Linux网络性能指标
 最常见的查看当前网络连接
最常见的查看当前网络连接在Linux下有多种方法来查看当前系统中的网络连接,及其状态、带宽、协议等,先看看英文原文中对连接状态的简介。
TCP Connection States
SYN_SENT
The socket is actively attempting to establish a connection.
Indicates that the sender has initiated the active open process with the receiver.
SYN_RECEIVED
A connection request has been received from the network.
Indicates that the receiver has received a SYN segment from the sender.
ESTABLISHED
The socket has an established connection.
Indicates that the receiver has received a SYN segment from the sender, the sequence numbers are synchronized, and a connection is established.
LISTEN
The socket is listening for incoming connections.
Indicates a state of readiness to accept connection requests.
FIN_WAIT_1
The socket is closed, and the connection is shutting down.
Indicates that an active close process has been initiated. This state forms the first state in the three-step connection termination process.
TIMED_WAIT
The socket is waiting after close to handle packets still in the network.
Indicates that this side is waiting for acknowledgement from another side after it has initiated an active close process. The wait period is timed by a timer mechanism on the sender's machine.
CLOSE
The socket is not being used.
CLOSING
Both sockets are shut down but we still don't have all our data sent.
CLOSE_WAIT
The remote end has shut down, waiting for the socket to close.
Indicates that a FIN segment has arrived from another side to begin the process of terminating the connection.
FIN_WAIT_2
Connection is closed, and the socket is waiting for a shutdown from the remote end.
Indicates that the acknowledgement for the FIN segment sent to another side has arrived. This state forms the second state in the three-step connection termination process.
LAST_ACK
The remote end has shut down, and the socket is closed. Waiting for acknowledgement.
Indicates that user input for terminating a connection is obtained and that a FIN segment can now be sent to complete the connection termination process. This state is the last state in the three-step connection termination process.
CLOSED
Indicates that the acknowledgement for the last FIN segment has arrived and that the connection is terminated.
UNKNOWN
The state of the socket is unknown.
1、ss
It dump socket (network connection) statistics such as all TCP / UDP connections, established connection per protocol (e.g., display all established ssh connections), display all the tcp sockets in various state such as ESTABLISHED or FIN-WAIT-1 and so on.
用于查看当前所有的tcp/udp连接情况。如:
连接情况汇总
#ss -s
所有侦听的端口
#ss -l
所有的tcp连接
#ss -t -a
所有的udp连接
#ss -u -a
2、netstat
It can display network connections, routing tables, interfaces and much more.它也是最为常见和通用的指令了。
连接情况汇总
#netstat -s
所有侦听的端口
#netstat -tulpn
所有的tcp连接
#netstat -nat
所有的udp连接
#netstat -nau
取得当前状态为'ESTABLISHED'的连接
#netstat -natu | grep 'ESTABLISHED'
tcptrack and iftop
Displays information about TCP connections it sees on a network interface and display bandwidth usage on an interface by host respectively.
tcptrack
它可以显示指定接口的tcp连接状态,可对状态、源及目标地址、带宽等进行可实时排序地察看。与top指令相似。
# tcptrack -i eth0
iftop
它可对源、目标地址的使用带宽查看。
# iftop -i eth1
显示或分析网络段的数据包流
# iftop -F 192.168.16.0/24
另外,也可以使用lsof来查看相应的端口使用情况。
# lsof -i :portNumber
# lsof -i tcp:portNumber
# lsof -i udp:portNumber
# lsof -i :80 | grep LISTEN
如果需要对流量进行详细的查看,请访问此处。
Linux 网络协议栈是根据 TCP/IP 模型来实现的,该模型由应用层、传输层、网络层和网络接口层,共四层组成,每一层都有各自的职责。
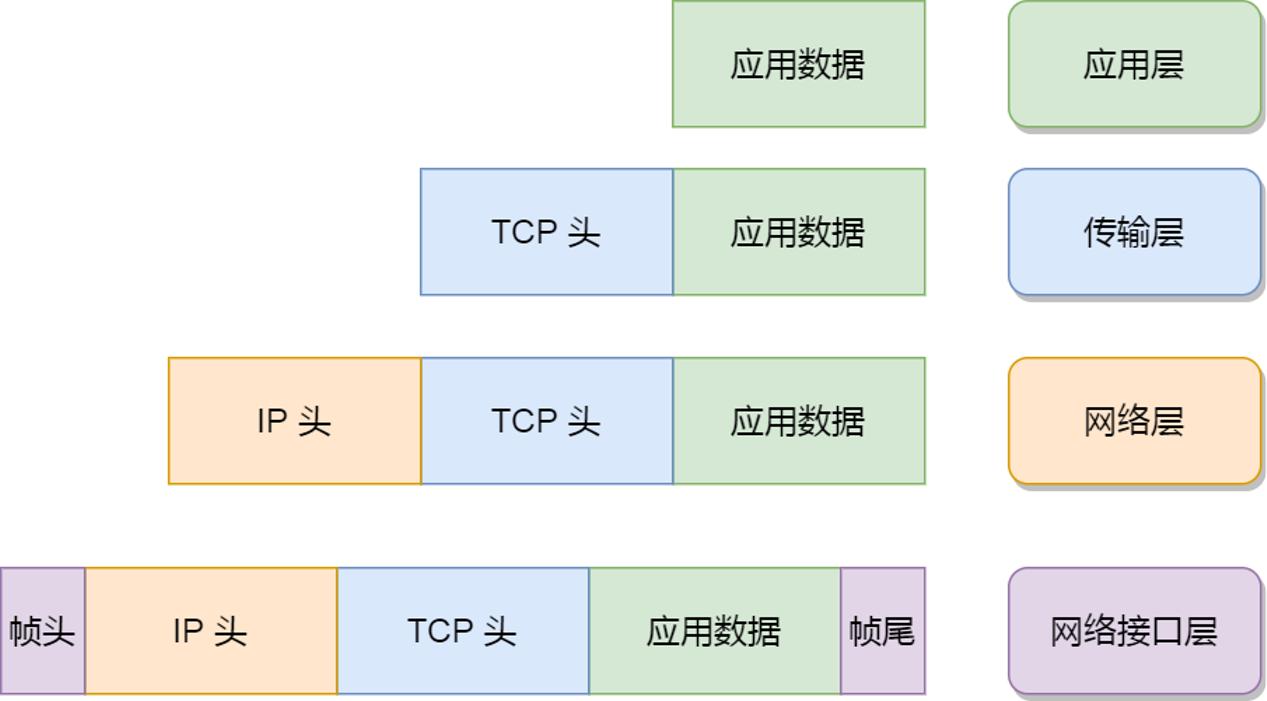
应用程序要发送数据包时,通常是通过 socket 接口,于是就会发生系统调用,把应用层的数据拷贝到内核里的 socket 层,接着由网络协议栈从上到下逐层处理后,最后才会送到网卡发送出去。而对于接收网络包时,同样也要经过网络协议逐层处理,不过处理的方向与发送数据时是相反的,也就是从下到上的逐层处理,最后才送到应用程序。
网络的速度往往跟用户体验是挂钩的,那又该用什么指标来衡量 Linux 的网络性能呢,当然是通过一系列的相关指标。
性能指标
常用性能指标
1.带宽,表示链路的最大传输速率。
2.吞吐量,表示单位时间内成功传输的数据量。
3.延时,表示从网络请求发出后,一直收到远端相应,所需要的时间延迟。
4.PPS,是 Packet Per Second(包/秒)的缩写,表示以网络包为单位的传输速率。
这四大指标可以稍细一点来说,通常是以 4 个指标来衡量网络的性能,分别是带宽、延时、吞吐率、PPS(Packet Per Second),它们表示的意义如下:
1.带宽,表示链路的最大传输速率,单位是 b/s (比特/秒),带宽越大,其传输能力就越强。
2.吞吐率,表示单位时间内成功传输的数据量,单位是 b/s(比特/秒)或者 B/s(字节/秒),吞吐受带宽限制,带宽越大,吞吐率的上限才可能越高。
3.延时,表示请求数据包发送后,收到对端响应,所需要的时间延迟。不同的场景有着不同的含义,比如可以表示建立 TCP 连接所需的时间延迟,或一个数据包往返所需的时间延迟。
4.PPS,全称是 Packet Per Second(包/秒),表示以网络包为单位的传输速率,一般用来评估系统对于网络的转发能力。
当然,除了以上这四种基本的指标,还有一些其它常用的性能指标,比如:
1.网络的可用性,表示网络能否正常通信;
2.并发连接数,表示 TCP 连接数量;
3.丢包率,表示所丢失数据包数量占所发送数据组的比率;
4.重传率,表示重传网络包的比例。
其它性能指标
网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
网络配置
# ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.116 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fed9:57d2 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:d9:57:d2 txqueuelen 1000 (Ethernet)
RX packets 108160 bytes 124836213 (119.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 96205 bytes 24091387 (22.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# ip -s addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:d9:57:d2 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.116/24 brd 192.168.1.255 scope global dynamic eth0
valid_lft 7770sec preferred_lft 7770sec
inet6 fe80::a00:27ff:fed9:57d2/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped missed mcast
125057209 108318 0 0 0 48
TX: bytes packets errors dropped carrier collsns
24120729 96362 0 0 0 0
虽然这两个命令输出的格式不尽相同,但是输出的内容基本相同,比如都包含了 IP 地址、子网掩码、MAC 地址、网关地址、MTU 大小、网口的状态以及网路包收发的统计信息,下面就来说说这些信息,它们都与网络性能有一定的关系。几个需要注意的指标:
1.网络接口的状态标志,ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的。
2.MTU 的大小。默认值是 1500 字节,其作用主要是限制网络包的大小,如果 IP 层有一个数据报要传,而且数据帧的长度比链路层的 MTU 还大,那么 IP 层就需要进行分片,即把数据报分成干片,这样每一片就都小于 MTU。事实上,每个网络的链路层 MTU 可能会不一样,所以你可能需要调大或者调小 MTU 的数值。
3.网口的 IP 地址、子网掩码、MAC 地址、网关地址。这些信息必须要配置正确,网络功能才能正常工作。
4.网络收发的字节数、包数、错误数以及丢包情况,特别是TX(发送)和RX(接收)部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
errors 表示发生错误的数据包数,比如校验错误,帧同步错误等;
dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
collisions 表示碰撞数据包数。
套接字信息
输出的内容都差不多, 比如都包含了 socket 的状态(State)、接收队列(Recv-Q)、发送队列(Send-Q)、本地地址(Local Address)、远端地址(Foreign Address)、进程 PID 和进程名称(PID/Program name)等。
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 840/systemd-resolve
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口(而不是名字)
# -p 表示显示进程信息
ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.53%lo:53 0.0.0.0:* users:(("systemd-resolve",pid=840,fd=13))
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=1459,fd=3))
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要特别关注,它们通常应该是 0。当发现其不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当 socket 状态处于 Established时:
1.Recv-Q 表示 socket 缓冲区中还没有被应用程序读取的字节数;
2.Send-Q 表示 socket 缓冲区中还没有被远端主机确认的字节数;
而当 socket 状态处于 Listen 时:
1.Recv-Q 表示全连接队列的长度;
2.Send-Q 表示全连接队列的最大长度;
在 TCP 三次握手过程中,当服务器收到客户端的 SYN 包后,内核会把该连接存储到半连接队列,然后再向客户端发送 SYN+ACK 包,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其增加到全连接队列 ,等待进程调用 accept() 函数时把连接取出来。
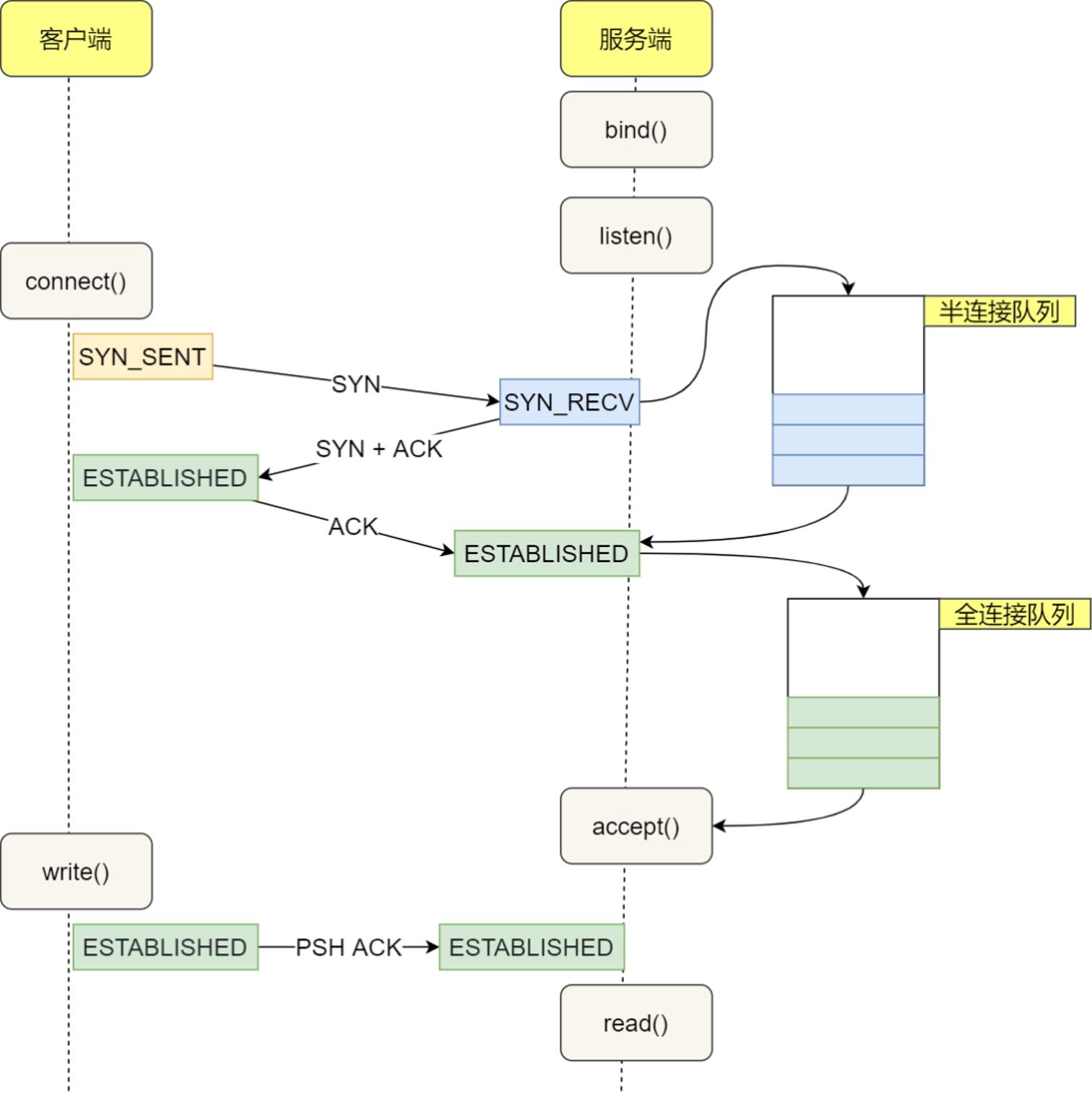
半连接队列与全连接队列
也就说,全连接队列指的是服务器与客户端完了 TCP 三次握手后,还没有被accept() 系统调用取走连接的队列。那对于协议栈的统计信息,依然还是使用 netstat 或 ss 来查看统计信息。
协议栈统计信息
netstat -s
...
Tcp:
3244906 active connection openings
23143 passive connection openings
115732 failed connection attempts
2964 connection resets received
1 connections established
13025010 segments received
17606946 segments sent out
44438 segments retransmitted
42 bad segments received
5315 resets sent
InCsumErrors: 42
...
$ ss -s
Total: 186 (kernel 1446)
TCP: 4 (estab 1, closed 0, orphaned 0, synrecv 0, timewait 0/0), ports 0
Transport Total IP IPv6
* 1446 - -
RAW 2 1 1
UDP 2 2 0
TCP 4 3 1
...
ss 命令输出的统计信息相比 netsat 比较少,ss 只显示已经连接(estab)、关闭(closed)、孤儿(orphaned) socket 等简要统计。而 netstat 则有更详细的网络协议栈信息,比如上面显示了 TCP 协议的主动连接(active connections openings)、被动连接(passive connection openings)、失败重试(failed connection attempts)、发送(segments send out)和接收(segments received)的分段数量等各种信息。
网络吞吐和 PPS
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。
sar -n DEV,显示网口的统计数据;
sar -n EDEV,显示关于网络错误的统计数据;
sar -n TCP,显示 TCP 的统计数据。
执行下面的命令就可以得到网络接口统计信息:
# 数字1表示每隔1秒输出一组数据
$ sar -n DEV 1
Linux 5.10.0-18-amd64 (freeoa.net) 2024年11月18日 _x86_64_ (4 CPU)
14时39分43秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
14时39分44秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时39分44秒 eth0 394.00 323.00 311.20 426.39 0.00 0.00 1.00 0.35
14时39分44秒 wlan0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
14时39分44秒 vpn0 1.00 1.00 0.05 0.16 0.00 0.00 0.00 0.01
rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包/秒。
rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包/秒。
%ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
连通性和延迟
ping -c3 10.206.19.98
PING 10.206.19.98 (10.206.19.98) 56(84) bytes of data.
64 bytes from 10.206.19.98: icmp_seq=1 ttl=117 time=6.46 ms
64 bytes from 10.206.19.98: icmp_seq=2 ttl=117 time=6.53 ms
64 bytes from 10.206.19.98: icmp_seq=3 ttl=117 time=6.76 ms
--- 10.206.19.98 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 6.462/6.583/6.758/0.142 ms
ping 的输出,可以分为两部分:
第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
第二部分,则是三次 ICMP 请求的汇总。
IP packet 的 TTL 与 tcp segment 的 MSL
IP 数据报头部中有个 TTL 字段,TTL 是 time to live 的缩写,即生存时间,不过其单位不是秒或分钟等具体时间,而是代表一个 IP数据报可以经过的最大路由数,IP数据报每经过一个路由器,它的值就减1,当此值为0时该数据报就会被丢弃,同时发送ICMP报文通知源主机。 TTL的初始值是由发送该数据报的源主机设置的,不同操作系统 TTL 的初始值可能不同,比如 Windows 的TTL的初始值是128,而Linux的TTL初始值大多是64。
TCP segment 的 MSL
MSL 是 Maximum Segment Lifetime 的英文缩写,可译为“报文最大生存时间/最长报文段寿命”,它是任何 TCP segment在网络上存在的最长时间,超过这个时间该报文就会被丢弃,也就是说任何 TCP Segment在网络上的存活时间都不会超过MSL。
RFC793定义了MSL为2分钟,但这完全是从工程上来考虑,对于现在的网络,MSL=2 分钟可能太长了一些,因此不同的TCP实现可以根据具体情况配置使用更小的MSL。那么如何查看MSL的值呢?在LINUX中事实上并没有直接配置 MSL而是配置了 tcp_fin_timeout,由于 tcp_fin_timeout=2MSL,所以我们可以查看tcp_fin_timeout并据此推断MSL:
### 查看 tcp_fin_timeout
sysctl net.ipv4.tcp_fin_timeout
more /proc/sys/net/ipv4/tcp_keepalive_time
### 修改 tcp_fin_timeout
sysctl -w net.ipv4.tcp_fin_timeout=30
或编辑 /etc/sysctl.conf 来实现,Linux中默认 net.ipv4.tcp_fin_timeout 的值是60s,所以MSL默认是30s。事实上通过命令 ss -no state time-wait 就能看到处于 time-wait状态的tcp连接,并能看到其剩余的超时时间:
IP 的 TTL 与 TCP 的 MSL,两者都跟数据包在网络上的传输与生存时间有关,两者不能直接在数值上对比大小,但在效果上MSL要大于TTL。为什么在 TIME_WAIT 后必须等待2MSL时间呢?主要原因有两点:
1.为了保证客户端(记为A端)发送的最后一个ACK报文段能够到达服务器端:这个ACK报文段在网络传输过程中有可能丢失,从而使处在LASK—ACK状态的服务端(记为B端)收不到对已发送的FIN报文段的回包,此时B会超时重传这个FIN报文段,而A就能在2MSL时间内收到这个重传的FIN报文段,接着A重传一次确认,重新启动2MSL计时器。最后,A和B都正常进入到CLOSED状态。如果A在TIME_WAIT状态不等待一段时间,而是在发送完ACK确认后立即释放连接,那么就无法收到B重传的FIN报文段,因而也不会再发送一次确认报文段,这样,B就无法正常进入CLOSED状态。
2.假如A发送的第一个请求连接报文段丢失而未收到确认,A就会重传一次连接请求,后来B收到了确认,建立了连接,数据传输完毕后,就释放了连接。这种情况下A共发送了两个连接请求报文段,其中第一个丢失,第二个到达了B。假如现在A发送的第一个连接请求报文段没有丢失,而是在某些网络节点长时间滞留了,以至于延误到连接释放后的某个时间才到达B,这本来是已失效的报文段,但B并不知道,就会又建立一次连接。而等待的这2MSL就是为了解决这个问题的,A在发送完最后一个确认报后再经过时间2MSL,就可以使本链接持续时间内所产生的所有报文段都从网络中消失,这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
说说MTU(Maximum Transmission Unit)
数据经过层层封装后最后通过数据链路层发往另外一个终端 , 那么当发往的数据的大小太大了,TCP/IP 就会通过分包(一个变多个),然后再传到链路层进行发送。
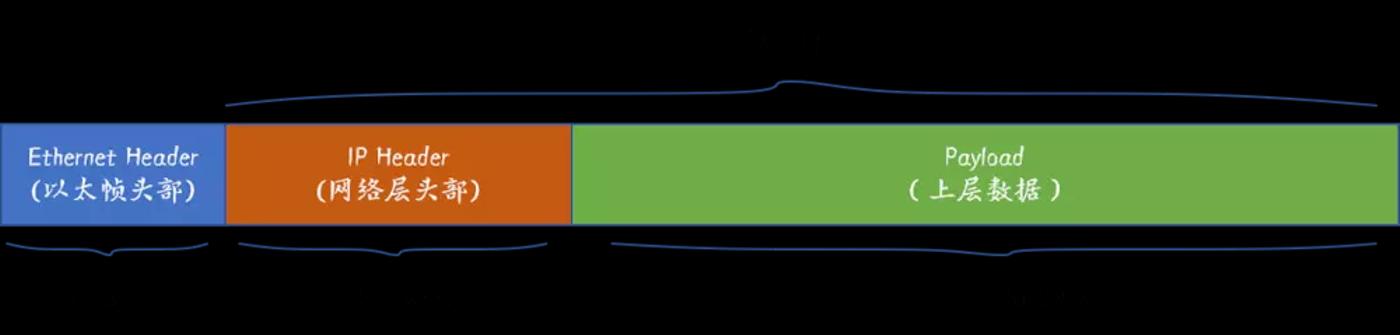
MTU大小指的是一个以太帧(Ethernet Frame)能携带的最大数据部分(payload)的以字节为单位大小,MTU的大小决定了发送端一次能够发送报文的最大字节数。当MTU值设置为9000 Bytes的时候也叫做巨型帧(Jumbo Frame):
以太帧(Ethernet Frame)
一般情况下网卡的MTU大小是1500(最大可配置到9000),然后为了在高性能的网络环境下调数据的传输效率,可以通过增加MTU只来实现,换句话说通过MTU的增加,每帧(Frame)传输的数据量就会更大。这就好比用面包车运输对比用大货车运输的区别。然而要实现大MTU需要网络里的每个设备都必须支持巨型帧,包括发送主机,目标主机以及网络中的路由器等。
如果MTU超过了接收端所能够承受的最大值,或者是超过了发送路径上途经的某台设备所能够承受的最大值,就会造成报文分片甚至丢弃,加重网络传输的负担。
如果太小,那实际传送的数据量就会过小,影响传输效率。在不同的协议中 MTU 的值是不同的 , 例如常见媒体的MTU表:
网络 MTU(Byte)
超通道 65535
16Mb/s令牌环 17914
4Mb/s令牌环 4464
FDDI 4352
以太网 1500
IEEE 802.3/802.2 1492
X.25 576
点对点(低时延) 296
ATM 48
如果IP层有一个数据报要传,而且数据帧的长度比链路层的MTU还大,那么IP层就需要进行分片(fragmentation),即把数据报分成干片,这样每一片就都小于MTU,为了解释 MTU 的概念可以看下面的例子:MTU 的值不是越大越好,更大的 MTU 意味着更低的额外开销,更小的 MTU 意味着更低的网络延迟。每一个物理设备都有自己的 MTU,两个主机之间的 MTU 依赖于底层的网络能力,它由整个链路上 MTU 最小的物理设备决定3,如下图所示,网络路径的 MTU 由 MTU 最小的红色物理设备决定,即 1000:

两台主机通信路径中的最小MTU,称为路径MTU( Path mtu,PMTU),也就是上面的这个 1000 个字节为该连接的 PMTU。
这里主要是记录如何探测网络中的MTU设置已经错误配置MTU带来的影响。
为了探测两个不同实验室的机器之间的网络是否支持Jumbo Frame, 我从实验室A的Centos主机(client) 发送ping命令到实验室B的服务器(server), 首先检查client的MTU配置:
# ifconfig eno16777736
eno16777736: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
可以看到默认的MTU值为1500, 此时我们发送一个大小为100B的ICMP数据包到目标server.
# ping -s 100 -c 1 10.245.194.61
PING 10.245.194.61 (10.245.194.61) 100(128) bytes of data.
108 bytes from 10.245.194.61: icmp_seq=1 ttl=50 time=23.0 ms
可以看到小于MTU的数据包(128 = 100 + 20(ip header) + 8(icmp header))成功地发出并得到服务器回应,接着增大包的大小到2000,超过了1500的MTU值, 同样数据ping成功ping发送并得到回应:
# ping -s 2000 -c 1 10.245.194.61
PING 10.245.194.61 (10.245.194.61) 2000(2028) bytes of data.
2008 bytes from 10.245.194.61: icmp_seq=1 ttl=50 time=24.2 ms
或许这里会有疑问,不是说最大只能发送1500字节的包吗? 为何2000字节也能成功发出?为了解答这个问题,通过wireshark抓个包来看看怎么回事
# tcpdump -i eno16777736 -s 50 -w mtu_1500.pcap
# tshark -t ud -P -O icmp,ip -Y "ip.addr==10.245.194.61" -r mtu_1500.pcap000>>mtu_1500.txt
打开mtu_1500.txt,找到ICMP包
icmp 帧
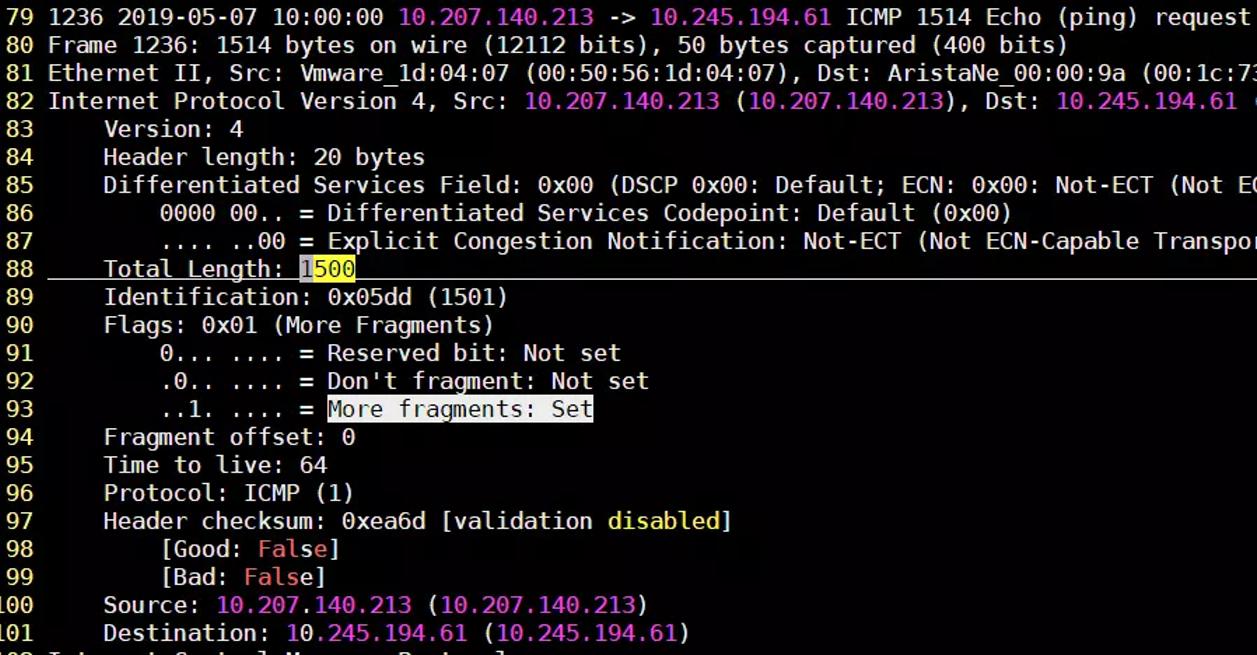
可以看到,即使指定的数据包大小是2000字节,但是IP层会根据当前MTU的设置对超过的ICMP数据进行分片(Fragmentation),以满足发送方的MTU设置要求。那么接收方是如何判定当前IP包是否被分片过?可以通过More Fragments 标志位(上图93行)和Flags字段(上图第90行)的值来判断,当接收方的IP层收到最后一个切片后(More Fragments: Not set),就会组装收到的所有切片包然后交给上层协议, 这里我们停下来想一想,IP层如何保证切片重组的顺序?其实很简单,IP包里有个Fragment offset属性,接收方可根据此属性的顺序重组切片, 此列中,理论上应当只有两个切片(1500 + 500 =2000), 所以接下来的一个Frame就是最后一个IP 切片:
第二个Fragment
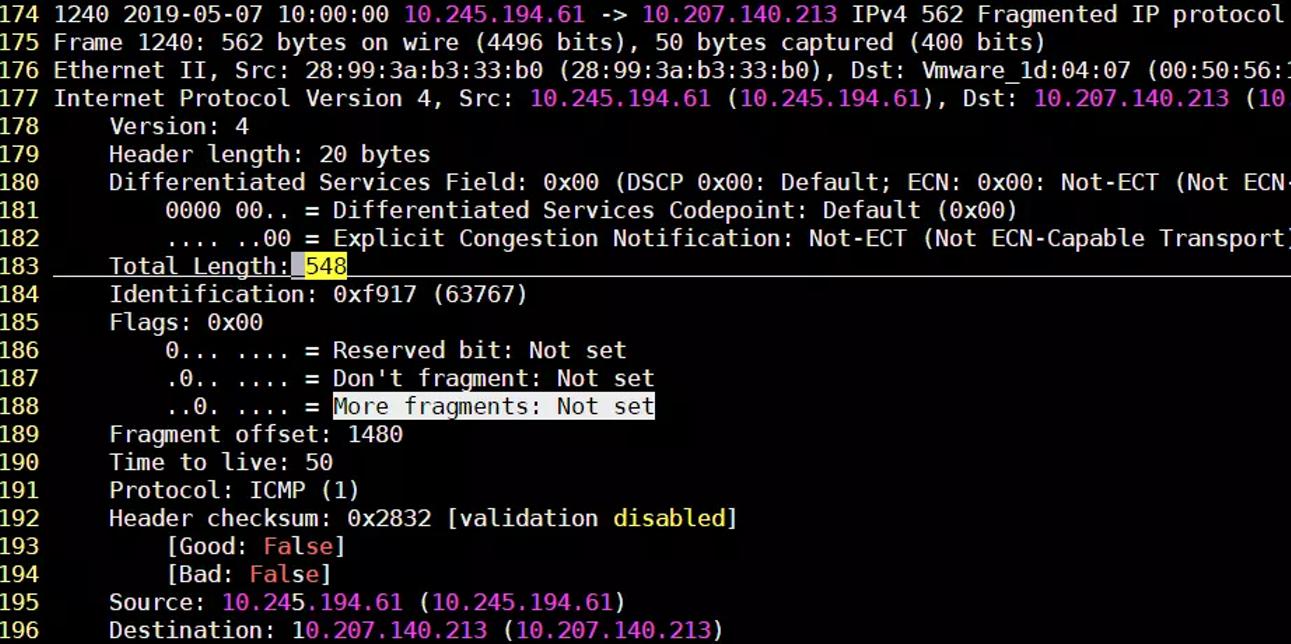
上图第二个切边也是最后一个,其IP包的大小为548字节,也就是着总的数据传输量为2048(1500+548)字节,其中1个icmp头(8B),2个ip头(20B+20B)和icmp的数据部分(2000)。所以可以看到,即便发送数据量超过了MTU的值,在IP层也会进行切片来适配所设置的MTU大小。
那么将发送发的MTU设置为9000字节启用巨型帧的话,会出现什么结果呢?
