端(字节)序
端序,又称字节顺序或尾序(英语:Endianness),在计算机科学领域中,指电脑内存中或在数字通信链路中组成多字节的字的排列顺序。字节序,或字节顺序("Endian"、"endianness" 或 "byte-order"),描述了计算机如何组织字节,组成对应的数字。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如在C语言中,一个类型为int的变量x地址为0x100,那么其对应地址表达式&x的值为0x100。且x的四个字节将被存储在电脑内存的0x100, 0x101, 0x102, 0x103位置。
字节的排列方式有两个通用规则。例如,将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化才能保证正确。
每个内存存储位置都有一个索引或地址。每一 字节可以存储一个8位数字(即介于0x00 和 0xff 之间),因此必须保留不止一个字节来储存一个更大的数字。现在大部分需占用多个字节的数字排序方式是 little-endian(又称小字节序、低字节序,即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。与之对应的 big-endian 排列方式相反,可称大字节序、高字节序),所有的英特尔处理器都使用 little-endian。little-endian 的意思是使用低位储存更重要的信息,least-to-most-significant(最不重要的(least significant)字节取第一个位置,或者说地址最低的位置),可类比欧洲通用的日期书写方式(例如,31 December 2050。译者注:年份是最重要的,月份其次,日期最后)。
自然, big-endian 是相反的顺序, 可类比 ISO 日期格式(例如 2050-12-31)。big-endian 通常被称作"网络字节顺序"("network byte order"),因为互联网标准通常要求数据使用 big-endian 存储,从标准 Unix 套接字(socket)层开始,一直到标准化网络的二进制数据结构。此外,老式 Mac 计算机的 68000 系列 和 PowerPC(IBM 与 Apple 公司联合生产的个人台式机)微处理器曾使用 big-endian。
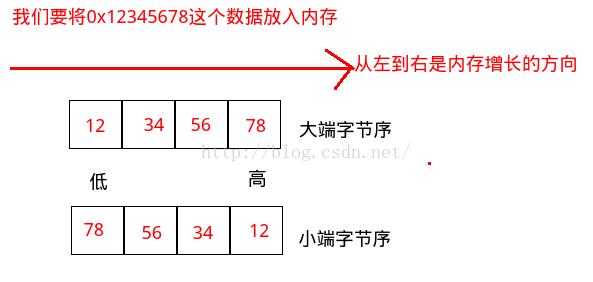
用不同字节序存储数字0x12345678(即十进制中的 305 419 896):
little-endian:0x78 0x56 0x34 0x12
big-endian:0x12 0x34 0x56 0x78
再假设变量x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。
大端法从首位开始将是:0x100: 0x01, 0x101: 0x23,..
而小端法将是:0x100: 0x67, 0x101: 0x45,..
Endian一词来源于十八世纪爱尔兰作家乔纳森·斯威夫特(Jonathan Swift)的小说《格列佛游记》(Gulliver's Travels)。小说中,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。1980年,丹尼·科恩(Danny Cohen),一位网络协议的早期开发者,在其著名的论文"On Holy Wars and a Plea for Peace"中,为平息一场关于字节该以什么样的顺序传送的争论,而第一次引用了该词。
在哪种字节顺序更合适的问题上,人们表现得非常情绪化,实际上,就像鸡蛋的问题一样,没有技术上的原因来选择字节顺序规则;因此争论沦为关于社会政治问题的争论,只要选择了一种规则并且始终如一地坚持,其实对于哪种字节排序的选择是任意的。
对于单一的字节(a byte),大部分处理器以相同的顺序处理位元(bit),因此单字节的存放方法和传输方式一般相同。
对于多字节数据,如整数(32位机中一般占4字节),在不同的处理器的存放方式主要有两种,以内存中0x0A0B0C0D的存放方式为例,分别有以下几种方式:
注: 0x前缀代表十六进制。
大端序(英:big-endian)或称大尾序
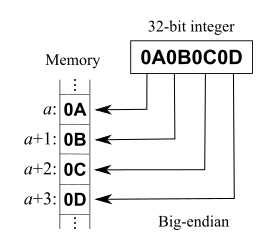
数据以8bit为单位:
地址增长方向 →
... 0x0A 0x0B 0x0C 0x0D ...
示例中,最高位字节是0x0A 存储在最低的内存地址处。下一个字节0x0B存在后面的地址处。正类似于十六进制字节从左到右的阅读顺序。
数据以16bit为单位:
地址增长方向 →
... 0x0A0B 0x0C0D ...
