Linux日志文件系统
 1991年,芬兰赫尔辛基大学的学生林纳斯·托瓦兹(Linus Torvalds)开始编写一个新的操作系统内核,这个内核最初被称为“Freax”。他的初衷只是想学习操作系统内核的开发,并为自己的个人计算机编写一个操作系统。然而,当他将这个内核发布在Internet上并开放源代码后,全球各地的程序员开始参与到这个项目中来,共同完善这个内核。最终,这个内核被命名为Linux,这个名字是由Linus Torvalds的名字和Unix操作系统的名字组合而成的。
1991年,芬兰赫尔辛基大学的学生林纳斯·托瓦兹(Linus Torvalds)开始编写一个新的操作系统内核,这个内核最初被称为“Freax”。他的初衷只是想学习操作系统内核的开发,并为自己的个人计算机编写一个操作系统。然而,当他将这个内核发布在Internet上并开放源代码后,全球各地的程序员开始参与到这个项目中来,共同完善这个内核。最终,这个内核被命名为Linux,这个名字是由Linus Torvalds的名字和Unix操作系统的名字组合而成的。
Linux从一开始就坚持源代码的公开和免费使用,任何人都可以对其进行修改和分发。这种开放性和自由性吸引了大量的开发者和用户,使得Linux逐渐成长并成熟起来。如今,Linux已经发展成为一个性能稳定、功能强大的多用户网络操作系统,支持32位和64位硬件,能运行主要的Unix工具软件、应用程序和网络协议。同时,Linux也有上百种不同的发行版,如基于社区开发的Debian、ArchLinux,以及基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。
Linux文件系统
1、磁盘的组成

盘片(Platters):通常是由金属或玻璃制成的圆盘,硬盘上通常有多个盘片叠放在一起。数据存储在盘片的表面上,通过磁性材料进行记录和读取。
磁头(Read/Write Heads):位于硬盘的读写头部,负责在盘片表面上读取和写入数据。每个盘片上都有一个读写头,它们可以在盘片上移动以访问不同的磁道。
磁道(Tracks):盘片的表面被划分为多个同心圆,称为磁道。每个磁道上都存储着一定数量的数据。
扇区(Sectors):每个磁道被划分为多个扇区,是硬盘上最小的可寻址单元。通常,一个扇区的大小为512字节或4KB。
主轴电机(Spindle Motor):用于旋转盘片的电机,控制盘片的旋转速度。
控制电路板(Controller Board):负责控制硬盘的各个部分,包括读写头的移动、数据的读写等。
磁盘分区表格式
磁盘分区表是一种数据结构,用于描述硬盘上的分区信息。
常见的磁盘分区表格式有两种:
1.MBR(Master Boot Record):MBR是传统的磁盘分区表格式,它位于硬盘的第一个扇区(扇区0),通常为512字节大小。MBR分区表最多支持4个主分区,或者3个主分区和1个扩展分区,每个主分区或扩展分区最多可以有2.2TB的容量限制。由于容量限制和其他限制,MBR分区表在现代计算机中已经逐渐被UEFI和GPT取代。
2.GPT(GUID Partition Table):GPT是一种更先进的磁盘分区表格式,它使用全局唯一标识符(GUID)来标识分区和磁盘。GPT分区表支持更大的磁盘容量(超过2TB),并且允许最多128个分区。除了提供更大的容量和更多的分区之外,GPT还提供了数据完整性校验和磁盘备份表等功能,使其在现代计算机系统中更为常见。
选择使用MBR还是GPT分区表格式取决于硬件要求、操作系统支持和数据需求。对于大容量硬盘和新型计算机系统,通常建议使用GPT分区表格式以获取更好的性能和可靠性。
Linux文件系统格式
Linux操作系统支持多种文件系统格式,每种格式都有其特定的用途和优势。以下是一些常见的Linux文件系统格式:
ext4:ext4是Linux中最常用的文件系统之一,它是ext文件系统的进化版本。ext4提供了更快的文件系统检查和更好的性能,支持更大的文件和分区大小。它是许多Linux发行版的默认文件系统。
XFS:XFS是一种高性能的日志文件系统,适用于大容量存储和大文件。它具有快速的读写速度、高效的空间管理和稳定的性能,在处理大文件和大型数据集时效果显著。
