从站点的崩溃看架构设计一例
 某站突然就崩了,到最后来了个404,线上故障快速排查始终是运维小哥们逃不过的宿命。
某站突然就崩了,到最后来了个404,线上故障快速排查始终是运维小哥们逃不过的宿命。有哪些常见的线上故障,如何快速定位问题呢?本文将详细总结工作中的经验,从服务器、应用、数据库、缓存、网络和业务六个层面分享线上故障排查的思路和技巧。下面从小到大总结一些处理的方式与方法,从具体的工具排查方法到总体的部署架构。
线上定位问题时,主要靠监控和日志。一旦超出监控的范围,则排查思路很重要,按照流程化的思路来定位问题,能够让我们在定位问题时从容、快速的定位到线上的问题。本文综合了两篇主要的故障分析和架构设计的文章。
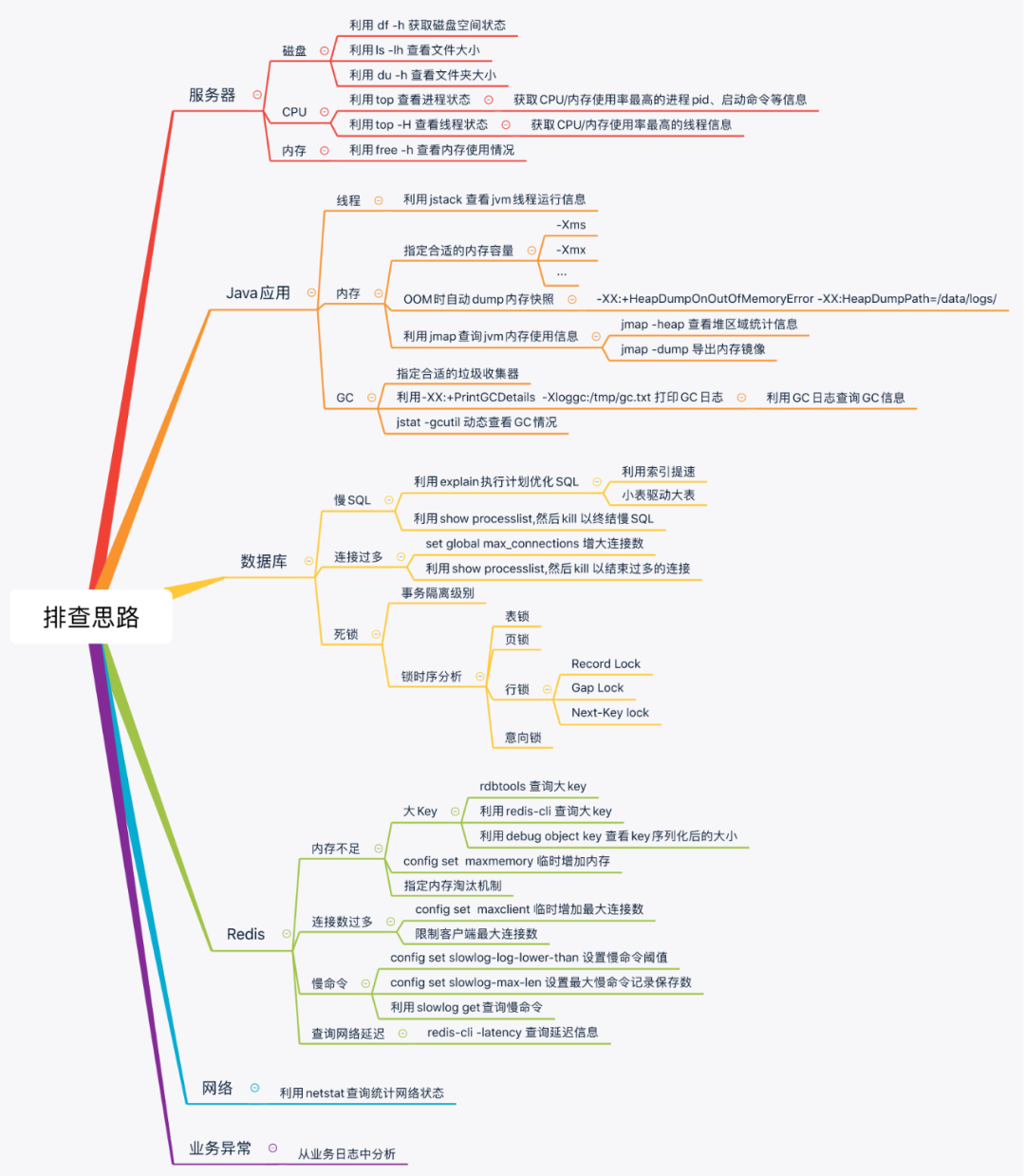
线上问题定位思维导图
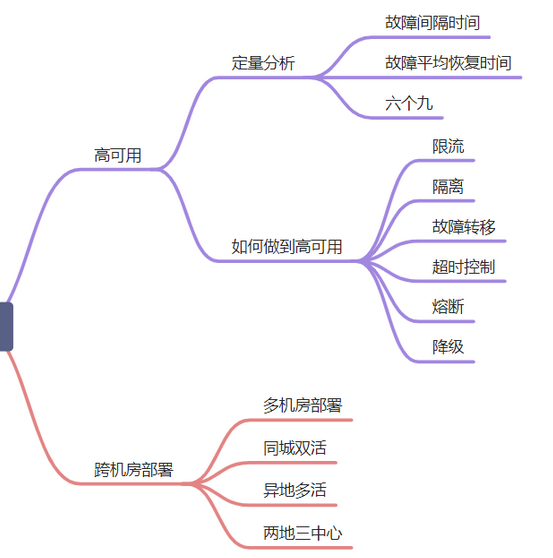
高可用以及跨IDC部署
一、服务器层面
1、 磁盘
问题现象:当磁盘容量不足的时候引起的应用异常,有基本的运维工具不会出现此类低级问题。
2、 CPU过高
问题现象:当CPU过高的时候,接口性能会快速下降,同时监控也会开始报警。
排查思路:利用 top 查询CPU使用率最高的进程,top进程内指令参数:
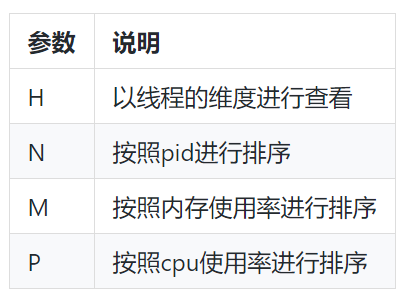
结果参数
二、应用层面
1、 后端应用假死
发现问题:监控平台发现某个Tomcat节点已经无法采集到数据,连上服务器查看服务器进程还在,netstat -anop|grep 8001端口也有监听,查看日志打印时断时续或间歇性出错。可根据不同类型的应用进行分析处理,java多用jdk中提供的系例工具,对GC类日志分析
2、 应用CPU使用率过高
查找问题进程
利用top查到占用cpu最高的进程pid为14。
查找问题线程
利用 top -H -p 查看进程内占用cpu最高线程,从下图可知,问题线程主要是activeCpu Thread,其pid为517。
查询线程详细信息
首先利用 printf "%x \n" 将tid换为十六进制:xid。
再利用 jstack | grep nid=0x -A 10 查询线程信息(若进程无响应,则使用 jstack -f )
分析代码
三、数据库
1、死锁
问题出现
最近线上随着流量变大,突然开始报如下异常,即发生了死锁问题:
Deadlock found when trying to get lock; try restarting transaction ;
查询事务隔离级别
利用 select @@tx_isolation 命令获取到数据库隔离级别信息。查询数据库死锁日志:利用 show engine innodb status 命令获取到如下死锁信息。
