Unix文件系统
 Unix文件系统(英语:Unix File System,缩写为UFS),是一种文件系统,为许多UNIX和类Unix操作系统所使用。它也被称为伯克利快速文件系统(Berkeley Fast File System),BSD快速文件系统(BSD Fast File System),缩写为FFS。
Unix文件系统(英语:Unix File System,缩写为UFS),是一种文件系统,为许多UNIX和类Unix操作系统所使用。它也被称为伯克利快速文件系统(Berkeley Fast File System),BSD快速文件系统(BSD Fast File System),缩写为FFS。FFS对Unix System V文件系统“FS”有所继承。FFS在Unix文件系统(1或2)之上,提供目录结构的信息,以及各种磁盘访问的优化。UFS(以及UFS2)定义了on-disk数据规格。在最初的FFS文件系统的设计中,为了使文件系统在遭到毁灭性打击,如硬盘发生整个磁道、整个盘面或者整个柱面损坏时能够得以恢复,在文件系统初始化时,会将文件系统的重要数据结构复制到整个磁盘的多个位置,以便在发生硬件损坏时能够读取,而UFS文件系统也继承了这些优良的特性。另外,为了提高运行效率,UFS文件系统与磁盘的结构也有着完美的结合,UFS将整个磁盘的所有逻辑柱面平均分配为若干个组,每组称为一个“柱面”。在UFS内部就用柱面组队文件系统进行分段组织和管理,每个柱面组中都有文件系统关键数据结构的备份,所有文件在各个柱面组中相对独立地存储而又有机地结合在一起。这就使磁盘中的磁头在访问文件系统中的数据时有效地减小了摆动,提高了访问效率。
UFS 最早发表于 1984 年,他的作者是 Marshall Kirk McKusick 和 William Joy。另外说一下这位 William Joy,实际上就是大名鼎鼎的 Bill Joy,此人后来创办了 Sun 公司。UFS 是 Solaris OS 中缺省的基于磁盘的文件系统,以前UFS文件系统在64位系统和32位系统上的大小仅限于约1 TB(Tbyte),现在所有UFS文件系统命令和公用程序已更新为支持多TB UFS文件系统。
UFS 可以说是现代文件系统的鼻祖,它的出现使得文件系统可以真正适用于生产环境。在 UFS 之前的文件系统最多只能使用 5% 的磁盘带宽,而 UFS 将这个数字提升到了 50%,这主要源于 UFS 中的两个设计:
将基础块大小从 1024 字节增加到 4096 字节增加 Cylinder Group 的概念,优化数据和元数据在磁盘上的分布,减少读写文件时磁头寻道的次数(减少磁头寻道次数是 HDD 时代文件系统在性能优化上的一个主要方向)。
Solaris 10 UFS文件系统的功能
扩展的基本类型(EFT) :提供32 位用户ID (user ID, UID)、组ID (group ID, GID) 和设备编号。
大文件系统:在最大大小可以为16 TB 的文件系统中,允许大小约为1TB的文件。可以在具有EFI 磁盘标号的磁盘上创建多TB UFS 文件系统。
日志记录 :UFS 日志记录会将组成一个完整UFS 操作的多个元数据更改打包成一个事务。事务集记录在盘上日志中,然后会应用于实际UFS 文件系统的元数据。
多TB 文件系统通过多TB 文件系统,可以创建最大可用空间约为16 TB 的UFS文件系统,其中会减去约1% 的开销。
状态标志显示文件系统的状态:clean、stable、active、logging 或unknown。这些标志可避免不必要的文件系统检查。如果文件系统的状态为“clean”、“stable” 或“logging”,则不运行文件系统检查。
Solaris 10典型的文件系统类型为UFS文件系统,但它也允许在/etc/default/fs中定义其他文件类型。在Solaris 10上,UFS文件系统驻留在硬盘上,这些硬盘同时具有原始设备接口和块设备接口,这两个接口分别位于/dev/rdsk目录和/dev/dsk目录中。Solaris 10文件系统所创建的每一个分区都在/dev/dsk和/dev/rdsk中有其自己的对应项,一个UFS文件系统的组成包括如下几部分:
引导块(boot block):在文件系统可引导的情况下,引导块中包含有引导数据。
超级块(super block):超级块中包含有关i节点的位置、文件系统大小、块数目,以及状态等信息。
i节点(inode):存储文件系统的文件细节信息。
