
“为什么这个功能用不了?” 程序员:“清一下缓存”
上篇洞悉系列文章给大家详细介绍了MySQL的存储内幕:洞悉MySQL底层架构:游走在缓冲与磁盘之间,获得了不错的好评,博客园也首页置顶推荐了,非常高兴能给大家带来如此多的帮助。既然聊过了磁盘存储,我们今天就进一步来聊聊内存存储。
大多数并发量稍微高点的项目中都不会让请求直达MySQL这类的关系型数据库,而是中间加一道或者几道缓存,就如同操作系统中的CPU的多级缓存,以及主存那样,通过更快速的硬件去提高数据读取的效率,进而加快系统的处理速度,避免让IO成为系统的瓶颈。
而Redis作为一个成熟的缓存中间件,被广大的互联网公司直接采用或者进行二次开发。如果要开发并发量高的项目,Redis是一个不错的缓存技术选型。在此就来详细聊聊Redis技术内幕。为了让大家对Redis有一个全面的了解,本文会从以下几个角度去分析Redis:
每个部分涉及的内容可能会比较多,为了让大家对每个部分的内容有一个整体的认识,在每个部分的最开头,都会把该部分的内容以思维导图的方式给出。下面开始进入正题吧。
Part Ⅰ. 存储
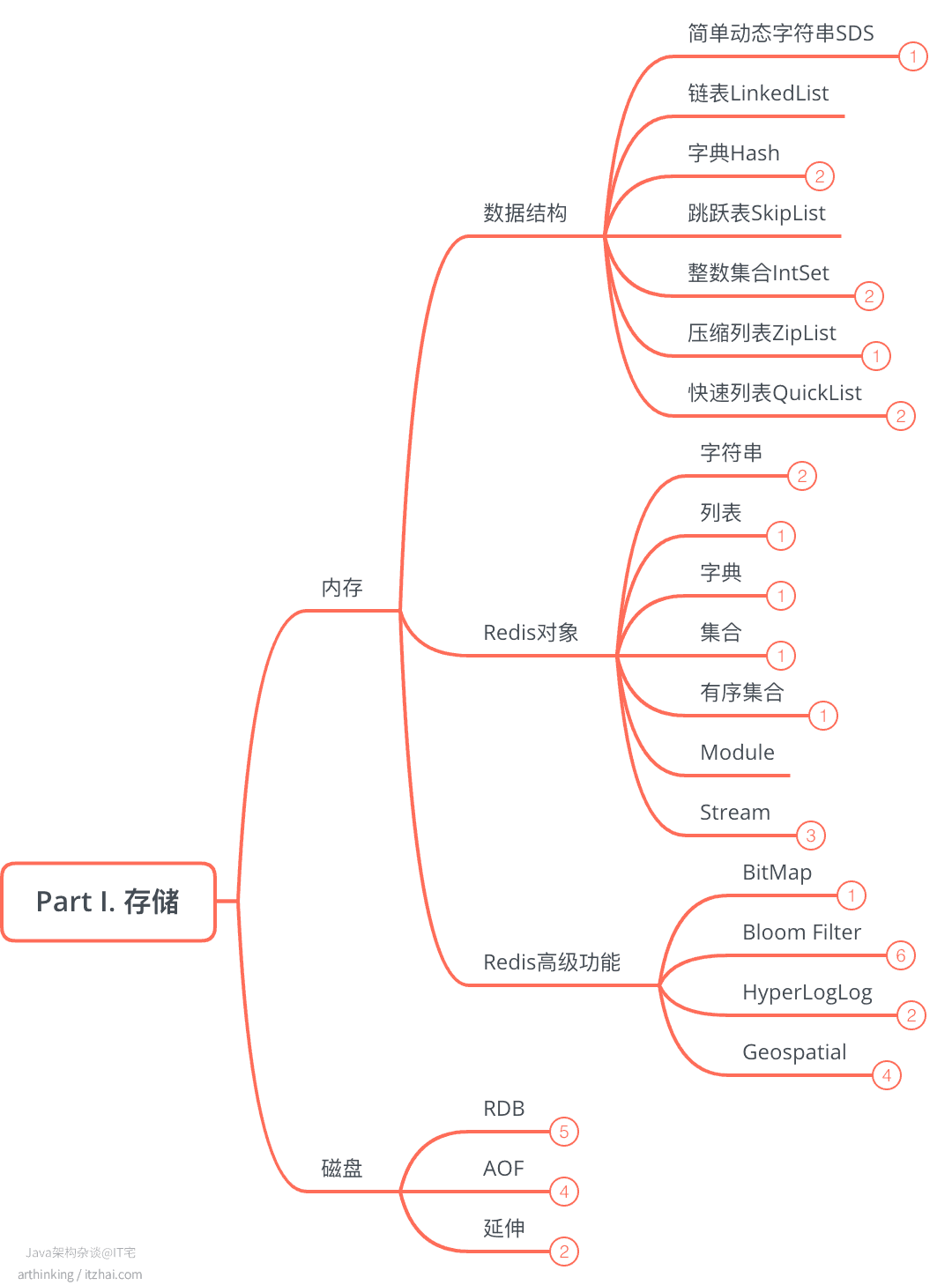
1、内存
既然要把数据放到内存中,就需要提供索引数据的方式,常见的索引实现技术有:Hash表,B+树,字典树等。MySQL中的索引是通过B+树实现的。而Redis作为KV内存数据库,其是采用哈希表来实现索引的。
为了实现键值快速访问,Redis使用了个哈希表来存储所有的键值对。
在内存中的布局如下:
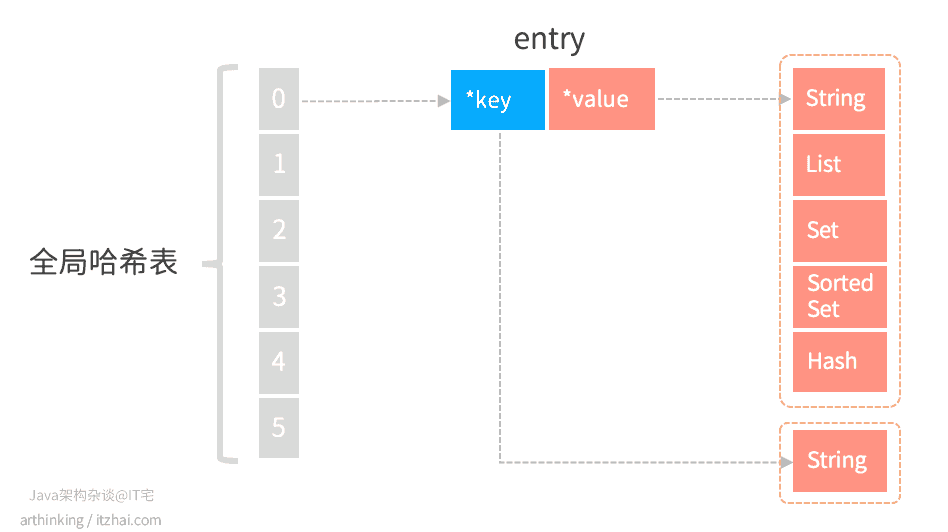
哈希桶中存储entry元素,entry元素包含了key和value指针,指向实际的key和value内容。
key指向的是字符串,value指向的是实际的各种redis数据结构。
这种结构下,只要哈希冲突不多,那么寻找kv键值对的效率就是很高的,而redis与Memcached相比,最重要的亮点就是value中提供的各种数据结构。这些数据结构的实现决定了执行各种操作命令获取数据的性能。
我们接下来看看这些数据结构。
1.1、redis中的各种数据结构
redis主要的数据类型有:String,List,Hash,Set,SortedSet,也称为对象,而这些数据类型,底层是基于特定的数据结构来实现的。之前也在IT宅(itzhai.com)以及Java架构杂谈中聊过了一些常见的数据结构:
- 常用数据结构(一) | 时间复杂度,Array,LinkedList,Stack,Queue,PQ,IPQ,BST,BBST,AVL
- 常用数据结构(二) | HashTable,并查集,树状数组,后缀数组
而Redis中,基于存储效率和访问效率的考虑,使用到了一些其他的数据结构。我们首先来看看Redis中常见的这些数据结构,然后在看看这些数据类型是由什么数据结构组成的。
1.1.1、SDS
我们知道,String类内部定义了常量数组进行存储字符串,是不可以修改的,每次对字符串操作都会另外分配一个新的常量数组空间。
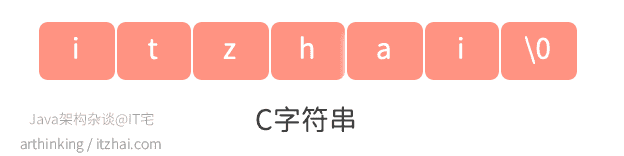
而Redis中的字符串是动态的。字符串是Redis中最为常见的存储类型,底层采用简单动态字符串实现(SDS[1], simple dynamic string),是可以修改的字符串,类似于Java中的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
Redis中的键值对中的键、值里面的字符串、缓冲区、AOF缓冲区、等都是用的SDS。
下面是SDS数据结构的一个图示:
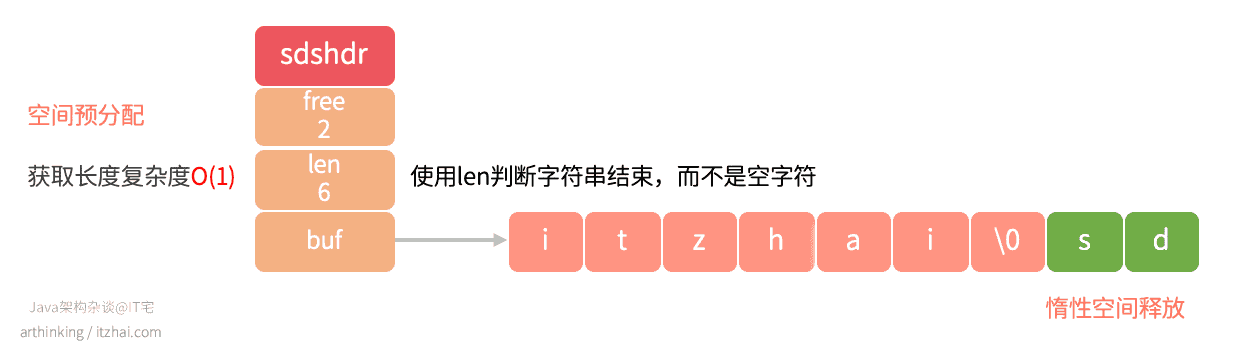
亮点:
- 获取字符串长度时间复杂度为O(1),而C语言则需要遍历整个数组才能得到长度;
- 采用空间预分配避免反复对字节数组进程扩容,如上图的SDS,还有2个字节的空闲空间,如果只是追加一个字符,就不用扩容了。避免了类似C语言要手动重新分配内存的情况下,忘记了进行分配而导致的缓冲区溢出或者内存泄露问题;
- 惰性空间释放:当要缩短字符串长度的时候,程序不会立刻释放内存,而是通过free属性将这些需要释放的字节数量记录下来,等待将来重复使用;
- 二进制安全:所有的SDS API都会以处理二进制的方式来处理SDS的buf数组数据,这样就避免了C字符串读取到空字符就返回,导致读取不完整字符串的问题。二进制安全的SDS,是的Redis可以保存任意格式的二进制数据,而不仅仅是文本数据。
- 如果是C语言,字符串存入了一种使用空字符(\0,不是指空格)来分隔单词的特殊数据格式,存储如下内容:

- 使用C字符串函数读取到的结果会丢失空字符后面的内容,得到:itzhai,丢失了com。
- SDS使用len属性的值来判断字符串是否结束,而不是空字符。
- 兼容部分C字符串函数:为了兼容部分C字符串函数库,SDS字符串遵循C字符串以空字符结尾的惯例。
空间预分配规则
- 字符串大小小于1M的时候,每次扩容加倍;
- 超过1M,扩容只会多扩容1M的空间,上限是512M。
更多关于Redis字符串的命令:Redis - Strings[2]
1.1.2、链表 linkedlist
Redis中List[3]使用的是双向链表存储的。
