使用Linux虚拟化十个理由
 通过虚拟机软件可以在自己的主机操作系统中创建一个或者多个客户虚拟机,这些客户操作系统允许你做任何想做的事情,比如测试alpha或者beta操作系统,或者不稳定的程序版本,而不用担心会破坏自己的主操作系统。当使用基于应用程序的虚拟机软件(也称为管理程序)时,你的计算机操作系统通常称为主机,在VM界面中运行的辅助操作系统通常称为客户。
通过虚拟机软件可以在自己的主机操作系统中创建一个或者多个客户虚拟机,这些客户操作系统允许你做任何想做的事情,比如测试alpha或者beta操作系统,或者不稳定的程序版本,而不用担心会破坏自己的主操作系统。当使用基于应用程序的虚拟机软件(也称为管理程序)时,你的计算机操作系统通常称为主机,在VM界面中运行的辅助操作系统通常称为客户。对于很多云技术供应商、虚拟软件生产商以及大型IT公司来说,Linux是其首选的虚拟化平台。Linux虚拟化有很多非常诱人的优点,让你无法割舍。以下就列出了Linux虚拟化的10大优势。软件和网络开发人员将从这个应用程序中受益最多,他们可以在单个物理机的预设环境中测试其软件,将节省大量时间。即使没有互联网连接,销售人员也可以在任何地方的笔记本电脑上显示正在运行的客户端/服务器应用程序。
10.大厂商支持
VMware、思杰、红帽和Ubuntu等大型软件厂商都选用Linux作为各自虚拟化技术的平台。为什么呢?原因有很多,但是最主要的原因在于Linux的性能。
9.价格
是的,我知道我是在白费口舌,但你必须承认,价格确实是一大卖点。物美价廉永远都是人们购买产品时的首要原则。尤其是在目前全球经济低迷,各大公司纷纷削减IT预算的条件下,价格是人们做出购买决策的一个重要因素。
8.性能
对大多数人来说,阻碍他们从物理机过渡到虚拟机的头号障碍就是性能。不过,Hypervisor技术和Linux的完美组合使得虚拟技术的性能能够与本地物理机性能相媲美。此外。SAN存储以及磁盘I/O性能瓶颈等疑难问题的解决,使得大多数对Linux虚拟化持怀疑态度的人心服口服。
7.稳定性
云供应商对于系统正常运行时间的要求是必须能够达到99.999 %。那么他们应该选择什么平台呢?答案就是Linux操作系统。为什么呢?因为Linux稳定性非常好。如果不更新内核,Linux不需要重新启动。
6.商业支持
VMware、思杰、红帽和Canonical Ubuntu各自都有一套Linux虚拟化商业支持解决方案。这些大型厂商提供的一流的支持,卓越的产品再加上最优秀的技术人员,让你没有任何后顾之忧。
5.硬件要求低
红帽,Ubuntu和Xen的虚拟化基础对于硬件的需求几乎低到了极点,它们能够安装在你使用的任何硬件设备上。关键在于使用Linux虚拟化技术你可以实现“梦寐以求”的少花钱多办事。廉价的硬件是人们选择虚拟化技术的主要原因之一,因为没有庞大的财政承担。
4.管理
一旦安装,VMware和CITrix Xen就能通过远程应用进行管理,而不是通过命令行。你可以与底层操作系统直接打较大,但你几乎不需要这么做。
3.Hypervisor技术
由于体积小,再加上能够作为并行操作系统运行,Linux成为了Hypervisor技术的首选平台。 VMware和Xen都是按照这者方式运作的。Hypervisor没有所谓的操作系统层这一概念,而是使用并行虚拟Linux系统,你仍然可以与系统本身进行互动。
2.社区支持
你不用担心遇到的任何问题,因为你拥有世界上最大的支持社区。类似DaniWeb这样的网站及其成员将会为你提供更方面的帮助。你无需为某个问题感到沮丧,你只需进行搜索或提问,那么一定会有热心人或遇到并解决过类似问题的人为你出谋划策。
1.开放性
开放的Linux虚拟化解决方案能够让你省去很多许可方面的麻烦。私有虚拟化解决俄方案比如Hyper-V并不可怕,但是如果你使用它,你就不会由某个厂商任其摆布。
下面将介绍虚拟化的相关分类:
全虚拟化 半虚拟化 硬件辅助虚拟化 操作系统级虚拟化
全虚拟化(Full Virtulization)
简介:主要是在客户操作系统和硬件之间捕捉和处理那些对虚拟化敏感的特权指令,使客户操作系统无需修改就能运行,速度会根据不同的实现而不同,但大致能满足用户的需求。这种方式是业界现今最成熟和最常见的,而且属于 Hosted 模式和 Hypervisor 模式的都有,知名的产品有IBM CP/CMS,VirtualBox,KVM,VMware Workstation和VMware ESX(它在其4.0版,被改名为VMware vSphere)。
优点:Guest OS无需修改,速度和功能都非常不错,更重要的是使用非常简单,不论是 VMware 的产品,还是Sun(Oracle?)的 VirtualBox。
缺点:基于Hosted模式的全虚拟产品性能方面不是特别优异,特别是I/O方面。
