图形硬件处理标准-OpenCL
 OpenCL全称Open Computing Language,是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
OpenCL全称Open Computing Language,是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。OpenCL™ is the first open, royalty-free standard for cross-platform, parallel programming of modern processors found in personal computers, servers and handheld/embedded devices. OpenCL (Open Computing Language) greatly improves speed and responsiveness for a wide spectrum of applications in numerous market categories from gaming and entertainment to scientific and medical software.
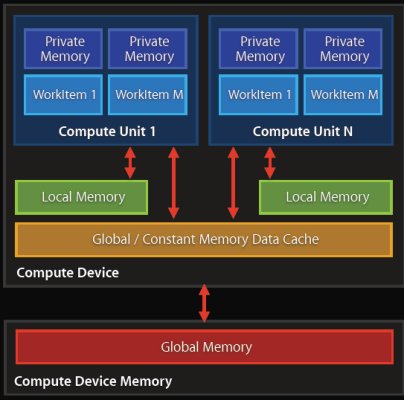
OpenCL 1.0主要由一个并行计算API和一种针对此类计算的编程语言组成,此外还特别定义了:
1、C99编程语言并行扩展子集;
2、适用于各种类型异构处理器的坐标数据和基于任务并行计算API;
3、基于IEEE 754标准的数字条件;
4、与OpenGL、OpenGL ES和其他图形类API高效互通。
OpenCL是由苹果首次提出的,随后Khronos Group成立相关工作组,以苹果草案为基础,联合业界各大企业共同完成了标准制定工作。工作组的26个成员来自各行各业,且都是各自领域的领导者,具体包括3DLABS、 Activision Blizzard、AMD、苹果、ARM、Barco、博通、Codeplay、EA、爱立信、飞思卡尔、HI、IBM、Intel、 Imagination、Kestrel Institute、摩托罗拉、Movidia、诺基亚、NVIDIA、QNX、RapidMind、三星、Seaweed、TAKUMI、德州仪器、瑞 典于默奥大学。
标准倡导者苹果将是最先应用OpenCL技术的厂商之一,代号Snow Leopard的新版操作系统Mac OS X 10.6就会集成该标准。相比之下,微软没有参与OpenCL的制定工作,Windows 7自然也不会提供支持,不过DirectX 11将会带来类似的Computer Shader技术,很可能会重演DirectX与OpenGL之战。
同时,AMD Stream SDK、Codeplay Sieve C++等都正在准备进行改革,以便完全符合OpenCL 1.0标准,NVIDIA的CUDA技术也有望借机大展拳脚。
GPU原本是为图像处理做专门工作的,但随着GPU技术发展的越来越快,它们也能从事一些原本CPU才能做的通用计算工作。GPU特别设计用于并行任务的执行,这些对于类似游戏中液体模拟喷溅等数学计算非常有帮助。要将GPU用于通用计算的一大难点在于,软件的编写必须针对GPU和CPU同时进行,编程人员需要处理协调工作和对内存数据的取用。
OpenCL主席,兼显示芯片制造商Nvidia的移动副总裁以及 Khronos Group的主席Neil Trevett说:“OpenCL 2.0解决了瓶颈问题,并且能够实现更灵活的程序设计技巧。”OpenCL提供了一个抽象层,令程序员在执行任务时无需了解GPU本身的细节情况。显示芯 片制造商编写驱动软件,这其中就为特定的芯片构建了OpenCL本地命令。
在Khronos提出的标准中,除了OpenCL 外,OpenGL更有名。OpenGL发展已有数年,但在电子游戏领域,受制于内建在Windows中微软自家DirectX技术的发展。但现在情况已有 很大不同,苹果的OS X就采用OpenGL,而Android和iOS都采用其子集OpenGL ES。OpenGL ES在计算领域还有另外一个伙伴:WebGL。WebGL提供了令Web应用实现硬件3D加速的标准,谷歌、Opera和Mozilla都对其提供了支持。
Web版OpenCL名为WebCL,则还面临着更大的发展难度。Firefox对WebCL的支持还处于静止状态,而谷歌则由于安全问题也拒绝支持WebCL。
苹果弃用 OpenCL 和 OpenGL 或遭全面淘汰
随着 MacOS 10.14 Mojave 在2018年6月的发布,苹果悄然证实:他们已弃用 OpenGL 和 OpenCL 。
在 MacOS 10.14 的更新文档中,苹果表示使用 OpenGL 和 OpenCL 构建的应用可以继续在 macOS 10.14 中运行,但这些遗留技术在 macOS 10.14 中不推荐使用。现在使用 OpenGL 的游戏和应用应转向 Metal 。同样使用 OpenCL 进行计算任务的应用也应该采用 Metal 和 Metal Performance Shaders 。
