开源MySQL多线程备份恢复工具-mydumper_myloader
 Oracle官方的多线程逻辑导入导出工具mysqlpump,但已经操作过会发现其多线程的单位还是表,换句话说,单表依然是单线程导出。推荐使用mydumper/myloader这样优秀的社区工具来进行逻辑的导入和导出。
Oracle官方的多线程逻辑导入导出工具mysqlpump,但已经操作过会发现其多线程的单位还是表,换句话说,单表依然是单线程导出。推荐使用mydumper/myloader这样优秀的社区工具来进行逻辑的导入和导出。mydumper/myloader简介
mydumper(&myloader)是用于对MySQL数据库进行多线程备份和恢复的开源 (GNU GPLv3)工具。开发人员主要来自MySQL、Facebook和SkySQL公司,目前由Percona公司开发和维护,是Percona Remote DBA项目的重要组成部分,包含在Percona XtraDB Cluster中。mydumper的第一版0.1发布于2010.3.26,最新版本0.9.1发布于2015.11.06。
mydumper 具有如下特性
1 支持多线程导出数据,速度比mysqldump快。
2 支持一致性备份,使用FTWRL(FLUSH TABLES WITH READ LOCK)会阻塞DML语句,保证备份数据的一致性。
3 支持将导出文件压缩,节约空间。
4 支持多线程恢复。
5 支持以守护进程模式工作,定时快照和连续二进制日志
6 支持按照指定大小将备份文件切割。
7 数据与建表语句分离。
mydumper的主要工作步骤
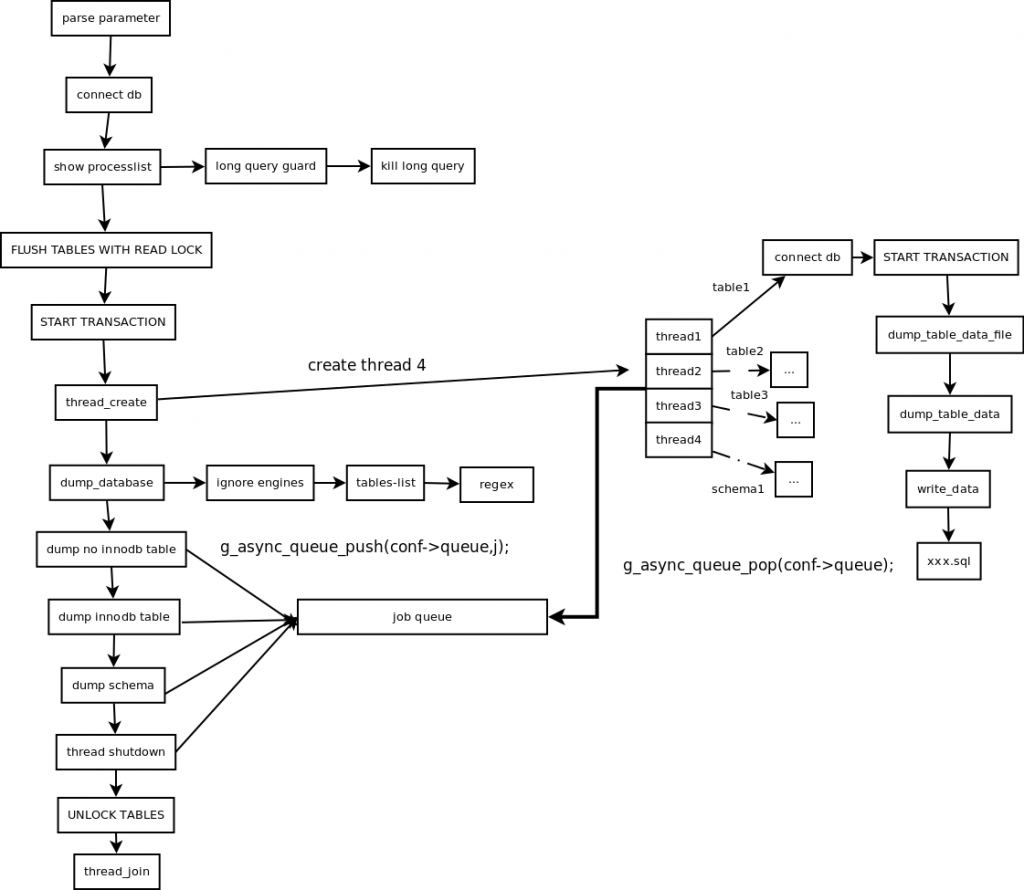
1 主线程 FLUSH TABLES WITH READ LOCK, 施加全局只读锁,以阻止DML语句写入,保证数据的一致性
2 读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供即使点恢复使用
3 START TRANSACTION WITH CONSISTENT SNAPSHOT; 开启读一致事务
4 启用N个(线程数可以指定,默认是4)dump线程导出表和表结构
5 备份非事务类型的表
6 主线程 UNLOCK TABLES,备份完成非事务类型的表之后,释放全局只读锁
7 dump InnoDB tables, 基于事物导出InnoDB表
8 事物结束
导入导出测试
可以发现,在备份时间上,mydumper性能比mysqldump好将近1倍,通过分析不难发现,两者性能的差距主要跟备份实例的IO性能以及mydumper开启的线程数有关系,如果外部实例的IO性能很差,那么可能mysqldump单线程就能够将IO吃满,那改为使用mydumper也无法带来性能提升,但如果实例的IO性能较好,通过增加备份线程数(测试所用为2线程),就可能带来成倍的性能提升。导入时间分别使用与mydumper配合使用的myloader多线程sql导入工具以及mysqldump对应的source命令得到。相应的,在IO性能较好的SSD上,myloader的多线程优势体现明显,比source的单线程执行时间上节省将近2倍(测试所用为4线程)。不过在HDD上,由于其本身性能原因,myloader带来的效益变小。
多线程导出原理
