优化Linux下的硬盘与文件系统
 在Windows系统中,磁盘碎片是一个常见的问题,如果不注意,系统性能可能被侵蚀。Linux使用第二扩展文件系统(ext2),它以一种完全不同的方式处理文件存储。Linux没有Windows系统中发现的那种问题,这使得许多人认为磁盘碎片化根本不是一个问题。但是,这是不正确的。 所有的文件系统随着时间的推移都趋向于碎片化。Linux文件系统减少了碎片化,但是并没有消除。由于它不经常出现,所以对于一个单用户的工作站来说,可能根本不是问题。然而在繁忙的服务器中,随着时间的过去,文件碎片化将降低硬盘性能,硬盘性能只有从硬盘读出或写入数据时才能注意到。下面是优化Linux系统硬盘性能的一些具体措施。
在Windows系统中,磁盘碎片是一个常见的问题,如果不注意,系统性能可能被侵蚀。Linux使用第二扩展文件系统(ext2),它以一种完全不同的方式处理文件存储。Linux没有Windows系统中发现的那种问题,这使得许多人认为磁盘碎片化根本不是一个问题。但是,这是不正确的。 所有的文件系统随着时间的推移都趋向于碎片化。Linux文件系统减少了碎片化,但是并没有消除。由于它不经常出现,所以对于一个单用户的工作站来说,可能根本不是问题。然而在繁忙的服务器中,随着时间的过去,文件碎片化将降低硬盘性能,硬盘性能只有从硬盘读出或写入数据时才能注意到。下面是优化Linux系统硬盘性能的一些具体措施。 一、清理磁盘
这种方法看上去很简单:清理磁盘驱动器,删除不需要的文件,清除所有需要被保存但将不被使用的文件。如果可能的话,清除多余的目录,并减少子目录的数目。这些建议似乎显而易见,但是你会惊讶地发现,每个磁盘上确实积累了非常多的垃圾。释放磁盘空间可以帮助系统更好地工作。
二、整理磁盘碎片
Linux系统上的磁盘碎片整理程序与Windows 98或Windows NT系统中的磁盘碎片整理程序不同。Windows 98引入FAT 32文件系统,虽然运行Windows 98不必转换为FAT 32文件系统。Windows可以被设置为使用FAT或一个叫NTFS的增强文件系统。所有这些文件系统以本质上相同的方式处理文件存储。
Linux最好的整理磁盘碎片的方法是做一个完全的备份,重新格式化分区,然后从备份恢复文件。当文件被存储时,它们将被写到连续的块中,它们不会碎片化。这是一个大工作,可能对于像/usr之类不经常改变的程序分区是不必要的,但是它可以在一个多用户系统的/home分区产生奇迹。它所花费的时间与Windows NT服务器磁盘碎片整理花费的时间大致上相同。
如果硬盘性能仍不令人满意,还有许多其它的步骤可以考虑,但是任何包含升级或购买新设备的硬件解决方案可能会是昂贵的。
三、从IDE升级到SCSI
如果你的硬盘是一个IDE驱动器,可以通过升级到SCSI驱动器获得更好的整体性能。因为IDE控制器必须访问CPU,CPU和磁盘密集型操作可能变得非常缓慢。SCSI控制器不用通过CPU处理读写。当IDE驱动器在读或写时,用户可能会因为CPU周期被IDE驱动器占用而抱怨系统的缓慢。
获取更快的控制器和磁盘驱动器:标准的SCSI控制器不能比标准的IDE控制器更快地读写数据,但是一些非常快的“UltraWide”SCSI控制器能够使读写速度有一个真正的飞跃。
EIDE和UDMA控制器是非常快的IDE控制器。新的UDMA控制器能够接近SCSI控制器的速度。UDMA控制器的顶级速度是猝发速度,但持续传输的速度明显慢得多。IDE控制器包括UDMA,是嵌入在驱动器本身中的。不需要购买一个控制器,只要购买一个驱动器,它就包含了控制器,可以获得UDMA性能。磁盘驱动器经常忽视的一个方面是磁盘本身的速度。磁盘的速度以rpm为单位给出,它代表每分钟旋转多少次。rpm越大,磁盘速度也越快。如果你有这方面的预算,大多数服务器系统厂商可提供7500rpm甚至10000rpm SCSI磁盘。标准SCSI和IDE磁盘提供5400rpm速度。
四、使用多个控制器
IDE和SCSI磁盘可以被链接。IDE链最多包括两个设备,标准SCSI链最多包括七个设备。如果在系统中有两个或更多SCSI磁盘,很可能被链接到同一个控制器。这样对大多数操作是足够的,尤其是把计算机当作单用户的工作站时。但是如果有一个服务器,那么就能够通过对每个SCSI驱动器提供一个控制器改善性能。当然,好的控制器是昂贵的。
五、调整硬盘参数
使用hdparm工具可以调整IDE硬盘性能,它设计时专门考虑了使用UDMA驱动器。在缺省情况下,Linux使用是最安全的,但是设置访问IDE驱动器是最慢的。缺省模式没有利用UDMA可能的最快的性能。使用hdparm工具激活下面的特性可以显著地改善性能:
◆ 32位支持 缺省设置是16位;
◆ 多部分访问 缺省设置是每次中断单部分传送。
注意:在使用hdparm之前,确保对系统已经做了完全的备份。使用hdparm改变IDE参数,如果出错可能会引起驱动器上全部数据的丢失。
hdparm可以提供关于硬盘的大量信息。打开一个终端窗口,输入下面命令获取系统中第一个IDE驱动器的信息(改变设备名获取其它IDE驱动器的信息):
hdparm -v /dev/hda
上面命令显示出当系统启动时从驱动器获得的信息,包括驱动器操作在16位或32位模式(I/O Support)下,是否为多部分访问(Multcount)。关于磁盘驱动器的更详细信息的显示可使用-i参数。
Hdparm也可以测试驱动器传输速率。输入命令测试系统中第一个IDE驱动器:
hdparm -Tt /dev/hda
此测试可测量驱动器直接读和高速缓冲存储器读的速度。结果是一个优化的“最好的事例”数字。改变驱动器设置,激活32位传输,输入下面的命令:
hdparm -c3 /dev/hda
-c3参数激活32位支持,使用-c0可以取消它。-c1参数也可激活32位支持并使用更少的内存开销,但是在很多驱动器下它不工作。
大多数新IDE驱动器支持多部分传输,但是Linux缺省设置为单部分传输。注意:这个设置在一些驱动器上,激活多部分传输能引起文件系统的完全崩溃。这个问题大多数发生在较老的驱动器上。输入下面的命令激活多部分传输:
hdparm -m16 /dev/hda
-m16参数激活16部分传输。除了西部数据的驱动器外,大多数驱动器设置为16或32部分是最合适的。西部数据的驱动器缓冲区小,当设置大于8部分时性能将显著下降。对西部数据驱动器来说,设置为4部分是最合适的。
激活多部分访问能够减少CPU负载30%~50%,同时可以增加数据传输速率到50%。使用-m0参数可以取消多部分传输。hdparm还有许多选项可设置硬盘驱动器,在此不详述。
六、使用软件RAID
RAID廉价驱动器的冗余阵列,也可以改善磁盘驱动器性能和容量。Linux支持软件RAID和硬件RAID。软件RAID嵌入在Linux内核中,比硬件RAID花费要少得多。软件RAID的惟一花费就是购买系统中的磁盘,但是软件RAID不能使硬件RAID的性能增强。硬件RAID使用特殊设计的硬件,控制系统的多个磁盘。硬件RAID可能是昂贵的,但是得到的性能改善与之相匹配。RAID的基本思想是组合多个小的、廉价的磁盘驱动器成为一个磁盘驱动器阵列,提供与大型计算机中单个大驱动器相同的性能级别。RAID驱动器阵列对于计算机来说像单独一个驱动器,它也可以使用并行处理。磁盘读写在RAID磁盘阵列的并行数据通路上同时进行。IBM公司在加利福尼亚大学发起一项研究,得到RAID级别的一个最初定义。现在有六个已定义的RAID级别,如下所示:
RAID0:级别0只是数据带。在级别0中,数据被拆分到多于一个的驱动器,结果是更高的数据吞吐量。这是RAID的最快和最有效形式。但是,在这个级别没有数据镜像,所以在阵列中任何磁盘的失败将引起所有数据的丢失。
RAID1:级别1是完全磁盘镜像。在独立的磁盘上创建和支持数据两份拷贝。级别1阵列与一个驱动器相比读速度快、写速度慢,但是如果任一个驱动器错误,不会有数据丢失。这是最昂贵的RAID级别,因为每个磁盘需要第二个磁盘做它的镜像。这个级别提供最好的数据安全。
RAID2:级别2设想用于没有内嵌错误检测的驱动器。因为所有的SCSI驱动器支持内嵌错误检测,这个级别已过时,基本上没用了。Linux不使用这个级别。
RAID3:级别3是一个有奇偶校验磁盘的磁盘带。存储奇偶校验信息到一个独立的驱动器上,允许恢复任何单个驱动器上的错误。Linux不支持这个级别。
RAID4:级别4是拥有一个奇偶校验磁盘的大块带。奇偶校验信息意味着任何一个磁盘失败数据可以被恢复。级别4阵列的读性能非常好,写速度比较慢,因为奇偶校验数据必须每次更新。
RAID5:级别5与级别4相似,但是它将奇偶校验信息分布到多个驱动器中。这样提高了磁盘写速度。它每兆字节的花费与级别4相同,提高了高水平数据保护下的高速随机性能,是使用最广泛的RAID系统。
软件RAID是级别0,它使多个硬盘看起来像一个磁盘,但是速度比任何单个磁盘快得多,因为驱动器被并行访问。软件RAID可以用IDE或SCSI控制器,也可以使用任何磁盘组合。
七、配置内核参数
通过调整系统内核参数改善性能有时是很明显的。如果你决定要这样做一定要小心,因为系统内核的改变可能优化系统,也可能引起系统崩溃。
