常用Linux系统诊断工具
 Linux 平台上的性能工具有很多,眼花缭乱,长期的摸索和经验发现最好用的还是那些久经考验的、简单的小工具。系统性能专家 Brendan D. Gregg 在最近的 LinuxCon NA 2014 大会上更新了他那个有名的关于 Linux 性能方面的 talk (Linux Performance Tools) 和幻灯片。其博客里关于分析和调优的干货琳琅满目,一篇名为 Linux Performance 文章全面而详细的整理了常用工具,覆盖了硬件、存储、网络及应用。下面的图片分别总结了 Linux 各个子系统以及监控、测试、优化这些子系统所用到的工具。
Linux 平台上的性能工具有很多,眼花缭乱,长期的摸索和经验发现最好用的还是那些久经考验的、简单的小工具。系统性能专家 Brendan D. Gregg 在最近的 LinuxCon NA 2014 大会上更新了他那个有名的关于 Linux 性能方面的 talk (Linux Performance Tools) 和幻灯片。其博客里关于分析和调优的干货琳琅满目,一篇名为 Linux Performance 文章全面而详细的整理了常用工具,覆盖了硬件、存储、网络及应用。下面的图片分别总结了 Linux 各个子系统以及监控、测试、优化这些子系统所用到的工具。作为运维员,和 Linux 打交道是必然的,在服务器上分析系统性能情况是每一个后端工程师都无法避开的事情。无论是开发还是运维,可能都经历过这样的场景:
流量高峰期,服务器 CPU 使用率过高报警,登录 Linux 上去 top 完之后,却不知道怎么进一步定位,到底是系统 CPU 资源太少,还是程序并发部分写得有问题?
一大早就收到监控告警,发现某台存放监控数据的数据库主机 CPU 的 I/O Wait 较高,该怎么办?
