SQL语句分类
 SQL(Structure Query Language)语言是数据库的核心语言。
SQL(Structure Query Language)语言是数据库的核心语言。SQL是一个标准的数据库语言,是面向集合的描述性非过程化语言。它功能强,效率高,简单易学易维护迄今为止。然而SQL语言由于以上优点,同时也出现了这样一个问题:它是非过程性语言,即大多数语句都是独立执行的,与上下文无关,而绝大部分应用都是一个完整的过程,显然用SQL完全实现这些功能是很困难的。所以大多数数据库公司为了解决此问题,作了如下两方面的工作:
(1)扩充SQL,在SQL中引入过程性结构;
(2)把SQL嵌入到高级语言中,以便一起完成一个完整的应用。
SQL语句大致可分为下面几类:
DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括create、drop、alter等。
DML(Data Manipulation Languages)语句:数据操纵语句,用于添加、删除、更新、查询操作,并检查数据完整性。常用的语句关键字包括:insert、delete、update、select等。
DCL(Data Control Languages)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke等。
还有一种是由DML语句所派生出来的DQL(Data Query Languages),用于查询数据库的记录。它的基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表> FROM <表或视图名> WHERE <查询条件>
关于数据控制语言-DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚--ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL>ROLLBACK;
3) COMMIT [WORK]:提交。
在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。提交数据有三种类型:显式提交、隐式提交及自动提交。下面分别说明这三种类型。
(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT;
(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。
(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
英文定义解析如下:
DDL
Data Definition Language (DDL) statements are used to define the database structure or schema. Some examples:
CREATE - to create objects in the database
ALTER - alters the structure of the database
DROP - delete objects from the database
TRUNCATE - remove all records from a table, including all spaces allocated for the records are removed
COMMENT - add comments to the data dictionary
RENAME - rename an object
DML
Data Manipulation Language (DML) statements are used for managing data within schema objects. Some examples:
SELECT - retrieve data from the a database
INSERT - insert data into a table
UPDATE - updates existing data within a table
DELETE - deletes all records from a table, the space for the records remain
MERGE - UPSERT operation (insert or update)
CALL - call a PL/SQL or Java subprogram
EXPLAIN PLAN - explain access path to data
LOCK TABLE - control concurrency
DCL
Data Control Language (DCL) statements. Some examples:
GRANT - gives user's access privileges to database
REVOKE - withdraw access privileges given with the GRANT command
这里以MySQL为参照,SQL语句主要分为三类:
DDL语句、DML语句、DCL语句
DDL(Data Definition Language)语句:
主要用于定义数据库、表结构、索引等内容,常用语句如下:
创建数据库:
CREATE DATABASE twitter CHARSET=utf8;
删除数据库:
DROP DATABASE twitter;
创建表:
create table `user`(
id int(11),
title varchar(50)
);
删除表:
DROP TABLE user;
增加字段:
ALTER TABLE user ADD COLUMN age tinyint(4) AFTER name;
删除字段:
ALTER TABLE user DROP COLUMN age;
修改字段:
ALTER TABLE user MODIFY name varchar(20);
修改字段名:
ALTER TABLE user CHANGE name nickname varchar(50);
增加索引:
ALTER TABLE user ADD INDEX idx_age(age);
删除索引:
ALTER TABLE user DROP INDEX idx_age;
DML(Data Manipulation Language)语句:
主要用于数据库表数据的增删改查等操作。
增加数据:
INSERT INTO user(id, name) VALUES(1, '小明'), (2, '小红');
删除数据:
//删除一张表数据
DELETE FROM user WHERE id = 1;
//同时删除多张
DELETE a,b FROM user AS a, user2 AS b WHERE a.id = 1 AND b.id = 2;
修改数据:
//修改一张表
UPDATE user SET age = 10 WHERE id = 1;
//同时修改多个表
UPDATE user, user2 SET user.age = 10, user2.age = 20;
查询数据:
//简单查询
SELECT id,name FROM user;
//查询去重
SELECT distinct name,id FROM user;
//查询总数
SELECT COUNT(1) FROM user;
//分页排序
SELECT id,name FROM user ORDER BY id DESC LIMIT 0, 10;
//分组筛选
SELECT name, COUNT(1) as t FROM user GROUP BY age HAVING t > 10;
//联合查询 不加ALL会隐藏重复数据
SELECT id,name FROM user UNION ALL SELECT id,name FROM user2;
//子查询
SELECT id,name FROM user WHERE id IN(SELECT id FROM user2);
SELECT id,name FROM user WHERE id = (SELECT id FROM user2 LIMIT 1);
//连接查询查询
SELECT * FROM user INNER JOIN user2 ON user.name = user2.name;
SELECT * FROM user LEFT JOIN user2 ON user.name = user2.name;
DCL(Data Control Language)语句:
增加账号并赋予权限:
GRANT SELECT,INSERT,DELETE ON twitter.* TO 'username@127.0.0.1' IDENTIFIED BY 'password';
撤销权限:
ROVOKE SELECT ON twitter.* FROM 'username@127.0.0.1';
-------------------------------
两阶段提交(2 Phase Commit简称2PC)
该协议是用于在多个节点之间达成一致的通信协议,它是实现“有状态的”分布式系统所必须面对的经典问题之一。在Google工程实践的基础上,分析一种优化延迟的2PC协议,针对分布式数据库中,跨域sharding的2PC方案的讨论。
主要参考文献:Gray J, Lamport L. Consensus on transaction commit[J]. ACM Transactions on Database Systems (TODS), 2006, 31(1): 133-160.
