虚拟网卡TUN/TAP学习笔记
 Tun/Tap是通过软件模拟的网络设备,提供与网络设备完全相同的功能。其中TAP模拟了以太网设备,即操作第二层数据包;TUN则模拟了网络层设备,即第三层数据包。Tun/Tap虚拟网络设备为用户空间程序提供了网络数据包的发送和接收能力。既可以当做点对点设备(TUN),也可以当做以太网设备(TAP)。不仅Linux支持Tun/Tap虚拟网络设备,其他UNIX也是支持的,只是有少许差别。Tun/Tap驱动程序实现了虚拟网卡的功能,Tun表示虚拟的是点对点设备,Tap表示虚拟的是以太网设备,这两种设备针对网络包实行不同的封装。利用Tun/Tap驱动,可以将tcp/ip协议栈处理好的网络分包传给任何一个使用Tun/Tap驱动的进程,由进程重新处理后再发到物理链路中。
Tun/Tap是通过软件模拟的网络设备,提供与网络设备完全相同的功能。其中TAP模拟了以太网设备,即操作第二层数据包;TUN则模拟了网络层设备,即第三层数据包。Tun/Tap虚拟网络设备为用户空间程序提供了网络数据包的发送和接收能力。既可以当做点对点设备(TUN),也可以当做以太网设备(TAP)。不仅Linux支持Tun/Tap虚拟网络设备,其他UNIX也是支持的,只是有少许差别。Tun/Tap驱动程序实现了虚拟网卡的功能,Tun表示虚拟的是点对点设备,Tap表示虚拟的是以太网设备,这两种设备针对网络包实行不同的封装。利用Tun/Tap驱动,可以将tcp/ip协议栈处理好的网络分包传给任何一个使用Tun/Tap驱动的进程,由进程重新处理后再发到物理链路中。在Linux网络虚拟化的领域中,TUN/TAP设备发挥着不可或缺的作用;它们是容器网络、VPN技术与虚拟机网络的核心组成部分。其巧妙地利用了 Linux “一切皆文件”的哲学,通过字符设备文件 /dev/net/tun 在内核网络协议栈与用户空间程序之间架起了一座桥梁。尽管它们完全由软件实现,但在内核看来,其行为与物理网卡无异。其核心价值在于将网络数据包的处理能力开放给用户空间。这种设计带来了极大的灵活性,催生了众多强大应用,如VPN、虚拟化网络和云原生基础设施等。
Linux 2.4 内核之后代码默认编译tun、tap驱动,使用的时候只需要将模块加载即可(modprobe tun,mknod /dev/net/tun c 10 200)。运行tun、tap设备之后,会在内核空间添加一个杂项设备(miscdevice,类比字符设备、块设备等)/dev/net/tun,实质上是主设备号10的字符设备。从功能上看,tun设备驱动主要应该包括两个部分,一是虚拟网卡驱动,其实就是虚拟网卡中对skb进行封装解封装等操作;二是字符设备驱动,用于内核空间与用户空间的交互。
源代码在/drivers/net/tun.c中,与其他netdev类似,tun这个netdev也提供open、close、read、write等API。
Tun/Tap虚拟网络设备的原理比较简单,它在Linux内核中添加了一个Tun/Tap虚拟网络设备的驱动程序和一个与之相关连的字符设备/dev/net/tun,字符设备tun作为用户空间和内核空间交换数据的接口。当内核将数据包发送到虚拟网络设备时,数据包被保存在设备相关的一个队列中,直到用户空间程序通过打开的字符设备tun的描述符读取时,它才会被拷贝到用户空间的缓冲区中,其效果就相当于,数据包直接发送到了用户空间。通过系统调用write发送数据包时其原理与此类似。
值得注意的是:一次read系统调用,有且只有一个数据包被传送到用户空间,并且当用户空间的缓冲区比较小时,数据包将被截断,剩余部分将永久地消失,write系统调用与read类似,每次只发送一个数据包。所以在编写此类程序的时候,请用足够大的缓冲区,直接调用系统调用read/write,避免采用C语言的带缓存的IO函数。
Tun/Tap是一类虚拟网卡的驱动。网卡驱动很好理解,就是netdev+driver,最后将数据包通过这些驱动发送出去,netdev可以参考内核或者OVS代码,基本使用的就是几个钩子函数。虚拟网卡就是没有物理设备的网卡,它的驱动就是需要开发人员自己编写。一般虚拟网卡用于实现物理网卡不愿意做的事情,例如tunnel封装(用于vpn,开源项目 openvpn 和 Vtun 都是利用tun/tap驱动实现的隧道封装),多个物理网卡的聚合等。一般使用虚拟网卡的方式与使用物理网卡一样,在协议栈中通过回调函数call到虚拟网卡的API,经过虚拟网卡处理之后的数据包再由协议栈发送出去。
什么是TUN/TAP设备
TUN/TAP设备是Linux内核中用于网络虚拟化的两种虚拟网络设备,主要用于创建和管理虚拟网络接口。
TUN(Network Tunneling)
TUN 设备模拟的是一个点对点的网络接口,通常用于实现路由功能。它将网络包从用户空间发送到内核,并支持IP层的协议。
TUN 设备常用于 VPN(虚拟私人网络)解决方案,能够将数据包封装在安全的隧道中进行传输。
TAP(Terminal Access Point)
