设置Linux系统最大使用的资源限制
 通常对Linux用户设置系统资源使用量,主要可以用ulimit命令来查看和设置。Linux系统默认open files数目为1024, 有时应用程序会报Too many open files的错误,是因为open files 数目不够。这就需要修改ulimit和file-max,特别是提供大量静态文件访问的web服务器,缓存服务器更要注意这个问题。网上的教程都只是简单说明要如何设置ulimit和file-max,但这两者之间的关系差别,并没有仔细说明。
通常对Linux用户设置系统资源使用量,主要可以用ulimit命令来查看和设置。Linux系统默认open files数目为1024, 有时应用程序会报Too many open files的错误,是因为open files 数目不够。这就需要修改ulimit和file-max,特别是提供大量静态文件访问的web服务器,缓存服务器更要注意这个问题。网上的教程都只是简单说明要如何设置ulimit和file-max,但这两者之间的关系差别,并没有仔细说明。Linux最大文件句柄数量之(file-max ulimit -n limit.conf)
到底最大文件数被什么限制了,too many open files错误到底可以通过什么参数控制,网上的很多文章说的大致步骤是有些让人迷惑的,表述大致如下:
Shell级限制
通过ulimit -n修改,如执行命令ulimit -n 1000,则表示将当前shell的当前用户所有进程能打开的最大文件数量设置为1000。
用户级限制
ulimit -n是设置当前shell的当前用户所有进程能打开的最大文件数量,但是一个用户可能会同时通过多个shell连接到系统,所以还有一个针对用户的限制,通过修改 /etc/security/limits.conf实现,例如往limits.conf输入以下内容:
root soft nofile 1000
root hard nofile 1200
soft nofile表示软限制,hard nofile表示硬限制,软限制要小于等于硬限制。上面两行语句表示root用户的软限制为1000,硬限制为1200,即表示root用户能打开的最大文件数量为1000,不管它开启多少个shell。
通过ulimit -Sn设置最大打开文件描述符数的soft limit,注意soft limit不能大于hard limit(ulimit -Hn可查看hard limit),另外ulimit -n默认查看的是soft limit,但是ulimit -n 1800000则是同时设置soft limit和hard limit。对于非root用户只能设置比原来小的hard limit。
系统级(内核)限制
修改/proc/sys/fs/file-max
Linux大部分的命令设置都是临时生效,而且ulimit命令只对当前终端生效,如果需要永久生效的话,我们有两种方法,一种是将命令写至profile和bashrc中,在有些网页中说写到rc.local;还有一种就是在limits.conf中添加记录(可能需要重启生效,并且在/etc/pam.d/中的seesion有使用到limit模块)。接下来讨论的就是在limits.conf用户最大文件打开数限制的相关内容。
In Linux resource limits can be set in various locations based on the type of requirement.
/etc/security/limits.conf file.
/etc/sysctl.conf file.
ulimit command
/etc/security/limits.conf is part of pam_limits and so the limits that are set in this file is read by pam_limits module during login sessions. The login session can be by ssh or through terminal. And pam_limits will not affect the daemon processes as mentioned here.
/etc/sysctl.conf is a system wide global configuration, we cannot set user specific configuration here. It sets the maximum amount of resource that can be used by all users/processes put to gether.
ulimit command is used to set the limits of the shell. And so when a limit is set with ulimit on a shell, the process which gets spawned from the shell gets that value too because of the rule that the child process inherits the parent processes properties.
一 、ulimit
ulimit查看当前限制
$ ulimit -n
$ ulimit -Sn
$ ulimit -Hn
网上很多文章说,ulimit -n限制用户单个进程的打开最大数量,这个说法其实是有些误解的。看看ulimit官方描述:Provides control over the resources available to the shell and to processes started by it, on systems that allow such control. The -H and -S options specify that the hard or soft limit is set for the given resource. A hard limit cannot be increased once it is set; a soft limit may be increased up to the value of the hard limit. If neither -H nor -S is specified, both the soft and hard limits are set. The value of limit can be a number in the unit specified for the resource or one of the special values hard, soft, or unlimited, which stand for the current hard limit, the current soft limit, and no limit, respectively.
If limit is omitted, the current value of the soft limit of the resource is printed, unless the -H option is given. When more than one resource is specified, the limit name and unit are printed before the value.
看第一句部分,是限制当前shell以及该shell启动的进程打开的文件数量,会给人造成限制单个进(线)程的最大文件数量的错觉;因为很多情况下,在一个shell环境里,虽然可能会有多个进程,但是非常耗费文件句柄的进程不会很多,只是其中某个进程非常耗费文件句柄,比如服务器上运行着一个服务进程要占用大多数文件句柄。此时ulimit设置的最大文件数和进程耗费的最大文件数基本是对应的。
任何用户都可以执行ulimit,但root用户和非root用户是不一样的:非root用户只能越设置越小,不能越设置越大。
$ ulimit -n 900
执行成功,再增大:
$ ulimit -n 901
-bash: ulimit: open files: cannot modify limit: Operation not permitted
root用户不受此限制,请自行实验。
ulimit里的最大文件打开数量的默认值
如果在limits.conf里没有设置,则默认值是1024,如果limits.conf中有设置,则默认值以limits.conf为准。登录进入一台服务器调用ulimit -n显示如下:
# ulimit -n
2000
这是因为limits.conf里的文件打开数是2000,如下:
# cat /etc/security/limits.conf
root soft nofile 2000
root hard nofile 2001
如果limits.conf里不做任何限制,则重新登录进来后,ulimit -n显示为1024。设置nofile的hard limit还有一点要注意的就是hard limit不能大于/proc/sys/fs/nr_open,假如hard limit大于nr_open,注销后无法正常登录,下文有详述。
ulimit修改后生效周期
修改后立即生效,重新登录进来后失效,因为被重置为limits.conf里的设定值。ulimit -SHn 65536 等效 ulimit -n 65536,-S指soft,-H指hard。
ulimit 是一个 shell(这里使用的是 bash) 内置命令,可以通过 type ulimit 验证。
-n 即表示查看或者设置 open file(s) 的限制,在 ulimit 中,每个限制都有两种类型:
-S, soft limit, 软限制,用户可以上调软限制到硬限制
-H, hard limit, 硬限制,非 root 用户不能修改
如果没有指明,则同时修改软限制和硬限制。
ulimit 命令
1、只对当前tty(终端有效),若要每次都生效的话,可以把ulimit参数放到对应用户的.bash_profile里面;
2、ulimit命令本身就有分软硬设置,加-H就是硬,加-S就是软;
3、默认显示的是软限制,如果运行ulimit命令修改的时候没有加上的话,就是两个参数一起改变.生效;