Btrfs:Btrfs是一种先进的复制文件系统,具有快速的快照、数据压缩、数据校验和数据恢复等功能。它支持在线扩展和压缩,以及快速的检查和修复功能。
ZFS:ZFS是一种先进的文件系统和卷管理器,最初由Sun Microsystems开发,现在在许多Linux发行版中可用。ZFS具有强大的数据完整性检查和修复功能,支持快照、压缩和加密等高级功能。
ext3:ext3是ext文件系统的一个稳定版本,它与ext4兼容,并提供了可靠的文件系统和数据保护。尽管已经被ext4取代,但在一些较老的系统上仍然广泛使用。
F2FS:F2FS(Flash-Friendly File System)是专门为闪存设备设计的文件系统,具有优化的读写性能和存储寿命管理。它适用于嵌入式设备和闪存存储介质。
选择合适的文件系统取决于系统的需求、硬件配置和预期的性能和功能。通常建议根据具体的用途和环境选择最合适的文件系统。
文件系统类型 文件系统说明
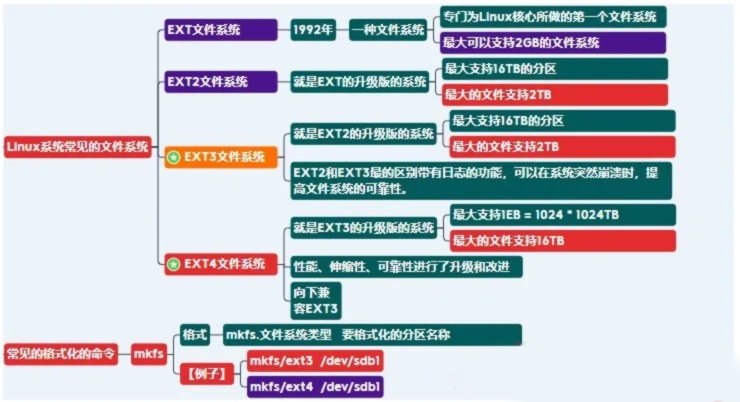
Ext 第一个专门针对liunx的文件系统
Ext2 为解决ext文件系统缺陷设计的高性能、可扩展的文件系统
Ext3 日志文件系统,ext2的升级版
Ext4 Ext4提供了更为可靠性的功能
swap Linux的交换分区
NFS 网络文件系统
smb 支持samba协议的网络文件系统
vfat 与windows系统兼容的linux文件系统
ntfs WinNT所采用的独特的文件系统结构
proc Unix/Linux操作系统中的一种基于内存的伪文件系统
xfs 由SGI开发的一个全64位、快速、安全的日志文件系统
众所周知,文件系统是操作系统最为重要的一部分,每种操作系统都有自己的文件系统,文件系统直接影响着操作系统的稳定性和可靠性。Linux下的文件系统通常有两种,即日志文件系统和非日志文件系统,以下简单介绍两类文件系统。
一、 非日志文件系统
非日志文件系统在工作时,不对文件系统的更改进行日志记录。文件系统通过为文件分配文件块的方式把数据存储在磁盘上。每个文件在磁盘上都会占用一个以上的磁盘扇区,文件系统的工作就是维护文件在磁盘上的存放,记录文件占用了哪几个扇区。另外扇区的使用情况也要记录在磁盘上。文件系统在读写文件时,首先找到文件使用的扇区号,然后从中读出文件内容。如果要写文件,文件系统首先找到可用扇区,进行数据追加。同时更新文件扇区使用信息。不同的文件系统用不同的方法分配和读取文件块。例如,dos/windows 就使用fat文件系统,而windows NT则采用NTFS文件系统。
非日志文件系统能够工作得很稳定,但是,它存在不少问题。各位请看,对于一个普通的日志文件系统,如Ext2文件系统,如果系统刚将文件的磁盘分区占用信息(meta-data)写入到磁盘分区中,还没有来得及将文件内容写入磁盘,这时意外发生了:系统断电了,结果会造成:文件的内容仍然是老内容,而meta-data信息是新内容,二者不一致了。
让我们再看一下Linux系统中fsck是如何工作的:通常情况下,当 Linux 系统启动时,首先运行fsck,由它扫描/etc/fstab 文件中列出的所有本地文件系统。fsck 的工作就是确保要装载的文件系统的元数据是处于可使用的状态。当系统关闭时,fsck又把所有的缓冲区数据转送到磁盘,并确保文件系统被彻底卸载,以保证系统下次启动时能够正常使用。
然而意想不到掉电或者其它故障会导致系统死机、重启。出现这种情况时,操作系统来不及卸载文件系统。重启后,fsck对磁盘进行彻底扫描,全面地检查元数据,竭尽全能修正检查过程中能找到的所有错误。对所有的元数据做彻底的一致性检查极其耗时。文件系统越大,完成彻底的扫描时间就越长。Fsck也会碰到它无法修复的磁盘错误。碰到这种情况,就是简单地将文件删除或另存为一个文件。在高密度访问的数据中心,fsck可能会造成极大的数据文件破坏。只有当fsck 完成扫描、检查与修复工作后,Linux系统才能开始使用。当然,如果有严重的文件或数据丢失的话,系统很可能无法重新启动了!
