虚拟机与容器谁才是未来
 我也曾经是容器技术尤其是 Docker 粉丝,但用了一年后觉得事情也没那么美好,而颇有一些同学以及一些公司依然认为容器就是银弹,虚拟机已经是昨儿黄花必须打倒,大家赶紧一切皆容器。这里我对这种观点吐吐槽,仅代表作者个人看法。
我也曾经是容器技术尤其是 Docker 粉丝,但用了一年后觉得事情也没那么美好,而颇有一些同学以及一些公司依然认为容器就是银弹,虚拟机已经是昨儿黄花必须打倒,大家赶紧一切皆容器。这里我对这种观点吐吐槽,仅代表作者个人看法。首先要明确的是,软件开发和运维活动中,可维护性、正确性、性能的优先级是依次降低的,因此不要在极端情况来讨论这一情形。适合的才是最好的。
虚拟化(Virtulization)是表示计算机资源的抽象方法。通过虚拟化可以对包括基础设施,系统和软件等计算机资源的表示,访问和管理进行简化,并为这些资源提供标准的接口来接受输入和提供输出。虚拟化技术有很多种,比如,网络虚拟化,存储虚拟化,桌面虚拟化,应用虚拟化,服务器虚拟化等等,每一类虚拟化都有各自的特点和侧重点。其中服务器虚拟化是我们下面要了解的部分。
虚拟机管控程序(Hypervisor)
作为虚拟机的管理平台,Hypervisor提供了虚拟机操作系统和宿主机硬件之间的必要协同。也就是说,多台虚拟主机可以共享诸如内存与处理能力等方面的资源。通常有如下两种类型的Hypervisor。
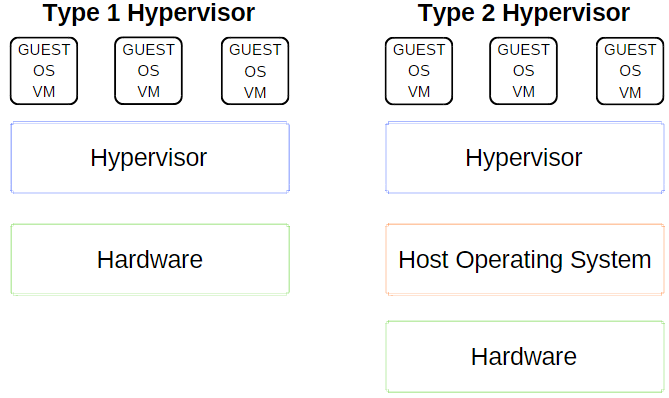
1类Hypervisor
1类Hypervisor直接运行在宿主机的硬件上,有时也称为“裸金属Hypervisor”。
Microsoft Hyper-V是1型Hypervisor的典型示例。它不需要通过外部软件包来进行额外安装,便可直接管理虚拟机的操作系统。另外,VMWare ESX、vSphere、Citrix XenServer和Oracle VM都属于1类Hypervisor。
2类Hypervisor
与其他任何软件一样,2类Hypervisor也需要被安装在操作系统上,因此也被称为“托管Hypervisor”。
虚拟机环境作为一个进程运行在主机上,并且仍能共享主机系统的硬件资源。不过对于虚拟机的管理必须通过主机的路由方可实现,而无法直接执行底层命令。此种设计带来的结果是在每一步操作之间都会有稍许等待的时间。VirtualBox、VMware Workstation和VMware Workstation Player都是2类Hypervisor的典型示例。
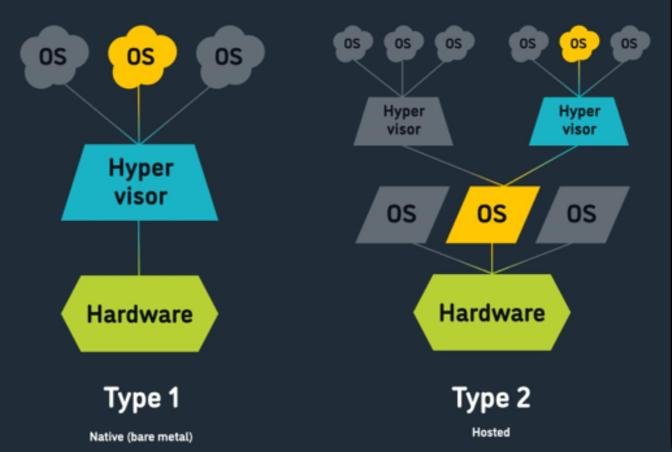
Hypervisor可以说是虚拟化的灵魂,作为虚拟机和物理机的桥梁,它们的主要功能是对物理设备进行抽象和管理,并作为中间人的角色管理虚拟机和宿主机设备之间的所有I/O操作。Hypervisor可以有效分隔物理资源,并将这些资源分配给不同虚拟环境(也就是需要这些资源的任务)使用。虚拟机监控程序可能位于操作系统的顶层(例如在便携式计算机上),或者直接安装在硬件上(例如服务器),这对应了目前主流的两种Hypervisor实现方式:Type 1和Type 2型,其区别主要在于Hypervisor和硬件之间有或没有额外的操作系统。大家所熟悉的VMware Workstation、VirtualBox、Parallels Desktop等运行在操作系统内的虚拟化软件都可以称作Type 2型Hypervisor;VMware ESX以及Citrix Hypervisor (Xen)、Microsoft Hyper- V、Red Hat KVM等都是Type 1型Hypervisor的代表,云计算中所使用的虚拟化技术,也大多是从这些Type 1型Hypervisor演化而来的。
主流虚拟化技术
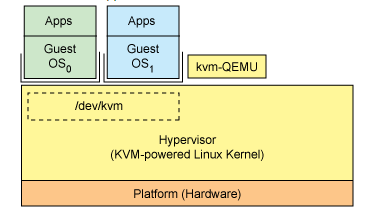
1.KVM
虚拟化方式:完全虚拟化
架构:寄居架构(linux内核); 裸金属架构RHEV-H
特点:裸金属架构RHEV-H或在关键的硬盘和网卡上支持半虚拟化VirtIO,达到最佳性能。
I/O协议栈:KVM重用了整个Linux I/O协议栈,所以KVM用户就自然获得了最新的驱动和I/O协议栈的改进。
架构图
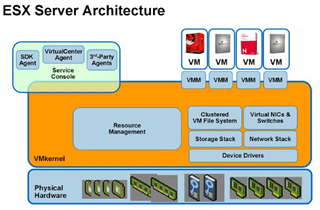
2.VMware ESX
虚拟化方式:完全虚拟化
架构:裸金属架构
I/O协议栈:VMware选择性能,把I/O协议栈放到了hypervisor里。但VMWare kernel是专有的,意味着你的新硬件可能要等一段时间才能得到VMware的支持。
架构图
3.Citrix XenServer
虚拟化方式:半虚拟化;完全虚拟化;硬件辅助虚拟化
架构:裸金属架构
架构图
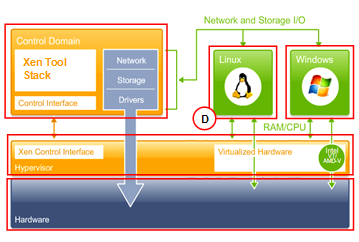
4 Microsoft Hyper-V
虚拟化方式:半虚拟化
架构:裸金属架构 Hyper-V; 寄居 Windows Server 2008
架构图
个人用虚拟机软件介绍
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统,通过虚拟机软件,你可以在一台物理计算机上模拟出另一台或多台虚拟的计算机,这些虚拟机完全就像真正的计算机那样进行工作,例如你可以安装操作系统、安装应用程序、访问网络资源等等。对于你而言它只是运行在物理计算机上的一个应用程序,但是对于在虚拟机中运行的应用程序而言,它就是一台真正的计算机。
通过虚拟机软件学习或者进行测试是最适合初学者最佳的学习方式。windows 平台下,流行的虚拟机软件有VMware 、Virtual Box和Virtual PC或Hyper-V,它们都能在一台物理机上虚拟出多个计算机。
VMware 虚拟化解决方案提供商领先者,其产品性能好,功能强,支持Windows,Mac, Linux等平台。但是程序体积非常庞大,而且收费昂贵。Virtual Box 是一款开源虚拟机软件,支持Windows、Linux等平台。可以说是最强大的免费虚拟机软件,它不仅具有丰富的特色,而且性能也很优异。功能比VMware稍微少一些,不过一直在更新,新版本直接兼容老版本创建的虚拟机。程序小巧精干,简单易用。
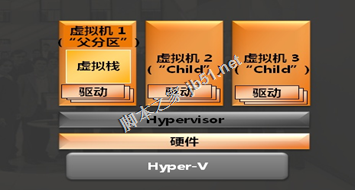
Hyper-V是微软推出的一款免费虚拟机产品,仅支持Windows平台。但是在此虚拟机上只能安装Windows和OS/2操作系统,即使安装上其他操作系统,还是可能出现兼容性问题。比较小巧,操作方便。其已经被预先集成到了Windows 10 Pro、Education和Enterprise中,但是在Home版上却并不自带。可以通过Windows Features或PowerShell命令来添加和启用Hyper-V,不过需要手动进行激活。完成激活后,Hyper-V将通过其对应的管理器,来提供快速的、或扩展性的虚拟机创建选项。值得注意的是,在使用快速创建虚拟机选项时,系统会自动填写相关设置,因此当尝试启动虚拟机时,这些设置可能会导致虚拟机的报错。在此,我建议您使用扩展性的自定义创建选项,以实现更灵活的设置与控制。
VirtualBox和VMware Workstation Player都自带有不同虚拟机创建的向导。例如:VirtualBox的向导会让您创建一个基本的虚拟机,之后可以在此基础上进行编辑和设置。当然它也提供了一些针对特定虚拟机类型的建议值。而VMware Workstation Player的向导,同样可以让您自定义地创建虚拟机。虽然差别不大,但是一旦完成向导,您即可运行虚拟机,而无需后续更多的设置更改。
