Linux虚拟文件系统VFS
 在Linux系统中一切皆文件,如果说文件系统是Linux系统的基石一点也不过分。在Linux系统中基本上把其中的所有内容都看作文件,除了普通意义理解的文件之外,目录、字符设备、块设备、 套接字、进程、线程、管道等都被视为是一个“文件”。例如对于块设备,通过fdisk -l显示块设备列表,其实块设备可以理解为在文件夹/dev下面的文件。只不过这些文件是特殊的设备文件。每个块设备的前面有一个字符串brw-rw----,这个用于描述文件的属性,其中b字符表示这个文件是一个块设备,如果是d字符则表示是一个文件夹。同样,还有其它类型的设备也是一文件的形式进行表示的。那么Linux的文件系统要支持如此之多类型的文件是怎么做到的呢?那就是通过虚拟文件系统(Virtual File System简称VFS)。
在Linux系统中一切皆文件,如果说文件系统是Linux系统的基石一点也不过分。在Linux系统中基本上把其中的所有内容都看作文件,除了普通意义理解的文件之外,目录、字符设备、块设备、 套接字、进程、线程、管道等都被视为是一个“文件”。例如对于块设备,通过fdisk -l显示块设备列表,其实块设备可以理解为在文件夹/dev下面的文件。只不过这些文件是特殊的设备文件。每个块设备的前面有一个字符串brw-rw----,这个用于描述文件的属性,其中b字符表示这个文件是一个块设备,如果是d字符则表示是一个文件夹。同样,还有其它类型的设备也是一文件的形式进行表示的。那么Linux的文件系统要支持如此之多类型的文件是怎么做到的呢?那就是通过虚拟文件系统(Virtual File System简称VFS)。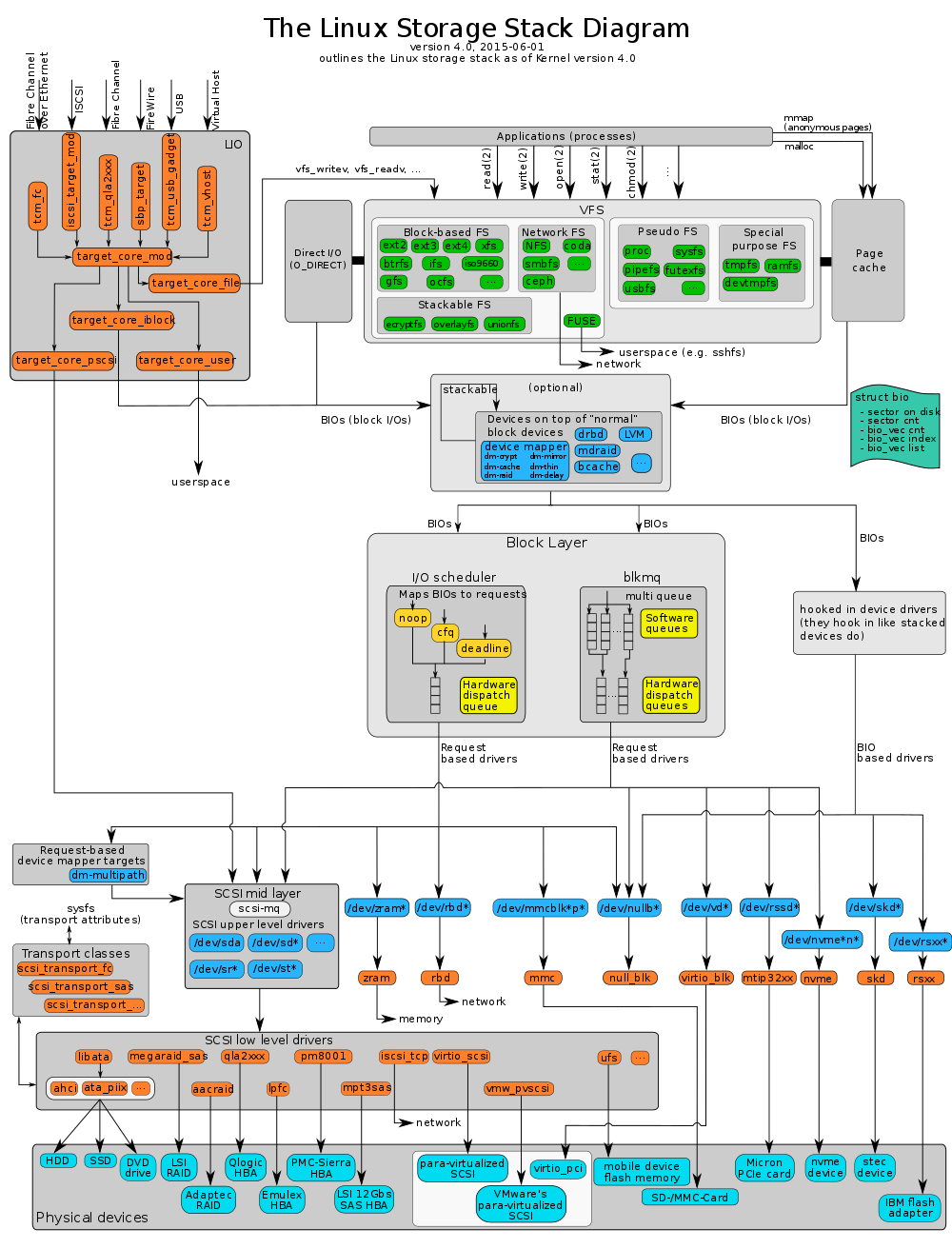
虚拟文件系统(英语:Virtual file system,缩写为VFS),又称虚拟文件切换系统(virtual filesystem switch),是操作系统的文件系统虚拟层,在其下是实体的文件系统。虚拟文件系统的主要功用,在于让上层的软件,能够用单一的方式,来跟底层不同的文件系统沟通。在操作系统与之下的各种文件系统之间,虚拟文件系统提供了标准的操作接口,让操作系统能够很快的支持新的文件系统。
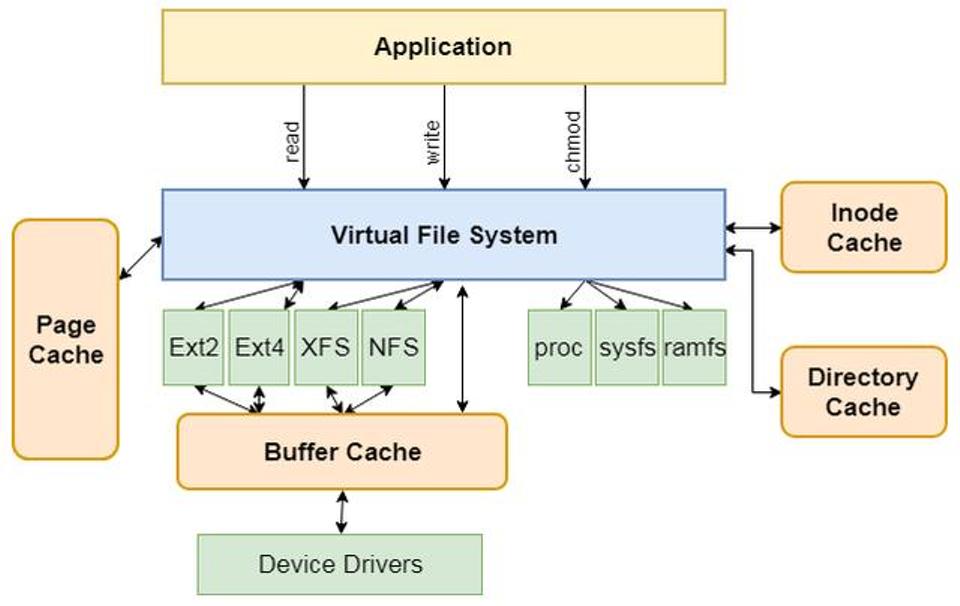
图 虚拟文件系统总图
VFS是一个抽象层,其向上提供了统一的文件访问接口,而向下则兼容了各种不同的文件系统。不仅仅是诸如Ext2、Ext4、XFS和Btrfs等常规意义上的文件系统,还包括伪文件系统和设备等等内容。由上图可以看出,虚拟文件系统位于应用与具体文件系统之间,其主要起适配的作用。对于应用程序来说,其访问的接口是完全一致的(例如open、read和write等),并不需要关系底层的文件系统细节。也就是一个应用可以对一个文件进行任何的读写,不用关心文件系统的具体实现。另外,VFS实现了一部分公共的功能,例如页缓存和inode缓存等,从而避免多个文件系统重复实现的问题。
VFS的存在可以让Linux操作系统实现非常复杂的文件系统关联关系。如下图所示,该系统根文件系统是Ext3文件系统,而在其/mnt目录下面又分别挂载了Ext4文件系统和XFS文件系统。最后形成了一个由多个文件系统组成的文件系统树。
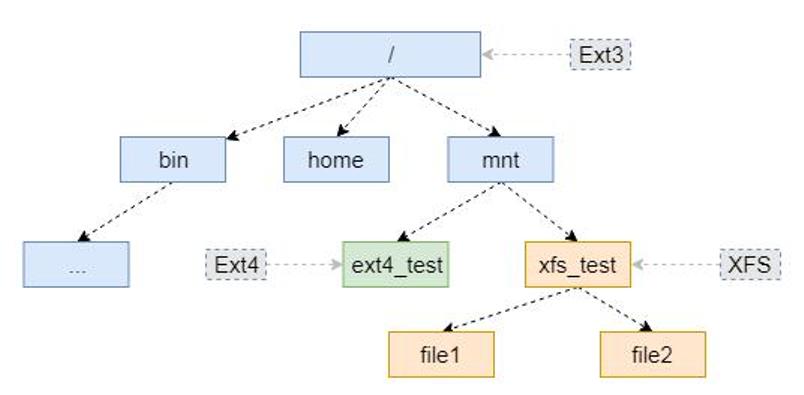
图 文件系统目录树
从VFS到具体文件系统
前文介绍到VFS是一个抽象层,VFS建立了应用程序与具体文件系统的联系,其提供了统一的访问接口实现对具体文件系统的访问(例如Ext2文件系统)。那么两者是怎么关联起来的呢?这里涉及如下几个处理流程:
1.挂载,也就是具体文件系统(例如Ext2)的挂载
2.打开文件,在访问一个文件之前首先要打开它(open)
3.文件访问,进行文件的读写操作(read或者write)
其中第1个流程其实是建立VFS和诸如Ext4文件系统的关联,这样当用户在后面打开某个文件的时候,VFS就知道应该调用那个文件系统的函数实现。而第2个流程则是初始化文件系统必要的数据结构和操作函数(例如read和write等),为后面的具体操作做准备。挂载的流程比较复杂,本文先概括的介绍一下,后续再做详细介绍。
挂载也是用户态发起的命令,就是我们知道的mount命令,该命令执行的时候需要指定文件系统的类型(本文假设Ext2)和文件系统数据的位置(也就是设备)。通过这些关键信息,VFS就可以完成Ext2文件系统的初始化,并将其关联到当前已经存在的文件系统中,也就是建立其图2所示的文件系统树。
在此不介绍代码细节,仅仅从数据结构方面介绍一下Linux文件系统挂载的具体原理。如下图是虚拟文件系统涉及的主要的数据结构。在挂载的过程中,最为重要的数据结构是vfsmount,它代表一个挂载点。其次是dentry和inode,这两个都是对文件的表示,且都会缓存在哈希表中以提高查找的效率。其中inode是对磁盘上文件的唯一表示,其中包含文件的元数据(管理数据)和文件数据等内容,但不含文件名称。而dentry则是为了Linux内核中查找文件方便虚拟出来的一个数据结构,其中包含文件名称、子目录(如果存在的话)和关联的inode等信息。如果想从开发角度了解,可以参考《解析Linux中的VFS文件系统机制》与《Linux虚拟文件系统vfs及proc详解》。
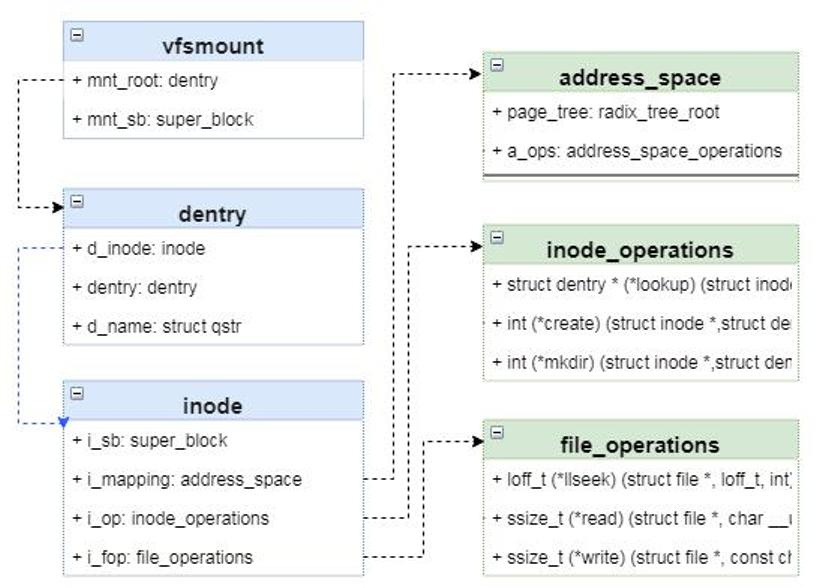
图 文件系统核心数据结构
这里面dentry结构体最为关键,其维护了内核中的文件目录树。其中里面比较重要的几个结构体分别是d_name、d_hash和d_subdirs。其中d_name代表一个路径节点的名称(文件夹名称)、d_hash则用于构建哈希表,d_subdirs则是下级目录(或文件)的列表。这样,通过dentry就可以形成一个非常复杂的目录树。
