ext2文件系统
 赵蔚
赵蔚2002年6月1日
本文主要讲述 Linux 上比较流行的 ext2 文件系统在硬盘分区上的详细布局情况。ext2 文件系统加上日志支持的下一个版本是 ext3文件系统,它和 ext2 文件系统在硬盘布局上是一样的,其差别仅仅是 ext3 文件系统在硬盘上多出了一个特殊的inode(可以理解为一个特殊文件),用来记录文件系统的日志,也即所谓的 journal。由于本文并不讨论日志文件,所以本文的内容对于 ext2 和 ext3 都是适用的。
前言
本文的资料来源是 Linux 内核中 ext3 文件系统的源代码。为了便于读者查阅源代码,本文中一些关键的技术词汇都使用了内核源代码中所使用的英语单词,而没有使用相应的中文翻译(这种方法是否恰当,还请读者朋友们指教)。
对于 ext2 文件系统来说,硬盘分区首先被划分为一个个的 block,一个 ext2 文件系统上的每个 block 都是一样大小的,但是对于不同的 ext2 文件系统,block 的大小可以有区别。典型的 block 大小是 1024 bytes 或者4096 bytes。这个大小在创建 ext2文件系统的时候被决定,它可以由系统管理员指定,也可以由文件系统的创建程序根据硬盘分区的大小,自动选择一个较合理的值。这些 blocks被聚在一起分成几个大的 block group。每个 block group 中有多少个 block 是固定的。
每个 block group 都相对应一个 group descriptor,这些 group descriptor被聚在一起放在硬盘分区的开头部分,跟在 super block 的后面。所谓 super block,我们下面还要讲到。在这个descriptor 当中有几个重要的 block 指针。我们这里所说的 block 指针,就是指硬盘分区上的 block号数,比如,指针的值为 0,我们就说它是指向硬盘分区上的 block 0;指针的值为 1023,我们就说它是指向硬盘分区上的 block 1023。我们注意到,一个硬盘分区上的 block 计数是从 0 开始的,并且这个计数对于这个硬盘分区来说是全局性质的。
在block group 的 group descriptor 中,其中有一个 block 指针指向这个 block group 的 block bitmap,block bitmap 中的每个 bit 表示一个 block,如果该 bit 为 0,表示该 block 中有数据,如果 bit 为 1,则表示该 block 是空闲的。注意,这个 block bitmap 本身也正好只有一个 block 那么大小。假设block 大小为 S bytes,那么 block bitmap 当中只能记载 8*S 个 block 的情况(因为一个 byte 等于 8个 bits,而一个 bit 对应一个 block)。这也就是说,一个 block group 最多只能有 8*S*S bytes 这么大。
在block group 的 group descriptor 中另有一个 block 指针指向 inode bitmap,这个 bitmap同样也是正好有一个 block 那么大,里面的每一个 bit 相对应一个 inode。硬盘上的一个 inode大体上相对应于文件系统上的一个文件或者目录。关于 inode,我们下面还要进一步讲到。
在 block group的 descriptor 中另一个重要的 block 指针,是指向所谓的 inode table。这个 inode table 就不止一个block 那么大了。这个 inode table 就是这个 block group 中所聚集到的全部 inode 放在一起形成的。一个 inode 当中记载的最关键的信息,是这个 inode 中的用户数据存放在什么地方。我们在前面提到,一个 inode大体上相对应于文件系统中的一个文件,那么用户文件的内容存放在什么地方,这就是一个 inode 要回答的问题。一个 inode 通过提供一系列的block 指针,来回答这个问题。这些 block 指针指向的 block,里面就存放了用户文件的内容。
现在回顾一下。硬盘分区首先被分为好多个 block。这些 block 聚在一起,被分成几组,也就是 block group。每个 blockgroup 都有一个 group descriptor。所有这些 descriptor 被聚在一起,放在硬盘分区的开头部分,跟在 super block 的后面。从 group descriptor 我们可以通过 block 指针,找到这个 block group 的 inode table 和 block bitmap 等等。从 inode table 里面,我们就可以看到一个个的 inode 了。从一个inode,我们通过它里面的 block 指针,就可以进而找到存放用户数据的那些 block。我们还要提一下,block指针不是可以到处乱指的。一个 block group 的 block bitmap 和 inode bitmap 以及 inode table,都依次存放在这个 block group 的开头部分,而那些存放用户数据的 block 就紧跟在它们的后面。一个 block group 结束后,另一个 block group 又跟着开始。
