Linux系统进程含义知多少
 理想情况下,应该明白在系统中运行的每一个进程,要获得所有进程的列表,可以执行命令 ps -ef(POSIX 风格)或 ps ax(BSD 风格)。进程名有方括号的是内核级的进程,执行辅助功能(比如将缓存写入到磁盘);所有其他进程都是使用者进程。可能会注意到,就算是在新安装的(最小化的)系统中,也会有很多进程在运行。有必要熟悉它们,并把它们记录到文档中。这些进程有:
理想情况下,应该明白在系统中运行的每一个进程,要获得所有进程的列表,可以执行命令 ps -ef(POSIX 风格)或 ps ax(BSD 风格)。进程名有方括号的是内核级的进程,执行辅助功能(比如将缓存写入到磁盘);所有其他进程都是使用者进程。可能会注意到,就算是在新安装的(最小化的)系统中,也会有很多进程在运行。有必要熟悉它们,并把它们记录到文档中。这些进程有:kswapd0,kjournald,pdflush,kthreadd,migration,watchdog,events,kblockd,aio,rpciod
先介绍5个核心级的系统进程,接着再此基础上介绍10个系统级进程。
1.kswapd0
Linux uses kswapd for virtual memory management such that pages that have been recently accessed are kept in memory and less active pages are paged out to disk.
(what is a page?)…Linux uses manages memory in units called pages.
So,the kswapd process regularly decreases the ages of unreferenced pages…and at the end they are paged out(moved out) to disk
系统每过一定时间就会唤醒kswapd,看看内存是否紧张,如果不紧张,则睡眠,在kswapd中,有2个阀值,pages_hige和pages_low,当空闲内存页的数量低于pages_low的时候,kswapd进程就会扫描内存并且每次释放出32个free pages,直到free page的数量到达pages_high.
2.kjournald
EXT3文件系统的日志进程,具有3种模式:
journal – logs all filesystem data and metadata changes. The slowest of the three ext3 journaling modes, this journaling mode minimizes the chance of losing the changes you have made to any file in an ext3 filesystem.(记录所有文件系统上的元数据改变,最慢的一种模式,)
ordered – only logs changes to filesystem metadata, but flushes file data updates to disk before making changes to associated filesystem metadata. This is the default ext3 journaling mode.(默认使用的模式,只记录文件系统改变的元数据,并在改变之前记录日志)
writeback – only logs changes to filesystem metadata but relies on the standard filesystem write process to write file data changes to disk. This is the fastest ext3 journaling mode.(最快的一种模式,同样只记录修改过的元数据,依赖标准文件系统写进程将数据写到硬盘)
修改模式EXT3的工作模式;
vim /etc/fstab
/dev/sda5 /opt ext3 data=writeback 1 0
详细介绍:http://www.linuxplanet.com/linuxplanet/reports/4136/5/
3.pdflush
pdflush用于将内存中的内容和文件系统进行同步,比如说,当一个文件在内存中进行修改,pdflush负责将它写回硬盘.每当内存中的垃圾页(dirty page)超过10%的时候,pdflush就会将这些页面备份回硬盘.这个比率是可调节的,通过/etc/sysctl.conf中的 vm.dirty_background_ratio项 默认值为10 也可以执行:cat /proc/sys/vm/dirty_background_ratio 查看当前的值
4.kblockd 块读写子系统
5.Migration 进程迁移
什么是进程迁移:进程迁移就是将一个进程从当前位置移动到指定的处理器上。它的基本思想是在进程执行过程中移动它,使得它在另一个计算机上继续存取它的所有资源并继续运行,而且不必知道运行进程或任何与其它相互作用的进程的知识就可以启动进程迁移操作,这意味着迁移是透明的。
进程迁移的好处
进程迁移是支持负载平衡和高容错性的一种非常有效的手段。对一系列的负载平衡策略的研究表明进程迁移是实现负载平衡的基础,进程迁移在很多方面具有适用性:
动态负载平衡:将进程迁移到负载轻或空闲的节点上,充分利用可用资源,通过减少节点间负载的差异来全面提高性能。
容错性和高可用性:某节点出现故障时,通过将进程迁移到其它节点继续恢复运行,这将极大的提高系统的可靠性和可用性。在某些关键性应用中,这一点尤为重要。
