 Linux下的关机和重启流程对于一般的桌面应用和网络服务器来说并不重要,但是在用户自己定义的嵌入式系统内核中就有一定的研究意义,通过了解Linux 关机重启的流程,我们对它可以修改和自定义,甚至以此为基础开发出全新的功能来。
Linux下的关机和重启流程对于一般的桌面应用和网络服务器来说并不重要,但是在用户自己定义的嵌入式系统内核中就有一定的研究意义,通过了解Linux 关机重启的流程,我们对它可以修改和自定义,甚至以此为基础开发出全新的功能来。
1、概述
在linux下的关机和重启可能由两种行为引发,一是通过用户编程,一是系统自己产生的消息。用户和系统进行交互的方式也有两个,一个是系统调用:sys_reboot,另一个就是apm或则acpi的设备文件,通过对其操作也可以使系统关机或者重启。
2、通过系统调用sys_reboot的重启
这个系统调用定义了一系列的MAGIC_NUMBER,在调用的开始部分首先检查MAGIC_NUMBER是否正确,只有正确才继续向下运行。在重启的时候转向分支
case LINUX_REBOOT_CMD_RESTART:
首先使用notifier_call_chain向其它部分发出重启的消息,然后调用machine_restart函数完成重启。
machine_restart函数的开始部分有一段SMP相关的代码,主要完成多CPU时由一个CPU完成重启操作,其它CPU处于等待状态。之后系统 根据一个变量reboot_thru_bios的内容判断重启方式,通过阅读reboot_setup我们可以得知,这个参数的内容是在系统启动时指定 的,决定了是否利用bios,事实上是系统复位后的入口(FFFF:0000)地址的程序进行重启。在不通过bios进行重启的情况下,系统首先设定了重 启标志,然后向端口0xfe写入数字0x64,这种重启的具体原理我还不大清楚,似乎是模拟了一次reset键的按下,希望大家和我讨论。在通过bios 重启的情况下,系统同样先设定了重启模式,然后切换到了实模式,通过一条ljmp $0xffff,$0x0完成了重启。
3、通过系统调用sys_reboot进行关机
在系统调用的处理分支上,我们可以看到,首先同样是检查MAGIC_NUMBER,然后在
case LINUX_REBOOT_CMD_POWER_OFF:
的执行流程里面,又是使用notifier_call_chain发出了关闭计算机电源的消息,紧接着执行了machine_power_off函数。我 们在machine_power_off函数中可以看到,如果pm_power_off这个函数指针不为空,那么系统就会通过调用这个函数进行关机。在 apm已经加载的情况下(SMP除外),实际上pm_power_off函数实际上指向了apm.c中的apm_power_off,在这个函数里系统通 过apm_info结构里的值,使用切换到实模式关机,或者使用apm_bios_call_simple函数调用保护模式下的apm接口关机两种方法。
4、apm驱动本身的关机过程
apm使用其注册的设备的ioctl接口完成apm的操作,在apm.c的do_ioctl函数中可以看见处理的分支。这里只有suspend和standby的代码,所以我们不能通过ioctl这种方法使用apm关机。
当用户按下POWER开关的时候,如果有apm模块,那么关机流程是由apm来处理的。apm驱动在初始化的时候启动了一个apm内核线程: apm_mainloop,系统会在这里检测到POWEROFF按键消息并且将其命名为APM_SYS_SUSPEND,以区别apm -s设置的APM_USER_SUSPEND模式。紧接着进入了apm_event_handler函数,又从apm_event_handler函数进 入了check_events函数,处理函数对应的case分支上。系统同样使用了suspend函数进行关机,不过由于其它参数的原因,suspend 最后调用的是关机的流程。
5、解决问题实例
1)按POWER键时某些主板死机
经查只有某些特定的驱动装载之后才会出现这样的情况,并且当使用关机系统调用sys_reboot的时候没有这样的问题。分析apm的处理流程,怀疑是在 关机前驱动程序没有正确处理apm发出的询问消息造成的。由于部分驱动程序没有源代码,决定hack掉apm.c的关机部分,让两种方式的关机走同样的流 程。于是把apm.c的check_events函数中对APM_SYS_SUSPEND部分改写为如下代码:
ret = exec_usermodehelper(poweroff_helper_path, argv, envp);
if (ret) {
printk(KERN_ERR
"apm.c: failed to exec %s , errno = %d\\n",
poweroff_helper_path, errno);
}
break;
For fast reboot support
static unsigned char fast_reboot_switch [] = {
0x66, 0x0f, 0x20, 0xc0, /* movl %cr0,%eax */
0x66, 0x25, 0x10, 0x11, 0x11, 0x11, /* andl $0x11111110,%eax */
0x66, 0x0f, 0x22, 0xc0, /* movl %eax,%cr0 */
0xea, 0x00, 0x00, 0x00, 0x70 /* ljmp $0x7000,$0x0000 */
};
系统就可以切换到实模式中,然后跳转到7000H:0位置开始执行。
6、ACPI概述
在2.4.20内核中ACPI模块被注明为试验和未完成,里面有一部分功能也许没有实现。如果APM和APCI两个模块同时编译进内核,APM在ACPI 前被加载,APM起作用使ACPI退出。对于系统电量、电源实践一类的支持(主要是在笔记本上有用),靠的是acpid这个daemon程序。
没有一个功能类似apm的应用程序切换状态,acpi的程序仅仅完成了对acpi状态的查询。用户实现S0-S4的功能可以直接向/proc/acpi/sleep文件中写入数字来实现。通过读出(cat)其中的内容可以知道系统到底支持那些模式。
acpi模块的源代码主程序在linux/drivers/acpi/driver.c中,如果向sleep文件写东西,就转到了 linux/drivers/acpi/ospm/system/sm_osl.c文件的sm_osl_proc_write_sleep函数中,这个函 数后来调用了sm_osl_suspend函数。在这个函数里完成了各种功能,包括保护各种状态。最后真正的sleep是通过对 acpi_enter_sleep_state的调用完成的,这个函数在linux/drivers/acpi/hardware/hwsleep.c文 件中,这里写了acpi的寄存器使系统进入sleep状态。写寄存器的指令在这个目录下面的hwregs.c中。
7、小结
本文对acpi的介绍非常简略,实际上ACPI必定会成为将来linux内核中首选的电源管理方式。由于目前官方代码中ACPI版本较低,所以没有太详细的论述,希望将来的内核能有所改变。
参考资料:linux-2.4.20源代码。
Linux启动过程(基于X86平台的redhat)
鉴于个人水平有限,本文仅以直观的角度,简单阐述从通电到用户登录界面出现的启动过程。从宏观来看,该过程可分为4个阶段:
1、开机加电
2、运行BIOS
3、启动引导程序
4、操作系统初始化
1、开机加电
机器上电后,如果电源系统工作正常,会发送低电平的"Power Good"到复位电路接口的#RES端,产生时钟同步的复位正脉冲RESET送到CPU的RESET引脚,脉冲的下降沿触发CPU执行初始化程序,设置CS和IP寄存器,进入实地址模式。而根据CS和IP的值得到的物理地址就是CPU执行的第一条指令地址。虽然知道了物理地址,但是内存还没有初始化,因此改物理地址指向BIOS ROM。
对于386前后,该物理地址是不同的,但都在内存的最高地址段。
386以前的CPU寻址范围为1M,即0x00000H~0xFFFFFH。此时CS=0xF000H,IP=0xFFF0H,段地址左移4位后,加上偏移地址得到物理地址0xFFFF0H。
而386的可寻址范围为4GB 即 0x00000000H~0xFFFFFFFFH。如果以0x000FFFF0H作为BIOS地址的话,系统内存不连续,因此,386使用硬件置1的方式将A20~A31地址线置1,就变成0xFFFFFFF0H,并以此作为BIOS地址。
2、运行BIOS
找到BIOS地址后,BIOS的第一条指令就是跳转,其跳转到BIOS的程序入口处,开始运行。比如jmp F000:E05B,跳到0xFE05BH处执行。
在1M的地址空间中,0x00000H~0x9FFFF为RAM,0xA0000H~0xBFFFFH为图形卡映射区,0xC0000H~0xFFFFFH为BIOS例程。其中0xA0000H~0xFFFFFH被称作Shadow RAM,BIOS在运行中会将自身从ROM中拷贝到RAM,以提高系统效率。
BIOS第一步是自检,即进行所谓的POST(Power On Self Test),对硬件进行检测。第二步是进行本地设备的枚举和初始化。根据其不同功能,BIOS 由两部分组成:POST 代码和运行时服务。当 POST 完成之后,它被从内存中清理了出来,但是 BIOS 运行时服务依然保留在内存中,目标操作系统可以使用这些服务。
引导操作系统时,BIOS 运行时会按照 CMOS 的设置定义的顺序来搜索处于活动状态并且可以引导的设备。引导设备可以是软盘、CD-ROM、硬盘上的某个分区、网络上的某个设备,甚至是 USB 闪存。通常,Linux 都是从硬盘上引导的,其中主引导记录(MBR)中包含主引导加载程序。MBR 是一个 512 字节大小的扇区,位于磁盘上的第一个扇区中(0道0柱面1扇区)。当 MBR 被加载到 RAM(0x07C00H)中之后,BIOS 就会将控制权交给 MBR。
3、启动引导程序
MBR就是主引导记录(Master Boot Record),包括0柱0头1扇区的512个字节,它的任务是完成BIOS到操作系统的交接。0000H~01BDH为MBR代码区,负责装载并允许系统引导程序;01BEH~01FDH为分区表信息;01FEH~01FFH的2个字节值为结束标志55AA,如果该标志错误系统就不能启动。
在单一的MBR中只能存储一个操作系统的引导记录,当需要多个操作系统时就会出现问题,所以需要更灵活的引导加载程序。Linux下常见的引导程序有GRUB和LILO。LILO将操作系统位置信息写到MBR中,而GRUB的操作系统位置信息是配置在文件系统中的配置文件里。这里以GRUB为例,进行引导。
GRUB根据其启动过程的文件stage1、xxx_stage1_5、stage2,可分为三个过程。
stage1的大小为512字节,使用grub命令设置启动盘时,会将stage1写入到MBR中,用于引导xxx_stage1_5或stage2。
xxx_stage1_5的前缀为文件系统类型,其功能为确保识别到启动磁盘的文件系统类型。
stage2为GRUB引导的主要阶段,它读取/boot/grub/menu.list(实际指向grub.conf)文件并提供交互界面,根据用户选择和相关配置加载内核。
default=0
timeout=5
splashimage=(hd0,0)/grub/splash.xpm.gz
hiddenmenu
title Fedora Core (2.6.18-1.2798.fc6)
root (hd0,0)
kernel /vmlinuz-2.6.18-1.2798.fc6 ro root=/dev/VolGroup00/LogVol00 rhgb quiet
initrd /initrd-2.6.18-1.2798.fc6.img
这是FC8中menu.list的配置,每一项的内容不再一一解释,只对initrd作相关说明。