详细的布局情况
Super Block
所谓 ext2 文件系统的 super block,就是硬盘分区开头(开头的第一个 byte 是 byte 0)从 byte 1024开始往后的一部分数据。由于 block size 最小是 1024 bytes,所以 super block 可能是在 block 1中(此时 block 的大小正好是 1024 bytes),也可能是在 block 0 中。
硬盘分区上 ext3
文件系统的 super block 的详细情况如下。其中 __u32 是表示 unsigned 不带符号的 32 bits的数据类型,其余类推。这是 Linux内核中所用到的数据类型,如果是开发用户空间(user-space)的程序,可以根据具体计算机平台的情况,用 unsigned long等等来代替。下面列表中关于 fragments 的部分可以忽略,Linux 上的 ext3 文件系统并没有实现 fragments这个特性。另外要注意,ext3 文件系统在硬盘分区上的数据是按照 Intel 的 Little-endian 格式存放的,如果是在 PC以外的平台上开发 ext3 相关的程序,要特别注意这一点。如果只是在 PC 上做开发,倒不用特别注意。
struct ext3_super_block {
/*00*/ __u32 s_inodes_count; /* inodes 计数 */
__u32 s_blocks_count; /* blocks 计数 */
__u32 s_r_blocks_count; /* 保留的 blocks 计数 */
__u32 s_free_blocks_count; /* 空闲的 blocks 计数 */
/*10*/ __u32 s_free_inodes_count; /* 空闲的 inodes 计数 */
__u32 s_first_data_block; /* 第一个数据 block */
__u32 s_log_block_size; /* block 的大小 */
__s32 s_log_frag_size; /* 可以忽略 */
/*20*/ __u32 s_blocks_per_group; /* 每 block group 的 block 数量 */
__u32 s_frags_per_group; /* 可以忽略 */
__u32 s_inodes_per_group; /* 每 block group 的 inode 数量 */
__u32 s_mtime; /* Mount time */
/*30*/ __u32 s_wtime; /* Write time */
__u16 s_mnt_count; /* Mount count */
__s16 s_max_mnt_count; /* Maximal mount count */
__u16 s_magic; /* Magic 签名 */
__u16 s_state; /* File system state */
__u16 s_errors; /* Behaviour when detecting errors */
__u16 s_minor_rev_level; /* minor revision level */
/*40*/ __u32 s_lastcheck; /* time of last check */
__u32 s_checkinterval; /* max. time between checks */
__u32 s_creator_os; /* 可以忽略 */
__u32 s_rev_level; /* Revision level */
/*50*/ __u16 s_def_resuid; /* Default uid for reserved blocks */
__u16 s_def_resgid; /* Default gid for reserved blocks */
__u32 s_first_ino; /* First non-reserved inode */
__u16 s_inode_size; /* size of inode structure */
__u16 s_block_group_nr; /* block group # of this superblock */
__u32 s_feature_compat; /* compatible feature set */
/*60*/ __u32 s_feature_incompat; /* incompatible feature set */
__u32 s_feature_ro_compat; /* readonly-compatible feature set */
/*68*/ __u8 s_uuid[16]; /* 128-bit uuid for volume */
/*78*/ char s_volume_name[16]; /* volume name */
/*88*/ char s_last_mounted[64]; /* directory where last mounted */
/*C8*/ __u32 s_algorithm_usage_bitmap; /* 可以忽略 */