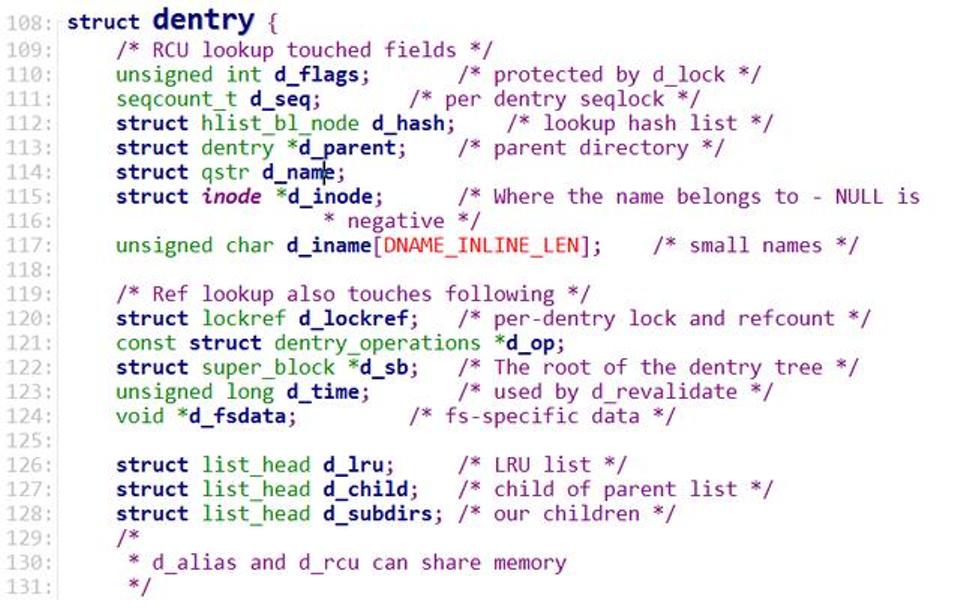
图 dentry数据结构
其中inode是文件的唯一表示,其中除了包含元数据和数据的索引之外,还包含关键操作的函数指针。比如对于文件读写和属性更改等操作接口都存在该结构体中,具体如图<文件系统核心数据结构>所示。这里面主要涉及3个结构体,分别是address_space、inode_operations和file_operations,其中每一个结构体中都包含很多函数指针。
回到正题,所谓文件系统的挂载过程,其实就是构建上述几个结构体的过程,特别是inode结构体的初始化。以Ext4为例,在挂载的时候就会将其中的address_space、inode_operations和file_operations函数指针初始化为Ext4文件系统的函数。因此当对文件进行访问的时候,只要找到这个inode,就能知道是什么类型的文件系统。
处理流程示例
我们都知道,在用户态打开一个文件是返回的是一个文件描述符,其实也就是一个整数值。同时,访问文件也是通过这个文件描述符进行的,如下面代码所示的函数原型。那么操作系统是怎么通过这个整数值实现不同类型文件系统的访问呢?前文我们知道不同文件系统的差异其实就是inode中初始化的函数指针的差异,因此问题的关键是这个文件描述符和inode是怎么关联起来的。
在Linux操作系统中,文件的打开必须要与进程(或者线程)关联,也就是说一个打开的文件必须隶属于某个进程。在linux内核当中一个进程通过task_struct结构体描述,而打开的文件则用file结构体描述,打开文件的过程也就是对file结构体的初始化的过程。在打开文件的过程中会将inode部分关键信息填充到file中,特别是文件操作的函数指针。在task_struct中保存着一个file类型的数组,而用户态的文件描述符其实就是数组的下标。这样通过文件描述符就可以很容易到找到file,然后通过其中的函数指针访问数据。
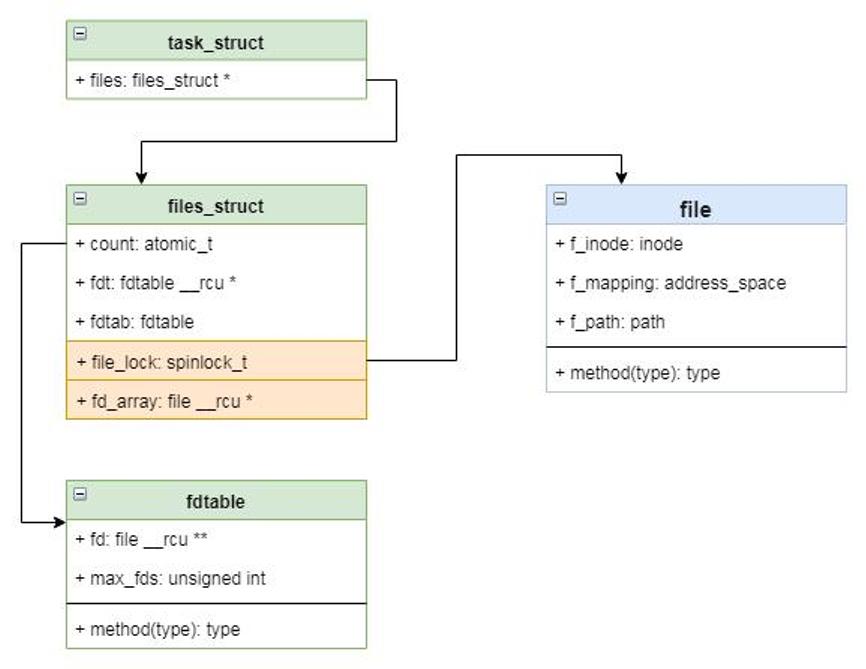
图 进程与文件
例如以Ext2文件系统的写数据为例,在调用用户态的写数据接口的时候,需要传入文件描述符。内核根据文件描述符找到file,然后调用函数接口(file->f_op->write)文件磁盘数据。其中file结构体的f_op指针就是在打开文件的时候通过inode初始化的。
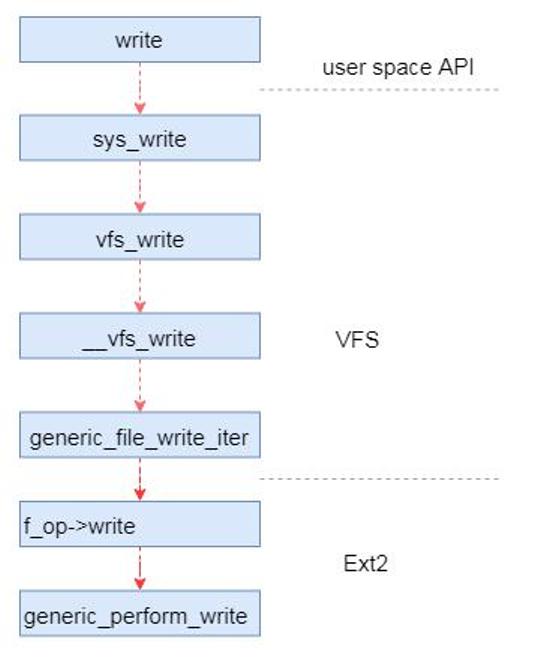
图 Ext2写数据流程
文件系统
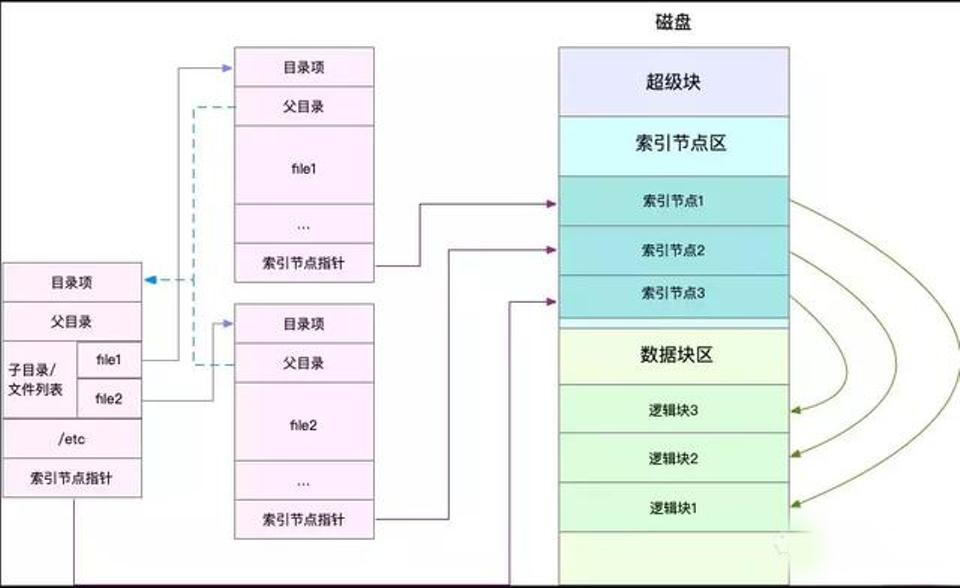
文件系统是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。
1.索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
2.目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
虚拟文件系统
磁盘内的分类
超级块:存储整个文件系统的状态。
索引节点区:用来存储索引节点。
数据块区:则用来存储文件数据。
目录项、索引节点、逻辑块以及超级块,构成了 Linux 文件系统的四大基本要素。为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样用户进程和内核中的其他子系统,就只需要跟 VFS 提供的统一接口进行交互。
IO栈
Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。
文件系统层:包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
通用块层:包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
设备层:包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
通用块层是 Linux 磁盘 I/O 的核心。向上,它为文件系统和应用程序,提供访问了块设备的标准接口;向下,把各种异构的磁盘设备,抽象为统一的块设备,并会对文件系统和应用程序发来的 I/O 请求进行重新排序、请求合并等,提高了磁盘访问的效率。
IO分类
阻塞/非阻塞针对的是 I/O 调用者(即应用程序),而同步 / 异步针对的是 I/O 执行者(即系统)。
阻塞 I/O:是指应用程序在执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,不能执行其他任务。
非阻塞 I/O:是指应用程序在执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务。
同步 I/O:是指收到 I/O 请求后,系统不会立刻响应应用程序;等到处理完成,系统才会通过系统调用的方式,告诉应用程序 I/O 结果。
异步 I/O:是指收到 I/O 请求后,系统会先告诉应用程序 I/O 请求已经收到,随后再去异步处理;等处理完成后,系统再通过事件通知的方式,告诉应用程序结果。
Linux对IO的优化
优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。
优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