# ifconfig eno16777736 mtu 9000 up
# ifconfig eno16777736
eno16777736: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9000
设置好巨型帧以后,再来ping一个大数据包看看这次结果有什么不一样。
# ping -s 2000 -c 1 10.245.194.61
PING 10.245.194.61 (10.245.194.61) 2000(2028) bytes of data.
--- 10.245.194.61 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
增大了MTU之后,反而ping不成功!这是怎么回事? 在看看网络包:
ping with jumbo frame
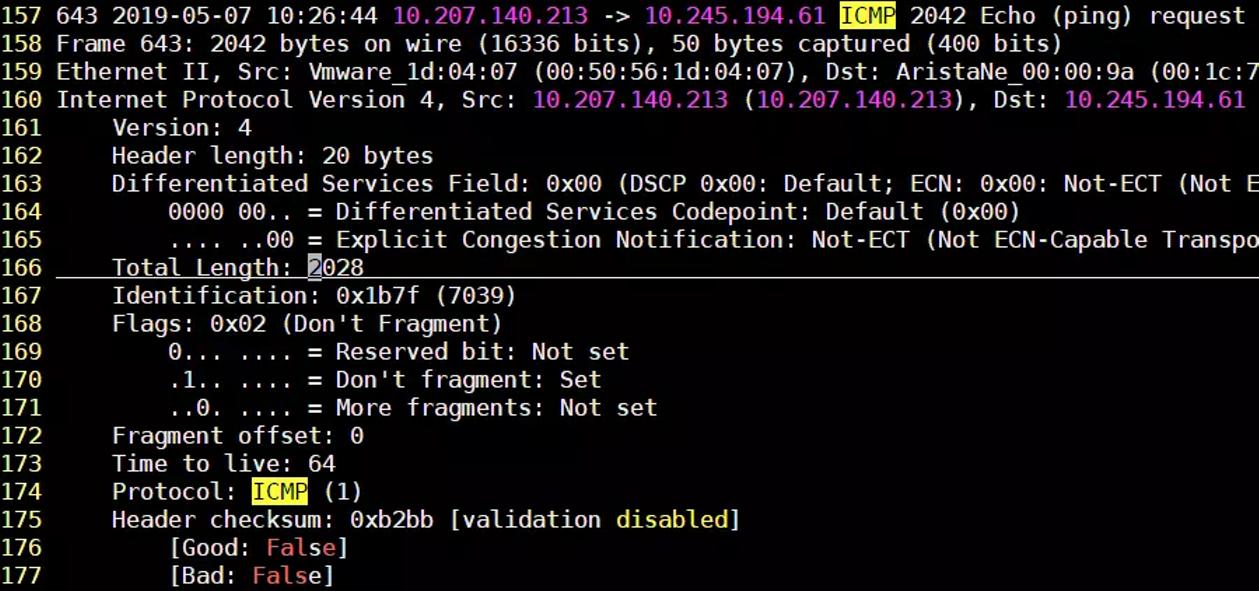
嗯,没问题,MTU设置应该是成功的,这次IP层没有分片,发送的数据也是2000字节,但是为什么服务器没有回应呢?
其实,这恰恰说明了此网络是不支持巨型帧的,只有网络里有一个转发节点的MTU值不是9000B并且发送方要求不分片(第170行, DF: Set)的情况下,转发节点会丢弃该报文。这也就是为什么会返回超时丢包的错误了。
简单来说,当一个转发点收到一个IP报文以后,先检查该报文的大小是否超过自己的MTU值,如果超过,再检查是否设置了DF标志(Don't Fragment), 如果设置,此报文将会被直接丢弃,如果没有设置Don't Fragment,那么该节点会对报文进行切片后再转发到下一个路由节点。
为什么以太网MTU通常被设置为1500
RFC标准定义以太网的默认MTU值为1500。那么这1500的取值是怎么来的呢?
早期的以太网使用共享链路的工作方式,为了保证CSMA/CD(载波多路复用/冲突检测)机制,所以规定了以太帧长度最小为64字节,最大为1518字节。最小64字节是为了保证最极端的冲突能被检测到,64字节是能被检测到的最小值;最大不超过1518字节是为了防止过长的帧传输时间过长而占用共享链路太长时间导致其他业务阻塞。所以规定以太网帧大小为64~1518字节,虽然技术不断发展,但协议一直没有更改。以太网最大的数据帧是1518字节,这样刨去帧头14字节和帧尾CRC校验部分4字节,那么剩下承载上层IP报文的地方最大就只有1500字节,这个值就是以太网的默认MTU值。该值就是网络层协议非常关心的地方,因为网络层协议比如IP协议会根据这个值来决定是否把上层传下来的数据进行分片,如果单个IP报文长度大于MTU,则会在发送出接口前被分片,被切割为小于或等于MTU长度的IP包。

MTU示意图
实际上,不同的厂商,甚至同一厂商的不同产品型号对MTU的定义也不尽相同,通常分为以下几种:
1.MTU用以指示整个IP报文的最大长度(IP头+三层Payload),MTU是一个三层的定义,即MTU = IP MTU。例如在Huawei NetEngine系列路由、CloudEngine系列交换机上,MTU是三层的定义,指IP MTU。
2.MTU的值等于IP报文与以太帧头的总和,即MTU = IP MTU + 14字节。例如在Cisco部分设备上,MTU是指IP MTU + 以太帧头。
3.MTU的值等于IP报文与以太帧头、CRC部分的总和,即MTU = IP MTU + 18字节。例如在Juniper部分设备上,MTU是指IP MTU + 以太帧头 + CRC部分。
在实际设置MTU值时,需要特别关注各厂商、产品对于MTU的定义。
IP 分片
IP 报文格式
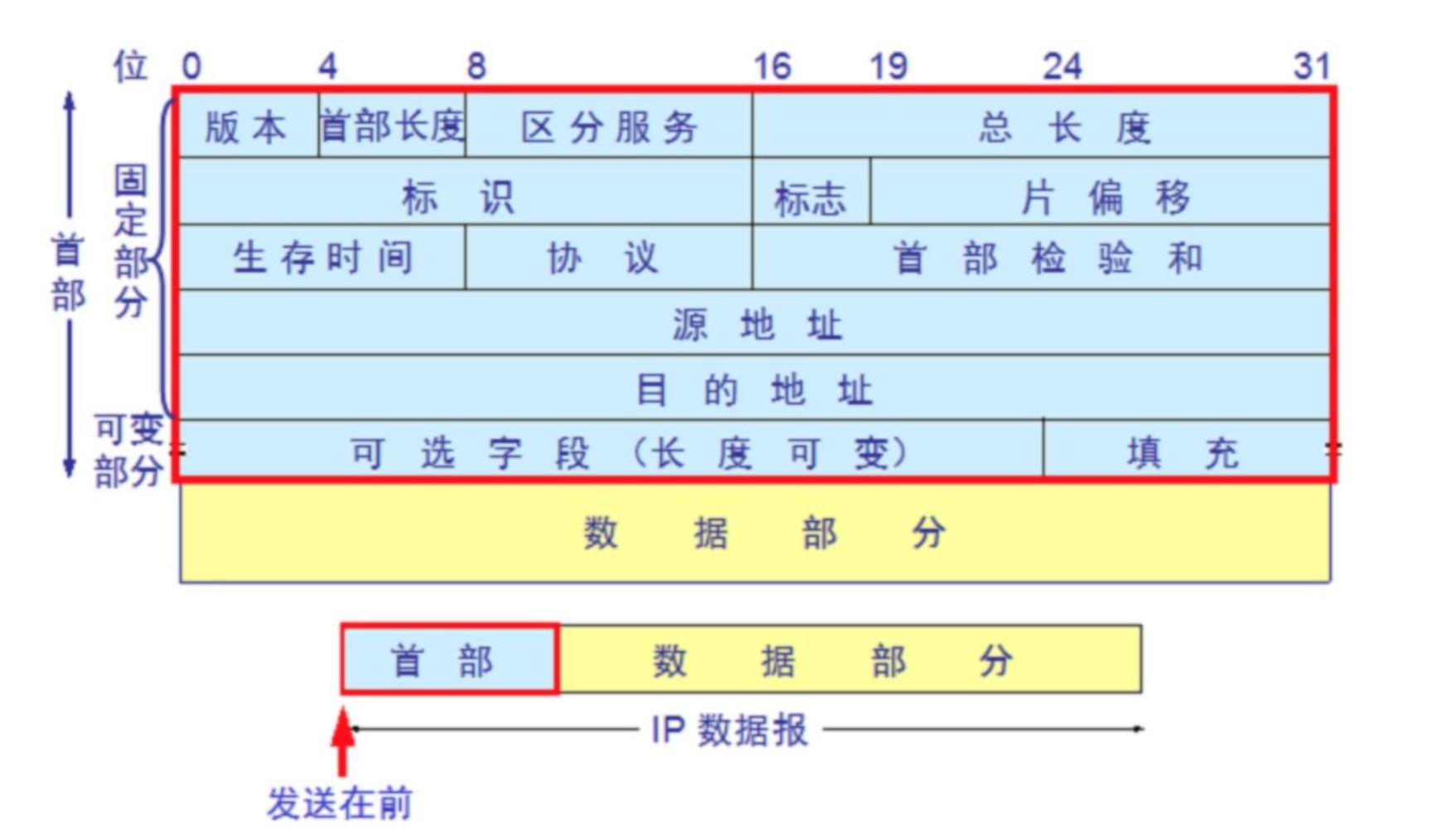
IP 分片过程
以太网缺省MTU=1500字节,这是以太网接口对IP层的约束,如果IP层有<=1500字节需要发送,只需要一个IP包就可以完成发送任务;如果IP层有>1500字节数据需要发送,需要分片才能完成发送。
以主机发送一个数据载荷长度为2000字节的报文为例说明其分片的过程(假设出接口的MTU值为1500)。在网络层会对报文进行封装,其结构组成:IP头部20字节+数据载荷长度2000字节,报文封装后,整个报文长度为2020字节。在出接口进行转发的时候,发现IP报文的长度超过了MTU的值1500,因此要进行分片处理,详情见下图。
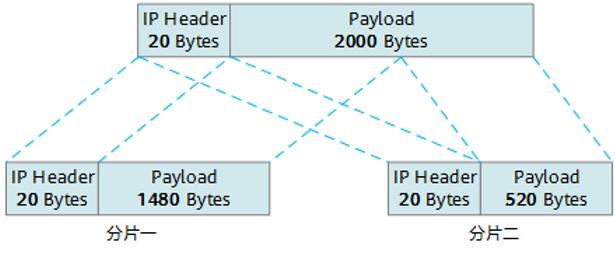
第一片报文,IP报文头固定20字节,数据载荷可以封装1480字节(MTU值1500字节-IP报文头20字节,数据载荷长度须是8的倍数);
第二片报文,复制第一片的IP头,IP报文头固定20字节,数据载荷为剩余的520字节(总数据载荷长度2000字节减去第一片中已封装的1480字节)。如果最后一片报文的长度不足46字节,会自动填充至46字节。
所有分片报文在发送至目的主机后,在目的主机进行分片重组,恢复为原报文。在进行重组时,通过IP标志位中的MF用来分辨这是不是最后一个分片,片偏移用来分辨这个分片相对原数据报的位置。通过这几个字段,可以准确的完成数据报的重组操作。
PMTU
顾名思义,Path MTU就是指传输路径的MTU,无需分片就能穿过某路径的数据包最大长度。在从发送端到接收端的传输路径上,如果网元的MTU设置不一致,则决定该路径可用MTU的,其实是整条路径上的最小MTU值。以Path MTU作为IP包长发送数据,既高效又能避免分片。
MSS(Maximum Segment Size,最大报文长度),是TCP协议定义的一个选项,MSS选项用于在TCP连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度
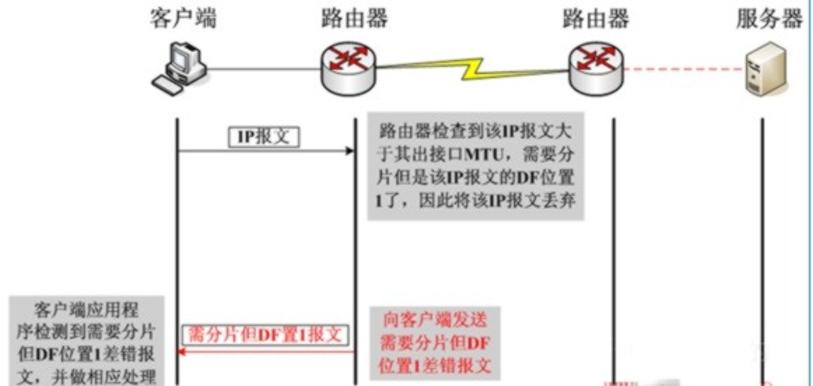
一旦DF位置一,(DF位为1的话则不允许分片)将不允许中间设备对该报文进行分片,那么在遇到IP报文长度超过中间设备转发接口的MTU值时,该IP报文将会被中间设备丢弃。在丢弃之后,中间设备会向发送方发送ICMP差错报文(告诉发送者,你发送的数据大小超过了我的MTU , 需要发小点体积的数据).这个过程如下 :
通过抓包可以看到
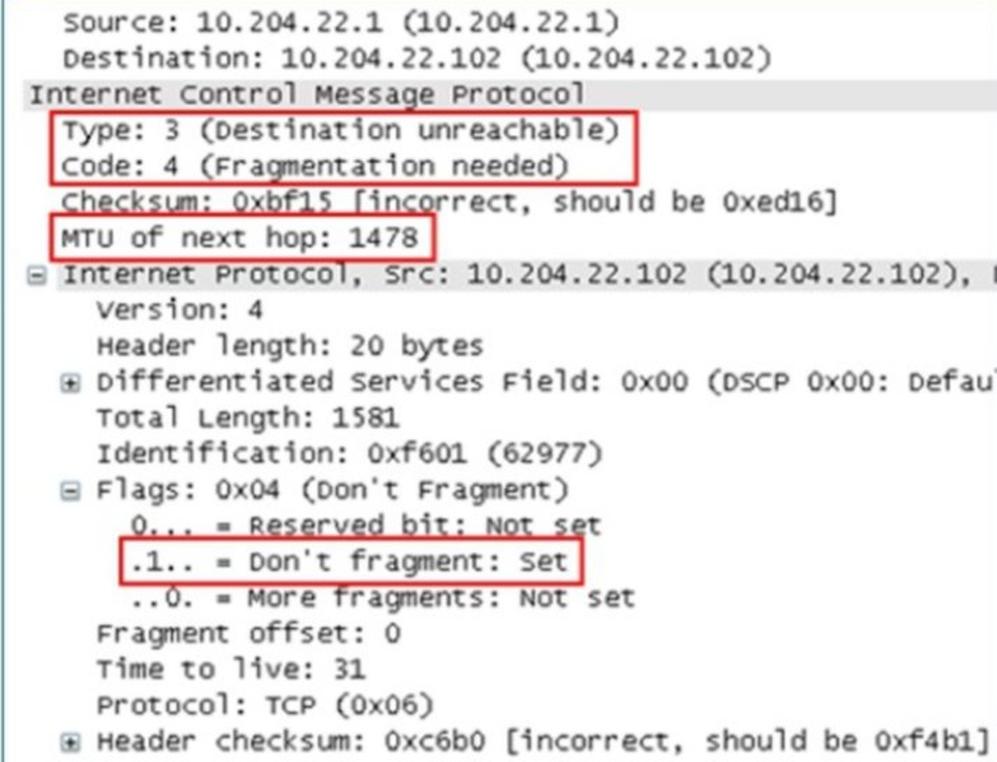
可以看到其差错类型为3,代码为4,并且告知了下一跳的MTU值为1478。在ICMP差错报文里封装导致此差错的原始IP报文的报头(包含IP报头和四层报头)。一旦出现这种因DF位置一而引起丢包,如果客户端无法正常处理的话,将会导致业务应用出现异常,外在表现为页面无法打开、页面打开不全、某些大文件无法传输等等,这将严重影响业务的正常运行。那么客户端如何处理这种状况呢?
TCP主要通过两种方式来应对:
1.协商MSS,在交互之前避免分片的产生
2.路径MTU发现(PMTUD)
PMTUD
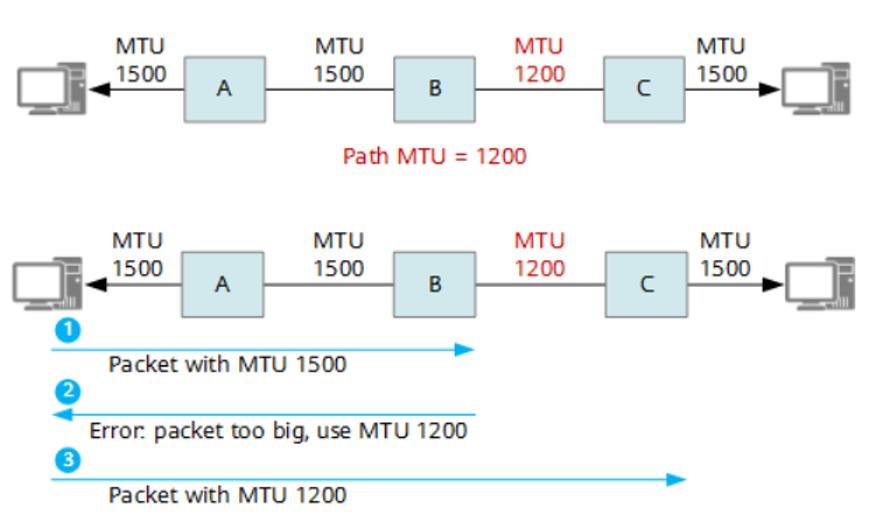
步骤一:向目的主机发送 IP 头中 DF 控制位为 1 的数据包,DF 是不分片(Don’t Fragment,DF)的缩写;路径上的网络设备根据数据包的大小和自己的 MTU 做出不同的决定:
(1) 如果数据包大于设备的 MTU,就会丢弃数据包并发回一个包含该设备 MTU 的 ICMP 消息;顺便带回去建议的MTU 大小
(2) 如果数据包小于设备的 MTU,就会继续向目的主机传递数据包;
步骤二:源主机收到 ICMP 消息后,会不断使用新的 MTU (根据带回来别人建议的 MTU 大小)发送 IP 数据包,直到 IP 数据包达到目的主机;
