
第 7 部分 ext3 简介
2001 年 11 月 01 日
Linux 的 2.4 发行版带来了使用多种新文件系统的可能性,包括 Reiserfs、XFS、GFS 以及其它文件系统。这些文件系统听起来很酷,但是它们到底能做什么,它们擅长于什么,还有,您到底如何着手在 Linux 生产环境下安全地使用它们呢?Daniel Robbins 通过向您展示如何在 Linux 2.4 上设置这些新的高级文件系统来回答这些问题。在这一部分,Daniel 研究了 ext3,它是 ext2 的新改进版,具有日志记录能力。
在前面几部分中,我们花费了一些精力去研究非传统文件系统(譬如 tmpfs 和 devfs)。现在,是时候回到基于磁盘的文件系统上来了,我们将通过研究 ext3 来实现这个目的。ext3 文件系统(由 Stephen Tweedie 博士设计)构建在现有的 ext2 文件系统的框架上;实际上,除了一个微小(但重要)的区别 ― ext3 支持日志记录以外,ext3 和 ext2 非常相似。但正是因为具有了这个小小的增加,您会发现 ext3 具有几种令人惊讶和富有吸引力的能力。在本文中,我将让您充分了解与当前可用的其它日志记录文件系统相比,ext3 有哪些优缺点。在我的下一篇文章中,我们将设置和运行 ext3。
理解 Ext3
那么,与 ReiserFS 相比,ext3 到底如何呢?在以前的文章中,我解释了 ReiserFS 是如何充分适合处理小文件的(4K 以下),并且,在某些情况下,ReiserFS 处理小文件的能力比 ext2 和 ext3 强十到十五 倍。但尽管 ReiserFS 有许多长处,它还是有弱点。在当前的 ReiserFS(版本 3.6)实现中,与 ext2 和 ext3 相比,尤其是读取大的邮件目录时,特定文件访问模式实际上可能导致 特别糟糕的性能。还有,ReiserFS 没有好的 NFS 兼容性跟踪记录,同时稀疏文件性能也较差。 相反,ext3 是一个非常 全面的文件系统。ext3 很象 ext2;它不会为您提供象 ReiserFS 那样特别快的小文件性能,但是,它也不会给您带来意外的性能或功能性瓶颈。
ext3 最妙的特性之一是:因为 ext3 基于 ext2 的代码,所以它的磁盘格式和 ext2 的相同;这意味着,一个干净卸装的 ext3 文件系统可以作为 ext2 文件系统毫无问题地重新挂装。并且不仅如此。应该感谢 ext2 和 ext3 都使用相同的元数据,因而有可能执行 ext2 到 ext3 文件系统的现场升级。是的,您的理解是正确的。通过升级一些关键系统实用程序、安装新的 2.4 内核,并在每个文件系统上输入单条 tune2fs 命令,就可以把现有的 ext2 服务器转换成日志记录 ext3 系统。甚至可以在 ext2 文件系统 已挂装的情况下进行这些操作。转换是安全的、可逆的、并且令人难以置信地简单,和到 XFS、JFS 或 ReiserFS 的转换不同,您不必备份和从头创建文件系统。现在花一些时间思考一下,有数以千计的 ext2 生产服务器,只要几分钟时间就能升级到 ext3;那么,您就会充分理解 ext3 对于 Linux 社区的重要性了。
如果非要用一个词来描述 ext3,我会说“舒适”。在已有的 ext2 系统上安装启用 ext3 的过程轻松得令人难以置信,并且升级以后,也不会导致任何意外的性能急剧下降。并且,ext3 在舒适方面还有一个优点,那就是,ext3 恰巧又是 Linux 可用的最 可靠的日志记录文件系统之一,我将在下面解释这一点。
Ext3 可靠性
除了与 ext2 兼容之外,ext3 还通过共享 ext2 的元数据格式继承了 ext2 的其它优点。譬如,ext3 用户可以使用一个稳固的 fsck 工具。您会回想起使用日志记录文件系统的要点之一是首先避免对彻底的 fsck 的需求,但是如果您确实要从脆弱的内核、坏的硬盘或者别的什么地方获得毁坏的元数据,您将非常感激 ext3 从 ext2 继承了 fsck 这个事实。相反,ReiserFS 的 fsck 还很幼稚,当脆弱的元数据 真的出现时,对脆弱元数据的修复过程将是困难和危险的。
仅元数据日志记录
有趣的是,ext3 处理日志记录的方式与 ReiserFS 和其它日志记录文件系统所用的方式迥异。使用 ReiserFS、XFS 和 JFS 时,文件系统驱动程序记录 元数据,但不提供 数据日志记录。使用 仅元数据日志记录,您的文件系统元数据将会异常稳固,因而可能永远不需要执行彻底 fsck。然而,意外的重新引导和系统锁定可能会导致最近修改 数据的明显毁坏。Ext3 使用一些创新的解决方案来避免这些问题,我们将对此做稍微深入的研究。
但首先,重要的是确切理解仅元数据日志记录最终是如何危害您的。举例来说,假设您正在修改名为 /tmp/myfile.txt 的文件时,机器意外锁定,被迫需要重新引导。如果您使用的是仅元数据日志记录文件系统,譬如 ReiserFS、XFS 或者 JFS,文件系统元数据将容易地修复,这要感谢元数据日志,您不必耐着性子等待艰苦的 fsck 了。
但是,存在一种明显的可能性:在将 /tmp/myfile.txt 文件装入到文本编辑器时,文件不仅仅丢失最近的更改,而且还包含许多乱码甚至可能完全不可读的信息。这种情况并不总会发生,但它 可能并且经常发生。
下面解释原因。典型的日志记录文件系统(譬如 ReiserFS、XFS 和 JFS)对元数据有特别处理,但是对数据不够重视。在上述示例中,文件系统驱动程序处于修改一些文件系统块的过程中。文件系统驱动程序更新适当的元数据,但是没有时间将其缓存中的数据刷新到磁盘的新块中。因此,当您将 /tmp/myfile.txt 文件装入文本编辑器时,文件的部分或全部包含乱码 ― 在系统锁定之前来不及初始化的数据块。
ext3 方法
既然我们对这个问题已经有了一个总的很好的理解,让我们来看 ext3 是如何实现日志记录的。在 ext3 里,日志记录代码使用一个特殊的称为“日志记录块设备”层或 JBD 的 API。JBD 被设计成在任何块设备上实现日志的特殊目的。Ext3 通过“钩入(hooking in)”JBD API 来实现其日志记录。例如,ext3 文件系统代码将正在执行的修改告知 JBD,并且还会在修改磁盘上包含的特定数据之前请求 JBD 的许可。通过执行这些操作,给予了 JBD 代表 ext3 文件系统驱动程序管理日志的适当机会。这是很好的安排,因为 JBD 是作为一个单独的、一般实体而开发的,将来它可以用于向其它文件系统添加日志记录能力。
关于 JBD 管理的 ext3 日志有一些巧妙的特性。其中之一是,ext3 的日志存储在一个索引节点中 ― 基本上是个文件。能否看到这个位于 /.journal 的文件,取决于您是如何在文件系统上“启用 ext3”的。当然,通过将日志存储在索引节点中,ext3 可以向文件系统添加必要的日志,而不需要对 ext2 元数据进行不兼容扩展。 这是 ext3 文件系统保持对 ext2 元数据,以及 ext2 文件系统驱动程序的向后兼容性的关键方式之一。
不同的日志记录方法
不必惊讶,确实有许多方法用于实现日志。例如,文件系统开发者可能会设计出一种日志,该日志存储在主机文件系统上需要修改的 字节范围。这种方法的好处在于,日志能够以一种非常高效的方式存储许多对文件系统的微小修改,这是因为它只记录需要修改的个别字节,而不记录除此以外的任何信息。
JBD 使用另外一种(从某种意义来说是更好的)方法。JBD 存储完整的被修改的文件系统块本身,而不是记录必定会被更改的字节范围。ext3 文件系统驱动程序也使用这种方法,存储内存中被修改的块(大小为 1K、2K 或 4K)的完整副本,以跟踪暂挂的 IO 操作。开始,这看起来有点浪费。毕竟,包含已修改数据的完整块中还可能包含 未修改的(已经在磁盘上)数据。
JBD 所使用的方法称为 物理日志记录,这意味着 JBD 使用完整的物理块,作为实现日志的主要媒介。相反,只存储已修改的字节范围而非完整块的方法称为 逻辑日志记录,这是 XFS 所使用的方法。因为 ext3 使用物理日志记录,所以 ext3 日志 将具有比其它文件系统日志(例如,XFS 日志)更大的相对磁盘占用。但是,因为 ext3 在文件系统内部和日志中使用完整块,ext3 处理的复杂度比实现逻辑日志记录的要小。另外,完整块的使用允许 ext3 执行一些额外的优化,譬如,将多个暂挂的 IO 操作“压扁”到同一内存数据结构的单个块中。 接下来,这种优化允许 ext3 将这多个更改在一次写操作中写到磁盘上,而不需要多次写操作。此外,因为文字块数据存储在内存中,这些内存数据在写到磁盘之前,不必或只需作很少更改,大大减少了 CPU 开销。
Ext3,数据保护者
现在,我们最后来了解一下 ext3 文件系统是如何高效地提供元数据 和数据日志记录,以避免在本文前面部分所描述的数据毁坏问题的。实际上,ext3 有两种确保数据和元数据完整性的方法。
最初,ext3 被设计用来执行完整数据和元数据日志记录。在这种方式下(称之为“data=journal”方式),JBD 将所有对数据和元数据的更改都记录到文件系统中。因为数据和元数据都被记录,JBD 可以使用日志将元数据 和数据恢复到一致状态。完整数据日志记录的缺点是它可能会比较慢,但可以通过设置相对较大日志来减少性能损失。
最近,ext3 添加了一种新的日志记录方式,该方式提供完整日志记录的好处而不会带来严重的性能损失。这种新方式只对元数据进行日志记录。但是,ext3 文件系统驱动程序保持对与每个元数据更新对应的特殊 数据块的跟踪,将它们分组到一个称为事务的实体中。当事务应用于适当的文件系统时,数据块首先被写到磁盘。一旦写入数据块,元数据将随后写入日志。通过使用这种技术(称为“data=ordered”方式),即使只有元数据更改被记录到日志中,ext3 也能够提供数据和元数据的一致性。ext3 缺省使用这种方式。
结束语
最近,有许多人在尝试确定哪种 Linux 日志记录文件系统是“最好的”。实际上,没有一个针对每个应用程序都“合适的”文件系统,每个文件系统都有自身的长处。这是有这么多下一代 Linux 文件系统供选择的好处之一。所以,理解每种文件系统的长处和弱点,以便对使用哪种文件系统作出一个有根据的选择,远远优于选出一个绝对的“最好的”文件系统,并将它用于所有可能的应用程序。
Ext3 具有许多长处。它被设计得极易部署。它基于稳固的 ext2 文件系统代码,并继承了一个很好的 fsck 工具。还有,ext3 的日志记录能力经过特别设计,以确保元数据和数据的完整性。总之,ext3 确实是一个很棒的文件系统,并且是现在仍受到推崇的 ext2 文件系统的一个合格的继承者。请关注我的下一篇文章,那时我们将设置和运行 ext3。在那之前,您可能会需要查看下列参考资料。