未来:因为使用这种模式,不仅Guest OS免于修改,而且将通过引入硬件辅助虚拟化技术来提高其性能,我个人判断,在未来全虚拟化还是主流。
半虚拟化(Parairtulization)
简介:它与完全虚拟化有一些类似,它也利用Hypervisor来实现对底层硬件的共享访问,但是由于在Hypervisor 上面运行的Guest OS已经集成与半虚拟化有关的代码,使得Guest OS能够非常好地配合Hyperivosr来实现虚拟化。通过这种方法将无需重新编译或捕获特权指令,使其性能非常接近物理机,其最经典的产品就是Xen,而且因为微软的Hyper-V所采用技术和Xen类似,所以也可以把Hyper-V归属于半虚拟化。
优点:这种模式和全虚拟化相比,架构更精简,而且在整体速度上有一定的优势。
缺点:需要对Guest OS进行修改,所以在用户体验方面比较麻烦。
未来:我觉得其将来应该和现在的情况比较类似,在公有云(比如Amazon EC2)平台上应该继续占有一席之地,但是很难在其他方面和类似VMware vSphere这样的全虚拟化产品竞争,同时它也将会利用硬件辅助虚拟化技术来提高速度,并简化架构。
硬件辅助虚拟化(Hardware Assisted Virtualization)
简介:Intel/AMD等硬件厂商通过对部分全虚拟化和半虚拟化使用到的软件技术进行硬件化(具体将在下文详述)来提高性能。硬件辅助虚拟化技术常用于优化全虚拟化和半虚拟化产品,而不是独创一派,最出名的例子莫过于VMware Workstation,它虽然属于全虚拟化,但是在它的6.0版本中引入了硬件辅助虚拟化技术,比如Intel的VT-x和AMD的AMD-V。现在市面上的主流全虚拟化和半虚拟化产品都支持硬件辅助虚拟化,包括VirtualBox,KVM,VMware ESX和Xen。
优点:通过引入硬件技术,将使虚拟化技术更接近物理机的速度。
缺点:现有的硬件实现不够优化,还有进一步提高的空间。
未来:因为通过使用硬件技术不仅能提高速度,而且能简化虚拟化技术的架构,所以预见硬件技术将会被大多数虚拟化产品所采用。
操作系统级虚拟化(Operating System Level Virtualization)
简介:这种技术通过对服务器操作系统进行简单地隔离来实现虚拟化,主要用于VPS。主要的技术有Parallels Virtuozzo Containers,Unix-like系统上的chroot和Solaris上的Zone等,以及现在流行的Docker。
优点:因为它是对操作系统进行直接的修改,所以实现成本低而且性能不错。
缺点:在资源隔离方面表现不佳,而且对Guest OS的型号和版本有限定。
未来:不明朗,我觉得除非有革命性技术诞生,否则还应该属于小众,比如VPS。
操作系统级虚拟化:Namespace与Cgroups技术原理与实践
在云计算与容器技术蓬勃发展的202x,Docker、Kubernetes等工具已成为开发者的日常。但是否想过这些工具背后,是什么技术支撑着容器的隔离与资源控制?答案正是操作系统级虚拟化——一种轻量、高效的虚拟化技术,它通过内核级机制实现了进程的"隔离可见性"与"资源可控性"。本节从基础概念出发,深入解析操作系统级虚拟化的两大核心技术——命名空间(Namespace) 与控制组(Cgroups),一起理解容器技术的底层逻辑。
1、操作系统级虚拟化:容器技术的基石
提到虚拟化,很多人会想到KVM、XEN等传统虚拟化技术。这类技术通过模拟硬件,让每个虚拟机(VM)拥有独立的操作系统内核,相当于在物理机上"套娃"多个完整系统。但这种方式资源开销大、启动慢——虚拟机的内核、系统库都会占用额外资源。而操作系统级虚拟化(又称容器化)则是另一种思路:它是操作系统内核的原生特性,不需要模拟硬件,而是通过内核机制将进程"分组隔离"。简单来说,它让多个"容器"共享同一个操作系统内核,但每个容器只能看到自己被分配的资源(进程、文件、网络等),仿佛独占一个系统。
举个例子:在宿主机器上,进程PID可能从1排到1000;但在容器内,进程PID可以从1重新开始,且看不到宿主或其他容器的进程。这种"隔离"不是通过额外的操作系统实现的,而是内核通过技术手段"欺骗"了容器内的进程。
核心目标:在共享内核的前提下,实现进程间的资源隔离与可控分配。而实现这一目标的两大核心技术,正是Namespace与Cgroups。
2、命名空间(Namespace)
如果说容器是一个"独立的小系统",那么命名空间(Namespace)就是这个系统的"边界"——它决定了容器内的进程能"看到"哪些资源。其核心逻辑是:将操作系统管理的资源(如进程ID、网络接口)进行"命名隔离",让不同容器的资源在各自的命名空间中独立编号,互不干扰。
1. 命名空间的本质:隔离"命名与编号"