并行文件IO:将进程迁移到文件服务器上进行IO,而不是通过传统的从文件服务器通过网络将数据传输给进程。对于那些需向文件服务器请求大量数据的进程,这将有效的减少了通讯量,极大的提高效率。
充分利用特殊资源:进程可以通过迁移来利用某节点上独特的硬件或软件能力。
内存导引(Memory Ushering)机制:当一个节点耗尽它的主存时,Memory Ushering机制将允许进程迁移到其它拥有空闲内存的节点,而不是让该节点频繁地进行分页或和外存进行交换。这种方式适合于负载较为均衡,但内存使用存在差异或内存物理配置存在差异的系统。
进程迁移的实现角度
进程迁移的实现复杂性及对OS的依赖性阻碍了进程迁移的广泛使用,尤其是对透明的进程迁移实现。根据应用的级别,进程迁移可以作为OS的一部分、用户空间、系统环境的一部分或者成为应用程序的一部分。
用户级迁移:用户级实现较为简单,软件开发和维护也较为容易,因此,现有的很多系统都是采用用户级实现,如Condor和Utopia。但由于在用户级无法获得Kernel的所有状态,因此,对于某类进程,无法进行迁移。另外,由于Kernel空间和User空间之间存在着壁垒,打破这个边界获得Kernel提供的服务需要巨大的开销。因此,用户级实现效率远远低于内核级实现。
应用级迁移:应用级迁移实现较为简单,可移植性好,但是需要了解应用程序语义并可能需对应用程序进行修改或重编译,透明性较差,这方面的系统有Freedman、Skordos等。
内核级迁移:基于内核的实现可以充分利用OS提供的功能,全面的获取进程和OS状态,因此实现效率较高,能够为用户提供很好的透明性。但是由于需要对OS进行修改,实现较为复杂。这方面的典型系统有MOSIX和 Sprite系统。
进程状态
进程迁移的主要工作就在于提取进程状态,然后在目的节点根据进程状态再生该进程。在现实中,一个进程拥有很多状态,并且随着操作系统的演化,进程状态也越来越多样。一般来说,一个进程的状态可以分为以下几类:
进程执行状态(Execution State):表示当前运行进程的处理器状态,和机器高度相关。包括内核在上下文切换时保存和恢复的信息,如通用和浮点寄存器值、栈指针、条件码等。
进程控制(Process Control):操作系统系统用来控制进程的所有信,一般包括进程优先级、进程标识,父进程标识等。一旦系统编排了进程控制信息,进程迁移系统必须冻结该进程的运行。
进程Memory状态和进程地址空间:包括进程的所有虚存信息,进程数据和进程的堆栈信息等,是进程状态的最主要的一部分。
进程的消息(Message)状态:包括进程缓冲的消息和连接(Link)的控制信息。进程迁移中通讯连接的保持以及迁移后连接的恢复是进程迁移中一项较有挑战意义的问题。
文件状态:进程的文件状态包括文件描述符和文件缓冲快。保持文件的Cache一致性和进程间文件同步访问也是进程迁移机制需要着重考虑的。
由于在同构的环境下(相同或兼容的机器体系结构和指令集以及操作系统)提取和恢复进程状态相对容易,现有的工作大多是以同构环境为前提的。不过,越来越多的人开始研究异构环境下的进程迁移机制,如TUI 系统。
盘点10个不得不说起的系统进程
1、kswapd0
系统每过一定时间就会唤醒kswapd,看看内存是否紧张,如果不紧张,则睡眠,在kswapd中,有2个阀值:pages_hige和pages_low,当空闲内存页的数量低于pages_low的时候,kswapd进程就会扫描内存并且每次释放出32个free pages,直到free page的数量到达pages_high。
Linux uses kswapd for virtual memory management such that pages that have been recently accessed are kept in memory and less active pages are paged out to disk.(what is a page?)…Linux uses manages memory in units called pages.So,the kswapd process regularly decreases the ages of unreferenced pages…and at the end they are paged out(moved out) to disk.
2、kjournald
journal:记录所有文件系统上的元数据改变,最慢的一种模式。
logs all filesystem data and metadata changes. The slowest of the three ext3 journaling modes, this journaling mode minimizes the chance of losing the changes you have made to any file in an ext3 filesystem.
ordered:默认使用的模式,只记录文件系统改变的元数据,并在改变之前记录日志。
only logs changes to filesystem metadata, but flushes file data updates to disk before making changes to associated filesystem metadata. This is the default ext3 journaling mode.
writeback :最快的一种模式,同样只记录修改过的元数据,依赖标准文件系统写进程将数据写到硬盘。
only logs changes to filesystem metadata but relies on the standard filesystem write process to write file data changes to disk. This is the fastest ext3 journaling mode.