非日志文件系统的种类:Linux可以支持种类繁多的文件系统,几乎所有的Linux发行版都用ext2作为默认的文件系统。Ext2文件系统就是一个非日志文件系统。此外,Linux支持的其它非日志文件系统还有:FAT、VFAT、HPFS(OS/2)、NTFS(Windows NT)、Sun的UFS等。
二、 日志式文件系统
日志文件系统则是在非日志文件系统的基础上,加入了文件系统更改的日志记录。日志文件的设计思想是:跟踪记录文件系统的变化,并将变化内容记录入日志。日志式文件系统的思想来自于大型数据库系统。数据库操作由多个相关的、相互依赖的子操作组成,任何一个子操作的失败都意味着整个操作的无效性,所以,对数据的任何修改都要求回复到操作以前的状态。日志式文件系统采用了类似的技术。
日志文件系统在磁盘分区中保存有日志记录,写操作首先是对记录文件进行操作,若整个写操作由于某种原因(如系统掉电)而中断,系统重启时,会根据日志记录来恢复中断前的写操作。这个过程只需要几秒钟到几分钟。
日志文件系统是如何工作的?
在日志文件系统中,所有的文件系统的变化、添加和改变都被记录到“日志”(即记录文件metadata信息的数据)中。每隔一定时间,文件系统会将更新后的文件metadata及文件内容写入磁盘,之后删除这部分日志。重新开始新日志记录。
在对元数据做任何改变以前,文件系统驱动程序会向日志中写入一个条目,这个条目描述了它将要做些什么。然后,它继续并修改元数据。通过这种方法,日志文件系统就拥有了近期元数据被修改的历史记录,当检查到没有彻底卸载的文件系统的一致性问题时,只要根据数据的修改历史进行相应的检查即可了。也即日志文件系统除了存储数据和元数据(metadata)以外,它们还保存有一个日志,我们可以称之为元元数据(关于元数据的元数据)。
日志文件系统使得数据、文件变安全了,但是系统开销加大了。每一次更新和大多数的日志操作都需要写同步,这需要更多的磁盘I/O操作。从日志文件的原理出发,将那些需要经常写操作的分区上使用日志文件系统是一个好的主意。
Linux系统中可以混合使用日志文件系统或非日志文件系统。日志增加了文件操作的时间,但是,从文件安全性角度出发,磁盘文件的安全性得到了重大的提高。笔者对日志文件系统进行了测试,日志文件系统的性能并不比ext2文件系统有太大的性能损失,有的日志文件系统由于采用B+树算法,在操作一些大尺寸的文件时,性能反面比非日志文件系统的性能还要好。
使用日志文件系统有什么好处?