说说经验吧,有三点觉得比较重要:
先掌握性能优化的思路和方法,尝试大量 Linux 性能工具;
把性能问题跟系统原理关联起来,特别是把应用程序、库函数、系统调用、内核和硬件等不同的层级贯穿起来;
最终从学习到输出,从实践中总结经验。
这其中有 Linux 性能工具的使用,它除了要考虑性能指标的目的外,还要结合待分析的环境来综合选取。
监控
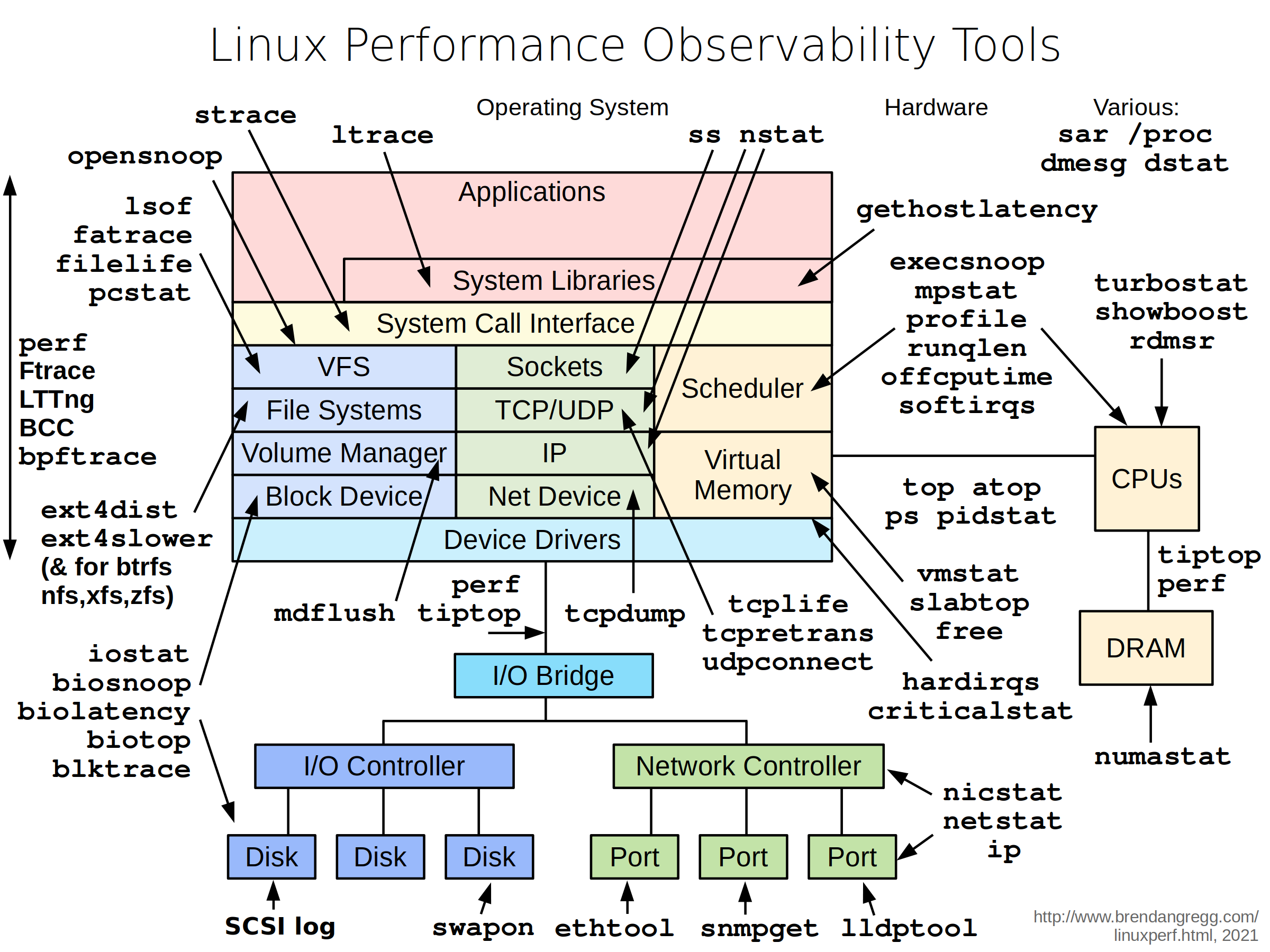
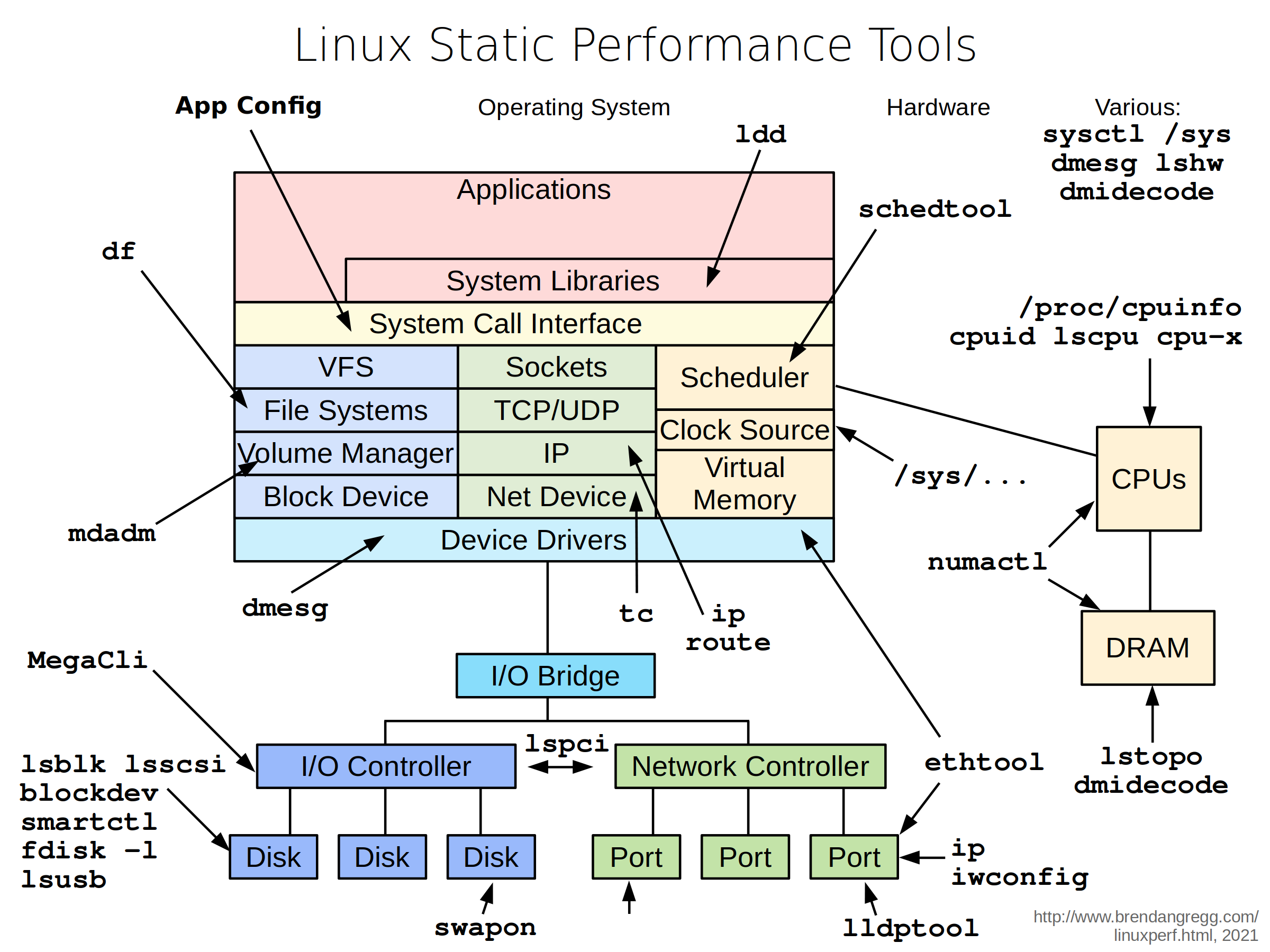
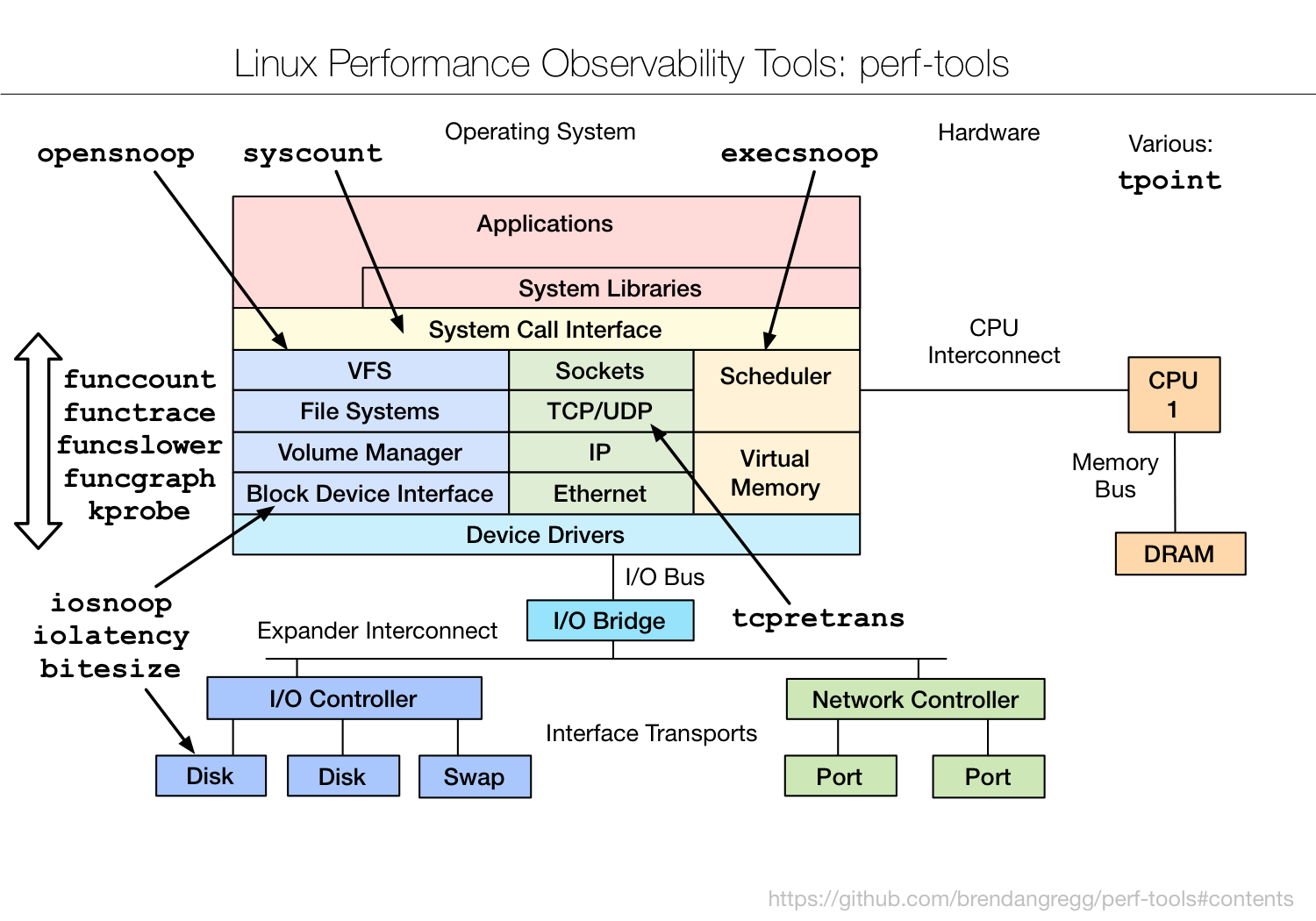
测试
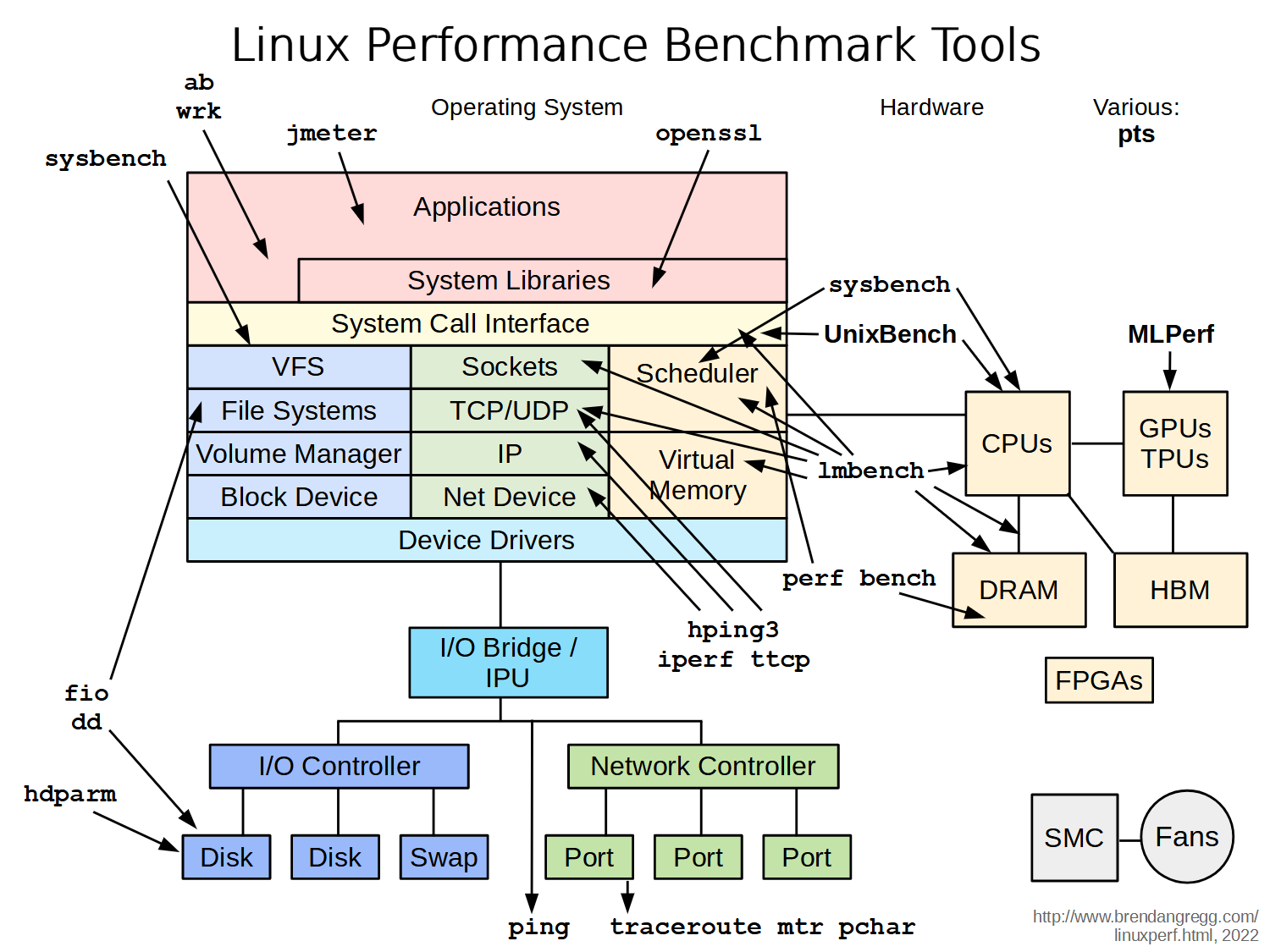
优化
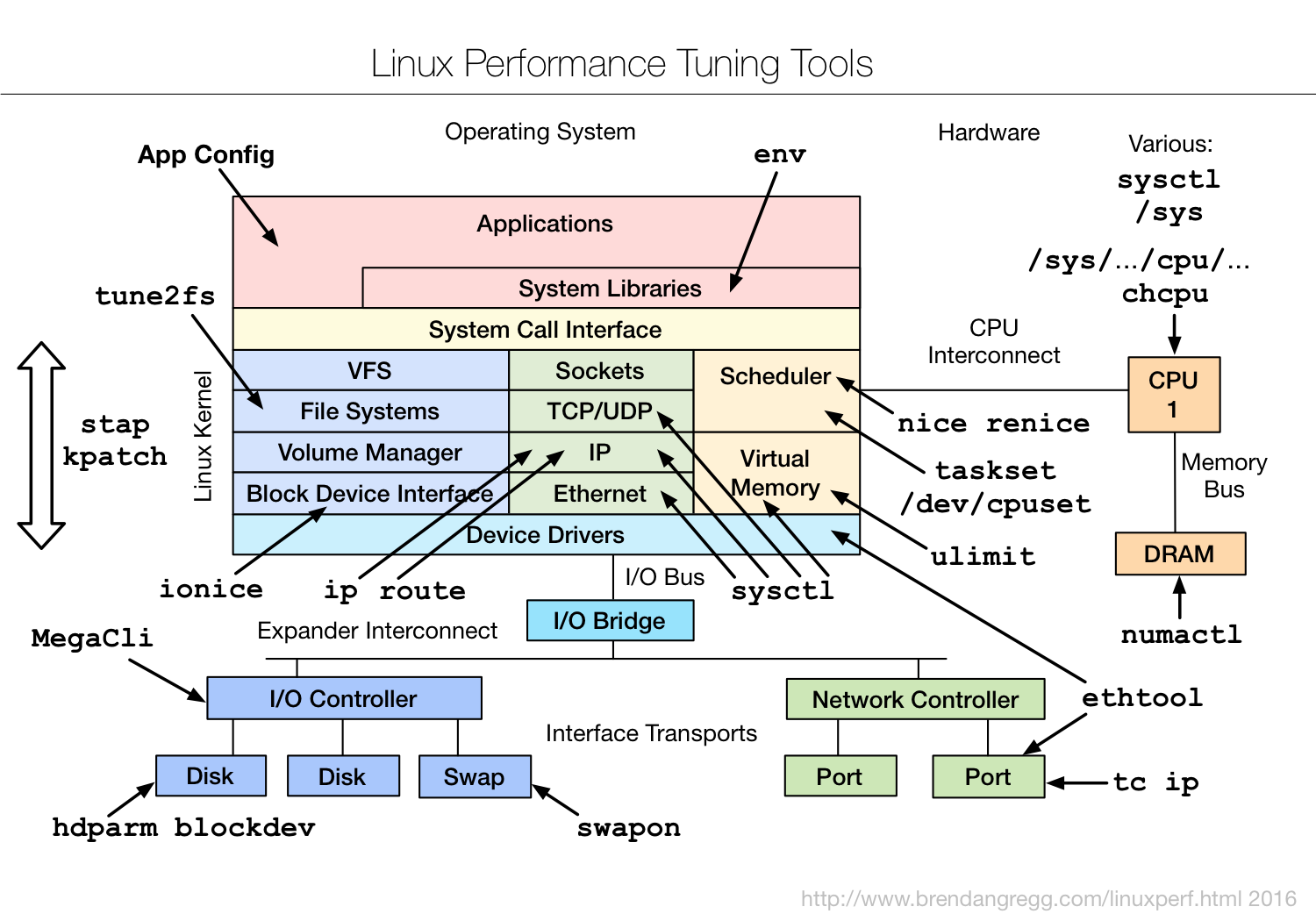
sar
