Linux CPU 管理入门
 对Zabbix中的 CPU utilization 监控参数的理解
对Zabbix中的 CPU utilization 监控参数的理解工作中查看Zabbix中Linux监控项的时候对linux监控的cpu使用的各个参数没怎么明白,特意查看了下资料。Zabbix Linux模板下的CPU utilization是自带的监控Linux CPU各个参数的监控项,其实就是Linux下top命令显示的cpu信息。

Zabbix下的监控信息的各个值分别是什么意思呢?

官方解释,Cpu(s)表示的是cpu信息。
us: user cpu time (or) % CPU time spent in user space
sy: system cpu time (or) % CPU time spent in kernel space
ni: user nice cpu time (or) % CPU time spent on low priority processes
id: idle cpu time (or) % CPU time spent idle
wa: io wait cpu time (or) % CPU time spent in wait (on disk)
hi: hardware irq (or) % CPU time spent servicing/handling hardware interrupts
si: software irq (or) % CPU time spent servicing/handling software interrupts
st: steal time - - % CPU time in involuntary wait by virtual cpu while hypervisor is servicing another processor (or) % CPU time stolen from a virtual machine
翻译一下:
us:用户态使用的cpu时间比
sy:系统态使用的cpu时间比
ni:用做nice加权的进程分配的用户态cpu时间比
id:空闲的cpu时间比
wa:cpu等待磁盘写入完成时间
hi:硬中断消耗时间
si:软中断消耗时间
st:虚拟机偷取时间
上面解释过就好理解了,idle就是cpu的空闲时间,也就是说idle的空闲时间90%,cpu使用率就是10%。
而iowait实际测量的是cpu时间:%iowait = (cpu idle time)/(all cpu time)
知道怎么回事以后,那监控cpu使用率就好办了,cpu使用率超过百分之90就告警。
CPU user percent gt 90%
{Template OS Linux:system.cpu.util[,idle].avg(1m)}<10

下面是博客园一位网友对各个参数的理解,图文并茂,逻辑清晰。
首先这个百分比是怎么算出来的呢?
比如一秒内有100个cpu时间片,这个cpu时间片就是cpu工作的最小单位。那么这100个cpu时间片在不同的区域和目的进行操作使用,就代表这个区域所占用的cpu时间比;也就是这里得出的cpu时间百分比。
比如下面一个程序:
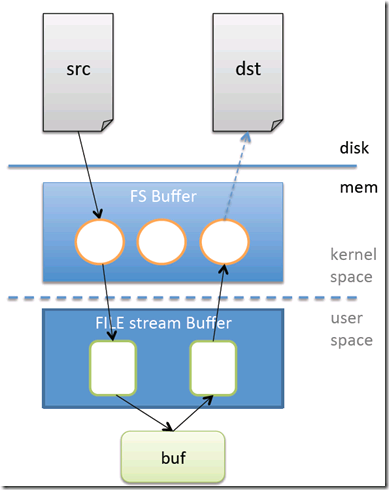
将文件从磁盘的src位置拷贝到磁盘的dst位置。文件会从src先读取进入到内核空间,然后再读取到用户空间,然后拷贝数据到用户空间的buf上,再通过用户空间,内核空间,数据才到磁盘的dst上。
所以从上面这个程序来看,cpu消耗在kernel space的时候就是sy(系统态使用的cpu百分比),cpu消耗在user space的时候就是us(用户态使用的cpu百分比)。下面来说说hi和si。
如果程序都没什么问题,那么是没有hi和si的,但是实际上有个硬中断和软中断的概念。比如硬中断,cpu在执行程序的时候,突然外设硬件(比如硬盘出现问题了)机器需要立刻通知cpu进行现场保存工作。这个时候会cpu会出现上下文切换。就是cpu会有一部分时间会被硬中断占用了,这个时间就是hi。相类似,si是软中断的cpu占用时间,软中断是由软件的指令方式触发的。
相关软中断和硬中断的概念可以参考这里。
ni
ni是nice的意思,nice是什么呢,每个linux进程都有个优先级,优先级高的进程有优先执行的权利,这个叫做pri。进程除了优先级外,还有个优先级的修正值。即比如你原先的优先级是20,然后修正值为-2,那么你最后的进程优先级为18。这个修正值就叫做进程的nice值。
那么nice是一个进程的优先级修正值,为什么会占用cpu时间呢?
ni是指用做nice加权的进程使用的用户态cpu时间比,我的理解就是一个进程的所谓修正值就意味着多分配一些cpu时间给这个进程的用户态,这个中间所多分配的cpu时间就是我们这里的ni。(这个理解没啥把握,如果有错误麻烦帮忙指出下)
wa
wa指的是CPU等待磁盘写入完成的时间,就是说前提是要进行IO操作,在进行IO操作的时候,CPU等待时间。比如上面那个程序,最后一步,从系统空间到dst硬盘空间的时候,如果程序是阻塞的,那么这个时候cpu就要等待数据写入磁盘才能完成写操作了。所以这个时候cpu等待的时间就是wa。所以如果一台机器看到wa特别高,那么一般说明是磁盘IO出现问题,可以使用iostat等命令继续进行详细分析。
st
st的名字很生动,偷取。。是专门对虚拟机来说的,一台物理是可以虚拟化出几台虚拟机的。在其中一台虚拟机上用top查看发现st不为0,就说明本来有这么多个cpu时间是安排给我这个虚拟机的,但是由于某种虚拟技术,把这个cpu时间分配给了其他的虚拟机了。这就叫做偷取。
id
剩下的id就是除了上面那么多cpu处理上下文以外的cpu时间片。当然在这些时间片上,cpu是空闲的。
top的所有这些cpu时间应该是相加为100%的。
上文转自:Zabbix CPU utilization监控参数
CPU性能指标可以从两方面来看:静态、动态
静态指标主要包括:型号、主频、核数、cache等
动态指标主要包括:平均负载状况、使用率、最耗CPU的进程有哪些
查看静态信息
在服务器运行过程中一般比较少关注CPU的静态信息,但刚开始拿到一台服务器时,就会很关心静态信息了。可根据这些信息判断分配给这台服务器多大的压力等,通过 /proc/cpuinfo文件来查看具体的信息。
查看动态信息
服务器变慢时,通常会先查看下CPU的负载是否过高,如果高了,再看下是哪些进程最耗费CPU,CPU使用率也是重要指标,可知道CPU消耗在哪些部分。
1)、CPU负载状况
通过负载信息能够直观的了解到CPU的压力状况,linux会给出最近1分钟、5分钟、15分钟的平均负载值:
可以通过 top 命令查看
uptime 命令更加简洁直观
查看到负载值后,怎么判断CPU的负载是否过高呢?
有一个经验型的标准:CPU负载上限值 = CPU的核数 * 4
例如是4核CPU,那么CPU的负载最好不要超过16,否则CPU的压力就很大了。
2)、耗费CPU的主要进程
发现CPU负载过高后,肯定想知道是谁把CPU搞的这么忙:
通过 top 命令查看
用 ps 命令根据CPU使用量对进程排序
# ps -aux --sort -pcpu | less
3)、CPU使用率
通过 top 命令查看,还可以查看每个核的使用率状况,执行 top 后按数字1键,就可以列出每个cpu的使用率。其中有几个主要信息项(上文也有说明):
id - CPU的空闲度
us - 用户进程对CPU的使用率
sy - 系统进程对CPU的使用率
wa - IO等待情况
st - 如果系统中运行了虚拟机,此项显示虚机使用CPU的情况
CPU 利用率的计算方法
本节转自张彦飞空间,感谢原作者。观察线上服务运行状态的时候,绝大多数人都是喜欢先用 top 命令看看当前系统的整体 cpu 利用率。例如一台机器的 top 命令显示的利用率信息如下:

这个输出结果说简单也简单,说复杂也不是那么容易就能全部搞明白的。例如:
问题 1:top 输出的利用率信息是如何计算出来的,它精确吗?
问题 2:ni 这一列是 nice,它输出的是 cpu 在处理啥时的开销?
问题 3:wa 代表的是 io wait,那么这段时间中 cpu 到底是忙碌还是空闲?
