Linux上核心转储(Core Dumps)的设置
 为诊断和调试Linux应用程序中的错误而创建的核心转储(Core Dumps)。它们也称为内存转储、崩溃转储、系统转储或ABEND转储。但核心转储可能包含敏感信息,例如密码、用户数据(如PAN、SSN)或加密密钥。因此必须在生产Linux服务器上禁用它们。在传统的init与systemd的初始方式下对其的关闭各有千秋。
为诊断和调试Linux应用程序中的错误而创建的核心转储(Core Dumps)。它们也称为内存转储、崩溃转储、系统转储或ABEND转储。但核心转储可能包含敏感信息,例如密码、用户数据(如PAN、SSN)或加密密钥。因此必须在生产Linux服务器上禁用它们。在传统的init与systemd的初始方式下对其的关闭各有千秋。简单地说,核心转储只不过是应用程序在Linux上崩溃时的内存记录。通常包括:应用程序名称、日期和时间、寄存器、程序计数器、堆栈指针、内存管理信息、其他CPU和Linux系统标志和信息。
正如前所述,早期的核心转储可能包含攻击者可能利用的信息,此外还占用了大量的磁盘空间。因此必须在生产服务器上禁用它们。请注意,出于调试目的,开发人员需要在其开发系统或服务器上启用并保持崩溃转储。默认情况下,Linux将转储存于/var/crash/目录中。使用systemd启动服务或进程时,它们将存于/var/lib/systemd/coredump/目录中。
在Linux上禁用核心转储
Linux提供了各种方法来禁用核心转储。当Linux内核在运行时由于段冲突或任何不可预见的错误而删除程序时,最常见有三种方式来关闭核心转储的方法。
如何使用limits.conf和sysctl方法禁用Linux核心转储文件
引导时禁用的过程如下:
打开终端应用程序,使用ssh命令登录远程云服务器。然后编辑/etc/security/limits.conf文件。追加以下行:
* hard core 0
* soft core 0
具有提升权限(或setuid位)的进程可能仍然能够执行核心转储,这取决于它的设置。由于这些进程通常具有更多的访问权限,因此它们可能在内存中包含更敏感的数据段。可以使用sysctl或直接通过/proc文件系统更改行为。对于永久设置,通常使用sysctl命令和配置。要使用要转储的setuid位禁用程序,请将fs.suid_dumpable设置为零。确保阻止setuid和setgid程序将核心转储到,编辑以下文件:
/etc/sysctl.d/99999-disable-core-dump.conf或/etc/sysctl.conf
然后追加:
fs.suid_dumpable=0
kernel.core_pattern=|/bin/false
关闭并保存文件。最后运行sudo sysctl-p/etc/sysctl.d/99999-disable-core-dump.conf命令来激活更改。
false命令(/bin/false)退出,状态代码指示失败。换言之,什么也不做都不成功,这将导致禁用Linux转储。
了解Linux下的fs.suid_dumpable和kernel.core_pattern选项
kernel.core_pattern变量用于指定核心转储文件模式名称,要查看当前设置,请使用sysctl命令:
sysctl kernel.core_pattern
以下是所看到的:
kernel.core_pattern=
|/usr/share/apprt/apprt %p %s %c %d %p %E
|/usr/share/apport/apport %p %s %c %P
apport命令自动从崩溃的Linux进程中收集数据,并在/var/crash/中编译问题报告。对于GNOME桌面,为kde destkop提供了apport gtk和apport kde。
core_pattern的格式说明符
| Option | Description |
|---|---|
| %<NUL> | ‘%’ is dropped |
| %% | output one ‘%’ |
| %p | pid |
| %P | global pid (init PID namespace) |
| %i | tid |
| %I | global tid (init PID namespace) |
| %u | uid (in initial user namespace) |
| %g | gid (in initial user namespace) |
| %d | Dump mode, matches PR_SET_DUMPABLE and /proc/sys/fs/suid_dumpable |
| %s | Signal number |
| %t | UNIX time of dump |
| %h | hostname |
| %e | executable filename (may be shortened) |
| %E | executable path |
| %<OTHER> | Both are dropped |
要在运行时禁用,在管理员模式下运行:
sysctl-w kernel.core_pattern=“|/bin/false”
要查询当前值,请使用sysctl命令:
sysctl fs.suid_dumpable
在运行时为setuid或其他受保护/受污染的二进制文件设置核心转储模式,如下所示:
sysctl -w fs.suid_dumpable=值
其中,值可以是以下任意一个:
0–这是默认和传统行为。任何更改了权限级别或仅执行的进程都不会被转储。
1–也称为调试模式。换句话说,所有进程都会在可能的情况下转储核心。当前用户拥有核心转储,并且不应用任何安全性。开发人员必须仅在系统或应用程序调试情况下使用此功能。进程跟踪(系统调用)也未选中。不要在生产Linux服务器和容器工作负载上启用此模式。它是不安全的,因为它允许普通用户检查特权进程的内存内容,并且可能包含敏感信息。
2–这种模式也称为自杀安全模式。任何通常不会转储的Linux程序都会被转储,但前提是“core_pattern”内核sysctl设置为管道处理程序或完全限定路径。当Linux系统管理员试图在特定环境中调试问题时,此模式非常合适。
使用systemd时如何禁用coredumps
systemd启动的服务将忽略limits.conf。因此需要有一个额外的配置。特别是一些发行版,如RHEL/CNTOS/Debian/Ubuuntu和其他发行版,systemd需要额外的配置来禁用核心转储。使用cat或more或less命令查找以下两个文件:
ls -l /usr/lib/sysctl.d/
more /usr/lib/sysctl.d/50-coredump.conf文件
ls -l /etc/systemd/*.conf文件
more /etc/systemd/coredump.conf
相关联的文件有:
/etc/systemd/coredump.conf
/etc/systemd/coredump.conf.d/*.conf
/run/systemd/coredump.conf.d/*.conf
/usr/lib/systemd/coredump.conf.d/*.conf
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
#
# Entries in this file show the compile time defaults.
# You can change settings by editing this file.
# Defaults can be restored by simply deleting this file.
#
# See coredump.conf(5) for details.
[Coredump]
#Storage=external
#Compress=yes
#ProcessSizeMax=2G
#ExternalSizeMax=2G
#JournalSizeMax=767M
#MaxUse=
#KeepFree=
使用mkdir命令创建一个新的目录,运行:
mkdir/etc/systemd/coredump.conf.d/
vim/etc/systemd/coredump.conf.d/custom.conf
##或者使用nano文本编辑器命令##
nano /etc/systemd/coredump.conf.d/custom.conf
然后附加以下内容:
[Coredump]
Storage=none
ProcessSizeMax=0
设置Storage=none和ProcessSizeMax=0将禁用除systemd下的日志项之外的所有核心转储处理。然后使用systemctl命令重新加载systemd的配置,如下所示:
systemctl daemon-reload
编辑/etc/systemd/system.conf文件,确保DefaultLimitCORE已注释掉。例如:
#DefaultLimitCORE=infinity
然后运行以下命令:
systemctl daemon-reexec
使用ulimit方法
Bash或zsh提供了一个内置的ulimit命令,可以用来查看或设置shell的资源限制以及shell启动的进程。例如:
#设置创建的核心文件的最大大小
ulimit -c 0
ulimit -S -c 0
#验证更改生效与否#
ulimit -a
硬限制
ulimit -H -c
软限制
ulimit -S -c