注意:不要在一个正在使用的系统上改变内核参数,因为有系统崩溃的危险。因此,必须在一个没有人使用的系统上进行测试。设置一个测试机器,对系统进行测试,确保所有工作正常。
Tweak内存性能
在Linux中,可以Tweak系统内存。如果遇到内存不足错误或者系统是用于网络的,可以调整内存分配设置。内存一般以每页4千字节分配。调整“空白页”设置,可以在性能上有显著的改善。打开终端窗口,输入下面的命令查看系统的当前设置:
cat /proc/sys/vm/freepages
这样将获得三个数字,就像下面这样:
128 256 384
这些是最小空白页、空白页低和空白页高设置。这些值在启动时决定。最小设置是系统中内存数量的两倍;低设置是内存数量的4倍,高设置是系统内存的6倍;自由内存不能小于最小空白页数。
如果空白页数目低于空白页高设置,则交换(使用磁盘空间分配到交换文件)开始。当达到空白页低设置时,密集型交换开始。
增加空白页高设置有时可以改善整体性能,比如试试增加高设置到1MB,用echo命令可以调整这个设置。使用样本设置,输入这个命令增加空白页高设置到1MB:
echo "128 256 1024" > /proc/sys/vm/freepages
注意:当系统还没有被使用时测试这个设置,以确保在做任何调整时监视系统性能。这样可以确定哪个设置对系统是最好的。
文件系统结构特性
传统的磁盘与文件系统之应用中,一个分割槽就是只能够被格式化成为一个文件系统,所以我们可以说一个filesystem就是一个partition。但是由于新技术的利用,例如我们常听到的LVM与软体磁盘阵列(software raid),这些技术可以将一个分割槽格式化为多个文件系统(例如LVM),也能够将多个分割槽合成一个文件系统(LVM,RAID)!所以说,目前我们在格式化时已经不再说成针对partition来格式化了,通常我们可以称呼一个可被挂载的资料为一个文件系统而不是一个分割槽!
那么文件系统是如何运作的呢?这与操作系统的文件资料有关。较新的操作系统的文件资料除了文件实际内容外,通常含有非常多的属性,例如Linux操作系统的文件权限(rwx)与文件属性(拥有者、群组、时间参数等)。文件系统通常会将这两部份的资料分别存放在不同的区块,权限与属性放置到inode中,至于实际资料则放置到data block区块中。另外,还有一个超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等。
每个inode 与block 都有编号,这三个资料的意义可以简略说明如下:
superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的资料所在的block 号码;
block:实际记录文件的内容,若文件太大时,会占用多个block 。
由于每个inode 与block 都有编号,而每个文件都会占用一个inode ,inode 内则有文件资料放置的block 号码。因此可以知道的是,如果能够找到文件的inode 的话,那么自然就会知道这个文件所放置资料的block 号码,当然也就能够读出该文件的实际资料了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的资料,读写的效能比较好。
将inode 与block 区块用图解来说明一下,如下图所示,文件系统先格式化出inode 与block 的区块,假设某一个文件的属性与权限资料是放置到inode 4 号(下图较小方格内),而这个inode 记录了文件资料的实际放置点为2, 7, 13, 15 这四个block 号码,此时我们的操作系统就能够据此来排列磁盘的读取顺序,可以一口气将四个block 内容读出来!那么资料的读取就如同下图中的箭头所指定的模样了。
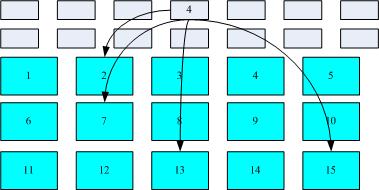
inode/block 资料存取示意图
这种资料存取的方法我们称为索引式文件系统(indexed allocation)。那有没有其他的惯用文件系统可以比较一下啊?有的,那就是我们惯用的U盘(快闪记忆体),U盘使用的文件系统一般为FAT格式。FAT这种格式的文件系统并没有inode存在,所以FAT没有办法将这个文件的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,读取方式有点像底下这样:
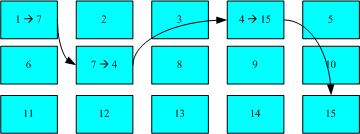
FAT文件系统资料存取示意图
上图中我们假设文件的资料依序写入1->7->4->15号这四个block 号码中, 但这个文件系统没有办法一口气就知道四个block 的号码,他得要一个一个的将block 读出后,才会知道下一个block 在何处。如果同一个文件资料写入的block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的资料, 因此磁盘就会多转好几圈才能完整的读取到这个文件的内容!
常常会听到所谓的『碎片整理』吧? 需要碎片整理的原因就是文件写入的block太过于离散了,此时文件读取的效能将会变的很差所致。此时可以透过碎片整理将同一个文件所属的blocks汇整在一起,这样资料的读取会比较容易啊!FAT的文件系统需要三不五时的碎片整理一下,那么Ext2是否需要磁盘重整呢?
由于Ext2 是索引式文件系统,基本上不太需要常常进行碎片整理的。但是如果文件系统使用太久,常常删除/编辑/新增文件时,那么还是可能会造成文件资料太过于离散的问题,此时或许会需要进行重整一下的。
EXT2文件系统(inode)
inode的内容在记录文件的权限与相关属性,至于block区块则是在记录文件的实际内容。而且文件系统一开始就将inode与block规划好了,除非重新格式化(或者利用resize2fs等指令变更文件系统大小),否则inode与block固定后就不再变动。但是如果仔细考虑一下,如果我的文件系统高达数百GB时,那么将所有的inode与block通通放置在一起将是很不智的决定,因为inode与block的数量太庞大,不容易管理。
为此,因此Ext2 文件系统在格式化的时候基本上是区分为多个区块群组(block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。感觉上就好像我们在当兵时,一个营里面有分成数个连,每个连有自己的联络系统,但最终都向营部回报连上最正确的信息一般!这样分成一群群的比较好管理啦!整个来说,Ext2 格式化后有点像底下这样:
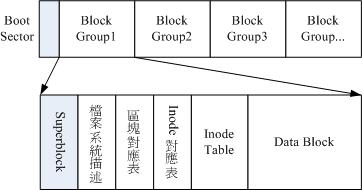
ext2文件系统示意图
在整体的规划当中,文件系统最前面有一个开机磁区(boot sector),这个开机磁区可以安装开机管理程式,这是个非常重要的设计,因为如此一来我们就能够将不同的开机管理程式安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的MBR,这样也才能够制作出多重开机的环境啊!至于每一个区块群组(block group)的六个主要内容说明如后:
data block (资料区块)
data block是用来放置文件内容资料地方,在Ext2文件系统中所支持的block大小有1K,2K及4K三种而已。在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录啦。不过要注意的是,由于block大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同。因为block大小而产生的Ext2文件系统限制如下:
Block 大小 1KB 2KB 4KB
最大单一文件限制 16GB 256GB 2TB
最大文件系统总容量 2TB 8TB 16TB
除此之外Ext2 文件系统的block 还有什么限制呢?有的!基本限制如下:
原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
每个block 内最多只能够放置一个文件的资料;
承上,如果文件大于block 的大小,则一个文件会占用多个block 数量;
承上,若文件小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
inode table (inode 表格)
基本上,inode记录的文件资料至少有底下这些:
该文件的存取模式(read/write/excute);
该文件的拥有者与群组(owner/group);
该文件的容量;
该文件建立或状态改变的时间(ctime);
最近一次的读取时间(atime);
最近修改的时间(mtime);
定义文件特性的旗标(flag),如SetUID…;
该文件真正内容的指向(pointer);
inode 的数量与大小也是在格式化时就已经固定了,除此之外inode 还有些什么特色呢?