性能
虚拟机的性能与用于运行该虚拟机的硬件有着直接的关系。当然虚拟机类别的不同也会导致巨大的性能差异。经过简单的测试发现VirtualBox的虚拟机性能最慢。对于某些配置较低的电脑来说, VirtualBox无法给用户提供最佳的虚拟化体验。而在同等硬件配置的情况下,VMware Workstation Player显然能够给使用者带来更为流畅的体验。
通过深入测试,发现Hyper-V在Lubuntu上的安装与运行效果都十分流畅。当然,我曾听闻有Windows 10用户反映在启用Hyper-V后出现了性能问题。我个人认为:这是由于Hyper-V属于BIOS级别,而不是在操作系统内运行的软件。因此即便您没有使用任何的虚拟机,虚拟化服务也始终处于“开启”的状态,这就耗费了一定比例的硬件资源。
快照和检查点
快照(Snapshots)和检查点(Checkpoint)分别是VirtualBox和Hyper-V的各自特色。尽管在各自的平台上所使用的名称不同,但是快照和检查点都有着非常相似的功能:它们都可以为虚拟机的当前状态保留一个映像,以便将来按需将虚拟机返回到该特定的时刻。可惜的是,VMware Workstation Player并不支持快照或检查点。您只能临时挂起客户机操作系统以便从特定点进行恢复。显然,这与为虚拟机创建映像的历史记录的机制是截然不同的。
文件共享
此处所讨论的三种Hypervisor,都能够支持宿主机与虚拟机操作系统之间的文件拖放。当然,对于建立共享文件、及共享文件夹的需求,Windows 10 Hyper-V会比VirtualBox或VMware Workstation Player复杂得多。
无缝模式
无缝模式摆脱了附加在虚拟机上的窗口和菜单,使得虚拟机操作系统更能融入宿主机上,成为它的一部分。VirtualBox和VMware Workstation Player都会使用无缝模式将虚拟机环境集成到宿主机的操作系统中。不过可惜的是,Windows 10 Hyper-V并不提供此类无缝模式。
虚拟机加密
此处三种Hypervisor都能够支持一种、或一种以上针对虚拟机的加密。当然它们也有着一定的平台独立性。具体如下:
VMware Workstation Player能够开箱即用地支持虚拟机加密。
VirtualBox通过安装VirtualBox Guest Additions,来支持针对每个虚拟机环境的加密。
Windows 10上的Hyper-V,能够支持使用Microsoft的BitLocker来进行加密。
费用
虽然此处三种Hypervisor都是免费的,但是其中的一些会为用户提供更大的自由度。对于VirtualBox和VMware Workstation Player来说,只要您的硬件可以支持多个虚拟机的运行,且不会影响到宿主机的性能,那么就可以免费使用这两款软件。而Windows 10 Hyper-V免费的前提是:您已经拥有了正版的Windows 10。另外,如前文所述,对于Windows 10 Home版用户而言,他们需要额外安装Hyper-V,并且不能保障其更新到Windows 10下一个版本之后,还能免费试用Hyper-V。
虚拟机操作系统
Windows 10 Hyper-V对于虚拟机操作系统的类型是有所限制的。目前,它主要支持Windows、Linux和FreeBSD类型的虚拟机,并不支持macOS。相比而言,VirtualBox和VMware Workstation Player能够支持几乎所有类型的虚拟机操作系统,包括macOS。值得注意的是,macOS虚拟机并非开箱即用的。
那么对于虚拟机 vs 容器,自然也需要从这三方面考察。
回合一:可维护性之争
虚拟机—维护性
从 hypervisor 讲,Xen/KVM/vSphere/HyperV 都很成熟了,久经考验,BSD 也在凑热闹搞 bhyve(FreeBSD) 和 vmm(OpenBSD),最近 unikernel 也在试图跑在 hypervisor 上,而 AWS/GCE/Azure 等等云计算巨头以及 Intel/AMD 等在CPU、磁盘和网络IO虚拟化技术上的投资显然不会立马推翻,Linux 上虚拟机的开源管理方案也已成熟定型:libvirt, OpenStack, 没人吃饱了撑的去弄个 “新的开源” 项目替换它们,虽然我很不喜欢 OpenStack 的乱糟和复杂。VM 的动态迁移也是成熟技术,出来好多年了,实现原理非常简单,反正整个 OS 内存一锅端弄过去,不操心少个依赖进程的内存没过去。想用不同版本内核? 想要自定义内核模块?想调整内核参数?期望更安全的隔离?期望如同物理机版几乎一致的使用体验?VM 就是虚拟机的缩写嘛,这些都是拿手戏。
容器—维护性
Linux 容器,Linux 一贯的作风,慢慢演化,不求仔细设计,然后就是 cgroup, pid/uts/ipc/net/uid namespace 一个个实现出来,凑出一个容器技术,貌似 uid namespace 还是最近刚刚出来的特性。用户空间则更是群雄并起,LXC,Docker,rkt,LXD,各有拥蹇,鹿死谁手,还真不好说,在这个局还没明朗的时 候,Mesos、Swarm、Kubernetes、Nomad 又出来一堆搅局的,眼下看来最吸引眼球的 Kubernetes 俨然有 OpenStack 继任者的感觉,但依然很嫩,没几个人敢在生产环境大规模使用。
Linux容器里进程的跨机器动态迁移我还没听说,不要说是个服务就得有集群有 HA 嘛,可还真有不少用户一个服务就单机顶着呢,就算有热备或者冷备,在线那台机器内存里的东西可宝贵了,轻易不能丢。用Linux容器就不能挑内核,不能加 载内核模块,不能挂载文件系统,不能调整内核参数,不能改网络配置,等等,不要告诉我你能——你是不是开了 docker run --privileged 了? 你是不是没 drop capability?你是不是没有 remap uid?话说某大公司的容器还真就用 --privileged 选项跑的呢。而 Linux 的隔离不彻底恐怕大部分人都没意识到,/sys, /dev, /selinux 还有 /proc 下的某些关键文件比如 /proc/kcore 没隔离呢。
Redhat 做的 project Atomic 意识到这些问题,正在积极的给 Docker 加 SELinux 支持,指定 SELinux policy,但 Docker 官方爱搭不理,而且 SELinux 这种高端技术是凡人玩的么? 结局大概依然是 "FAQ 1: 关掉 SELinux"。Linux 容器本来并不局限在一个容器里跑几个进程,但 Docker 官方为了加强“轻量级”这词的洗脑效果,搞出个无比脑残的 single process 理念,被无数人捧臭脚,所幸有些人慢慢意识到问题,Yelp 搞了个 dumb-init 擦了一半屁股,还有无数 docker image 用 runit、supervisor 之类的做 /sbin/init 替换,但问题在于这要自定义启动脚本,需要加 ssh/cron/syslog/logrotate 等等边角料——这已然是解决了无数遍的问题,还要解决一遍,不觉得麻烦吗?难道没有人认为这些包的作者或者打包者更善于处理服务启动脚本么?像 systemd 那种搞法还算正道,特意考虑容器环境,跳过一些步骤,但貌似还没做完善,需要手动删除一些 .service 文件。