在编程语言中,命名空间用于避免变量名冲突(如Python的module、C++的namespace);Linux内核的命名空间作用类似:为系统资源的"标识符"划分独立空间。例如,在没有命名空间的系统中,所有进程的PID(进程ID)是全局唯一的(从1开始递增);而有了PID命名空间后,每个容器可以拥有自己的"PID空间"——容器内的第一个进程PID为1(类似宿主的init进程),且看不到其他容器的PID。
2. Linux中的6种基础命名空间(及扩展)
截至2025年,Linux内核已支持多种命名空间,覆盖了进程、网络、文件系统等核心资源。其中最基础的6种如下:
| 命名空间类型 | 标识常量 | 隔离资源 | 作用示例 |
| 挂载点(mnt) | CLONE_NEWNS | 文件系统挂载点 | 容器内挂载的目录不会影响宿主或其他容器 |
| 进程(pid) | CLONE_NEWPID | 进程ID(PID) | 容器内进程PID独立编号,看不到外部进程 |
| 网络(net) | CLONE_NEWNET | 网络接口、端口、路由 | 容器有独立的虚拟网卡、端口(如容器内80端口与宿主80端口不冲突) |
| 进程间通信(ipc) | CLONE_NEWIPC | 信号量、消息队列 | 容器内的IPC资源(如共享内存)与外部隔离 |
| 主机名(uts) | CLONE_NEWUTS | 主机名、域名 | 容器可以设置独立的主机名(如docker run --hostname mycontainer) |
| 用户(user) | CLONE_NEWUSER | 用户ID(UID)、组ID(GID) | 容器内的root用户可映射为宿主的普通用户,提升安全性 |
近年来,Linux内核还新增了时间命名空间(CLONE_NEWTIME)(隔离进程的时钟)、cgroup命名空间(CLONE_NEWCGROUP)(隔离控制组视图)等,进一步增强了隔离能力。
3. 操作命名空间的3个核心系统调用
命名空间的创建、修改依赖于3个内核系统调用,它们是容器工具(如Docker)实现隔离的底层接口:
1). clone():创建新进程时,同时创建一个或多个新命名空间,新进程会加入这些命名空间。例如:clone(child_func, stack, CLONE_NEWPID | SIGCHLD, args) 会创建一个带独立PID命名空间的子进程。
2). unshare():不创建新进程,仅为当前进程"脱离"原命名空间,创建新命名空间;后续当前进程创建的子进程会加入新命名空间。例如:unshare(CLONE_NEWNET) 后,当前进程的子进程会拥有独立的网络命名空间。
3). setns():将当前进程加入已存在的命名空间(需通过命名空间的文件描述符操作)。例如:通过/proc/[pid]/ns/pid打开某个进程的PID命名空间,再用setns()让当前进程的子进程加入该空间。
4. 用代码验证命名空间的隔离性
下面通过一段C代码,直观感受PID命名空间的隔离效果:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define STACK_SIZE (10 * 1024 * 1024)
char child_stack[STACK_SIZE];
int child_main(void* args) {
pid_t child_pid = getpid();
printf("I'm child process and my pid is %d \n", child_pid);
// 子进程会被放到clone系统调用新创建的pid命名空间中, 所以其pid应该为1
sleep(300);
// 命名空间中的所有进程退出后该命名空间的inode将会被删除, 为后续操作保留它
return 0;
}
int main() {
/* Clone */
pid_t child_pid = clone(child_main, child_stack + STACK_SIZE, \
CLONE_NEWPID | SIGCHLD, NULL);
if(child_pid < 0) {
perror("clone failed");
}
/* Unshare */
int ret = unshare(CLONE_NEWPID); // 父进程调用unshare, 创建了一个新的命名空间,
//但不会创建子进程. 之后再创建的子进程将会被加入到新的命名空间中
if (ret < 0) {
perror("unshare failed");
}
int fpid = fork();
if (fpid < 0) {
perror("fork error");
} else if (fpid == 0) {
printf("I am child process. My pid is %d \n", getpid());
// Fork后的子进程会被加入到unshare创建的命名空间中, 所以pid应该为1