每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes);
每个文件都仅会占用一个inode 而已;
承上,因此文件系统能够建立的文件数量与inode 的数量有关;
系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
粗略来分析一下EXT2 的inode/block 与文件大小的关系好了。inode 要记录的资料非常多,但偏偏又只有128bytes 而已,而inode 记录一个block 号码要花掉4byte,假设我一个文件有400MB 且每个block 为4K 时,那么至少也要十万笔block 号码的记录呢!inode 哪有这么多可记录的信息?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。这是啥?我们将inode 的结构画一下好了。
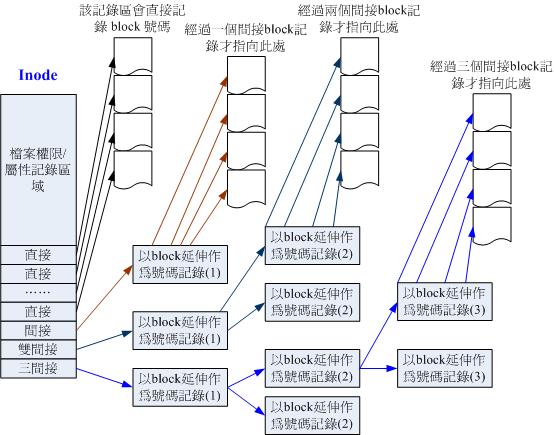
inode 结构示意图
这样子inode 能够指定多少个block 呢?我们以较小的1K block 来说明好了,可以指定的情况如下:
12个直接指向:12*1K=12K
由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示;
间接:256*1K=256K
每笔block号码的记录会花去4bytes,因此1K的大小能够记录256笔记录,因此一个间接可以记录的文件大小如上;
双间接:256*256*1K=256 2 K
第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上;
三间接:256*256*256*1K=256 3 K
第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上;
总额:将直接、间接、双间接、三间接加总,得到12 + 256 + 256*256 + 256*256*256 (K) = 16GB
Superblock (超级区块)
记录的信息主要有:
block 与inode 的总量;
未使用与已使用的inode/block 数量;
block 与inode 的大小(block 为1, 2, 4K,inode 为128bytes 或256bytes);
filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁盘(fsck) 的时间等文件系统的相关信息;
一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1 。
一般来说, superblock的大小为1024bytes。相关的superblock信息等一下会以dumpe2fs指令来呼叫出来观察。
此外,每个block group 都可能含有superblock!但是我们也说一个文件系统应该仅有一个superblock 而已,那是怎么回事啊?事实上除了第一个block group 内会含有superblock 之外,后续的block group 不一定含有superblock , 而若含有superblock 则该superblock 主要是做为第一个block group 内superblock 的备份咯,这样可以进行superblock的救援呢!
Filesystem Description (文件系统描述说明)
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间。这部份也能够用dumpe2fs来观察的。
block bitmap (区块对照表)
如果你想要新增文件时总会用到block 吧!那你要使用哪个block 来记录呢?当然是选择『空的block 』来记录新文件的资料啰。那你怎么知道哪个block 是空的?这就得要透过block bitmap 的辅助了。从block bitmap 当中可以知道哪些block 是空的,因此我们的系统就能够很快速的找到可使用的空间来处置文件啰。
同样的,如果你删除某些文件时,那么那些文件原本占用的block 号码就得要释放出来, 此时在block bitmap 当中相对应到该block 号码的标志就得要修改成为『未使用中』啰!这就是bitmap 的功能。
inode bitmap (inode 对照表)
这个其实与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码!
dumpe2fs:查询Ext文件系统的superblock信息的指令
# dumpe2fs [-bh]装置档名
选项与参数:
-b:列出保留为坏轨的部分(一般用不到吧!?)
-h:仅列出superblock 的资料,不会列出其他的区段内容!
范例:鸟哥的一块1GB ext4档案系统内容
# blkid <==这个指令可以叫出目前系统有被格式化的装置
/dev/vda1: LABEL="myboot" UUID="ce4dbf1b-2b3d-4973-8234-73768e8fd659" TYPE="xfs"
/dev/vda2: LABEL="myroot" UUID="21ad8b9a-aaad-443c-b732-4e2522e95e23" TYPE="xfs"
/dev/vda3: UUID="12y99K-bv2A-y7RY-jhEW-rIWf-PcH5-SaiApN" TYPE="LVM2_member"
/dev/vda5: UUID="e20d65d9-20d4-472f-9f91-cdcfb30219d6" TYPE="ext4" <==看到ext4了!
# dumpe2fs /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none> #档案系统的名称(不一定会有)
Last mounted on: <not available> #上一次挂载的目录位置
Filesystem UUID: e20d65d9-20d4-472f-9f91-cdcfb30219d6
Filesystem magic number: 0xEF53 #上方的UUID为Linux对装置的定义码
Filesystem revision #: 1 (dynamic) #下方的features为档案系统的特征资料
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit
flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl #预设在挂载时会主动加上的挂载参数
Filesystem state: clean #这块档案系统的状态为何,clean是没问题
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 65536 # inode的总数
Block count: 262144 # block的总数
Reserved block count: 13107 #保留的block总数
Free blocks: 249189 #还有多少的block可用数量
Free inodes: 65525 #还有多少的inode可用数量
First block: 0
Block size: 4096 #单个block的容量大小
Fragment size: 4096
Group descriptor size: 64
....(中间省略)....
Inode size: 256 # inode的容量大小,已经是256了!
....(中间省略)....
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 3c2568b4-1a7e-44cf-95a2-c8867fb19fbc
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M # Journal日志式资料的可供纪录总容量
Journal length: 8192
Journal sequence: 0x00000001
Journal start: 0
Group 0: (Blocks 0-32767) #第一块block group位置
Checksum 0x13be, unused inodes 8181
Primary superblock at 0, Group descriptors at 1-1 #主要superblock的所在
Reserved GDT blocks at 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode table at 161-672 (+161) # inode table的所在
28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes
Free blocks: 142-144, 153-160, 4258-32767 #底下两行说明剩余的容量有多少
Free inodes: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT] #后续为更多其他的block group
....(底下省略)....
#由于资料量非常的庞大,因此鸟哥将一些信息省略输出了!上表与你的萤幕会有点差异。
# 前半部在秀出supberblock 的内容,包括标头名称(Label)以及inode/block的相关信息
# 后面则是每个block group 的个别信息了,可以看到各区段资料所在的号码
# 也就是说,基本上所有的资料还是与block 的号码有关就是了
至于block group 的内容我们单纯看Group0 信息好了,从上表中可以发现:
Group0 所占用的block 号码由0 到32767 号,superblock 则在第0 号的block 区块内!
文件系统描述说明在第1 号block 中;
block bitmap 与inode bitmap 则在129 及145 的block 号码上。
至于inode table 分布于161-672 的block 号码中!
由于(1)一个inode 占用256 bytes ,(2)总共有672 - 161 + 1(161本身) = 512 个block 花在inode table 上,(3)每个block 的大小为4096 bytes(4K)。由这些数据可以算出inode 的数量共有512 * 4096 / 256 = 8192 个inode 啦!
这个Group0 目前可用的block 有28521 个,可用的inode 有8181 个;
剩余的inode 号码为12 号到8192 号。
与目录树的关系
由前一小节的介绍我们知道在Linux系统下,每个文件(不管是一般文件还是目录文件)都会占用一个inode ,且可依据文件内容的大小来分配多个block给该文件使用。那么目录与文件在文件系统当中是如何记录资料的呢?基本上可以这样说:
目录
当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的档名与该档名占用的inode号码资料。如果想要实际观察root家目录内的文件所占用的inode 号码时,可以使用ls -i 这个选项来处理:
# ls -li
53735697 -rw-------. 1 root root 1816 May 4 17:57 anaconda-ks.cfg
53745858 -rw-r--r--. 1 root root 1864 May 4 18:01 initial-setup-ks .cfg
而由这个目录的block 结果我们现在就能够知道,当你使用'll /'时,出现的目录几乎都是1024 的倍数,为什么呢?因为每个block 的数量都是1K, 2K, 4K。
# ll -d / /boot /usr/sbin /proc /sys
dr-xr-xr-x. 17 root root 4096 May 4 17:56 / <== 1个4K block
dr-xr- xr-x. 4 root root 4096 May 4 17:59 /boot <== 1个4K block
dr-xr-xr-x. 155 root root 0 Jun 15 15:43 /proc <==这两个为记忆体内资料,不占磁盘容量
dr-xr-xr-x. 13 root root 0 Jun 15 23:43 /sys
dr-xr-xr-x. 2 root root 16384 May 4 17:55 /usr/sbin <== 4个4K block
文件:当我们在Linux下的ext2建立一个一般文件时,ext2 会分配一个inode 与相对于该文件大小的block 数量给该文件。例如:假设我的一个block 为4 Kbytes ,而我要建立一个100 KBytes 的文件,那么linux 将分配一个inode 与25 个block 来储存该文件!但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录喔!
