Memcache内存分配策略和存储机制
 在正文开始前,首先了解以下几个概念:
在正文开始前,首先了解以下几个概念:Page:分配给Slab 的内存空间,默认是1MB。分配给Slab 之后根据slab 的大小切分成chunk。
Chunk:用于缓存记录的内存空间。
Slab Class:特定大小的chunk 的组。
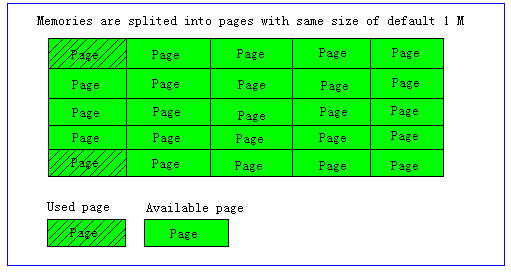
Page为内存分配的最小单位。
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配(page ressign已经从1.2.8版移除了)
Slabs划分数据空间
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。如下图,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:slab 3只存储大小介于137 到 224 bytes的数据。如果一个数据大小为230byte将被分配到slab 4中。从下图可以看出,每个slab负责的空间其实是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长因子。

Chunk才是存放缓存数据的单位
Chunk是一系列固定的内存空间,这个大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached实际存放缓存数据的地方,因为chunk的大小固定为slab能够存放的最大值,所以所有分配给当前slab的数据都可以被chunk存下。如果时间的数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。

Slab的内存分配
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。
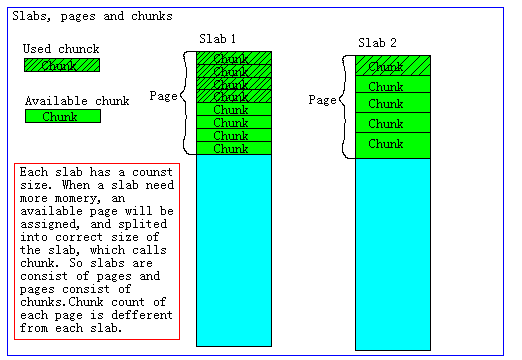
如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请。slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储数据。如下图,slab 1和slab 2都分配了一个page,并按各自的大小切分成chunk数组。
内存分配策略注意点
综合上面的介绍,memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。这里有几个特点要注意:
Memcached分配出去的page不会被回收或者重新分配
Memcached申请的内存不会被释放
slab空闲的chunk不会借给任何其他slab使用
知道了这些以后,就可以理解为什么总内存没有被全部占用的情况下,memcached却出现了丢失缓存数据的问题了(例如chuck存储时浪费的一些空间,当page分配完,而又有新数据要存入某个slab的chunk时)。
其内存没有被占用完,但是已经被分配完了,这样每个slab能够获得的内存其实已经确定了,当部分比较密集(或者开始不密集,后续增多,例如在已经基本定型的memcache上附加新的类型的应用数据,导致内存分配与数据密集程度不符)的slab出现内存不够时,会使用最久未使用算法进行移除,即使没有到达过期时间,这个时候就出现数据丢失了。但是从一些工具中,此时实际使用的内存其实没有达到最大。
理解memcached的内存存储机制
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定,分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合),如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配,以解决内存碎片问题。