__u8 s_prealloc_blocks; /* 可以忽略 */
__u8 s_prealloc_dir_blocks; /* 可以忽略 */
__u16 s_padding1; /* 可以忽略 */
/*D0*/ __u8 s_journal_uuid[16]; /* uuid of journal superblock */
/*E0*/ __u32 s_journal_inum; /* 日志文件的 inode 号数 */
__u32 s_journal_dev; /* 日志文件的设备号 */
__u32 s_last_orphan; /* start of list of inodes to delete */
/*EC*/ __u32 s_reserved[197]; /* 可以忽略 */
};
可以看到,super block 一共有1024 bytes 那么大。在 super block 中第一个要关心的字段是 magic 签名,对于 ext2 和 ext3文件系统来说,这个字段的值应该正好等于 0xEF53。如果不等的话,那么这个硬盘分区上肯定不是一个正常的 ext2 或 ext3文件系统。从这里也可以估计到,ext2 和 ext3 的兼容性一定是很强的,不然的话,Linux 内核的开发者应该会为 ext3文件系统另选一个 magic 签名才对。在 super block 中另一个重要的字段是s_log_block_size。从这个字段可以得出真正的 block 的大小。把真正 block 的大小记作 B,B = 1
Group Descriptors
继续往下,看跟在 super block 后面的一堆 group descriptors。首先注意到 super block 是从 byte 1024 开始,一共有 1024 bytes 那么大。而 group descriptors 是从 super block 后面的第一个block 开始。也就是说,如果 super block 是在 block 0,那么 group descriptors 就是从 block1 开始;如果 super block 是在 block 1,那么 group descriptors 就是从 block 2 开始。因为super block 一共只有 1024 bytes 那么大,所以不会超出一个 block 的边界。如果一个 block 正好是 1024 bytes 那么大的话,我们看到 group descriptors 就是紧跟在 super block 后面的了,没有留一点空隙。而如果一个block 是 4096 bytes 那么大的话,那么在 group descriptors(从 byte 4096 开始)和 super block 的结尾之间,就有一定的空隙(4096 - 2048 bytes)。
那么硬盘分区上一共有多少个block group,或者说一共有多少个 group descriptors,这我们要在 super block 中找答案。Super block 中的 s_blocks_count 记录了硬盘分区上的 block 的总数,而 s_blocks_per_group 记录了每个group 中有多少个 block。显然,文件系统上的 block groups 数量,我们把它记作 G,G =(s_blocks_count - s_first_data_block - 1) /s_blocks_per_group + 1。为什么要减去 s_first_data_block,因为 s_blocks_count是硬盘分区上全部的 block 的数量,而在 s_first_data_block 之前的 block 是不归 block group管的,所以当然要减去。最后为什么又要加一,这是因为尾巴上可能多出来一些 block,这些 block 我们要把它划在一个相对较小的 group里面。
注意,硬盘分区上的所有这些 group descriptors 要能塞在一个 block 里面。也就是说 groups_count * descriptor_size 必须小于等于 block_size。
知道了硬盘分区上一共有多少个 block group,就可以把这么多个 group descriptors 读出来了。先来看看 group descriptor 是什么样子的。
struct ext3_group_desc{
__u32 bg_block_bitmap; /* block 指针指向 block bitmap */
__u32 bg_inode_bitmap; /* block 指针指向 inode bitmap */
__u32 bg_inode_table; /* block 指针指向 inodes table */
__u16 bg_free_blocks_count; /* 空闲的 blocks 计数 */
__u16 bg_free_inodes_count; /* 空闲的 inodes 计数 */
__u16 bg_used_dirs_count; /* 目录计数 */
__u16 bg_pad; /* 可以忽略 */
__u32 bg_reserved[3]; /* 可以忽略 */
};