目录树读取:
我们提到『新增/删除/更名档名与目录的w权限有关』!那是因为档名是记录在目录的block当中,因此当我们要读取某个文件时,就务必会经过目录的inode与block ,然后才能够找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的资料。
由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode号码,此时就能够得到根目录的inode内容,并依据该inode读取根目录的block 内的档名资料,再一层一层的往下读到正确的档名。举例来说,如果想要读取/etc/passwd 这个文件时,系统是如何读取的呢?
ll -di / /etc /etc/passwd
128 dr-xr-x r-x . 17 root root 4096 May 4 17:56 /
33595521 drwxr-x r-x . 131 root root 8192 Jun 17 00:20 /etc
36628004 -rw-r-- r-- . 1 root root 2092 Jun 17 00:20 /etc/passw
该文件的读取流程为(假设读取者身份为dmtsai 这个一般身份使用者):
/的inode:
透过挂载点的信息找到inode号码为128的根目录inode,且inode的权限属性允许我们可以读取该block的内容(有r与x) ;
/的block:
经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521);
etc/的inode:
读取33595521号inode得知dmtsai具有r与x的权限,因此可以读取etc/的block内容;
etc/的block:
经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码(36628004);
passwd的inode:
读取36628004号inode得知dmtsai具有r的权限,因此可以读取passwd的block内容;
passwd的block:
最后将该block内容的资料读出来。
File System Implementation
1.Levels of A Unix-Like File System
Symbolic Link Files that contain file names
File Names e.g. “a/b”, “foo.c”, “/a///c/d”
File Name Components Names of directory entries e.g. “foo.c”, “usr”
inodes ino_t
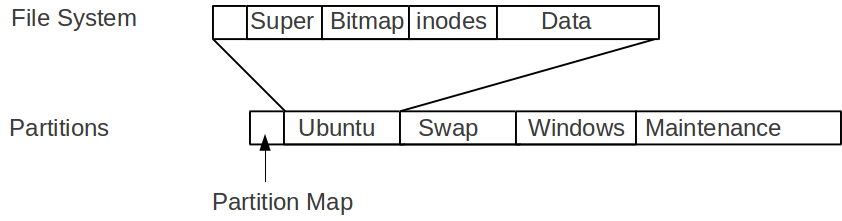
File System (See figure below)
Partitions (See figure below)
Blocks (8192 Bytes) on a disk Linear array (in your head)
Sectors (512 Bytes) on a disk Linear array (in your head)
The following figure illustrates the relationship between file system and partitions.
2.Symlink File Name Length Limit
Questions: Can a symlink has a file name that is a TB long?
Answer: No. There is a limit on the file name length of a symlink.
The following discuss several ways to store a file name in symlink.
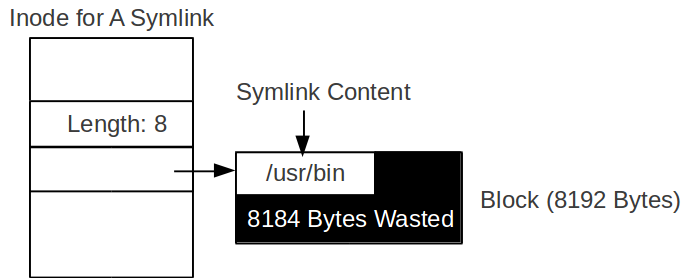
i. Use A Whole Block to Store the File Name
The following figure shows how we use a whole block (8192 Bytes) to store the file name of a symlink.
Inside the inode for a symlink, there is a pointer to a data block in which we store the file name.
Since each block has 8192 bytes, the limit on the file name of the symlink is 8192 bytes long.
So if the symlink content is small, a lot of storage will be wasted.
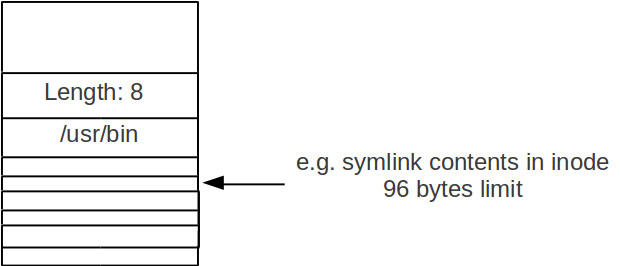
ii. Store the File Name inside the Inode
The following figure shows how we store the content of the symlink inside the inode.
Since the inode size is fixed, the file name of a symlink must be smaller than the size of an inode.
iii. Symlinks Don't Get Inodes; Symlinks Are Merely Directory Entries
Instead of storing the content of a symlink in the inode, we store the content as directory entry as shown in the table below.
Name Inode # Flag
mysl /usr/bin/ls (symlink content) Symlink
abc 27
This implementation makes the contents look up faster as we don't need to find the inode.
The following figure illustrates the Linux – ext3 v2 directory entry that uses idea above.

There are two reasons for using both the 16-bit directory entry length and the 8-bit name length.
The first reason is that by using both of these two fields, we get a better alignment.
The second reason is that keeping two fields makes unlink much faster.
The following figures explains why it's faster.
Before:
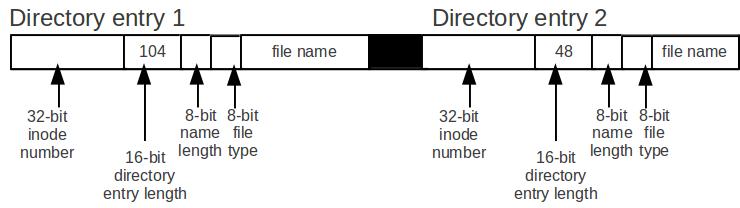
After:
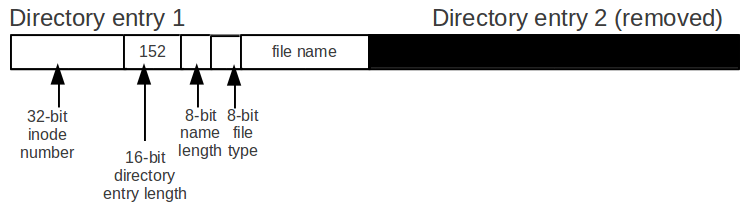
Assume we have two directory entries, directory entry 1 with a entry size of 104 and directory entry 2 with a entry size of 48, and we want to unlink directory entry 2.
The simplest way to unlink directory entry 2 is to increase the directory entry length of directory entry 1 by the directory entry length of directory length 2.
3.Remove Data from the Disk
i. Time Complexity Analysis
Using the implementation discussed above, the time complexity to execute the command rm -rf directory, is O(N^2), where N is the number of entries, because the entries are represented linearly.
To speed up this command, we can use a hash table to store the directory entries' offset in the directory's inode, which will improve the performance to O(N).
ii. Safety Analysis
Question: After we execute the command rm -rf *, are data of files still accessible?
Answer: Yes, the data blocks, inodes, and meta data are still on the disk.
To wipe the meta data out, we can use the command > filename , but the actual data may still be on the disk.
To wipe the actual data out, we first output something random into the file, and then remove that file.
The sequence of commands dd if=/dev/random of=x and rm x will wipe out the actual data on the disk.
(Note: A faster version of this command is to use /dev/urandom, although this is not as randomized as /dev/random, it's enough for wiping out the data from the disk.)
Question: Why prefer writing random data instead of writing zeros?
Answer: There are devices that can read previous traces of data. If we use zero, it's easier read the previous traces of data. But if we use random value, it will be harder.
iii. Shred A File
The program shred is roughly the same as using urandom, but it uses its own random data generator, and it does this three times.
The shred program works on magnetic disks, but doesn't work on solid-state drives (SSD) because of the wear-level algorithm.
The only way to wipe out the data on an SSD is to throw it in the fire.
iv. shred Program Issues
A) Bad blocks
A disk has a bad block table that keeps where the bad blocks get mapped to.
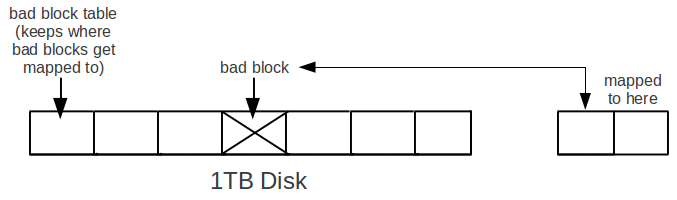
A malicious user can still get the content of the remapped blocks.