这里对 cpu 利用率统计进行深入的学习。通过学习不但能了解 cpu 利用率统计实现细节,还能 nice、io wait 等指标有更深入的理解。
一、先思考一下
抛开 Linux 的实现先不谈,如果有如下需求,有一个四核服务器,上面跑了四个进程。
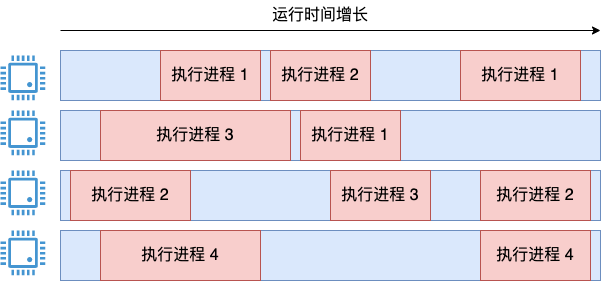
来设计计算整个系统 cpu 利用率的这个需求,支持像 top 命令这样的输出,满足以下要求:
cpu 使用率要尽可能地准确
要能地体现秒级瞬时 cpu 状态
这个看起来很简单的需求,实际还是有点小复杂的。其中一个思路是把所有进程的执行时间都加起来,然后再除以系统执行总时间*4。
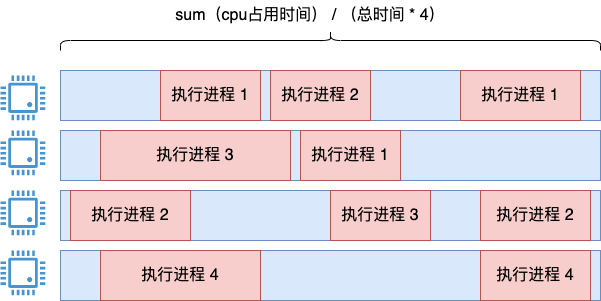
这个思路是没问题的,用这种方法统计很长一段时间内的 cpu 利用率是可以的,统计也足够的准确。
但只要用过 top 就知道 top 输出的 cpu 利用率并不是长时间不变的,而是默认 3 秒为单位会动态更新一下(这个时间间隔可以使用 -d 设置)。这个方案体现总利用率可以,体现这种瞬时的状态就难办了。可能会想到那我也 3 秒算一次不就行了?但这个 3 秒的时间从哪个点开始呢。粒度很不好控制。
上一个思路问题核心就是如何解决瞬时问题。提到瞬时状态,可能就又来思路了。就用瞬时采样去看,看看当前有几个核在忙。四个核中如果有两个核在忙,那利用率就是 50%。这个思路思考的方向也是正确的,但是问题有两个:
算出的数字都是 25% 的整数倍
这个瞬时值会导致 cpu 使用率显示的剧烈震荡。比如下图:

在 t1 的瞬时状态看来,系统的 cpu 利用率毫无疑问就是 100%,但在 t2 时间看来,使用率又变成 0% 了。思路方向是对的,但显然这种粗暴的计算无法像 top 命令一样优雅地工作。
再改进一下它,把上面两个思路结合起来,可能就能解决我们的问题了。在采样上把周期定的细一些,但在计算上把周期定的粗一些。引入采用周期的概念,定时比如每 1 毫秒采样一次。如果采样的瞬时,cpu 在运行,就将这 1 ms 记录为使用。这时会得出一个瞬时的 cpu 使用率,把它都存起来。
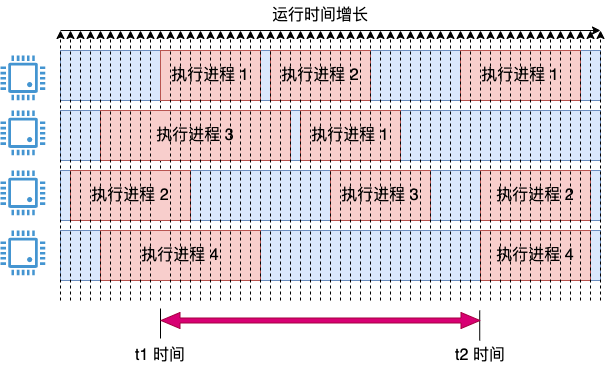
在统计 3 秒内的 cpu 使用率的时候,比如上图中的 t1 和 t2 这段时间范围。那就把这段时间内的所有瞬时值全加一下,取个平均值。这样就能解决上面的问题了,统计相对准确,避免了瞬时值剧烈震荡且粒度过粗(只能以 25 %为单位变化)的问题了。可能有同学会问了,假如 cpu 在两次采样中间发生变化了呢,如下图这种情况。
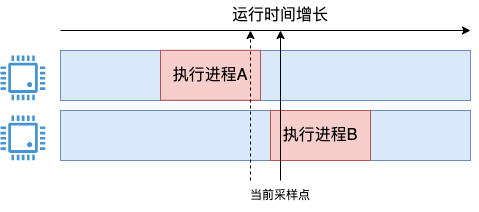
在当前采样点到来的时候,进程 A 其实刚执行完,有一点点时间没有既没被上一个采样点统计到,本次也统计不到。对于进程 B,其实只开始了一小段时间,把 1 ms 全记上似乎有点多记了。
确实会存在这个问题,但因为采样是 1 ms 一次,而实际查看使用的时候最少也有是秒级别地用,会包括有成千上万个采样点的信息,所以这种误差并不会影响对全局的把握。事实上,Linux 也就是这样来统计系统 cpu 利用率的。虽然可能会有误差,但作为一项统计数据使用已经是足够了的。在实现上,Linux 是将所有的瞬时值都累加到某一个数据上的,而不是真的存了很多份的瞬时数据。接下来进入 Linux 来查看它对系统 cpu 利用率统计的具体实现。
二、top 命令使用数据在哪儿
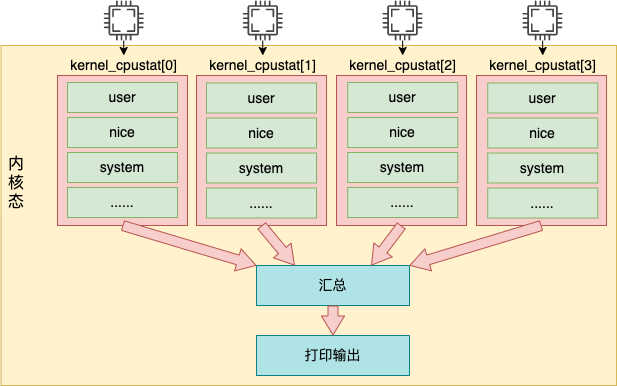
上一节说的 Linux 在实现上是将瞬时值都累加到某一个数据上的,这个值是内核通过 /proc/stat 伪文件来对用户态暴露。Linux 在计算系统 cpu 利用率的时候用的就是它。整体上看,top 命令工作的内部细节如下图所示。

top 命令访问 /proc/stat 获取各项 cpu 利用率使用值
内核调用 stat_open 函数来处理对 /proc/stat 的访问
内核访问的数据来源于 kernel_cpustat 数组,并汇总
打印输出给用户态
接下来我们把每一步都展开来详细看看。通过使用 strace 跟踪 top 命令的各种系统调用,可以看的到它对该文件的调用。
# strace top
...
openat(AT_FDCWD, "/proc/stat", O_RDONLY) = 4
openat(AT_FDCWD, "/proc/2351514/stat", O_RDONLY) = 8
openat(AT_FDCWD, "/proc/2393539/stat", O_RDONLY) = 8
...
除了 /proc/stat 外,还有各个进程细分的 /proc/{pid}/stat,是用来计算各个进程的 cpu 利用率时使用的。
内核为各个伪文件都定义了处理函数,/proc/stat 文件的处理方法是 proc_stat_operations。
//file:fs/proc/stat.c
static int __init proc_stat_init(void){
proc_create("stat", 0, NULL, &proc_stat_operations);
return 0;
}
static const struct file_operations proc_stat_operations = {
.open = stat_open,
...
};
proc_stat_operations 中包含了该文件时对应的操作方法。当打开 /proc/stat 文件的时候,stat_open 就会被调用到。stat_open 依次调用 single_open_size,show_stat 来输出数据内容。来看看它的代码:
//file:fs/proc/stat.c
static int show_stat(struct seq_file *p, void *v){
u64 user, nice, system, idle, iowait, irq, softirq, steal;
for_each_possible_cpu(i) {
struct kernel_cpustat *kcs = &kcpustat_cpu(i);
user += kcs->cpustat[CPUTIME_USER];
nice += kcs->cpustat[CPUTIME_NICE];
system += kcs->cpustat[CPUTIME_SYSTEM];
idle += get_idle_time(kcs, i);
iowait += get_iowait_time(kcs, i);
irq += kcs->cpustat[CPUTIME_IRQ];
softirq += kcs->cpustat[CPUTIME_SOFTIRQ];
...
}
//转换成节拍数并打印出来
seq_put_decimal_ull(p, "cpu ", nsec_to_clock_t(user));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(system));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq));
...
}
在上面的代码中,for_each_possible_cpu 是在遍历存储着 cpu 使用率数据的 kcpustat_cpu 变量。该变量是一个 percpu 变量,它为每一个逻辑核都准备了一个数组元素。里面存储着当前核所对应各种事件,包括 user、nice、system、idel、iowait、irq、softirq 等。在这个循环中,将每一个核的每种使用率都加起来。最后通过 seq_put_decimal_ull 将这些数据输出出来。
注意,在内核中实际每个时间记录的是纳秒数,但是在输出的时候统一都转化成了节拍单位。至于节拍单位多长,下一节介绍。总之 /proc/stat 的输出是从 kernel_cpustat 这个 percpu 变量中读取出来的。接着再看看这个变量中的数据是何时加进来的。
三、统计数据怎么来的
前面提到内核是以采样的方式来统计 cpu 使用率的。这个采样周期依赖的是 Linux 时间子系统中的定时器。Linux 内核每隔固定周期会发出 timer interrupt (IRQ 0),这有点像乐谱中的节拍的概念。每隔一段时间,就打出一个拍子,Linux 就响应之并处理一些事情。
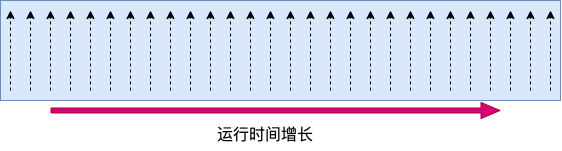
一个节拍的长度是多长时间,是通过 CONFIG_HZ 来定义的。它定义的方式是每一秒有几次 timer interrupts。不同的系统中这个节拍的大小可能不同,通常在 1 ms 到 10 ms 之间。可以在自己的 Linux config 文件中找到它的配置。
# grep ^CONFIG_HZ /boot/config-5.4.56.bsk.10-amd64
CONFIG_HZ=1000
从上述结果中可以看出,机器的每秒要打出 1000 次节拍。也就是每 1 ms 一次。每次当时间中断到来的时候,都会调用 update_process_times 来更新系统时间。更新后的时间都存储在我们前面提到的 percpu 变量 kcpustat_cpu 中。

来详细看下汇总过程 update_process_times 的源码,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
void update_process_times(int user_tick){
struct task_struct *p = current;
//进行时间累积处理
account_process_tick(p, user_tick);
...
}
这个函数的参数 user_tick 值得是采样的瞬间是处于内核态还是用户态。接下来调用 account_process_tick。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick){
cputime = TICK_NSEC;
...
if (user_tick)
//3.1 统计用户态时间
account_user_time(p, cputime);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
//3.2 统计内核态时间
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
//3.3 统计空闲时间
account_idle_time(cputime);
}
在这个函数中,首先设置 cputime = TICK_NSEC, 一个 TICK_NSEC 的定义是一个节拍所占的纳秒数。接下来根据判断结果分别执行 account_user_time、account_system_time 和 account_idle_time 来统计用户态、内核态和空闲时间。
3.1 用户态时间统计
//file:kernel/sched/cputime.c
void account_user_time(struct task_struct *p, u64 cputime){
//分两种种情况统计用户态 CPU 的使用情况
int index;
index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER;
//将时间累积到 /proc/stat 中
task_group_account_field(p, index, cputime);
......
}
account_user_time 函数主要分两种情况统计:
如果进程的 nice 值大于 0,那么将会增加到 CPU 统计结构的 nice 字段中。
如果进程的 nice 值小于等于 0,那么增加到 CPU 统计结构的 user 字段中。
至此开篇的问题 2 就有答案了,其实用户态的时间不只是 user 字段,nice 也是。之所以要把 nice 分出来,是为了让 Linux 用户更一目了然地看到调过 nice 的进程所占的 cpu 周期有多少。平时如果想要观察系统的用户态消耗的时间的话,应该是将 top 中输出的 user 和 nice 加起来一并考虑,而不是只看 user!接着调用 task_group_account_field 来把时间加到前面我们用到的 kernel_cpustat 内核变量中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,u64 tmp){
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
...