exit(0);
} else {
}
waitpid(fpid, NULL, 0);
/* Setns */
char path[80] = "";
sprintf(path, "/proc/%d/ns/pid", child_pid);
int fd = open(path, O_RDONLY);
if (fd == -1)
perror("open error");
if (setns(fd, 0) == -1)
// setns并不会改变当前进程的命名空间, 而是会设置之后创建的子进程的命名空间
perror("setns error");
close(fd);
int npid = fork();
if (npid < 0) {
perror("fork error");
} else if (npid == 0) {
printf("I am child process. My pid is %d \n", getpid());
// 新的子进程会被加入到第一个子进程的pid命名空间中, 所以其pid应该为2
exit(0);
} else {
}
return 0;
}
编译运行(需root权限,因为命名空间操作需要CAP_SYS_ADMIN能力):
gcc ns_demo.c -o ns_demo && ./ns_demo
输出结果:
I'm child process and my pid is 1
I am child process. My pid is 1
I am child process. My pid is 2
从结果可见:同一进程在宿主中PID为13805,但在自己的PID命名空间中显示为1——这正是命名空间"隔离可见性"的直观体现。
5. 如何查看进程的命名空间?
Linux通过/proc/[pid]/ns/目录暴露进程所属的命名空间,每个命名空间以"inode号"唯一标识(类似文件系统的inode)。
例如,查看PID为13805的进程命名空间:
ls -l /proc/13805/ns/
输出类似:
lrwxrwxrwx 1 root root 0 8月 2 10:00 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 8月 2 10:00 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 8月 2 10:00 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 8月 2 10:00 net -> net:[4026531963]
lrwxrwxrwx 1 root root 0 8月 2 10:00 pid -> pid:[4026532100]
lrwxrwxrwx 1 root root 0 8月 2 10:00 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 8月 2 10:00 uts -> uts:[4026531838]
不同进程若某类命名空间的inode号相同,则说明它们属于同一命名空间。
3、控制组(Cgroups)
命名空间解决了"隔离可见性",但无法限制资源使用——如果一个容器内的进程疯狂占用CPU或内存,仍会影响宿主和其他容器。这就需要控制组(Cgroups,Control Groups)出场:它负责对进程组的资源进行"限制、监控与统计",是容器资源管控的核心。
1. Cgroups的核心作用
Cgroups的设计目标可以概括为三点:
1). 限制(Limit):对CPU、内存、IO等资源设置使用上限(如限制某容器最多使用1核CPU)
2). 监控(Monitor):统计进程组的资源使用情况(如某容器的内存占用峰值)
3). 控制(Control):对进程组执行操作(如暂停、恢复、优先级调整)
2. Cgroups的子系统:资源管控的"分工"
Cgroups通过"子系统(Subsystem)"对不同类型的资源进行精细化管理。截至Linux 5.10+,常用子系统包括:
| 子系统 | 作用 | 典型场景 |
| cpu | 控制CPU调度优先级、使用率上限(如限制使用50%的CPU) | 避免某容器抢占过多CPU资源 |
| memory | 限制物理内存、swap使用量,监控内存占用 | 防止容器内存泄漏导致系统崩溃 |
| blkio | 限制块设备(硬盘、SSD)的IO速率(如读/写速度) | 避免某容器大量读写磁盘影响其他服务 |
| cpuset | 绑定进程组到指定CPU核心或NUMA节点 | 高性能场景下的CPU核心专属分配 |
| devices | 限制进程组可访问的设备(如禁止使用GPU) | 增强容器安全性,限制硬件访问 |