mydumper是一种比MySQL官方mysqldump更优秀的备份工具,主要体现在多线程和备份文件保存方式上。在MySQL 5.7版本中,官方发布了一种新的备份工具mysqlpump,也是多线程的,其实现方式给人耳目一新的感觉,但遗憾的是其仍为表级别的并行。而mydumper能够实现记录级别的并行备份,其备份框架由主线程和多个工作线程组成。
主线程负责建立数据一致性备份点、初始化工作线程和为工作线程推送备份任务:
对备份实例加读锁,阻塞写操作以建立一致性数据备份快照点,记录备份点BinLog信息;
创建工作线程,初始化备份任务队列,并向队列中推送数据库元数据(schema)、非InnoDB表和InnoDB表的备份任务;
工作线程负责将备份任务队列中的任务按顺序取出并完成备份:
分别建立与备份实例连接,将session的事务级别设置为repeatable-read,用于实现可重复读;
在主线程仍持有全局读锁时开启事务进行快照读,这样保证了读到的一致性数据与主线程相同,实现了备份数据的一致性;
按序从备份任务队列中取出备份任务,工作线程先进行MyISAM等非InnoDB表备份,再完成InnoDB表备份;这样可以在完成非InnoDB表备份通知后主线程释放读锁,尽可能减小对备份实例业务的影响;
mydumper的记录级备份由主线程负责任务拆分,由多个工作线程完成。主线程通过将表数据拆分为多个chunk,每个chunk作为一个备份任务。表数据拆分方式如下所述:mydumper优先选择主键索引的第一列作为chunk划分字段,若不存在主键索引,则选择第一个唯一索引作为划分依据,若还不存在,则选择区分度(Cardinality)最高的任意索引。如果还是无法满足,则只能进行表级的并行备份。在确定了chunk划分字段后,先获取该字段的最大和最小值,再通过执行“explain select field from db.table”来估计该表的记录数,最后根据所设的每个任务(文件)记录数来将该表划分为多个chunk。
以上描述可知,mydumper并不能保证记录级备份时,每个备份任务中的记录数是相同的。另外,目前记录级备份存在一个bug:所用索引字段为负数时主线程会进入死循环无法退出,导致备份失败。
与mysqldump另一个不同是,mydumper为每个备份任务建立至少一个备份文件。在0.9.1版本中,文件类型包括schema-create、schema、schema-post文件等表元数据文件分别用保存建数据库语句、建表语句(包括触发器)、函数/存储过程/事件定义语句等;数据文件可以根据用户设置为固定大小或固定记录数的文件。这样便以进行更细粒度的数据恢复和数据删除,比如可以在myloader的时候仅选择某几个数据库/表进行恢复。
这里对mydumper的工作原理做个分析,看一下mydumper如何巧妙的利用Innodb引擎提供的MVCC版本控制的功能,实现多线程并发获取一致性数据。这里一致性数据指的是在某个时间点,导出的数据与导出的Binlog文件信息相匹配,如果导出了多张表的数据,这些不同表之间的数据都是同一个时间点的数据。在mydumper进行备份的时候,由一个主线程以及多个备份线程完成。其主线程的流程是:
连接数据库
FLUSH TABLES WITH READ LOCK 将脏页刷新到磁盘并获得只读锁
START TRANSACTION /!40108 WITH CONSISTENT SNAPSHOT / 开启事物并获取一致性快照
