开源日志系统比较:scribe_chukwa_kafka_flume_es_doris
 1. 背景介绍
1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:
(1) 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
(2) 支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;
(3) 具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
任何完整的大数据平台,一般包括以下的几个过程:
数据采集
数据存储
数据处理
数据展现(可视化,报表和监控)
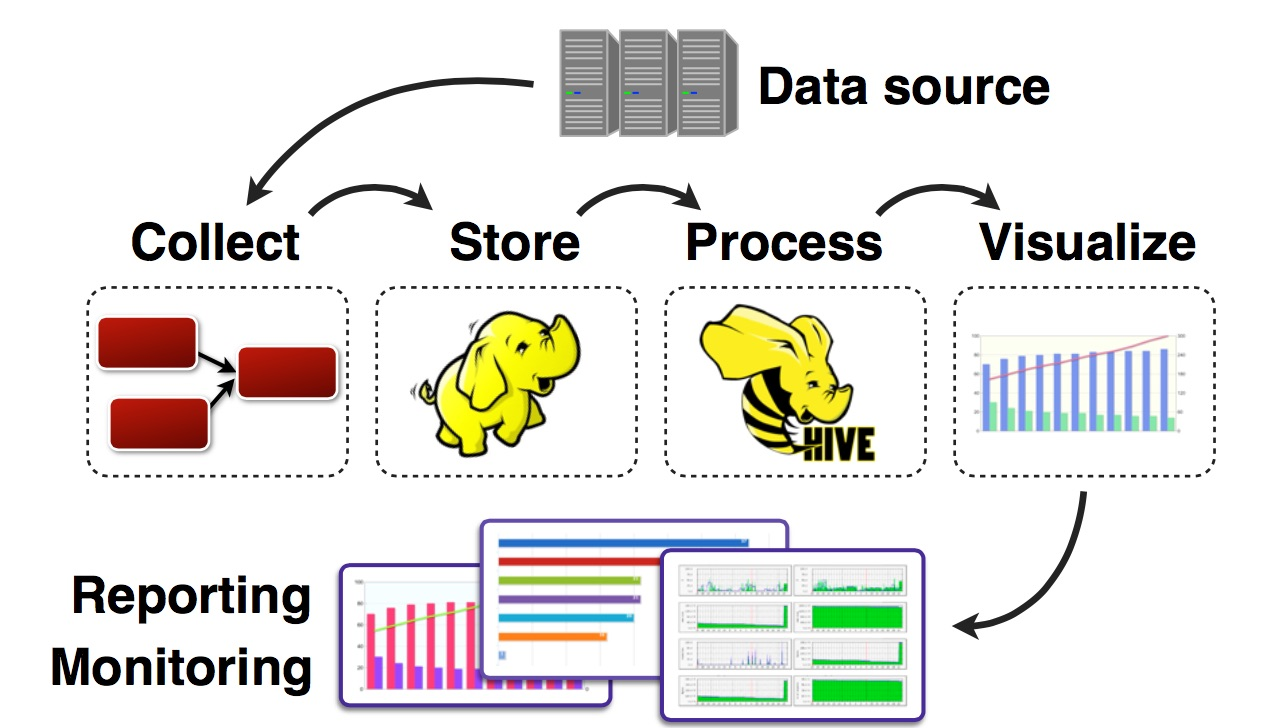
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
数据源多种多样
数据量大,变化快
如何保证数据采集的可靠性的性能
如何避免重复数据
如何保证数据的质量
本文从设计架构,负载均衡,可扩展性和容错性等方面对比了当今开源的日志系统,包括facebook的scribe,apache的chukwa,linkedin的kafka和cloudera的flume等。可就来看看当前可用的一些数据采集的产品,重点关注一些它们是如何做到高可靠,高性能和高扩展。
2. FaceBook的Scribe
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
它最重要的特点是容错性好。当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中。已经多年不维护了。
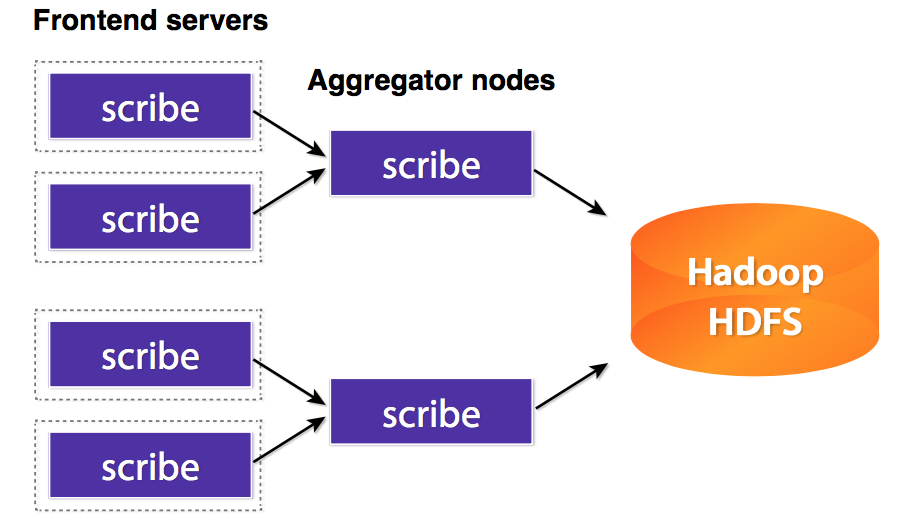
架构:
scribe的架构比较简单,主要包括三部分,分别为scribe agent, scribe和存储系统。
(1) scribe agent
scribe agent实际上是一个thrift client。 向scribe发送数据的唯一方法是使用thrift client, scribe内部定义了一个thrift接口,用户使用该接口将数据发送给server。
(2) scribe
scribe接收到thrift client发送过来的数据,根据配置文件,将不同topic的数据发送给不同的对象。scribe提供了各种各样的store,如 file, HDFS等,scribe可将数据加载到这些store中。
(3) 存储系统
存储系统实际上就是scribe中的store,当前scribe支持非常多的store,包括file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务器),bucket(包含多个 store,通过hash的将数据存到不同store中),null(忽略数据),thriftfile(写到一个Thrift TFileTransport文件中)和multi(把数据同时存放到不同store中)。
3. Apache的Chukwa
Apache Chukwa是一个非常新的开源项目,由于其属于hadoop系列产品,因而使用了很多hadoop的组件(用HDFS存储,用mapreduce处理数据),它提供了很多模块以支持hadoop集群日志分析。为Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和Map Reduce来构建(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次github的更新事7年前。可见该项目应该已经不活跃了。
Chukwa的部署架构如下。
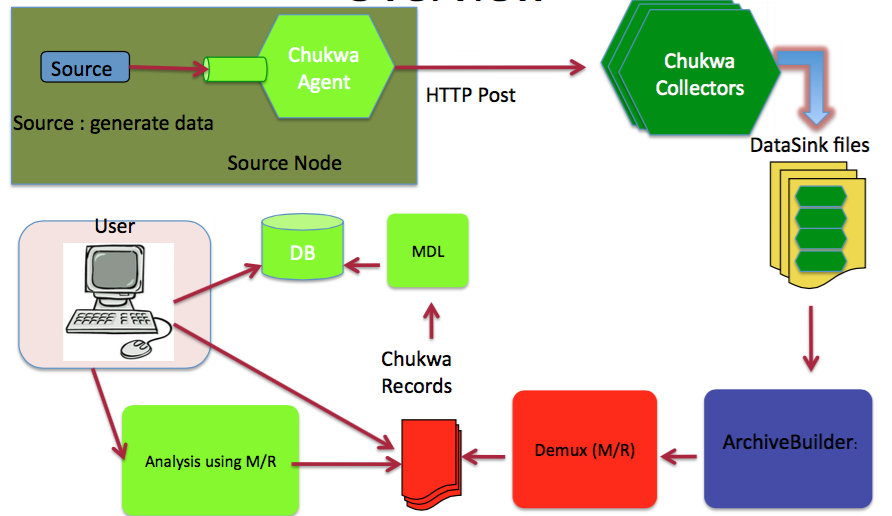
Chukwa的主要单元有:Agent,Collector,DataSink,ArchiveBuilder,Demux等等,看上去相当复杂。由于该项目已经不活跃就不细看了。
需求:
(1) 灵活的,动态可控的数据源
(2) 高性能,高可扩展的存储系统
(3) 合适的框架,用于对收集到的大规模数据进行分析
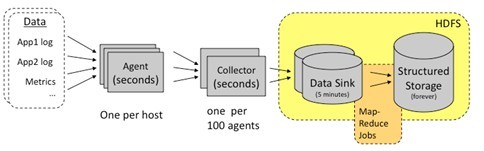
架构:
Chukwa中主要有3种角色,分别为:adaptor,agent,collector。
(1) Adaptor 数据源
可封装其他数据源,如file,unix命令行工具等
目前可用的数据源有:hadoop logs,应用程序度量数据,系统参数数据(如linux cpu使用流率)。
(2) HDFS 存储系统