文件的安全提高了,文件被破坏的机率降低了,对磁盘的扫描时间缩短了,扫描次数减少了。当系统意外宕机后,不会再有文件内容的丢失,至少文件应该保持上一个版本的内容;采用日志文件系统,通常系统每重新启动20-30次后,才会对磁盘进行一次整体扫描,扫描次数减少了。
Linux操作系统下的日志文件系统:
XFS文件系统(SGI的xfs)
JFS文件系统(IBM的jfs)
Reiserfs文件系统
EXT3文件系统
GFS文件系统
Linux日志文件系统面面观
文件系统是用来管理和组织保存在磁盘驱动器上的数据的系统软件,其实现了数据完整性的保证,也就是保证写入磁盘的数据和随后读出的内容的一致性。除了保存以文件方式存储的数据以外,一个文件系统同样存储和管理关于文件和文件系统自身的一些重要信息(例如:日期时间、属主、访问权限、文件大小和存储位置等等)。这些信息通常被称为元数据(metadata)。
由于为了避免磁盘访问瓶颈效应,一般文件系统大都以异步方式工作,因此如果磁盘操作被突然中断可能导致数据被丢失。例如如果出现这种情况:如果当你处理一个在linux的ext2文件系统上的文档,突然机器崩溃会出现什么情况?有这几种可能:
当你保存文件以后,系统崩溃。这是最好的情况,你不会丢失任何信息。只需要重新启动计算机然后继续工作。
在你保存文件之前系统崩溃。你会丢失你所有的工作内容,但是老版本的文档还会存在。
当正在将保存的文档写入磁盘时系统崩溃。这是最糟的情况:新版文件覆盖了旧版本的文件。这样磁盘上只剩下一个部分新部分旧的文件。如果文件是二进制文件那么就会出现不能打开文件的情况,因为其文件格式和应用所期待的不同。
在最后这种情况下,如果系统崩溃是发生在驱动器正在写入元数据时,那么情况可能更糟。这时候就是文件系统发生了损坏,你可能会丢失整个目录或者整个磁盘分区的数据。
linux标准文件系统(ext2fs)在重新启动时会通过调用文件扫描工具fsck试图恢复损坏的元数据信息。由于ext2文件系统保存有冗余的关键元数据信息的备份,因此一般来说不大可能出现数据完全丢失。系统会计算出被损坏的数据的位置,然后或者是通过恢复冗余的元数据信息,或者是直接删除被损坏或是元数据信息损毁的文件。
很明显,要检测的文件系统越大,检测过程费时就越长。对于有几十个G大小的分区,可能会花费很长时间来进行检测。由于Linux开始用于大型服务器中越来越重要的应用,因此就越来越不能容忍长时间的当机时间。这就需要更复杂和精巧的文件系统来替代ext2。因此就出现了日志式文件系统(journalling filesystems)来满足这样的需求。
什么是日志式文件系统
这里仅仅对日志式文件系统进行简单的说明,如果需要更深入的信息请参考文章日志式文件系统,或者是日志式文件系统介绍。
大多数现代文件系统都使用了来自于数据库系统中为了提高崩溃恢复能力而开发的日志技术。磁盘事务在被真正写入到磁盘的最终位置以前首先按照顺序方式写入磁盘中日志区(或是log区)的特定位置。
根据日志文件系统实现技术的不同,写入日志区的信息是不完全一样的。某些实现技术仅仅写文件系统元数据,而其他则会记录所有的写操作到日志中。
现在,如果崩溃发生在日志内容被写入之前发生,那么原始数据仍然在磁盘上,丢失的仅仅是最新的更新内容。如果当崩溃发生在真正的写操作时(也就是日志内容已经更新),日志文件系统的日志内容则会显示进行了哪些操作。因此当系统重启时,它能轻易根据日志内容,很快地恢复被破坏的更新。
在任何一种情况下,都会得到完整的数据,不会出现损坏的分区的情况。由于恢复过程根据日志进行,因此整个过程会非常快只需要几秒钟时间。应该注意的是使用日志文件系统并不意味着完全不需要使用文件扫描工具fsck了。随机发生的文件系统的硬件和软件错误是根据日志是无法恢复的,必须借助于fsck工具。
目前Linux环境下的日志文件系统
在下面的内容里将讨论三种日志文件系统:第一种是ext3,由Linux内核Stephen Tweedie开发。ext3是通过向ext2文件系统上添加日志功能来实现的,是自redhat7.2的默认文件系统;Namesys开发的 ReiserFs日志式文件系统,可以从www.namesys.com下载,目前Mandrake8.1采用该日志式文件系统。SGI在2001年3月发布了XFS日志式文件系统。可以在 oss.sgi.com/projects/xfs/下载。下面将对这三种日志文件系统采用不同的工具进行检测和性能测试。
Linux各种文件系统(ext3,ReiserFS,jfs,xfs)的性能
现在还可以得到的许多Linux filesystems比较,但是他们中大多数是古老的,基于为人任务的或者在更老的情况下完成。这篇基准测试文基于与老一代的适合一台文件服务器的11项硬件(奔腾II/III,EIDE硬盘)。从最初编制到出版,文章已经产生许多变化,意见和建议改进。我目前正努力进行一些新的试验(回答在原文范围的问题)。
为什么要做基准测试?
