认为它就是个命令行小工具,可以不用通过 docker 引擎,直接运行容器。事实上,runC 是标准化的产物,它根据 OCI 标准来创建和运行容器。而 OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。
RunC支持一普通用户的身份运行容器。
RunC 支持容器的热迁移操作,所谓热迁移就是将一个容器进行 checkpoint 操作,并获得一系列文件,使用这一系列文件可以在本机或者其他主机上进行容器的 restore 工作。这也是 checkpoint 和 restore 两个命令存在的原因。热迁移属于比较复杂的操作,目前 runC 使用了 CRIU 作为热迁移的工具。RunC 主要是调用 CRIU(Checkpoint and Restore in Userspace)来完成热迁移操作。CIRU 负责冻结进程,并将作为一系列文件存储在硬盘上。并负责使用这些文件还原这个被冻结的进程。
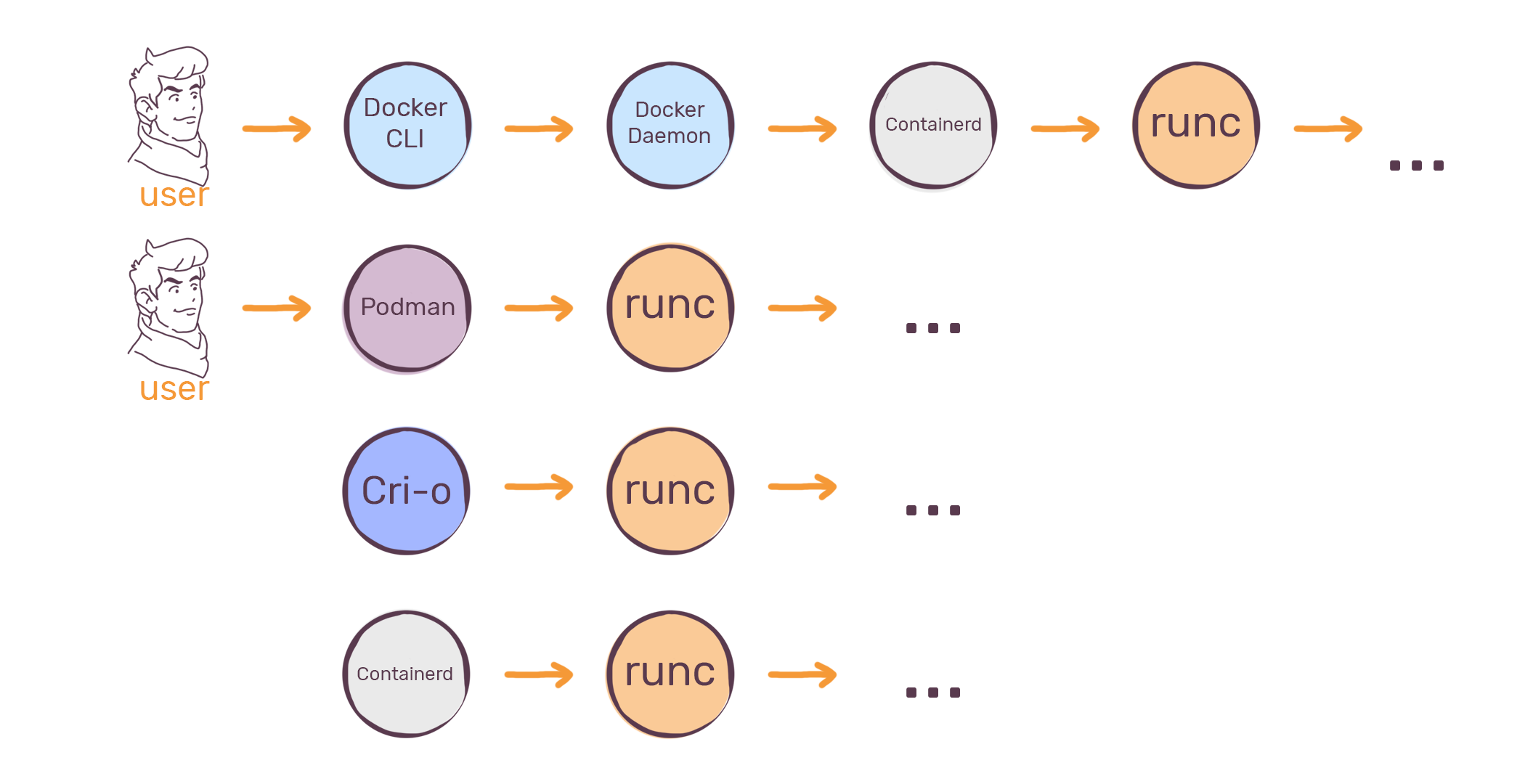
The tool that really runs your containers: deep dive into runc and ...
上图显示了不同的容器技术是如何使用RunC的,可以看到,Docker/Podman/CRI-O都使用了RunC。那么我们看看除了Docker,现在还有那些容器的运行时呢?
