InfiniBand
 InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。随着人工智能的兴起,它也是 GPU 服务器的首选网络互连技术。
InfiniBand(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。InfiniBand也用作服务器与存储系统之间的直接或交换互连,以及存储系统之间的互连。随着人工智能的兴起,它也是 GPU 服务器的首选网络互连技术。InfiniBand 的发展历程:
1999 年,一家名为 InfiniBand Trade Association(IBTA)的组织发布了 InfiniBand 架构,该架构的目的是为了取代 PCI 总线,旨在提供一种高性能、低延迟的计算和存储互连技术。
2000 年,InfiniBand 架构规范的 1.0 版本正式发布。紧接着在 20021 年,首批 InfiniBand 产品问世,多家厂商也开始推出支持 InfiniBand 的产品,包括服务器、存储系统和网络设备等。
2003 年,InfiniBand 转向一个新的应用领域 —— 计算机集群互联,并在当时的 TOP500 超级计算机中得到了广泛应用。
在接下来的几年中,InfiniBand 多次引入新的特性和改进,支持双倍带宽的 DDR (Double Date Rate)、远程直接内存访问和更好的虚拟化支持,这些新特性为高性能计算和存储系统提供了更多的灵活性和性能优势。
2014年,它是超级计算机最常用的互连技术。Mellanox和英特尔制造InfiniBand主机总线适配器和网络交换器,并根据2016年2月的报道,甲骨文公司已经设计了自己的Infiniband交换机单元和服务器适配芯片,用于自己的产品线和第三方。Mellanox IB卡可用于Solaris、RHEL、SLES、Windows、HP-UX、VMware ESX、AIX。它被设计为可扩展和使用交换结构的网络拓扑。
到 2019 年的 TOP500 超级计算机中,已经有 181 个采用了 InfiniBand 技术,当时的 Ethernet(以太网)仍然是主流。在 2015 年 InfiniBand 技术在 TOP500 超级计算机中的占比首次超过了 50%,达到 51.4%。这标志着 InfiniBand 技术首次实现了对以太网技术的逆袭,成为超级计算机中最受欢迎的内部连接技术。