Chukwa采用了HDFS作为存储系统。HDFS的设计初衷是支持大文件存储和小并发高速写的应用场景,而日志系统的特点恰好相反,它需支持高并发低速率的写和大量小文件的存储。需要注意的是,直接写到HDFS上的小文件是不可见的,直到关闭文件,另外HDFS不支持文件重新打开。
(3) Collector和Agent
为了克服(2)中的问题,增加了agent和collector阶段。
Agent的作用:给adaptor提供各种服务,包括:启动和关闭adaptor,将数据通过HTTP传递给Collector;定期记录adaptor状态,以便crash后恢复。
Collector的作用:对多个数据源发过来的数据进行合并,然后加载到HDFS中;隐藏HDFS实现的细节,如,HDFS版本更换后,只需修改collector即可。
(4) Demux和achieving
直接支持利用MapReduce处理数据。它内置了两个mapreduce作业,分别用于获取data和将data转化为结构化的log。存储到data store(可以是数据库或者HDFS等)中。
4. LinkedIn的Kafka
Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群。
设计目标:
(1) 数据在磁盘上的存取代价为O(1)
(2) 高吞吐率,在普通的服务器上每秒也能处理几十万条消息
(3) 分布式架构,能够对消息分区
(4) 支持将数据并行的加载到hadoop
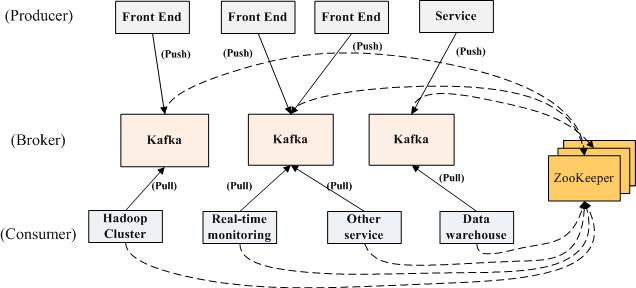
架构:
Kafka实际上是一个消息发布订阅系统。producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer。 在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。同时,它也使用了zookeeper进行负载均衡。
Kafka中主要有三种角色,分别为producer,broker和consumer。
(1) Producer
Producer的任务是向broker发送数据。Kafka提供了两种producer接口,一种是low_level接口,使用该接口会向特定的broker的某个topic下的某个partition发送数据;另一种那个是high level接口,该接口支持同步/异步发送数据,基于zookeeper的broker自动识别和负载均衡(基于Partitioner)。
其中,基于zookeeper的broker自动识别值得一说。producer可以通过zookeeper获取可用的broker列表,也可以在zookeeper中注册listener,该listener在以下情况下会被唤醒:
a.添加一个broker
b.删除一个broker
c.注册新的topic
d.broker注册已存在的topic
当producer得知以上时间时,可根据需要采取一定的行动。
(2) Broker
Broker采取了多种策略提高数据处理效率,包括sendfile和zero copy等技术。
(3) Consumer
consumer的作用是将日志信息加载到中央存储系统上。kafka提供了两种consumer接口,一种是low level的,它维护到某一个broker的连接,并且这个连接是无状态的,即,每次从broker上pull数据时,都要告诉broker数据的偏移量。另一种是high-level 接口,它隐藏了broker的细节,允许consumer从broker上push数据而不必关心网络拓扑结构。更重要的是,对于大部分日志系统而言,consumer已经获取的数据信息都由broker保存,而在kafka中,由consumer自己维护所取数据信息。
5. Cloudera的Flume
Flume是cloudera于2009年7月开源的日志系统。它内置的各种组件非常齐全,用户几乎不必进行任何额外开发即可使用。现为Apache旗下,开源,高可靠,高扩展,容易管理,支持客户扩展的数据采集系统。Flume使用JRuby来构建,所以依赖Java运行环境。它最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。
设计目标:
(1) 可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
(2) 可扩展性
Flume采用了三层架构,分别问agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(3) 可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。
(4) 功能可扩展性