然后通过抓包实验可以看到这里就是置为不分片的情况。
数据包在Linux内核中的路径(The Path of a Packet Through the Linux Kernel)
网络堆栈是通信和信息交换的骨干。本节研究了 Linux 中最常见的服务器操作系统的 TCP/IPv4 和 UDP/IPv4 网络堆栈。描述了 Linux 内核 5.10.8 中最重要的网络功能的一个追踪。尽管存在 Linux 网络代码文档,但它通常已经过时,或者只涵盖了 IP 或 TCP 层等特定方面。我们全面地解决了这个问题,涵盖了数据包在 Linux 网络堆栈中的出口(egress)和入口(ingress)路径。此外,我们强调了实现的复杂性,并展示了 Linux 内核如何实现网络协议。我们的论文可以作为性能优化、安全分析、网络可观测性或调试的基础。
索引术语:Linux内核,网络堆栈,包处理
1. 引言
如今几乎所有设备都会联网,从个人电脑到冰箱[1]。尽管联网对现代计算至关重要,但很少有人了解从网线发送和接收数据包的复杂性。鉴于基于 Linux 的服务器[2],[3]的普遍性,数据包通常会穿越 Linux 网络栈。然而理解 Linux 中复杂的数据包处理需要时间和精力。尽管如此,这一知识通常至关重要,因为它有助于性能优化、安全性分析、调试和网络可观测性。
基于 Linux 内核的 5.10.8 版本 来研究数据包的入站和出站路径。该版本文档完善、稳定,并包含现代功能,如用于 Berkely Packet Filters 的即时编译器(JIT)[4]。我们主要通过内核源代码进行观察,并将其与引用的内核符号链接。尽管 Linux 内核网络变得越来越多样化,例如通过添加多路径 TCP[5],但大多数流量仍然使用标准的 TCP 和 UDP 协议栈。此外,尽管 IPv6 的采用速度加快,但大多数设备仍然通过 IPv4 进行通信[6]。因此,我们将此分析限制在 TCP/IPv4 和 UDP/IPv4 上。
本文的其余部分结构如下:首先在第 2 节中将本文与现有文献进行比较。然后在第 3 节中解释了 Linux 网络栈的一般设计和 sk_buff 数据结构。在第 4 节中深入探讨了入站和出站数据包路径的复杂性。最后在第 5 节中简要总结了最重要的发现。
2. 相关工作
我们尽所能地评估了关于 Linux 网络栈的文献。在此过程中,我们得出了以下观察结果。
过时的 Linux 内核版本。在 2000 年代,出现了更多详细的论文,使用了 Linux 内核版本 2 或 3[7]–[9]。尽管网络栈中较旧协议的实现是稳定的,但已经过去了很长时间。因此,我们研究了可能的偏差。
信息碎片化。许多论文专注于特定的层次,最常见的是 TCP 和 IP 实现[10]–[13]。其他论文则确定了网络开销的原因[14],[15]。在这些情况下,缺乏全局视角。特别是,即使作者描述了数据包在多个层次的路径时[7]–[10],他们也忽略了 UDP ——这与本文不同。
尽管有一篇涵盖 Linu x版本 5 的整个入站和出站路径的演讲[16],但它属于高层次,主要提供直觉。因此旨在在详细的层次特定信息和高级网络栈追溯之间找到一个中间地带。
3. 背景
我们假设读者对 Linux 和网络有一定的基本了解。然而,我们简要描述了在整个数据包路径中相关的重要 Linux 网络概念。
3.1. Linux网络栈
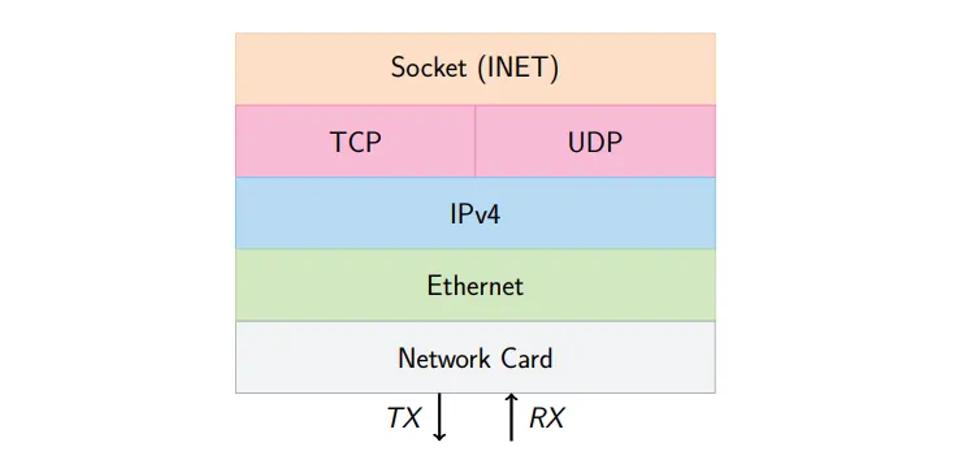
图 1:描述了在 Linux 中,从用户空间到网线的标准 TCP/IP 和 UDP/IP 栈所使用的技术
如图 1 所示,一个套接字要么将数据包传递给用户空间应用程序,要么从传输层协议的实现(即 TCP 或 UDP)接收数据包。然后,IP 层将数据包路由到网络层。在此层之下,Linux 允许通过防火墙规则过滤流量。网络接口卡(NIC)将其从接收(RX)缓冲区接收的数据包转发到内核,并从传输(TX)缓冲区读取数据包进行传输。
3.2. 套接字缓冲区(sk_buff)
内核将数据包保存在称为 sk_buff 的C结构体中。沿数据包路径的几乎所有函数都与其交互。sk_buff跟踪数据包的元数据,并维护内存中数据包数据的起始和结束指针[17]。通过引用数据包数据,允许通过调整指针来高效地修改数据包,例如,当剥离一个协议头时。此外,sk_buff结构可以使用内存引用在不同的进程之间高效地共享[17]。因此,复制数据包也是高效的,因为只需要复制元数据[17],假设是只读的工作负载。我们在图 2 中展示了这一点。sk_buff的这些特性构成了 Linux 上高效数据包处理的基础。
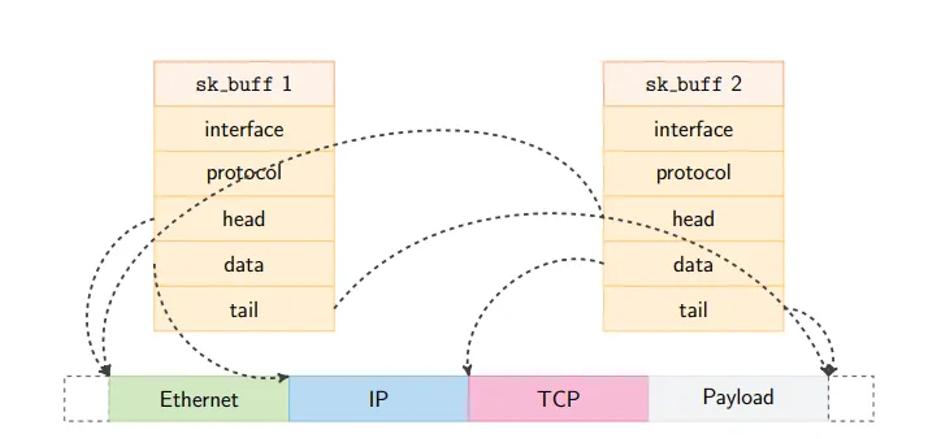
图 2:两个简化的 sk_buff 结构指向同一数据包缓冲区内的不同位置。head标记缓冲区的填充起始位置,而tail指向实际数据包数据的末尾。data指向当前正在处理的头部。
4. 数据包流
在这里,我们感兴趣的是入口(ingress)和出口(egress)路径。这两条路径独立运行。
4.1. 出口路径
首先分析出口路径,即 Linux 如何发送数据包——从用户空间应用程序到NIC,如图 3 所示。本质上,出口侧构建协议头,并将它们推送到 sk_buff 结构中,然后发送出去。
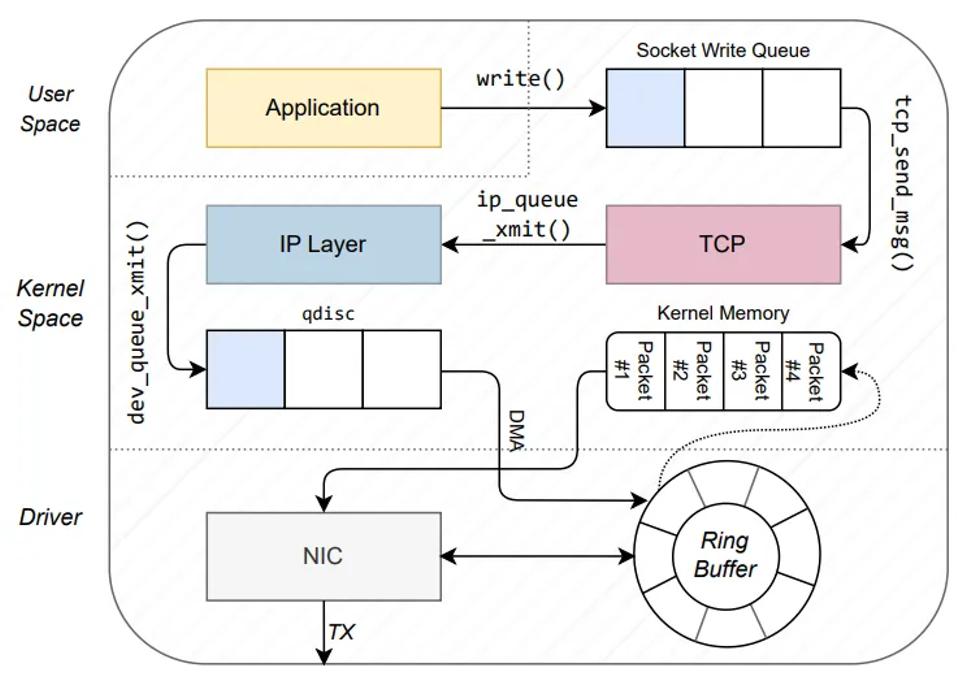
图 3:TCP情况下数据包的出口路径,如第4.1节所述(改编自[10])
4.1.1. 套接字层
一切开始于一个具备相关域的套接字,例如 AF_UNIX、AF_XDP,或者在我们的情况下,AF_INET 用于 IPv4。一个系统调用封装函数,如 write() 或 sendto(),使得我们可以通过套接字发送数据,比如由 GNU C库[18]提供的。在本节的语境中选择使用 write(filedescriptor, buffer, length)以避免不必要的复杂性。写入文件描述符是 UNIX 哲学中“一切皆文件”的经典示例,因为文件描述符抽象了套接字[19]。对于套接字,write()调用 sock_sendmsg() 函数。sock_sendmsg()从用户空间应用程序提供的文件描述符中获取 struct sock 套接字结构。通常,套接字操作的套接字控制消息包含进程的进程 ID(PID)、用户ID(UID)和组ID(GID)[19]。sock_sendmsg()从 task_struct 中检索这个控制消息,task_struct 是 Linux 数据结构,包含调用进程的这些信息。有了这些信息,sock_sendmsg()通常会将数据包通过 Linux 安全模块(例如SELinux)进行流量过滤。
最后,它通过宏 INDIRECT_CALL_INET 调用相应的传输层处理程序,在我们的例子中是 TCP 或 UDP。这个宏会自动根据 sk_buff 中的字段 sk_prot 指定的协议,选择传输协议入口函数的相应 IPv4 或 IPv6 变体。
4.1.2. 传输层
在这里到达与 IPv4 相关的入口函数,对于 TCP 是 tcp_sendmsg(),对于 UDP 是 udp_sendmsg()。