3、pdflush
pdflush用于将内存中的内容和文件系统进行同步。
即:当一个文件在内存中进行修改,pdflush负责将它写回硬盘。每当内存中的垃圾页(dirty page)超过10%的时候,pdflush就会将这些页面备份回硬盘。这个比率是可调节的,通过/etc/sysctl.conf中的 vm.dirty_background_ratio项默认值为10也可以。
4、kthreadd
这种内核线程只有一个,它的作用是管理调度其它的内核线程。
它在内核初始化的时候被创建,会循环运行一个叫做kthreadd的函数,该函数的作用是运行kthread_create_list全局链表中维护的kthread。可以调用kthread_create创建一个kthread,它会被加入到kthread_create_list链表中,同时kthread_create会weak up kthreadd_task。kthreadd在执行kthread会调用老的接口——kernel_thread运行一个名叫kthread的内核线程去运行创建的kthread,被执行过的kthread会从kthread_create_list链表中删除,并且kthreadd会不断调用scheduler 让出CPU。这个线程不能关闭。
5、migration
这种内核线程共有N(cpu核数)个,从migration/0到migration/(N-1),每个处理器核对应一个migration内核线程,主要作用是作为相应CPU核的迁移进程,用来执行进程迁移操作,内核中的函数是migration_thread()
属于2.6内核的负载平衡系统,该进程在系统启动时自动加载(每个 cpu 一个),并将自己设为 SCHED_FIFO 的实时进程,然后检查 runqueue::migration_queue 中是否有请求等待处理,如果没有,就在 TASK_INTERRUPTIBLE 中休眠,直至被唤醒后再次检查。migration_thread() 仅仅是一个 CPU 绑定以及 CPU 电源管理等功能的一个接口。这个线程是调度系统的重要组成部分。
6、watchdog
这种内核线程共有N个,从watchdog/0到watchdog/(N-1), 每个处理器核对应一个watchdog 内核线程,watchdog用于监视系统的运行,在系统出现故障时自动重新启动系统,包括一个内核 watchdog module 和一个用户空间的 watchdog 程序。
在Linux 内核下,watchdog的基本工作原理是:当watchdog启动后(即/dev/watchdog设备被打开后),如果在某一设定的时间间隔(60秒)内/dev/watchdog没有被执行写操作,硬件watchdog电路或软件定时器就会重新启动系统,每次写操作会导致重新设定定时器。
7、events
这种内核线程共有N个,从events/0到events/(N-1),每个处理器核对应一个events内核线程。用来处理内核事件很多软硬件事件(比如断电,文件变更)被转换为events,并分发给对相应事件处理线程进行响应。
8、kblockd
这种内核线程共有N个,从kblockd/0到kblockd/(N-1),每个处理器核对应一个kblockd内核线程。用于管理系统的块设备,它会周期地激活系统内的块设备驱动。如果拥有块设备,那么这些线程就不能被去掉。
9、aio
这种内核线程共有N个,从aio/0到aio/(N-1),每个处理器核对应一个 aio 内核线程,代替用户进程管理I/O,用以支持用户态的AIO(异步I/O),不应该被关闭。
10、rpciod
这种内核线程共有N个,从rpciod/0到rpciod/(N-1),每个处理器核对应一个rpciod内核线程,主要作用是作为远过程调用服务的守护进程,用于从客户端启动I/O服务,通常启动NFS服务时要用到它。
#ps 相关进程 (k开头的基本上都是内核驱动,不建议杀掉)
PID TTY STAT TIME COMMAND
1 ? Ss 0:00 init [3] (引导用户空间服务,管理孤儿线程,不能杀)
2 ? S 0:00 [migration/0]
3 ? SN 0:00 [ksoftirqd/0] (内核调度/管理第0个CPU软中断的守护进程,不能杀)
4 ? S 0:00 [watchdog/0] (系统监控应用,能够在系统出现故障时自动重新启动系统。不能杀)
5 ? S 0:00 [migration/1] (管理多核心(包括HypterThreading衍生的那个不大管用的、线程在各核心的迁移,不能杀)
6 ? SN 0:00 [ksoftirqd/1] (内核调度/管理第1个CPU软中断的守护进程,不能杀)
7 ? S 0:00 [watchdog/1] (系统监控应用,能够在系统出现故障时自动重新启动系统。不能杀)
8 ? S< 0:00 [events/0] (处理内核事件守护进程,不能杀)
9 ? S< 0:00 [events/1] (处理内核事件守护进程,不能杀)
10 ? S< 0:00 [khelper] (没查出来,感觉不能杀)
11 ? S< 0:00 [kthread] (父内核线程,不能杀)
15 ? S< 0:00 \_ [kblockd/0] (管理磁盘块读写,不能杀)
16 ? S< 0:00 \_ [kblockd/1] (管理磁盘块读写,不能杀)
17 ? S< 0:00 \_ [kacpid] (内核电源管理,不能杀)
120 ? S< 0:00 \_ [cqueue/0] (队列数据结构,不能杀)
121 ? S< 0:00 \_ [cqueue/1] (队列数据结构,不能杀)
124 ? S< 0:00 \_ [khubd] (内核的usb hub,不能杀)
126 ? S< 0:00 \_ [kseriod] 内核线程
193 ? S 0:00 \_ [pdflush](pdflush内核线程池是Linux为了回写文件系统数据而创建的进程,不能杀)
194 ? S 0:00 \_ [pdflush](pdflush内核线程池是Linux为了回写文件系统数据而创建的进程,不能杀)