| freezer | 暂停/恢复进程组(类似"冻结") | 容器暂停、快照等功能 |
| net_cls/net_prio | 标记网络数据包、设置网络优先级 | 结合流量控制器(tc)实现网络带宽限制 |
3. Cgroups的使用方式:文件系统操作
与命名空间不同,Cgroups不通过系统调用直接操作,而是通过特殊的文件系统(cgroupfs)进行管理。简单来说:
1). 挂载cgroupfs到目录(如/sys/fs/cgroup);
2). 通过创建目录表示"进程组";
3). 通过读写目录下的文件配置资源限制(如cpu.cfs_quota_us设置CPU使用率);
4). 通过tasks文件将进程加入组(写入PID即可)。
4. 实战:用Cgroups限制进程的CPU核心
下面通过一个实例,演示如何用cpuset子系统将进程绑定到指定CPU核心(以CPU核心2为例):
步骤1:准备一个"吃CPU"的测试脚本
创建cpu_test.sh,让它无限循环消耗CPU:
#!/bin/bash
while true; do :; done # 空循环,持续占用CPU
赋予执行权限并后台运行:
chmod +x cpu_test.sh && ./cpu_test.sh &
记录进程PID(假设为1380):
echo $! # 输出后台进程PID,如1380
步骤2:查看进程当前运行的CPU核心
用ps命令查看进程所在CPU核心(psr列表示CPU编号):
ps -eLo pid,lwp,psr,args | grep 1380 | grep -v grep
输出类似:
1380 1380 3 ./cpu_test.sh # 当前在CPU核心3上运行
步骤3:通过Cgroups绑定到CPU核心2
挂载cpuset子系统(部分系统默认已挂载在/sys/fs/cgroup/cpuset):
mkdir -p /tmp/cgroup_cpuset && mount -t cgroup -o cpuset none /tmp/cgroup_cpuset
创建一个新的进程组my_group:
cd /tmp/cgroup_cpuset && mkdir my_group
将进程1380加入my_group:
echo 1380 > my_group/tasks
配置my_group只能使用CPU核心2:
echo 2 > my_group/cpuset.cpus # 允许使用的CPU核心(0、1、2...)
步骤4:验证结果
再次查看进程所在CPU核心:
ps -eLo pid,lwp,psr,args | grep 1380 | grep -v grep
输出变为:
1380 1380 2 ./cpu_test.sh # 已绑定到CPU核心2
通过这个例子可见,Cgroups能精准控制进程的资源使用范围,是容器"资源隔离"的关键。
5. Cgroups v2:新一代资源管理架构
Linux内核在4.5版本引入了Cgroups v2,相比v1有诸多改进:
1). 统一的层次结构(v1子系统独立层次,v2所有子系统共享同一层次);
2). 更强的资源控制能力(如支持内存+IO联合限制);
3). 更好的安全性(禁止跨层次移动进程)。
目前Docker(20.10+)、Kubernetes(1.25+)已默认支持Cgroups v2,成为云原生环境的主流选择。
4、小结
操作系统级虚拟化之所以能支撑起Docker等容器技术,核心在于两大技术的配合:
命名空间(Namespace) 负责"隔离可见性":让容器内的进程"误以为"自己独占系统,看不到外部资源;
控制组(Cgroups) 负责"控制资源使用":给容器的资源上"枷锁",避免过度占用导致的相互干扰。
正是这两者的结合,让容器实现了"轻量隔离"与"高效资源利用",成为云计算、微服务架构的核心基础设施。理解这些底层技术,不仅能帮助你更深入地使用Docker、K8s,更能让人在排查容器问题(如资源泄露、隔离失效)时,快速定位根源。
在十佳评测网上有对目前主流的虚拟机软件在各个方面的点评:"2019年最好的虚拟机软件推荐",此文值得一看。
从系统修复到环境隔离的秘器-chroot
在 Linux 系统的管理工具箱中,chroot 是一个强大却略显低调的命令,其名字源自 Change Root,即“更改根目录”。对于初学者来说它可能只是一个简单的目录切换命令;但对于系统管理员、开发者和安全专家而言,chroot 是系统修复、软件测试和环境隔离的强力工具。在此说一下其原理、作用、使用方法及典型应用场景。
1、chroot 的原理与本质
chroot 的核心功能是为一个正在运行的进程及其子进程更改其可见的根目录。简单来说,它将一个指定的目录变成进程所能看到的文件系统的“根”(即 /)。
正常进程:看到的文件系统结构是 / -> /home -> /usr -> /etc ...