磁盘性能指标
使用率:是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
饱和度:是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
IOPS(Input/Output Per Second):是指每秒的 I/O 请求数。
吞吐量:是指每秒的 I/O 请求大小。
响应时间:是指 I/O 请求从发出到收到响应的间隔时间。
在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
再回顾理解Linux的VFS
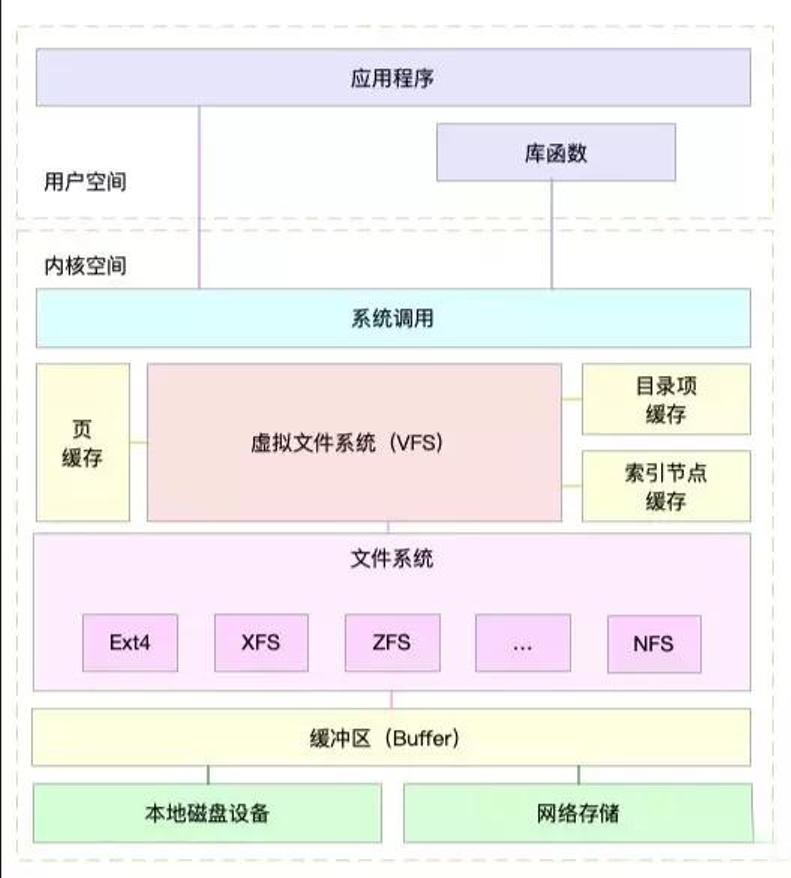
Linux 采用 Virtual Filesystem(VFS)的概念,通过内核在物理存储介质上的文件系统和用户之间建立起一个虚拟文件系统的软件抽象层,使得 Linux 能够支持目前绝大多数的文件系统,不论它是 windows、unix 还是其他一些系统的文件系统,都可以挂载在 Linux 上供用户使用。
VFS 在 Linux 中是一个处理所有 unix 文件系统调用的软件层,同时给不同类型的文件系统提供一个统一的接口。VFS 支持以下归类的三种类型的文件系统:
1.磁盘文件系统,存储在本地磁盘、U盘、CD等的文件系统,它包含各种不同的文件系统格式,比如 windows NTFS、VFAT,BSD 的 UFS,CD的 CD-ROM 等
2.网络文件系统,它们存储在网络中的其他主机上,通过网络进行访问,例如 NFS
3.特殊文件系统,例如 /proc、sysfs 等
VFS 背后的思想就是建立一个通用的文件模型,使得它能兼容所有的文件系统,这个通用的文件模型是以 Linux 的文件系统 EXT 系列为模版构建的。每个特定的文件系统都需要将它物理结构转换为通用文件模型。例如,通用文件模型中,所有的目录都是文件,它包含文件和目录;而在其他的文件类型中,比如 FAT,它的目录就不属于文件,这时,内核就会在内存中生成这样的目录文件,以满足通用文件模型的要求。同时,VFS 在处理实际的文件操作时,通过指针指向特定文件的操作函数。可以认为通用文件模型是面向对象的设计,它实现了几个文件通用模型的对象定义,而具体的文件系统就是对这些对象的实例化。通用文件模型包含下面几个对象:
1.superblock 存储挂载的文件系统的相关信息
2.inode 存储一个特定文件的相关信息
3.file 存储进程中一个打开的文件的交互相关的信息
4.dentry 存储目录和文件的链接信息
这几个通用文件模型中的对象之间的关系如下图所示:
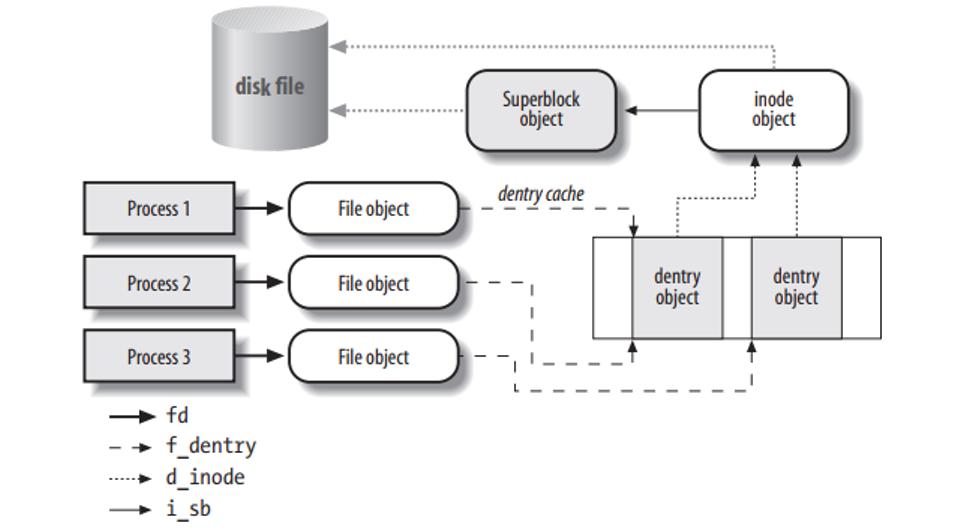
VFS 除了提供一个统一文件系统接口,它还提供了名为 dentry cache 的磁盘缓存,用于加速文件路径的查找过程。磁盘缓存将磁盘中文件系统的一些数据存放在系统内存中,这样每次访问这样的数据就不需要操作实际的物理磁盘,可以大大提高访问性能。
superblock
superblock 由 super_block 结构体存储,所有的 superblock 都通过一个双向链表链接在一起,这个链表的头是 super_blocks 。通过 sget 或者 sget_fc 向这个链表中添加 superblock。对于 superblock 的方法存放在 super_operations 数据结构中。这其中包含了对这种文件类型的各种的基础操作,比如 write_inode & read_inode。s_dirt 标志用于指示 superblock 是否与磁盘中的 superblock 一致,如果不一致,则需要进行同步。
inode
文件系统中用于操作文件的所有信息都存储在 inode 这样一个数据结构中。对于一个文件而言,它的文件名只是一个标签,是可以改变的,但是 inode 是不变的,它对应着一个真正的文件。inode 中的 i_state 用于指示当前 inode 的状态,有下面一些比较常见的标志:
I_DIRTY:与磁盘中的内容不一致,需要同步
I_LOCK:在进行 IO 操作
I_FREEING:这个 inode 已经被 free 了
I_CLEAR:inode 中的内容已经没有意义了
I_NEW:这个 inode 是新建的,里面还没有与磁盘中的数据进行同步
每个 inode 会被链接进下面三个链表中(通过 inode 中的 i_list 进行链接):
unused inodes:i_count 为0,也就是没有被引用,并且它是 no dirty 的。链表头是 inode_unused
in-use inodes:i_count > 0 并且是 no dirty 的,链表头是 inode_in_use
dirty inodes:链表头是 superblock 中的 s_dirty
同时,属于同一个文件系统的 inode 会通过 i_sb_list 字段链接到一个链表中,这个链表的头存放在 superblock 中 s_inodes 字段。为了加快查找速度,inode 存放在一个 inode_hashtable 的 hash 表中,其中的 i_hash 则用于 hash 查找冲突时的链表。inode 的方法则存放在 inode_operations 结构数据中。
file