195 ? S< 0:00 \_ [kswapd0] (内存回收,确保系统空闲物理内存的数量在一个合适的范围,不能杀)
196 ? S< 0:00 \_ [aio/0] (代替用户进程管理io,不能杀)
197 ? S< 0:00 \_ [aio/1] (代替用户进程管理io,不能杀)
354 ? S< 0:00 \_ [kpsmoused] (内核鼠标支持,可以杀掉)
387 ? S< 0:00 \_ [ata/0] (ata硬盘驱动,不能杀)
388 ? S< 0:00 \_ [ata/1] (ata硬盘驱动,不能杀)
389 ? S< 0:00 \_ [ata_aux] (ata硬盘驱动,不能杀)
393 ? S< 0:00 \_ [scsi_eh_0] (scsi设备,不建议杀)
394 ? S< 0:00 \_ [scsi_eh_1] (scsi设备,不建议杀)
395 ? S< 0:00 \_ [scsi_eh_2] (scsi设备,不建议杀)
396 ? S< 0:00 \_ [scsi_eh_3] (scsi设备,不建议杀)
432 ? S< 0:00 \_ [kauditd] (内核审核守护进程,不能杀)
1160 ? S< 0:00 \_ [hda_codec]
1418 ? S< 0:00 \_ [kmirrord] (内核守护进程控制和监视镜像模块,不能杀)
400 ? S< 0:00 \_ [kjournald]
1442 ? S< 0:00 \_ [kjournald]
1444 ? S< 0:00 \_ [kjournald]
1446 ? S< 0:00 \_ [kjournald] (kjournald Ext3文件系统的日志管理,通常每个mount_的 Ext3分区会有一个 kjournald看管,各分区的日志
是独立的,不能杀)
466 ? S<s 0:00 /sbin/udevd -d (udevd 支持用户态设备操作,不能杀)
1825 ? Ss 0:00 syslogd -m 0 (syslogd 系统日志进程,不能杀)
1828 ? Ss 0:00 klogd -x (klogd 从内核信息缓冲区获取打印信息,不能杀)
1844 ? Ss 0:00 irqbalance (多个CPU之间均衡分配硬件中断,可以关闭,但不建议)
1864 ? Ss 0:00 /usr/sbin/sshd (sshd守护进程,不能杀)
1881 ? Ss 0:00 crond (执行定时任务,不能杀)
1888 tty1 Ss+ 0:00 /sbin/mingetty tty1 (mingetty 等待用户从tty登录,可以杀)
1892 tty2 Ss+ 0:00 /sbin/mingetty tty2 (mingetty 等待用户从tty登录,可以杀)
1893 tty3 Ss+ 0:00 /sbin/mingetty tty3 (mingetty 等待用户从tty登录,可以杀)
刚刚开机之后,使用ps查看系统内的内核线程,主要情况如下:
共发现有232个内核线程存在,它们分别是:
(1)kthreadd:这种内核线程只有一个,它的作用是管理调度其它的内核线程。它在内核初始化的时候被创建,会循环运行一个叫做kthreadd的函数,该函数的作用是运行kthread_create_list全局链表中维护的kthread。可以调用kthread_create创建一个kthread,它会被加入到kthread_create_list链表中,同时kthread_create会weak up kthreadd_task。kthreadd在执行kthread会调用老的接口——kernel_thread运行一个名叫“kthread”的内核线程去运行创建的kthread,被执行过的kthread会从kthread_create_list链表中删除,并且kthreadd会不断调用scheduler 让出CPU。这个线程不能关闭。
(2)migration:这种内核线程共有32个,从migration/0到migration/31,每个处理器核对应一个migration内核线程,主要作用是作为相应CPU核的迁移进程,用来执行进程迁移操作,内核中的函数是migration_thread()。属于2.6内核的负载平衡系统,该进程在系统启动时自动加载(每个 cpu 一个),并将自己设为 SCHED_FIFO 的实时进程,然后检查 runqueue::migration_queue 中是否有请求等待处理,如果没有,就在 TASK_INTERRUPTIBLE 中休眠,直至被唤醒后再次检查。migration_queue仅在set_cpu_allowed() 中添加,当进程(比如通过 APM 关闭某 CPU 时)调用set_cpu_allowed()改变当前可用 cpu,从而使某进程不适于继续在当前 cpu 上运行时,就会构造一个迁移请求数据结构 migration_req_t,将其植入进程所在 cpu 就绪队列的migration_queue 中,然后唤醒该就绪队列的迁移 daemon(记录在runqueue::migration_thread 属性中),将该进程迁移到合适的cpu上去在目前的实现中,目的 cpu 的选择和负载无关,而是"any_online_cpu(req->task->cpus_allowed)",也就是按 CPU 编号顺序的第一个 allowed 的CPU。所以,和 load_balance() 与调度器、负载平衡策略密切相关不同,migration_thread() 应该说仅仅是一个 CPU 绑定以及 CPU 电源管理等功能的一个接口。这个线程是调度系统的重要组成部分,也不能被关闭。
(3)watchdog:这种内核线程共有32个,从watchdog/0到watchdog/31, 每个处理器核对应一个watchdog 内核线程,watchdog用于监视系统的运行,在系统出现故障时自动重新启动系统,包括一个内核 watchdog module 和一个用户空间的 watchdog 程序。在Linux 内核下,watchdog的基本工作原理是:当watchdog启动后(即/dev/watchdog设备被打开后),如果在某一设定的时间间隔(1分钟)内/dev/watchdog没有被执行写操作,硬件watchdog电路或软件定时器就会重新启动系统,每次写操作会导致重新设定定时器。/dev/watchdog是一个主设备号为10, 从设备号130的字符设备节点。