第 8 部分 ext3 中的惊喜
2001 年 12 月 01 日
随着 Linux 发行版 2.4 的出现,带来了许多新的文件系统的可能性,包括 Reiserfs、XFS、GFS 等等。这些文件系统听上去很酷,但它们究竟能做什么、擅长哪些方面,以及您究竟如何在 Linux 生产环境中安全地使用它们?Daniel Robbins 通过向您展现如何在 Linux 2.4 下设置这些新的高级文件系统来解答这些问题。在这一部分中,Daniel 继续着眼于 ext3,这是带有日志记录能力的 ext2 的一种新改进的版本。他揭示了 ext3 的所有内在信息,并演示了 ext3 data=journal 某些极其出色的的交互式性能测试数据。
我实话实说。我本来计划用这篇文章向您展示如何在系统上设置和运行 ext3。尽管我这么说,但我并不打算这么做。Andrew Morton 那个很棒的“在 2.4 内核中使用 ext3 文件系统”页面(请参阅本文后面的 参考资料)已经很好地解释了如何在系统上启用 ext3,因此我没必要在这里重复所有基本概念。而是深入钻研某些更耐人寻味的 ext3 主题,我认为您会发现这些主题非常有用。阅读了这篇文章后,当您准备设置和运行 ext3 时,请参考 Andrew 的页面。
2.4 内核更新
首先,让我们从 2.4 内核更新开始。我在介绍 ReiserFS 时最后讨论到 2.4 内核稳定性。在那个时候,要找到一个稳定的 2.4 内核是个难题,我建议坚持使用已知的内核(那时最前沿的是 2.4.4-ac9 内核)― 特别对于计划在生产环境中使用 ReiserFS 文件系统的那些人。您可能猜到,自从 2.4.4-ac9 以来发生了许多事,而现在无疑是着眼于更新的内核的时候了。
随着内核 2.4.10 的出现,在性能和可伸缩性方面,2.4 系列达到了新的层次(这是我们盼望已久的)。那么,是什么碰巧让 Linux 2.4 最终成长起来的呢?用首字母缩写词表示,就是 VM。在认识到 2.4 系列表现不是非常出色后,Linus 去除了 Linux 有问题的 VM 代码,并用 Andrea Archangeli 开发的简单而普通的 VM 实现来替代。Andrea 的新 VM 实现(最先出现在 2.4.10 中)非常了不起;它真正提高了内核速度,并使整个系统反应更迅速。2.4.10 绝对是 2.4 Linux 内核开发中一个主要的转折点;到那时为止,事物还不是非常完美,我们当中有许多人都奇怪为什么自己不是 FreeBSD 开发人员。我们都应该感谢 Linus 在 2.4 稳定内核系列中所做的这些主要(但迫切需要)的更改。这的确是一件了不起的事。
因为 Andrea 的新 VM 代码需要一些时间才能与内核其余部分达到无缝集成,所以使用 2.4.13+。使用 2.4.16+ 会更好,因为稳固的 ext3 文件系统代码最终是集成到从 2.4.15-pre2 发行版开始的正式 Linus 内核中的。没有理由避免使用 2.4.16+ 内核,它能使设置和运行 ext3 的工作更为轻松。如果确实使用 2.4.16+ 内核,记住不再需要象 Andrew 的页面上所描述的那样应用 ext3 补丁了(请参阅 参考资料)。Linus 已经为您添加了它 :)
您会注意到我建议使用 2.4.16+ 而非 2.4.15+,这是有充分理由的。随着内核 2.4.15-pre9 的发行,给内核引入一个非常讨厌的文件系统崩溃错误。直到 2.4.16-pre1 才发现并解决了这个问题,导致人们应该不计任何代价地避免使用这两个发行版之间的内核(包括 2.4.15)。选择 2.4.16+ 内核可以让您完全避免这个错误的批处理。
膝上电脑……小心?
Ext3 是一种稳固的文件系统,这个好名声由来已久,因此我在知道有相当多的膝上电脑用户在切换到 ext3 时有文件系统崩溃问题时很诧异。一般来说,对这些类型的报告做出的反映往往是完全避免使用 ext3;不过,在到处打听之后,我发现人们所遇到的磁盘崩溃问题与 ext3 本身并没有关系,而是由某些膝上电脑硬盘所引起的。
写高速缓存
您可能不知道,但大多数新式硬盘有一个称为“写高速缓存”的东西,硬盘使用它来收集暂时被挂起的写操作。通过将暂挂的写操作放到高速缓存中,硬盘固件就可以重新为它们排序,并为它们分组,以便用尽可能最快的方式将它们写到磁盘中。通常认为写高速缓存是个非常好的事物(请阅读 参考资料中 Linus 对写高速缓存的解释和看法)。
不幸的是,现在市场上某些膝上电脑的硬盘具有这样一种不可靠的特性,即忽略将它们的写高速缓存刷新到磁盘上的所有正式 ATA 请求。虽然直到最近 ATA 规范 还允许这种做法,但这并不是一种完美的设计特性。使用这些类型的驱动器,内核无法保证某一特定块实际上是否被记录到磁盘上。尽管听上去这是个棘手的问题,但这个特定问题本身可能不是人们所遇到的数据毁坏问题的原因。
不过,情况越来越差。一些新式膝上电脑的硬盘有一个更令人讨厌的习惯:每当重新引导或暂挂系统,就 丢弃它们的写高速缓存。很明显,如果硬盘有这两个问题,就会定期破坏数据,而 Linux 对于防止这种情况束手无策。
那么,解决方案是什么呢?如果您有膝上电脑,请小心使用。在对文件系统执行任何重大更改之前备份所有重要文件。如果遇到似乎符合上面我所描述的模式的数据毁坏问题,特别在使用 ext3 时,记住这可能是您膝上电脑硬盘的错。在这种情况下,您需要与膝上电脑制造商联系,并询问更换驱动器事宜。希望在几个月后,这些脆弱的硬盘将从市场上消失,我们就再也不必担心这个问题了。
既然我已经警告过您要小心,就让我们看看 ext3 的各种数据日志记录选项。
日志记录选项和写等待时间
在安装文件系统时,Ext3 允许您从三种数据日志记录方式中选择一个: data=writeback 、 data=ordered 和 data=journal 。
要指定日志方式,可以向 /etc/fstab 的选项节添加适当的字符串(例如 data=journal ),也可以在调用 mount 时直接指定 -o data=journal 命令行选项。如果您愿意指定用于根文件系统的数据日志记录方法( data=ordered 是缺省值),则可以使用名为 rootflags 的特殊内核引导选项。因此,如果愿意将根文件系统置于完整数据日志记录方式下,则向内核引导选项添加 rootflags=data=journal 。
data=writeback 方式
处于 data=writeback 方式下,ext3 根本不执行任何形式的数据日志记录,提供给您的是和在 XFS、JFS 和 ReiserFS 文件系统中找到的类似的日志记录(仅元数据)。正如我在 前一篇文章中讲到过,这会让最近修改的文件在出现意外的重新引导事件中被毁坏。如果不考虑这个缺点, data=writeback 方式在大多数情况下应该能够为您提供最佳的 ext3 性能。
data=ordered 方式
处于 data=ordered 方式下,ext3 只是正式记录元数据,而在逻辑上将元数据和数据块分组到称为事务的单个单元中。到了将新的元数据写到磁盘上的时候, 首先写的是相关的数据块。 data=ordered 方式有效地解决了在 data=writeback 方式 下和大多数其它日志记录文件系统中发现的毁坏问题,而这是在不需要完整数据日志记录的情况下做到的。一般说来, data=ordered ext3 文件系统执行的速度比 data=writeback 文件系统执行的速度稍微慢一些,但比对应的完整数据日志记录还是要快出许多。
将数据 附加到文件时,data=ordered 方式提供了 ext3 完整数据日志记录方式提供的所有完整性保证。不过,如果正在 覆盖某一部分文件,而此时系统崩溃,那么有可能所写的区将包含原始块和在其中散布了更新块的组合。这是因为 data=ordered 不提供首先覆盖哪一个数据块的保证,因此不能假设只是因为更新了被覆盖的块 x,也就更新了被覆盖的块 x-1。 data=ordered 让写操作顺序由硬盘的写高速缓存决定。一般说来,这个限制并不经常对人们具有负面影响,因为附加的文件一般比覆盖的文件更普遍。出于这个原因, data=ordered 方式是对完整数据日志记录的一个很好的更高性能的替代。
data=journal 方式
data=journal 方式提供了完整数据和元数据日志记录。所有新数据首先写入日志,然后再写入它的最终位置。在崩溃情况下,可以重放日志,使数据和元数据处于一致的状态。
从理论上说, data=journal 方式是所有日志记录方式中最慢的,因为要将数据写入磁盘两次而不是一次。不过,在某些情况下, data=journal 方式也可以是极快的。Andrew Morton 在听取了有关 LKML 的报告(ext3 data=journal 文件系统为人们提供了难以置信的出色的交互式文件系统性能)后,决定组合出一个小测试。首先,他创建了一个简单的 shell 脚本,该脚本设计用来将数据尽快写入测试文件系统:
快速写
while true
do
dd if=/dev/zero of=largefile bs=16384 count=131072
done
在将数据写入测试文件系统的同时,他尝试从 位于同一磁盘上的另一个 ext2 文件系统中读取 16Mb 的数据,并对此进行计时:
读取 16Mb 的文件
time cat 16-meg-file > /dev/null
结果让人惊奇。 data=journal 方式允许 16 兆文件以比其它 ext3 方式、ReiserFS,甚至 ext2(没有日志记录开销)高出 9 到 13 倍的速度读取:
写入文件系统 16 兆读取时间(秒)
ext2 78
ReiserFS 67
ext3 data=ordered 93
ext3 data=writeback 74
ext3 data=journal 7
Andrew 重复这个测试,但尝试从测试文件系统(而不是从其它文件系统)读取 16Mb 的文件,获得的结果是相同的。那么,这意味着什么呢?不知什么原因,ext3 的 data=journal 方式非常适合于需要同时从磁盘读写数据的情况。 因此,ext3 的 data=journal 方式(被认为在几乎所有情况中是所有 ext3 方式中最慢的)实际上证明在需要最大化交互式 IO 性能的繁忙环境中具有重要的性能优势。可能 data=journal 方式毕竟没那么缓慢!
