分布式文件系统-Ceph
 Ceph 最初是一项关于存储系统的 PhD 研究项目,由 Sage Weil 在 University of California, Santa Cruz(UCSC)实施。2010年4月可以在主线 Linux 内核(从 v2.6.34 版开始)中找到 Ceph 的身影。Ceph 文件系统及其独有的功能让它成为可扩展分布式存储的最有吸引力的备选。
Ceph 最初是一项关于存储系统的 PhD 研究项目,由 Sage Weil 在 University of California, Santa Cruz(UCSC)实施。2010年4月可以在主线 Linux 内核(从 v2.6.34 版开始)中找到 Ceph 的身影。Ceph 文件系统及其独有的功能让它成为可扩展分布式存储的最有吸引力的备选。“Ceph” 对一个文件系统来说是个奇怪的名字,它打破了大多数人遵循的典型缩写趋势。这个名字和 UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,提供了一个分布式文件系统的最形象比喻。它作为一种开源的、可伸缩的分布式存储解决方案,正逐渐成为企业级存储领域的热门选择。Ceph是一种由Radicalbit公司开发的开源分布式存储系统,它通过将数据分布在一个或多个存储节点上,实现了高可靠性、高性能和高扩展性。
Ceph is a distributed network storage and file system designed to provide excellent performance, reliability, and scalability. Ceph is based on a reliable and scalable distributed object store, with a distributed metadata management cluster layered on top to provide a distributed file system with POSIX semantics. There are a variety of ways to interact with the system:
* Distributed file system. An dynamic cluster of metadata servers create and manage and file system hierarchy, providing POSIX file system access via the Ceph file system client in recent Linux kernels or via a FUSE driver.
* Object storage. A librados library provides applications direct access to the underlying distributed object store. Clients talk directly with storage nodes to store named blobs of data and attributes, while the cluster transparently handles replication and recovery internally.
* S3-compatible storage. A radosgw proxy server provides an S3-compatible REST interface to the distributed object storage system, allowing applications designed to work with Amazon’s S3 service to use an private installation of Ceph instead.
* Rados block device (RBD). The RBD driver provides a shared network block device via a Linux kernel block device driver (2.6.37+) or a Qemu/KVM storage driver based on librados. In contrasts to alternatives like iSCSI or AoE, RBD images are striped and replicated across the Ceph object storage cluster, providing reliable, scalable, and thinly provisioned access to block storage. RBD supports read-only snapshots with rollback.
Ceph fills two significant gaps in the array of currently available file systems:
1. Robust, open-source distributed storage — Ceph is released under the terms of the LGPL, which means it is free software (as in speech and beer). Ceph will provide a variety of key features that are generally lacking from existing open-source file systems, including seamless scalability (the ability to simply add disks to expand volumes), intelligent load balancing, and efficient, easy to use snapshot functionality.
2. Scalability — Ceph is built from the ground up to seamlessly and gracefully scale from gigabytes to petabytes and beyond. Scalability is considered in terms of workload as well as total storage. Ceph is designed to handle workloads in which tens thousands of clients or more simultaneously access the same file, or write to the same directory–usage scenarios that bring typical enterprise storage systems to their knees.