我发现quantitative and reproductible benchmark基准使用2.6.x kernel。Benoit在2003年在有512 MB RAM 的PIII 500服务器上使用大文件(1 + GB)实现12次试验。 这次试验信息十分丰富,但是结果对2.6.x kernel开始。
Piszcz 在2006年实现21项任务(有768 MB RAM 和一个400GBEIDE-133硬盘在PIII-500 模拟多种文件操作)。到目前为止,这测试看起来是在2.6.x kernel上的最全面的工作。但是,很多任务是人造的(例如,复制和删除10,000个空目录,新建10,000个文件,递归分割文件),把这些结论应用到现实世界可能是无意义的。因此,这里测试的基准的目标是验证一些Piszcz(2006)的结论,通过专门应用于现实世界在小型企业文件服务器(看见任务描述)里找到。
测试基础
* Hardware Processor : Intel Celeron 533
* RAM : 512MB RAM PC100
* Motherboard : ASUS P2B
* Hard drive : WD Caviar SE 160GB (EIDE 100, 7200 RPM, 8MB Cache)
* Controller : ATA/133 PCI (Silicon Image)
* OS Debian Etch (kernel 2.6.15), distribution upgraded on April 18, 2006
* All optional daemons killed (cron,ssh,saMBa,etc.)
* Filesystems Ext3 (e2fsprogs 1.38)
* ReiserFS (reiserfsprogs 1.3.6.19)
* JFS (jfsutils 1.1.8)
* XFS (xfsprogs 2.7.14)
选择的测试任务描述
*在一个大文件(ISO 镜像文件,700 MB)的从第2个磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个 ISO 一次
*删除这个ISO 的两个副本
*操作一文件树(有7500 文件,900 目录,1.9GB),从第2 磁盘复制到这个试验磁盘
*再从在另一个位置再复制这个文件树一次
*删除这个文件树的两个副本
*用递归的方法遍历文件树目录和文件树的全部内容,复制到这个试验磁盘
*匹配通配符,在文件树查找具体的文件
*用(mkfs) 建立filesystem(全部FS都使用默认值)
*mount filesystem
*Umount filesystem
上述11项任务(从建立filesystem到umounting filesystem)的顺序,编写为Bash script运行完成3 次(报告平均成绩)。每个顺序花费大约7分种,完成任务的时间用秒计算, GNU time utility (version 1.7) 记录任务时的CPU 的利用百分比。
结果
分区能力
(在filesystem 创造之后)初始化分区并重新划分block的过程里,Ext3有最差的初始利用率(92.77%), 其它的filesystem 几乎可是使用全部的容量(ReiserFS = 99.83%,JFS = 99.82%,XFS = 99.95%)。
结论: 为了使用你的分区的的最大容量,选择ReiserFS,JFS或者XFS。
建立文件系统,mount和unmounting在20GB的分区创造filesystem测试,划分为Ext3带14.7秒, 与为相比其他filesystem多2秒或更少。(ReiserFS = 2.2,JFS = 1.3,XFS = 0.7)。