可以将以下命令添加到shell启动文件中,如/etc/profile或~/.bash_profile或~/.profile,以便为当前用户永久禁用它:
echo'ulimit -S -c 0'>>~/.bash_profile
或
echo "ulimit -c 0 > /dev/null 2>&1" > /etc/profile.d/disable-coredumps.sh
在Linux中反向操作即启用coredumps
编辑/etc/security/limits.conf删除以下两行:
* hard core 0
* soft core 0
接下来,删除/etc/sysctl.d/99999-disable-core-dump.conf或编辑/etc/sysctl.conf:
rm /etc/sysctl.d/99999-disable-core-dump.conf
#通过创建新配置启用更改#
vim /etc/sysctl.d/99999-enable-core-dump.conf
然后附加以下内容以在Linux上启用核心转储:
#### A value of 1 permits core dumps that are readable by the owner of the dumping process only. ###
#### A value of 2 permits core dumps that are readable only by root. ####
fs.suid_dumpable=2
kernel.core_pattern='|/usr/share/apport/apport %p %s %c %d %P %E'
运行sysctl命令:
sysctl -p
接下来,编辑shell配置文件(全局或个人),如/etc/profile或~/.bash_profile或~/.profile,并删除ulimit命令行:
ulimit -c 0
#*注:如果只想为调试提供对foo应用程序的操作权限,请添加以下内容*#
ulimit -S -c unlimited foo
#适配到所有应用
ulimit -S -c unlimited
最后,删除systemd配置文件:
rm /etc/systemd/coredump.conf.d/custom.conf
让设定生效
systemctl daemon-reload
此外,编辑/etc/systemd/system.conf并确保DefaultLimitCORE设置如下:
DefaultLimitCORE=infinity
然后运行:
systemctl daemon-reexec
需要在不同的地方应用设置来禁用或启用Linux下的核心转储。随着systemd的引入,操作变得复杂起来。因此,除了sysctl命令(Linux内核)和PAM的limits.conf使用的配置文件之外,还需要编辑systemd的额外配置文件。
在systemd下,使用journalctl显示了相关的崩溃,所以这是一个开始。
Sep 06 15:19:21 hardening kernel: traps: crash[2232] trap divide error ip:4004e5 sp:7fff3c2fc651 error:0 in crash[400000+1000]
Core Dump 测试
选项1:创建一个不稳定的程序
创建一个简单的程序。它的主要目标是在执行时崩溃,然后有选择地创建一个核心转储。在系统上安装gcc,并在主目录中创建一个文件crash.c。
int main(){
return 1/0;
}
该程序将启动主函数并返回一个整数值(数字)。但它将1除以0,这是不允许的,并且会崩溃。下一步是编译我们的小程序。
gcc -o crash crash.c
甚至编译器也显示程序包含严重问题并显示警告,现在运行它可看到是这样。
Floating point exception (core dumped)
从这句话中可知程序在退出时有一个异常,特别是指浮点。这是程序的十进制数字格式,所以它可能表示在做一些数学运算时发生了一些事情。另一个结论是,coredumps被生成;如果禁用了核心转储,则不会出现这种情况。
根据相关的Linux发行版,处理核心转储和默认设置的方式不同。最新的Linux发行版现在也使用systemd,规则也随之略有变化。
选项2:终止正在运行的进程
也可以终止现有进程,而不是使用测试程序。这是通过使用SIGSEGV来完成的,SIGSEGV是分割违规的缩写,也被称为分割错误。
kill -s SIGSEGV PID
如果将PID替换为“$$”,则当前程序(很可能是您的shell)将崩溃。
选项3:使用gdb
如果安装了开发人员调试工具gdb,则使用进程ID(PID)连接到所选的进程。
gdb -p 1234
然后在gdb提示符下,通过调用generate core file指令生成核心转储;使用此命令后,它应该会返回您的输出。
Saved corefile core.1234
Core Dump工作机制
coredump文件的生成机制
coredump的作用
个人理解的就是触发了一些底层的错误,从而产生的当时进程上下文的记录,以用于后续的分析。这些底层的错误包括:
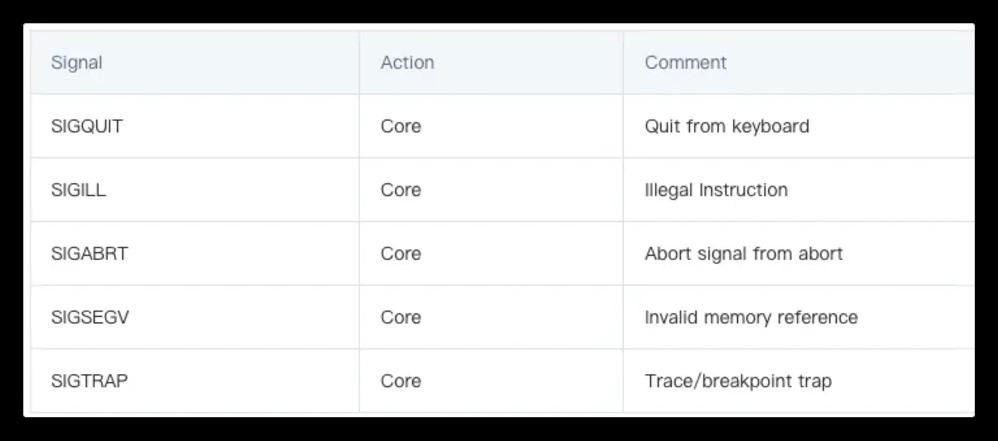
进程触发Linux内核的“致命信号”时,内核会触发Core Dump(默认可能关闭),常见触发信号(对应死机场景):
| 信号 | 含义 | 场景示例 |
| SIGSEGV (11) | 段错误(非法内存访问) | 空指针解引用、数组越界、访问已释放内存(最常见) |
| SIGABRT (6) | 进程主动终止 | 断言失败(assert)、调用abort()函数 |
| SIGILL (4) | 非法指令 | 编译架构不匹配、代码段被篡改 |
| SIGFPE (8) | 浮点运算错误 | 除零、数值溢出 |
| SIGBUS (7) | 总线错误 | 内存对齐错误(ARM架构高频) |
coredump文件产生的原理
什么情况下进程会收到信号
当进程接收到某些信号而导致异常退出时,就会生成 coredump 文件。当进程从内核态返回到用户态前,内核会查看进程的信号队列中是否有信号没有处理,如果有就调用 do_signal 内核函数处理信号。
进程从内核态返回到用户态的地方有很多,如从系统调用返回、从硬中断处理程序返回和从进程调度程序返回等
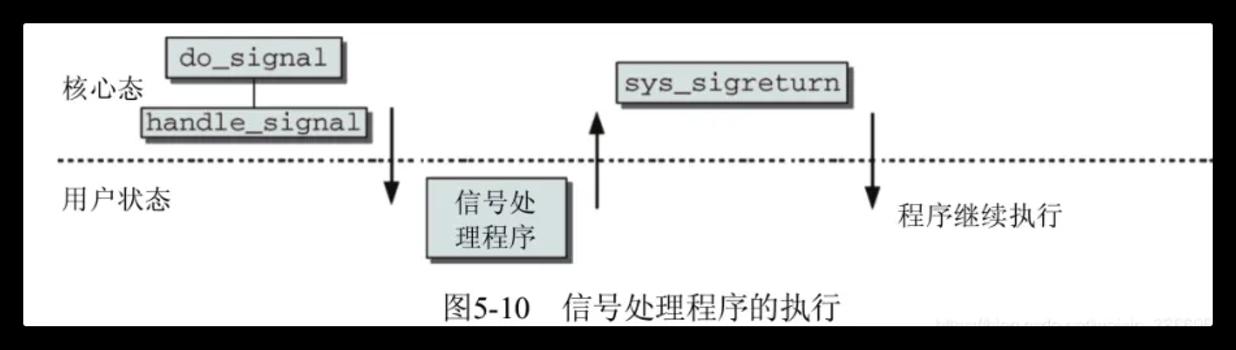
从处理信号到生成coredump文件
do_signal
get_signal_to_deliver
// 1. 从进程信号队列中获取一个信号
signr = dequeue_signal(current, mask, info)
// 2. 判断是否会生成 coredump 文件的信号
if (sig_kernel_coredump(signr)) {
// 3. 调用 do_coredump() 函数生成 coredump 文件
do_coredump((long)signr, signr, regs)
生成coredump文件过程
do_coredump
binfmt = current->binfmt; // 当前进程所使用的可执行文件格式(如ELF格式)
// 1. 判断当前进程可生成的 coredump 文件大小是否受到资源限制
if (current->signal->rlim[RLIMIT_CORE].rlim_cur < binfmt->min_coredump)
goto fail_unlock;
// 2. 生成 coredump 文件名
ispipe = format_corename(corename, core_pattern, signr);
// 3. 创建 coredump 文件