CRI-O
CRI-O是Kubernetes的轻量级容器运行时,这就是CRI-O提供的。该名称源于CRI(Container Runtime Interface)加开放容器倡议(OCI open container initiative ),因为CRI-O严格关注符合OCI的运行时和容器映像。CRI-O的范围是与Kubernetes一起使用,以管理和运行OCI容器。尽管该项目确实具有一些用于故障排除的面向用户的工具,但它并不是面向开发人员的工具。
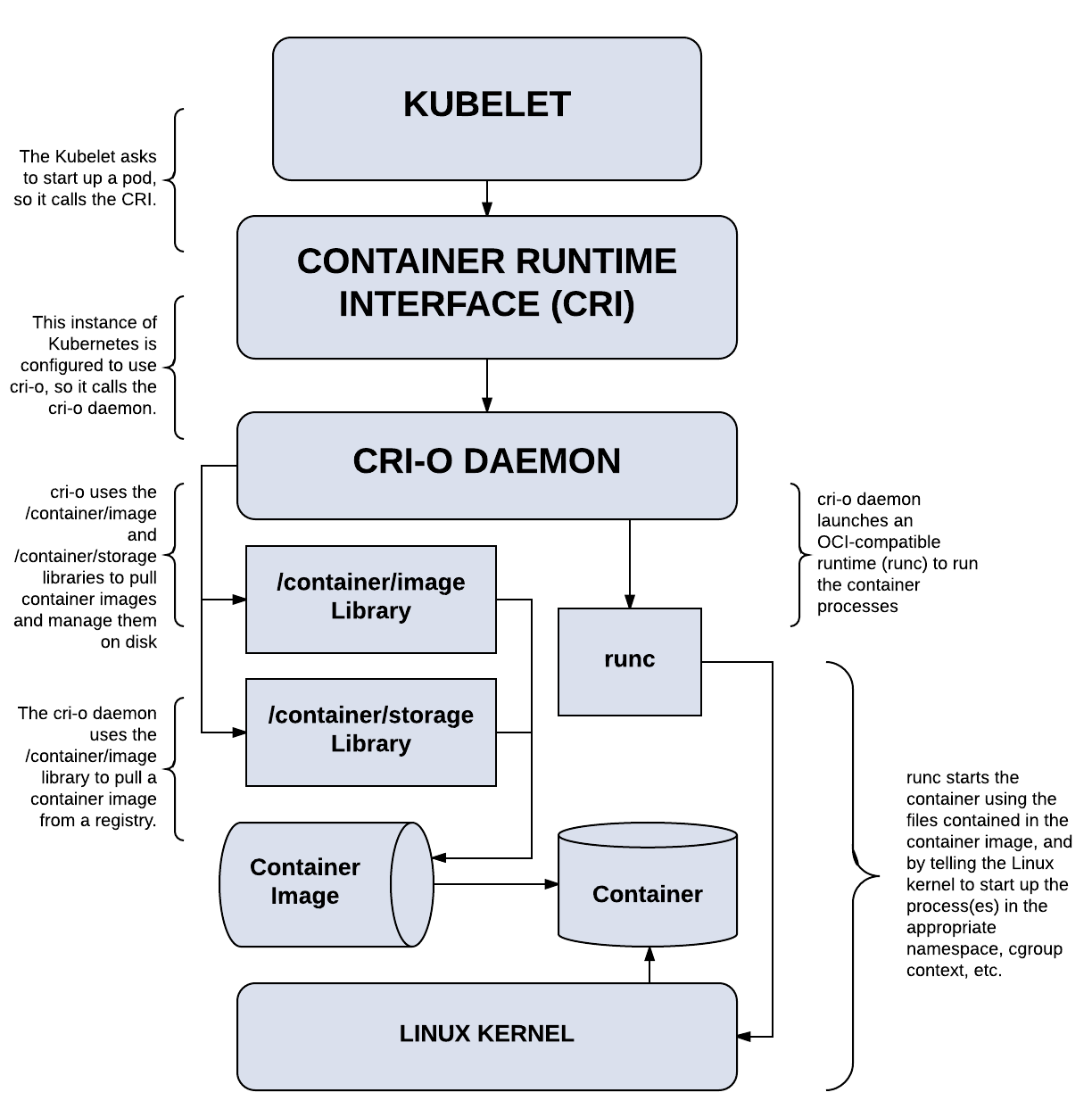
CRI-O Overview
上图是CRI-O的架构。
简而言之,CRI-O是用于Kubernetes内部的容器运行时接口的标准。它的出现我的理解是K8s(google)为了摆脱docker的束缚,走向开放平台的一步棋。可以看到,Docker作为一个成功的技术产品,它在商业上却似乎不是那么成功,k8s如果完成对docker的解耦,docker的前景似乎不太妙。
Podman
守护进程是人们对Docker架构的主要诟病,它带来了很多管理和安全上的问题。
Podman是一个无守护进程的容器引擎,用于在Linux系统上开发,管理和运行OCI容器。容器可以以root用户或普通用户的模式运行。
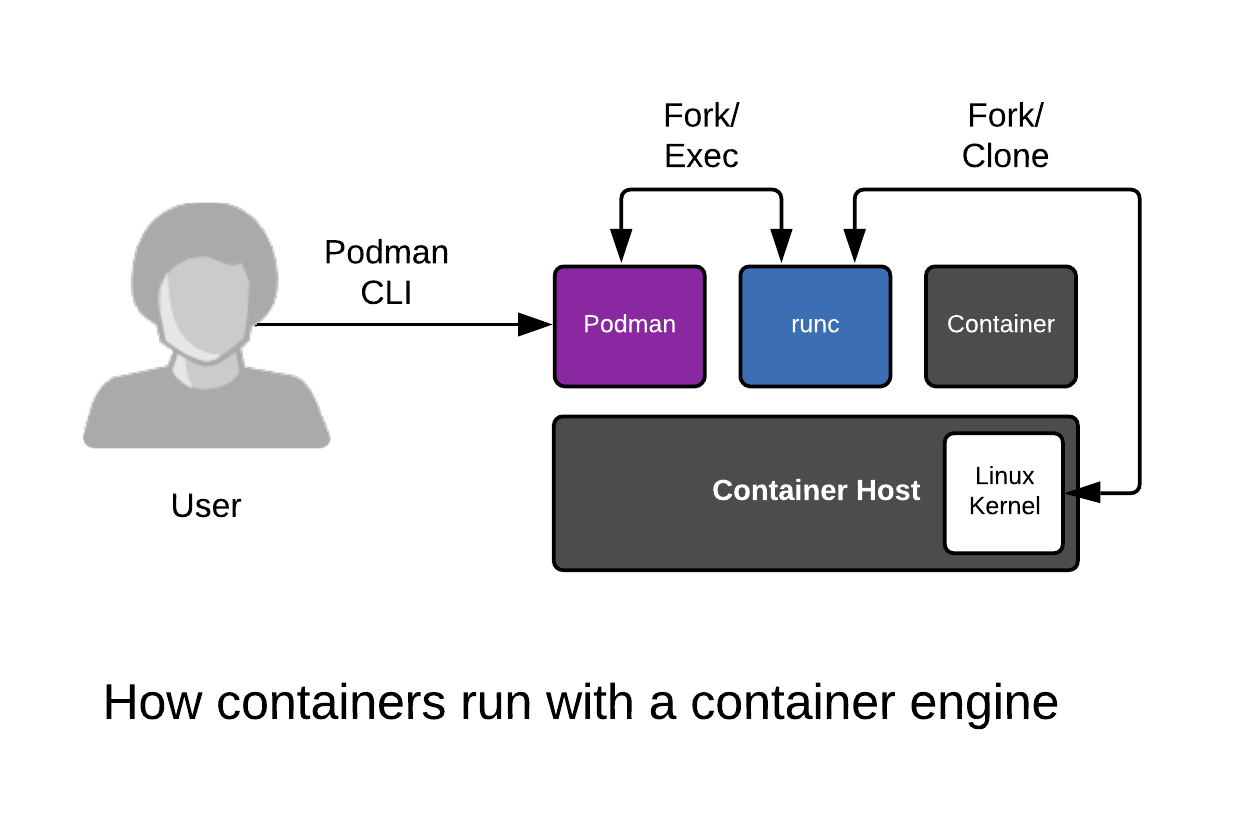
Podman管理容器使用传统的fork/exec模型,因此容器进程是Podman进程的后代。 Docker使用客户端/服务器模型。执行的docker命令是Docker客户端工具,它通过客户端/服务器操作与Docker守护进程通信。然后,Docker守护程序创建容器并处理stdin /stdout与Docker客户端工具的通信。Podman可以运行于非root用户模式下,而docker的守护进程必须用root用户启动。Podman的模型被认为是更为安全的模型。同时因为唯有守护进程,你的系统看上去也更为干净。
当然Podman的问题是它还很新,管理工具和功能都和弱,你可能需要buildah来构建镜像,社区和生态都还很小。如果你想用Podman取代Docker,请谨慎操作。
LXC/LXD
LXC是Linux内核容器功能的用户空间接口。通过功能强大的API和简单的工具,它使Linux用户可以轻松地创建和管理系统或应用程序容器。