TAP 设备则模拟以太网设备,允许以太网帧在用户空间与内核之间传输。它工作在数据链路层,适合处理以太网协议。
TAP 设备通常用于虚拟机和容器之间的网络通信,可以让不同的虚拟网络设备共享同一物理网络接口。
TUN与TAP之间的区别
TUN 设备:虚拟化的是点对点网络接口,工作在网络层(第三层),专门处理IP数据包。由于tun设备没有 MAC 地址,因此无法处理 ARP 请求或以太网广播。
TAP 设备:虚拟化的是以太网接口,工作在数据链路层(第二层),负责处理完整的以太网帧。tap 设备拥有 MAC 地址,可以参与桥接网络,类似于一块虚拟的以太网卡。
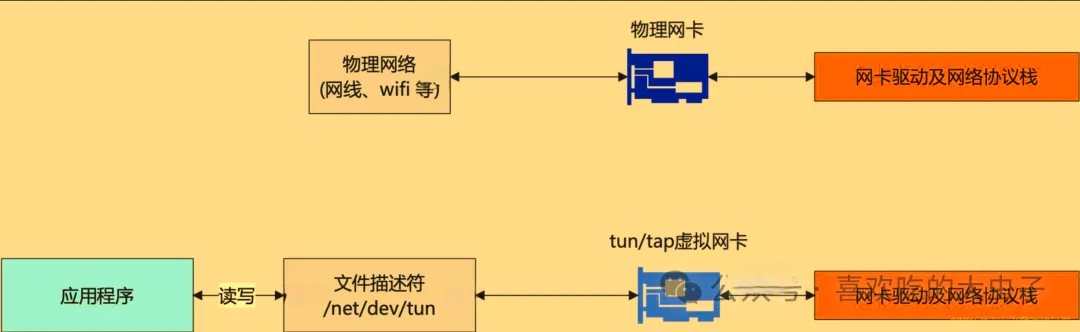
Tun/Tap有什么作用
Tun/tap设备的用处是将协议栈中的部分数据包转发给用户空间的应用程序,给用户空间的程序一个处理数据包的机会。于是比较常用的数据压缩,加密等功能就可以在应用程序中实现,tun/tap设备最常用的场景是VPN,包括tunnel以及应用层的IPSec等,比较有名的项目是VTun。
简单图示
+----------------------------------------------------------------+
| |
| +--------------------+ +--------------------+ |
| | User Application A | | User Application B |<-----+ |
| +--------------------+ +--------------------+ | |
| | 1 | 5 | |
|...............|......................|...................|.....|
| ↓ ↓ | |
| +----------+ +----------+ | |
| | socket A | | socket B | | |
| +----------+ +----------+ | |
| | 2 | 6 | |
|.................|.................|......................|.....|
| ↓ ↓ | |
| +------------------------+ 4 | |
| | Newwork Protocol Stack | | |
| +------------------------+ | |
| | 7 | 3 | |
|................|...................|.....................|.....|
| ↓ ↓ | |
| +----------------+ +----------------+ | |
| | eth0 | | tun0 | | |
| +----------------+ +----------------+ | |
| 10.32.0.11 | | 192.168.3.11 | |
| | 8 +---------------------+ |
| | |
+----------------|-----------------------------------------------+
↓
Physical Network
上图中有两个应用程序A和B,都在用户层,而其它的socket、协议栈(Newwork Protocol Stack)和网络设备(eth0和tun0)部分都在内核层,其实socket是协议栈的一部分,这里分开来的目的是为了看的更直观。
tun0是一个Tun/Tap虚拟设备,从上图中可以看出它和物理设备eth0的差别,它们的一端虽然都连着协议栈,但另一端不一样,eth0的另一端是物理网络,这个物理网络可能就是一个交换机,而tun0的另一端是一个用户层的程序,协议栈发给tun0的数据包能被这个应用程序读取到,并且应用程序能直接向tun0写数据。
这里假设eth0配置的IP是10.32.0.11,而tun0配置的IP是192.168.3.11。
这里列举的是一个典型的tun/tap设备的应用场景,发到192.168.3.0/24网络的数据通过程序B这个隧道,利用10.32.0.11发到远端网络的10.33.0.1,再由10.33.0.1转发给相应的设备,从而实现VPN。
下面来看看数据包的流程:
应用程序A是一个普通的程序,通过socket A发送了一个数据包,假设这个数据包的目的IP地址是192.168.3.1
socket将这个数据包丢给协议栈
协议栈根据数据包的目的IP地址,匹配本地路由规则,知道这个数据包应该由tun0出去,于是将数据包交给tun0
tun0收到数据包之后,发现另一端被进程B打开了,于是将数据包丢给了进程B
进程B收到数据包之后,做一些跟业务相关的处理,然后构造一个新的数据包,将原来的数据包嵌入在新的数据包中,最后通过socket B将数据包转发出去,这时候新数据包的源地址变成了eth0的地址,而目的IP地址变成了一个其它的地址,比如是10.33.0.1.