虚拟机 vs 容器
也许有人会说 docker pull/push 多方便啊,docker build 多方便啊,可不要忘了,vm image storage 早在 openstack 里就解决了,自己处理也不是个大事,vm image build 也有 Hashicorp 的 Packer 工具代劳,不是个事。Docker 自豪的官方 docker registry 其实大家最多用用 base os image,那些 app 级别的出于信任以及定制考虑都会自己 build。而 Docker 自豪的 layered storage 也是无数血泪,aufs & overlayfs 坑了多少人?容器社区最近还特崇拜 immutable deployment,以把容器根文件系统弄做只读的为荣,全然不管有紧急安全更新或者功能修正怎么处理——什么,你要说 docker rm && docker run 再起一批不就完事么?真有这么简单就好了。
像 Linux kernel 和 git 那种才是正经 unix 设计的思想,分层堆叠,底层提供mechanism,高层提供 policy,各取所需,可惜人总是易于被洗脑,在接受各种高大上policy的时候全然忘了mechanism还在不在自己手里。
回合二:正确性之争
强隔离、full OS 体验、保留 mechanism,这才是正道。另外容器还隐藏了一个坑,/proc/cpuinfo和free命令输出是host os的,这坑了无数探测系统资源自动决定默认线程池和内存池大小的程序,尤以Java最为普遍。
回合三:性能之争
容器粉丝津津乐道——启动容器快,容器的开销少。 这两点确实如此但好处真的有那么巨大么?谁有事没事不停创建虚拟机?谁的虚拟机生命周期平均在分钟级别?谁的“用完全启动时间”平均在秒级? 至于说到虚拟机浪费的资源太多,其实也就是个障眼法。理论上服务器的资源利用率平均不应该超过 80%而实际上绝大部分公司的服务器资源利用率应该都不到 50%,大量的CPU、内存、本地磁盘都是常年浪费的,所以 VM 的额外开销不过是浪费了原本就在浪费的资源罢了。就单机的巅峰 I/O 能力来言,VM 确实不敌容器。但平时根本就用不到巅峰状态, 原本一个 VM 里多进程干的事,非得搞多个容器跑,这容器开销,这人力开销怎么算?
关于容器还有一个幻想,那就是可以在物理机上直接跑容器,开销巨低、管理巨方便,用专用物理机方式提供多租户强隔离。前面两点上面已经驳过了,话说还有人用 openstack 管理 docker 容器呢。
我只是说一下第三点,在一台物理机上直接跑容器的一个最容易被忽视的问题:现在用来提供云服务的物理机一般都是硬件超级牛逼,跑上百个容器都没问题,但问题在于用户很可能只需要几个容器,所以要么跟人共用物理机,要么浪费资源白交钱。哪怕用户需要上百个容器,出于容灾考虑,也不可以把上百容器部署到一台物理机上,所以还是要么跟人共用物理机,要么浪费资源。
方案
以上是我的观点,我并不是“容器黑”,而是“实用白”。AWS、Azure、GCE 都主推在虚拟机上跑容器,按虚拟机收费,这非常明智的解决了问题:老的纯 VM 基础设施不用动,计费照旧,单物理机可以被安全的多租户共用,资源隔离有保证(起码比共享内核强多了),把容器管理软件如“kubernetes”给用户,既满足用户的容器需求,又不担心容器的多租户问题。
所以我认为:以 VM 为基础,以容器为辅助点,要买就买 VM,自己管理容器,别买 CAAS 直接提供的容器,别看不到底下物理机或者虚拟机。用 VM 还是用容器,冷静考察自己的应用上容器是否有好处。最后,残念,VM 开源管理软件能搞个比 OpenStack 简单的东西吗?
容器技术极简史
Docker和K8S已经是当下运维的必备技能,无论是行业技能要求还是前沿技术领域,现在还不能很好掌握这两门技术的技术人员,在新一轮的技术迭代中将最终被抛弃。
LXC
Docker其实是一门容器化技术,也是虚拟化技术的一种,只是相对传统的kvm,xen,vmware虚拟化技术而言,是基于进程级别的虚拟化技术,更为轻量,因而性能损耗更小。虚拟化技术并不是一门新技术,最小可以追溯到LXC技术!

LXC为Linux Container的简写。可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。相当于C++中的NameSpace。容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。与传统虚拟化技术相比,它的优势在于:
与宿主机使用同一个内核,性能损耗小;
不需要指令级模拟;
不需要即时(Just-in-time)编译;
容器可以在CPU核心的本地运行指令,不需要任何专门的解释机制;
避免了准虚拟化和系统调用替换中的复杂性;
轻量级隔离,在隔离的同时还提供共享机制,以实现容器与宿主机的资源共享。
小结:Linux Container是一种轻量级的虚拟化的手段,提供了在单一可控主机节点上支持多个相互隔离的server container同时执行的机制。Linux Container有点像chroot,提供了一个拥有自己进程和网络空间的虚拟环境,但又有别于虚拟机,因为LXC是一种操作系统层次上的资源的虚拟化
这里衍生出来另外一个问题?LXC技术最早可以追溯到20世纪70年代,计算机系统刚诞生的时代,即LXC和系统是强关联,为什么一直到2010年左右才开始在历史舞台大紫大红呢?
这里其实要讲到进程和隔离了。
进程与隔离
操作系统在整个过程中是非常重要的。由于计算机只认识二进制 0 和 1,所以无论哪种语言的实现,最后都需要通过某种方式编译为二进制文件,才能在计算机操作系统中运行起来。而为了能够让这些代码正常运行,我们还需要数据、代码运行平台即操作系统。比如我们这个加法程序所需要的输入文件。这些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”,也叫代码的可执行镜像executable image。然后,我们就可以在计算机上运行这个程序了:
首先,操作系统从“程序”中发现输入数据保存在一个文件中
然后,这些数据就会被加载到内存中待命
接着,操作系统又读取到了计算加法的指令
这时,它就需要指示 CPU 完成加法操作。
而 CPU 与内存协作进行加法计算,又会使用寄存器存放数值、内存堆栈保存执行的命令和变量。同时,计算机里还有被打开的文件,以及各种各样的 I/O 设备在不断地调用中修改自己的状态。这样一旦程序被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就是我们今天的主角:进程。
从上面可以看到,操作系统也是进程,只是其无比复杂,复杂到可以把自己“虚拟成平台”并承载其它进程运行的程序,而操作系统在这个过程中起到两个非常重要的角色是:资源分配和资源隔离。
资源分配
众所周知,Linux多用户操作系统,即意味着可以多个同时使用操作系统,但操作系统只有一个大脑(无论是几个物理核心,其实真正都在同一时间只有一个核心工作,虽然现代多核心技术在多核心协作上做了非常精巧的设计)。