Slab Allocation的构造图
Page
分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk
用于缓存记录的内存空间。
Slab Class
特定大小的chunk的组。
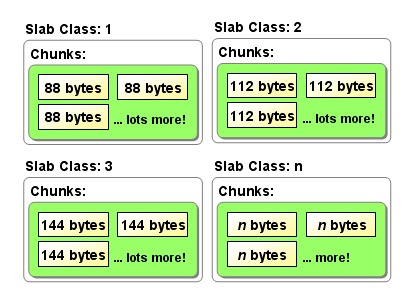
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列slabs,每个slab只负责一定范围内的数据存储。memcached根据收到的数据的大小,选择最适合数据大小的slab。memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。

选择存储记录的组的方法图
如图所示,每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:100字节大小的字符串会被存到slab2(88-112)中,每个slab负责的空间是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长比例。
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。chunk是memcached实际存放缓存数据的地方,这个大小就是管理它的slab的最大存放大小。每个slab中的chunk大小是一样的,如上图所示slab1的chunk大小是88字节,slab2是112字节。由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。这里需要注意的是chunk中不仅仅存放缓存对象的value,而且保存了缓存对象的key,expire time, flag等详细信息。所以当set 1字节的item,需要远远大于1字节的空间存放。

chunk空间的使用图
memcached在启动时指定 Growth Factor因子(通过-f选项), 就可以在某种程度上控制slab之间的差异。默认值为1.25,关于这个数值如何得来的,有如下的解释:可以在某种程度上控制slab之间的差异。默认值为1.25。但在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。让我们用以前的设置,以verbose模式启动memcached试试看:
$ memcached -f 2 -vv
下面是启动后的verbose输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从128字节的组开始,组的大小依次增大为原来的2倍。这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存。因此为尽量减少内存浪费,多年前追加了growth factor这个选项。
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10组):
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。将memcached引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。
slab的内存分配具体过程如下:
Memcached在启动时通过-m参数指定最大使用内存,但是这个不会一启动就占用完,而是逐步分配给各slab的。如果一个新的数据要被存放,首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请,slab申请内存时以page为单位,无论大小为多少,都会有1M大小的page被分配给该slab(该page不会被回收或者重新分配,永远都属于该slab)。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,再从这个chunk数组中选择一个用于存储数据。若没有空闲的page的时候,则会对改slab进行LRU,而不是对整个memcache进行LRU。