作为互连技术,IB与以太网、光纤通道和其他专有技术(例如克雷公司的SeaStar)竞争。该技术由InfiniBand贸易联盟推动。其源于1999年两个竞争设计的合并:未来I/O与下一代I/O。这促成了InfiniBand贸易联盟(InfiniBand Trade Association,缩写IBTA),其中包括康柏、戴尔、惠普、IBM、英特尔、微软及昇阳。当时有人认为一些更强大的电脑正在接近PCI总线的互连瓶颈,尽管有像PCI-X的升级。InfiniBand架构规范的1.0版本发布于2000年。最初,IBTA的IB愿景是取代PCI的I/O,以太网的机房、计算机集群的互连以及光纤通道。IBTA也设想在IB结构上分担服务器硬件。随着互联网泡沫的爆发,业界对投资这样一个意义深远的技术跳跃表现为犹豫不决。
特点及优势
InfiniBand 最突出的一个优势,就是率先引入了 RDMA(Remote Direct Memory Access)协议。RDMA 是一种绕过远程主机而访问其内存中数据的技术,解决网络传输中数据处理延迟而产生的一种远端内存直接访问技术。
在传统的 TCP/IP 网络通信中,数据发送方需要将数据进行多次内存拷贝,并经过一系列的网络协议的数据包处理工作;数据接收方在应用程序中处理数据前,也需要经过多次内存拷贝和一系列的网络协议的数据包处理工作。而 RDMA 允许应用与网卡之间的直接数据读写,允许接收端直接从发送端的内存读取数据,RDMA 可以显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。
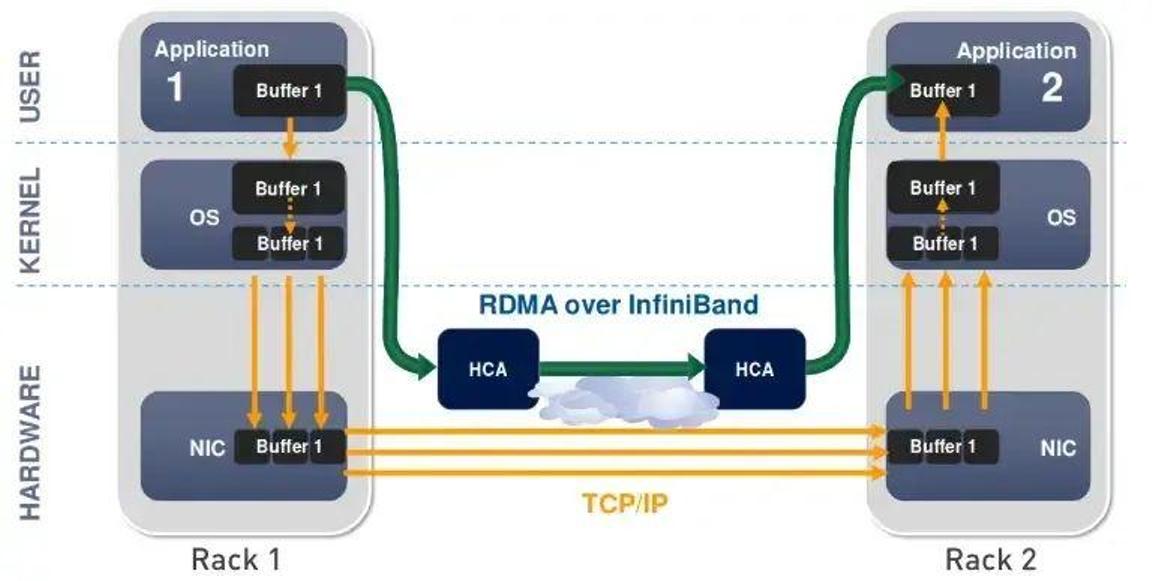
传统传输 VS RDMA
除了 InfiniBand 对 RDMA 协议的支持,还有以下优势:
1.低延迟:InfiniBand 网络以其极低的延迟而著称。RDMA 零拷贝网络减少了操作系统开销,使得数据能够在网络中快速移动,InfiniBand 网络延迟可达到 0.7 微秒。
2.高带宽:InfiniBand 网络提供高带宽的数据传输能力。它通常支持数十 Gb/s 甚至更高的带宽,取决于网络设备和配置。高带宽使得节点之间可以以高速进行数据交换,适用于大规模数据传输、并行计算和存储系统等应用。
3.可扩展性:IB 网络具有出色的可扩展性,适用于构建大规模计算集群和数据中心。它支持多级拓扑结构,如全局互连网络、树状结构和扁平结构,可以根据应用需求和规模进行灵活配置和扩展。此外,IB 网络还支持多个子网的互连,使得不同子网之间的节点可以进行通信和数据交换。这种可扩展性使得 IB 网络能够应对不断增长的计算和存储需求。