initrd(boot loader initialized RAM disk)就是由 boot loader 初始化的内存盘。在内核启动前,GRUB将存储介质中的 initrd 文件加载到内存,内核启动时会在访问真正的根文件系统前先访问该内存中的initrd文件系统。在GRUB配置了initrd的情况下,内核启动被分成了两个阶段,第一阶段先执行initrd文件系统中的“某个文件”,完成加载驱动模块等任务,第二阶段才会执行真正的根文件系统中的/sbin/init进程。第一阶段启动的目的是为第二阶段的启动扫清一切障碍,最主要的是加载根文件系统存储介质的驱动模块。initrd有cpio-initrd和 image-initrd 这两种格式,前者的制作方式和处理流程都更为清晰。
内核加载完成以后会启动/sbin/init,至此进入操作系统加载过程。
4、操作系统初始化
init进程是系统所有进程的起点,进程号是1。init进程是所有进程的发起者和控制者。init进程有两个作用:一是扮演终结父进程的角色,二是根据/etc/inittab来执行相应的脚本进行系统初始化。
inittab是以行为单位的描述性(非执行性)文本,每一个指令行都具有以下格式:
id:runlevel:action:process
其中id为入口标识符,runlevel为运行级别,action为动作代号,process为具体的执行程序。
通过inittab的内容,初始化过程为:
首先寻找initdefault,设置默认的启动级别,如果没有设置initdefault项,init将在控制台上请求输入runlevel。
运行脚本/etc/rc.d/rc.sysinit。该阶段主要进行各个运行级别中相同的初始化工作。完成后进入选定的运行级别中停止或运行相应的服务。
以ttyn为参数运行/sbin/mingetty,打开ttyn终端用于用户登录。如果进程退出则再运行mingetty。
至此进入用户登录界面,启动完毕。
Linux命令行关机和重启命令详解
在linux下一些常用的关机/重启命令有shutdown、halt、reboot及init,它们都可以达到重启系统的目的,但每个命令的内部工作过程是不同的。
1、shutdown
shutdown命令安全地将系统关机。 有些用户会使用直接断掉电源的方式来关闭linux,这是十分危险的。因为linux与windows不同,其后台运行着许多进程,所以强制关机可能会导致进程的数据丢失﹐使系统处于不稳定的状态﹐甚至在有的系统中会损坏硬件设备。而在系统关机前使用shutdown命令﹐系统管理员会通知所有登录的用户系统将要关闭。
并且login指令会被冻结,即新的用户不能再登录。直接关机或者延迟一定的时间才关机都是可能的,还可能重启。这是由所有进程〔process〕都会收到系统所送达的信号〔signal〕决定的。这让像vi之类的程序有时间储存目前正在编辑的文档﹐而像处理邮件〔mail〕和新闻〔news〕的程序则可以正常地离开等等。
shutdown执行它的工作是送信号〔signal〕给init程序﹐要求它改变runlevel。Runlevel 0被用来停机〔halt〕﹐runlevel 6是用来重新激活〔reboot〕系统﹐而runlevel 1则是被用来让系统进入管理工作可以进行的状态﹔这是预设的﹐假定没有-h也没有-r参数给shutdown。要想了解在停机〔halt〕或者重新开机〔reboot〕过程中做了哪些动作﹐你可以在这个文件/etc/inittab里看到这些runlevels相关的资料。
shutdown 参数说明:
[-t] 在改变到其它runlevel之前﹐告诉init多久以后关机。
[-r] 重启计算器。
[-k] 并不真正关机﹐只是送警告信号给每位登录者〔login〕。
[-h] 关机后关闭电源〔halt〕。
[-n] 不用init﹐而是自己来关机。不鼓励使用这个选项﹐而且该选项所产生的后果往往不总是你所预期得到的。
[-c] cancel current process取消目前正在执行的关机程序。所以这个选项当然没有时间参数﹐但是可以输入一个用来解释的讯息﹐而这信息将会送到每位使用者。
[-f] 在重启计算器〔reboot〕时忽略fsck。
[-F] 在重启计算器〔reboot〕时强迫fsck。
[-time] 设定关机〔shutdown〕前的时间。
2、halt—-最简单的关机命令
其实halt就是调用shutdown -h。halt执行时﹐杀死应用进程﹐执行sync系统调用﹐文件系统写操作完成后就会停止内核。
参数说明:
[-n] 防止sync系统调用﹐它用在用fsck修补根分区之后﹐以阻止内核用老版本的超级块〔superblock〕覆盖修补过的超级块。
[-w] 并不是真正的重启或关机﹐只是写wtmp〔/var/log/wtmp〕纪录。
[-d] 不写wtmp纪录〔已包含在选项[-n]中〕。
[-f] 没有调用shutdown而强制关机或重启。
[-i] 关机〔或重启〕前﹐关掉所有的网络接口。
[-p] 该选项为缺省选项。就是关机时调用poweroff。
3、reboot
reboot的工作过程差不多跟halt一样﹐不过它是引发主机重启﹐而halt是关机。它的参数与halt相差不多。
4、init
init是所有进程的祖先﹐它的进程号始终为1﹐所以发送TERM信号给init会终止所有的用户进程﹑守护进程等。shutdown 就是使用这种机制。
init定义了8个运行级别(runlevel),init 0为关机、init 1为重启。
关于init可以长篇大论﹐这里就不再叙述。另外还有telinit命令可以改变init的运行级别﹐比如telinit -iS可使系统进入单用户模式﹐并且得不到使用shutdown时的信息和等待时间。
5、对shutdown、reboot、poweroff、halt的对比说明
1)、shutdown:最安全、最专业的选择
shutdown 是管理关机和重启的首选命令,尤其是在服务器和多用户环境中。其核心优势在于“优雅”和“可调度”。
工作机制:当执行shutdown命令时,它并不会立即粗暴地终止系统。它会执行如下操作:
通知所有已登录用户
通过 wall 命令向所有终端发送消息,告知系统即将关闭或重启,给用户保存工作的缓冲时间。
阻止新用户登录
系统进入预定关机流程后,会阻止新的登录请求。
优雅地终止服务
它会按照预设的顺序,向所有正在运行的服务(守护进程)发送 SIGTERM 信号。这是一个“礼貌”的信号,允许服务自行完成清理工作(如保存数据、关闭文件描述符)然后再退出。
最后才杀死顽固进程
在等待一段时间后,如果仍有进程没有退出,shutdown会发送SIGKILL信号进行强制终止。
同步磁盘并执行最终操作
完成所有进程的关闭后,它会同步文件系统,确保所有缓存数据都写入磁盘,最后才执行真正的重启或关机动作。
常用语法与范例:
立即关机并切断电源:
shutdown -h now
# 或在现代系统中 -P (Poweroff) 更为明确最终关闭电源
shutdown -P now
立即重启:
shutdown -r now
预定关机时间:
# 10分钟后关机
shutdown -h +10 "系统将在10分钟后进行维护,请保存您的工作。"
# 在晚间11点准时重启
shutdown -r 23:00
取消一个预定的关机任务
shutdown -c
只发送警告,不实际执行(“演习”)
shutdown -k +15 "警告:系统将在15分钟后重启,不过这次是演习。"
2)、reboot, poweroff, halt:直接的快捷方式
这三个命令比shutdown更直接,可以看作是特定场景下的快捷方式。
1. reboot
行为:它的意图非常明确——重启系统。
它会执行必要的系统关闭流程(如同步磁盘、终止进程),然后重新引导系统。它不像shutdown那样提供丰富的调度选项和广播通知功能。
2.poweroff
行为:它的目标是关闭系统并确保切断电源。
它会执行与reboot类似的关闭流程,但最后一步是向主板的ACPI发送关机指令,使计算机彻底断电。
3. halt
历史渊源:halt是这几个命令中最容易引起混淆的一个。
历史含义
在早期的计算机和没有ACPI(高级配置与电源接口)的年代,halt的字面意思是“停止所有CPU功能”。
它会使操作系统停止运行,但不一定会切断电源。机器会停在一个“僵住”的状态,需要手动按下电源按钮来关闭。
现代行为
在现代Linux系统中,halt的行为变得复杂。它通常会调用shutdown -h。
而shutdown -h在支持ACPI的系统上,最终效果等同于poweroff。可以通过 halt -p 或 halt --poweroff 来强制它在停机后执行断电操作。
3)、现代Linux系统中的真相:
systemd 的统一管理,在大多数现代Linux发行版(如CentOS 7+, Ubuntu 16.04+, Debian 8+),系统初始化和服务管理都由 systemd 接管。这是一个重要的背景知识,因为它揭示了这几个命令的“幕后关系”。可以通过一个简单的命令来验证这一点:
ls -l /sbin/reboot /sbin/poweroff /sbin/halt
会看到类似这样的输出:
lrwxrwxrwx 1 root root 16 Jul 11 15:37 /sbin/halt -> ../bin/systemctl
lrwxrwxrwx 1 root root 16 Jul 11 15:37 /sbin/poweroff -> ../bin/systemctl
lrwxrwxrwx 1 root root 16 Jul 11 15:37 /sbin/reboot -> ../bin/systemctl
由上可见:reboot, poweroff, halt 实际上都只是指向 /bin/systemctl 的符号链接(symlink)。
当执行reboot时实际上是在执行 systemctl reboot。
当执行poweroff时是在执行systemctl poweroff。
systemd作为现代Linux的“大管家”,统一了这些操作的接口;shutdown命令虽然没有被链接,但它在执行时也会与systemd进行交互来完成最终的任务。
4)、最佳实践与建议
养成使用 shutdown 的好习惯。即使是在个人电脑上,使用 shutdown -r now 也比 reboot 更能体现你的专业性。在服务器上,shutdown 几乎是唯一正确的选择。将 reboot 和 poweroff 视为方便的非交互式快捷键,适用于完全确定不会影响任何其他用户或正在运行的关键任务的场合。除非有非常明确的理由(如处理非常古老的系统或编写需要兼容旧行为的脚本),必用 poweroff 来代替 halt 以避免歧义。
systemd时代的开机启动流程(UEFI+systemd)
本节转自骏马金龙的个人网站,感谢原作者。计算机启动流程可以分为几个大阶段:
内核加载前
本阶段和操作系统无关,Linux或Windows或其它系统在这阶段的顺序是一样的
内核加载中–>内核启动完成
内核加载后–>系统环境初始化完成
终端加载、用户登录
这几个阶段中又有很多小阶段,每个阶段都各司其职。这里主要介绍UEFI+systemd环境下的Linux系统启动流程,如果想要了解Bios+MBR+SysV环境下的详细系统启动流程(如CentOS 6),可参考后文的章节,在需要的时候也会稍微介绍一些Bios+MBR+SysV的内容以作比较和整合。
开机流程图预览
下图是开机的全局流程图,具体的细节后文再详细描述。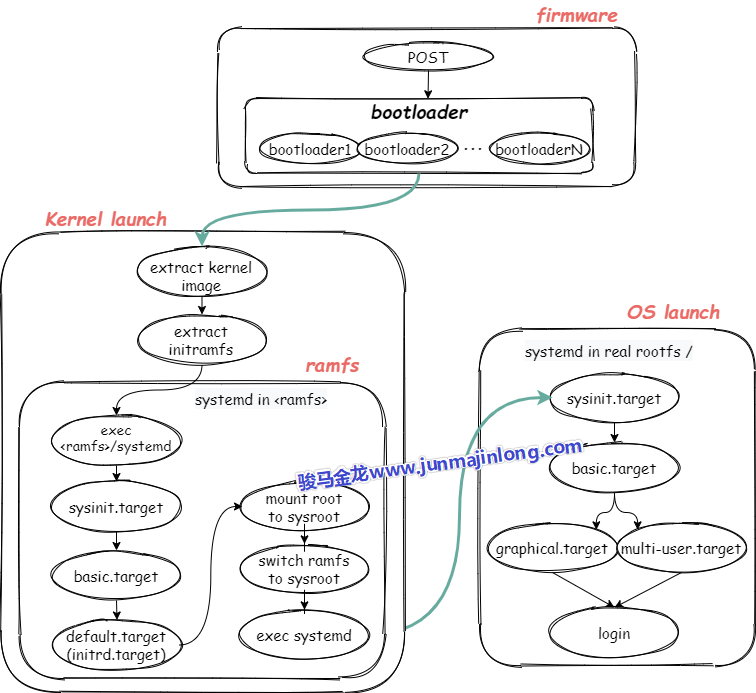
按下电源和固件阶段
按下电源,计算机开始通电,最重要的是要接通cpu的电路,然后通过cpu的针脚让cpu运行起来,只有cpu运行起来才能执行相关代码跳到第一个程序:bios或uefi上,并将CPU控制权交给bios或uefi程序。
下面不考虑从网络启动系统的方式,只考虑启动本地系统。
使用bios的固件阶段
对于BIOS来说,BIOS的工作包括:
(1).POST,即加电对部分硬件进行检查
(2).POST自检之后,BIOS初始化一部分启动所需的硬件(比如会启动磁盘,某些机器可能还会启动键盘)
(3).根据启动顺序找到排在第一位的磁盘
(4).BIOS跳转到所选择磁盘的前446字节,这446字节的代码是第一个bootloader程序,BIOS加载bootloader并将CPU控制权交给bootloader程序