苹果想要弃用 OpenCL 和 OpenGL 其实早有迹象,他们近几年一直在推动其 Metal API 在 MacOS 和 iOS 上的应用。苹果的 OpenGL Stack 多年来一直没有更新,已严重落后于 Khronos Group 的 OpenGL 4.x 。虽然苹果目前没有表示何时会删除实际的驱动程序支持,但时间应该不会持续太久。
OpenCL 最初由苹果公司开发,并拥有其商标权。就桌面应用的采用而言,OpenCL 并非一帆风顺。现在随着 macOS 的弃用,我们应该很难看到 OpenCL 未来出现在更多的桌面应用中。
最新版本:2
可为显示芯片提供更好的独立性,以便能为通用软件计算出更大的力。OpenCL是让显示芯片也能为通用软件提供计算能力的标准,标准制定者就是 Khronos Group。
最新版本:3
在 v3.0 临时版本发布6年后,Khronos Group 于2026年5月上旬已正式发布了 v3.1,将之前作为扩展或可选功能实现的成熟功能整合到了 OpenCL 核心规范中。所有符合 OpenCL v3.1 标准的实现都必须支持 SPIR-V 内核。SPIR-V 是 Khronos 的可移植中间表示形式,由包括 Clang/LLVM、SPIR-V LLVM 转换器和更新的 SPIR-V LLVM 后端在内的多种开源编译器生成。除了增强源代码语言的灵活性之外,SPIR-V 还允许内核以预编译、优化的中间形式而非源代码形式分发 —— 从而保护内核知识产权、缩短应用程序启动时间并实现提前特化。
v3.1 还要求支持 SPIR-V 查询扩展,该扩展使应用程序能够枚举设备支持的 SPIR-V 功能、扩展和版本,从而简化新 SPIR-V 功能的采用。
OpenCL 工作组主席 Neil Trevett 称,“强制集成 SPIR-V 是 v3.1 中最具深远意义的改变。SPIR-V 已成为越来越多高级语言和框架(包括 SYCL、ChipStar 以及各种领域特定编译器)的自然编译目标。确保所有符合规范的实现都具备集成 SPIR-V 的能力,消除了这些工具完全采用 OpenCL 作为运行时环境的最后一个障碍。结合工作组的‘扩展优先’方法(该方法确保了 3.1 版本中强制要求的所有功能目前都已投入使用),v3.1 进一步增强了现代异构计算所需的可靠、可移植的运行时基础架构。”
高性能计算和 AI 内核的几个关键特性现在也成为 OpenCL v3.1 核心规范的强制性要求:
1.Subgroups,包括 shuffles、rotations 以及扩展支持的数据类型集。是优化归约、扫描和矩阵核的基本构建模块。
2.整数点积(包括饱和和累加变体)以及扩展位运算:两者都直接映射到各类现代芯片上的专用硬件指令,并且都是矩阵乘法和推理工作负载核心的低精度算术的常用构建模块。
3.针对建议的本地工作组大小的新查询。这为应用程序和性能分析器提供运行时提示,以确定给定内核和设备的最佳工作组大小,从而无需手动调整或在多个队列中重复计算大小,并提高在各种硬件上的性能可预测性。
4.标准的设备 UUID 查询,与 Vulkan 的 VkPhysicalDeviceIDProperties::deviceUUID 相对应。这使得应用程序能够跨 API 关联同一物理设备,这对于多设备系统以及跨越 OpenCL 和 Vulkan 的外部内存共享场景至关重要。
v3.1 还包含一些改进,可以提升日常开发效率:
1.开发者无需依赖扩展即可使用新的语言特性。这意味着内核代码更简洁、更易于移植,能够在所有符合规范的实现中可靠地编译,而无需特定于供应商的扩展保护。
2.OpenCL C 的 printf 函数实现现在支持 z (size_t) 和 t (ptrdiff_t) 长度修饰符。这弥合了与标准 C 之间长期存在的移植性差距,使得设备端调试输出能够正确格式化指针大小和差值类型的值,而无需进行类型转换或使用格式化字符串等变通方法。
3.CL_DEVICE_HOST_UNIFIED_MEMORY 的语义已得到明确,现可用于区分集成 GPU 与独立 GPU。应用程序现在可以可靠地使用此标志在运行时选择内存分配策略 —— 例如,在主机和设备共享同一物理内存的集成 GPU 上,跳过显式缓冲区复制。
4.可以将本地内存内核参数设置为零,以表明不需要本地内存。这样,对于那些不需要本地内存的配置,即使内核偶尔会使用本地内存,也可以无需单独的代码路径来分发这些内核。
5.现事件状态为 CL_COMPLETE 即为同步点,无需再像以前那样显式等待。这消除了一个不易察觉的正确性风险,即轮询事件状态的代码可能与内存可见性发生竞争,从而使事件驱动的同步更加简单且形式上更安全。
6.内存模型的 “inclusive scopes” 规则已放宽,作用域不再需要完全匹配。这意味着更细粒度的作用域现在可以满足更粗粒度的同步需求。
目前已有多个厂商正在开发对 OpenCL v3.1 的支持,包括 Mesa 驱动程序和 Rusticl。此外还有作为 Mesa 项目一部分的 Rusticl、PoCL 和 CLVK 等开源实现方案。
公告还提到,针对低开销可重放工作负载的命令缓冲区、统一共享内存的改进、协作矩阵运算以及适用于低精度格式的全新 AI 数据类型,相关扩展功能也即将推出。除了扩展之外,该工作组还在积极探索 OpenCL 作为更高级别编程模型的基础、在安全关键型市场以及在包括 NPU 和 RISC-V 加速器在内的新兴设备类别中的作用。
项目主页:http://www.khronos.org/opencl/