Ceph环境的核心组件包括:Ceph OSD、Ceph Monitor、Ceph MDS、CEPH MGR。
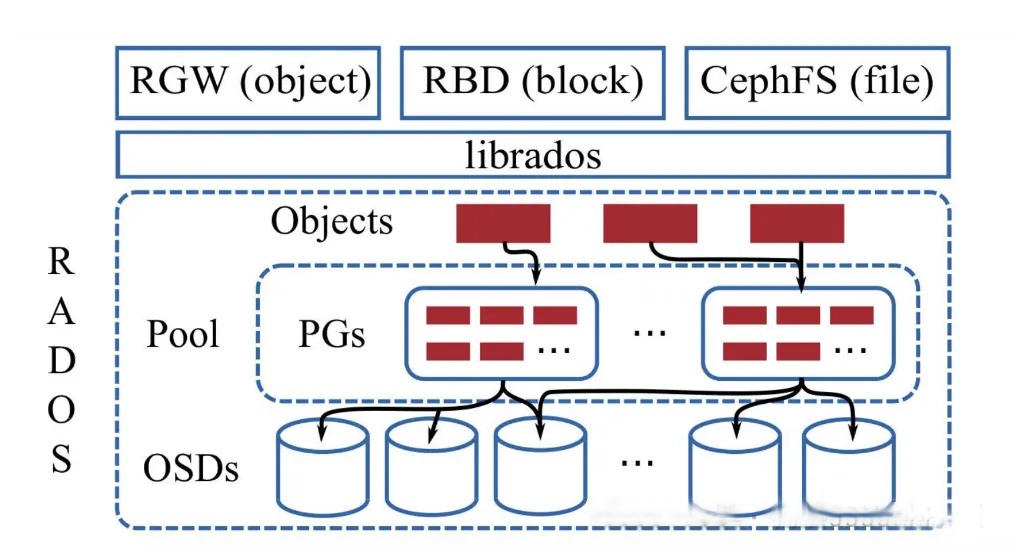
• Ceph OSDs (Object Storage Daemons):OSD是Ceph集群中负责存储实际数据的守护进程。每个OSD守护进程负责管理一个存储设备(如硬盘或分区)。OSD负责处理数据复制、恢复、再平衡和数据的分发。在Ceph集群中,通常会有大量的OSD,它们分布在不同的服务器上,以确保高可用性和数据冗余。
• Ceph Monitors (MONs):Monitor维护集群的状态信息,包括映射信息(如数据在哪些OSD上)、OSD状态、归置组(Placement Group, PG)状态等。Monitor负责在发生故障时,确保集群能够自动恢复。为了高可用性,通常会有多个Monitor实例,它们之间通过Paxos算法保持状态一致。
• Ceph Metadata Server (MDS):MDS仅用于Ceph文件系统(CephFS)。它负责存储文件系统的元数据,如目录树、文件权限等信息。MDS能够提高文件系统的性能和可扩展性。在CephFS集群中,可以有一个或多个MDS实例,以支持大规模的并行文件系统访问。
• Ceph Manager (MGR):Manager是一个相对较新的组件,它在Ceph Luminous版本(即12.0版本)中首次被引入。Manager提供了一个集中的服务,用于管理和监控Ceph集群的各个方面。它收集和存储集群的监控数据,提供报警和通知,管理服务,执行集群管理任务,生成集群报告,并提供一个REST API。
Ceph支持多种存储类型,以满足不同应用场景的需求。主要包括:对象存储、块存储、文件系统存储:
• 对象存储:Ceph提供了一个名为RADOSGW(RADOS Gateway)的组件,它实现了符合Amazon S3和Swift API的接口,允许用户通过HTTP/HTTPS协议存储和检索对象数据。对象存储适合于需要高可用性和可扩展性的应用,如备份、归档和多媒体内容分发。
• 块存储:Ceph的块存储服务称为RBD(RADOS Block Device),它提供了一个高性能、可扩展的块存储解决方案。RBD可以在物理服务器或虚拟机中作为磁盘使用,支持快照、克隆和 thin-provisioning 等功能。块存储适用于需要持久化存储的应用,如虚拟机镜像和数据库。
• 文件系统存储:Ceph提供了一个名为CephFS的POSIX-compliant文件系统。CephFS允许用户将Ceph集群作为传统的网络文件系统挂载到服务器上,支持文件层次结构和权限管理。文件系统存储适用于需要共享文件存储的应用,如企业文件共享和协同工作环境。
目标
开发一个分布式文件系统需要多方努力,但是如果能准确地解决问题,它就是无价的。Ceph 的目标简单地定义为:
* 可轻松扩展到数 PB 容量
* 对多种工作负载的高性能(每秒输入/输出操作[IOPS]和带宽)
* 高可靠性
不幸的是,这些目标之间会互相竞争(例如,可扩展性会降低或者抑制性能或者影响可靠性)。Ceph 开发了一些非常有趣的概念(例如,动态元数据分区,数据分布和复制),这些概念在本文中只进行简短地探讨。其设计还包括保护单一点故障的容错功能,它假设大规模(PB 级存储)存储故障是常见现象而不是例外情况。最后它的设计并没有假设某种特殊工作负载,但是包括适应变化的工作负载,提供最佳性能的能力。它利用 POSIX 的兼容性完成所有这些任务,允许它对当前依赖 POSIX 语义(通过以 Ceph 为目标的改进)的应用进行透明的部署。最后,Ceph 是开源分布式存储,也是主线 Linux 内核(2.6.34)的一部分。
Features
1. Seamless scaling — A Ceph filesystem can be seamlessly expanded by simply adding storage nodes (OSDs). However, unlike most existing file systems, Ceph proactively migrates data onto new devices in order to maintain a balanced distribution of data. This effectively utilizes all available resources (disk bandwidth and spindles) and avoids data hot spots (e.g., active data residing primarly on old disks while newer disks sit empty and idle).