TCP:tcp_sendmsg() 首先等待 TCP 连接建立。然后,它为段分配 sk_buff 结构,并将它们排队到套接字写队列中,如图 3 所示。tcp_sendmsg()还保证遵守最大段大小(MSS)。处理队列后,内核调用 tcp_write_queue_tail()。它还构建 TCP 头,并将用户空间中的数据推入 sk_buff。如果数据适合现有的缓冲区,将使用 skb_add_data_nocache()。否则,它会创建新的缓冲区,这会增加更多的开销。然后将 transport_header 指针设置为该头部的起始位置。接下来,它根据套接字选项构建网络层协议头,例如对于 AF_INET 是 IPv4。tcp_write_xmit() 保证在拥塞控制限制下内核会保留数据。它还设置重传计时器,即如果在规定时间内没有收到 ACK,将重新发送数据包。最后,tcp_transmit_skb()读取包含先前构建段的写队列,并通过 socket 中指定的 queue_xmit() 函数将它们传递给网络层。
UDP:类似地,udp_sendmsg()函数也会写入套接字写队列。接下来,该函数等待直到没有待处理的 UDP 数据报帧。同样该函数会构建头部,设置目标端口和其他字段。
存在 corking 和 non-corking 两种情况:
1.corking 描述的是等待帧以批量处理多个UDP数据报。
2.non-corking 则意味着直接构建sk_buff。
在构建数据报之后,ip_route_output_flow() 对数据包进行路由并构建网络层协议头。最后,ip_append_data() 创建一个 IP 数据包,将多个 UDP 数据报组合在一起。总体而言,UDP实现的简单性和无锁特性使其性能优于 TCP 实现。
4.1.3. IP 层
IP 处理始于函数 __ip_queue_xmit()。首先,该函数确定到目的地的路由。如果在 sk_buff->_skb_refdst 中已经有路由,它将跳过路由过程。在这种情况下,函数立即构建报头。然而,如果没有目的地,路由过程将继续。它从 sk_buff 的 socket 字段确定目的地,例如,如果套接字先前接收到 IP 数据包,则会设置该字段。如果这不可能,它会查询路由缓存,称为转发信息库 (FIB) —— 一个从 IP 路由表生成的表。最终,如果没有找到路由,它将返回主机不可达并停止处理。否则,内核在找到路由时构建 IP 报头。
现在,调用 ip_options_build() 来设置 IP 选项。它使用 sk_buff 的 network_header 字段标记报头的开始。接下来,它触发 Linux 防火墙机制 netfilter 的 LOCAL_OUT 阶段。之后,dst_output() 通过函数指针调用实际的路由函数。
然后,内核调用 ip_output() 路由函数来处理最常见的单播数据包。由于路由已经完成,这个阶段被称为 POST_ROUTING。它更新数据包的元数据并调用 NF_INET_POST_ROUTING 钩子。它设置 sk_buff 的元数据并再次调用 netfilter。此外,如果数据包超过最大长度(最大传输单元,MTU),它会将数据包分片。
在通过 NF_INET_LOCAL_OUT 钩子传递数据包之后,ip_output() 调用 ip_finish_output()。它为多播和广播数据包增加计数器。还检查 sk_buff 是否有足够的空间来容纳 MAC 报头。目的 MAC 地址要么被缓存,要么通过邻居输出函数 neigh_resolve_output() 确定。后者使用地址解析协议 (ARP) [20]。如果没有 ARP 回复,它会再次排队数据包。获得 MAC 地址后,内核构建以太网报头并将其添加到 sk_buff 中。
4.1.4. 以太网层
首先,dev_queue_xmit() 在 sk_buff 中设置 mac_header 字段,然后将其传递给 tc_egress()。它将数据包排队到排队规则(qdisc)[21] 中。只要 NIC 缓存被填充,__qdisc_run() 就会从缓冲区中取出数据包。在 validate_xmit_skb() 中进行一些后续处理,例如计算以太网校验和或添加 VLAN 标签后,内核调用 ndo_start_xmit,并将数据包添加到 NIC 的 TX 环。最终,NIC 的队列可能会满。在这种情况下,内核会停止 qdisc [21] 并排队 sk_buff。最后,它在添加更多 sk_buff 元数据后,将数据包映射到内存中的固定位置以供直接内存访问(DMA)使用。dev_direct_xmit 允许绕过 qdisc [21],直接将数据包写入 NIC 的 TX 环。eXpress 数据路径(XDP)[22] 就是这种情况的一个用例。最终,该函数通过中断通知 NIC 结束处理并释放 sk_buff。
4.2. 入站路径
现在追踪一个数据包从到达 NIC 到用户空间应用程序通过套接字读取它的路径,参见图 4。最值得注意的是,它会分析报头以确定后续函数调用并剥离这些报头。
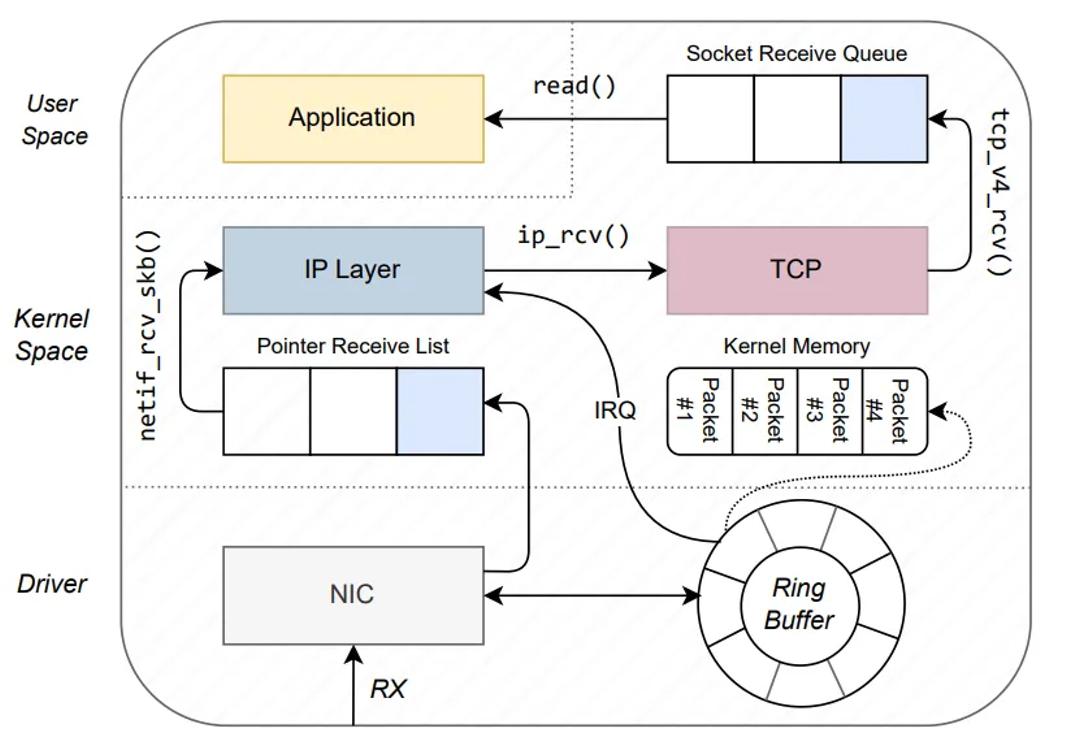
图 4:在第 4.2 节中描述的 TCP 情况下数据包的入站路径(改编自 [10])
4.2.1. 以太网层
在验证并可选地将以太网校验和归零并应用 MAC 地址过滤器后,NIC 通过 DMA 将数据包复制到系统内存中。然后,它通过中断通知操作系统并指示数据包数据的位置。这样,操作系统就可以分配一个 sk_buff。现在,内核在 sk_buff 中插入元数据,例如协议字段(以太网)、接收接口和数据包类型,在我们的情况下是 IP。
在这一阶段,内核知道以太网报头的起始位置,因此它将 mac_header 字段设置为 sk_buff 的开头。最后,在将数据包传递到网络堆栈的更上层之前,它会从 sk_buff 中移除以太网报头。接下来,数据包到达 netif_receive_skb()。该函数克隆 sk_buff 并将其转发到虚拟 TAP 接口。TAP 接口在同一网络中的虚拟机 (VM) 和主机之间实现通信。这里另一个重要的案例是将 VLAN 标记的数据包转发到 VLAN 接口。此外,当接口有物理主设备时,即它是虚拟接口或网络桥的一部分,rx_handler() 窃取数据包。rx_handler() 还设置 sk_buff 的 network_header 字段。最后,它调用 IPv4 协议处理函数 ip_rcv()。
4.2.2. IP 层
以太网层通过函数 ip_rcv() 将数据包传递给 IP 层。同样,ip_rcv() 检查 MAC 地址并丢弃外来的地址。然后,验证版本、长度和校验和字段。接下来,该函数设置 sk_buff 的 transport_header 字段。它还应用 netfilter 的 PRE_ROUTING 规则。通过将数据包转发到 NF_INET_PRE_ROUTING 钩子来实现过滤。该钩子获取指向 ip_rcv_finish()函数的指针,并在完成之后调用它。如果注册了网络层主设备,它将 sk_buff 传递给其处理程序。它调用 ip_route_input_noref(),该函数从 sk_buff 读取 IP 报头。接下来,内核通过 ip_rcv_options() 处理 IP 选项。之后,它通过 dst_input() 调用先前选择的路由函数。路由数据包有三个选项:
1.ip_forward:该函数用于目的IP地址不是当前机器IP地址的数据包。它通过不进行额外处理而直接转发数据包。
2.ip_local_deliver():如果我们将作为数据包的最终接收者(本地主机),内核不会转发数据包,而是将其传递到网络堆栈的上层。
3.ip_mr_input():此函数用于多播数据包,即地址为多播地址的数据包。
由于我们主要关注数据包在最终接收者处的处理方式,并考虑到所有层次,我们将继续讨论 ip_local_deliver()。最重要的是,该函数通过调用 ip_defrag() 处理 IP 分片,将数据包排队直到接收到所有分片。之后,触发 NF_INET_LOCAL_IN 事件,该事件反过来调用 ip_local_deliver_finish(),从 sk_buff 中剥离 IP 报头。最后,它通过 dst_input() 函数将数据包从 IP 层传递到 TCP/UDP 层,交给 tcp_v4_rcv() 或相应的函数。它通过检查指向 sk_buff 的报头来确定相应的协议处理程序。