2、 慢SQL
问题出现
应用TPS下降,应用甚至挂起。分析执行计划:利用explain指令获得该SQL语句的执行计划,根据该执行计划,可能有两种场景。
2.1.SQL不走索引或扫描行数过多等致使执行时长过长。
2.2.SQL没问题,只是因为事务并发导致等待锁,致使执行时长过长。
通过增加索引,调整SQL语句的方式优化执行时长, 例如下的执行计划:
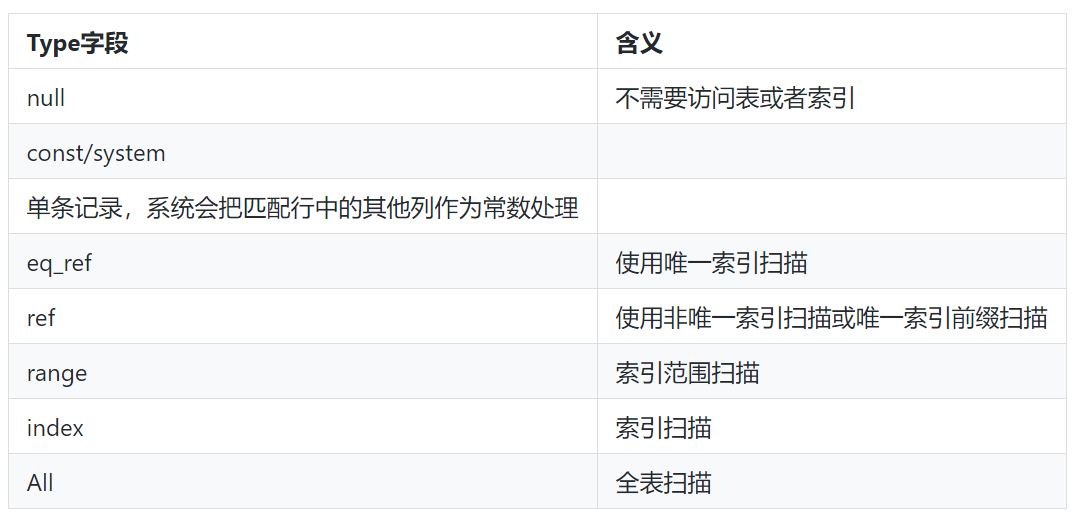
该SQL的执行计划的type为ALL,同时根据以下type语义,可知无索引的全表查询,故可为其检索列增加索引进而解决。
3、 连接数过多
问题出现
常出现too many connections异常,数据库连接到达最大连接数:
3.1.通过set global max_connections=XXX增大最大连接数。
3.2.先利用show processlist获取连接信息,然后利用kill杀死过多的连。
4、常见的优化建议
小表驱动大表
MySQL 表关联的算法是Nest Loop Join(嵌套循环连接),是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
使用自增长主键
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
总之,数据库这块有太多的专业上的知识涉及,规模稍大的公司都要配备DBA。
四、Redis
1、 问题处理思路
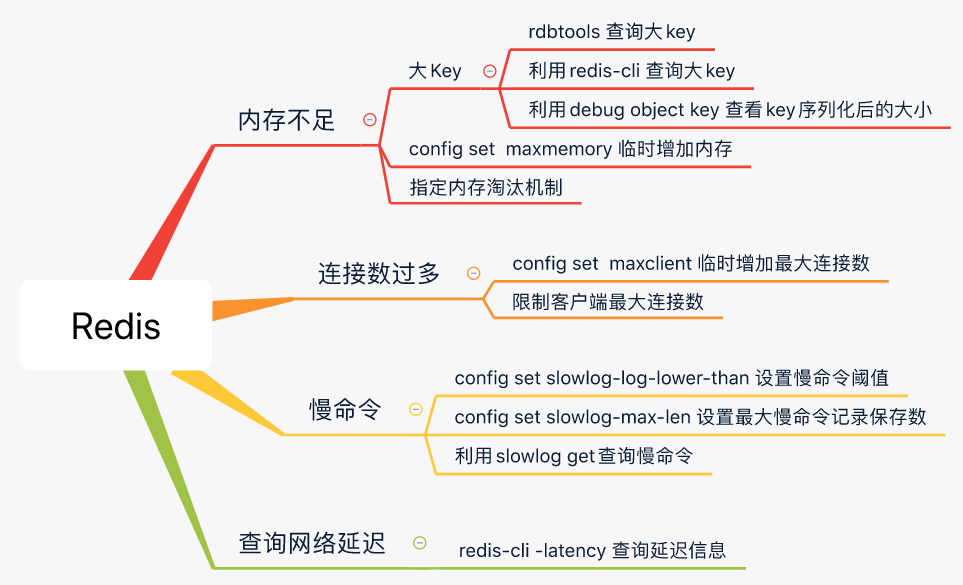
2、 内存告警
时常会出现下述异常提示信息:
OOM command not allowed when used memory
1)设置合理的内存大小
设置maxmemory和相对应的回收策略算法,设置最好为物理内存的3/4,或者比例更小,因为redis复制数据等其他服务时,也是需要缓存的。以防缓存数据过大致使redis崩溃,造成系统出错不可用。
通过redis.conf 配置文件指定
maxmemory xxxxxx
通过命令修改
config set maxmemory xxxxx
2)设置合理的内存淘汰策略
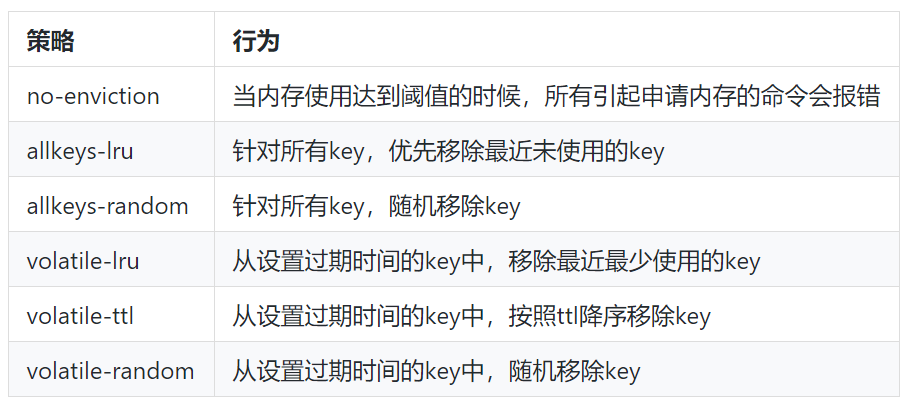
通过redis.conf 配置文件指定
maxmemory-policy allkeys-lru
3)查看大key
有工具的情况下:
安装工具dbatools redisTools,列出最大的前N个key
redis-cli-new -h <ip> -p <port> --bigkeys --bigkey-numb 3
得到如下结果:
Sampled 122114 keys in the keyspace!