2. Strong reliability and fast recovery — All data in Ceph is replicated across multiple OSDs. If any OSD fails, data is automatically re-replicated to other devices. However, unlike typical RAID systems, the replicas for data on each disk are spread out among a large number of other disks, and when a disk fails, the replacement replicas are also distributed across many disks. This allows recovery to proceed in parallel (with dozens of disks copying to dozens of other disks), removing the need for explicit “spare” disks (which are effectively wasted until they are needed) and preventing a single disk from becoming a “RAID rebuild” bottleneck.
3. Adaptive MDS — The Ceph metadata server (MDS) is designed to dynamically adapt its behavior to the current workload. As the size and popularity of the file system hierarchy changes over time, that hierarchy is dynamically redistributed among available metadata servers in order to balance load and most effectively use server resources. (In contrast, current file systems force system administrators to carve their data set into static “volumes” and assign volumes to servers. Volume sizes and workloads inevitably shift over time, forcing administrators to constantly shuffle data between servers or manually allocate new resources where they are currently needed.) Similarly, if thousands of clients suddenly access a single file or directory, that metadata is dynamically replicated across multiple servers to distribute the workload.
架构
现在探讨一下 Ceph 的架构以及高端的核心要素,然后会拓展到另一层次,说明其中一些关键的方面,提供更详细的探讨。Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图1. Ceph 生态系统的概念架构
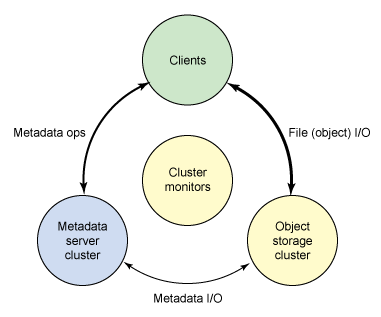
如图1所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。元数据服务器管理数据位置,以及在何处存储新数据。值得注意的是,元数据存储在一个存储集群(标为“元数据 I/O”)。实际的文件 I/O 发生在客户和对象存储集群之间。这样一来,更高层次的 POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过 POSIX 功能(例如读和写)则直接由对象存储集群管理。
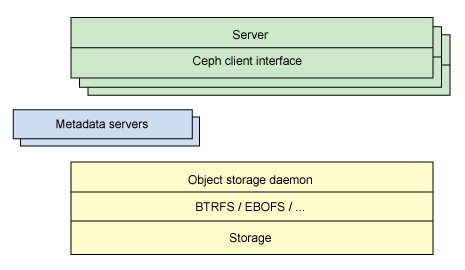
另一个架构视图由图2 提供。一系列服务器通过一个客户界面访问 Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做 Reliable Autonomic Distributed Object Storage(RADOS)。最后,监视器用于识别组件故障,包括随后的通知。
图2. Ceph 生态系统简化后的分层视图
Ceph 组件
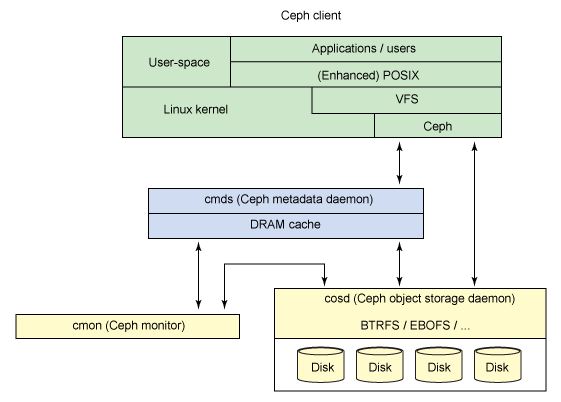
了解了 Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在 Ceph 中实现的主要组件。Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
图3显示了一个简单的 Ceph 生态系统。Ceph Client 是 Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而 Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客户、对象存储端点、元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。那么这个文件系统是如何分布的呢?