file 是用于进程与文件之间进行交互的一个数据结构,它是一个纯软件的对象,没有关联的磁盘内容,所以它没有 dirty 的概念。file 中最重要的内容是文件指针,也就是当前文件的操作位置。同一个文件可能被不同的进程打开,它们都是对同一个 inode 进行操作,不过由于文件指针的不同,它们操作的位置也就不一样。file 结构体通过一个 flip 的 slab cache 进行分配。所以 file 的数目存在一个限制,它通过 files_stat 中 max_files 指示最大的可分配的 file 的数量。in-use file 被链接在属于各自文件系统的 superblock 中,链表的头是 s_files 。f_count 字段则记录着文件被引用的计数。
VFS 在操作文件时候,类似面向对象中多态概念,不同的文件系统会关联不同的 file operations 。这样 VFS 统一的文件操作接口存放在 file 中的 f_op 中。当打开一个文件的时候,VFS 会根据 inode 中的 i_fop 对 f_op 进行初始化,而在之后的操作中,VFS 可能会更改 f_op 中的值,也就是改变文件操作的行为。
dentry
在 VFS 的统一文件模型中,目录也是被当作文件的,它有着对应的 inode 。每当一个目录项被读入内存的时候,就会通过一个 dentry 的结构数据存放,它通过 dentry_cache 的 slab cache 进行分配。每个 dentry 可能存在下面4种状态:
free:VFS没有在使用,只是一个空的空间
unused:d_count = 0,不过里面的数据还是有效的,这样的 dentry 会按顺序被回收
in-use:d_count > 0,数据有效,正在被系统所使用
negative:d_count > 0,d_inode = NULL,也就是这个 dentry 没有关联的 inode,不过它依旧在路径查找中被使用
unused dentry 会被链接到一个 LRU 链表中,当 dentry cache 需要 shrink 的时候,就会从这个链表的尾部回收空间。这个 LRU 链表的头是 dentry_unused ,通过 dentry 中的 d_lru 字段进行链接。in-use dentry 则会被链接到 inode 中的 i_dentry 链表,这是因为同一个 inode 可能存在好几个硬链接。同时为了加快目录的查找,dentry 也会被加入到名为 dentry_hashtable 的 hash 表中。
每一个进程,都有一个 fs_struct 结构数据,用于存放 root 目录、当前目录等文件相关的信息。还有一个 file_struct 的数据结构用于存放进程打开的文件相关信息。file_struct 中的 fd 字段是一个指向当前进程打开的文件的一个数组,这个数据的大小由 max_fds 字段指示。这个数组的默认大小是 32,如果打开的文件多于这个数,那么就会重新开辟一个大的数组进行扩展。我们在用户态的文件描述符就是这个数组的序号,通常0号文件是标准输入,1号文件是标准输出,2号文件是错误输出。通过 dup()、fcnt() 这样的系统调用,我们可以让这个数组不同的序号指向同一个文件。一个进程能打开的文件数是有限制的,在运行过程中,这个最大值由 signal->rlim[RLIMIT_NOFILE] 指示,它可以在运行时动态的修改,默认值是 1024。而在代码中,NR_OPEN 这个宏指示着进程所能支持的最大的文件打开数。在 file_struct 中 open_fds 是一个用来标志打开文件序号的数组,这个数组中的每个 bit 表示对应序号的文件是否被打开,max_fdset 指示着这个数组的长度,它的默认值是 1024 个 bit。如果打开的文件数超过这个值,那么就需要动态扩展这个数组的大小。
内核中通过 fget 函数来引用文件,它将返回 current->files->fd[fd],同时增加 f_count 的计数,释放文件则通过 fput 函数,它将减少 f_count 计数,如果减少到0,内核将调用 release 方法做真正的释放动作。
文件系统类型
相对于以网络和磁盘为载体的文件系统,特殊文件系统是一些数据的集合,利用了 VFS 的接口,方便内核或者用户的使用。常见的特殊文件系统有:rootfs、proc、sysfs、pipefs、tmpfs等。这些特殊的文件系统没有物理载体,不过内核中把它们都统一分配一个虚拟的块设备(编号为0)。这些特殊的文件系统通过调用 set_anon_super 函数来初始化 superblock。
file_system_type 是用于存放注册到内核的文件系统类型的信息的数据结构,所有的 file_system_type 链接在一个单向链表中,表头是 file_systems 。字段 fs_supers 则是这个文件类型下所有的 superblock 的链表。get_sb & kill_sb 则是用于构建和销毁 superblock 的方法。
文件系统通过调用 register_filesystem & unregister_filessytem 函数实现文件系统在内核的注册和注销。
rootfs 文件系统是内核在启动阶段注册的,它包含了文件系统初始化的脚本以及一些重要的系统程序。其他的文件系统则可以通过脚本或者命令 mount 到系统的目录节点中。
namespaces
通常的 unix 系统中,只有一颗文件系统树,都是从 rootfs 这个根开始,进程通过在这个文件树中特定的路径名访问文件。而在 Linux 中,引入了 namespace 的概念,也就是每一个进程都可以有自己的一个文件系统树。通常进程都是共享系统中的 rootfs(也就是 init 进程的 namespace )。不过如果在 clone() 系统调用的时候,设置了 CLONE_NEWNS 标志,那么这个进程就会创建一个新的 namespace,通过 pivot_root() 系统调用可以修改进程的 namespace。不同 namespace 之间的文件系统 mount & unmount 互不影响。