经典两阶段提交概述
先来回顾下经典的2PC协议,有两个角色:一个协调者(coordinator)和若干参与者(participant),协议执行可以分为如下几个阶段:
预处理阶段:严格来说,预处理阶段并不是2PC的一部分,在实际的分布式数据库中,这个阶段由协调者向若干参与者发送SQL请求或执行计划,包括获取行锁,生成redo数据等操作。
Prepare阶段:客户端向协调者发送事务提交请求,协调者开始执行两阶段提交,向所有的事务参与者发送prepare命令,参与者将redo数据持久化成功后,向协调者应带prepare成功。这里隐含的意思是,参与者一旦应答prepare成功,就保证后续一定能够成功执行commit命令(redolog持久化成功自然保证了后续能够成功commit)。
Commit阶段
执行Commit:协调者收到所有参与者应答prepare成功的消息后,执行commit,先在本地持久化事务状态,然后给所有的事务参与者发送commit命令。参与者收到commit命令后,释放事务过程中持有的锁和其他资源,将事务在本地提交(持久化一条commit日志),然后向协调者应答commit成功。协调者收到所有参与者应答commit成功的消息后,向客户端返回成功。
执行Abort:prepare阶段中如果有参与者返回prepare失败或者超时未应答,那么协调者将执行abort,同样先在本地持久化事务状态,然后给所有参与者发送abort命令。参与者收到abort命令后,释放锁和其他资源,将事务回滚(有必要的情况下还要持久化一条abort日志)。
经典2PC的局限
协调者宕机:2PC是一个阻塞式的协议,在所有参与者执行commit/abort之前的任何时间内协调者宕机,都将阻塞事务进程,必须等待协调者恢复后,事务才能继续执行。
交互延迟:协调者要持久化事务的commit/abort状态后才能发送commit/abort命令,因此全程至少2次RPC延迟(prepare+commit),和3次持久化数据延迟(prepare写日志+协调者状态持久化+commit写日志)。
-------------------------------
数据库分表的策略
垂直、水平、取模、hash(crc32)、一致性hash。
-------------------------------
CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
-------------------------------
数据分析人员应该掌握的SQL技能
以下内容是个人整理的分析人员应该掌握的一些SQL技能,相比开发人员的SQL教程存在不同的侧重点:
一般查询语句
子查询
CTE(Common Table Expressions)
UNION 与 UNION ALL
CASE WHEN
常用函数
窗口函数
其他操作
一般查询语句
需要掌握的关键词(包含顺序):SELECT、FROM、JOIN、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT
SELECT
指定需要先择的列,存在多个时用逗号分隔。如果想要查看全部列,则可以使用*号代替。如果需要对查询结果去重,可以添加DISTINCT关键词。另外可对选定的列使用AS关键词进行重命名。
示例代码:
SELECT name, age, occupation,season_contestant FROM bachelorette;
SELECT * FROM bachelorette;
SELECT DISTINCT season_contestant FROM bachelorette;
SELECT name, age, occupation,season_contestant as sc FROM bachelorette;