4.高吞吐量:由于低延迟和高带宽的特性,IB 网络能够实现高吞吐量的数据传输。它支持大规模数据流的并行传输,同时减少了中间处理和拷贝操作,提高了系统的整体性能。高吞吐量对于需要大规模数据共享和并行计算的应用非常重要,如科学模拟、大数据分析和机器学习。
架构
InfiniBand 是处理器和 I/O 设备之间数据流的通信链路,支持多达 64,000 个可寻址设备。InfiniBand 架构 (IBA) 是一种行业标准规范,定义了用于互连服务器、通信基础设施、存储设备和嵌入式系统的点对点交换输入 / 输出框架。
网络架构
InfiniBand 具有普遍性、低延迟、高带宽和低管理成本,非常适合在单个连接中连接多个数据流(集群、通信、存储、管理),具有数千个互连节点。最小的完整 IBA 单元是子网,多个子网通过路由器连接起来形成一个大的 IBA 网络。
InfiniBand 系统由通道适配器、交换机、路由器、电缆和连接器组成。CA 分为主机通道适配器 (HCA) 和目标通道适配器 (TCA)。IBA 交换机在原理上与其他标准网络交换机类似,但必须满足 InfiniBand 的高性能和低成本要求。HCA 是 IB 端节点(例如服务器或存储设备)连接到 IB 网络的设备点。TCA 是一种特殊形式的通道适配器,主要用于存储设备等嵌入式环境。
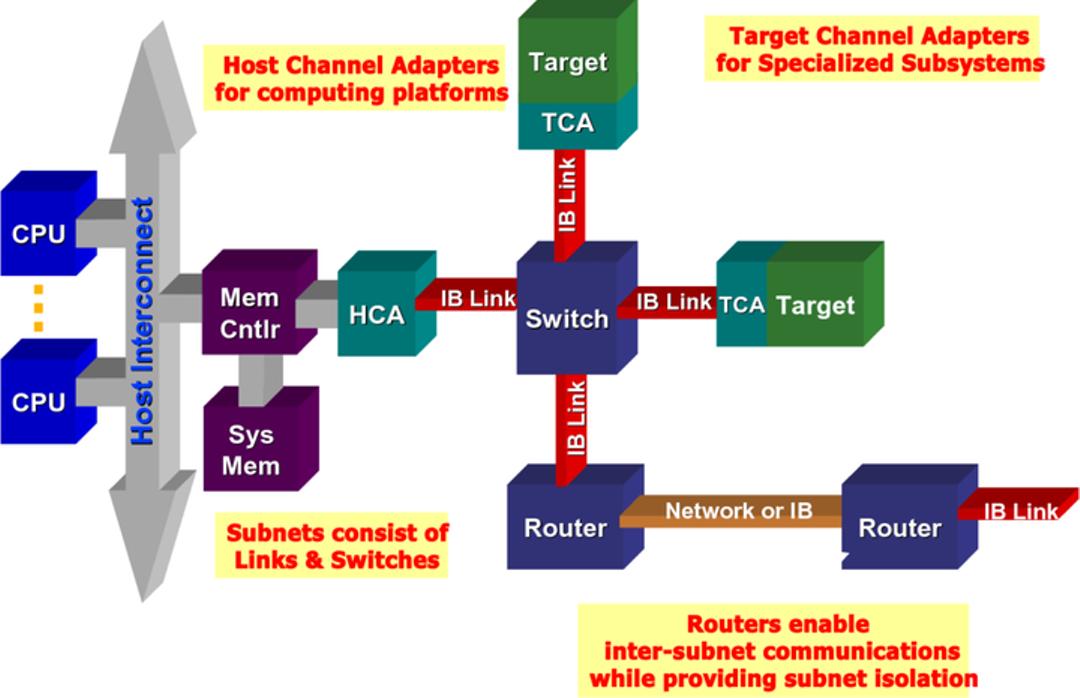
InfiniBand 的网络拓扑结构
分层架构
InfiniBand 架构分为多个层,每个层彼此独立运行,其可分为以下几层:物理层、链路层、网络层、传输层和上层。
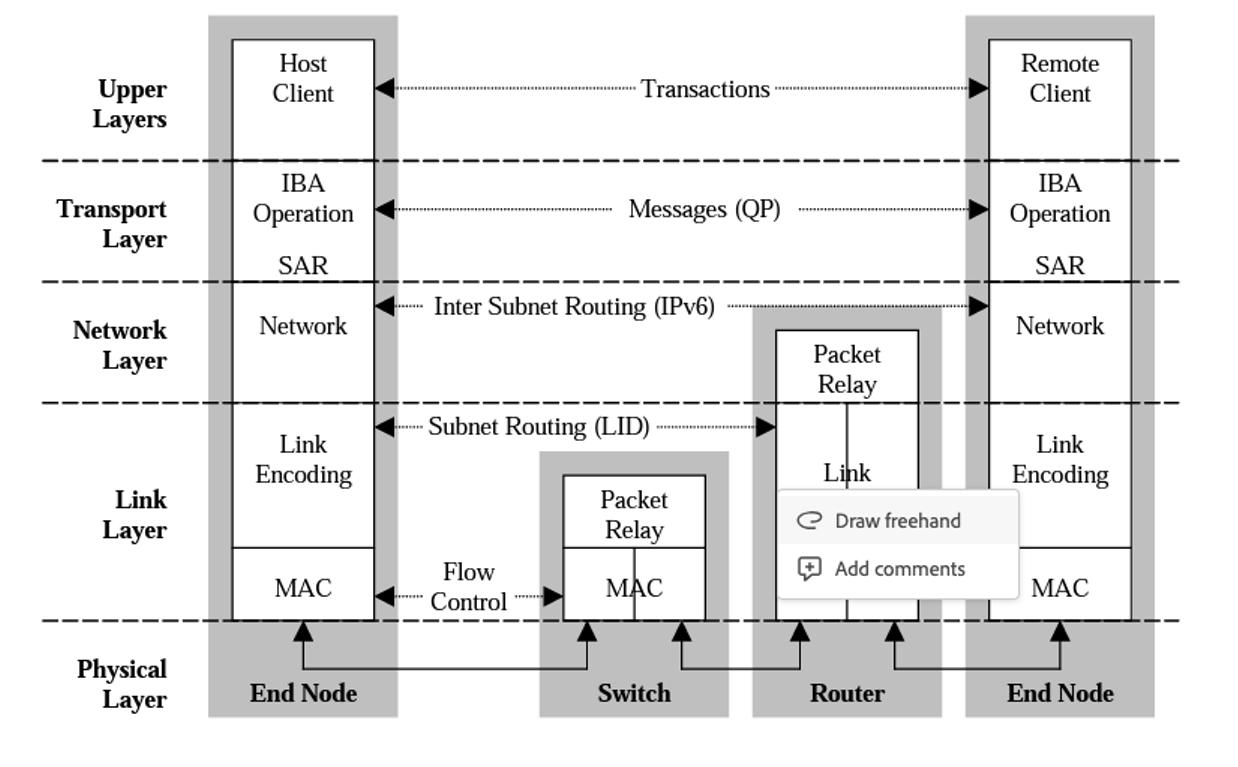
物理层:物理层服务于链路层并提供这两层之间的逻辑接口。物理层由端口信号连接器、物理连接(电和光)、硬件管理、电源管理、编码线等模块组成,
链路层:链路层负责处理分组中链路数据的发送和接收,提供寻址、缓冲、流量控制、错误检测和数据交换等服务。服务质量(QoS)主要由这一层体现。
网络层:网络层负责在 IBA 子网之间路由数据包,包括单播和多播操作。网络层不指定多协议路由(例如,非 IBA 类型上的 IBA 路由),也不指定原始数据包如何在 IBA 子网之间路由。
传输层:每个 IBA 数据都包含一个传输头。传输头包含端节点执行指定操作所需的信息。通过操纵 QP,传输层的 IBA 通道适配器通信客户端形成 “发送” 工作队列和 “接收” 工作队列。