Total key length in bytes is 3923725 (avg len 32.13)
Biggest string Key Top 1 found 'xx1' has 36316 bytes
Biggest string Key Top 2 found 'xx2' has 1191 bytes
Biggest string Key Top 3 found 'xx3' has 234 bytes
Biggest list Key Top 1 found 'x4' has 204480 items
Biggest list Key Top 2 found 'x5' has 119999 items
Biggest list Key Top 3 found 'x6' has 60000 items
Biggest set Key Top 1 found 'x7' has 14205 members
Biggest set Key Top 2 found 'x8' has 292 members
Biggest set Key Top 3 found 'x,7' has 21 members
Biggest hash Key Top 1 found 'x' has 302939 fields
Biggest hash Key Top 2 found 'xc' has 92029 fields
Biggest hash Key Top 3 found 'xd' has 39634 fields
原生命令为:
redis-cli -c -h <ip> -p <port> --bigkeys
分析rdb文件中的全部key/某种类型的占用量:
rdb -c memory dump.rdb -t list -f dump-formal-list.csv
查看某个key的内存占用量:
# redis-memory-for-key -s <ip> -p <port> x
Key x
Bytes 4274388.0
Type hash
Encoding hashtable
Number of Elements 39634
Length of Largest Element 29
无工具的情况下可利用以下指令评估key大小:
debug object key
3、 Redis的慢命令
1)设置Redis的慢命令的时间阈值(单位:微妙)
通过redis.conf配置文件方式
# 执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
slowlog-log-lower-than 1000
# 最多能保存多少条日志
slowlog-max-len 200
通过命令方式
# 配置查询时间超过1毫秒的, 第一个参数单位是微秒
config set slowlog-log-lower-than 1000
# 保存200条慢查记录
config set slowlog-max-len 200
2)查看Redis的慢命令
slowlog get
4、 连接过多
通过redis.conf 配置文件指定最大连接数
maxclients 10000
通过命令修改
config set maxclients xxx
5、 线上Redis节点挂掉一个之后的处理流程
1)查看节点状态
执行 cluster nodes 后发现会有一个节点dead:
redis-cli -c -h <ip> -p <port>
ip:port> cluster nodes
2)移除错误节点
一开始执行如下的删除操作失败,需要针对于每一个节点都执行 cluster forget:
ip:port> cluster forget THEUUID
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点
删除挂掉的节点:
redis-trib.rb del-node m3 THEUUID
>>> Removing node THEUUID from cluster m3
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
清理掉节点配置目录下的rdb aof nodes.conf 等文件,否则节点的启动会有如下异常:
[ERR] Node s3 is not empty. Either the node already knows other nodes (check with CLUSTER NODES)or contains some key in database 0.
3)恢复节点
后台启动Redis某个节点:
redis-server /etc/redis/7001/redis.conf &
将该节点添加进集群:
redis-trib.rb add-node --slave --master-id THEUUID s3 m3
>>> Adding node s3 to cluster m3
>>> Performing Cluster Check (using node m3)
M: THEUUID m3
slots:0-5460 (5461 slots)master
0 additional replica(s)
M: THEUUID m1
slots:10923-16383 (5461 slots)master
1 additional replica(s)
S: a38c6f957f2706f269cf5d9b628586a9372265e9 s1
slots: (0 slots)slave
replicates THEUUID
S: 77ce43ec23f25f77ec68fe71ae3cb799e7300c6d s2
slots: (0 slots)slave
replicates THEUUID
M: THEUUID m2
slots:5461-10922 (5462 slots)master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node s3 to make it join the cluster.
Waiting for the cluster to join..
>>> Configure node as replica of m3.
[OK] New node added correctly.
s3:本次待添加的从节点ip:port
m3:主节点的ip:port
THEUUID:主节点编号
五、网络
1、 排查流程
1)现象出现
在非压测或者高峰期的情况下,突然出现大量的503等错误码,页面无法打开。
2)查看是否遭受了DOS攻击
当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
netstat -n|grep SYN_RECV
3)查看TCP连接状态
首先利用以下查看tcp总连接数,判断连接数是否正常:
netstat -anoe|grep 8000|wc -l 查看8000
然后利用如下命令判断各个状态的连接数是否正常:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S)print a, S[a]}'
根据上述信息,如果TIME_WAIT 状态数量过多,可利用如下命令查看连接CLOSE_WAIT最多的IP地址,再结合业务分析问题:
netstat -n|grep TIME_WAIT|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -10
2、 相关知识
1)TCP连接
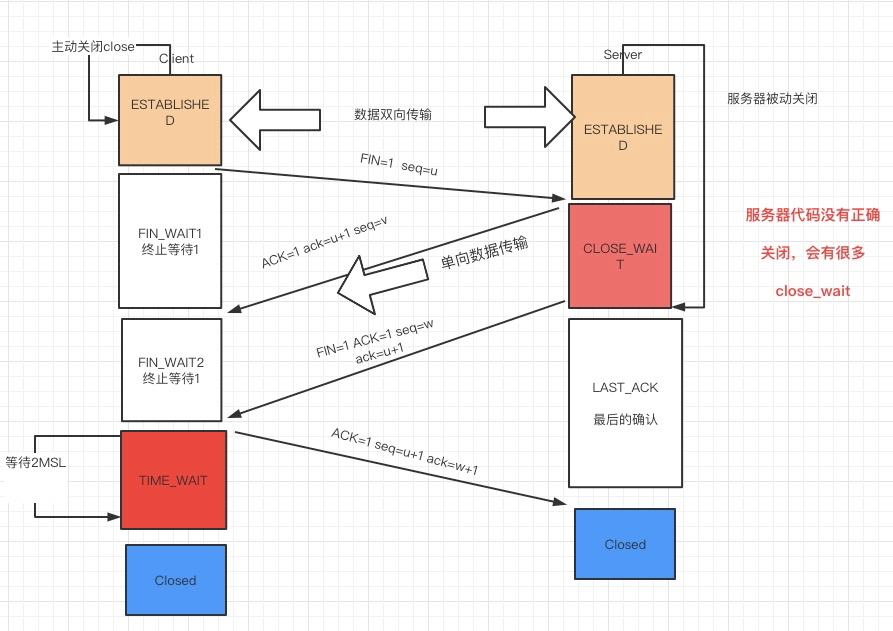
TCP三次握手四次挥手
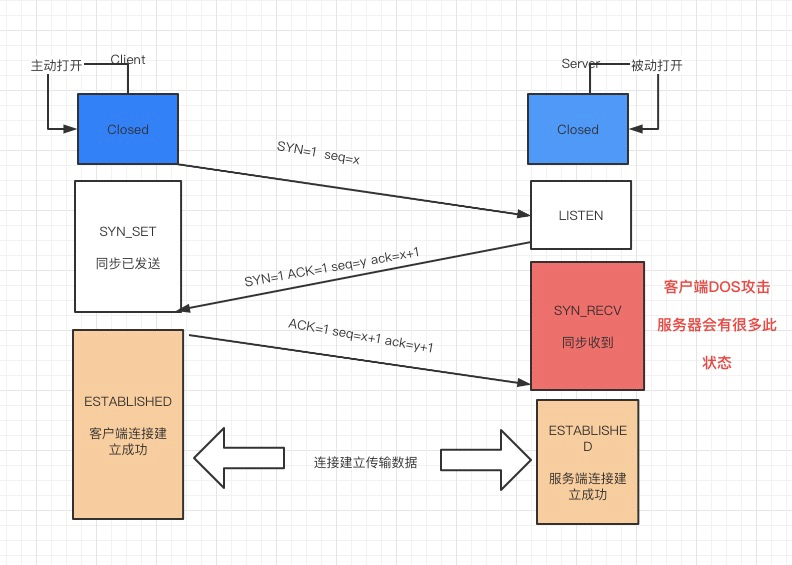
为什么在第3步中客户端还要再进行一次确认呢?这主要是为了防止已经失效的连接请求报文段突然又传回到服务端而产生错误的场景:
所谓"已失效的连接请求报文段"是这样产生的。正常来说,客户端发出连接请求,但因为连接请求报文丢失而未收到确认。于是客户端再次发出一次连接请求,后来收到了确认,建立了连接。数据传输完毕后,释放了连接,客户端一共发送了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,没有"已失效的连接请求报文段"。
现在假定一种异常情况,即客户端发出的第一个连接请求报文段并没有丢失,只是在某些网络节点长时间滞留了,以至于延误到连接释放以后的某个时间点才到达服务端。本来这个连接请求已经失效了,但是服务端收到此失效的连接请求报文段后,就误认为这是客户端又发出了一次新的连接请求。于是服务端又向客户端发出请求报文段,同意建立连接。假定不采用三次握手,那么只要服务端发出确认,连接就建立了。
由于现在客户端并没有发出连接建立的请求,因此不会理会服务端的确认,也不会向服务端发送数据,但是服务端却以为新的传输连接已经建立了,并一直等待客户端发来数据,这样服务端的许多资源就这样白白浪费了。
采用三次握手的办法可以防止上述现象的发生。比如在上述的场景下,客户端不向服务端的发出确认请求,服务端由于收不到确认,就知道客户端并没有要求建立连接。
SYN攻击时一种典型的DDOS攻击,检测SYN攻击的方式非常简单,即当Server上有大量半连接状态且源IP地址是随机的,则可以断定遭到SYN攻击了,使用如下命令可以让之现行:
netstat -nap | grep SYN_RECV
2)一些常见问题
为什么TCP连接的建立只需要三次握手而TCP连接的释放需要四次握手呢?