socket B将数据包丢给协议栈
协议栈根据本地路由,发现这个数据包应该要通过eth0发送出去,于是将数据包交给eth0
eth0通过物理网络将数据包发送出去
10.33.0.1收到数据包之后,会打开数据包,读取里面的原始数据包,并转发给本地的192.168.3.1,然后等收到192.168.3.1的应答后,再构造新的应答包,并将原始应答包封装在里面,再由原路径返回给应用程序B,应用程序B取出里面的原始应答包,最后返回给应用程序A。
这里不讨论Tun/Tap设备tun0是怎么和用户层的进程B进行通信的,对于Linux内核来说,有很多种办法来让内核空间和用户空间的进程交换数据。从上面的流程中可以看出,数据包选择走哪个网络设备完全由路由表控制,所以如果我们想让某些网络流量走应用程序B的转发流程,就需要配置路由表让这部分数据走tun0。
工作原理:连接用户空间与内核空间
1、TUN/TAP 设备与物理网卡的区别
物理网卡:一端连接物理网络,另一端连接网络协议栈。
TUN/TAP设备:在操作系统内部将内核网络协议栈与用户空间的应用程序相连接。一端连接应用程序,另一端连接网络协议栈。
TUN/TAP 设备的工作原理
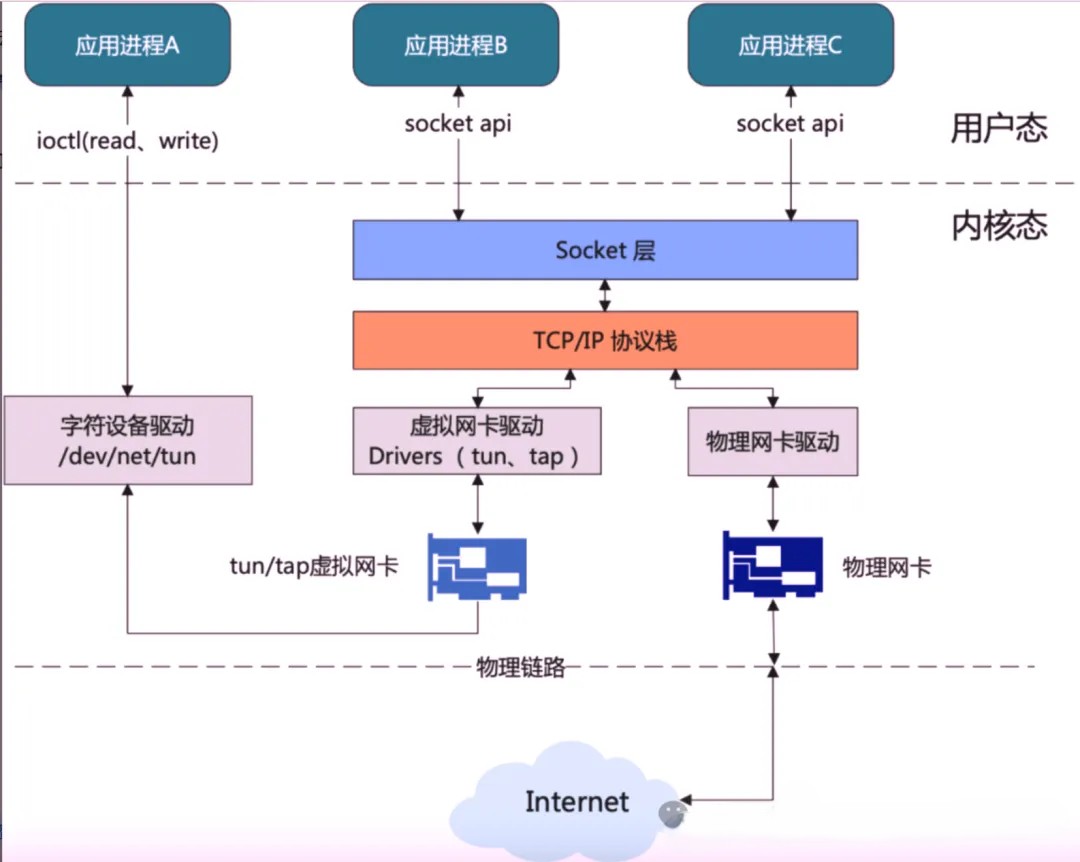
1、Socket 数据交互原理
在讲解 TUN/TAP 设备之前,先简单介绍物理设备上的数据是如何通过 Linux 网络协议栈传递到用户态程序的(参见上面章节中 TUN 设备的工作模式图,涉及应用进程B和应用进程C)。物理网卡接收到网络数据后,将其传送至内核的网络协议栈进行处理。用户态程序通过创建的 Socket 套接字从协议栈中读取数据;同样在发送数据时,用户程序也通过 Socket 将数据交给协议栈,最终由物理网卡发出。
2、TUN/TAP 设备的工作原理
从网络协议栈的角度来看,TUN/TAP 设备与物理网卡并无区别。不同之处在于 TUN/TAP 设备的数据源并非来自物理链路,而是来自用户态,这也是其最大价值所在。
TUN/TAP 设备通过 Linux 的设备文件实现内核态与用户态之间的数据交互。在访问设备文件时,会调用相应的设备驱动例程,因此设备驱动可以视为内核态与用户态之间的一个接口。以下是 TUN 设备的工作模式示意图。
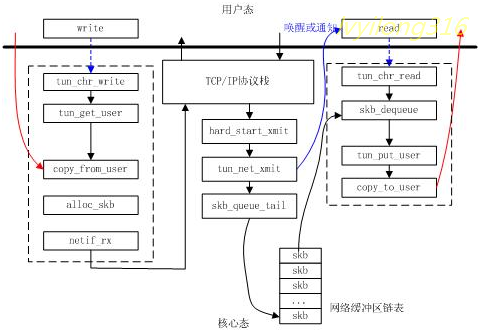
普通的物理网卡通过网线收发数据包,而 tun 设备通过一个设备文件(/dev/net/tun)收发数据包。应用的数据收发过程:
1).数据发送:应用进程 A 通过打开 /dev/net/tun 字符设备,并使用 ioctl 调用创建虚拟接口(tunx或tapx)。ioctl调用返回一个文件描述符 fd,应用进程A可以通过该描述符写入格式化的数据。这些数据通过虚拟网卡驱动到达协议栈,对于协议栈而言,这些数据就像是从真实网卡接收到的一样。
2).数据接收:当网络协议栈将数据发送到虚拟接口(tunx或tapx)时,应用进程 A 可以通过上述创建的设备文件描述符 fd 读取接口发送的数据,然后进行相应的处理。
Tun/Tap的区别
用户层程序通过tun设备只能读写IP数据包,而通过tap设备能读写链路层数据包,类似于普通socket和raw socket的差别一样,处理数据包的格式不一样。它俩的工作原理完全相同,主要区别在于:
1).TUN 设备的 /dev/net/tun 文件传输的是 IP 包,因此只能工作在网络层(L3),无法与物理网卡进行桥接,但可以通过三层交换(如ip_forward)与物理网卡连接。
2).而 TAP 设备的 /dev/net/tun 文件则处理链路层数据包。从这一点来看,TAP 虚拟设备与真实物理网卡的功能更为接近,可以实现与物理网卡的桥接。
注意事项:
1).无论是 TUN 设备还是 TAP 设备,均通过打开 /dev/net/tun 字符设备文件,并使用 ioctl 系统调用在内核中创建新的TUN或TAP设备。创建的设备不会以文件形式显示在 /dev/ 目录下,而是在 sys/class/net/ 下可以找到对应的网络接口(tunx或tapx)。
2).设备 /dev/net/tun 必须以读写模式打开,且被称为克隆设备,是创建任何 TUN/TAP 虚拟接口的起点。在执行 open 系统调用时,虚拟文件系统(VFS)会为此次操作分配一个独立的内核态文件结构。也就是说每次打开时,内核为该操作分配的文件结构实例都是不同的,代表不同的字符设备。