SHOW MASTER STATUS 获得binlog信息
创建子线程并连接数据库
为子线程分配任务并push到队列中
UNLOCK TABLES / FTWRL / 释放锁
子线程的主要流程是:
连接数据库
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE
START TRANSACTION /!40108 WITH CONSISTENT SNAPSHOT /
从队列中pop任务并执行
上述两个线程的流程的关系如图
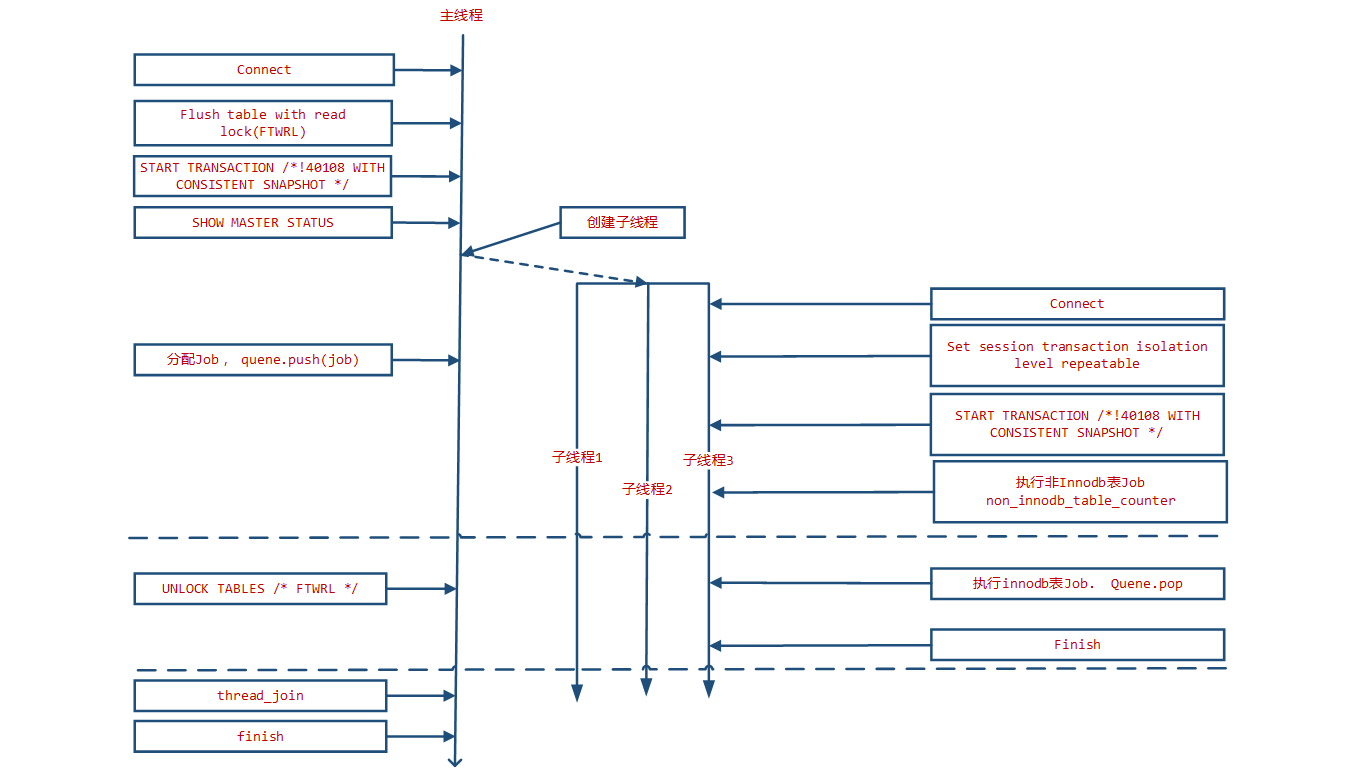
从图中可以看到,主线程释放锁是在子线程开启事物之后。这里是保证子线程获得的数据一定为一致性数据的关键。主线程在连接到数据库后立即通过Flush tables with read lock(FTWRL) 操作将脏页刷新到磁盘,并获取一个全局的只读锁,这样便可以保证在锁释放之前由主线程看到的数据是一致的。然后立即通过 Start Transaction with consistent snapshot 创建一个快照读事物,并通过 show master status获取binlog位置信息。然后创建完成dump任务的子线程并为其分配任务。
主线程在创建子线程后通过一个异步消息队列 ready 等待子线程准备完毕。 子线程在创建后立即创建到MySQL数据库的连接,然后设置当前事务隔离级别为Repeatable Read。
设置完成之后开始快照读事务。在完成这一系列操作之后,子线程才会通过ready队列告诉主线自己程准备完毕。主线程等待全部子线程准备完毕开启一致性读Snapshot事务后才会释放全局只读锁(Unlock Table)。
如果只有Innodb表,那么只有在创建任务阶段会加锁。但是如果存在MyIsam表或其他不带有MVCC功能的表,那么在这些表的导出任务完成之前都必须对这些表进行加锁。Mydumper本身维护了一个 non_innodb_table 列表,在创建任务阶段会首先为非Innodb表创建任务。同时还维护了一个全局的unlock_table队列以及一个原子计数器 non_innodb_table_counter , 子线程每完成一个非Innodb表的任务便将 non_innodb_table_counter 减一,如果non_innodb_table_counter 值为0 遍通过向 unlock_table 队列push一个消息的方式通知主线程完成了非Innodb表的导出任务可以执行 unlock table操作。
mydumper支持记录级别的并发导出。在记录级别的导出时,主线程在做任务分配的时候会对表进行拆分,为表的一部分记录创建一个任务。这样做一个好处就是当有某个表特别大的时候可以尽可能的利用多线程并发以免某个线程在导出一个大表而其他线程处于空闲状态。在分割时,首先选取主键(PRIMARY KEY)作为分隔依据,如果没有主键则查找有无唯一索引(UNIQUE KEY)。在以上尝试都失败后,再选取一个区分度比较高的字段做为记录划分的依据(通过 show index 结果集中的cardinality的值确定)。