WHERE
可以用来对查询的项进行过滤。语法格式为:列名+过滤操作符+具体要求。常用的过滤操作符有:
比较操作符:=、>、<、>=、<=、!=和<>,其中!=和<>都表示不等于
多项匹配:in,采用括号将多个需要配匹配的放在一起
范围限定:BETWEEN AND,匹配某一个范围,请注意,在不同的数据库中,BETWEEN 操作符会产生不同的结果!在使用前需要先确定包含规则,所以推荐使用比较操作符替换BETWEEN AND
在某些数据库中,BETWEEN 选取介于两个值之间但不包括两个测试值的字段。
在某些数据库中,BETWEEN 选取介于两个值之间且包括两个测试值的字段。
在某些数据库中,BETWEEN 选取介于两个值之间且包括第一个测试值但不包括最后一个测试值的字段。
模糊匹配:LIKE,阈值配合使用的时%代表任意个字符,_代表一个字符。
空值判断:IS NULL。注意,对于字符串为空不能应用控制判断,而使用!=''
语法组合关键词 AND、OR、NOT。优先级可用用()号进行显式声明(括号内的优先)。
示例代码:
SELECT * from Customers WHERE country = 'USA';
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil';
SELECT * from Products WHERE Price BETWEEN 10 AND 20;
SELECT * from Customers WHERE CustomerName LIKE '%to%';
SELECT * FROM student WHERE dept_name IN ('Comp. Sci.', 'Physics', 'Elec. Eng.');
GROUP BY与聚集函数
GROUP BY允许你对指定的一个或多个列进行分组统计。而分组统计中常会用到聚集函数。常用的聚集函数如下:
COUNT:对列进行计数。还可以与DISTINCT一起使用,用来统计不同项目的数量。想对所有列进行统计可以使用count(1)或count(*),两个表示的含义是一致的。
AVG:取列的平均值(部分数据库使用的是AVERAGE关键词)
MIN:取列的最小值
MAX:取列的最大值
SUM:取列的和
示例代码:
SELECT Country, COUNT(CustomerID) FROM Customers GROUP BY Country;
HAVING
和WHERE一样也是一种数据过滤的方法,和WHERE条件不同的是它针对的是使用GROUP BY以后的聚合函数的值。
SELECT Country, COUNT(CustomerID) FROM Customers GROUP BY Country HAVING COUNT(CustomerID) > 3;
ORDER BY
指定要进行排序的以恶个或多个列,与ASC(正序)和DESC(倒序)一起使用。默认为ASC。
示例代码:
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil' ORDER BY CustomerName;
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil' ORDER BY CustomerName DESC;
JOIN
可以将多在表组合成一张表后进行查询。其中JOIN的常用操作主要有以下几类:
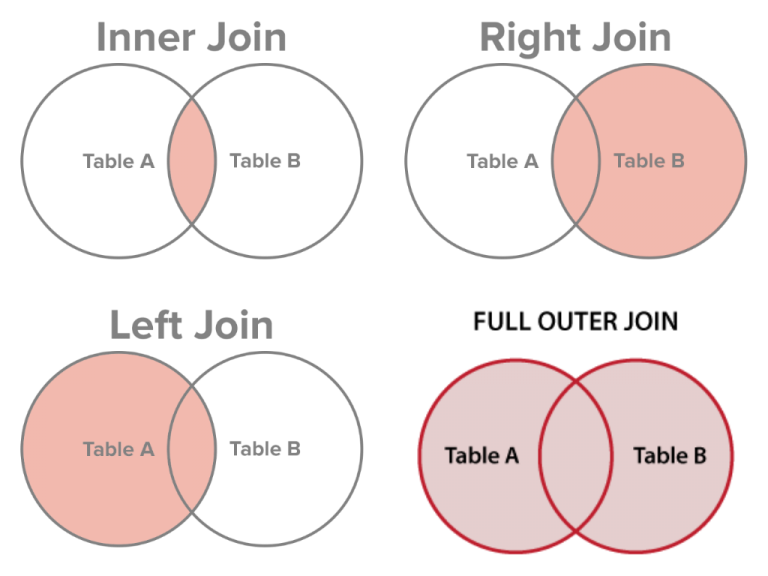
JOIN的时候需要使用ON关键词指定两张表中关联的列。另外可以对表使用AS关键词进行重命名,避免出现两张表相同列名的问题。重命名后取对应列的方法为表名.列名。
示例代码:
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName FROM Orders RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID;
SELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID;
其他的一些JOIN:
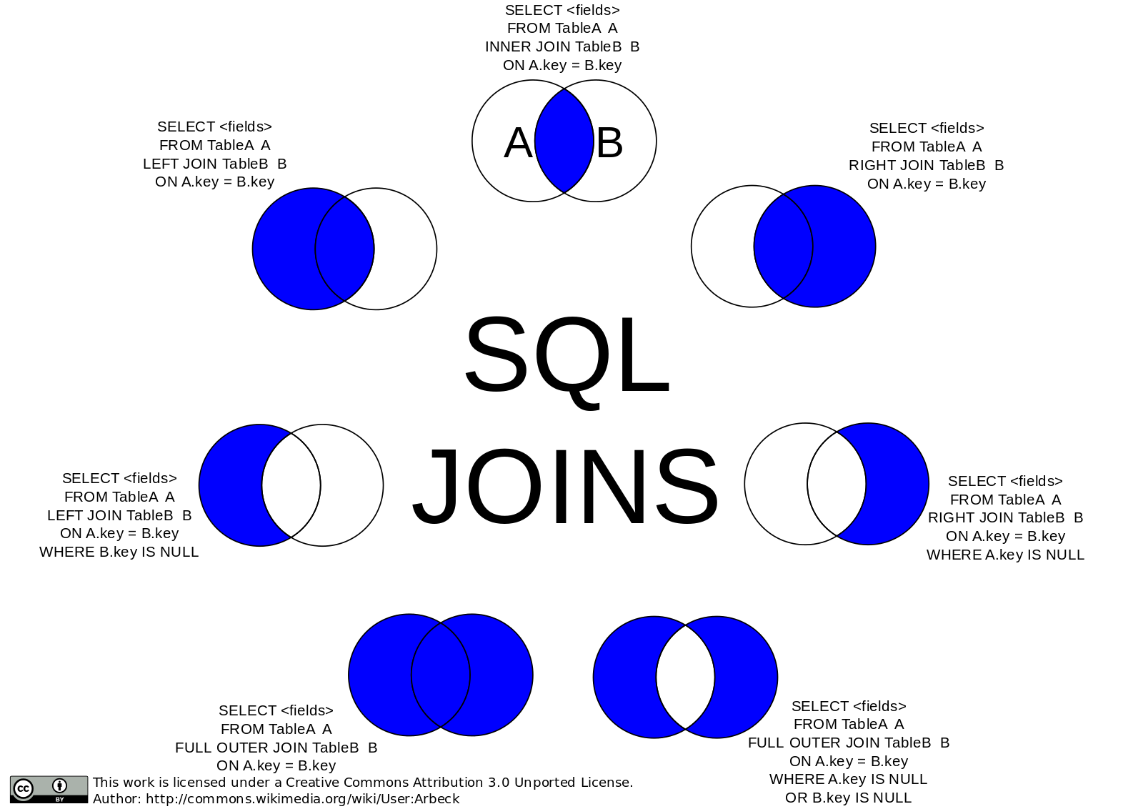
另外还有一种JOIN是Cross Join,代表的是取2张表的笛卡尔积
LIMIT
限制需要返回的数据条目。比如LIMIT 100,则表示只返回100条数据。如果是LIMIT 10,100则表示返回从第10个开始,返回100条记录。
子查询
嵌套SELECT语句也叫子查询,一个 SELECT 语句的查询结果能够作为另一个语句的输入值。子查询不但能够出现在WHERE子句中,也能够出现在FROM子句中,作为一个临时表使用,也能够出现在SELECT LIST中,作为一个字段值来返回。
子查询必须括在圆括号中。
子查询的 SELECT 子句中只能有一个列,除非主查询中有多个列,用于与子查询选中的列相比较。
子查询不能使用 ORDER BY,不过主查询可以。在子查询中,GROUP BY 可以起到同 ORDER BY 相同的作用。
返回多行数据的子查询只能同多值操作符一起使用,比如 IN 操作符。
SELECT 列表中不能包含任何对 BLOB、ARRAY、CLOB 或者 NCLOB 类型值的引用。
子查询不能直接用在集合函数中。
BETWEEN 操作符不能同子查询一起使用,但是 BETWEEN 操作符可以用在子查询中。
示例代码:
SELECT ename,deptno,sal FROM emp WHERE deptno=(SELECT deptno FROM dept WHERE loc='NEW YORK');
SELECT ename,job,sal,rownum FROM (SELECT ename,job,sal FROM EMP ORDER BY sal);
CTE(Common Table Expressions)
CTE相当于生成一张临时表,与临时表不同的是生存周期的不同。不需要显式的创建或删除,也不需要创建表的权限。更准确的说,CTE更像是一个临时的VIEW,可同时定义多个CTE,但只能用一个with,多个CTE中间用逗号”,”分隔。
代码示例:
WITH t1 AS (SELECT CountryRegionCode FROM person.CountryRegion WHERE Name LIKE 'C%')
SELECT *
FROM person.CountryRegion;
WITH t1 AS (SELECT * FROM table1 WHERE name LIKE 'abc%'),
t2 AS (SELECT * FROM table2 WHERE id > 20),
t3 AS (SELECT * FROM table3 WHERE price < 100)
SELECT a.*
FROM t1 a LEFT JOIN t2 ON t1.id = t2.id
INNER JOIN t3 ON t1.id = t3.id;
和临时表有个重要的区别,就是生存周期,
CTE也就是common table expressions是sql标准里的语法,CTE与derived table最大的不同之处是:
可以自引用,递归使用(recursive cte)
在语句级别生成独立的临时表. 多次调用只会执行一次
一个cte可以引用另外一个cte
一个CTE语句其实和CREATE [TEMPORARY] TABLE类似。
UNION 与 UNION ALL
