NUMA for Linux
 现代计算机体系结构被称为Non-Uniform Memory Access(NUMA),NUMA下物理内存是分布式的,由多个计算节点组成,每个CPU核都会有自己的本地内存。CPU在访问它的本地内存的时候就比较快,访问其他CPU核内存的时候就会比较慢。其逻辑视图大致如下:
现代计算机体系结构被称为Non-Uniform Memory Access(NUMA),NUMA下物理内存是分布式的,由多个计算节点组成,每个CPU核都会有自己的本地内存。CPU在访问它的本地内存的时候就比较快,访问其他CPU核内存的时候就会比较慢。其逻辑视图大致如下: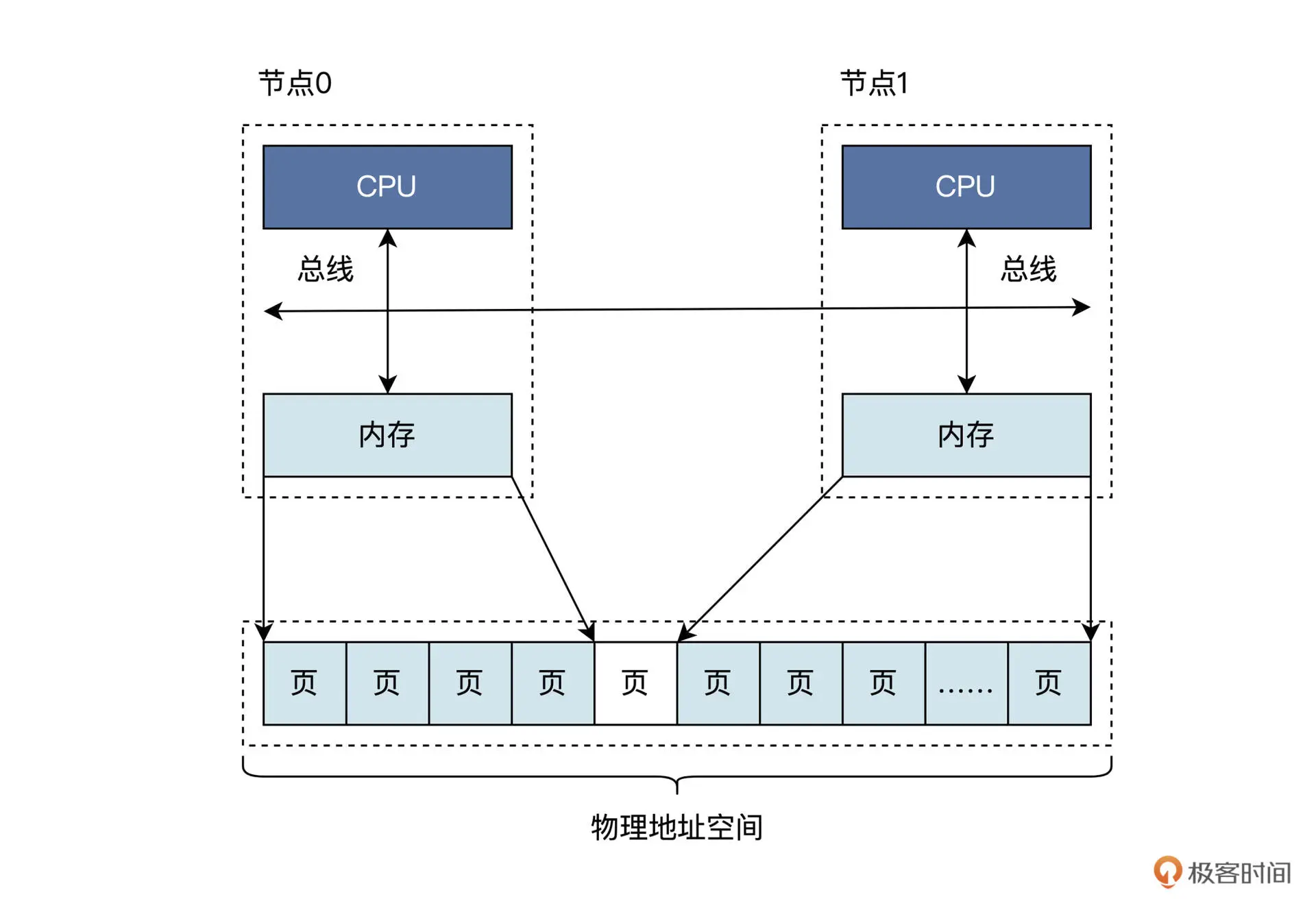