数据块(data block):实际存储的文件。
Solaris操作系统下每个常规文件必须包含一个文件名和与之相关联的inode(信息节点),inode中存储文件的相关信息(如文件的所有者、权限和大小等信息),以及该文件所关联的数据块的指针。因此,inode数量的多少决定着一个UFS文件系统所允许创建的文件数。一个UFS文件系统在其创建时,所允许最大的indoe数就已经固定,当该文件系统中有大量的(上千万甚至上亿个)小文件存在时,有可能出现inode数量不够用的情况,由于文件需要用inode来存储元数据(MetaData),inode数量超出将导致新文件无法被创建,尽管此时实际的存储空间还远远不到极限,所以在创建此类文件系统的时候需要考虑到这一点。
UFS 磁盘布局
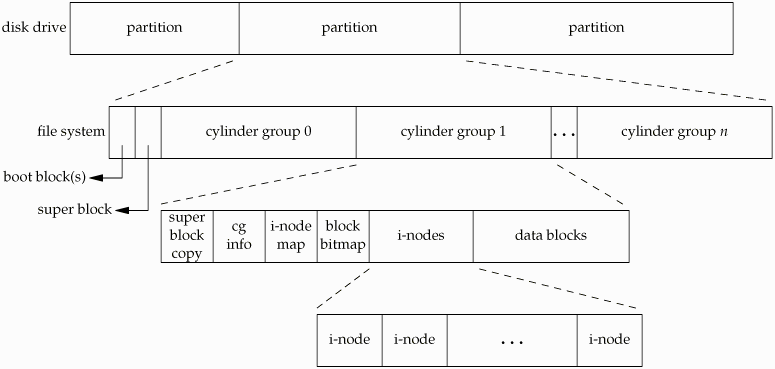
UFS 的磁盘 layout 如上图。磁盘被分成了多个 Cylinder Group,每个 Cylinder Group 包含了一份 Superblock 的拷贝,以及这个 Cylinder Group 内部的元信息。由于操作文件时,通常都会先读取文件的 Inode,再操作文件的 Data Block。如果 Inode 和 Data Block 被放置在磁盘上相邻的位置,那就意味着不需要额外的寻道时间。
UFS 最早被实现在 BSD 系统上,此后 Sun 的 Solaris,IBM 的 System V,以及 HP-UX 等 Unix 操作系统都移植了 UFS。包括现在存储界的巨头 EMC 公司的很多存储产品,操作系统是源于 Unix 的,文件系统则是基于 UFS 演进而来的。作为 BSD 的变种,自然也采用了 UFS。Linux 上并没有 UFS 的实现,但著名的 ext2 文件系统在设计上很大程度借鉴了 UFS 的思想。而 ext3,ext4 又是基于 ext2 设计的扩展,同样也继承了 UFS 的思想。
UFS结构总览
UFS文件系统在创建时,磁盘的盘片被分成若干个柱面组,每个柱面组由一个或多个联系的磁盘柱面组成,在文件系统的前部会有一个叫做“柱面组概要”的结构对整个文件系统中的每个柱面组信息进行统计,并且在每个柱面组中还有一个“柱面组描述符”用来管理当前柱面组。每个柱面组又进一步被分成若干个可寻址的块,以控制和组织柱面组中文件的结构,所以“块”是UFS文件系统中文件分配和存储的基本单位,类似于FAT文件系统和NTFS文件系统中“簇”的概念。
在UFS文件系统中,“块”有多种类型,每种类型的块都具有特定的功能。UFS文件系统主要具有四种类型的块:引导块、超级块、i-节点、数据块。
引导块:在引导系统时使用的信息
超级块:记录文件系统的详细信息
i-节点:记录文件的各种信息
数据块:存储每个文件的实际内容
UFS文件系统中的“块”又被分成更小的单位,叫做“段”。在创建UFS文件系统时,可定义段的大小,默认的段大小一般为1KB。每个块都可以分成若干个段,段大小的上限就是块的大小,下限实际上为磁盘扇区大小,通常为512字节。
当文件写入文件系统时,首先为文件分配完整的块,然后为不满一个块的剩余部分分配某个块的一个或者多个段。对于比较小的文件,首先分配段进行存储。能够为文件分配块中的段而不是仅分配完整的块,就减少了块中未使用的空间,从而提高了磁盘的利用率。
在创建文件系统时,选择段的大小需要考虑时间和空间的平衡,小的段大小可节省空间,但是需要更多的时间进行分配,通常,当大多数文件都很大时,要提高存储效率,应为文件系统使用较大的段大小,当大多数文件都比较小时,应为文件系统使用较小的段大小。
综上所述,UFS文件系统由若干个“柱面组”构成,每个柱面组包含一定数量的“块”,每个块又由若干个“段”组成。“段”是UFS文件系统的最小存储单元。每个柱面组、块、段在文件系统中都有自身的编号,它们的起始编号都是0。
另外,“超级块”是UFS文件系统中非常重要的一个结构,其重要性类似于FAT文件系统和NTFS文件系统中的DBR,所以UFS在每个柱面组中都对超级块做了备份,但备份的位置却各不相同,在每个柱面组中都会发生一定的偏转,这是因为在原来的硬盘中每个磁道具有相同的扇区数,这个就导致每个柱面组的第一个扇区都位于同一个盘面上。为了减小因无力故障而产生的数据损坏,将超级块的备份在每个柱面组中错位存放就可以使它们不再存储于同一个盘面,从而降低了风险。而现在的新式硬盘每个柱面的扇区数并不相等,所以也就不存在这样的隐患,实际上UFS2已经不再考虑数据错位存放的问题。