如下图:
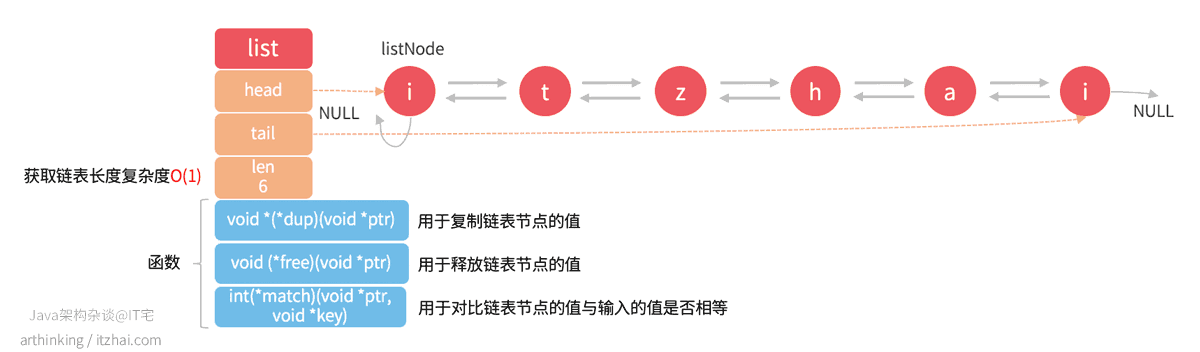
List特点:
- 双向链表;
- 无环;
- 带head和tail指针;
- 带链表长度;
- 多态,链表节点可存储不同类型的值;
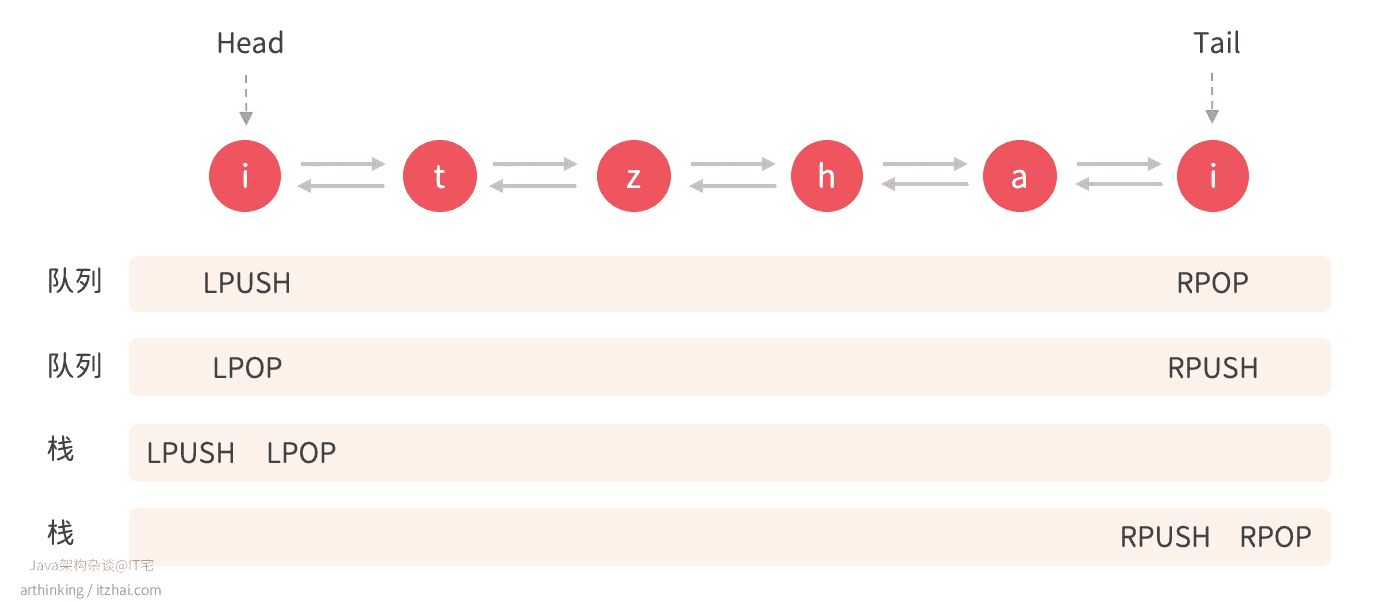
List提供了以下常用操作参考:命令列表:redis.io/commands#list[3:1]
通过LPUSH,LPOP,RPUSH,RPOP操作,可以把List当成队列或者栈来使用:
1.1.3、Hash字典
Redis的字典使用哈希表作为底层实现。该数据结构有点复杂,我直接画一个完整的结构图,如下:
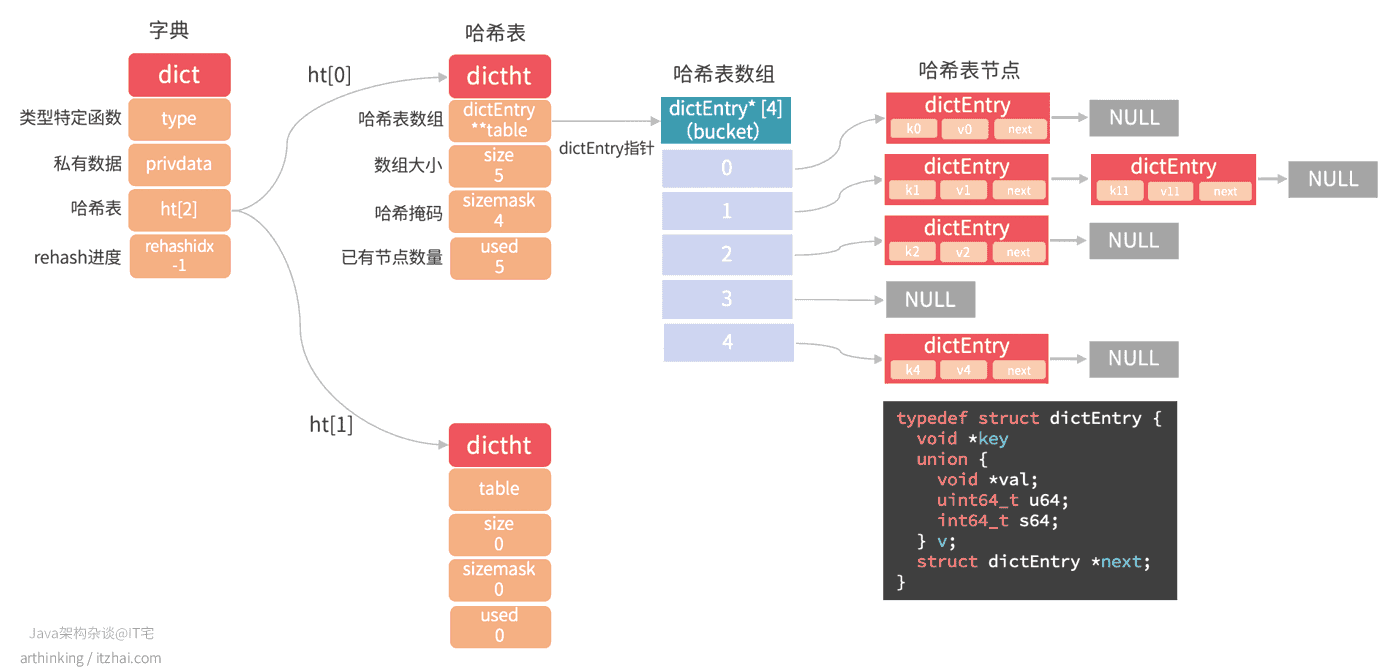
如上图,字典结构重点属性:
type和privdata主要是为创建多态字典而设置的;
ht[1]: 包含两个哈希表,正常情况下,只使用ht[0],当需要进行rehash的时候,会使用到ht[1];
rehashidx: 记录rehash目前的进度,如果没有在rehash,则值为-1;
而哈希表又有如下属性:
- 哈希表数组,里面的元素作为哈希表的哈希桶,该数组每个元素都会指向一个dictEntry结构指针,dictEntry结构保存具体的键值对;
- 数组大小,记录了哈希表数组的大小;
- 哈希掩码,主要用于计算哈希索引值,这个属性和哈希值决定一个键在哈希表数组中的位置;
- 已有节点个数,记录哈希表目前已有节点的数量。
dictEntry结构如图中代码所示:
- key保存键值对的键的指针;
- v保存着键值对的值,值可以是一个指针,或者是unit64_t整数,或者是int64_t整数。
1.1.3.1、hash和hash冲突
作为哈希表,最重要的就是哈希函数,计算新的数据应该存入哪个哈希桶中。
具有良好统一的哈希函数的时候,才能真正的实现花费恒定时间操作哈希表。由于哈希算法计算的数据是无限的,而计算结果是有限的,因此最终会出现哈希冲突。常用的两种解决哈希冲突的方式是链地址法和开放定址法。而Redis中使用的是链地址法。
1.1.3.2、字典是如何进行rehash的?
随着哈希冲突的不断加剧,hash查找的效率也就变慢了,为了避免这种情况的出现,我们要让哈希表的负载因子维持在一个合理地范围之内。
当哈希冲突增加的时候,就需要执行rehash操作了。
rehash操作,也就是指增加哈希表中的哈希桶数量,让超负载哈希桶中的entry元素重新分散到更多的桶里面,从而减少单个桶中的元素数量,减少哈希冲突,从而提高查找效率。
rehash的流程
Redis的rehash是一个渐进的rehash的过程。为什么要这样做呢?
如果需要rehash的字典非常大,有几百上千万个键值对,那么执行rehash就要很长的时间了,这个期间有客户端需要写入新的元素,就会被卡住了,因为Redis执行命令是单线程的,最终将导致Redis服务器在这段时间不能正常提供服务,后果还是比较严重的。
这种这种情况,我们可以采用分而治之的思想,把rehash的过程分小步一步一步来处理,每一步迁移少量键值对,并在对字典的操作流程中做一些兼容处理,确保rehash流程对客户端无感知,这就是我们所说的渐进式rehash。
大致流程如下:
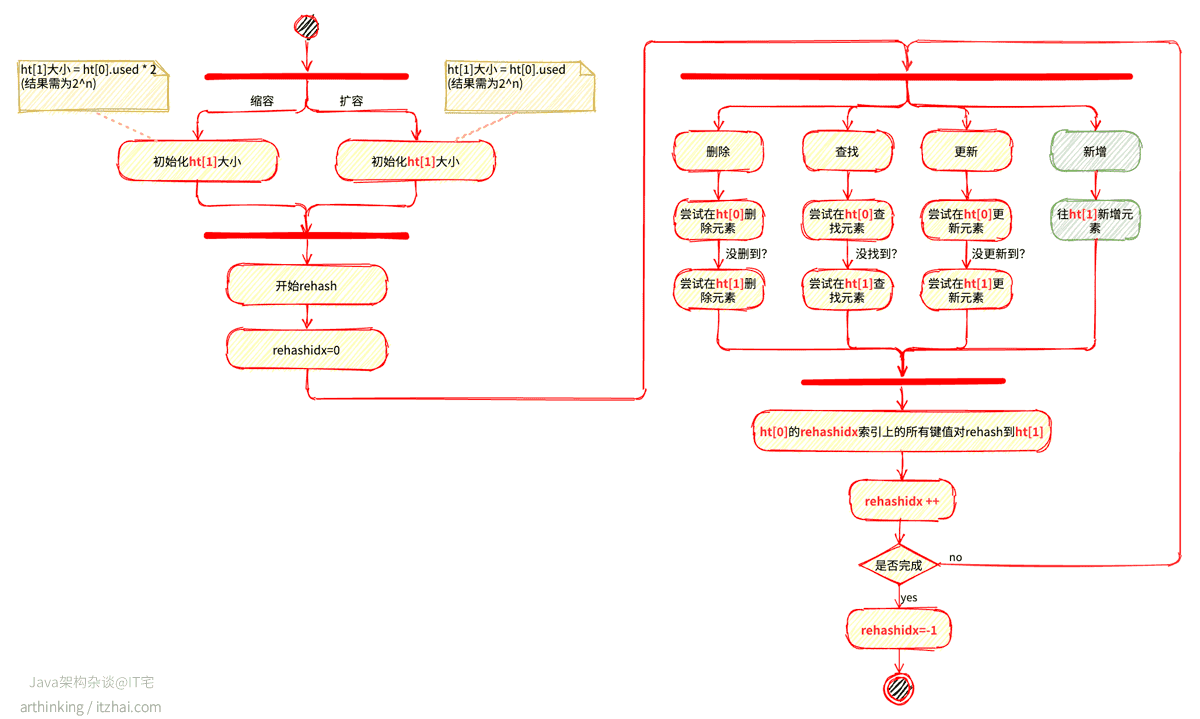
这样,从第0个哈希桶开始,每次执行命令的时候,都rehash下一个哈希桶中的entry,并且新增的元素直接往ht[1]添加。于是ht[0]的元素逐渐减少,最终全部转移到了ht[1]中,实现了哈希表的平滑rehash,最小程度的降低对Redis服务的影响。
1.1.4、跳跃表 skiplist
Redis中的跳跃表是一种有序数据结构,通过在每个节点维持指向其他节点的指针,从而实现快速访问节点的目的。
Redis中的有序集合就是使用跳跃表来实现的。
为了简化跳跃表模型,我们先来看看,假设所有跳跃表节点的层级都是1的情况,如下图:
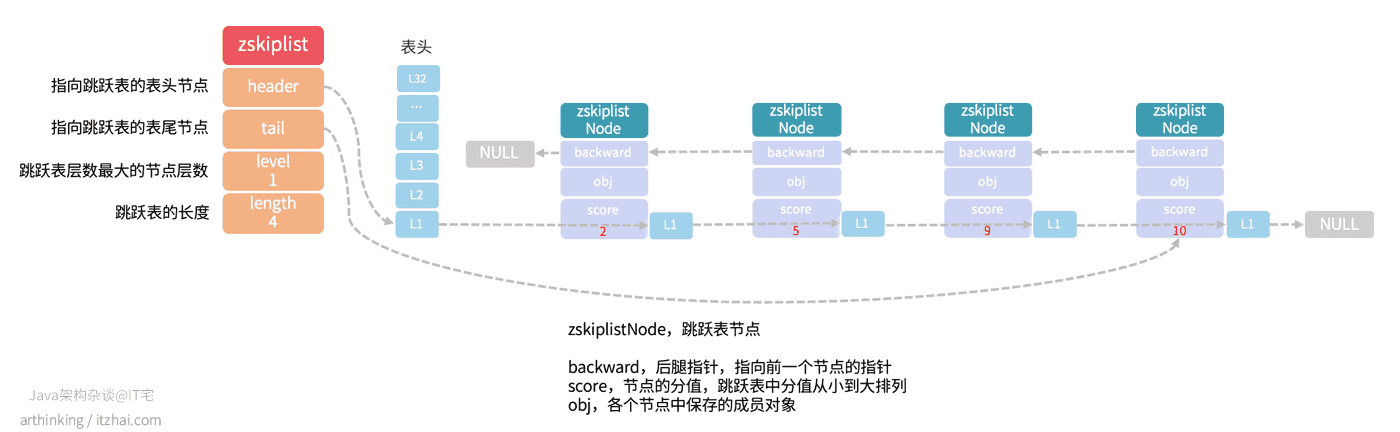
这个时候,跳跃表相当于一个双向链表,查找元素的复杂度为最差的O(N),即需要遍历所有的节点。
为了提高遍历效率,让跳跃表真正的跳起来,现在我们尝试在各个节点添加更多的Level,让程序可以沿着这些Level在各个节点之间来回跳跃,如下图,我们现在要查找score=9的节点,查找流程如下图红线所示:
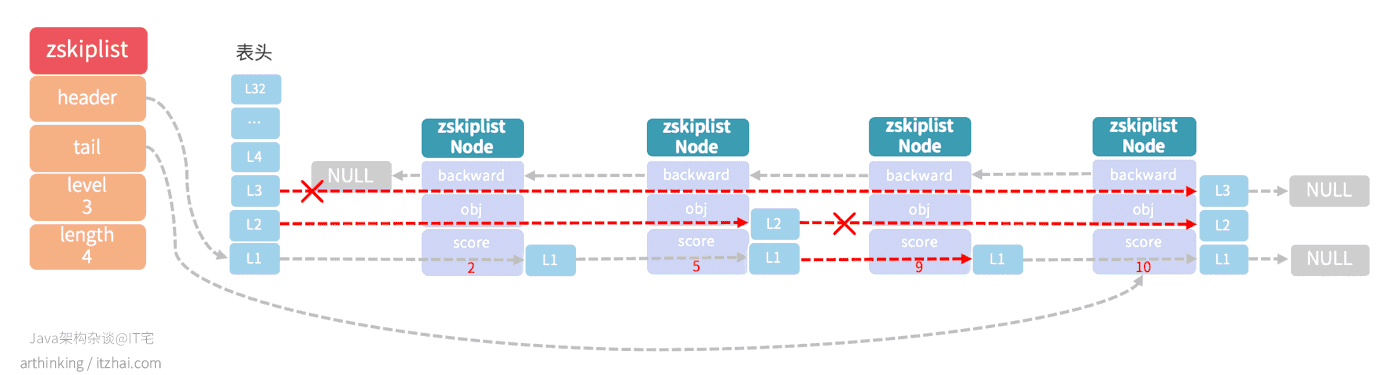
这种查找类似于二分查找,首先从最高层L3进行查找,发现L3的下一个节点score=10,比目标节点大,于是下降到L2继续比较,发现L2的下一个节点为5,比目标节点小,于是继续找下一个节点,为10,比目标节点大,于是在score为5的节点中继续下降到L1,查找下一个节点,刚好为9,至此,我们就找到了目标节点,查找的时间复杂度为O(log N)。
如果每一层节点数是下面一层节点个数的一半,那就是最理想的类,跟二分查找一样。但是这样每次插入新元素,都会打乱上下两层链表节点个数2:1的比例关系,如果要维持这种关系,就必须对插入节点的后面所有节点进行重新调整。为了避免这种问题,跳跃表不做这个严格的上下级比例约束,而是每个节点随机出一个Level层数。
跳跃表节点如何生成level数组?