那么操作系统究竟该如何分配资源呢?如图是top命令的返回,第一列是进程ID,大家可能已经想到了,就是进程ID. 进程ID越小,优先级越高。进程ID是系统判断资源分配的重要依据 。当然,现代操作系统都是并行性操作系统,想像这么一个场景:如果有多个进程都在申请同一块内存,而另外一个进程一直在占用这块内存不肯释放,此时操作系统该怎么办呢?这种情形称为“死琐”,早在2.6版本以前的内核,在资源分配和资源隔离做的并不理想。尤其是资源隔离。
资源隔离
程序的正常运行最少需要如下这些资源:
网络资源
磁盘资源
内存资源
CPU计算资源
容器化
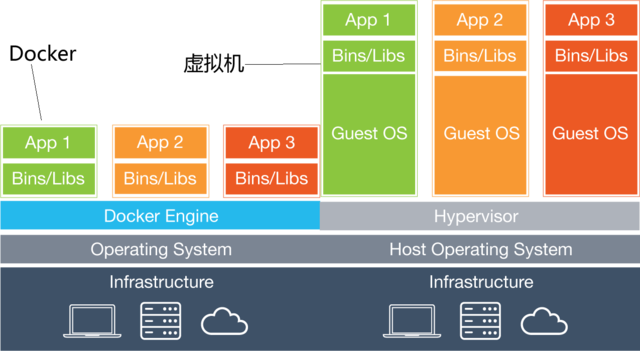
其次还有非常重要的文件系统资源,和传统虚拟化不同。传统虚拟化是在磁盘上划分出来一块空间,在此空间上虚拟一个完整的操作系统,所有的资源与真实主机隔离。隔离安全性有保障,但性能损失不容忽视。而Docker容器化不同的地方是Docker并不是一个操作系统,而只是真实物理机操作系统中的一个进程,通过该进程来调用内核资源,使用rootfs文件系统技术和cgroup隔离动技术,实现资源隔离。
性能几乎无损耗,但隔离技术门槛较高,且3.10之前的内核版本不支持。时至今日,Docker在虚拟化隔离也不能做到安全性100%。介绍这么多,大家千万不要误解是因为Docker性能损耗少所以大红大紫,真正促使Docker如日中天的原因其实是PAAS的发展。
从本世纪初开始,云计算的呼声不断,到2009年王坚博士“骗”了马云10个亿创建阿里云,到现在阿里3年2000亿、腾讯5年5000亿在新基建的大力投入,不过短短20年时间。从早期的AWS,azure外资独大,到现在阿里、腾讯、华为云独占云市场鳌头,如日中天的AWS和盛极一时的OpenStack带动整个IT产品迈向PAAS时代。但事情的发展总不以人的意识为导向。在家名为dotCloud的公司在PAAS的浪潮中坚持不下去,无奈开源他们容器化项目:Docker。令dotCloud公司自己都没想到的是,这竟然会让他们站在浪潮之巅并有机会和RedHat和Google一战雌雄,甚至逼的Google不得不和RedHat合作,并拿出自家核秘密武器Brog却只为求得生存。
“容器”这个概念从来就不是什么新鲜的东西,也不是 dotCloud 公司发明的。所以dotCloud 开源的决定在当时根本没人在乎。
PaaS 项目被大家接纳的一个主要原因,就是它提供了一种名叫“应用托管”的能力。在当时,虚拟机和云计算已经是比较普遍的技术和服务了,用户主流用法,就是租一批 AWS 或者 OpenStack 的虚拟机,然后像以前管理物理服务器那样,用脚本或者手工的方式在这些机器上部署应用。当然,这个部署过程难免会碰到云端虚拟机和本地环境不一致的问题,所以当时的云计算服务,比的就是谁能更好地模拟本地服务器环境,能带来更好的“上云”体验。而 PaaS 开源项目的出现,就是当时解决这个问题的一个最佳方案。
Cloud Foundry是当时 PAAS 的平台龙头。在Docker开源时,其产品经理james Bayer在社区做过详细对比,并告诉大家 Docker 实际上只是一个同样使用了 cgroup 和Namespace 的"沙盒"工具而已,并不需要特别关注。但仅在短短几个月后,Docker就迅速崛起,速度之快连包括 Cloud Foudry 在内的所有 PAAS 公司没来得及反应就感觉落伍了。而引导这一现象的原因却仅仅是**Docker的镜像功能**。恐怕连 Docker 项目的作者 Solomon Hykes 自己当时都没想到,这个小小的创新,在短短几年内就如此迅速地改变了整个云计算领域的发展历程。
PaaS 之所以能够帮助用户大规模部署应用到集群里,是因为它提供了一套应用打包的功能。可偏偏就是这个打包功能,却成了 PaaS日后不断遭到用户诟病的一个“软肋”。
用户一旦使用了 PaaS,就必须为每种语言、每种框架,甚至每个版本的应用维护一个打好的包。这个打包过程,没有任何章法可循,更麻烦的是,明明在本地运行得好好的应用,却需要做很多修改和配置工作才能在 PaaS 里运行起来。而这些修改和配置,并没有什么经验可以借鉴,基本上得靠不断试错,直到你摸清楚了本地应用和远端 PaaS 匹配的“脾气”才能够搞定。
而 Docker 镜像解决的,恰恰就是打包这个根本性的问题。就这样,容器化的时代开始了!
Docker中文叫容器,和虚拟机有很多相似之处,也有诸多不同之处。用来运行生产系统,都是没问题的。虚拟机具有普适性,而Docker的轻量化更适合微服务架构的应用,下面我们就来了解一下:
1、Docker和虚拟机异同点
①、虚拟机
说起虚拟机我们都非常熟悉。它利用虚拟化技术将操作系统和物理服务器脱离关系,虚拟机通过虚拟层和宿主物理服务器打交道。这样,我们的宿主物理服务器只要性能足够,就可以运行大量的虚拟机。而虚拟机因为脱离了物理硬件的捆绑关系,也就具备了很多优点:
完整性:虚拟机就是打包了操作系统、虚拟硬件等等的一组文件,它具有真实计算的完整功能;
独立性:虚拟机和虚拟机之间本身是互相隔离的,就算两台虚拟机在同一台宿主机上,也不会因为其中一台虚拟机出问题,导致另外一台虚拟机出问题。
可移植性:整个虚拟机是一组文件,可以很方便的复制迁移。一迁移就是这个系统都迁移出去了。
高可用性:虚拟机因为和物理服务器脱离了捆绑关系,它可以在被虚拟化的服务器中自由漂移。任何一台物理服务器出现故障,虚拟机并不会因此无法工作。同时,当然虚拟化平台还提供了性能负载均衡和灾备的一些特性。
高性能:单个虚拟机是无法突破宿主物理服务器的性能的,那如果要实现更大的性能,虚拟机可以组建集群,将集群虚拟机分布在不同的物理服务器中来实现。

当然,虚拟机不止我这里说的好处。它是云计算的最基础技术,没有它就无法实现云计算。
②、Docker
Docker是在虚拟机之后才出现的技术。它也是在操作系统之上的轻量化虚拟技术。它可以运行在传统的物理服务器上,也可以运行在虚拟机之中。它是将应用系统的运行环境和应用软件打包在一起的技术,它也具备很多优点:
独立性:每一个Docker都是一套应用软件和配套环境,和其他Docker是互相隔离的;
便捷性:软件从开发者手上开发出来到使用者这边,只需一个Docker镜像就可以把开发者的完整环境搬到使用者这边。无需重新配置环境。
可移植性:Docker的可移植性主要是应用软件和环境可以快速迁移。
高可用:Docker本身无法实现高可用。它需要借助分布式管理平台来实现高可用性,比如:著名的谷歌K8S,是一整套非常不错的分布式管理程序,已经可以实现所谓的“容器云”
高性能:同样是通过分布式管理平台,来实现多个Docker的集群。性能不够就加Docker。

③、两者相同点和不同点
虚拟机和Docker都具有高可用和高性能的特点,他们都是一种虚拟化的技术。但两者也存在很多的不同点:
虚拟机的虚拟化处在更宏观的层面,操作系统都被打包进去。优点在于无需重装系统,而且虚拟化可以和硬件直接打交道,性能调度掌握在虚拟平台上,缺点在于,每一个虚拟机都需要运行一套操作系统。
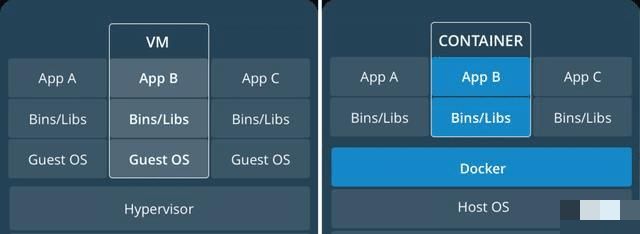
而Docker的虚拟化则在更微观的层面,它并不是完整计算环境,它只打包了应用程序和环境,所以缺点在于调度硬件的性能取决于外在操作系统,同时,Docker太多后关系非常复杂,人工是很难理清楚性能问题和故障的,还好容器平台都有自动化工具。它的优点就是非常轻量化,应用可移植性非常强,对软件开发来说非常方便。
2、Docker可以取代虚拟机的地方
通过上面虚拟机和Docker的对比发现,Dokcer更适合当前采用微服务架构的应用软件开发、部署、运维的所有过程。那到底什么是微服务架构呢?