图 3. 简单的 Ceph 生态系统
内核或用户空间?
早期版本的 Ceph 利用在 User SpacE(FUSE)的 Filesystems,它把文件系统推入到用户空间,还可以很大程度上简化其开发。但如今 Ceph 已经被集成到主线内核,使其更快速,因为用户空间上下文交换机对文件系统 I/O 已经不再需要。
客户端
因为 Linux 显示文件系统的一个公共界面(通过虚拟文件系统交换机 [VFS]),Ceph 的用户透视图就是透明的。管理员的透视图肯定是不同的,考虑到很多服务器会包含存储系统这一潜在因素。从用户的角度看,他们访问大容量的存储系统,却不知道下面聚合成一个大容量的存储池的元数据服务器,监视器,还有独立的对象存储设备。用户只是简单地看到一个安装点,在这点上可以执行标准文件 I/O。
Ceph 文件系统 — 或者至少是客户端接口 — 在 Linux 内核中实现。值得注意的是,在大多数文件系统中,所有的控制和智能在内核的文件系统源本身中执行。但是在 Ceph 中,文件系统的智能分布在节点上,这简化了客户端接口,并为 Ceph 提供了大规模(甚至动态)扩展能力。
Ceph 使用一个有趣的备选,而不是依赖分配列表(将磁盘上的块映射到指定文件的元数据)。Linux 透视图中的一个文件会分配到一个来自元数据服务器的 inode number(INO),对于文件这是一个唯一的标识符。然后文件被推入一些对象中(根据文件的大小)。使用 INO 和 object number(ONO),每个对象都分配到一个对象 ID(OID)。在 OID 上使用一个简单的哈希,每个对象都被分配到一个放置组。放置组(标识为 PGID)是一个对象的概念容器。最后,放置组到对象存储设备的映射是一个伪随机映射,使用一个叫做 Controlled Replication Under Scalable Hashing(CRUSH)的算法。这样一来,放置组(以及副本)到存储设备的映射就不用依赖任何元数据,而是依赖一个伪随机的映射函数。这种操作是理想的,因为它把存储的开销最小化,简化了分配和数据查询。
分配的最后组件是集群映射。集群映射是设备的有效表示,显示了存储集群。有了 PGID 和集群映射就可以定位任何对象。
元数据服务器
元数据服务器(cmds)的工作就是管理文件系统的名称空间。虽然元数据和数据两者都存储在对象存储集群,但两者分别管理,支持可扩展性。事实上,元数据在一个元数据服务器集群上被进一步拆分,元数据服务器能够自适应地复制和分配名称空间,避免出现热点。如图 4 所示,元数据服务器管理名称空间部分,可以(为冗余和性能)进行重叠。元数据服务器到名称空间的映射在 Ceph 中使用动态子树逻辑分区执行,它允许 Ceph 对变化的工作负载进行调整(在元数据服务器之间迁移名称空间)同时保留性能的位置。
图4. 元数据服务器的 Ceph 名称空间的分区
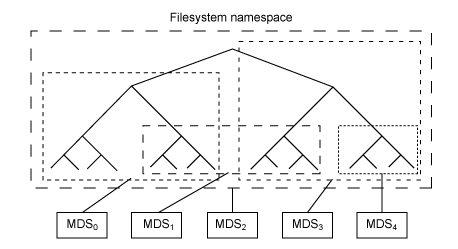
但是因为每个元数据服务器只是简单地管理客户端人口的名称空间,它的主要应用就是一个智能元数据缓存(因为实际的元数据最终存储在对象存储集群中)。进行写操作的元数据被缓存在一个短期的日志中,它最终还是被推入物理存储器中。这个动作允许元数据服务器将最近的元数据回馈给客户(这在元数据操作中很常见)。这个日志对故障恢复也很有用:如果元数据服务器发生故障,它的日志就会被重放,保证元数据安全存储在磁盘上。
元数据服务器管理 inode 空间,将文件名转变为元数据。元数据服务器将文件名转变为索引节点,文件大小,和 Ceph 客户端用于文件 I/O 的分段数据(布局)。
监视器
Ceph 包含实施集群映射管理的监视器,但是故障管理的一些要素是在对象存储本身中执行的。当对象存储设备发生故障或者新设备添加时,监视器就检测和维护一个有效的集群映射。这个功能按一种分布的方式执行,这种方式中映射升级可以和当前的流量通信。Ceph 使用 Paxos,它是一系列分布式共识算法。
对象存储
和传统的对象存储类似,Ceph 存储节点不仅包括存储,还包括智能。传统的驱动是只响应来自启动者的命令的简单目标。但是对象存储设备是智能设备,它能作为目标和启动者,支持与其他对象存储设备的通信和合作。