每次创建新的跳跃表节点的时候,都会根据幂次定律,随机生成一个介于1~32之间的数组大小,这个大小就是level数组元素个数。
插入节点操作只需要修改插入节点前后的指针就可以了,降低了插入的复杂度。
1.1.5、整数集合 intset
在Redis中,当一个集合只包含整数值,并且集合元素不多的时候,会使用整数集合保存整数集,集合中的数据不会出现重复,集合元素从小到大有序排列,可以保存int16_t,int32_t,int64_t的整数值。
下面是整数集合的数据结构:
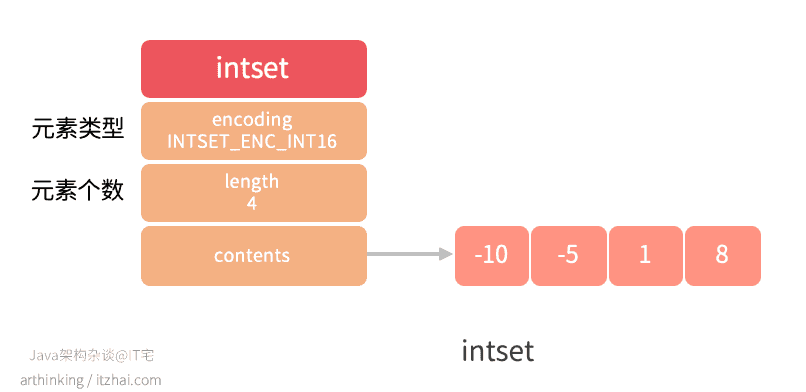
在内存中,整数集合是在一块连续的内存空间中的,如下图所示:

- contents数组按从小到大的顺序保存集合的元素;
- encoding编码,可选编码:
- INTSET_ENC_INT16(From −32,768 to 32,767)
- INTSET_ENC_INT32(From −2,147,483,648 to 2,147,483,647)
- INTSET_ENC_INT64(From −9,223,372,036,854,775,808 to 9,223,372,036,854,775,807)
整数集合是如何升级的?
当往整数集合添加的元素比当前所有元素类型都要长的时候,需要先对集合进行升级,确保集合可以容纳这个新的元素。
升级方向:INTSET_ENC_INT16 --> INTSET_ENC_INT32 --> INTSET_ENC_INT64
注意,一旦升级之后,就不可以降回去了。
下面是一个升级的过程说明:
原本整数数组存的都是INTSET_ENC_INT16编码的元素,接下来往里面插入一个元素 32768,刚好超出了原来编码的范围,于是需要对整数集合进行升级。于是对intset进行内存扩容,扩容后也是通过一块连续空间存储的,这有可能带来一次数据拷贝。
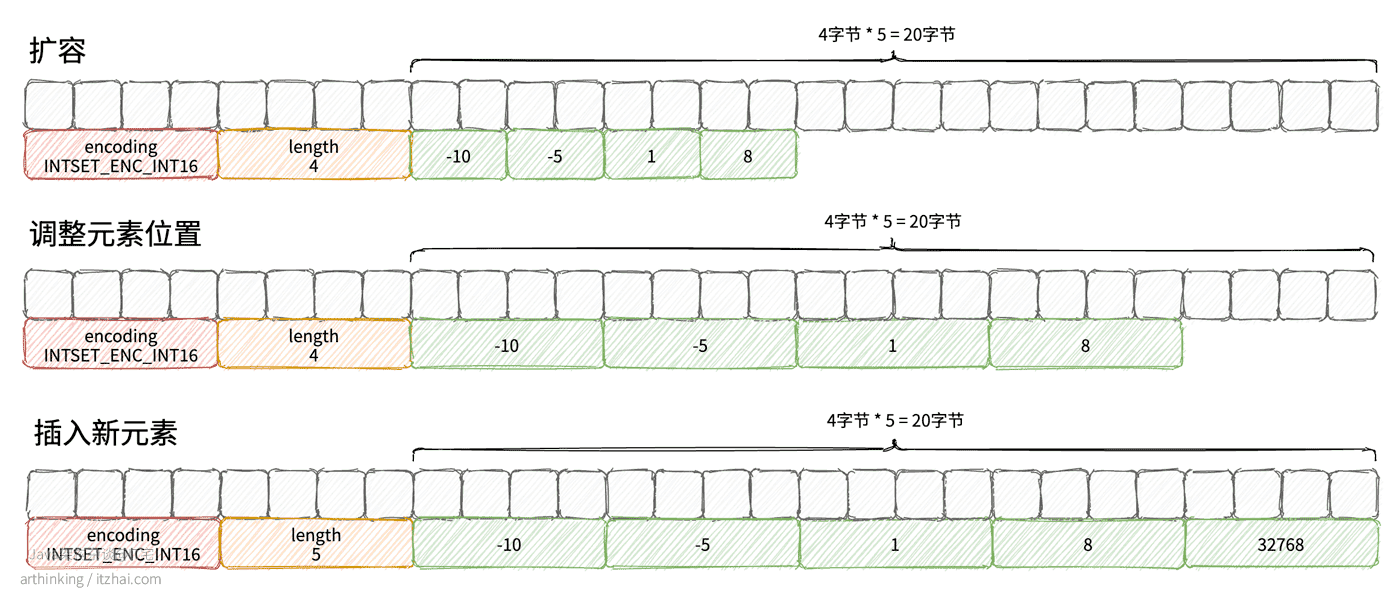
如果要插入的元素在中间,说明不用进行升级,这个时候会使用二分查找算法找到插入的位置,然后扩容插入元素,重新调整元素位置。
intset特点
- 由于intset是从小到到排列的,所以可以进行二分查找,查找性能比ziplist的遍历查找性能高;
- intset只能存储整数,并且由于是内存紧凑的存储模式,没有携带len信息,所以每个元素必须统一编码;
- intset存储可能变成字典存储,条件:
- 添加了一个超过64bit的有符号数字之后;
- 添加的集合元素个数超过了
set-max-intset-entries配置的值;
1.1.6、压缩列表 ziplist
压缩列表是为了节省Redis内存,提高存储效率而开发的数据结构,是列表键和哈希键的底层实现之一,当hash中的数据项不多,并且hash中的value长度不大的时候,就会采用压缩列表存储hash。
为什么要这样设计呢?是因为ziplist不擅长存储大量数据:
- 数据量大了,每次插入或者修改引发的realloc操作可能会造成内存拷贝,加大系统开销;
- ziplist数据量大了,由于是遍历查找,查找性能会变得很低。
以下是压缩列表的数据结构:

尾节点地址 = 压缩列表起始指针地址 + zltail(偏移量)
我们再来看看压缩列表节点的结构:
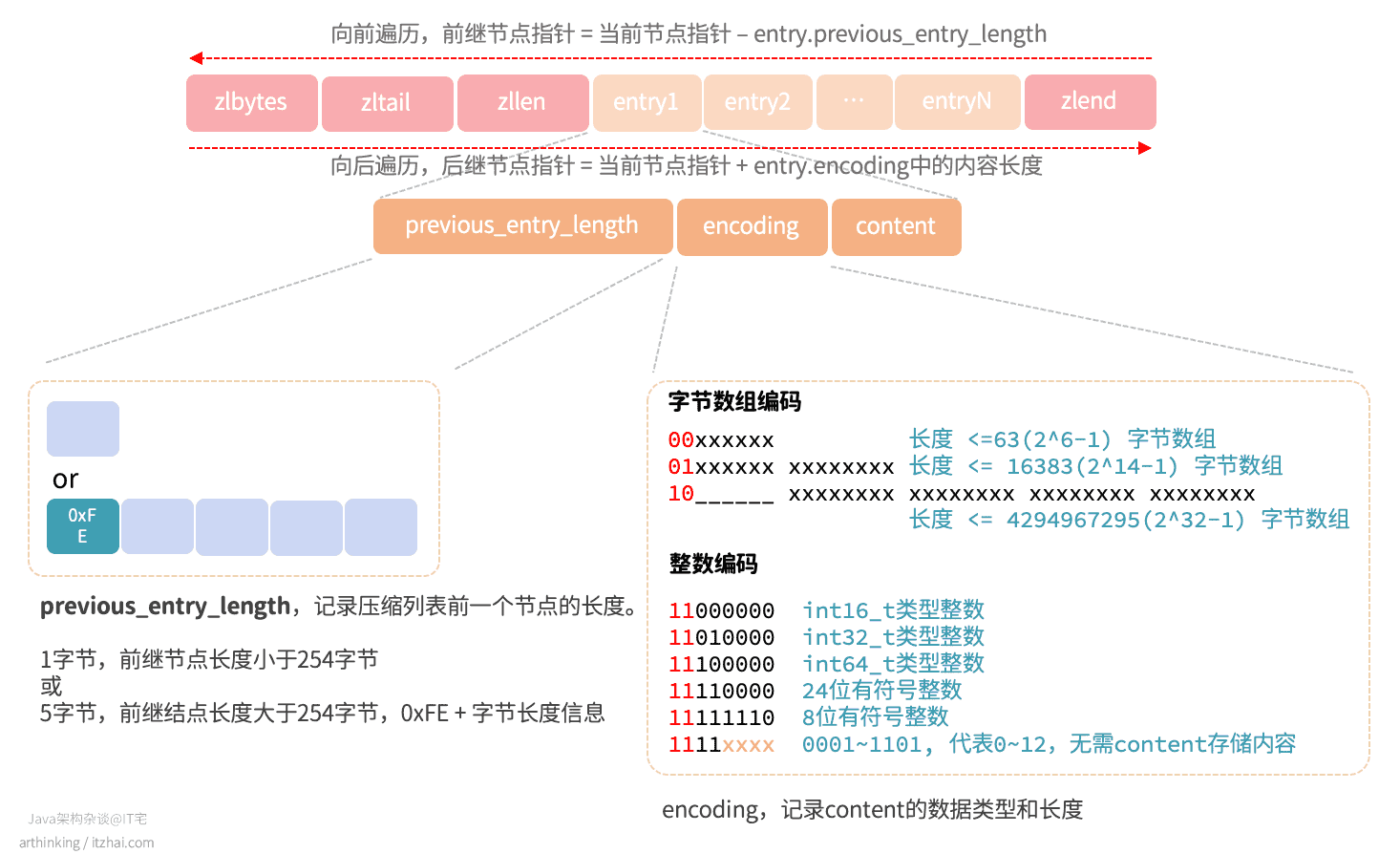
xxxx部分表示存储的长度内容,或者是0~12整数。
压缩列表的content可以保存一个字节数组或者一个整数值。
如上图,ziplist通过特殊的编码约定,通过使用尽可能少的空间,很巧妙的存储了编码和长度信息,并且通过entry中的属性,可以在ziplist中进行双向遍历,效果相当于双向链表,但是占用更少的内存。
整数编码 1111xxxx为什么能存储2^4-1个整数?
由于11110000,11111110分别跟24位有符号整数和8位有符号整数冲突了,所以只能存储 00011101范围,代表113数值,但是数值应该从0开始计数,所以分别代表 0~12。
什么是ziplist连锁更新问题?
假设我们有一个ziplist,所有节点都刚好是253字节大小,突然往中间插入了一个254字节以上大小的节点,会发生什么事情呢?