file = filp_open(corename, O_CREAT|2|O_NOFOLLOW|O_LARGEFILE|flag, 0600);
// 4. 把进程的内存信息写入到 coredump 文件中
retval = binfmt->core_dump(signr, regs, file);
实际上,这个流程并不是coredump独用,而是一套通用流程。
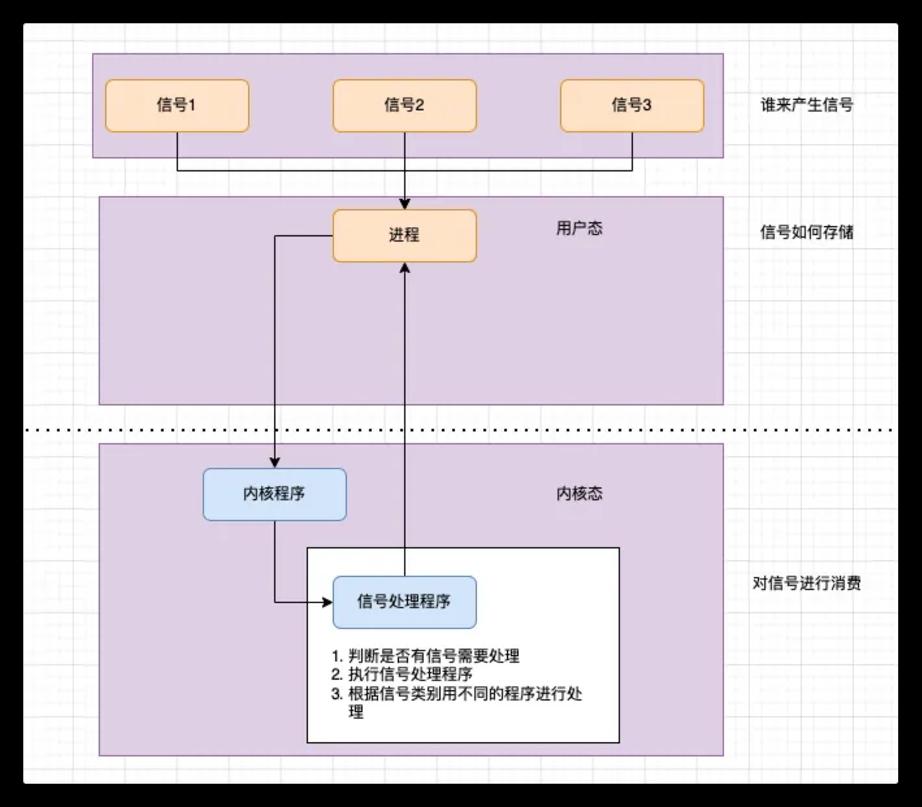
在这个流程中,有信号产生方、信号存储方、信号消费方。
在这三个阶段,其中信号和中断有类似的地方,但是二者并不等价。
信号本质上是在软件层次上对中断机制的一种模拟,其主要有以下几种来源:
1.程序错误:除零,非法内存访问等。
2.外部信号:终端 Ctrl-C 产生 SGINT 信号,定时器到期产生SIGALRM等
3.显式请求:kill函数允许进程发送任何信号给其他进程或进程组。

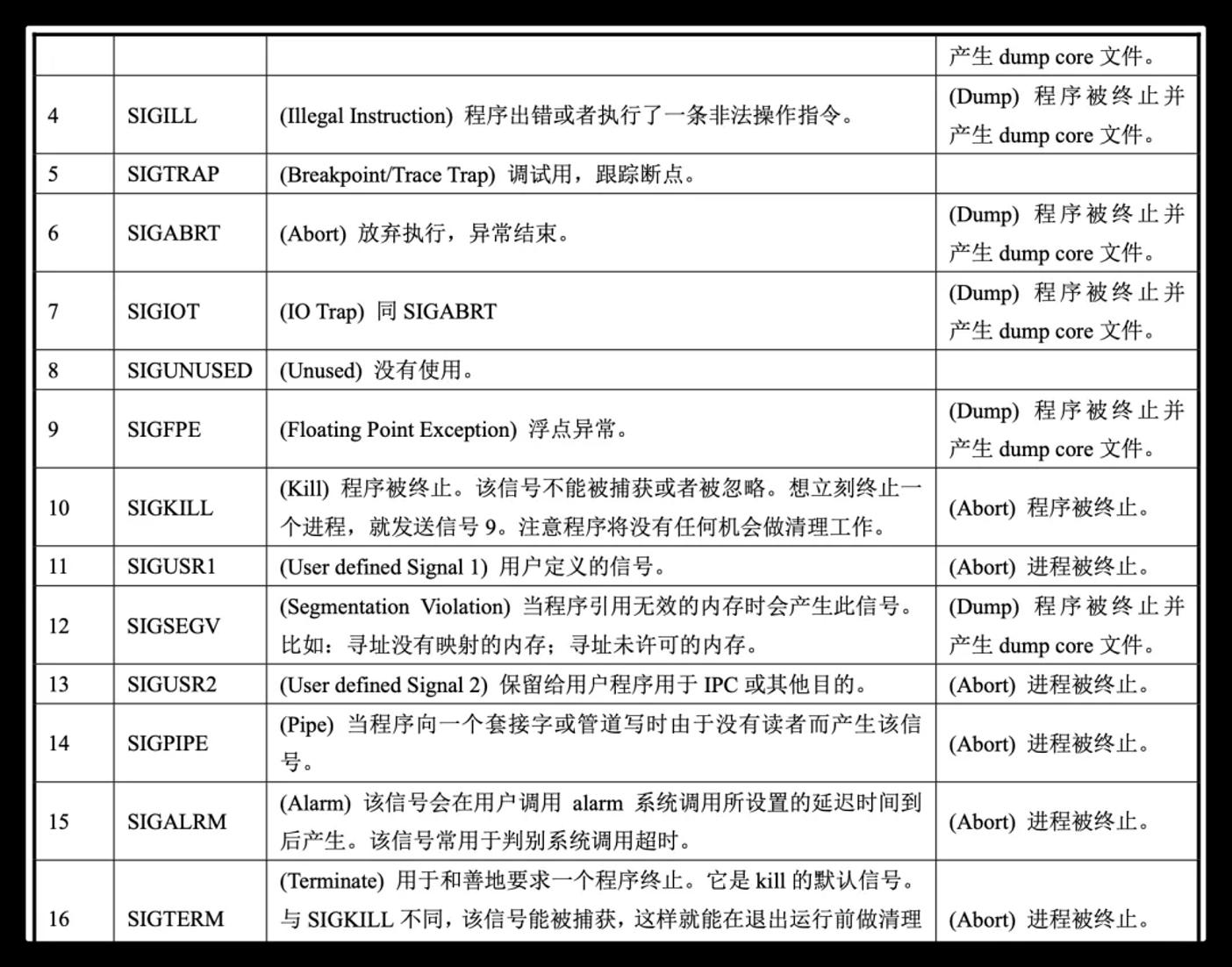
信号如何被接收的在此并不做介绍,只对信号存储和消费两部分进行说明。
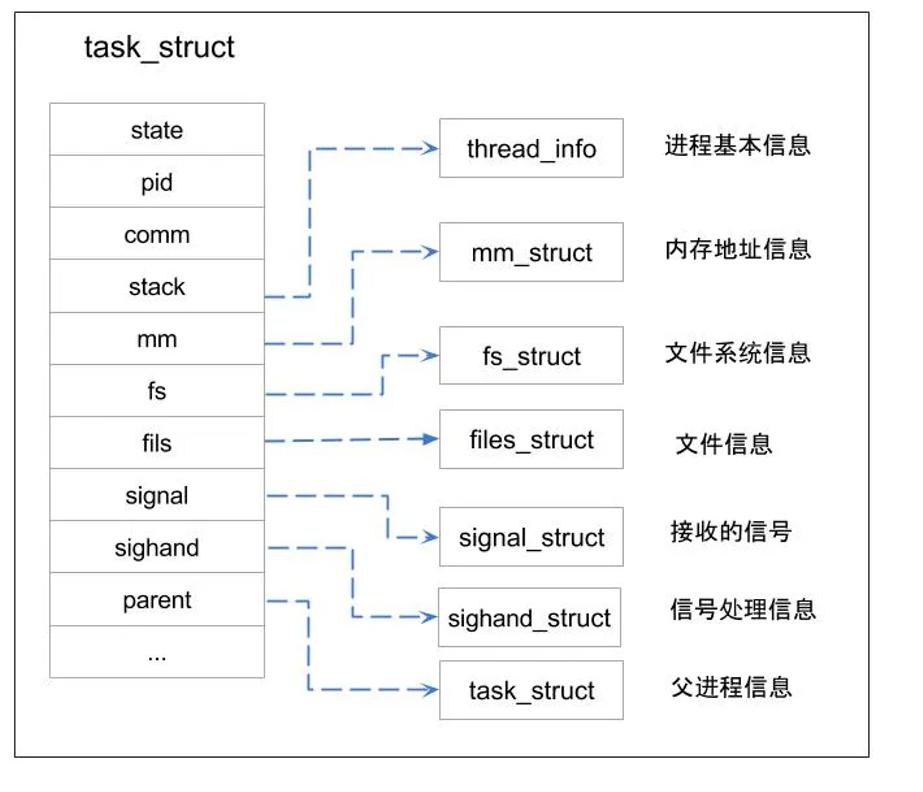
首先每个进程的结构体里都有信号的信息存储:
struct task_struct {
...
int sigpending;
...
struct signal_struct *sig;
sigset_t blocked;
struct sigpending pending;
...
}
sigpending 表示进程是否有信号需要处理(1表示有,0表示没有);成员 blocked 表示被屏蔽的信息,每个位代表一个被屏蔽的信号;成员 sig 表示信号相应的处理方法,其类型是 struct signal_struct。
在进程从用户态陷入内核态时,内核态完成了相关工作之后,返回用户态之前,都会例行对进程的信号队列进行检查。
这段逻辑是汇编实现的,因为在linux内核中,用户态的切换就是汇编来控制的。【可能有同学对用户态和内核态的切换不太了解,其实用大白话讲就是,只是对cpu的寄存器的赋值进行更换,跟普通的进程切换可能没什么区别,但是同时又有区别,因为用户态和内核态的堆栈是分离开的,这样二者在切换的时候是需要在两个堆栈上进行操作,并且保存上下文信息】
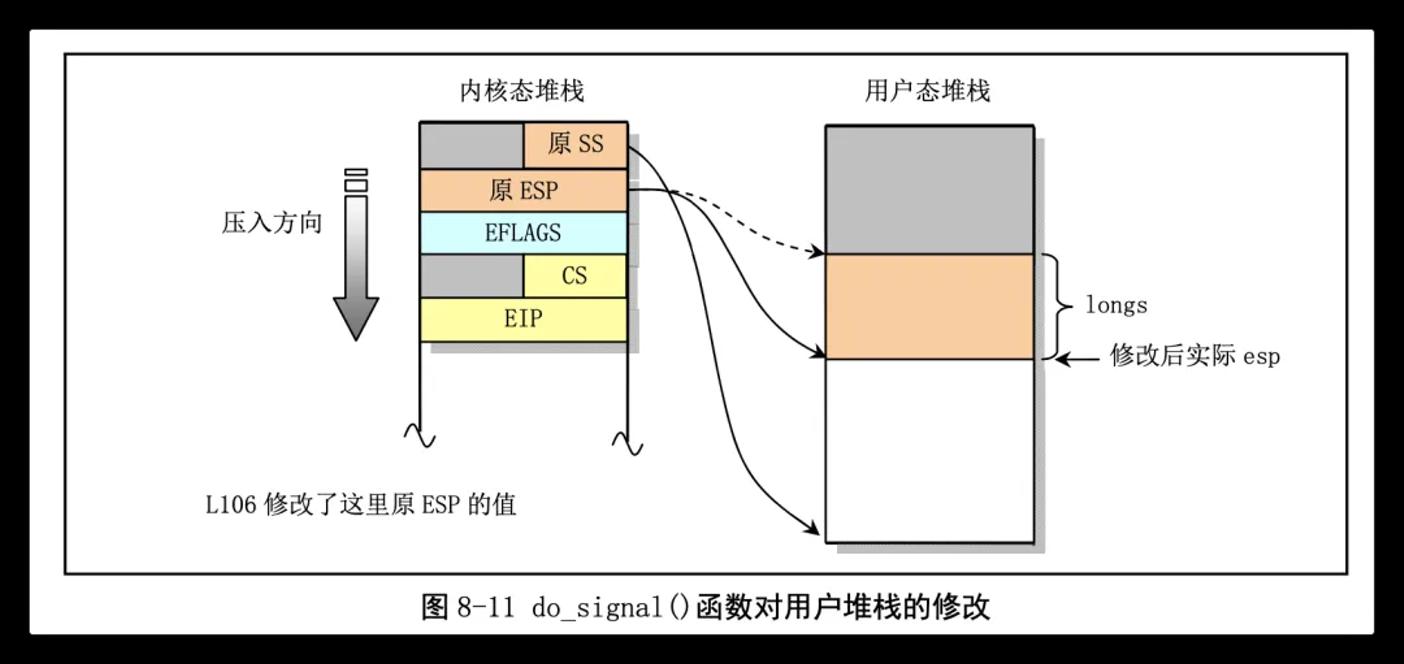
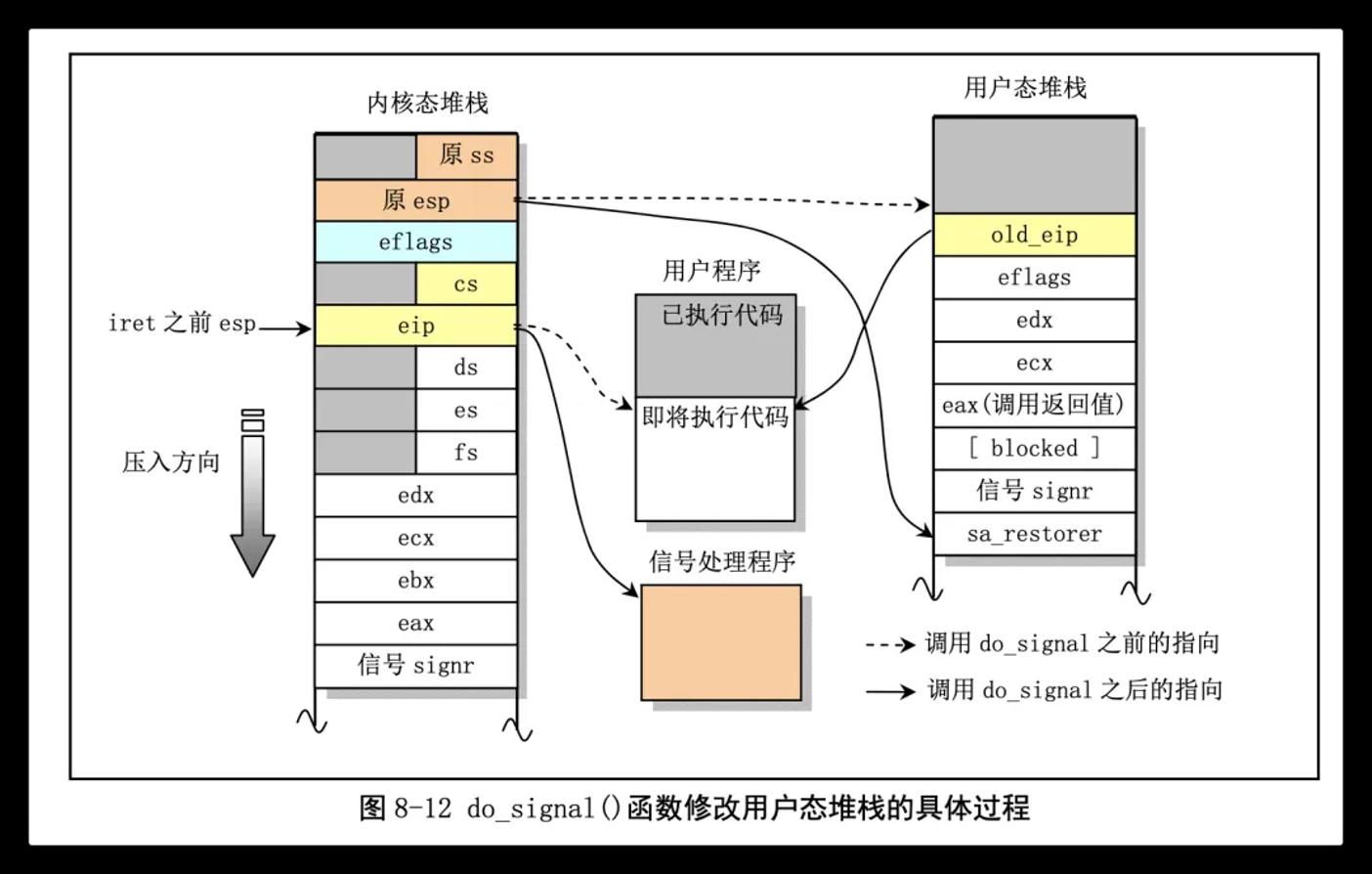
ENTRY(ret_from_sys_call)
...
ret_with_reschedule:
...