# ulimit -a 命令的输出信息:
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited # 一个进程的数据段的最大值
scheduling priority (-e) 0
file size (blocks, -f) unlimited # Shell创建文件的最大体积, 1block = 512bytes
pending signals (-i) 1031426 # 最多允许多少个待处理的信号
max locked memory (kbytes, -l) 64 # 每个进程可以锁住的物理内存的最大值
max memory size (kbytes, -m) unlimited # 每个进程可以使用的常驻内存的最大值
open files (-n) 65536 # 每个进程可以同时打开的最大文件数, 不能是unlimited
pipe size (512 bytes, -p) 8 # 管道的最大值, 1block = 512bytes
POSIX message queues (bytes, -q) 819200 # POSIX的消息队列的最大值
real-time priority (-r) 0
stack size (kbytes, -s) 10240 # 单个进程能够使用的最大栈大小
cpu time (seconds, -t) unlimited # 单个进程的最大CPU时间, 也就是可使用CPU的秒数, 到硬极限时, 这个进程就会立即自杀; 到软极限时, 每秒发送一次限制超时信号SIGXCPU
max user processes (-u) 131072 # 单个用户可同时运行的最大进程数, 不能是unlimited
virtual memory (kbytes, -v) unlimited # 每个进程可使用的最大虚拟内存
file locks (-x) unlimited # 每个进程能锁住的最大文件个数
ulimit的其它命令:
-H 设置某个给定资源的硬极限. 如果用户拥有root权限, 可以增大硬极限. 任何用户均可减少硬极限
-S 设置某个给定资源的软极限, 软极限可增大到硬极限的值
注意事项:unlimited是指不限制用户可以使用的资源,但这个设置对系统可打开的最大文件数(max open files)和各个用户可同时运行的最大进程数(max user processes)无效。如果某个指标没有明确指定-H和-S限制,那么当前的极限值就是 -H 和 -S 两者的极限值。
表 1. ulimit 参数说明
| 选项 [options] | 含义 | 例子 |
| -H | 设置硬资源限制,一旦设置不能增加。 | ulimit -Hs 64;限制硬资源,线程栈大小为 64K。 |
| -S | 设置软资源限制,设置后可以增加,但是不能超过硬资源设置。 | ulimit -Sn 32;限制软资源,32 个文件描述符。 |
| -a | 显示当前所有的 limit 信息。 | ulimit -a;显示当前所有的 limit 信息。 |
| -c | 最大的 core 文件的大小, 以 blocks 为单位。 | ulimit -c unlimited; 对生成的 core 文件的大小不进行限制。 |
| -d | 进程最大的数据段的大小,以 Kbytes 为单位。 | ulimit -d unlimited;对进程的数据段大小不进行限制。 |
| -f | 进程可以创建文件的最大值,以 blocks 为单位。 | ulimit -f 2048;限制进程可以创建的最大文件大小为 2048 blocks。 |
| -l | 最大可加锁内存大小,以 Kbytes 为单位。 | ulimit -l 32;限制最大可加锁内存大小为 32 Kbytes。 |
| -m | 最大内存大小,以 Kbytes 为单位。 | ulimit -m unlimited;对最大内存不进行限制。 |
| -n | 可以打开最大文件描述符的数量。 | ulimit -n 128;限制最大可以使用 128 个文件描述符。 |
| -p | 管道缓冲区的大小,以 Kbytes 为单位。 | ulimit -p 512;限制管道缓冲区的大小为 512 Kbytes。 |
| -s | 线程栈大小,以 Kbytes 为单位。 | ulimit -s 512;限制线程栈的大小为 512 Kbytes。 |
| -t | 最大的 CPU 占用时间,以秒为单位。 | ulimit -t unlimited;对最大的 CPU 占用时间不进行限制。 |
| -u | 用户最大可用的进程数。 | ulimit -u 64;限制用户最多可以使用 64 个进程。 |
| -v | 进程最大可用的虚拟内存,以 Kbytes 为单位。 | ulimit -v 200000;限制最大可用的虚拟内存为 200000 Kbytes。 |
针对用户打开最大文件数的限制, 在limits.conf对应的nofile,不管是man手册还是文件中说明都只是一句话"maximum number of open files",它其实对应是单个进程能打开的最大文件数,通常为了省事,我们想取消它的限制,根据man手册中,"values -1, unlimited or infinity indicating no limit",-1、unlimited、infinity都是表明不做限制,可是当你实际给nofile设置成这个值,等你重启就会发现无法登录系统了。
二、内核相关参数
网上有许多文章说,ulimit -n 和limits.conf里最大文件数设定不能超过/proc/sys/fs/file-max的值,/proc/sys/fs/file-max是系统给出的建议值,系统会计算资源给出一个和合理值,一般跟内存有关系,内存越大该值越大,但是仅仅是一个建议值,limits.conf的设定完全可以超过/proc/sys/fs/file-max。
查看系统最大打开文件描述符数
cat /proc/sys/fs/file-max
查看当前系统使用的打开文件描述符数
cat /proc/sys/fs/file-nr
修改file-max(内核空间)
# echo 102400 > /proc/sys/fs/file-max
# sysctl -w "fs.file-max=102400",上面的操作方式在重启机器后会恢复为默认值
# vim /etc/sysctl.conf, 加入以下内容,不用担心重启会不再生效
fs.file-max=102400
修改ulimit的open file(用户空间),系统默认的ulimit对文件打开数量的限制是1024,可将limits.conf里文件最大数量设定为1610496,保存后打印出来:
# cat /etc/security/limits.conf
root soft nofile 1610496
root hard nofile 1610496
Linux系统级别限制所有用户进程能打开的文件描述符总数可以通过如下的命令查看:
$ cat /proc/sys/fs/file-max
2259544
kernel 级别有2个配置,分别是:
fs.nr_open:进程级别
fs.file-max:系统级别
fs.nr_open 默认设置的上限是 1048576,所以用户的 open file(s) 不可能超过这个上限。
有两种方法修改系统级别的限制:
1).通过命令动态修改(重启后失效)
sysctl -w fs.file-max=102400
2).通过配置文件修改
vim /etc/sysctl.conf
在文件末尾添加
fs.file-max=102400
保存退出后使用sysctl -p 命令使其生效,和fs.file-max有关的一个参数是file-nr,该参数是只读的。
cat /proc/sys/fs/file-nr
3296 0 2259544
file-nr的值由3部分组成:字段1:已经分配的文件描述符数;字段2:内核2.4之后废弃;字段3:已经分配但未使用的文件描述符数。
内核最大能分配的文件描述符数:只要你的内存足够大,file-max的值可以非常大。
用户级别的限制是通过可以通过命令ulimit命令和文件/etc/security/limits.conf(上文有述)
$ ulimit -n
655350
//查看硬资源限制
$ ulimit -Hn
//查看软资源限制
$ ulimit -Sn
//设置软/硬件资源限制
ulimit -Sn 655350 或 ulimit -Hn 655350
limits.conf文件
cat /etc/security/limits.conf
* hard nofile 655350
* soft nofile 655350
limits.conf 文件的格式是:
<domain> <type> <item> <value>
每个域的取值说明:如果domain的值是一个用户名,则可以限制该用户下的所有进程能打开的文件描述符总数,如果是*则表示针对每个用户都起作用。
注意:针对同一item取值,soft的值不能大于hard。
file-max的含义,man proc可得到file-max的描述:
/proc/sys/fs/file-max:This file defines a system-wide limit on the number of open files for all processes. (See also setrlimit(2), which can be used by a process to set the per-process limit,RLIMIT_NOFILE, on the number of files it may open.) If you get lots of error messages about running out of file handles, try increasing this value:
即file-max是设置系统所有进程一共可以打开的文件数量。同时一些程序可以通过setrlimit调用,设置每个进程的限制。如果得到大量使用完文件句柄的错误信息,是应该增加这个值。也就是说这项参数是系统级别的。
ulimit:Provides control over the resources available to the shell and to processes started by it, on systems that allow such control.