用户可以根据需要添加自己的agent,colletor或者storage。此外,Flume自带了很多组件,包括各种agent(file,syslog等),collector和storage(file,HDFS等)。
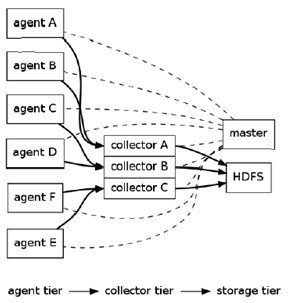
架构:
正如前面提到的,Flume采用了分层架构,由三层组成,分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
(1) agent
agent的作用是将数据源的数据发送给collector,Flume自带了很多直接可用的数据源(source),如:
text(“filename”):将文件filename作为数据源,按行发送
tail(“filename”):探测filename新产生的数据,按行发送出去
fsyslogTcp(5140):监听TCP的5140端口,并且接收到的数据发送出去
同时提供了很多sink,如:
console[("format")] :直接将将数据显示在桌面上
text(“txtfile”):将数据写到文件txtfile中
dfs(“dfsfile”):将数据写到HDFS上的dfsfile文件中
syslogTcp(“host”,port):将数据通过TCP传递给host节点
(2) collector
collector的作用是将多个agent的数据汇总后,加载到storage中。它的source和sink与agent类似。
下面例子中,agent监听TCP的5140端口接收到的数据,并发送给collector,由collector将数据加载到HDFS上。
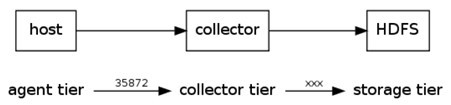
host : syslogTcp(5140) | agentSink("localhost",35853) ;
collector : collectorSource(35853) | collectorSink("hdfs://namenode/user/flume/ ","syslog");
一个更复杂的例子如下:
有6个agent,3个collector,所有collector均将数据导入HDFS中。agent A,B将数据发送给collector A,agent C,D将数据发送给collectorB,agent C,D将数据发送给collectorB。同时为每个agent添加end-to-end可靠性保障(Flume的三种可靠性保障分别由agentE2EChain, agentDFOChain, and agentBEChain实现),如,当collector A出现故障时,agent A和agent B会将数据分别发给collector B和collector C。
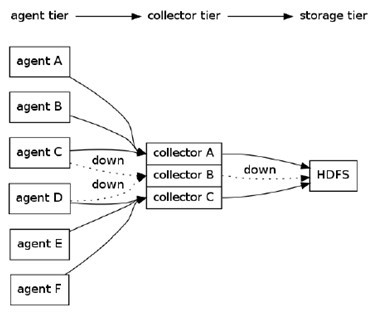
下面是简写的配置文件片段:
agentA : src | agentE2EChain("collectorA:35853","collectorB:35853");
agentB : src | agentE2EChain("collectorA:35853","collectorC:35853");
agentC : src | agentE2EChain("collectorB:35853","collectorA:35853");
agentD : src | agentE2EChain("collectorB:35853","collectorC:35853");
agentE : src | agentE2EChain("collectorC:35853","collectorA:35853");
agentF : src | agentE2EChain("collectorC:35853","collectorB:35853");
collectorA : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorB : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorC : collectorSource(35853) | collectorSink("hdfs://...","src");
此外,使用autoE2EChain,当某个collector 出现故障时,Flume会自动探测一个可用collector,并将数据定向到这个新的可用collector上。
(3) storage
storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。