每个 group descriptor 是 32 bytes 那么大。从上面看到了三个关键的 block 指针,这三个关键的 block 指针已经在前面都提到过了。
Inode
前面都准备好了以后,我们现在终于可以开始读取文件了。首先要读的,当然是文件系统的根目录。注意,这里所谓的根目录,是相对于这一个文件系统或者说硬盘分区而言的,它并不一定是整个 Linux 操作系统上的根目录。这里的这个 root 目录存放在一个固定的 inode 中,这就是文件系统上的inode 2。需要提到 inode 计数同 block 计数一样,也是全局性质的。这里需要特别注意的是,inode 计数是从 1开始的,而前面我们提到过 block 计数是从 0 开始,这个不同在开发程序的时候要特别留心(这一奇怪的 inode计数方法,曾经让本文作者大伤脑筋)。
那么先来看一下得到一个 inode 号数以后,怎样读取这个 inode中的用户数据。在 super block 中有一个字段 s_inodes_per_group 记载了每个 block group 中有多少个inode。用我们得到的 inode 号数除以 s_inodes_per_group,我们就知道了我们要的这个 inode 是在哪一个block group 里面,这个除法的余数也告诉我们,我们要的这个 inode 是这个 block group 里面的第几个inode;然后,我们可以先找到这个 block group 的 group descriptor,从这个 descriptor,我们找到这个group 的 inode table,再从 inode table 找到我们要的第几个 inode,再以后,我们就可以开始读取 inode中的用户数据了。
这个公式是这样的:block_group = (ino - 1) /s_inodes_per_group。这里 ino 就是我们的 inode 号数。而 offset = (ino - 1) %s_inodes_per_group,这个 offset 就指出了我们要的 inode 是这个 block group 里面的第几个inode。
找到这个 inode 之后,来具体的看看 inode 是什么样的。
struct ext3_inode {
__u16 i_mode; /* File mode */
__u16 i_uid; /* Low 16 bits of Owner Uid */
__u32 i_size; /* 文件大小,单位是 byte */
__u32 i_atime; /* Access time */
__u32 i_ctime; /* Creation time */
__u32 i_mtime; /* Modification time */
__u32 i_dtime; /* Deletion Time */
__u16 i_gid; /* Low 16 bits of Group Id */
__u16 i_links_count; /* Links count */
__u32 i_blocks; /* blocks 计数 */
__u32 i_flags; /* File flags */
__u32 l_i_reserved1; /* 可以忽略 */
__u32 i_block[EXT3_N_BLOCKS]; /* 一组 block 指针 */
__u32 i_generation; /* 可以忽略 */
__u32 i_file_acl; /* 可以忽略 */
__u32 i_dir_acl; /* 可以忽略 */
__u32 i_faddr; /* 可以忽略 */
__u8 l_i_frag; /* 可以忽略 */
__u8 l_i_fsize; /* 可以忽略 */
__u16 i_pad1; /* 可以忽略 */
__u16 l_i_uid_high; /* 可以忽略 */
__u16 l_i_gid_high; /* 可以忽略 */
__u32 l_i_reserved2; /* 可以忽略 */
};
我们看到在 inode 里面可以存放EXT3_N_BLOCKS(= 15)这么多个 block 指针。用户数据就从这些 block 里面获得。15 个 blocks不一定放得下全部的用户数据,在这里 ext3 文件系统采取了一种分层的结构。这组 15 个 block 指针的前 12 个是所谓的direct blocks,里面直接存放的就是用户数据。第 13 个 block,也就是所谓的 indirect block,里面存放的全部是block 指针,这些 block 指针指向的 block 才被用来存放用户数据。第 14 个 block 是所谓的 double indirect block,里面存放的全是 block 指针,这些 block 指针指向的 block 也被全部用来存放 block指针,而这些 block 指针指向的 block,才被用来存放用户数据。第 15 个 block 是所谓的 triple indirect block,比上面说的 double indirect block 有多了一层 block 指针。作为练习,读者可以计算一下,这样的分层结构可以使一个 inode中最多存放多少字节的用户数据。(计算所需的信息是否已经足够?还缺少哪一个关键数据?)