}
3.2 内核态时间统计
我们再来看内核态时间是如何统计的,找到 account_system_time 的代码。
//file:kernel/sched/cputime.c
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime){
if (hardirq_count() - hardirq_offset)
index = CPUTIME_IRQ;
else if (in_serving_softirq())
index = CPUTIME_SOFTIRQ;
else
index = CPUTIME_SYSTEM;
account_system_index_time(p, cputime, index);
}
内核态的时间主要分 3 种情况进行统计。
如果当前处于硬中断执行上下文, 那么统计到 irq 字段中
如果当前处于软中断执行上下文, 那么统计到 softirq 字段中
否则统计到 system 字段中
判断好要加到哪个统计项中后,依次调用 account_system_index_time、task_group_account_field 来将这段时间加到内核变量 kernel_cpustat 中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,u64 tmp){
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
}
3.3 空闲时间的累积
没错,在内核变量 kernel_cpustat 中不仅仅是统计了各种用户态、内核态的使用统计,空闲也一并统计起来了。如果在采样的瞬间,cpu 既不在内核态也不在用户态的话,就将当前节拍的时间都累加到 idle 中。
//file:kernel/sched/cputime.c
void account_idle_time(u64 cputime){
u64 *cpustat = kcpustat_this_cpu->cpustat;
struct rq *rq = this_rq();
if (atomic_read(&rq->nr_iowait) > 0)
cpustat[CPUTIME_IOWAIT] += cputime;
else
cpustat[CPUTIME_IDLE] += cputime;
}
在 cpu 空闲的情况下,进一步判断当前是不是在等待 IO(例如磁盘 IO),如果是的话这段空闲时间会加到 iowait 中,否则就加到 idle 中。从这里,我们可以看到 iowait 其实是 cpu 的空闲时间,只不过是在等待 IO 完成而已。看到这里,开篇问题 3 也有非常明确的答案了,io wait 其实是 cpu 在空闲状态的一项统计,只不过这种状态和 idle 的区别是 cpu 是因为等待 io 而空闲。
四、小结
本节深入分析了 Linux 统计系统 CPU 利用率的内部原理,全文的内容可以用如下一张图来汇总:

Linux 中的定时器会以某个固定节拍,比如 1 ms 一次采样各个 cpu 核的使用情况,然后将当前节拍的所有时间都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一项上。top 命令是读取的 /proc/stat 中输出的 cpu 各项利用率数据,而这个数据在内核中的是根据 kernel_cpustat 来汇总并输出的。
回到开篇问题 1,top 输出的利用率信息是如何计算出来的,它精确吗?
/proc/stat 文件输出的是某个时间点的各个指标所占用的节拍数。如果想像 top 那样输出一个百分比,计算过程是分两个时间点 t1, t2 分别获取一下 stat 文件中的相关输出,然后经过个简单的算术运算便可以算出当前的 cpu 利用率。提供了一个简单的 Shell 脚本,可以用它来实际查看一下你服务器的 cpu 利用率。
再说是否精确。这个统计方法是采样的,只要是采样,肯定就不是百分之百精确。但由于查看 cpu 使用率的时候往往都是计算 1 秒甚至更长一段时间的使用情况,这其中会包含很多采样点,所以查看整体情况是问题不大的。另外也学到了 top 中输出的 cpu 时间项目其实大致可以分为三类:
第一类:用户态消耗时间,包括 user 和 nice。如果想看用户态的消耗,要将 user 和 nice 加起来看才对。
第二类:内核态消耗时间,包括 irq、softirq 和 system。
第三类:空闲时间,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空闲状态,只不过是在等 io 完成而已。如果只是想看 cpu 到底有多闲,应该把 io_wait 和 idle 加起来才对。
CPU 优化思路及案例
在Linux系统的世界里,无论是运行关键业务的服务器,还是开发者手中的开发环境,CPU 就如同跳动的心脏,其性能直接决定了系统的生命力。当 CPU 性能出现问题,就像心脏供血不足,会引发一系列连锁反应,其中最明显的就是服务卡顿和响应迟缓。正因如此,深入了解 CPU 性能问题,掌握优化技巧,对 Linux 系统的稳定高效运行至关重要。接下来一同开启探索 CPU 性能优化之旅,找出那些拖慢系统性能的 “元凶”。本节选自“深度Linux”的博客空间,感谢原作者。
1、认识CPU性能指标
在深入排查 CPU 性能问题前先来认识几个关键的 CPU 性能指标,它们如同 CPU 的 “健康密码”,能帮助我们准确判断 CPU 的工作状态。
1.1平均负载(Load Average)
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数 ,也就是平均活跃进程数。简单来说,它反映了系统的繁忙程度。可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程;不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,最常见的是等待硬件设备的 I/O 响应。
可以使用 uptime 命令或 top 命令来查看系统的平均负载。比如执行 uptime 命令后,得到的结果 “14:21:38 up 1 day, 1:22, 2 users, load average: 0.58, 0.65, 0.70”,其中最后三个数字 0.58、0.65、0.70 分别表示过去 1 分钟、5 分钟、15 分钟的平均负载。
平均负载与 CPU 核心数密切相关。对于一个单核 CPU 系统来说,如果平均负载为 1,意味着 CPU 刚好被完全占用;如果平均负载大于 1,则表示有进程在等待 CPU 资源,系统出现了过载。而在一个 4 核 CPU 系统中,当平均负载为 4 时,CPU 才被完全占用;若平均负载为 2,说明 CPU 还有 50% 的空闲。一般认为,当平均负载高于 CPU 数量 70% 的时候,就需要关注并分析负载高的问题了。例如,在一个拥有 2 个 CPU 核心的服务器上,如果 1 分钟平均负载长期高于 1.4,就可能会出现性能问题,需要进一步排查原因。
1.2 CPU 使用率
CPU 使用率,简单来说就是在一段时间内,CPU 被占用的时间占总时间的比例,是一个百分比数值。它就像衡量 CPU 工作强度的 “体温计”,直观地反映了 CPU 在单位时间内有多 “忙”。
其计算方式并不复杂。对于单核 CPU 而言,在某一时间段内,若 CPU 执行程序指令的时间为 t1,总时间为 T,那么该时间段内的 CPU 使用率 = (t1 / T)× 100%。例如,在 1 秒钟内,CPU 有 0.5 秒在执行程序指令,那么这 1 秒内的 CPU 使用率就是 50%。而对于多核 CPU,计算方式则是将每个核心在单位时间内的使用率相加,再除以核心数。假设一个四核 CPU,每个核心在 1 秒内分别被占用 0.3 秒、0.4 秒、0.2 秒和 0.1 秒,那么总的 CPU 使用率就是(0.3 + 0.4 + 0.2 + 0.1)÷ 4 × 100% = 25%。
当 CPU 使用率较高时,如达到 80% - 90% 及以上,就意味着 CPU 正在承担大量的计算任务,计算机的响应速度可能会变慢。以运行大型 3D 游戏为例,游戏运行时,CPU 需要处理复杂的图形算法、物理模拟以及大量的游戏逻辑,这使得 CPU 的使用率急剧上升。若此时 CPU 性能不足,就会导致游戏画面卡顿、帧率不稳定等问题。相反,当 CPU 使用率较低,如在待机或者只运行一些简单的文本编辑软件时,CPU 使用率可能只有 10% - 20% 左右,计算机能够快速响应用户的其他操作指令。
1.3 上下文切换
在多任务处理的环境中,Linux 系统看似能够同时运行多个任务,但实际上,在同一时刻,CPU 只能执行一个任务。为了实现多任务并发执行的效果,操作系统引入了上下文切换机制,这就好比一场接力赛跑中的 “接力棒交接”。
上下文切换,是指操作系统保存当前正在执行的任务(可以是进程或线程)的状态(即上下文),并加载另一个任务的状态,使得 CPU 能够从一个任务快速切换到另一个任务执行。这里的上下文,既包括虚拟内存、栈、全局变量等用户态的资源,也包括内核堆栈、寄存器等内核态的资源。
在 Linux 系统中,进程有多种状态,不同状态与 CPU 的关系也各不相同:
1.运行态(Running):表示进程正在被 CPU 执行,或者在运行队列中等待被调度执行。处于运行态的进程直接占用 CPU 资源,是 CPU 忙碌的直接原因。例如,当我们启动一个计算密集型的程序时,该程序的进程会处于运行态,大量占用 CPU 时间进行计算。
2.可中断睡眠态(Interruptible Sleep):进程正在等待某一事件的发生,例如等待 I/O 操作完成、等待信号等。此时进程处于睡眠状态,但可以通过信号唤醒。处于这种状态的进程不会占用 CPU 资源,直到被唤醒进入就绪态,才有可能被 CPU 调度执行。比如,一个进程发起了磁盘读取操作,在等待磁盘返回数据的过程中,它就处于可中断睡眠态。
3.不可中断睡眠态(Uninterruptible Sleep):进程等待某种无法通过信号唤醒的资源,通常是在等待硬件操作完成,如等待磁盘 I/O、等待网络传输完成等。此时进程不会响应任何信号,直到所等待的事件发生。不可中断睡眠态的进程虽然不占用 CPU 执行时间,但会使系统的平均负载增加,因为它处于不可中断的关键流程中。例如,当进程向磁盘写入大量数据时,为了保证数据一致性,在写入完成前,进程会处于不可中断睡眠态。
4.暂停态(Stopped):进程被暂停运行,通常是接收到 SIGSTOP 信号导致。进程停止运行但没有终止,所有的上下文信息都会被保留。暂停态的进程不占用 CPU 资源,直到接收到 SIGCONT 信号恢复执行并进入就绪态。比如,我们在调试程序时,可以使用调试工具将进程暂停在某个断点处,此时进程就处于暂停态。