chroot 后的进程:如果我们将 /mnt/new_root 设置为新的根,那么该进程看到的 / 实际上就是宿主系统的 /mnt/new_root。它无法访问 /mnt/new_root 之外的任何文件路径。
工作原理
Linux 系统中的每个进程都有一个与之关联的“当前工作目录”和“根目录”的概念。chroot 通过系统调用(chroot())修改了进程的根目录属性。
关键点:
1.并非虚拟化:chroot 并不创建一个虚拟化的环境(如 Docker 或虚拟机)。它只是对文件系统视图进行了一个“裁剪”或“重定向”。
2.进程级隔离:隔离性仅针对被 chroot 的进程及其子进程。宿主系统的其他进程不受影响。
3.非完全安全:chroot 最初并非为安全隔离而设计,有经验的用户可能通过特定方法(如获取 root 权限、访问特定设备文件等)“越狱”。因此它不应被用作主要的安全沙箱。对于安全隔离,应使用 namespaces、cgroups 和 Seccomp 等现代容器技术(如 Docker 的实现基础)。
2、chroot 的作用与价值
尽管存在局限性,chroot 在众多场景下依然不可或缺:
1.系统恢复与引导修复:当主系统无法启动时,可以从Live CD/USB启动,将损坏系统的根目录挂载到Live环境的一个子目录(如 /mnt/sysroot),然后 chroot 进去进行修复(例如重装引导程序、修复核心配置文件)。
2.软件测试与依赖隔离:为软件或服务创建一个独立的根环境,其中包含其运行所需的所有依赖库和文件。这样可以避免与宿主系统的库版本发生冲突,方便测试不同版本的软件。
3.构建纯净的编译环境:在构建大型软件(如 Linux 发行版本身)时,可以使用 chroot 创建一个干净、无污染的基础环境,确保编译过程只依赖于明确指定的工具和库,提高构建结果的可重复性和可靠性。
4.运行遗留或特定环境服务:某些老旧或特定软件可能需要在特定版本的系统库上运行。通过 chroot,可以为其量身定制一个环境,而无需扰乱宿主系统。
3、使用方法与步骤详解
使用 chroot 通常需要 root 权限,并且需要提前准备好一个“根文件系统”。基本命令语法
chroot [OPTION] NEWROOT [COMMAND [ARG]...]
NEWROOT:要作为新根目录的路径。
COMMAND:在新的根环境中要执行的命令。如果未指定,默认执行 $SHELL 环境变量指定的 shell,否则执行 /bin/sh。
典型操作流程
步骤1:准备目标根文件系统这个系统可以是从另一个Linux系统复制而来,由debootstrap等工具构建,或是一个已挂载的磁盘分区。
步骤2:挂载必要的虚拟文件系统chroot 环境需要访问核心的虚拟文件系统才能正常工作。
# 挂载 proc 文件系统(提供进程信息)
mount -t proc /proc /mnt/new_root/proc
# 挂载 sys 文件系统(提供系统设备和驱动信息)
mount -t sysfs /sys /mnt/new_root/sys
# 挂载 devtmpfs 文件系统(提供设备文件)
mount -t devtmpfs /dev /mnt/new_root/dev
# 推荐也挂载 devpts(用于伪终端)和 tmpfs(用于临时文件)
mount -t devpts /dev/pts /mnt/new_root/dev/pts
mount -t tmpfs /tmp /mnt/new_root/tmp
# 如果需要使用网络,还需要复制宿主机的 resolv.conf 以获取DNS
cp /etc/resolv.conf /mnt/new_root/etc/resolv.conf