磁盘的第一个扇区(前512字节)称为MBR,其中前446字节是bootloader程序,中间64字节是磁盘分区表,最后两个字节是固定0x55AA的魔数标记,标记该磁盘的MBR是否有效,如果无效,则读取启动顺序中的第二位磁盘
MBR中的bootloader是硬编码在磁盘第一个扇区中的,像grub类的启动管理器会安装各个阶段的boot loader,包括这个MBR bootloader
(5).执行MBR中的bootloader程序,这个bootloader可能会直接加载内核,也可能会跳转到更多的bootloader程序上
因为MBR中的bootloader只有446字节,代码量非常有限,所以有些系统会使用多段bootloader的方式。比如grub在安装MBR的时候,所安装的MBR bootloader最后的代码逻辑是跳转到下一个阶段的bootloader(也是grub安装的),如果下一个阶段的bootloader还不够,那么还可以有更多阶段的bootloader。这种模式称为链式启动
因为内核镜像和启动管理器配置文件等内核启动所必须的文件都在boot分区下,所以中间某个bootloader程序会加载boot分区所在文件系统驱动,使之能够识别boot分区并读取boot分区中的文件
(6).最后一个bootloader将获取内核启动参数(比如从boot分区读取grub配置文件获取内核参数),并加载操作系统的内核镜像(grub配置文件中指定了内核镜像的路径),同时向内核传递内核启动参数,然后将CPU控制权交给内核程序
至此,内核已经加载到内存中,并进入到了内核启动阶段,CPU控制权将转移到内核,内核开始工作。
注:Bios典型支持的是MBR分区类型,但也支持GPT分区类型。UEFI典型支持的是GPT分区类型,但也支持MBR。
从系统启动的角度看,无需在乎是MBR还是GPT,其基本目的都是找到各阶段的bootloader。
使用uefi的固件阶段
UEFI支持读取分区表,也支持直接读取一个文件系统。UEFI不会启动任何MBR扇区中的bootloader(即使有安装MBR),而是从非易失性存储中找到启动条目(boot entry)并启动它。
典型的UEFI支持的非易失性存储有FAT12、FAT16和FAT32文件系统(即EFI系统分区),但是发行商也可以加入额外的文件系统,只要提供对应文件系统的驱动程序即可。比如Macs支持HFS+文件系统。此外,UEFI也支持ISO-9660光盘。
UEFI会启动EFI系统分区中的EFI程序,所谓的EFI程序即类似bootloader的程序,比如单纯的bootloader程序,类似GRUB的启动管理器、UEFI shell程序等(作为systemd系列文章之一,在此有必要一提,systemd-boot工具也可以制作基于UEFI的bootloader)。这些程序通常位于efi系统分区下的/EFI/vendor_name目录中,不同发行商可加入不同的efi程序。在EFI分区的/efi/目录下还有一个boot目录,这个目录中保存了所有的启动条目。
如下图,EFI目录下除了Boot目录外,还有4个发行商(Acronis、deepin、Microsoft、Ubuntu)各自的EFI程序目录。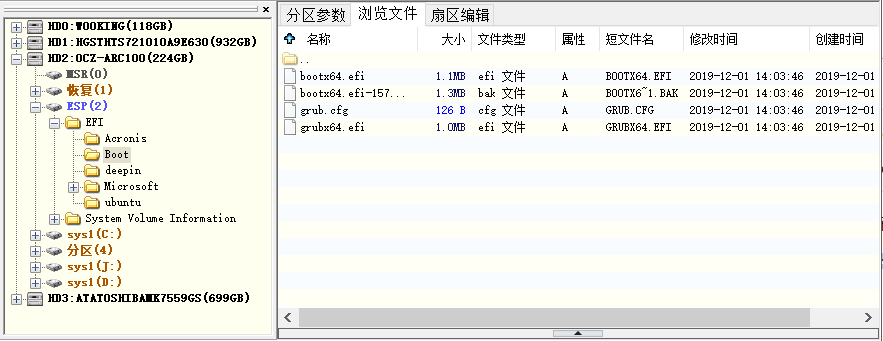
当使用UEFI固件时,CPU通电后,UEFI的工作内容主要包括:
至此,内核已经加载到内存中,并进入到了内核启动阶段,CPU控制权将转移到内核,内核开始工作。
内核启动阶段
到目前为止,内核已经被加载到内存掌握了控制权,且收到了boot loader最后传递的内核启动参数,包括init ramdisk镜像的路径。
但注意,所有的内核镜像都是以bzImage方式压缩过的,压缩后CentOS 6的内核大小大约为4M,CentOS 7的内核大小大约为5M,CentOS 8的内核大小约9M。所以内核要能正常运作下去,它需要进行解压释放。
# CentOS 8内核大小
$ ls -lh /boot/vmlinuz-4.18.0-193.el8.x86_64
-rwxr-xr-x. 1 root root 8.6M May 8 19:07 /boot/vmlinuz-4.18.0-193.el8.x86_64
注:谁解压内核?
内核引导协议要求bootloader最后将内核镜像读取到内存中,内核镜像是以bzImage格式被压缩。bootloader读取内核镜像到内存后,会调用内核镜像中的startup_32()函数对内核解压,也就是说,内核是自解压的。解压之后,内核被释放,开始调用另一个startup_32()函数(同名),startup32函数初始化内核启动环境,然后跳转到start_kernel()函数,内核就开始真正启动了,PID=0的0号进程也开始了……
当内核真正开始运行后,将从/boot分区找到initial ram disk image(后面简称init ramdisk)并解压。init ramdisk要么是initrd,要么是initramfs,它们可使用dracut工具生成,早期系统用initrd比较多,因为现在就会都用initramfs,所以后面可能会以initramfs来描述init ramdisk。
init ramdisk解压之后就得到了内核空间的根文件系统(这是启动过程中的早期根分区,也称为虚根)。对于使用systemd的系统来说,得到虚根之后就可以调用集成在initramfs中的systemd程序,其PID=1。从现在开始,就进入了早期的用户空间(early userspace),systemd进程可以在此时做一些内核启动剩余的必要操作。
完成内核启动的必要操作后,systemd最后会将虚根切换为真实的根分区(即系统启动后用户看到的根分区),并进入真正的用户空间阶段。systemd从此开始就成为了用户空间的总管进程,也是所有用户空间进程的祖先进程。
详细分析内核启动阶段
上面描述的内核启动过程很简单,但里面还有一些『细节』值得思考。
1.如何找到init ramdisk
实际上,内核运行后,会创建一个负责内核运行环境初始化的进程,该进程会根据boot loader传递过来的内核启动参数找到init ramdisk的路径。正常情况下,该路径在boot分区中。之所以能够读取Boot分区是因为在固件阶段,bootloader程序已经加载了boot分区的文件系统驱动。
2.为什么要用init ramdisk
因为直到现在还无法读取根分区,甚至目前还没有根分区的存在,但显然,之后是要挂载根分区的。但是要挂载根分区进而访问根分区,要求知道根分区的类型(比如是xfs还是ext4),从而装在根文件系统的驱动模块。
由于不同用户在安装操作系统时,可能会选择不同的文件系统作为根文件系统的类型,所以不同用户的操作系统在内核启动过程中,根文件系统类型是不同的。如何知道该用户所装的操作系统的根文件系统是哪种类型的?
事实上,在安装操作系统的最后阶段,会自动收集当前所装操作系统的信息,并根据这些信息动态生成一些文件,包括用户所选择的根文件系统的类型以及对应的文件系统驱动模块。这个过程收集的内容会保存在init ramdisk镜像中。
如下图,是某次安装CentOS 7过程中截取下来的生成initramfs镜像文件的图片。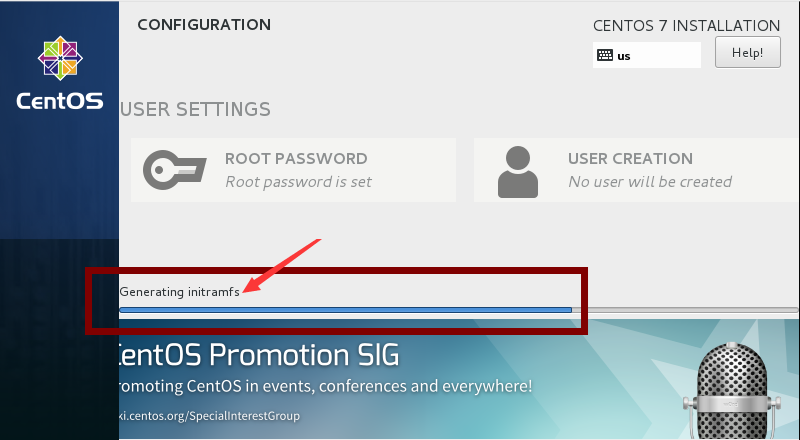
3.内核中根分区的来源
内核会将init ramdisk镜像解压在一个位置下,这个位置称为rootfs,即根文件系统,这个根分区称为虚根,因为这个根分区和系统启动后用户看到的根分区不是同一个根分区。
对于使用initramfs镜像的ramdisk来说,这个rootfs即为ramfs(ram file system),它是一个在解压initramfs镜像后就存在且挂载的文件系统,但是系统启动之后用户并不能找到它,因为在内核启动完成后它就会被切换到真实的根文件系统。
用户也可以手动解压/boot/initramdisk-xxx.img镜像:
$ mkdir /tmp/hhh
$ cd /tmp/hhh
$ /usr/lib/dracut/skipcpio /boot/initramfs-$(uname -r).img | zcat | cpio -idmv
可以想象一下,init ramdisk镜像解压在/tmp/hhh目录下,那么这个目录就可以看作是在内核启动过程中的rootfs。解压得到的根目录和系统启动后的根目录内核很相似:
$ cd /tmp/hhh
$ ls
bin lib run sysroot
dev lib64 sbin tmp
etc proc shutdown usr
init root sys var
再深入一点看,会发现ramdisk中已经生成了我当前操作系统根分区和boot分区的驱动模块。
# boot分区是ext4,根分区是xfs
$ df -T
Filesystem Type ... Mounted on
...
/dev/mapper/cl-root xfs ... /
/dev/nvme0n1p1 ext4 ... /boot
# initramfs中已经具备了ext4和xfs的驱动模块
$ cd /tmp/hhh
$ tree usr/lib/modules/4.18.0-193.el8.x86_64/kernel/fs/
usr/lib/modules/4.18.0-193.el8.x86_64/kernel/fs/
├── ext4
│ └── ext4.ko.xz
├── jbd2
│ └── jbd2.ko.xz
├── mbcache.ko.xz
└── xfs
└── xfs.ko.xz
4.PID=1进程的来源
或者说,PID=1的init程序集成在init ramdisk中?在内核启动过程中就加载了它?
对于早期的initrd来说,init程序并没有集成在initrd中,所以那时的内核会在装载完根分区驱动模块后去根分区寻找/sbin/init程序并调用它。且对于使用initrd的启动过程来说,加载/sbin/init的时机比较晚,很多内核启动过程中的环境都是由内核进程而非init进程完成的。
对于initramfs,它已经将init程序集成在init ramdisk镜像文件中了。如下:
$ cd /tmp/hhh
$ ls -l
total 8
lrwxrwxrwx. ... bin -> usr/bin
drwxr-xr-x. ... dev
drwxr-xr-x. ... etc
lrwxrwxrwx. ... init -> usr/lib/systemd/systemd
lrwxrwxrwx. ... lib -> usr/lib
lrwxrwxrwx. ... lib64 -> usr/lib64
drwxr-xr-x. ... proc
drwxr-xr-x. ... root
drwxr-xr-x. ... run
lrwxrwxrwx. ... sbin -> usr/sbin
-rwxr-xr-x. ... shutdown
drwxr-xr-x. ... sys
drwxr-xr-x. ... sysroot
drwxr-xr-x. ... tmp
drwxr-xr-x. ... usr
drwxr-xr-x. ... var
仔细观察上面的文件结构。init是一个指向systmed的软链接(因为这里使用的是systemd而不是SysV),此外还有几个重要的目录proc、sys、dev、sysroot。
由于内核加载到这里已经初始化一些运行环境了,有些环境是可以保留下来的,这样系统启动后就能直接使用这些已经初始化的环境而无需再次初始化。比如内核的运行状态等参数保存在虚根的/proc和/sys(当然,内核运行环境是保存在内存中的,这两个目录只是内核暴露给用户的路径),再比如,已经收集到的硬件设备信息以及设备的运行环境也要保存下来,保存的位置是/dev。
sysroot则是最重要的,它就是系统启动后用户看到的真正的根分区。没错,真正的根分区只是ramdisk中的一个目录。
systemd在内核启动阶段做的事
在内核启动阶段,当调用了集成在initramfs中的systemd之后,systemd将接管后续的启动操作。但是在这个阶段,systemd具体会做哪些操作呢?