3、TUN/TAP 驱动
TUN/TAP 驱动程序由两个部分组成:字符设备驱动和网卡驱动。
1).网卡驱动部分负责接收来自 TCP/IP 协议栈的网络分包,并将其发送出去,或反过来将接收到的网络分包传递给协议栈进行处理。
2).字符设备驱动部分则在内核与用户态之间传输网络分包,模拟物理链路的数据接收和发送。用户态程序通过 ioctl、read 和 write 系统调用与字符设备 /dev/net/tun 进行数据交互。
数据通道实现
下面我们看tun/tap设备是如何进行数据转发的,我们从两个方向分析,首先是用户态到内核态,然后是内核态到用户态。整个过程如下图所示:
Tun/Tap网口创建
确认内核是否支持tun/tap:modinfo tun
加载内核模块# modprobe tun
创建和配置虚拟网卡
确认是否有tunctl命令,如果没有安装即可。
创建虚拟网卡设备# tunctl -t tap0 -u root
设置虚拟网卡# ifconfig tap0 192.168.9.1 netmask 255.255.255.0 promisc
经过如上操作后,虚拟网卡已经建立和配置好了。
Tun/Tap驱动程序工作原理
做为虚拟网卡驱动,Tun/Tap驱动程序的数据接收和发送并不直接和真实网卡打交道,他在Linux内核中添加了一个TUN/TAP虚拟网络设备的驱动程序和一个与之相关连的字符设备 /dev/net/tun,字符设备tun作为用户空间和内核空间交换数据的接口。当内核将数据包发送到虚拟网络设备时,数据包被保存在设备相关的一个队列中,直到用户空间程序通过打开的字符设备tun的描述符读取时,它才会被拷贝到用户空间的缓冲区中,其效果就相当于,数据包直接发送到了用户空间。通过系统调用write发送数据包时其原理与此类似。
在linux下要实现内核空间和用户空间数据的交互有多种方式:可以通用socket创建特殊套接字,利用套接字实现数据交互;通过proc文件系统创建文件来进行数据交互;还可以使用设备文件的方式,访问设备文件会调用设备驱动相应的例程,设备驱动本身就是内核空间和用户空间的一个接口,Tun/tap驱动就是利用设备文件实现用户空间和内核空间的数据交互。
从结构上来说,Tun/Tap驱动并不单纯是实现网卡驱动,同时它还实现了字符设备驱动部分,以字符设备的方式连接用户空间和内核空间。下面是示意图:
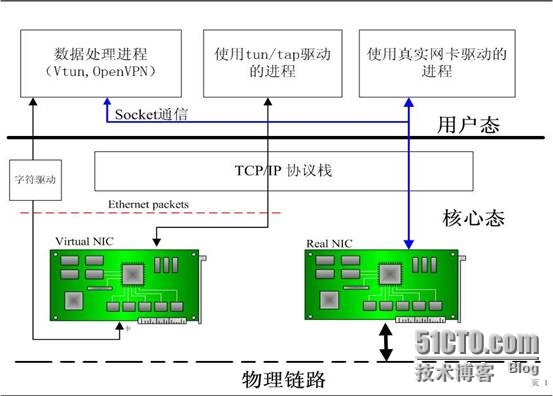
Tun/Tap驱动程序中包含两个部分,一部分是字符设备驱动,还有一部分是网卡驱动部分。利用网卡驱动部分接收来自TCP/IP协议栈的网络分包并发送或者反过来将接收到的网络分包传给协议栈处理,而字符驱动部分则将网络分包在用户空间和内核空间之间传送,模拟物理链路的数据接收和发送。Tun/Tap驱动很好的实现了两种驱动的结合。
应用场景
1、虚拟专用网络(VPN)
VPN 客户端程序会创建一个 TUN 设备(如tun0)。当操作系统需要访问远程公司内网时,目标地址为内网的IP数据包会被路由到 tun0 设备。随后 VPN 程序从 tun0 的文件描述符中读取该原始IP数据包,对其进行加密和封装(例如,封装成 UDP 包),最终通过真实的物理网卡发送给 VPN 服务器。服务器在解密后,将原始 IP 包注入其网络栈,确保数据最终送达目标内网。这一过程为用户创建了一条安全的“网络隧道”。
2、虚拟机与容器网络
在虚拟化环境中,TAP 设备发挥着关键作用。当 QEMU 等虚拟机管理器启动虚拟机时,通常会在宿主机上创建一个 TAP 设备(如tap0),作为虚拟机的“网卡接口”。该 tap0 设备会被添加到宿主机的 Linux 网桥(如br0)中,同时物理网卡也可能加入此网桥。这样虚拟机发出的以太网数据帧通过 TAP 设备被宿主机上的网络程序(如QEMU)读取,并转发到网桥,从而实现与外部网络或其他虚拟机的通信,仿佛是在使用宿主机上的真实设备。这种机制也是许多容器网络方案的基础。
TUN/TAP设备浅析
TUN设备