可看到每个节点都是由CPU、总线、内存组成。节点之间的内存大小可能不同,但这些地址会统一编址到同一个物理地址空间的,即无论是节点0的内存还是节点1的内存都有唯一的物理地址,在一个节点内部的物理内存之间可能会存在空洞,节点与节点之间的物理内存页也可能有空洞。空洞就是一段地址是不对应到内存单元的。
Linux物理内存管理
NUMA体系结构上,节点内部的内存和节点之间的内存,访问速度是不一样的,这就提升了Linux的内存管理的复杂度,因此Linux用了大量的数据结构来表示计算节点、内存、内存页面,以及它们之间的关系
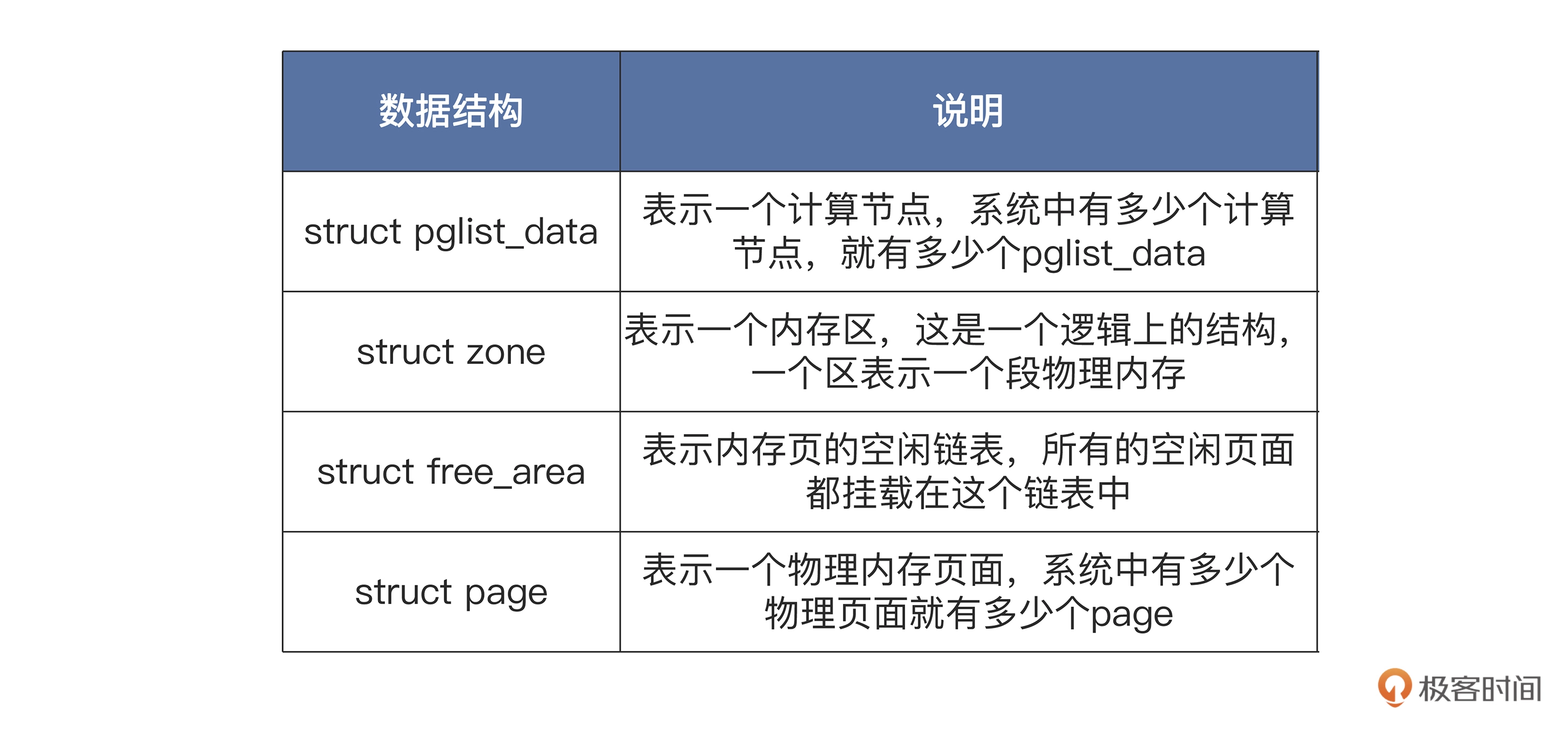
在计算机系统中,至少会有一个默认的pglist_data结构,如果计算节点增加,pglist_data结构也会随之增加。
pglist_data结构中包含自身节点CPU的id,有指向本节点和其他节点的内存区zone结构的指针。而在zone结构中包含一个free_area结构的数组,用于挂载本内存区中的所有物理内存页,也就是page结构。