5.僵尸态(Zombie):进程已完成执行,但其父进程尚未通过 wait () 或 waitpid () 系统调用获取其退出状态并清理资源,因此进程仍然保留着一个条目以供父进程读取其退出状态。僵尸态进程不会消耗任何 CPU 资源,但其进程表项仍占用系统资源,长时间存在可能会导致系统资源耗尽。例如,一个父进程创建了多个子进程,却没有正确处理子进程的退出,就可能产生僵尸进程。

在多任务处理中,上下文切换发挥着至关重要的作用。它使得多个任务能够公平、高效地共享CPU资源,从而提高系统的吞吐量和响应时间。例如,当你在电脑上同时打开浏览器浏览网页、播放音乐以及运行文档编辑软件时,操作系统通过上下文切换,在这些任务之间快速切换CPU的执行权,让你感觉这些任务在同时进行。
然而,频繁的上下文切换也会对CPU性能产生负面影响。这是因为每次上下文切换都需要保存当前任务的上下文信息,并加载新任务的上下文信息,这个过程涉及到 CPU 寄存器的读写、内存访问等操作,会消耗一定的时间和CPU资源。过多的上下文切换,会占用CPU过多时间,缩短真正运行时间,导致系统整体性能大幅下降。假设一个系统频繁进行上下文切换,CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,真正用于执行任务的时间就会减少,从而使得系统的运行速度变慢,响应延迟增加。
那么,哪些因素可能导致上下文切换过多呢?系统中同时存在过多的进程或线程,是一个常见的原因。当进程或线程数量超出 CPU 的处理能力时,操作系统就需要频繁地在它们之间进行切换,以满足每个任务的执行需求。低优先级进程的竞争也可能导致频繁的上下文切换。如果多个低优先级进程在争用 CPU 资源,操作系统为平衡负载而频繁切换,也会增加上下文切换的次数。I/O 操作也是一个重要因素。当进程需要等待 I/O 操作(如磁盘读写或网络请求)完成时,会被挂起,操作系统会切换到其他进程,若I/O操作非常频繁,就会导致上下文切换频繁发生。
2、排查性能元凶
当对 CPU 性能指标有了清晰认识后,就需要借助一些强大的工具来排查那些导致 CPU 性能下降的 “元凶”。在 Linux 系统中,有许多实用工具,它们就像经验丰富的侦探,有助于从复杂的系统运行状态中找到问题的关键所在。
2.1 top与 htop:系统资源的实时 “监视器”
top 命令堪称 Linux 系统性能监控的 “元老”,它以简洁直观的方式展示系统资源的实时使用情况,时刻守护着系统的性能健康。在终端输入 top,瞬间就能开启这场系统资源的 “实时之旅”。
top 命令的输出信息丰富而全面,第一行展示了系统的基本信息,包括当前时间、系统运行时长、当前登录用户数以及系统的平均负载(分别是过去 1 分钟、5 分钟和 15 分钟的平均负载)。这些信息就像系统的“健康档案”,提供了一个宏观的系统运行概览。平均负载是一个重要的指标,它反映了系统中正在运行的进程和等待运行的进程数量。如果平均负载持续高于系统的 CPU 核心数,就像一个人同时承担了过多的任务,会导致系统运行缓慢,响应延迟。
第二行呈现了系统的任务(进程)信息,如进程总数、正在运行的进程数、睡眠状态的进程数、停止状态的进程数以及僵尸进程数。进程是系统运行的基本单元,了解进程的状态对于判断系统性能至关重要。僵尸进程是已经结束运行,但父进程没有正确回收其资源的进程,它们虽然不占用 CPU 时间,但会占用系统资源,过多的僵尸进程会导致系统资源浪费。
第三行则聚焦于 CPU 状态信息,详细列出了用户空间占用 CPU 的百分比(us)、内核空间占用CPU的百分比(sy)、改变过优先级的进程占用 CPU 的百分比(ni)、空闲CPU百分比(id)、IO 等待占用 CPU 的百分比(wa)、硬中断占用 CPU 的百分比(hi)、软中断占用CPU的百分比(si)以及虚拟机偷取时间(st)。这些指标就像CPU的 “健康指标”,通过它们,我们能深入了解 CPU 的工作状态。当us值较高时,说明用户进程消耗了大量的 CPU 资源,可能是某个用户程序存在性能问题,比如算法效率低下,需要频繁进行复杂的计算;sy 值高则表示系统内核在 CPU 资源上的开销较大,这可能是由于频繁的系统调用、大量的 I/O 操作或者内核模块的性能问题导致的;wa 值高通常意味着系统在等待 I/O 操作完成,可能是磁盘读写速度过慢、网络延迟过高或者 I/O 设备出现故障。
除了这些基本信息,top命令还支持一些便捷的交互操作,让我们能更灵活地监控系统性能。按下大写的“M”,结果会按照内存占用从高到低排序,帮助我们快速找出占用内存最多的进程;按下大写的“P”,则按照CPU占用率从高到低排序,让 CPU 占用大户无所遁形;当服务器含有多个 CPU 时,按下数字 “1”,可以切换显示各个CPU的详细信息,让我们能精准了解每个 CPU 核心的工作情况。
如果说 top 命令是一位简洁高效的 “传统侦探”,那么 htop 则是一位功能强大、更具交互性的 “现代神探”,它在 top 命令的基础上进行了全面升级。htop 支持图形界面的鼠标操作,就像为我们提供了一个直观的操作面板,让我们能更轻松地与系统监控界面交互。它还可以横向或纵向滚动浏览进程列表,即使面对长长的进程列表和完整的命令行,也能轻松查看所有进程信息,不放过任何一个细节。在杀进程时,htop 无需像 top 那样输入繁琐的进程号,只需轻松操作,就能快速结束目标进程。
htop 的功能远不止这些。按下 F2 键,可以进入设定布局界面,根据自己的需求调整监控信息的显示布局,让监控界面更符合个人使用习惯;按下 F3 键,能快速搜索进程,就像在茫茫进程海洋中找到了精准定位的 “指南针”;按下 F4 键,可使用增量进程过滤器,根据特定条件筛选出我们关注的进程;按下 F5 键,能以树形结构显示进程关系,清晰呈现进程之间的父子关系,帮助我们更好地理解系统的进程架构;按下 F6 键,可以选择排序方式,按照不同的指标对进程进行排序,以便更方便地分析进程的资源占用情况;按下 F7 和 F8 键,可以分别减少或增加进程的 nice 值,从而调整进程的优先级,合理分配系统资源;按下 F9 键,能对进程传递信号,实现对进程的更多控制操作。
在实际应用中,top 和 htop 都有着广泛的用途。在服务器运维场景中,系统管理员可以通过 top 实时监控服务器的 CPU、内存等资源使用情况,及时发现资源占用异常的进程,如某个进程突然占用大量 CPU 资源,导致服务器响应变慢,管理员可以迅速通过 top 或 htop 定位到该进程,并采取相应措施,如优化程序代码、调整进程优先级或者直接结束进程,以保障服务器的稳定运行。在开发和测试环境中,开发人员可以利用 htop 的强大交互功能,深入分析程序运行时的资源占用情况,找出程序中的性能瓶颈,如某个函数在执行过程中占用过多 CPU 时间,开发人员可以针对该函数进行优化,提高程序的整体性能。
2.2 vmstat 与 iostat:系统状态的深度 “探测器”
vmstat 命令如同一位深入系统内部的 “探测器”,能够提供关于进程、内存、内存分页、堵塞IO、traps及CPU 活动的详细信息,对系统的运行状态有更全面、深入的了解。在终端输入vmstat,即可开启这个系统状态的深度探测之旅。
vmstat 命令的输出结果分为多个部分,每个部分都蕴含着丰富的系统运行信息。procs 部分展示了进程相关信息,其中 r 表示运行队列中进程的数量,这些进程都处于可运行状态,正急切地等待 CPU 的分配。当这个值超过了 CPU 的核心数目,就如同众多乘客争抢有限的出租车,必然会出现 CPU 瓶颈。此时,系统的运行效率会大幅下降,表现为程序响应迟缓、操作卡顿等。b 表示被 blocked(阻塞)的进程数,这些进程正在等待 IO 操作完成,就像在交通拥堵的路口等待通行的车辆,它们的存在也会影响系统的整体性能。
memory 部分呈现了内存的使用情况,swpd 表示使用的虚拟内存的大小,如果该值大于 0,就像一个人在小房间里放置了过多的物品,说明机器的物理内存可能不足。这时候,我们需要进一步排查原因,可能是程序存在内存泄露问题,也可能是系统本身的内存配置无法满足当前的业务需求。free 表示可用的物理内存大小,它反映了系统当前还有多少 “空闲资源” 可供使用。buff 和 cache 分别表示物理内存用来缓存读写操作的 buffer 大小以及用来缓存进程地址空间的 cache 大小。
合理利用buffer和cache可以提高系统的IO性能,因为它们可以减少对磁盘的直接读写次数。当程序需要读取数据时,首先会在 cache 中查找,如果找到,就可以直接从 cache 中读取,而无需访问磁盘,大大提高了数据读取速度;同样,当程序需要写入数据时,数据会先写入 buffer,然后由系统在适当的时候将 buffer 中的数据写入磁盘,这样可以减少磁盘的随机写入次数,提高写入效率。
swap 部分展示了系统的交换空间使用情况,si 表示每秒从磁盘读入虚拟内存的大小,so 表示每秒虚拟内存写入磁盘的大小。当内存够用时,这两个值通常都是 0。但如果这两个值长期大于 0,就像在一个繁忙的港口,货物频繁地装卸,说明系统在频繁地进行内存和磁盘之间的数据交换,这会严重影响系统性能。
io 部分提供了输入输出信息,bi 表示每秒从文件系统或 SWAP 读入到 RAM(blocks in)的块数,bo 表示每秒从 RAM 写出到文件系统或 SWAP(blocks out)的块数。在随机磁盘读写操作中,如果这两个值越大(如超出 1024k),就像高速公路上的车流量过大,能看到 CPU 在 IO 等待的值也会越大,这表明系统的 IO 性能可能存在瓶颈。
system 部分呈现了系统信息,in 表示每秒的中断数,cs 表示系统每秒进行上下文切换的次数。上下文切换是指 CPU 从一个进程或线程切换到另一个进程或线程的过程,这个过程需要保存和恢复进程或线程的上下文信息,会消耗一定的 CPU 资源。因此,cs 值越小越好,如果上下文切换次数过多,就像一个人频繁地在不同任务之间切换,会导致 CPU 大部分时间浪费在上下文切换上,真正用于执行任务的时间就会减少。
cpu 部分展示了 CPU 活动的相关信息,us 表示用户空间占用 CPU 的百分比,当 us 的值较高时,说明用户进程消耗的 CPU 时间比较多,如果长期超过 50%,就像一个员工承担了过多的工作任务,我们就需要考虑优化程序算法或者进行加速,以提高 CPU 的使用效率。sy 表示内核空间占用 CPU 的百分比,sy 值高时,说明系统内核消耗的 CPU 资源多,这可能是由于频繁的系统调用、大量的 I/O 操作或者内核模块的性能问题导致的,需要进一步排查原因。
id 表示 CPU 空闲的百分比,它反映了 CPU 当前的空闲程度。wa 表示 CPU 等待 IO 的百分比,wa 值高时,说明 CPU 在等待 I/O 操作完成的时间比较多,这可能是由于大量的磁盘随机访问造成的,也有可能是磁盘出现瓶颈,需要对磁盘性能进行优化。st 表示来自于虚拟机偷取的 CPU 所占的百分比,在虚拟化环境中,这个指标对于评估虚拟机对物理机 CPU 资源的占用情况非常重要。