分析systemd在启动阶段所做的事之前,最好对启动流程中的systemd能有一个全局的了解。
注:下图适用于即将解释的内核启动阶段中systemd的流程,也适用于内核启动完成后systemd的流程。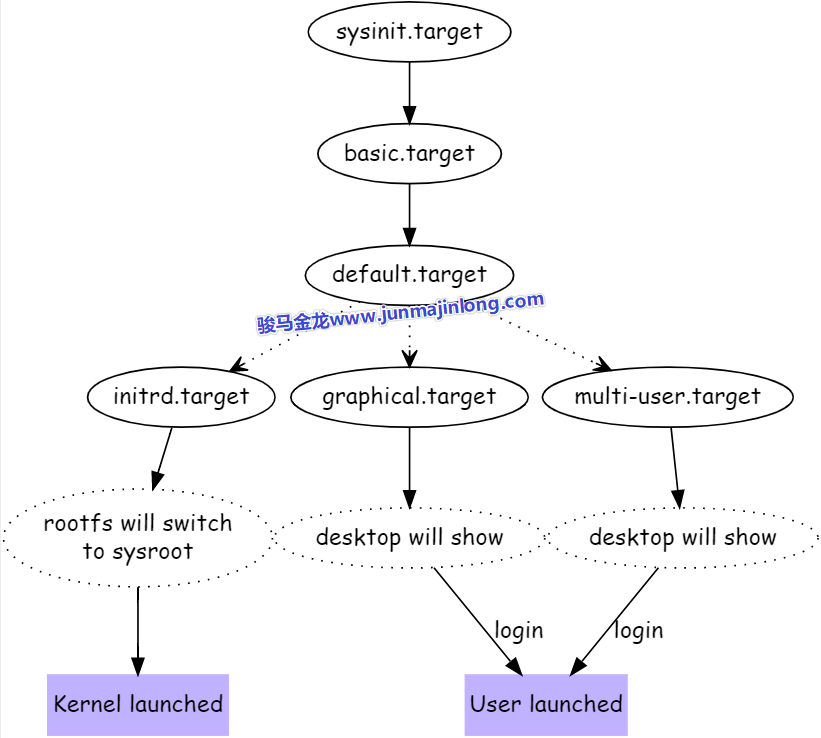
在启动过程中,systemd有几个大目标,每个目标以.target表示。systemd的target主要作用是对多个任务进行分组,比如basic.target中,可能包含了很多任务。
第一个大目标:sysinit.target
sysinit.target主要目的是读系统运行环境做初始化,初始化完成后进入下一个大目标
第二个大目标:basic.target
basic.target的作用主要是在环境初始化完成后执行一些基本任务,算是做一些早期的开机自启动任务,basic.target完成后进入第三个大目标
第三个大目标:『default.target运行级别』
default.target是一个软链接,链接到不同的target表示进入不同的『运行级别』,运行级别阶段的目的是为最终的登录做准备:
如果是内核启动过程中(内核启动时调用了集成在initramfs中的systemd就处于这个过程),那么大目标是initrd.target,该target的目标是为后续虚根切换到实根做初始化准备,比如检查并挂载根文件系统,最终虚根切换实根,并进入真正的用户空间,也即完成了内核启动或内核已经成功登录
如果不是内核启动过程中,可能会选择不同的『运行级别』,通常是图形终端的graphical.target,或者多用户的运行级别multi-user.target,它们的目标都是完成系统启动,并准备让用户登录系统
所以,在内核启动阶段,要分析systemd的工作流程,沿着sysinit-->basic-->initrd-->kernel launched这条路线即可。
回到在内核启动阶段,systemd接管后续的启动操作,具体会做哪些事呢?在man bootup手册中给出了内核启动阶段中systemd的工作流程图。
如下图。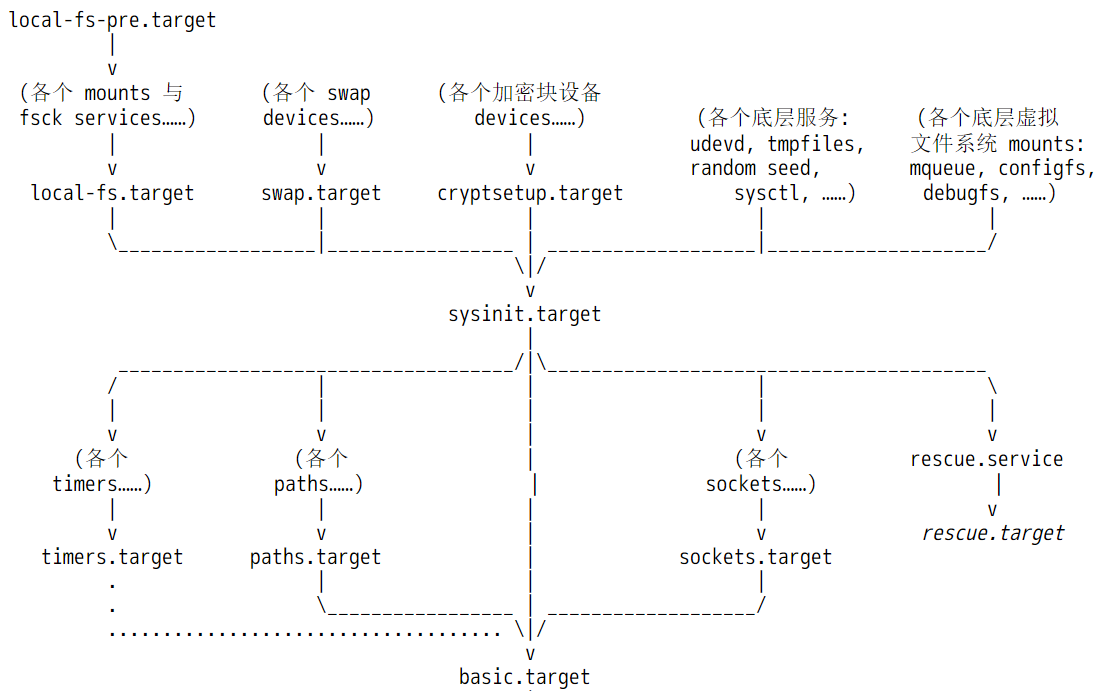
注意,图中所有涉及到的unit文件均来自initramfs镜像解压后的目录,也即虚根,而不是来自真实的根文件系统,因为现在还没有真实的根文件系统。例如<ramfs>/usr/lib/systemd/system/sysinit.target文件。
对于已经启动完成的正常系统来说,sysinit.target是用于做系统初始化的,basic.target则是系统初始化完成后执行的一些基本任务,比如启动所有定时器任务,开始监控指定文件等,算是系统启动过程中早期的开机自启动任务。但是在内核启动阶段,sysinit.target和basic.target所代表的含义,显然与启动完成后这两个文件代表的含义有所不同。在内核启动阶段,sysinit.target中的sys指的是内核阶段的虚拟系统,basic则代表ramdisk决定要执行的基础任务。
换句话说,在内核启动阶段,systemd也将initramfs所启动的环境看作是一个操作系统,只不过是一个虚拟的操作系统。
当basic.target完成后,进入initrd.target,之所以是initrd.target,是因为initramfs中的default.target软链接指向的是initrd.target。
$ cd /tmp/hhh/usr/lib/systemd/system
$ ls -l default.target
...... default.target -> initrd.target
下图描述了initrd.target阶段的工作流程。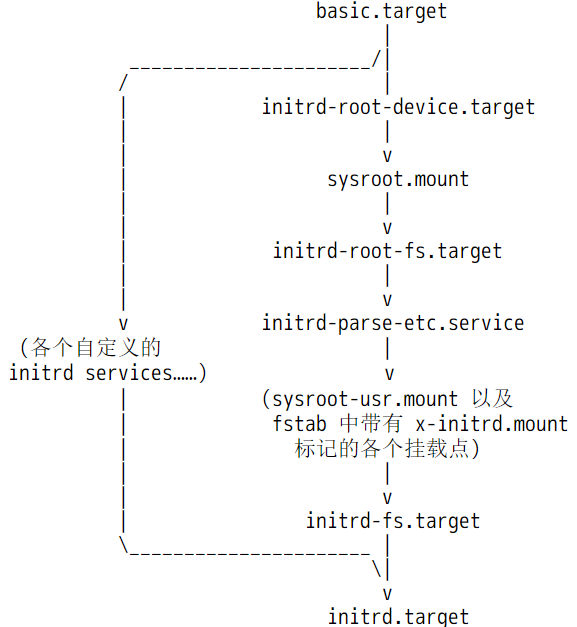
在initrd阶段,systemd为后续切换到真实的根文件系统做准备,比如检查根文件系统并将其挂载在<ramfs>/sysroot下,再比如从/etc/fstab中找出部分需要在这个阶段挂载的分区。如果一切没问题,将进入最后的阶段:从initramfs的虚根<ramfs>/切换到实根<ramfs>/sysroot。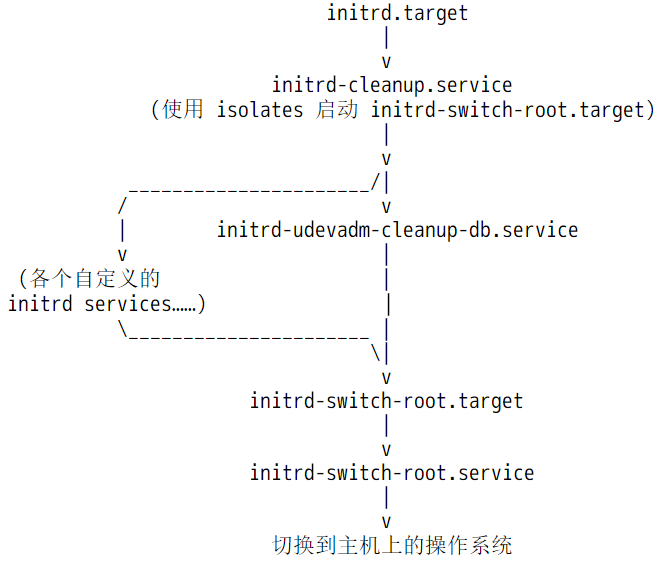
从此开始,<ramfs>/sysroot将代表真实的根文件系统,systemd也将从这个根文件系统调用init程序(systemd)替换当前的systemd进程(所以PID仍然为1)。从此内核引导阶段退出舞台,开始进入真正的用户空间,systemd进程也将在这个用户空间开始下一阶段的流程:sysinit->basic->default->login。
所以,总结一下内核启动阶段中systemd接管控制权后到用户登录中间的流程。如下图。虽然图中内核启动之后的阶段还未展开介绍,但我想大家应该能理解,即使不理解也没关系,稍后会展开。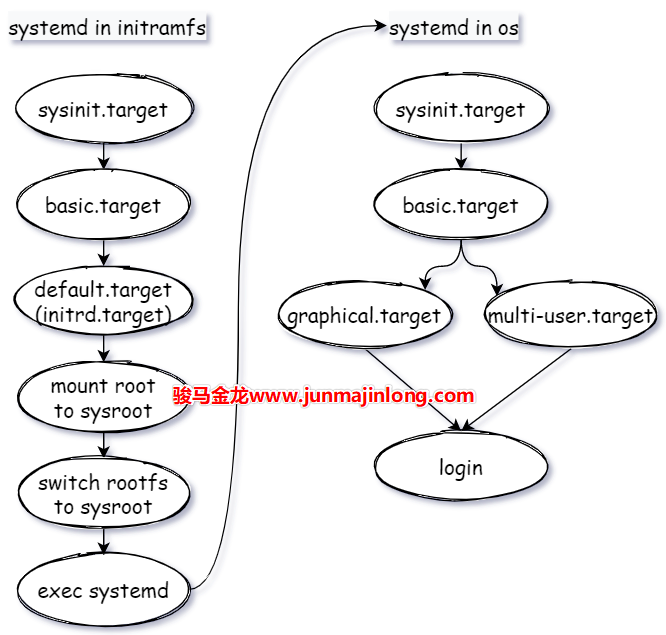
内核启动后,用户登录前
当systemd(这个是来自真实根文件系统的systemd进程)进入到用户空间后,systemd将执行下一轮工作流程,全局路线为:sysinit.target->basic.target->default.target->...->login。
其中default.target是一个软链接,一般指向graphical.target(图形界面)或multi-user.target(多用户模式),对应于SysV系统中的『运行级别』阶段。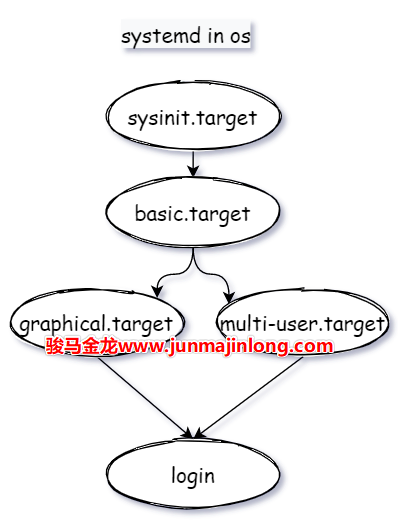
需注意,在这里涉及到的所有unit文件都来自于真实的根文件系统,例如/usr/lib/systemd/system/sysinit.target。而内核启动阶段systemd工作路线中涉及到的unit文件都来自于initramfs构建的虚根,例如<ramfs>/usr/lib/systemd/system/sysinit.target,而且前文也提到过,在systemd眼中,initramfs构建的也是一个系统,只不过是虚拟系统,最终systemd会从这个虚拟系统中切换到真实的系统中,切换的内容主要包括两项:切换根分区,切换systemd进程自身。
在流程的每一个大阶段,和前面介绍的initramfs中的systemd是类似的。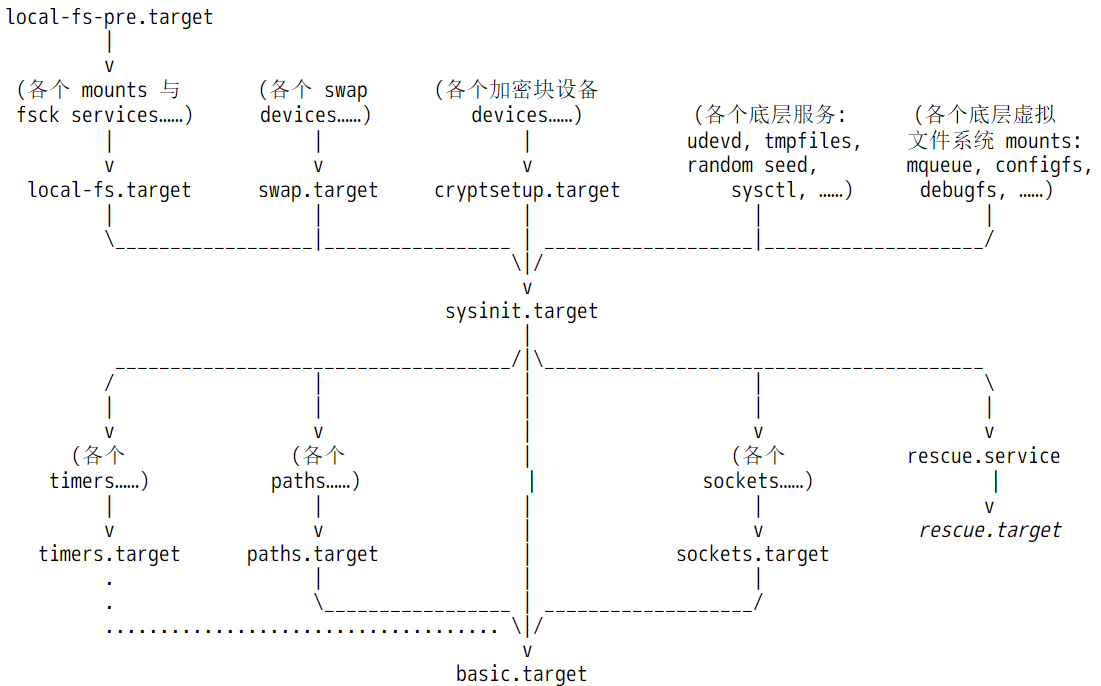
basic.target完成后,将通过default.target决定进入哪一个『运行级别』。如果是进入graphical.target,那么会启动和图形终端相关的服务任务,如果是进入multi-user.target,那么:
$ cd /usr/lib/systemd/system/
$ ls -1 multi-user.target.wants
dbus.service
getty.target
systemd-ask-password-wall.path
systemd-logind.service
systemd-update-utmp-runlevel.service
systemd-user-sessions.service
其中几项需要注意:
getty.target:启动虚拟终端实例(或容器终端实例)并初始化它们
systemd-logind:负责管理用户登录操作
systemd-user-sessions:控制系统是否允许登录
systemd-update-utmp-runlevel:切换运行级别时在utmp和wtmp中记录切换信息
systemd-ask-password-wall:负责查询用户密码
除了这几个multi-user.target所依赖的服务外,在/etc/systemd/system/multi-user.target.wants下也有需要启动的服务,这里的服务是用户定义的systemd类的开机自启动服务。
$ cd /etc/systemd/system
$ ls multi-user.target.wants
atd.service mcelog.service
auditd.service mdmonitor.service
chronyd.service NetworkManager.service
crond.service remote-fs.target
dnf-makecache.timer smartd.service
firewalld.service sshd.service
irqbalance.service sssd.service
kdump.service tuned.service
libstoragemgmt.service vdo.service