B) shred is too slow
Time to shred a 1TB disk takes a long time.
The solution to this problem is to encrypt the disk.
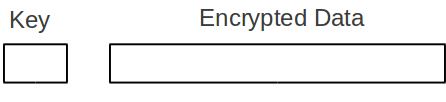
We keep a key that specifies how to decrypt the data on the disk, then to shred the disk is the same as throwing the key away.
4.Symlink vs. Hard Link
i. Overview
Consider the command ln -s d/a e/b, which creates a symbolic link e/b that contains the file name “d/a”.
And consider the command ln d/a e/b, which create a hard link e/b that points to the file d/a.
The following figure illustrates the difference of creating a symbolic link and a hard link.
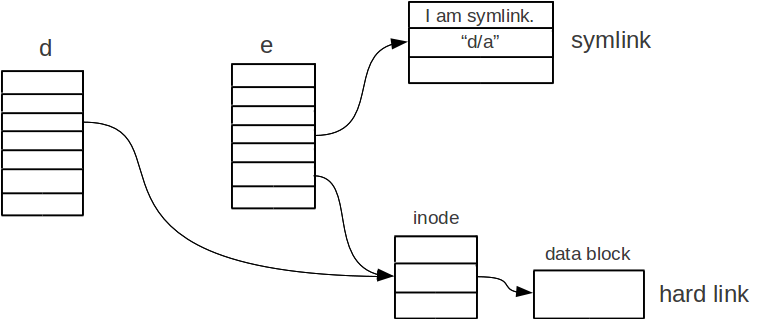
As illustrated, when we create a symbolic link, we create an inode that contains the file name of the file that we want to link to.
When we create a hard link, we set the inode number to be the inode of the file that we want to link to.
This will increase the link count of that file by one.
ii. Difference #1: Symlinks Can Dangle, Hard Links Can't
If we remove the file “d/a” (assume that the link count has dropped to zero), then we arrive at a dangling symlink.
And if we execute the command cat e/b, we will get a e/b not found error.
Hard links can't dangle because before all the hard links are removed, the link count is always greater than 0, and thus the file can not be freed.
iii. Difference #2: Symlink Is Relative to the Containing Directory
The following commands illustrate this point.
ln -s foo d/x
ln d/x e/y
cat d/x
cat e/y
On the first line, we create a symbolic link d/x that links to a file named “foo”.
On the second line, we create a hard link e/y that links to the symbolic link d/x.
On the third line, we try to print out the content of the file the symbolic d/x links to. This is command is equivalent to cat d/foo.
On the fourth line, we try to print out the content that e/y links to, which is the symbolic link d/x.
Since now the containing directory of the file is e, the command cat e/y is equivalent to the command cat e/foo.
iv. Difference #3: Symlinks Can Loop
If we execute the command ln -s / /usr we will create a loop.
The following figure illustrates this loop.
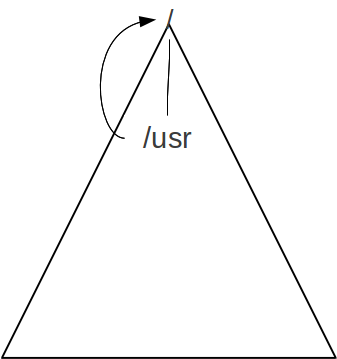
Then the commands ls -l /usr/bin and ls -l /usr/usr/usr/bin etc. will be equivalent.
The following commands also create loops.
ln -s a b; ln -s b a
ln -s x x
When we create the symbolic link, the program cannot detect the loop because it's slow with a time complexity of O(N).
The program can detect a loop when resolving a symbolic link.
If the program follows 16 symbolic links and still cannot resolve the symbolic link, it will give up.
