使用Dtrace和XPerf监视操作系统中的系统调用
 监视系统调用 (syscall) 和分析系统行为可以帮助您调试产品并提高其性能、安全性和合规性。然而,由于缺乏内置工具以及需要逆向工程和应用程序行为分析的专业知识,监视操作系统中的系统调用面临着挑战。
监视系统调用 (syscall) 和分析系统行为可以帮助您调试产品并提高其性能、安全性和合规性。然而,由于缺乏内置工具以及需要逆向工程和应用程序行为分析的专业知识,监视操作系统中的系统调用面临着挑战。在本文中讨论在 Windows 中监视系统调用的一些核心方法;并于其后会附上对 Linux 的动态分析与调优。
监控 Windows 中的系统调用:查看内容以及原因
系统调用是一种使程序能够从操作系统内核请求各种类型的服务和任务的机制。系统调用为用户级程序访问系统资源提供了一种安全且受控的方式,而不会影响操作系统 (OS) 的稳定性或安全性。当执行请求的操作时,系统调用在用户模式和内核模式之间转移控制。
系统调用是ring-0/ring-3隔离的标准部分,让我们仔细看看。
在操作系统中,有两种代码环境:
以完全权限运行的内核代码(环 0)
以有限权限运行的用户代码(环 3)
在这些环境之间,有一个系统调用接口。
环 0 和环 3 之间的划分(内核级别和用户级别)是观察应用程序行为和原始操作的最佳点。当代码达到系统调用级别时,应用程序无法混淆其操作。例如,如果用户级代码秘密调用CreateFile()函数,您仍然可以通过监视系统调用来检测到这一点,因为您将看到 NtCreateFile 系统调用的执行。
对于大多数流行的体系结构,包括 x86、AMD64、ARM64 和 PowerPC,处理系统调用的方法是相同的:
在用户级别,一组系统 API 充当系统调用的包装器。
在内核级别,内核 API 实现系统调用的处理程序并由内核驱动程序使用。
在某些体系结构中,系统调用称为系统服务。
Windows 中系统调用的常见示例包括:
文件输入/输出 (I/O) 操作,例如读取或写入文件
流程管理,例如创建新流程或终止现有流程
内存管理,例如分配内存
进程间通信,例如在进程之间发送或接收消息
设备驱动程序操作,例如向硬件设备发送命令
为什么您的开发人员需要监视系统调用?
Windows 系统调用监控对于研究多层软件和分析具有混淆代码的应用程序的行为至关重要。使用这种方法,您可以确定特定应用程序的行为方式,而无需分析应用程序每个级别的代码。
监控系统调用的常见原因包括:
调试:跟踪应用程序中的问题,确定其根本原因,并快速修复错误。
性能优化:识别瓶颈并优化有问题的代码部分以提高整体性能。
安全:检测可疑的、潜在的恶意行为,并采取措施阻止其发生。
合规性:通过分析应用程序访问和使用特定类型数据的方式,确保应用程序符合相关要求。

然而,在实践中应用这种方法面临着多重挑战。它需要深入了解操作系统的细节以及逆向工程和应用程序行为分析的利基知识。在下一节中,我们将根据 Apriorit 专家的经验,讨论开发人员在尝试监视 Windows 中的系统调用时可能面临的关键问题。
Windows 中的系统调用监控挑战
与 Linux 具有用于监视任何进程中的系统调用的strace工具相比,Windows 由于安全原因没有用于此任务的内置工具。然而在 Windows XP 之前,任何需要监视或控制用户级代码的软件(例如防病毒软件)都可以在两个表中设置挂钩:
系统服务描述符表(SSDT)
影子系统服务描述符表(影子SSDT)
这些表包含指向处理特定系统调用的内核函数的指针。
在 SSDT 和 Shadow SSDT 中设置挂钩会导致大量冲突和不稳定,导致 Windows 声誉受损,并使其看起来像一个不可靠的操作系统。除此之外,rootkit 和病毒还能够在 SSDT 和 Shadow SSDT 中设置挂钩。这就是为什么微软被迫阻止对这些表的访问,并且从Windows XP开始,实施了PatchGuard,也称为内核补丁保护。从那时起,系统监控工具只能为一小部分内核事件设置回调,这使得系统调用的监控变得非常具有挑战性。
下面讨论如何监视 Windows 中的系统调用,并解释一种安全有效的方法来分析 Windows 中的程序行为。
使用 XPerf 监控 Windows 系统调用
在 Windows XP 中,Microsoft 引入了Windows 事件跟踪 (ETW)机制,用于XPerf工具使用的详细事件日志记录。后者现在是Windows Performance Toolkit的一部分。一般来说,微软将 ETW 回调放置在整个 Windows 子系统中,以便能够跟踪低级事件。使用 ETW,您可以获取系统事件,因此 XPerf 对于监视系统调用也可能很有用。来看看如何使用 XPerf 来监视 Windows 中的系统调用。
首先查询 ETW 提供者,看看是否有与系统调用相关的内容:
logman.exe query providers
在从 XPerf 收到的信息中,没有任何看起来像系统调用的内容。转到 TraceView 并监视名称如 Microsoft-Windows-Kernel-* 的内核提供程序事件,也带来了各种类型的内核事件,但没有有关系统调用的结果。