UFS文件系统的引导块:
引导块是UFS文件系统中的第一个块,也就是0号块。它的结构因操作系统的不同而稍有区别,但一般都是由磁盘标签和引导程序组成。只有当UFS文件系统中包含操作系统内核时,引导块中才会有引导程序。如果UFS文件系统中不保护操作系统内核,引导块中则没有引导程序,只有磁盘标签。
UFS文件系统的超级块:
UFS文件系统超级块的重要性类似于FAT文件系统和NTFS文件系统中的DBR,但比DBR的结构复杂很多,超级块中记录着许多参数 ,主要包括:
文件系统的大小和状态
文件系统名称和卷名称
文件系统块的大小及段大小
上次更新的日期和时间
柱面组的大小
柱面组中的数据块数
柱面组概要的地址
文件系统状态
最后一个挂载点的路径名
由于超级块包含文件系统的关键数据,因此在创建文件系统时建立了多个超级块,在每个柱面组内都有一个超级块的备份。
UFS的i节点
UFS文件系统的i节点用来存储与文件相关的除文件名以外的所有信息,包括指向文件的硬链接数、文件大小、文件的时间信息、文件属主的用户ID、文件所属的组ID、文件内容存放地址的块指针等重要信息,这些重要信息也被称为元数据。
UFS文件系统的每个柱面组中都有一个自己的i节点表。i节点表由很多i-节点组成,每个文件或者目录使用一个i节点。UFS1的i节点在文件系统创建时即被初始化,而UFS2的i节点则在需要时才被初始化,所以当文件系统中的数据块不够使用时,UFS2能够使用i-节点表中的空闲空间存放数据。
在每个柱面组的组描述符中都有一个i-节点位图,用来管理i-节点表中的i-节点使用和分配情况。如果要确定一个i-节点属于哪个柱面组,可以用当前i节点号对每个柱面组的i节点数做取整运算得到,而每个柱面组的i节点数在超级块和柱面组描述符中都有记录。
UFS日志记录
UFS 日志记录会将组成一个完整操作的多个元数据更改打包成一个事务。事务集记录在盘上日志中,然后会应用于实际文件系统的元数据。重新引导时,系统会废弃未完成的事务,但是会对已完成的操作应用事务。文件系统将保持一致,因为仅应用了已完成的事务。即使在系统崩溃时,也仍会保持此一致性,系统崩溃可能会中断系统调用,并导致 UFS 文件系统出现不一致。
UFS 日志记录功能有两个好处:
如果文件系统已经通过事务日志达到一致,则在系统崩溃或异常关机后可能不必运行 fsck 命令。从 Solaris 9 开始,UFS 日志记录的性能已经提高甚至超过了无日志记录功能的文件系统的性能级别。这一改进之所以能够实现是由于启用日志记录功能的文件系统可以将对相同数据的多重更新转换为单一更新,因此减少了磁盘操作所需的开销。
UFS 事务日志具有以下特征:
从文件系统上的空闲块分配而来,对于每 1 GB 的文件系统,其大小约为 1 MB,最大为 64 MB。
填满时会不断刷新,取消挂载文件系统或使用任何 lockfs 命令之后也会刷新。
所有 UFS 文件系统均缺省启用 UFS 日志记录。如果需要禁用 UFS 日志记录,请在 /etc/vfstab 文件中或手动挂载文件系统时,向文件系统的项添加 nologging 选项。如果需要启用 UFS 日志记录,请在 /etc/vfstab 文件中或手动挂载文件系统时,在 mount 命令中指定-o logging选项。可以在包括根 (/) 文件系统的任何 UFS 文件系统上启用日志记录。另外,fsdb 命令还包含支持 UFS 日志记录的新调试命令。在一些操作系统中,启用了日志记录的文件系统称为日记记录文件系统。
参考来源
Little UFS2 FAQ (2003/04/25, v15.a)
Derived from contributions to freebsd-current@freebsd.org
Jeroen C. van Gelderen
jeroen@vangelderen.org
Copyright © 2003 by The FreeBSD Documentation Project
1 Introduction
This Mini-FAQ contains tips and information regarding the newly ported UFS2 filesystem. This is intended to be a rapidly evolving document. The latest version of this document is always available from the UFS2 Mini-FAQ.
