 Redis 5 的变化大多是面向用户的,即在现有的基础上增加新的数据类型和操作类型,以下是此版本的主要功能:
Redis 5 的变化大多是面向用户的,即在现有的基础上增加新的数据类型和操作类型,以下是此版本的主要功能:1.新的流数据类型(Stream data type) https://redis.io/topics/strea...
2.新的 Redis 模块 API:定时器、集群和字典 API(Timers, Cluster and Dictionary APIs)
3.RDB 增加 LFU 和 LRU 信息
4.集群管理器从 Ruby (redis-trib.rb) 移植到了redis-cli 中的 C 语言代码
5.新的有序集合(sorted set)命令:ZPOPMIN/MAX 和阻塞变体(blocking variants)
6.升级 Active defragmentation 至 v2 版本
7.增强 HyperLogLog 的实现
8.更好的内存统计报告
9.许多包含子命令的命令现在都有一个 HELP 子命令
10.客户端频繁连接和断开连接时,性能表现更好
11.许多错误修复和其他方面的改进
12.升级 Jemalloc 至 5.1 版本
13.引入 CLIENT UNBLOCK 和 CLIENT ID
14.新增 LOLWUT 命令
15.在不存在需要保持向后兼容性的地方,弃用 "slave" 术语
16.网络层中的差异优化
17.Lua 相关的改进
18.引入动态的 HZ(Dynamic HZ) 以平衡空闲 CPU 使用率和响应性
19.对 Redis 核心代码进行了重构并在许多方面进行了改进
Redis 5的新优势:
新增的stream数据结构,丰富的应用场景,内核的改进和bugfix,使用更健壮
支持账号体系,根据账号用途赋予相应的权限,更加安全
审计日志,记录了读写操作、敏感操作(keys、flushall等)、慢日志、管理类命令,供用户查询
大key分析,更准确地基于快照的完整内存分析,直接输出内存消耗top排行的key;在运行期进行自动内存碎片清理,释放内存空间,通过内存报告了解整个系统的内存使用情况。支持单机和集群版的平滑迁移
Redis开源社区版新特性
Streams
全新的数据类型:Streams。官方把这个当做是最重要的改进(The most important user facing improvement is without doubts the introduction
of the new general purpose data type after years: the streams.)。而且官方提到在发版本的几个小时前还在修复streams的问题,所以官方也不敢保证release版本是否有一些比较严重的BUG,官方还是建议大家在生产环境不要使用streams,这样可能会有更好的体验,(People not using the streams can have probably a better production-ready
experience with Redis 5)。这样可以把streams当做一个MQ,甚至把streams当做kafka都没问题!关于Streams的更多的特性下文会更详细地介绍。
使用c开发的工具来管理集群
redis终于还是抛弃了ruby,维护过redis3.x和redis4.x的都知道,主要依赖redis-trib.rb脚本,redis5.0彻底抛弃了它,将集群管理功能全部集成到完全用C写的redis-cli中。可以通过命令redis-cli --cluster help查看帮助信息。
Lua改进
lua脚本能更好的传播到replicas/AOF。replicas也就是以前的slave,大家都知道redis的slave事件前段时间闹的沸沸扬扬,现在redis官方都改称replicas了,并且申明除非为了API向后兼容,否则不再使用slave这个词(We no longer use the "slave" word if not for API backward compatibility.)。lua脚本现在还能支持超时,并且可以在replica中进入BUSY状态。
动态HZ
以前redis版本的hz都是固定的,5.0将hz动态化是为了平衡空闲CPU的使用率和响应能力。当然这个是可配置的,只不过在5.0中默认是动态的,其对应的配置为:dynamic-hz yes
ZPOPMIN&ZPOPMAX
用法:ZPOPMIN|ZPOPMAX key [count]
作用是移除并返回sorted set中count个最低|最高得分,count默认值为1。
127.0.0.1:6379> ZADD exam 98 "a1" 90 "a2" 78 "a3" 60 "a4" 58 "a5" 50 "a6"
(integer) 6
127.0.0.1:6379> zrange exam 0 -1
1) "a6"
2) "a5"
3) "a4"
4) "a3"
5) "a2"
6) "a1"
# 移除两个最低得分
127.0.0.1:6379> ZPOPMIN exam 2
1) "a6"
2) "50"
3) "a5"
4) "58"
# 移除一个最低低分(没有指定COUNT参数,就是1)
127.0.0.1:6379> ZPOPMIN exam