上层:上层协议和应用层负责处理更高级别的通信功能和应用需求。上层协议可以包括诸如 TCP/IP(传输控制协议/互联网协议)、UDP(用户数据报协议)、MPI(消息传递接口)等常见的网络协议。它们利用底层提供的基础通信能力,通过 InfiniBand 网络进行数据传输和通信,用于实现应用程序之间的通信和数据交换。此外,上层还包括运行在 InfiniBand 网络上的应用程序。
性能
| SDR | DDR/th> | QDR | FDR-10 | FDR | EDR | HDR | NDR | |
|---|---|---|---|---|---|---|---|---|
| 信令速率 (Gb/s) | 2.5 | 5 | 10 | 10.3125 | 14.0625 | 25 | 50 | 100 |
| 理论有效吞吐量,Gb/s,每1x | 2 | 4 | 8 | 10 | 13.64 | 24.24 | ||
| 4x链路速度 (Gbit/s) | 8 | 16 | 32 | 40 | 54.54 | 96.97 | ||
| 12x链路速度 (Gbit/s) | 24 | 48 | 96 | 120 | 163.64 | 290.91 | ||
| 编码(比特) | 8/10 | 8/10 | 8/10 | 64/66 | 64/66 | 64/66 | ||
| 延迟时间(微秒) | 5 | 2.5 | 1.3 | 0.7 | 0.7 | 0.5 | ||
| 年 | 2001、 2003 | 2005 | 2007 | 2011 | 2014 | 2017 | 2020年后 |
链路可以聚合:大多数系统使用一个4X聚合。12X链路通常用于计算机集群和超级计算机互连,以及用于内部网络交换器连接。InfiniBand也提供远程直接内存访问(RDMA)能力以降低CPU负载。
拓扑
InfiniBand使用一个交换结构拓扑,不同于早期的共享介质以太网。所有传输开始或结束于通道适配器。每个处理器包含一个主机通道适配器(HCA),每个外设具有一个目标通道适配器(TCA)。这些适配器也可以交换安全性或QoS信息。
消息
InfiniBand以最高4 KB的数据包发送消息数据。一条消息可以为:
一个直接存储器访问的读取或写入,对于一个远程节点(RDMA)。
一个信道发送或接收
一个基于事务的操作(可以逆向)
一个多播传输
一个原子操作
除了板式连接,它还支持有源和无源铜缆(最多30米)和光缆(最多10公里)。使用QSFP连接器。Inifiniband Association也指定了CXP铜连接器系统,用于通过铜缆或有源光缆达到高达120 Gbit/s的能力。