最高的16bit单元0x0A0B存储在低位。
小端序(英:little-endian)或称小尾序
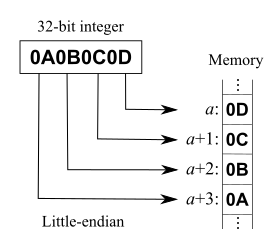
数据以8bit为单位:
地址增长方向 →
... 0x0D 0x0C 0x0B 0x0A ...
最低位字节是0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
数据以16bit为单位:
地址增长方向 →
... 0x0C0D 0x0A0B ...
最低的16bit单元0x0C0D存储在低位。
更改地址的增长方向:
当更改地址的增长方向,使之由右至左时,表格更具有可阅读性。
← 地址增长方向
... 0x0A 0x0B 0x0C 0x0D ...
最低有效位(LSB)是0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
← 地址增长方向
... 0x0A0B 0x0C0D ...
最低的16bit单元0x0C0D存储在低位。
混合序(英:middle-endian)具有更复杂的顺序。以PDP-11为例,0x0A0B0C0D被存储为:
32bit在PDP-11的存储方式
地址增长方向 →
... 0x0B 0x0A 0x0D 0x0C ...
可以看作高16bit和低16bit以大端序存储,但16bit内部以小端存储。
处理器体系
x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器为小端序;
Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器为大端序;
ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
网络
网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。Berkeley套接字定义了一组转换函数,用于16和32bit整数在网络序和本机字节序之间的转换。htonl,htons用于本机序转换到网络序;ntohl,ntohs用于网络序转换到本机序(下文会再进行讲解)。
位序
一般用于描述串行设备的传输顺序,网络协议中只有数据链路层的底端会涉及到。
小端序(先传低位)的串行协议
RS-232
RS-422
RS-485
USB
以太网(虽然高字节先传,但每一字节内低位先传)
大端序(先传高位)的串行协议
I2C协议
SPI协议
摩尔斯电码
《深入理解计算机系统》 第2章 信息的表示和处理 中对此有比较权威的描述。
在计算机设计之初,对内存中数据的处理也有不同的方式(低位数据存储在低位地址处或者高位数据存储在低位地址处),然而在通信的过程中(ISO/OSI模型和TCP/IP四层模型中),数据被一步步封装(然后加入信息首部),当传到目的段时,被一步步解封,然后获取数据。因此数据在传输的过程中就一定有一个标准化的过程:从主机a到主机b进行通信数据的交换格式标准。
a的固有数据存储--标准化--转化成b的固有格式
如上而言:a或者b的固有数据存储格式就是自己的主机字节序,标准化就是网络字节序(也就是大端字节序)
a的主机字节序--网络字节序--b的主机字节序
字节序,顾名思义,指字节在内存中存储的顺序。比如一个int32_t类型的数值占用4个字节,这4个字节在内存中的排列顺序就是字节序。字节序有两种:
1、大端字节序(big-endian):按照内存的增长方向,数值高位存储在内存的低地址,低位存储在内存的高地址
2、小端字节序(little-endian):按照内存的增长方向,数值低位存储在内存的低地址,高位存储在内存的高地址
下面以32位位宽数值0x12345678为例,小端字节序与大端字节序具体的存储区别如下所示:
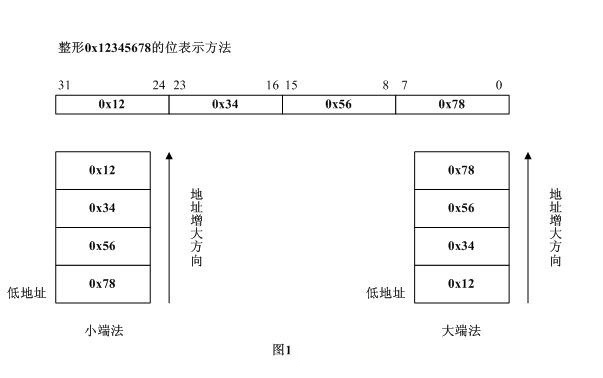
主机字节序
在主机内部的内存中数据的处理方式,可以分为上述两种。
主机字节序,即CPU存储数据时采用的字节顺序。不同的CPU设计时采用的字节序是不同的,谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86与x86_64(该指令集由AMD率先设计推出)系列CPU。PowerPC系列采用big endian方式存储数据,而x86与x86_64系列则采用little endian方式存储数据。多数PC与服务器如果使用的是Intel与AMD CPU,一般都是little endian。
但如何知道所使用主机是那一种的呢,可以通过程序来进行验证:
#include <stdio.h>;
#include <arpa/inet.h>;
int main(){
unsigned long a=0x12345678;
unsigned char *p = (unsigned char *)(&a);
printf("主机字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
unsigned long b = htonl(a); //将主机字节序转化成了网络字节序
p = (unsigned char *)(&b);
printf("网络字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
return 0;
}
运行结果:
$ gcc -o byteorder1 byteorder1.c
$ ./byteorder1
主机字节序:78 56 34 12
网络字节序:12 34 56 78
可以看出当前主机是:小端字节序,再提供一个小的示例:
//@ret:返回0小端字节序,返回1大端字节序
int dGetHostByteOrder(){
uint32_t a = 0x12345678;
uint8_t *p = (uint8_t *)(&a);
if(*p==0x78){
return 0
}else{
return 1;
}
}
如果上面的C代码看起来有困难的话,下面提供一个Perl的示例:
use v5.20;
#判定当前系统的端序(大端或小端)
my $x=pack("S",256);
my $borl=ord(substr($x,0,1));#1 for bigendian,0 for littleendian
my $rs=$borl?'BigEndian':'LittleEndian';
END{
say "Your System IS $rs.";
}
运行结果:
Your System IS LittleEndian.