1) "a4"
2) "60"
# 移除3个后,exam只剩下两个元素
127.0.0.1:6379> zrange exam 0 -1
1) "a3"
2) "a2"
3) "a1"
其他一些比如HyperLogLog实现改进,RDB文件新增存储LFU和LRU信息,Jemalloc升级到5.1等等。
内存使用优化
Redis5.x在上一版本基础上,在内存使用上做了进一步优化,包括:
主动碎片整理
当key被频繁修改,value长度不断变化时,Redis会为key分配新的内存空间。由于Redis追求高性能,实现了自己的内存分配器来管理内存,因此并不会将原有内存释放给OS,从而导致出现内存碎片。当used_memory_rss/used_memory高于1.5,一般认为内存碎片占比过高,内存利用率低。因此合理规划和使用缓存数据,规范数据写入,将有助于减少内存碎片的产生。
Redis3.x及以下:可以通过定期重启服务解决内存碎片问题,建议实际缓存数据不超过配置可用内存的50%。
Redis4.x:支持主动整理内存碎片,服务在运行期间进行自动内存碎片清理,同时Redis4.x支持通过memory purge命令手动清理内存碎片。
Redis5.0:增强版主动碎片整理,配合Jemalloc版本更新,更快更智能,延时更低。
HyperLogLog算法优化
HyperLogLog是一种基数计数方法,使用少量的内存空间完成海量数据的计数统计,在Redis5.0中,HyperLogLog算法得到改进,优化了计数统计时的内存使用效率。举个例子:B树计数效率非常高,但是内存消耗也比较多,而HyperLogLog可节省大量存储空间。当B树需要1M内存统计,HyperLogLog只需要1kb。
内存信息统计报告能力增强,INFO命令返回信息更加详实。
Redis Enterprise 新特性
Redis开源许可从AGPL 迁移到将 Apache v2.0 与 Commons Clause 相结合的许可证,下面介绍的这些特性不再是开源软件,而是源码可用(source available)。
备注:Commons Clause 的初衷是为了抵御一些不良行为,如那些使用源代码,却不对开源代码维护做出补偿的公司。---- Commons Clause 开发者兼 FOSSA 创始人 Kevin Wang。
Redis Labs' Modules
Redis Labs开发了3个模块,并且被Redis企业软件(简称RS)认证,这些模块是:
RediSearch:这个模块将RS变成了一个基于内存的分布式全文索引和搜索引擎(ES要表示不服)。
ReJSON:通过模块名称就知道,JSON作为Redis的内置数据类型。
ReBloom:RS具有可扩展的Bloom过滤器,并且是一个数据类型。Bloom过滤器是一种概率性的数据结构,在快速判断某些元素是否被包含在一个集合这方便表现的非常好。
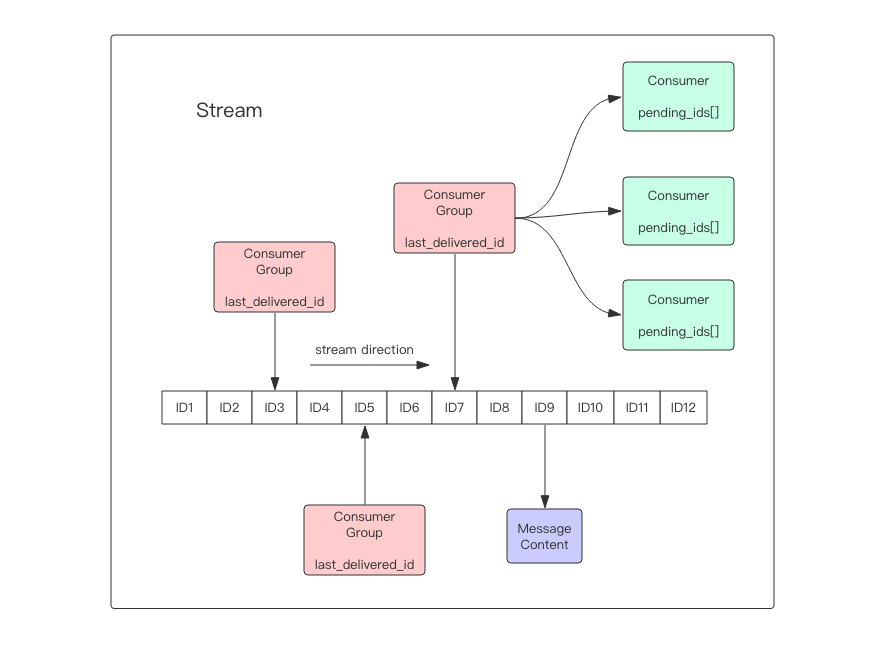
Redis5.0最大的新特性就是多出了一个数据结构Stream,它是一个新的强大的支持多播的可持久化的消息队列,作者坦言Redis Stream借鉴了Kafka的设计。Redis Stream有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容,消息是持久化的,Redis重启后内容还在。
Redis Stream的结构示意图如图所示,它是一个可持久化的数据结构,用一个消息链表,将所有加入进来的消息都串起来。
Stream数据结构具有以下特性:
可以有多个消费者组。
每个消费组都含有一个Last_delivered_id,指向消费组当前已消费的最后一个元素(消息)。
每个消费组可以含有多个消费者对象,消费者共享消费组中的Last_delivered_id,相同消费组内的消费者存在竞争关系,即一个元素只能被其中一个消费者进行消费。
消费者对象内还维持了一个Pending_ids,Pending_ids记录已发送给客户端,但是还没完成ACK(消费确认)的元素id。
Redis stream本质上是个时序数据结构,具有如下特点:
每条记录是结构化、可扩展的对
每条记录在日志中有唯一标识,标识中包含了时间戳信息,单调递增
可以根据需要自动清理历史记录
保存在内存中,支持持久化
底层是修改版的radix tree,每个node存储了一个listpack。listpack是一块连续的内存block,用于序列化msg entry及相关元信息,如msg ID,使用了多种编码,用于节省内存,是ziplist的升级版。如果XADD每次添加的对中的field是一样的,那么field不会重复存储。
表1-1 Stream与Redis现有数据结构比较
Stream | List, Pub/Sub, Zset |
获取元素高效,复杂度为O(logN) | List获取元素的复杂度为O(N) |
支持offset,每个消息元素有唯一id。不会因为新元素加入或者其他元素淘汰而改变id。 | List没有offset概念,如果有元素被逐出,无法确定最新的元素 |
支持消息元素持久化,可以保存到AOF和RDB中。 | Pub/Sub不支持持久化消息。 |
支持消费分组 | Pub/Sub不支持消费分组 |
支持ACK(消费确认) | Pub/Sub不支持 |