下一个可能性是使用SystemTraceProvider 一个跟踪内核事件的内核提供程序。将这个提供程序的 GUID 添加到 TraceView 后,我们仍然没有结果。
为了寻找设置挂钩的可能替代方案,我们尝试了不同的方法来监视 Windows 中的系统调用,包括通过虚拟机管理程序挂钩 SSDT 函数以及使用 Windows 事件跟踪的未记录部分。
使用 Syscall Monitor 和 InfinityHook 监控 Windows 系统调用
为了寻找替代解决方案,我们决定研究一下记录较少的监控系统调用的方法。
免责声明:以下操作仅用于研究目的。
在研究了几种可能性之后,在 GitHub 上发现了两个有前途的项目:
系统调用监视器
无限钩
从测试 Syscall Monitor 工具开始。该项目使用虚拟机扩展通过虚拟机管理程序挂钩 SSDT 功能。该方法本身有效,使得监视 Windows 中的系统调用成为可能。不幸的是,作者决定实现该工具作为ProcessMonitor的替代品。因此 Syscall Monitor 的能力有限,只能监控一小部分系统调用:
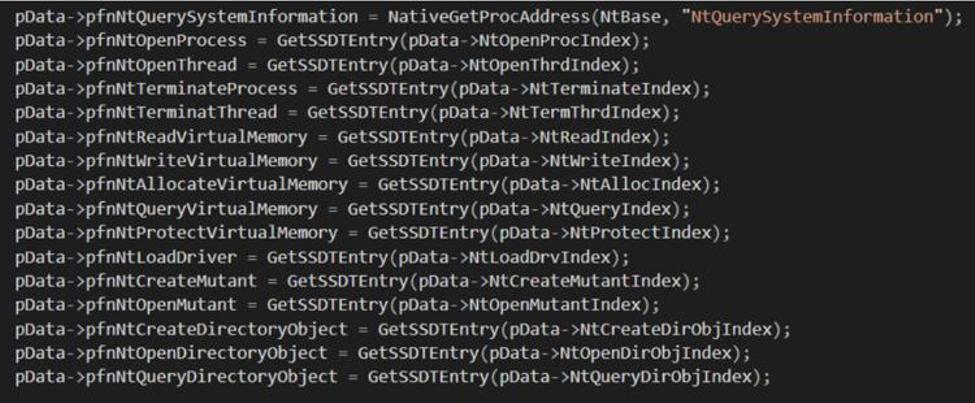
屏幕截图 1. 使用 Syscall Monitor 的结果
总而言之,Syscall Monitor 是一个很好的工具,可以帮助您开始研究 SSDT 挂钩,但如果您想监视图形设备接口 (GDI) 系统调用等内容,则该工具就没用了。
现在继续测试 InfinityHook 工具的使用。根据该工具的描述,在使用它之前,需要了解ETW的基础知识。
为了监视 Windows 中的系统调用,InfinityHook 在系统调用处理程序的内核代码中使用 ETW 跟踪的未记录部分。值得注意的是,该项目无法轻松地开箱即用,我们必须在设法运行代码之前实现一些细微的更改。然而,结果我们得到了 BSOD:
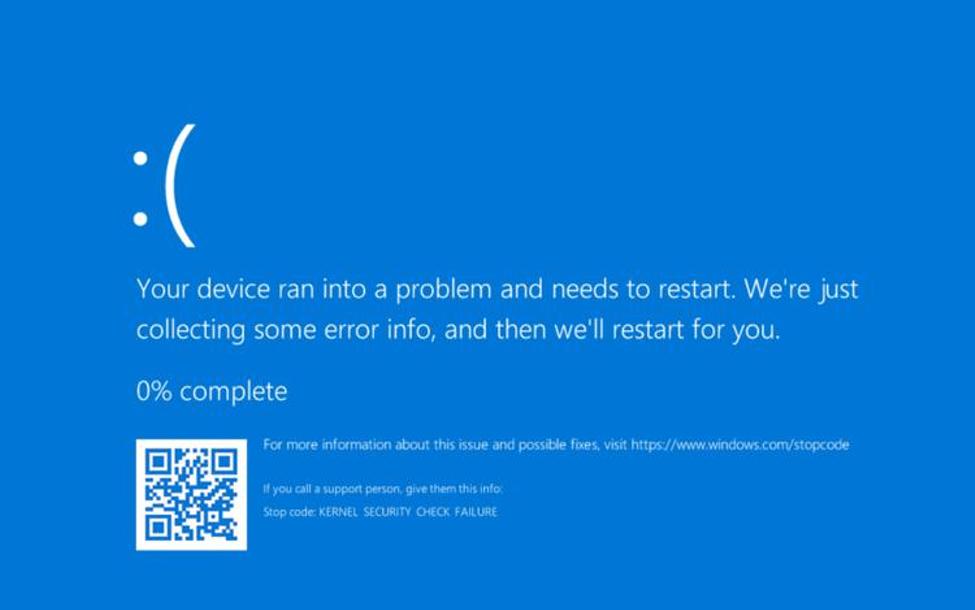
屏幕截图 2. 使用 InfinityHook 工具的结果
从上面的屏幕截图中可以看到,我们收到一条错误消息,内容为“停止代码:KERNEL_SECURITY_CHECK_FAILURE”。此消息意味着内核补丁保护已被触发。显然,最新版本的 Windows 保护内核 ETW 提供程序回调免受修改,因此为了监视 Windows 系统调用,需要禁用 PatchGuard。
在 Windows 10 中禁用 PatchGuard 的一种方法是使用EfiGuard项目。按照 GitHub 的说明,我们使用软盘映像启动 Windows 10 的 VMWare 实例,用于此类研究和实验:
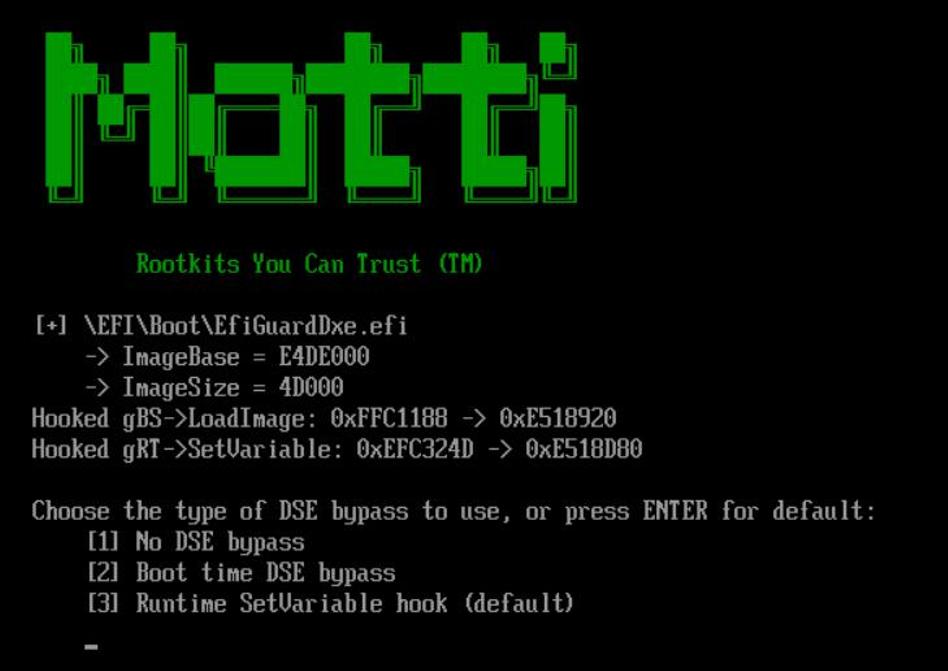
屏幕截图 3. 使用 EfiGuard 工具的结果
尝试了几种不同的驱动程序签名强制绕过方法,但结果仍然相同 - 仍然遇到由内核补丁保护触发的 BSOD。经过进一步调查,确定 EfiGuard 在不同的 Windows 版本上成功运行 - 具体来说,Windows 10 版本 1511。
然后创建了一个新的 VMWare 映像,并在其上安装了 Windows 10 build 1511,并尝试使用 EfiGuard 再次禁用 PatchGuard。这一次成功了,终于成功运行了InfinityHook项目。InfinityHook 使用DbgPrint()
函数打印有关来自驱动程序的系统调用的信息。因此需要使用DebugView工具来查看其日志。
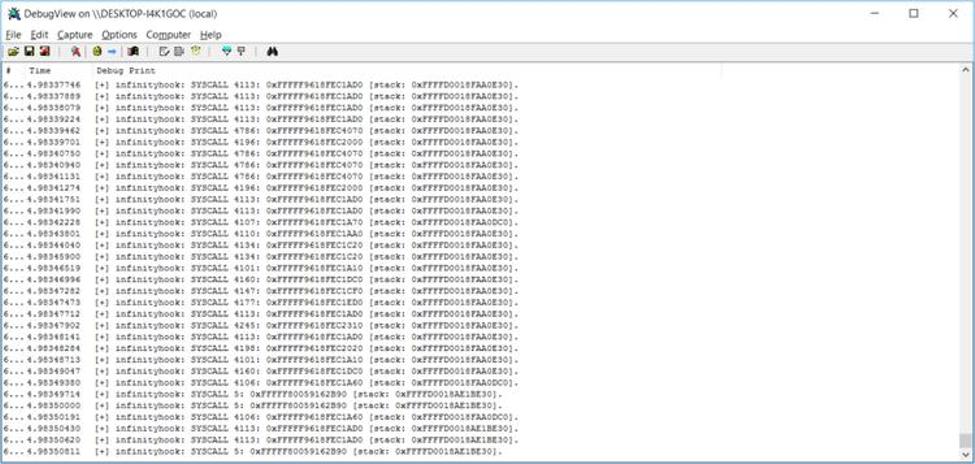
屏幕截图 4. InfinityHook 中的系统调用监控结果
从上面的截图可以看出,InfinityHook提供了以下数据:
系统调用索引
EPROCESS值
系统调用的堆栈指针
索引超过 4000 的系统调用是 GDI 调用。为了正确地将索引映射到系统调用的名称,您需要知道与您的计算机运行的内核版本相关的系统调用索引。您还可以尝试使用互联网上提供的系统调用表之一进行进一步研究。然而,由于这种方法需要额外的努力,我们尝试寻找一种更方便、更安全的方法来监视 Windows 中的系统调用。在下一节中,我们将详细讨论如何使用 DTrace 来监视 Windows 系统调用。
使用 DTrace 监控 Windows 系统调用
DTrace是一个动态跟踪框架,允许开发人员在用户模式和内核模式下实时分析系统行为。该框架最初由 Sun Microsystems 为 Solaris 操作系统开发,后来移植到其他类 Unix 操作系统,例如macOS和 Linux。
目前微软还支持DTrace,使开发人员和软件研究人员能够监控从Windows 10 Build 1903开始的64位平台上的系统调用。但该工具只能捕获64位进程的痕迹。
GitHub 上的DTrace on Windows页面包含有关如何安装它的易于遵循的说明,因此我们将在概述中省略这部分。默认情况下,系统将 DTrace 放置在C:\Program Files\DTrace文件夹中。要使用它需要以管理员身份运行以下命令:
dtrace -ln syscall:::
运行此命令后,DTrace 应打印系统中可用于监视的系统调用列表。
注意:每个系统调用都会打印两次,因为您可以监视系统调用参数及其返回值。
接下来运行以下用D语言编写的脚本继续进行系统调用监控:
syscall::: /pid == 9140/ { printf ("%s called\n", execname); }
这个特定的脚本打印 PID = 9140 的进程的所有系统调用。通过更改 PID,可以监视您感兴趣的任何其他进程的系统调用。
将脚本保存为 test.d 文件,然后可以使用简单的命令运行它:
dtrace -s test.d
要了解其工作原理,让我们运行记事本脚本。收到以下结果:
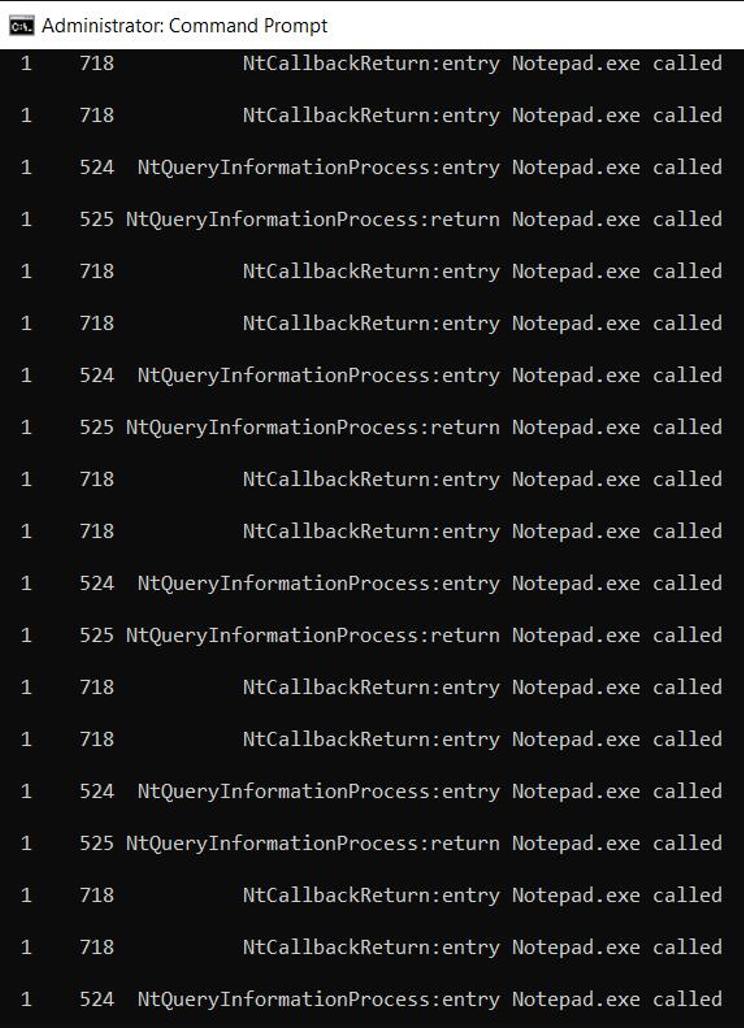
屏幕截图 5. 使用 DTrace 监控记事本系统调用
可以随时按Ctrl+C停止使用 DTrace 监视 Windows 系统调用。要了解有关使用 DTrace 脚本和可能的系统监控方法的更多信息,您可以探索 Microsoft 在 DTrace GitHub 页面上提供的示例。
结论
监视系统调用可以提供有关应用程序行为和性能的宝贵见解,从而帮助开发人员创建更可靠、更高效、更安全的应用程序。要监视 Windows 中的系统调用,可以使用 Microsoft 官方支持的 DTrace 实现。
参考及来源。
浅析Linux动态追踪技术(转自大师兄的个人空间,感谢原作者)
动态追踪技术原因
当碰到内核线程的资源使用异常时,很多常用的进程级性能工具,并不能直接用到内核线程上。这时就可以使用内核自带的 perf 来观察它们的行为,找出热点函数,进一步定位性能瓶颈。不过 perf 产生的汇总报告并不直观,所以通常也推荐用火焰图来协助排查。
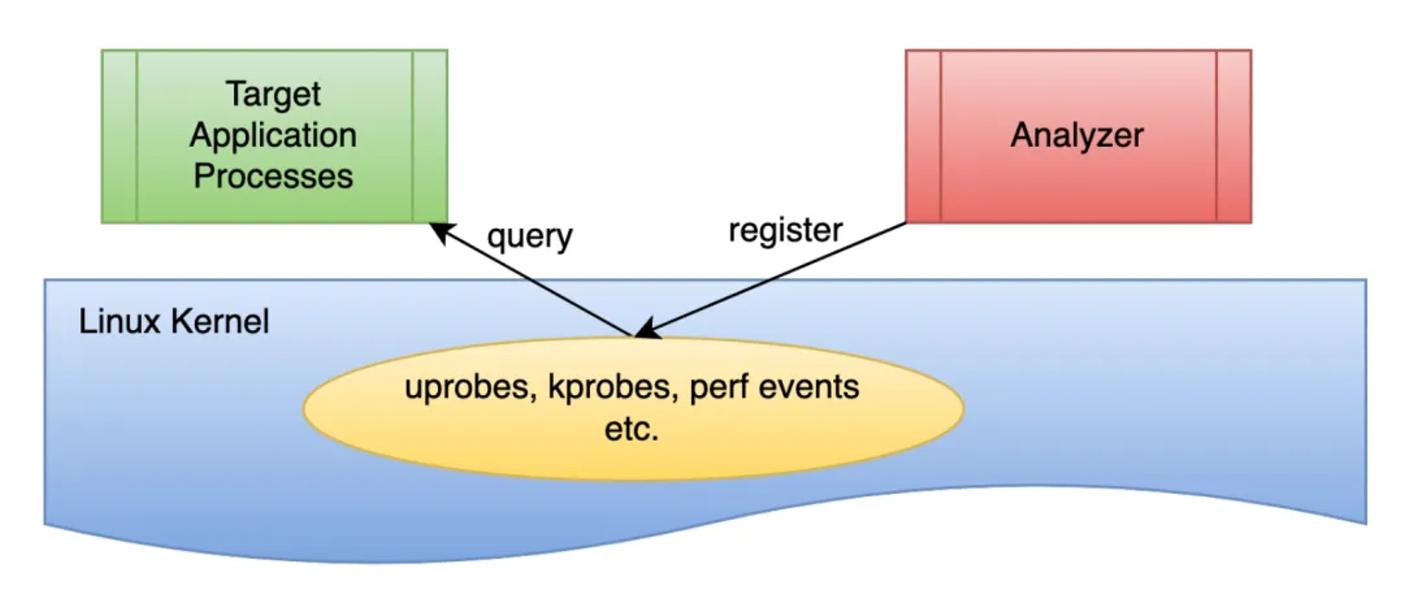
其实使用 perf 对系统内核线程进行分析时,内核线程依然还在正常运行中,所以这种方法也被称为动态追踪技术。
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
以往在排查和调试性能问题时,我们往往需要先为应用程序设置一系列的断点(比如使用GDB),然后以手动或者脚本(比如 GDB 的 Python 扩展)的方式,在这些断点处分析应用程序的状态。或者增加一系列的日志,从日志中寻找线索。
不过,断点往往会中断应用的正常运行;而增加新的日志,往往需要重新编译和部署。这些方法虽然在今天依然广泛使用,但在排查复杂的性能问题时,往往耗时耗力,更会对应用的正常运行造成巨大影响。
此外,这类方式还有大量的性能问题。比如出现的概率小,只有线上环境才能碰到。这种难以复现的问题,亦是一个巨大挑战。
而动态追踪技术的出现,就为这些问题提供了完美的方案:它既不需要停止服务,也不需要修改应用程序的代码;所有一切还按照原来的方式正常运行时,就可以帮你分析出问题的根源。同时相比以往的进程级跟踪方法(比如 ptrace),动态追踪往往只会带来很小的性能损耗(通常在 5% 或者更少)。
动态追踪
说到动态追踪(Dynamic Tracing),就不得不提源于 Solaris 系统的 DTrace。它是动态追踪技术的鼻祖,它提供了一个通用的观测框架,并可以使用 D 语言进行自由扩展。
DTrace 的工作原理如下图所示。它的运行常驻在内核中,用户可以通过 dtrace 命令,把 D 语言编写的追踪脚本,提交到内核中的运行时来执行。DTrace 可以跟踪用户态和内核态的所有事件,并通过一些列的优化措施,保证最小的性能开销。
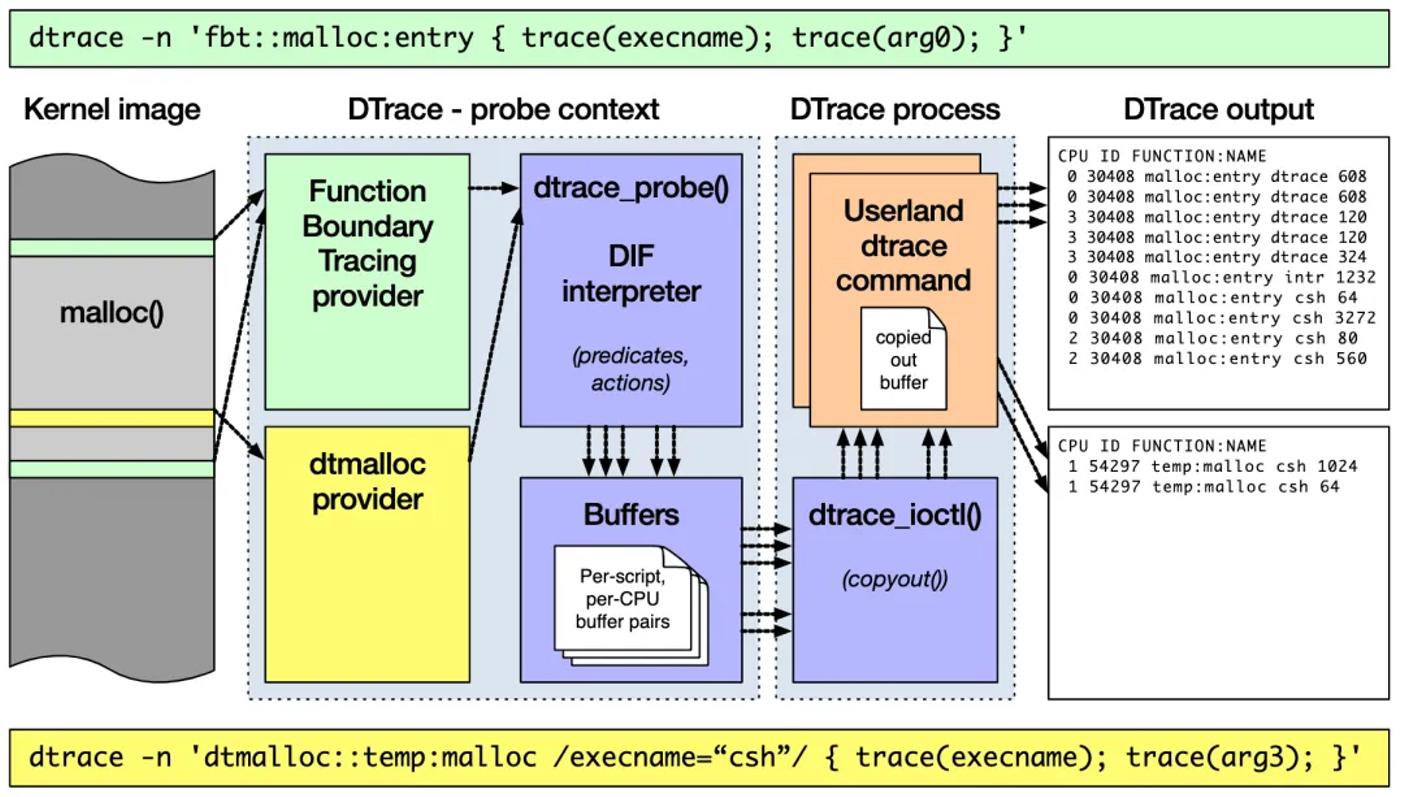
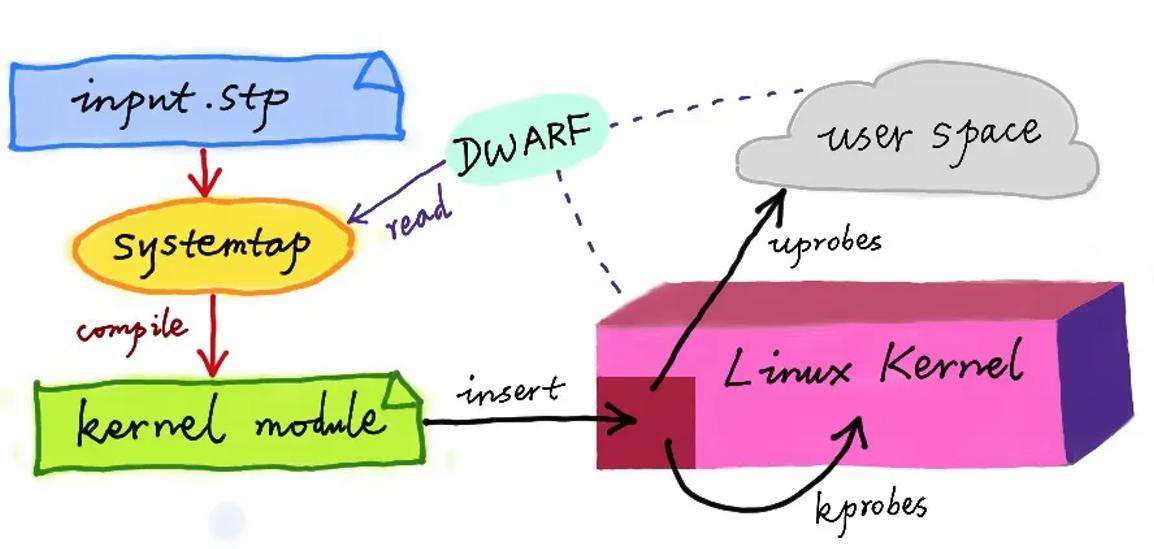
虽然直到今天,DTrace 本身依然无法在 Linux 中运行,但它同样对 Linux 动态追踪产生了巨大的影响。很多工程师都尝试过把 DTrace 移植到 Linux 中,这其中,最著名的就是 RedHat 主推的 SystemTap。
同 DTrace 一样,SystemTap 也定义了一种类似的脚本语言,方便用户根据需要自由扩展。不过,不同于 DTrace,SystemTap 并没有常驻内核的运行时,它需要先把脚本编译为内核模块,然后再插入到内核中执行。这也导致 SystemTap 启动比较缓慢,并且依赖于完整的调试符号表。
总的来说,为了追踪内核或用户空间的事件,Dtrace 和 SystemTap 都会把用户传入的追踪处理函数(一般称为 Action),关联到被称为探针的检测点上。这些探针,实际上也就是各种动态追踪技术所依赖的事件源。
动态追踪的事件源
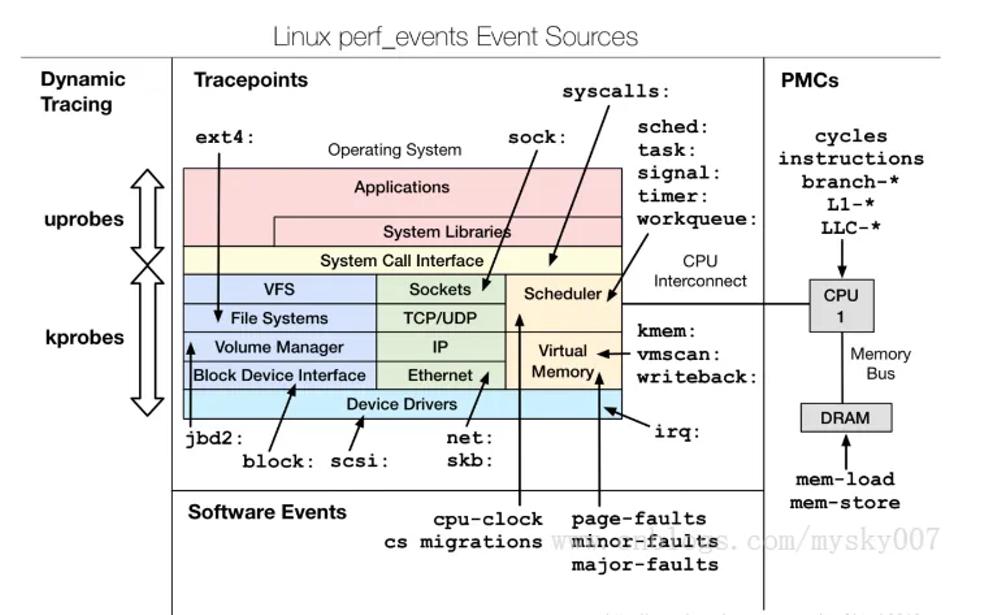