关于:htonl
相关函数定义如下:
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
h是主机host,n是网络net,l是长整形long,s是短整形short,上面这些函数还是很好理解的。
#include <stdio.h>
#include <arpa/inet.h>
int main(){
struct in_addr ipaddr;
unsigned long addr = inet_addr("192.168.9.72");
printf("addr = %u\n", ntohl(addr));
ipaddr.s_addr = addr;
printf("%s\n", inet_ntoa(ipaddr));
return 0;
}
运行结果:
$ gcc -o net2host net2host.c
$ ./net2host
addr = 3232237896
192.168.9.72
值得注意的是:
in_addr_in inet_addr(const char *strptr);
inet_addr的参数是一个:点分十进制字符串,返回的值为一个32位的二进制网络字节序的IPv4地址,不然就是:INADDR_NONE
而返回值为:in_addr_t:IPv4,一般为uint32_t
所以也可以定义为:unsigned long
char * inet_ntoa(struct in_addr inaddr);
参数是一个结构体,所以要调用必须先定义一个结构体。
网络字节序
是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用big endian排序方式。
网络字节序与主机字节序的相互转换
1)、常用系统调用
Linux socket网络编程中,经常会使用下面四个C标准库函数进行字节序间的转换(上文亦有提及)。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); //把uint32_t类型从主机序转换到网络序
uint16_t htons(uint16_t hostshort); //把uint16_t类型从主机序转换到网络序
uint32_t ntohl(uint32_t netlong); //把uint32_t类型从网络序转换到主机序
uint16_t ntohs(uint16_t netshort); //把uint16_t类型从网络序转换到主机序
2)、64位数值的转换
现在如果需要对64位类型数据进行主机字节序与网络字节序的转换,没有现成系统API可用,可以通过下面几种方法进行转换:
(1)使用移位
(2)使用联合体union
根据联合体的特性:联合中所有成员引用的是内存中相同的位置,其长度为最长成员的长度。
(3)使用编译器内置函数
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如在C语言中,一个类型为int的变量x地址为0x100,那么其对应地址表达式&x的值为0x100。且x的四个字节将被存储在电脑内存的0x100, 0x101, 0x102, 0x103位置。
字节的排列方式有两个通用规则。例如,将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化才能保证正确。
每个内存存储位置都有一个索引或地址。每一 字节可以存储一个8位数字(即介于0x00 和 0xff 之间),因此必须保留不止一个字节来储存一个更大的数字。现在大部分需占用多个字节的数字排序方式是 little-endian(又称小字节序、低字节序,即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。与之对应的 big-endian 排列方式相反,可称大字节序、高字节序),所有的英特尔处理器都使用 little-endian。little-endian 的意思是使用低位储存更重要的信息,least-to-most-significant(最不重要的(least significant)字节取第一个位置,或者说地址最低的位置),可类比欧洲通用的日期书写方式(例如,31 December 2050。译者注:年份是最重要的,月份其次,日期最后)。
自然, big-endian 是相反的顺序, 可类比 ISO 日期格式(例如 2050-12-31)。big-endian 通常被称作"网络字节顺序"("network byte order"),因为互联网标准通常要求数据使用 big-endian 存储,从标准 Unix 套接字(socket)层开始,一直到标准化网络的二进制数据结构。此外,老式 Mac 计算机的 68000 系列 和 PowerPC(IBM 与 Apple 公司联合生产的个人台式机)微处理器曾使用 big-endian。
用不同字节序存储数字0x12345678(即十进制中的 305 419 896):
little-endian:0x78 0x56 0x34 0x12
big-endian:0x12 0x34 0x56 0x78
再假设变量x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。
大端法从首位开始将是:0x100: 0x01, 0x101: 0x23,..