Flume设计成一个分布式的管道架构,可以看作在数据源和目的地之间有一个Agent的网络,支持数据路由。
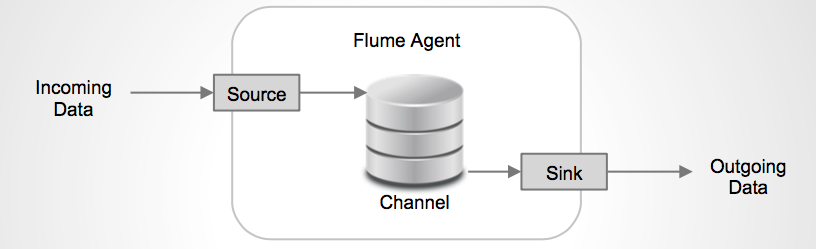
每一个agent都由Source,Channel和Sink组成。
Source
Source负责接收输入数据,并将数据写入管道。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或者文件,解析其中新生成的事件。
Channel
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如内存,文件,JDBC等。使用内存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如内存。
Sink
Sink负责从管道中读出数据并发给下一个Agent或者最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或者其它的Flume Agent
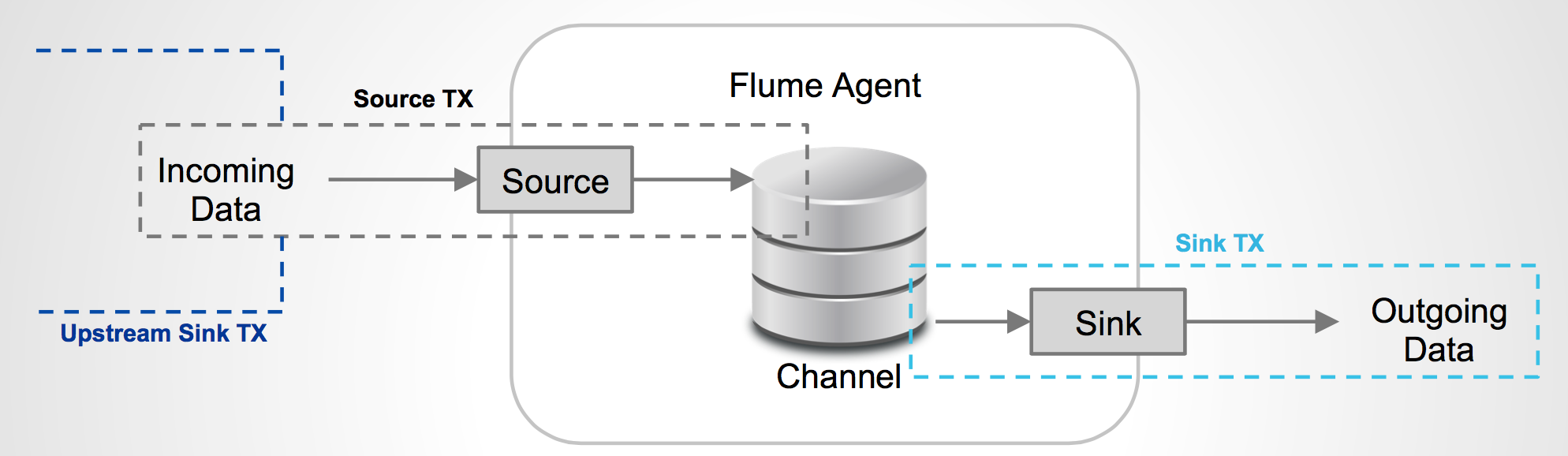
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据丢失。
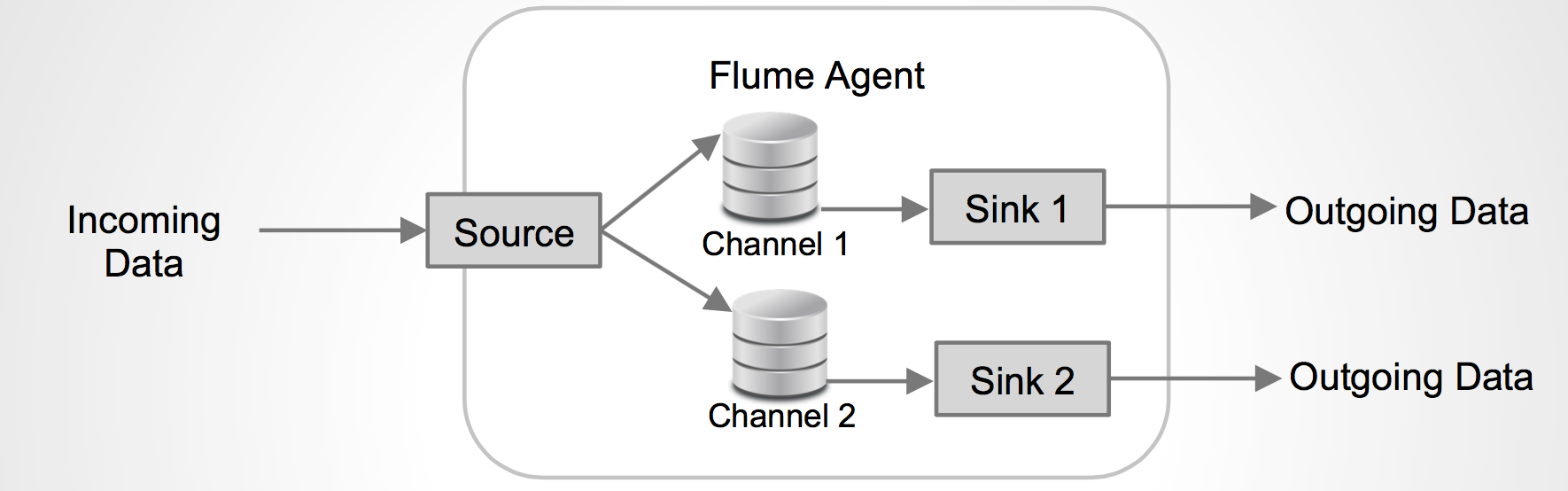
Source上的数据可以复制到不同的通道上。每一个Channel也可以连接不同数量的Sink。这样连接不同配置的Agent就可以组成一个复杂的数据收集网络。通过对agent的配置,可以组成一个路由复杂的数据传输网络。
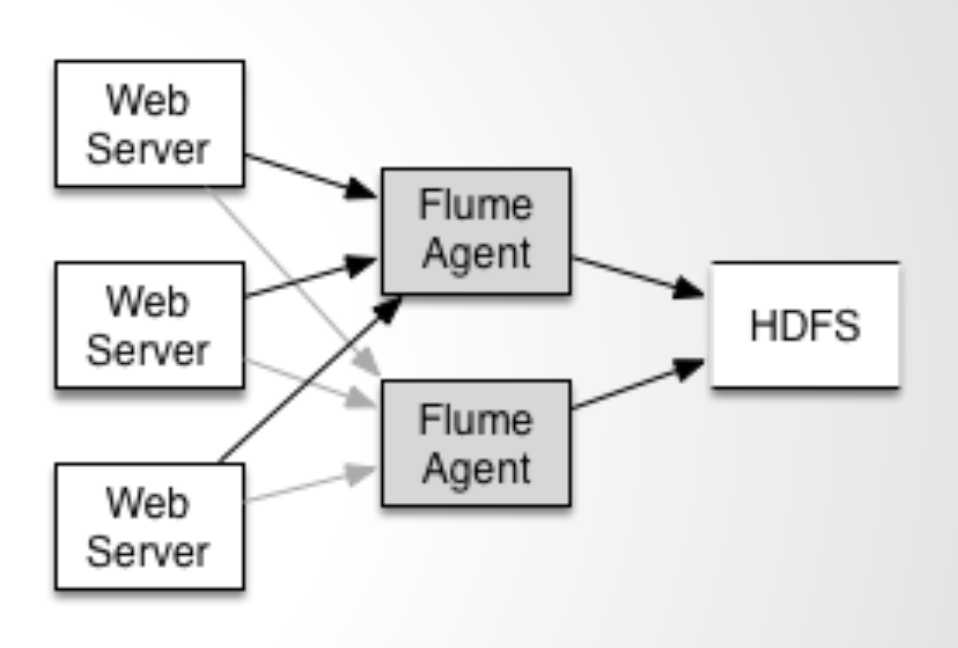
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证即使有一个agent失效的情况下,整个系统仍能正常收集数据。

Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发:
Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的这些客户端都不能满足需求,用户可以定制的客户端,和已有的FLume的Source进行通信,或者定制实现一种新的Source类型。
同时,用户可以使用Flume的SDK定制Source和Sink,似乎不支持定制的Channel。
6. Fluentd
Fluentd是另一个开源的数据收集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出,最后它也同时提供了高可靠和很好的扩展性。Treasure Data, Inc对该产品提供支持和维护。
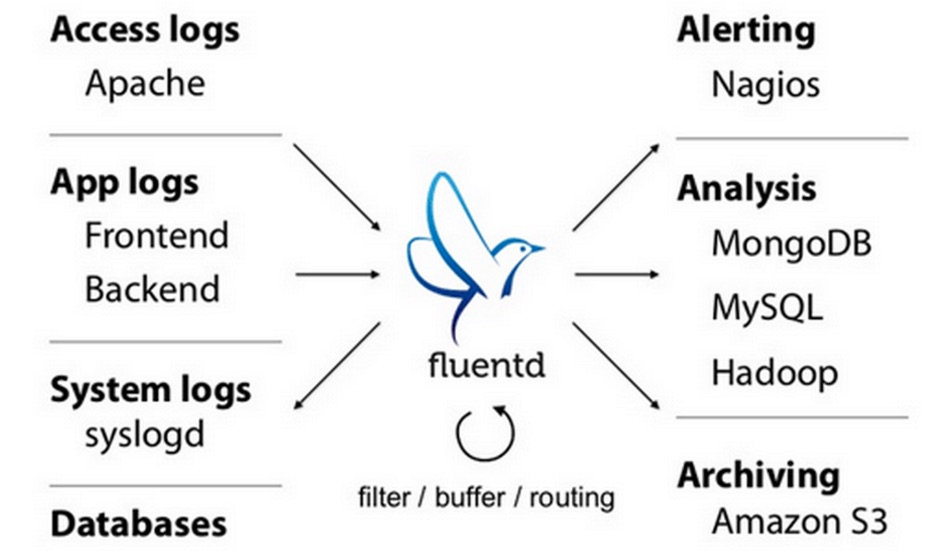
Fluentd的部署和Flume非常相似:
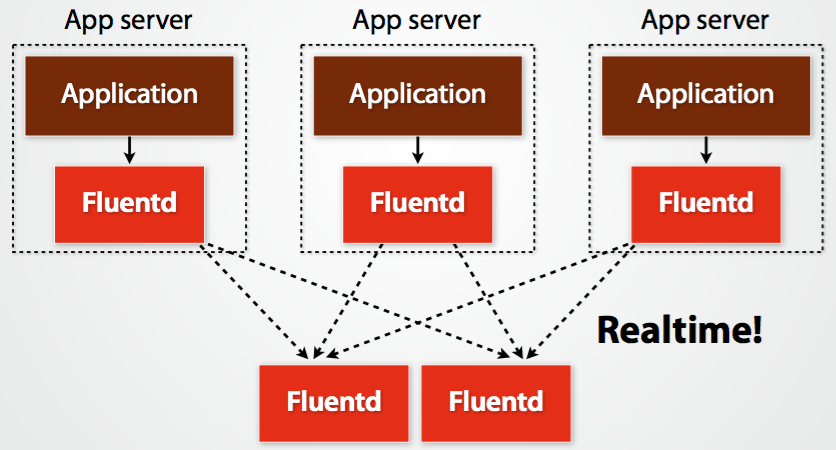
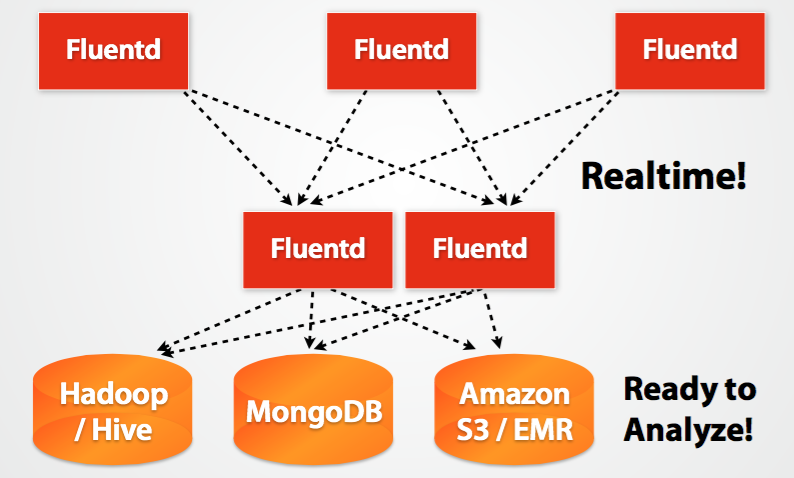
Fluentd的架构设计和Flume如出一辙:
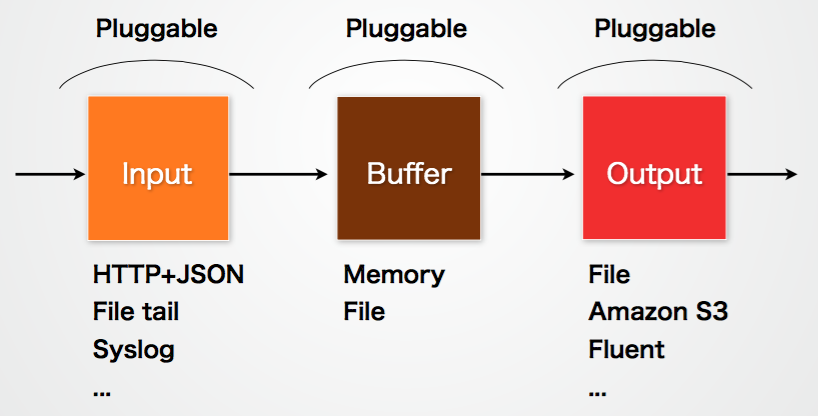
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。
Input
Input负责接收数据或者主动抓取数据。支持syslog,http,file tail等。
Buffer
Buffer负责数据获取的性能和可靠性,也有文件或内存等不同类型的Buffer可以配置。
Output
Output负责输出数据到目的地例如文件,AWS S3或者其它的Fluentd。
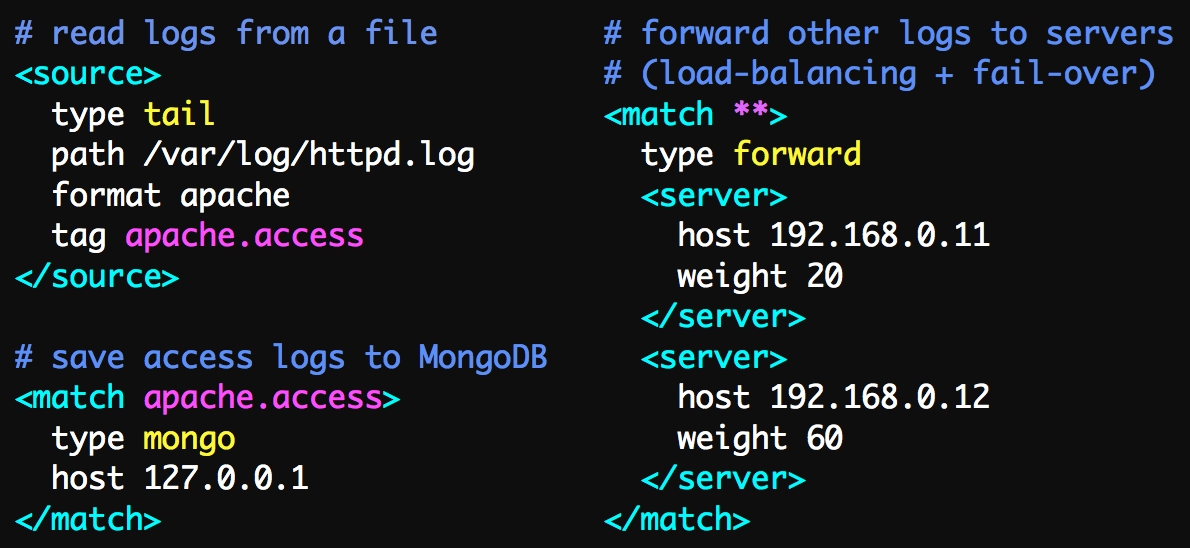
Fluentd的配置非常方便,如下图:
Fluentd的技术栈如下图:
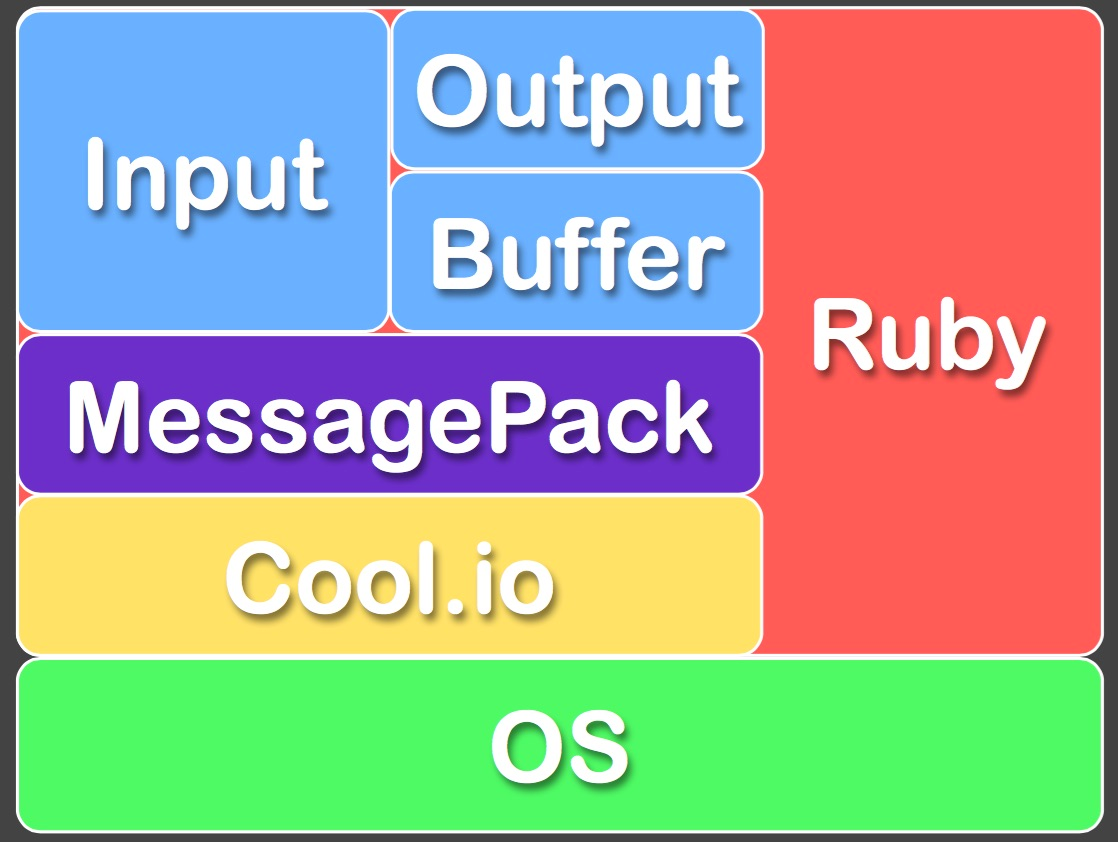
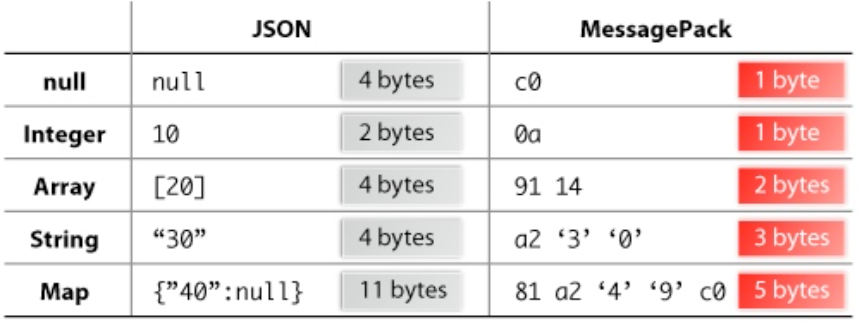
FLuentd和其插件都是由Ruby开发,MessgaePack提供了JSON的序列化和异步的并行通信RPC机制。
Cool.io是基于libev的事件驱动框架。
FLuentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。
Fluentd从各方面看都很像Flume,区别是使用Ruby开发,Footprint会小一些,但是也带来了跨平台的问题,并不能支持Windows平台。另外采用JSON统一数据/日志格式是它的另一个特点。相对去Flumed,配置也相对简单一些。
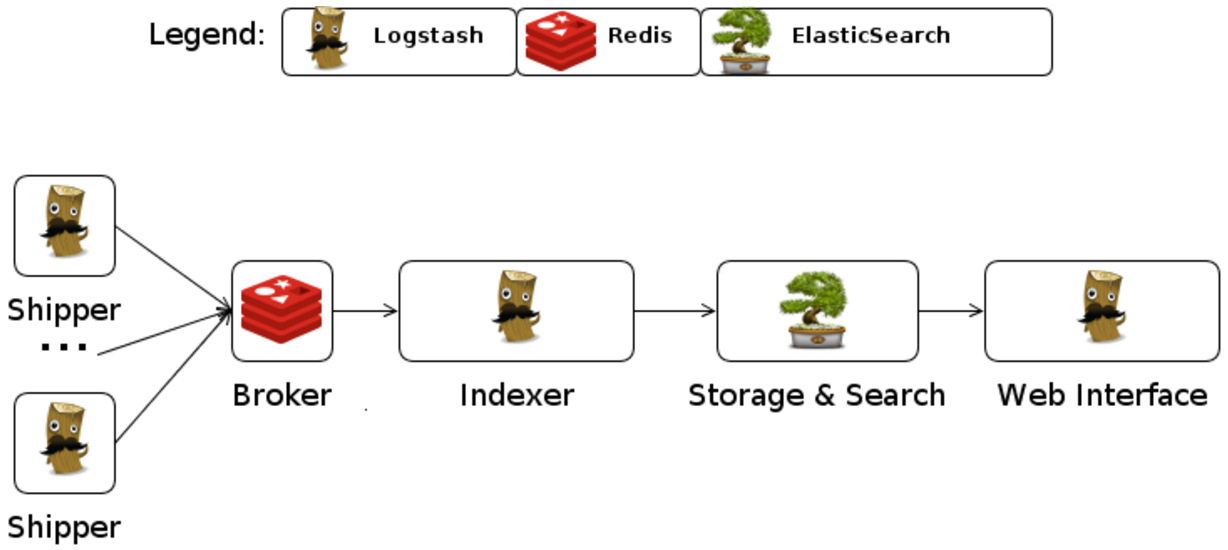
7. Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。
Logstash用JRuby开发,所有运行时依赖JVM。
Logstash的部署架构如下图,当然这只是一种部署的选项。
一个典型的Logstash的配置如下,包括了Input,filter的Output的设置。
input {
file {
type => "apache-access"
path => "/var/log/apache2/freeoa-net_access.log"
}
file {
type => "apache-error"
path => "/var/log/apache2/error.log"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
stdout { }
redis {
host => "192.168.10.20"
data_type => "list"
key => "logstash"
}
}
几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSearch的情况下,logstash是首选。
8. Splunk Forwarder
以上的所有系统都是开源的,在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据存储,数据分析和处理,以及数据展现的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
Search Head负责数据的搜索和处理,提供搜索时的信息抽取。
Indexer负责数据的存储和索引
Forwarder,负责数据的收集,清洗,变形,并发送给Indexer
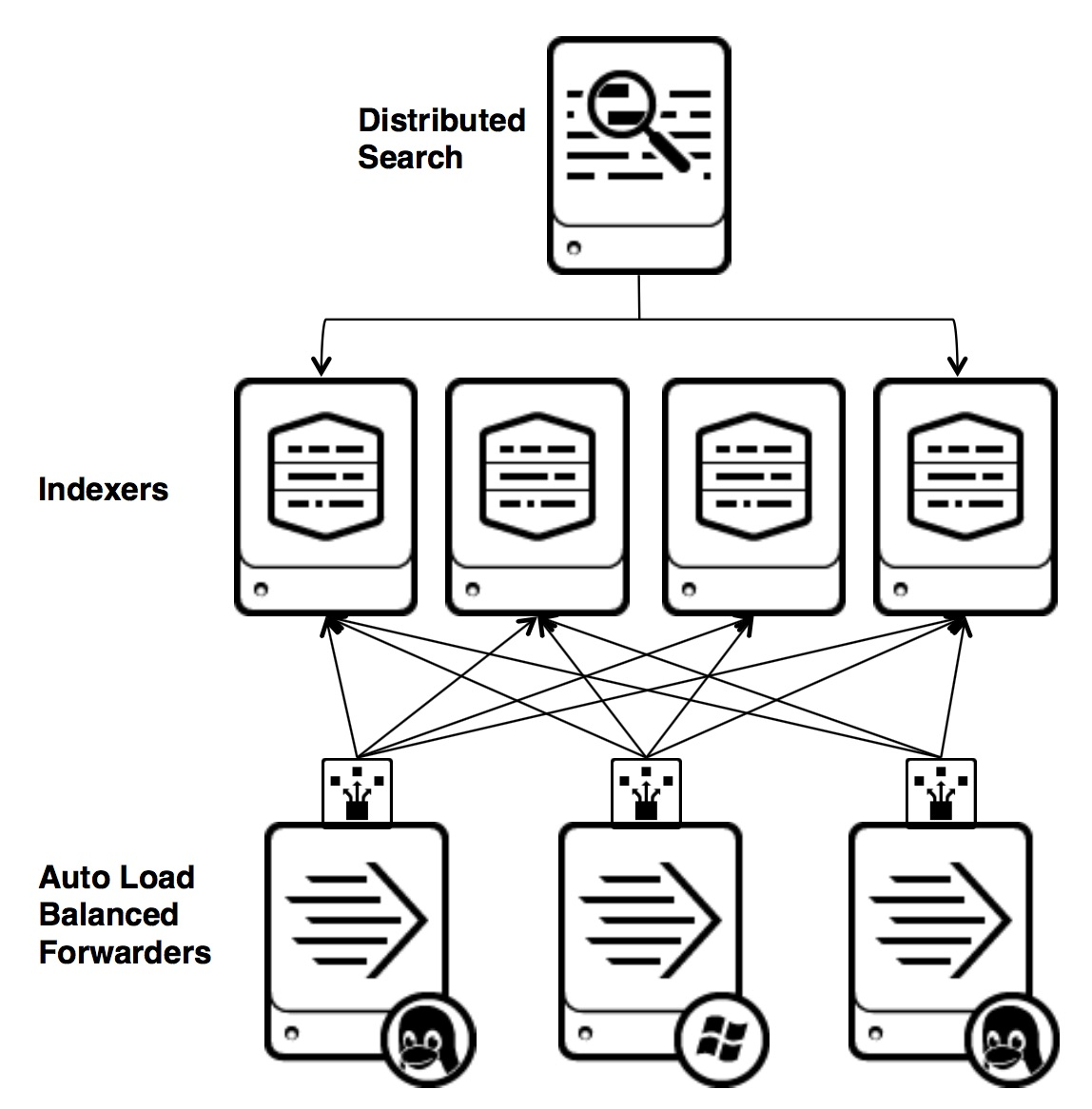
Splunk内置了对Syslog,TCP/UDP,Spooling的支持,同时,用户可以通过开发Script Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以方便的从云或者是数据库中获取数据进入Splunk的数据平台做分析。
这里要注意的是,Search Head和Indexer都支持Cluster的配置,也就是高可用,高扩展的,但是Splunk现在还没有针对Farwarder的Cluster的功能。也就是说如果有一台Farwarder的机器出了故障,数据收集也会随之中断,并不能把正在运行的数据采集任务Failover到其它的Farwarder上。
9. 从 Elasticsearch 到 Apache Doris,构建新一代日志存储分析平台
原作者:肖康,SelectDB 技术副总裁
日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris 借鉴了信息检索的核心技术,在存储引擎上实现了面向 AP 场景优化的高性能倒排索引,对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,相较于 Elasticsearch 实现性价比 10 余倍的提升,以此为日志存储与分析场景提供了更优的选择。
日志数据分析的需求与特点
日志数据在企业大数据中非常普遍,其体量往往在企业大数据体系中占据非常高的比重,包括服务器、数据库、网络设备、IoT 物联网设备产生的系统运维日志,与此同时还包含了用户行为埋点等业务日志。日志数据对于保障系统稳定运行和业务发展至关重要:基于日志的监控告警可以发现系统运行风险,及时预警;在故障排查过程中,实时日志检索能帮助工程师快速定位到问题,尽快恢复服务;日志报表能通过长历史统计发现潜在趋势。而用户埋点日志数据则是用户行为分析以及智能推荐业务所依赖的决策基础,有助于用户需求洞察与体验优化以及后续的业务流程改进。
由于其在业务中能发挥的重要意义,因此构建统一的日志分析平台,提供对日志数据的存储、高效检索以及快速分析能力,成为企业挖掘日志数据价值的关键一环。而日志数据和应用场景往往呈现如下的特点:
1).数据增长快:每一次用户操作、系统事件都会触发新的日志产生,很多企业每天新增日志达到几十甚至几百亿条,对日志平台的写入吞吐要求很高;
2).数据总量大:由于自身业务和监管等需要,日志数据经常要存储较长的周期,因此累积的数据量经常达到几百 TB 甚至 PB 级,而较老的历史数据访问频率又比较低,面临沉重的存储成本压力;
3).时效性要求高:在故障排查等场景需要能快速查询到最新的日志,分钟级的数据延迟往往无法满足业务极高的时效性要求,因此需要实现日志数据的实时写入与实时查询。
这些日志数据和应用场景的特点,为承载存储和分析需求的日志平台提出了如下挑战:
1).高吞吐实时写入:既需要保证日志流量的大规模写入,又要支持低延迟可见;
2).低成本大规模存储:既要存储大量的数据,又要降低存储成本;
3).支持文本检索的实时查询:既要能支持日志文本的全文检索,又要做到实时查询响应;
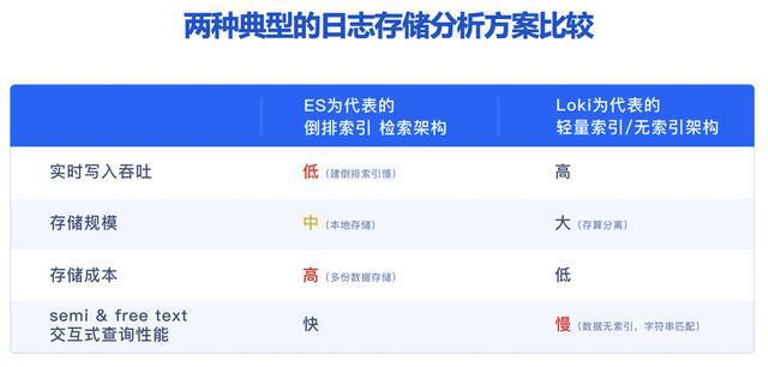
业界日志存储分析解决方案
当前业界有两种比较典型的日志存储与分析架构,分别是以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构,如果我们从实时写入吞吐、存储成本、实时交互式查询性能等几方面进行对比,不难发现以下结论:
1).以 ES 为代表的倒排索引检索架构,支持全文检索、查询性能好,因此在日志场景中被业内大规模应用,但其仍存在一些不足,包括实时写入吞吐低、消耗大量资源构建索引,且需要消耗巨大存储成本;
2).以 Loki 为代表的轻量索引或无索引架构,实时写入吞吐高、存储成本较低,但是检索性能慢、关键时候查询响应跟不上,性能成为制约业务分析的最大掣肘。
ES 在日志场景的优势在于全文检索能力,能快速从海量日志中检索出匹配关键字的日志,其底层核心技术是倒排索引(Inverted Index)。
倒排索引是一种用于快速查找文档中包含特定单词或短语的数据结构,最早应用于信息检索领域。如下图所示,在数据写入时,倒排索引可以将每一行文本进行分词,变成一个个词(Term),然后构建词(Term)-> 行号列表(Posting List) 的映射关系,将映射关系按照词进行排序存储。当需要查询某个词在哪些行出现的时候,先在 词 -> 行号列表 的有序映射关系中查找词对应的行号列表,然后用行号列表中的行号去取出对应行的内容。这样的查询方式,可以避免遍历对每一行数据进行扫描和匹配,只需要访问包含查找词的行,在海量数据下性能有数量级的提升。
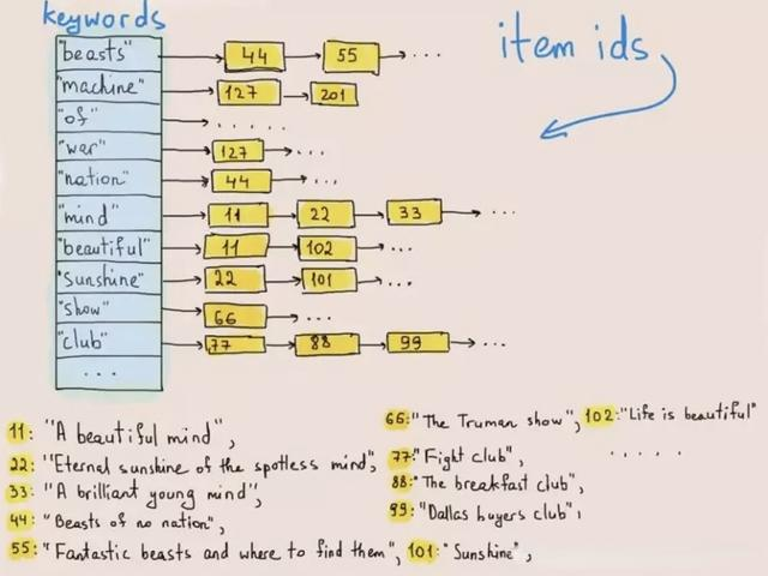
图:倒排索引原理示意
倒排索引为 ES 带来快速检索能力的同时,也付出了写入速度吞吐低和存储空间占用高的代价——由于数据写入时倒排索引需要进行分词、词典排序、构建倒排表等 CPU 和内存密集型操作,导致写入吞吐大幅下降。而从存储成本角度考虑,ES 会存储原始数据和倒排索引,为了加速分析可能还需要额外存储一份列存数据,因此 3 份冗余也会导致更高的存储空间占用。Loki 则放弃了倒排索引,虽然带来来写入吞吐和存储空间的优势,但是损失了日志检索的用户体验,在关键时刻不能发挥快速查日志的作用。成本虽然有所降低,但是没有真正解决用户的问题。
更高性价比的日志存储分析解决方案
从以上方案对比可知,以 Elasticsearch 为代表的倒排索引检索架构以及以 Loki 为代表的轻量索引/无索引架构无法同时兼顾 高吞吐、低存储成本和实时高性能的要求,只能在某一方面或某几方面做权衡取舍。如果在保持倒排索引的文本检索性能优势的同时,大幅提升系统的写入速度与吞吐量并降低存储资源成本,是否日志场景所面临的困境就迎刃而解呢?答案是肯定的。
如果希望使用 Apache Doris 来更好解决日志存储与分析场景的痛点,其实现路径也非常清晰——在数据库内部增加倒排索引、以满足字符串类型的全文检索和普通数值/日期等类型的等值、范围检索,同时进一步优化倒排索引的查询性能、使其更加契合日志数据分析的场景需求。
在同样实现倒排索引的情况下,相较于 ES, Apache Doris 怎么做到更高的性能表现呢?或者说现有倒排索引的优化空间有哪些呢?
1).ES 基于 Apache Lucene 构建倒排索引,Apache Lucene 自 2000 年开源至今已有超过 20 年的历史,设计之初主要面向信息检索领域、功能丰富且复杂,而日志和大多数 OLAP 场景只需要其核心功能,包括分词、倒排表等,而相关度排序等并非强需求,因此存在进一步功能简化和性能提升的空间;
2).ES 和 Apache Lucene 均采用 Java 实现,而 Apache Doris 存储引擎和执行引擎采用 C++ 开发并且实现了全面向量化,相对于 Java 实现具有更好的性能;
3).倒排索引并不能决定性能表现的全部,作为一个高性能、实时的 OLAP 数据库,Apache Doris 的列式存储引擎、MPP 分布式查询框架、向量化执行引擎以及智能 CBO 查询优化器,相较于 ES 更为高效。
通过在 Apache Doris 2.0.0 最新版本的探索与持续优化,在相同硬件配置和数据集的测试表现上,Doris 在数据库内核实现高性能倒排索引后,相对于 ES 实现了日志数据写入速度提升 4 倍、存储空间降低 80%、查询性能提升 2 倍,再结合 Doris 2.0 版本引入的冷热数据分离特性,整体性价比提升 10 倍以上!