Suggestions and contributions should be sent to <jeroen@vangelderen.org>.
Contributors include:
Alex Wilkinson <Alex.Wilkinson@dsto.defence.gov.au>
Alexander Pohoyda <alexander.pohoyda@gmx.net>
Anthony CARTER <a.carter@cordis.lu>
Bernd Walter <ticso@cicely9.cicely.de>
Bruce Evans <bde@zeta.org.au>
Daniel C. Sobral <dcs@tcoip.com.br>
David Schultz <das@FreeBSD.ORG>
Frank van der Linden <fvdl@wasabisystems.com>
Lucky Green <shamrock@cypherpunks.to>
Manfred Antar <null@pozo.com>
Marcin Dalecki <mdcki@gmx.net>
Narvi <narvi@haldjas.folklore.ee>
Peter Schultz <peter@jocose.org>
Poul-Henning Kamp <phk@phk.freebsd.dk>
Robert Watson <rwatson@freebsd.org>
Takahashi Yoshihiro <nyan@jp.FreeBSD.org>
Terry Lambert <tlambert2@mindspring.com>
The Anarcat <anarcat@anarcat.ath.cx>
Tomi Vainio <Tomi.Vainio@Sun.COM>
1.1. Which OSes support UFS2?
1.2. Is this FAQ (and UFS2) applicable to FreeBSD 4-STABLE?
1.3. What is UFS1?
1.4. What is UFS2?
1.5. What is the difference between UFS and FFS?
1.6. What platforms currently run UFS2?
1.7. What is the rationale for UFS2?
1.8. Who is responsible for UFS2?
1.9. Why did you not add feature while you were at it?
1.10. Does UFS2 offer any performance improvement over UFS1?
1.11. What is the UFS2 status on FreeBSD?
1.12. What is the UFS2 status on NetBSD?
1.13. On which platforms can UFS2 be used for the root filesystem?
1.14. Is there a UFS1 to UFS2 conversion tool?
1.15. Can a UFS1 dump be restored to a UFS2 filesystem?
1.16. Does UFS2 dynamically allocate inodes?
1.17. Does Grub work with UFS2?
1.18. My /boot/loader reports "Invalid format"?
1.1. Which OSes support UFS2?
Currently, FreeBSD 5-CURRENT and NetBSD. (Others?)
1.2. Is this FAQ (and UFS2) applicable to FreeBSD 4-STABLE?
Nope. MFC is not planned for UFS2.
1.3. What is UFS1?
The long-time BSD(?) native filesystem.
1.4. What is UFS2?
UFS2 -introduced in FreeBSD 5-CURRENT- is an extension to the well-known UFS. It adds 64 bit block pointers (breaking the 1T barrier), support for extended file storage, and a few other things.
Short summary of changes:
64-bit pointers up the wazoo (implies that inodes have doubled in size, and now are 256 bytes)
Layout and functional changes to help support variable-size blocks (extent-like allocation)
Extension of various flag fields
Addition of per-inode extended attribute extent
Lazy inode initialization (watch newfs(8) fly)
Apart from these modifications all UFS1 code is being used in UFS2 unchanged.