以上大致讲解了memcache的内存分配策略,下面来说明如何查看memcache的使用状况。
memcache状态和性能查看
1、命中率 :stats命令
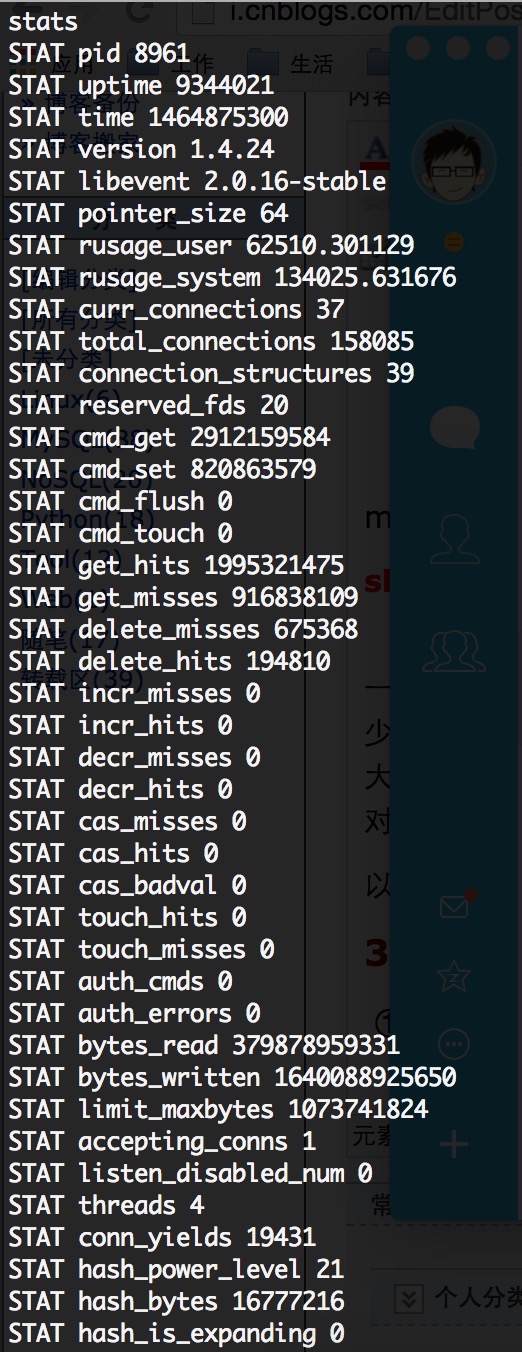
显示服务器信息、统计数据等,按照下面的图来解读分析

get_hits表示读取cache命中的次数,get_misses是读取失败的次数,即尝试读取不存在的缓存数据。即:
命中率=get_hits / (get_hits + get_misses)
命中率越高说明cache起到的缓存作用越大。但是在实际使用中,这个命中率不是有效数据的命中率,有些时候get操作可能只是检查一个key存在不存在,这个时候miss也是正确的,这个命中率是从memcached启动开始所有的请求的综合值,不能反映一个时间段内的情况,所以要排查memcached的性能问题,还需要更详细的数值。但是高的命中率还是能够反映出memcached良好的使用情况,突然下跌的命中率能够反映大量cache丢失的发生。
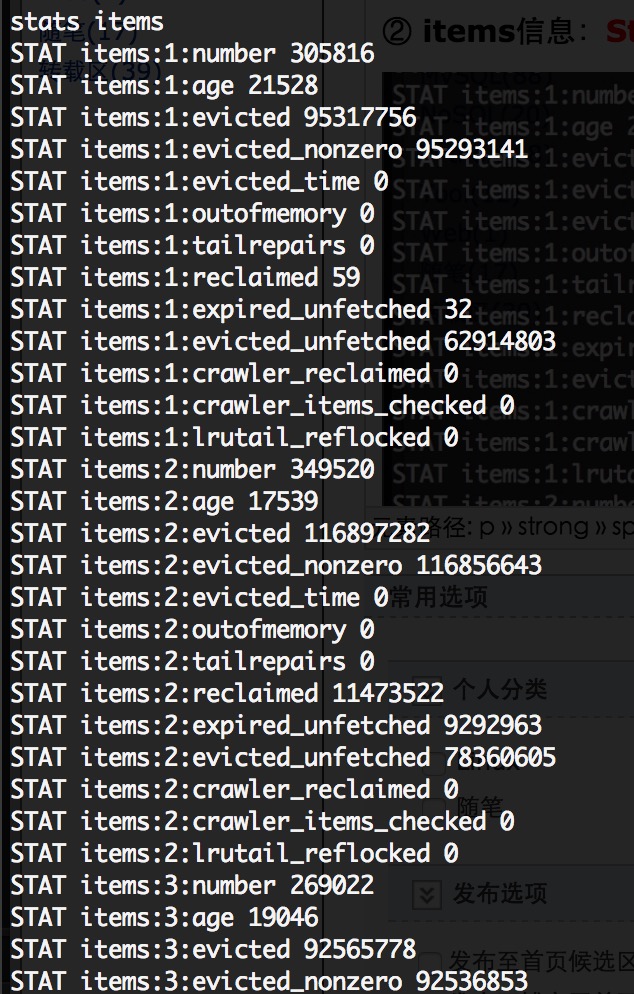
2、观察各slab的items的情况:stats items 命令(显示各个slab中item的数目和最老item的年龄(最后一次访问距离现在的秒数))
主要参数说明:
| outofmemory | slab class为新item分配空间失败的次数。这意味着你运行时带上了-M或者移除操作失败 |
| number | 存放的数据总数 |
| age | 存放的数据中存放时间最久的数据已经存在的时间,以秒为单位 |
| evicted | 不得不从LRU中移除未过期item的次数 |
| evicted_time | 自最后一次清除过期item起所经历的秒数,即最后被移除缓存的时间,0表示当前就有被移除,用这个来判断数据被移除的最近时间 |
| evicted_nonzero | 没有设置过期时间(默认30天),但不得不从LRU中称除该未过期的item的次数 |
stats items:
stats items命令可以查看每个slab中存储的item的一些详细信息。关键属性有:
最后被剔除的数据在cache中存放的时间,以秒为单位。
stats items可以详细的观察各slab的数据对象的情况,因为memcached的内存分配策略导致一旦memcached的总内存达到了设置的最大内存,代表所有的slab能够使用的page都已经固定,这个时候如果还有数据放入,将开始导致memcached使用LRU策略剔除数据。而LRU策略不是针对所有的slabs,而是只针对新数据应该被放入的slab,例如有一个新的数据要被放入slab 3,则LRU只对slab 3进行。通过stats items就可以观察到这些剔除的情况。
具体分析如下:
evicted属性:如果一个slab的evicted属性不是0,则说明当前slab出现了提前剔除数据的情况,这个slab可能是你需要注意的。
evicted_time属性:如果evicted不为0,则evicited_time代表最后被剔除的数据时间缓存的时间。并不是发生了LRU就代表memcached负载过载了,因为有些时候在使用cache时会设置过期时间为0,注意,为0并不代表永远不过期,这样缓存将被存放30天,如果内存慢了还持续放入数据,而这些未过期的数据很久没有被使用,则可能被剔除。需要注意的是,最后剔除的这个数据已经被缓存的时间,把evicted_time换算成标准时间看下是否已经达到了你可以接受的时间,例如:你认为数据被缓存了2天是你可以接受的,而最后被剔除的数据已经存放了3天以上,则可以认为这个slab的压力其实可以接受的;但是如果最后被剔除的数据只被缓存了20秒,不用考虑,这个slab已经负载过重了。
