Linux ipip隧道及实现

一、IP隧道技术
IP隧道技术:是路由器把一种网络层协议封装到另一个协议中以跨过网络传送到另一个路由器的处理过程。IP 隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。IP隧道技术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。移动IPv4主要有三种隧道技术,它们分别是:IP in IP、最小封装以及通用路由封装。更多信息可以参看百度百科:IP隧道和隧道技术。
Linux系统内核实现的IP隧道技术主要有三种(PPP、PPTP和L2TP等协议或软件不是基于内核模块的):ipip、gre、sit。这三种隧道技术都需要内核模块 tunnel4.ko 的支持。
ipip 需要内核模块 ipip.ko,该方式最为简单!但不能通过IP-in-IP隧道转发广播或者IPv6数据包。只是连接了两个一般情况下无法直接通讯的IPv4网络而已。至于兼容性,这部分代码已经有很长一段历史了,它的兼容性可以上溯到1.3版的内核。据网上查到信息,Linux的IP-in-IP隧道不能与其他操作系统或路由器互相通讯。它很简单,也很有效。
GRE 需要内核模块 ip_gre.ko,GRE是最初由CISCO开发出来的隧道协议,能够做一些IP-in-IP隧道做不到的事情。比如你可以使用GRE隧道传输多播数据包和IPv6数据包。
sit 的作用是连接 ipv4 与 ipv6 的网络,感觉不如gre使用广泛。
三个模块的信息如下:
# sit模块
# modinfo sit
filename: /lib/modules/2.6.32-642.el6.x86_64/kernel/net/ipv6/sit.ko
alias: netdev-sit0
license:GPL
srcversion: AF73F62BA39C407E20C4F05
depends:ipv6,tunnel4
vermagic: 2.6.32-642.el6.x86_64 SMP mod_unload modversions
# ipip模块
# modinfo ipip
filename: /lib/modules/2.6.32-642.el6.x86_64/kernel/net/ipv4/ipip.ko
alias: netdev-tunl0
license:GPL
srcversion: AF7433BD67CBFC54C10C108
depends:tunnel4
vermagic: 2.6.32-642.el6.x86_64 SMP mod_unload modversions
# ip_gre模块
# modinfo ip_gre
filename: /lib/modules/2.6.32-642.el6.x86_64/kernel/net/ipv4/ip_gre.ko
alias: netdev-gretap0
alias: netdev-gre0
alias: rtnl-link-gretap
alias: rtnl-link-gre
license:GPL
srcversion: 163303A830259507CA00C15
depends:ip_tunnel
vermagic: 2.6.32-642.el6.x86_64 SMP mod_unload modversions
二、ip tunnel 配置

实际应用中,以上提到的三种ip tunnel 技术和VPN技术一样,多用于跨公网的网络中(当然跨网段的内网环境也适用)。如上图所示,两台虚机,其中eth0网段就类似于常见的公网网络;eth1网络为各自的私网。最终实现效果是实现两台主机的 eth1网络可以互通。这里测试中使用的是基于gre模式进行的实现,如果使用ipip、sit,只需要把modprobe后面的模块名换掉,把ip tunnel 命令中mode后面的字符替换掉即可。
1、ipv4网络中的配置
a主机配置如下:
#modprobe ipip
#modprobe ip_gre
#ip tunnel add tun0 mode gre remote 192.168.122.90 local 192.168.122.80 ttl 64
#ip link set tun0 up
#ip addr add 192.168.1.80 peer 192.168.2.90 dev tun0
#ip route add 192.168.2.0/24 dev tun0
#iptables -F
b主机配置如下:
#modprobe ipip
#modprobe ip_gre
#ip tunnel add tun0 mode gre remote 192.168.122.80 local 192.168.122.90 ttl 64
#ip link set tun0 up
#ip addr add 192.168.2.90 peer 192.168.1.80 dev tun0
#ip route add 192.168.1.0/24 dev tun0
#iptables -F
两边互ping发现可以ping通,即为实验成功。这里需要注意iptables项,执行iptables -F是必须的,不然两边不通。如果在需要开启防火墙的情况下,也可以执行如下步骤:
iptables -I INPUT -p gre -j ACCEPT
或
firewall-cmd --permanent --direct --add-rule ipv4 filter INPUT 0 -i eth0 -p gre -j ACCEPT (rhel7下默认使有的firewalld)