Stream性能与消费者数量无明显关系 | Pub/Sub性能与客户端数量正相关 |
允许按时间线逐出历史数据,支持block,给予radix tree和listpack,内存开销少。 | Zset不能重复添加相同元素,不支持逐出和block,内存开销大。 |
不能从中间逐出消息元素。 | Zet支持删除任意元素 |
Stream相关命令介绍
接下来按照使用流程中出现的顺序介绍Stream相关命令:
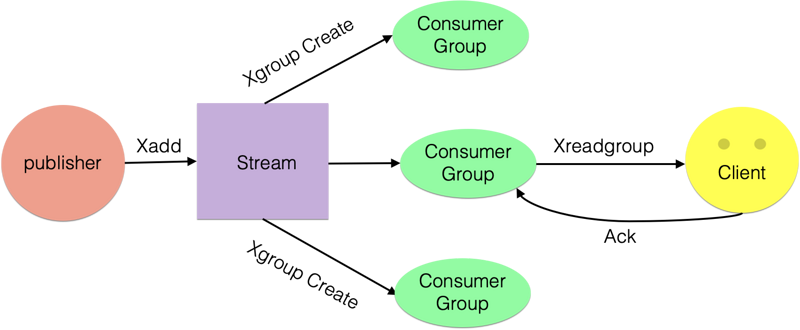
首先使用XADD添加流元素,即创建Stream,添加流元素时可指定消息数量最大保存范围。
然后通过XGROUP创建消费者组。
消费者使用XREADGROUP指令进行消费。
客户端消费完毕后使用XACK命令确认消息已消费成功。
表1-2 Stream的详细命令
命令 | 说明 | 语法 |
XACK | 从流的消费者组的待处理条目列表(简称PEL)中删除一条或多条消息。 | XACK key group ID [ID ...] |
XADD | 将指定的流条目追加到指定key的流中。 如果key不存在,作为运行这个命令的副作用,将使用流的条目自动创建key。 | XADD key ID field string [field string ...] |
XCLATM | 在流的消费者组上下文中,此命令改变待处理消息的所有权, 因此新的所有者是在命令参数中指定的消费者。 | XCLAIM key group consumer min-idle-time ID [ID ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID] |
XDEL | 从指定流中移除指定的条目,并返回成功删除的条目的数量,在传递的ID不存在的情况下, 返回的数量可能与传递的ID数量不同。 | XDEL key ID [ID ...] |
XGROUP | 该命令用于管理流数据结构关联的消费者组。使用XGROUP你可以: l 创建与流关联的新消费者组。 l 销毁一个消费者组。 l 从消费者组中移除指定的消费者。 l 将消费者组的最后交付ID设置为其他内容。 | XGROUP [CREATE key groupname id-or-$] [SETID key id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] |
XINFO | 检索关于流和关联的消费者组的不同的信息。 | XINFO [CONSUMERS key groupname] key key [HELP] |
XLEN | 返回流中的条目数。如果指定的key不存在,则此命令返回0,就好像该流为空。 | XLEN key |
XPENDING | 通过消费者组从流中获取数据。检查待处理消息列表的接口,用于观察和了解消费者组中哪些客户端是活跃的,哪些消息在等待消费,或者查看是否有空闲的消息。 | XPENDING key group [start end count] [consumer] |
XRANGE | 返回流中满足给定ID范围的条目。 | XRANGE key start end [COUNT count] |
XREAD | 从一个或者多个流中读取数据,仅返回ID大于调用者报告的最后接收ID的条目。 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
XREADGROUP | XREAD命令的特殊版本,指定消费者组进行读取。 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] |
XREVRANGE | 与XRANGE相同,但显著的区别是以相反的顺序返回条目,并以相反的顺序获取开始-结束参数 | XREVRANGE key end start [COUNT count] |
XTRIM | XTRIM将流裁剪为指定数量的项目,如有需要,将驱逐旧的项目(ID较小的项目)。 | XTRIM key MAXLEN [~] count |
消息(流元素)消费确认
Stream与相比Pub/Sub,不仅增加消费分组模式,还支持消息消费确认。
当一条消息被某个消费者调用XREADGROUP命令读取或调用XCLAIM命令接管的时候, 服务器尚不确定它是否至少被处理了一次。一旦消费者成功处理完一条消息,它应该调用XACK知会Stream,这样这个消息就不会被再次处理,同时关于此消息的PEL(pending_ids)条目也会被清除,从Redis服务器释放内存。在某些情况下,因为网络问题等,客户端消费完毕后没有调用XACK,这时候PEL内会保留对应的元素ID。待客户端重新连上后,XREADGROUP的起始消息ID建议设置为0-0,表示读取所有的PEL消息及自last_id之后的消息。同时消费者消费消息时需要能够支持消息重复传递。
Redis Stream使用
使用场景
可用作时通信等,大数据分析,异地数据备份等
客户端可以平滑扩展,提高处理能力
Zpop
Sorted Sets 增加了类似List的pop命令:
ZPOPMAX 命令用于移除并弹出有序集合中分值最大的 count 个元素
ZPOPMIN 命令用于移除并弹出有序集合中分值最小的 count 个元素
BZPOPMAX 和 BZPOPMIN 是上述两个命令的阻塞变种.