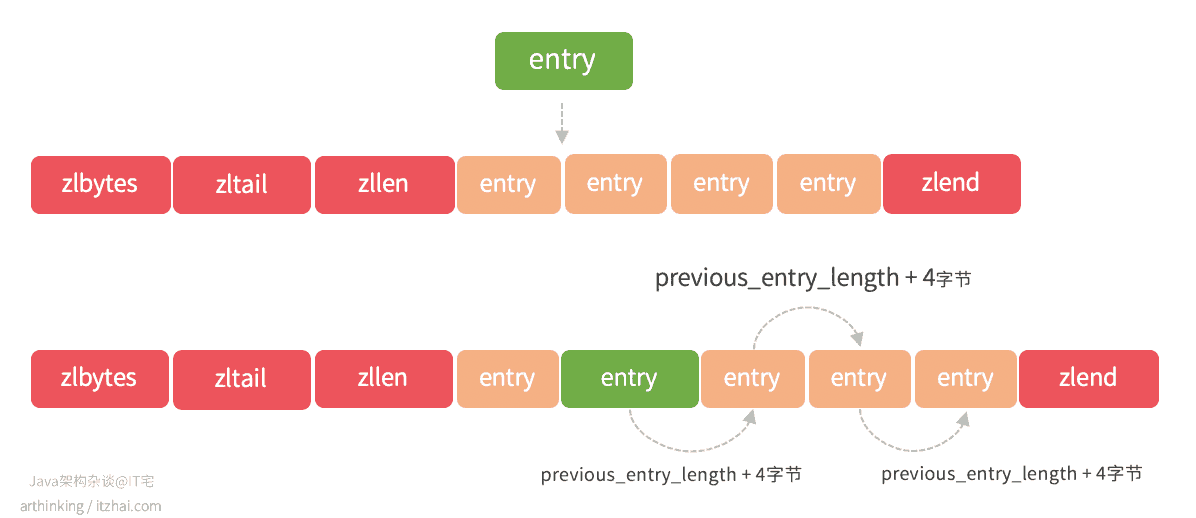
如下图,由于新的节点插入之后,新节点的下一个节点的previous_entry_length为了记录新节点的大小,就必须扩大4个字节了。然后又会触发后续节点的previous_entry_length扩大4个字节,一直这样传递下去。所以这个过程也成为连锁更新。
最坏情况进行N次空间重新分配,每次重新分配最坏复杂度O(N)。触发连锁更新的最坏复杂度为O(N^2)。
但是实际情况,出现连续多个节点长度结语250~253之间的情况还是比较少的,所以实际被连续更新的节点数量不会很多,平均时间复杂度为O(N)。
由于ziplist的数据是存储在一块连续的空间中,并不擅长做修改操作,数据发生改动则会触发realloc并且触发连锁更新,可能导致内存拷贝,从而降低操作性能。
1.1.7、quicklist
linkedlist由于需要存储prev和next指针,消耗内存空间比较多,另外每个节点的内存是单独分配的,会加剧内存的碎片化,影响内存管理的效率。
于是,在Redis 3.2之后的版本,重新引入了一个新的数据结构:quicklist,用来代替ziplist和linkedlist。
为何需要quicklist?
我们得先来说说ziplist和linkedlist的优缺点:
- linkedlist优点:插入复杂度很低;
- linkedlist缺点:有prev和next指针,内存开销比较大;
- ziplist优点:数据存储在一段连续的内存空间中,存储效率高;
- ziplist缺点:修改复杂度高,可能会触发连锁更新。
为了整合linkedlist和ziplist的优点,于是引入了quicklist。quicklist底层是基于ziplist和linkedlist来实现的。为了进一步节省空间,Redis还会对quicklist中的ziplist使用LZF算法进行压缩
quicklist结构
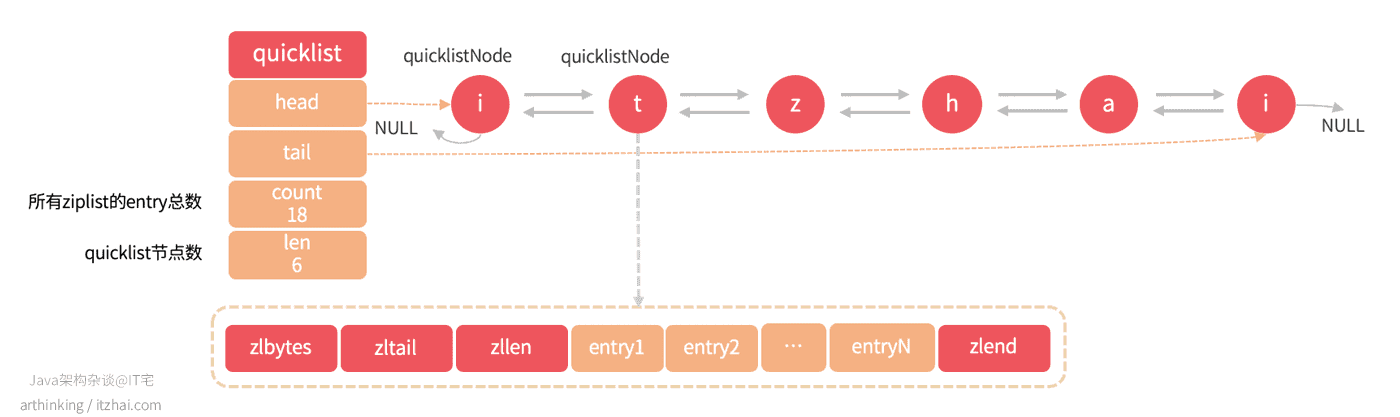
如上图所示,quicklist结构重点属性:
- head:指向链表表头;
- tail:指向链表表尾;
- count:所有quicklistNode中的ziplist的所有entry节点数;
- len:链表的长度,即quicklistNode的个数。
quicklistNode重点属性:
- *prev:指向链表前一个节点的指针;
- *next:指向链表后一个节点的指针;
- *zl:数据指针,如果当前节点数据没有被压缩,那么指向一个ziplist结构;否则,指向一个quicklistLZF结构;
- sz:不管有没有被压缩,sz都表示zl指向的ziplist占用的空间大小;
- count:ziplist里面包含的entry个数;
- encoding:ziplist是否被压缩,1没有被压缩,2被压缩了;
- container:预留字段,固定为2,表示使用ziplist作为数据容器;
- recompress:之前是否已经压缩过此节点?当我们使用类似index这样的命令查看已经压缩的节点数据的时候,需要暂时解压数据,通过这个属性标记后边需要把数据重新压缩。
quicklist配置项
list-max-ziplist-size:指定quicklist中每个ziplist最大的entry元素个数,负数表示:
- -5:指定快速列表的每个ziplist不能超过64 KB;
- -4:指定快速列表的每个ziplist不能超过32 KB;
- -3:指定快速列表的每个ziplist不能超过16 KB;
- -2:指定快速列表的每个ziplist不能超过8 KB。这是默认值;
- -1:指定快速列表的每个ziplist不能超过4 KB。
list-compress-depth:指定列表中两端未压缩的条目数。有效值:0到65535。
- 0:不压缩列表中的节点。这是默认值;
- 1到65535:不压缩列表两端的指定节点数,但是压缩所有中间节点。
可以看出,表头和表尾总是不会被压缩,以便在两端进行快速存取。
而实际上,Redis顶层是以对象(数据类型)的形式提供数据的操作API的,而对象的底层实现,则是用到了以上的数据结构。
接下来我们继续看看Redis中的对象。
1.2、对象
对象可以理解为Redis的数据类型,数据类型底层可以使用不同的数据结构来实现。
我们先来看看对象的基本格式:
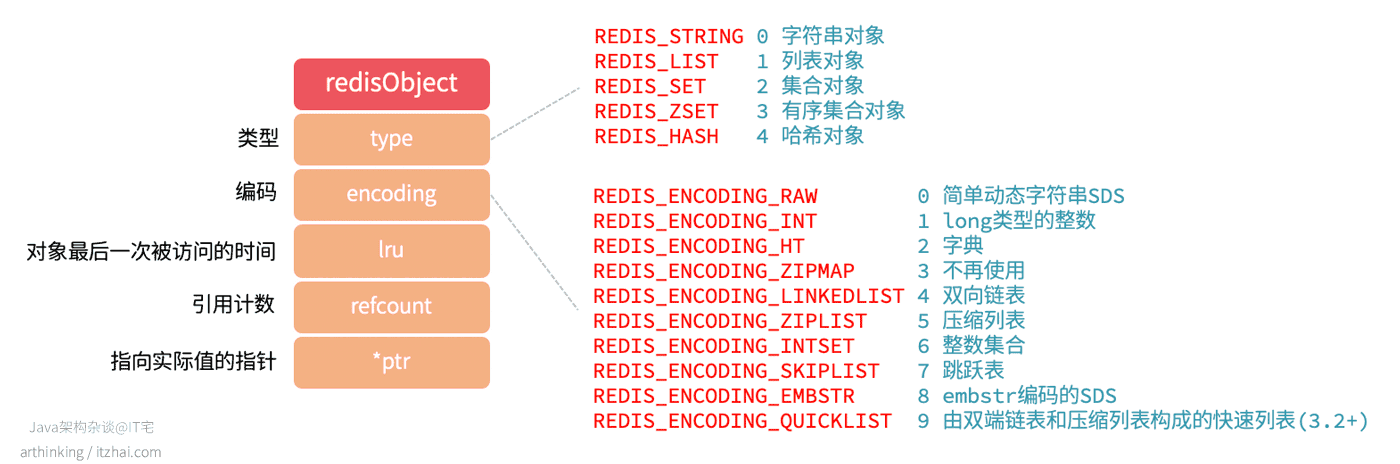
常见的有5种数据类型,底层使用10种数据结构实现,随着Redis版本的升级,数据类型和底层的数据结构也会增加。
而这5种数据类型,根据不同场景来选择不同的编码格式,如下表所示:
| 数据类型 | 编码格式 |
|---|---|
| REDIS_STRING | REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR | |
| REDIS_ENCODING_RAW | |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST |
| REDIS_ENCODING_ZIPLIST | |
| REDIS_ENCODING_QUICKLIST | |
| REDIS_SET | REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT | |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST | |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
Redis对象的其他特性:
- 对象共享:多个键都需要保存同一个字面量的字符串对象,那么多个键将共享同一个字符串对象,其中对象的refcount记录了该对象被引用的次数;
- 内存回收:Redis实现了基于引用计数的内存回收机制,当对象的refcount变为0的时候,就表示对象可以被回收了;
- 空转时长:通过
OBJECT IDLETIME命令,可以获取键的空转时长,该时长为当前时间 - 对象lru时间计算得到,lru记录了对象最后一次被命令访问的时间。
接下来我们逐个展示。
1.2.1、REDIS_STRING
REDIS_ENCODING_INT
如果一个字符串对象保存的是整数,并且可以用long类型表示,那么ptr会从void * 变为long类型,并且设置字符串编码为REDIS_ENCODING_INT。
1 2 3 4 | 127.0.0.1:6379> set itzhai 10000 OK 127.0.0.1:6379> OBJECT ENCODING itzhai "int" |

REDIS_ENCODING_EMBSTR
如果存储的是字符串,并且值长度小于等于44个字节,那么将使用embstr编码的SDS来保存这个字符串值。
raw编码的SDS会调用两次内存分配函数来分别创建redisObject和sdshdr结构,而embstr编码只需要调用一次内存分配函数就可以了,redisObject和sdshdr保存在一块连续的空间中,如下图:

1 2 3 4 | 127.0.0.1:6379> set name "itzhai" OK 127.0.0.1:6379> OBJECT ENCODING name "embstr" |
REDIS_ENCODING_RAW
如果存储的是字符串值,并且值长度大于44字节,那么将使用SDS来保存这个字符串值,编码为raw:
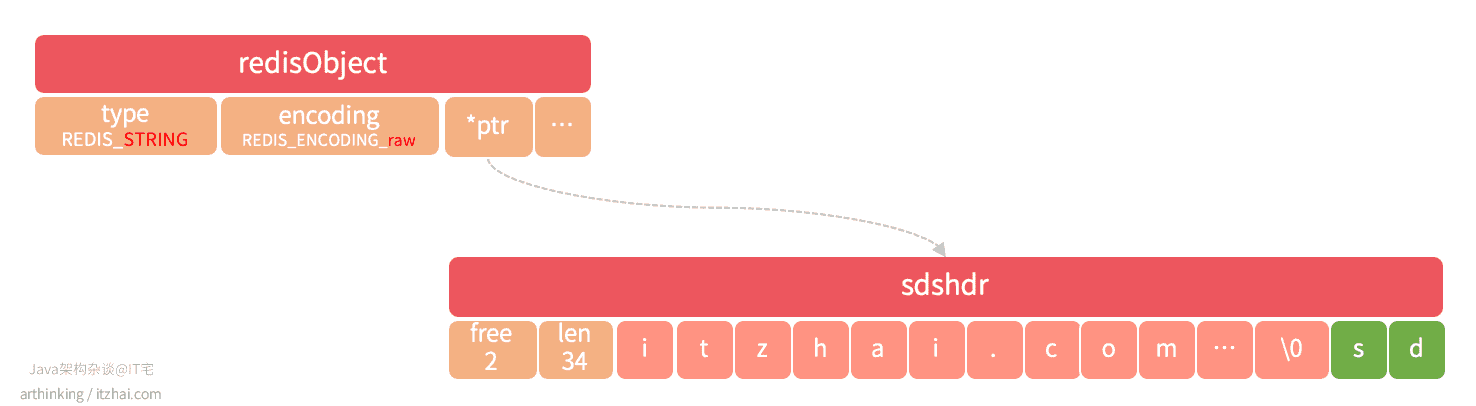
1 2 3 4 5 6 7 8 9 10 11 12 | 27.0.0.1:6379> set raw_string "abcdefghijklmnopqrstuvwxyzabcdefghijklumnopqr" OK 127.0.0.1:6379> STRLEN raw_string (integer) 45 127.0.0.1:6379> OBJECT ENCODING raw_string "raw" 127.0.0.1:6379> set raw_string "abcdefghijklmnopqrstuvwxyzabcdefghijklumnopq" OK 127.0.0.1:6379> STRLEN raw_string (integer) 44 127.0.0.1:6379> OBJECT ENCODING raw_string "embstr" |
注意:不同版本的Redis,Raw和embstr的分界字节数会有所调整,本节指令运行于 Redis 6.2.1
STRING是如何进行编码转换的?