接下来进一步介绍设计与实现细节。
高性能倒排索引的设计与实现
业界各类系统为了支持全文检索和任意列索引,往往有两种实现方式:一是通过外接索引系统来实现,原始数据存储在原系统中、索引存储在独立的索引系统中,两个系统通过数据的 ID 进行关联。数据写入时会同步写入到原系统和索引系统,索引系统构建索引后不存储完整数据只保留索引。查询时先从索引系统查出满足过滤条件的数据 ID 集合,然后用 ID 集合去原系统查原始数据。这种架构的优势是实现简单,借力外部索引系统,对原有系统改动小。但是问题也很明显:
1).数据写入两个系统,异常有数据不一致的问题,也存在一定冗余存储;
2).查询需在两个系统进行网络交互有额外开销,数据量大时用 ID 集合去原系统查性能比较低;
3).维护两套系统的复杂度高,将系统的复杂性从开发测转移到运维测;
而另一种方式则是直接在系统中内置倒排索引,尽管技术难度更高,但性能更好、且无需花费额外的系统维护成本,对用户更加友好,这也是 Apache Doris 所选择的方式。
数据库内置倒排索引
在选择了在数据库内核中内置倒排索引后,需要进一步对 Apache Doris 索引结构进行分析,判断能否通过在已有索引基础上进行拓展来实现。Doris 现有的索引存储在 Segment 文件的 Index Region 中,按照适用场景可以分为跳数索引和点查索引两类:
1).跳数索引:包括 ZoneMap 索引和 Bloom Filter 索引。
1.1).ZoneMap 索引对每一个数据块和文件保存 Min/Max/isnull 等汇总信息,可以用于等值、范围查询的粗粒度过滤,只能排除不满足查询条件的数据块和文件,不能定位到行,也不支持文本分词。
1.2).BloomFilter 索引也是数据块和文件级别的索引,通过 Bloom Filter 判断某个值是否在数据块和文件中,同样不能定位到行、不支持文本分词;
2).点查索引:包括 ShortKey 前缀排序索引和 Bitmap 索引。
2.1).ShortKey 在排序的基础上,根据给定的前缀列实现快速查询数据的索引方式,能够对前缀索引的列进行等值、范围查询,但不支持文本分词,另外由于数据要按前缀索引排序、因此一个表只允许一组前缀索引。
2.2).Bitmap 索引记录数据值 -> 行号 Bitmap 的有序映射,是一种很基础的倒排索引,但是索引结构比较简单、查询效率不高、不支持文本分词。
原有索引结构很难满足日志场景实时文本检索的需求,因此设计了全新的倒排索引。倒排索引在设计和实现上我们采取了无侵入的方式、不改变 Segment 数据文件格式,而是增加了新的 Inverted Index File,逻辑上在 Table 的 Column 级别。具体流程如下:
1).数据写入和 Compaction 阶段:在写 Segment 文件的同时,同步写入一个 Inverted Index 文件,文件路径由 Segment ID + Index ID 决定。写入 Segment 的 Row 和 Index 中的 Doc 一一对应,由于同步顺序写入,Segment 中的 Rowid 和 Index 中的 Docid 完全对应。
2).查询阶段:如果查询 Where 条件中有建了倒排索引的列,会自动去 Index 文件中查询,返回满足条件的 Docid List,将 Docid List 一一对应的转成 Rowid Bitmap,然后走 Doris 通用的 Rowid 过滤机制只读取满足条件的行,达到查询加速的效果。
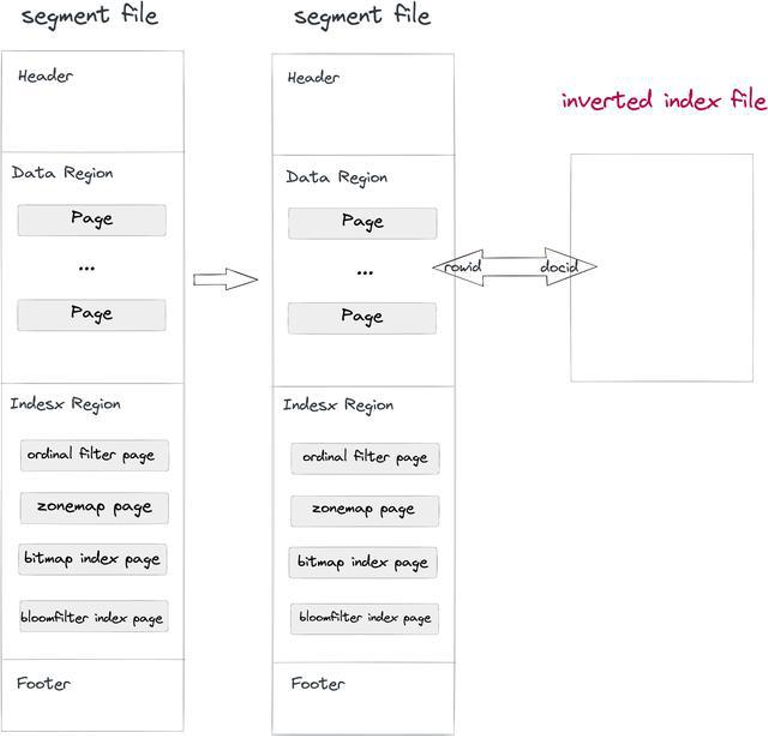
图:Doris倒排索引架构图
这个设计的好处是已有的数据文件无需修改,可以做到兼容升级,而且增减索引不影响数据文件和其他索引,用户增建索引没有负担。
通用倒排索引优化
C++和向量化实现
Apache Doris 使用 CLucene 作为底层的倒排索引库,CLucene 是一个用 C++ 实现的高性能、稳定的 Lucene 倒排索引库,它的功能比较完整,支持分词和自定义分词算法,支持全文检索查询和等值、范围查询。Doris 的存储模块和 CLucene 都用 C++ 实现,避免了Java Lucene 的 JVM GC 等开销,同样的计算 C++ 实现相对于 Java 性能优势明显,而且更利于做向量化加速。Doris 倒排索引进行了向量化优化,包括分词、倒排表构建、查询等,性能得到进一步提升。整体来看 Doris 的倒排索引写入速度可以超过单核 20MB/s,而 ES 的单核写入速度不到 5MB/s,有 4 倍的性能优势。
列式存储和压缩
Lucene 本身是文档存储模型,主数据采用行存,而 Doris 中不同列的倒排索引是相互独立的,因此倒排索引文件也采用列式存储,有利于向量化构建索引和提高压缩率。采用压缩比高且速度快的 ZSTD,通常可以达到 5 ~10倍的压缩比,与常用的GZIP压缩相比有50%以上的空间节省且速度更快。
BKD 索引与数值、日期类型列优化
针对数值、日期类型的列,我们还实现了 BKD 索引,可以对范围查询提高性能,存储空间也相对于转成定长字符串更加高效,具有以下主要特性和优势:
1).高效范围查询:BKD 索引采用多维数据结构,为范围查询带来高效率。它能迅速定位数值或日期类型列中所需的数据范围,降低查询时间复杂度。
2).存储空间优化:与其他索引方法相比,BKD 索引在存储空间使用上更高效。通过聚合并压缩相邻数据块,减少索引所需存储空间,降低存储成本。
3).多维数据支持:BKD 索引具备良好扩展性,支持多维数据类型,如地理坐标(GEO poInt)和范围(Range),使其在处理复杂数据类型时具有高适应性。
此外,我们在原有 BKD 索引能力基础上进行了进一步拓展:
1).优化低基数场景:针对数值分布集中、单个数值倒排列表较多的低基数场景,我们调整了针对性的压缩算法,降低大量倒排表解压缩和反序列化所带来的CPU性能消耗。
2).预查询技术:针对查询结果命中数较高的场景,我们采用预查询技术进行命中数预估。若命中数显著超过阈值,可跳过索引查询,直接利用Doris在大数据量查询下的技术优势进行数据过滤。
面向 OLAP 的倒排索引优化
日志存储和分析场景对检索的需求很简单,不需要特别复杂的功能(比如相关性排序),更需要降低存储成本和快速按照条件查出数据。因此,在面对海量数据的写入和查询时,Apache Doris 还针对 OLAP 数据库的特点优化了倒排索引的结构,使其更加简洁高效。例如:
1).在写入流程保证不会多个线程写入一个索引,从而避免写入时多线程锁竞争的开销;
2).在存储结构上去掉了不必要的正排、norm 等文件,减少写入 IO 开销和存储空间占用;
3).查询过程中简化相关性打分和排序逻辑,降低不必要的开销,提升查询性能。
针对日志等数据有按时间分区、历史数据访问频度低的特点,基于独立的索引文件设计,Apache Doris 还将在后续的版本中提供更细粒度、更灵活的索引管理功能:
1).指定分区构建倒排索引,比如新增一个索引的时候指定最近7天的日志构建索引,历史数据不建索引;
2).指定分区删除倒排索引,比如删除超过1个月的日志的索引,释放访问频度低的索引存储空间。
性能测试
高性能是 Doris 倒排索引设计和实现的首要出发点,通过公开的测试数据集分别与 ES 以及 Clickhouse 进行性能测试,测试效果如下:
vs Elasticsearch
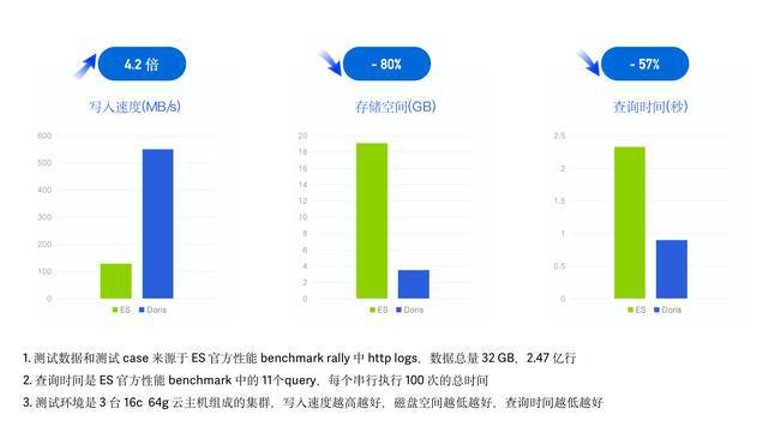