Linux内核不仅为各种不同类型的watchdog硬件电路提供了驱动,还提供了一个基于定时器的纯软件watchdog驱动。如果不需要这种故障处理机制,或者有相应的替代方案,可以在menuconfig的
Device Drivers-->
Watchdog Timer Support
处取消watchdog功能。
(4)events:这种内核线程共有32个,从events/0到events/31, 每个处理器核对应一个 events内核线程。用来处理内核事件很多软硬件事件(比如断电,文件变更)被转换为events,并分发给对相应事件感兴趣的线程进行响应。用来处理内核事件的重要线程,不能被去掉
(5)khelper:这种内核线程只有一个,主要作用是指定用户空间的程序路径和环境变量, 最终运行指定的user space的程序,属于关键线程,不能关闭
(6)kblockd:这种内核线程共有32个,从kblockd/0到kblockd/31, 每个处理器核对应一个 kblockd 内核线程。用于管理系统的块设备,它会周期地激活系统内的块设备驱动。如果拥有块设备,那么这些线程就不能被去掉,要是想去掉,需要在.config中直接将CONFIG_BLOCK设成n,同时在menuconfig中取消
Device Drivers -->
Block devices
(7)kseriod:这种内核线程只有一个,主要作用是管理Serio总线上的设备的各种事件,Serio是一种虚拟总线,是Serial I/O的输写,表示串行的输入输出设备。对应内核中的serio_thread函数,流程大致是这样的:调用serio_get_event()从链表中取出struct serio_event元素,然后对这个元素的事件类型做不同的时候,处理完了之后,调用serio_remove_duplicate_events()在链表中删除相同请求的event。例如:如果要注册新的serio设备,它产生的事件类型是SERIO_REGISTER_PORT,然后流程会转入serio_add_port()。使用Serio总线的主要是标准AT键盘、PS/2鼠标、串口鼠标、Sun键盘,以及一些游戏手柄,不过由于I2C依赖于Serio,所以不关闭I2C就无法关闭Serio,menuconfig中SerialI/O的开关位于
Device Driver -->
Inputdevice support
HardwareI/O ports
SerialI/O support
(8)pdflush:这种内核线程共有两个,线程名都是pdflush,主要作用是回写内存中的脏页,回收脏页占据的空间。由于页高速缓存的缓存作用,写操作实际上会被延迟。当页高速缓存中的数据比后台存储的数据更新时,那么该数据就被称做脏数据。在内存中累积起来的脏页最终必须被写回。在以下两种情况发生时,脏页被写回:
1.当空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
2.当脏页在内存中驻留时间超过一个特定的阈值时,内核必须将超时的脏页写回磁盘,以确保脏页不会无限期地驻留在内存中。
对于第一个目标,pdflush线程在系统中的空闲内存低于一个特定的阈值时,将脏页刷新回磁盘。该后台回写例程的目的在于在可用物理 内存过低时,释放脏页以重新获得内存。特定的内存阈值可以通过dirty_background_ratiosysctl系统调用设置。当空闲内存比阈值:dirty_ background_ratio还低时,内核便会调用函数wakeup_bdflush()唤醒一个pdflush线程,随后pdflush线程进一步调用函数background_writeout()开始将脏页写回磁盘。函数background_writeout()需要一个长整型参数,该参数指定试图写回的页面数目。函数background_writeout()会连续地写出数据,直到满足以下两个条件:
1. 已经有指定的最小数目的页被写出到磁盘。
2. 空闲内存数已经回升,超过了阈值dirty_background_ratio。
上述条件确保了pdflush操作可以减轻系统中内存不足的压力。回写操作不会在达到这两个条件前停止,除非pdflush写回了所有的脏页,没有剩下的脏页可再被写回了。
对于第二个目标,pdflush后台例程会被周期性唤醒(和空闲内存是否过低无关),将那些在内存中驻留时间过长的脏页写出,确保内存中不会有长期存在的脏页。如果系统发生崩溃,由于内存处于混乱之中,所以那些在内存中还没来得及写回磁盘的脏页就会丢失,所以周期性同步页高速缓存和磁盘非常重要。在系统启动时,内核初始化一个定时器,让它周期地唤醒pdflush线程,随后使其运行函数 wb_kupdate()。该函数将把所有驻留时间超过百分之dirty_expire_centisecs秒的脏页写回。然后定时器将再次被初始化为百分之dirty_expire_ centisecs秒后唤醒pdflush线程。总而言之,pdflush线程周期地被唤醒并且把超过特定期限的脏页写回磁盘。
系统管理员可以在/proc/sys/vm中设置回写相关的参数,也可以通过sysctl系统调用设置它们。
属于核心的内存管理线程,这个线程也不能被关闭
(9)kswapd0:这种内核线程只有一个,主要作用是用来回收内存。在kswapd中,有2个阀值,pages_hige和pages_low。当空闲内存页的数量低于pages_low的时候,kswapd进程就会扫描内存并且每次释放出32个 free pages,直到freepage的数量到达pages_high。具体回收内存有如下原则:
1. 如果页未经更改就将该页放入空闲队列;
2. 如果页已经更改并且是可备份回文件系统的,就理解将内存页的内容写回磁盘;