根据事件类型的不同,动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类。它们的关系如下图所示:其中,硬件事件通常由性能监控计数器 PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。
静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时,才会被执行到;未开启时并不会执行。常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(Userland Statically Defined Tracing)探针。
1.跟踪点(tracepoints),实际上就是在源码中插入的一些带有控制条件的探测点,这些探测点允许事后再添加处理函数。
比如在内核中,最常见的静态跟踪方法就是 printk,即输出日志。Linux 内核定义了大量的跟踪点,可以通过内核编译选项,来开启或者关闭。
2.USDT探针,全称是用户级静态定义跟踪,需要在源码中插入 DTRACE_PROBE() 代码,并编译到应用程序中。
不过也有很多应用程序内置了 USDT 探针,比如 MySQL、PostgreSQL等。
动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的 kprobes 和用于用户态的 uprobes。
1.kprobes用来跟踪内核态的函数,包括用于函数调用的 kprobe 和用于函数返回的kretprobe。
2.uprobes用来跟踪用户态的函数,包括用于函数调用的 uprobe 和用于函数返回的uretprobe。
注意,kprobes 需要内核编译时开启 CONFIG_KPROBE_EVENTS;而 uprobes则需要内核编译时开启 CONFIG_UPROBE_EVENTS。
动态追踪机制
而在这些探针的基础上,Linux 也提供了一系列的动态追踪机制,比如 ftrace、perf、eBPF 等。
ftrace 最早用于函数跟踪,后来又扩展支持了各种事件跟踪功能。ftrace 的使用接口跟我们之前提到的 procfs 类似,它通过 debugfs(4.1 以后也支持 tracefs),以普通文件的形式,向用户空间提供访问接口。
这样不需要额外的工具就可以通过挂载点(通常为 /sys/kernel/debug/tracing 目录)内的文件读写,来跟 ftrace 交互,跟踪内核或者应用程序的运行事件。
perf 是我们的老朋友了,在前面的好多案例中都使用了它的事件记录和分析功能,这实际上只是一种最简单的静态跟踪机制。你也可以通过 perf ,来自定义动态事件(perf probe),只关注真正感兴趣的事件。
eBPF 则在 BPF(Berkeley Packet Filter)的基础上扩展而来,不仅支持事件跟踪机制,还可以通过自定义的 BPF 代码(使用 C 语言)来自由扩展。所以,eBPF 实际上就是常驻于内核的运行时,可以说就是 Linux 版的 DTrace。
ftrace
ftrace 通过 debugfs(或者 tracefs),为用户空间提供接口。所以使用 ftrace,往往是从切换到 debugfs 的挂载点开始。
cd /sys/kernel/debug/tracing
$ ls
README instances set_ftrace_notrace trace_marker_raw
available_events kprobe_events set_ftrace_pid trace_options
...
如果这个目录不存在,则说明当前系统还没有挂载 debugfs,可以执行下面的命令来挂载它:
mount -t debugfs nodev /sys/kernel/debug
ftrace 提供了多个跟踪器,用于跟踪不同类型的信息,比如函数调用、中断关闭、进程调度等。具体支持的跟踪器取决于系统配置,你可以执行下面的命令,来查询所有支持的跟踪器:
cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
这其中,function 表示跟踪函数的执行,function_graph 则是跟踪函数的调用关系,也就是生成直观的调用关系图。这便是最常用的两种跟踪器。
除了跟踪器外,使用 ftrace 前,还需要确认跟踪目标,包括内核函数和内核事件。其中,
1.函数就是内核中的函数名。
2.而事件,则是内核源码中预先定义的跟踪点。
同样地,可以执行下面的命令,来查询支持的函数和事件:
cat available_filter_functions
$ cat available_events
ls 命令会通过 open 系统调用打开目录文件,而 open 在内核中对应的函数名为do_sys_open。
第一步就是把要跟踪的函数设置为 do_sys_open:
echo do_sys_open > set_graph_function
第二步,配置跟踪选项,开启函数调用跟踪,并跟踪调用进程:
echo function_graph > current_tracer
$ echo funcgraph-proc > trace_options