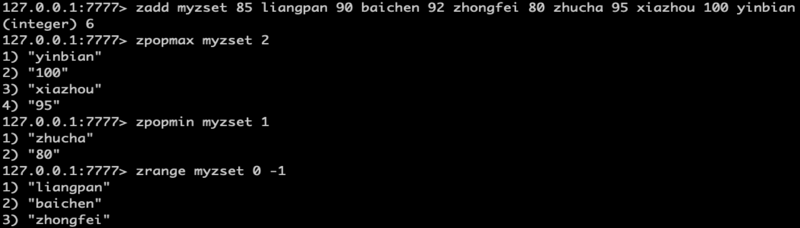
CLIENT
Client id返回当前连接的ID,每个ID符合如下约束:
永不重复,可以判断当前链接是否断链过
单调递增,可以判断不同链接的接入顺序
Client unblock:
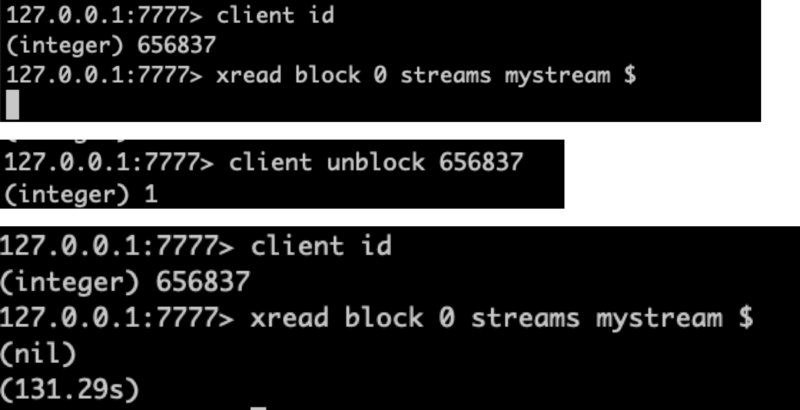
当客户端因为执行具有阻塞功能的命令(如BRPOP、XREAD或者WAIT)被阻塞时,该命令可以通过其他连接解除客户端的阻塞。
每个Stream都有唯一的名称,它就是Redis的key,在我们首次使用xadd指令追加消息时自动创建。每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响,也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者有一个组内唯一名称。消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
消息ID
消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
消息内容
消息内容就是键值对,形如hash结构的键值对,这没什么特别之处。
增删改查
xadd 追加消息
xdel 删除消息,这里的删除仅仅是设置了标志位,不影响消息总长度
xrange 获取消息列表,会自动过滤已经删除的消息
xlen 消息长度
del 删除Stream
# *号表示服务器自动生成ID,后面顺序跟着一堆key/value
# 名字叫freeoa,年龄30岁
127.0.0.1:6379> xadd codehole * name freeoa age 30
1527849609889-0 # 生成的消息ID
127.0.0.1:6379> xadd codehole * name xiaoyu age 29
1527849629172-0
127.0.0.1:6379> xadd codehole * name xiaoqian age 1
1527849637634-0
127.0.0.1:6379> xlen codehole
(integer) 3
# -表示最小值, +表示最大值
127.0.0.1:6379> xrange codehole - +
1) 1) 1527849609889-0
2) 1) "name"
2) "freeoa"
3) "age"
4) "30"
2) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
3) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
# 指定最小消息ID的列表
127.0.0.1:6379> xrange codehole 1527849629172-0 +
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
# 指定最大消息ID的列表
127.0.0.1:6379> xrange codehole - 1527849629172-0
1) 1) 1527849609889-0
2) 1) "name"
2) "freeoa"
3) "age"
4) "30"
2) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
127.0.0.1:6379> xdel codehole 1527849609889-0
(integer) 1
# 长度不受影响
127.0.0.1:6379> xlen codehole
(integer) 3
# 被删除的消息没了
127.0.0.1:6379> xrange codehole - +
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
# 删除整个Stream
127.0.0.1:6379> del codehole
(integer) 1
独立消费
我们可以在不定义消费组的情况下进行Stream消息的独立消费,当Stream没有新消息时,甚至可以阻塞等待。Redis设计了一个单独的消费指令xread,可以将Stream当成普通的消息队列(list)来使用。使用xread时,我们可以完全忽略消费组(Consumer Group)的存在,就好比Stream就是一个普通的列表(list)。
# 从Stream头部读取两条消息
127.0.0.1:6379> xread count 2 streams codehole 0-0
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "freeoa"
3) "age"
4) "30"
2) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
# 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息
127.0.0.1:6379> xread count 1 streams codehole $
