异构数据迁移工具-Sqoop
 Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(postgresql、mysql...)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(postgresql、mysql...)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。Sqoop - “SQL到Hadoop和Hadoop到SQL”。
Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具,它用于从关系数据库(如PostgreSQL,MySQL,Oracle)导入数据到Hadoop HDFS,并从Hadoop文件系统导出到关系数据库。
Apache的Hadoop计算框架是一个越来越通用的分布式计算环境,主要用来处理大数据。随着云提供商利用这个框架,更多的用户将数据集在Hadoop和传统数据库之间转移,能够帮助数据传输的工具变得更加重要。Apache Sqoop就是这样一款工具,可以在Hadoop和关系型数据库之间转移大量数据。对于某些NoSQL数据库它也提供了连接器。类似于其它ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建maptask任务来处理每个区块。由于Sqoop将数据移入和移出关系型数据库的能力,其对于Hive—Hadoop生态系统里的著名的类SQL数据仓库有专门的支持就显得不足为奇。命令“create-hive-table”可以用来将数据表定义导入到Hive。
当大数据存储和Hadoop生态系统的MapReduce,Hive,HBase,Cassandra,Pig等分析器出现时,他们需要一种工具来与关系数据库服务器进行交互,以导入和导出驻留在其中的大数据。在这里,Sqoop在Hadoop生态系统中占据一席之地,以便在关系数据库服务器和Hadoop的HDFS之间提供可行的交互。
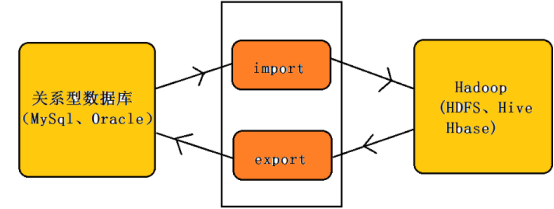
Sqoop导入:导入工具从RDBMS向HDFS导入单独的表。表中的每一行都被视为HDFS中的记录。所有记录都以文本文件的形式存储在文本文件中或作为Avro和Sequence文件中的二进制数据存储。
Sqoop导出:导出工具将一组文件从HDFS导出回RDBMS。给Sqoop输入的文件包含记录,这些记录在表中被称为行。这些被读取并解析成一组记录并用用户指定的分隔符分隔。
由于Sqoop是Hadoop的子项目,因此它只能在Linux操作系统上运行。
Sqoop的优点:
A. 可以高效、可控的利用资源,可以通过调整任务数来控制任务的并发度。
B. 可以自动的完成数据映射和转换。由于导入数据库是有类型的,它可以自动根据数据库中的类型转换到Hadoop 中,当然用户也可以自定义它们之间的映射关系
C.支持多种数据库,如mysql,orcale等数据库
Sqoop工作的机制:
将导入或导出命令翻译成MapReduce程序来实现在翻译出的,MapReduce 中主要是对InputFormat和OutputFormat进行定制
Sqoop版本介绍:sqoop1和sqoop2
A. sqoop的版本sqoop1和sqoop2是两个不同的版本,它们是完全不兼容的
B. 版本划分方式: apache1.4.X之后的版本是1,1.99.0之上的版本是2
C. Sqoop2相比sqoop1的优势有:
1) 它引入的sqoop Server,便于集中化的管理Connector或者其它的第三方插件;
2) 多种访问方式:CLI、Web UI、REST API;
3) 它引入了基于角色的安全机制,管理员可以在sqoop Server上配置不同的角色。
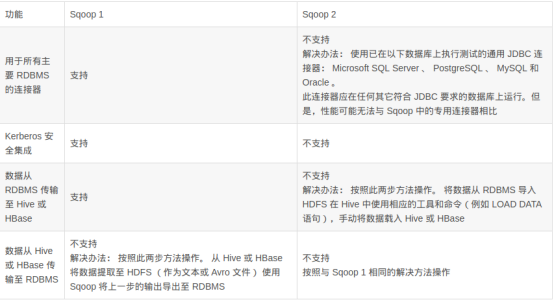
D. Sqoop2和sqoop1的功能性对比:
E. sqoop1和sqoop2的架构区别:
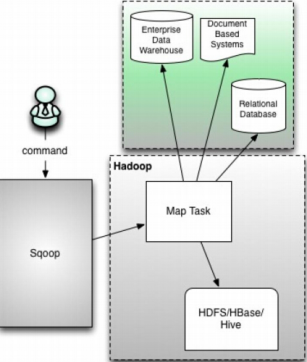
1)sqoop1的架构图:
版本号:1.4.X以后的sqoop1
在架构上:sqoop1使用sqoop客户端直接提交代码方式
访问方式:CLI命令行控制台方式访问
安全性:命令或者脚本指定用户数据库名和密码
原理:Sqoop工具接收到客户端的shell命令或者Java api命令后,通过Sqoop中的任务翻译器(Task Translator)将命令转换为对应的MapReduce任务,而后将关系型数据库和Hadoop中的数据进行相互转移,进而完成数据的复制。
2)sqoop2架构图:
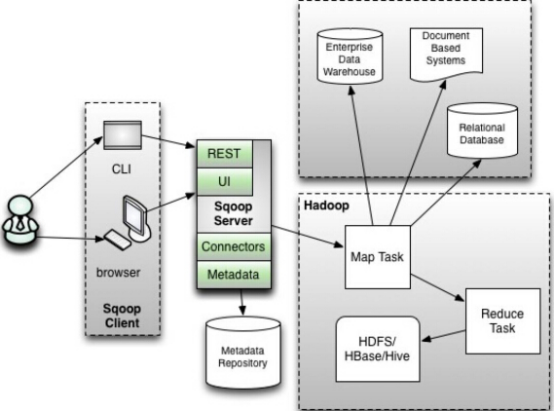
版本号:1.99.X以上的版本sqoop2
在架构上:sqoop2引入了 sqoop server,对connector实现了集中的管理访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问。
CLI方式访问会通过交互过程界面,输入的密码信息会被看到,同时Sqoop2引入基于角色的安全机制,Sqoop2比Sqoop1多了一个Server端。
F. sqoop1和sqoop2优缺点:
sqoop1优点:架构部署简单
sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,安装需要root权限,connector必须符合JDBC模型
sqoop2优点:多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
sqoop2缺点:sqoop2的缺点,架构稍复杂,配置部署更繁琐
Sqoop的使用
1. 查看数据库的名称:
sqoop list-databases --connect jdbc:mysql://ip:3306/ --username 用户名--password 密码
2. 列举出数据库中的表名:
sqoop list-tables --connect jdbc:mysql://ip:3306/数据库名称 --username 用户名 --password 密码
3. 导入:
sqoop import
--connect jdbc:postgresql://ip:5432/databasename #指定JDBC的URL 其中database指的是(Mysql或者PostgreSQL)中的数据库名
--table tablename #要读取数据库database中的表名
--username freeoa #用户名
--password 123456 #密码
--target-dir /path #指的是HDFS中导入表的存放目录(注意:是目录)
--fields-terminated-by '\t' #设定导入数据后每个字段的分隔符,默认;分隔
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
-- where '查询条件' #导入查询出来的内容,表的子集
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string '' #导入的字段为空时,用指定的字符进行替换
以上导入到hdfs中
--hive-import #导入到hive
--hive-overwrite #可以多次写入
--hive-database databasename #创建数据库,如果数据库不存在的必须写,默认存放在default中
--create-hive-table #sqoop默认自动创建hive表
--delete-target-dir #删除中间结果数据目录
--hive-table tablename #创建表名
4. 导入所有的表放到hdfs中:
sqoop import-all-tables --connect jdbc:mysql://ip:3306/库名 --username 用户名 --password 密码 --target-dir 导入存放的目录
5. 导出(目标表必须在mysql数据库中已经建好,数据存放在hdfs中):
sqoop export
--connect jdbs:postgresql://ip:5432/库名 #指定JDBC的URL 其中database指的是(PostgreSQL)中的数据库名
--username 用户名 #数据库的用户名
--password 密码 #数据库的密码
--table表名 #需要导入到数据库中的表名
--export-dir导入数据的名称 #hdfs上的数据文件
--fields-terminated-by '\t' #HDFS中被导出的文件字段之间的分隔符
--lines-terminated-by '\n' #设定导入数据后每行的分隔符
--m 1 #并发的map数量1,如果不设置默认启动4个map task执行数据导入,则需要指定一个列来作为划分map task任务的依据
--incremental append #增量导入
--check-column:column_id #指定增量导入时的参考列
--last-value:num #上一次导入column_id的最后一个值
--null-string '' #导出的字段为空时,用指定的字符进行替换
6. 创建和维护sqoop作业:sqoop作业创建并保存导入和导出命令。
A.创建作业:
sqoop job --create 作业名 -- import --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --password 密码 --m 1 --target-dir 存放目录
B. 验证作业(显示已经保存的作业):
sqoop job --list
C. 显示作业详细信息:
sqoop job --show 作业名称
D.删除作业:
sqoop job --delete 作业名
E. 执行作业:
sqoop job --exec 作业
7. eval:它允许用户针对各自的数据库服务器执行用户定义的查询,并在控制台中预览结果,可以使用期望导入结果数据。
A.选择查询:
sqoop eval -connect jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query "select * from emp limit 1"
B.插入查询:
sqoop eval jdbc:mysql://ip:3306/数据库 --username 用户名 --password 密码 --query "insert into emp values(4,'ceshi','hebei')"
8. codegen:从面向对象的应用程序的角度来看,每个数据库表都有一个DAO类,它包含用于初始化对象的'getter'和'setter'方法。该工具(-codegen)自动生成DAO类。
它根据表模式结构在Java中生成DAO类。Java定义被实例化为导入过程的一部分。这个工具的主要用途是检查Java是否丢失了Java代码。如果是这样,它将使用字段之间的默认分隔符创建Java的新版本,其实就是生成表名.java
语法:sqoop codegen --connect jdbc:mysql://ip:3306/数据库 --username 用户名 --table 表名 --m 1 --password 密码
回显中会显示文件存放的位置。
更多的示例可参考:Sqoop快速入门
最新版本:1.4
项目主页:https://sqoop.apache.org