第三步,也就是开启跟踪:
echo 1 > tracing_on
第四步,执行一个 ls 命令后,再关闭跟踪:
ls
$ echo 0 > tracing_on
实际测试代码如下:
# cat available_tracers
blk function_graph wakeup_dl wakeup_rt wakeup function nop
# cat available_events|head
kvmmmu:kvm_mmu_pagetable_walk
kvmmmu:kvm_mmu_paging_element
kvmmmu:kvm_mmu_set_accessed_bit
kvmmmu:kvm_mmu_set_dirty_bit
kvmmmu:kvm_mmu_walker_error
kvmmmu:kvm_mmu_get_page
kvmmmu:kvm_mmu_sync_page
kvmmmu:kvm_mmu_unsync_page
kvmmmu:kvm_mmu_prepare_zap_page
kvmmmu:mark_mmio_spte
# echo do_sys_open > set_graph_function
# echo funcgraph-proc > trace_options
-bash: echo: write error: Invalid argument
# echo function_graph > current_tracer
# echo funcgraph-proc > trace_options
# echo 1 > tracing_on
# ls
available_events dynamic_events kprobe_events saved_cmdlines set_ftrace_pid timestamp_mode trace_stat
available_filter_functions dyn_ftrace_total_info kprobe_profile saved_cmdlines_size set_graph_function trace tracing_cpumask
available_tracers enabled_functions max_graph_depth saved_tgids set_graph_notrace trace_clock tracing_max_latency
buffer_percent events options set_event snapshot trace_marker tracing_on
buffer_size_kb free_buffer per_cpu set_event_pid stack_max_size trace_marker_raw tracing_thresh
buffer_total_size_kb function_profile_enabled printk_formats set_ftrace_filter stack_trace trace_options uprobe_events
current_tracer instances README set_ftrace_notrace stack_trace_filter trace_pipe uprobe_profile
# echo 0 > tracing_on
第五步,也是最后一步,查看跟踪结果:
cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-12276 | | do_sys_open() {
0) ls-12276 | | getname() {
0) ls-12276 | | getname_flags() {
0) ls-12276 | | kmem_cache_alloc() {
0) ls-12276 | | _cond_resched() {
0) ls-12276 | 0.049 us | rcu_all_qs();
0) ls-12276 | 0.791 us | }
0) ls-12276 | 0.041 us | should_failslab();
0) ls-12276 | 0.040 us | prefetch_freepointer();
0) ls-12276 | 0.039 us | memcg_kmem_put_cache();
0) ls-12276 | 2.895 us | }
0) ls-12276 | | __check_object_size() {
0) ls-12276 | 0.067 us | __virt_addr_valid();
0) ls-12276 | 0.044 us | __check_heap_object();
0) ls-12276 | 0.039 us | check_stack_object();
0) ls-12276 | 1.570 us | }
0) ls-12276 | 5.790 us | }
0) ls-12276 | 6.325 us | }
...