不过,挂载ReiserFS 要比其他的FS多花费5-15倍时间(2.3秒)(Ext3 = 0.2, JFS = 0.2, XFS = 0.5),umount以及要比其他的FS多花费2 倍时间(0.4秒)。
所有的FS都花费差不多CPU占用来创建FS(59%(ReiserFS) -74%(JFS)),挂载FS(在6和9%之间)。 不过,Ext3 和XFS多用2倍的CPU占用给umount(37% 和45%), ReiserFS和JFS(14% 和27%)。
结论: 对创建FS性能和mounting/unmounting来说,选择JFS或者XFS。
大文件操作性能(ISO image,700 MB)
把大文件复制到Ext3(38.2秒)和ReiserFS(41.8),要比JFS和XFS(35.1和34.8)需要更多时间。使用XFS有助于提高在相同的磁盘上复制相同的文件(XFS=33.1,Ext3 = 37.3,JFS = 39.4,ReiserFS = 43.9)相比。 在JFS和XFS上删除那些ISO 大约要快100 倍(0.02秒),(ReiserFS1.5秒,Ext32.5秒)!所有FS复制时的CPU利用(在46和51%之间),再复制时(在38%到50%之间)。当其他FS使用大约10%时,ReiserFS使用49%的CPU。 比他FS大约少5到10%),JFS使用较少的CPU。
结论: 对大文件操作性能来说,最好选择JFS或者XFS。 如果你需要使CPU利用减到最小,更推荐JFS。
目录树(7500个文件,900份目录,1.9GB)的操作
最初复制目录树时,Ext3(158.3秒)和XFS(166.1秒)更迅速,ReiserFS和JFS(172.1和180.1)。在第二次复制的时候有相似的结果。(Ext3=120秒,XFS = 135.2,ReiserFS = 136.9 和JFS = 151)。但是,移动目录树时Ext3(22秒)相比ReiserFS(8.2秒,XFS(10.5秒)和JFS(12.5秒))大约多2倍时间!所有FS在复制和再复制目录树时都使用较多的CPU (复制在27和36%之间),(再复制在29%-JFS和45%-ReiserFS之间)。
令人吃惊,ReiserFS 和XFS使用更多的CPU 删除目录树(86% 和65%),而其他FS只使用大约15%的(Ext3和JFS)。再次,与任何其他FS相比较,JFS的明显使用较少CPU。当有较多的数量较小页面时适合ReiserFS。这个差别在目录树的再复制和移动里的ReiserFS将有更高的速度。
结论:对在大容量的目录树操作来说,选择Ext3或者XFS。来自其他作者的基准测试已经证明如果使用ReiserFS,对大量的小文件更为合适。但是,目前包括各种各样尺寸(10KB在5 MB)数千文件的目录树操作上,建议使用Ext3或者XFS可能获得更好的性能。如果JFS的CPU占用减到最小,这种FS带着相当高的性能。
目录列表和文件查找
递归显示目录的目录列表,ReiserFS(1.4秒)和XFS更迅速的1.8), Ext3和JFS(2.5和3.1)。文件查找有着相同的结果。在文件查找项目,ReiserFS(0.8秒)相比XFS(2.8)和Ext3(4.6秒)和JFS(5秒)更迅速。Ext3和JFS有更好CPU占用:目录列表(35%),文件查找(6%)。 XFS目录列表(70%)使用更多的CPU,文件查找(10%)。 ReiserFS看起来是占用CPU最多的FS,目录列表71%,文件查找36% 。
结论: 结果表明那, 对于这些CPU占用任务来说,(ext3和JFS)filesystems 能更少的使用CPU的。XFS作为好备选,带有相对适中的性能和CPU的占用。
结论