浮点数会以REDIS_ENCODING_EMBSTR编码的格式存储到Redis中:
1 2 3 4 5 6 | 127.0.0.1:6379> OBJECT ENCODING test "embstr" 127.0.0.1:6379> INCRBYFLOAT test 2.0 "3.28000000000000025" 127.0.0.1:6379> OBJECT ENCODING test "embstr" |
long类型的数字,存储之后,为REDIS_ENCODING_INT编码,追加字符串之后,为REDIS_ENCODING_RAW编码:
1 2 3 4 5 6 7 8 | 127.0.0.1:6379> set test 12345 OK 127.0.0.1:6379> OBJECT ENCODING test "int" 127.0.0.1:6379> APPEND test " ..." (integer) 9 127.0.0.1:6379> OBJECT ENCODING test "raw" |
REDIS_ENCODING_EMBSTR 类型的数据,操作之后,变为REDIS_ENCODING_RAW编码:
1 2 3 4 5 6 | 127.0.0.1:6379> OBJECT ENCODING test "embstr" 127.0.0.1:6379> APPEND test "c" (integer) 3 127.0.0.1:6379> OBJECT ENCODING test "raw" |
总结一下:
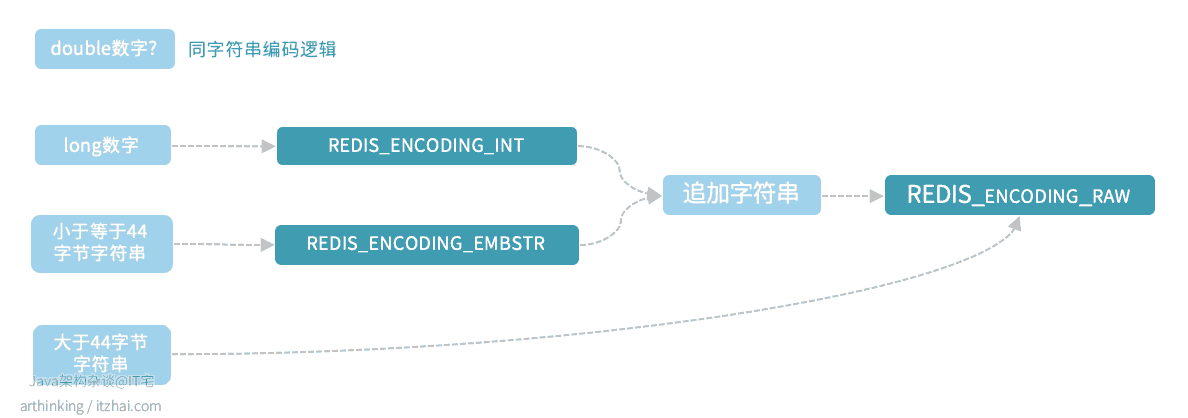
EMBSTR编码的字符串不管追加多少字符,不管有没有到达45字节大小,都会转为RAW编码,因为EMBSTR编码字符串没有提供修改的API,相当于是只读的,所以修改的时候,总是会先转为RAW类型再进行处理。
1.2.2、REDIS_LIST
Redis 3.2版本开始引入了quicklist,LIST底层采用的数据结构发生了变化。
Redis 3.2之前的版本
列表对象底层可以是ziplist或者linkedlist数据结构。
使用哪一种数据结构:
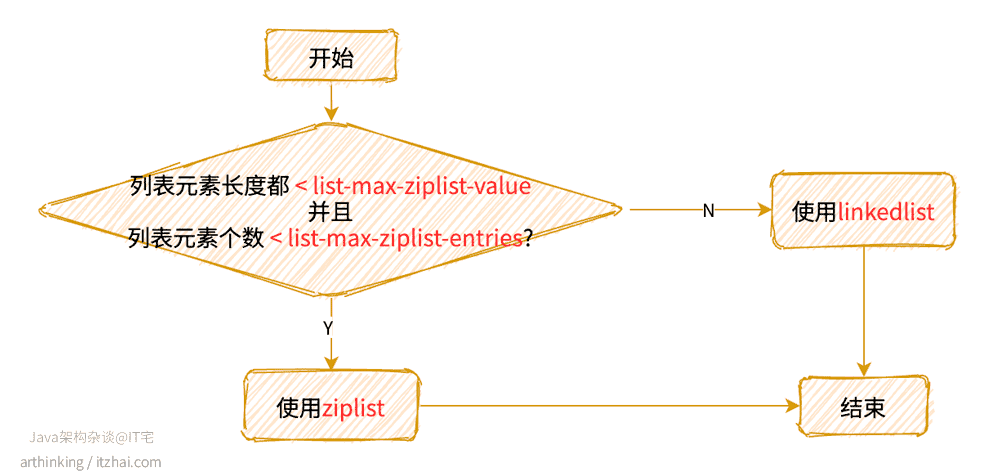
REDIS_ENCODING_ZIPLIST
ziplist结构的列表对象如下图所示:
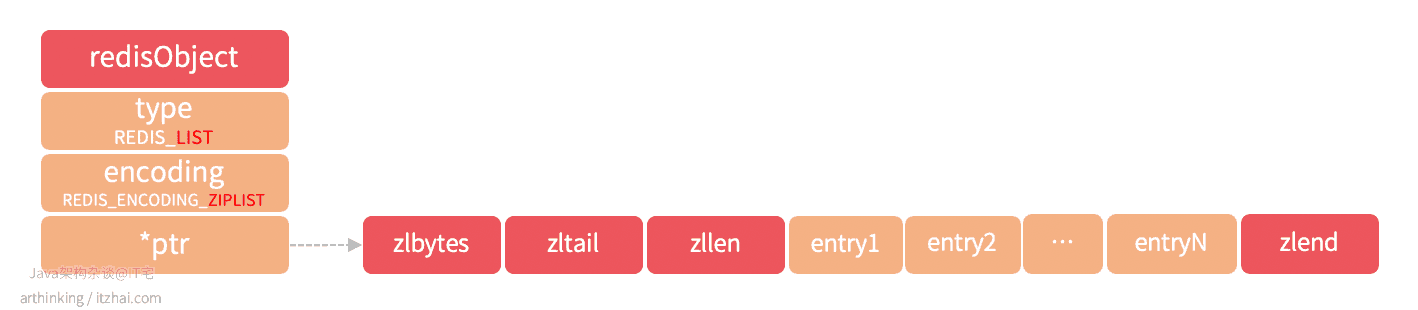
REDIS_ENCODING_LINKEDLIST
linkedlist结构的列表对象如下图所示
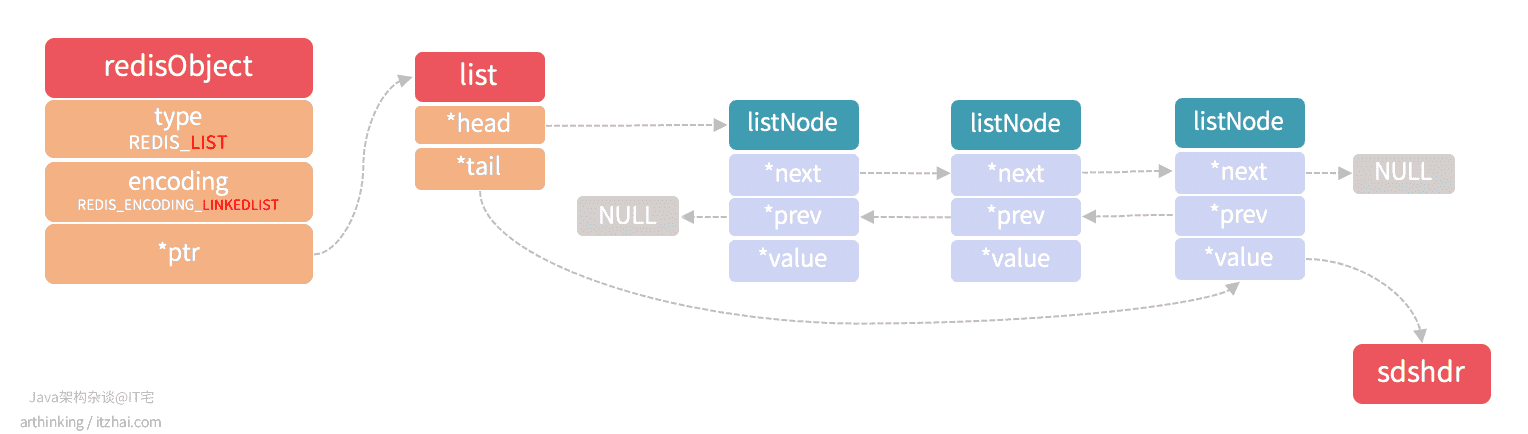
linkedlist为双向列表,每个列表的value是一个字符串对象,在Redis中,字符串对象是唯一一种会被其他类型的对接嵌套的对象。
Redis 3.2之后的版本
而Redis 3.2之后的版本,底层采用了quicklist数据结构进行存储。
1.2.3、REDIS_HASH
哈希对象的编码可以使ziplist或者hashtable数据结构。
使用哪一种数据结构:
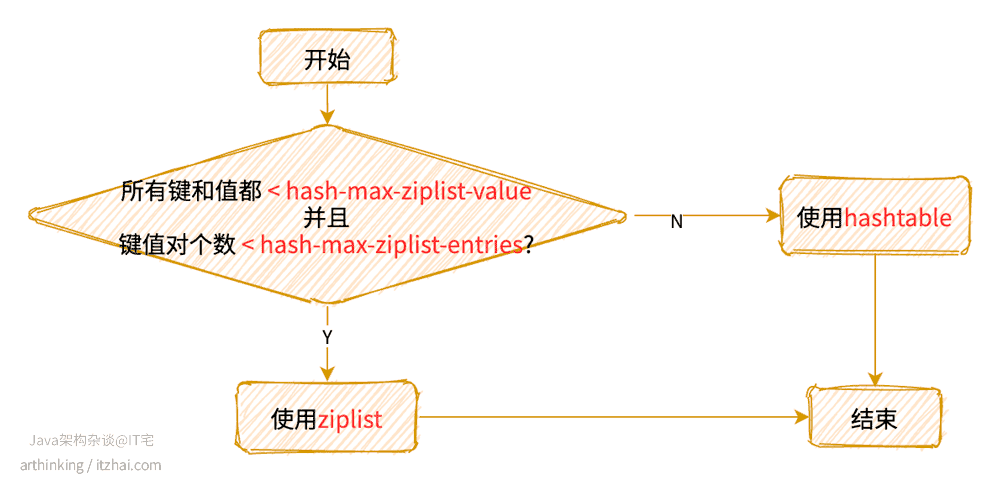
REDIS_ENCODING_ZIPLIST
我们执行以下命令:
1 2 3 4 | 127.0.0.1:6379> HSET info site itzhai.com (integer) 1 127.0.0.1:6379> HSET info author arthinking (integer) 1 |
得到如下ziplist结构的哈希对象:
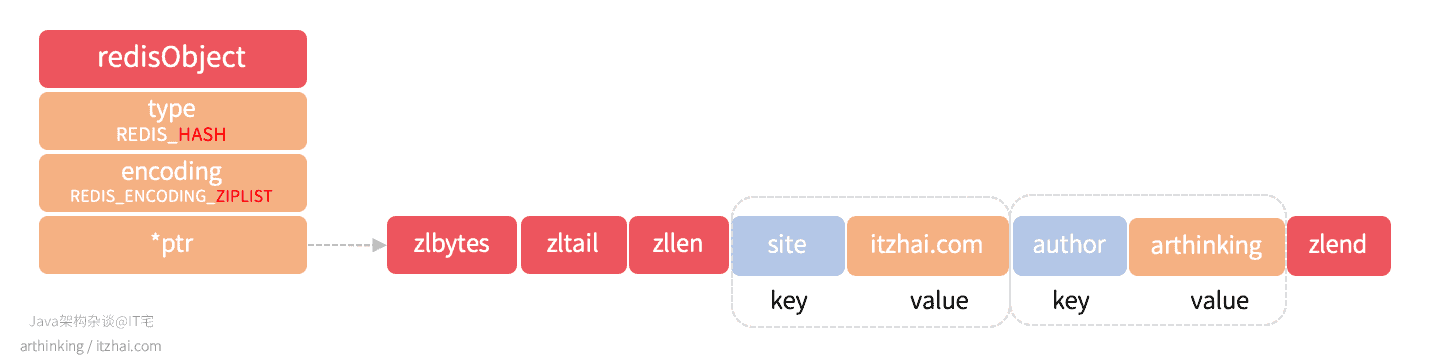
REDIS_ENCODING_HT
hashtable结构的哈希对象如下图所示:
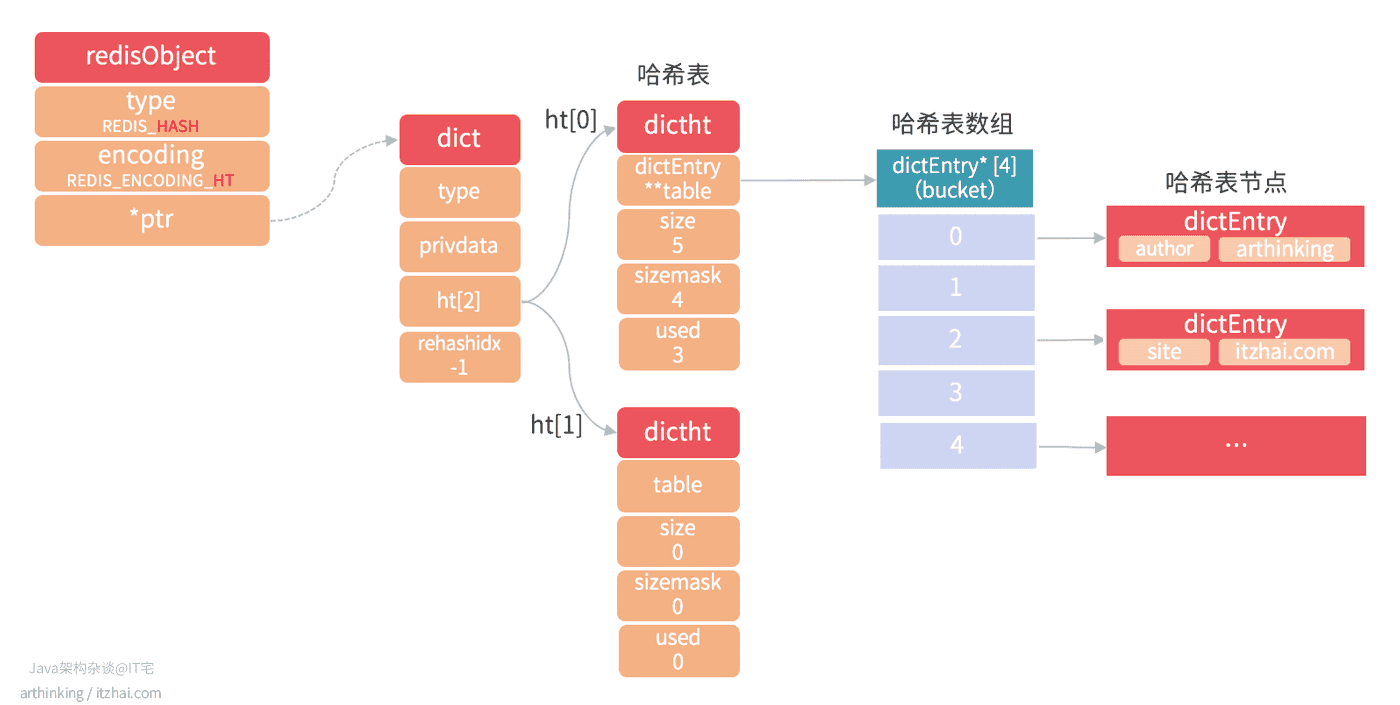
其中,字典的每个键和值都是一个字符串对象。
1.2.4、REDIS_SET
集合对象的编码可以是intset或者hashtable数据结构。
使用哪一种数据结构:
REDIS_ENCODING_INTSET
执行以下命令:
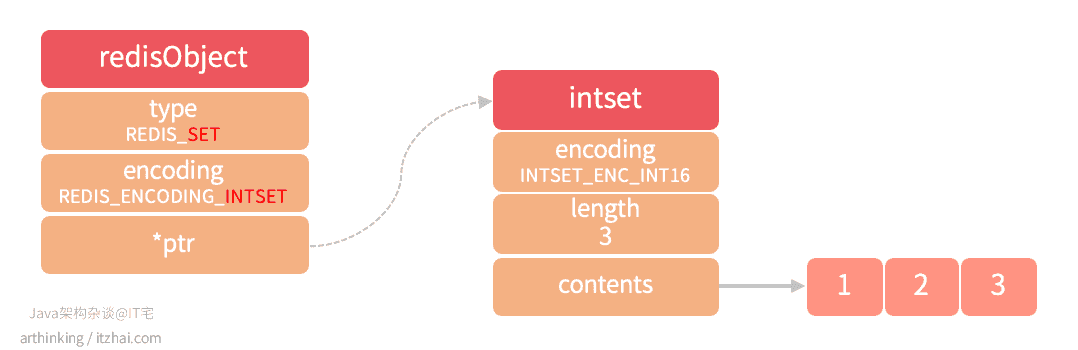
1 2 3 4 | 127.0.0.1:6379> SADD ids 1 3 2 (integer) 3 127.0.0.1:6379> OBJECT ENCODING ids "intset" |
则会得到一个intset结构的集合对象,如下图:
REDIS_ENCODING_HT
执行以下命令:
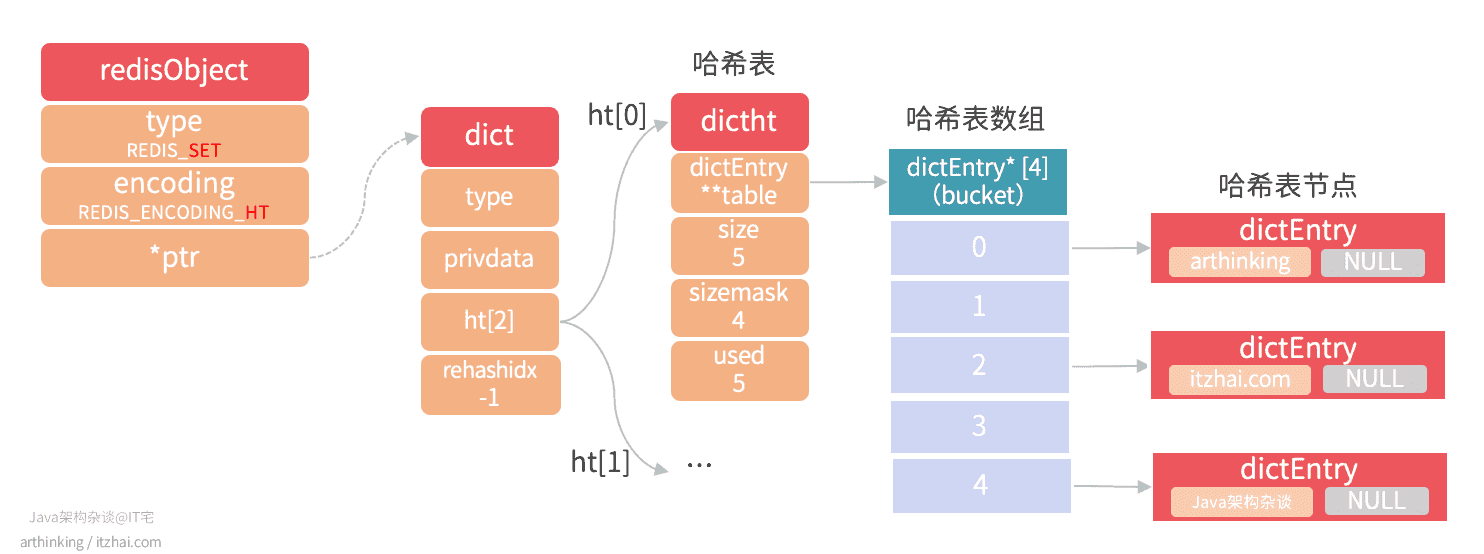
1 2 3 4 | 127.0.0.1:6379> SADD site_info "itzhai.com" "arthinking" "Java架构杂谈" (integer) 3 127.0.0.1:6379> OBJECT ENCODING site_info "hashtable" |
则会得到一个hashtable类型的集合对象,hashtable的每个键都是一个字符串对象,每个字符串对象包含一个集合元素,hashtable的值全部被置为NULL,如下图:
1.2.5、REDIS_ZSET
有序集合可以使用ziplist或者skiplist编码。
使用哪一种编码:
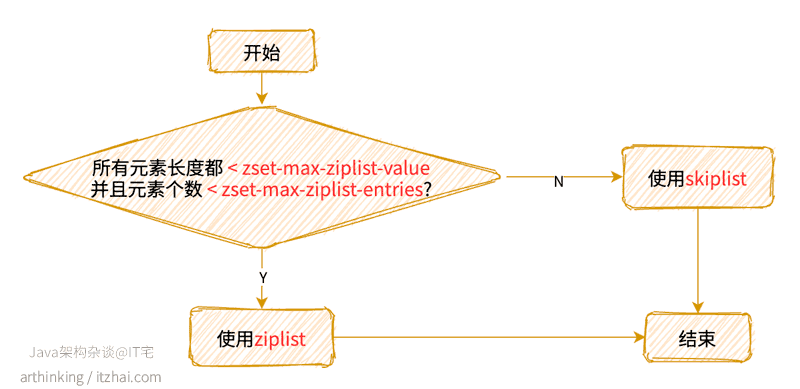
REDIS_ENCODING_ZIPLIST
执行以下命令:
1 2 3 4 5 6 7 | 127.0.0.1:6379> ZADD weight 1.0 "Java架构杂谈" 2.0 "arthinking" 3.0 "itzhai.com" (integer) 3 127.0.0.1:6379> OBJECT ENCODING weight "ziplist" 127.0.0.1:6379> ZRANGE weight 1 2 1) "arthinking" 2) "itzhai.com" |
则会得到一个ziplist编码的zset,如下图:

REDIS_ENCODING_SKIPLIST
执行以下命令:
1 2 3 4 | 127.0.0.1:6379> ZADD weight 1 "itzhai.com" 2 "aaaaaaaaaabbbbbbbbbccccccccccddddddddddeeeeeeeeeeffffffffffgggggg" (integer) 1 127.0.0.1:6379> OBJECT ENCODING weight "skiplist" |
则会得到一个skiplist编码的zset,skiplist编码的zset底层同时包含了一个字典和跳跃表:
1 2 3 4 | typedef struct zset { zskiplist *zsl; dict * dict; } zset; |
如下图所示:
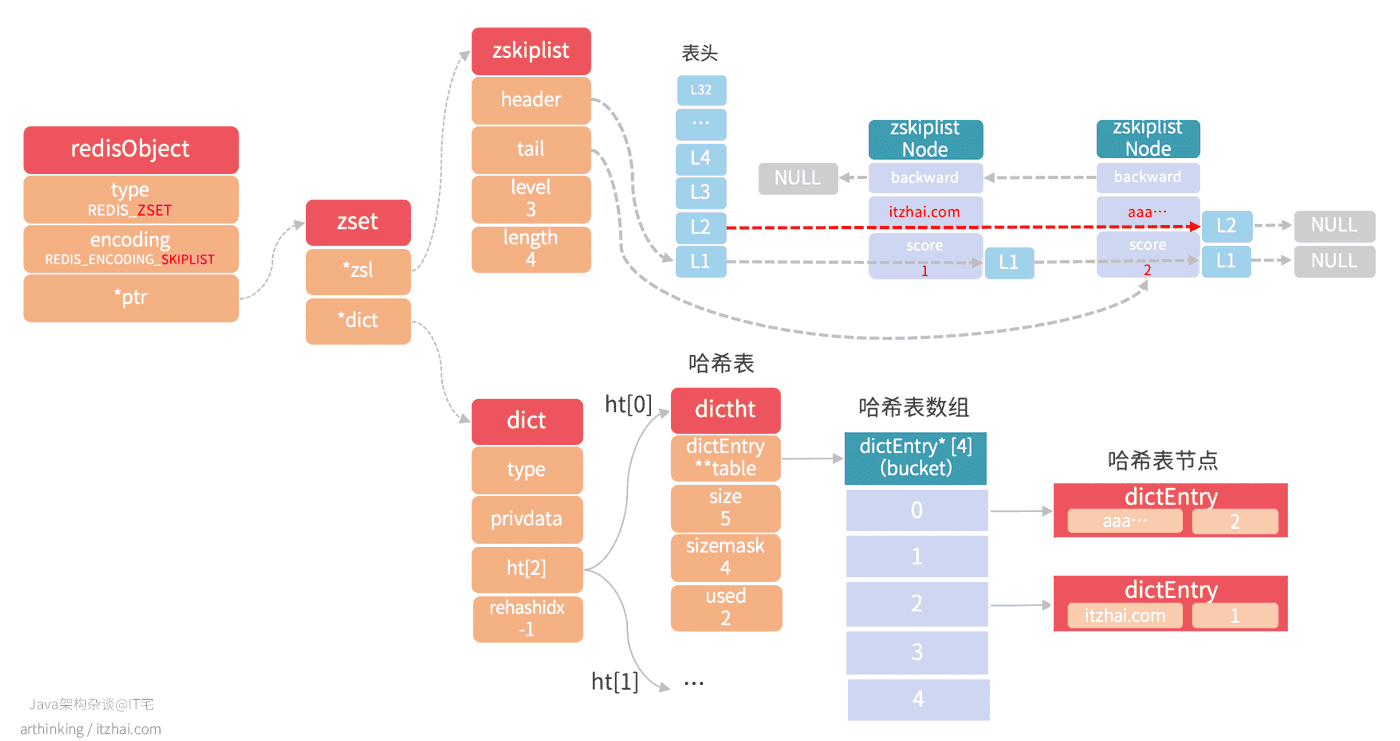
其中:
- 跳跃表按照分值从小到大保存了所有的集合元素,一个跳跃表节点对应一个集合元素,object属性保存元素成员,score属性保存元素的分值,ZRANK,ZRANGE,ZCARD,ZCOUNT,ZREVRANGE等命令基于跳跃表来查找的;