从存储角度来看,Ceph 对象存储设备执行从对象到块的映射(在客户端的文件系统层中常常执行的任务)。这个动作允许本地实体以最佳方式决定怎样存储一个对象。Ceph 的早期版本在一个名为 EBOFS 的本地存储器上实现一个自定义低级文件系统。这个系统实现一个到底层存储的非标准接口,这个底层存储已针对对象语义和其他特性(例如对磁盘提交的异步通知)调优。今天,B-tree 文件系统(BTRFS)可以被用于存储节点,它已经实现了部分必要功能(例如嵌入式完整性)。因为 Ceph 客户实现 CRUSH,而且对磁盘上的文件映射块一无所知,下面的存储设备就能安全地管理对象到块的映射。这允许存储节点复制数据(当发现一个设备出现故障时)。分配故障恢复也允许存储系统扩展,因为故障检测和恢复跨生态系统分配。Ceph 称其为 RADOS。
其他功能
如果文件系统的动态和自适应特性不够,Ceph 还执行一些用户可视的有趣功能。用户可以创建快照,例如在 Ceph 的任何子目录上(包括所有内容)。文件和容量计算可以在子目录级别上执行,它报告一个给定子目录(以及其包含的内容)的存储大小和文件数量。
展望未来
Ceph 不只是一个文件系统,还是一个有企业级功能的对象存储生态环境。使用者通过设置一个简单 Ceph 集群(包括元数据服务器,对象存储服务器和监视器)来快速掌握其要领。Ceph 填补了分布式存储中的空白,看到这个开源产品如何在未来演变也将会是很有趣的。虽然 Ceph 现在被集成在主线 Linux 内核中,但只是标识为实验性的。在这种状态下的文件系统对测试是有用的,但是对生产环境没有做好准备。但是考虑到 Ceph 加入到 Linux 内核的行列,还有其创建人想继续研发的动机,不久之后它应该就能用于解决您的海量存储需要了。
集群环境搭建与使用入门
部署规划:
ip 别名 角色
10.0.1.33 node1 osd、mds、mon、mgr、ceph-deploy
10.0.1.34 node2 osd、mds
10.0.1.35 node3 osd、mds
1. 修改 /etc/hosts 增加映射
2. 关闭防火墙
#关闭防火墙
systemctl stop firewalld.service
#禁止防火墙开启自启
systemctl disable firewalld.service
3. 配置ssh免密登录(node1)
#4个回车 生成公钥、私钥
ssh-keygen
# 将公钥给三台主机
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
4. 集群时间同步
5. 添加可靠的 Ceph 安装源
6. 安装 ceph-deploy 组件(node1)
yum -y install ceph-deploy
7. 初始化 ceph 集群信息(node1)
安装所需依赖:
yum install -y python-setuptools
创建配置目录
mkdir /etc/ceph && cd /etc/ceph
初始化
ceph-deploy new node1
修改 ceph.conf ,默认 osd 最少3个节点,在此可以改成2个,在 [global] 下新增如下配置:
osd_pool_default_size = 2
8. 在所有节点安装 ceph(node1)
该操作会自动使用 ssh 连接,需要确保配置好了免密登录。
ceph-deploy install node1 node2 node3
证安装,查看 ceph 版本
ceph -v
9. 创建 mon 监控节点(node1)
ceph-deploy mon create-initial
将配置文件信息同步到所有节点
ceph-deploy admin node1 node2 node3
查看集群状态:
ceph -s
从结果可知已经有一个 mon 了,当然是node1。
10. 部署 mgr(node1)
ceph-deploy mgr create node1
查看集群状态:
ceph -s
services:
mgr: node1(active)
11. 部署osd服务(node1)
查看磁盘:
lsblk
这里使用未挂载的 /dev/sdb 磁盘
创建 osd
ceph-deploy osd create node1 --data /dev/sdb
再次查看磁盘可发现该盘已经被 ceph 使用。
同样,将 node2、node3 的磁盘创建 osd :
ceph-deploy osd create node2 --data /dev/sdb
ceph-deploy osd create node3 --data /dev/sdb
查看集群状态:
ceph -s
services:
osd: 3 osds: 3 up,3 in
data:
usage: ...