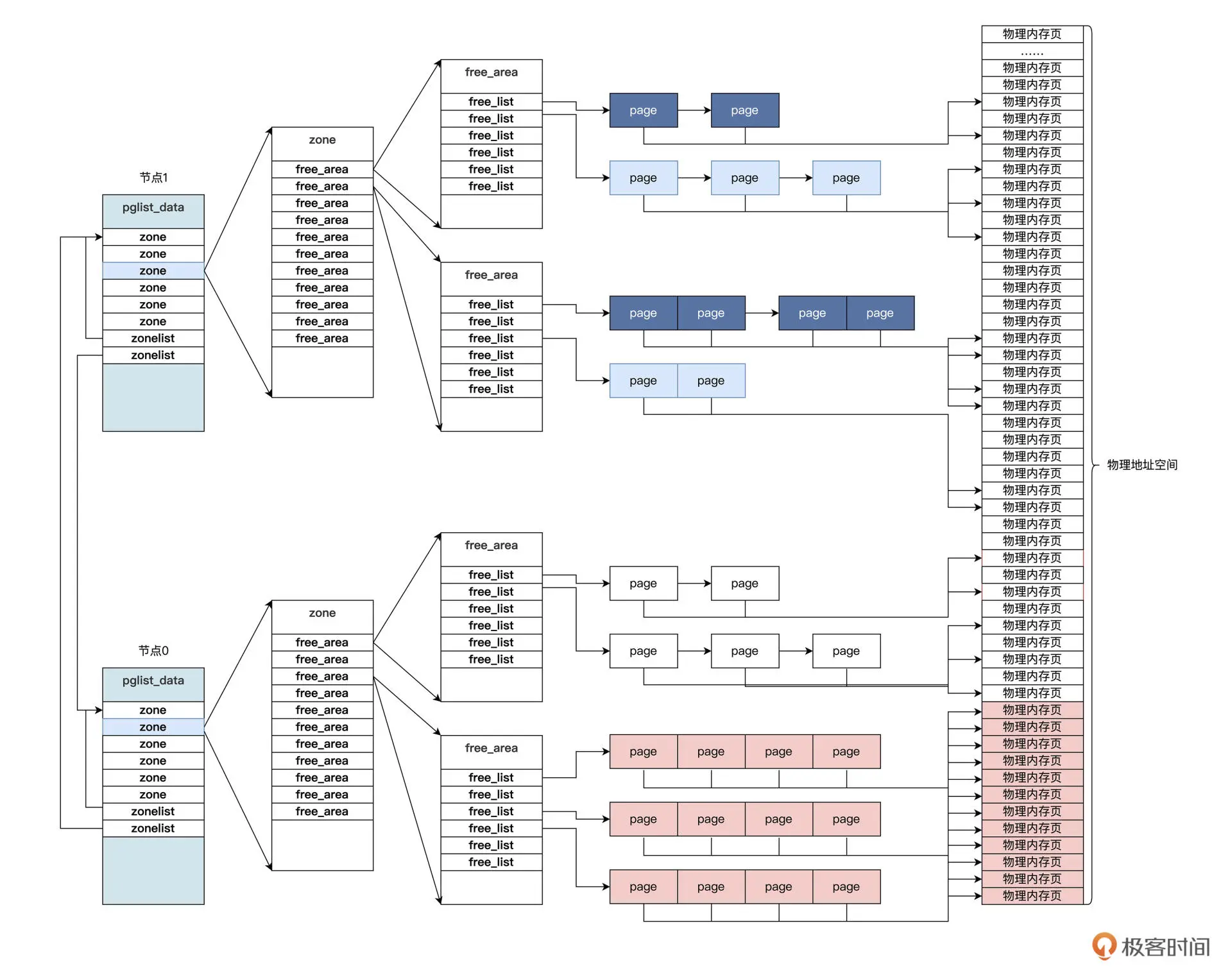
Linux的物理内存分配过程如下:通过pglist_data结构,先找到自己节点的zone结构的指针,如果不能满足要求,则查找其他节点的zone结构;然后找到zone结构中的free_area结构数组;最后也要找到其中的page结构并返回。释放过程则是分配过程的反过程。
It consists of a numactl program to run other programs with a specific NUMA policy and a libnuma shared library ("NUMA API") to set NUMA policy in applications.