iostat 命令则是专门用于监控系统设备的 IO 负载情况的 “专家”,它能为我们提供丰富的 IO 性能状态数据,帮助我们准确判断系统的 IO 性能瓶颈。iostat 首次运行时,会显示自系统启动开始的各项统计信息,之后运行 iostat 将显示自上次运行该命令以后的统计信息。我们可以通过指定统计的次数和时间来获得所需的统计信息,非常灵活方便。
iostat 命令的输出结果主要包括 CPU 信息和磁盘信息两个部分。在 CPU 信息部分,% user 表示用户态 CPU 占用百分比,% nice 表示 nice 优先级较高的进程的 CPU 占用百分比,% system 表示系统态 CPU 占用百分比,% iowait 表示等待 I/O 的 CPU 占用百分比,% steal 表示虚拟机监控器占用的 CPU 时间百分比(仅在虚拟化环境中出现),% idle 表示 CPU 空闲百分比。这些指标与 vmstat 中 CPU 部分的指标类似,但 iostat 的输出更加专注于 CPU 与 IO 相关的性能情况。当 % iowait 值较高时,说明 CPU 在等待 I/O 操作的时间较长,这可能是磁盘读写速度过慢、I/O 设备繁忙或者 I/O 调度不合理等原因导致的。
磁盘信息部分是 iostat 命令的重点,它详细展示了每个磁盘设备的性能指标。Device 表示磁盘设备的名称,tps 表示每秒传输的块数量,它反映了磁盘的 I/O 操作频率,就像高速公路上每秒通过的车辆数。kB_read/s 表示每秒从设备读取的数据量,kB_wrtn/s 表示每秒向设备写入的数据量,这两个指标直观地展示了磁盘的读写速度。kB_read 和 kB_wrtn 分别表示读取和写入的总数据量。
此外,iostat 还可以通过 - x 选项显示更详细的扩展数据,如 rrqm/s 表示每秒这个设备相关的读取请求有多少被 Merge 了,wrqm/s 表示每秒这个设备相关的写入请求有多少被 Merge 了,rsec/s 和 wsec/s 分别表示每秒读取和写入的扇区数,avgrq-sz 表示平均请求扇区的大小,avgqu-sz 表示平均请求队列的长度,await 表示每一个 IO 请求的处理的平均时间,svctm 表示平均每次设备 I/O 操作的服务时间,% util 表示在统计时间内所有处理 IO 时间除以总共统计时间,它反映了设备的繁忙程度。当 % util 接近 100% 时,说明磁盘设备已经接近满负荷运行,可能会出现 I/O 性能瓶颈。
在实际应用中,vmstat 和 iostat 常用于排查系统性能问题。当系统出现卡顿、响应迟缓等问题时,我们可以先使用 vmstat 查看系统的整体运行状态,包括 CPU、内存、IO 等方面的情况,初步判断问题所在。如果发现 CPU 等待 IO 的时间较长,或者内存使用异常,就可以进一步使用 iostat 命令来深入分析磁盘的 IO 性能,找出具体是哪个磁盘设备出现了问题,以及问题的具体表现,如读写速度过慢、请求队列过长等。通过这些工具的配合使用,我们能够更准确地定位系统性能问题的根源,为后续的优化工作提供有力支持。
2.3 perf:CPU 性能分析的专业 “手术刀”
perf工具堪称Linux系统中 CPU 性能分析的 “手术刀”,它功能强大,能够利用处理器硬件性能监控单元进行性能事件采样,帮助深入剖析程序的性能瓶颈,精确找出进程的热点函数,是解决CPU性能问题的得力助手。
perf 工具基于硬件性能计数器(Hardware Performance Counters,HPC)工作,这些计数器是 CPU 内部的特殊寄存器,就像一个个精密的传感器,能够记录特定事件的发生次数。perf 通过与 Linux 内核的 perf_event 子系统交互,读取这些计数器的值,从而获取程序运行时的各种性能数据,如 CPU 利用率、缓存命中率、指令执行次数等。
perf 工具提供了丰富多样的子命令,每个子命令都有其独特的功能,就像一把把不同的手术刀,适用于不同的性能分析场景。
perf list 子命令用于列出当前系统支持的硬件性能事件、软件事件和跟踪点。这就像一本详细的 “性能事件字典”,当需要进行特定的性能分析时,可以先使用 perf list 查看系统支持的事件类型,以便选择合适的事件进行采样和分析。例如想要分析网络相关的性能问题,可以使用 “perf list 'net:*'” 命令查看所有与网络相关的事件。
perf top 子命令能够实时动态地显示系统中 CPU 占用最高的函数。它就像一个实时的 “性能放大镜”,能够直观地看到当前系统中哪些函数正在大量消耗 CPU 资源。在实际应用中,当系统出现 CPU 使用率过高的情况时,可以通过 perf top 快速定位到占用 CPU 资源最多的函数,进而深入分析这些函数的代码逻辑,找出性能瓶颈所在。比如,在一个大型数据库应用中,通过 perf top 发现某个查询函数占用了大量 CPU 时间,经过进一步分析,发现是该函数中的查询语句没有使用合适的索引,导致全表扫描,从而消耗了大量 CPU 资源。通过优化查询语句,添加合适的索引,成功降低了该函数的 CPU 占用率,提高了系统性能。
perf stat 子命令用于统计程序运行时的硬件事件,如缓存未命中、分支预测错误等。它就像一个精准的 “性能计数器”,能够帮助了解程序在运行过程中的各种硬件事件发生情况。通过分析这些事件的统计数据来评估程序对硬件资源的利用效率,找出可能存在的性能问题。例如可以使用 “perf stat -a -r 3 sleep 5” 命令对系统进行全局统计,统计 5 秒内的硬件事件,并重复 3 次。在输出结果中可以看到诸如 “cpu-clock”(CPU 时钟周期)、“context-switches”(上下文切换次数)、“page-faults”(页面错误次数)等硬件事件的统计信息。如果发现缓存未命中次数过高,说明程序对缓存的利用效率较低,可能需要优化程序的内存访问模式,以提高缓存命中率。
perf record 子命令用于记录程序运行时的性能事件,并将这些事件保存到一个文件(默认为 perf.data)中,以便后续进行详细的性能分析。它就像一个忠实的 “记录员”,能够准确地记录程序运行时的各种性能细节。可以使用 “perf record -g -F 99 -p 5678” 命令记录 PID 为 5678 的进程的调用图,每秒采样 99 次。这样,在程序运行结束后就可以通过其他子命令对保存的性能数据进行分析。
perf report 子命令用于分析 perf record 保存的性能事件,生成详细的性能报告。它就像一个专业的 “分析师”,能够对记录的性能数据进行深入解读,展示程序中各个函数的性能消耗情况。可以使用 “perf report -n --stdio” 命令以文本模式显示样本数量,也可以使用 “perf report -s symbol” 命令按函数名排序,以便更清晰地查看各个函数的性能情况。在性能报告中可以看到每个函数的 CPU 占用百分比、调用次数等信息,从而快速找出性能瓶颈所在的函数。
perf script 子命令用于导出原始数据,将 perf.data 文件转换为文本格式。这对于生成火焰图或进行自定义分析非常有用。火焰图是一种直观展示程序性能的工具,它能够以图形化的方式呈现函数的调用关系和 CPU 占用情况。我们可以使用 “perf script> out.stack” 命令将 perf.data 文件中的数据导出为调用栈数据,然后使用相关工具生成火焰图。通过火焰图,我们可以更直观地看到程序中哪些函数调用频繁,哪些函数占用 CPU 时间较长,从而有针对性地进行性能优化。
在实际使用perf工具时,可以根据具体的性能分析需求,灵活组合使用这些子命令。例如当怀疑某个程序存在性能问题时,可以先使用perf top实时查看该程序中占用CPU资源最多的函数,初步定位性能瓶颈。然后,使用perfrecord记录该程序运行时的性能事件,并使用perf report对记录的数据进行分析,深入了解各个函数的性能消耗情况。如果需要进一步分析函数的调用关系和CPU占用的详细情况,可以使用perf script导出原始数据,生成火焰图进行分析。
3、常见CPU性能问题
3.1 CPU 使用率过高
在 Linux 系统的日常运行中,CPU 使用率过高是一种常见且棘手的问题,它就像身体持续高烧不退,警示着系统内部可能出现了严重的 “病症”。导致 CPU 使用率过高的原因多种多样,其中 CPU 密集型进程是一个常见因素。这类进程通常执行大量的计算任务,比如大数据分析程序在进行复杂的数据计算和处理时,会持续占用 CPU 资源,使得 CPU 使用率急剧上升。
死循环也是导致 CPU 使用率飙升的 “罪魁祸首” 之一。在程序编写过程中,如果出现逻辑错误导致死循环,进程会不断地重复执行相同的代码,无法正常结束,从而将 CPU 资源紧紧 “锁住”,使其无法分配给其他进程。例如,在一段简单的 Python 代码中,如果误将循环条件设置错误,就可能陷入死循环:
i = 0
while i >= 0:
i += 1
这个循环没有设置合理的结束条件,会一直运行下去,导致 CPU 使用率迅速达到 100%。
资源竞争同样会引发 CPU 使用率过高的问题。当多个进程同时竞争 CPU 资源时,系统需要频繁地进行进程调度和上下文切换,这会增加 CPU 的额外开销。以数据库服务器为例,在高并发访问的情况下,多个查询请求同时到达,每个请求对应的进程都在争夺 CPU 资源,导致 CPU 忙于处理这些调度任务,使用率大幅提高。
针对 CPU 使用率过高的问题,可以采取一系列有效的优化方法。从代码层面入手,优化算法和数据结构是关键。对于一些复杂的计算任务,通过改进算法可以减少不必要的计算步骤,提高计算效率。例如,在排序算法中,选择更高效的快速排序算法代替冒泡排序算法,能够显著降低计算时间和 CPU 消耗。同时合理使用缓存机制,避免重复计算,也能有效减少 CPU 的工作量。比如在 Web 应用中,对于一些频繁访问且数据变动较小的页面或数据,可以将其缓存起来,当再次请求时直接从缓存中获取,而不需要重新进行复杂的计算和数据库查询,从而降低 CPU 的使用率。
在系统层面,调整调度策略也是一种有效的优化手段。Linux 系统提供了多种进程调度算法,如完全公平调度算法(CFS)等。可以根据系统的实际负载情况和应用需求,调整调度算法的参数,以优化 CPU 资源的分配。例如对于一些对实时性要求较高的应用程序,如视频直播、实时监控等,可以适当提高其进程的优先级,使其能够优先获得 CPU 资源,保证应用的流畅运行;而对于一些后台批处理任务,可以降低其优先级,让它们在 CPU 空闲时再执行,避免与前台关键任务争抢资源。
当系统资源确实不足时,增加 CPU 资源也是一种直接有效的解决方法。可以通过升级硬件,增加 CPU 核心数或更换更高性能的 CPU 来满足系统的计算需求。例如对于一些大型企业的服务器,随着业务量的不断增长,原有的 CPU 配置可能无法满足日益增长的计算需求,此时可以考虑增加 CPU 核心数或者更换为更高级的 CPU 型号,以提升系统的整体性能。
3.2 平均负载过高
平均负载过高是另一个需要关注的 CPU 性能问题,它反映了系统在一段时间内的繁忙程度和压力状况。当平均负载持续高于系统 CPU 核心数时,说明系统正面临着较大的压力,可能会出现性能下降甚至服务中断的风险。