UNION和UNION ALL关键字都是将两个结果集合并为一个,主要区别:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
代码示例:
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2;
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2;
CASE WHEN
CASE WHEN是对列的数据进行判断,然后设定新的值,CASE WHEN通常使用在SELECT语句内,但有时也会用在WHERE语句内
示例代码:
SELECT STUDENT_NAME,
(CASE WHEN score < 60 THEN '不及格'
WHEN score >= 60 AND score < 80 THEN '及格'
WHEN score >= 80 THEN '优秀'
ELSE '异常' END) AS REMARK
FROM TABLE
常用函数
上面讲过聚集函数,这里主要介绍的是除聚集函数以外的其他函数。
常用数值处理函数
ROUND: 确定数字要保存的位数,遵循四舍五入
ABS: 取绝对值
MOD: 取除法余数
SIGN: 正数返回1,负数返回-1,0 返回0
SQRT: 开方
FLOOR/CEIL: 向下取整或向上取整
POWER: 指数
常用字符串处理函数
TRIM: 删除字符串前后的空格,另外还有RTRIM和LTRIM,可以指定删除左侧还是右侧空格
SUBSTR: 取得字符串中指定起始位置和长度的字符串默认是从起始位置到结束的子串
LOWER/UPPER: 转换大小写
CONCAT: 字符串拼接
CONTAINS: 寻找是否包含某个字符
REPLACE:用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式
LEN:返回字符串长度
日期时间处理函数
NOW(): 返回当前时间
CURRENT_DATE(): 返回 当前日期
DATE_ADD/DATE_SUB: 日期的加减
MONTH/YEAR/DAY/WEEKDAY/QUARTER/WEEK: 返回日期中的年月日周几(看数据库设置,通常0代表周一、1代表周二)
TO_DATE:将字符串时间转化为日期格式
DATEDIFF:计算两个日期间的天数
DATE_FORMAT(date, format)函数
DATE_FORMAT(date, format)函数可根据format字符串格式化日期或日期和时间值date,返回结果串。也可用DATE_FORMAT()来格式化DATE或DATETIME值,以便得到所希望的格式。根据format字符串格式化date值:
%S, %s 两位数字形式的秒( 00,01, . . ., 59)
%i 两位数字形式的分( 00,01, . . ., 59)
%H 两位数字形式的小时,24 小时(00,01, . . ., 23)
%h, %I 两位数字形式的小时,12 小时(01,02, . . ., 12)
%k 数字形式的小时,24 小时(0,1, . . ., 23)
%l 数字形式的小时,12 小时(1, 2, . . ., 12)
%T 24 小时的时间形式(hh:mm:ss)
%r 12 小时的时间形式(hh:ss AM 或hh:ss PM)
%p AM 或P M
%W 一周中每一天的名称( Sunday, Monday, . . ., Saturday)
%a 一周中每一天名称的缩写( Sun, Mon, . . ., Sat)
%d 两位数字表示月中的天数( 00, 01, . . ., 31)
%e 数字形式表示月中的天数( 1, 2, . . ., 31)
%D 英文后缀表示月中的天数( 1st, 2nd, 3rd, . . .)