The libnuma binary interface is supposed to stay binary compatible. Incompatible changes will use new symbol version numbers.In addition there are various test and utility programs, like numastat to display NUMA allocation statistics and memhog.
numactl and the demo programs are under the GNU General Public License, v2,libnuma is under the GNU Lesser General Public License, v2.1.
NUMA(Non-Uniform Memory Access)字面直译为“非一致性内存访问”,对于Linux内核来说最早出现在2.6.7版本上。这种特性对于当下大内存+多CPU为潮流的X86平台来说确实会有不少的性能提升,但相反的,如果配置不当的话,也是一个很大的坑。本文就从头开始说说Linux下关于CPU NUMA特性的配置和调优。
最早Intel在Nehalem架构上实现了NUMA,取代了在此之前一直使用的FSB前端总线的架构,用以对抗AMD的HyperTransport技术。一方面这个架构的特点是内存控制器从传统的北桥中移到了CPU中,排除了商业战略方向的考虑之外,这样做的方法同样是为了实现NUMA。
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了!
在SMP多CPU架构中,传统上多CPU对于内存的访问是总线方式。是总线就会存在资源争用和一致性问题,而且如果不断的增加CPU数量,总线的争用会愈演愈烈,这就体现在4核CPU的跑分性能达不到2核CPU的2倍,甚至1.5倍!理论上来说这种方式实现12core以上的CPU已经没有太大的意义。
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
Intel的NUMA解决方案,Litrin始终认为它来自本家的安藤。他的模型有点类似于MapReduce。放弃总线的访问方式,将CPU划分到多个Node中,每个node有自己独立的内存空间。各个node之间通过高速互联通讯,通讯通道被成为QuickPath Interconnect即QPI。
这个架构带来的问题也很明显,如果一个进程所需的内存超过了node的边界,那就意味着需要通过QPI获取另一node中的资源,尽管QPI的理论带宽远高于传统的FSB,比如当下流行的内存数据库,在这种情况下就很被动了。
现在的机器上都是有多个CPU和多个内存块的。以前我们都是将内存块看成是一大块内存,所有CPU到这个共享内存的访问消息是一样的,这就是之前普遍使用的SMP模型。但是随着处理器的增加,共享内存可能会导致内存访问冲突越来越厉害,且如果内存访问达到瓶颈的时候,性能就不能随之增加。NUMA(Non-Uniform Memory Access)就是这样的环境下引入的一个模型。比如一台机器是有2个处理器,有4个内存块,我们将1个处理器和两个内存块合起来,称为一个NUMA node,这样这个机器就会有两个NUMA node。在物理分布上,NUMA node的处理器和内存块的物理距离更小,因此访问也更快。比如这台机器会分左右两个处理器(cpu1, cpu2),在每个处理器两边放两个内存块(memory1.1, memory1.2, memory2.1,memory2.2),这样NUMA node1的cpu1访问memory1.1和memory1.2就比访问memory2.1和memory2.2更快。所以使用NUMA的模式如果能尽量保证本node内的CPU只访问本node内的内存块,那这样的效率就是最高的。
事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。
在运行程序的时候使用numactl -m和-physcpubind就能制定将这个程序运行在哪个cpu和哪个memory中,当程序只使用一个node资源和使用多个node资源的比较表(差不多是38s与28s的差距)。所以限定程序在numa node中运行是有实际意义的。
但是呢,话又说回来了,制定numa就一定好吗?--numa的陷阱。现象是当你的服务器还有内存的时候,发现它已经在开始使用swap了,甚至已经导致机器出现停滞的现象。这个就有可能是由于numa的限制,如果一个进程限制它只能使用自己的numa节点的内存,那么当自身numa node内存使用光之后,就不会去使用其他numa node的内存了,会开始使用swap,甚至更糟的情况,机器没有设置swap的时候,可能会直接死机!所以你可以使用numactl --interleave=all来取消numa node的限制。