这些结果从Piszcz(2006)关于分解的Ext3,ReiserFS的磁盘能力报告一样。这两篇文章两篇已经显示JFS是最低的CPU利用的FS。最后,这份报告看起来没有显示出ReiserFS的high page faults activity。
由于一个分区只能有一个filesystem,认识每种filesystem的优缺点很重要。如果,以这篇文章的全部测试为基准,XFS看起来是家庭或者小型企业最适合的应用于文件服务器的filesystem:
*它使用你的服务器硬盘(s)的拥有最大的容量
*创建FS,mount和unmount很迅速
*操作大文件最迅速的FS(>500 MB)
*这FS得第二名地方给经营关于许多在适度尺寸文件和目录小
*在CPU占用和目录列表或者文件搜寻性能之间比较平衡,
*没有最小CPU要求,老一代硬件也可十分接受
Piszcz(2006)当时没有明确推荐XFS,他只是说:"就个人来说,我仍然愿意选择同时具备性能和可伸缩性的XFS"。 现在我只能支持这个结论。
参考
贝努瓦,M.(2003)。 Linux 文件系统基准。
Piszcz,J.(2006)。 基准问题测试Filesystems第二部分。 Linux Gazette, 122 (January 2006)。
ext4 文件系统重要的概念
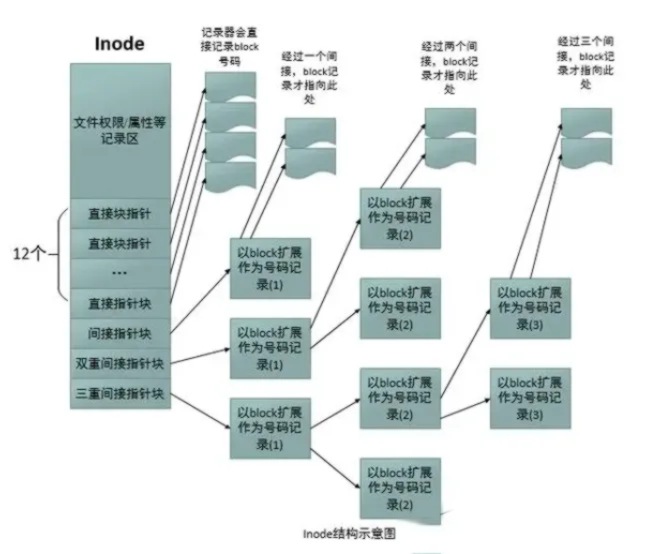
inode(索引节点):inode 是文件系统中的一个数据结构,用于存储文件或目录的元数据信息,如文件类型、权限、拥有者、大小、时间戳等。每个文件或目录都有一个对应的 inode 来描述其属性和位置。
数据区块:数据区块是用于存储文件内容的实际数据块。当文件被创建或修改时,其内容被存储在数据区块中。ext4 文件系统将文件内容分散存储在多个数据块中,以提高文件系统的效率和性能。
超级块:超级块是 ext4 文件系统的关键数据结构之一,它存储了文件系统的元数据信息,如文件系统的大小、inode 数量、数据块数量、挂载选项等。每个文件系统只有一个超级块,位于文件系统的开头位置。
块组(Block Group):块组是 ext4 文件系统的逻辑单元,用于组织和管理文件系统中的数据。每个块组包含一组连续的数据块、inode 和位图等。块组有助于提高文件系统的性能和可管理性。
位图:位图是用于跟踪数据块和 inode 的使用情况的数据结构。每个块组都有自己的位图,用于标记已分配和未分配的数据块和 inode。
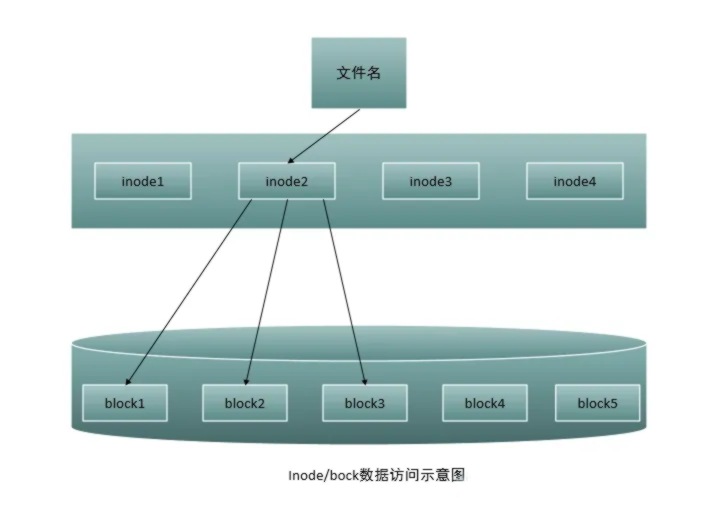
数据的存储
1、目录与文件在文件系统当中如何记录数据
在 Linux 文件系统中,目录和文件都是通过索引节点(inode)来记录和管理的。每个文件和目录都有一个对应的 inode 来描述其属性和位置。当文件系统被创建时,会分配一块区域用于存储 inode,每个 inode 记录了文件或目录的元数据信息,如文件类型、权限、拥有者、大小、时间戳等,以及指向文件数据块的指针。
对于文件来说,inode 中存储了文件的元数据信息以及指向文件数据块的指针。文件数据块则用于存储文件的实际内容。
对于目录来说,inode 中存储了目录的元数据信息,如目录的权限和拥有者等,并包含了一个目录项列表,每个目录项对应一个子文件或子目录的名字和对应的 inode 号。这样的设计实现了目录与文件之间的映射关系。
当用户在文件系统中创建、修改或删除文件和目录时,实际上是在 inode 中进行操作,修改相应的元数据信息或者更新指向数据块的指针。文件系统会根据 inode 中的信息来读取或写入文件的内容,并根据目录项列表来管理目录结构和文件的索引关系。
总的来说,Linux 文件系统通过 inode 来记录和管理文件和目录的元数据信息,并通过指向数据块的指针来存储和访问文件的实际内容,从而实现了文件系统的组织和管理。
2、挂载点(mount point)