划分的方式比较暴力,直接通过 select min(filed),max(filed) from table 获得划分字段的取值范围,通过 explain select filed from table 获取字段记录的行数,然后通过一个确定的步长获得每一个子任务的执行时的where条件。这种计算方式只支持数字类型的字段。
以上就是mydumper的并发获取一致性数据的方式,其关键在于利用了Innodb表的MVCC功能,可以通过快照读因此只有在任务创建阶段才需要加锁。
mydumper的工作原理
网易对mydumper的改进
mydumper是一款优秀的备份工具,但也存在不足,包括多线程导出数据对实例业务的影响、逻辑备份方式对热点数据污染和持锁时对业务的阻塞等。网易RDS在mydumper实践中对其进行了多方面的优化。
多线程备份固然好,但在进行备份时往往数据库还在正常提供对外服务,多线程全表select数据会占用很大部分的系统IO能力,导致正常的业务IO性能下降,严重时甚至会使数据库连接爆掉。通过为mydumper增加负载自适应能力来最大限度缓解对线上业务影响:工作线程在每次数据导出前,都会首先观察实例的当前负载情况,举MySQL状态Thread_connected为例,其反映的是目前已连接到该实例的请求数,如果该数值大于设定的阈值,则本次导出操作会暂停,直到数值小于阈值才会恢复,这样就起到了根据实例业务负载情况,灵活调整用于数据导出的线程数来适应线上业务负载的作用。
逻辑备份的全表select不可避免会污染InnoDB Buffer Pool的热点数据,缓存的热点数据被换出,降低了命中率的同时增大了业务的IO量,在使用mydumper时应尽量减小对Buffer Pool的影响;通过调整Buffer Pool的热点算法,使得热点数据尽可能不被换出。修改innodb_old_blocks_time和innodb_old_blocks_pct,用于将全表select进入Buffer Pool放在其old sublist中,同时减小old sublist块在Buffer Pool中的比例,起到最小化污染的作用。其原理详见http://dev.mysql.com/doc/innodb-plugin/1.0/en/idm47548325357504.html
在进行数据备份时,由于MyISAM表是非事务的,为了得到一致性的数据,导出MyISAM表需要全程持有读锁。在通常的MySQL实例中,MyISAM表数据都是很少的,所以持锁时间很短,但若有实例存在大量的MyISAM表数据,那么就会因持锁时间过长对业务的数据更新和插入造成影响。通过为mydumper增加持锁超时时间来避免该问题,所在数据备份过程中,持锁时间超过所设置时间,则mydumper返回失败,通过将MyISAM表转化为InnoDB表后再开始导出。
此外,在对大数据量数据库进行备份时,往往需要耗费较长时间,如果能够实时了解备份进度,相信是一个很好的体验,为此,给mydumper增加了进度查询功能,能够查询mydumper所需执行的所有备份任务数、当前已经完成的备份任务数及每个备份任务所花费时间。
编译安装
mydumper 基于c语言编写,需要编译安装,因此需要安装编译工具。
yum install glib2-devel mysql-devel zlib-devel pcre-devel zlib gcc-c++ gcc cmake -y #CentOS