进程中的文件系统 namespace 信息通过一个 namespace 数据结构进行存储。list 字段是一个链接了所有属于这个 namespace 的文件系统的链表,而 root 字段则是表示这个 namespace 的根文件系统。
在 Linux 中,文件系统的 mount 具有以下一些特性:
同一个文件系统可以被多次 mount 到不同的路径点,这样同一个文件系统可以通过不同的路径进行访问,不过代表这个文件系统的 superblock 只会有一个
mount 的文件系统下的路径可以 mount 其他的文件系统,以此类推,可以形成一个 mount 的等级图
同一个路径点,可以被栈式地进行 mount,新的文件系统被 mount 后就会覆盖老的文件系统的路径,而 unmount 之后,路径又会恢复之前一个的文件系统
用于存储这些 mount 的关系信息的数据结构叫做 vfsmount ,vfsmount 数据被链接在下面这些链表中:
所有的 vfsmount 加入到 mount_hashtable hash表中
对于每一个 namespace ,通过一个环形链表,链接属于自己的 vfsmount
对于每一个文件系统,通过一个环形链表,链接 mount 到自己路径下的子文件系统 vfsmount
mount 根文件系统
根文件系统的 mount 过程分为2个阶段:
内核 mount 一个特殊的文件系统——rootfs,它提供了一个空的路径作为初始的挂载点
内核 mount 实际的文件系统系统,覆盖之前的空路径
内核之所以搞一个 rootfs 这样一个特殊的文件系统,而不是直接使用实际的文件系统作为根文件系统,其原因是为了方便在系统运行时更换根文件系统。目前用于启动的 Ramdisk 就是这样一个例子,在系统起来后,先加载一个包含最小驱动文件和启动脚本的 Ramdisk 文件系统作为根文件系统,然后将系统中其他的设备加载起来后,再选择一个完整的文件系统替换这个最小系统。
文件路径查找
文件路径查找的简单过程:文件路径通过 / 划分为一个个的目录项,查找到匹配的目录,然后读取它的 inode ,寻找到符合下一级路径的目录,如此循环,知道最后。dentry cache 的机制可以加快对于目录项的访问速度。然而Linux中下面的这些特性,让这个循环查找的过程变得非常复杂:
每一级路径需要匹配用户的访问权限
一个文件名可能是任意一个路径的软链接
软链接可能存在循环引用的情况,需要发现并打破这样的无限循环
一个路径名可以是另一个文件系统的挂载点
路径名需要在进程的 namespace 中查找,不能超出这个范围
文件路径的查找通过函数 path_lookup 实现。
文件锁
当一个文件可以被多个进程同时访问的时候,同步的问题就产生了。POSIX 标准是要求通过 fcntl() 系统调用实现一个文件锁的机制,这样就能避免竞争关系。这个文件锁可以对整个文件或者文件中的某个区域(小到一个字节)进行锁定,由于可以锁文件的部分内容,所以一个进程可以同时获取同一个文件的多个锁。
POSIX 标准的这种文件锁被称之为 advisory lock,就跟用于同步的信号量一样,只有双方约定在访问临界区的时候都先查看一下锁的状态,这种同步机制才能实现,如果某个进程单方面不获取锁的状态就直接操作临界区,那么这个锁是管不住的。与劝告锁相对的就是强制锁。
在 linux 中可以通过 fcntl() & flock() 系统调用对文件进行上锁。通常在类 unix 系统中,flock() 系统调用会无视 MS_MANDLOCK 的挂载标志,只产生劝告锁。
Linux 对于劝告锁和强制锁都有实现,一个进程获取劝告锁的方式有2种:
通过 flock() 系统调用,这个锁只能对整个文件上锁
通过 fcntl() 系统调用,可以文件的特定部分进行上锁
一个进程获取强制锁比较麻烦,需要下面几个步骤:
mount 文件系统的时候,添加强制锁的标志 MS_MANDLOCK,也就是 mount 命令添加 -o 选项。mount 的默认情况下是不带这个标志的
使能 Set-Group-ID,清除 Group-Execute-Bit ,chmod g+s,g-x xxx.file
使用 fcntl() 系统调用,获得强制锁
fcntl() 系统调用还支持一种名为 lease 的强制锁,A进程在访问被B进程上锁的文件时,A进程会被阻塞,同时B进程会收到一个信号,此时B进程应该尽快处理完并主动释放文件锁。如果在一定时间内(/proc/sys/fs/lease-break-time中配置,通常是45s)B进程还没有释放这个锁,那么这个锁就会被内核自动释放掉,此时A进程就能继续访问这个文件了。
fcntl() 是 POSIX 标准的用于文件锁的系统调用,而 flock() 是许多其他类 unix 系统中实现的系统调用,Linux 对这2者都支持。它们的锁也是互不影响的,也就是通过 fcntl() 上的锁对 flock() 是无效的,反之亦然,之所以这样,是为了防止不同的用户程序使用不同的接口,会导致死锁的情况发生。
由于强制锁会带来一些程序兼容性的问题,所以一般不鼓励使用强制锁,并且 Linux 中的强制锁还存在一些 bug,会导致无法真正地实现全面的强制锁,同时从4.5版本开始,强制锁已经变成一个可配置的选项,在后面的内核版本中将会移除这个特性(详情请看编程手册 fcntl 页面)。