3. 如果页已经更改但是没有任何磁盘上的备份,就将其写入swap分区。
同样,属于核心的内存管理线程,这个线程也不能被关闭
(10)aio:这种内核线程共有32个,从aio/0到aio/31, 每个处理器核对应一个 aio 内核线程, 代替用户进程管理I/O,用以支持用户态的AIO(异步I/O),不应该被关闭。
(11)unionfs_siod: 这种内核线程共有32个,但是名称都是 unionfs_siod/,每个处理器核对应一个 unionfs_siod 内核线程
(12)nfsiod:这种内核线程只有一个,主要作用是为nfs提供高效的缓冲机制,从而改善nfs文件系统的性能,如果不需nfs,可以取消这一线程,取消这一线程的方法为menuconfig中取消
File systems-->
Network File Systems
(13)rpciod:这种内核线程共有32个,从rpciod/0到rpciod/31,每个处理器核对应一个rpciod内核线程,主要作用是作为远过程调用服务的守护进程,用于从客户端启动I/O服务,通常启动NFS服务时要用到它,想要关闭它,需要在.config中把CONFIG_SUNRPC,CONFIG_SUNRPC_GSS,CONFIG_SUNRPC_XPRT_RDMA的值设成n。
(14)kpsmoused:这种内核线程只有一个,主要作用是支持ps/2接口的鼠标驱动。如要没有鼠标,可以取消,取消方法是menuconfig中取消。
DeviceDrivers-->
Input device support
Mice
Linux进程状态
进程常用命令
|- w查看当前系统信息
|- ps进程查看命令
|- kill终止进程
|- 一个存放内存中的特殊目录/proc
|- 进程的优先级
|- 进程的挂起与恢复
|- 通过top命令查看进程
计划任务
|- 计划任务的重要性
|- 一次性计划at和batch
|- 周期性计划crontab
进程和程序区别
1.程序是静态概念,本身作为一种软件资源长期保存;而进程是程序的执行过程,它是动态概念,有一定的生命期,是动态产生和消亡的。
2.程序和进程无一一对应关系。一个程序可以由多个进程共用;另一方面,一个进程在活动中有可顺序地执行若干个程序
父子进程的关系
1.子进程是由一个进程所产生的进程,产生这个子进程的进程称为父进程
2.在linux系统中,使用系统调用fork创建进程。fork复制的内容包括父进程的数据和堆栈段以及父进程的进程环境。
3.父进程终止子进程自然终止。
前台进程和后台进程
前台进程
在shell提示处理打入命令后,创建一个子进程,运行命令,Shell等待命令退出,然后返回到对用户给出提示符。这条命令与Shell异步运行,即在前台运行,用户在它完成之前不能执行别一个命令。
后台进程
在Shell提示处打入命令,若后随一个&,Shell创建子进程运行此命令,但不等待命令退出,而直接返回到对用户给出提示。这条命令与Shell同步运行,即在后台运行。“后台进程必须是非交互式的”
进程的状态
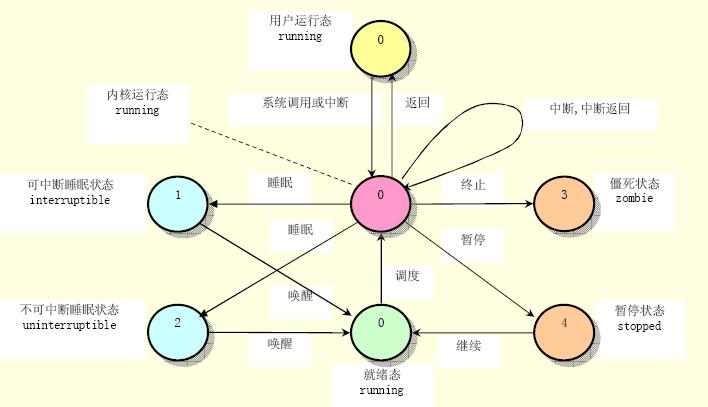
运行状态(TASK_RUNNING)
当进程正在被CPU执行,或已经准备就绪随时可由调度程序执行,则称该进程为处于运行状态(running)。进程可以在内核态运行,也可以在用户态运行。当系统资源已经可用时,进程就被唤醒而进入准备运行状态,该状态称为就绪态。这些状态(图中中间一列)在内核中表示方法相同,都被成为处于TASK_RUNNING状态。
可中断睡眠状态(TASK_INTERRUPTIBLE)
当进程处于可中断等待状态时,系统不会调度该进行执行。当系统产生一个中断或者释放了进程正在等待的资源,或者进程收到一个信号,都可以唤醒进程转换到就绪状态(运行状态)。
暂停状态(TASK_STOPPED)
当进程收到信号SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU时就会进入暂停状态。可向其发送SIGCONT信号让进程转换到可运行状态。
僵死状态(TASK_ZOMBIE)
当进程已停止运行,但其父进程还没有询问其状态时,则称该进程处于僵死状态。
不可中断睡眠状态(TASK_UNINTERRUPTIBLE)
与可中断睡眠状态类似。但处于该状态的进程只有被使用wake_up()函数明确唤醒时才能转换到可运行的就绪状态。
当一个进程的运行时间片用完,系统就会使用调度程序强制切换到其它的进程去执行。另外,如果进程在内核态执行时需要等待系统的某个资源,此时该进程就会调用sleep_on()或sleep_on_interruptible()自愿地放弃CPU的使用权,而让调度程序去执行其它进程。进程则进入睡眠状态(TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE)。
只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程切换操作。在内核态下运行的进程不能被其它进程抢占,而且一个进程不能改变另一个进程的状态。为了避免进程切换时造成内核数据错误,内核在执行临界区代码时会禁止一切中断。
注意:
进程已死亡,但父进程没有收尸,该进程就成僵尸进程
僵尸进程不打开任何文件,几乎不占内存,但是占据进程表的资源,进程表记录pid、进程状态、CPU时间等
僵尸状态是每个子进程结束时必经的状态
系统监控中出现大量僵尸进程,应检查其父进程代码
Linux进程状态及负载的理解
R(TASK_RUNNING) 可执行状态 会被平均负载统计
处于该状态的进程可能正在CPU上执行,也可能处在CPU的可执行队列中,进程调度器可从CPU的可执行队列中选择一个进程在该 CPU上执行。 教科书将等待CPU执行的状态称之为就绪状态,但是在linux上都称为可执行状态(TASK_RUNNING)。
S(TASK_INTERRUTILBE) 可中断的睡眠状态 不会被平均负载统计