4.2.3. 传输层
现在检查 egress TCP 和 UDP 函数的对应部分。
TCP。首先,数据段到达传输层函数 tcp_ipv4_recv(),此时 sk_buff 报头指针移动到 TCP 或 UDP 报头的起始位置。然后,它通过 pskb_may_pull() 验证传输报头,并验证 TCP 校验和。与之前一样,它从 sk_buff 中移除 TCP 报头。为了进一步传递数据包,它通过 __inet_lookup_skb() 定位相应的 TCP 套接字。它将数据包写入套接字接收队列(见图 4),并发出新数据可用的信号,例如通过 SIGIO 或 SIGURG。这种通知机制允许对套接字进行高效的轮询。至于 egress,内核在处理数据包期间维护 TCP 状态机。例如,它不会处理通过 TCP_CLOSING 终止的 TCP 连接的任何新数据包。
简要介绍两个在处理过程中重要的情景:TCP_NEW_SYN_RECV 和 TCP_TIME_WAIT。TCP_NEW_SYN_RECV 表示有一个新连接。在这种情况下,内核通过 tcp_filter() 在 TCP 级别拒绝连接。在 TCP_TIME_WAIT 期间,内核丢弃任何进一步的 TCP 段。
此外,传输层还存在慢速路径和快速路径。慢速路径包含更多的错误检查和查找操作。相比之下,快速路径经过优化以提高速度,但不支持内省和流量分析。在慢速路径中,我们等待直到状态机进入 TCP_ESTABLISHED 状态,在 tcp_v4_do_rcv() 中完成这一状态更新。一旦更新完成,tcp_v4_do_rcv() 调用 tcp_rcv_established(),该函数在快速路径和慢速路径中都处理数据包。它还验证了序列号是否按升序排列。快速路径直接将数据包复制到用户空间。内核总是尽可能尝试使用快速路径。但例如在建立 TCP 连接时,这是不可能的,因为内核必须跟踪新连接。
在处理完 TCP 状态机并选择了路径后,内核将数据包入队到套接字队列中,以便用户程序可以读取它(见图 4)。
由于 TCP 非常复杂,本文的范围不包括进一步的细节。然而,[7]、[10]、[11] 中有更详细的描述。
UDP。与 TCP 相比,UDP 的实现相对简单。它从 IP 层通过 dst_input() 调用的 udp_rcvmsg() 开始。首先,该函数调用 __skb_recv_udp() 从套接字中读取数据报,使用之前计算的偏移量。特别是,它会持续尝试从套接字中读取 sk_buff,直到新的 UDP 数据报到达时停止。然后,验证数据报的校验和。接着,该函数复制目标 IP 和 UDP 端口,以将数据报映射到正确的套接字。随后,通过 skb_consume_udp() 消费 UDP 数据报。最后,它调整 peek 偏移量,处理引用计数器,并通过 __consume_stateless_skb() 释放 sk_buff。
4.2.4. 套接字层
在这里,内核通过从套接字调用的 read() 函数收集写入 TCP 或 UDP 套接字的新数据,并从套接字接收队列中解队数据包(见图 4)。为了与 egress 中使用 IPv4 的情况相匹配,我们使用 AF_INET 接收套接字。sys_recv() 函数实现了这一点,首先调用 sys_recvfrom() 查找套接字。然后,它调用 sock_recvmsg() 从套接字读取,并将接收到的消息传递给 Linux 安全模块,类似于 egress 的处理。对于 IPv4,inet_recvmsg() 调用 tcp_recvmsg() 或 udp_recvmsg()。它们将数据包从队列取出,并将其写入用户空间缓冲区,例如堆上的数组。最后,它们释放 sk_buff。
小结
图 5:UDP 出站和入站处理中最重要的函数概览,如第 4 节所述
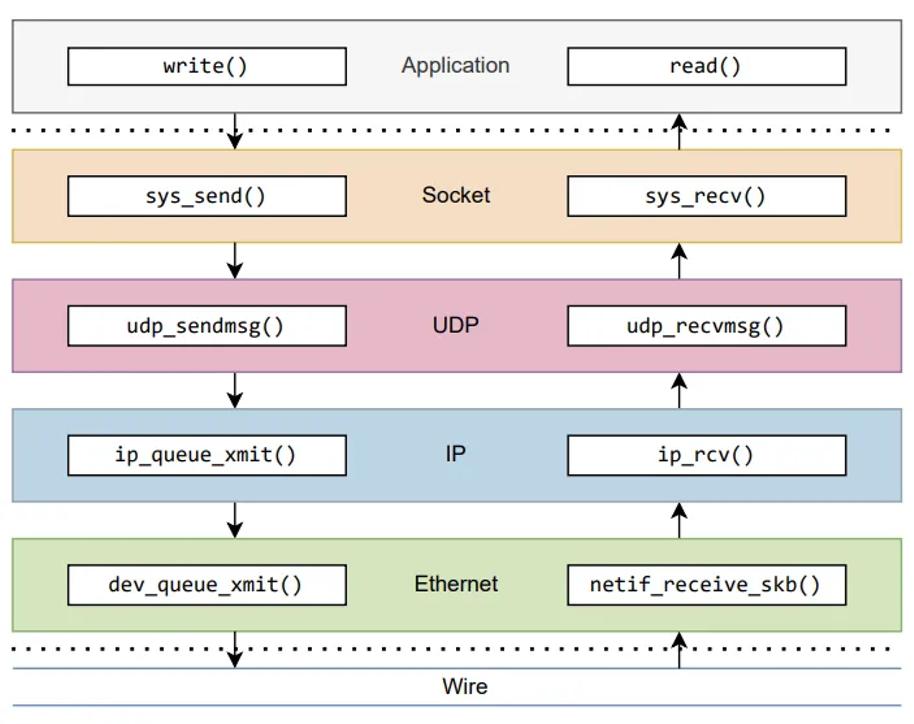
本文介绍了数据包如何在 Linux 内核中通过 TCP/IPv4 和 UDP/IPv4 的处理流程。图 5 概括了数据包出站和入站路径,突出了各层中最重要的函数。此外还描述了数据包处理的复杂性,包括路由、过滤和排队机制,这些都是由 Linux 内核所采用的。此外也还看到了内核中不同层之间的通信方式。通过利用这些知识,网络管理员和开发人员可以在优化网络性能、设计安全措施或解决网络问题时做出明智的决策。
总体而言,与现有文献相比,观察到的变化主要是增强而非重写,例如重构或安全改进。一个典型的例子是 TCP 初始化序列号的选择。出于安全原因,内核作者多次修订了底层哈希算法[23]。保守的变化是有意义的,因为协议本身变化不大,而错误的影响却很大。对 Multipath TCP 或 QUIC 进行类似的分析是未来的工作。
参考文献
[1] T.-H. Lee, S.-W. Kang, T. Kim, J.-S. Kim, and H.-J. Lee, “Smart Refrigerator Inventory Management Using Convolutional Neural Networks,” in 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), 2021, pp. 1–4.
[2] W3Techs. (2019) Usage Statistics of Operating Systems for Websites. https://w3techs.com/technologies/overview/operating_ system. [Online; accessed 02-December-2023].
[3] ——. (2019) Usage Statistics of Unix for Websites. https://w3techs. com/technologies/details/os-unix. [Online; accessed 02-December2023].
[4] J. Corbet. (2011) A JIT for Packet Filters. https://lwn.net/Articles/ 437981/. [Online; accessed 02-December-2023].
[5] C. Paasch and O. Bonaventure, “Multipath TCP,” Commun. ACM, vol. 57, no. 4, p. 51–57, apr 2014. [Online]. Available: https://doi.org/10.1145/2578901
[6] M. T. Hossain, “A Review on IPv4 and IPv6: A Comprehensive Survey,” 01 2022, International Interconnect Technology Conference (IITC). [Online]. Available: https://doi.org/10.13140/RG.2.2.18673.61284
[7] J. Crowcroft and I. Phillips, TCP/IP and Linux Protocol Implementation: Systems Code for the Linux Internet. USA: John Wiley & Sons, Inc., 2001.