因为服务端在LISTEN状态下,收到建立请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而连接关闭时,当收到对方的FIN报文时,仅仅表示对方没有需要发送的数据了,但是还能接收数据,己方未必数据已经全部发送给对方了,所以己方可以立即关闭,也可以将应该发送的数据全部发送完毕后再发送FIN报文给客户端来表示同意现在关闭连接。
从这个角度而言,服务端的ACK和FIN一般都会分开发送。如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。
MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
六、业务异常
主要是通过业务日志监控主动报警或者是查看错误日志被动发现。在日志文件中检索异常至分析出应用的具体问题,可使用高可用技术实现部分可用。
七、高可用
常见的高可用的方案就是一主多从,主节点挂了,可以快速切换到从节点,从节点充当主节点,继续提供服务。比如 SQL Server 的主从架构,Redis 的主从架构,它们都是为了达到高可用性,即使某台服务器宕机了,也能继续提供服务。
有两个相关的概念需要提及:MTBF 和 MTTR。
MTBF:故障间隔时间,可以理解为从上次故障到这次故障,间隔多久,间隔的越长,系统稳定性越高。
MTTR:故障平均恢复时间,可以理解为突然发生故障了,到系统恢复正常,经历了多长时间,这个时间越短越好,不然用户等着急了,会收到很多投诉。
可用性计算公式:MTBF/(MTBF+MTTR)* 100%,就是用故障的间隔时间除以故障间隔时间+故障平均恢复时间的总和。通常情况下,我们使用几个九来表示系统的可用性,之前我们项目组的系统要求达到年故障时间不超过 5 分钟,也就是五个九的标准。
一个九和两个九
非常容易达到,一个正常的线上系统不会每天宕机 15 分钟吧,不然真用不下去了。
三个就和四个九
允许故障的时间很短,年故障时间是 1 小时到 8 小时,需要从架构设计、代码质量、运维体系、故障处理手册等入手,其中非常关键的一环是运维体系,如果线上出了问题,第一波收到异常通知的肯定是运维团队,根据问题的严重程度,会有不同的运维人员来处理,像 B 站这种大事故,就得运维负责人亲自上阵了。
另外在紧急故障发生时,是否可以人工手段降级或者加开关,限制部分功能,也是需要考虑的。之前我遇到过一个问题,二维码刷卡功能出现故障,辛亏之前做了一个开关,可以将二维码功能隐藏,如果用户要使用二维码刷卡功能,统一引导用户走线下刷卡功能。
五个九
年故障时间 5 分钟以内,这个相当短,即使有强大的运维团队每天值班也很难在收到异常报警后,5 分钟内快速恢复,所以只能用自动化运维来解决。也就是服务器自己来保证系统的容灾和自动恢复的能力。
六个九
这个标准相当苛刻了,年故障时间 32 秒。针对不同的系统,其实对几个九也不相同。比如公司内部的员工系统,要求四个九组以,如果是给全国用户使用,且使用人数很多,比如某宝、某饿,那么就要求五个九以上了,但是即使是数一数二的电商系统,它里面也有非核心的业务,其实也可以放宽限制,四个九足以,这个就看各家系统的要求,都是成本、人力、重要程度的权衡考虑。
高可用的方案也是很常见,故障转移、超时控制、限流、隔离、熔断、降级。
7.1 限流
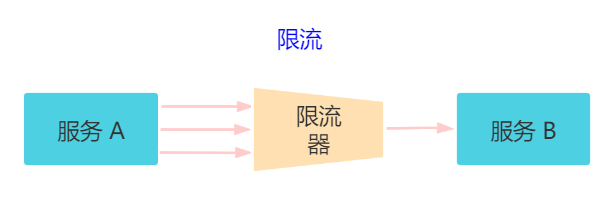
对请求的流量进行控制, 只放行部分请求,使服务能够承担不超过自己能力的流量压力。
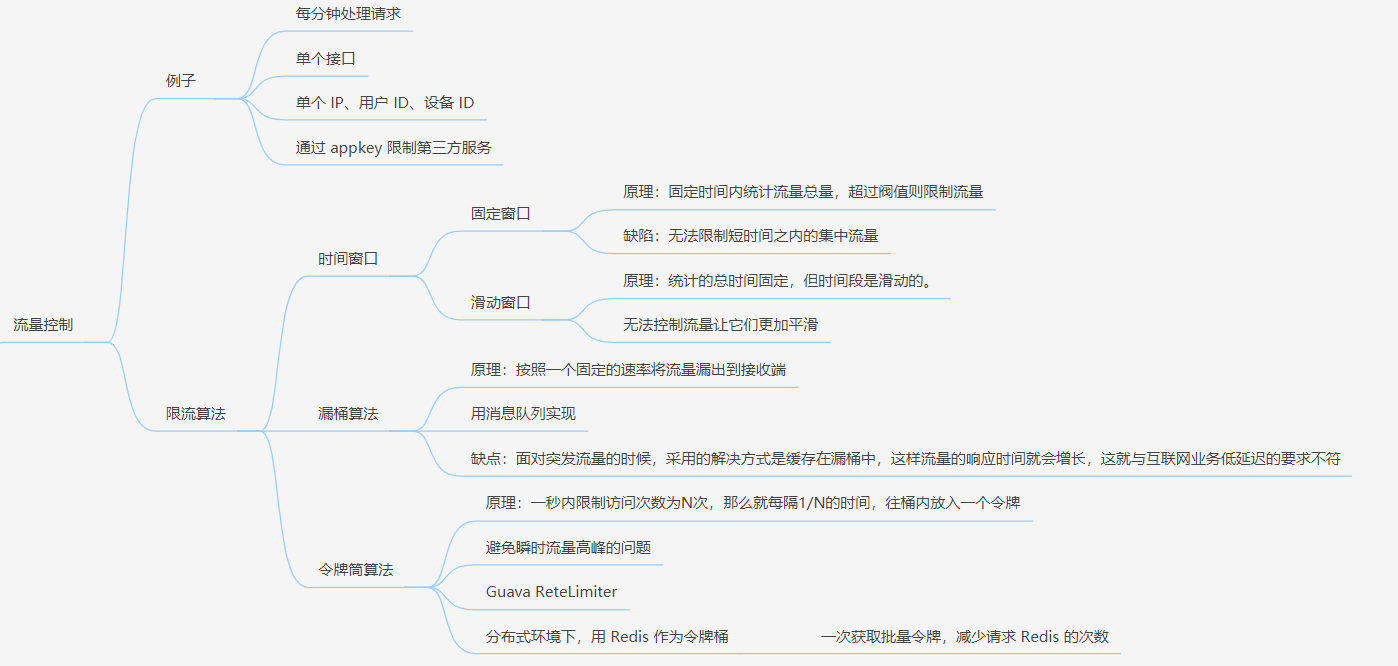