And the function open(“symlink_file”, …...); will fail, and errno will be set to ELOOP.
Question: Why can't hard links loop?
Answer: Since resolving hard links can be slow, we don't allow hard link loops to be created.
5.Name Lookup
For a file “a/b/c”, we map the name components “a”, “b”, and “c” to inodes.
If the file name “a/b/c” is given, the system will assume that the directory a is in the current working directory, which is stored in the process descriptor.
If the file name “/a/b/c” is given, the file name knows that the directory a is in the root directory.
The function chdir(“a/b”); changes the process's working directory to a/b.
The function chroot(“a/b”); changes the process's root directory to a/b, and will result in “chroot jail”.
物联网心球说Linux根文件系统
根文件系统被认为是Linux内核启动后挂载的第一个文件系统,是Linux文件树的根,是所有绝对路径的起点。笔者认为,这种表达并不够精准。接下来从v6.10的内核视角出发了解Linux根文件系统。真实根文件系统启动流程分为三步:首先,挂载rootfs文件系统,创建根目录,解决文件系统从0到1的问题;接着,解析initramfs并将initramfs中的文件保存至rootfs文件系统;最后执行initramfs中的init脚本,init脚本将完成真实根文件系统挂载。
1、根文件系统从何而来?
Linux用户接触到的根文件系统只是挂载在根目录(“/”)下的一个真实的文件系统,习惯把它称为真实根文件系统。内核初始化时,会挂载一个rootfs文件系统(伪文件系统,只存在内存中),rootfs是Linux内核启动后第一个挂载的文件系统,所以它才是Linux的根文件系统。从rootfs到真实根文件系统需要经历三个环节:
挂载rootfs伪文件系统;
解析initramfs至rootfs;
挂载真实根文件系统(如ext4)。
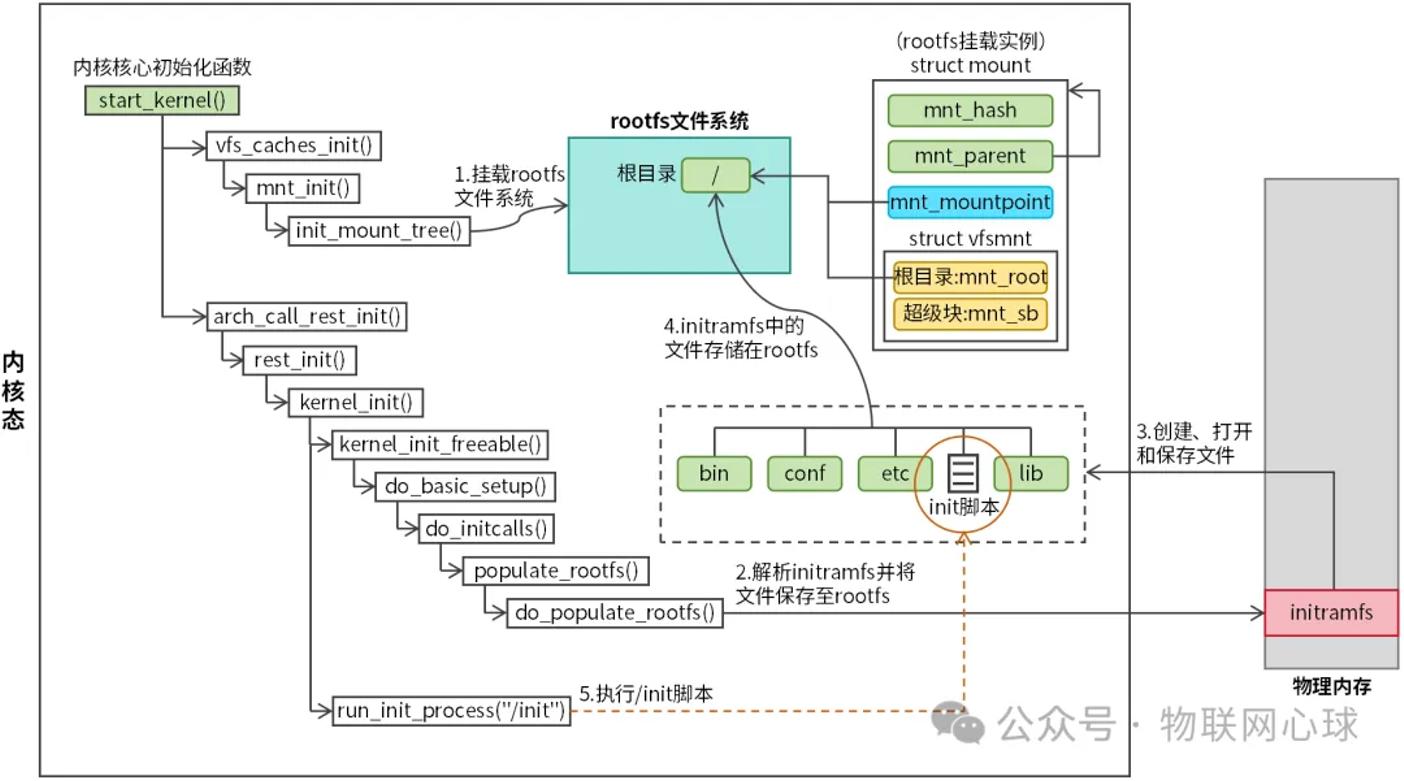
图1 真实根文件系统挂载流程
真实根文件系统挂载流程如图1所示。首先来看rootfs伪文件系统的挂载流程,rootfs文件系统定义如下:
struct file_system_type rootfs_fs_type = {
.name = "rootfs",
.init_fs_context = rootfs_init_fs_context,
.kill_sb = kill_litter_super,
};
展开rootfs_init_fs_context函数:
static int rootfs_init_fs_context(struct fs_context *fc) {
if (IS_ENABLED(CONFIG_TMPFS) && is_tmpfs)
return shmem_init_fs_context(fc);
return ramfs_init_fs_context(fc);
}
发现rootfs实际上是一个tmpfs或ramfs文件系统实例。ramfs和tmpfs都是 Linux系统中基于内存的文件系统。它们将数据直接存储在RAM(物理内存)中,因此读写速度极快,但数据在系统重启后会丢失。
内核启动过程会调用start_kernel函数,该函数会执行一些列初始化工作,rootfs的初始化路径为:start_kernel()->vfs_caches_init()->mnt_init()->init_mount_tree()。init_mount_tree函数将会创建rootfs挂载实例和rootfs根目录,并将这些信息记录在内核。
rootfs解决的是Linux文件树从0到1的问题,rootfs的根目录就是Linux文件树的根,后续的真实根文件系统需要挂载在rootfs的根目录。
有了根文件系统后,接下来,内核会解析initramfs至rootfs。initramfs是Linux启动过程中使用的临时文件系统,在真实根文件系统挂载前提供必要的驱动和工具。initramfs经常被当做Linux文件系统,其实它并不是真正的文件系统,内核中并没有定义该类型的文件系统。initramfs本质是一个cpio归档文件,包含了挂载真实根文件系统需要用到的所有文件。内核会对initramfs进行解析,并将解析出来的文件一个个保存在rootfs文件系统中(注意此处并不是挂载,可以理解为文件拷贝)。initramfs解析对应的初始化路径为:start_kernel()->arch_call_rest_init()->rest_init()->kernel_init()->......->do_populate_rootfs()。
initramfs解析完毕后,rootfs根目录下会有一个init脚本,init脚本将会完成真实文件系统挂载,并将系统运行环境也切换至真实文件系统。对应的初始化路径为:start_kernel()->vfs_caches_init()->rest_init()->kernel_init()->run_init_process("/init")。run_init_process函数将会执行init脚本。