TUN 设备是一种虚拟网络设备,通过此设备,程序可以方便地模拟网络行为。TUN 模拟的是一个三层设备,也就是说通过它可以处理来自网络层的数据,更通俗一点的说,通过它我们可以处理 IP 数据包。先来看看物理设备是如何工作的:
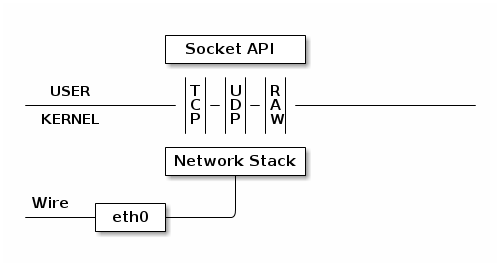
上图中的 eth0 表示我们主机已有的真实的网卡接口 (interface)。
网卡接口 eth0 所代表的真实网卡通过网线(wire)和外部网络相连,该物理网卡收到的数据包会经由接口 eth0 传递给内核的网络协议栈(Network Stack)。然后协议栈对这些数据包进行进一步的处理。
对于一些错误的数据包,协议栈可以选择丢弃;对于不属于本机的数据包,协议栈可以选择转发;而对于确实是传递给本机的数据包,而且该数据包确实被上层的应用所需要,协议栈会通过 Socket API 告知上层正在等待的应用程序。
下面看看 TUN 的工作方式:
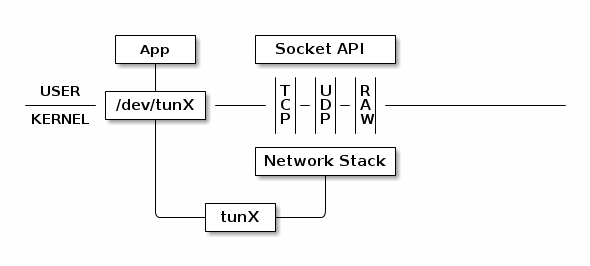
数据包处理过程
普通的网卡是通过网线来收发数据包的话,而 TUN 设备比较特殊,它通过一个文件收发数据包。如上图所示,tunX 和上面的 eth0 在逻辑上面是等价的, tunX 也代表了一个网络接口,虽然这个接口是系统通过软件所模拟出来的。
网卡接口 tunX 所代表的虚拟网卡通过文件 /dev/tunX 与我们的应用程序(App) 相连,应用程序每次使用 write 之类的系统调用将数据写入该文件,这些数据会以网络层数据包的形式,通过该虚拟网卡,经由网络接口 tunX 传递给网络协议栈,同时该应用程序也可以通过 read 之类的系统调用,经由文件 /dev/tunX 读取到协议栈向 tunX 传递的所有数据包。
此外,协议栈可以像操纵普通网卡一样来操纵 tunX 所代表的虚拟网卡。比如说给 tunX 设定 IP 地址,设置路由,总之,在协议栈看来,tunX 所代表的网卡和其他普通的网卡区别不大,当然硬要说区别,那还是有的:tunX 设备不存在 MAC 地址,这个很好理解,tunX 只模拟到了网络层,要 MAC地址没有任何意义。如果是 tapX 的话,在协议栈的眼中,tapX 和真是网卡没有任何区别。
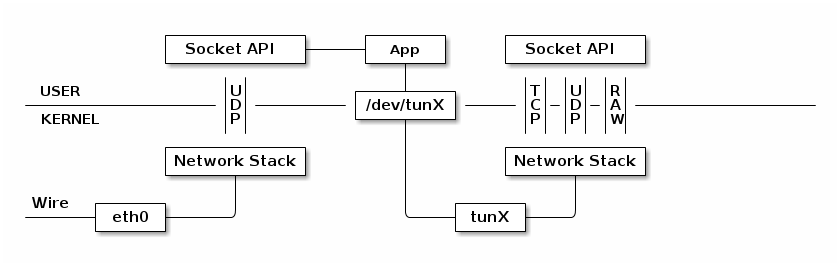
如果使用 TUN 设备搭建一个基于 UDP 的 VPN ,那么整个处理过程可能就是这幅样子。
首先应用程序通过 eth0 和远程的 UDP 程序相连,对方传递过来的 UDP 数据包经由左边的协议栈传递给了应用程序,UDP 数据包的内容其实是一个网络层的数据包,比如说 IP 数据报,应用程序接收到该数据包的数据(剥除了各种头部之后的 UDP 数据)之后,然后进行一定的处理,处理完成后将处理后的数据写入文件 /dev/tunX,这样数据会第二次到达协议栈。需要注意的是,上图中绘制的两个协议栈其实是同一个协议栈,之所以这么画是为了叙述的方便。
TAP设备
TAP 设备与 TUN 设备工作方式完全相同,区别在于:
1.TUN 设备是一个三层设备,它只模拟到了 IP 层,即网络层,可以通过 /dev/tunX 文件收发 IP 层数据包,它无法与物理网卡做 bridge,但是可以通过三层交换(如 ip_forward)与物理网卡连通。可以使用ifconfig之类的命令给该设备设定 IP 地址。
2.TAP 设备是一个二层设备,它比 TUN 更加深入,通过 /dev/tapX 文件可以收发 MAC 层数据包,即数据链路层,拥有 MAC 层功能,可以与物理网卡做 bridge,支持 MAC 层广播。同样也可以通过ifconfig之类的命令给该设备设定 IP 地址,如果愿意可以给它设定 MAC 地址。
启动设备之前
有的linux 并没有将tun 模块编译到内核之中,所以我们要做的第一件事情就是检查我们的系统是否支持 TUN/TAP。具体如何检查和解决,请查看上面的参考,这里就不再赘述。
只有 tun 模块还不够,还要创建上篇文章中所提到的文件,运行命令:
% sudo mknod /dev/net/tun c 10 200 # c表示为字符设备,10和200分别是主设备号和次设备号
这样到 /dev/net/ 目录下就可以看到一个名称为 tun 的文件了,当然这里的 tun 可以改成任意的喜欢的名称。
启动设备
对于TUN设备,一般这样来初始化:
int tun_alloc(char dev[IFNAMSIZ]) // dev数组用于存储设备的名称
{
struct ifreq ifr;
int fd, err;
if ((fd = open("/dev/net/tun", O_RDWR)) < 0) { // 打开文件
perror("open");
return -1;
}
bzero(&ifr, sizeof(ifr));
/* Flags : IFF_TUN - TUN设备
* IFF_TAP - TAP设备
* IFF_NO_PI - 不需要提供包的信息
*/
ifr.ifr_flags = IFF_TUN | IFF_NO_PI; // tun设备不包含以太网头部,而tap包含,仅此而已
if (*dev) {
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
if ((err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0) { // 打开设备
perror("ioctl TUNSETIFF");
close(fd);
return err;
}
// 一旦设备开启成功,系统会给设备分配一个名称对于tun设备,一般为tunX,X为从0开始的编号,对于tap设备
// 一般为tapX,X为从0开始的编号
strcpy(dev, ifr.ifr_name); // 拷贝设备的名称至dev中
return fd;
}
如果想启动一个TAP 设备的话,很简单,将上面的ifr.ifr_flags = IFF_TUN | IFF_NO_PI;改为ifr.ifr_flags = IFF_TAP | IFF_NO_PI;即可,那么就启动了一个 TAP 设备。
设定网络地址
上面的代码打开了文件,并且返回了文件的描述符,但是还不够,对于一张网卡来说,还要给其配置网络地址,有时候甚至是路由信息,网卡才能够正常地工作。一旦虚拟的 TUN/TAP 设备启动成功,便可以通过命令来给其设定地址。
以一个 TAP 设备为例:
% sudo ip link set dev tap0 up # 启动tap0网卡,虽然网卡已经启动,但是此时使用ipconfig命令并不能看到tap0这个设备,因为还没有给其配置ip地址
% sudo ip address add dev tap0 10.0.1.5/24 # 给tap0设置ip地址
% ifconfig # 此时在ifconfig命令下已经可以看到tap0设备了
tap0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.1.5 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::1872:80ff:fe20:46e2 prefixlen 64 scopeid 0x20<link>
ether 1a:72:80:20:46:e2 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
% ip route show # 显示所有的路由信息
default via 192.168.140.2 dev ens33 proto static metric 100
10.0.0.0/24 dev ens39 proto kernel scope link src 10.0.0.130 metric 100
10.0.1.0/24 dev tap0 proto kernel scope link src 10.0.1.5 # 给网卡设定ip后,系统自动添加了路由
192.168.140.0/24 dev ens33 proto kernel scope link src 192.168.140.133 metric 100
通过手动敲命令的方式来配置 tap0 设备,略显麻烦,其实可以直接在程序中调用 system 函数:
int run_cmd(char *cmd, ...) {
va_list ap;
char buf[CMDBUFLEN];
va_start(ap, cmd);
vsnprintf(buf, CMDBUFLEN, cmd, ap);