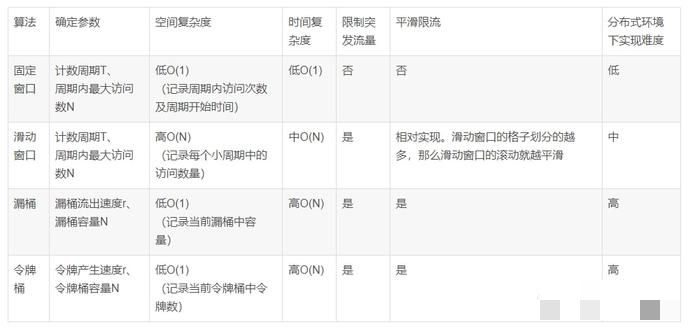
常见限流算法有三种:时间窗口、漏桶算法、令牌桶算法。
7.1.1 时间窗口
时间窗口又分为固定窗口和滑动窗口。具体原理可以看这篇:东汉末年,他们把「服务雪崩」玩到了极致(干货)
固定时间窗口:
原理:固定时间内统计流量总量,超过阀值则限制流量。
缺陷:无法限制短时间之内的集中流量。
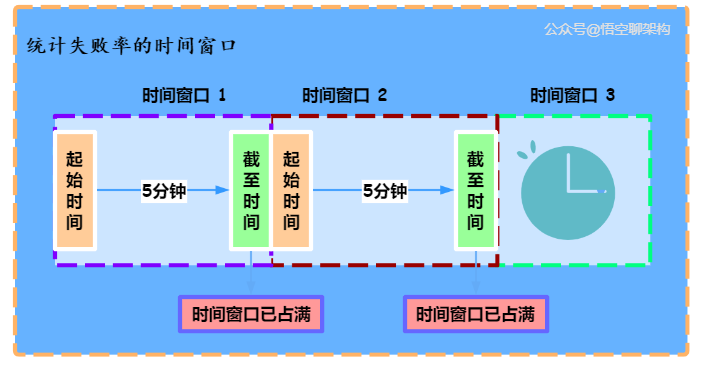
滑动窗口原理:
原理:统计的总时间固定,但时间段是滑动的。
缺陷:无法控制流量让它们更加平滑
时间窗口的原理图在这里:
7.1.2 漏桶算法。
原理:按照一个固定的速率将流量露出到接收端。
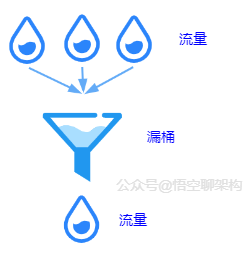
缺陷:面对突发流量的时候,采用的解决方式是缓存在漏桶中,这样流量的响应时间就会增长,这就与互联网业务低延迟的要求不符。
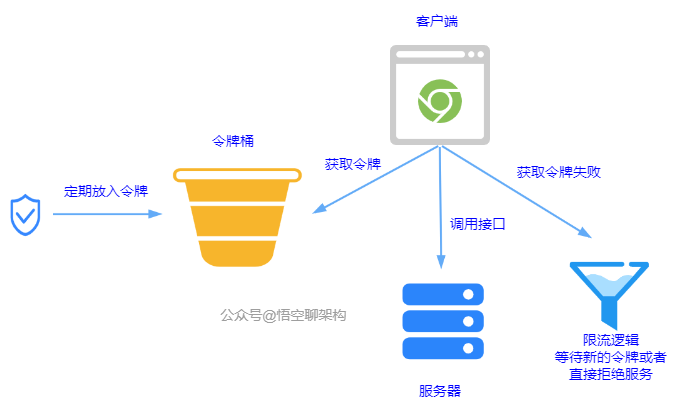
7.1.3 令牌桶算法
原理:一秒内限制访问次数为 N 次。每隔 1/N 的时间,往桶内放入一个令牌。分布式环境下,用 Redis 作为令牌桶。原理图如下:
总结的思维导图在这里:
7.1.4 另外再盘点常用4种限流算法
1、计数器(固定窗口)算法
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。此算法在单机还是分布式环境下实现都非常简单,使用redis的incr原子自增性和线程安全即可轻松实现。
这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题,如下图:
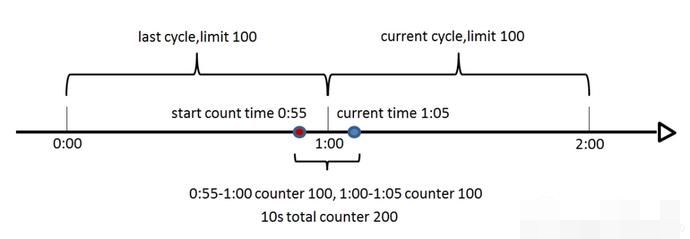
假设1min内服务器的负载能力为100,因此一个周期的访问量限制在100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入100的访问量,虽然没有超过每个周期的限制量,但是整体上10秒内已达到200的访问量,已远远超过服务器的负载能力,由此可见,计数器算法方式限流对于周期比较长的限流,存在很大的弊端。
2、滑动窗口算法
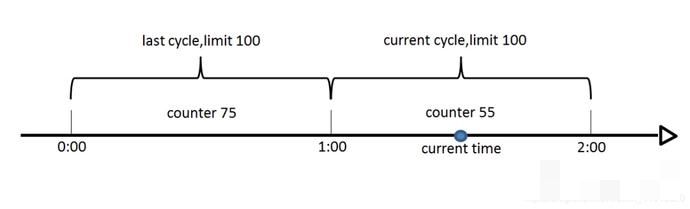
滑动窗口算法是将时间周期分为N个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。
如下图,假设时间周期为1min,将1min再分为2个小周期,统计每个小周期的访问数量,则可以看到,第一个时间周期内,访问数量为75,第二个时间周期内,访问数量为100,超过100的访问则被限流掉了。
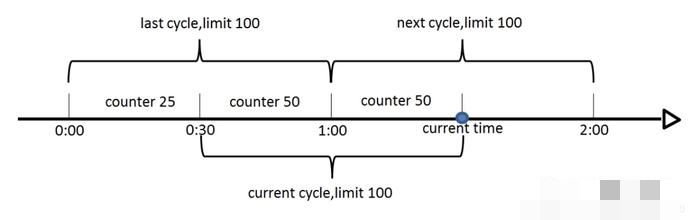
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。此算法可以很好的解决固定窗口算法的临界问题。
3、漏桶算法
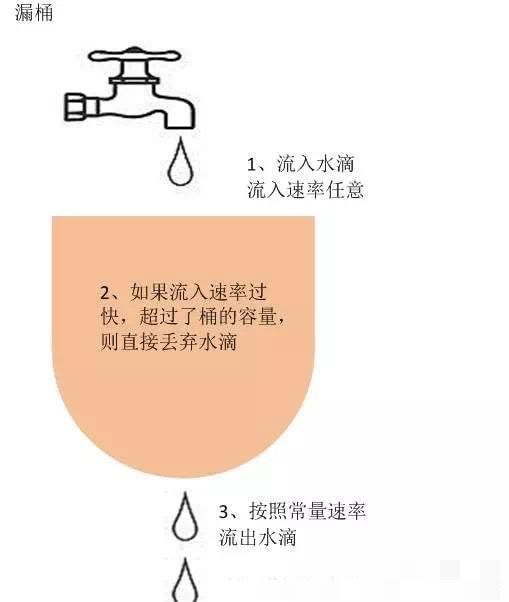
漏桶算法是访问请求到达时直接放入漏桶,如当前容量已达到上限(限流值),则进行丢弃(触发限流策略)。漏桶以固定的速率进行释放访问请求(即请求通过),直到漏桶为空。
4、令牌桶算法
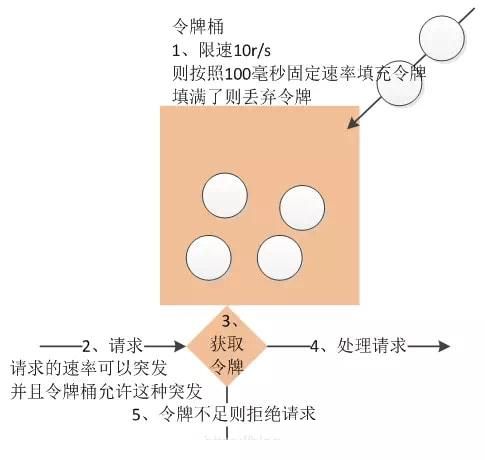