一个 inode里面实际有多少个 block,这是由 inode 字段 i_size 再通过计算得到的。i_size记录的是文件或者目录的实际大小,用它的值除以 block 的大小,就可以得出这个 inode 一共占有几个 block。注意上面的i_blocks 字段,粗心的读者可能会以为是这一字段记录了一个 inode 中实际用到多少个block,其实不是的。那么这一字段是干什么用的呢,读者朋友们可以借这个机会,体验一下阅读 Linux 内核源代码的乐。
文件系统的目录结构
现在我们已经可以读取 inode 的内容了,再往后,我们将要读取文件系统上文件和目录的内容。读取文件的内容,只要把相应的 inode的内容全部读出来就行了;而目录只是一种固定格式的文件,这个文件按照固定的格式记录了目录中有哪些文件,以及它们的文件名和 inode 号数等等。
struct ext3_dir_entry_2 {
__u32 inode; /* Inode 号数 */
__u16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT3_NAME_LEN]; /* File name */
};
上面用到的 EXT3_NAME_LEN 是 255。注意,在硬盘分区上的 dir entry 不是固定长度的,每个 dir entry 的长度由上面的 rec_len 字段记录。
小结
有了以上的这些信息,我们就可以读取一个 ext3 文件系统的全部内容了。如果读者有 Windows 驱动程序开发的经验,从本文的信息,开发一个Windows 下只读的 ext3 文件系统是可能的。但是要想又读又写,那还需要了解 ext3的日志文件的结构,而本文限于篇幅,并没有包括这方面的内容。
参考资料
1.Remy Card, Theodore Ts'o, Stephen Tweedie, Design and Implementation of the Second Extended Filesystem,http://web.mit.edu/tytso/www/linux/ext2intro.html
2.Linux Kernel 2.4.18 Source Code
接下来再接上文与编程接口来描述相关的知识(英文原文)
Most of the material in these notes comes from chapters 14 and 18 of The Linux Programming Interface by Michael Kerrisk.
File systems and device drivers
When an application wants to interact with a file it will use various system calls such as open() and read(). These system calls go to the kernel, which then will communicate with a file system, which in turn will talk to a device driver to access the file on a device.
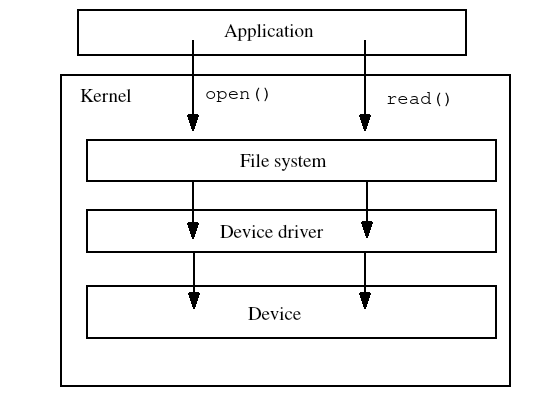
Devices
Each storage device in a Linux system is a device. The kernel uses a device driver to communicate with the device. Device drivers support all of the usual system calls for working with files, such as open(), close(), read(), and write().
The system associates a special file, called a device file, with each device in the system. These device files can be found in /dev. In addition, information about currently active devices is exported to files in /sys.
Each device file has a major ID number, which associates the file with a particular device driver, and a minor ID number, which is used to number devices in each device type.
cd /sys
ls -l
Disk partitions
Each disk is divided into one or more (nonoverlapping) partitions. Each partition is treated by the kernel as a separate device residing under the /dev directory. A disk partition may hold any type of information, but usually contains one of the following:
1.a file system holding regular files and directories
2.a data area accessed as a raw-mode device
3.a swap area used by the kernel for memory management.
File systems
Linux systems can actually use several different kinds of file systems, including ext2, ext3, ext4, FAT32, NTFS, HFS, and NFS. Why are there so many different file systems?
1.Different operating systems commonly use different file systems. For example, Windows uses FAT32 and NTFS. If you want to use a device that was formatted on a non-Linux operating system you need to be able to work with its file system.
2.NFS is a network file system that allows you to access files on file servers over a network.
3.Linux uses several different virtual file systems for special purposes. For example, the /proc directory uses a special virtual file system to display information about running processes as a collection of special files.
Although the Linux file system appears to be a single, unified file system rooted at /, in reality a given Linux system can make use of many different file systems at different points in the directory tree.