不仅如此,为了兼容早期sysV的rc.local开机自启动功能,systemd会检查/etc/rc.local是否具有可执行权限,如果具备,systemd会在此阶段自动执行rc.local中的命令。
CentOS 6开机流程(BIOS+MBR+SysV)
计算机启动分为内核加载前、加载时和加载后3个大阶段,这3个大阶段又可以分为很多小阶段,本文将非常细化分析每一个重要的小阶段。
内核加载前的阶段和操作系统无关,Linux或Windows在这部分的顺序是一样的。由于使用anaconda安装Linux时,默认的图形界面是不支持GPT分区的,即使是目前最新的CentOS 7.3也仍然不支持,所以在本文中主要介绍传统BIOS平台(MBR方式)的启动方式(其实是本人愚笨,看不懂uefi启动方式)。
在内核加载时和加载后阶段,由于CentOS 7采用的是systemd,和CentOS 5或CentOS 6的sysV风格的init大不相同,所以本文也只介绍sysV风格的init。
按下电源和bios阶段
按下电源,计算机开始通电,最重要的是要接通cpu的电路,然后通过cpu的针脚让cpu运行起来,只有cpu运行起来才能执行相关代码跳到bios。
bios是按下开机键后第一个运行的程序,它会读取CMOS中的信息,以了解部分硬件的信息,比如硬件自检(post)、硬件上的时间、硬盘大小和型号等。其实,手动进入bios界面看到的信息,都是在这一阶段获取到的,如下图。对本文来说,最重要的还是获取到了启动设备以及它们的启动顺序(顺序从上到下)信息。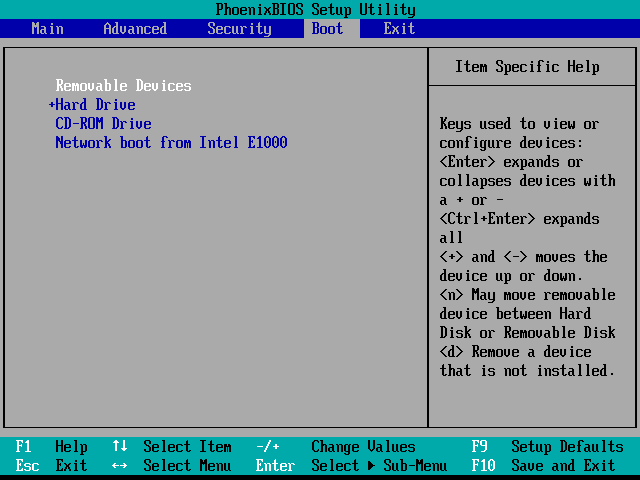
当硬件检测和信息获取完毕,开始初始化硬件,最后从排在第一位的启动设备中读取MBR,如果第一个启动设备中没有找到合理的MBR,则继续从第二个启动设备中查找,直到找到正确的MBR。
MBR和各种bootloader阶段
这小节将介绍各种BR(boot record)和各种boot loader,但只是简单介绍其基本作用。
MBR是主引导记录,位于磁盘的第一个扇区,和分区无关,和操作系统无关,Bios一定会读取MBR中的记录。
在MBR中存储了bootloader/分区表/BRID。bootloader占用446个字节,用于引导加载;分区表占用64个字节,每个主分区或扩展分区占用16个字节,如果16个字节中的第一个字节为0x80,则表示该分区为激活的分区(活动分区),且只允许有一个激活的分区;最后2个字节是BRID(boot record ID),它固定为0x55AA,用于标识该存储设备的MBR是否是合理有效的MBR,如果bios读取MBR发现最后两个字节不是0x55AA,就会读取下一个启动设备。
boot loader
MBR中的bootloader只占用446字节,所以可存储的代码有限,能加载引导的东西也有限,所以在磁盘的不同位置上设计了多种boot loader。下面将说明各种情况。
在创建文件系统时,是否还记得有些分区的第一个block是boot sector?这个启动扇区中也放了boot loader,大小也很有限。如果是主分区上的boot sector,则该段boot loader所在扇区称为VBR(volumn boot record),如果是逻辑分区上的boot sector,则该段boot loader所在扇区称为EBR(Extended boot sector)。但很不幸,这两种方式的boot loader都很少被使用上了,因为它们很不方便,加上后面出现了启动管理器(LILO和GRUB),它们就被遗忘了。但即使如此,在分区中还是存在boot sector。
分区表
硬盘分区的好处之一就是可以在不同的分区中安装不同的操作系统,但boot loader必须要知道每个操作系统具体是在哪个分区。
分区表的长度只有64个字节,里面又分成四项,每项16个字节。所以,一个硬盘最多只能分四个主分区。
每个主分区表项的16个字节,都由6个部分组成:
(1).第1个字节:只能为0或者0x80。0x80表示该主分区是激活分区,0表示非激活分区。单磁盘只能有一个主分区是激活的。
(2).第2-4个字节:主分区第一个扇区的物理位置(柱面、磁头、扇区号等等)。
(3).第5个字节:主分区类型。
(4).第6-8个字节:主分区最后一个扇区的物理位置。
(5).第9-12字节:该主分区第一个扇区的逻辑地址。
(6).第13-16字节:主分区的扇区总数。
最后的四个字节『主分区的扇区总数』,决定了这个主分区的长度。也就是说,一个主分区的扇区总数最多不超过2的32次方。如果每个扇区为512个字节,就意味着单个分区最大不超过2TB。
采用VBR/EBR方式引导操作系统
暂且先不讨论grub如何管理启动操作系统的,以VBR和EBR引导操作系统为例。
当bios读取到MBR中的boot loader后,会继续读取分区表。分两种情况:
如果查找分区表时发现某个主分区表的第一个字节是0x80,也就是激活的分区,那么说明操作系统装在了该主分区,然后执行已载入的MBR中的boot loader代码,加载该激活主分区的VBR中的boot loader,至此,控制权就交给了VBR的boot loader了;
如果操作系统不是装在主分区,那么肯定是装在逻辑分区中,所以查找完主分区表后会继续查找扩展分区表,直到找到EBR所在的分区,然后MBR中的boot loader将控制权交给该EBR的boot loader。
也就是说,如果一块硬盘上装了多个操作系统,那么boot loader会分布在多个地方,可能是VBR,也可能是EBR,但MBR是一定有的,这是被bios给『绑定』了的。在装LINUX操作系统时,其中有一个步骤就是询问你MBR装在哪里的,但这个MBR并非一定真的是MBR,可能是MBR,也可能是VBR,还可能是EBR,并且想要单磁盘多系统共存,则MBR一定不能被覆盖(此处不考虑grub)。
如下图,是我测试单磁盘装3个操作系统时的分区结构。其中/dev/sda{1,2,3}是第一个CentOS 6系统,/dev/sda{5,6,7}是第二个CentOS 7系统,/dev/sda{8,9,10}是第三个CentOS 6系统,每一个操作系统的分区序号从前向后都是/boot分区、根分区、swap分区。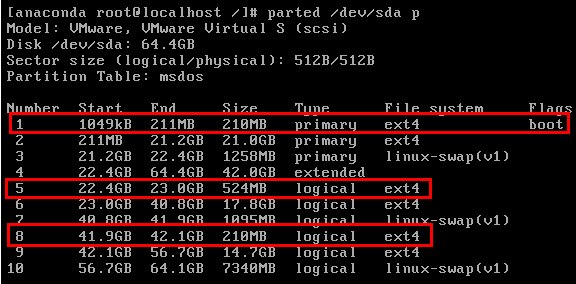
再看下图,是装第三个操作系统时的询问boot loader安装位置的步骤。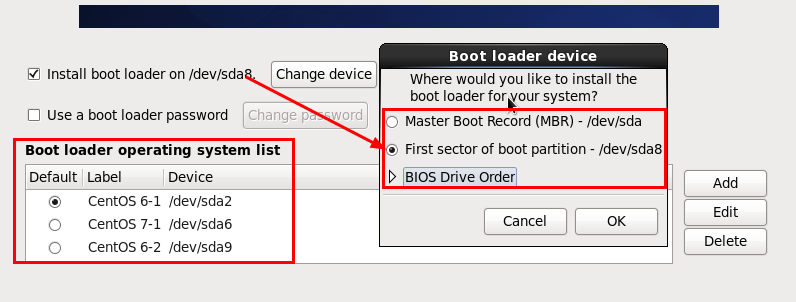
装第一个操作系统时,boot loader可以装在/dev/sda上,也可以选择装在/dev/sda1上,这时装的是MBR和VBR,任选一个都会将另一个也装上,从第二个操作系统开始,装的是EBR而非MBR,且应该指定boot loader位置(如/dev/sda5和/dev/sda8),否则默认选项是装在/dev/sda上,但这会覆盖原有的MBR。
另外,在指定boot loader安装路径的下方,还有一个方框是操作系统列表,这就是操作系统菜单,其中可以指定默认的操作系统,这里的默认指的是MBR默认跳转到哪个VBR或EBR上。所以MBR/VBR和EBR之间的跳转关系如下图。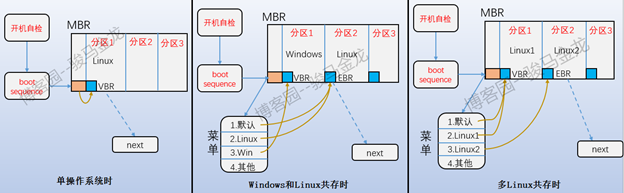
使用这种方式的菜单管理操作系统启动,无需什么stage1,stage1.5和stage2的概念,只要跳转到了分区上的VBR或EBR,那么直接就可以加载引导该分区上的操作系统。
但是,这种管理操作系统启动的菜单已经没有意义了,现在都是使用grub来管理,所以装第二个操作系统或第n个操作系统时不手动指定boot loader安装位置,覆盖掉MBR也无所谓,想要实现单磁盘多系统共存所需要做的,仅仅只是修改grub的配置文件而已。
使用grub管理引导菜单时,VBR/EBR就毫无用处了,具体的见下文。
grub阶段
使用grub管理启动,则MBR中的boot loader是由grub程序安装的,此外还会安装其他的boot loader。CentOS 6使用的是传统的grub,而CentOS 7使用的是grub2。
如果使用的是传统的grub,则安装的boot loader为stage1、stage1_5和stage2,如果使用的是grub2,则安装的是boot.img和core.img。传统grub和grub2的区别还是挺大的,所以下面分开解释,如果对于grub有不理解之处,见grub2详解。
使用grub2时的启动过程
grub2程序安装grub后,会在/boot/grub2/i386-pc/目录下生成boot.img和core.img文件,另外还有一些模块文件,其中包括文件系统类的模块。
$ find /boot/grub2/i386-pc/ -name '*.img' -o -name "*fs.mod" -o -name "*ext[0-9].mod"