LXC是一个系统容器运行时,旨在执行“完整的系统容器”,通常由完整的操作系统映像组成。在最常见的用例中,LXC进程将引导完整的Linux发行版,如Debian,Fedora,Arch等,并且用户将与虚拟机映像进行交互。LXC也可以用于运行(但不下载)应用程序容器,但是这种用法需要对底层操作系统的详细信息有更多的了解,并且这种做法不太常见。 LXC可以从各种公共镜像下载“完整系统容器”映像,并以密码方式对其进行验证。 LXC没有中央守护程序,可以与instart系统(例如upstart和systemd)集成。
LXD与LXC相似,但它是liblxc之上的REST API,它派生了一个监视器和容器进程。这样可以确保LXD守护程序不是故障的中心点,并且在LXD守护程序发生故障的情况下容器可以继续运行。所有其他细节与LXC几乎相同。简单的说LXD = LXC + RestAPI
LXC是一种容器技术,可为您提供轻量级Linux容器,而Docker是基于容器的单个应用程序虚拟化引擎。它们听起来可能相似,但完全不同。与LXC容器不同,Docker容器的行为不像轻量级VM,因此不能被视为轻量级VM。Docker容器在设计上仅限于单个应用程序。你可以登录到LXC容器,将其像OS一样对待,然后安装您的应用程序和服务,它将按预期运行。您无法在Docker容器中做到这一点。Docker基础OS模板被简化为单个应用程序环境,并且没有适当的初始化或支持诸如服务,守护程序,syslog,cron或运行多个应用程序之类的东西。
rkt
rkt是为现代生产云原生环境开发的应用程序容器引擎。它具有pod-native方法,可插入执行环境以及定义明确的表面积,使其非常适合与其他系统集成。
rkt的核心执行单元是Pod,它是在共享上下文中执行的一个或多个应用程序的集合(rkt的Pod与Kubernetes编排系统中的概念同义)。 rkt允许用户在Pod级别和更细粒度的每个应用程序级别应用不同的配置(例如隔离参数)。 rkt的体系结构意味着在一个独立的,独立的环境中,每个pod都可以直接在经典的Unix流程模型(即没有中央守护程序)中执行。 rkt实施了现代,开放,标准的容器格式,即App Container(appc)规范,但还可以执行其他容器映像,例如使用Docker创建的那些。