处于该状态的进程一般都在等待某事件的发生(比如等待socket连接,等待信号量),这些进程会被内核放在对应事件的等待队列,如果事件发生,则等待队列的一个或者多个进程就被唤醒,变为可执行状态 linux大部分进程会处于这个状态。
D(TASK_UNINTERRUPTIBLE) 不可中断的睡眠状态 会被平均负载统计
进程处于这个状态,其实还是睡眠状态,它将不会响应异步信号(比如使用kill -9杀不死这个进程),但是还会响应硬件中断。 一般由同步IO操作引起,同步IO在做读或写操作时,cpu不能做其它事情,只能等待,这个时候进程还是会霸占这个cpu,不会调度其它进程执行。 如果程序采用异步IO,这种状态就很少会看到 不可中断的睡眠状态很短暂,用ps命令一般捕捉不到。
T(TASK_STOPPED or TASK_TRACED) 暂停状态或跟踪状态 不会平均负载统计
向进程发送一个SIGSTOP信号,它会响应该信号而进入TASK_STOPPED状态,SIGSTOP与SIGKILL信号一样,非常强制,不允许用户进程通过signal系列系统调用重新设置对应的信号处理函数。若向进程发送SIGCONT信号,可以让进程从TASK_STOPPED状态恢复到TASK_RUNNING状态 通过ptrace系统调用来调试进程时,会让进程进入TASK_TRACED状态。
Z(EXIT_ZOMBIE) 僵尸状态 不会被平均负载统计
进程退出过程中进程占有的所有资源都会被回收,内核中只会保留task_struct结构,如果父进程通过wait系列的调用来等待子进程退出,子进程退出后,父进程可以通过wait调用返回的数据来得到子进程的退出信息。但是如果父进程没有通过wait系列调用来等待子进程退出,那么子进程的退出信息将不被父进程获得,内核会一直保留子进程的task_struct信息,因此子进程会进入僵尸状态。进程的task_struct结构信息里有退出状态信息。
X(EXIT_DEAD) 退出状态 不会被平均负载统计
进程退出过程中进程占有的所有资源都会被回收,包括它的task_struct结构。进程即将被销毁时会处于这个状态,这个状态是非常短暂的,几乎不可能通过ps命令捕捉。
操作系统描述的进程状态:就绪、执行、阻塞
就绪能切换到执行状态,执行状态可能切换到就绪状态或者阻塞状态,阻塞状态只能切换到执行状态。
对于单个cpu且单核的机器来说,如果是CPU密集型应用,我们可以用系统平均负载来衡量系统利用率。如果是多个CPU或者多核的情况下,我们必须拿平均负载除以所有的核心数,才能用来衡量系统利用率。
举例来说,如果单cpu系统的系统平均负载的数值是1.73 0.60 7.98:
过去1分钟 系统平均负载超负荷73%(1.73个可执行进程,那么有0.73个进程需要等待这个cpu资源才可以运行)
过去5分钟 cpu有40%是空闲的
过去15分钟 系统平均负载超负荷698%(7.98个可执行进程,那么6.98个进程需要等待cpu资源才可以运行)
上述的例子以为着这台机器(CPU,磁盘,内存等资源)如果能快1.73倍,那么它能处理过去1分钟内的所有任务,也可以看出来过去15分钟到过去5分钟这一段时间内的任务都被系统处理完了,所以过去5分钟的负载还有40%的空闲。
如果一台机器上有4个cpu,3.73的平均负载意味着有3.73个进程可以运行,这样每个进程都可以占用一个cpu来运行,如果只1个4核的cpu,每个进程也都可以占用一个核来运行。
一般认为单核cpu平均负载小于等于0.7是一个理想状态,如果超过则想办法降低负载。
系统平均负载与CPU利用率
CPU利用率:表示程序在运行期间实时占用的CPU百分比
CPU利用率高,并不意味着负载一定大
举例来说:如果我有一个程序它需要一直使用CPU的运算功能,那么此时CPU的利用用率可能达到100%,但是CPU的工作负载则是趋近于"1",因为CPU仅负责一个工作!如果同时执行这样的程序两个呢?CPU的使用率还是100%,但是工作负载则变成2了。所以也就是说,当CPU的工作负载越大,表示CPU必须要在不同的工作之间进行频繁的工作切换。
系统平均负载比CPU利用率能更好的评估系统的压力,但是容器内通常只会跑一个应用服务,所以看系统平均负载并没有太大的意义,一般看CPU利用率。
相关的操作指令
vmstat命令
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 851348 2360012 3943904 0 0 9 145 2 11 2 1 97 0 0
procs部分的解释
r: The number of runnable processes (running or waiting for run time). 如果长期大于1,说明cpu不足,需要增加cpu。
b: The number of processes in uninterruptible sleep. 比如正在等待I/O(同步IO操作才会有这种情况)、或者内存交换等。
cpu部分的解释
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。 id 列显示了cpu处在空闲状态的时间百分比。
system部分的解释 in 列表示在某一时间间隔中观测到的每秒设备中断数。 cs 列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory部分的解释 swpd the amount of virtual memory used free the amount of idle memory buff the amount of memory used as buffers。 cache: the amount of memory used as cache inact: the amount of inactive memory. (-a option) active: the amount of active memory. (-a option)
swap部分的解释 si: Amount of memory swapped in from disk (/s). so: Amount of memory swapped to disk (/s).