1.5. What is the difference between UFS and FFS?
UFS (and UFS2) define on-disk data layout. FFS sits on top of UFS (1 or 2) and provides directory structure information, and a variety of disk access optimizations. FFS is described in A Fast File System for Unix. This FAQ is about a revision of UFS named UFS2.
1.6. What platforms currently run UFS2?
Currently, FreeBSD 5-CURRENT and NetBSD. (Others?)
1.7. What is the rationale for UFS2?
The motivating factor in the layout change was the need for better Extended Attribute (EA) support, and while the developers were at it they figured they would do a bunch of other useful things too. UFS2 uses the same basic technologies as modern UFS1 (inodes, linear directory layout, soft updates, snapshotting, background file system checking, etc) so it was a relatively low-risk change.
1.8. Who is responsible for UFS2?
UFS2 was developed by Kirk McKusick and Poul-Henning Kamp, but is based in large part on the existing UFS1 file system, which had a host of contributors. UFS2 development was sponsored by DARPA and Network Associates Laboratories, and motivated by the requirements of the TrustedBSD Project. UFS2 was ported to NetBSD by Frank van der Linden, sponsored by Wasabi Systems.
1.9. Why did you not add feature while you were at it?
It would most likely require significant changes whereas the developers wanted to restrict themselves to low-risk modifications only. See previous question.
1.10. Does UFS2 offer any performance improvement over UFS1?
UFS2 has the potential to be faster for really large files by using jumbo blocks, but the code to do that has yet to be written. Additionally, because inodes are lazily initialized in UFS2, newfs(8) runs much faster. Other than that, UFS2 performance should not significantly differ from UFS1.
1.11. What is the UFS2 status on FreeBSD?
As of FreeBSD-CURRENT 2003/04/20, newfs(8) and sysinstall(8) will create UFS2 file systems by default. Users wanting to create UFS1 file systems for whatever reason (interoperability with earlier versions, etc.) should be sure to employ the -O1 flag to newfs(8), or hit 1 in the label editor in sysinstall(8) to select UFS1.
Note: PC98 machines are exempt and still default to UFS1. See "On which platforms can UFS2 be used for the root filesystem?"
1.12. What is the UFS2 status on NetBSD?
As of 2003/04/02 UFS2 is not (yet) the default type for FFS filesystems. newfs(8) will create a normal FFS filesystem by default. If you want a UFS2 fileystem, specify -O 2 as an option.
No additional kernel options are needed for UFS2 support; it's contained within the FFS code.
Please note that older fsck(8) binaries will complain a bit about UFS2 filesystems, because of some superblock changes. This is harmless. However, if you have 1.6 fsck(8) binaries, they will signal a fatal superblock mismatch with the first alternate, because they compare too many fields (even ones that aren't useful). This is annoying, and pepole should upgrade their fsck_ffs(8) binaries before using UFS2. fsck_ffs(8) 1.6.1 will be fully UFS2 compatible.
1.13. On which platforms can UFS2 be used for the root filesystem?
The answer to this is defined by /boot/loader. FreeBSD Alpha, IA64, and SPARC have no problems.
On FreeBSD i386, the answer is yes, modulo the restriction that the root filesystem cannot be larger than 1.5TB. David Schultz, et al., have proposed a patch to remove this limitation. FreeBSD PC98 does not support UFS2 root partitions and it is unknown if work is underway to address this.
NetBSD support is unknown to the author of this document as of this writing.
1.14. Is there a UFS1 to UFS2 conversion tool?
No, but see next question.
1.15. Can a UFS1 dump be restored to a UFS2 filesystem?
The following sequence has been reported to work. Substitute the correct device name on your system.
newfs -U -O 2 /dev/da1s1a
mount /dev/da1s1a /mnt
cd /mnt
dump 0buf 126 - / | restore xbf 126 -
Other suggestions for a dump - restore pipeline include:
dump 0abf 64 - / | restore rbf 64 -
Use of the dump -C option (-C 32) has also been suggested.
Check the freebsd-current email archives (April 25, 2003 and following) for more discussion. Refer to dump(8) and restore(8) for additional details.
1.16. Does UFS2 dynamically allocate inodes?
No it does not. Inodes are preallocated, but UFS2 lazily initializes them. This mainly means that newfs(8) runs much faster.
1.17. Does Grub work with UFS2?
No. Not yet(?).