即设置当前shell以及由它启动的进程的资源限制。对服务器来说,file-max、ulimit都需要设置,否则就可能出现文件描述符用尽的问题。
内核参数fs.file-max指定了系统范围内所有进程可打开的文件句柄的数量限制,该数值取决于内存。合理计算方法:每1M内存可用于100个文件句柄,默认情况下,不要将超过10%的内存用于文件。将文件句柄数设置太大的危害是当大量的文件句柄都为sockets时,会占用大量的内存,这些内存都是不可交换的。网络套接字连接符也是文件,对于百万级连接数的进程来说,要设置单个进程可打开的文件句柄数为百万个。一般为内存大小(KB)的10%来计算,不需要主动设置这个值,除非这个值确实较小;比如256G内存,应该配置的值为:256*0.1*1024*100=2621440。
内核参数fs.nr_open指定了单个进程可打开的文件句柄的数量限制。nofile可设置的上限受fs.nr_open的限制,不可超过fs.nr_open的值。nr_open的默认值为1048576(1024*1024),这个值一般不用更改,对于百万级别的单进程最大文件句柄打开数应该也够,nofile基本不会超过这个值。
内核参数fs.file-nr可以查看系统中当前打开的文件句柄的数量。里面包括3个数字:第一个表示已经分配了的文件描述符数量,第二个表示空闲的文件句柄数量(待重新分配的),第三个表示能够打开文件句柄的最大值(与fs.file-max一致)。
单个进程实际能够打开的最大文件句柄数量为ulimit -n,默认为1024个,针对单个进程实际可打开的最大文件数的限制,在/etc/security/limits.conf中对应nofile的值。针对用户打开最大文件数的限制,在limits.conf对应的nofile,不管是man手册还是配置文件中说明都只是一句话“maximum number of open files",它其实对应是单个进程能打开的最大文件数,通常可以取消它的限制,根据man手册中,“values -1, unlimited or infinity indicating no limit”,-1、unlimited、infinity都是表明不做限制,可当实际给nofile设置成这个值时,等重启就会发现无法登录系统了。
由此可见,nofile是有上限的,同时用ulimit测试:
# ulimit -n unlimited
bash: ulimit: open files: cannot modify limit: 不允许的操作
写一个简单的for循环得出:
# for V in `seq 100000 10000000`;do ulimit -n $V;[[ $? != 0 ]]&&break;done
再执行ulimit -n,可以看到1048576就是nofile的最大值了,但为什么是这个值?1048576是1024*1024,当然这并没有什么用。再跟踪一下就会发现这个值其实是由内核参数nr_open定义的:# cat /proc/sys/fs/nr_open
1048576
到此就要说起nr_open与file-max了,网上在说到设置最大文件数时偶尔有些帖子也说到要修改file-max,字面上看file-max确实像是对应最大文件数,而在linux内核文档中对它们俩的解释是:
/proc/sys/fs/file-max:
The value in file-max denotes the maximum number of filehandles that the Linux kernel will allocate. When you get lots of error messages about running out of file handles, you might want to increase this limit.
This file defines a system-wide limit on the number of open files for all processes. (See also setrlimit(2), which can be used by a process to set the per-process limit, RLIMIT_NOFILE, on the number of files it may open.) If you get lots of error messages about running out of file handles, try increasing this value:
echo 100000 > /proc/sys/fs/file-max
The kernel constant NR_OPEN imposes an upper limit on the value that may be placed in file-max.
If you increase /proc/sys/fs/file-max, be sure to increase /proc/sys/fs/inode-max to 3-4 times the new value of file-max, or you will run out of inodes.
即修改file-max,最好同时也要修改inode-max约等于3或4倍于file-max。
执行:grep -r MemTotal /proc/meminfo | awk '{printf("%d",$2/10)}',可以看到与file-max是相近的,这也充分说明该项值是受内存大小深度影响的。
/proc/sys/fs/file-nr:
This (read-only) file gives the number of files presently opened. It contains three numbers: the number of allocated file handles; the number of free file handles; and the maximum number of file handles. The kernel allocates file handles dynamically, but it doesn’t free them again. If the number of allocated files is close to the maximum, you should consider increasing the maximum. When the number of free file handles is large, you’ve encountered a peak in your usage of file handles and you probably don’t need to increase the maximum.
/proc/sys/fs/nr_open:
This denotes the maximum number of file-handles a process can allocate. Default value is 1024*1024 (1048576) which should be enough for most machines. Actual limit depends on RLIMIT_NOFILE resource limit.
在此需要理解操作系统的文件句柄和描述符,file-handles(即文件句柄),相比而言在Unix中接触更多是file discriptor(FD,即文件描述符),file-handle应该是一个高层的对象,使用fopen,fread等函数来调用;而FD是底层的一个对象,可以通过open,read等函数来调用。
到此可以小结一下了,file-max是内核可分配的最大文件数,nr_open是单个进程可分配的最大文件数,所以在使用ulimit或limits.conf来设置时,如果要超过默认的1048576值时就需要先增大nr_open值(sysctl -w fs.nr_open=100000000或者直接写入sysctl.conf文件)。当然百万级别的单进程最大file-handle打开数应该也够用了。
通过 man 5 proc 找到file-max的解释:它指定了系统范围内所有进程可以打开的文件句柄的数量限制,是内核级别的;只读文件/proc/sys/fs/file-nr中记录整个系统目前使用的文件句柄数量的情况。
file-max的默认值为何会比nr_open值要小,fs.nr_open 要大于等于 /etc/security/limits.conf 的 hard nofile。
ulimit是进程级别的,也就是说系统中某个session及其启动的每个进程能打开多少个文件描述符,能fork出多少个子进程等。limits中的hard limit不能超过nr_open,所以要先改nr_open。而且最好是在sysctl.conf中改,避免重启的时候 hard limit生效了,nr_open不生效导致启动问题。如果fs.nr_open比ulimit中设置的文件打开数值小,那么会出现用户不能正常登陆的情况,或部分应用无法向外主动通信。
相关参数再说明
1)nofile
该值是指单进程的最大打开文件数。
2)nr_open
该值是指单个进程可分配的最大文件数,通常默认值为1024*1024=1048576。
3)file-max
该值是系统内核一共可以打开的最大值,默认值是185745。
提示:为了让一个程序的open files数目扩大,可以在启动脚本前面加上ulimit -HSn 102400命令,但当程序是一个daemon时,可能这种方法无效,因为没有终端。如果某项服务已经启动,再动态调整ulimit是无效的,特别是涉及到线上业务就更麻烦了。这时可以考虑通过修改/proc/pid/limits来实现动态修改。如何修改将会在下文详述。
三、3种修改方式
1)、在/etc/security/limits.conf最后增加如下两行记录:
# nofile - 可以打开的最大文件数, '*'通配符表示对所有用户有效
* soft nofile 65536
* hard nofile 65536
修改完成后保存退出当前用户并重新登录(不用重启服务器)就会生效。
2)、在/etc/profile中增加一行ulimit -SHn 65535,然后运行source /etc/profile命令让修改立即生效。/etc/profile文件是所有系统用户的配置文件,修改后会影响当前系统的所有注册用户。
3)、在/etc/rc.local文件中增加一行ulimit -SHn 65535,修改完后重启服务器就可生效。
这3种修改方式在不同的发行版本(甚至同一发行厂商的不同版本)下表现不同:CentOS中使用第1种方式无效果,使用第3种方式有效果,而在Debian中使用第2种有效果,Crux使用第2、3种方式都有效。centos6修改线程参数:sed -i "s/1024/65535/g" /etc/security/limits.d/90-nproc.conf,centos7修改线程参数:sed -i "s/4096/65535/g" /etc/security/limits.d/20-nproc.conf
尝试将 ulimit 设置为 1000 万,结果提示出错:
# ulimit -n 10000000
-bash: ulimit: open files: cannot modify limit: Operation not permitted
显然它有一个上限值,大概在 100-200 万之间。解决问题的办法在于怎样提高这个上限。open file(s) kernel 级别有2个配置项(上文有提及),分别是:
fs.nr_open:进程级别
fs.file-max:系统级别
fs.nr_open 默认设置的上限是 1048576,所以用户的 open file(s) 不可能超过这个上限。
# sysctl -w fs.nr_open=10000000
# ulimit -n 10000000
# ulimit -n
10000000
修改后即可设置更大的 open file(s) 了。同样对于 kernel 参数的修改,sysctl 命令修改的是当前运行时,如果需要永久修改, 则将配置添加到 /etc/sysctl.conf 中,例如:
# echo "fs.nr_open = 10000000" >> /etc/sysctl.conf
# echo "fs.file-max = 11000000" >> /etc/sysctl.conf
注意:fs.nr_open 总是应该小于等于 fs.file-max。如果要查看当前打开的文件数,使用下面的命令:
# sysctl fs.file-nr
fs.file-nr = 1760 0 11000000
增大这些值意味着能够打开更多的文件(因为在 Linux 中,everything is file,包括 socket),但是同时也意味着消耗更多的资源,所以基本上在物理机上才会遇到这种问题。
在内核文档/usr/src/linux/Documentation/sysctl/fs.txt里找到下面一段话:
file-max & file-nr:
The kernel allocates file handles dynamically, but as yet it doesn't free them again. The value in file-max denotes the maximum number of file-handles that the Linux kernel will allocate. When you get lots of error messages about running out of file handles, you might want to increase this limit.