va_end(ap);
if (debug) { // DEBUG模式下输出信息
printf("EXEC: %s\n", buf);
}
return system(buf);
}
将上面的命令直接传递给 run_cmd 函数即可,当然如果不喜欢这种方式,还可以有其他的方法,比如说使用下面的函数:
int set_stack_attribute(char *dev){
struct ifreq ifr;
struct sockaddr_in addr;
int sockfd, err = -1;
bzero(&addr, sizeof(addr));
addr.sin_family = AF_INET;
inet_pton(AF_INET, tapaddr, &addr.sin_addr);
bzero(&ifr, sizeof(ifr));
strcpy(ifr.ifr_name, dev);
bcopy(&addr, &ifr.ifr_addr, sizeof(addr));
sockfd = socket(AF_INET, SOCK_DGRAM, 0);
if (sockfd < 0) {
perror("socket");
return -1;
}
// ifconfig tap0 10.0.1.5 #设定ip地址
if ((err = ioctl(sockfd, SIOCSIFADDR, (void *)&ifr)) < 0) {
perror("ioctl SIOSIFADDR");
goto done;
}
/* 获得接口的标志 */
if ((err = ioctl(sockfd, SIOCGIFFLAGS, (void *)&ifr)) < 0) {
perror("ioctl SIOCGIFADDR");
goto done;
}
/* 设置接口的标志 */
ifr.ifr_flags |= IFF_UP;
// ifup tap0 #启动设备
if ((err = ioctl(sockfd, SIOCSIFFLAGS, (void *)&ifr)) < 0) {
perror("ioctl SIOCSIFFLAGS");
goto done;
}
inet_pton(AF_INET, "255.255.255.0", &addr.sin_addr);
bcopy(&addr, &ifr.ifr_netmask, sizeof(addr));
// ifconfig tap0 10.0.1.5/24 #设定子网掩码
if ((err = ioctl(sockfd, SIOCSIFNETMASK, (void *) &ifr)) < 0) {
perror("ioctl SIOCSIFNETMASK");
goto done;
}
done:
close(sockfd);
return err;
}
上面的函数主要干的事情和上面的命令大致相同。
收发数据
收发数据非常简单,每次读取返回的文件描述符即可接收数据,没有数据到来时,会一直阻塞在哪里,当然也可以玩一下非阻塞 IO,然后想要发送数据的话,只需要将数据写入到该文件描述符对应的文件中即可。
原作者用一篇文章来介绍了TUN/TAP设备的应用,请点击前往。
Loopback Address and Adaptor
回环网卡(Loopback adaptor),是一种特殊的网络接口,不与任何实际设备连接,而是完全由软件实现。与回环地址(127.0.0.0/8 或 ::1/128)不同,回环网卡对系统“显示”为一块硬件。任何发送到该网卡上的数据都将立刻被同一网卡接收到。例子有 Linux 下的 lo 接口和 Windows 下的 Microsoft Loopback Interface 网卡。
The loopback address, also called localhost, is probably familiar to you. It is an internal address that routes back to the local system. The loopback address in IPv4 is 127.0.01. In IPv6, the loopback address is 0:0:0:0:0:0:0:1 or ::1.