假如这边还有台主机C,C主机只有一块网卡,其IP为192.168.1.100,和a主机同在eth1网段,可以将a主机配置为一个简单的路由器,其可以访问b主机的IP 192.168.2.90 。只需要在a主机中做如下配置即可:
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -I POSTROUTING -o eth0 -j MASQUERADE
注意:该场景下,需要将C主机的网关指向a主机。
2、ipv6网络中的配置
两台主机的信息如下:
a. PC1 eth0:2001::1/64; eth1:192.168.1.1/24;
b. PC2 eth0:2001::2/64; eth1:192.168.2.1/24;
配置如下:
a主机配置
#modprobe ip6_tunnel
#ip -6 tunnel add tun0 mode ipip6 remote 2001::2 local 2001::1 ttl 64
#ip link set tun0 up
#ip addr add 192.168.1.1 peer 192.168.2.1 dev tun0
#ip route add 192.168.2.0/24 dev tun0
#iptables -F
b主机配置
#modprobe ip6_tunnel
#ip -6 tunnel add tun0 mode ipip6 remote 2001::1 local 2001::2 ttl 64
#ip link set tun0 up
#ip addr add 192.168.2.1 peer 192.168.1.1 dev tun0
#ip route add 192.168.1.0/24 dev tun0
#iptables -F
三、其他及拓展
上文提到的linux下的三种模块级的tunnel技术传输都是不加密的,这是和很多VPN技术比较大的一个区别,同时三都之间在实现原理上也略有区别。
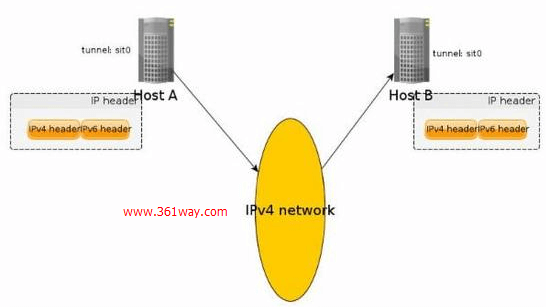
上图是ipip tunnel的原理图,明显是其点对点的一种tunnel。这个非常容易理解,这也是其不能广播的原因。据网上的资料说sit也属于点对点的tunnel,这个由于未翻阅到sit tunnel 比较详细的信息,不能确定其属于不属于简单的点对点 tunnel,个人感觉sit不属于简单的点对点 tunnel,因为在一些路由网络设备中发现其有支持,和gre tunnel一样。
由于ip tunnel技术目前只技术linux技术,所以上面的两台主机上的技术实现只能运用在类linux主机上。
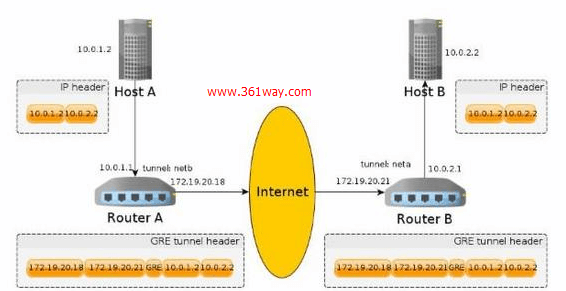
重点说下gre tunnel,除了外层的 IP 头和内层的 IP 头之间多了一个GRE头之外,它最大的不同是,tunnel不是建立在最终的 host 上,而是在中间的 router 上!换句话说,对于端点host A 和 host B来说,该tunnel是透明的(对比上面的 ipip tunnel)。添加外部的 IP 头是在 router A 上完成的,而去掉外面的 IP 头是在 router B上完成的,两个端点的 host 上几乎什么都不用做(除了配置路由,把发送到 10.0.2.0 的包路由到 router A)!
从这个原理就可以了解到,gre tunnel 是支持广播和多播的。所以除了上面的route A和route B需要为类linux平台,上面的host a 和host b选用什么类型的系统无所谓。
发送过程是很简单的,因为 router A 上配置了一条路由规则,凡是发往 10.0.2.0 网络的包都要经过 netb 这个 tunnel 设备,在内核中经过 forward 之后就最终到达这个 GRE tunnel 设备的 ndo_start_xmit(),也就是 ipgre_tunnel_xmit() 函数。这个函数所做的事情无非就是通过 tunnel 的 header_ops 构造一个新的头,并把对应的外部 IP 地址填进去,最后发送出去。
稍微难理解的是接收过程,即 router B 上面进行的操作。这里需要指出的一点是,GRE tunnel 自己定义了一个新的 IP proto,也就是 IPPROTO_GRE。当 router B 收到从 router A 过来的这个包时,它暂时还不知道这个是 GRE 的包,它首先会把它当作普通的 IP 包处理。因为外部的 IP 头的目的地址是该路由器的地址,所以它自己会接收这个包,把它交给上层,到了 IP 层之后才发现这个包不是 TCP,UDP,而是 GRE,这时内核会转交给 GRE 模块处理。
GRE 模块注册了一个 hook:
static const struct gre_protocol ipgre_protocol = {
handler = ipgre_rcv,
err_handler = ipgre_err,
};
所以真正处理这个包的函数是 ipgre_rcv() 。ipgre_rcv() 所做的工作是:通过外层IP 头找到对应的 tunnel,然后剥去外层 IP 头,把这个“新的”包重新交给 IP 栈去处理,像接收到普通 IP 包一样。到了这里,“新的”包处理和其它普通的 IP 包已经没有什么两样了:根据 IP 头中目的地址转发给相应的 host。注意:这里我所谓的“新的”包其实并不新,内核用的还是同一个copy,只是skbuff 里相应的指针变了。
四、参考页面
linux的tunnel技术实现代码级分析
linux tunnel 技术
IP 隧道概述
三种tunnel的配置
本文转自:Linux ipip隧道及实现