[8] A. Chimata, “Path of a Packet in the Linux Kernel Stack,” 01 2005. [Online]. Available: https://www.cs.dartmouth.edu/~sergey/ netreads/path-of-packet/Network_stack.pdf
[9] C. Guo and Z. Shaoren, “Analysis and Evaluation of the TCP/IP Protocol Stack of Linux,” vol. 1, 02 2000, pp. 444–453 vol.1.
[10] Helali Bhuiyan and Mark E. McGinley and Tao Li and Malathi Veeraraghavan, “TCP Implementation in Linux : A Brief Tutorial,” 2008. [Online]. Available: https://api.semanticscholar. org/CorpusID:14676835
[11] Antti Jaakkola, “Implementation of Transmission Control Protocol in Linux,” 2012. [Online]. Available: https://wiki.aalto.fi/download/ attachments/70789052/linux-tcp-review.pdf
[12] F. U. Khattak. (2012) IP Layer Implementation of Linux Kernel Stack. [Online]. Available: https://wiki.aalto.fi/download/ attachments/70789059/linux-kernel-ip.pdf
[13] M. C. Wenji Wu, “The Performance Analysis of Linux Networking - Packet Receiving,” 2006, 15th International Conference on Computing in High Energy and Nuclear Physics (CHEP 2006).
[14] Q. Cai, S. Chaudhary, M. Vuppalapati, J. Hwang, and R. Agarwal, “Understanding Host Network Stack Overheads,” in Proceedings of the 2021 ACM SIGCOMM 2021 Conference, ser. SIGCOMM ’21. New York, NY, USA: Association for Computing Machinery, 2021, p. 65–77. [Online]. Available: https://doi.org/10.1145/ 3452296.3472888
[15] M. Abranches, O. Michel, and E. Keller, “Getting Back What Was Lost in the Era of High-Speed Software Packet Processing,” in Proceedings of the 21st ACM Workshop on Hot Topics in Networks, ser. HotNets ’22. New York, NY, USA: Association for Computing Machinery, 2022, p. 228–234. [Online]. Available: https://doi.org/10.1145/3563766.3564114
[16] J. Benc, “The Network Packet’s Diary: A Kernel Journey,” 2018, devcon.cz 2018.
[17] The kernel development community. struct sk_buff. https: //docs.kernel.org/networking/skbuff.html. [Online; accessed 02- December-2023].
[18] G. Foundation. (2023) The GNU C Library Reference Manual. https://sourceware.org/glibc/manual/2.38/html_mono/libc.html# Transferring-Data. [Online; accessed 05-December-2023].
[19] M. Kerrisk, The Linux Programming Interface: A Linux and UNIX System Programming Handbook, 1st ed. USA: No Starch Press, 2010.
[20] “An Ethernet Address Resolution Protocol: Or Converting Network Protocol Addresses to 48.bit Ethernet Address for Transmission on Ethernet Hardware,” RFC 826, Nov. 1982. [Online]. Available: https://www.rfc-editor.org/info/rfc826
[21] tc - traffic control utility, Linux Documentation Project, December 2023, https://man7.org/linux/man-pages/man8/tc.8.html.
[22] T. Høiland-Jørgensen, J. D. Brouer, D. Borkmann, J. Fastabend, T. Herbert, D. Ahern, and D. Miller, “The eXpress Data Path: Fast Programmable Packet Processing in the Operating System Kernel,” in Proceedings of the 14th International Conference on Emerging Networking EXperiments and Technologies, ser. CoNEXT ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 54–66. [Online]. Available: https://doi.org/10. 1145/3281411.3281443
[23] F. Gont and S. Bellovin, “Defending Against Sequence Number Attacks,” RFC 6528, Feb. 2012. [Online]. Available: https: //www.rfc-editor.org/info/rfc6528
Source
NET-2024-04-1_16