自2014年12月由CoreOS引入以来,rkt项目已经非常成熟并得到了广泛使用。它可用于大多数主要的Linux发行版,并且每个rkt发行版都会构建供用户安装的独立rpm / deb软件包。这些软件包还可以作为Kubernetes存储库的一部分使用,以支持rkt + Kubernetes集成的测试。 rkt在Google Container Image和CoreOS Container Linux如何运行Kubernetes方面也起着核心作用。RKT以其快速,可组合和安全的提供功能而闻名。许多用户已经注意到docker的安全问题,因此CoreOS必须在2014年发布RKT作为docker的竞争对手,并且由于其功能(如安全性,可互操作性等)而变得流行。
类似Podman,rkt没有集中的守护进程,而是直接从客户端命令启动容器,从而使其与系统初始化功能(例如systemd,upstart等)兼容。
Kata Container
Kata Containers 是由 OpenStack 基金会管理,但独立于 OpenStack 项目之外的容器项目。它是一个可以使用容器镜像以超轻量级虚机的形式创建容器的运行时工具,Kata Containers 创建的不同容器跑在一个个不同的虚拟机(kernel)上,比起传统容器提供了更好的隔离性和安全性。同时继承了容器快速启动和快速部署等优点。
我们之前提到了虚拟机技术因为其开销的原因,受到了一定的使用限制。Kata Container可以说是虚拟机技术的逆袭,可以多快好省的建设容器社会。
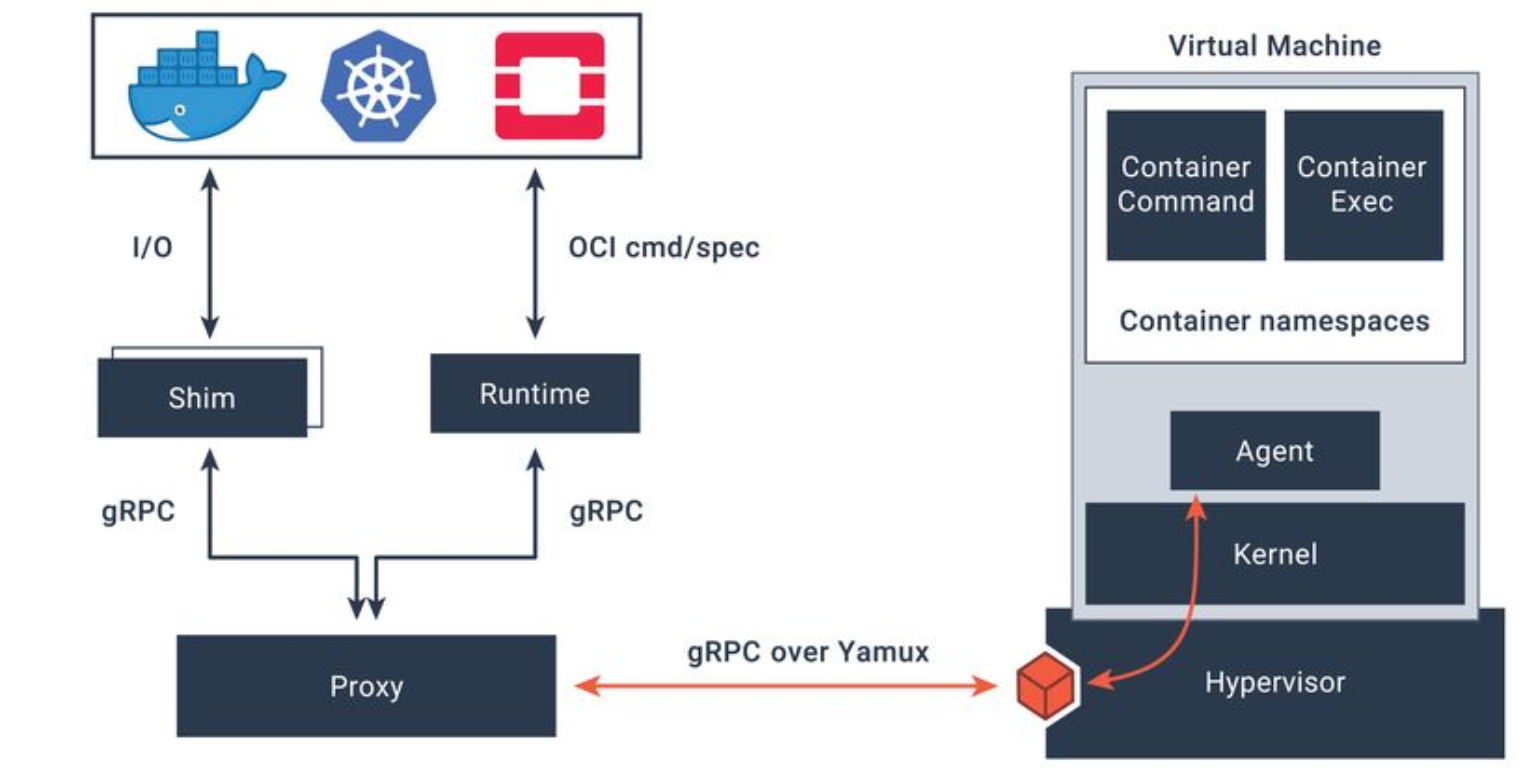
如上图的架构所示,Kata Containers 其实跟 RunC 类似,也是一个符合 OCI 运行时规范的一种实现。不同之处是它给每个 Docker 容器或每个 K8S Pod 增加了一个独立的 Linux 内核 (不共享宿主机的内核),使容器具有更好的隔离性、安全性。
其它
除了我们之前提到的,还有其他一些容器技术,我们简单的看看。
systemd-nspawn 是一个容器运行时,旨在在Linux容器内部执行进程。 systemd-nspawn的名字来源从“从命名空间spawn”,这意味着它仅处理进程隔离,而不执行内存,CPU等资源隔离。systemd-nspawn可以运行应用程序容器或系统容器,但不能单独运行,下载或验证镜像。 systemd-nspawn没有集中的守护程序,可以与系统启动(例如upstart和systemd)集成。