Andrew 仍然在尝试发现究竟为什么 data=journal 方式比其它方式好这么多。在这样做的同时,他也许能够对 ext3 的另外两种方式做必要调整,以便也能看到 data=writeback 和 data=ordered 方式的好处。
对 data=journal 的调整
有些人在繁忙的服务器上 ― 特别是在繁忙的 NFS 服务器上 ― 使用 ext3 的 data=journal 方式时曾经碰到一个特殊的性能问题。每隔 30 秒,服务器就会遇到磁盘写活动高峰,导致系统几乎陷于停顿。如果您遇到这个问题,修复它很容易。只要以 root 用户输入以下命令,就可以调整 Linux“脏”缓冲区刷新算法:
调整 bdflush
echo 40 0 0 0 60 300 60 0 0 > /proc/sys/vm/bdflush
这些新的 bdflush 设置将导致 kupdate 每隔 0.6 秒而不是每隔 5 秒运行。另外,它们告诉内核每隔 3 秒而不是 30 秒(缺省值)刷新“脏”缓冲区。通过更有规律地将最近修改的数据刷新到磁盘,可以避免这些写操作的高峰。以这种方式执行的效率比较低,因为内核不太有机会组合写操作。但对于繁忙的服务器,写操作将更一致地进行,并将极大地改进交互式性能。
第 9 部分 XFS 简介
2002 年 1 月 01 日
随着 Linux 2.4 发行版的到来,给我们带来了使用多种新文件系统的可能性,包括 Reiserfs、XFS、GFS 以及其它文件系统。这些文件系统听起来很酷,但是它们到底能做什么,它们擅长于什么,还有,您到底如何着手在 Linux 生产环境下安全地使用它们呢?Daniel Robbins 通过向您展示如何在 Linux 2.4 下设置这些新的高级文件系统来回答这些问题。在这一部分,Daniel 介绍了 XFS ― 目前可用于 Linux 的 SGI 的免费企业级文件系统。
在本文中,我们将研究 XFS ― 用于 Linux 的 SGI 的免费、64 位高性能文件系统。首先,我将说明,XFS 与 ext3 和 ReiserFS 相比,各有什么优缺点,并描述许多 XFS 内部使用的技术,然后,在 下一篇文章中,我将全程指导您在自己的系统上设置 XFS,并讲述了 XFS 调优技巧和诸如 ACL(访问控制表)及扩展属性支持之类有用的 XFS 特性。
XFS 简介
XFS 最初是由 Silicon Graphics,Inc. 于 90 年代初开发的。那时,SGI 发现他们的现有文件系统(existing filesystem,EFS)正在迅速变得不适应当时激烈的计算竞争。为解决这个问题,SGI 决定设计一种全新的高性能 64 位文件系统,而不是试图调整 EFS在先天设计上的某些缺陷。因此,XFS 诞生了,并于 1994 年随 IRIX 5.3 的发布而应用于计算。它至今仍作为 SGI 基于 IRIX 的产品(从工作站到超级计算机)的底层文件系统来使用。现在,XFS 也可以用于 Linux。XFS 的 Linux 版的到来是激动人心的,首先因为它为 Linux 社区提供了一种健壮的、优秀的以及功能丰富的文件系统,并且这种文件系统所具有的可伸缩性能够满足最苛刻的存储需求。
XFS、ReiserFS 和 ext3 的性能
到目前为止,选择合适的下一代 Linux 文件系统一直很简单。那些只寻求原始性能的人通常倾向于使用 ReiserFS,而那些更关心数据完整性特性的人则首选 ext3。然而,随着 XFS 的 Linux 版的发布,事情突然变得令人困惑。尤其是,对于 ReiserFS 是否依然是下一代文件系统性能方面的佼佼者,人们开始感到疑惑。
最近,我进行了一系列测试,试图比较 XFS、ReiserFS 和 ext3 在原始性能方面的优劣。在与您分享该结果之前,理解以下事实很重要:该结果只着重比较了在单处理器系统上,系统负载较轻的情况下,常规文件系统的性能趋势,它并 不是衡量某一个文件系统是否比另一个文件系统“更好”的绝对尺度。尽管如此,我的结果应该可以帮助您形成一些概念,那就是:哪个文件系统可能最适于某个特定任务。再次声明,不应该将我的结果视为结论性的;最好的测试总是:在每个文件系统上运行您的特定应用程序,以观察它是如何执行的。
结果
在测试中,我发现 XFS 通常是相当快的。在大文件操作方面,XFS 在所有测试中一直处于领先地位,这是意料之中的,因为其设计者花了数年时间设计和调整它,以便能够极出色地完成此类任务。我还发现 XFS 有一个单点性能缺陷:它删除文件不是很快;在这一方面,ReiserFS 和 ext3 轻易地胜过了它。据 Steve Lord(SGI 的文件系统软件总工程师)说,刚编写完一个补丁来解决该问题,并且不久将可以使用该补丁。
除此以外,XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。XFS 最佳表现之一在于:象 ReiserFS 一样,它不产生不必要的磁盘活动。XFS 设法在内存中缓存尽可能多的数据,并且,通常仅当内存不足时,才会命令将数据写到磁盘时。当它将数据清仓(flushing)到磁盘时,其它 IO 操作在很大程度上似乎不受影响。相反,在 ext3(“data=ordered”缺省方式)下,将数据清仓到磁盘时,将导致许多额外寻道,甚至还会引起某种不必要的磁盘抖动(thrashing)(取决于 IO 负载)。
我的性能和调整测试主要是关于将 RAM 磁盘中未压缩的内核源文件 tar 包(tarball)抽取到要测试的文件系统,然后递归地将新源文件树复制到同一文件系统中的一个新目录中。XFS 对这类任务执行得很好,尽管,最初 XFS 性能比 ReiserFS 略差一点。然而,在调整了测试 XFS 文件系统的 mkfs.xfs 和 mount 选项以后,当处理诸如在内核源文件树中的中等大小的文件时,XFS 执行效率比 ReiserFS 略好一点。但这不包括删除操作;至少目前,ReiserFS 和 ext3 删除文件要比 XFS 快得多。
性能总结
XFS 在哪些方面可以给您提供哪种性能,对于这一点,希望我的测试结果有助于您形成总的概念;我的测试结果显示,如果需要操作大文件,XFS 文件系统是您最好的选择。对于小文件和中等大小的文件,如果您使用一些能够增强性能的选项创建和挂装 XFS 文件系统的话,它可以与 ReiserFS 匹敌,有时甚至比 ReiserFS 更快。在“data=journal”方式下的 ext3 提供了良好性能,但是它很难获得一致的性能数据,原因在于,ext3 将先前测试中的数据清仓到磁盘所使用的方式,具有明显的不规律性,这将导致某种磁盘抖动。
XFS 设计
在 USENIX '96 上刊载的文章“Scalability in the XFS Filesystem”中(请参阅本文后面的参考资料),SGI 工程师解释:他们设计 XFS 的主要思想只有一个,那就是:“考虑大东西”。确实,XFS 的设计消除了传统文件系统中的一些限制。现在,让我们研究 XFS 幕后一些有趣的设计特性,正是这些设计特性使这一点成为可能。
分配组(allocation groups)简介
当创建 XFS 文件系统时,底层块设备被分割成八个或更多个大小相等的线性区域(region)。您可以将它们想象成“块”(chunk)或者“线性范围(range)”,但是在 XFS 术语中,每个区域称为一个“分配组”。分配组是唯一的,因为每个分配组管理自己的索引节点(inode)和空闲空间,实际上,是将这些分配组转化为一种文件子系统,这些子系统正确地透明存在于 XFS 文件系统内。
分配组与可伸缩性
那么,XFS 到底为什么要有分配组呢?主要原因是,XFS 使用分配组,以便能有效地处理并行 IO。因为,每个分配组实际上是一个独立实体,所以内核可以 同时与多个分配组交互。如果不使用分配组,XFS 文件系统代码可能成为一种性能瓶颈,迫使大量需求 IO 的进程“排队”来使索引节点进行修改或执行其它种类的元数据密集操作。多亏了分配组,XFS 代码将允许多个线程和进程持续以并行方式运行,即使它们中的许多线程和进程正在同一文件系统上执行大规模 IO 操作。因此,将 XFS 与某些高端硬件相结合,您将获得高端性能而不会使文件系统成为瓶颈。分配组还有助于在多处理器系统上优化并行 IO 性能,因为可以同时有多个元数据更新处于“在传输中”。
B+ 树无处不在
分配组在内部使用高效的 B+ 树来跟踪主要数据,譬如空闲空间的范围和索引节点。实际上,每个分配组使用 两棵 B+ 树来跟踪空闲空间;一棵树按空闲空间的大小排序来存储空闲空间的范围,另一棵树按块设备上起始物理位置的排序来存储这些区域。XFS 擅长于迅速发现空闲空间区域,这种能力对于最大化写性能很关键。
当对索引节点进行管理时,XFS 也是很有效的。每个分配组在需要时以 64 个索引节点为一组来分配它们。每个分配组通过使用 B+ 树来跟踪自己的索引节点,该 B+ 树记录着特定索引节点号在磁盘上的位置。您会发现 XFS 之所以尽可能多地使用 B+ 树,原因在于 B+ 树的优越性能和极大的可扩展性。
日志记录
当然,XFS 也是一种日志记录文件系统,它允许意外重新引导后的快速恢复。象 ReiserFS 一样,XFS 使用逻辑日志;即,它不象 ext3 那样将文字文件系统块记录到日志,而是使用一种高效的磁盘格式来记录元数据的变动。就 XFS 而言,逻辑日志记录是很适合的;在高端硬件上,日志经常是整个文件系统中争用最多的资源。通过使用节省空间的逻辑日志记录,可以将对日志的争用降至最小。另外,XFS 允许将日志存储在另一个块设备上,例如,另一个磁盘上的一个分区。这个特性很有用,它进一步改进了 XFS 文件系统的性能。
象ReiserFS 一样,XFS 只对元数据进行日志记录,并且在写元数据之前,XFS 不采取任何专门的预防措施来确保将数据保存到磁盘。这意味着,使用 XFS(就象使用 ReiserFS)时,如果发生意外的重新引导,则最近修改的数据有可能丢失。然而,XFS 日志有两个特性使得这个问题不象使用 ReiserFS 时那么常见。
使用 ReiserFS 时,意外重新引导可能导致最近修改的文件中包含先前删除文件的部分内容。除了数据丢失这个显而易见的问题以外,理论上,这还可能引起安全性威胁。相反,当 XFS 日志系统重新启动时,XFS 确保任何未写入的数据块在重新引导时 置零。因此,丢失块由空字节来填充,这消除了安全性漏洞 ― 这是一种好得多的方法。
现在,关于数据丢失问题本身,该怎么办呢?通常,使用 XFS 时,该问题被最小化了,原因在于以下事实:XFS 通常比 ReiserFS 更频繁地将暂挂元数据更新写到磁盘,尤其是在磁盘高频率活动期间。因此,如果发生死锁,那么,最近元数据修改的丢失,通常比使用 ReiserFS 时要少。当然,这不能彻底解决不及时写数据块的问题,但是,更频繁地写元数据也确实促进了更频繁地写数据。
延迟分配
研究一下 延迟分配这个 XFS 独有的特性,然后我们将结束关于 XFS 的技术概述。正如您可能知道的,术语 分配(allocation)是指:查找空闲空间区域并用于存储新数据的过程。
XFS 通过将分配过程分成两个步骤来处理。首先,当 XFS 接收到要写入的新数据时,它在 RAM 中记录暂挂事务,并只在底层文件系统上 保留适当空间。然而,尽管 XFS 为新数据保留了空间,但 它却没有决定将什么文件系统块用于存储数据,至少现在还没决定。XFS 进行拖延,将这个决定延迟到最后可能的时刻,即直到该数据真正写到磁盘之前作出。
通过延迟分配,XFS 赢得了许多机会来优化写性能。到了要将数据写到磁盘的时候,XFS 能够以这种优化文件系统性能的方式,智能地分配空闲空间。尤其是,如果要将一批新数据添加到单一文件,XFS 可以在磁盘上分配一个 单一、相邻区域来储存这些数据。如果 XFS 没有延迟它的分配决定,那么,它也许已经不知不觉地将数据写到了多个非相邻块中,从而显著地降低了写性能。但是,因为 XFS 延迟了它的分配决定,所以,它能够一下子写完数据,从而提高了写性能,并减少了整个文件系统的碎片。
在性能上,延迟分配还有另一个优点。在要创建许多“短命的”临时文件的情况下,XFS 可能根本不需要将这些文件全部写到磁盘。因为从未给这些文件分配任何块,所以,也就不必释放任何块,甚至根本没有触及底层文件系统元数据。
结束语
我希望您喜欢阅读这篇关于 XFS(Linux的、功能强大的下一代文件系统之一)的性能和技术特征的文章。在下一篇文章中,我们再见,那时我将向您展示如何设置 XFS,并在您的系统上运行它。在下一篇文章中,我们还将研究 XFS 的一些高级特性,譬如 ACL 和扩展属性。那么我们下次见!