cmpl $0, sigpending(%ebx) // 检查进程的sigpending成员是否等于1
jne signal_return // 如果是就跳转到 signal_return 处执行
restore_all:
RESTORE_ALL
ALIGN
signal_return:
sti // 开启硬件中断
testl $(VM_MASK),EFLAGS(%esp)
movl %esp,%eax
jne v86_signal_return
xorl %edx,%edx
call SYMBOL_NAME(do_signal) // 调用do_signal()函数进行处理
jmp restore_all
前面已经简单描述了coredump文件的生成机制和触发机制,但是在触发机制中并没有对信号产生以及信号存储这块有什么比较具体的说明。
在此就以具体的例子,来描述一个coredump信号产生的详细过程。
信号的产生源是多样的,比如可以直接用kill 命令向进程发送信号,也可以用一些快捷键来向终端的前端进程发送一些信号,还有就是程序中本身存在一些bug触发内核去向用户进程发送一些信号。
这些信号,在不同的场景下流程不同,只能说有的信号其信号捕获流程是基本一致的,比如代码中的bug所产生的段错误、页错误等。
示例代码如下,其中给addr指针赋值为NULL。
int main(int argc, char *argv[]){
char *addr = (char *)0; // 设置 addr 变量为内存地址 "0"
*addr = '\0'; // 向内存地址 "0" 写入数据
return 0;
}
当运行该代码时,就会报段错误
root@freeoa.net:~# ./coredump
Segmentation fault
现在所要探究的就是其背后的原理。
root@freeoa.net:~# ./coredump1
root@freeoa.net:~# cat coredump1.c
int main(int argc, char *argv[]){
char *addr = (char *)0; // 设置 addr 变量为内存地址 "0"
return 0;
}
如上所示,当把给*addr写数据时才会报段错误。其根本原因在于cpu在执行代码时,想要向*addr写数据时,是无法进行正常写入的。
CPU 使用页表将虚拟地址转换为物理地址。在这个过程中,CPU 会查找当前进程的页表项,以确定该虚拟地址(例如 0x0)是否有对应的物理地址。
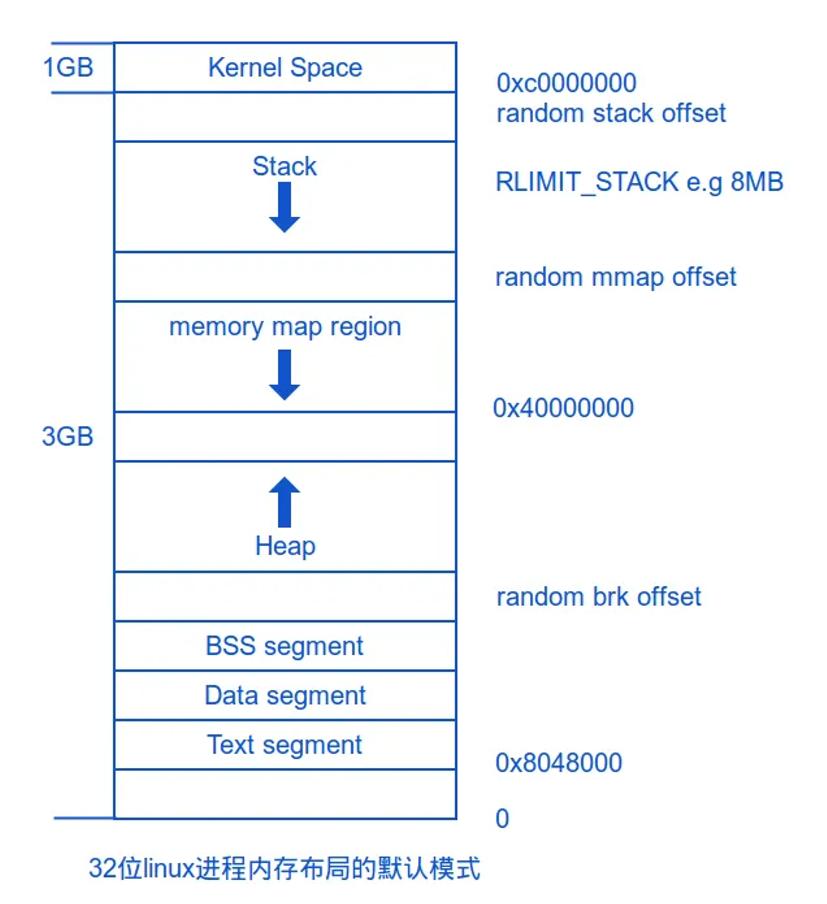
如果页表中没有找到对应的物理页,或者找到的页没有相应的访问权限(例如没有读权限),CPU 将产生一个缺页异常。这一异常会触发一个硬件中断,导致控制权从当前进程转移到内核的异常处理程序。
其实此处为何0x0虚拟地址无法与物理地址映射,原因有点多,此处不做缀述。
虚存空间有效地址的最低位是 0x0000000000000040。因此,显而易见 0x0 此时是一个非法的地址,所以使用它会导致段错误。
这后边的事情就交给了中断程序来执行
// arch/x86/mm/fault.c
asmlinkage void __kprobes do_page_fault(struct pt_regs *regs, unsigned long error_code) {
unsigned long address;
struct task_struct *tsk;
struct mm_struct *mm;
struct vm_area_struct *vma;
int fault;
// 获取引发异常的地址
address = read_cr2(); // CR2 寄存器保存了导致缺页异常的地址
tsk = current; // 获取当前进程
mm = tsk->mm; // 获取进程的内存描述符
// 如果 mm 为 NULL 或者地址超出用户态地址空间,处理非法访问
if (unlikely(!mm || address >= TASK_SIZE)) {
bad_area_nosemaphore(regs, error_code, address);
return;
}
// 查找地址对应的虚拟内存区域(VMA)
vma = find_vma(mm, address);
// 如果没有找到对应的 VMA,处理非法访问
if (unlikely(!vma || vma->vm_start > address)) {
bad_area(regs, error_code, address);
return;
}
// 检查访问权限等
// ... 其他处理代码 ...
}
如果地址无效(例如地址为 0),内核调用 bad_area 函数处理非法访问,并向当前进程发送 SIGSEGV 信号:
static void bad_area(struct pt_regs *regs, unsigned long error_code, unsigned long address) {
struct task_struct *tsk = current;
// 将异常信息保存到进程的线程结构中
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
// 如果是在用户态发生的异常,发送 SIGSEGV 信号
if (user_mode(regs)) {
force_sig_fault(SIGSEGV, SEGV_MAPERR, (void __user *)address, tsk);
} else {
// 内核态异常处理
// 通常会引发内核恐慌(kernel panic)
// ... 内核态处理代码 ...