VFS 全篇看来就那4个对象的关系图,其次就是文件操作的接口标准,代码部分值得一看的应该是文件路径查找与文件系统mount的处理。而文件锁作为一个同步机制,也是值得去研究一下它的实现的。对 VFS 这部分的兴趣还是不大,遗留它的代码没有去看了。
文件系统架构简述
1、一切皆文件(Everything is a file)
Unix/Linux设计哲学的核心就是“一切皆文件”。普通文件、目录、设备、进程、套接字、管道……在用户态看来都是“文件”。这极大简化了运维操作:用同一套 API(open、read、write、close)就能操作所有资源。
运维意义:
可以用 ls /proc 查看进程信息,就像 ls 一个普通目录。
可以用 cat /dev/null 清空文件,也可以用 echo > /proc/sys/vm/drop_caches 释放缓存。
故障排查时,一切都可追溯到“文件”层面:权限、inode、块设备。
但这个统一抽象背后,是内核的 Virtual File System (VFS) 层在默默工作。它让 ext4、XFS、Btrfs、NFS 等不同文件系统对上层呈现一致接口。主流发行版(Ubuntu 24.04 LTS、Rocky Linux 9、openSUSE 等)依然以 VFS 为核心,新增了对 Btrfs 子卷、ZFS 模块、immutable root 等特性的更好支持,但底层架构未变。
2、VFS 架构深度解析:超级块、索引节点、目录项
VFS 是内核中最重要的抽象层之一,它不存储数据,只负责“翻译”和“调度”。核心数据结构有四个,系统管理员必须理解其运维含义:
1).超级块 (super_block)
cat /proc/mounts 或 findmnt 看到的每一条记录背后都有一个 super_block。
卸载失败(device is busy)往往是因为 super_block 仍有引用(open 文件、进程 cwd)。
命令查看:tune2fs -l /dev/sda1(ext4)或 xfs_info /dev/sda1 可读超级块信息。
2026 年实践:LVM 快照或 Btrfs 子卷挂载时,超级块 freeze 操作(fsfreeze -f)用于一致性备份。
代表一个已挂载的文件系统实例。
包含文件系统类型、大小、块大小、inode 总数、魔数(magic number)等元数据。
2).索引节点 (inode)
场景:日志文件碎片化、小文件爆炸(/tmp 下数十万临时文件)。
检查命令:df -i(显示 inode 使用率)。
解决:find /var/log -type f -name "*.log" -mtime +30 -delete 或启用 logrotate。
生产建议:大分区建议格式化时提高 inode 比例(ext4:mkfs.ext4 -i 16384)。
硬链接数 >1 时,删除一个链接 inode 不释放,只有计数归零才真正删除。
每个文件/目录在磁盘上对应一个 inode,存储元数据:大小、权限、时间戳、数据块指针、硬链接数等。
文件名不存 inode 里,文件名存 dentry。
运维杀手级问题:inode 耗尽。
3).目录项 (dentry)
高并发 Web 服务下 dcache 占用内存激增 → 监控 /proc/slabinfo | grep dentry。
路径过深(>255 层)或 symlink 循环会导致 dentry 查找失败。
命令清理:echo 3 > /proc/sys/vm/drop_caches(慎用生产)。
目录缓存(dcache),把路径解析成 inode 的映射,全部缓存在内存。
极大加速 ls、cd、open 等操作。
4).文件操作结构 (file_operations)
定义 read/write/mmap 等具体行为,由具体文件系统实现。
运维中用 strace 追踪系统调用,就能看到 VFS 如何切换到具体 FS 的操作。
小结:VFS 让运维“一次学习,全局通用”。不管是本地 ext4 还是远程 NFS,mount、umount、stat 命令行为一致。
3、FHS 文件系统层次标准:生产服务器目录结构
Linux 遵循 Filesystem Hierarchy Standard (FHS),Ubuntu Server、CentOS/Rocky、Debian 等企业级系统均严格遵守。理解每个目录的“职责”,是运维日常巡检、备份策略、权限收紧的基础。
以 Ubuntu Server 24 LTS 为例的核心目录详解:
/(根目录):整个文件系统的起点。通常单独分区或 LVM 逻辑卷。
/bin → /usr/bin 的符号链接:基础用户命令(ls、cp、cat)。
/boot:内核、initramfs、GRUB。强烈建议独立分区(至少 1GB),升级内核时最活跃。
/dev:设备文件(由 udev 动态创建)。/dev/sda(磁盘)、/dev/null、/dev/random。运维常用 lsblk -f 查看。
/etc:主机专属配置文件。/etc/fstab、/etc/passwd、/etc/ssh/sshd_config。每日备份重点!ansible 配置也常放这里。
/home:用户家目录。生产建议独立分区 + quota。
/lib、/lib64:共享库。
/media、/mnt:可移动介质与临时挂载点。
/opt:第三方软件(如 Oracle、自定义应用)。
/proc:虚拟文件系统(procfs),进程和内核信息。cat /proc/meminfo、cat /proc/cpuinfo 是运维监控神器。不占磁盘空间,重启消失。
/root:root 用户家目录,独立于 /home。
/run:运行时数据(tmpfs),存放 PID、socket。systemd 时代取代了旧 /var/run。