第 10 部分 部署 XFS
2002 年 4 月 01 日
列图标随着 Linux 发行版 2.4 的出现,带来了许多新的文件系统的可能性,包括 Reiserfs、XFS、GFS 等等。这些文件系统听上去很酷,但它们究竟能做什么、擅长哪些方面,以及您究竟如何在 Linux 生产环境中安全地使用它们?Daniel Robbins 通过向您展现如何在 Linux 2.4 下设置这些新的高级文件系统来解答这些问题。在这一部分中,Daniel 向您展现了如何在您的系统上安装 XFS 并使其运行,他也探讨了 XFS 的一些更高级特性。
在本文中,我将为您演示如何在您的系统上安装 XFS 并使其运行。首先,请确保您知道并已经浏览了 SGI XFS 项目页面(请参阅本文后面的 参考资料)。如果您点击“下载”链接,您将发现补丁程序、工具甚至 Red Hat 的支持 XFS 的内核。
但是,请等一等。虽然通过使用这些预先编译好的官方发行版来安装 XFS 是可能的,但是我不推荐这种方法。在写本文时,最新官方 XFS 发行版是 1.0.2,它早在 2001 年 11 月就发布了。自那以后 XFS 经历了许多改进,为了从这些改进中获益,最好使用来自 XFS CVS 树的最新源代码。根据 Gentoo Linux 开发人员和用户的反馈,使用来自 CVS 的 XFS 的人比那些尝试过使用略微有些过时的官方发布版的人有好得多的 XFS 体验。
使用 CVS
如果您以前从没有使用过 CVS,那么您可能会对我的教程 CVS for the developer or amateur感兴趣(请参阅 参考资料)。如果您只想随意试试,那么,也很好。只需确保在您的系统上安装了某种 CVS 软件包,以便您可以使用 cvs 命令。
我在这里提供的 CVS 指导信息也可以在 SGI 的站点(请参阅 参考资料)上找到。当您通过使用 cvs 获取源代码之后,您将有一个新的目录树,它含有最新的支持 XFS 的内核源代码以及最新的 XFS 工具。要从 XFS CVS 获取源代码,请首先将 CVSROOT 环境变量设置成您要从中获取源代码的资源库。在 bash 提示符下,输入:
$ export CVSROOT=':pserver:cvs@oss.sgi.com:/cvs'
现在,将目录改为您希望创建新 XFS 目录树的位置,然后输入:
$ cvs login
当提示输入密码时,输入 cvs 。您现在登录到了公共 CVS 资源库;要获取最新 XFS 源代码,请输入:
$ cvs -z3 checkout linux-2.4-xfs
检出过程将启动。这可能会花一段时间,因为您正在获取的文件包含完整的 Linux 源代码树。过一会儿, cvs checkout 命令将完成,在您的当前工作目录下将有一个新的 linux-2.4-xfs 目录。为了将来的引用,如果您任何时候需要更新您的新源代码树,只需进入 linux-2.4-xfs 目录并输入:
$ cvs -z3q update -dP
使用树
有两个重要的目录位于新的 linux-2.4-xfs 目录中。第一个名为 linux ,它含有支持 XFS 的内核源代码树,而第二个称为 cmd ,它包含各种 XFS 用户空间程序源代码。要使用内核源代码,您可以将 linux 目录复制到 /usr/src ,或者在当前位置简单地编译一个新内核。
下面是如何安装该内核并运行它。进入 linux 目录并将 Makefile 装入您最喜欢的编辑器。在文件的顶部,您将看到类似下面的几行:
VERSION = 2
PATCHLEVEL = 4
SUBLEVEL = 17
EXTRAVERSION = -xfs
这几行告诉 Makefile 构建一个官方名称为 2.4.17-xfs 的内核。有些人更愿意有一个官方的 uname -a 内核名中不含有 -xfs 的内核;如果您属于他们中的一员,那么就请将最后一行改成:
EXTRAVERSION =
现在进行内核配置。要启用 XFS,请输入 make menuconfig 并进入 File systems 节。向下滚动一点,您将会看到下列选项:
SGI XFS filesystem support
启用它(推荐将它直接编译进您的内核)。键入 y ,将出现下列三个子选项:
[ ] Enable XFS Realtime support
[ ] Enable XFS Quota
Enable XFS DMAPI
“XFS Realtime”选项将启用 XFS 中的实时子卷支持,它让您配置可以为实时应用程序提供更确定性的性能的存储区域。“XFS Quota”选项将 ― 您猜得到的 ― 启用对将磁盘使用限制与确定的用户和组关联的支持。“XFS DMAPI”选项(如果选中的话)将启用一个特殊的 API,这个 API 将打算供存储管理应用程序使用。目前,还没有生产级 Linux 工具利用 DMAPI(这包括 Sistina 的 LVM 和 SGI XFS 实用程序本身)的优点;然而,SGI 和 IBM 目前正在开发一些支持 DMAPI 的应用程序。
一旦您选中了“SGI XFS filesystem support”,并且按照您希望的方式配置了内核的剩余部分,那么您就可以进行 make dep && make bzImage && make modules && make modules_install ,安装您的内核并且重新引导。
安装工具
既然已经安装并且运行了支持 XFS 的内核,您就可以安装各种 XFS 工具。XFS 的一个优点是它带有一套十分完备的工具和实用程序。进入 linux-2.4-xfs/cmd 目录,然后以“root”用户在 bash 提示符下输入下面的 shell 脚本:
# for x in attr acl xfsprogs dmapi xfsdump
do
cd $x
autoconf
/configure --prefix=/usr
make
make install
cd ..
done
输入最后一行 done 之后,我们特定的构建脚本将开始执行,并且将开始安装所有不同的 XFS 工具。现在,您可以通过安装几个与开发人员有关的文件来结束这个过程,以前的 make install 命令不会安装这些文件:
# for x in attr dmapi xfsprogs
do
cd $x
make install-dev
cd ..
done
创建和挂装文件系统
一旦完成了这一最后的脚本,所有各种与 XFS 有关的程序都应该正确地安装,并且可以使用了。现在,您即将创建调整成最佳性能的 XFS 测试文件系统。
但是首先,如果您正在以前是 ReiserFS 文件系统之上创建一个 XFS 文件系统,那么您将需要使用一个小技巧。在 bash 提示符下,使用下面的命令将块设备的开始位置“置零”,该处本来用于存储 ReiserFS 文件系统,并将被初始化以包含您的新 XFS 文件系统:
# dd if=/dev/zero of=/dev/hdc9
为了擦除任何剩余的 ReiserFS 元数据,这一步是必需的;否则, mount 可能会混淆并且无意中将您的新 XFS 文件系统挂装成有缺陷的 ReiserFS 文件系统!您只需让 dd 运行大约 10 秒钟,之后,您可以使用 control-C 终止该命令。这时,以前存在的 ReiserFS 元数据的关键部分将被清除, mount 的文件系统类型自动检测代码将不会再混淆。现在是创建新文件系统的时候了。要做到这一点,您 可以象下面那样使用 mkfs.xfs :
# mkfs.xfs /dev/hdc9
虽然上述命令会起作用,但是要使用 mkfs.xfs 将您的新 XFS 文件系统配置成最佳性能,有两个选项。
第一个这样的选项是 -l size=32m ,它告诉 mkfs.xfs 配置您的文件系统使之拥有一个高达 32 MB 的元数据日志。这通过降低在文件系统处于繁忙使用期间元数据日志将“填满”的可能性而改善了性能。
第二个选项通过告诉 mkfs.xfs 将创建的分配组的数目 最小化,让您增强新文件系统的性能。通常, mkfs.xfs 自动选择分配组的数目,但是,根据我的经验,它通常会选择一个比大多数用于一般用途的 Linux 工作站和服务器过高一点的数目。正如您将从 我前一篇文章所回忆的一样,分配组让 XFS 并行执行多个元数据操作。这为高端服务器带来了便利,但是太多的分配组确实会增加一些开销。因此,不要让 mkfs.xfs 为您的文件系统选择分配组的数目,而是通过使用 -d agcount=x 选项指定一个数目。将 x 设置成一个小数目,如 4、6 或 8。您需要使得您的目标块设备中每 4 GB 容量至少有一个分配组。同时进行这两项调整,使用下面的命令创建“优化的”XFS 文件系统:
# mkfs.xfs -d agcount=4 -l size=32m /dev/hdc9
既然已经创建了文件系统,您就可以挂装它了。挂装时,您将使用一些性能增强 mount 选项来最大程度地发掘出(或发挥出)您的新文件系统的性能。
# mount /dev/hdc9 /mnt -o noatime,nodiratime,osyncisdsync
前面的两个 mount 选项关闭 atime 更新,几乎不需要 atime 更新,并且它除了降低文件系统性能之外几乎不起任何作用。 osyncisdsync 选项调整 XFS 的同步/异步行为,以便它同 ext3 更一致。多亏了我们的 mkfs.xfs 和 mount 调整,您的新 XFS 文件系统比没这么调整时的性能要好得多。
好功能
XFS 的一个优点是它包含许多好功能。其中之一是一些名为“访问控制表”或 ACL 的特殊功能,现在在 XFS 文件系统上缺省启用这些功能。访问控制表让您定义细粒度的文件许可权。例如,您不再仅限于为用户、组及所有其它人定义“rwx”访问权限,您现在可以添加任意数目的额外用户或组并为它们指定“rwx”许可权。
全面讨论访问控制表超出了本文的范围,但是您可以在 bestbits 站点(请参阅 参考资料)上找到对 ACL 的极佳介绍。如果您浏览“Why you may want Access Control Lists (ACLs)”页面,尤其是如此。请注意,该站点上的大多数高深技术信息都同在 ext2 和 ext3 下启用 ACL 支持有关(但是不需要额外的步骤使 ACL 在 XFS 文件系统上工作)。
XFS 包含另外一个名为“扩展属性”的优秀功能特性。扩展属性让您将用户定义的数据同文件系统对象相关联。例如,如果您有一幅名为 mygraphic.png 的图像,您可以附加一个名为“thumbnail”的属性,它包含该图像的一个小版本。普通文件 IO 操作将看不到这个数据,但任何程序都可以使用一个特殊的扩展属性 API 来访问它。扩展属性在某些方面类似 MacOS 系统中的“资源分支”。
下面是如何使用 attr 可执行命令行来与扩展属性交互的示例。假定我想将 description 属性添加到我的主目录。我可以输入:
$ attr -s description -V "Home of Daniel Robbins" /home/drobbins
Attribute "description" set to a 22 byte value for /home/drobbins:
Home of Daniel Robbins
然后,要查看与 /home/drobbins 相关联的属性列表,我可以输入:
$ attr -l /home/drobbins
Attribute "description" has a 22 byte value for /home/drobbins/
要查看 description 属性的内容,我应输入:
$ attr -q -g description /home/drobbins/
Home of Daniel Robbins
扩展属性简单易用,并且使用起来也很有趣。您可以通过输入 man attr 来了解关于扩展属性的更多内容。XFS 还包含一个用于与扩展属性交互的 C API。如果您对使用扩展属性的 C++ IOStream 接口感兴趣,那么您可能要查看 SourceForge 上的 libferris(请参阅 参考资料)。
是的,扩展属性和 ACL 的确很有趣,但是,当心 ― 大多数备份程序目前仍然忽略 EA 和 ACL 数据。其中著名的例外就是随 XFS 分发包一起包含的 xfsdump 和 xfsrestore 命令。如果您正在使用任何其它备份程序,请确保无论在何处使用扩展属性和 ACL 之前都做一些研究。
希望您喜欢这篇对 XFS 文件系统的快速介绍。下篇文章见!