这个起源于互联网公司,互联网的软件都是需要快速上线,持续迭代更新,又有大量的轻量并发访问。基于这些特点,互联网公司通常将一个大型的应用程序和服务拆分为数个甚至数十个的支持微服务,通常扩展单个组件而不是整个的应用程序堆栈,从而满足互联网访问这种特性。这就是我们常说的微服务。架构对比示意图如下:
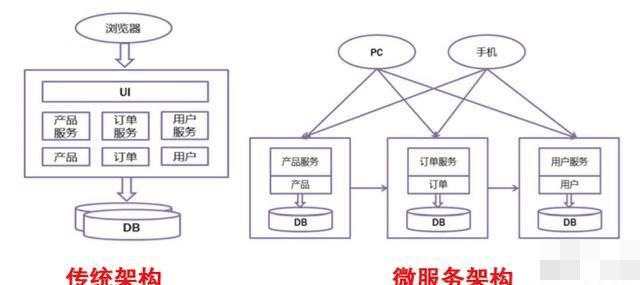
从图中,我们可以看到传统架构是一个紧耦合的应用,各个模块都是集成在一个应用里面。不仅应用对性能要求高,数据库对性能要求也高。自然不适合Docker来做,更适合虚拟化或者物理集群来做。而微服务架构则不同,拆散成了很多个微小的服务组件,这样就比较适合Docker来开发部署了。
当然,现在微服务架构已经不局限在互联网公司用了。只要具有互联网软件相似特点的应用,都可以采用微服务架构来开发。所以Docker也就被用的越来越多。但Docker和虚拟化并不是互相排斥的,反而是相互贯通的。
3、Docker和虚拟机是互相贯通的
因为Docker是微型虚拟化的容器,它可以运行在物理机操作系统上,也可以运行在虚拟机的操作系统之上。所以,Docker和虚拟机并不互相矛盾。反而是相辅相成的。现在,很多互联网应用都是在虚拟机组建的云端上部署Docker应用。这样既有云计算的弹性性能提供,也有Docker快速灵活部署应用的特点。是相辅相成的绝佳方法。
Docker是轻量级的虚拟化,只打包软件和软件运行环境。而虚拟机则是打包操作系统的重量级虚拟化。两者之间有虚拟化的共同特点,也有自己的独特性。在实际使用中,Docker非常适合采用微服务架构的软件开发、部署、运维。而虚拟机则普适性比较广,但它和Docker是互相贯通的,相辅相成的,并不矛盾冲突。
那Docker和k8s又有什么关系呢?
前面介绍,Docker 项目一日千里的发展势头,但用户们最终要部署的,还是他们的网站、服务、数据库,甚至是云计算业务。这就意味着,只有那些能够为用户提供平台层能力的工具,才会真正成为开发者们关心和愿意付费的产品。而 Docker 项目这样一个只能用来创建和启停容器的小工具,最终只能充当这些平台项目的“幕后英雄”。
即要想Docker能大面积普及,还需要解决大量Docker的协作编排问题。
谈到Docker容器编排问题,就不得不说说 Docker 公司的老朋友和老对手 CoreOS 了。CoreOS 是一个基础设施领域创业公司。它的核心产品是一个定制化的操作系统,用户可以按照分布式集群的方式,管理所有安装了这个操作系统的节点。从而,用户在集群里部署和管理应用就像使用单机一样方便了.
Docker 项目发布后,CoreOS 公司很快就认识到可以把“容器”的概念无缝集成到自己的这套方案中,从而为用户提供更高层次的 PaaS 能力。所以,CoreOS 很早就成了 Docker 项目的贡献者,并在短时间内成为了 Docker 项目中第二重要的力量。然而,这段短暂的蜜月期到 2014 年底就草草结束了。CoreOS 公司以强烈的措辞宣布与 Docker 公司停止合作,并直接推出了自己研制的 Rocket后来叫rkt容器。
这次决裂的根本原因,正是源于 Docker 公司对 Docker项目定位的不满足。Docker 公司解决这种不满足的方法就是,让 Docker 项目提供更多的平台层能力,即向 PaaS 项目进化。而这显然与 CoreOS 公司的核心产品和战略发生了严重冲突。
大红大紫不差钱的 Docker 开始大私收购来完善自己的生态和平台能力。最出名的莫过于 Fig项目,即现在的 Compose,除此外,还有 SocketPlane, Flocker, Tutum等项目。
Docker的异常繁荣终于引起了行业巨头的关注。作为 Docker 项目早期的重要贡献者,RedHat 也是因为对 Docker 公司平台化战略不满而愤愤退出。但此时,它竟只剩下 OpenShift 这个跟 Cloud Foundry 同时代的经典 PaaS 一张牌可以打,跟 Docker Swarm 和转型后的 Mesos完全不在同一个“竞技水平”之上。
2014年6月,基础设施领域的翘楚 Google 公司突然发力,正式宣告了一个名叫 Kubernetes项目的诞生。而这个项目,不仅挽救了当时的 CoreOS 和 RedHat,还如同当年 Docker项目的横空出世一样,再一次改变了整个容器市场的格局。
2015年6月22日,由 Docker 公司牵头,CoreOS、Google、RedHat 等公司共同宣布,Docker公司将 Libcontainer 捐出,并改名为 RunC 项目,交由一个完全中立的基金会管理,然后以 RunC 为依据,大家共同制定一套容器和镜像的标准和规范。但由于 OCI 的成立更多的是这些容器玩家出于自身利益进行干涉的一个妥协结果,所以OCI的组织效率一直很低下。
Docker 公司之所以不担心 OCI 的威胁,原因就在于它的 Docker 项目是容器生态的事实标准,而它所维护的 Docker 社区也足够庞大。可是,一旦这场斗争被转移到容器之上的平台层,或者说 PaaS 层,Docker 公司的竞争优势便立刻捉襟见肘了。
Google、RedHat 等开源基础设施领域玩家们,为了牵制Docker,共同牵头发起了一个名为 CNCFCloud Native Computing Foundation的基金会。这个基金会的目的其实很容易理解:它希望,以 Kubernetes 项目为基础,建立一个由开源基础设施领域厂商主导的、按照独立基金会方式运营的平台级社区,来对抗以 Docker 公司为核心的容器商业生态。
k8s早先在社区一直被认为太过前卫先进,但随着时间的发展,谷歌的工程能力也逐步得到社区的认可。而没有大规模验证的 swarm 逐步淡出人们视野。
2016 年,Docker 公司宣布了一个震惊所有人的计划:放弃现有的 Swarm 项目,将容器编排和集群管理功能全部内置到 Docker 项目当中。
2020年12月, Kubernetes 在 v1.20 版本之后将废弃 Docker 作为容器运行时。Docker 作为底层运行时被废弃,转而使用为 Kubernetes 创建的 Container Runtime Interface(CRI) 的运行时,Docker 生成的镜像将继续在你的集群中与所有运行时一起工作。
如果你是 Kubernetes 的终端用户,对你来说不会有太大的改变,这并不意味着 Docker 的死亡,也不意味着你不能或者不应该再使用 Docker 作为开发工具。Docker 仍然是一个非常有用的构建容器的工具,docker build 产生的镜像仍然可以在你的 Kubernetes 集群中运行。
如果你使用的是像 GKE 或 EKS 这样的托管 Kubernetes 服务,在未来的 Kubernetes 版本中删除 Docker 支持之前,你需要确保你的 worker 节点使用的是支持的容器运行时,如果你有节点定制的需求,那么你可能需要根据你的环境和运行时需求来更新它们。请与你的云服务商合作,以确保适当的升级测试和规划。
如果你要升级自己的集群,那么你还需要进行一些更改来避免集群崩溃。在 v1.20 时,你会收到 Docker 的废弃警告。当 Docker 运行时支持在 Kubernetes 的未来版本目前计划在2021年底发布1.23版本中被移除时,它将不再被支持,你需要切换到其他符合标准的容器运行时,如 containerd 或 CRI-O。只需确保你选择的容器运行时支持当前使用的 docker 守护程序配置即可例如日志。
作为一个开发者,Docker 对你来说仍然是有用的,在宣布这个变化之前它的所有方式都是有用的。Docker 产生的镜像并不是真正的 Docker 专用的镜像,它是一个 OCIOpen Container Initiative镜像。任何符合 OCI 的镜像,无论你用什么工具来构建它,对 Kubernetes 来说都是一样的,containerd 和 CRI-O 都知道如何拉取这些镜像并运行它们。这就是为什么我们有一个关于容器应该是什么样子的标准。
Kubernetes架构的八大问题
Kubernetes架构非常适合有一定服务规模的组织,但它对其他人来说可能过于复杂。