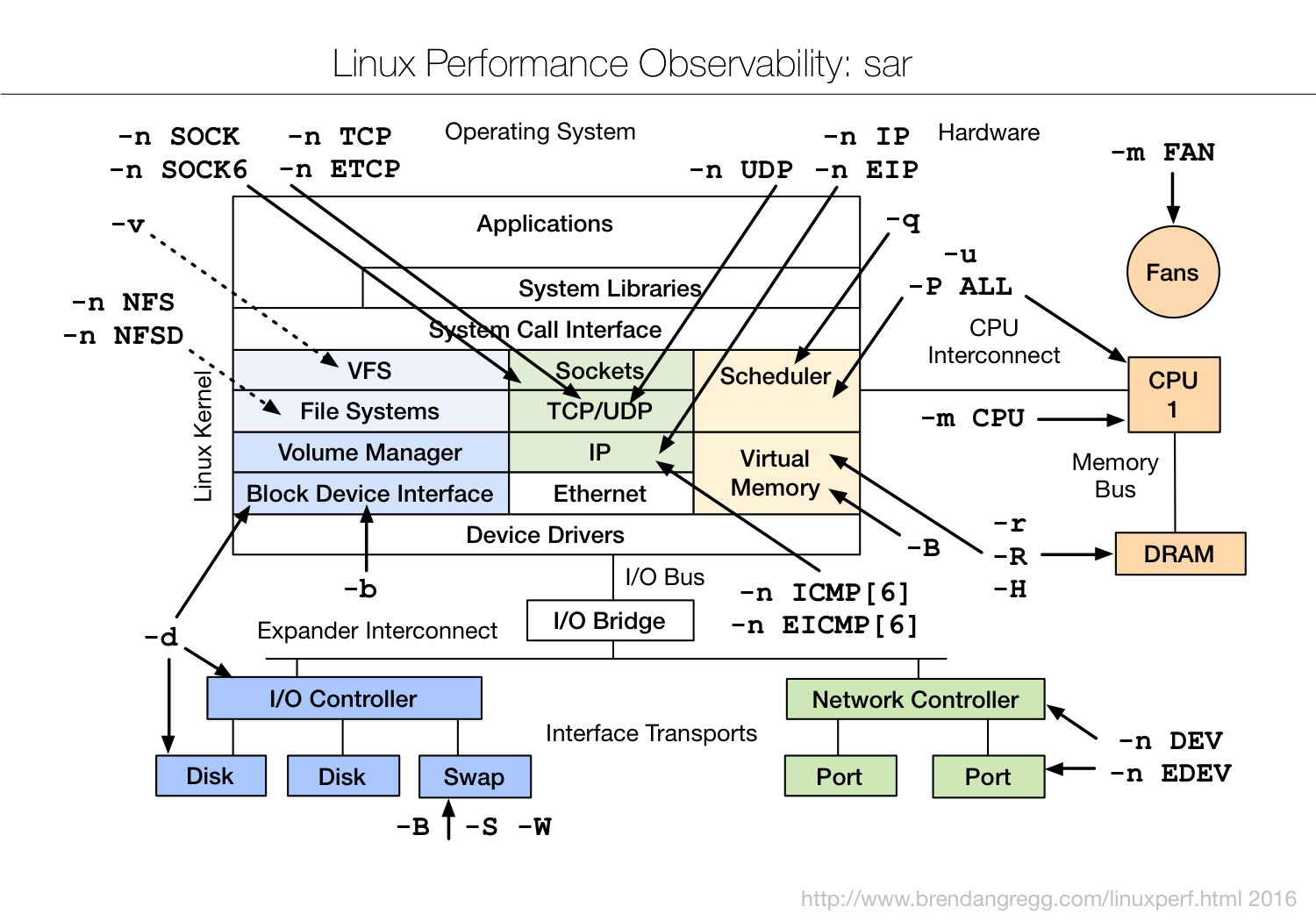
BPF
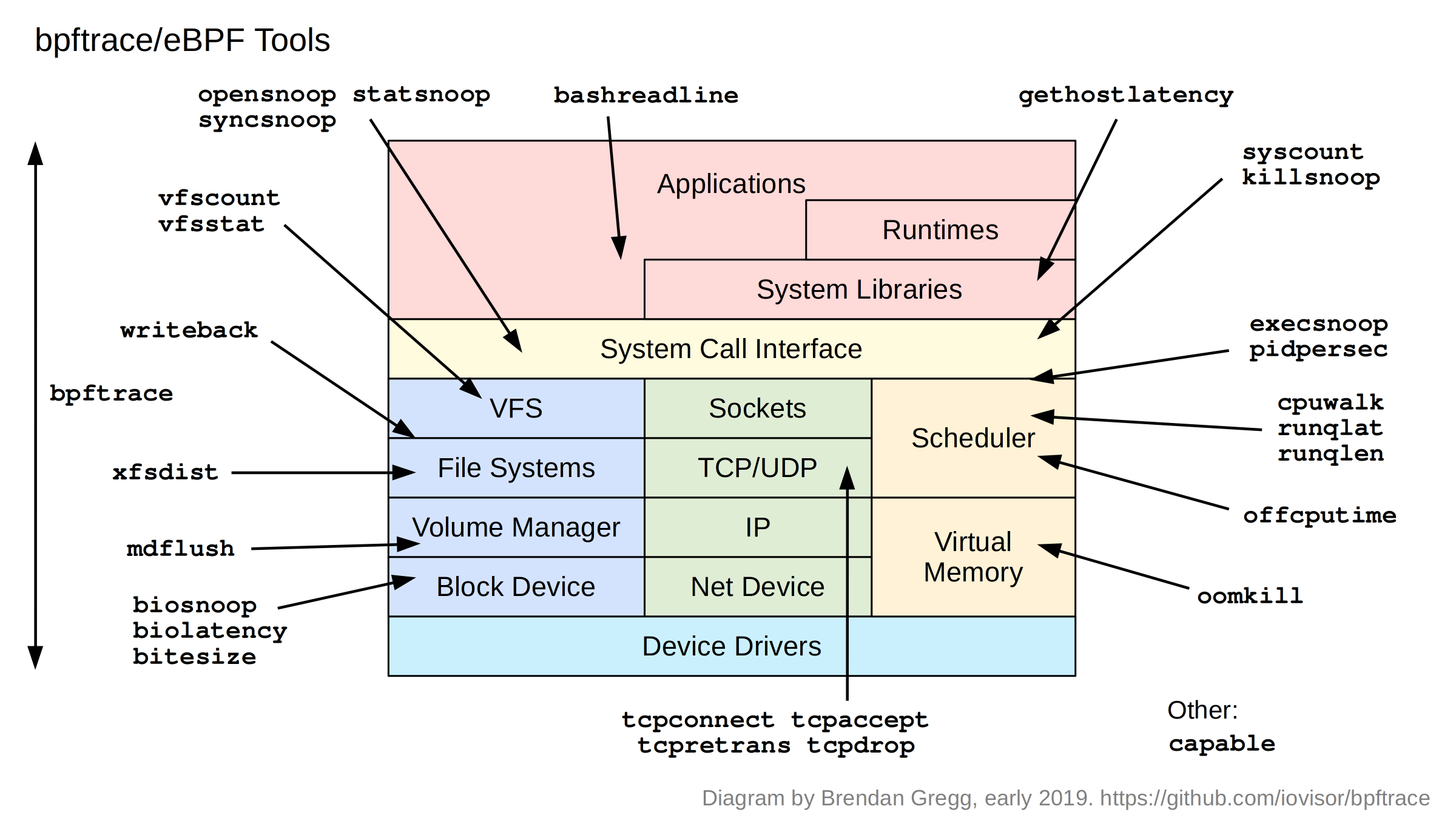
虽说咱有布伦丹·格雷格(Brendan Gregg)大师整理的性能工具图谱,相信你也多少参考过,但其实它还不够具体,使用时还要去查找每个工具的手册,对比分析做出选择。
所以每次用的时候就在想,有没有更好的方法来理解这些工具呢?刚刚开始研究的时候,可没少在网上找资料,最终解决我问题的,是倪朋飞《Linux 性能优化实战》中总结的几个性能工具图。
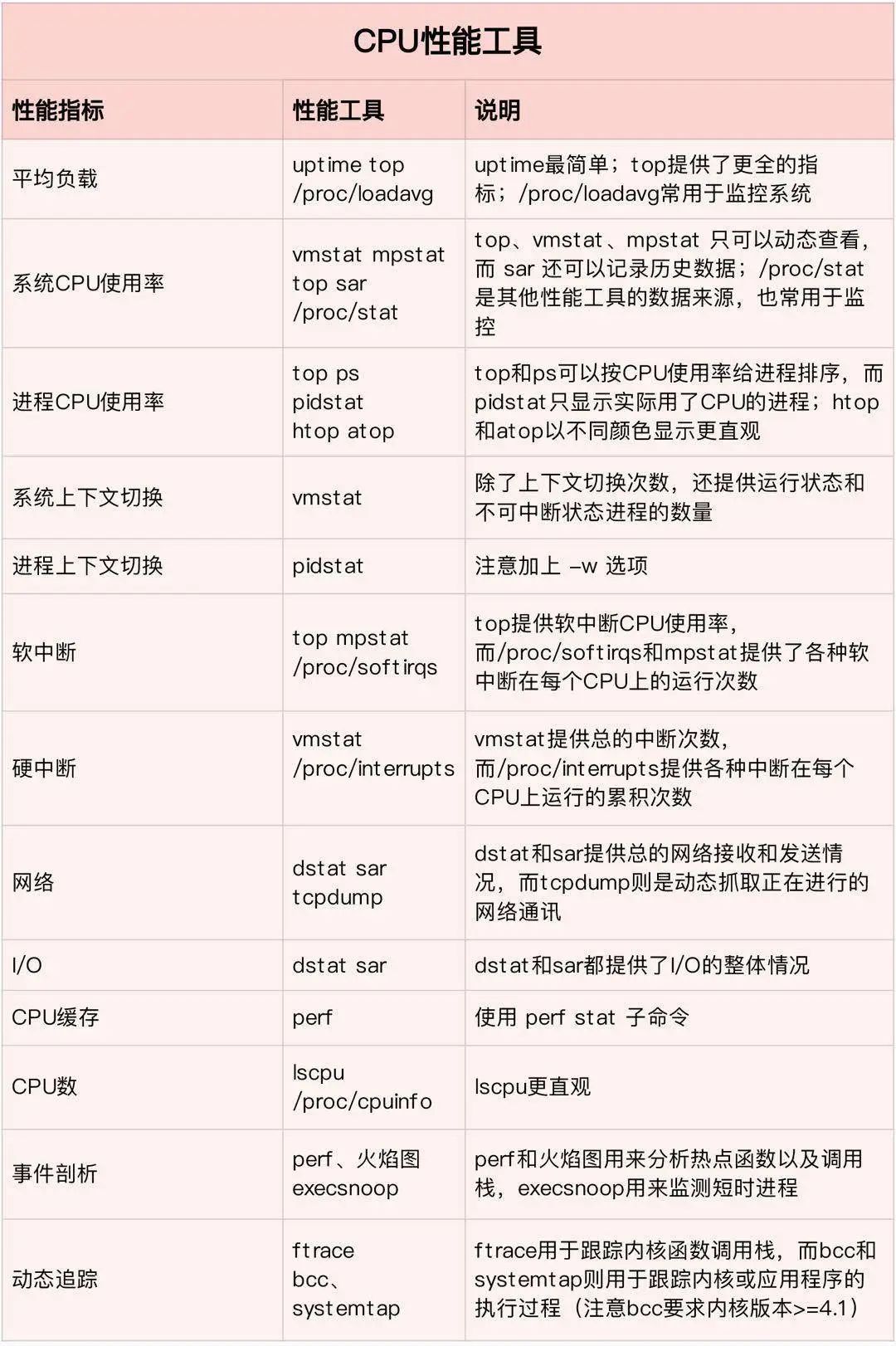
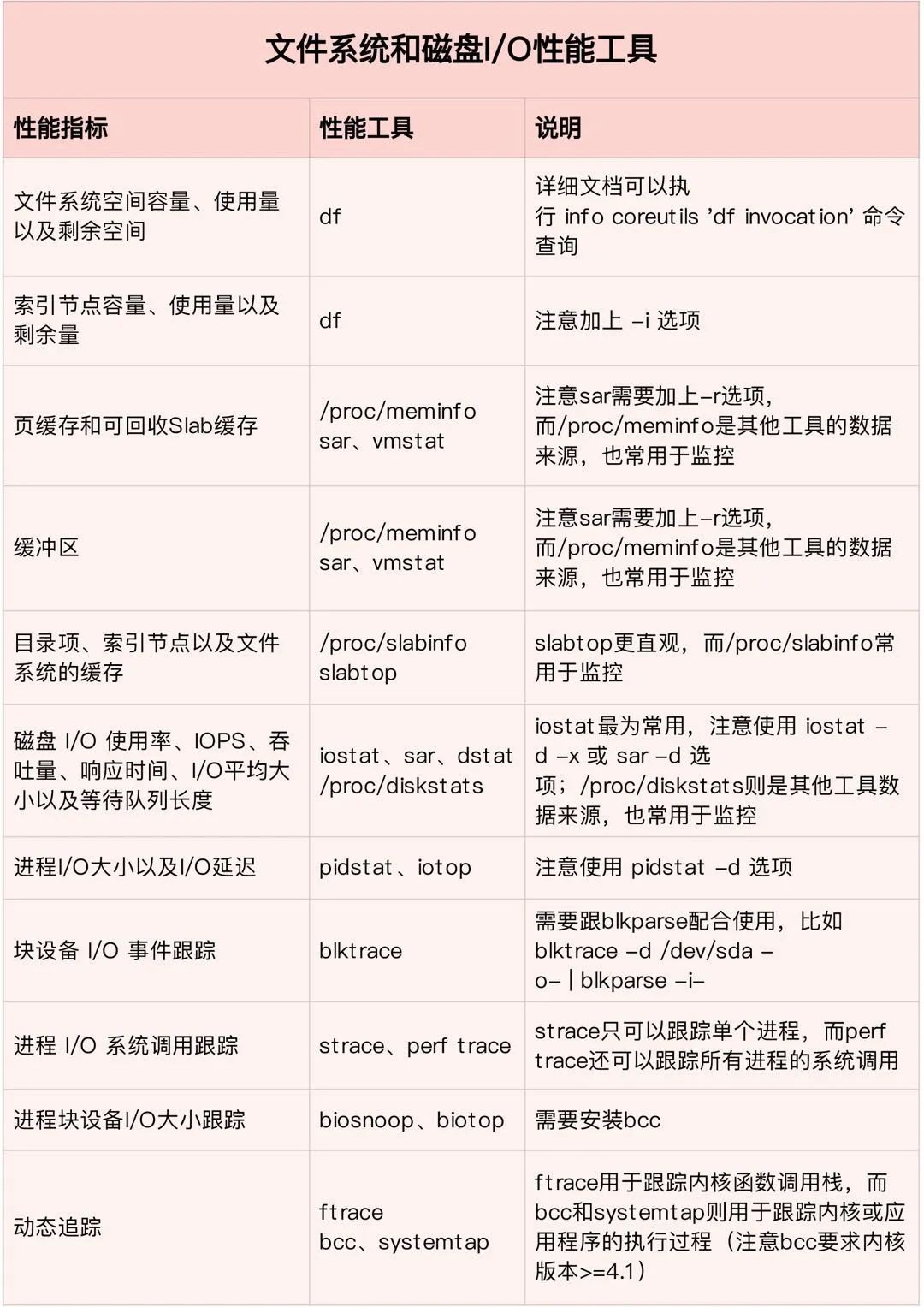
他根据「性能指标」的不同,将工具划分为 CPU、内存、磁盘 I / O及网络,4 大类型,总算是一次性让我把性能工具搞明白了。