导致平均负载过高的因素较为复杂,进程阻塞是其中之一。当进程在执行过程中等待某些资源(如 I/O 操作、锁资源等)时,会进入阻塞状态,此时虽然进程不占用 CPU 执行时间,但会使系统的平均负载增加。例如,当一个进程需要从磁盘读取大量数据时,如果磁盘 I/O 速度较慢,进程就会在等待数据读取的过程中处于阻塞状态,导致系统中可运行的进程数量减少,平均负载升高。
I/O 等待也是导致平均负载过高的常见原因。在系统进行大量的 I/O 操作(如磁盘读写、网络通信等)时,如果 I/O 设备的性能瓶颈限制了数据传输速度,进程就需要花费大量时间等待 I/O 操作完成,这会使 CPU 处于空闲状态,但平均负载却在不断上升。比如,在一个频繁进行文件读写操作的服务器上,如果磁盘的读写速度跟不上进程的请求速度,就会出现大量的 I/O 等待,导致平均负载过高。
CPU 资源不足同样会导致平均负载过高。当系统中运行的进程数量过多,而 CPU 核心数有限时,进程之间会竞争 CPU 资源,导致部分进程长时间处于等待状态,从而使平均负载升高。例如在一个小型服务器上同时运行多个大型应用程序,由于 CPU 资源有限,这些应用程序的进程会不断争抢 CPU,导致平均负载持续上升。
针对平均负载过高的问题,我们可以采取多种解决措施。优化 I/O 是关键一步,通过使用高性能的 I/O 设备,如固态硬盘(SSD)代替传统机械硬盘,可以显著提高 I/O 读写速度,减少 I/O 等待时间,从而降低平均负载。同时,合理调整 I/O 调度算法,根据应用的特点选择合适的调度策略,也能提高 I/O 性能。例如,对于数据库应用,选择 Deadline 调度算法可以更好地满足其对 I/O 响应时间的要求。
调整进程优先级也是一种有效的方法。通过提升关键进程的优先级,确保它们能够优先获得 CPU 资源,及时完成任务,从而降低系统的平均负载。例如,对于一个同时运行 Web 服务器和后台数据备份任务的系统,可以将 Web 服务器进程的优先级设置为较高,保证用户的请求能够得到及时响应,而将数据备份任务的优先级设置为较低,让它在系统空闲时再执行。
优化系统配置同样不可或缺。合理调整系统参数,如增大文件系统缓存、优化内存分配等,可以提高系统的整体性能,缓解平均负载过高的问题。例如,通过增大系统的文件系统缓存,可以减少磁盘 I/O 操作的次数,提高数据访问速度,从而降低平均负载。
3.3 进程 CPU 占用不均衡
在 Linux 系统中,进程 CPU 占用不均衡也是一种常见的性能问题,它表现为部分进程占用大量 CPU 资源,而其他进程却无法充分利用 CPU,导致系统资源分配不合理,整体性能下降。
造成进程 CPU 占用不均衡的原因主要有程序设计不合理和资源分配不均等。在程序设计方面,如果开发者没有充分考虑多线程或多进程的资源分配和调度问题,可能会导致某些线程或进程过度占用 CPU。例如,在一个多线程的网络爬虫程序中,如果没有对各个线程的任务进行合理分配和协调,可能会出现某些线程频繁发起网络请求并进行数据处理,占用大量 CPU 资源,而其他线程则处于空闲状态。
资源分配不均也是导致进程 CPU 占用不均衡的重要因素。当系统资源(如内存、I/O 等)分配不合理时,会使得某些进程在获取资源时处于优势地位,从而能够占用更多的 CPU 资源。比如,在一个共享内存的多进程应用中,如果某个进程占用了过多的内存,导致其他进程在进行内存访问时出现频繁的页错误,这些进程就需要花费更多的 CPU 时间来处理这些错误,从而导致 CPU 占用不均衡。
为了解决进程 CPU 占用不均衡的问题,我们可以采取以下优化方式。调整进程绑定 CPU 是一种有效的方法,通过使用 taskset 命令或在程序中设置 CPU 亲和性,将特定的进程绑定到指定的 CPU 核心上,避免进程在多个 CPU 核心之间频繁切换,从而提高 CPU 的使用效率。例如,对于一个计算密集型的进程,可以将其绑定到一个空闲的 CPU 核心上,让它充分利用该核心的资源,避免与其他进程争抢资源。
优化资源分配算法也是关键。在程序设计中,合理设计资源分配算法,确保各个进程能够公平地获取系统资源,避免资源过度集中在某些进程上。例如,在一个多进程的任务调度系统中,可以采用轮询或优先级队列等方式来分配任务和资源,保证每个进程都有机会获得 CPU 资源,实现资源的均衡分配。
4、优化实战策略
在深入了解了 CPU 性能指标以及排查出性能问题的 “元凶” 后,接下来就到了关键的优化实战环节。这就好比医生在准确诊断出病人的病因后,开始对症下药进行治疗。下面,我们将从进程调度、CPU 频率调整以及应用程序优化这三个关键方面入手,为 Linux 系统的 CPU 性能 “插上翅膀”。
4.1 进程调度优化:合理分配 CPU “蛋糕”
Linux 进程调度器就像是一位精明的资源分配者,负责管理系统中进程对 CPU 资源的使用。它的工作原理基于一系列复杂而精妙的算法,旨在确保系统高效、稳定地运行,同时兼顾各个进程的公平性和响应性。
在 Linux 系统中,常见的调度算法有多种,每种算法都有其独特的设计理念和适用场景。先来先服务(FCFS)算法按照进程到达就绪队列的先后顺序来分配 CPU,简单直观,如同排队买票,先到先得。但它存在明显的缺陷,若一个长进程先到达并占用 CPU,后面的短进程就只能苦苦等待,导致整体效率低下,就像前面有个购物清单很长的顾客在结账,后面的顾客都得等很久。这种算法适用于批处理系统中任务序列简单、对响应时间要求不高的场景。
短作业优先(SJF)算法则优先调度估计运行时间最短的进程,能有效降低平均周转时间,提高系统吞吐量。然而,准确预估进程的运行时间并非易事,而且长进程可能会因为不断有短进程进入而长时间得不到执行,出现 “饥饿” 现象。比如在一个数据处理中心,有大量不同数据量的任务,小数据量的短任务可以用 SJF 算法快速处理,提升整体效率,但长任务可能会被忽视。它比较适合分时系统中短任务处理以及小型服务器的日常请求处理等场景。
时间片轮转(RR)算法将 CPU 的处理时间划分为固定长度的时间片,所有就绪进程按照顺序轮流在 CPU 上运行一个时间片。当时间片用完,进程无论是否完成任务,都会被暂停并放回就绪队列末尾,等待下一轮调度。这就像一场接力赛,每个进程都有机会在规定时间内 “跑一段”,保证了每个进程都能得到处理,具有很好的公平性。但如果时间片设置过小,会导致频繁的上下文切换,增加系统开销;若时间片过大,又会退化成先来先服务算法,无法体现其优势。时间片轮转算法广泛应用于分时系统和交互式系统,比如多用户的服务器环境,能让每个用户的进程都快速获得 CPU 服务,提升用户体验。
优先级调度算法为每个进程分配一个优先级,优先级高的进程优先执行。这就像在医院里,急诊病人会比普通病人优先得到救治。该算法能保证高优先级任务及时执行,但可能出现 “优先级反转” 和 “饥饿” 问题,即低优先级进程占用资源,导致高优先级进程无法执行,或者某些进程长时间得不到调度。为缓解这些问题,可以引入老化机制,逐渐提高长时间等待进程的优先级。它适用于对任务优先级有严格要求的实时系统,如工业自动化控制、航空航天等领域。
多级反馈队列调度算法结合了多种算法的优点,将进程分配到多个优先级队列中,每个队列有不同的时间片长度和优先级。优先级高的队列时间片较短,优先处理高优先级队列的进程。在任务执行过程中,还可以动态调整优先级,长时间等待的低优先级进程会被提升到更高优先级队列,避免长作业 “饥饿”。这种算法虽然复杂,管理多个队列需要额外开销,但能高效处理不同类型的任务,适用于需要高响应速度和公平性的操作系统。
在实际应用中可以通过调整进程优先级来优化调度策略。在 Linux 系统中,可以使用 nice 和 renice 命令来调整进程的 nice 值,从而改变进程的优先级。nice 值的范围是 - 20 到 19,值越小优先级越高。例如使用 nice -n -5 command 命令可以以较高优先级启动一个新进程;对于已经运行的进程,使用 renice -n 10 -p pid 命令可以将进程 ID 为 pid 的进程优先级降低。对于实时进程,还可以使用 chrt 命令设置调度策略和优先级。比如,chrt -f 50 command 命令可以将程序以实时 FIFO 策略运行,并设置优先级为 50。在调整进程优先级时,需要注意权限问题,普通用户只能提高进程的 nice 值(降低优先级),设置低于 0 的 nice 值或实时优先级需要超级用户权限。同时要谨慎调整优先级,不当的设置可能会导致系统不稳定或响应变慢。
4.2 CPU 频率调整:动态调节 CPU “马力”
CPU频率就像是汽车的发动机转速,直接影响着CPU的运算速度和性能表现。在 Linux 系统中可以根据系统负载的变化,动态调整 CPU 频率,实现性能和功耗的平衡,让CPU在不同的工作场景下都能发挥出最佳效能。
CPU 频率调整的原理基于现代 CPU 的动态频率调整(DFA)技术。CPU 内部有一个智能的频率调节器,它就像一位经验丰富的驾驶员,时刻监测着 CPU 的工作负载。当负载较低时,比如系统处于待机状态或只运行一些简单的后台任务,频率调节器会降低 CPU 频率,就像汽车在空路上行驶时降低发动机转速,以节省能耗。相反,当负载较高,如运行大型游戏、进行复杂的数据分析或编译大型程序时,频率调节器会提高 CPU 频率,让 CPU 全力运转,提供更好的性能,如同汽车在爬坡或高速行驶时提高发动机转速。
在 Linux 系统中可以使用 cpupower 工具来实现 CPU 频率的调整。cpupower 工具功能强大,提供了丰富的命令选项,让我们能够灵活地管理 CPU 的电源和性能选项。在使用 cpupower 工具之前,首先需要确保它已经安装在系统中。对于基于 Debian 的系统(如 Ubuntu),可以使用 apt-get install linux-tools-common linux-tools-generic linux-tools-$(uname -r) 命令进行安装;对于基于 RPM 的系统(如 Fedora 或 CentOS),可以使用 yum install cpupower 或 dnf install cpupower 命令进行安装。
安装完成后可以使用 cpupower frequency-info 命令来查看CPU频率的相关信息,包括当前 CPU 的运行频率、支持的频率范围、可用的频率调节策略等。例如,执行该命令后,我们可能会看到类似如下的输出:
analyzing CPU 0:
driver: intel_cpufreq
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: 20.0 us
hardware limits: 800 MHz - 3.50 GHz
available cpufreq governors: performance schedutil
current policy: frequency should be within 800 MHz and 3.50 GHz.