- 字典维护了一个从成员到分值的映射,通过该结构查找给定成员的分值(ZSCORE),复杂度为O(1);
- 实际上,字典和跳跃表会共享元素成员和分值,所以不会造成额外的内存浪费。
1.2.6、REDIS_MODULE
从Redis 4.0开始,支持可扩展的Module,用户可以根据需求自己扩展Redis的相关功能,并且可以将自定义模块作为插件附加到Redis中。这极大的丰富了Redis的功能。
关于Modules的相关教程:Redis Modules: an introduction to the API[4]
Redis第三方自定义模块列表(按照GitHub stars数排序):Redis Modules[5]
1.2.7、REDIS_STREAM
这是Redis 5.0引入的一个新的数据类型。为什么需要引入这个数据类型呢,我们可以查阅一下:RPC11.md | Redis Change Proposals[6]:
1 2 3 4 5 6 | This proposal originates from an user hint: During the morning (CEST) of May 20th 2016 I was spending some time in the #redis channel on IRC. At some point Timothy Downs, nickname forkfork wrote the following messages: <forkfork> the module I'm planning on doing is to add a transaction log style data type - meaning that a very large number of subscribers can do something like pub sub without a lot of redis memory growth <forkfork> subscribers keeping their position in a message queue rather than having redis maintain where each consumer is up to and duplicating messages per subscriber |
这使得Redis作者去思考Apache Kafka提供的类似功能。同时,它有点类似于Redis LIST和Pub / Sub,不过有所差异。
STREAM工作原理
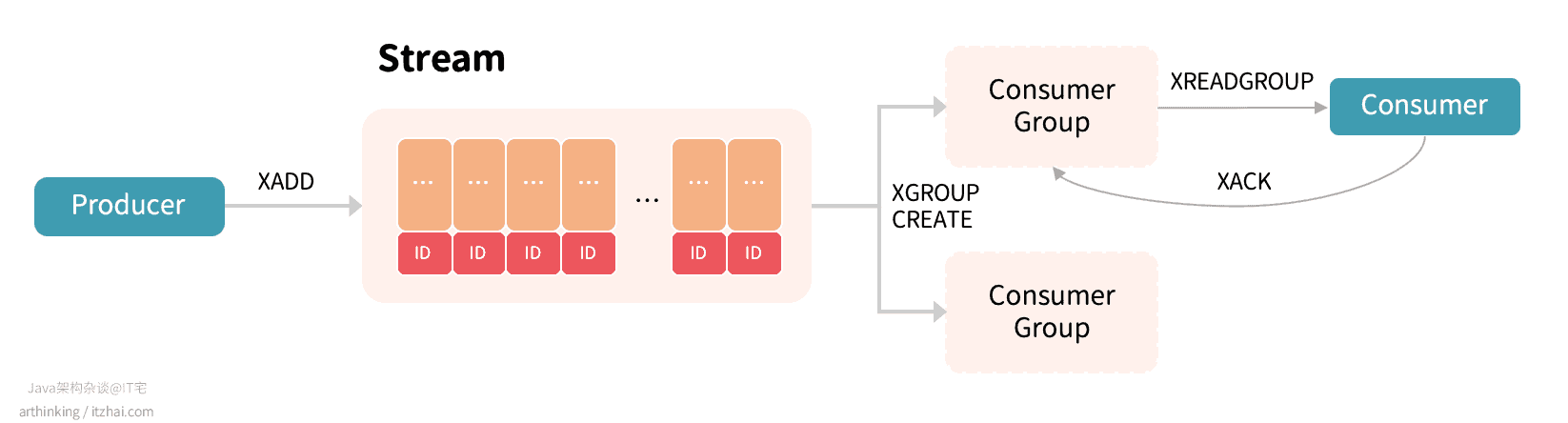
如上图:生产者通过XADD API生产消息,存入Stream中;通过XGROUP相关API管理分组,消费者通过XREADGROUP命令从消费分组消费消息,同一个消费分组的消息只会分配各其中的一个消费者进行消费,不同消费分组的消息互不影响(可以重复消费相同的消息)。
Stream中存储的数据本质是一个抽象日志,包含:
- 每条日志消息都是一个结构化、可扩展的键值对;
- 每条消息都有一个唯一标识ID,标识中记录了消息的时间戳,单调递增;
- 日志存储在内存中,支持持久化;
- 日志可以根据需要自动清理历史记录。
Stream相关的操作API
添加日志消息:
XADD:这是将数据添加到Stream的唯一命令,每个条目都会有一个唯一的ID:1 2 3 4 5 6
# * 表示让Redis自动生成消息的ID 127.0.0.1:6379> XADD articles * title redis author arthinking # 自动生成的ID 1621773988308-0 127.0.0.1:6379> XADD articles * title mysql author Java架构杂谈 1621774078728-0
读取志消息:
XREAD:按照ID顺序读取日志消息,可以从多个流中读取,并且可以以阻塞的方式调用:1 2 3 4 5 6 7 8 9 10 11 12
# 第一个客户端执行以下命令,$ 表示获取下一条消息,进入阻塞等待 127.0.0.1:6379> XREAD BLOCK 10000 STREAMS articles $ # 第二个客户端执行以下命令: 127.0.0.1:6379> XADD articles * title Java author arthinking 1621774841555-0 # 第一个客户端退出阻塞状态,并输出以下内容 articles 1621774841555-0 title Java author arthinking
XRANGE key start end [COUNT count]:按照ID范围读取日志消息;XREVRANGE key end start [COUNT count]:以反向的顺序返回日志消息;
删除志消息:
XDEL key ID [ID ...]:从Stream中删除日志消息;XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]:XTRIM将Stream裁剪为指定数量的项目,如有需要,将驱逐旧的项目(ID较小的项目);
消息消费:
XGROUP:用于管理消费分组:1 2 3 4 5 6 7 8
# 给articles流创建一个group,$表示使用articles流最新的消息ID作为初始ID,后续group内的Consumer从初始ID开始消费 127.0.0.1:6379> XGROUP CREATE articles group1 $ # 指定消费组的消费初始ID 127.0.0.1:6379> XGROUP SETID articles group1 1621773988308-0 OK # 删除指定的消费分组 127.0.0.1:6379> XGROUP DESTROY articles group1 1
XREADGROUP:XREADROUP是对XREAD的封装,支持消费组:1 2 3 4 5 6 7 8
# articles流的group1分组中的消费者consumer-01读取消息,> 表示读取没有返回过给别的consumer的最新消息 127.0.0.1:6379> XREADGROUP GROUP group1 consumer-01 COUNT 1 STREAMS articles > articles 1621774078728-0 title mysql author Java架构杂谈
XPENDING key group [start end count] [consumer]:检查待处理消息列表,即每个消费组内消费者已读取,但是尚未得到确认的消息;XACK:Acknowledging messages,用于确保客户端正确消费了消息之后,才提供下一个消息给到客户端,避免消息没处理掉。执行了该命令后,消息将从消费组的待处理消息列表中移除。如果不需要ACK机制,可以在XREADGROUP中指定NOACK:1 2
127.0.0.1:6379> XACK articles group1 1621776474608-0 1
XCLAIM:如果某一个客户端挂了,可以使用此命令,让其他Consumer主动接管它的pending msg:1 2