The three values in file-nr denote the number of allocated file handles, the number of unused file handles and the maximum number of file handles. When the allocated file handles come close to the maximum, but the number of unused file handles is significantly greater than 0, you've encountered a peak in your usage of file handles and you don't need to increase the maximum.
这两段话的大致意思是:
内核动态地分配和释放"file handles"(句柄),file-max的值是内核所能分配到的最大句柄数。当你收到大量关于句柄用完的错误信息时,你可以需要增加这个值以打破旧的限制。
file-nr中的三个值的含意分别是:系统已经分配出去(正在使用)的句柄数,没有用到的句柄数和所有分配到的最大句柄数。当分配出去的句柄数接近最大句柄数,而"无用的句柄数"大于零时,表明你遇到了一个"句柄"使用高峰,这意为着你不需要增加file-max的值。
看完这段话,相信大家都明白了。file-max是系统全局的可用句柄数。根据我后来又翻查的信息,以及对多个系统的查看求证,这个参数的默认值是跟内存大小有关系的,增加物理内存以后重启机器,这个值会增大。大约1G内存10万个句柄的线性关系。
fs.file-nr 三列的意思原文如下
The file-nr file displays three parameters:
the total allocated file handles.
the number of currently used file handles (with the 2.4 kernel); or the number of currently unused file handles (with the 2.6 kernel).
the maximum file handles that can be allocated (also found in /proc/sys/fs/file-max).
The kernel dynamically allocates file handles whenever a file handle is requested by an application but the kernel does not free these file handles when they are released by the application. The kernel recycles these file handles instead. This means that over time the total number of allocated file handles will increase even though the number of currently used file handles may be low.
fs.nr_open
This denotes the maximum number of file-handles a process can allocate. Default value is 1024*1024 (1048576) which should be enough for most machines. Actual limit depends on RLIMIT_NOFILE resource limit.
就是说nr_open表示一个进程做多能分配的文件句柄数,默认值是1048576,针对大多数的情况该值是足够的。
4)、修改策略
一般情况下,nofile 的值不允许超过 nr_open 和 file-max 的值,因此在修改 nofile 时要考虑是否超过以上两个值的情况:
当要修改的nofile值(最大打开文件数)未超过nr_open和file-max两个值时,直接修改nofile值即可;当要修改的nofile值超过nr_open和file-max两个值时,不仅要修改nofile的值,还要先修改nr_open和file-max的值各自满足大于nofile值。
注意临时生效与永久生效的区别:全局内核级在/etc/sysctl.conf中设置fs.nr_open与fs.file-max,用户进程级在/etc/security/limits.conf文件中 设定nofile 值,在用户登录执行的/etc/pam.d/login配置文件,确保有下面内容:
session required pam_limits.so
重新登录后可验证,通过查看/proc/$$/limits查看单进程最大打开文件数:
Limit Soft Limit Hard Limit Units
...
Max open files 1024 1048576 files
NR_FILE
NR_FILE is the limit on total number of files in the system at any given point in time
NR_FILE 是系统在某一给定时刻,限制的文件总数。
While initializing the kernel we setup the vfs cache with start_kernel
vfs_caches_init(num_physpages);
files_init(mempages);
fs/file_table.c says
/* One file with associated inode and dcache is very roughly 1K.
Per default don't use more than 10% of our memory for files.
n = (mempages * (PAGE_SIZE / 1024)) / 10;
this n can never be greater than NR_FILE
NR_OPEN 与 NR_FILE
在内核源码/fs/pipe.c中,函数sys_pipe()里面出现了2个宏定义,NR_OPEN 与 NR_FILE。下面说明一下它们的区别:
1. NR_OPEN is the maximum number of files that can be opened by process。
NR_OPEN是一个进程可以打开的最大文件数。
A process cannot use more than NR_OPEN file descriptors.
一个进程不能使用超过NR_OPEN文件描述符。
The kernel also enforces a dynamic bound on the maximum number of file descriptors in the signal-<rlim[RLIMIT_NOFILE] structure of the process descriptor; this value is usually 1,024, but it can be raised if the process has root privileges.
2. NR_FILE is the limit on total number of files in the system at any given point in time
NR_FILE 是系统在某一给定时刻,限制的文件总数(上文有提及)。
Linux的内核参数 nr_open 只有在内核版本是 2.6.25 之后的版本才可设置。
还有一种说法:ulimit -n设定的值不能超过limits.conf里设定的文件打开数(即soft nofile),其实这要分两种情况,root用户是可以超过的,比如当前limits.conf设定如下:
root soft nofile 2000
root hard nofile 2001
非root用户是不能超出limits.conf的设定。
修改了limits.conf需要重启系统?
不用。
四、阶段小结
/proc/sys/fs/file-max限制不了/etc/security/limits.conf
只有root用户才有权限修改/etc/security/limits.conf,对于非root用户,/etc/security/limits.conf会限制ulimit -n,但是限制不了root用户。对于非root用户,ulimit -n只能越设置越小,root用户则无限制。
任何用户对ulimit -n的修改只在当前环境有效,退出后失效,重新登录后,ulimit -n由limits.conf决定:
如果limits.conf没有做设定,则默认值是1024;
当前环境的用户所有进程能打开的最大文件数量由ulimit -n决定,除非在执行程序前执行了ulimit -n NN的设置操作。
file-max, nr_open, nofile之间的关系
针对用户打开最大文件数的限制,可以通过修改文件limits.conf来实现
nofile中soft的值小于hard,最大值由nr_open来决定
file-max表示内核针对整个系统,限制能所有进程能打开的文件描述符数
nofile < nr_open < file-max
所有进程打开的文件描述符数不能超过/proc/sys/fs/file-max
单个进程打开的文件描述符数不能超过user limit中nofile的soft limit(/etc/security/limits.conf)
nofile的soft limit不能超过其hard limit
nofile的hard limit不能超过/proc/sys/fs/nr_open
五、其它方式
上面总结的方式适用于两大主流派系(Rpm vs Deb)的Linux系统修改文件打开数的修改方法,通过对limits.conf文件的修改来实现此目的,最关键的作用还是通过PAM系统来实现的,这也很多文章没有提及的。如果你的Linux系统中没有使用pam系统,那么要修改最大文件打开数不能通过对limits.conf文件的修改来直接实现了,对sysctl.conf和ulimit指令的调用还是可以的。但有个问题,设定的最大文件打开数还是相当大的限制,与预期相差比较大。可以看见在非root用户在登录时调用ulimit时失败的消息,而root用户在登录时,如果在ulimit时设定的比较大时也会失败。
这就要通过修改内核相关的源码文件中所定义的值来完成了:
在/usr/src/linux目录(linux默认的源码目录)下:
include/uapi/linux/limits.h
#define NR_OPEN 1024000
include/uapi/linux/fs.h
#undef NR_OPEN
#define INR_OPEN_CUR 65535 /* Initial setting for nfile rlimits */