The governor "schedutil" may decide which speed to use within this range.
current CPU frequency: Unable to call hardware
current CPU frequency: 3.19 GHz (asserted by call to kernel)
boost state support:
Supported: yes
Active: yes
3200 MHz max turbo 4 active cores
3200 MHz max turbo 3 active cores
3400 MHz max turbo 2 active cores
3500 MHz max turbo 1 active cores
从输出信息中可以了解到当前 CPU 的驱动为 intel_pstate,硬件支持的频率范围是 800 MHz - 3.50 GHz,可用的频率调节策略有 performance 和 powersave,当前采用的是 powersave 策略,CPU 频率为 800 MHz,并且还能看到不同频率下的使用统计信息。
接下来可以根据实际需求,使用 cpupower frequency-set 命令来设置 CPU 的频率调节策略。如果希望系统在任何情况下都能以最高性能运行,比如在进行大型数据库查询、3D 图形渲染等对性能要求极高的任务时,可以使用 cpupower frequency-set -g performance 命令将频率调节策略设置为 performance。在这种策略下,CPU 会始终运行在最高频率,以提供最强的计算能力,但相应地,功耗也会增加,就像汽车始终保持高速行驶,油耗会上升。
相反如果更注重节能,比如在笔记本电脑使用电池供电时,希望延长电池续航时间,可以使用 cpupower frequency-set -g powersave 命令将频率调节策略设置为 powersave。在 powersave 策略下,CPU 会根据负载自动降低频率,以减少功耗,类似汽车在经济模式下行驶,发动机转速较低,油耗也较低。
除了这两种常见的策略,Linux 系统还支持其他一些频率调节策略,如 ondemand 和 conservative。ondemand 策略会根据 CPU 的负载情况动态调整频率,当负载增加时,快速提高频率;当负载降低时,迅速降低频率。它在性能和功耗之间取得了较好的平衡,适用于大多数日常使用场景,就像一个智能的驾驶员,根据路况灵活调整车速。conservative 策略与 ondemand 类似,但频率调整相对更为保守,不会像 ondemand 那样快速地改变频率,适用于对频率变化较为敏感的应用程序。
在实际应用中,根据系统负载动态调整 CPU 频率能带来显著的好处。在服务器环境中,当业务量较低时,将 CPU 频率降低,可以节省大量的电力成本,减少服务器的散热压力,延长硬件的使用寿命。而当业务量突然增加,如电商网站在促销活动期间,将 CPU 频率提高,能够保证系统的响应速度,避免因性能不足而导致用户流失。在移动设备上,合理调整 CPU 频率更是至关重要,它可以在保证用户体验的前提下,最大限度地延长电池续航时间,让用户能够更长久地使用设备。
4.3 应用程序优化:从源头提升 CPU 效率
应用程序作为 CPU 资源的主要使用者,其代码质量和算法设计对 CPU 性能有着深远的影响。从代码层面深入分析影响 CPU 性能的因素,并采取有效的优化措施,是提升 CPU 效率的关键所在,就像从源头上治理河流污染,才能让河水清澈见底。
算法复杂度是影响 CPU 性能的重要因素之一。简单来说,算法复杂度描述了算法执行所需的时间和空间资源随着输入规模增长的变化情况。常见的算法复杂度有 O (1)、O (n)、O (n^2)、O (log n) 等。以查找算法为例,线性查找算法的时间复杂度为 O (n),它需要遍历整个数据集合来查找目标元素。当数据规模 n 很大时,如在一个包含百万条记录的数据库中进行线性查找,CPU 需要执行大量的比较操作,消耗大量时间。而二分查找算法的时间复杂度为 O (log n),它利用数据有序的特点,每次比较都能排除一半的数据,查找速度大大加快。在一个同样规模的有序数据集中,二分查找的效率要远远高于线性查找,对 CPU 资源的消耗也更少。因此,在编写应用程序时,我们应尽量选择复杂度较低的算法,避免使用那些随着数据规模增长,时间和空间复杂度急剧上升的算法,以减少 CPU 的计算量。
循环嵌套也是一个容易导致 CPU 性能问题的因素。当循环嵌套层数过多时,就像一个迷宫中有很多层嵌套的房间,CPU 需要执行大量的循环迭代,计算量呈指数级增长。例如,一个三层嵌套的循环,最内层循环的执行次数等于三层循环各自迭代次数的乘积。如果每层循环都迭代 100 次,那么最内层循环将执行 100 * 100 * 100 = 1000000 次,这对 CPU 来说是一个巨大的负担。为了优化循环嵌套,可以尽量减少不必要的循环层数,将一些重复的计算移出循环体,或者使用更高效的算法来替代嵌套循环。比如在计算矩阵乘法时,传统的三重循环实现虽然直观,但效率较低。可以通过优化算法,利用矩阵的分块技术,将大矩阵分成多个小矩阵进行计算,减少循环次数,提高计算效率,从而降低 CPU 的占用。
除了算法复杂度和循环嵌套,代码中的其他一些细节也会影响 CPU 性能。频繁的函数调用会带来一定的开销,因为每次函数调用都需要保存和恢复寄存器状态、创建和销毁栈帧等。因此可以尽量减少不必要的函数调用,将一些短小的函数定义为内联函数,这样在编译时,函数代码会直接嵌入调用处,避免了函数调用的开销。内存访问模式也对 CPU 性能有重要影响。CPU 缓存是提高内存访问速度的关键,如果代码中的内存访问模式不合理,导致频繁的缓存未命中,就会大大降低内存访问速度,进而影响 CPU 性能。应尽量保持内存访问的连续性,避免随机访问内存,以提高缓存命中率。
在实际的应用程序优化中,有许多成功的案例可供我们借鉴。在一个大数据分析项目中,最初的数据分析算法使用了复杂的递归算法,虽然代码简洁,但在处理大规模数据时,CPU 占用率极高,处理时间很长。通过深入分析算法,开发团队将递归算法改为迭代算法,并对数据结构进行了优化,减少了不必要的内存操作。优化后的程序在处理相同规模的数据时,CPU 占用率降低了 50% 以上,处理时间缩短了近三分之二,大大提高了数据分析的效率。在一个图形渲染应用中,原来的代码存在大量的循环嵌套和重复计算,导致在渲染复杂场景时,画面卡顿严重。开发人员对代码进行了重构,将一些常用的计算结果缓存起来,避免重复计算,同时优化了循环结构,减少了循环层数。经过优化后,图形渲染的帧率得到了显著提升,画面更加流畅,用户体验得到了极大改善。
综上所述,从代码层面优化应用程序是提升 CPU 效率的重要途径。通过选择合适的算法、优化循环结构、减少函数调用开销、改善内存访问模式等措施,我们能够让应用程序更加高效地利用 CPU 资源,从而提升整个系统的性能。在实际开发过程中应养成良好的编程习惯,注重代码的性能优化,从源头上为 CPU 性能的提升奠定坚实的基础。
5、CPU性能分析工具实操
5.1 Stress:制造负载的工具指令
在进行 CPU 性能优化时,首先需要一种工具来模拟系统高负载的情况,以便观察和分析 CPU 在不同压力下的表现,Stress 就是这样一位得力助手。其是一款专为 Linux 系统设计的压力测试工具,它能够模拟各种资源消耗场景,帮助评估系统在高负载下的稳定性和性能极限,特别适合在测试环境中使用。
假设要模拟一个高 CPU 密集的场景,只需在终端输入 “stress -c 4” 命令,这里的 “-c” 参数表示创建 CPU 负载,数字 “4” 则指定了要创建 4 个进程。执行命令后,stress 会迅速创建 4 个进程,每个进程都全力以赴地计算随机数的平方根,使得 CPU 使用率急剧上升。此时就像给 CPU 施加了一场高强度的 “体能训练”,让它在极限状态下 “奔跑”。
在另一个终端中可以使用 top 命令来实时查看系统状态。可以看到,系统的平均负载逐步上升,接近到 4,这表明系统的负载压力在不断增大。同时有 4 个进程的 CPU 使用率接近 100%,几乎所有的时间都在用户态,整个系统就像一个忙碌的蜂巢,每个 “工蜂”(进程)都在拼命工作,而 CPU 则是那个全力协调的 “指挥官”,在高负荷下运转。通过这样的模拟可以直观地感受到高 CPU 负载对系统的影响,为后续的性能分析和优化提供了真实的场景依据。
5.2 Sysstat:系统性能的 “监控官”
Sysstat 是一个功能强大的系统性能监控工具集,包含了多个实用工具,如 mpstat、iostat、sar 等,它们就像一群专业的 “监控官”,从不同角度对系统性能进行全方位的监控和分析。
以 mpstat 为例,它主要用于监控多处理器系统中每个 CPU 的使用情况,能提供详细的 CPU 使用率、中断次数、上下文切换等关键指标。在终端输入 “mpstat -P ALL 5” 命令,其中 “-P ALL” 表示监控所有 CPU,数字 “5” 表示每隔 5 秒采样一次。执行命令后会得到类似如下的输出:
Linux 4.15.0-109-generic (ubuntu-server) 08/28/2020 _x86_64_ (8 CPU)
11:03:10 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:03:11 PM all 12.49 0.00 7.10 4.34 0.00 0.29 0.00 0.00 0.00 75.78
11:03:12 PM all 13.33 0.00 7.67 3.83 0.00 0.17 0.00 0.00 0.00 74.99
Average: all 12.91 0.00 7.38 4.08 0.00 0.23 0.00 0.00 0.00 75.39
在这些输出数据中,“% usr” 表示用户空间下的 CPU 使用率,反映了用户程序在 CPU 上的活动时间;“% sys” 表示系统空间下的 CPU 使用率,体现了内核态程序对 CPU 的占用情况;“% iowait” 表示等待 I/O 操作完成时 CPU 的空闲时间百分比,若该值较高,可能意味着系统存在 I/O 瓶颈;“% idle” 表示 CPU 的空闲时间百分比,展示了 CPU 的闲置程度。通过分析这些数据,我们能深入了解 CPU 的工作状态,精准定位性能问题。例如,如果发现某个 CPU 核心的 “% usr” 使用率持续过高,可能是某个用户程序存在性能问题,需要进一步排查和优化。
5.3 Top:实时监控的 “仪表盘”
Top 命令是 Linux 系统中最常用的性能分析工具之一,它就像汽车的仪表盘,能够实时显示系统中各个进程的资源占用状况,对系统状态一目了然。