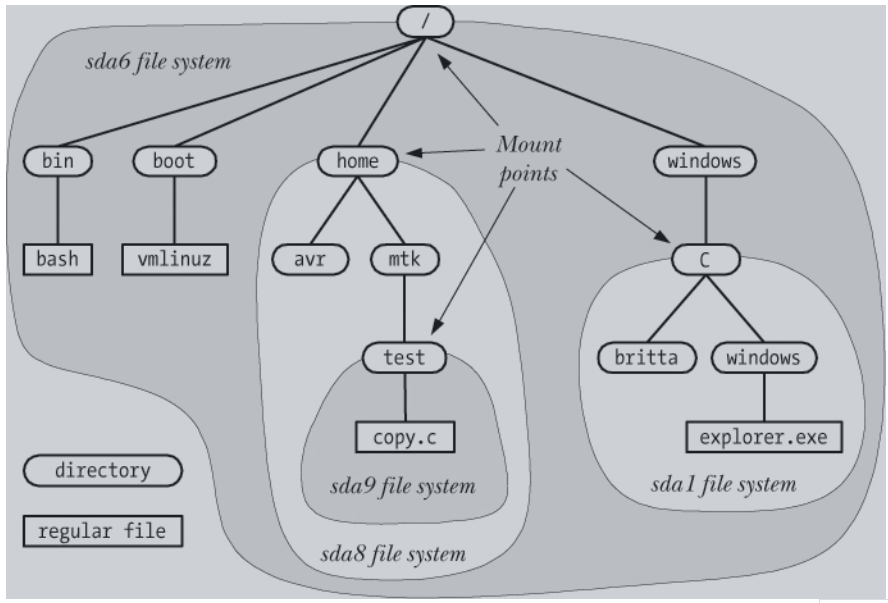
Mount points
The mount command allows you to mount a device to a directory.
$ mount device directory
You can also use the mount command to see a list of currently mounted devices and their mount points.
$ mount
/dev/sda6 on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,mode=0620,gid=5)
/dev/sda8 on /home type ext3 (rw,acl,user_xattr)
/dev/sda1 on /windows/C type vfat (rw,noexec,nosuid,nodev)
/dev/sda9 on /home/mtk/test type reiserfs (rw)
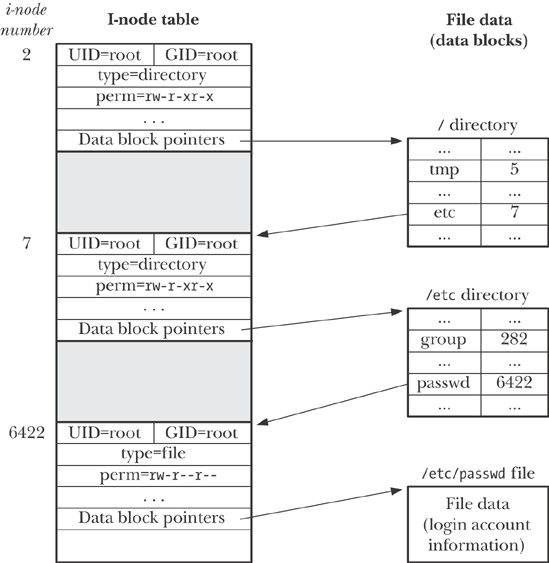
An example file system: ext2
The original file system on Linux systems was the ext file system. In time, this was superceded by the ext2 file system, which supported larger files and larger partitions. In turn, ext2 has been superceded by ext3 and ext4, which offer more advanced features such as journaling.
ext2 is a nice example of a file system to look at, since it is simple enough to understand easily.
In ext2 each file is represented by an inode, which is a fixed-size structure on disk that stores data about the file and provides information about the data blocks that make up the file.
The structure of ext2:
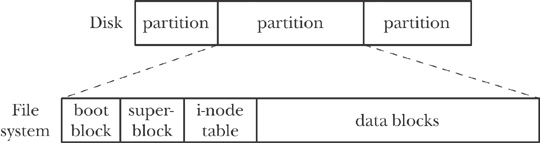
The superblock contains information about the file system itself. The inode table contains a list of inodes, each of which is identified by an inode number. inodes are numbered starting at 1. inode 1 contains information about bad data blocks that are not available to use. inode 2 gives information about the root directory on the file system. All other parts of the file system can be accessed starting from that root directory. When the file system gets mounted into a Linux system's full file system the root directory of the file system gets mapped to a mount point in the full file system.