# 1621776677265-0 消息闲置至少10秒并且没有原始消费者或其他消费者进行推进(确认或者认领它)时,将所有权分配给消费者consumer-02 XCLAIM articles group1 consumer-02 10000 1621776677265-0
运行信息:
XINFO:用于检索关于流和关联的消费者组的不同的信息;XLEN:给出流中的条目数。
Stream与其他数据类型的区别
| 特性 | Stream | List, Pub/Sub, Zset |
|---|---|---|
| 查找元素复杂度 | O(long(N)) | List: O(N) |
| 偏移量 | 支持,每个消息有一个ID | List:不支持,如果某个项目被逐出,则无法找到最新的项目 |
| 数据持久化 | 支持,Streams持久化道AOF和RDB文件中 | Pub/Sub:不支持 |
| 消费分组 | 支持 | Pub/Sub:不支持 |
| ACK | 支持 | Pub/Sub:不支持 |
| 性能 | 不受客户端数量影响 | Pub/Sub:受客户端数量影响 |
| 数据逐出 | 流通过阻塞以驱逐太旧的数据,并使用Radix Tree和listpack来提高内存效率 | Zset消耗更多内存,因为它不支持插入相同项目,阻止或逐出数据 |
| 随机删除元素 | 不支持 | Zset:支持 |
Redis Stream vs Kafka
Apache Kafka是Redis Streams的知名替代品,Streams的某些功能更收到Kafka的启发。Kafka运行所需的配套比较昂贵,对于小型、廉价的应用程序,Streams是更好的选择。
1.3、Redis高级功能
基于基础的数据类型,Redis扩展了一些高级功能,如下图所示:
| 数据类型 | 数据类型 |
|---|---|
| Bitmap | REDIS_STRING |
| HyperLogLog | REDIS_STRING |
| Bloom Filter | REDIS_STRING,Bitmap实现 |
| Geospatial | REDIS_ZSETZ |
作为一个注重系统化学习的博客 IT宅(itzhai.com),作为一个追求技术发展的公众号,Java架构杂谈怎么能少了这些高级特性的内容了,下面,arthinking我就详细展开来看看这些特性。
1.3.1、BitMap
Bitmap,位图算法,核心思想是用比特数组,将具体的数据映射到比特数组的某个位置,通过0和1记录其状态,0表示不存在,1表示存在。通过使用BitMap,可以将极大域的布尔信息存储到(相对)小的空间中,同时保持良好的性能。
由于一条数据只占用1个bit,所以在大数据的查询,去重等场景中,有比较高的空间利用率。
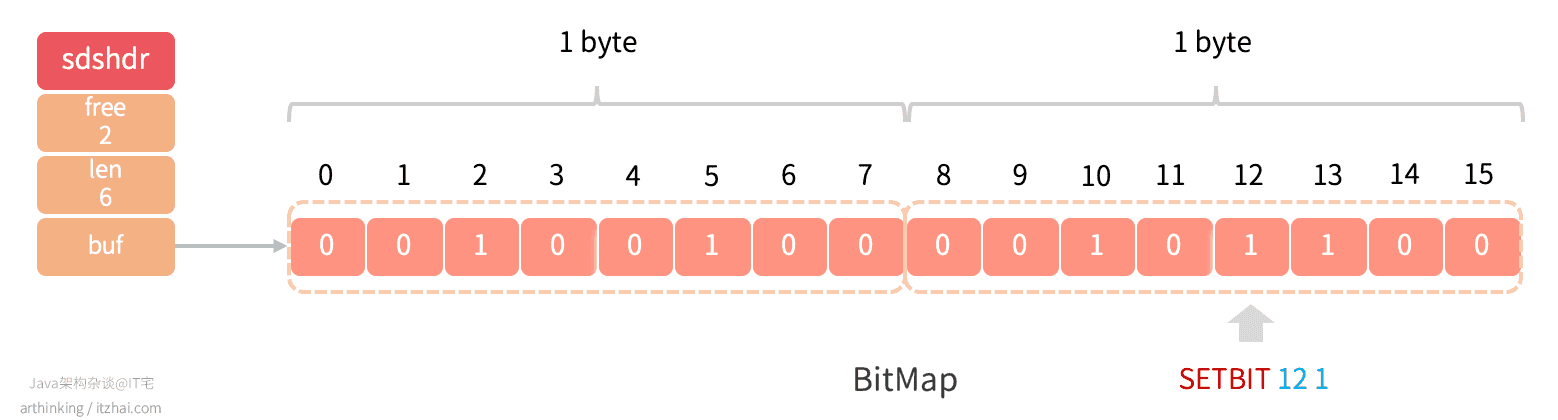
注意:BitMap数组的高低位顺序和字符字节的位顺序是相反的。
由于位图没有自己的数据结构,**BitMap底层使用的是REDIS_STRING进行存储的。**而STRING的存储上限是512M(2^32 -1),如下,最大上限为4294967295:
1 2 3 4 5 6 | 127.0.0.1:30001> setbit user_status 4294967295 1 0 127.0.0.1:30001> memory usage user_status 536887352 127.0.0.1:30001> setbit user_status 4294967296 1 ERR bit offset is not an integer or out of range |
如果要存储的值大于2^32 -1,那么就必须通过一个的数据切分算法,把数据存储到多个bitmap中了。
Redis中BitMap相关API
- SETBIT key offset value:设置偏移量offset的值,value只能为0或者1,O(1);
- GETBIT key offset:获取偏移量的值,O(1);
- BITCOUNT key start end:获取指定范围内值为1的个数,注意:start和end以字节为单位,而非bit,O(N);
- BITOP [operations] [result] [key1] [key2] [key...]:BitMap间的运算,O(N)
- operations:位移操作符
- AND 与运算 &
- OR 或运算 |
- XOR 异或 ^
- NOT 取反 ~
- result:计算的结果,存储在该key中
- key:参与运算的key
- 注意:如果操作的bitmap在不同的集群节点中,则会提示如下错误:
CROSSSLOT Keys in request don't hash to the same slot,可以使用HashTag把要对比的bitmap存储到同一个节点中;
- operations:位移操作符
- BITPOS [key] [value]:返回key中第一次出现指定value的位置
如下例子,两个bitmap AND操作结果:
1 2 3 4 5 6 7 8 | 127.0.0.1:30001> SETBIT {user_info}1 1001 1 0 127.0.0.1:30001> SETBIT {user_info}2 1001 0 1 127.0.0.1:30001> BITOP AND {user_info}3 {user_info}1 {user_info}2 126 127.0.0.1:30001> GETBIT {user_info}3 1001 0 |
性能与存储评估
关于BitMap的空间大小
BitMap空间大小是一个影响性能的主要因素,因为对其主要的各种操作复杂度是O(N),也就意味着,越大的BitMap,执行运算操作时间越久。
Redis的BitMap对空间的利用率是很低的,我们可以做个实验:
1 2 3 4 | 127.0.0.1:30002> SETBIT sign_status 100000001 1 1 127.0.0.1:30002> memory usage sign_status 12501048 |
可以看到,我们只是往BitMap里面设置了一位,就给BitMap分配了12501048的空间大小。
这是由于Redis的BitMap的空间分配策略导致的。由于底层是用的Redis字符串存储的,所以扩容机制跟字符串一致。执行SETBIT命令,当空间不足的时候,就会进行扩容,以确保可以在offset处保留一个bit。
所以我们一开始给100000001偏移量进行设置,就会立刻申请一个足够大的空间,这个申请过程中,会短时间阻塞命令的执行。
为了避免使用较大的BitMap,Redis文档建议将较大的BitMap拆分为多个较小的BitMap,处理慢速的BITOP建议在从节点上执行。提前拆分,这样可以了更好的应对未来潜在的数据增长。
关于BitMap的存储空间优化
从上面的分析可知,直接就设置很大的offset,会导致数据分布式很稀疏,产生很多连续的0。针对这种情况,我们可以采用RLE(行程编码,Run Length Encoding, 又称游程编码、行程长度编码、变动长度编码)编码对存储空间进行优化,不过Redis中是没有做相关存储优化的。
大致的思想是:表达同样的一串数字 000000,没有编码的时候是这样说的 :零零零零零零,编码之后可以这样说:6个零,是不是简单很多呢?