/sbin → /usr/sbin:系统管理命令(fdisk、reboot)。
/srv:服务数据(如网站文件 /srv/www)。
/sys:sysfs,设备驱动视图。/sys/block/sda/queue/rotational 可判断是 HDD 还是 SSD。
/tmp:临时文件(通常 tmpfs)。重启自动清理,生产中加 noexec,nosuid 挂载选项防攻击。
/usr:用户程序与只读数据。/usr/bin、/usr/lib、/usr/share。现代发行版倾向于只读根文件系统 + /usr 可更新。
/var:可变数据。/var/log(日志)、/var/cache(缓存)、/var/lib(数据库、docker)。最易占满磁盘的目录,必须单独分区或监控。
备份策略:/etc + /var/log + /home + 数据分区。
监控重点:/var、/tmp、/proc(内存映射)。
容器时代:/var/lib/docker、/var/lib/kubelet 体积爆炸常见。
4、常见文件系统类型与选型建议
ext4:最成熟、兼容性最好。日志、extent 分配、延迟分配。适合根分区、通用服务器。
XFS:高性能、大文件、高并发 I/O。默认于 Rocky/AlmaLinux。适合数据库、日志服务器。
Btrfs:Copy-On-Write,快照、子卷、压缩、RAID。2026 年在 openSUSE、Fedora 中更流行,适合需要回滚的开发/测试环境。但生产大集群仍需谨慎(碎片化问题)。
tmpfs/ramfs:内存文件系统。/tmp、/run 默认使用,速度极快但重启丢失。
其他:ZFS(通过 OpenZFS 模块)、overlayfs(容器)。
选型:
业务 I/O 模式(小文件 vs 大文件)。
是否需要快照(Btrfs > LVM)。
SSD 还是 HDD(ext4 discard、XFS discard)。
内核版本支持(6.x 内核对 Btrfs 优化显著)。
下文在第9节还会接着讲解。
5、文件类型、链接与特殊文件
用 ls -l 第一列字符判断类型:
- 普通文件
d 目录
b 块设备
c 字符设备
p 管道
s 套接字
l 符号链接
硬链接 vs 软链接:
硬链接:同一 inode,节省空间,不能跨文件系统。ln file hardlink
软链接:独立 inode,存路径,可跨文件系统,易成“悬空链接”。ln -s file softlink
rm 软链接只删链接,rm -rf 目录时小心。
find -L 查找断链:find / -type l -xtype l。
6、基础命令
空间与 inode 检查:
df -hT # 类型 + 空间
df -i # inode
du -sh /var/* | sort -hr # 目录占用排序
lsof +L1 | grep deleted # 删除后仍占用空间的罪魁祸首
元数据查看:
stat /etc/passwd
ls -i /etc/passwd # inode 号
查找与权限:
find /var/log -type f -name "*.log" -mtime +7 -exec ls -l {} \;
getfacl /data/private # ACL
7、常见运维故障排查案例
案例1:磁盘满但 du 不显示
原因:删除文件但进程仍打开(deleted 文件)。
排查:lsof +L1 → kill 或 restart 服务 → 空间释放。
案例2:权限问题导致 Nginx 502
原因:/var/www 属主错误或无 x 权限。
排查:namei -m /var/www/html/index.html(路径逐级权限)。
案例3:inode 耗尽无法写入
原因:/tmp 下海量小文件。
解决:tmpwatch 或 systemd-tmpfiles 清理 + 调整 /tmp 挂载为 tmpfs 大小。
案例4:卸载失败
原因:进程 cwd 或 open 文件。fuser -u /mnt/data 或 lsof /mnt/data。
8、运维最佳实践
挂载选项:noatime,nodiratime,discard(SSD)、nosuid,noexec(/tmp)。
UUID 而非 /dev/sdX:/etc/fstab 用 UUID 更稳定(blkid 获取)。
定期 fsck:开机自动或 tune2fs -c 50 设置检查次数。
监控工具:Prometheus node_exporter + 自定义 inode 指标。
一些发行版默认 Btrfs + Snapper 快照(回滚如手机)。
只读根文件系统 + rpm-ostree 原子更新(Fedora Silverblue、openSUSE MicroOS)。
可用的安全加固:
umask 0027
aide 或 tripwire 文件完整性监控
/etc/fstab 禁用 suid
9、文件系统选型建议
ext4、XFS、Btrfs 在生产环境的抉择
1). 主流企业发行版 Linux 文件系统选型背景与核心考量:
Ubuntu 24.04/26.04 LTS 默认仍以 ext4 为根文件系统;
Rocky Linux 9 / AlmaLinux 9 默认 XFS;
openSUSE Leap / Tumbleweed、Fedora Server 大力推荐 Btrfs + Snapper;
容器 & 云原生环境越来越多使用 overlayfs + 下层 ext4/XFS。
选型核心 6 大维度(灵魂拷问):
I/O 模式:小文件随机读写?大文件顺序读写?还是混合?