(nil)
# 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来
127.0.0.1:6379> xread block 0 count 1 streams codehole $
# 我们从新打开一个窗口,在这个窗口往Stream里塞消息
127.0.0.1:6379> xadd codehole * name youming age 60
1527852774092-0
# 再切换到前面的窗口,我们可以看到阻塞解除了,返回了新的消息内容
# 而且还显示了一个等待时间,这里我们等待了93s
127.0.0.1:6379> xread block 0 count 1 streams codehole $
1) 1) "codehole"
2) 1) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
(93.11s)
客户端如果想要使用xread进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息ID。下次继续调用xread时,将上次返回的最后一个消息ID作为参数传递进去,就可以继续消费后续的消息。
block 0表示永远阻塞,直到消息到来,block 1000表示阻塞1s,如果1s内没有任何消息到来,就返回nil
127.0.0.1:6379> xread block 1000 count 1 streams codehole $
(nil)
(1.07s)
创建消费组
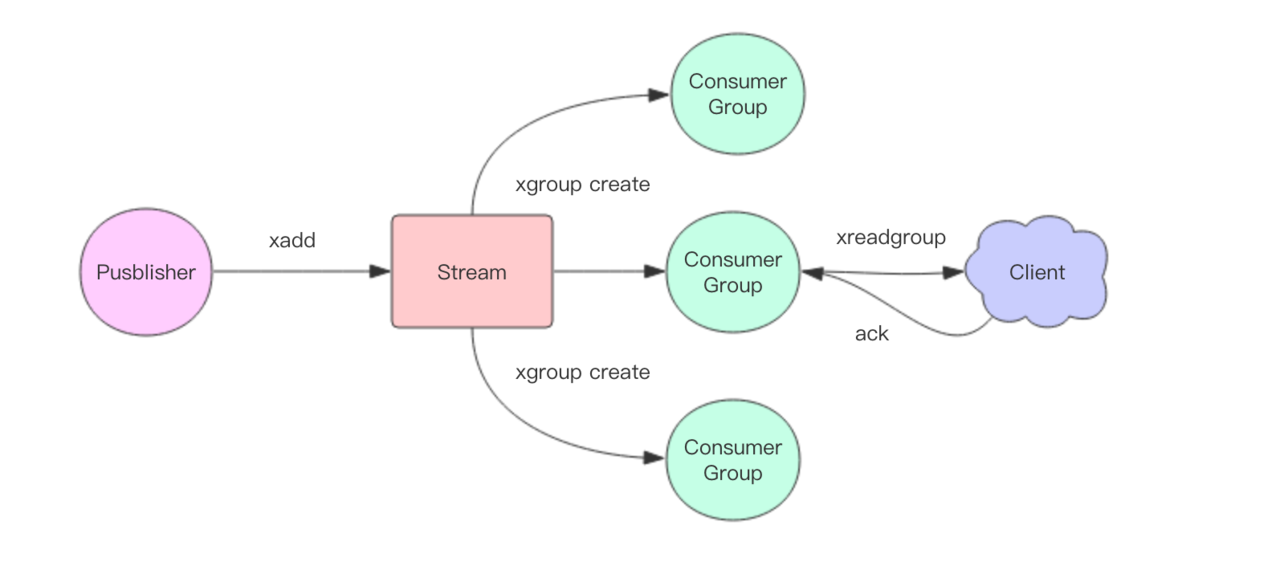
Stream通过xgroup create指令创建消费组(Consumer Group),需要传递起始消息ID参数用来初始化last_delivered_id变量。
# 表示从头开始消费
127.0.0.1:6379> xgroup create codehole cg1 0-0
OK
# $表示从尾部开始消费,只接受新消息,当前Stream消息会全部忽略
127.0.0.1:6379> xgroup create codehole cg2 $
OK
# 获取Stream信息
127.0.0.1:6379> xinfo codehole
1) length
2) (integer) 3 # 共3个消息
3) radix-tree-keys
4) (integer) 1
5) radix-tree-nodes
6) (integer) 2
7) groups
8) (integer) 2 # 两个消费组
9) first-entry # 第一个消息
10) 1) 1527851486781-0
2) 1) "name"
2) "freeoa"
3) "age"
4) "30"
11) last-entry # 最后一个消息
12) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
# 获取Stream的消费组信息
127.0.0.1:6379> xinfo groups codehole
1) 1) name
2) "cg1"
3) consumers
4) (integer) 0 # 该消费组还没有消费者
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
2) 1) name
2) "cg2"
3) consumers # 该消费组还没有消费者
4) (integer) 0
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
消费
Stream提供了xreadgroup指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息ID。它同xread一样,也可以阻塞等待新消息。读到新消息后,对应的消息ID就会进入消费者的PEL(正在处理的消息)结构里,客户端处理完毕后使用xack指令通知服务器,本条消息已经处理完毕,该消息ID就会从PEL中移除。
# >号表示从当前消费组的last_delivered_id后面开始读
# 每当消费者读取一条消息,last_delivered_id变量就会前进
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "freeoa"
3) "age"
4) "30"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 2 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
2) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
# 再继续读取,就没有新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
(nil)
# 那就阻塞等待吧
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