OpenVZ OpenVZ是基于Linux内核的操作系统级虚拟化技术。OpenVZ允许物理服务器运行多个操作系统,该技术常用于虚拟专用服务器(VPS,Virtual Private Server)。OpenVZ是一种系统容器运行时,旨在执行通常是完整系统映像的“完整系统容器”。在最常见的用例中,OpenVZ进程将引导完整的Linux 发行版,例如Debian,Fedora,Arch等,并且用户将与虚拟机映像类似地与其交互。 OpenVZ可以从各种公共镜像下载“完整系统容器”镜像,并以密码方式对其进行验证。 OpenVZ没有中央守护程序,可以与inup系统(例如upstart和systemd)集成。
FreeBSD jail,一种操作系统层虚拟化技术,在FreeBSD操作系统中运作。利用这个技术,FreeBSD的系统管理者,可以创造出几个小型的软件系统,这些软件系统被称为jail。 这个技术被Poul-Henning Kamp采纳,加入FreeBSD系统中。
Solaris Containers,以及Solaris Zones,一个操作系统层虚拟化技术的实作,由Sun开发。2004年2月,伴随着Solaris 10 build 51 beta首次对外发布,经过完整测试后,在2005年,与Solaris 10一同完整发布。
Linux-VServer是通过向Linux内核添加操作系统级虚拟化功能而创建的虚拟专用服务器实现。它是作为开源软件开发和发布的。
总结
随着微服务和云原生技术的大行其道,容器的生态系统的吸引了越来越多的玩家。Docker作为昔日王者,受到了诸多其它后起之秀的挑战,我们可以预期未来更多的组织会加入到下面的这张图里。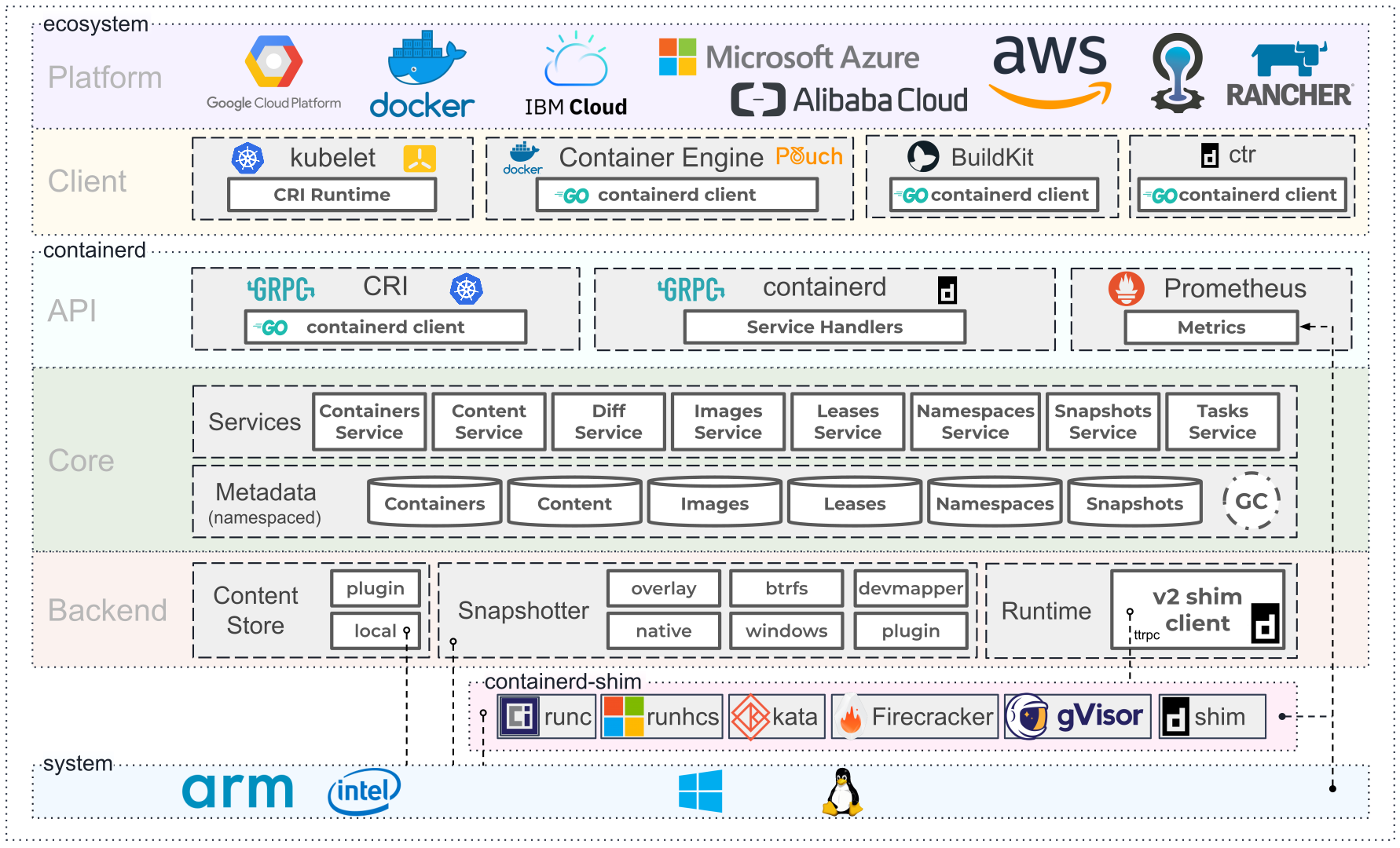
containerd architecture diagram
希望本文能够帮助你了解容器技术的基本知识,在面对诸多容器技术的术语和各种容器运行时的时候,不在手足无措。下面介绍一些容器集群管理平台的解决方案。
容器集群管理平台的比较
容器化和微服务是当前最热话题,不久之前,笔者参加QCon上海一个微服务监控的Session,场面爆棚,不得不在拥挤的过道听完了整个session。随着要管理的容器越来越多,容器的集群管理平台成为了刚需!