2、initramfs详解
initramfs并不是真正的文件系统,它是压缩(如lz4、gzip、zstd等压缩格式)了的cpio归档文件,cpio(Copy In and Out)是一种在Unix和Linux系统中广泛使用的归档工具,用于将多个文件和目录打包成一个单独的归档文件,同时保留文件的元数据(如权限、所有者、时间戳等)。
cpio支持多种归档格式:bin、odc、newc、crc、tar等。initramfs采用的是newc格式,如图2所示。
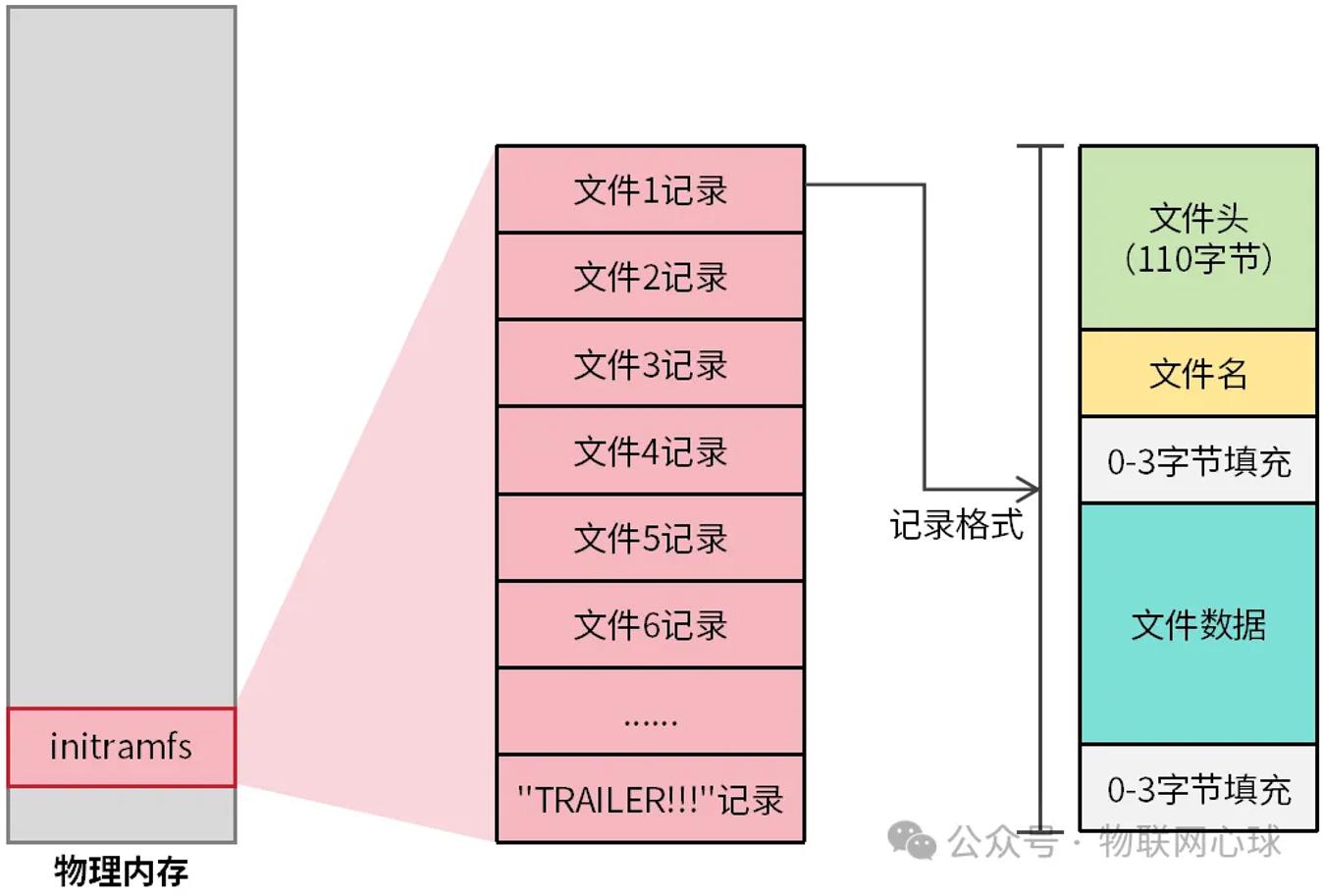
图2 initramfs格式
initramfs由一条条文件记录构成,每条文件记录格式为:
文件头(110字节)
文件名
0-3字节填充
文件数据
0-3字节填充
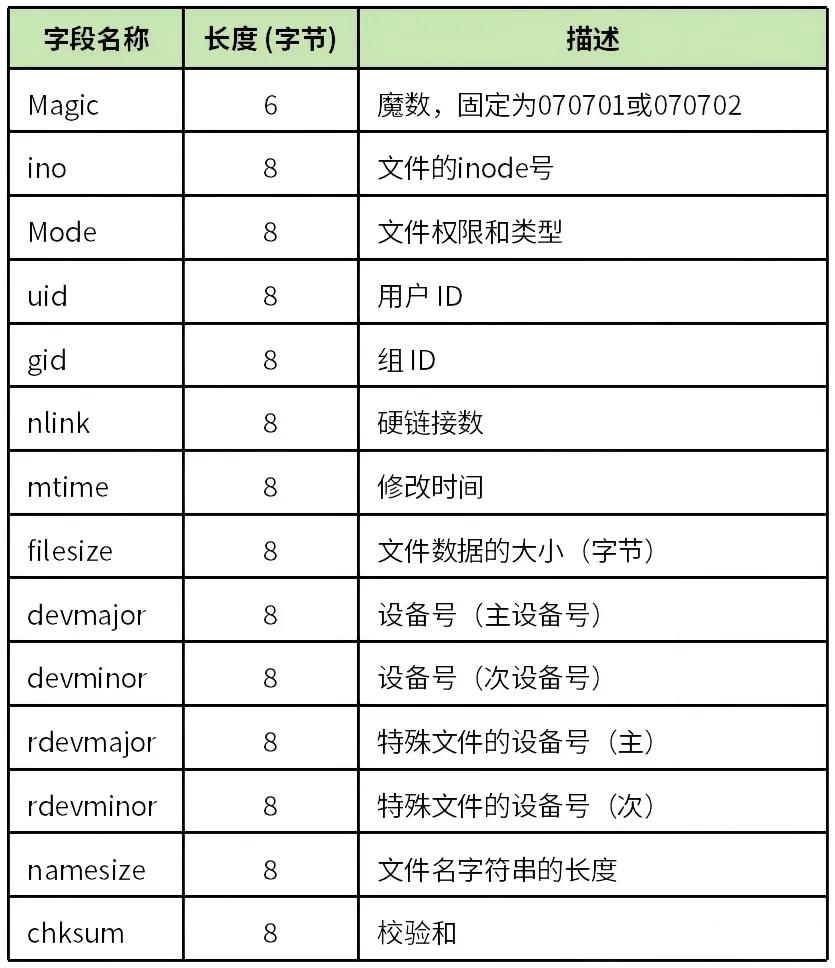
文件头包含文件的元数据,固定大小为110字节,其格式见表1。
表1 newc文件头
为了加深大家对newc格式的理解,这里创建一个最小initramfs并打包成newc格式,测试脚本如下:
#!/bin/bash
#创建文件树
mkdir bin conf etc lib
touch etc/test.txt
#创建init脚本
echo "#!/bin/sh" > init
#打包为newc格式
find bin conf etc lib init -depth | cpio -o -H newc > initramfs.cpio
执行测试脚本后将生成一个initramfs.cpio归档文件,执行以下命令验证文件清单:
cpio -t < demo.cpio
文件清单如下:
# cpio -t < initramfs.cpio
bin
conf
etc/test.txt
etc
lib
init
执行hexdump -C initramfs.cpio查看归档文件记录,输出结果如下:
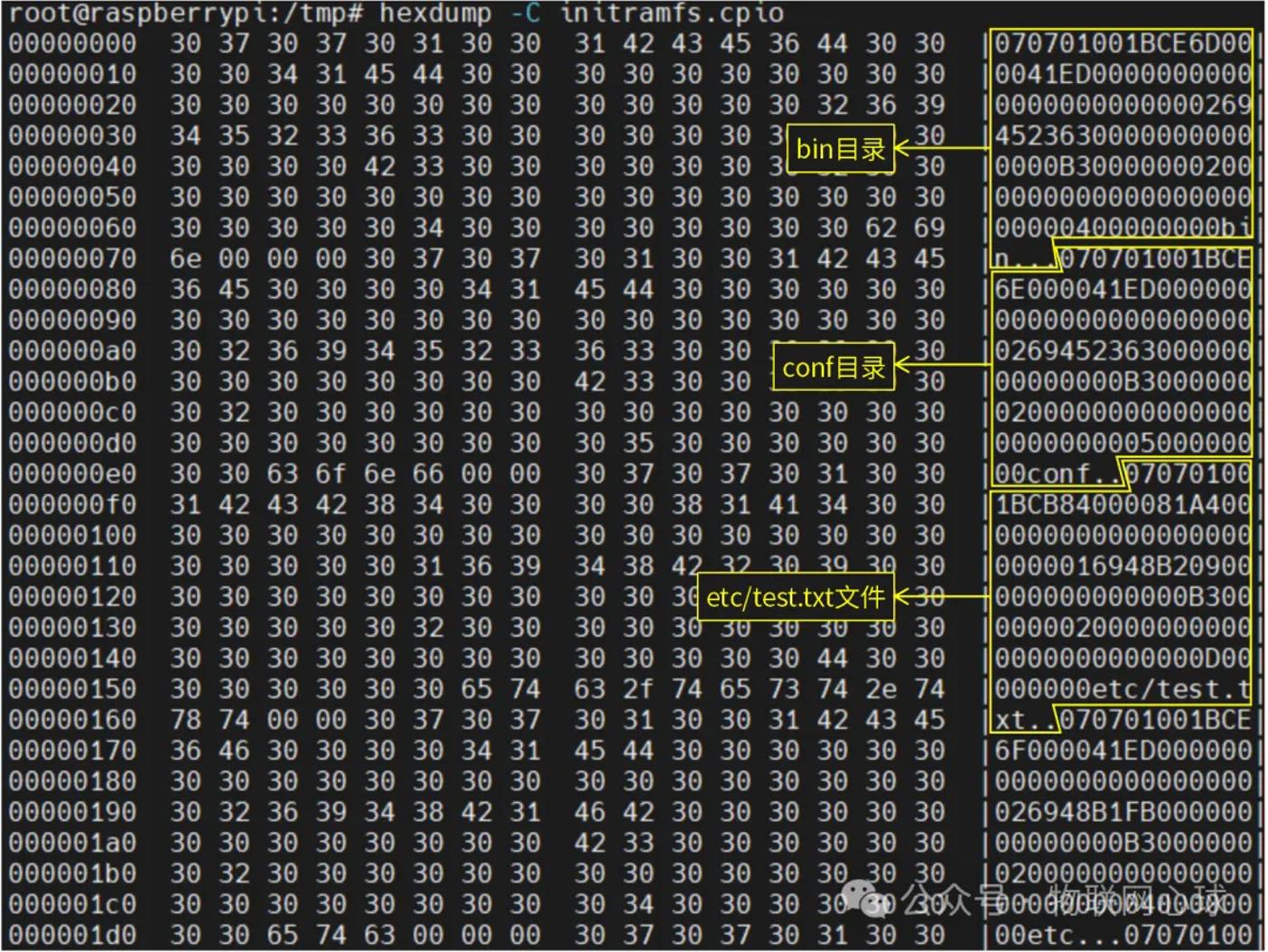
最终cpio中的文件记录将一条条被解析,并存储在rootfs文件系统中。
3、/init脚本
/init脚本是initramfs的核心,它将完成以下关键任务:
挂载/proc, /sys, /dev等虚拟文件系统,并创建必要的设备节点。
加载访问存储设备和文件系统所需的内核模块,并挂载真实根文件系统。
将系统根目录切换到真实根文件系统,并启动/sbin/init进程(1号进程)。
实际的/init脚本一般都比较复杂,为了便于讲解,我们只关注根文件系统挂载相关的内容,如图3所示。
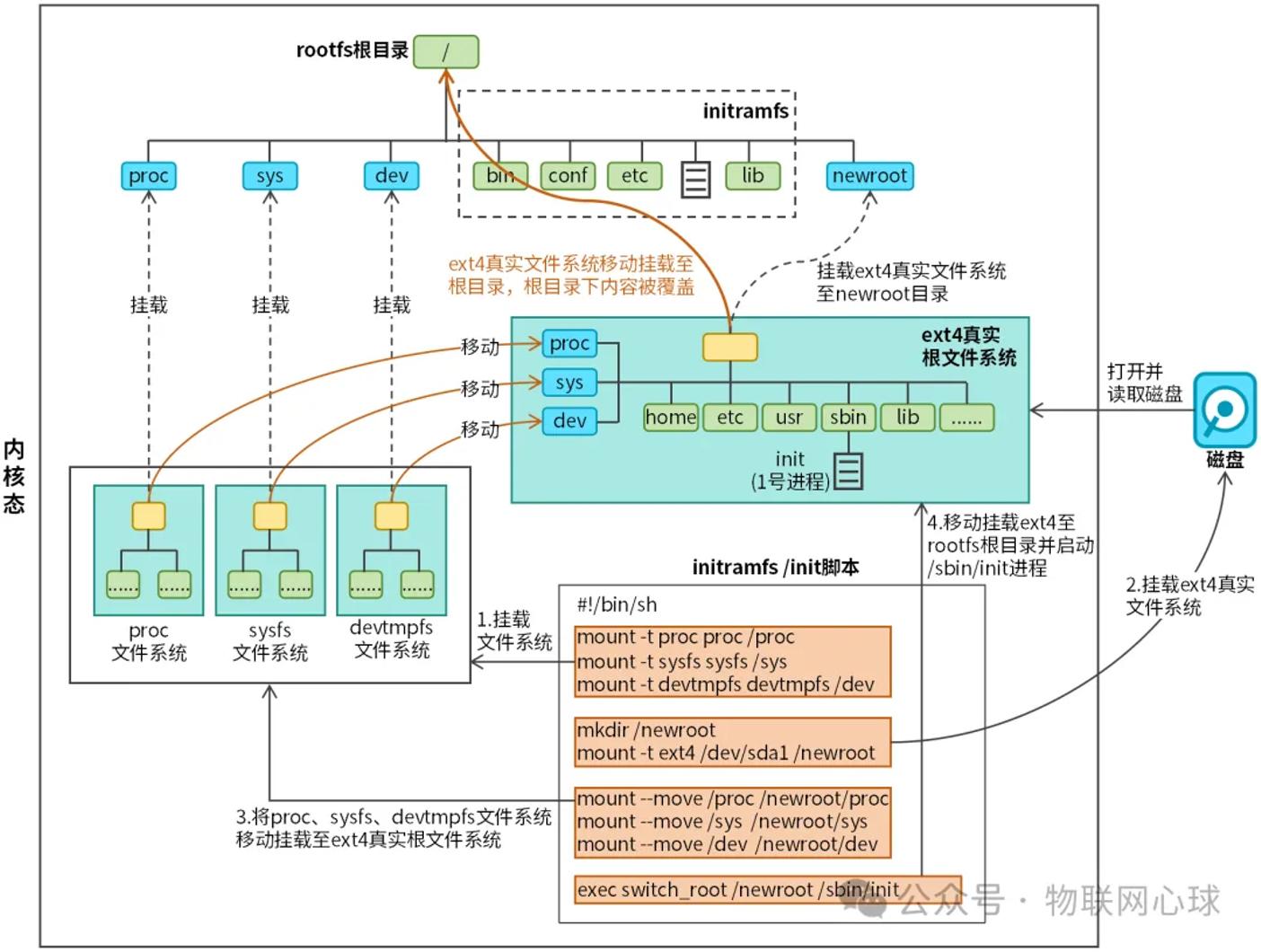
图3 /init脚本工作原理
内核调用run_init_process("/init")函数将会执行init脚本,run_init_process函数主要任务是执行用户空间的第一个进程,从而完成从内核态到用户态的切换。
真实根文件系统(如ext4)未挂载之前,系统执行文件相关的操作都是在rootfs文件系统中进行。/init脚本首先会挂载伪文件系统(proc、sysfs、devtmpfs等)至rootfs。接着内核会读取块设备,并挂载块设备中的真实根文件系统挂载至rootfs(挂载点由用户自行定义)。最后将已挂载的伪文件系统移动至真实根文件系统,以及执行initramfs中的switch_root命令将运行环境切换至真实根文件系统。
switch_root 命令的核心功能包括:
将新根目录设置为系统的根文件系统。
执行新根文件系统中的init程序(通常是 /sbin/init)。
清理并释放initramfs占用的内存空间。
switch_root语法格式如下:
switch_root [-c /dev/console] NEW_ROOT NEW_INIT [ARGUMENTS_TO_INIT]
NEW_ROOT:已经挂载好的真正根文件系统挂载点,例如 /newroot。
NEW_INIT:真正根文件系统中的init程序路径,通常是/sbin/init(软链接,指向init或systemd)。
-c:可选,重定向新系统的控制台设备。
磁盘操作工具之partx,lsblk,blkid,partprobe
partx
在使用fdisk命令创建分区后,可以使用partx和partprobe使系统内核加载分区信息,然后使用lsblk或'partx -s 设备名'来查看修改后的设备分区信息,给分区做上文件系统后,可以使用blkid命令查看设备信息,以及其文件系统等信息。
使用partx -s 或 partx -l 查看分区信息如果出错,可能是信息未被登记,可使用'partx -a 设备名'来添加,再进行查看。patrx修改磁盘分区表后,无需重启,用partx命令告诉内核,分区已改动,内核可以读入新的分区表信息。
/proc/partitions 记录了系统中所有硬盘及其上面的分区,包括已挂载和未挂载的。有些硬盘没有记录分区信息,可能是没有分区,也可能是未记录。对于分区完成,但是尚未挂载的硬盘分区,partx告诉内核去做登记,已备挂载。partx告诉内核去识别,登记某个硬盘上的分区信息。并不是加载,只是识别并记录而已,或者删除某个分区的信息。
# partx --help
Usage: partx [-a|-d|-s|-u] [--nr <n:m> | <partition>] <disk>
Options:
-a, --add add specified partitions or all of them
-d, --delete delete specified partitions or all of them
-s, --show list partitions
-u, --update update specified partitions or all of them
-b, --bytes print SIZE in bytes rather than in human readable format