# 开启另一个窗口,往里塞消息
127.0.0.1:6379> xadd codehole * name lanying age 61
1527854062442-0
# 回到前一个窗口,发现阻塞解除,收到新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527854062442-0
2) 1) "name"
2) "lanying"
3) "age"
4) "61"
(36.54s)
# 观察消费组信息
127.0.0.1:6379> xinfo groups codehole
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1 # 一个消费者
5) pending
6) (integer) 5 # 共5条正在处理的信息还有没有ack
2) 1) name
2) "cg2"
3) consumers
4) (integer) 0 # 消费组cg2没有任何变化,因为前面我们一直在操纵cg1
5) pending
6) (integer) 0
# 如果同一个消费组有多个消费者,我们可以通过xinfo consumers指令观察每个消费者的状态
127.0.0.1:6379> xinfo consumers codehole cg1 # 目前还有1个消费者
1) 1) name
2) "c1"
3) pending
4) (integer) 5 # 共5条待处理消息
5) idle
6) (integer) 418715 # 空闲了多长时间ms没有读取消息了
# 接下来我们ack一条消息
127.0.0.1:6379> xack codehole cg1 1527851486781-0
(integer) 1
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 4 # 变成了5条
5) idle
6) (integer) 668504
# 下面ack所有消息
127.0.0.1:6379> xack codehole cg1 1527851493405-0 1527851498956-0 1527852774092-0 1527854062442-0
(integer) 4
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 0 # pel空了
5) idle
6) (integer) 745505
Stream消息太多怎么办
读者很容易想到,要是消息积累太多,Stream的链表岂不是很长,内容会不会爆掉就是个问题了。xdel指令又不会删除消息,它只是给消息做了个标志位。Redis自然考虑到了这一点,所以它提供了一个定长Stream功能。在xadd的指令提供一个定长长度maxlen,就可以将老的消息干掉,确保最多不超过指定长度。
127.0.0.1:6379> xlen codehole
(integer) 5
127.0.0.1:6379> xadd codehole maxlen 3 * name xiaorui age 1
1527855160273-0
127.0.0.1:6379> xlen codehole
(integer) 3
可以看到Stream的长度被砍掉了。
消息如果忘记ACK会怎样
Stream在每个消费者结构中保存了正在处理中的消息ID列表PEL,如果消费者收到了消息处理完了但是没有回复ack,就会导致PEL列表不断增长,如果有很多消费组的话,那么这个PEL占用的内存就会放大。
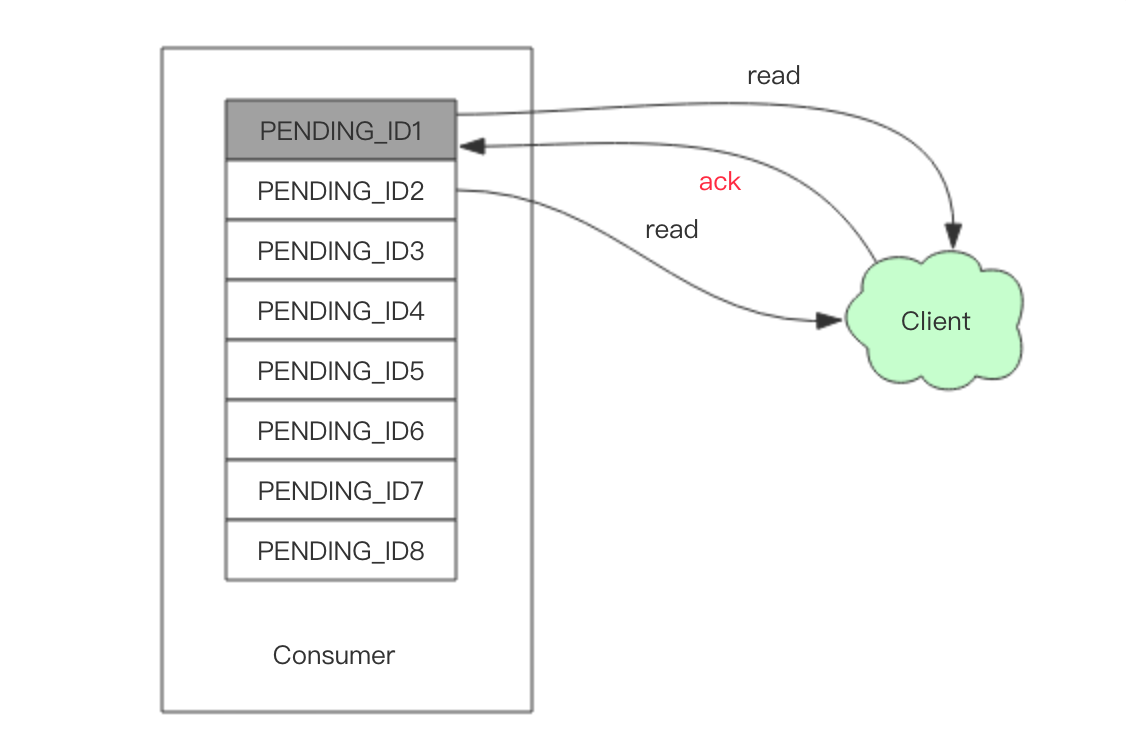
PEL如何避免消息丢失
在客户端消费者读取Stream消息时,Redis服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。但是PEL里已经保存了发出去的消息ID。待客户端重新连上之后,可以再次收到PEL中的消息ID列表。不过此时xreadgroup的起始消息ID不能为参数>,而必须是任意有效的消息ID,一般将参数设为0-0,表示读取所有的PEL消息以及自last_delivered_id之后的新消息。
小结
Stream的消费模型借鉴了kafka的消费分组的概念,它弥补了Redis Pub/Sub不能持久化消息的缺陷。但是它又不同于kafka,kafka的消息可以分partition,而Stream不行。如果非要分parition的话,得在客户端做,提供不同的Stream名称,对消息进行hash取模来选择往哪个Stream里塞。如果读者稍微研究过Redis作者的另一个开源项目Disque的话,这很可能是作者意识到Disque项目的活跃程度不够,所以将Disque的内容移植到了Redis里面。
再来一个全功能的示例:
===============================
添加消息
Streams 添加数据使用 XADD 指令进行添加,消息中的数据以 K-V 键值对的形式进行操作。一条消息可以存在多个键值对,添加命令格式:
XADD key ID field string [field string ...]