采用了 ES 官方的性能测试 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同样的硬件资源、数据、测试Case 以及测试工具下,记录并对比各自的数据写入时间、吞吐以及查询延迟。
1).测试数据:esrally HTTP Logs track 中自带测试数据集,1998 年 World Cup HTTP Server Logs,未压缩前 32G、共 2.47 亿行、单行平均长度 134 字节;
2).测试查询:esrally HTTP Logs 测试关键词检索、范围查询、聚合、排序等 11 个 Query,所有查询跑 100 次串行执行;
3).测试环境:3 台 16C 64G 云主机组成的集群。
在最终的测试结果中,Doris 写入速度是 ES 的 4.2 倍、达到 550 MB/s,写入后的数据压缩比接近 1:10、存储空间节省超**80%**,查询耗时下降 57%、查询性能是 ES 的 2.3 倍。加上冷热数据分离降低冷数据存储成本,整体相较 ES 实现 10倍以上的性价比提升。
vs Clickhouse
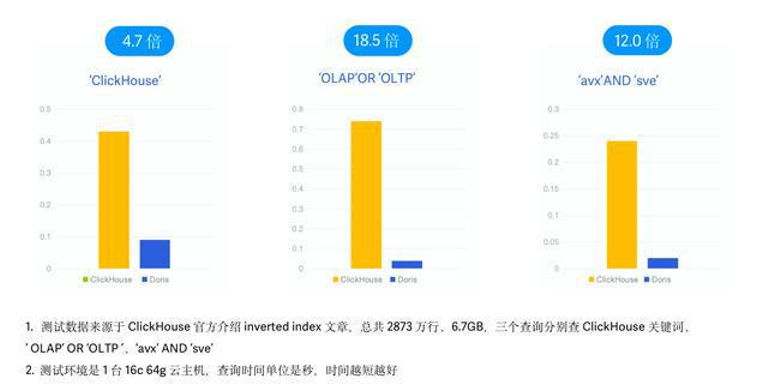
Clickhouse 近期的 v23.1 版本也引入了类似 Feature,将倒排索引作为实验性功能发布,因此我们同样进行了跟 Clickhouse 倒排索引的性能对比。在本次测试中,我们采用了 Clickhouse 官方 Inverted Index 介绍博客中使用的 Hacker News 样例数据以及查询 SQL ,同样保持相同的物理资源、数据、测试 Case 以及测试工具。参考文章
1).测试数据:Hacker News 2873 万条数据,6.7G,Parquet 格式;
2).测试查询:3 个查询,分别查询 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等关键字出现的次数;
3).测试机器:1 台 16C 64G 云主机。
在最终的测试结果中,3 个 SQL中 Doris 的查询性能分别是 Clickhouse 的 4.7 倍、12.0 倍以及 18.5 倍,有明显的性能优势。
如何使用
下面以一个 Hacker News 100 万条测试数据的示例展示 Doris 如何利用倒排索引实现高效的日志分析。
建表时指定索引
INDEX idx_comment (comment) 指定对 comment 列建一个名为 idx_comment 的索引
USING INVERTED 指定索引类型为倒排索引
PROPERTIES("parser" = "english") 指定分词类型为英文分词
CREATE TABLE hackernews_1m`id` BIGINT,`deleted` TINYINT,`type` String,`author` String,`timestamp` DateTimeV2,`comment` String,`dead` TINYINT,`parent` BIGINT,`poll` BIGINT,`children` Array,`url` String,`score` INT,`title` String,`parts` Array,`descendants` INT,INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'DUPLICATE KEY(`id`)DISTRIBUTED BY HASH(`id`) BUCKETS 10PROPERTIES ("replication_num" = "1");
注:对于已经存在的表,也可以通过 ADD INDEX idx_comment ON hackernews_1m(`comment`) USING INVERTED PROPERTIES("parser" = "english")来增加索引。值得一提的是,和 Doris 原先存储在 Segment 数据文件中的智能索引和二级索引相比,增加倒排索引的过程只会读 comment 列构建新的倒排索引文件,不会读写原有的其他数据,效率有明显提升。
导入数据后查询,使用 MATCH_ALL 在 comment 这一列上匹配 OLAP 和 OLTP 两个词,和 LIKE 扫描硬匹配相比,查询性能有十余倍的提升。(这仅是 100 万条数据下的测试效果,而随着数据量增大、性能提升越明显)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';| count() || 15 |1 row in set (0.13 sec)mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';| count() || 15 |1 row in set (0.01 sec)
更多详细功能介绍和测试步骤可以参考Apache Doris倒排索引官方文档。
小结
通过内置高性能倒排索引,Apache Doris 对于字符串类型的全文检索和普通数值、日期等类型的等值、范围检索具有更高效的支持,进一步提升了数据查询的效率和准确性,对于大规模日志数据查询分析有了更好的性能表现,为需要检索能力的用户提供了更高性价比的选择。
目前倒排索引已经支持了 String、Int、Decimal、Datetime 等常用 Scalar 数据类型和 Array 数组类型,后续还会增加对 JSONB、Map 等复杂数据类型的支持。而 BKD 索引可以支持多维度类型的索引,为未来 Doris 增加 GEO 地理位置数据类型和索引打下了基础。与此同时 Doris 在半结构化数据分析方面还有更多能力扩展,比如自动根据导入数据扩展表结构的 Dynamic Table、丰富的复杂数据类型(Array、Map、Struct、JSONB)以及高性能字符串匹配算法等。
除倒排索引以外,Doris 在 2.0.0 Alpha 版本中还实现了单节点数万 QPS 的高并发点查询能力、基于对象存储的冷热数据分离、基于代价模型的全新查询优化器以及 Pipeline 执行引擎等,欢迎下载体验。高并发点查询的详细介绍可以查看 SelectDB 技术团队过往发布的技术博客,其他功能的使用介绍请参考社区官方文档,同时也敬请持续关注后续发布的特性解读系列文章。
10. 总结
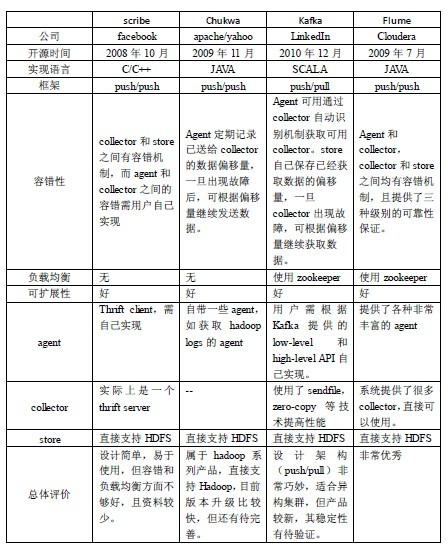
根据这四个系统的架构设计,可以总结出典型的日志系统需具备三个基本组件,分别为agent(封装数据源,将数据源中的数据发送给collector),collector(接收多个agent的数据,并进行汇总后导入后端的store中),store(中央存储系统,应该具有可扩展性和可靠性,应该支持当前非常流行的HDFS)。下面表格对比了这四个系统:
上文简单讨论了几种流行的数据收集平台,它们大都提供高可靠和高扩展的数据收集。大多平台都抽象出了输入,输出和中间的缓冲的架构。利用分布是的网络连接,大多数平台都能实现一定程度的扩展性和高可靠性。其中Flume,Fluentd是两个被使用较多的产品。如果你用ElasticSearch,Logstash也许是首选,因为ELK栈提供了很好的集成。Chukwa和Scribe由于项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据收集的解决方案。
11. 参考资料
scribe主页
chukwa主页
kafka主页
Flume主页
本文源自:开源日志系统比较,大数据系统数据采集产品的架构分析
该文章最后由 阿炯 于 2023-05-08 16:31:20 更新,目前是第 2 版。