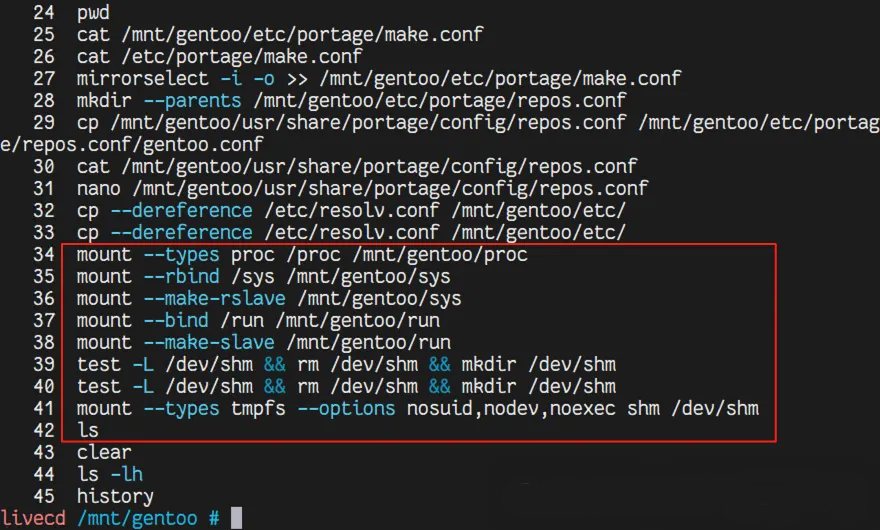
步骤3:执行chroot,现在可以进入准备好的环境了。
# 基本用法,进入新的根并启动一个 shell
chroot /mnt/new_root
# 或者指定要运行的程序
chroot /mnt/new_root /bin/bash
步骤4:在 chroot 环境中工作此时,您就在一个“全新的”系统里了。可以安装软件、修改配置、运行服务等。
步骤5:退出并清理完成工作后,退出 chroot shell,然后卸载之前挂载的文件系统。
# 退出 chroot 环境
exit
# 回到宿主机后,卸载虚拟文件系统
umount /mnt/new_root/proc
umount /mnt/new_root/sys
umount /mnt/new_root/dev/pts
umount /mnt/new_root/dev
umount /mnt/new_root/tmp
# 最后再卸载根目录本身(如果它是一个独立分区)
umount /mnt/new_root
4、经典使用场景实例
场景1:修复 Grub 引导程序
从 Linux Live USB 启动。
挂载原来的根分区(假设为 /dev/sda1)到 /mnt。
mount /dev/sda1 /mnt
挂载虚拟文件系统
mount --bind /dev /mnt/dev
mount --bind /proc /mnt/proc
mount --bind /sys /mnt/sys
Chroot 进入原系统
chroot /mnt
重新安装和配置 Grub
grub-install /dev/sda
update-grub
退出、卸载、重启。
场景2:构建一个最小的测试环境
使用 debootstrap 为 Ubuntu 22 构建一个基础环境:
# 1. 安装 debootstrap
apt install debootstrap
# 2. 构建最小根文件系统
debootstrap jammy /opt/jammy-chroot http://archive.ubuntu.com/ubuntu
# 3. 进入该环境
chroot /opt/jammy-chroot
5、注意事项与常见问题
权限问题:chroot 必须由 root 用户执行。
架构一致性:目标根文件系统必须与宿主机的 CPU 架构兼容(例如,不能在一个 x86_64 主机上 chroot 到一个 ARM 的文件系统)。
依赖缺失:如果目标环境中缺少 chroot 后要执行的命令所需的动态库,命令会失败。使用 ldd 命令可以检查二进制文件的依赖关系。
“chroot: cannot run command ‘/bin/bash’: No such file or directory” :这是一个最常见错误,通常不是因为 /bin/bash 不存在,而是因为它依赖的库(如 libc.so.6)在新根环境中找不到。确保你的根文件系统是完整的。
chroot 是一个通过改变进程根目录来实现文件系统层面隔离的基础工具。它虽然古老,但在系统修复、环境隔离和软件构建等领域依然发挥着不可替代的作用。理解其原理和正确的工作流程是有效使用它的关键。然而也必须认识到它并非万能的银弹,尤其是在安全性方面存在固有缺陷。对于更高级的隔离需求,现代容器技术(如 Docker、LXC)是更好的选择,它们正是在 chroot 的基础上,结合了 Namespace、Cgroup 等机制,提供了更完善、更安全的隔离环境。