#define INR_OPEN_MAX 1024000 /* Hard limit for nfile rlimits */
涉及2个文件,3处需要修改,上面只是一个建议值,linux默认的值实在太保守了。重新编译安装后重启完成即可生效,免去了上述的修改配置的痛苦过程。
查看某个进程的最大打开文件数
cat /proc/<pid>/limits
为守护进程设置最大打开文件数
编辑其启动脚本(/etc/init.d/tomcat),在最上面开始设定。
ulimit -Hn 16384
ulimit -Sn 16384
Linux下最大打开进程数之nproc
Linux操作系统中利用ulimit限制shell启动进程占用的资源,ulimit支持对用户的打开进程数、进程打开文件句柄数、进程打开文件的大小、进程coredump文件大小等资源进行限制,从而防止某个用户进程过度占用系统资源,避免影响整个操作系统和其他应用的正常运行。但是使用ulimit进行限制后,当用户资源超限制时会出现各种各样的报错,其中相关的一项是用户打开进程数,即nproc参数。
nproc是操作系统级别对每个用户创建的进程数的限制,在Linux下运行多线程时,每个线程的实现其实是一个轻量级的进程,对应的术语是:light weight process(LWP)。怎么知道一个用户创建了多少个进程呢,默认的ps是不显示全部进程的,需要'-L' 才能看到所有的进程。
例1:查看所有用户创建的进程数:
ps h -Led -o user | sort | uniq -c | sort -n
ps -u user -f
此方法是查看当前user用户打开的进程数量。但这种方法在用户的应用在多线程模式下不好使,使用此统计方法,统计出来的进程数量要小于限制值。那么应该如何查询,可以先来看一段官方文档 man 2 setrlimit。因此在Linux主机上我们应该统计用户打开的进程线程的数量,ps命令需要加-L参数用于查看线程,所以给出下面的命令:ps -u user -Lf
统计出来的进程数在某些情况下仍然小于限制值,再看一下上面的文档,其实nproc限制值是限制的real user创建的进程线程数。进程创建的时候存在real user和effective user两个属性,用ps命令统计的时候默认显示的是effective user的进程数,当进程的real user跟effective user不一致的时候会导致上面的命令统计的结果小于限制值。上面-u参数查看的是effective user。因此当我们要统计用户打开的进程线程数的任务,一定要统计real user的进程的线程数,下面的方法可以正确统计主机所有用户的进程线程数:ps -eLo realuser | awk 'NR>1' | sort | uniq -c
例2:确定某用户的进程(LWP)数的分布情况:
根据步骤 1 可确定 nproc 参数接近上限的问题用户,随后应确定该用户进程数(LWP)的分布情况。命令如下,查询结果类似如下。
# ps -o nlwp,pid,lwp,args -u username | sort -n
查看hfds用户创建的进程数:
ps -o nlwp,pid,lwp,args -u hdfs | sort -n
何时需要修改这个nproc呢
当日志或操作过程中出现以下情况中的一种时需要考虑这个nproc:
1. Cannot create GC thread. Out of system resources
2. java.lang.OutOfMemoryError: unable to create new native thread
3. fatal: setresuid 801: Resource temporarily unavailable
4. 如果某个用户的 nproc 的软限制小于其运行中的进程数,则切换用户时将报错 "su: cannot set user id: Resource temporarily unavailable"
其原因大概有3种:
1. 用户的nproc达到限制,无法创建新的进程
2. 系统没有可分配的的pid,即进程号已经达到内核参数kernel.pid_max的限制
3. 系统可用内存低,新的进程无法申请到内存导致不能启动。
如何修改:
1.需要先看linux操作系统内核版本,通过uname -a查看内核版本,因为2.6版本的内核默认是在/etc/security/limits.d/90-nproc.conf里的配置会覆盖/etc/security/limits.conf的配置。
2.修改配置文件
vim /etc/security/limits.d/90-nproc.conf
注释掉'* soft nproc 1024'
3.修改limits.conf文件
vim /etc/security/limits.conf
添加
* soft nproc 655350
4. 在控制台执行(修改这个不需要重启)
ulimit -u 655350
5.检查下是否生效,在控制台切到该用户下
ulimit -u
进程限制也可以根据内存简单的计数(会比系统的限制大一点)
计算公式:default_nproc = total_memory/128K
查看内存大小
cat /proc/meminfo |grep MemTotal
内存大小计算
echo "5993104 / 128"| bc
修改系统的配置
打开90-nproc.conf (部分老版本的系统是在 /etc/security/limits.conf)
vim /etc/security/limits.d/90-nproc.conf
设置限制数量,第一列表示用户,'*'表示所有用户。
root soft nproc unlimited
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535
soft 软限制,hard硬限制。当数量达到软限制的时候会出现报警,达到硬限制的时候才不会增加
soft nproc: 单个用户可用的最大进程数量(软限制)
hard nproc: 单个用户可用的最大进程数量(硬限制)
soft nofile:可打开的文件描述符的最大数(软限制)
hard nofile:可打开的文件描述符的最大数(硬限制)
重启系统后全局生效。
通过一个实例看用户nproc hard的默认值是如何取到的。
在一台虚拟机中的/etc/security/limits.d/90-nproc.conf修改了用户nproc的soft值,如下:
* soft nproc 102400
root soft nproc unlimited
该配置设置了root用户的nproc的soft值为ulimited,其他用户的nproc的soft值为10240。然而当检查每个用户的nproc值的时候惊奇地发现用户的nproc的hard和soft值均为7387,如下:
ulimit -HSu
7387
在一台宿主机和其上的虚拟机在同样的限制配置中有不同的显示:
[root@vmaster ~]# ulimit -Hu
385944
[root@vm2 ~]# ulimit -Hu
31191
这个值很奇怪,用户nproc的soft和hard值并不是102400,但是在其他主机上这个配置能够达到预期的值。经过分析,认为上面的配置中由于并没有设置用户nproc的hard值,导致用户nproc的soft值受到hard值的限制,取不到预期的值,因此关键问题还需要搞清楚hard值是由哪些因素(cpu核心数、内存大小等)决定的。后经分析认为nproc的hard值是在内核获取到的,翻看了内核代码,在内核代码fork.c(kernel v4.1)中发现一些暗示:
static void set_max_threads(unsigned int max_threads_suggested)
{
u64 threads;
/*
* The number of threads shall be limited such that the thread
* structures may only consume a small part of the available memory.
*/
if (fls64(totalram_pages) + fls64(PAGE_SIZE) > 64)
threads = MAX_THREADS;
else
threads = div64_u64((u64) totalram_pages * (u64) PAGE_SIZE,
(u64) THREAD_SIZE * 8UL);
if (threads > max_threads_suggested)
threads = max_threads_suggested;
max_threads = clamp_t(u64, threads, MIN_THREADS, MAX_THREADS);
}
其中totalram_pages是物理内存页的总个数,PAGE_SIZE为4K,THREAD_SIZE在x86平台是16K,所以最后默认的nproc值为:
default_nproc = max_threads/2 = MemTotal(KB) / 256(KB)
即默认nproc大小取决于主机内存大小。在8G内存(实际虚拟机内存为7821M,vbox管理虚拟机有内存开销)的虚拟机上,计算一下:
default_nproc = 7821*1024/256 = 31284
由于kernel会占用一部分的内存,实际的nproc(本例中为31284)要比计算值稍小一些。如果仅设置了用户nproc的soft值,则其soft值被限制在default_nproc。因此有两种解决方法:
1. 评估需求,用户nproc的要是少于7387的话,就降低;
2. 在配置文件中,通过设置用户nproc的hard值来提升hard值来满足预期。
由nproc导致的资源不可用案例分析一例
-bash: fork: retry: Resource temporarily unavailable
报错一般为下面三个原因:
1).用户的nproc达到限制,无法创建新的进程
2).系统没有可分配的的pid,即进程号已经达到内核参数kernel.pid_max的限制
3).系统可用内存低,新的进程无法申请到内存导致不能启动
查看/proc/<pid>/limits获取限制设置。
limits.conf未生效原因
初步分析初步判断并非设置过小导致,16384设置并不算小,RHEL默认/etc/sysctl.conf中内核参数kernel.pid_max为32768也足够使用,需要排查如下:
1)./etc/security/limits.conf与/etc/security/limits.d是否设置过低?
2).是否/etc/profile、/etc/profile.d/、/etc/bashrc、家目录下.bashrc、.bash_profile是否有相关ulimit配置脚本设置nproc设置过低 ?
3).是否grid用户下真有超过16384 process占用导致无法su – grid ?