-g, --noheadings don't print headings for --show
-n, --nr <n:m> specify the range of partitions (e.g. --nr 2:4)
-o, --output <type> define which output columns to use
-P, --pairs use key="value" output format
-r, --raw use raw output format
-t, --type <type> specify the partition type (dos, bsd, solaris, etc.)
-v, --verbose verbose mode
-h, --help display this help and exit
-V, --version output version information and exit
Available columns (for --show, --raw or --pairs):
NR partition number
START start of the partition in sectors
END end of the partition in sectors
SECTORS number of sectors
SIZE human readable size
NAME partition name
UUID partition UUID
TYPE partition type hex or uuid
FLAGS partition flags
SCHEME partition table type (dos, gpt, ...)
For more details see partx(8).
partx常用命令:
-a 设备:登记某块盘上的所有分区信息。如果分区信息有记录,则报错。
-d 设备:删除内核中关于某磁盘的所有分区的记录。(不是卸载)
-s 设备:显示磁盘的分区信息
通过partx工具让内核重读磁盘分区表信息:
partx -d /dev/sdb #因为内核中存在部分未调整磁盘的信息,故先将所有信息清零
partx -a /dev/sdb #添加调整后的磁盘分区信息
partx -s /dev/sdb #显示磁盘分区信息
NR START END SECTORS SIZE NAME UUID
1 2048 2099199 2097152 1G
2 2099200 419430399 417331200 199G
lsblk
列出所有可用块设备的信息,而且还能显示他们之间的依赖关系,但是它不会列出RAM盘的信息。块设备有硬盘,闪存盘,CD-ROM等等。
lsblk -f 也可以查看 UUID
lsblk和df的区别:lsblk 查看的是block device,也就是逻辑磁盘的大小
df 查看的是file system,也就是文件系统层的磁盘大小,并且已挂载
# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 ext2 bb39ae66-c08a-43d0-a8e9-86bde4b213f7 /boot
└─sda2 LVM2_member kFrsl9-idEz-KH5j-PY0Z-Ft7l-eeMP-IhcKuf
├─freeoa-root xfs freeoa-root 61c11857-63cc-4916-b515-4d9d879f97b2 /
└─freeoa-swap swap freeoa-swap 02053708-79b1-401c-a7a5-e75406ec0096 [SWAP]
sr0 iso9660 VBox_GAs_6.1.16 2020-10-15-14-48
NAME :这是块设备名。
MAJ:MIN :本栏显示主要和次要设备号。
RM :本栏显示设备是否可移动设备。注意,在本例中设备sdb和sr0的RM值等于1,这说明他们是可移动设备。
SIZE :本栏列出设备的容量大小信息。例如298.1G表明该设备大小为298.1GB,而1K表明该设备大小为1KB。
RO :该项表明设备是否为只读。在本案例中,所有设备的RO值为0,表明他们不是只读的。
TYPE :本栏显示块设备是否是磁盘或磁盘上的一个分区。在本例中,sda和sdb是磁盘,而sr0是只读存储(rom)。
MOUNTPOINT :本栏指出设备挂载的挂载点。
blkid
显示关于可用块设备的信息,他可以识别一个块设备内容的类别(如文件系统,交换区)以及从内容的元数据(如卷标或UUID字段)中获取属性(如tokens和键值对)。它主要有两类作用:用指定的键值对搜索一个设备,或是显示一个或多个设备的键值对。
不添加任何参数直接运行blkid将会输出所有可用的设备,他们的通用唯一识别码(UUID),文件系统类型以及卷标(如果有设置过)
# blkid
/dev/sr0: UUID="2020-10-15-14-48" LABEL="VBox_GAs_6.1.16" TYPE="iso9660"
/dev/sda1: UUID="bb39ae66-c08a-43d0-a8e9-86bde4b213f7" TYPE="ext2"
/dev/sda2: UUID="kFrsl9-idEz-KH5j-PY0Z-Ft7l-eeMP-IhcKuf" TYPE="LVM2_member"
/dev/mapper/freeoa-root: LABEL="freeoa-root" UUID="61c11857-63cc-4916-b515-4d9d879f97b2" TYPE="xfs"
/dev/mapper/freeoa-swap: LABEL="freeoa-swap" UUID="02053708-79b1-401c-a7a5-e75406ec0096" TYPE="swap"
partprobe
通知系统分区表的变化
使用fdisk或其他命令创建一个新的分区,然后使用partprobe命令重新读取分区表。这个命令执行完毕后不会输出任何返回信息。