第 11 部分 文件系统更新
2002 年 9 月 16 日
Daniel Robbins 在“高级文件系统实现者指南”系列文章中向您展示了如何使用 Linux 2.4 内文件系统的最新技术。此外,他还将给您一些很有价值而且实用的实现建议,告诉您性能信息以及重要的技术说明以使您能尽可能愉快的使用新文件系统。在这篇文章中,Daniel 介绍了 XFS、ReiserFS 和 ext3 文件系统的最新状况,告诉您一些他在 Gentoo Linux 担任首席架构师的经历。而且,他还大致介绍了这几种文件系统在接下来的半年到一年内的发展方向。
在浏览过去的文章时,我突然发现,“高级文件系统实现者指南”系列文章从出现到现在已经近一年了!别担心,等我介绍了 IBM 用于 Linux 系统的 JFS 和 EVMS(企业卷管理,enterprise volume management)技术,这一系列文章就 快要结束了。但由于这是 IBM 的一个站点,我想在我介绍完其它全部用于 Linux 文件系统的新技术 之后,最好能再介绍一下由 IBM 开发的技术。
在我们开始 JFS 和 EVMS 之前,我要同您谈谈官方对 Linux 文件系统领域所发生的事情的当前状况所做的最新表述。我们遇到过许多 2.4 内核;其中一些很好,另外一些就没那么好。伴随着内核的开发进程,XFS、ext3 和 ReiserFS 的开发正紧锣密鼓地进行。在此期间,许多 Gentoo Linux用户使用 XFS、ext3 和 ReiserFS 文件系统的不同组合得出了各种各样的结果。一般来说,不管 Gentoo Linux 用户在使用哪个新出现的文件系统时遇到了问题,我肯定会听说那个问题。那么,哪些文件系统最受欢迎?哪些又最可靠呢?在这篇文章中,我会与您分享我的经验,以及来自 ReiserFS、ext3 和 XFS 开发团队的反馈和状况的更新。
XFS 有什么新鲜事吗?
在过去的几个月中,选择 XFS 作为 Linux 文件系统成为一件很流行的事。根据来自 Gentoo Linux 用户的反馈,人们之所以喜欢是因为它具有健壮的功能集,而且一般情况下,它的整体性能良好。不过,XFS 的 1.0.x 发行版有一个严重的问题。您也许还记得,如果更新的是文件的元数据,但是某种不可预知的情况(如崩溃)导致无法将新数据写到磁盘上,那么象 XFS 和 ReiserFS 这样的“只支持元数据”的日志文件系统就会引起数据破坏。对于 ReiserFS,受影响的文件会包含受损的或无用的数据块,而对于 XFS,该文件会包含整块的二进制零。事实证明,如果您的服务器碰巧崩溃或者意外断电,XFS 1.0.x 有一种很不好的倾向,那就是会破坏最近修改过的文件。那些刚好在承受力较强的服务器上使用 XFS 的人一般都没问题,但那些在遇到某种软件或硬件稳定性问题的系统上运行 XFS 的人就面临着丢失很多数据的风险。
幸运的是,SGI XFS 的开发人员在 XFS 1.1 中大大减少了这个问题的出现次数。这个问题之所以在 XFS 1.0 中更加频繁的发生,原因在于对某类元数据的更新 必须按照其发生的顺序记录到文件系统中。这些按照顺序的元数据更新(被称为“同步”元数据更新)同样有将所有以前还没更新到磁盘上的元数据都刷新的效果。问题就出在这儿。如果这些早先的元数据刷新中也有一些相应的数据块需要被刷新,那么很可能在元数据被记录之后的半分钟内新的数据块仍然没有被写到磁盘上去。这就给发生数据丢失创造了一个很大的漏洞。
技术说明
对于 XFS 1.1,文件系统的元数据只在两种情况下会同步(有序)更新:
* 如果文件系统需要分配空间,并且有一个紧随的事务来释放同一块空间
* 在 XFS 处理用 O_SYNC (同步)选项打开的文件事务的时候;在这种情况下,对这个文件进行写操作将会使得文件系统对元数据所做的其它任何紧随其后的更改被刷新到磁盘。
幸运的是,绝大多数典型的服务器的 I/O 操作在本质上都是异步的。
如果在这个漏洞开启 期间(在元数据被刷新之后但是在相应的数据被写到磁盘上之前)重新启动系统或系统死机,那么新老数据都会丢失。出现这种情况的原因如下:元数据更新删除了对原先数据块的任何引用,却指向磁盘上没有填充过数据的数据块。服务器在崩溃后再次启动时,XFS 代码会查看日志,了解情况,把那些不完整的数据块填上二进制零以预防安全性问题。不幸的是,数据就永远丢失了。
这个问题在频繁使用全新的数据覆盖文件的情况下尤其麻烦。在这样的情况下,如果系统恰好在不合适的时候死机了,那么前面刷新过的元数据会导致文件内容整个丢失。这种特殊的情况 gentoo.org 服务器也遇到过几次,丢失了数据。由于每隔几分钟我们的邮差邮件列表软件就会用新数据覆盖它自己的配置文件,因此它最有可能发生上面所描述的情况。
这个故事寓意是这样的:SGI 的开发者在 XFS 1.1 中已经大大改善了这种局面,如果您运行的是 XFS 1.0,那么您应该下定决心尽快升级到 XFS 1.1。XFS 1.1 还包括了许多附加的修订。在 SGI 缓解了 XFS 对同步元数据更新的依赖的时候,它还能改进 XFS 1.0.x 的弱点之一 — 文件删除。真是太棒了!
过不了多久,我们还可以期待看到 XFS 的新发行版,它将更适合于 Intel Itanium 平台。目前,XFS 的 Linux 版本要求 XFS 文件系统块的大小与平台的内存页面大小相同。这常常使得在 x86 系统上的磁盘不可能移到 Itanium 系统上,因为 Itanium 可以使用最大 64K 的页面,而 x86 只能用 4K。此外,对于大多数的任务来说,大小为 64K 的文件系统块并非最佳选择,但当前的代码迫使一些 Itanium 系统必须使用这样的文件系统块大小。如果修复了这个块大小问题,不仅将 XFS 文件系统从 x86 迁移到 ia64 上变得容易了,而且提供了一个额外的好处,就是允许系统管理员选择适合于他们的需要的 XFS 文件系统块大小。
ReiserFS
ReiserFS 文件系统堪称最有魄力的日志文件系统开发项目,因为它不只是将现有的文件系统移植到 Linux 内核(比如:XFS、JFS),它的设计也不是象 ext3 那样基于早先的文件系统。相反,ReiserFS 的设计完全是从头开始的,就其处理小文件而言,有一些 非常吸引人的性能指标。那么,自从 ReiserFS 被引入到 2.4 内核以来,它是怎样解决稳定性问题和一般的文件系统健壮性问题的呢?
从引入 ReiserFS 开始,它一直有数目非常多的稳定性和崩溃问题。有很多内核对 ReiserFS 用户来说根本就是噩梦,其中包括 2.4.3、2.4.9 甚至相对较新的 2.4.16。不过,尽管这些问题中有些是因 ReiserFS 文件系统代码本身的错误引起的,但有数目惊人的问题会因对内核的其它部分所做的修改而产生不希望的副作用。Linux 内核的开发过程中有一件不幸的事就是,无论您多么细心的测试您自己的代码,还是可能会有某个另外的内核开发者插入的一条很可能没有经过测试的更改而导致您的代码崩溃。最常见的情况是,只有在这些不希望的副作用已经被引入并向深信不疑的 Linux 计算公众用户发行 之后,开发者之间才会有交流。我认为,公平的说,有相当多的伤心的 ReiserFS 用户,他们发现自己正处于这一不幸的失败的环境中。
但是,我的朋友,好消息来了。在过去的几个月中,对于 ReiserFS 来说,情况看上去已经开始好转许多了。一是内核源代码开始稳定在 2.4.17 发行版。此外,在过去的几个月来 Namesys 的开发者(ReiserFS 的开发者)已经能修复相当多隐藏在他们的代码中的错误了。甚至还有更好的消息,内核 2.4.18 好象有一个 非常稳定的 ReiserFS 实现。2.4.18 绝非新出现的 — 在写这篇文章的时候,它出现已经将近三个月了,在代码中还没有发现任何重大问题。事实上,由于缺少新来的错误报告,Namesys 已经重新给发行版经理(Release Manager)指派了新的工作,改进 ReiserFS 的性能。
因此,ReiserFS 和 2.4 内核好象最终解决了它们的差异问题。就我个人观点而言,这真是振奋人心的消息;我很想再开始使用 ReiserFS,并计划在我下一次重新加载我的开发工作站时用它作为我的根文件系统。因为内核方面的问题已经平静下来了,我确信,现在有许多别的前 ReiserFS 用户也很愿意再次回到 ReiserFS。坦白的说,一旦您看到 ReiserFS 的小文件性能可以给某些应用程序的性能带来多大的提升,就很难再离开它了。
那么,在不远的将来我们期望在 ReiserFS 看到些什么呢?据 Hans Reiser 和他的开发者小组所说,预计在 2.4.20_pre1 会有一些非常好的改进,包括对 Chris Mason 的数据日志(象 ext3 的“data=journal”模式)的支持、伸缩性要好得多的新的块分配代码以及对大文件性能方面的一些改进,预计从 IDE 驱动器读取大文件时性能的提高要高达 15%。除这些马上就要着手进行的重大改进之外,我们很可能会看到 ReiserFS 将支持与 ext3 的“data=ordered”模式等价的模式。在这个问题上,ReiserFS 将提供和在 ext3 文件系统中发现的一样的数据完整性功能。我很高兴的看到 ReiserFS 开发小组正在将数据完整性(而不只是元数据完整性)提到这样高的优先级。
Ext3
那么,ext3 的情况如何呢?通常,ext3 相当稳定,还没有遇到过重大问题。为此,ext3 堪称非常可靠而且健壮的日志文件系统选择。尽管有些人也许会认为这个文件系统很“沉闷”,因为除很好的日志实现之外,看不出它对 ext2 做了任何重大改进,但“沉闷”在文件系统世界中是一件好事。它意味着文件系统很擅长只是不紧不慢的执行它的工作。此外,虽然与 ResierFS、XFS 和 JFS 相比,ext3 的可伸缩性具有局限性,但 ext3 已经证明,在大多数服务器和工作站所执行的典型文件系统操作中使用,它不仅速度很快而且很容易调整。很明显,ext3 开发者已经达到了他们要创建一个高质量的日志文件系统的目标,Linux 用户不用费什么力气就可以放心的升级到这一文件系统。
对于内核 2.4.19_pre5,现在同步安装 ext3 文件系统和“chattr +S”文件比从前快大约十倍。很快,我们有望看到添加一个选项用于特定目录树的同步更新,这个功能将主要用于邮件程序。此外,我们还期望能看到定期对代码进行小错误修复和性能改进,但是不会修改主要部分;ext3 已经很完美了,现在代码似乎处于维护模式。
非常感谢您花时间阅读我的这篇文章,请您下一次继续阅读我的文章,我们要看看 JFS!