4).是否有进程real user不属于grid但是effective user为grid消耗了grid所有进程数?
nproc到底是如何构成
RLIMIT_NPROC
The maximum number of processes (or, more precisely on Linux, threads) that can be created for the real user ID of the calling process. Upon encountering this limit, fork(2) fails with the error EAGAIN.
- nproc from /etc/security/limits.conf is to count the threads
- Threads differ from traditional multitasking operating system processes in that:
Raw
* processes are typically independent, while threads exist as subsets of a process
* processes carry considerably more state information than threads, whereas multiple threads within a process share process state as well as memory and other resources
* processes have separate address spaces, whereas threads share their address space
* processes interact only through system-provided inter-process communication mechanisms
* context switching between threads in the same process is typically faster than context switching between processes.
At the kernel level, a process contains one or more kernel threads, which share the process's resources, such as memory and file handles – a process is a unit of resources, while a thread is a unit of scheduling and execution.
A process is a "heavyweight" unit of kernel scheduling, as creating, destroying, and switching processes is relatively expensive. Processes own resources allocated by the operating system. Resources include memory (for both code and data), file handles, sockets, device handles, windows, and a process control block.
A kernel thread is a "lightweight" unit of kernel scheduling. At least one kernel thread exists within each process. If multiple kernel threads can exist within a process, then they share the same memory and file resources.
可以看到nproc是指thread,并不是process,也就是需要使用ps -L选项获取nproc占用总数。
# ps -eLo ruser| sort |uniq -c|sort -rn
注:按real user分类,nproc限制real user线程数,进程创建分为real user与effective user,这里统计real user。
经过查看当前服务器线程数,如下:
# ps -eLf|grep grid|wc -l
44609
注:当时未注意使用ruser统计真实线程数,所以上述44609实际要比真实freeoa用户占用的线程大很多,但是依然可以从中看出确实线程数占用很多,基本可以判断16384的nproc设置不足以支撑这么多会话导致su - freeoa时报错-bash: fork: retry: Resource temporarily unavailable
知道了确实是nproc不足导致无法su - freeoa,通过ps -ef来查看谁占用了这么多线程。nproc是如何计算的呢,如何更合理的设置该值呢?
1、nproc控制
文件:/etc/profile 、/etc/profile.d/下脚本、/etc/bashrc、家目录.bashrc、.bash_profile
使用命令ulimit来设置。
2、在不设置情况下默认值
可以从redhat官网文章:
What are the default ulimit values and where do they come from?
有如下说明:
- On RHEL 6 and 7, nproc is unlimited for root by default (directly inherited from the kernel). For the other users, this value is equal to 4096, because it is limited at the PAM level by one of these files:
/etc/security/limits.d/90-nproc.conf on RHEL 6
/etc/security/limits.d/20-nproc.conf on RHEL 7
- On RHEL 8, these files have been removed, and the nproc default for the users is inherited from the kernel.
- 可以看到在不设置情况下,默认除root用户外,在RHEL6、7默认为4096。
3、nproc上限如何计算呢
可以从Redhat官网文章:How is the nproc hard limit calculated
可以找到如下计算公式说明:
For nproc, the limit is calculated in the kernel before the first process is forked in kernel/fork.c called by start_kernel:
RLIMIT_NPROC = max_threads/2
- The value of these variables are:
-> max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE);
mempages comes from the function argument : fork_init(totalram_pages);
-> #define THREAD_ORDER 2
-> #define THREAD_SIZE (PAGE_SIZE << THREAD_ORDER)
-> PAGE_SIZE = 4096 (but useless)
公式为
RLIMIT_NPROC= max_threads/2
那么max_threads如何计算呢
max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE)
mempages为物理内存页数,可通过如下命令获得:
# dmesg | awk '/Total.pages:/ {print $NF}'
真实值也可通过下面命令获得:
# dmesg |grep Mem
thrad_size为线程尺寸,可通过如下计算公式获得:
THREAD_SIZE (PAGE_SIZE << THREAD_ORDER)
其中page_size可通过命令
# getconf PAGE_SIZE 获得,RHEL6、7均为4096
THREAD_ORDER在RHEL 6、7中均为2。
上述公式含义为:*将PAGE_SIZE转化为2进制,然后左移THREAD_ORDER位,即将4096转化为2进制,向左移动2位,2进制向左移动2位,即2^2=4。
所以公式演变为:
THREAD_SIZE=PAGE_SIZE*4
则最终RHEL6/RHEL7 x86_64中公式演变为:
RLIMIT_NPROC= max_threads/2max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE)RLIMIT_NPROC=( mempages / (8 * THREAD_SIZE / PAGE_SIZE))/2RLIMIT_NPROC=( mempages / (8 * PAGE_SIZE*4 / PAGE_SIZE))/2RLIMIT_NPROC=( mempages / (8 * 4 ))/2RLIMIT_NPROC= mempages / 64
计算示例:
# dmesg|grep Mem[0.000000] Memory: 4015580k/4718592k available (6764k kernel code, 524744k absent, 178268k reserved, 4433k data, 1680k init)
使用上述4015580代入公式得到如下值:
# echo "4015580/4/32/2"|bc
15685
# ulimit -Hu15685
可以看到确实计算一致,也就是当默认不设置limits.conf时,root用户默认的hard nproc为上述公式计算值。
注:真实情况下,由于内核版本不同,相关参数可能发生变化,也由于启动时,内存分配不同,会导致计算出来与实际值存在一些偏差,但是偏差不会很大。
4、那使用内存计算的nproc是硬限制吗
通过测试,虽然使用内存计算出来的nproc是有限的,且相对更为合理,但是并不是说该值为硬限制,依然可以通过文件limits.conf、profile.d、limits.d、bashrc、ulimit等方式设置大于计算出来的值。但是一般建议通过计算设置更为合理,防止内存耗尽。
说一点关于文件描述符
文件描述符是内核为了高效管理已被打开的文件所创建的索引,用于指向被打开的文件,所有执行I/O操作的系统调用都通过文件描述符;文件描述符是一个简单的非负整数,用以表明每个被进程打开的文件。程序刚刚启动时,第一个打开的文件是0,第二个是1,以此类推,也可以理解为文件的身份ID。用户通过操作系统处理信息的过程中,使用的交互设备文件(键盘、鼠标、显示器)。
| 文件描述符 | 通道名 | 描述 | 默认连接 | 用途 |
| 0 | stdin | 标准输入 | 键盘 | read only |
| 1 | stdout | 标准输出 | 终端 | write only |
| 2 | stderr | 标准错误 | 终端 | write only |
| 3以上 | filename | 其他文件 | none | read and/or write |
标准输入输出说明
stdin,标准输入,默认设备是键盘,文件编号为0
stdout,标准输出,默认设备是显示器,文件编号为1,也可以重定向到文件
stderr,标准错误,默认设备是显示器,文件编号为2,也可以重定向到文件
查看一个进程打开了哪些文件
语法: ll /proc/[进程ID]/fd
$ vim freeoa.txt
[1]+ 已停止 vim freeoa.txt
$ ps -aux | grep vim
xf 11990 0.6 0.2 151796 5396 pts/0 T 16:37 0:00 vim freeoa.txt
xf 11998 0.0 0.0 112724 988 pts/0 S+ 16:37 0:00 grep --color=auto vim
$ ll /proc/11990/fd
总用量 0
lrwx------. 1 xf xf 64 2月 21 16:37 0 -> /dev/pts/0
lrwx------. 1 xf xf 64 2月 21 16:37 1 -> /dev/pts/0
lrwx------. 1 xf xf 64 2月 21 16:37 2 -> /dev/pts/0
lrwx------. 1 xf xf 64 2月 21 16:37 4 -> /home/xf/.freeoa.txt.swp
0、1、2也就是宏STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO。
/proc/[进程ID]/fd这个目录专门用于存放文件描述符,另外还可以使用'ls -l /proc/self/fd'来查看。
Linux下最大打开进程数之nofile
设置普通用户最大打开文件数(Number of Open Files | Open File Descriptors)
通过相关的资料检索,其大致过程如下:
查看、修改系统配置、验证。本节
用户直接登录操作系统查看目前的大小:
Check Hard Limit in Linux
# ulimit -Hn
Check Soft Limits in Linux
# ulimit -Sn
查看全部相关限制为:ulimit -a
$> ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 257564
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
关于上面强调是直接登录而不是像在root会话下'su - User'过去,再执行查看指令,所看到的大小与直接登录会有不同,原因后续在说明。
如要修改用户freeoa的最大文件数为100k
修改/etc/security/limits.conf
* soft nofile 1000000
* hard nofile 1000000
此将所有用户的nofile设定为100k,当然这一个前提,操作系统所在主机的资源支持才行(主要是物理内存的数量)。
虚拟文件系统中的/proc/sys/fs/file-max指定了系统能打开文件的最大数。其对应的系统参数文件(/etc/sysctl.conf)变量为:
fs.file-max=N
该参数建议采用系统自动所生成的数值。另外在修改完成后记得用'sysctl -p'使用设置在下次登录后生效。
系统级的资源使用限制在/etc/security/limits.conf中指定,格式大致如下:
<domain> <type> <item> <value>
通过手册:'man limits.conf'可查看其较为详细的使用方法。当然也可以将配置拆分后放置于/etc/security/limits.d/目录下。
This is implemented via the pam_limits.so module which is called for various services configured in /etc/pam.d/.