/boot/grub2/i386-pc/affs.mod
/boot/grub2/i386-pc/afs.mod
/boot/grub2/i386-pc/bfs.mod
/boot/grub2/i386-pc/btrfs.mod
/boot/grub2/i386-pc/cbfs.mod
/boot/grub2/i386-pc/ext2.mod # ext2、ext3和ext4都使用该模块
/boot/grub2/i386-pc/hfs.mod
/boot/grub2/i386-pc/jfs.mod
/boot/grub2/i386-pc/ntfs.mod
/boot/grub2/i386-pc/procfs.mod
/boot/grub2/i386-pc/reiserfs.mod
/boot/grub2/i386-pc/romfs.mod
/boot/grub2/i386-pc/sfs.mod
/boot/grub2/i386-pc/xfs.mod
/boot/grub2/i386-pc/zfs.mod
/boot/grub2/i386-pc/core.img # 注意此行
/boot/grub2/i386-pc/boot.img # 注意此行
其中boot.img就是安装在MBR中的boot loader。当然,它们的内容是不一样的,安装boot loader时grub2-install会将boot.img转换为合适的汇编代码写入MBR中的boot loader部分。
core.img是第二段Boot loader段,grub2-install会将core.img转换为合适的汇编代码写入到紧跟在MBR后面的空间,这段空间是MBR之后、第一个分区之前的空闲空间,被称为MBR gap,这段空间最小31KB,但一般都会是1MB左右。
实际上,core.img是多个img文件的结合体。它们的关系如下图: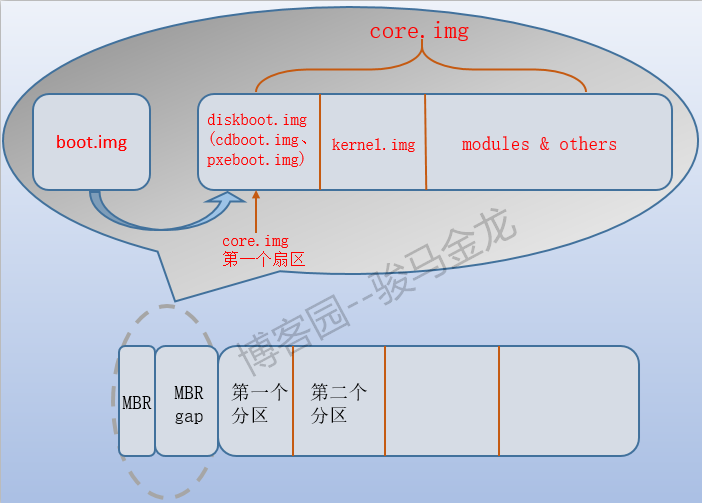
这张图解释了开机过程中grub2阶段的所有过程,boot.img段的boot loader只有一个作用,就是跳转到core.img对应的boot loader的第一个扇区,对于从硬盘启动的系统来说,该扇区是diskboot.img的内容,diskboot.img的作用是加载core.img中剩余的内容。
由于diskboot.img所在的位置是以硬编码的方式写入到boot.img中的,所以boot.img总能找到core.img中diskboot.img的位置并跳转到它身上,随后控制权交给diskboot.img。随后diskboot.img加载压缩后的kernel.img(注意,是grub的kernel不是操作系统的kernel)以初始化grub运行时的各种环境,控制权交给kernel.img。
但直到目前为止,core.img都还不识别/boot所在分区的文件系统,所以kernel.img初始化grub环境的过程就包括了加载模块,严格地说不是加载,因为在安装grub时,文件系统类的模块已经嵌入到了core.img中,例如ext类的文件系统模块ext2.mod。
加载了模块后,kernel.img就能识别/boot分区的文件系统,也就能找到grub的配置文件/boot/grub2/grub.cfg,有了grub.cfg就能显示启动菜单,我们就能自由的选择要启动的操作系统。
当选择某个菜单项后,kernel.img会根据grub.cfg中的配置加载对应的操作系统内核(/boot目录下vmlinuz开头的文件),并向操作系统内核传递启动时参数,包括根文件系统所在的分区,init ramdisk(即initrd或initramfs)的路径。例如下面是某个菜单项的配置:
menuentry 'CentOS 6' --unrestricted {
search --no-floppy --fs-uuid --set=root f5d8939c-4a04-4f47-a1bc-1b8cbabc4d32
linux16 /vmlinuz-2.6.32-504.el6.x86_64 root=UUID=edb1bf15-9590-4195-aa11-6dac45c7f6f3 ro quiet
initrd16 /initramfs-2.6.32-504.el6.x86_64.img
}
加载完操作系统内核后grub2就将控制权交给操作系统内核。
总结下,从MBR开始后的过程是这样的:
1.执行MBR中的boot loader(即boot.img)跳转到diskboot.img。
2.执行diskboot.img,加载core.img剩余的部分,并跳转到kernel.img。
3.kernel.img读取/boot/grub2/grub2.cfg,并显示启动管理菜单。
4.选中某菜单后,kernel.img加载该菜单项配置的操作系统内核/boot/vmlinux-XXX,并传递内核启动参数,包括根文件系统所在分区和init ramdisk的路径。
5.控制权交给操作系统内核。
使用传统grub时的启动过程
传统grub对应的boot loader是stage1和stage2,从stage1跳转到stage2大多数情况下还会用到stage1_5对应的boot loader。
与grub2相比,stage1和boot.img的作用是类似的,都在MBR中。当该段boot loader执行后,它的目的是跳转到stage1_5的第一个扇区上,然后由该扇区的代码加载剩余的内容,并跳转到stage2的第一个扇区上。
stage1_5存在的理由是因为stage2功能较多,导致其文件体积较大(一般至少都有100多K),所以并没有像core.img一样嵌入到磁盘上,而是简单地将其放在了boot分区上,但stage1并不识别boot分区的文件系统类型,所以借助中间的辅助boot loader即stage1_5来跳转。
stage1_5的目的之一是识别文件系统,但文件系统的类型有很多,所以对应的stage1_5也有很多种。
$ ls -C /boot/grub/*stage1_5*
/boot/grub/e2fs_stage1_5 /boot/grub/jfs_stage1_5
/boot/grub/vstafs_stage1_5 /boot/grub/fat_stage1_5
/boot/grub/minix_stage1_5 /boot/grub/xfs_stage1_5
/boot/grub/ffs_stage1_5 /boot/grub/reiserfs_stage1_5
/boot/grub/iso9660_stage1_5 /boot/grub/ufs2_stage1_5
虽然有很多种stage1_5,但每个boot分区也只能对应一种stage1_5。这个stage1_5对应的boot loader一般会被嵌入到MBR后、第一个分区前的中间那段空间(即MBR gap)。
当执行了stage1_5对应的boot loader后,stage1_5就能识别出boot所在的分区,并找到stage2文件的第一个扇区,然后跳转过去。
当控制权交给了stage2,stage2就能加载grub的配置文件/boot/grub/grub.conf并显示菜单并初始化grub的运行时环境,当选中操作系统后,stage2将和kernel.img一样加载操作系统内核,传递内核启动参数,并将控制权交给操作系统内核。
所以stage1、stage1_5和stage2之间的关系如下图: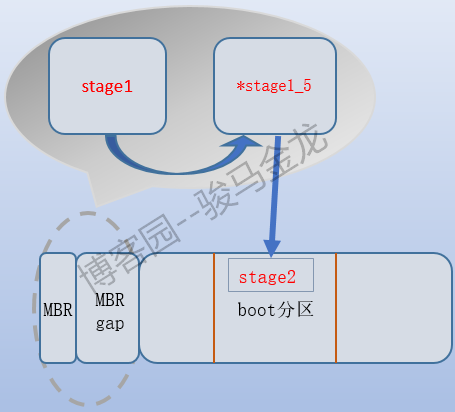
虽然绝大多数都提供了stage1_5,但它不是必须的,它的作用仅仅只是识别boot分区的文件系统类型,对于一个会编程的人来说,可以将固定boot分区的文件系统识别代码嵌入到stage1中,这样stage1自身就能识别boot分区,就不需要stage1_5了。
看看安装grub时,grub到底做了些什么工作。
grub> setup (hd0)
Checking if "/boot/grub/stage1" exists... yes
Checking if "/boot/grub/stage2" exists... yes
Checking if "/boot/grub/e2fs_stage1_5" exists... yes
Running "embed /boot/grub/e2fs_stage1_5 (hd0)"... 15 sectors are embedded.
succeeded
Running "install /boot/grub/stage1 (hd0) (hd0)1+15 p (hd0,0)/boot/grub/stage2 /boot/grub/menu.lst"... succeeded
Done.