API
InfiniBand没有标准的应用程序接口。标准只列出一组的动作例如 ibv_open_device 或是 ibv_post_send,这些都是必须存在的子程序或方法的抽象表示方式。这些子程序的语法由供应商自行定义。事实标准的软件堆栈标准是由 OpenFabrics Alliance 所开发的。它以双许可证方式发布,GNU通用公共许可证或BSD许可证用于 GNU/Linux 以及 FreeBSD,且 WinOF 在 Windows 下可以选择 BSD许可证。它已被大多数 InfiniBand 供应商采用,用于 GNU/Linux、FreeBSD 以及 Windows。
里程碑
2001年:Mellanox售出InfiniBridge 10Gbit/s设备和超过10,000个InfiniBand端口。
2002年:英特尔宣布将着眼于开发PCI Express而不是采用IB芯片,以及微软停止IB开发以利于扩展以太网,IB发展受挫,尽管Sun和日立继续支持IB。
2003年:弗吉尼亚理工学院暨州立大学建立了一个InfiniBand集群,在当时的TOP500排名第三。
2004年:IB开始作为集群互连采用,对抗以太网上的延迟和价格。OpenFabrics Alliance开发了一个标准化的基于Linux的InfiniBand软件栈。次年,Linux添加IB支持。
2005年:IB开始被实现为存储设备的互连。
2009年:世界500强超级计算机中,259个使用千兆以太网作为内部互连技术,181个使用InfiniBand。
2010年:市场领导者Mellanox和Voltaire合并,IB供应商只剩下另一个竞争者——QLogic,它主要是光纤通道供应商。Oracle makes a major investment in Mellanox.
2011年:FDR交换机和适配器在国际超级计算会议上宣布。
2012年:英特尔收购QLogic的InfiniBand技术。
2016年:甲骨文公司制造自己的InfiniBand互连芯片和交换单元。
2019年:Nvidia以69亿美元收购Mellanox。
2022年以 ChatGPT 为代表的 AI 大模型强势崛起,而 ChatGPT 所使用的网络,正是 InfiniBand,这也让其快速流行起来。据行业机构的预测,InfiniBand 的市场规模在 2029 年将达到 983.7 亿美元,相比 2021 年的 66.6 亿美元,增长 14.7 倍。在高性能计算和 AI 的强力推动下,其发展前景令人期待。