age属性:age属性反应了当前还在缓存的数据中最久的时间,它的大小和evicted_time没有必然的大小关系,因为可能时间最久的数据确实频繁被读取的,这时候不会被LRU清理掉,但是如果它小于evicted_time的话,则说明数据在被下去读取前就被清理了,或者存放了很多长时间但是不被使用的缓存对象。
因为memcached的内存分配策略导致一旦memcached的总内存达到了设置的最大内存,表示所有的slab能够使用的page都已经固定,这时如果还有数据放入,将导致memcached使用LRU策略剔除数据。而LRU策略不是针对所有的slabs,而是只针对新数据应该被放入的slab,例如有一个新的数据要被放入slab 3,则LRU只对slab 3进行,通过stats items就可以观察到这些剔除的情况。
通过上面的说明可以看到当前的memcache的slab1的状态:
items有305816个,有效时间最久的是21529秒,通过LRU移除未过期的items有95336839个,通过LRU移除没有设置过期时间的未过期items有95312220个,当前就有被清除的items,启动时没有带-M参数。
3、观察各slabs的情况:stats slabs命令(显示各个slab的信息,包括chunk的大小、数目、使用情况等)
从Stats items中如果发现有异常的slab,则可以通过stats slabs查看下该slab是不是内存分配的确有问题。
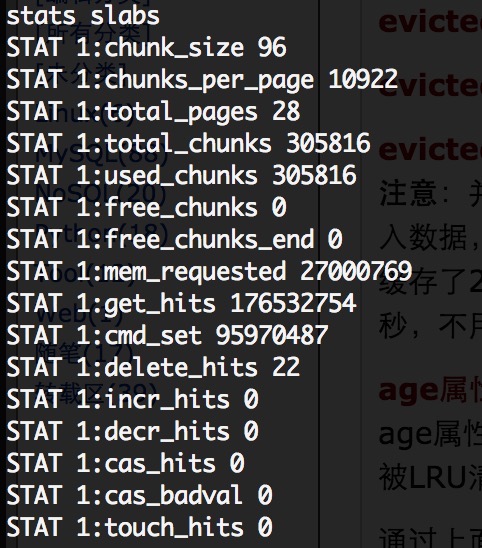
主要参数说明:
| 属性名称 | 属性说明 |
|---|---|
| chunk_size | 当前slab每个chunk的大小 |
| chunk_per_page | 每个page能够存放的chunk数 |
| total_pages | 分配给当前slab的page总数,默认1个page大小1M,可以计算出该slab的大小 |
| total_chunks | 当前slab最多能够存放的chunk数,应该等于chunck_per_page * total_page |
| used_chunks | 已经被占用的chunks总数 |
| free_chunks | 过期数据空出的chunk但还没有被使用的chunk数 |
| free_chunks_end | 新分配的但是还没有被使用的chunk数 |
这里需要注意:total_pages 这个是当前slab总共分配大的page总数,如果没有修改page的默认大小的情况下,这个数值就是当前slab能够缓存的数据的总大小(单位为M)。如果这个slab的剔除非常严重,一定要注意这个slab的page数是不是太少了。还有一个公式:
total_chunks = used_chunks + free_chunks + free_chunks_end
另外stats slabs还有2个属性:
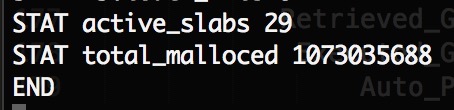
| 属性名称 | 属性说明 |
active_slabs | 活动的slab总数 |
total_malloced | 实际已经分配的总内存数,单位为byte,这个数值决定了memcached实际还能申请多少内存,如果这个值已经达到设定的上限(和stats settings中的maxbytes对比),则不会有新的page被分配。 |
stats slabs:
从stats items中如果发现有异常的slab,则可以通过stats slabs查看下该slab是不是内存分配的确有问题。这个命令的信息量很大,所有属性都很有价值。综合上面的数据,可以发现造成memcached的内存使用率降低的属性有:
chunk_size, chunk_per_page