令牌桶算法是程序以r(r=时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满,请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略
5、各个算法比较
7.2 隔离
每个服务看作一个独立运行的系统,即使某一个系统有问题,也不会影响其他服务。
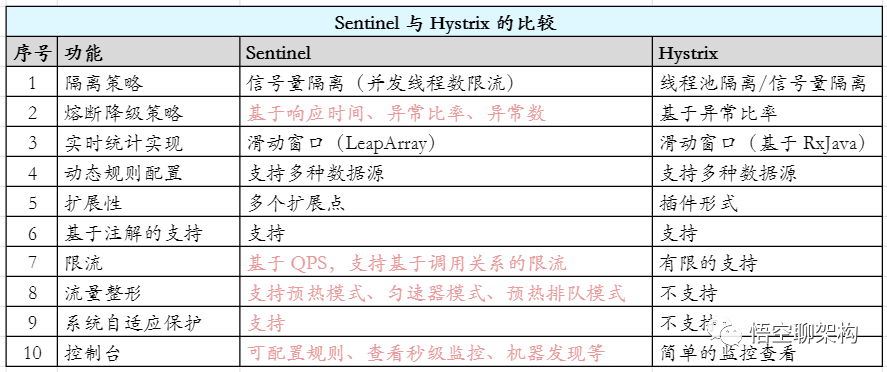
而常规的方案是使用两款组件:Sentinel 和 Hystrix。
7.3 故障转移
故障转移分为两种:
完全对等节点的故障转移。节点都是同等性质的。
不对等节点的故障转移。不对等就是主备节点都存在。
对等节点的系统中,所有节点都承担读写流量,并且节点不保存状态,每个节点就是另外一个的镜像。如果某个节点宕机了,按照负载均衡的权重配置访问其他节点就可以了。
不对等的系统中,有一个主节点,多个备用节点,可以是热备(备用节点也在提供在线服务),也可以是冷备(只是备份作用)。如果主节点宕机了,可以被系统检测到,立即进行主备切换。
而如何检测主节点宕机,就需要用到分布式 Leader 选举的算法,常见的就有 Paxos 和 Raft 算法。
7.4 超时控制
超时控制就是模块与模块之间的调用需要限制请求的时间,如果请求超时的设置得较长,比如 30 s,那么当遇到大量请求超时的时候,由于请求线程都阻塞在慢请求上,导致很多请求都没来得及处理,如果持续时间足够长,就会产生级联反应,形成雪崩。
还是以我们最熟悉的下单场景为例:用户下单了一个商品,客户端调用订单服务来生成预付款订单,订单服务调用商品服务查看下单的哪款商品,商品服务调用库存服务判断这款商品是否有库存,如有库存,则可以生成预付款订单。
雪崩如何造成的?
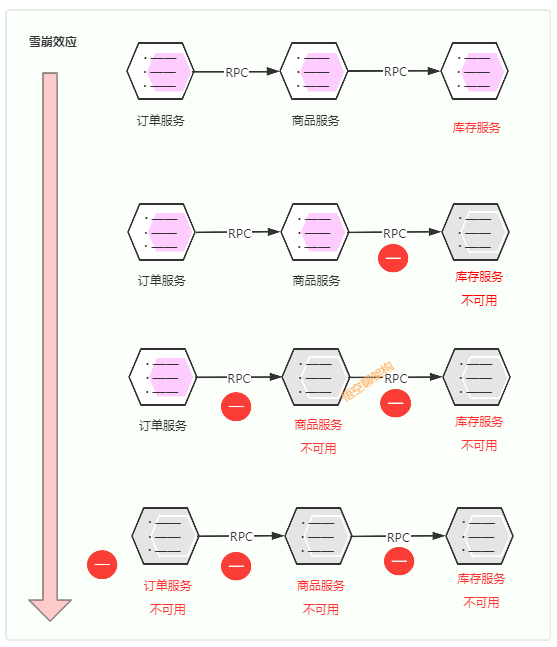
第一次滚雪球:库存服务不可用(如响应超时等),库存服务收到的很多请求都未处理完,库存服务将无法处理更多请求。
第二次滚雪球:因商品服务的请求都在等库存服务返回结果,导致商品服务调用库存服务的很多请求未处理完,商品服务将无法处理其他请求,导致商品服务不可用
第三次滚雪球:因商品服务不可用,订单服务调用商品服务的的其他请求无法处理,导致订单服务不可用。
第四次滚雪球:因订单服务不可用,客户端将不能下单,更多客户将重试下单,将导致更多下单请求不可用。
所以设置合理的超时时间非常重要。具体设置的地方:模块与模块之间、请求数据库、缓存处理、调用第三方服务。
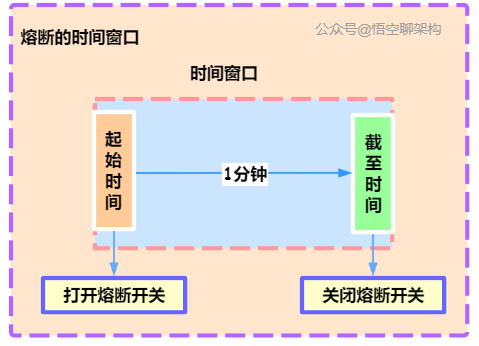
7.5 熔断
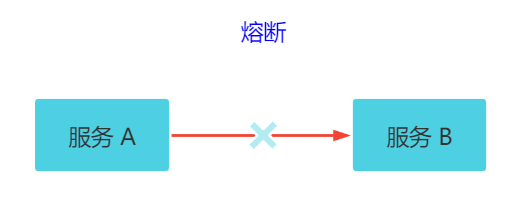
关键字:断路保护。比如 A 服务调用 B 服务,由于网络问题或 B 服务宕机了或 B 服务的处理时间长,导致请求的时间超长,如果在一定时间内多次出现这种情况,就可以直接将 B 断路了(A 不再请求B)。而调用 B 服务的请求直接返回降级数据,不必等待 B 服务的执行。因此 B 服务的问题,不会级联影响到 A 服务。
7.6 降级
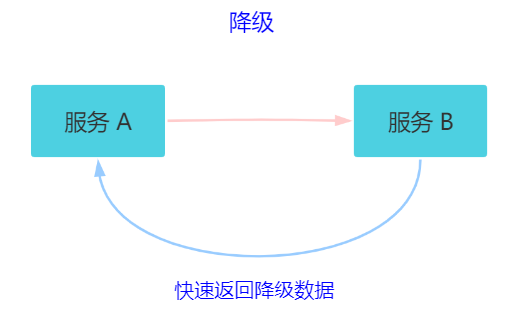
关键字:返回降级数据。网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级(停止服务,所有的调用直接返回降级数据)。以此缓解服务器资源的压力,保证核心业务的正常运行,保持了客户和大部分客户得到正确的响应。降级数据可以简单理解为快速返回了一个 false,前端页面告诉用户“服务器当前正忙,请稍后再试。”
熔断和降级的相同点?