而小端法将是:0x100: 0x67, 0x101: 0x45,..
Endian一词来源于十八世纪爱尔兰作家乔纳森·斯威夫特(Jonathan Swift)的小说《格列佛游记》(Gulliver's Travels)。小说中,小人国为水煮蛋该从大的一端(Big-End)剥开还是小的一端(Little-End)剥开而争论,争论的双方分别被称为“大端派”和“小端派”。1980年,丹尼·科恩(Danny Cohen),一位网络协议的早期开发者,在其著名的论文"On Holy Wars and a Plea for Peace"中,为平息一场关于字节该以什么样的顺序传送的争论,而第一次引用了该词。
在哪种字节顺序更合适的问题上,人们表现得非常情绪化,实际上,就像鸡蛋的问题一样,没有技术上的原因来选择字节顺序规则;因此争论沦为关于社会政治问题的争论,只要选择了一种规则并且始终如一地坚持,其实对于哪种字节排序的选择是任意的。
对于单一的字节(a byte),大部分处理器以相同的顺序处理位元(bit),因此单字节的存放方法和传输方式一般相同。
对于多字节数据,如整数(32位机中一般占4字节),在不同的处理器的存放方式主要有两种,以内存中0x0A0B0C0D的存放方式为例,分别有以下几种方式:
注: 0x前缀代表十六进制。
大端序(英:big-endian)或称大尾序
数据以8bit为单位:
地址增长方向 →
... 0x0A 0x0B 0x0C 0x0D ...
示例中,最高位字节是0x0A 存储在最低的内存地址处。下一个字节0x0B存在后面的地址处。正类似于十六进制字节从左到右的阅读顺序。
数据以16bit为单位:
地址增长方向 →
... 0x0A0B 0x0C0D ...
最高的16bit单元0x0A0B存储在低位。
小端序(英:little-endian)或称小尾序
数据以8bit为单位:
地址增长方向 →
... 0x0D 0x0C 0x0B 0x0A ...
最低位字节是0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
数据以16bit为单位:
地址增长方向 →
... 0x0C0D 0x0A0B ...
最低的16bit单元0x0C0D存储在低位。
更改地址的增长方向:
当更改地址的增长方向,使之由右至左时,表格更具有可阅读性。
← 地址增长方向
... 0x0A 0x0B 0x0C 0x0D ...
最低有效位(LSB)是0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
← 地址增长方向
... 0x0A0B 0x0C0D ...
最低的16bit单元0x0C0D存储在低位。
混合序(英:middle-endian)具有更复杂的顺序。以PDP-11为例,0x0A0B0C0D被存储为:
32bit在PDP-11的存储方式
地址增长方向 →
... 0x0B 0x0A 0x0D 0x0C ...
可以看作高16bit和低16bit以大端序存储,但16bit内部以小端存储。
处理器体系
x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器为小端序;
Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器为大端序;
ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
网络
网络传输一般采用大端序,也被称之为网络字节序,或网络序。IP协议中定义大端序为网络字节序。Berkeley套接字定义了一组转换函数,用于16和32bit整数在网络序和本机字节序之间的转换。htonl,htons用于本机序转换到网络序;ntohl,ntohs用于网络序转换到本机序(下文会再进行讲解)。
位序
一般用于描述串行设备的传输顺序,网络协议中只有数据链路层的底端会涉及到。
小端序(先传低位)的串行协议
RS-232
RS-422
RS-485
USB
以太网(虽然高字节先传,但每一字节内低位先传)
大端序(先传高位)的串行协议
I2C协议
SPI协议
摩尔斯电码
《深入理解计算机系统》 第2章 信息的表示和处理 中对此有比较权威的描述。
在计算机设计之初,对内存中数据的处理也有不同的方式(低位数据存储在低位地址处或者高位数据存储在低位地址处),然而在通信的过程中(ISO/OSI模型和TCP/IP四层模型中),数据被一步步封装(然后加入信息首部),当传到目的段时,被一步步解封,然后获取数据。因此数据在传输的过程中就一定有一个标准化的过程:从主机a到主机b进行通信数据的交换格式标准。
a的固有数据存储--标准化--转化成b的固有格式
如上而言:a或者b的固有数据存储格式就是自己的主机字节序,标准化就是网络字节序(也就是大端字节序)
a的主机字节序--网络字节序--b的主机字节序
字节序,顾名思义,指字节在内存中存储的顺序。比如一个int32_t类型的数值占用4个字节,这4个字节在内存中的排列顺序就是字节序。字节序有两种:
1、大端字节序(big-endian):按照内存的增长方向,数值高位存储在内存的低地址,低位存储在内存的高地址
2、小端字节序(little-endian):按照内存的增长方向,数值低位存储在内存的低地址,高位存储在内存的高地址
下面以32位位宽数值0x12345678为例,小端字节序与大端字节序具体的存储区别如下所示:
主机字节序
在主机内部的内存中数据的处理方式,可以分为上述两种。