%w 以数字形式表示周中的天数( 0 = Sunday, 1=Monday, . . ., 6=Saturday)
%j 以三位数字表示年中的天数( 001, 002, . . ., 366)
% U 周(0, 1, 52),其中Sunday 为周中的第一天
%u 周(0, 1, 52),其中Monday 为周中的第一天
%M 月名(January, February, . . ., December)
%b 缩写的月名( January, February, . . ., December)
%m 两位数字表示的月份( 01, 02, . . ., 12)
%c 数字表示的月份( 1, 2, . . ., 12)
%Y 四位数字表示的年份
%y 两位数字表示的年份
%% 直接值“%”
NULL相关函数
COALESCE()对NULL值进行替换
ISNULL:判断是否为空
ISEXIST:判断是否存在
窗口函数
窗口函数针对指定的行集合(分组)执行聚合运算。不同之处在于,窗口函数能够为每个分组返回多个值,而聚合函数只能返回单一值。聚合运算的对象其实是一组行记录,我们称之为“窗口”(因此才有了术语“窗口函数”)
FIRST_VALUE:取出分组内排序后,截止到当前行,第一个值
LAST_VALUE:取出分组内排序后,截止到当前行,最后一个值
LEAD(col, n, DEFAULT):用于统计窗口内往下第n行的值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时,取默认值)
LAG(col,n,DEFAULT):与lead相反,用于统计窗口内往下第n个值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1)
分析函数
ROW_NUMBER()从1开始,按照顺序,生成分组内记录的序列,比如按照pv降序排列,生成分组内每天的pv名次,ROW_NUMBER()的应用 场景非常多,再比如,获取分组内排序第一的记录,获取一个session中的第一条refer等
RANK()生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK()生成数据项在分组中的排名,排名相等会在名次中不会留下空位
CUME_DIST()小于等于当前值的行数除以分组内总行数。比如,统计小于等于当前薪水的人数所占总人数的比例
PERCENT_RANK()分组内当前行的RANK值/分组内总行数
NTILE(n)用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。
OVER从句
使用标准的聚合函数COUNT,SUM,MIN,MAX,AVG
使用PARTITION BY语句,使用一个或者多个原始数据类型的列
使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
使用窗口规范
其他操作
查看当前有哪些数据库
SHOW DATABASES;
创建一个数据库
CREATE DATABASE <database_name>;
使用一个数据库
USE <database_name>;
数据.sql文件中导入指令
SOURCE <path_of_.sql_file>;
删除一个数据库
DROP DATABASE <database_name>;
查看选定的库下有哪些表
SHOW TABLES;
创建一张临时表
CREATE TABLE <table_name1> (
<col_name1> <col_type1>,
<col_name2> <col_type2>,
<col_name3> <col_type3>
PRIMARY KEY (<col_name1>),
FOREIGN KEY (<col_name2>) REFERENCES <table_name2>(<col_name2>)
);
显示表字符描述
DESCRIBE <table_name>;
插入数据
INSERT INTO <table_name> (<col_name1>, <col_name2>, <col_name3>, …)
VALUES (<value1>, <value2>, <value3>, …);
更新数据
UPDATE <table_name>
SET <col_name1> = <value1>, <col_name2> = <value2>, ...