}
}
force_sig_fault 函数用于构建 siginfo 结构体,并通过 force_sig_info 函数将 SIGSEGV 信号发送给当前进程:
// kernel/signal.c
void force_sig_fault(int sig, int code, void __user *addr, struct task_struct *t) {
struct siginfo info;
// 清空并初始化 siginfo 结构体
clear_siginfo(&info);
info.si_signo = sig;
info.si_errno = 0;
info.si_code = code;
info.si_addr = addr;
// 发送信号
force_sig_info(sig, &info, t);
}
以上就是一个段错误信号产生以及发送给当前进程信号队列的基本过程。
另外一个例子
其实可以再举个例子,比如在终端上输入 Ctrl+C 时。这个其实也是在向前端进程发送信号。当按下 Ctrl+C 时,Linux 系统如何知道这是一个发送信号的操作,其背后涉及了一系列硬件和软件的协同工作。以下是这一过程的详细描述:
1.键盘输入的硬件层面
当按下 Ctrl+C 键,键盘会将这一信息转换为一系列电信号,通过键盘接口发送到计算机。这些电信号被键盘控制器接收和解释为特定的键盘扫描码。——此处触发硬件中断
2.键盘扫描码的处理
键盘控制器将扫描码传送给操作系统的内核。内核中的键盘驱动程序会将这些扫描码转换为对应的键值(keycode)。
3.终端(TTY)处理
在终端(TTY,Teletypewriter)环境中,Linux 内核的 TTY 子系统负责处理来自键盘的输入。当检测到 Ctrl+C 键组合时,TTY 子系统会识别出这是一个SIGINT信号(SIGINT)。
4.发送信号
TTY 子系统将生成的 SIGINT 信号发送给前台进程组(foreground process group)。具体过程如下:
1).识别前台进程组:每个终端都有一个关联的前台进程组。前台进程组中的所有进程都会接收到信号。
2).发送信号:内核通过进程控制块(PCB)将 SIGINT 信号发送给前台进程组中的每一个进程。
5.前台进程的信号处理
前台进程收到 SIGINT 信号后,会根据其对该信号的处理方式做出响应。通常情况下,默认的处理方式是终止进程,但进程也可以定义自己的信号处理函数来处理 SIGINT 信号。
Core Dump与GDB配合使用
“系统死机”多数是用户态进程触发致命错误(如段错误、栈溢出等)导致的进程崩溃(表现为服务无响应、设备卡死),而GDB与Core Dump是定位这类死机根因的“最佳搭档”,二者结合可有效还原死机瞬间的程序状态,精准定位问题。
GDB(GNU Debugger)
1.核心定位:跨平台调试工具,支持ARM/x86等架构,是嵌入式Linux下调试用户态程序的核心工具;
2.现场场景:无需实时调试(死机后进程已退出),可通过加载Core文件“复盘”崩溃现场,还原死机前的程序状态;
3.关键适配:嵌入式需用对应架构的GDB(如ARM64用gdb-multiarch/aarch64-linux-gnu-gdb),且程序编译时需加-g保留调试符号(否则无法解析函数/行号)。
Core Dump(核心转储)
1.核心功能:进程触发致命错误(如SIGSEGV/SIGABRT/SIGILL)导致死机时,操作系统将进程的内存镜像、寄存器状态、调用栈、线程信息 等保存到磁盘的二进制文件(即Core文件);
2.现场场景:相当于“死机现场的黑匣子”,是事后定位死机根因的唯一有效手段(实时调试无法复现偶发死机时,Core Dump是关键);
3.注意:
仅保存用户态进程数据(内核态死机需分析内核panic日志);
文件大小通常与进程占用内存相当(设备要注意存储空间了)。
内核处理流程(出意外时Core Dump生成过程)
1.进程触发致命信号 → 内核接收到信号并判断是否允许生成Core Dump;
2.内核检查ulimit -c限制(默认0,禁止生成),若限制为“unlimited”则允许;
3.内核根据/proc/sys/kernel/core_pattern配置的路径,创建Core文件;
4.内核将进程的:
虚拟内存布局(堆/栈/代码段/数据段);
寄存器状态(PC:程序计数器,SP:栈指针,LR:链接寄存器等);
线程信息(所有LWP的状态);
函数调用栈、局部变量值;
5.写入Core文件,完成后终止进程(表现为系统死机/服务无响应)。
关键限制
通过 ulimit -c 限制文件大小;
通过 /proc/sys/kernel/core_pattern 控制保存路径;
默认仅对有写权限的目录生成。
4步完成配置流程(对上文过程的总结,同理在root账户下操作)
步骤1:配置系统允许生成Core Dump
若未配置,死机后不会生成Core文件,需提前在设备执行:
# 1. 允许生成无大小限制的 core 文件
ulimit -c unlimited
# 2. 永久生效(写入 /etc/security/limits.conf)
* soft core unlimited
* hard core unlimited
# 3. 设置 core 文件命名规则
echo"/tmp/core.%e.%p.%h.%t" > /proc/sys/kernel/core_pattern
# `%e`:程序名
# `%p`:进程 ID
# `%h`:主机名
# `%t`:时间戳
# 4. 创建目录 & 赋权
mkdir -p /var/crash
chmod 1777 /var/crash # sticky bit,允许所有用户写入
步骤 2:编译带调试符号的程序
# 关键:-g 保留调试符号,-O0 关闭优化
gcc -g -O0 -o critical_service service.c
实用小技巧:
保留带符号的二进制文件,部署时剥离符号(strip)提升性能,崩溃时用备份符号文件分析。
步骤 3:触发崩溃并捕获 Coredump
# 运行程序(假设会因空指针崩溃)
./critical_service
# 输出:
# Segmentation fault (core dumped)
# 验证 core 文件生成
ls /var/crash/core.critical_service.3681.1650000000
步骤 4:使用 GDB 分析 Coredump
# 基础命令
gdb ./critical_service /var/crash/core.critical_service.3681.1650000000
# 或先进入 GDB 再加载
gdb ./critical_service
(gdb) core-file /var/crash/core.critical_service.3681.1650000000