开源容器编排平台Kubernetes已经成为任何在生产环境中部署容器化应用程序的人事实上的解决方案。这有很多原因,包括Kubernetes提供了高度的可靠性、自动化和可伸缩性。尽管如此,我有时认为Kubernetes的架构被过分夸大了。尽管现在已经6岁多了,它还是有各种各样的缺点。其中一些是Kubernetes本身固有的,而另一些则是围绕平台发展起来的生态系统的产物。
在您加入Kubernetes的行列之前,请考虑以下关于开源容器编排平台的问题。
Kubernetes是为有一定网络规模的公司设计的
首先,Kubernetes体系结构是为那些需要管理非常大规模的应用程序环境的公司而构建的。
如果您是谷歌(它的Borg orchestrator为后来的开源Kubernetes项目奠定了基础),那么Kubernetes是一个伟大的工具。如果你是Netflix、Facebook、亚马逊(Amazon)或其他拥有数十个数据中心、数百个应用程序和服务的网络规模公司,这也是正确的。
但是,如果您是一个拥有一个数据中心和十几个应用程序需要部署的较小的组织,那么Kubernetes体系结构可以说是多余的。这就像用推土机为后院草地翻土一样。除非大规模地使用它,否则配置和管理它所需要的努力是不值得的。这并不是说Kubernetes永远不适合小规模的部署。我认为它正朝着那个方向发展。但是,现在每当我启动Kubernetes集群,在少数服务器上部署一两个应用程序时,我就确信使用更简单的解决方案会更好。
支离破碎的Kubernetes生态
Kubernetes架构的另一个问题是,有太多的Kubernetes发行版——以及与之相关的太多不同的工具、哲学和观点——Kubernetes生态系统已经高度断裂。
当然,在某种程度上,任何开源生态系统都会发生破裂。
例如,Red Hat Enterprise Linux与Ubuntu Linux有不同的包管理器、管理工具等。然而,Red Hat和Ubuntu的相似之处多于它们的不同之处。如果你是Red Hat的系统管理员,如果你想要迁移到Ubuntu,你不需要花六个月的时间来教自己新的工具。
我不认为Kubernetes也能这么说。如果你现在正在使用OpenShift,但想要切换到VMware Tanzu,你将面临一个非常陡峭的学习曲线。尽管这两个Kubernetes发行版使用相同的底层平台——Kubernetes,但它们所添加的方法和工具却截然不同。
基于云计算的Kubernetes服务也存在类似的分裂。谷歌Kubernetes引擎(GKE)的用户体验和管理工具套件与Amazon EKS等AWS云平台截然不同。
当然,这不是Kubernetes架构本身的错。这是不同供应商试图将Kubernetes产品区分开来的结果。但从Kubernetes用户的角度来看,这仍然是一个真正的问题。
Kubernetes的组件太多了
我们谈论Kubernetes时,好像它是一个单一的平台,但实际上它包含了超过6个不同的组件。这意味着,当你安装或更新Kubernetes时,你必须分别处理每个部分。而且大多数Kubernetes发行版都缺乏很好的自动化解决方案来做这些事情。
当然,Kubernetes确实是一个复杂的平台,它需要多个部分来工作。但是与其他复杂的平台相比,Kubernetes在将其各个部分集成到一个易于管理的整体方面做得特别差。典型的Linux发行版也由许多不同的软件组成。但是您可以以一种集中的、精简的方式安装和管理它们。Kubernetes的架构并非如此。
Kubernetes不会自动保证高可用性
使用Kubernetes的一个最常见的原因是,它神奇地以一种方式管理你的应用程序,以确保它们永远不会失败,即使你的部分基础设施失败。
Kubernetes体系结构确实能够智能、自动地决定在集群中将工作负载放置在何处。然而,Kubernetes并不是高可用性的灵丹妙药。例如,它在只有一个主节点的生产环境中正常运行,这将导致整个集群崩溃。(如果主服务器故障,整个集群将基本停止工作。)
Kubernetes也不能自动保证在集群中运行的不同工作负载之间合理分配资源。为此,您需要手动设置资源配额。
很难手动控制Kubernetes
尽管Kubernetes需要大量的手动干预来提供高可用性,但如果您真正想要手动控制的话,它会使手动控制变得相当困难。
可以肯定的是,有一些方法可以修改Kubernetes执行探针时间,以确定容器是否正确地执行,或者强制工作负载在集群中的特定服务器上运行。但是Kubernetes体系结构的设计初衷并不是让管理员手动进行这些更改。它假设您总是喜欢使用默认值。
这是有意义的,因为(如上所述)Kubernetes首先是为web规模的部署而创建的。如果您有数千台服务器和数百个工作负载,您不需要手动配置很多东西。但是,如果您是一个规模较小的企业,希望对集群内的工作负载结构有更多的控制,那么Kubernetes很难做到这一点。
Kubernetes监控和性能优化存在一些挑战
Kubernetes试图让您的工作负载保持正常运行(尽管如上所述,它做到这一点的能力取决于一些因素,比如您设置了多少个主机以及您如何结构化的进行资源分配)。
但是Kubernetes体系结构并不能帮助您监控工作负载或确保它们的性能达到最佳。当出现问题时,它不会向您发出警报,而且从集群中收集监控数据并不容易。Kubernetes发行版附带的大多数监视仪表板也没有提供对环境的深入可见性。有第三方工具可以给你提供可见性,但如果你想运行Kubernetes,这些是你必须建立、学习和管理的另一件事。同样,Kubernetes也不擅长帮助您优化成本。如果集群中的服务器仅被使用了20%的容量,它不会通知您,这可能意味着您在过度供应的基础设施上浪费资源。在这里,第三方工具可以帮助您应对类似的挑战,但它们增加了更多的复杂性。
Kubernetes将一切都简化为代码
在Kubernetes中,完成任何任务都需要编写代码。通常,这些代码采用YAML文件的形式,然后必须应用于Kubernetes命令行。
许多人将Kubernetes体系结构的一切皆代码的需求视为一种特性,而不是一个bug。然而,当然我理解使用单一方法和工具(意味着YAML文件)管理整个平台的价值,但我确实希望Kubernetes能为需要它们的人们提供其他选项。
有时候,我不想编写一个很长的YAML文件(或者从GitHub中提取一个YAML文件,然后手动调整其中的随机部分以适应我的环境)来部署一个简单的工作负载。我真希望我可以按下一个按钮或运行一个简单的命令(我指的是kubectl命令不需要12个参数,其中许多配置了神秘的数据字符串必须复制粘贴)有没有办法在Kubernetes做一些简单的操作就可以完成这个过程。但就目前而言无法实现。
Kubernetes想要控制一切
对Kubernetes的最后一个抱怨是,它的设计并不能很好地与其他类型的系统一起运行。它希望成为您用于部署和管理应用程序的唯一平台。如果所有工作负载都是容器化的,并且可以由Kubernetes进行编排,那就太好了。但是,如果您的遗留应用程序不能作为容器运行呢?或者,如果希望在Kubernetes集群上运行部分工作负载,而在外部运行另一部分工作负载,又该怎么办?Kubernetes没有提供原生的功能来做这类事情。它的设计假设是每个人都想一直使用容器运行所有的内容。
为了避免有人指责我讨厌Kubernetes,让我重申一下,它是编排大型容器化应用程序的强大工具。然而Kubernetes架构也有一些缺点。总的来说,如果您需要管理的工作负载,或者您的部署规模不够大,不足以证明Kubernetes带来的复杂性,那么它就不是一个很好的解决方案。为了证明它的全部价值,Kubernetes应该解决您的复杂问题,这样它才能完全达到它在IT生态系统的某些领域所享有的声誉。
Kubernetes重点知识小结
1、k8s是什么,请说出你的了解?
答:Kubenetes是一个针对容器应用,进行自动部署,弹性伸缩和管理的开源系统。主要功能是生产环境中的容器编排。是Google公司推出的,它来源于由Google公司内部使用了15年的Borg系统,集结了Borg的精华。
2、K8s架构的组成是什么?