实际测试代码如下:
# cat trace|head -n 100
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-9986 | | do_sys_open() {
0) ls-9986 | | getname() {
.......
0) ls-9986 | | dput() {
0) ls-9986 | | _cond_resched() {
0) ls-9986 | 0.184 us | rcu_all_qs();
0) ls-9986 | 0.535 us | }
0) ls-9986 | 0.954 us | }
0) ls-9986 | 9.782 us | }
在最后得到的输出中:
第一列表示运行的 CPU;
第二列是任务名称和进程 PID;
第三列是函数执行延迟;
最后一列,则是函数调用关系图。
可以看到,函数调用图通过不同级别的缩进,直观展示了各函数间的调用关系。
当然可能也发现了 ftrace 的使用缺点——五个步骤实在是麻烦,用起来并不方便。不过不用担心,trace-cmd 已经帮助把这些步骤给包装了起来。这样就可以在同一个命令行工具里,完成上述所有过程。
可以执行下面的命令,来安装 trace-cmd :
# Ubuntu
$ apt-get install trace-cmd
# CentOS
$ yum install trace-cmd
安装好后,原本的五步跟踪过程,就可以简化为下面这两步:
trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd report
...
ls-12418 [000] 85558.075341: funcgraph_entry: | do_sys_open() {
ls-12418 [000] 85558.075363: funcgraph_entry: | getname() {
ls-12418 [000] 85558.075364: funcgraph_entry: | getname_flags() {
ls-12418 [000] 85558.075364: funcgraph_entry: | kmem_cache_alloc() {
ls-12418 [000] 85558.075365: funcgraph_entry: | _cond_resched() {
ls-12418 [000] 85558.075365: funcgraph_entry: 0.074 us | rcu_all_qs();
ls-12418 [000] 85558.075366: funcgraph_exit: 1.143 us | }
ls-12418 [000] 85558.075366: funcgraph_entry: 0.064 us | should_failslab();
ls-12418 [000] 85558.075367: funcgraph_entry: 0.075 us | prefetch_freepointer();
ls-12418 [000] 85558.075368: funcgraph_entry: 0.085 us | memcg_kmem_put_cache();
ls-12418 [000] 85558.075369: funcgraph_exit: 4.447 us | }
ls-12418 [000] 85558.075369: funcgraph_entry: | __check_object_size() {
ls-12418 [000] 85558.075370: funcgraph_entry: 0.132 us | __virt_addr_valid();
ls-12418 [000] 85558.075370: funcgraph_entry: 0.093 us | __check_heap_object();
ls-12418 [000] 85558.075371: funcgraph_entry: 0.059 us | check_stack_object();
ls-12418 [000] 85558.075372: funcgraph_exit: 2.323 us | }
ls-12418 [000] 85558.075372: funcgraph_exit: 8.411 us | }
ls-12418 [000] 85558.075373: funcgraph_exit: 9.195 us | }
...
实际测试代码如下:
# trace-cmd report|head -n 100
CPU 0 is empty
cpus=2
ls-10015 [001] 3232.717769: funcgraph_entry: 1.802 us | mutex_unlock();
ls-10015 [001] 3232.720548: funcgraph_entry: | do_sys_open() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname_flags() {
ls-10015 [001] 3232.720549: funcgraph_entry: | kmem_cache_alloc() {
ls-10015 [001] 3232.720550: funcgraph_entry: | _cond_resched() {