熔断和限流都是为了保证集群大部分服务的可用性和可靠性。防止核心服务崩溃。
给终端用户的感受就是某个功能不可用。
熔断和降级的不同点?
熔断是被调用放出现了故障,主动触发的操作。
降级是基于全局考虑,停止某些正常服务,释放资源。
八、异地多活
8.1 多机房部署
含义:在不同地域的数据中心(IDC)部署了多套服务,而这些服务又是共享同一份业务数据的,而且他们都可以处理用户的流量。
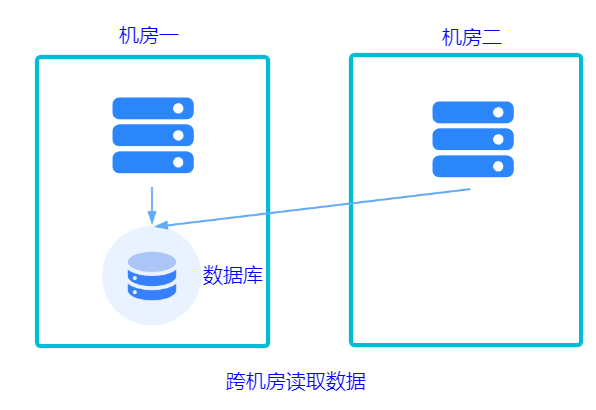
某个服务挂了,其他服务随时切换到其他地域的机房中。现在服务是多套的,那数据库是不是也要多套,无非就两种方案:共用数据库或不共用。
共用一套机房的数据库。
不共用数据库。每个机房都有自己的数据库,数据库之间做同步。实现起来这个方案更复杂。
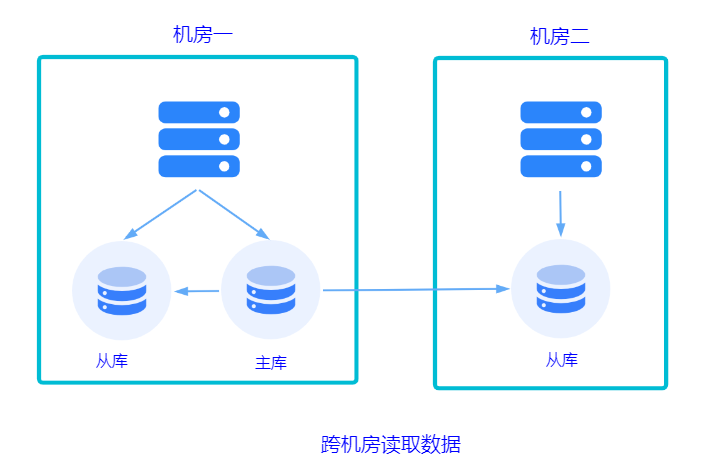
不论使用哪种方式,都涉及到跨机房数据传输延迟的问题:
同地多机房专线,延迟 1ms~3 ms。
异地多机房专线,延迟 50 ms 左右。
跨国多机房,延迟 200 ms 左右。
8.2 同城双活
高性能的同城双活,核心思想就是避免跨机房调用:
保证同机房服务调用:不同的 PRC(远程调用)服务,向注册中心注册不同的服务组,而 RPC 服务只订阅同机房的 RPC 服务组,RPC 调用只存在于本机房。
保证同机房缓存调用:查询缓存发生在本机房,如果没有,则从数据库加载。缓存也是采用主备的方式,数据更新采用多机房更新的方式。
保证同机房数据库查询:和缓存一样,读取本机房的数据库,同样采用主备方式。
8.3 异地多活
同城双活无法做到城市级别的容灾。所以需要考虑异地多活。
比如上海的服务器宕机了,还有重庆的服务器可以顶上来。但两地距离不要太近,因为发生自燃灾害时有可能会被另外一地波及到。和同城双活的核心思想一样,避免跨机房调用。但是因为异地方案中的调用延迟远大于同机房的方案,所以数据同步是一个非常值得探讨的点。提供两种方案:
基于存储系统的主从复制,MySQL 和 Redis 天生就具备。但是数据量很大的情况下,性能是较差的。
异步复制的方式。基于消息队列,将数据操作作为一个消息放到消息队列,另外的机房消费这条消息,操作存储组件。
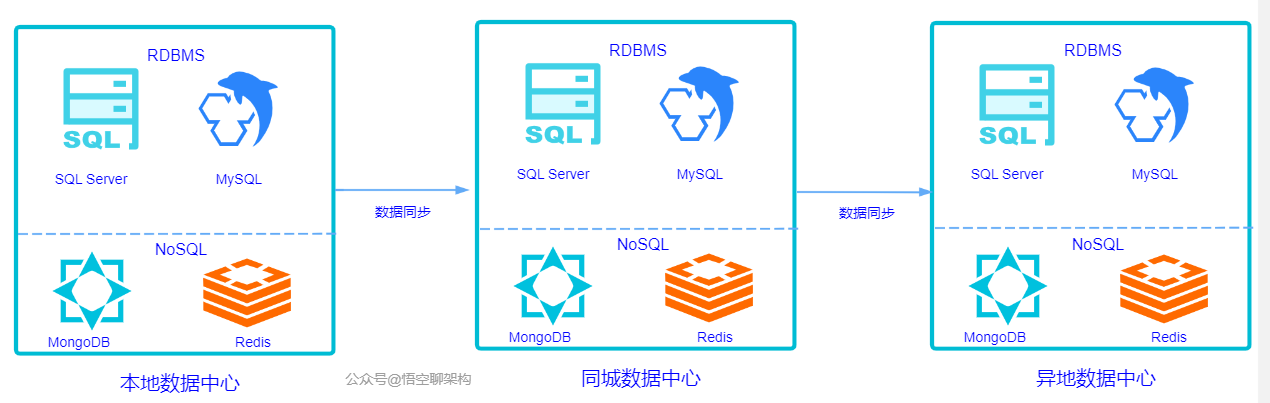
8.4 两地三中心
这个概念也被业界提到过很多次。
两地:本地和异地。
三中心:本地数据中心、同城数据中心、异地数据中心。
这两个概念也就是我上面说的同城双活和异地多活的方式,只是针对的是数据中心。原理如下图所示:
九、故障排查
运维工作中,遇到各种系统、网络、应用、数据库故障是常见的。为了帮助运维人员高效排查问题并快速修复,特总结了多个常见的故障排查及修复要点。
1、系统层面
检查系统日志:
要点: 查看 journalctl、/var/log 下的日志,找出问题线索。
修复: 根据日志内容,调整服务配置,重启服务。
高负载排查:
要点: 使用 top、htop 分析 CPU、内存和 I/O 的使用情况。
修复: 优化负载进程、调整优先级或增加资源。
内存泄漏排查:
要点: 使用 free、vmstat 查看内存使用,valgrind 分析进程内存使用。
修复: 重启进程,修复内存泄漏问题。
磁盘空间不足:
要点: 使用 df -h 检查磁盘使用,du -sh 查找占用大量空间的文件。
修复: 删除不必要的文件,清理日志,扩容磁盘。
服务无法启动:
要点: 使用 systemctl 查看服务状态,查阅相关日志。
修复: 检查依赖、配置文件错误,修复后重启服务。
内核参数调优:
要点: 使用 sysctl 查看和调整系统内核参数。
修复: 优化 TCP 缓冲区、最大连接数等参数,提升系统性能。
进程崩溃:
要点: 使用 dmesg 查看内核日志,分析进程崩溃原因。
修复: 排查资源耗尽、代码错误等问题,修复后重启进程。
CPU瓶颈排查:
要点: 使用 mpstat、sar 检查 CPU 使用情况。
修复: 优化应用代码、调整负载均衡、增加 CPU 核心数。
文件系统问题:
要点: 使用 fsck 检查文件系统错误。
修复: 在系统重启时运行 fsck 修复文件系统。
内存交换(swap)使用过高:
要点: 使用 vmstat 检查 swap 使用情况。
修复: 增加物理内存,调整 swap 使用策略。
2、网络层面
网络连通性检查:
要点: 使用 ping、traceroute 检查连通性和路由问题。
修复: 修复网络配置,检查防火墙规则。
端口占用问题:
要点: 使用 netstat、ss 查看端口占用情况。
修复: 终止占用端口的进程或修改应用程序端口配置。
防火墙问题:
要点: 使用 iptables、firewalld 检查和调整防火墙规则。
修复: 修改防火墙规则,开放必要端口。
DNS解析问题:
要点: 使用 nslookup、dig 查看域名解析情况。
修复: 检查本地 DNS 配置,更换 DNS 服务器。
网络拥塞:
要点: 使用 iftop、nload 分析网络流量。
修复: 限制大流量任务,优化网络拓扑或升级带宽。
TCP连接超时问题:
要点: 使用 netstat 或 ss 检查 TCP 连接状态。