Docker Swarm
Swarm是Docker公司在2014年12月初新发布的容器集群管理工具。它可以把多个主机变成一个虚拟的Docker主机来管理。Swarm使用Go语言开发,并且开源,在github上可以找到它的全部source code。Swarm使用标准的Docker API,给Docker用户带来无缝的集群使用体验。2016年7月, Swarm已经被整合进入Docker Engine。
功能
Docker Swarm提供API 和CLI来在管理运行Docker的集群,它的功能和使用本地的Docker并没有本质的区别。但是可以通过增加Node带来和好的扩展性。理论上,你可以通过增加节点Node的方式拥有一个无限大的Docker主机。
Swarm并不提供UI,需要UI的话,可以安装UCP,不过很不幸,这个UCP是收费的。
架构
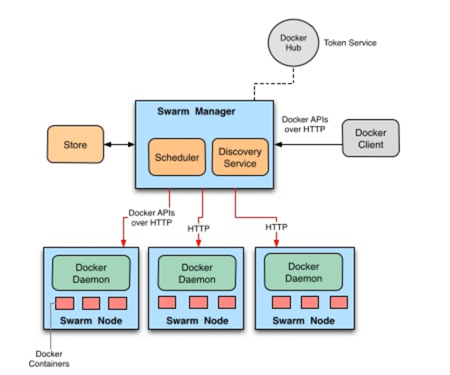
Swarm的架构并不复杂,可以说非常简单。Manager负责容器的调度,Node负责容器的运行,Node运行Docker Daemon和Manager之间通过HTTP来通信。Docker Client通过Manager上暴露的标准Docker API来使用Docker的功能。
Swarm的集群协调和业务发现可以支持不同的第三方组件,包括:
Consul
Etcd
ZooKeeper
Docker Hub
Swarm的基本容器调度策略有三种:
spread 容器尽可能分布在不同的节点上
binpack 容器尽可能分布在同一个节点上
random 容器分布在随机的节点上
Swarm集群的高可用配置很容易,以下图为例:
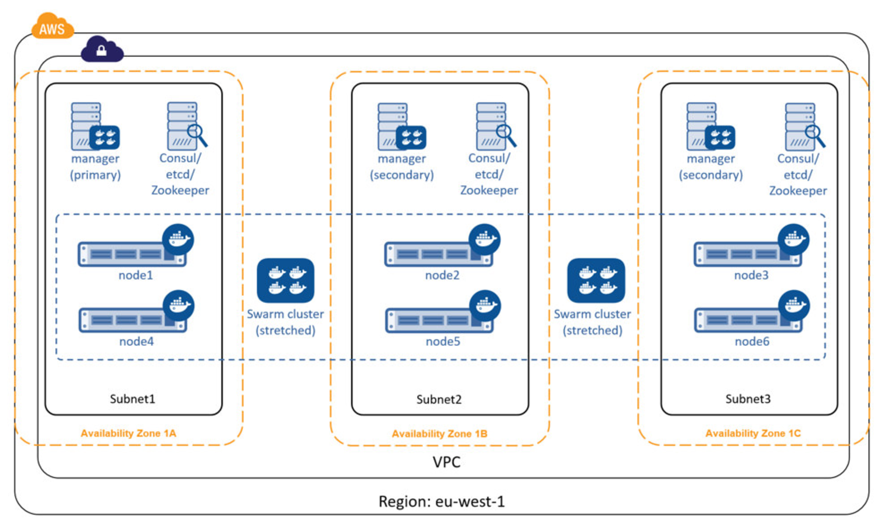
manager配置在不同的AWS AZ中,通过领导选举选出Primary manager。
多个节点分布在不同的AZ中,同时Consul/etcd/ZooKeeper也需要配成冗余的。
特点
Docker Swarm的特点是配置和架构都很简单,使用Docker原生的API,可以很好的融合Docker的生态系统。
Kubernetes
Kubernetes是Google开发的一套开源的容器应用管理系统,用于管理应用的部署,维护和扩张。利用Kubernetes能方便地管理跨机器运行容器化的应用。Kubernetes也是用Go语言开发的,在github上可以找到源代码。它源于谷歌公司的内部容器管理系统Borg,经过了多年的生产环境的历炼,所以功能非常强大。
功能
Kubernetes主要提供一下的功能:
使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run)。
以集群的方式运行、管理跨机器的容器。
解决Docker跨机器容器之间的通讯问题。
Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态。
应用的高可用和靠扩展
支持应用的在线升级Rolling Update
支持跨云平台IaaS的部署
为了支持这些功能,Kubernetes做了做了很多的抽象概念,所以,刚开始使用Kubernetes,需要学习不少的新概念,包括:
Pod
Pod是Kubernetes的基本操作单元,把相关的一个或多个容器构成一个Pod,通常Pod里的容器运行相同的应用,或者是相关的应用。Pod包含的容器运行在同一个Minion(Host)上,看作一个统一管理单元,共享相同的volumes和network namespace/IP和Port空间。
Job
Job是一个生命周期比较短的应用,一般只会在出错的情况下重启,可以通过配置Job的并发和运行次数来扩展Job
Service
Service是一个生命周期比较长的应用,会在任何退出时重启,可以通过配置Service的复制Replica来达到高扩展和高可用
Recplica Controller