1.18. My /boot/loader reports "Invalid format"?
UNRESOLVED
You need a loader and bootblocks that support UFS2. Try using disklabel -B
You need a new boot block. What I'd recommend is booting an install floppy or cd, going to custom installation, checking the partitioning (ensuring everything is correct), writing, and then selecting the boot loader. I *think* this should work. What I *don't* recommend is getting a fixit disk and running boot0cfg. Last time I did that I spent three days recovering my partitions.
--From Daniel Sobral
Unix V7 File System
翻译自:《50 years in filesystems》 由 KRISTIAN KÖHNTOPP 撰写,译者:Juicedata。
Unix V7 是 Unix 操作系统的一个重要的早期版本,于 1979 年发布,是贝尔实验室最后一个广泛分发的版本。它是第一个真正可移植的 Unix 版本,被移植到了多种平台上,包括 DEC PDP-11, VAX, x86, Motorola 68000 等。Unix V7 的 VAX 移植版本,叫做 UNIX/32V,是流行的 4BSD 系列 Unix 系统的直接祖先。许多老牌的 Unix 用户认为 Unix V7 是 Unix 发展的顶峰。Unix V7 Research Release 的源代码可以在 unix-history-repo 这个由 Diomidis Spinellis 维护的项目中找到。如果你想深入了解 Unix 的设计原理,可以参考 Maurice J. Bach 的经典著作 The Design of the Unix Operating System,并查看 Research V7 Snapshot 这个分支的代码库。
Machines
1974 年,计算机拥有一个 “核心”,即中央处理单元。然而在某些计算机中,这个 “核心” 已经发生了变化。不再是由多个部件(如算术逻辑单元、寄存器、顺序控制器和微码存储器)组成的设备,而是一颗单一的集成芯片,单个芯片上集成了数千个晶体管。它们被叫做 “小型计算机”。
Kernels
在 Unix 中通过配置头文件(header file)来处理系统资源。如下图所示,这里显示了头文件中配置的默认值,数据结构是数组,所示值是相应的数组大小。如果要更改它们,则需要编辑文件,重新编译和链接内核,然后重新启动系统。

它有一个文件系统缓冲区缓存(file system buffer cache),使用 NBUF(29)个磁盘块,每个磁盘块的大小是 512 字节,用来暂时存储磁盘上的数据块和 inode,从而加速文件系统访问。另外还有一个索引节点数组(inode array),它有 NINODE(200)个条目,每个条目对应一个文件的元数据,还可以同时挂载 NMOUNT(8)个文件系统。每个用户最多可以运行 MAXUPRC(25)个进程,总共有 NPROC(150)个系统进程。每个进程最多可以打开 NOFILE(20)个文件。
阅读 Bach 的著作和 V7 源代码是很有趣的,尽管它们已经完全过时。因为这些源代码中呈现出的许多核心概念更加清晰,结构更简洁,有时甚至带有古老的风格。然而正是这些概念定义了 Unix 文件系统。V7 Unix 被写入了 POSIX 标准,之后的每个文件系统都必须遵守它。如果想了解更多相关示例,请参考 But Is It Atomic?
核心概念
Unix 文件系统的基本概念和结构来自这个系统,其中一些概念甚在现代系统中依然存在。