ls-10015 [001] 3232.720550: funcgraph_entry: 0.206 us | rcu_all_qs();
ls-10015 [001] 3232.720550: funcgraph_exit: 0.724 us | }
ls-10015 [001] 3232.720550: funcgraph_entry: 0.169 us | should_failslab();
ls-10015 [001] 3232.720551: funcgraph_entry: 0.177 us | memcg_kmem_put_cache();
ls-10015 [001] 3232.720551: funcgraph_exit: 1.792 us | }
ls-10015 [001] 3232.720551: funcgraph_entry: | __check_object_size() {
ls-10015 [001] 3232.720552: funcgraph_entry: 0.167 us | check_stack_object();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.207 us | __virt_addr_valid();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.212 us | __check_heap_object();
ls-10015 [001] 3232.720553: funcgraph_exit: 1.286 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 3.744 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 4.134 us | }
trace-cmd 的输出跟上述 cat trace 的输出是类似的。
通过这个例子我们知道,想要了解某个内核函数的调用过程时,使用 ftrace ,就可以跟踪到它的执行过程。
perf
perf 的功能
1.perf 可以用来分析 CPU cache、CPU 迁移、分支预测、指令周期等各种硬件事件;
2.perf 也可以只对感兴趣的事件进行动态追踪
3.先对事件进行采样,然后再根据采样数,评估各个函数的调用频率
perf例子
1.内核函数 do_sys_open 的例子
很多人只看到了 strace 简单易用的好处,却忽略了它对进程性能带来的影响。从原理上来说,strace 基于系统调用 ptrace 实现,这就带来了两个问题:
1.1.由于 ptrace 是系统调用,就需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
1.2.ptrace 需要借助 SIGSTOP 信号挂起目标进程。这种信号控制和进程挂起,会影响目标进程的行为。
在性能敏感的应用(比如数据库)中,我并不推荐你用 strace(或者其他基于 ptrace 的性能工具)去排查和调试。在 strace 的启发下,结合内核中的 utrace 机制, perf 也提供了一个 trace 子命令,是取代 strace 的首选工具。相对于 ptrace 机制来说,perf trace 基于内核事件,自然要比进程跟踪的性能好很多。
第二个 perf 的例子是用户空间的库函数
# 为/bin/bash添加readline探针
$ perf probe -x /bin/bash 'readline%return +0($retval):string'
# 采样记录
$ perf record -e probe_bash:readline__return -aR sleep 5
# 查看结果
$ perf script
bash 13348 [000] 93939.142576: probe_bash:readline__return: (5626ffac1610 <- 5626ffa46739) arg1="ls"
# 跟踪完成后删除探针
$ perf probe --del probe_bash:readline__return
BPF
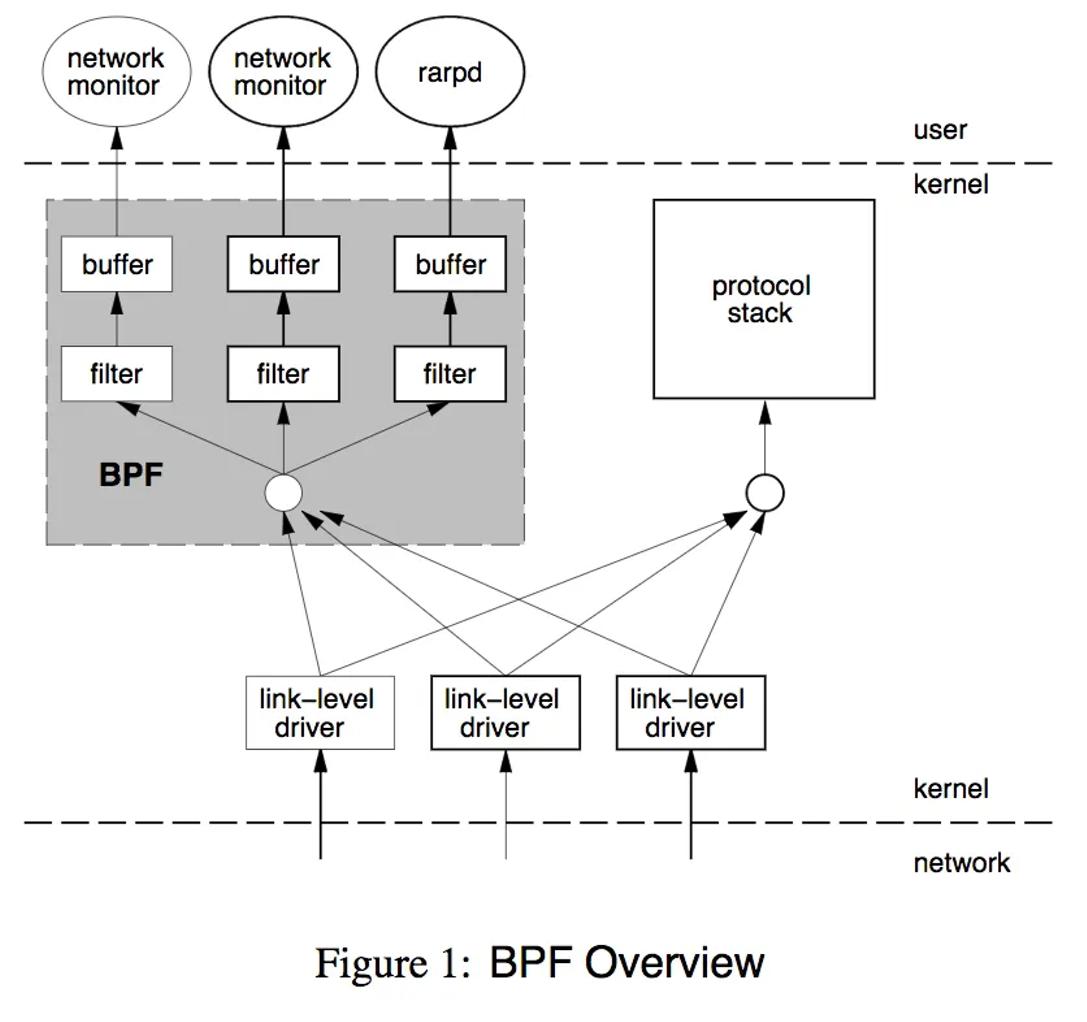
上图是BPF的位置和框架,需要注意的是kernel和user使用了buffer来传输数据,避免频繁上下文切换。BPF虚拟机非常简洁,由累加器、索引寄存器、存储、隐式程序计数器组成
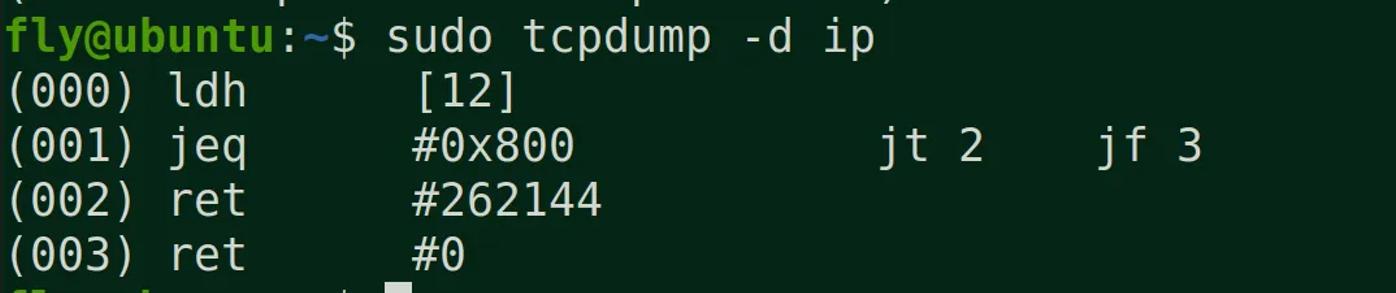
BPF只使用了4条虚拟机指令,就能提供非常有用的IP报文过滤
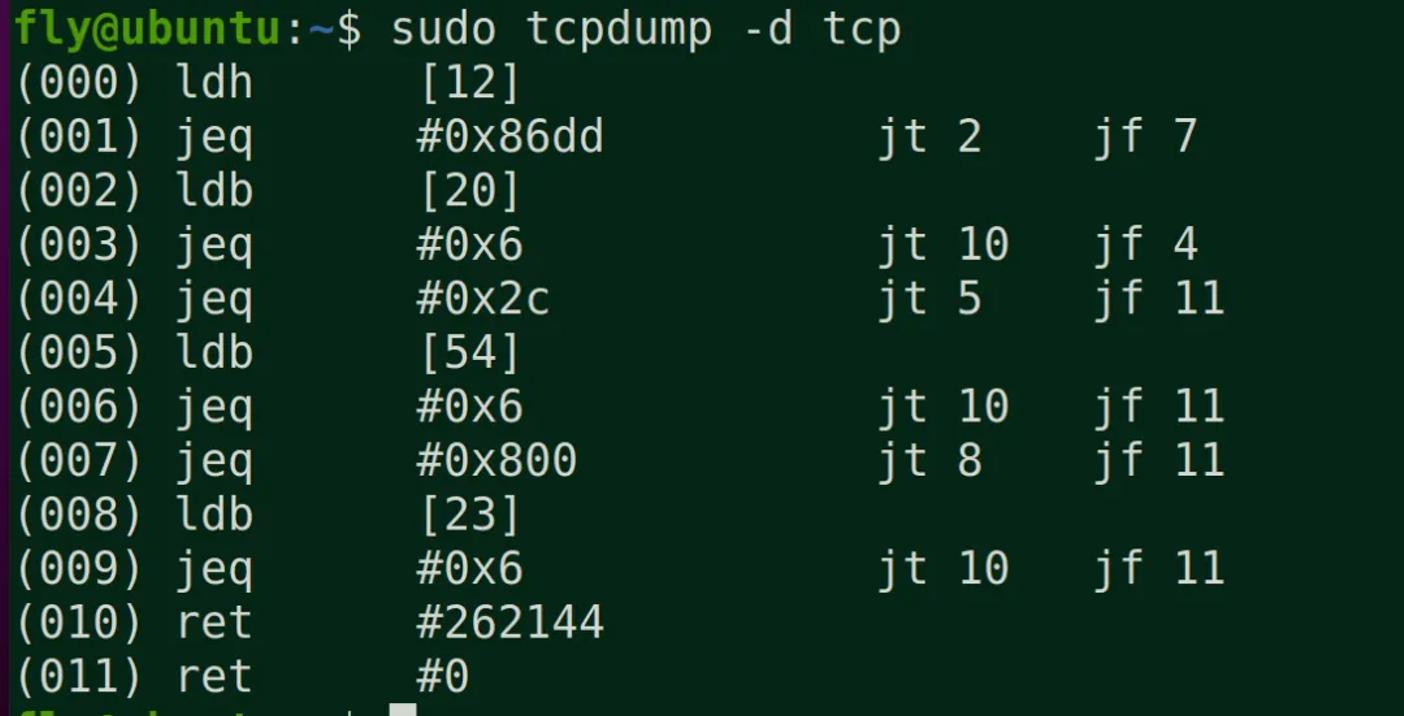
1 (000) ldh [12] // 链路层第12字节的数据(2字节)加载到寄存器,ethertype字段
2 (001) jeq #0x86dd jt 2 jf 7 // 判断是否为IPv6类型,true跳到2,false跳到7
3 (002) ldb [20] // 链路层第20字节的数据(1字节)加载到寄存器,IPv6的next header字段
4 (003) jeq #0x6 jt 10 jf 4 // 判断是否为TCP,true跳到10,false跳到4
5 (004) jeq #0x2c jt 5 jf 11 // 可能是IPv6分片标志,true跳到5,false跳到11
6 (005) ldb [54] // 我编不下去了...