第 12 部分 EVMS 简介
2002 年 9 月 16 日
在这个由多篇文章组成的“高级文件系统实现者指南”专栏中,Daniel Robbins 向您展示了如何在 Linux 2.4 中使用最新的文件系统技术。在此期间,他与您一同分享有关对现实实现的宝贵建议、性能信息和一些重要的技术说明,以便您尽可能轻松愉快地体验新的文件系统。在本文中,Daniel 介绍了用于 Linux 的企业卷管理系统(Enterprise Volume Management System (EVMS))。他说明了 EVMS 是什么、为什么迫切需要它以及为什么它很可能改变在 Linux 系统上管理存储的方法。
您是否曾经停下来思考有多少种可用于 Linux 的功能强大的与存储相关的技术?仅考虑日志记录文件系统这一项,就有 ReiserFS、ext3、XFS 和 JFS 这些文件系统。几年以前,Linux 甚至连一个日志记录文件系统也 没有。而现在,我们有许多日志记录文件系统,并且发现自己的处境很妙 — 可以按自己的需求选择最好的文件系统。有选择余地显然是件好事情。
现在,让我们来考虑纯文件系统之外的一些内容。Linux 的软件 RAID 功能(已经出现了一段时间)给 Linux 管理提供了另一组可能性(要获取更多信息,请参阅 参考资料,那里有一些链接,通过它们可以阅读我的关于 Linux 软件 RAID 的两部分系列文章)。最近,我们幸运地拥有了 Sistina 的 Linux LVM 技术(逻辑卷管理;请参阅 参考资料,那里有一些链接,通过它们您可以阅读我的关于 LVM 的两部分系列文章,还可以下载 Sistina)。LVM 使管理员可以用更加灵活的方式来管理其存储资源,这要比用静态磁盘分区这种传统方式灵活得多。使用 LVM,管理员可以在运行中的服务器上扩大和缩小文件系统,并可以利用其它一些令人惊讶的功能,如文件系统快照。
存储管理问题
因此,总体而言,Linux 拥有一组极其丰富的与存储相关的技术。但问题也出在这里;就 总体而言,我们确实有一些很棒的工具。但是尝试将这些存储技术中的几种结合起来使用,事情就变得复杂了。例如,设想我们希望创建位于 LVM 逻辑卷上的 ReiserFS 文件系统(这样就可以按需动态地扩展它),而 LVM 又位于 RAID-1 软件 RAID 卷上(针对磁盘故障而提供的一些保护)。
要做到这一点,我们首先在系统中添加两个新驱动器,然后使用 fdisk 在每个驱动器上建立分区。接下来,指定 /etc/raidtab 文件,并使用 mkraid 来启用 RAID-1 卷。做完这些之后,使用 pvcreate 、 vgcreate 和 lvcreate 在 RAID-1 卷之外创建 LVM 逻辑卷。最后,使用 mkreiserfs 在这个新逻辑卷之上创建文件系统。在完成这些工作之后,就可以准备挂装新的 ReiserFS 文件系统了。
是的,我们完成了任务,但是我们必须使用四种不同类型的工具来完成这一切,而且我们的工具没有一致的界面。当我们继续维护卷时,必要时将需要使用软件 RAID 和 LVM 这两种工具。而且这些工具都不能看到所有各层是如何关联的“总览图”,确切地讲,是以下方面:
有两个磁盘;
每个磁盘上有一个分区;
合并成一个 RAID-1 卷;
用来创建一个 LVM 物理卷;
将其添加到 LVM 卷组;
在卷组中创建了一个 LVM 逻辑卷;
在此逻辑卷上放置了 ReiserFS 文件系统。
这其中所涉及的所有工具的数量(更不要提每个工具都不可以与其它工具交互这一事实了)足以让许多管理员对尝试任何如此具有挑战性的任务感到灰心。并且,如果一个新管理员要接管我们这台经过巧妙配置的服务器,则即使是为了首先理解我们如何配置每件东西,也要采取相当多的探测工作。即便这位新管理员真的领悟了这个问题(或者即使我们向他交接了这方面的文档,这是我们应该做的!),他还是会冲出服务器机房,充满恐惧地尖叫。为什么会这样呢?因为,尽管 Linux 有许多与存储相关的技术,但是提供给管理员的用于管理这些技术的界面肯定既不容易管理也不易保持一致;这种一致性和统一性的缺乏使得这种复杂的存储配置错综复杂地交织在一起,从而难以实现和维护。
初识 EVMS
如果您猜测我将会说:EVMS 一下子就轻易地解决了所有这些问题,那么您完全正确。它确实做到了这一点。EVMS 为 Linux 下的所有存储技术提供了统一的、可扩展的、基于插件的 API。这意味着什么?它意味着由于 EVMS,您可以使用单个工具来对磁盘分区、创建 LVM 对象以及甚至创建 Linux 软件 RAID 卷。并且可以使用这一工具以强有力的方式合并这些技术。EVMS 可以看见“总览图”;它可以确切地知道每件东西是如何分层的,从文件系统一直到底层保存数据的物理磁盘。不仅如此,EVMS 还与所有现有的 Linux 技术兼容。它不会强迫您替换分区、LVM 或软件 RAID 卷。相反,它会“愉快”地工作并通过其统一的存储管理界面与现有的存储配置交互。实际上,EVMS 目前向您提供的选项包括命令行界面、基于 ncurses 的界面和用 GTK+ 编写的很棒的存储管理 GUI。为了增强您这方面的兴趣,我将向您展示两张运行中的 GTK+ EVMS Administration Utility(来自版本 1.0.0)的抓屏。在 图 1 中,您可以看到 lvm/vg1/swap 区域(region)所包含的数据是来自 hda2 段(segment),该段位于 hda 磁盘。
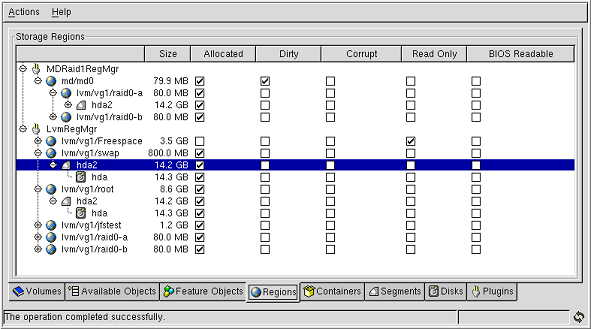
图 1. GTK+ EVMS Administration Utility 的 Regions 选项卡
lvm/vg1/swap 区域
图 2 显示了根卷的快照。快照数据来自 lvm/vg1/root 区域。即使是将文件添加到根文件系统或从中除去文件时,根快照仍将保持不变。
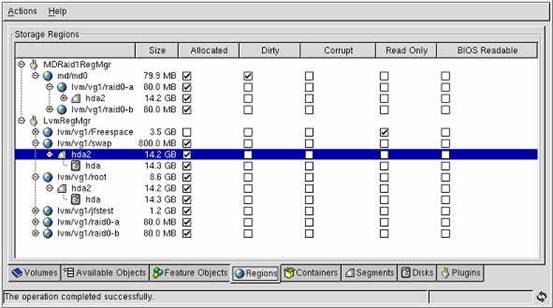
图 2. GTK+ EVMS Administration Utility 的 Volumes 选项卡
根卷的快照
EVMS 不但与您现有的存储管理兼容,而且还提供了新的、您迄今为止未曾获得的功能。1.0.1 发行版中的一个这样的功能是 EVMS 快照特性。您可能熟悉 Linux LVM 的快照;使用快照,您可以创建现有文件系统的不变“视图”,这对于备份很方便。虽然 EVMS 支持 LVM 快照,但它自己独有的快照功能要强大得多,因为您可以快照 任何类型的卷,甚至是标准的 Linux 分区!此外,EVMS 快照允许您创建读/写快照 — 实际上是您现有文件系统的一个“分支”。EVMS 开发人员目前正在从事添加异步快照支持(用于快速的、临时的快照)和“回滚”支持的开发,它将丢弃从快照创建以来对底层卷所作的任何更改,如果管理员希望这样做的话。
既然您理解了对 EVMS 的需求,并对其作用有了基本理解,那么让我们看一下使 EVMS 启动和运行起来需要做哪些工作。
安装 EVMS
EVMS 由一组内核补丁和用户空间工具组成。要让 EVMS 启动和运行起来,得先获取 EVMS 源代码压缩文档,然后将它解压缩,并用其中所包含的内核补丁给内核源代码树打补丁。然后,我们将构建 EVMS 用户空间工具。为了完成安装,我们将配置和构建支持 EVMS 的内核,并用它进行重新引导;在系统重新引导之后,EVMS 已经就绪,可以使用它了。
如果您正在寻找开始研究 EVMS 的捷径,那么可以考虑下载 Gentoo Linux Game 迷你 CD(请参阅 参考资料以获取链接)。除了允许您在使用 NVIDIA 显卡的系统上玩用 OpenGL 加速的 lightcycle 游戏之外,我们的 Games 迷你 CD 还引导到包括完整的 EVMS 支持的 Gentoo Linux 运行时版本。Gentoo Linux 的正式 1.4 发行版(在撰写本文时还没有发布)也将包括完整的 EVMS 支持。我们的 Game/Install 迷你 CD 以及正式 Gentoo Linux 1.4 CD 将允许您安装 Linux 时将根文件系统放在 EVMS 卷上。
我们的第一步是访问 EVMS 项目的主页。在该页的“Latest file releases”一节,您应该可以看到 EVMS 的最新版本的入口。单击“download”链接将把您导航到主下载页面。我将带您遍历从源压缩文档安装 EVMS 版本 1.0.1 的过程,所以请选择下载 evms-1.0.1.tar.gz 文件(或与此类似的文件)。在选择您首选的下载镜像站点之后,下载就应该开始了。
得到压缩文档之后,将它解压缩到一个临时目录中:
# cd /tmp
# tar xzvf /path/to/evms-1.0.1.tar.gz
这个压缩文档包含 EVMS 用户空间工具以及我们需要应用到内核源代码树的补丁。为了 EVMS 用户空间工具正确地编译,我们需要首先安装补丁。要看您的 EVMS 发行版支持什么内核,更改目录并输入 ls ,如下所示:
清单 1. EVMS 目录清单
# cd evms-1.0.1/kernel
# ls
evms-1.0.1-linux-2.4.patch evms-linux-2.4.7-common-files.patch
evms-1.0.1-linux-2.5.patch evms-linux-2.4.9-common-files.patch
evms-linux-2.4.10-common-files.patch evms-linux-2.5.1-common-files.patch
evms-linux-2.4.12-common-files.patch evms-linux-2.5.2-common-files.patch
evms-linux-2.4.13-common-files.patch evms-linux-2.5.3-common-files.patch
evms-linux-2.4.14-common-files.patch evms-linux-2.5.4-common-files.patch
evms-linux-2.4.16-common-files.patch evms-linux-2.5.5-common-files.patch
evms-linux-2.4.17-common-files.patch lilo-22.2-evms.patch