其中 key 为 Streams 的名称,ID 为消息的唯一标志,不可重复,field string 就为键值对。下面我们就添加以 person 为名称的流,进行操作。
XADD person * name freeoa des https://freeoa.net
上面添加案例中,ID 使用 * 号复制,这里代表着服务端自动生成 Id,添加后返回数据 "1578238486193-0"
这里自动生成的 Id 格式为 <millisecondstime>-<sequencenumber> Id 是由两部分组成:
millisecondsTime 为当前服务器时间毫秒时间戳。
sequenceNumber 当前序列号,取值来源于当前毫秒内,生成消息的顺序,默认从 0 开始加 1 递增。
比如:1578238486193-3 表示在 1578238486193 毫秒的时间戳时,添加的第 4 条消息。除了服务端自动生成 Id 方式外,也支持指定 Id 的生成,但是指定 Id 有以下条件限制:
Id 中的前后部分必须为数字。
最小 Id 为 0-1,不能为 0-0,但是 2-0,3-0 .... 是被允许的。
添加的消息,Id 的前半部分不能比存在 Id 最大的值小,Id 后半部分不能比存在前半部分相同的最大后半部分小。
否则,当不满足上述条件时,添加后会抛出异常:
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
实际上,当添加一条消息时,会进行两部操作。第一步,先判断如果不存在 Streams,则创建 Streams 的名称,再添加消息到 Streams 中。即使添加消息时,由于 Id 异常,也可以在 Redis 中存在以当前 Streams 的名称。 Streams 中 Id 也可作为指针使用,因为它是一个有序的标记。
生产中,如果这样使用添加消息,会存在一个问题,那就是消息数量太大时,会使服务宕机。这里 Streams 的设计初期也有考虑到这个问题,那就是可以指定 Streams 的容量。如果容量操作这个设定的值,就会对调旧的消息。在添加消息时,设置 MAXLEN 参数。
XADD person MAXLEN 5 * name freeoa des https://freeoa.net
这样就指定该了 Streams 中的容量为 5 条消息。也可使用 XTRIM 截取消息,从小到大剔除多余的消息:
XTRIM person MAXLEN 8
消息数量
查看消息数量使用 XLEN 指令进行操作。
XLEN key
例:查看 person 流中的消息数量:
> XLEN person
(integer) 5
查询消息
查询 Streams 中的消息使用 XRANGE 和 XREVRANGE 指令。
XRANGE
查询数据时,可以按照指定 Id 范围进行查询,XRANGE 查询指令格式:
XRANGE key start end [COUNT count]
参数说明:
key 为 Streams 的名称
start 为范围查询开始 Id,包含本 Id。
start 为范围查询结束 Id,包含本 Id。
Count 为查询返回最大的消息数量,非必填。
这里 start 和 end 有-和+两个非指定值,他们分别表示无穷小和无穷大,所以当使用这个两个值时,会查询出全部的消息。
> XRANGE person - +
1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
2) 1) "0-2"
2) 1) "name"
2) "luffy"
3) "des"
4) "valiant!"
3) 1) "2-0"
2) 1) "name"
2) "gaga"
3) "des"
4) "fishion!"
上面查询的消息数据,可以看到是按照先进先出的顺序查询出来的。
使用 COUNT 指定查询返回的数量:
# 查询所有的消息,并且返回一条数据
> XRANGE person - + COUNT 1
1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
在范围查询中,Id 的后半部分可省略,后半部分中的数据会全部查询到。
XREVRANGE
XREVRANGE 的查询和 XRANGE 指令中的使用类似,但查询的 start 和 end 参数顺序进行了调换:
XREVRANGE key end start [COUNT count]
使用案例:
> XREVRANGE person + -
1) 1) "2-0"
2) 1) "name"
2) "gaga"
3) "des"
4) "fishion!"
2) 1) "0-2"
2) 1) "name"
2) "luffy"
3) "des"
4) "valiant!"
3) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
查询后的结果与 XRANGE 的结果顺序刚好相反,其他都一样,这两个指令可进行消息的升序和降序的返回。
删除消息
删除消息使用 XDEL 指令操作,只需指定将要删除的 Streams 名称和 Id 即可,支持一次删除多个消息 。
XDEL key ID [ID ...]
删除案例:
# 查询所有消息
> XRANGE person - +
1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
2) 1) "0-2"
2) 1) "name"
2) "luffy"
3) "des"
4) "valiant!"
3) 1) "2-0"
2) 1) "name"
2) "gaga"
3) "des"
4) "fishion!"
# 删除消息
> XDEL person 2-0
(integer) 1
# 再次查询删除后的所有消息
> XRANGE person - +
1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
2) 1) "0-2"
2) 1) "name"
2) "luffy"
3) "des"
4) "valiant!"
# 查询删除后的长度
> XLEN person
(integer) 2
从上面可以看到,删除消息后,长度也会减少相应的数量。
消费消息
在 Redis 的 PUB/SUB 中,我们是通过订阅来消费消息,在 Streams 数据结构中,同样也能实现同等功能,当没有新的消息时,可进行阻塞等待。不仅支持单独消费,而且还可以支持群组消费。
单独消费
单独消费使用 XREAD 指令。可以看到,下面命令中,STREAMS,key, 以及 ID 为必填项。ID 表示将要读取大于该 ID 的消息。当 ID 值使用 $ 赋予时,表示已存在消息的最大 Id 值。
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
上面的 COUNT 参数用来指定读取的最大数量,与 XRANGE 的用法一样。
> XREAD COUNT 1 STREAMS person 0
1) 1) "person"
2) 1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
> XREAD COUNT 2 STREAMS person 0
1) 1) "person"
2) 1) 1) "0-1"
2) 1) "name"
2) "freeoa"
3) "des"
4) "https://freeoa.net"
2) 1) "0-2"
2) 1) "name"
2) "luffy"
3) "des"
4) "valiant!"