apt-get install cmake make libglib2.0-dev libmysqlclient15-dev zlib1g-dev libpcre3-dev g++ #Debiantar xf mydumper-0.9.1.tar.gz
cd mydumper-0.9.1/
cmake .
make && make install
装好之后 ,会生成两个文件:
/usr/local/bin/mydumper
/usr/local/bin/myloader
注意:
一般会遇到找不到 mysql-libraries 的问题,可以参考 stackoverflow 的回答,如果再解决不了,则可能是自己制定的MySQL安装目录的问题,比如我自己的安装目录是/opt/mysql/
则需要做一个软连接
ln -s /opt/mysql/lib/libperconaserverclient.so /usr/lib64/libperconaserverclient.so
编译过程中的问题集
-- Checking for one of the modules 'glib-2.0'
CMake Error at /usr/local/share/cmake-3.8/Modules/FindPkgConfig.cmake:641 (message):
None of the required 'glib-2.0' found
Call Stack (most recent call first):
cmake/modules/FindGLIB2.cmake:10 (pkg_search_module)
CMakeLists.txt:10 (find_package)
-- Checking for one of the modules 'gthread-2.0'
CMake Error at /usr/local/share/cmake-3.8/Modules/FindPkgConfig.cmake:641 (message):
None of the required 'gthread-2.0' found
Call Stack (most recent call first):
cmake/modules/FindGLIB2.cmake:11 (pkg_search_module)
CMakeLists.txt:10 (find_package)
-- Checking for module 'libpcre'
-- No package 'libpcre' found
CMake Error at /usr/local/share/cmake-3.8/Modules/FindPkgConfig.cmake:416 (message):
A required package was not found
安装好glib2-devel后,不再报glib-2.0、gthread-2.0找不到的错误了,pcre-devel被安装之后不再报找不到libpcre相关的问题了。
apt-get install libglib2.0-dev libpcre3
需要安装依赖:
Fedora, RedHat and CentOS: yum install glib2-devel mysql-devel zlib-devel pcre-devel openssl-devel
最新版本:0.91
项目主页:https://github.com/maxbube/mydumper