evms-linux-2.4.18-common-files.patch linux-2.4.12-VFS-lock.patch
evms-linux-2.4.4-common-files.patch linux-2.4.18-VFS-lock.patch
evms-linux-2.4.5-common-files.patch linux-2.4.4-VFS-lock.patch
evms-linux-2.4.6-common-files.patch linux-2.4.9-VFS-lock.patch
在这个目录清单中,可以看到 EVMS 的这个版本支持大多数内核,从 2.4.10 到 2.4.18,以及从 2.5.1 到 2.5.5。这意味着为了创建支持 EVMS 的内核,我们应该对从 kernel.org 下载的现成的内核源代码树应用这些补丁。在这些选项中,将 EVMS 应用于 2.4.18 源代码树是最佳选择,因为在撰写本文时,这是目前支持的最新的稳定(2.4)的内核版本。如果您手边没有象 linux-2.4.18.tar.gz 或 .tar.bz2 这样最新稳定内核的源压缩文档,则需要下载一个(请参阅 参考资料以获取链接)。现在,在 /usr/src 中解压缩该新内核源代码树并应用适当的 EVMS 补丁:
清单 2. EVMS 补丁
# cd /usr/src
if /usr/src/linux is a symbolic link, type:
# rm linux
otherwise, do this:
# mv linux linux.old
# tar xzvf /path/to/linux-2.4.18.tar.gz
# mv linux linux-2.4.18-evms
# ln -s linux-2.4.18-evms linux
现在,/usr/src/linux-2.4.18-evms 中将有您要打补丁的源代码树,并让您的 /usr/src/linux 符号链接指向 /usr/src/linux-2.4.18-evms。现在准备开始应用 EVMS 补丁。首先,应用 evms-1.0.1-linux-2.4.patch ;这个补丁包含新的与 EVMS 相关的文件,它可用于 任何 2.4.x 的内核源代码树:
# cd linux
# patch p1 < /tmp/evms-1.0.1/kernel/evms-1.0.1-linux-2.4.patch
接下来,应用专门针对特定内核版本的 EVMS 补丁。这个补丁修改 Linux 内核源代码树中的现有文件,因此如果您将它应用于某个内核,而该内核不是它本应修补的那个版本,则可能出问题。
# patch -p1 < /tmp/evms-1.0.1/kernel/evms-linux-2.4.18-common-files.patch
现在,检查是否有可用于特定内核版本的 VFS-lock 补丁。如果有,最好应用它,因为它有助于 EVMS 更方便地使快照具有一致的状态:
# patch -p1 < /tmp/evms-1.0.1/kernel/linux-2.4.18-VFS-lock.patch
如果您按照我的建议,在打补丁的过程中使用了适当的现成的内核,那么所有补丁都会干净利落地应用到内核,而不会有“被拒的补丁”。要进行确认,可以在打过补丁的内核源代码树中搜索 '.rej' 文件:
# find -name '*.rej'
如果存在任何 .rej 文件,则意味着未正确地应用某个补丁,需要手工修改。通常,只有在您认为自己很聪明,对 -ac(或其它一些)非现成的内核应用 EVMS 补丁时,才会看到“被拒的补丁”;在这种情况下,我认为您知道自己在做什么,并认为您自己能修正这些被拒的补丁 :)。我亲自将 EVMS 补丁应用于基于 -ac 的内核;被拒的补丁不是很多,但我确实遇到了少数被拒的补丁和编译问题,理解和修正它们需要一定的技巧。如果您碰到了这类问题,可以向 EVMS 列表发送消息或访问 IRC 上的 #evms 频道(请参阅 参考资料以获得这些链接)。
现在,让我们配置自己的新内核。输入 make menuconfig 或 make xconfig ,然后按您的意愿配置内核。接下来,确保 禁用任何“Multi-device support (RAID and LVM)”选项,因为 EVMS 在内部包括了对 LVM 和 RAID 的支持。然后,转到“Enterprise Volume Management System”,启用所有选项以便将它们直接编译进内核:
清单 3. EVMS 内核配置
EVMS Kernel Runtime
EVMS Local Device Manager Plugin
EVMS DOS Partition Manager Plugin
EVMS SnapShot Feature
EVMS DriveLink Feature
EVMS Bad Block Relocation (BBR) Feature
EVMS Linux LVM Package
EVMS Linux MD Package
EVMS MD Linear (append) mode
EVMS MD RAID-0 (stripe) mode
EVMS MD RAID-1 (mirroring) mode
EVMS MD RAID-4/RAID-5 mode
EVMS AIX LVM Package
EVMS OS/2 LVM Package
EVMS Clustering Package
(Default) EVMS Debug Level
完成之后,保存配置,然后执行标准的内核构建/安装步骤。但还是请不要重新引导 — 首先,让我们编译和安装 EVMS 用户空间工具:
清单 4. 编译和安装 EVMS 用户空间工具
# cd /tmp/evms-1.0.1/engine
# ./configure --prefix=/usr --libdir=/lib --sbindir=/sbin
# --includedir=/usr/include --with-kernel=/usr/src/linux
# make
# make install
# ldconfig
现在已经安装了用户空间 EVMS 工具,并有了一个新的、可以使用的、支持 EVMS 的内核。接下来,准备重新引导;当系统成功启动后,将启用 EVMS。遗憾的是,必需等到我的下一篇文章才能真正向您展示 如何使用 EVMS。但是,如果您等不及(谁不是这样呢?)并想看到 EVMS 的一些奇妙之处,那么以 root 身份输入 evmsgui ,这将弹出 GTK+ EVMS Administration Utility GUI。
一句警告的话 — 除非您选择“ Commitchanges ”这个菜单项,否则 EVMS Administration Utility 不会应用您所作的任何更改,对此要小心。尽管 GTK+ 界面对用户十分友好,但 EVMS 是一个复杂的系统;要快速地掌握 EVMS 术语和用法 会花费一点时间。当然,如果您可以耐心等待我发表下一篇文章时才开始实验,那么我将全程指导您如何去做。下次见!
第 13 部分 EVMS 详情
2002 年 9 月 16 日
在高级文件系统实现者指南中,Daniel Robbins 向您展示了如何在 Linux 2.4 中使用最新的文件系统技术。在 AFIG 系列文章的这一结束篇中,Daniel 继续讨论用于 Linux 的企业卷管理系统(Enterprise Volume Management System,简称 EVMS)。他向您显示了如何使用来利用新硬盘,对它分区并在其上创建 LVM 卷。接着,他向您介绍了重要的 EVMS 概念,当您继续研究此功能强大的技术时,您会发现这些概念是必不可少的。
欢迎阅读高级文件系统实现者指南的最后一篇专栏文章。在本文中,Daniel 继续探讨他在 EVMS 简介中所遗留下来的内容,并一步一步地指导您使用 evmsn (EVMS 的基于 ncurses 的管理工具)的过程。他向您展示了如何使用 evmsn 来利用新硬盘、对它分区并在其上创建 LVM 卷。接着,他向您介绍了重要的 EVMS 概念,当您继续研究此功能强大的技术时,您会发现这些概念是必不可少的。
新磁盘
开始使用 EVMS 的最佳方法是找一个空闲的硬盘,并将其安装到系统上。然后,就可以为您重要的内容在这个空闲硬盘上创建和删除分区和卷,而不必担心您的数据会遭到破坏。下面,通过引导 Gentoo Linux Game CD(请参阅本文后面的 参考资料),我遵循了这个方法,这张 CD 实际上正好包含了 EVMS 1.0.1 支持。我使用 vmware(请查阅 参考资料,获取链接)来引导这张 CD,并将我的虚拟 PC 配置成包含一个 SCSI 磁盘,sda。当出现带有“login:”提示符的欢迎界面时,输入 root,并在密码提示符下按一下 Enter 键,这样我就以 root 用户登录到这个生动的基于 Gentoo Linux CD 的系统。然后输入 evmsn 启动 ncurses 版本的 EVMS 管理界面。当然,也可以选择仅仅将一个新硬盘挂装在已有的支持 EVMS 的系统上。另外,如果您有 X,那么可以考虑使用 evmsgui ,这是一个基于 GTK+ 的 EVMS 管理界面。尽管 evmsn 运行在使用 ncurses 的控制台上,而 evmsgui 使用更现代的、基于 GTK+ 的界面,但这两个程序的界面非常相似。了解了其中一个,则很容易转到另外一个。
现在,让我们开始使用 EVMS。由于我正在用这个控制台,所以我输入 evmsn ,出现以下屏幕:
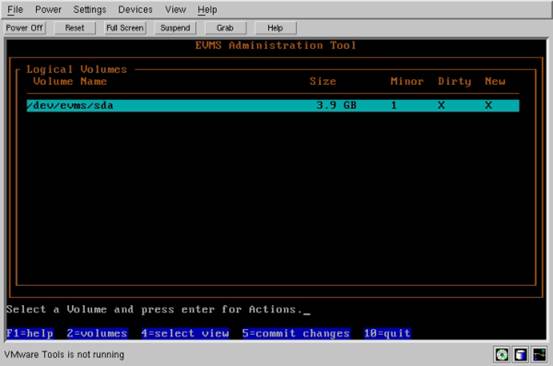
图 1. EVMS 管理工具
EVMS 管理工具
在这个屏幕上,可以看到 /dev/evms/sda ,它是我系统上唯一的卷。如果您在自己的机器上运行 EVMS,那么肯定会看到至少列出了两个额外的 /dev/evms/---- 项。通过使用上下方向键,可以在每个设备节点间移动。