The structure of an i-node:
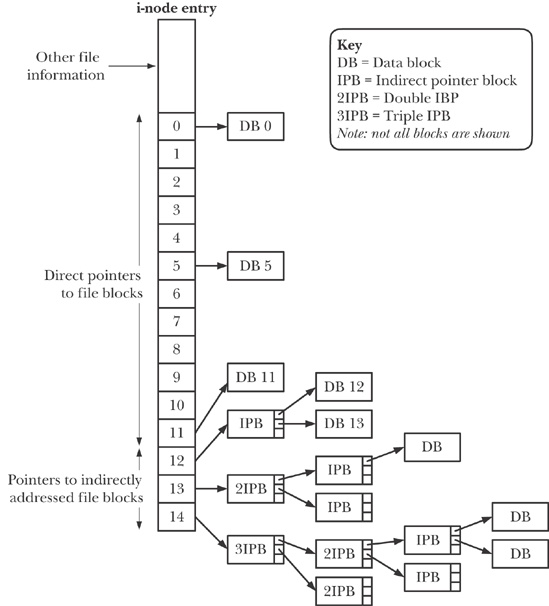
The "other file information" portion of an inode contains file metadata for the file. Metadata includes:
1.File permissions: who can do what with the file
2.The file's owner and group
3.The file's size in bytes
4.The number of data blocks used by the file
5.Access time, change time, modification time, deletion time
6.The number of links to the file
7.Extended information, including access control lists
In a program you can access most of this metadata by using the stat() function. stat() returns information about the file in a stat structure:
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
struct timespec st_atim; /* Time of last access */
struct timespec st_mtim; /* Time of last modification */
struct timespec st_ctim; /* Time of last status change */
/* Backward compatibility */
#define st_atime st_atim.tv_sec
#define st_mtime st_mtim.tv_sec
#define st_ctime st_ctim.tv_sec
};
In the terminal, the ls command and its various options also displays this information.
Obtaining Information About a File System: statvfs()
The statvfs() and fstatvfs() library functions obtain information about a mounted file system.
#include <sys/statvfs.h>
int statvfs(const char *pathname, struct statvfs *statvfsbuf);
int fstatvfs(int fd, struct statvfs *statvfsbuf);
The only difference between these two functions is in how the file system is identified. For statvfs(), we use pathname to specify the name of any file in the file system. For fstatvfs(), we specify an open file descriptor, fd, referring to any file in the file system. Both functions return a statvfs structure containing information about the file system in the buffer pointed to by statvfsbuf. This structure has the following form:
struct statvfs {
unsigned long f_bsize; /* File-system block size (in bytes) */
unsigned long f_frsize; /* Fundamental file-system block size(in bytes) */
fsblkcnt_t f_blocks; /* Total number of blocks in file system(in units of 'f_frsize') */
fsblkcnt_t f_bfree; /* Total number of free blocks */
fsblkcnt_t f_bavail; /* Number of free blocks available to unprivileged process */
fsfilcnt_t f_files; /* Total number of i-nodes */
fsfilcnt_t f_ffree; /* Total number of free i-nodes */
fsfilcnt_t f_favail; /* Number of i-nodes available to unprivileged process (set to 'f_ffree' on Linux) */
unsigned long f_fsid; /* File-system ID */
unsigned long f_flag; /* Mount flags */
unsigned long f_namemax; /* Maximum length of filenames on this file system */
};
Directories and links
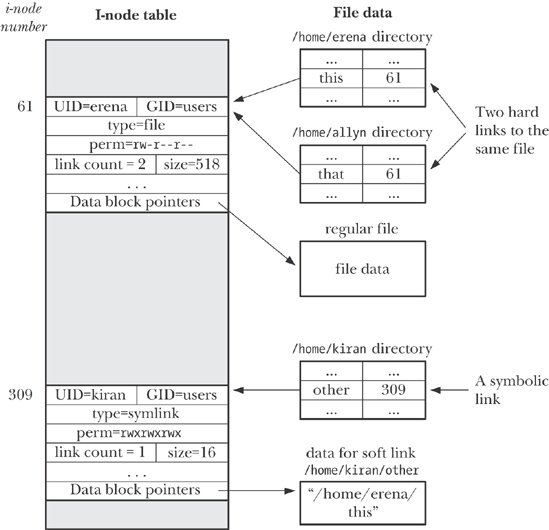
All file systems organize files into directories. A directory is simply a container for a set of files and other directories. In ext2, for example, each directory is actually a special file that contains a table of names and inode numbers. Some of these inodes will refer to files, while others will refer to directories.