磁盘由一系列数据块(block)组成,从第 0 块开始,一直到第 n 块结束。在文件系统的开始部分,我们可以找到超级块(superblock)。它位于文件系统的第 1 块。超级块存储了文件系统的一些基本信息,比如文件系统的大小、空闲块的数量、空闲索引节点的数量等。当我们执行挂载(mount)系统调用时,系统会找到一个空闲的挂载结构(mount structure),并且从磁盘上读取超级块,把它作为挂载结构的一部分。
Inode
内存中的超级块(in-memory superblock)是磁盘上超级块的副本,用于加快文件系统的访问速度。它包含一个 short 类型的字段,用于存储一个索引节点数组(inode array)在磁盘上的位置。
索引节点(inode)是一个描述文件内容和属性的结构,文件内容由一系列数据块(block)组成,每个数据块的大小是固定的(通常是 512 字节或 1024 字节),文件属性包含文件名、大小、权限、时间戳等元数据(metadata)。

文件系统中的 inode 数组是一个 short 类型的计数器,它的最大值是 65535,也就是说文件系统中最多只能有 65535 个 inode。由于每个文件都需要一个 inode,因此每个文件系统最多只能容纳 65535 个文件。 每个文件具有一些固定属性:
(2 字节)mode,它包含了文件的类型和访问权限;
(2 字节)nlink,它表示这个文件有多少个名字;
(2 字节)uid,文件的所有者;
(2 字节)gid,文件所有者的组 ID;
(4 字节)size,文件的长度,以字节为单位(定义为 off_t,长整型);
(40 字节)addr 数组,包含了文件的数据块在磁盘上的地址;
(3x 4 字节)三个时间,atime(访问时间),mtime(修改时间)和 ctime(所谓的创建时间,但实际上是最后一个 inode 更改的时间)。
总大小为 64 字节。
bmap()
Addr 数组包含 40 个字节,但它存储了 13 个磁盘块地址,每个地址使用 3 个字节。这对于 24 位来说非常适用,或者说对应于 16 个大小为 512 字节的兆块,总文件系统大小为 8M 千字节,即 8GB。
PDP-11 RL02K 磁盘盒可容纳 10.4 MB,而更新的 RA92 可存储 1.5 GB。 Addr 数组在 bmap() 函数中被使用。该函数接收一个 inode(ip)和一个逻辑块号 bn,并返回一个物理块号。也就是说,它将文件中的一个块映射到磁盘上的一个块,因此得名。
前 10 个块指针直接存储在 inode 中。例如要访问块 0,bmap() 将在 inode 中查找 di_addr[0] 并返回该块号。
额外的块存储在一个间接块中,而间接块则存储在 inode 中。对于更大的文件,会分配一个双间接块,并指向更多的间接块,最终非常大的文件需要甚至三次间接块。
代码首先确定需要多少层间接寻址,也就是要通过多少个间接块才能找到文件内容的磁盘块。然后,获取相应的间接块。最后,代码按照适当的次数解析间接寻址,也就是根据层数依次从间接块中读取其他间接块或直接块的地址,直到找到文件内容的磁盘块。
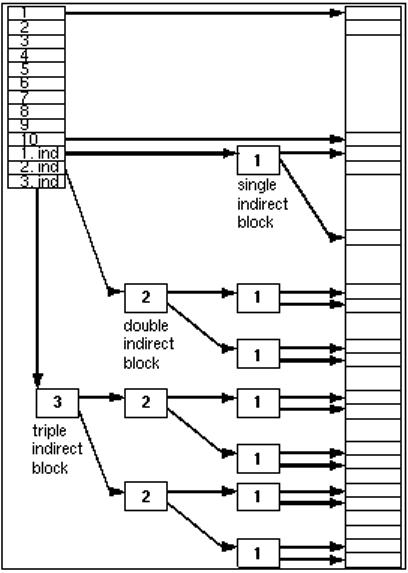
对于越来越大的文件,原始的 Unix 文件结构采用了逐渐增加的间接访问次数。这样形成了一个压缩的数组,其中较短的文件可以直接通过 inode 中的数据进行访问,而较大的文件则需要通过越来越多的间接访问来获取数据。为了提高性能,保持间接块在文件系统缓冲区高速缓存中是至关重要的。这种扩展性取决于块大小(早期为 512 字节,现在为 4096 字节)和块号的字节大小(最初为 3 字节,后来为 4 字节甚至 8 字节)。
Atomic writes
文件的写入是在加锁的状态下进行的,因此它们始终具有原子性。即使是跨越多个数据块的写入操作,也是如此。这一点在 But Is It Atomic? 中有详细讨论。 这也意味着即使有多个写入进程,在单个文件上,任何时刻只能有一个磁盘写入操作处于活跃状态。这对数据库系统的开发者来说非常不便利。
Naming files
目录是一个具有特殊类型和固定记录结构的文件。

一个目录条目包含一个 inode 号(一个无符号整数)和一个文件名,文件名的长度最多可以达到 14 个字节。这使得一个磁盘块可以容纳 32 个目录条目,而一个目录文件的直接块可以引用的 10 个磁盘块可以容纳 320 个目录条目。