在终端输入 “top” 命令后,会出现一个动态更新的界面,展示了丰富的系统信息。界面的第一行显示了系统当前时间、系统运行时长、当前登录用户数以及系统在 1 分钟、5 分钟、15 分钟内的平均负载,就像汽车仪表盘上的时间、里程和综合性能指标。第二行展示了当前进程总数、正在运行的进程数、睡眠的进程数、停止的进程数和僵尸进程数,对系统中的进程状态有一个整体的了解。第三行则详细列出了 CPU 的使用情况,包括用户态(us)、内核态(sy)、改变过优先级的用户进程(ni)、空闲(id)、I/O 等待(wa)、硬中断(hi)、软中断(si)、虚拟机(st)等状态下的 CPU 使用率,如同仪表盘上各个性能参数的详细展示。
在实际使用中可以通过一些常用参数来定制 Top 的显示内容,使其更符合分析需求。比如,按下 “1” 键,可以查看每个 CPU 核心的详细使用情况,就像切换仪表盘的显示模式,聚焦到每个核心的性能表现;按下 “P” 键,会按照 CPU 使用率对进程进行排序,方便我们快速找到占用 CPU 资源最多的进程,就像在仪表盘上突出显示关键性能指标。如果发现某个进程的 CPU 使用率持续居高不下,比如某个大型数据库查询进程,我们就可以进一步分析该进程的代码逻辑、查询语句等,看是否可以通过优化算法、调整查询条件等方式来降低 CPU 消耗。
6、实战案例解析
6.1 案例一:Java 进程 CPU 飙升优化
在实际开发中经常会遇到各种性能问题,其中 Java 进程 CPU 飙升是一个较为常见且棘手的问题。下面来看一个具体的案例。
最近负责的一个项目上线后,运行一段时间就发现对应的进程竟然占用了 700% 的 CPU,导致公司的物理服务器都不堪重负,频繁宕机。面对这类 Java 进程 CPU 飙升的问题,该如何定位解决呢?
首先采用 top 命令定位进程。登录服务器执行 top 命令,查看 CPU 占用情况,很快就能发现,PID 为 29706 的 Java 进程的 CPU 飙升到 700% 多,且一直降不下来,很显然出现了问题。
接着使用 top -Hp 命令定位线程。使用 top -Hp 命令(其中为 Java 进程的 id 号)查看该 Java 进程内所有线程的资源占用情况(按 shft+p 按照 cpu 占用进行排序,按 shift+m 按照内存占用进行排序)。在这里很容易发现,多个线程的 CPU 占用达到了 90% 多。可挑选线程号为 N 的线程继续分析。
然后使用 jstack 命令定位代码。先将线程号转换为 16 进制,使用 printf “% x\n” 命令(tid 指线程的 id 号)将 10 进制的线程号转换为 16 进制。转换后的结果为 7665,由于导出的线程快照中线程的 nid 是 16 进制的,而 16 进制以 0x 开头,所以对应的 16 进制的线程号 nid 为 0x7665。再采用 jstack 命令导出线程快照,通过使用 jdk 自带命令 jstack 获取该 java 进程的线程快照并输入到文件中。最后在生成的文件中根据线程号 nid 搜索对应的线程描述,判断应该是 ImageConverter.run() 方法中的代码出现问题。
下面是 ImageConverter.run() 方法中的部分核心代码。这段代码的逻辑是存储 minicap 的 socket 连接返回的数据,设置阻塞队列长度,防止出现内存溢出。在 while 循环中,不断读取堵塞队列dataQueue 中的数据,如果数据为空,则执行 continue 进行下一次循环。如果不为空,则通过 poll() 方法读取数据,做相关逻辑处理。初看这段代码好像没什么问题,但是如果dataQueue对象长期为空的话,这里就会一直空循环,导致 CPU 飙升。
// 全局变量
private BlockingQueue<byte[]> dataQueue = new LinkedBlockingQueue<byte[]>(100000);
// 消费线程
@Override
public void run() {
// long start = System.currentTimeMillis();
while (isRunning) {
// 分析这里从LinkedBlockingQueue
if (dataQueue.isEmpty()) {
continue;
}
byte[] buffer = device.getMinicap().dataQueue.poll();
int len = buffer.length;
}
}
那么如何解决呢?分析 LinkedBlockingQueue 阻塞队列的 API 发现,有两种取值的 API。take() 方法取出队列中的头部元素,如果队列为空则调用此方法的线程被阻塞等待,直到有元素能被取出,如果等待过程被中断则抛出 InterruptedException;poll () 方法取出队列中的头部元素,如果队列为空返回 null。显然 take 方法更适合这里的场景。将代码修改如下:
while (isRunning) {
/* if (device.getMinicap().dataQueue.isEmpty()) {
continue;
}*/
byte[] buffer = new byte[0];
try {
buffer = device.getMinicap().dataQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
……
}
重启项目后,测试发现项目运行稳定,对应项目进程的 CPU 消耗占比不到 10%。通过这个案例可以看出,在面对 Java 进程 CPU 飙升问题时可以借助 top、jstack 等工具,逐步定位到问题代码,并通过合理的代码修改来解决问题。
6.2 案例二:UV 通道下采样代码优化
在图像和视频处理等领域,常常会涉及到对图像数据的各种操作,UV 通道下采样就是其中常见的一种。下面来看一个 UV 通道下采样代码从标量处理转换为向量处理的优化案例。假设有一个 UV 通道下采样的任务,输入是 u8 类型的数据,通过邻近的 4 个像素求平均,输出 u8 类型的数据,达到 1/4 下采样的目的。假定每行数据长度是 16 的整数倍。最初的 C 代码实现如下:
void DownscaleUv(uint8_t *src, uint8_t *dst, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) {
for (int32_t j = 0; j < dst_height; j++) {
uint8_t *src_ptr0 = src + src_stride * j * 2;
uint8_t *src_ptr1 = src_ptr0 + src_stride;
uint8_t *dst_ptr = dst + dst_stride * j;
for (int32_t i = 0; i < dst_width; i += 2) {
// U通道
dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] + src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;
// V通道
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] + src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;
}
}
}
为了提升代码性能可以将其转换为向量处理,利用 NEON 指令集进行优化。具体步骤如下:
①内层循环向量化
内层循环是代码执行次数最多的部分,因此是向量化的重点。由于输入和输出都是 u8 类型,NEON 寄存器 128bit,所以每次可以处理 16 个数据。修改后的内层循环代码如下:
// 每次有16个数据输出
for (i = 0; i < dst_width; i += 16) {
//数据处理部分......
}
②数据类型和指令选择
输入数据加载时,UV 通道的数据是交织的,使用 vld2 指令可以实现解交织。在数据处理过程中,选择合适的指令进行计算。例如,水平两个数据相加可以使用 vpaddlq_u8 指令,上下两个数据相加之后求均值可以使用 vshrn_n_u16 和 vaddq_u16 指令。
③代码实现
#include <arm_neon.h>
void DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) {
//load偶数行的源数据,2组每组16个u8类型数据
uint8x16x2_t v8_src0;
//load奇数行的源数据,需要两个Q寄存器
uint8x16x2_t v8_src1;
//目的数据变量,需要一个Q寄存器
uint8x8x2_t v8_dst;
//目前只处理16整数倍部分的结果
int32_t dst_width_align = dst_width & (-16);
//向量化剩余的部分需要单独处理
int32_t remain = dst_width & 15;
int32_t i = 0;
//外层高度循环,逐行处理
for (int32_t j = 0; j < dst_height; j++) {
//偶数行源数据指针
uint8_t *src_ptr0 = src + src_stride * j * 2;
//奇数行源数据指针
uint8_t *src_ptr1 = src_ptr0 + src_stride;
//目的数据指针
uint8_t *dst_ptr = dst + dst_stride * j;
//内层循环,一次16个u8结果输出
for (i = 0; i < dst_width_align; i += 16) {
//提取数据,进行UV分离
v8_src0 = vld2q_u8(src_ptr0);
src_ptr0 += 32;
v8_src1 = vld2q_u8(src_ptr1);
src_ptr1 += 32;
//水平两个数据相加
uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);
uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);
uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);
uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);
//上下两个数据相加,之后求均值
v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);
v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);
//UV通道结果交织存储
vst2_u8(dst_ptr, v8_dst);
dst_ptr += 16;
}
//process leftovers......
}
}
通过这样的优化,将原本的标量处理转换为向量处理,充分利用了 NEON 指令集的并行处理能力,大大提升了 UV 通道下采样的效率。在实际应用中,对于图像和视频处理等对性能要求较高的场景,这种基于向量处理的优化方式能够显著提高程序的运行速度,为用户带来更好的体验。