在 XREAD 里面还有个 BLOCK 参数,这个是用来阻塞订阅消息的,BLOCK 携带的参数为阻塞时间,单位为毫秒,如果在这个时间内没有新的消息消费,那么就会释放该阻塞。当这里的时间指定为 0 时,会一直阻塞,直到有新的消息来消费到。
# 窗口 1 开启阻塞,等待新消息的到来
> XREAD BLOCK 0 STREAMS person $
# 另开一个连接窗口 2,添加一条新的消息
> XADD person 2-2 name tao des coder
"2-2"
# 窗口 1,获取到有新的消息来消费,并且带有阻塞的时间
> XREAD BLOCK 0 STREAMS person $
1) 1) "person"
2) 1) 1) "2-2"
2) 1) "name"
2) "tao"
3) "des"
4) "coder"
(60.81s)
当使用 XREAD 进行顺序消费时,需要额外记录下读取到位置的 Id,方便下次继续消费。
群组消费
群组消费的主要目的也就是为了分流消息给不同的客户端处理,以更高效的速率处理消息。为达到这一肝功能需求,我们需要做三件事:创建群组,群组读取消息,向服务端确认消息以处理。
群组操作
操作群组使用 XGROUP 指令:
XGROUP [CREATE key groupname id-or-$] [SETID key id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
上面命令中,包含操作有:
CREATE 创建消费组。
SETID 修改下一个处理消息的 Id。
DESTROY 销毁消费组。
DELCONSUMER 删除消费组中指定的消费者。
我们当前需要使用的是创建消费组:
# 以当前存在的最大 Id 作为消费起始
> XGROUP CREATE person group1 $
OK
群组读取消息
群组读取使用 XREADGROUP 指令,COUNT和BLOCK的使用类似 XREAD 的操作,只是多了个群组和消费者的指定:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
由于群组消费和单独消费类似,这里只进行个阻塞分析,这里 Id 也有个特殊值>,表示还未进行消费的消息:
# 窗口 1,消费群组中,taotao 消费者建立阻塞监听
XREADGROUP GROUP group1 taotao BLOCK 0 STREAMS person >
# 窗口 2,消费群组中,yangyang 消费者建立阻塞监听
XREADGROUP GROUP group1 yangyang BLOCK 0 STREAMS person >
# 窗口 3,添加消费消息
> XADD person 3-1 name tony des 666
"3-1"
# 窗口 1,读取到新消息,此时 窗口 2 没有任何反应
> XREADGROUP GROUP group1 taotao BLOCK 0 STREAMS person >
1) 1) "person"
2) 1) 1) "3-1"
2) 1) "name"
2) "tony"
3) "des"
4) "666"
(77.54s)
# 窗口 3,再次添加消费消息
> XADD person 3-2 name james des abc!
"3-2"
# 窗口 2,读取到新消息,此时 窗口 1 没有任何反应
> XREADGROUP GROUP group1 yangyang BLOCK 0 STREAMS person >
1) 1) "person"
2) 1) 1) "3-2"
2) 1) "name"
2) "james"
3) "des"
4) "abc!"
(76.36s)
以上执行流程中,group1 群组中有两个消费者,当添加两条消息后,这两个消费者轮流消费。
消息ACK
消息消费后,为避免再次重复消费,这是需要向服务端发送 ACK,确保消息被消费后的标记。例如下列情况,我们上面我们将最新两条消息已进行了消费,但是当我们再次读取消息时,还是被读到:
> XREADGROUP GROUP group1 yangyang STREAMS person 0
1) 1) "person"
2) 1) 1) "3-2"
2) 1) "name"
2) "james"
3) "des"
4) "abc!"
这时,我们使用 XACK 指令告诉服务器,我们已处理的消息:
XACK key group ID [ID ...]0
让服务器标记 3-2 已处理:
> XACK person group1 3-2
(integer) 1
再次获取群组读取消息:
> XREADGROUP GROUP group1 yangyang STREAMS person 0
1) 1) "person"
2) (empty list or set)
队列中没有了可读消息。 除了上面以讲解到的 API 外,查看消费群组信息可使用 XINFO 指令查看。
===============================
stream 相关命令参考
XADD
作用:创建一个stream
用法:XADD key ID field string [field string ...]
ID:毫秒的unix时间戳 - sequence(同一毫秒的序列号)组成
XADD wangzhe * hero luban 创建默认id的key为hero的流数据
XLEN
作用:返回stream中元素的个数
用法:XLEN key
XDEL
作用:删除id
用法:XDEL key id,返回删除个数
XRANGER
作用:返回给定ID范围内的stream数据
用法:XRANGE key start end [COUNT count]
特殊ID:+:最大ID -:最小ID
XREAD
作用:从一个或多个stream读取数据
用法:XREAD[COUNT count][BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
XREAD count 1 STREAMS LOL 1-1 读取流LOL中从id为1-1开始的的1条数据
XREAD BLOCK 0 STREAMS key $ 永久堵塞,知道流key接收到最新数据,会显示阻塞时间
XGROUP
作用:创建一个Consumer Group
用法:XGROUP CREATE key groupname ID
XREADROUP
作用:从Consumer Group中读取数据
用法:XREADGROUP GROUP groupname consumer [COUNT count][BLOCK milliseconds STREAMS key [key ...] ID [ID ...]
XREADGROUP GROUP fashi chuanrong STREAMS wangzhe > 表示查询最新数据
新的Sorted Set
ZPOPMAX
作用:删除返回集合中分值最高的元素
用法:ZPOPMAX key [count]
ZPOPMIN
作用:删除返回集合中分值最小的元素
用法:ZPOPMIN key [count]
BZPOPMAX
作用:ZPOPMAX的阻塞版
用法:BZPOPMAX key [key ...] timeout
BZPOPMIN
作用:ZPOPMIN的阻塞版
用法:BZPOPMIN key [key ...] timeout
参考来源:
Redis5.0 新功能简介
Redis5.0新特性Stream尝鲜
Redis5新特性Streams作消息队列