Replication Controller确保任何时候Kubernetes集群中有指定数量的pod副本(replicas)在运行, 如果少于指定数量的pod副本(replicas),Replication Controller会启动新的Container,反之会杀死多余的以保证数量不变。Replication Controller使用预先定义的pod模板创建pods,一旦创建成功,pod 模板和创建的pods没有任何关联,可以修改pod 模板而不会对已创建pods有任何影响,也可以直接更新通过Replication Controller创建的pods
以上是一些核心概念,除了这些,Kubernetes还提供其它一些概念,来支持应用程序的运维,包括:
Label
对系统中的对象通过Label的方式来管理
Namespace
对对象,资源分组,可以用于支持多租户
Config Map
提供全局的配置数据存储
总之,功能强大,系统概念繁多,比较复杂。
Kubernetes支持安装UI的addon,来管理整个系统:
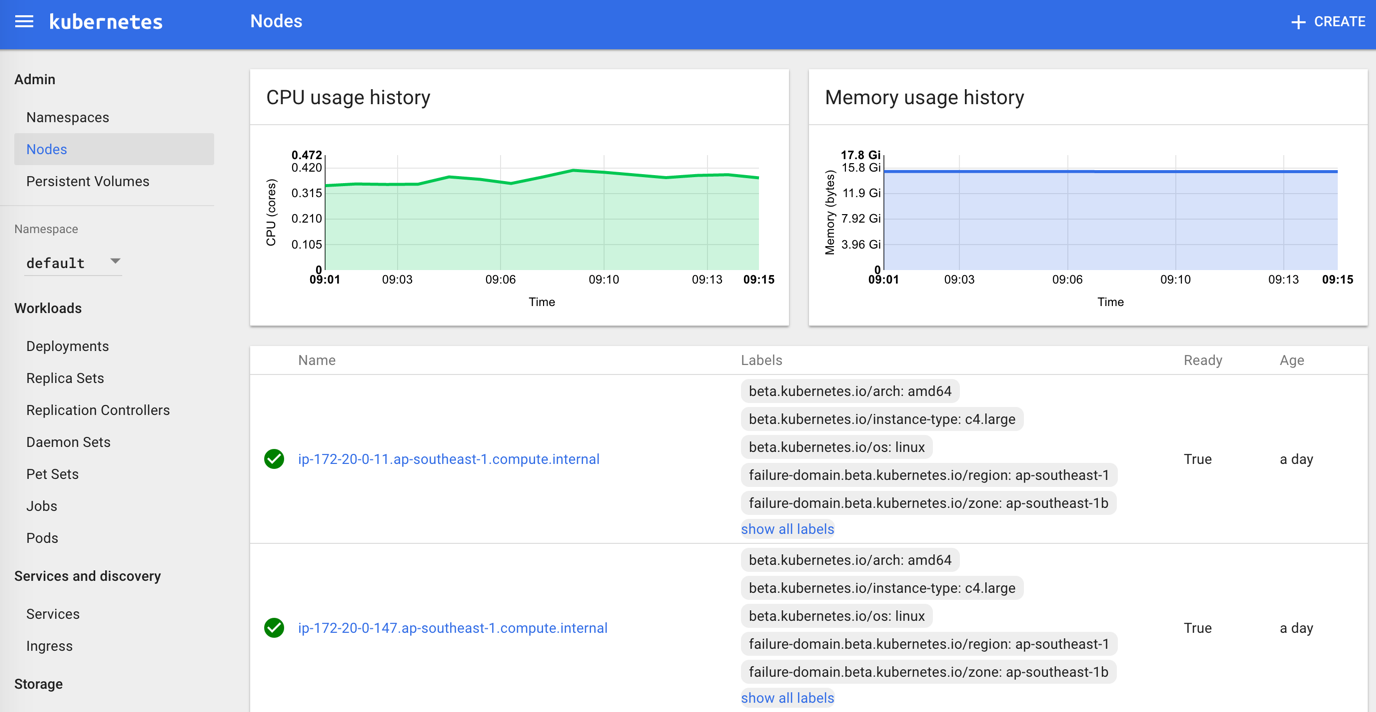
架构
下图是Kubernetes的基本架构:
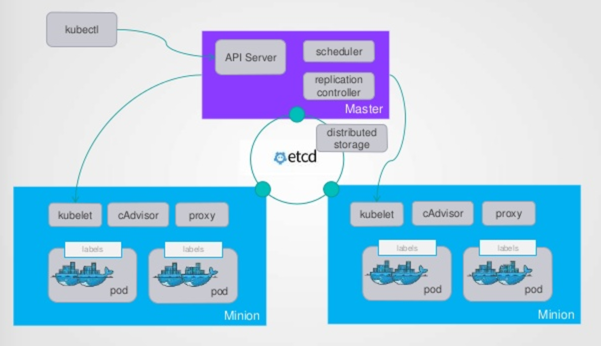
Master
Master定义了Kubernetes 集群Master/API Server的主要声明,Client(Kubectl)调用Kubernetes API,管理Kubernetes主要构件Pods、Services、Minions、容器的入口。Master由API Server、Scheduler以及Registry等组成。
Scheduler收集和分析当前Kubernetes集群中所有Minion节点的资源(内存、CPU)负载情况,然后依此分发新建的Pod到Kubernetes集群中可用的节点。由于一旦Minion节点的资源被分配给Pod,那这些资源就不能再分配给其他Pod,除非这些Pod被删除或者退出,因此,Kubernetes需要分析集群中所有Minion的资源使用情况,保证分发的工作负载不会超出当前该Minion节点的可用资源范围。
Minion
Minion负责运行Pod,Service,Jobs, Minion通过Kubelet和Master通信。Proxy解决了外部网络能够访问跨机器集群中容器提供的应用服务。
etcd
负责集群的协调和服务发现。
特点
Kubernetes提供了很多应用级别的管理能力,包括高可用可高扩展,当然为了支持这些功能,它的架构和概念都比较复杂,当然个人觉得为了获得这些功能,值!
Apache Mesos
Mesos是为软件定义数据中心而生的操作系统,跨数据中心的资源在这个系统中被统一管理。Mesos的初衷并非管理容器,只是随着容器的发展,Mesos加入了容器的功能。Mesos可以把不同机器的计算资源统一管理,就像同一个操作系统,用于运行分布式应用程序。
Mesos的起源于Google的数据中心资源管理系统Borg。你可以从WIRED杂志的这篇文章中了解更多关于Borg起源的信息及它对Mesos影响。
功能
Mesos的主要功能包括:
高度的可扩展和高可用
可自定义的两级调度
提供API进行应用的扩展
跨平台
下图是Mesos的管理界面:
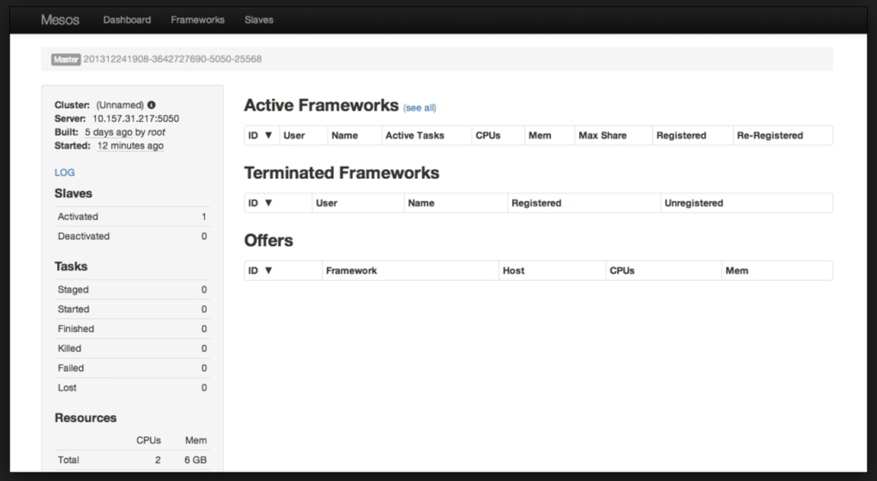
架构
Mesos的基本架构如下
Master
Master负责资源的统一协调和Slave的管理。 Master协调全部的Slave,并确定每个节点的可用资源,聚合计算跨节点的所有可用资源的报告,然后向注册到Master的Framework作为Master的客户端发出资源邀约。Mesos实现了两级调度架构,它可以管理多种类型的应用程序。第一级调度是Master的守护进程,管理Mesos集群中所有节点上运行的Slave守护进程。集群由物理服务器或虚拟服务器组成,用于运行应用程序的任务,比如Hadoop和MPI作业。第二级调度由被称作Framework的“组件”组成。
Slave
Salve运行执行器Executor进程来运行任务。
Framework