容量与扩展性:单分区 >10TB?是否需要在线扩容?
数据安全与恢复:是否需要原生快照?CoW(写时复制)特性?
性能与碎片化:SSD/HDD 混合环境?高并发日志写入?
运维复杂度:团队熟悉程度、工具链成熟度;
稳定性与社区支持:生产事故历史、内核版本兼容性。
快速对比如下:
| 维度 | ext4 | XFS | Btrfs | ZFS (OpenZFS) |
| 成熟度 | ★★★★★(最成熟) | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| 大文件性能 | 优秀 | ★★★★★(最佳) | 良好 | 优秀 |
| 小文件性能 | 良好 | 优秀 | ★★★★★(CoW 优势) | 优秀 |
| 快照支持 | 无(靠 LVM) | 无(靠 LVM) | 原生子卷快照(最佳) | 原生(最强) |
| 最大单卷大小 | 1EB | 500PB+ | 16EB | 256ZB |
| 碎片化倾向 | 中 | 低 | 中高(长期使用需 defrag) | 低 |
| 压缩/去重 | 无原生 | 无 | 原生支持 | 原生(最强) |
| 生产推荐场景 | 根分区、通用服务器 | 数据库、大文件存储 | 开发测试、需要回滚场景 | 高端存储服务器 |
| 运维难度 | 最低 | 低 | 中 | 高 |
2). ext4 原生选择
ext4 是 ext3 的进化版,2008 年进入主线内核,如今仍是大多数生产环境的“默认选择”。
核心特性:
日志模式(journal):保证一致性;
Extent 块分配:减少碎片,提升大文件顺序读写;
延迟分配 + 多块分配器:提升小文件写入性能;
最大文件大小 16TB,单分区 1EB;
支持 64 位 inode(默认)。
生产优势:
工具链最完善:tune2fs、e2fsck、resize2fs 成熟稳定;
兼容性极高,几乎所有备份、监控工具都优先支持;
SSD 优化好:discard(TRIM)支持优秀。
性能基准参考(基于 fio 测试,SSD 环境,2025年的测量数据):
顺序读写:约 2.8-3.2 GB/s;
随机 4K 读写:优秀,尤其元数据操作快;
小文件创建(10万文件):比 XFS 略胜。
格式化与调优命令模板(生产推荐):
# 推荐参数(SSD)
mkfs.ext4 -F -L data -m 1 -i 16384 -O extents,uninit_bg,dir_index,has_journal /dev/nvme1n1p1
# 挂载选项(/etc/fstab)
UUID=xxx /data ext4 defaults,noatime,nodiratime,discard,barrier=1,data=ordered 0 2
tune2fs 常用调优:
tune2fs -o journal_data_ordered /dev/sda1 # 日志模式
tune2fs -c 30 -i 30d /dev/sda1 # 强制 fsck 间隔
tune2fs -m 1 /dev/sda1 # 预留块降至 1%
适用场景:
操作系统根分区(/);
/etc、/boot 等小容量分区;
中小型 Web 应用、通用业务服务器;
对稳定性要求极高、不想折腾的场景。
局限性:无原生快照、大卷扩展需 offline 或 LVM 辅助、去重/压缩需用户态工具。
3). XFS 高性能大文件必备
XFS 起源于 SGI IRIX,2001 年进入 Linux,主打高吞吐、大文件、高度并行。Rocky Linux / CentOS Stream 默认使用它。
核心特性:
基于 B+ 树管理 inode 和目录;
Allocation Groups(AG)实现并行分配;
实时子卷(realtime subvolume)支持极致性能;
日志与元数据分离优化。
生产亮点:
大文件顺序读写性能领先;
碎片化控制优秀(xfs_fsr 在线碎片整理);
支持 reflink(轻量级 copy-on-write 克隆,类似 cp --reflink)。
格式化推荐:
mkfs.xfs -f -L data -i size=512 -m crc=1,reflink=1 /dev/nvme1n1p1
挂载选项:
UUID=xxx /data xfs defaults,noatime,nodiratime,discard,allocsize=4m 0 2
常用运维命令:
xfs_info /data # 查看详细信息
xfs_growfs /data # 在线扩展
xfs_fsr /data # 碎片整理
xfs_admin -U uuid /dev/xxx # 修改 UUID
适用场景:
MySQL / PostgreSQL / MongoDB 数据目录(尤其是大表、WAL 日志);
视频/图像/备份存储;
日志密集型服务(如 ELK、Kafka);
10TB+ 大容量分区。
真实案例:某电商公司将 /var/lib/mysql 从 ext4 迁移到 XFS 后,慢查询减少 40%,高峰期 IOPS 提升 65%。
4). Btrfs 现代特性
Btrfs(B-tree FS)由 Oracle 主导开发,采用写时复制(CoW)架构,是目前特性最丰富的开源文件系统。
核心杀手级特性:
原生子卷(subvolume)与快照(snapshot);
在线压缩(zstd、lzo)、去重;
RAID0/1/5/6/10 支持(无需 mdadm);
Send/Receive 增量传输(完美异地备份);
透明加密、配额。
现状:内核 6.8+ 对 Btrfs 稳定性大幅提升,碎片化问题通过 btrfs filesystem defragment 得到缓解。openSUSE MicroOS、Fedora Atomic 等已默认使用。
格式化与子卷实战:
mkfs.btrfs -f -L data --checksum crc32c /dev/nvme1n1p1
mount /dev/nvme1n1p1 /data
btrfs subvolume create /data/@data
btrfs subvolume create /data/@snapshots
常用运维命令:
btrfs filesystem df /data # 详细空间使用
btrfs filesystem usage /data
btrfs subvolume snapshot -r /data/@data /data/@snapshots/snap_$(date +%F)
btrfs send /data/@snapshots/snap_xxx | btrfs receive /backup/
btrfs balance start -dusage=80 /data # 平衡数据块
btrfs scrub start /data # 数据校验修复
挂载选项:
compress=zstd:3,noatime,space_cache=v2,autodefrag
适用场景:
需要频繁回滚的开发/测试/ CI 环境;
家庭 NAS、私有云存储;
Docker / Kubernetes 本地持久卷(配合 subvolume);
追求特性丰富的团队。
注意风险:长期高负载下碎片化较严重,修复工具 btrfs check --repair 使用需谨慎。生产大集群仍建议结合 LVM 或硬件 RAID 使用。
5). ZFS 与其他文件系统简要对比
OpenZFS:特性最强(RAID-Z、dRAID、原生去重、快照、加密),但内存消耗大(ARC 缓存)、许可争议。适合专用存储服务器,不推荐作为根文件系统。
F2FS:专为 NAND Flash 设计,手机/嵌入式常用,服务器极少使用。
overlayfs:容器时代必备,上层可写、下层只读,Kubernetes PV 常用。
6). 生产选型决策
根分区 (/) → 优先 ext4(最稳)。
数据库、大文件存储 → XFS。
需要快照、回滚、压缩 → Btrfs(搭配 Snapper 或 Timeshift)。
超大规模存储 (>50TB) → XFS + LVM 或 OpenZFS。
高安全合规 → 结合 LUKS 加密 + 选型以上任意。
迁移建议:
rsync + --inplace 或 LVM 快照 + dd;
生产迁移必须灰度 + 回滚计划。
7). 生产事故复盘
事故1:某金融公司使用 Btrfs 未开启 autodefrag,高负载运行六个月后碎片化导致数据库写入延迟从 2ms 飙升到 120ms,最终切换回 XFS。
事故2:ext4 分区未设置 discard,SSD 使用十八个月后性能衰退 50%。
事故3:XFS 大卷手动扩展时未用 xfs_growfs,导致空间不可用。