在计算机领域,挂载点(mount point)是指将文件系统连接到文件系统树中的特定位置,使得该文件系统中的内容可以在该位置访问。当文件系统被挂载到一个挂载点上时,该挂载点就成为了该文件系统的访问入口。
在 Linux 和类 Unix 系统中,挂载点通常是一个目录,可以通过 mount 命令将文件系统挂载到指定的目录上。例如:
mount /dev/sdb1 /mnt
上述命令将 /dev/sdb1 设备上的文件系统挂载到 /mnt 目录上,这样就可以通过 /mnt 访问该文件系统中的内容。
挂载点的作用:
扩展文件系统空间:通过将新的文件系统挂载到现有目录下,可以扩展该目录下的文件存储空间。
分离文件系统:将不同用途的文件系统挂载到不同的目录下,可以对文件进行分组和管理,提高文件系统的组织性和可管理性。
网络文件共享:通过将远程服务器上的文件系统挂载到本地目录下,可以实现网络文件共享和访问。
安装新设备:将新设备(如磁盘、光驱等)上的文件系统挂载到系统中,使得系统可以识别和使用该设备上的内容。
挂载点在操作系统中扮演着重要的角色,是文件系统管理和访问的核心概念之一。
XFS文件系统简介
XFS(X File System)是一个高性能、高可靠性的日志文件系统,旨在提供对大型存储设备的高效管理。它采用了许多先进的技术,如延迟分配、日志化结构等,以提供出色的读写性能。同时,XFS使用了元数据日志来保证文件系统的一致性和可靠性,避免数据损坏和文件系统崩溃问题。
XFS文件系统具有快速恢复机制,可以在文件系统错误或意外断电后更快地进行修复和恢复。此外,它还支持诸如快照、在线扩容、透明压缩等高级特性,提供了更灵活和强大的功能。其特别适合用于大型存储设备的管理,例如存储服务器、文件共享服务器等。同时,它也适用于对文件和目录的权限和安全性要求较高的应用场景,如数据库服务器、Web服务器等。XFS文件系统能够满足需要高性能和稳定性的应用需求,例如高负载的应用服务器、高并发的应用程序等。
XFS(eXtended File System)最初由SGI(Silicon Graphics, Inc.)开发,旨在用于 UNIX 类操作系统。它具有以下特点:
高性能: XFS设计用于高性能工作负载,能够处理大型文件和大容量文件系统。
大容量支持: XFS支持非常大的文件系统和文件,最大文件系统大小和最大文件大小都非常高。
日志功能: XFS使用日志来跟踪文件系统的更改,这使得在意外断电或系统崩溃时可以更快速地恢复文件系统的一致性。
高并发性: XFS支持高并发访问,可以有效地处理多个并发读写请求。
灵活性: XFS提供了灵活的配置选项,可以根据不同的应用场景进行调整和优化。
ext4与xfs
ext4和XFS它们各自具有一些特点和优势,适用于不同的使用场景。
ext4(Fourth Extended File System):
成熟稳定:ext4是Linux中最常见的文件系统之一,它是ext3文件系统的改进版本,因此在Linux系统中被广泛使用。
向下兼容:ext4保留了ext3的许多特性,并提供了更高的性能和更大的文件系统支持。
易于维护:ext4提供了较好的稳定性和易于维护的特性,适合用于标准的桌面和服务器环境。
XFS(eXtended File System):
高性能:XFS专为高性能工作负载而设计,能够处理大型文件和大容量文件系统,适用于需要高并发和高吞吐量的场景。
日志功能:XFS使用日志功能来跟踪文件系统的更改,提高了系统的稳定性和恢复能力。
大容量支持:XFS支持非常大的文件系统和文件,适合用于大型服务器和存储环境。
选择使用ext4还是XFS取决于具体的需求和应用场景。一般来说,在标准的桌面和服务器环境中,ext4是一个不错的选择,而在需要处理大型文件和高性能工作负载的情况下,XFS可能更适合。