12. 部署 mds (node1)
ceph-deploy mds create node1 node2 node3
到此 Ceph 的集群就基本搭建完毕。
CephFS 创建及客户端挂载
1. 创建存储池
创建数据池 cephfs_data,用户存储数据:
ceph osd pool create cephfs_data 128
创建 cephfs_metadata,用于存储元数据:
ceph osd pool create ceph_metadata 60
2. 创建 FS
ceph fs new cephfs cephfs_data ceph_metadata
new fs with metadata poll 4 and data pool 5
查看集群状态:
ceph -s
data:
pools: 2 pools, 188 pgs
3 客户端挂载
首先在 node1 查看客户端的秘钥:
cat ceph.client.admin.keyring
下面在客户端安装依赖
yum -y install epel-release
yum -y install ceph-fuse ceph-common
创建配置目录:
mkdir /etc/ceph && cd /etc/ceph
将上面查出来的 key 写入 admin.key 文件中:
echo '...' >>admin.key
创建挂载目录:
mkdir /cephfs_data
挂载:
mount -t ceph node1:6789:/ /cephfs_data -o name=admin,secretfile=/etc/ceph/admin.key
查看挂载:
df -hT
可见一个Type为ceph的挂载项出现。
最新版本:10.2
这是 Infernalis 周期的第一个开发版本,而且也是 Ceph 版本发布采用另一个版本号模式的第一个版本。“9” 代表这是第 9 个 cycle-I(Infernalis),I 是第九个字母。第一个 “0”表示这是一个开发版本(“1” 表示候选版本, “2”表示稳定版本),最后一个 “0” 表示这个这个开发版本的第一个版本。值得关注的改进如下:
新的 ‘ceph daemonperf’命令,用来实时查看 perfcounter 统计数据
降低 MDS 内存使用
大量的 MDS 快照修复
在图像自身 librbd 可以存储选项
RGW Swift API 支持方面的大量修复
OSD 性能提升
大量文档更新和小的 bug 修复
更多内容请看发行说明。
最新版本:17.2
v17.2.0 Quincy 现已于2022年4月下旬发布。Quincy 是 Ceph 的第 17 个稳定版本,它以海绵宝宝的章鱼 Quincy 触手命名,这是 Ceph Quincy 的第一个稳定版本。
Cephadm
SNMP 支持
守护进程托管 (mgr, mds, rgw)
osd内存自动调整
与新的 NFS 管理模块集成
能够在 osd 被删除时对其进行删除
用于提高性能/可扩展性的 cephadm 代理
Dashboard:
新的“集群扩展向导”将引导用户完成安装后的步骤:添加新主机、存储设备或服务。
NFS:仪表板现在允许用户从一个地方完全管理所有 NFS 导出。
新的 mgr 模块(反馈):用户可以直接从 Dashboard 或 CLI 快速报告 Ceph 跟踪器问题或建议。
新的“每日消息”:集群管理员可以在横幅中发布自定义消息。
Cephadm 集成改进:
主机管理:维护、规格和标签,
服务管理:编辑和显示日志,
守护进程管理(启动、停止、重启、重新加载),
支持的新服务:入口(HAProxy)和 SNMP 网关。
监控和警报:
添加了 43 个新警报(总共 68 个),提高了对影响以下事件的可观察性:集群运行状况、监视器、存储设备、PG 和 CephFS。
现在可以通过新的 SNMP 网关服务(提供 MIB)将警报作为 SNMP 陷阱发送到外部。
改进的集成完整/接近完整事件通知。
Grafana 仪表板现在使用 grafonnet 格式(尽管它们仍以 JSON 格式提供)。
堆栈更新:用于监控容器的图像已更新。Grafana 8.3.5、Prometheus 2.33.4、Alertmanager 0.23.0 和 Node Exporter 1.3.1。这减少了对多个 Grafana 漏洞(CVE-2021-43798、CVE-2021-39226、CVE-2021-43798、CVE-2020-29510、CVE-2020-29511)的暴露。