Localhost is often considered synonymous with the IP address 127.0.0.1. Although they are functionally the same, there are substantial differences between localhost and 127.0.0.1.
Localhost is an alias used to refer to IP addresses reserved for loopback. While IPv4 uses the last block of class A addresses (from 127.0.0.1 to 127.255.255), IPv6 reserves the first (0:0:0:0:0:0:0:1 - or : :1, in short) as its loopback address.
Unix中的/etc/hosts文件中记录了这些地址。配置该主机文件可以很容易地将localhost链接到不同的IP地址,因为该文件包含IP地址到主机名的映射。因此,必须查找或解析localhost的地址,而使用127.0.0.1则直接指向该IP地址。
$ getent hosts localhost
::1 localhost ip6-localhost ip6-loopback
$ ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.012 ms
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.012/0.012/0.012/0.000 ms
$ ping6 127.0.0.1
ping6: 127.0.0.1: 不支持的主机名地址族
$ ping6 ::1
PING ::1(::1) 56 data bytes
64 bytes from ::1: icmp_seq=1 ttl=64 time=0.013 ms
--- ::1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.013/0.022/0.031/0.009 ms
0000:0000:0000:0000:0000:0000:0000:0001 or shorter 0:0:0:0:0:0:0:1 or even shorter ::1
如果在IPv6套接字上接受传入的IPv4连接,则IPv4地址必须填充为128位。这是通过预写::ffff:来完成的。所以看到的是IPv4环回地址。
当检查地址是否为IPv6环回地址时,答案将是否定的,因为::1是IPv6环回的地址。看到的地址被分类为IPv4映射的IPv6地址。映射的IPv4地址恰好是IPv4回环地址,但从IPv6堆栈的角度来看,它只是一个映射的地址。
getent tool uses functions defined and implemented by the musl library. When we run the command
$ getent hosts localhost
The tool calls the hosts_keys() function under getent.c in order to resolve the provided key. The function tries resolving by 4 methods:
gethostbyaddr for IPv6 (fails in this instance).
gethostbyaddr for IPv4 (fails in this instance).
gethostbyname2 for IPv6 (succeeds always for localhost due to hard-coded values).
gethostbyname2 for IPv4 (doesn't try due to success on #3).
All musl functions are implemented under /src/network/, see gethostbyname2() (implemented in gethostbyname2.c) calls gethostbyname2_r() (implemented in gethostbyname2_r.c), which calls __lookup_name() (in lookup_name.c). __lookup_name(), again, as a few options of how to resolve the host name, the first one being name_from_null (in the same file):
static int name_from_null(struct address buf[static 2], const char *name, int family, int flags){
int cnt = 0;
if (name) return 0;
if (flags & AI_PASSIVE) {
if (family != AF_INET6)
buf[cnt++] = (struct address){ .family = AF_INET };
if (family != AF_INET)
buf[cnt++] = (struct address){ .family = AF_INET6 };
} else {
if (family != AF_INET6)
buf[cnt++] = (struct address){ .family = AF_INET, .addr = { 127,0,0,1 } };
if (family != AF_INET)
buf[cnt++] = (struct address){ .family = AF_INET6, .addr = { [15] = 1 } };
}
return cnt;
}
At the very end, we can see that when family == AF_INET6 we will get the hard-coded value of ::1. Since getent tries IPv6 before IPv4, this would be the returned value. As I showed above, forcing resolve as IPv4 in getent will result in the hard coded 127.0.0.1 value from the function above.
If you wish to change the functionality to return IPv4 address for localhost, best thing would be to submit/request a fix for getent to search for IPv4 first.
参考来源:
Linux tun/tap设备的实现
Tun/Tap interface tutorial
Linux虚拟网络设备之tun/tap