PAM之迷
commenting "session required pam_limits.so" in all files in "/etc/pam.d" solves
su: cannot open session: Permission denied
runuser: cannot open session: Permission denied
使用sed工具指令放开或关闭pam_limits功能:
sed -i -r 's/^(session\s+required\s+pam_limits.so)/#\1/' /etc/pam.d/*
/etc/ssh/sshd_config中开启
UsePAM yes
涉及的PAM配置文件有
/etc/pam.d/sshd
/etc/pam.d/login
/etc/pam.d/system-auth
文件涉及的程序
login – rules for local (console login)
system-auth – common rules many services
password-auth – common rules for many remote services
sshd – rules for SSHD daemon only
注:在RedHat系Linux中不开启'UsePAM'选项会有问题,这在其配置文件有明示。
'UsePAM no' is not supported in Red Hat Enterprise Linux and may cause several problems.
不少用户通过对shell的运行环境配置参数文件来设定来达到上述目的:
echo ulimit -n 65535 >>/etc/profile
echo "ulimit -n 1000000" >> .bashrc ; echo "ulimit -n 1000000" >> .bash_profile
在使用systemd管理系统服务后,它也来接管资源的限制了:
/lib/systemd/system/<servicename>.service
...
[Unit]
Description=Some Daemon
After=syslog.target network.target
[Service]
Type=notify
LimitNPROC=65535
LimitNOFILE=65535
ExecStart=/usr/sbin/somedaemon
[Install]
WantedBy=multi-user.target
使用systemctl daemon-reload来使systemd设置生效,在重启服务以使服务的设置生效。
systemd全局设置(/etc/systemd/system.conf)中可为所有服务指定一个默认值:
DefaultLimitNOFILE=65535
DefaultLimitNPROC=65535
注意:小心systemd中的配置与系统级的设置相冲突!
openssh-7.3之后版本中的ssh登陆PAM认证过程发生了变化。/etc/pam.d下没有单独认证授权配置文件。导致没有成功的加载limits.conf的配置。因此需要通过修改sshd的认证方式,使其在用户登录认证的时调用pam_limits.so这个模块应用/etc/security/limits.conf中所修改的限制值。下述两种方法皆针对sshd的配置文件(sshd_config)的修改来进行
方法1
UseLogin yes
说明:
• 一旦开启该选项,表示调用系统的login进行登录验证
• login会调用系统的/etc/pam.d/login进行相应的验证授权和会话记录等控制。
• 在/etc/pam.d/login中已经有配置 session required pam_limits.so 因此会应用上针对limit.conf的修改。
重启服务,重启服务过程中,报出一个提示:
Starting sshd:/etc/ssh/sshd_config line 95: Deprecated option UseLogin
这个说明ssh不推荐使用这个配置。
原因如下:
• 如果开启此选项,那么 X11Forwarding 将会被禁止,因为 login 命令不知道如何处理 xauth cookies。
• 同时login命令是禁止用于远程执行命令的。
• 所以需要同时保证UsePrivilegeSeparation开启,那么它将在认证完成后被禁用,该选项为缺省开启。
重新ssh登录后用ulimit -n检查,发现已经应用上文件数限制的修改。
方法2
UsePAM yes
说明:
• 一旦开启该选项,表示调用独立的pam认证文件进行登录验证
• 需要在/etc/pam.d/目录创建名为sshd的pam配置文件。
• 在pam配置文件中需保证有session required pam_limits.so部分
重启服务使之生效。
注意:
• 有可能重启服务后报错,错误提示为,不支持UsePAM yes这个选项。
• 这说明,之前在编译安装openssh的时候,没有加上-with-pam选项,需要重新编译安装(该问题上面有提及)。
小结一下
- 最大文件句柄数设置
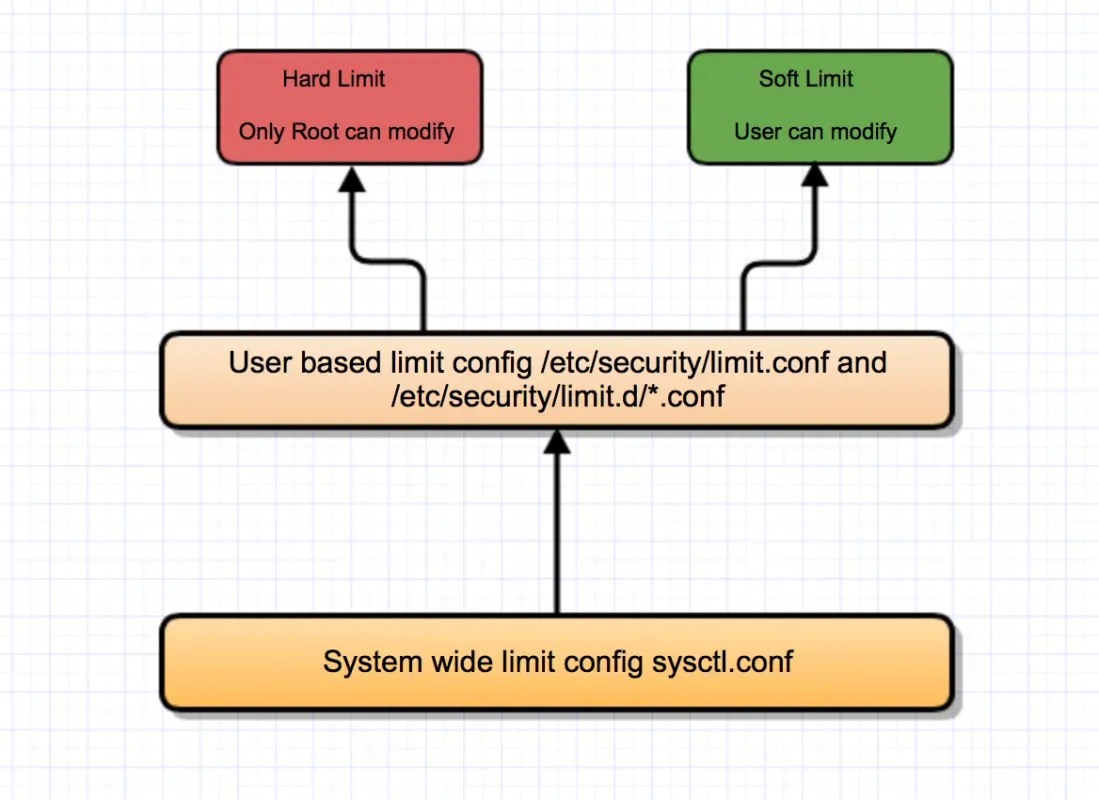
a).查看系统级别的所有进程允许打开的最大文件句柄数
# cat /proc/sys/fs/file-max
可通过编辑/etc/sysctl.conf 来设定,比如:
fs.file-max = 1024000
保存好后,执行sysctl -p来生效。
b).设置用户级别的所有进程的允许打开的最大文件句柄数
可以编辑/etc/security/limit.conf, 也可以在/etc/security/limit.d/目录下添加文件,比如添加user.conf:
* hard nofile 200000
* soft nofile 200000
root hard nofile 500000
root soft nofile 500000
以上设置表示root用户允许的最大文件句柄数为500000,其他用户都为200000,设置好后,需要退出terminal,或关闭session ,然后再登录进入,执行ulimit -a就可以看到效果了。下对mysql服务进行了资源限制:
/etc/security/limits.d/mysql.conf
mysql soft nofile 55000
mysql hard nofile 655000
mysql soft nproc 55000
mysql hard nproc 655000
对于部分操作系统发行版本,在增加文件句柄数的时候可能会遇到这样的错误:
ulimit open files cannot modify limit operation not permitted
这说明OS对用户的最大文件句柄数有限制,最大只能设为1024000。
在修改了limit.conf文件后,先别着急退出或关闭终端,要再打开一个终端连接试试看能不能登录,若不能登录,而且在/var/log/secure日志中有如下错误,说明最大文件句柄数设置的有问题。
pam_limits(sshd:session): Could not set limit for 'nofile': Operation not permitted
c).查看运行进程的文件句柄数
/proc/$PID/limits
/proc/`pidof mysqld`/limits
若要对已经在运行的进程更改文件句柄数,可以使用prlimit , 这个指令工具需要安装util-linux-2.21包
prlimit --pid <pid> --<limit>=<soft>:<hard>
prlimit --pid 12345 --nofile=1024:2048
如果上述的步骤都实施了,而该用户的限制依然没有达到,还有可能的原因吗?