7 (006) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11
8 (007) jeq #0x800 jt 8 jf 11 // 判断是否为IP类型,true跳到8,false跳到11
9 (008) ldb [23] // 链路层第23字节的数据(1字节)加载到寄存器,next proto字段
10 (009) jeq #0x6 jt 10 jf 11 // 判断是否为TCP,true跳到10,false跳到11
11 (010) ret #262144 // 返回true
12 (011) ret #0 // 返回0
应用
tcpdump就是使用的bpf过滤规则
eBPF
eBPF 就是 Linux 版的 DTrace,可以通过 C 语言自由扩展(这些扩展通过 LLVM 转换为 BPF 字节码后,加载到内核中执行)。相对于BPF做了一些重要改进,首先是效率,这要归功于JIB编译eBPF代码;其次是应用范围,从网络报文扩展到一般事件处理;最后不再使用socket,使用map进行高效的数据存储。
根据以上的改进,内核开发人员在不到两年半的事件,做出了包括网络监控、限速和系统监控。目前eBPF可以分解为三个过程:
1.以字节码的形式创建eBPF的程序。编写C代码,将LLVM编译成驻留在ELF文件中的eBPF字节码。
2.将程序加载到内核中,并创建必要的eBPF-maps。eBPF具有用作socket filter,kprobe处理器,流量控制调度,流量控制操作,tracepoint处理,eXpress Data Path(XDP),性能监测,cgroup限制,轻量级tunnel的程序类型。
3.将加载的程序attach到系统中。
根据不同的程序类型attach到不同的内核系统中。
程序运行的时候,启动状态并且开始过滤,分析或者捕获信息
源码路径:
bpf的系统调用:kernel/bpf/syscall.c
bpf系统调用的头文件:include/uapi/linux/bpf.h
入口函数:int bpf(int cmd, union bpf_attr *attr, unsigned int size)
eBPF命令
BPF_PROG_LOAD 验证并且加载eBPF程序,返回一个新的文件描述符。
BPF_MAP_CREATE 创建map并且返回指向map的文件描述符
BPF_MAP_LOOKUP_ELEM 通过key从指定的map中查找元素,并且返回value值
BPF_MAP_UPDATE_ELEM 在指定的map中创建或者更新元素(key/value 配对)
BPF_MAP_DELETE_ELEM 通过key从指定的map中找到元素并且删除
BPF_MAP_GET_NEXT_KEY 通过key从指定的map中找到元素,并且返回下个key值
eBPF 追踪的工作原理:
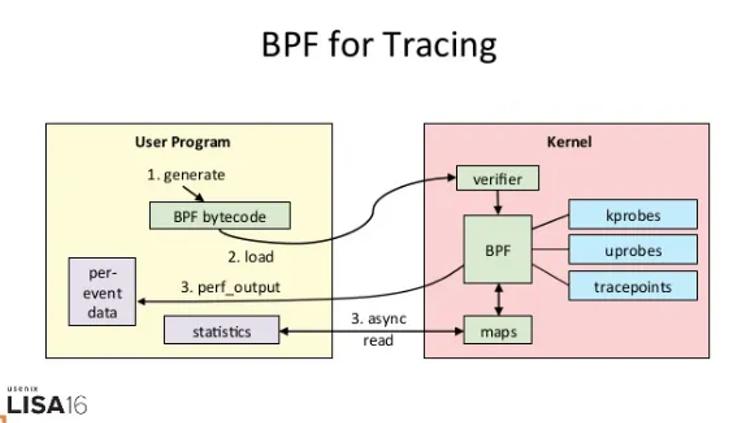
其执行需要三步:
1.从用户跟踪程序生成 BPF 字节码;
2.加载到内核中运行;
3.向用户空间输出结果
SystemTap 和 sysdig
SystemTap 也是一种可以通过脚本进行自由扩展的动态追踪技术。在 eBPF 出现之前,SystemTap 是 Linux 系统中功能最接近 DTrace 的动态追踪机制。
所以从稳定性上来说,SystemTap 只在 RHEL 系统中好用,在其他系统中则容易出现各种异常问题。当然支持 3.x 等旧版本的内核也是 SystemTap 相对于 eBPF 的一个巨大优势。
sysdig 则是随着容器技术的普及而诞生的,主要用于容器的动态追踪。其汇集了一些列性能工具的优势,可以说是集百家之所长。
这个公式来表示 sysdig 的特点:sysdig = strace + tcpdump + htop + iftop + lsof + docker inspect
如何选择追踪工具
1.在不需要很高灵活性的场景中,使用 perf 对性能事件进行采样,然后再配合火焰图辅助分析,就是最常用的一种方法;
2.而需要对事件或函数调用进行统计分析(比如观察不同大小的 I/O 分布)时,就要用 SystemTap 或者 eBPF,通过一些自定义的脚本来进行数据处理
Linux 5.15 内核版本的进程调度子系统
核心组件与实现原理
1. 分层调度框架
Linux 采用 调度类(sched_class) 实现策略分离,优先级从高到低为:
停机调度类
(stop_sched_class):CPU 热插拔等场景
Deadline 类
(dl_sched_class):基于 EDF 算法,保障截止时间
实时调度类
(rt_sched_class):支持 SCHED_FIFO/SCHED_RR
公平调度类
(fair_sched_class):默认 CFS 算法
空闲调度类
(idle_sched_class):CPU 无任务时运行
关键设计:
调度类通过函数指针表实现多态,每个类独立实现入队、选任务等方法:
// kernel/sched/sched.h
structsched_class{
void(*enqueue_task)(structrq*rq,structtask_struct*p,int flags);
void(*dequeue_task)(structrq*rq,structtask_struct*p,int flags);
structtask_struct*(*pick_next_task)(structrq*rq);
void(*task_tick)(structrq*rq,structtask_struct*p,int queued);
// ...
};
2. CFS 调度器实现
核心机制:虚拟时间(vruntime)实现公平性
计算公式:
vruntime += Δt * (NICE_0_LOAD / weight)
其中 weight 由进程优先级(nice 值)映射,优先级越高权重越大,vruntime 增长越慢。
数据结构:
使用红黑树管理就绪队列,键值为 vruntime:
// kernel/sched/sched.h
structcfs_rq{
structrb_root_cached tasks_timeline;// 红黑树根节点
u64 min_vruntime;// 当前最小 vruntime
};
调度触发:
时钟中断更新 vruntime 并检查抢占:
// kernel/sched/fair.c
voidtask_tick_fair(structrq*rq,structtask_struct*curr,int queued){
update_curr(cfs_rq_of(se));// 更新当前任务 vruntime
if(check_preempt_tick(cfs_rq, se))// 检查是否需抢占
resched_curr(rq);
}