主机字节序,即CPU存储数据时采用的字节顺序。不同的CPU设计时采用的字节序是不同的,谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86与x86_64(该指令集由AMD率先设计推出)系列CPU。PowerPC系列采用big endian方式存储数据,而x86与x86_64系列则采用little endian方式存储数据。多数PC与服务器如果使用的是Intel与AMD CPU,一般都是little endian。
但如何知道所使用主机是那一种的呢,可以通过程序来进行验证:
#include <stdio.h>;
#include <arpa/inet.h>;
int main(){
unsigned long a=0x12345678;
unsigned char *p = (unsigned char *)(&a);
printf("主机字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
unsigned long b = htonl(a); //将主机字节序转化成了网络字节序
p = (unsigned char *)(&b);
printf("网络字节序:%0x %0x %0x %0x\n", p[0], p[1], p[2], p[3]);
return 0;
}
运行结果:
$ gcc -o byteorder1 byteorder1.c
$ ./byteorder1
主机字节序:78 56 34 12
网络字节序:12 34 56 78
可以看出当前主机是:小端字节序,再提供一个小的示例:
//@ret:返回0小端字节序,返回1大端字节序
int dGetHostByteOrder(){
uint32_t a = 0x12345678;
uint8_t *p = (uint8_t *)(&a);
if(*p==0x78){
return 0
}else{
return 1;
}
}
如果上面的C代码看起来有困难的话,下面提供一个Perl的示例:
use v5.20;
#判定当前系统的端序(大端或小端)
my $x=pack("S",256);
my $borl=ord(substr($x,0,1));#1 for bigendian,0 for littleendian
my $rs=$borl?'BigEndian':'LittleEndian';
END{
say "Your System IS $rs.";
}
运行结果:
Your System IS LittleEndian.
关于:htonl
相关函数定义如下:
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
h是主机host,n是网络net,l是长整形long,s是短整形short,上面这些函数还是很好理解的。
#include <stdio.h>
#include <arpa/inet.h>
int main(){
struct in_addr ipaddr;
unsigned long addr = inet_addr("192.168.9.72");
printf("addr = %u\n", ntohl(addr));
ipaddr.s_addr = addr;
printf("%s\n", inet_ntoa(ipaddr));
return 0;
}
运行结果:
$ gcc -o net2host net2host.c
$ ./net2host
addr = 3232237896
192.168.9.72
值得注意的是:
in_addr_in inet_addr(const char *strptr);
inet_addr的参数是一个:点分十进制字符串,返回的值为一个32位的二进制网络字节序的IPv4地址,不然就是:INADDR_NONE
而返回值为:in_addr_t:IPv4,一般为uint32_t
所以也可以定义为:unsigned long
char * inet_ntoa(struct in_addr inaddr);
参数是一个结构体,所以要调用必须先定义一个结构体。
网络字节序
是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用big endian排序方式。
网络字节序与主机字节序的相互转换
1)、常用系统调用
Linux socket网络编程中,经常会使用下面四个C标准库函数进行字节序间的转换(上文亦有提及)。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); //把uint32_t类型从主机序转换到网络序
uint16_t htons(uint16_t hostshort); //把uint16_t类型从主机序转换到网络序
uint32_t ntohl(uint32_t netlong); //把uint32_t类型从网络序转换到主机序
uint16_t ntohs(uint16_t netshort); //把uint16_t类型从网络序转换到主机序
2)、64位数值的转换
现在如果需要对64位类型数据进行主机字节序与网络字节序的转换,没有现成系统API可用,可以通过下面几种方法进行转换:
(1)使用移位
(2)使用联合体union
根据联合体的特性:联合中所有成员引用的是内存中相同的位置,其长度为最长成员的长度。
(3)使用编译器内置函数