看这些图,就很清晰了,比如,当遇到 I/O 性能问题时,可以根据不同的性能指标,使用 iostat、iotop、blktrace 等工具分析磁盘 I/O 的瓶颈。
性能监控三工具:
mpstat,主要用来查看CPU报告,包括user/system、iowait和中断等。
vmstat,这里是虚拟内存的m,也包括物理内存(包括cache和buffer等)了。
iostat,除了生成磁盘使用信息的报告,还包括CPU的使用情况。
Linux 开发者最常用的性能工具
在 Linux 的世界里,性能分析是一名开发者、运维工程师、架构师的“看家本领”。不论你是调优大规模服务器、优化网络转发性能(如 DPDK)、还是分析系统卡顿问题,各种性能工具都是你最可靠的伙伴。本节带你深度掌握 24 个最常用、最有价值的 Linux 性能工具 —— 包括 CPU、内存、磁盘、网络、内核、容器等多个方面。
目录
Linux 性能分析的基础认知
24 大核心性能工具介绍(按领域分类)
工具对比表(CPU/内存/网络/IO/内核)
性能分析思维:如何定位瓶颈?
DPDK 调优专章:NUMA、Hugepage、isolcpus、RPS/XPS
1. Linux 性能分析的基础认知
Linux 的性能工具虽然多,但它们可以归类为 5 大方向:
| 分类 | 关注点 | 核心问题 |
| CPU | 调度、上下文切换、热点函数 | CPU 在忙什么?谁最消耗? |
| 内存 | 内存占用、缺页、NUMA | 为什么内存不够/失衡? |
| IO(磁盘) | IOPS、延迟、队列深度 | 为什么磁盘慢? |
| 网络 | 带宽、丢包、队列、IRQ | 网络去哪儿了?瓶颈在哪里? |
| 内核/系统 | 调度、锁、抢占、软中断 | 为什么系统卡顿? |
2. Linux 最常用的 24 个性能工具
1). CPU 性能工具(8 个)
① top / htop — CPU 整体使用率
定位:系统是否真的“忙”
最常用的资源查看工具,适合快速评估系统状态:
load average
CPU 使用率(user/system/idle)
进程占用
上下文切换(htop 可显示)
适用场景
初步查看系统是否有瓶颈
CPU 是否被 IRQ 或 kernel 占用
② mpstat — 多核 CPU 利用率分析
定位:每个 CPU 核心负载是否均衡
mpstat -P ALL 1
可以看出:
每个核的 user/sys/irq/softirq 的占比
是否存在“某几个核特别忙”的问题
对 DPDK 观测隔离核尤其重要
③ pidstat — 查看某个进程的 CPU/上下文切换
pidstat -w -p <pid>
可以定位:
某个线程的调度开销大不大
进程上下文切换是不是异常多(常见瓶颈!!)