综上所述得出的结论就是,根据具体业务决定NUMA的使用。
如果你的程序是会占用大规模内存的,你大多应该选择关闭numa node的限制。因为这个时候你的程序很有几率会碰到numa陷阱。另外,如果你的程序并不占用大内存,而是要求更快的程序运行时间,你大多应该选择限制只访问本numa node的方法来进行处理。
Linux提供了一个一个手工调优的命令numactl(默认不安装),首先你可以通过它查看系统的numa状态
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 131037 MB
node 0 free: 3019 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 131071 MB
node 1 free: 9799 MB
node distances:
node 0 1
0: 10 20
1: 20 10
此系统共有2个node,各领取16个CPU和128G内存。
这里假设我要执行一个java param命令,此命令需要120G内存,一个python param命令,需要16G内存。最好的优化方案时python在node0中执行,而java在node1中执行,那命令是:
#numactl --cpubind=0 --membind=0 python param
#numactl --cpubind=1 --membind=1 java param
当然,也可以自找没趣:
#numactl --cpubind=0 --membind=0,1 java param
对于一口气吃掉内存大半的MongoDB,我的配置是:
numactl --interleave=all mongod -f /etc/mongod.conf
即分配所有的node供其使用,这也是官方推荐的用法。通过numastat命令可以查看numa状态:
# numastat
node0 node1
numa_hit 1775216830 6808979012
numa_miss 4091495 494235148
numa_foreign 494235148 4091495
interleave_hit 52909 53004
local_node 1775205816 6808927908
other_node 4102509 494286252
other_node过高意味着需要重新规划numa。
NUMA架构的优缺点
numa把一台计算机分成多个节点(node),每个节点内部拥有多个CPU,节点内部使用共有的内存控制器,节点之间是通过互联模块进行连接和信息交互。因此节点的所有内存对于本节点所有的CPU都是等同的,对于其他节点中的所有CPU都不同。因此每个CPU可以访问整个系统内存,但是访问本地节点的内存速度最快(不经过互联模块),访问非本地节点的内存速度较慢(需要经过互联模块),即CPU访问内存的速度与节点的距离有关,该距离成为Node Distance。
查看当前numa的节点情况:
numactl --hardware
节点之间的距离(Node Distance)指从节点1上访问节点0上的内存需要付出的代价的一种表现形式,Numa内存分配策略有一下四种:
缺省default:总是在本地节点分配(当前进程运行的节点上)。
绑定bind:强制分配到指定节点上。
交叉interleavel:在所有节点或者指定节点上交叉分配内存。
优先preferred:在指定节点上分配,失败则在其他节点上分配。
查看当前系统numa策略:
numactl --show
因为numa默认的内存分配策略是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点内存不足时,会导致swap产生,而不是从远程节点分配内存,这就是swap insanity现象。
MySQL服务器为什么需要关闭numa
MySQL是单进程多线程架构数据库,当numa采用默认内存分配策略时,MySQL进程会被并且仅仅会被分配到numa的一个节点上去。假设这个节点的本地内存为10GB,而MySQL配置20GB内存,超出节点本地内存部分(20GB-10GB)Linux会使用swap而不是使用其他节点的物理内存。在这种情况下,能观察到虽然系统总的可用内存还未用完,但是MySQL进程已经开始在使用swap了。如果单机只运行一个MySQL实例,可以选择关闭numa,关闭nuam有两种方法:
1.硬件层,在BIOS中设置关闭;
2.OS内核,启动时设置numa=off。