有,
在limit.conf或相关资源限制配置文件中没有显式指定用户进行指定,这就是可能的原因:
freeoa hard nofile 655000
freeoa hard nproc 655000
*'表示所有用户似乎有时不那么有效?
其它相关的错误现象
Too many open files
System unable to allocate necessary resources for the monitor thread
can't create new thread, closing connection
Linux下CoreDump设置
最快入门
开启与关闭
执行ulimit -c 输出如果为0,则说明coredump没有打开;ulimit -c 输出如果为unlimited,则说明coredump已打开。通过 ulimit -c unlimited 就可以打开它,通过 ulimit -c 0 就可以关闭它。
永久生效
vim /etc/security/limits.conf
soft core unlimited
hard core unlimited
添加后重启或source一下系统的配置文件。
一般Linux内核给我们提供的核心文件,记录了进程在崩溃时候的信息。但是生成core文件需要设置开关,具体步骤如下:
1、查看生成core文件的开关是否开启,输入命令:ulimit -a
其中的core行文件大小如果为0,则表示没有开启此功能。
2、使用 ulimit -c [kbytes] 可以设置系统允许生成的core文件大小。
ulimit -c 0 #不产生core文件
ulimit -c 100 #设置core文件最大为100k
ulimit -c unlimited #不限制core文件大小
设定coredump的大小限制
ulimit -c 查看core文件的生成开关
ulimit -c filesize命令,可以限制core文件的大小(filesize的单位为kbyte)
ulimit -c unlimited 设置core文件的大小不受限制
ulimit -c 0 阻止系统生成core文件
ulimit -a 检查生成core文件的选项是否打开,该命令将显示所有的用户定制,其中选项-a代表“all”。
执行命令 ulimit -c unlimited,然后ulimit -a查看core行。这样进程崩溃就可以生成core文件了,这种方法只能在当选shell中生效,需要此设置一直生效可做如下设置
vim /etc/profile #然后进入编辑模式,在profile文件中加入
ulimit -c unlimited
保存退出,重启服务器,改文件就长久生效,或者source /etc/profile,使文件马上生效。
查询core dump文件路径
方法1:
# cat /proc/sys/kernel/core_pattern
方法2:
# /sbin/sysctl kernel.core_pattern
kernel.core_pattern = core
kernel.core_pattern = |/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e %P %I %h
修改core dump文件路径
方法1:临时修改,修改/proc/sys/kernel/core_pattern文件,但/proc目录本身是动态加载的,每次系统重启都会重新加载,因此这种方法只能作为临时修改。
/proc/sys/kernel/core_pattern
例:echo '/tmp/corefile/%e.core.%p' > /proc/sys/kernel/core_pattern
方法2:永久修改:使用sysctl -w name=value命令。
# /sbin/sysctl -w kernel.core_pattern=/tmp/corefile/%e.core.%p
3、指定生成文件的路径和名字
默认情况下,core dump生成的文件名为core,而且就在程序当前目录下。新的core会覆盖已存在的core或后缀以当时进程的pid,通过修改/proc/sys/kernel/core_uses_pid可以控制core文件保存位置和文件格式。
vim /etc/sysctl.conf #进入编辑模式,加入下面两行
kernel.core_pattern=/tmp/corefile/core_%t_%e_%p
kernel.core_uses_pid=0
在/tmp下创建corefile目录,用
sysctl –p /etc/sysctl.conf
让修改立即生效。
core_pattern的命名参数如下:
%c 转储文件的大小上限
%e 所dump的文件名
%g 所dump的进程的实际组ID
%h 主机名
%p 所dump的进程PID
%s 导致本次coredump的信号
%t 转储时刻(由1970年1月1日起计的秒数)
%u 所dump进程的实际用户ID
# format the name of core file.
%% – 符号%
%p – 进程号
%u – 进程用户id
%g – 进程用户组id
%s – 生成core文件时收到的信号
%t – 生成core文件的时间戳(seconds since 0:00h, 1 Jan 1970)
%h – 主机名
%e – 程序文件名
## for centos6 system
echo -e "/tmp/corefile/core-%e-%s-%u-%g-%p-%t" > /proc/sys/kernel/core_pattern
# for centos7 system
echo -e "/tmp/corefile/core-%e-%s-%u-%g-%p-%t" >> /etc/sysctl.conf
# suffix of the core file name by pid
echo -e "1" > /proc/sys/kernel/core_uses_pid
4、terminal中执行命令: kill -s SIGSEGV $$ , 可以看到/tmp/corefile下生成了一个core文件,说明已经设置成功。但在下列条件下不产生core 文件:
进程是设置- 用户-ID ,而且当前用户并非程序文件的所有者;
进程是设置- 组-ID ,而且当前用户并非该程序文件的组所有者;
用户没有写当前工作目录的许可权;
文件太大。core 文件的许可权(假定该文件在此之前并不存在) 通常是用户读/ 写,组读和其他读。
5、coredump的产生原理
发生coredump一般都是在进程收到某个信号的时候,Linux上现在大概有60多个信号,可以使用 kill -l 命令全部列出来。针对特定的信号,应用程序可以写对应的信号处理函数。如果不指定,则采取默认的处理方式,默认处理是coredump的信号如下:
3)SIGQUIT 4)SIGILL 6)SIGABRT 8)SIGFPE 11)SIGSEGV 7)SIGBUS 31)SIGSYS 5)SIGTRAP 24)SIGXCPU 25)SIGXFSZ 29)SIGIOT
我们看到SIGSEGV在其中,一般数组越界或是访问空指针都会产生这个信号。
可以使用gdb命令来对core dump文件进行调试。
参考来源
Red Hat Linux How to set ulimit values
理解操作系统的文件句柄和描述符
Linux修改系统的max open files、max user processes
Linux下有效修改最大文件句柄数max open files及ulimit原理
该文章最后由 阿炯 于 2024-05-14 14:48:42 更新,目前是第 2 版。