④ mpstat / sar(CPU 子集)— 历史 CPU 分析
sar -u 1
可跟踪历史 CPU 变化趋势。
⑤ perf — 函数级 CPU 火焰图、热点分析
Linux 性能分析之王
能做的事情非常多:
采样火焰图
内核/用户态热点函数
分析 cache-miss、分支预测失败
分析软中断开销
示例:
perf top -C 1
perf record -F 99 -g -- sleep 10
perf report
⑥ ftrace — 内核追踪
可以追踪:
调度延迟
内核函数执行流程
ISR、中断处理流程
适合分析:
系统卡顿
内核锁导致延迟
⑦ trace-cmd
比 ftrace 更易用的封装工具。
⑧ turbostat(x86 专用)
查看 CPU C-state/P-state
适合分析 CPU 节能导致的性能问题。
2). 内存分析工具(5 个)
⑨ free / /proc/meminfo
基础内存查看工具。
重要指标:
available memory
buffers/cached
slab
hugepages 使用情况(DPDK 必看)
⑩ vmstat — 内存 + IO + 调度 三合一
vmstat 1
重要字段:
si/so → swap 交换(系统被打爆)
cs → 上下文切换
bi/bo → IO
⑪ slabtop — 内核对象内存统计
可查看内核是否因为某个对象耗尽内存(如 TCP skbuffer)。
⑫ numastat — NUMA 失衡分析
DPDK 调优重点工具。
可查看:
内存是否跨 NUMA
numa_miss / numa_foreign 是否过高
⑬ smem / pmap — 进程内存分析
3). 磁盘/IO 工具(4 个)
⑭ iostat — IO 延迟/IOPS 查看
iostat -x 1
关注字段:
r/s, w/s
await(延迟)
util(设备利用率)
⑮ pidstat -d — 单进程 IO
可定位“哪个进程疯狂 IO”。
⑯ blktrace — 低层级 IO 事件
用于深入分析 IO 队列行为。
⑰ fio — 压测工具
常用于 SSD/HDD 性能测试。
4). 网络性能工具(5 个)
⑱ ss — 更高级的 netstat
ss -s
ss -tulnp
能看到 socket、队列、TCP 状态等。
⑲ ethtool — 网卡能力、队列、中断信息
DPDK 需要关闭 RPS/XPS/TSO 之前常查:
ethtool -S eth0
ethtool -l eth0
ethtool -k eth0
⑳ tcpdump — 抓包排障
㉑ nstat / dropwatch — 丢包分析
可查看:
网卡层丢包
内核层丢包(skb 失败)
DPDK 驱动之前丢包位置
㉒ nicstat / iperf
网络带宽测试工具。
5). 系统与内核工具(5 个)
㉓ dstat — 综合监控
CPU + 内存 + IO + 网络 全部合一。
㉔ ps / pstree — 进程和线程结构
配合 perf、pidstat 排查问题。
㉕ strace — 系统调用跟踪
适用:
为什么程序卡住?
某行代码为什么执行慢?
程序被哪个 syscall 阻塞?
㉖ lsof — 文件句柄追踪
可查看:
某程序是否泄漏文件句柄
哪个进程占用了某个端口
㉗ sysctl — 修改系统内核参数
用于性能优化,如:
网络队列长度
调度器参数
内核内存管理参数
3. 工具对比图
按业务场景分类
| 场景 | 最常用工具 |
| CPU 热点分析 | perf, ftrace, mpstat |
| 内存泄漏/异常 | smem, vmstat, slabtop |
| 网络丢包 | ethtool, nstat, dropwatch |
| 系统卡顿 | perf, trace-cmd, vmstat |
| 内核分析 | ftrace, trace-cmd |
| 进程调试 | strace, lsof, pidstat |
领域分布:CPU、内存、IO、网络、内核
CPU:top, mpstat, pidstat, perf, turbostat
内存:free, vmstat, numastat, smem, slabtop
IO:iostat, pidstat -d, blktrace, fio
网络:ethtool, ss, nstat, dropwatch, iperf
内核:ftrace, trace-cmd, ps, strace, sysctl
4. 性能分析思维模型
99% 的故障能用以下 5 步定位:
① 先判断“哪一类资源”忙?
CPU?内存?网络?磁盘?
工具:top、vmstat、iostat、sar
② 找到“哪个进程”在消耗资源?
工具:ps, pidstat, top
③ 找到“哪个函数/模块”最耗时?
工具:perf、ftrace、火焰图
④ 判断是否是内核瓶颈
工具:trace-cmd、ftrace
⑤ 定位到底是谁导致业务变慢
TCP 排队?
内存 NUMA 跨节点?
磁盘延迟?
CPU 被中断打满?
程序逻辑 bug?
5. DPDK 专用调优指南(含 NUMA/IRQ 优化)
① CPU 隔离 isolcpus/nohz_full
isolcpus=1-10 nohz_full=1-10 rcu_nocbs=1-10
避免内核调度干扰
减少调度开销
配合 taskset 绑定 DPDK lcore
② Hugepage(必须)
DPDK 依赖大页减少 TLB miss:
echo 4096 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
③ 关闭 IRQ Balance
systemctl stop irqbalance
④ 关闭 RPS/XPS
echo 0 > /sys/class/net/eth0/queues/rx-0/rps_cpus
⑤ NUMA 绑定
--lcores "1@(0) 2@(1) 3@(1)"
⑥ BIOS 调优
关 C-State
关 HT
关节能策略
开大缓存模式
⑦ 调整 UIO / VFIO 驱动
DPDK 场景下:
vfio-pci(安全)
igb_uio(性能更高)
该文章最后由 阿炯 于 2025-11-18 10:25:14 更新,目前是第 2 版。