首先检测各stage文件是否存在于/boot/grub目录下,随后嵌入stage1_5到磁盘上,该文件系统类型的stage1_5占用了15个扇区,最后安装stage1,并告知stage1 stage1_5的位置是第1到第15个扇区,之所以先嵌入stage1_5再嵌入stage1就是为了让stage1知道stage1_5的位置,最后还告知了stage1 stage2和配置文件menu.lst(它是grub.conf的软链接)的路径。
内核加载阶段
提前说明,下文所述均为sysV init系统启动风格,systemd的启动管理方式大不相同,所以不要将systemd管理的启动方式与此做比较。
到目前为止,内核已经被加载到内存掌握了控制权,且收到了boot loader最后传递的内核启动参数以及init ramdisk的路径。
所有的内核都是以bzImage方式压缩过的,压缩后CentOS 6的内核大小大约为4M,CentOS 7的内核大小大约为5M。内核要能正常运作下去,它需要进行解压释放。
解压释放之后,将创建pid为0的idle进程,该进程非常重要,后续内核所有的进程都是通过fork它创建的,且很多cpu降温工具就是强制执行idle进程来实现的。
然后创建pid=1和pid=2的内核进程。pid=1的进程也就是init进程,pid=2的进程是kthread内核线程,它的作用是在真正调用init程序之前完成内核环境初始化和设置工作,例如根据grub传递的内核启动参数找到init ramdisk并加载。
所谓的救援模式就是刚加载完内核,init进程接收到控制权的那一阶段,因为没有进行任何操作系统初始化过程,所以可以修复和操作系统相关的很多问题。另外,安装镜像中也有内核,可以通过安装镜像进入救援模式,这种进入救援模式的方式几乎可修复任何操作系统启动相关的问题,即使是/boot目录下内核镜像缺失都可以重装。(还有一种单用户模式,它是运行级别为1的环境,所以已经初始化完运行级别,见后文)
加载init ramdisk
在前面,已经创建了pid=1的init进程和pid=2的kthread进程,但注意,它们都是内核线程,全称应该是kernel_init和kernel_kthread,而真正能被ps捕获到的pid=1的init进程是由kernel_init调用init程序后形成的。要加载/sbin/init程序,首先要找到根分区,根分区是有文件系统的,所以内核需要先识别文件系统并加载文件系统的驱动,但文件系统的驱动又是放在根分区的,这就出现了先有鸡还是先有蛋的矛盾。
解决的方法之一是像grub2识别boot分区的文件系统一样,将根文件系统驱动模块嵌入到内核中,但文件系统的种类太多,而且会升级,这样就导致内核不断的嵌入新的文件系统驱动模块,内核不断增大,这显然是不合适的。
解决方法之二则像传统grub借助中间过渡引导段stage1_5一样,将根文件系统的驱动模块放入一个中间过渡文件,在加载根文件系统之前先加载这个过渡文件,再由过渡文件跳转到根文件系统。
方法二正是现在采用的,其采用的中间过渡文件称为init ramdisk,它是在安装完操作系统时生成的,这样它会收集到当前操作系统的根文件系统是什么类型的文件系统,也就能只嵌入一个对应的文件系统驱动模块使其变得足够小。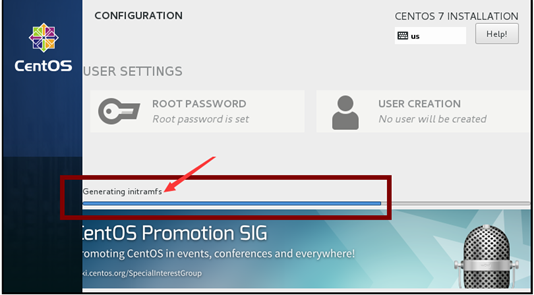
在CentOS 5上采用的init ramdisk称为initrd,而CentOS 6和CentOS 7采用的则是initramfs,它们的目的是一样的,但在实现上却大有不同。但它们都存放在/boot目录下。
$ ll -h /boot/init*
-rw-------. 1 root root 19M Feb 25 11:53 /boot/initramfs-2.6.32-504.el6.x86_64.img
可以看到,它们的大小有十多兆,由此也可知道init ramdisk的作用肯定不仅仅只是找到根文件系统,它还会做其他工作。具体还做什么工作,请继续阅读下文。
initrd
initrd其实是一个镜像文件系统,是在内存中划分一片区域模拟磁盘分区,在该文件中包含了找到根文件系统的脚本和驱动。
既然是文件系统,那么内核也必须要带有对应文件系统的驱动,另外文件系统要使用就必须有根/,这个根是内存中的虚根。由于内核加载到这里已经初始化一些运行环境了,所以内核的运行状态等参数也要保存下来,保存的位置就是内存中虚根下的/proc和/sys,此外还有收集到的硬件设备信息以及设备的运行环境也要保存下来,保存的位置是/dev。到此为止,pid=2的内核线程kernel_kthread就完成了基本工作,开始转到kernel_init进程上了。
再之后就是kernel_init挂载真正的根文件系统并从虚根切换到实根,最后kernel_init将调用init程序,也就是真正的pid=1的init进程,然后将控制权交给init,所以从现在开始,将切换到用户空间,后续剩余的事情都将由用户空间的程序完成。
以下是CentOS 5.8中initrd文件的解压过程和解包后的目录结构。
$ cp /boot/initrd-2.6.18-308.el5.img /tmp/initrd.gz
$ gunzip initrd.gz
$ cpio -id < initrd
$ ls
bin dev etc init initrd lib proc sbin sys sysroot
initramfs
initramfs比initrd又先进了一些,initrd必须是一个文件系统,是在内存中模拟出磁盘分区的,所以内核必须要带有它的文件系统驱动,而initramfs则仅仅只是一个镜像压缩文件而非文件系统,所以它不需要带文件系统驱动,在加载时,内核会将其解压的内容装入到一个tmpfs 中。
initramfs和initrd最大的区别在于init进程的区别对待。initramfs为了尽早进入用户空间,它将init程序集成到了initramfs镜像文件中,这样就可以在initramfs装入tmpfs时直接运行init进程,而不用去找根文件系统下的/sbin/init,由此挂载根文件系统的工作将由init来完成,而不再是内核线程kernel_init完成。最后从虚根切换到实根。
那根分区下的/sbin/init是干嘛的呢?可以认为是init ramdisk中init的一个备份,如果ramdisk中找不到init就会去找/sbin/init。另外在正常运行的操作系统环境下,/sbin/init还经常用来完成其他工作,如发送信号。
其实initramfs完成了很多工作,解开它的镜像文件就能发现它的目录结构和真实环境下的目录结构类似。以下是CentOS 7上initramfs-3.10.0-327.el7.x86_64解包过程和解包后的目录结构。
[~]$ cp /boot/initramfs-3.10.0-327.el7.x86_64.img /tmp/initramfs.gz
[~]$ cd /tmp; gunzip /tmp/initramfs.gz
[tmp]$ cpio -id < initramfs
[tmp]$ ls -l
total 8
lrwxrwxrwx 1 root root 7 Jun 29 23:28 bin -> usr/bin
drwxr-xr-x 2 root root 42 Jun 29 23:28 dev
drwxr-xr-x 11 root root 4096 Jun 29 23:28 etc
lrwxrwxrwx 1 root root 23 Jun 29 23:28 init -> usr/lib/systemd/systemd
lrwxrwxrwx 1 root root 7 Jun 29 23:28 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Jun 29 23:28 lib64 -> usr/lib64
drwxr-xr-x 2 root root 6 Jun 29 23:28 proc
drwxr-xr-x 2 root root 6 Jun 29 23:28 root
drwxr-xr-x 2 root root 6 Jun 29 23:28 run
lrwxrwxrwx 1 root root 8 Jun 29 23:28 sbin -> usr/sbin
-rwxr-xr-x 1 root root 3041 Jun 29 23:28 shutdown
drwxr-xr-x 2 root root 6 Jun 29 23:28 sys
drwxr-xr-x 2 root root 6 Jun 29 23:28 sysroot
drwxr-xr-x 2 root root 6 Jun 29 23:28 tmp
drwxr-xr-x 7 root root 61 Jun 29 23:28 usr
drwxr-xr-x 2 root root 27 Jun 29 23:28 var
另外,还可以在其sbin目录下发现init程序。
[tmp]$ ll sbin/init
lrwxrwxrwx 1 root root 22 Jun 29 23:28 sbin/init -> ../lib/systemd/systemd
操作系统初始化
下文解释的是sysV风格的系统环境,与systemd初始化大不相同。
当init进程掌握控制权后,意味着已经进入了用户空间,后续的事情也将以用户空间为主导来完成。
init的名称是initialize的缩写,是初始化的意思,所以它的作用也就是初始化的作用。在内核加载阶段,也有初始化动作,初始化的环境是内核的环境,是由kernel_init、kernel_thread等内核线程完成的。而init掌握控制权后,已经可以和用户空间交互,意味着真正的开始进入操作系统,所以它初始化的是操作系统的环境。
操作系统初始化涉及了不少过程,大致如下:读取运行级别;初始化系统类的环境;根据运行级别初始化用户类的环境;执行rc.local文件完成用户自定义开机要执行的命令;加载终端;
运行级别
在sysV风格的系统下,使用了运行级别的概念,不同运行级别初始化不同的系统类环境,你可以认为windows的安全模式也是使用运行级别的一种产物。在Linux系统中定义了7个运行级别,使用0-6的数字表示。
0:halt,即关机
1:单用户模式
2:不带NFS的多用户模式
3:完整多用户模式
4:保留未使用的级别
5:X11,即图形界面模式
6:reboot,即重启
实际上,执行关机或重启命令的本质就是向init进程传递0或6这两个运行级别。
sysV的init程序读取/etc/inittab文件来获取默认的运行级别,并根据此文件所指定的配置执行默认运行级别对应的操作。注意,systemd管理的系统是没有/etc/inittab文件的,即使有也仅仅只是出于提醒的目的,因为systemd没有了运行级别的概念。
CentOS 6.6上该文件内容如下:
# cat /etc/inittab
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# System initialization is started by /etc/init/rcS.conf
#
# Individual runlevels are started by /etc/init/rc.conf
#
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
#
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
#
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
#
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:initdefault:
该文件告诉我们,系统初始化过程由/etc/init/rcS.conf完成,运行级别类的初始化过程由/etc/init.conf来完成,按下CTRL+ALT+DEL键要执行的过程由/etc/init/control-alt-delete.conf来完成,终端加载的过程由/etc/init/tty.conf和/etc/init/serial.conf读取配置文件/etc/sysconfig/init来完成。再文件最后,还有一行id:3:initdefault,表示默认的运行级别为3,即完整的多用户模式。
确认了要进入的运行级别后,init将先读取/etc/init/rcS.conf来完成系统环境类初始化动作,再读取/etc/init/rc.conf来完成运行级别类动作。
系统环境初始化
先看看/etc/init/rcS.conf文件的内容。
# cat /etc/init/rcS.conf
# rcS - runlevel compatibility
#
# This task runs the old sysv-rc startup scripts.
#
# Do not edit this file directly. If you want to change the behaviour,
# please create a file rcS.override and put your changes there.
start on startup
stop on runlevel
task
# Note: there can be no previous runlevel here, if we have one it's bad
# information (we enter rc1 not rcS for maintenance). Run /etc/rc.d/rc
# without information so that it defaults to previous=N runlevel=S.
console output
pre-start script
for t in $(cat /proc/cmdline); do
case $t in
emergency)
start rcS-emergency
break
;;
esac
done
end script
exec /etc/rc.d/rc.sysinit
post-stop script
if [ "$UPSTART_EVENTS" = "startup" ]; then
[ -f /etc/inittab ] && runlevel=$(/bin/awk -F ':' '$3 == "initdefault" && $1 !~ "^#" { print $2 }' /etc/inittab)
[ -z "$runlevel" ] && runlevel="3"
for t in $(cat /proc/cmdline); do
case $t in
-s|single|S|s) runlevel="S" ;;
[1-9]) runlevel="$t" ;;
esac
done
exec telinit $runlevel
fi
end script
其中exec /etc/rc.d/rc.sysinit这一行就表示要执行/etc/rc.d/rc.sysinit文件,该文件定义了系统初始化(system initialization)的内容,包括:
(1).确认主机名。
(2).挂载/proc和/sys等特殊文件系统,使得内核参数和状态可与人进行交互。是否还记得在内核加载阶段时的/proc和/sys?