修改/etc/grub.conf文件,在kernel那行追加numa=off:
kernel /vmlinuz-2.6.32.el6.x86_64 ro root=LABEL=/ rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rhgb quiet numa=off
保存后重启服务器,再次检查numa只剩下一个节点就成功了:
# numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0
node 0 size: 2047 MB
node 0 free: 1514 MB
node distances:
node 0
0: 10
IO调度
在不同场景下选择不同的IO调度器:在完全随机访问环境下,由于CFQ可能会造成小IO的相应延时增加,所以应设置为deadline,这样更稳定。对于SSD设备,采用NOOP或者deadline也可以获取比默认调度器更好的性能。
永久修改IO调度算法,可以通过修改内核引导参数,增加elevator=调度算法:
root=LABEL=/ elevator=deadline
/etc/grub.conf
kernel /vmlinuz-2.6.32-358.el6.x86_64 ro root=LABEL=/ rhgb quiet numa=off elevator=deadline
交换分区
swappiness是Linux的一个内核参数,用户控制Linux物理内存进行swap页交换的相对权重,尽量减少系统的页缓存被从内存中清除的情况。取值范围是0~100,vm.swappiness的值越低,Linux内核会尽量不进行swap交换页的操作,vm.swappiness的值越高,Linux会越多的使用swap空间。Linux系统默认值是60,当系统需要内存时,有60%的概率使用swap。对于大多数桌面系统,设置为100可以提高系统的整体性能;对于数据库应用服务器,设置为0,可以提高物理内存的使用率,进而提高数据库服务的响应性能。
vim /etc/sysctl.conf
vm.swappiness=0
sysctl -p 生效
# sysctl -a|grep swap
vm.swappiness = 0
MySQL在NUMA架构上会出现的问题
Jeremy Cole大神推荐的三个方案如下,如果想详细了解可以阅读原文:
numactl --interleave=all
在MySQL进程启动前,使用sysctl -q -w vm.drop_caches=3清空文件缓存所占用的空间
Innodb在启动时,就完成整个Innodb_buffer_pool_size的内存分配
这三个方案也被业界普遍认可可行,同时在 Twitter 的5.5patch 和 Percona 5.5 Improved NUMA Support 中作为功能被支持。
不过这种三合一的解决方案只是减少了NUMA内存分配不均,导致的MySQL SWAP问题出现的可能性。如果当系统上其他进程,或者MySQL本身需要大量内存时,Innodb Buffer Pool的那些Page同样还是会被Swap到存储上。于是又在这基础上出现了另外几个进阶方案:
配置vm.zone_reclaim_mode = 0 使得内存不足时去remote memory分配优先于swap out local page
echo -15 > /proc/<pid_of_mysqld>/oom_adj 调低MySQL进程被OOM_killer强制Kill的可能
memlock
对MySQL使用Huge Page(黑魔法,巧用了Huge Page不会被swap的特性)
NUMA本身没有错,是CPU发展的一种必然趋势。但是NUMA的出现使得操作系统不得不关注内存访问速度不平均的问题。分配策略的初衷是好的,为了内存更接近需要他的线程,但是没有考虑到数据库这种大规模内存使用的应用场景。同时缺乏动态调整的功能,使得这种悲剧在内存分配的那一刻就被买下了伏笔。
数据库设计者不懂NUMA?
数据库设计者也许从一开始就不会意识到NUMA的流行,或者甚至说提供一个透明稳定的内存访问是操作系统最基本的职责。那么在现状改变非常困难的情况下(下文会提到为什么困难)是不是作为内存使用者有义务更好的去理解使用NUMA?其实无论是NUMA还是Linux Kernel,亦或是程序开发他们都没有错,只是还做得不够极致。如果NUMA在硬件级别可以提供更多低成本的profile接口;如果Linux Kernel可以使用更科学的动态调整策略;如果程序开发人员更懂NUMA,那么我们完全可以更好的发挥NUMA的性能,使得无限横向扩展CPU核数不再是一个梦想。
参考来源:
深挖NUMA
Numa for linux 项目主页
NUMA架构的CPU -- 你真的用好了么