答:和大多数分布式系统一样,K8S集群至少需要一个主节点(Master)和多个计算节点(Node)。
主节点主要用于暴露API,调度部署和节点的管理;
计算节点运行一个容器运行环境,一般是docker环境(类似docker环境的还有rkt),同时运行一个K8s的代理(kubelet)用于和master通信。计算节点也会运行一些额外的组件,像记录日志,节点监控,服务发现等等。计算节点是k8s集群中真正工作的节点。
K8S架构细分:
1)、Master节点(默认不参加实际工作):
Kubectl:客户端命令行工具,作为整个K8s集群的操作入口;
Api Server:在K8s架构中承担的是“桥梁”的角色,作为资源操作的唯一入口,它提供了认证、授权、访问控制、API注册和发现等机制。客户端与k8s群集及K8s内部组件的通信,都要通过Api Server这个组件;
Controller-manager:负责维护群集的状态,比如故障检测、自动扩展、滚动更新等;
Scheduler:负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;
Etcd:担任数据中心的角色,保存了整个群集的状态;
2)、Node节点:
Kubelet:负责维护容器的生命周期,同时也负责Volume和网络的管理,一般运行在所有的节点,是Node节点的代理,当Scheduler确定某个node上运行pod之后,会将pod的具体信息(image,volume)等发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向master返回运行状态。(自动修复功能:如果某个节点中的容器宕机,它会尝试重启该容器,若重启无效,则会将该pod杀死,然后重新创建一个容器);
Kube-proxy:Service在逻辑上代表了后端的多个pod。负责为Service提供cluster内部的服务发现和负载均衡(外界通过Service访问pod提供的服务时,Service接收到的请求后就是通过kube-proxy来转发到pod上的);
container-runtime:是负责管理运行容器的软件,比如docker
Pod:是k8s集群里面最小的单位。每个pod里边可以运行一个或多个container(容器),如果一个pod中有两个container,那么container的USR(用户)、MNT(挂载点)、PID(进程号)是相互隔离的,UTS(主机名和域名)、IPC(消息队列)、NET(网络栈)是相互共享的。我比较喜欢把pod来当做豌豆夹,而豌豆就是pod中的container;
3、容器和主机部署应用的区别是什么?
答:容器的中心思想就是秒级启动;一次封装、到处运行;这是主机部署应用无法达到的效果,但同时也更应该注重容器的数据持久化问题。另外,容器部署可以将各个服务进行隔离,互不影响,这也是容器的另一个核心概念。
4、请说一下kubenetes针对pod资源对象的健康监测机制?
答:K8s中对于pod资源对象的健康状态检测,提供了三类probe(探针)来执行对pod的健康监测:
1) livenessProbe探针
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。
2) ReadinessProbe探针
同样是可以根据用户自定义规则来判断pod是否健康,如果探测失败,控制器会将此pod从对应service的endpoint列表中移除,从此不再将任何请求调度到此Pod上,直到下次探测成功。
3) startupProbe探针
启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉,这个问题也可以换另一种方式解决,就是定义上面两类探针机制时,初始化时间定义的长一些即可。
每种探测方法能支持以下几个相同的检查参数,用于设置控制检查时间:
initialDelaySeconds:初始第一次探测间隔,用于应用启动的时间,防止应用还没启动而健康检查失败
periodSeconds:检查间隔,多久执行probe检查,默认为10s;
timeoutSeconds:检查超时时长,探测应用timeout后为失败;
successThreshold:成功探测阈值,表示探测多少次为健康正常,默认探测1次。
上面两种探针都支持以下三种探测方法:
1)Exec: 通过执行命令的方式来检查服务是否正常,比如使用cat命令查看pod中的某个重要配置文件是否存在,若存在,则表示pod健康。反之异常。Exec探测方式的yaml文件语法如下:
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe: #选择livenessProbe的探测机制
exec: #执行以下命令
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 #在容器运行五秒后开始探测
periodSeconds: 5 #每次探测的时间间隔为5秒
在上面的配置文件中,探测机制为在容器运行5秒后,每隔五秒探测一次,如果cat命令返回的值为“0”,则表示健康,如果为非0,则表示异常。
2)Httpget: 通过发送http/htps请求检查服务是否正常,返回的状态码为200-399则表示容器健康(注http get类似于命令curl -I)。Httpget探测方式的yaml文件语法如下:
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
livenessProbe: #采用livenessProbe机制探测
httpGet: #采用httpget的方式
scheme:HTTP #指定协议,也支持https
path: /healthz #检测是否可以访问到网页根目录下的healthz网页文件
port: 8080 #监听端口是8080
initialDelaySeconds: 3 #容器运行3秒后开始探测
periodSeconds: 3 #探测频率为3秒
上述配置文件中,探测方式为项容器发送HTTP GET请求,请求的是8080端口下的healthz文件,返回任何大于或等于200且小于400的状态码表示成功。任何其他代码表示异常。
3)tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康,这种方式与HTTPget的探测机制有些类似,tcpsocket健康检查适用于TCP业务。tcpSocket探测方式的yaml文件语法如下:
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
#这里两种探测机制都用上了,都是为了和容器的8080端口建立TCP连接
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
在上述的yaml配置文件中,两类探针都使用了,在容器启动5秒后,kubelet将发送第一个readinessProbe探针,这将连接容器的8080端口,如果探测成功,则该pod为健康,十秒后,kubelet将进行第二次连接。
除了readinessProbe探针外,在容器启动15秒后,kubelet将发送第一个livenessProbe探针,仍然尝试连接容器的8080端口,如果连接失败,则重启容器。探针探测的结果无外乎以下三者之一:
Success:Container通过了检查;
Failure:Container没有通过检查;
Unknown:没有执行检查,因此不采取任何措施(通常是我们没有定义探针检测,默认为成功)。
若觉得上面还不够透彻,可以移步其官网文档。https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
5、如何控制滚动更新过程?
答:可以通过下面的命令查看到更新时可以控制的参数:
# kubectl explain deploy.spec.strategy.rollingUpdate
maxSurge:此参数控制滚动更新过程,副本总数超过预期pod数量的上限。可以是百分比,也可以是具体的值,默认为1(上述参数的作用就是在更新过程中,值若为3,那么不管如何先运行三个pod,用于替换旧的pod,以此类推)。
maxUnavailable:此参数控制滚动更新过程中,不可用的Pod的数量(这个值和上面的值没有任何关系,举个例子:我有十个pod,但是在更新的过程中,我允许这十个pod中最多有三个不可用,那么就将这个参数的值设置为3,在更新的过程中,只要不可用的pod数量小于或等于3,那么更新过程就不会停止)。
6、K8s中镜像的下载策略是什么?
答:可通过命令“kubectl explain pod.spec.containers”来查看imagePullPolicy这行的解释。
K8s的镜像下载策略有三种:Always、Never、IFNotPresent;
Always:镜像标签为latest时,总是从指定的仓库中获取镜像;
Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像;
IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。
默认的镜像下载策略是:当镜像标签是latest时,默认策略是Always;当镜像标签是自定义时(也就是标签不是latest),那么默认策略是IfNotPresent。
7、image的状态有哪些?
Running:Pod所需的容器已经被成功调度到某个节点,且已经成功运行,
Pending:APIserver创建了pod资源对象,并且已经存入etcd中,但它尚未被调度完成或者仍然处于仓库中下载镜像的过程
Unknown:APIserver无法正常获取到pod对象的状态,通常是其无法与所在工作节点的kubelet通信所致。
8、pod的重启策略是什么?
答:可以通过命令`kubectl explain pod.spec查看pod的重启策略(restartPolicy字段)。
Always:但凡pod对象终止就重启,此为默认策略。
OnFailure:仅在pod对象出现错误时才重启
9、Service这种资源对象的作用是什么?
答:用来给相同的多个pod对象提供一个固定的统一访问接口,常用于服务发现和服务访问。
10、版本回滚相关的命令?
# kubectl apply -f httpd2-deploy1.yaml --record
#运行yaml文件,并记录版本信息;
# kubectl rollout history deployment httpd-devploy1
#查看该deployment的历史版本
# kubectl rollout undo deployment httpd-devploy1 --to-revision=1
#执行回滚操作,指定回滚到版本1
#在yaml文件的spec字段中,可以写以下选项(用于限制最多记录多少个历史版本):
spec:
revisionHistoryLimit: 5
#这个字段通过 kubectl explain deploy.spec 命令找到revisionHistoryLimit 行获得
11、标签与标签选择器的作用是什么?