(3).启动udev,也就是启动类似windows中的设备管理器。
(4)初始化硬件参数,如加载某些驱动,设置时钟等。
(5).设置主机名。
(6).执行fsck检测磁盘是否健康。
(7).挂载/etc/fstab中除/proc和NFS的文件系统。
(8).激活swap。
(9).将所有执行的操作写入到/var/log/dmesg文件中。
运行级别环境初始化
执行完系统初始化后,接下来就是执行运行级别的初始化。先看看/etc/init/rc.conf的内容。
# cat /etc/init/rc.conf
# rc - System V runlevel compatibility
#
# This task runs the old sysv-rc runlevel scripts. It
# is usually started by the telinit compatibility wrapper.
#
# Do not edit this file directly. If you want to change the behaviour,
# please create a file rc.override and put your changes there.
start on runlevel [0123456]
stop on runlevel [!$RUNLEVEL]
task
export RUNLEVEL
console output
exec /etc/rc.d/rc $RUNLEVEL
最后一行exec /etc/rc.d/rc $RUNLEVEL说明调用/etc/rc.d/rc这个脚本来初始化指定运行级别的环境。Linux采用了将各运行级别初始化内容分开管理的方式,将0-6这7个运行级别要执行的初始化脚本分别放入rc[0-6].d这7个目录中。
# ls -l /etc/rc.d/
total 60
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 init.d
-rwxr-xr-x. 1 root root 2617 Oct 16 2014 rc
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc0.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc1.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc2.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc3.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc4.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc5.d
drwxr-xr-x. 2 root root 4096 Jun 11 02:42 rc6.d
-rwxr-xr-x. 1 root root 220 Oct 16 2014 rc.local
-rwxr-xr-x. 1 root root 19914 Oct 16 2014 rc.sysinit
实际上/etc/init.d/下的脚本才是真正的脚本,放入rcN.d目录中的文件只不过是/etc/init.d/目录下脚本的软链接。注意,/etc/init.d是Linux耍的一个小把戏,它是/etc/rc.d/init.d的一个符号链接,在有些类unix系统中是没有/etc/init.d的,都是直接使用/etc/rc.d/init.d。
以/etc/rc.d/rc3.d为例。
# ll /etc/rc.d/rc3.d/ | head
total 0
lrwxrwxrwx. 1 root root 16 Feb 25 11:52 K01smartd -> ../init.d/smartd
lrwxrwxrwx. 1 root root 16 Feb 25 11:52 K10psacct -> ../init.d/psacct
lrwxrwxrwx. 1 root root 19 Feb 25 11:51 K10saslauthd -> ../init.d/saslauthd
lrwxrwxrwx 1 root root 22 Jun 10 08:59 K15htcacheclean -> ../init.d/htcacheclean
lrwxrwxrwx 1 root root 15 Jun 10 08:59 K15httpd -> ../init.d/httpd
lrwxrwxrwx 1 root root 15 Jun 11 02:42 K15nginx -> ../init.d/nginx
lrwxrwxrwx. 1 root root 18 Feb 25 11:52 K15svnserve -> ../init.d/svnserve
lrwxrwxrwx. 1 root root 20 Feb 25 11:51 K50netconsole -> ../init.d/netconsole
lrwxrwxrwx 1 root root 17 Jun 10 00:50 K73winbind -> ../init.d/winbind
可见,rcN.d中的文件都以K或S加一个数字开头,其后才是脚本名称,且它们都是/etc/rc.d/init.d中文件的链接。S开头表示进入该运行级别时要运行的程序,S字母后的数值表示启动顺序,数字越大,启动的越晚;K开头的表示退出该运行级别时要杀掉的程序,数值表示关闭的顺序。
所有这些文件都是由/etc/rc.d/rc这个程序调用的,K开头的则传给rc一个stop参数,S开头的则传给rc一个start参数。
打开rc0.d和rc6.d这两个目录,你会发现在这两个目录中除了S00killall和S01reboot,其余都是K开头的文件。
而在rc[2-5].d这几个目录中,都有一个S99local文件,且它们都是指向/etc/rc.d/rc.local的软链接。S99表示最后启动的一个程序,所以rc.local中的程序是2345这4个运行级别初始化过程中最后运行的一个脚本。这是Linux提供给我们定义自己想要在开机时(严格地说是进入运行级别)就执行的命令的文件。
当初始化完运行级别环境后,将要准备登录系统了。
所谓的单用户模式(runlevel=1),就是初始化完运行级别1对应的环境。因为已经初始化了操作系统和运行级别,所以单用户模式所处的层次要比救援模式高的多,能修复的问题也就只有它后面还未初始化的过程:终端初始化和用户登录问题。
终端初始化和登录系统
Linux是多任务多用户的操作系统,它允许多人同时在线工作。但每个人都必须要输入用户名和密码才能验证身份并最终登录。但登陆时是以图形界面的方式给用户使用,还是以纯命令行模式给用户使用呢?这是终端决定的,也就是说在登录前需要先加载终端。
终端初始化
在Linux上,每次开机都必然会开启所有支持的虚拟终端,如下图。
这些虚拟终端是由getty命令(get tty)来完成的,getty命令有很多变种,有mingetty、agetty、rungettty等,在CentOS 5和CentOS 6都使用mingetty,在CentOS 7上使用agetty。getty命令的作用之一是调用登录程序/bin/login。
例如,在CentOS 6下,捕获tty终端情况。
# ps -elf | grep tt[y]
4 S root 1412 ... 1016 n_tty_ Jun21 tty2 ... /sbin/mingetty /dev/tty2
4 S root 1414 ... 1016 n_tty_ Jun21 tty3 ... /sbin/mingetty /dev/tty3
4 S root 1417 ... 1016 n_tty_ Jun21 tty4 ... /sbin/mingetty /dev/tty4
4 S root 1419 ... 1016 n_tty_ Jun21 tty5 ... /sbin/mingetty /dev/tty5
4 S root 1421 ... 1016 n_tty_ Jun21 tty6 ... /sbin/mingetty /dev/tty6
4 S root 1492 ... 27118 n_tty_ Jun21 tty1 ... -bash
在CentOS 7下,捕获tty终端情况。
# ps -elf | grep tt[y]
4 S root 8258 ... 27507 n_tty_ 04:17 tty2 ... /sbin/agetty --noclear tty2 linux
4 S root 8259 ... 27507 n_tty_ 04:17 tty3 ... /sbin/agetty --noclear tty3 linux
4 S root 8260 ... 27507 n_tty_ 04:17 tty4 ... /sbin/agetty --noclear tty4 linux
4 S root 8262 ... 29109 n_tty_ 04:17 tty1 ... -bash
4 S root 8307 ... 29109 n_tty_ 04:17 tty5 ... -bash
4 S root 8348 ... 29136 n_tty_ 04:17 tty6 ... -bash
细心一点会发现,有的tty终端仍然以/sbin/mingetty进程或/sbin/agetty进程显示,有些却以bash进程显示。这是因为getty进程在调用/bin/login后,如果输入用户名和密码成功登录了某个虚拟终端,那么gettty程序会融合到bash(假设bash是默认的shell)进程,这样getty进程就不会再显示了。
虽然getty不显示了,但并不代表它消失了,它仍以特殊的方式存在着。是否还记得/etc/inittab文件?此文件中提示了终端加载的过程由/etc/init/tty.conf读取配置文件/etc/sysconfig/init来完成。
# grep tty -A 1 /etc/inittab
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
那么就看看/etc/init/tty.conf文件。
# cat /etc/init/tty.conf
# tty - getty
#
# This service maintains a getty on the specified device.
#
# Do not edit this file directly. If you want to change the behaviour,
# please create a file tty.override and put your changes there.
stop on runlevel [S016]
respawn
instance $TTY
exec /sbin/mingetty $TTY
usage 'tty TTY=/dev/ttyX - where X is console id'
此文件中的respawn表示进程由init进程监视,即使被杀掉了也会由init来重启它。所以,只要getty进程一结束,init会立即监视到而重启该进程。因此,用户登录成功后getty只是融合到了bash进程中,并非退出,否则init会立即重启它,而它会调用login程序让你再次输入用户和密码。
再看看/etc/sysconfig/init文件。
# cat /etc/sysconfig/init
# color => new RH6.0 bootup
# verbose => old-style bootup
# anything else => new style bootup without ANSI colors or positioning
BOOTUP=color
# column to start "[ OK ]" label in
RES_COL=60
# terminal sequence to move to that column. You could change this
# to something like "tput hpa ${RES_COL}" if your terminal supports it
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
# terminal sequence to set color to a 'success' color (currently: green)
SETCOLOR_SUCCESS="echo -en \\033[0;32m"
# terminal sequence to set color to a 'failure' color (currently: red)
SETCOLOR_FAILURE="echo -en \\033[0;31m"
# terminal sequence to set color to a 'warning' color (currently: yellow)
SETCOLOR_WARNING="echo -en \\033[0;33m"
# terminal sequence to reset to the default color.
SETCOLOR_NORMAL="echo -en \\033[0;39m"
# Set to anything other than 'no' to allow hotkey interactive startup...
PROMPT=yes
# Set to 'yes' to allow probing for devices with swap signatures
AUTOSWAP=no
# What ttys should gettys be started on?
ACTIVE_CONSOLES=/dev/tty[1-6]
# Set to '/sbin/sulogin' to prompt for password on single-user mode
# Set to '/sbin/sushell' otherwise
SINGLE=/sbin/sushell
其中ACTIVE_CONSOLES指令决定了要开启哪些虚拟终端。SINGLE决定了在单用户模式下要调用哪个login程序和哪个shell。
登录过程
如果不在虚拟终端登录,而是通过为ssh分配的伪终端登录,那么到创建完getty进程那一步其实开机流程已经完成了。但不管在哪种终端下登录,登录过程也可以算作开机流程的一部分,所以也简单说明下。
getty进程启用虚拟终端后将调用login进程提示用户输入用户名或密码(或伪终端的连接程序如ssh提示输入用户名和密码),当用户输入完成后,将验证输入的用户名是否合法,密码是否正确,用户名是否是明确被禁止登陆的,PAM模块对此用户的限制是如何的等等,还要将登录过程记录到各个日志文件中。如果登录成功,将加载该用户的bash,加载bash过程需要读取各种配置文件,初始化各种环境等等。但不管怎么说,只要登录成功就表示开机流程全部完成了。