WHERE <condition>;
删除表中内容,可以条件WHERE条件来限定要删除的内容
DELETE FROM <table_name> WHERE <condition>;
清空表中所有数据
TRUNCATE <table_name>;
删除数据库表
DROP TABLE <table_name>;
创建视图
数据库中的数据都是存储在表中的,而视图只是一个或多个表依照某个条件组合而成的结果集,一般来说你可以用update,insert,delete等sql语句修改表中的数据,而对视图只能进行select操作。
表是物理存在的
视图是虚拟的内存表
CREATE VIEW <view_name> AS
SELECT <col_name1>, <col_name2>, …
FROM <table_name> WHERE <condition>;
删除视图
DROP VIEW <view_name>;
-------------------------------
OLTP与OLAP
**联机事务处理( OLTP)**由业务数据库所支持,数据固定,操作负载少,强调数据库一致性与可恢复性。
**在线分析处理(OLAP )**由数据仓库支持,反应历史数据、多来源数据,通常多维建模,典型的OLAP操作有:上钻(聚合)、下钻(展开)、切割(选择和投影)、轴转(多维视图)。
OLAP的查询问题有不确定性,它最关键的两个因素是:并行处理与可扩展性。
ROLAP(关系型OLAP):在标准的或扩展的关系DBMS 上,支持扩展SQL和特殊访问。
MOLAP(多维OLAP):直接把多维数据存储在特定的数据结构。
OLAP场景的关键特征
大多数是读请求
数据总是以相当大的批(> 1000 rows)进行写入
不修改已添加的数据
每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
宽表,即每个表包含着大量的列
较少的查询(通常每台服务器每秒数百个查询或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小: 数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
事务不是必须的
对数据一致性要求低
每一个查询除了一个大表外都很小
查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
数据共享的方式
shared everything(SMP):网络与磁盘是瓶颈(SQLServer)
shared disk(NUMA):存储器接口达到饱和的时候,增加节点并不能获得更高的性能 (Oracle Rac)
shared nothing(MPP):各自处理自己的数据,可扩展,成本低
MPP大规模并行处理架构
任务并行执行;
数据分布式存储(本地化);
分布式计算;
私有资源;
横向扩展;
Shared Nothing架构。
MPPDB特征
(1)无master的扁平结构
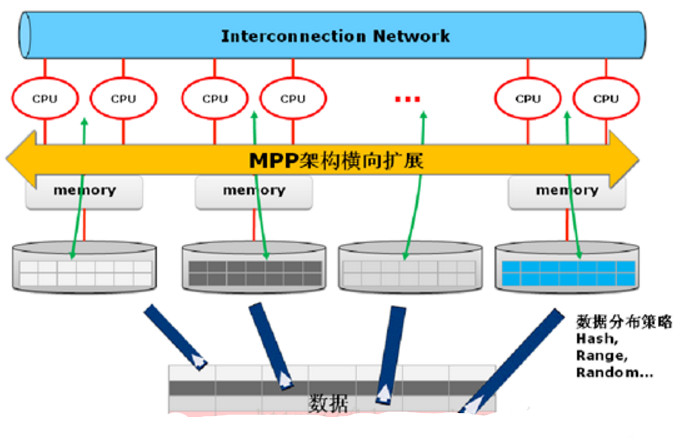
(2)可处理 PB 级数据,采用 hash 分布、random 策略存储,采用先进压缩算法
(3)高扩展,支持集群扩容缩容
(4)高并发:读写不互斥,可边加载边查询
(5)行列混合存储
LSM-Tree (long structured merge tree)
最大的特点就是写入速度快,主要利用了磁盘的顺序写,也主要针对的场景是写密集、少量查询的场景。 被用于各种键值数据库
读:查询时是一层一层向下查
写:一次写操作会先写入内存(f0层), 数据达到一定大小,就使用归并排序来合并,并写入磁盘(f1层),当磁盘f1层达到一定大小会继续合并为c2层。
lsm-tree 的一种实现 LevelDB:文件分三种,内存中有memtable,immutable,磁盘中有SStable(sorted string table)写会写入memtable,当达到阈值,就把immutable合并入磁盘并把memtable转为immutable。
RAID
ACID属性
原子性、一致性、隔离性和持久性。DB执行的每个事务都必须遵守这四个属性。

原子性:一个事务要么失败要么通过。这意味着,即使交易部分失败了,也意味着整个交易都失败了。通常情况下,这被称为 "全有或全无 "规则。
一致性: 事务将总是导致数据库的有效状态。
隔离性: 如果有多个事务同时被执行,DB的结果/状态应该与它们逐一执行的情况相同。
持久性: 一旦事务完成并提交,任何外部因素,如断电或崩溃,都不能改变它。
数据完整性
对于任何CRUD操作,共享数据的更新和最新的值/状态应该出现在所有的表格和屏幕上。
C Create:创建 - 当用户 "保存 "任何新事务时,"创建 "操作被执行。
R Retrieve:检索 - 当用户 "搜索 "或 "查看 "任何已保存的事务时,会执行 "检索 "操作。
U Update:更新 - 当用户'编辑'或'修改'现有的记录,DB的'更新'操作被执行。
D Delete:删除 - 当用户从系统中'删除'任何记录时,将执行DB的'删除'操作。
该文章最后由 阿炯 于 2025-05-22 15:32:40 更新,目前是第 2 版。