Directories can also contain links. A link simply points to something else.
The ln command creates a link between two files. The link can either be a hard link or a soft link.
$ echo -n 'It is good to collect things,' > abc
$ ls -li abc
122232 -rw-r--r-- 1 mtk users 29 Jun 15 17:07 abc
$ ln abc xyz
$ echo ' but it is better to go on walks.' >> xyz
$ cat abc
It is good to collect things, but it is better to go on walks.
$ ls -li abc xyz
122232 -rw-r--r-- 2 mtk users 63 Jun 15 17:07 abc
122232 -rw-r--r-- 2 mtk users 63 Jun 15 17:07 xyz
From the shell, symbolic links are created using the ln -s command. The ls -F command displays a trailing @ character at the end of symbolic links.
Manipulating files and directories
The rename() system call can be used both to rename a file and to move it into another directory on the same file system.
#include <stdio.h>
int rename(const char *oldpath, const char *newpath);
The mkdir() system call creates a new directory.
#include <sys/stat.h>
int mkdir(const char *pathname, mode_t mode);
The rmdir() system call removes the directory specified in pathname, which may be an absolute or a relative pathname.
#include <unistd.h>
int rmdir(const char *pathname);
The remove() library function removes a file or an empty directory.
#include <stdio.h>
int remove(const char *pathname);
Traversing a directory
The opendir() function opens a directory and returns a handle that can be used to refer to the directory in later calls.
#include <dirent.h>
DIR *opendir(const char *dirpath);
The readdir() function reads successive entries from a directory stream.
#include <dirent.h>
struct dirent *readdir(DIR *dirp);
Each call to readdir() reads the next directory entry from the directory stream referred to by dirp and returns a pointer to a statically allocated structure of type dirent, containing the following information about the entry:
struct dirent {
ino_t d_ino; /* File i-node number */
char d_name[]; /* Null-terminated name of file */
};
This structure is overwritten on each call to readdir().
The closedir() function closes the open directory stream referred to by dirp, freeing the resources used by the stream.
#include <dirent.h>
int closedir(DIR *dirp);
The nftw() function walks through the directory tree specified by dirpath and calls the programmer-defined function func once for each file in the directory tree.
#define _XOPEN_SOURCE 500
#include <ftw.h>
int nftw(const char *dirpath,
int (*func) (const char *pathname, const struct stat *statbuf,
int typeflag, struct FTW *ftwbuf),
int nopenfd, int flags);
Working directory
A process can retrieve its current working directory using getcwd().
#include <unistd.h>
char *getcwd(char *cwdbuf, size_t size);
On success, getcwd() returns a pointer to cwdbuf as its function result. If the pathname for the current working directory exceeds size bytes, then getcwd() returns NULL, with errno set to ERANGE.
The chdir() system call changes the calling process’s current working directory to the relative or absolute pathname specified in pathname (which is dereferenced if it is a symbolic link).
#include <unistd.h>
int chdir(const char *pathname);
Every process has a root directory, which is the point from which absolute pathnames (i.e., those beginning with /) are interpreted. By default, this is the real root directory of the file system. (A new process inherits its parent’s root directory.) On occasion, it is useful for a process to change its root directory, and a privileged process can do this using the chroot() system call.
#define _BSD_SOURCE
#include <unistd.h>
int chroot(const char *pathname);
The chroot() system call changes the process’s root directory to the directory specified by pathname (which is dereferenced if it is a symbolic link). Thereafter, all absolute pathnames are interpreted as starting from that location in the file system. This is sometimes referred to as setting up a chroot jail, since the program is then confined to a particular area of the file system.
Working with paths
The realpath() library function dereferences all symbolic links in pathname (a null-terminated string) and resolves all references to /. and /.. to produce a null-terminated string containing the corresponding absolute pathname.
#include <stdlib.h>
char *realpath(const char *pathname, char *resolved_path);
The dirname() and basename() functions break a pathname string into directory and filename parts.
#include <libgen.h>
char *dirname(char *pathname);
char *basename(char *pathname);