RADOS
OSD:Ceph 现在mclock_scheduler默认使用 BlueStore OSDosd_op_queue来提供 QoS。Filestore OSD 不支持“mclock_scheduler”。因此,默认的 'osd_op_queue' 设置为wpq用于 Filestore OSD,即使用户尝试更改它也会强制执行。有关配置 mclock 的更多详细信息,请参阅此处。运行时存在一个突出问题,在使用命令切换到custommclock 配置文件后,无法修改与预留、重量和限制相关的 mclock 配置选项。在问题得到解决之前,建议用户避免使用“自定义”配置文件或使用跟踪器中提到的解决方法。
MGR:pg_autoscaler 现在可以使用标志在全局范围内on转动。默认情况下,它设置为,但此标志可以派上用场,以防止在集群升级和维护期间由自动缩放触发重新平衡。现在可以使用该标志创建池,这允许自动缩放器将更多 PG 分配给此类池。这对于为数据密集型池获得更好的开箱即用性能很有用。
offOSD:默认支持 osd-osd 通信的在线压缩。
OSD:集群日志中慢速操作的简明报告。可以通过设置osd_aggregated_slow_ops_logging为 false 来恢复旧的和更详细的日志记录行为。
“kvs” Ceph 对象类不再打包。“kvs” Ceph 对象类提供了在 librados 对象 omap 之上实现的分布式平面 b 树键值存储。由于该对象类没有现有的内部用户,因此不再对其进行打包。
RBD block storage
rbd-nbd:rbd device attach和rbd device detach添加的命令,这些允许在rbd-nbd守护进程自 Linux 内核 5.14 以来重新启动后安全重新连接。
rbd-nbd:notrim添加了映射选项以支持厚配置映像,类似于 krbd。
SSD 设备上客户端持久缓存的大量稳定工作,也可在 16.2.8 中使用。有关使用的详细信息,请参阅此处。
使用快速差异图像特征 + 整个对象(不精确)模式时,差异计算中的几个错误修复。在极少数情况下,这些长期存在的问题可能会导致不正确的rbd export. 也在 15.2.16 和 16.2.8 中修复。
修复了在 krbd 上运行 Windows VM 时潜在的性能下降问题。
RGW object storage
RGW 现在支持按用户和/或按桶进行速率限制。使用此功能,可以限制用户和/或存储桶,可以交付总操作数和/或每分钟字节数。此功能允许管理员仅限制 READ 操作和/或 WRITE 操作。通过使用全局配置,可以将限速配置应用于所有用户和所有存储桶。
radosgw-admin realm delete已重命名为radosgw-admin realm rm. 这与帮助信息一致。
S3 存储桶通知事件现在包含一个eTag键而不是etag,并且 eventName 值不再带有s3:前缀,从而修复了与在 AWS 上观察到的消息格式的偏差。
现在可以为野兽前端指定 ssl 选项和密码。默认 ssl 选项设置为“no_sslv2:no_sslv3:no_tlsv1:no_tlsv1_1”。如果要返回旧行为,请将 'ssl_options='(空)添加到rgw frontends配置中。
分段上传的行为已修改,以便在分段上传结束时仅发送 CompleteMultipartUpload 通知。上传开始时的 POST 通知和每个部分上发送的 PUT 通知不再发送。
CephFS distributed file system
fs:可以使用特定ID(“fscid”)创建文件系统。这在某些恢复方案中很有用(例如,当监视器数据库丢失并重新构建时,并且恢复的文件系统预计具有与以前相同的 ID)。
fs:可以使用该fs rename命令重命名文件系统。任何为旧文件系统名称授权的 cephx 凭据都需要重新授权为新文件系统名称。由于使用这些重新授权的 ID 的客户端的操作可能会中断,因此该命令需要“--yes-i-really-mean-it”标志。此外,预计将在文件系统上禁用镜像。
MDS 升级不再需要在升级文件系统的唯一活动 MDS 之前停止所有备用 MDS 守护程序。
CephFS:如果备用重放守护进程重放日志失败,现在会导致等级被标记为“损坏”。
官方主页:https://ceph.com/en/
该文章最后由 阿炯 于 2024-07-02 16:13:18 更新,目前是第 2 版。