您可能对这些 /dev/evms/--? 设备节点是什么正感到疑惑。乍一看,似乎它们可能仅仅是 /dev 中各个设备节点的副本;例如, /dev/evms/sda 仅仅与更传统的 /dev/sda 设备节点一样,表示同一个磁盘。那么,在 /dev/evms/ 目录中创建重复的设备节点有什么意义呢?回答是:EVMS 的工作之一是为系统上所有的卷创建统一的名称空间,而且它将这个名称空间创建在 /dev/evms 之下。所以,EVMS 检测到 sda 并识别出它应该属于 EVMS 名称空间,因此 EVMS 在 /dev/evms 中创建了相应的设备节点。现在正是一个最佳时间来指出:如果您没有在用 devfs,那么您可能需要运行 evms_devnode_fixup 程序来更新 /dev/evms 名称空间。
以下是另一段巧妙却又很重要的事实。尽管 EVMS 可以看到系统上所有的存储资源,但它可能不会为它找到的所有资源都创建 /dev/evms/ 设备节点项。例如,在我的开发系统中有两个硬盘 /dev/hde 和 /dev/hdg 。但是,没有对应的 /dev/evms/hde 和 /dev/evms/hdg 设备节点。当我查看 /dev/evms/ 时,发现的唯一设备节点是 /dev/evms/hde1 ,它表示第一个硬盘上的引导分区。现在,为什么是 /dev/evms/hde1 而不是 /dev/evms/hde 呢?唔,看来 EVMS 十分智能,它已识别出 hde 和 hdg 没有将其自身加入到卷中;相反,EVMS 可以看到我已经对 hde 和 hdg 进行了分区。它还可以看到我已用这些分区创建了 LVM 逻辑卷。/dev/evms/hde2 分区上的空间正用于更高级的存储对象,所以 EVMS 没有创建“ /dev/evms/hde2 ”设备节点。相反,它识别出我已创建的 LVM 卷,并在 /dev/evms/lvm 下为这些卷创建了设备节点:
清单 1. /dev/evms/lvm 下的设备节点
$ ls /dev/evms/lvm/*/* -l
brw-rw-rw- 1 root root 117, 2 Dec 31 1969 /dev/evms/lvm/mainvg/root
brw-rw-rw- 1 root root 117, 3 Dec 31 1969 /dev/evms/lvm/raid0vg/swap
brw-rw-rw- 1 root root 117, 4 Dec 31 1969 /dev/evms/lvm/raid0vg/tmplv
这说明了 EVMS 遵循的一个重要原则:它只为它在系统上找到的 最终(而不是临时)存储对象创建设备节点。EVMS 将这些最终存储对象统称为“逻辑卷”,而不管它们实际上正好是磁盘、分区,还是 LVM 逻辑卷。正如稍后将看到的,当我们使用 evmsn 和 evmsgui 管理工具时,在能看到 /dev/evms/ 中 EVMS 卷相对应的设备节点之前,需要显式地从存储对象上创建 EVMS 卷。假如我们不打算直接使用存储对象,而是计划用它来创建更高级的存储对象,在将存储对象转换成卷之前,EVMS 将不会为它创建设备节点。EVMS 主张在创建 /dev/evms 设备节点之前先创建卷,这样可以为我们提供保护,以免在输入 mke2fs /dev/evms/foo 时,会在不应该使用的设备节点上创建文件系统。由于存在这个行为,所以我们可以获得保证,即 /dev/evms/ 下的每个设备节点都包含或打算包含文件系统或交换空间。
尽管这个行为非常巧妙、有用而且还减少了混乱,但确实需要花些功夫才能领会它。为了真正理解这一点,以下是在我的开发工作站上运行的 evmsgui 的抓屏。正如您可以看到的,在我的存储资源中,只有四项被配置为卷,而且它们都被用于文件系统或交换空间。
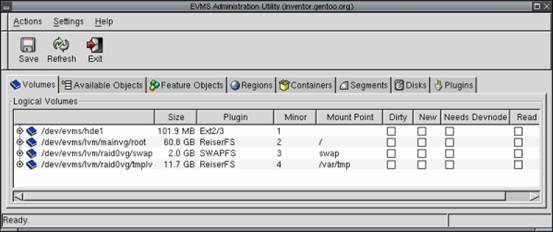
图 2. evmsgui 实用程序
evmsgui 实用程序
现在,回到 vmware EVMS 配置示例。如果您看了本文的第一个抓屏,那么会注意到,尽管 /dev/evms/sda 为空,但该磁盘还是显示为卷。这只是“细心的” EVMS 的另一个示例;尽管它不能检测到磁盘上任何有效的存储资源类型,但它还是将整个磁盘标记为卷,以便在开始使用该磁盘上的存储空间之前必须先 删除这个卷。这是一个极好的行为,因为理论上磁盘 可能包含一些 EVMS 完全不能识别的重要数据。通过采用这个方法,EVMS 就不会让人认为磁盘为空,也就不可能愚弄管理员(例如使他覆盖原始的 FreeBSD 卷),从而可以避免有风险的行为。这再一次说明了 EVMS 很巧妙,但乍一看它的行为稍微有点费解。
当然,在我这个特定情况下,/dev/emvs/sda 为空,而且我需要对它进行分区。为此,我需要按如下那样先破坏 /dev/evms/sda 卷。首先,选中 /dev/evms/sda 之后,按一下 Enter 键:
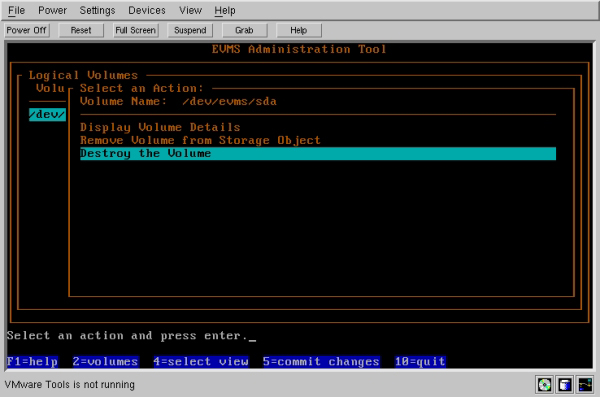
图 3. 破坏卷
破坏卷
正如您可以看到的,这一操作产生了一个子菜单,其中有查看有关卷的细节、删除存储对象上的卷或破坏卷等选项。“破坏卷”和“删除存储对象上的卷”之间有一个很重要的区别;如果选择了前者,那么卷(以及该卷下的任何子对象)将被分解成它们的基本组件。但是,如果选择只删除卷,那么该卷将被破坏,但其子对象(如果存在的话)将完好无损地保留下来。“删除”和“破坏”之间的区别类似于剥去一层洋葱皮和将整只洋葱放到食品加工机中。
但是,在这个特定的例子中,我的洋葱只有一层,所以这两个选项将完成相同的事情。我决定选择“Destroy the volume”;在确认了我的选择并按任意键以返回到卷列表之后,现在您会看到这个操作的结果:“No logical volumes found”。
这个特定的视图突然变得非常令人讨厌,所以我将更改它。按一下“4”将弹出一个选择视图的子窗口。刚才,我在“Logical volumes”视图;现在转到“Available topmost storage objects”。完成选择后,现在我们能看到“sda”又在我们的列表中了!但与前面的操作不同,我们不查看卷,而是查看存储对象。如果接着做下去,对这个存储对象按一下 Enter 键,那么您将看到可以在“sda”上创建几个事物,其中包括一个 EVMS 或兼容性卷。
但是,我们真的不想这样做 — 如果我们想在 sda 上创建卷,应该回到本文开始的地方,即首次装入 evmsn 时,一个卷包括了整个磁盘。相反,我想创建分区,然后将分区转换成卷。为此,我按一下“4”(来选择视图),然后选择“Logical disks”。这里我看到了逻辑磁盘“sda”。是的,在“sda”存储对象和“sda”逻辑磁盘之间 存在一个重要的区别。把“sda”作为存储对象来处理,我们可以将它转换成卷,或使用它来构建更高级的存储对象。但把“sda”作为磁盘来处理允许我把磁盘分割成多个分区(在 EVMS 的行话中称为“段(segment)”),这些分区反过来可以用作存储对象。为此,我按一下 Enter 键,弹出一个菜单,其中提供对磁盘分配段管理器的选项:
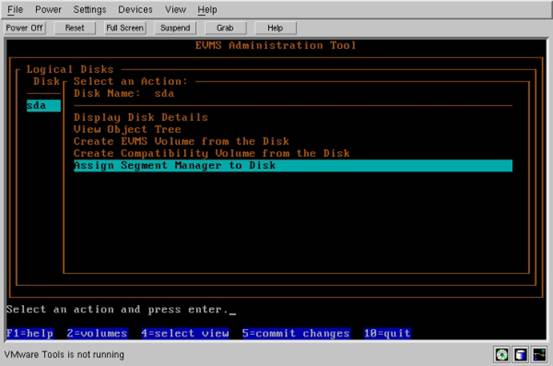
图 4. 分配段管理器
分配段管理器
现在,如果 段与分区是一回事,则您可能想知道 段管理器是什么。可以将段管理器比作“分区方法”或方案。一旦我们选择了段管理器,EVMS 会在磁盘上存放一些元数据,同时创建主引导记录并将磁盘上的剩余空间标记为“freespace”,使之用于新段。要划分新段,可以从屏幕的菜单上选择 “DefaultSegMgr”,再按一下 Enter 键,然后按下空格键。选择“sda”作为接收段管理器的对象。然后,再按一下 Enter 键,选择磁盘的类型为“Linux”(选项中还有“OS/2”),并按一下 Enter 键继续。按下一个键后,现在我按一下“4”(选择视图),然后选择“Disk Segments”以查看我已创建的新段:
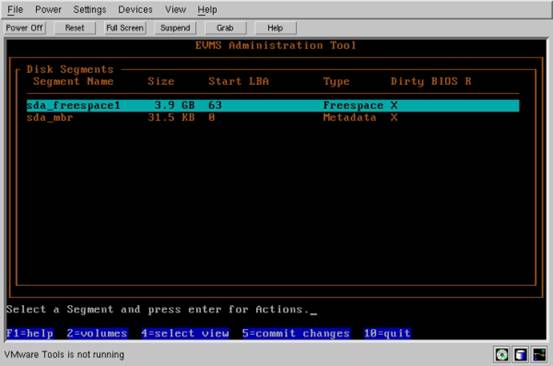
图 5. 创建新段
创建新段
现在我的磁盘有一个主引导记录,然后准备创建新的分区,即 EVMS 行话中的“段”。当我创建新段时,“sda_freespace1”段的大小将减少;如果我将磁盘上所有可用空间都用于创建分区,则 sda_freespace1 段将完全消失。如果硬盘上的可用存储空间确实完全映射到我选择的分区大小,则也可能继续保留剩余的很小的 sda_freespace1。
现在,为了创建那些段,当鼠标停留在“sda_freespace1”上时按一下 Enter 键,随后选择“Create a New Segment”。接着,选择 DefaultSegMgr 插件,并通过按一下空格键来接受使用 sda_freespace1 对象,随后按一下 Enter 键。接着,在磁盘的开始部分,创建一个很小的引导分区,用来保存内核。为此,我将按两次空格键,然后输入“100”以将分区大小设置为 100 MB,接着在 Bootable 选项上按两次空格键来将“Bootable”设置为真。最后,按一下 Enter 键以创建新的分区。重复这些步骤,然后可以创建用于文件系统的其它分区和交换分区。一些注意事项:如果需要创建的分区多于四个,那么请记住在创建引导卷之后切换掉“Primary Partition”选项。还要记住在创建交换分区时,将“Partition Type”设置为“Linux Swap”。
最后一步是在“sda1”、“sda2”和“sda3”上按一下 Enter 键。会出现一个菜单,其中会显示“Create Compatibility Volume from the Segment”的选项。在选择这个选项之后,段将被配置成包含一个可以使用的逻辑卷,这意味着它现在在 /dev/evms/ 下有一个设备节点。另外,因为我选择创建 兼容性卷,所以即使刚好用非 EVMS 内核重新引导了系统,也可以使用新卷。如果选择了“Create EVMS Volume”,那么这就是另外的情况了。请注意 EVMS 版本 1.1.0 及其更高级版本允许您将兼容性卷转换成 EVMS 卷,反之亦然。
结束语
至此,您应该掌握 EVMS 了吧,通过使用 EVMS,我已经对一个系统磁盘进行了分区。尽管这不是一个惊天动地的成就,但在您尝试如创建存储容器、LVM 逻辑卷、RAID 卷、快照以及其它吸引人的事物之前,这样一次经历将有助于向您提供所需的 EVMS 基础知识。当然,本文中我没有留出篇幅涉及这些主题,但我希望在明年能陆续讨论其中某些 EVMS 应用程序。但首先,在讨论其它话题之前,先结束“高级文件系统实现者指南”。希望您喜欢这次旅行:)