标签:是当相同类型的资源对象越来越多的时候,为了更好的管理,可以按照标签将其分为一个组,为的是提升资源对象的管理效率。
标签选择器:就是标签的查询过滤条件。目前API支持两种标签选择器:
基于等值关系的,如:“=”、“”“==”、“!=”(注:“==”也是等于的意思,yaml文件中的matchLabels字段);
基于集合的,如:in、notin、exists(yaml文件中的matchExpressions字段);
注:in:在这个集合中;notin:不在这个集合中;exists:要么全在(exists)这个集合中,要么都不在(notexists);
使用标签选择器的操作逻辑:
在使用基于集合的标签选择器同时指定多个选择器之间的逻辑关系为“与”操作(比如:- {key: name,operator: In,values: [zhangsan,lisi]} ,那么只要拥有这两个值的资源,都会被选中);
使用空值的标签选择器,意味着每个资源对象都被选中(如:标签选择器的键是“A”,两个资源对象同时拥有A这个键,但是值不一样,这种情况下,如果使用空值的标签选择器,那么将同时选中这两个资源对象)
空的标签选择器(注意不是上面说的空值,而是空的,都没有定义键的名称),将无法选择出任何资源;
在基于集合的选择器中,使用“In”或者“Notin”操作时,其values可以为空,但是如果为空,这个标签选择器,就没有任何意义了。
两种标签选择器类型(基于等值、基于集合的书写方法):
selector:
matchLabels: #基于等值
app: nginx
matchExpressions: #基于集合
- {key: name,operator: In,values: [zhangsan,lisi]} #key、operator、values这三个字段是固定的
- {key: age,operator: Exists,values:} #如果指定为exists,那么values的值一定要为空
12、常用的标签分类有哪些?
标签分类是可以自定义的,但是为了能使他人可以达到一目了然的效果,一般会使用以下一些分类:
版本类标签(release):stable(稳定版)、canary(金丝雀版本,可以将其称之为测试版中的测试版)、beta(测试版);
环境类标签(environment):dev(开发)、qa(测试)、production(生产)、op(运维);
应用类(app):ui、as、pc、sc;
架构类(tier):frontend(前端)、backend(后端)、cache(缓存);
分区标签(partition):customerA(客户A)、customerB(客户B);
品控级别(Track):daily(每天)、weekly(每周)。
13、有几种查看标签的方式?
答:常用的有以下三种查看方式:
# kubectl get pod --show-labels #查看pod,并且显示标签内容
# kubectl get pod -L env,tier #显示资源对象标签的值
# kubectl get pod -l env,tier #只显示符合键值资源对象的pod,而“-L”是显示所有的pod
14、添加、修改、删除标签的命令?
#对pod标签的操作
# kubectl label pod label-pod abc=123 #给名为label-pod的pod添加标签
# kubectl label pod label-pod abc=456 --overwrite #修改名为label-pod的标签
# kubectl label pod label-pod abc- #删除名为label-pod的标签
# kubectl get pod --show-labels
#对node节点的标签操作
# kubectl label nodes node01 disk=ssd #给节点node01添加disk标签
# kubectl label nodes node01 disk=sss –overwrite #修改节点node01的标签
# kubectl label nodes node01 disk- #删除节点node01的disk标签
15、DaemonSet资源对象的特性?
DaemonSet这种资源对象会在每个k8s集群中的节点上运行,并且每个节点只能运行一个pod,这是它和deployment资源对象的最大也是唯一的区别。所以,在其yaml文件中,不支持定义replicas,除此之外,与Deployment、RS等资源对象的写法相同。
它的一般使用场景如下:
在去做每个节点的日志收集工作;
监控每个节点的的运行状态;
16、说说你对Job这种资源对象的了解?
答:Job与其他服务类容器不同,Job是一种工作类容器(一般用于做一次性任务)。使用常见不多,可以忽略这个问题。
#提高Job执行效率的方法:
spec:
parallelism: 2 #一次运行2个
completions: 8 #最多运行8个
template:
metadata:
17、描述一下pod的生命周期有哪些状态?
Pending:表示pod已经被同意创建,正在等待kube-scheduler选择合适的节点创建,一般是在准备镜像;
Running:表示pod中所有的容器已经被创建,并且至少有一个容器正在运行或者是正在启动或者是正在重启;
Succeeded:表示所有容器已经成功终止,并且不会再启动;
Failed:表示pod中所有容器都是非0(不正常)状态退出;
Unknown:表示无法读取Pod状态,通常是kube-controller-manager无法与Pod通信。
18、创建一个pod的流程是什么?
客户端提交Pod的配置信息(可以是yaml文件定义好的信息)到kube-apiserver;
Apiserver收到指令后,通知给controller-manager创建一个资源对象;
Controller-manager通过api-server将pod的配置信息存储到ETCD数据中心中;
Kube-scheduler检测到pod信息会开始调度预选,会先过滤掉不符合Pod资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行pod的节点,然后将pod的资源配置单发送到node节点上的kubelet组件上。
Kubelet根据scheduler发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给scheduler,scheduler将返回的pod运行状况的信息存储到etcd数据中心。
19、删除一个Pod会发生什么事情?
答:Kube-apiserver会接受到用户的删除指令,默认有30秒时间等待优雅退出,超过30秒会被标记为死亡状态,此时Pod的状态Terminating,kubelet看到pod标记为Terminating就开始了关闭Pod的工作;
关闭流程如下:
pod从service的endpoint列表中被移除;
如果该pod定义了一个停止前的钩子,其会在pod内部被调用,停止钩子一般定义了如何优雅的结束进程;
进程被发送TERM信号(kill -14)
当超过优雅退出的时间后,Pod中的所有进程都会被发送SIGKILL信号(kill -9)。
20、K8s的Service是什么?
答:Pod每次重启或者重新部署,其IP地址都会产生变化,这使得pod间通信和pod与外部通信变得困难,这时候,就需要Service为pod提供一个固定的入口。Service的Endpoint列表通常绑定了一组相同配置的pod,通过负载均衡的方式把外界请求分配到多个pod上。
21、k8s是怎么进行服务注册的?
答:Pod启动后会加载当前环境所有Service信息,以便不同Pod根据Service名进行通信。
22、k8s集群外流量怎么访问Pod?
答:可以通过Service的NodePort方式访问,会在所有节点监听同一个端口,比如:30000,访问节点的流量会被重定向到对应的Service上面。
23、k8s数据持久化的方式有哪些?
答:
1)EmptyDir(空目录)
没有指定要挂载宿主机上的某个目录,直接由Pod内部映射到宿主机上。类似于docker中的manager volume。
主要使用场景:
只需要临时将数据保存在磁盘上,比如在合并/排序算法中;
作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的数据存入其中,同时由同一个webserver容器对外提供这些页面。
emptyDir的特性:
同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的数据也会被删除。如果仅仅是容器被销毁,pod还在,则不会影响volume中的数据。
总结来说:emptyDir的数据持久化的生命周期和使用的pod一致。一般是作为临时存储使用。
2)Hostpath
将宿主机上已存在的目录或文件挂载到容器内部。类似于docker中的bind mount挂载方式。
这种数据持久化方式,运用场景不多,因为它增加了pod与节点之间的耦合。
一般对于k8s集群本身的数据持久化和docker本身的数据持久化会使用这种方式,可以自行参考apiService的yaml文件,位于:/etc/kubernetes/main…目录下。
3)PersistentVolume(简称PV)
基于NFS服务的PV,也可以基于GFS的PV。它的作用是统一数据持久化目录,方便管理。
在一个PV的yaml文件中,可以对其配置PV的大小,指定PV的访问模式:
ReadWriteOnce:只能以读写的方式挂载到单个节点;
ReadOnlyMany:能以只读的方式挂载到多个节点;
ReadWriteMany:能以读写的方式挂载到多个节点。以及指定pv的回收策略:
recycle:清除PV的数据,然后自动回收;
Retain:需要手动回收;
delete:删除云存储资源,云存储专用;
注意:这里的回收策略指的是在PV被删除后,在这个PV下所存储的源文件是否删除)。
若需使用PV,那么还有一个重要的概念:PVC,PVC是向PV申请应用所需的容量大小,K8s集群中可能会有多个PV,PVC和PV若要关联,其定义的访问模式必须一致。定义的storageClassName也必须一致,若群集中存在相同的(名字、访问模式都一致)两个PV,那么PVC会选择向它所需容量接近的PV去申请,或者随机申请。