下层(lower)的文件系统中充满了大量的文件。这些文件没有名称,只有编号。上层 (upper)的文件系统使用一种特殊类型的文件,具有简单的 16 字节记录结构,用于为文件分配最多 14 个字符的名称。一个特殊的函数 namei() 将文件名转换为 inode 号。
传递给 namei() 的路径名具有层次结构:它们可以包含/作为路径分隔符,并以 \0(NUL)作为终止符。路径名若以/开头,则遍历将从文件系统的根目录开始,形成绝对路径名;若不以/开头,则遍历将从 u.u_cdir,即当前目录开始。该函数逐个消耗路径名的各个组成部分,使用当前活动目录,并在该目录中线性搜索当前组件的名称。当找到最后一个路径名组件或在任何阶段找不到组件时,该函数结束。如果在路径中的任何目录的任何点上,我们没有 x 权限,它也会结束。
该函数按顺序逐个处理路径名的各个组成部分。它使用当前目录,并在该目录中线性搜索当前组成部分的名称。函数的结束条件有两种情况:一是找到了路径名的最后一个组成部分,二是在路径的任何目录中,出现了无法访问的情况。 挂载点是特殊条目,它会从当前节点和文件系统的目录条目切换到挂载文件系统的根 inode。这使得 Unix 中的所有文件系统看起来像是一棵单一的树,如果要进行 "硬盘修改" 的操作,只需简单地切换到不同的目录。
最终该函数将返回给定路径名的 inode 指针,根据需要和需求创建(或删除)inode(和目录条目),它是目录遍历和访问权限检查的集中点。
一些创新的想法以及限制
这个早期的 Unix 文件系统具有许多很好的特性:
它将多个文件系统呈现为一个统一的树形结构;
文件是无结构的字节数组;
这些数组以可动态增加深度的动态数组的形式存储。它们内部使用一种逐渐嵌套的间接块系统,其中数组的元素可以是指向其他数组或数据的指针,从而形成层次嵌套的结构。这使得磁盘搜索的复杂度为 O(1);
下层文件系统创建文件和上层的文件系统组织文件互相隔离,分工明确。获取 inode 的唯一方式是路径名遍历,并且在此过程中始终检查权限;
文件名中只有很少的特殊字符,即 / 和 \0(空字符)。
但也有明显的限制:
文件只能有 16M 个块;
文件系统只能有非常有限的 65535 个 inode。
还有一些令人讨厌的限制:
文件只能有一个正在写入的进程,这会导致并发性受限;
目录查找是线性扫描,因此对于大型目录(超过 320 个条目),速度变得非常慢;
没有强制文件锁定系统。但存在几种用于咨询式文件锁定的系统。
还有一些特殊情况:
在 Unix V7 系统中,没有 delete() 系统调用,而是 unlink() 系统调用,它可以删除一个文件的名字,并且那些没有任何文件名和打开文件句柄的文件会被自动清理。这会导致一些不符合预期的结果,例如,只有当一个完全没有文件名的文件被完全关闭时,它占用的磁盘空间才会被释放。许多 Unix 系统管理员都曾经问过他们的磁盘空间去哪了,当他们删除了 /var/log 目录下的日志文件,却忘记了有一些进程还在使用它;
最初没有 mkdir() 和 rmdir() 系统调用,这导致了存在可被利用的竞态条件。竞态条件是指在多线程或多进程环境中,由于操作的顺序和时机不确定性,可能导致安全漏洞或错误行为的情况。这在 Unix 的后续版本中得到了修复;
有一些操作在特定条件下具有原子性(例如 write(2) 系统调用),或者经过修改后具有原子性(mknod(2) 和 mkdir(2))。
在结构上,inode 表和块和 inode 的空闲映射位于文件系统的开头,磁盘空间也是从磁盘的前端线性分配的。这导致了频繁的寻址操作,并且可能导致文件系统的碎片化(即文件存储在非相邻的块中)。遍历目录结构意味着从磁盘开头读取目录的 inode,然后向后移动到更远的数据块,再从磁盘开头读取下一个路径名组成部分的下一个 inode,并向后移动到相应的数据块。这个过程在每个路径名组成部分上来回进行,速度并不快。
改进
在之后的发展中,minix 文件系统忠实继承了 PDP-11 V7 Unix 文件系统,保留了它的特性包括局限。然而,随着时间的推移,在现代的 Linux 系统中,由于其不再具备实用性,它已经从内核源代码中移除。在稍后的一篇文章中,我们将会了解到关于 BSD 快速文件系统,如何更好地布局磁盘上的数据,如何实现更长的文件名、更多的 inode,以及如何通过考虑磁盘的物理特性来加快速度。要解决目录查找时间线性增长、单个写入者或有限的文件元数据这些问题需要更新的文件系统。