IO部分的解释 bi: Blocks received from a block device (blocks/s). bo: Blocks sent to a block device (blocks/s).
dstat命令
dstat也可以看cpu的信息。
iostat命令
可以使用iostat查看IO负载。
iostat 1 1
Linux 2.6.32.el6.x86_64 () 2018年12月29日 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
19.32 0.00 45.44 0.06 0.26 34.93
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
xvda 14.17 29.94 265.17 63120486 558975100
解释说明: avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值 %user: 在用户级别运行所使用的CPU的百分比. %nice: nice操作所使用的CPU的百分比. %sys: 在系统级别(kernel)运行所使用CPU的百分比. %iowait: CPU等待硬件I/O时,所占用CPU百分比. %idle: CPU空闲时间的百分比.
Device段:各磁盘设备的IO统计信息 tps: 每秒钟发送到的I/O请求数. Blk_read /s: 每秒读取的block数. Blk_wrtn/s: 每秒写入的block数. Blk_read: 读入的block总数. Blk_wrtn: 写入的block总数.
iostat -x -k -d 1
Linux 2.6.32.el6.x86_64 (centos6-vm02) 01/08/2018 _x86_64_ (4 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
scd0 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 0.36 0.36 0.00 0.36 0.00
vda 0.01 0.13 0.04 0.13 0.60 0.89 18.12 0.00 2.78 0.19 3.53 2.55 0.04
dm-0 0.00 0.00 0.04 0.22 0.58 0.88 11.25 0.00 3.27 0.25 3.82 1.61 0.04
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 0.13 0.13 0.00 0.04 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 7.91 0.00 0.19 0.10 5.00 0.16 0.00
解释说明:rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率。
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。idle小于70% IO压力就较大了,一般读取速度有较多的wait。同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
如何定位系统平均负载过高的问题原因并解决
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分引起,任意一项使用过量,都将导致服务器负载的急剧攀升。
排查是否是cpu利用率过高 或者内存占用过高导致的负载过高
首先排查是否是cpu利用率过高或者内存占用太高,这时候通过top命令就可以看出来cpu利用率以及内存剩余情况,或者内存是否有频繁swap in 或者swap out,也可以使用free命令查看内存使用情况,通过free命令也可以查看剩余的内存以及交换区的工作情况。
如果发现cpu利用率过高,则使用top命令查看占用cpu最多的进程,再分析进程为啥需要这么多资源,然后看是否有优化空间,如果没有优化空间,则添加更多的cpu核。如果发现内存利用率过高,或者剩余内存较少,或者频繁将物理内存的内容交换到交换区,则使用top命令查看占用内存最多的进程,再分析该进程为啥需要这么多内存,然后看是否有优化空间,如果没有优化空间则添加更多的cpu核。
排查是否是io问题
可以使用命令iostat -x 1 10来看io开销,可以直接看"util"的百分比,until就是io利用率,如果until达到100%,则说明磁盘的负载特别大, 这时候再分析是哪个进程造成磁盘的负载特别大(可以使用ps命令),然后再看是否有优化空间,没有优化空间则换更高效的硬盘。
Linux进程相关知识速看
查看内核版本:uname -a // uname -r
进程快照
ps report a snapshot of the current processes
USER 进程所属用户
PID 进程ID 进程号
%CPU 进程占用CPU百分比
%MEM 进程占用内存的百分比
VSZ 虚拟内存
RSS 真实内存
TTY 终端 terminal
STAT 进程的状态
主要状态(NOTE: 主机状态一条进程只有一个)
D 不可中断的睡眠
S 可中断的睡眠
X 死掉的进程不可见
R 正在执行的或者是正要执行的进程
Z defunct(zombie)
T stop程序暂停
次要状态(NOTE: 可多个)
s 进程组长 session leader
l multi-thread 多线程
L page-lock 页锁
< 高优先级但是不优先于其它进程
N 低优先级但是优先于其它进程
+ foreground 前台
START 开启时间
TIME 运行时间
COMMAND 进程运行指令(进程间的关系)
用法:
1.简单点用ps xf //NOTE: ps -xf is not right
2.ps auxf 全的
进程监控(monitor)
top
PID 进程ID 进程号
USER 进程所属用户
PR 系统优先级
NI 真正优先级
VIRT 虚拟内存
RES 真实内存
SHR 共享内存
S 运行状态
%CPU CPU使用率
%MEM 内存使用率
TIME+ 时间
COMMAND 命令
可以按h for help来调整自己所需要的指令。
如何将一个程序掉到后台
./xxx & 将xxx程序掉到后台执行
./xxx
ctrl + z 将程序掉到后台并且暂停该程序
查看后台任务:jobs
将后台任务掉到前台执行
fg + 将后台带上+号的程序掉到前台
fg - 将后台带上-号的程序掉到前台
fg 1 将后台任务号为1的程序掉到前台