这两个属性是固定的,但是它反映当前slab存储的数据大小,可以供你分析缓存数据的散列区间,通过调整增长因子可以改变slab的区间分布,从而改变数据散列到的区域。如果大量的230byte到260byte的数据,而刚好一个slab大小是250byte,则250byte到260byte的数据将被落到下一个slab,从而导致大量的空间浪费。
total_pages
这个是当前slab总共分配大的page总数,如果没有修改page的默认大小的情况下,这个数值就是当前slab能够缓存的数据的总大小(单位为M)。如果这个slab的剔除非常严重,一定要注意这个slab的page数是不是太少了。一个项目因为memcache之前被另外的一个项目使用过,而且memcache已经运行了很长时间,导致page都已经全部被分配完,而两个项目的缓存数据大小差别很大,导致新项目数据最多的slab 4竟然只有一个page,所以数据缓存很快就被替换了,失去了缓存的意义。针对遇到的那种情况,解决方案是重新分配page,或者重启memcache服务。但是page reassign方法从1.2.8版已经完全移除了,所以现在没有办法在线情况下重新分配page,只能重启服务。
另外一种有些时候是不可以接受的,因为一次缓存服务器的重启将导致所有缓存的数据将重新从DB取出,这个可能造成db的压力瞬间增大。而且有的缓存数据时不入库的,这个时候我们就需要做memcache的导入和导出了。
total_chunks
这个的作用和total_pages基本相同,不过这个属性可以更准确的反应实际可以存放的缓存对象总数。
used_chunks, free_chunks, free_chunks_end,这三个属性相关度比较高,从数值上来看它们满足:
total_chunks = used_chunks + free_chunks + free_chunks_end
used_chunks就是字面的意思,已经使用的chunk数;free_chunks却不是所有的未被使用的chunk数,而是曾经被使用过但是因为过期而被回收的chunk数;free_chunks_end是page中从来没有被使用过的chunk数。
为什么要分两种free chunk呢
如果free_chunks_end不为零,说明当前slab没有出现过容量不够的时候;而如果free_chunks始终为0,说明很多数据过期时间过长或者在过期前就被剔除了,这个要结合剔除数据和数据保留的时间(age属性)来看待。所以分开统计这两个值可以准确的判断实际空闲的chunk的状态,一旦所有的chunk被使用过一次以后,除非重新申请page,否则free_chunks_end始终为0。所以对于运行时间比较久的memcached,可能大部分这个值都是0。
active_slabs, total_malloced
在stats slabs输出的最后两项是两个统计数据,active_slabs一个是活动的slab总数,因为slab虽然带编号,但是这个编号不一定是连续的,因为有可能有些中间区间的slab没有值就没有初始化,这样以后该slab有值的时候就不用改变slab的编号了。所以活动的slab总数不一定等于slab的最大编号。
total_malloced这个是实际已经分配的总内存数,单位为byte,这个数值决定了memcached实际还能申请多少内存,如果这个值已经达到设定的上限,则不会有新的page被分配,以前分配的page也已经固定slab了。
综合上面的数据,可以发现造成memcached的内存使用率降低的属性有:
page中从来没有被使用过的chunks;
chunk中存放数据和chunk实际大小的差值;
由于短时间的数据集中在某个slab区域,导致大量page被分配,而之后被闲置的内存,这些即使有整个page的空闲也不会被分配给实际压力很大的slab区域,slab空间是不会互相借用的。
4、对象数量的统计:stats sizes
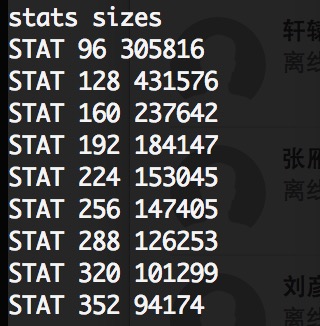
注意:该命令会锁定服务,暂停处理请求。该命令展示了固定chunk大小中的items的数量。也可以看出slab1(96byte)中有多少个chunks。