修复: 调整 TCP 超时参数,优化连接池配置。
带宽占用过高:
要点: 使用 iftop 查看带宽使用情况。
修复: 限制带宽占用高的进程或用户,优化带宽分配。
ARP冲突:
要点: 使用 arp -a 查看 ARP 表冲突情况。
修复: 修正IP地址分配,避免冲突。
MTU不匹配问题:
要点: 使用 ping -M do -s 测试 MTU 配置。
修复: 调整 MTU 设置,匹配网络设备参数。
SSL证书问题:
要点: 使用 openssl 工具检查 SSL 证书状态。
修复: 更新或重新生成 SSL 证书。
3、应用层面
应用服务宕机:
要点: 检查日志文件,查看崩溃前的记录。
修复: 优化服务配置或修复应用程序错误,确保服务稳定运行。
高并发引起的瓶颈:
要点: 使用 netstat、sar 检查并发连接数。
修复: 增加负载均衡节点,优化应用代码和数据库查询。
应用死锁:
要点: 使用 strace 或 gdb 调试进程,定位死锁问题。
修复: 修复代码逻辑,避免并发操作导致死锁。
应用启动慢:
要点: 使用 strace 跟踪启动过程中的系统调用。
修复: 优化启动流程,减少加载时间。
应用日志过大:
要点: 定期检查日志文件大小,使用 logrotate 进行日志轮转。
修复: 调整日志级别,定期清理日志。
应用端口冲突:
要点: 使用 lsof 或 netstat 查看端口占用情况。
修复: 释放被占用端口或修改应用的端口配置。
连接池耗尽:
要点: 检查应用日志中的连接池耗尽错误。
修复: 调整连接池配置,增加连接数或优化数据库查询。
应用配置错误:
要点: 检查配置文件中的参数设置,确保其正确性。
修复: 修正配置文件,重新加载服务。
应用超时问题:
要点: 使用 curl 或 ab 工具测试应用响应时间。
修复: 增加应用超时设置,优化数据库查询速度。
依赖服务不可用:
要点: 使用 curl 或 telnet 测试依赖服务的可用性。
修复: 检查依赖服务的运行状态,修复或重启服务。
4、数据库层面
数据库连接失败:
要点: 检查数据库端口、用户权限和网络连通性。
修复: 修正权限问题或网络配置。
慢查询问题:
要点: 使用 EXPLAIN 分析 SQL 查询的执行计划。
修复: 优化 SQL 查询,增加索引或进行分区。
数据库死锁:
要点: 使用数据库的锁状态命令(如 MySQL 的 SHOW ENGINE INNODB STATUS)。
修复: 优化事务处理,避免长时间锁定表。
性能瓶颈:
要点: 使用 mysqltuner 或数据库自带的性能监控工具。
修复: 增加数据库缓存,优化查询,升级硬件资源。
主从复制延迟:
要点: 查看复制状态,检查主从同步情况。
修复: 优化主库的负载,增加从库数量或调整复制策略。
表锁定:
要点: 使用 SHOW PROCESSLIST 或等效命令查看锁状态。
修复: 优化查询,减少大批量操作对数据库的影响。
数据库备份失败:
要点: 检查备份日志,确认备份失败的原因。
修复: 增加存储空间或调整备份策略。
磁盘 I/O 问题:
要点: 使用 iostat 检查数据库的 I/O 使用情况。
修复: 使用 SSD 或增加 RAID 阵列,优化 I/O 性能。
表空间不足:
要点: 使用 SHOW TABLE STATUS 查看表空间使用情况。
修复: 增加表空间,清理无用数据。
连接数过多:
要点: 使用 SHOW STATUS 查看数据库连接数。
修复: 增加最大连接数或优化连接池管理。
5、安全与权限管理
权限错误导致无法访问:
要点: 使用 chmod、chown 修复文件或目录的权限。
修复: 调整权限设置,确保合理分配用户权限。
SSH登录失败:
要点: 检查 /var/log/auth.log 或 journalctl 查看 SSH 登录失败原因。
修复: 检查 SSH 配置文件,调整防火墙规则。
系统防暴力破解:
要点: 使用 fail2ban 等工具监控异常登录尝试。
修复: 配置自动封禁策略,保护服务器。
防火墙规则过于严格:
要点: 使用 iptables 或 firewalld 查看防火墙规则。
修复: 放行必要的端口,合理设置策略。
定期密码更换:
要点: 设置定期密码策略,避免密码泄露。
修复: 强制用户定期更换密码。
日志审计:
要点: 使用 auditd 审计用户操作日志。
修复: 定期审查日志,排查异常操作。
文件完整性检测:
要点: 使用 tripwire 或 aide 检查文件完整性。
修复: 发现异常后及时修复或报警。
应用漏洞扫描:
要点: 使用 OpenVAS 或 Nessus 扫描应用系统漏洞。
修复: 根据扫描结果修复漏洞,及时打补丁。
访问控制列表(ACL)管理:
要点: 使用 setfacl 查看和调整文件 ACL。
修复: 设置合理的访问控制,防止越权访问。
日志轮转失败:
要点: 检查 logrotate 配置文件,确保其正确性。
修复: 修改轮转策略,保证日志文件定期归档。
小结
这些排查及修复要点,涵盖了系统、网络、应用、数据库和安全管理等多个层面。通过熟练掌握这些要点,运维人员可以快速定位故障,并采取有效的修复措施,确保系统的稳定性和安全性。