Framework包括调度器Scheduler和执行器Executor进程,其中每个节点上都会运行执行器。Mesos能和不同类型的Framework通信,每种Framework由相应的应用集群管理。Framework可以根据应用程序的需求,选择接受或拒绝来自master的资源邀约。一旦接受邀约,Master即协调Framework和Slave,调度参与节点上任务,并在容器中执行,以使多种类型的任务
ZooKeeper
Zookeeper负责集群的协调,Master的领导选举等
特点
Mesos相比Kubernetes和Swarm更为成熟,但是Mesos主要要解决的是操作系统级别的抽象,并非为了容器专门设计,如果用户出了容器之外,还要集成其它的应用,例如Hadoop,Spark,Kafka等,Mesos更为合适。Mesos是一个更重量级的集群管理平台,功能更丰富,当然很多功能要基于各种Framework。
Mesos的扩展性非常好,最大支持50000节点,如果对扩展性要求非常高的话么,Mesos是最佳选择。
AWS ECS
ECS Amazon EC2 Container Service 是亚马逊开发出的高度可扩展的高性能容器集群服务。在托管的 Amazon EC2 实例集群上轻松运行容器应用和服务。他最大的好处就是在云上,不需要自己管理数据中心的机器和网络。
功能
ECS继承了AWS服务的高扩展和高可用性,安全也可以得到保证。在基本容器管理的基础上,ECS使用Task和Service的概念来管理应用。
Task类似Docker Compose,使用一个JSON描述要运行的应用。Service是更高一层的抽象,包含多个task的运行实例,通过修改task实例的数量,可以控制服务的伸缩。同时Service可以保证指定数量的Task在运行,当出现错误的时候,重启失败的Task
架构
下图是ECS的架构图:
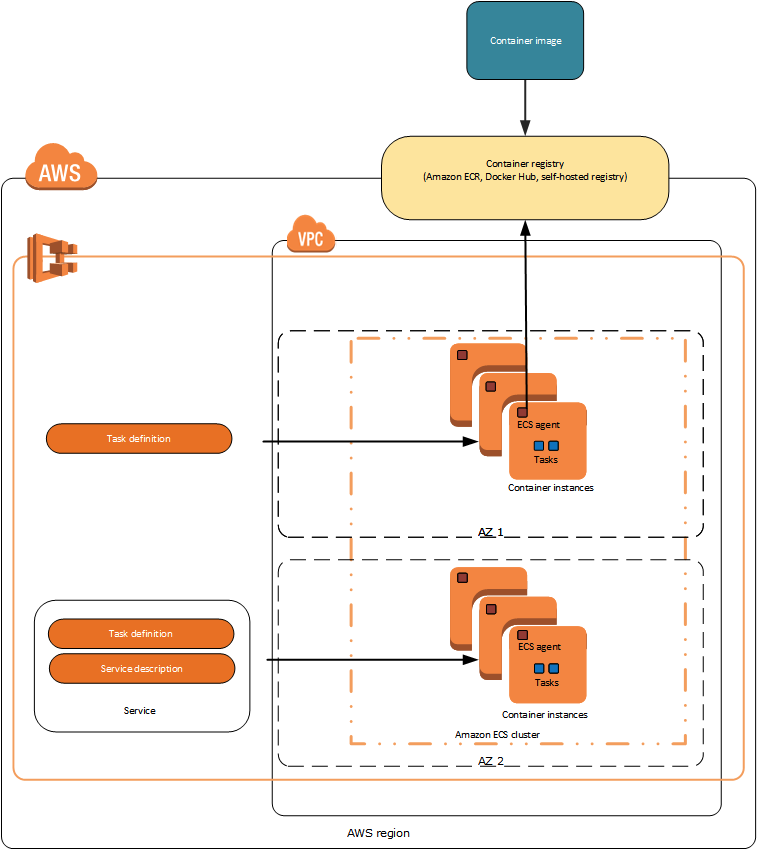
使用EC2,ELB,安全组等大家熟悉的AWS的概念,AWS用户可以轻松管理你的容器集群。并且不需要付初基本资源以外的费用。
通过ECS agent可以是Container连接到ECS集群。ECS Agent使用Go开发,已开源。
我们并不清楚ECS的调度策略,但是AWS提供了一个例子,如果继承第三方的调度策略。
通过Cloud Watch Log,我们可以很方便的对整个集群进行监控。
特点
如果你是一个AWS的重度用户,ECS是个不错的选择,因为你可以是把你的容器集群运行在AWS的云上,管理起来非常方便。
比较
这里对几个平台做一个简单的比较:
| Swarm | Kubernetes | Mesos | ECS | |
| 基本功能 | Docker原生的集群管理工具 | 开源的容器集群工具,提供应用级别的部署,维护和扩张功能 | 基于数据中心的操作系统 | 基于云的高可用,高扩展容器集群 |
| 高层次抽象 | 无 | Pod | 无 | Task Service |
| 应用扩展性 | 无 | 支持 | Framework 支持 | 支持 |
| 应用高可用性 | 无 | 支持 | Framework 支持 | 支持 |
| 集群协调和服务发现 | etcd | etcd | ZooKeeper | / |
| 调度策略(Schedule) | 内置,可扩展 | 内置 | 两级别,可扩展 | 可扩展 |
| 监控 | Logging Driver | Heapter,ELK Addon | 内置 | CloudWatch |
| 用户界面 | CLI | CLI API UI | API UI | CLI |
| 开发语言 | Go | Go | Java | NA |
| 开源 | 是 | 是 | 是 | 否 |
| 最大支持管理节点数 | 官方1000 | 官方1000 | 10000 | / |
总结
四个平台,Swarm是最轻量级的,功能也最简单,适于有大量Docker实例环境的用户。Kubernetes增加了很多应用级别的功能,适用于快速应用的部署和维护。Mesos最重,适用于已经有了相当的应用和容器混合的环境。ECS则推荐给AWS的用户或者不希望自己管理数据中心的云用户。