5、查看、导出key:stats cachedump
在进入memcache中,大家都想查看cache里的key,类似redis中的keys *命令,在memcache里也可以查看,但是需要2步完成。
一是先列出items:
stats items --命令
...
...
STAT items:29:number 228
STAT items:29:age 34935
...
END
二是通过itemid取key,上面的id是29,再加上一个参数:为列出的长度,0为全部列出。
stats cachedump 29 0 --命令
ITEM 26457202 [49440 b; 1467262309 s]
...
ITEM 30017977 [45992 b; 1467425702 s]
ITEM 26634739 [48405 b; 1467437677 s]
END --总共228个key
get 26634739 取value
如何导出key呢?这里就需要通过 echo ... nc 来完成了:
echo "stats cachedump 29 0" | nc 10.2.1.1 11212 >/home/freeoa/memcache.log
在导出的时候需要注意的是:cachedump命令每次返回的数据大小只有2M,这个是memcached的代码中写死的一个数值,除非在编译前修改。
6、其它的命令
stats reset
清空统计数据
stats cachedump slab_id limit_num
显示某个slab中的前limit_num个key列表,显示格式如下:
ITEM key_name [ value_length b; expire_time|access_time s],其中,memcached 1.2.2及以前版本显示的是访问时间(timestamp),1.2.4以上版本,包括1.2.4显示过期时间(timestamp),如果是永不过期的key,expire_time会显示为服务器启动的时间。
stats cachedump 7 2
ITEM copy_test1 [250 b; 1207795754 s]
ITEM copy_test [248 b; 1207793649 s]
注意:不要试图通过此命令导出Memcache服务中某个slab的所有Key列表,该命令默认只返回1M的内存数据。
stats detail [on|off|dump]
设置或者显示详细操作记录
参数为on,打开详细操作记录
参数为off,关闭详细操作记录
参数为dump,显示详细操作记录(每一个键值get、set、hit、del的次数)
stats detail dump
PREFIX copy_test2 get 1 hit 1 set 0 del 0
PREFIX copy_test1 get 1 hit 1 set 0 del 0
PREFIX cpy get 1 hit 0 set 0 del 0
7、另一个监控工具:memcached-tool,一个由perl编写的工具。
解释:
| 列 | 含义 |
| # | slab class编号 |
| Item_Size | chunk大小 |
| Max_age | LRU内最旧的记录的生存时间 |
| pages | 分配给Slab的页数 |
| count | Slab内的记录数、chunks数、items数、keys数 |
| Full? | Slab内是否含有空闲chunk |
| Evicted | 从LRU中移除未过期item的次数 |
| Evict_Time | 最后被移除缓存的时间,0表示当前就有被移除 |
| OOM | -M参数? |
实际应用Memcached时,我们遇到的很多问题都是因为不了解其内存分配机制所致,希望本文能让大家初步了解Memcached在内存方便的分配机制。
本文参考自:互联网