给如下的BitMap:
1
| 000000110000000000100001000000
|
可以优化存储为:
1
| 0,6,2,10,1,4,1,6
|
表示第一位是0,连续有6个0,接下来是2个1,10个0,1个1,4个0,1个1,6个0。这个例子只是大致的实现思路。
guava中的EWAHCompressedBitmap是一种压缩的BitMap的实现。EWAH是完全基于RLE进行压缩的,很好的解决了存储空间的浪费问题。
1.3.2、Bloom Filter
考虑一个这样的场景,我们在网站注册账号,输入用户名,需要立刻检测用户名是否已经注册过,如果已注册的用户数量巨大,有什么高效的方法验证用户名是否已经存在呢?
我们可能会有以下的解法:
- 线性查找,复杂度O(n)这是最低效的方式;
- 二分查找,复杂度O(log2n),比线性查找好很多,但是仍绕需要多个查找步骤;
- HashTable查找,快速,占用内存多。
而如果使用Boolean Filter,则可以做到既节省资源,执行效率又高。
布隆过滤器是一种节省空间的概率数据结构,用于测试元素是否为集合的成员,底层是使用BitMap进行存储的。
例如,检查用户名是否存在,其中集合是所有已注册用户名的列表。
它本质上是概率性的,这意味着可能会有一些误报:它可能表明给定的用户名已被使用,但实际上未被使用。
布隆过滤器的有趣特性
- 与HashTable不同,固定大小的布隆过滤器可以表示具有任意数量元素的集合;
- 添加元素永远不会失败。但是,随着元素的添加,误判率会越来越高。如果要降低误报结果的可能性,则必须使用更多数量的哈希函数和更大的位数组,这会增加延迟;
- 无法从过滤器中删除元素,因为如果我们通过清除k个散列函数生成的索引处的位来删除单个元素,则可能会导致其他几个元素的删除;
- 重点:判定不在的数据一定不存在,存在的数据不一定存在。
Bloom Filter如何工作
我们需要k个哈希函数来计算给定输入的哈希值,当我们要在过滤器中添加项目时,设置k个索引h1(x), h2(x), ...hk(x)的位,其中使用哈希函数计算索引。
如下图,假设k为3,我们在Bloom Filter中标识"itzhai.com"存在,则需要分别通过三个哈希函数计算得到三个偏移量,分别给这三个偏移量中的值设置为1:
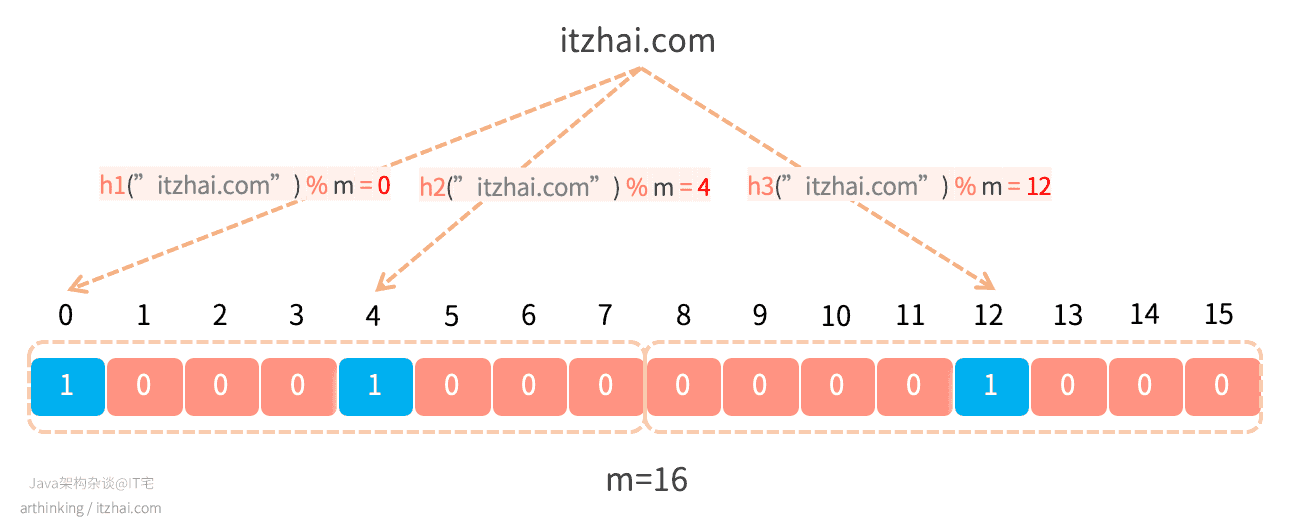
当我们需要检索判断"itzhai.com"是否存在的时候,则同样的使用者三个哈希函数计算得到三个偏移量,判断三个偏移量所处的位置的值是否都为1,如果为1,则表示"itzhai.com"是存在的。
Bloom Filter中的误判
假设我们继续往上面的Bloom Filter中记录一个新的元素“Java架构杂谈”,这个时候,我们发现h3函数计算出来的偏移量跟上一个元素相同,这个时候就产生了哈希冲突:
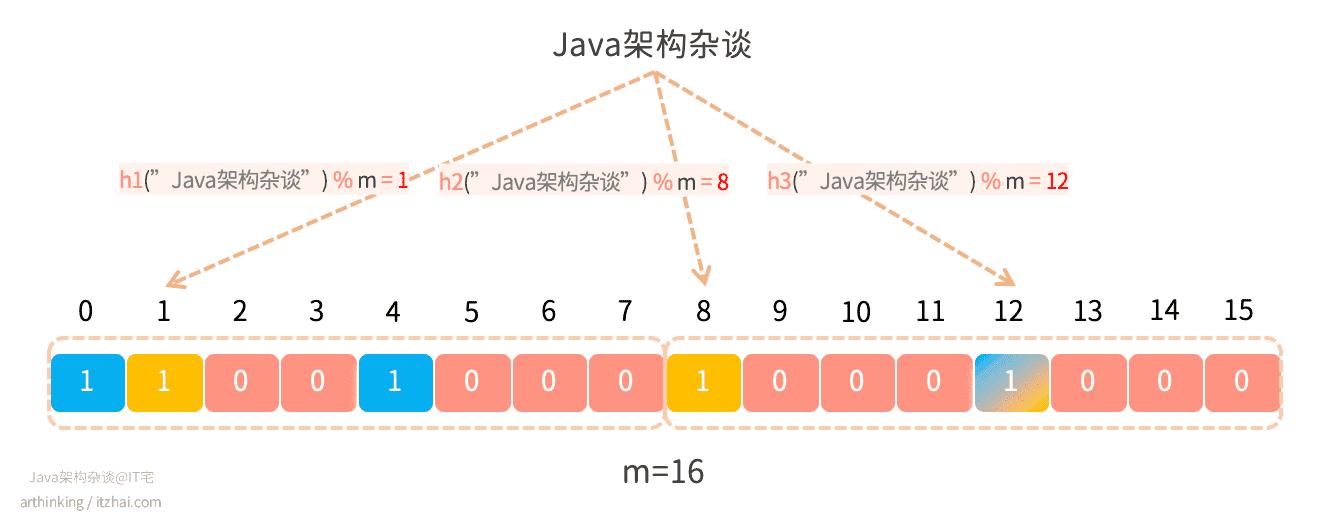
这就会导致,即使偏移量为12的这个值为1,我们也不知道究竟是“Java架构杂谈”这个元素设置进去的,还是"itzhai.com"这个元素设置进去的,这就是误判产生的原因。
在Bloom Filter中,我们为了空间效率而牺牲了精度。
如何减少误判
Bloom Filter的精度与BitMap数组的大小以及Hash函数的个数相关,他们之间的计算公式如下:
1
| p = pow(1−exp(−k/(m/n)),k)
|
其中:
- m:BitMap的位数
- k:哈希函数的个数
- n:Bloom Filter中存储的元素个数
为了更方便的合理估算您的数组大小和哈希函数的个数,您可以使用Thomas Hurst提供的这个工具来进行测试:Bloom Filter Calculator [7]。
Redis中的Bloom Filter
Redis在4.0版本开始支持自定义模块,可以将自定义模块作为插件附加到Redis中,官网推荐了一个RedisBloom[8]作为Redis布隆过滤器的Module。可以通过以下几行代码,从Github获取RedisBloom,并将其编译到rebloom.so文件中:
1 2 3 4 | $ git clone --recursive git@github.com:RedisBloom/RedisBloom.git $ cd RedisBloom $ make $ redis-server --loadmodule /path/to/rebloom.so |
这样,Redis中就支持Bloom Filter过滤器数据类型了:
1 2 | BF.ADD visitors arthinking BF.EXISTS visitors arthinking |
除了引入这个模块,还有以下方式可以引入Bloom Filter:
- pyreBloom(Python + Redis + Bloom Filter = pyreBloom);
- lua脚本来实现;
- 直接通过Redis的BitMap API来封装实现。
Bloom Filter在业界的应用
- Medium使用Bloom Filter通过过滤用户已看到的帖子来向用户推荐帖子;
- Quora在Feed后端中实现了一个共享的Bloom Filter,以过滤掉人们以前看过的故事;
- Google Chrome浏览器曾经使用Bloom Filter来识别恶意网址;
- Google BigTable,Apache HBase和Apache Cassandra以及Postgresql使用Bloom Filter来减少对不存在的行或列的磁盘查找。
1.3.3、HyperLogLog
HyperLogLog是从LogLog算法演变而来的概率算法,用于在不用存储大集合所有元素的情况下,统计大集合里面的基数。
基数:本节该术语用于描述具有重复元素的数据流中不同元素的个数。而在多集合理论中,该术语指的是多集合的重复元素之和。
HyperLogLog算法能够使用1.5KB的内存来估计超过10^9个元素的基数,并且控制标准误差在2%。这比位图或者Set集合节省太多的资源了 。
HyperLogLog算法原理
接下来我们使用一种通俗的方式来讲讲HyperLogLog算法的原理,不做深入推理,好让大家都能大致了解。
我们先从一个事情说起:你正在举办一个画展,现在给你一份工作,在入口处记下每一个访客,并统计出有多少个不重复的访客,允许小的误差,你会如何完成任务呢?
你可以把所有的用户电话号码都记下来,然后每次都做一次全量的对比,统计,得到基数,但这需要耗费大量的工作,也没法做到实时的统计,有没有更好的方法呢?
我们可以跟踪每个访客的手机号的后6位,看看记录到的后六位的所有号码的最长前导0序列。
例如:
- 123456,则最长前导0序列为0
- 001234,则最长前导0序列为2
随着你记录的人数越多,得到越长的前导0序列的概率就越大。
在这个案例中,平均每10个元素就会出现一次0序列,我们可以这样推断:
假设L是您在所有数字中找到的最长前导0序列,那么估计的唯一访客接近10ᴸ。
当然了,为了获得更加均匀分布的二进制输出,我们可以对号码进行哈希处理。最后在引入一个修正系数φ用于修正引入的可预测偏差,最终我能可以得到公式:
2ᴸ/ φ
这就是**Flajolet-Martin算法**(Philippe Flajolet和G. Nigel Martin发明的算法)。
但是假如我们第一个元素就碰到了很长的前导0序列,那么就会影响我们的预测的准确度了。
为此,我们可以将哈希函数得到的结果拆到不同的存储区中,使用哈希值的前几位作为存储区的索引,使用剩余内容计算最长的前导0序列。根据这种思路我们就得到了LogLog算法。
为了得到更准确的预测结果,我们可以使用调和平均值取代几何平均值来平均从LogLog得到的结果,这就是HyperLogLog的基本思想。
更加详细专业的解读,如果觉得维基百科的太学术了,不好理解,可以进一步阅读我从网上找的几篇比较好理解的讲解:
- Redis 中 HyperLogLog 讲解[9]
- HyperLogLog: A Simple but Powerful Algorithm for Data Scientists[10]
- Redis 中 HyperLogLog 的使用场景[11]
Redis中的HyperLogLog
Redis在2.8.9版本中添加了HyperLogLog结构。在Redis中,每个HyperLogLog只需要花费12KB的内存,就可以计算接近2^64个不同元素的基数。
Redis中提供了以下命令来操作HyperLogLog:
PFADD key element [element ...]:向HyperLogLog添加元素PFCOUNT key [key ...]:获取HyperLogLog的基数PFMERGE destkey sourcekey [sourcekey ...]:将多个HyperLogLog合并为一个,合并后的HyperLogLog基数接近于所有被合并的HyperLogLog的并集基数。
以下是使用例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # 存储第一个HyperLogLog 127.0.0.1:6379> PFADD visitors:01 arthinking Jim itzhai 1 # 获取第一个HyperLogLog的基数 127.0.0.1:6379> PFCOUNT visitors:01 3 # 存储第二个HyperLogLog 127.0.0.1:6379> PFADD visitors:02 arthinking itzhai Jay 1 # 获取第二个HyperLogLog的基数 127.0.0.1:6379> PFCOUNT visitors:02 3 # 合并两个HyperLogLog 127.0.0.1:6379> PFMERGE result visitors:01 visitors:02 OK # 获取合并后的基数 127.0.0.1:6379> PFCOUNT result 4 # 获取HyperLogLog中存储的内容 127.0.0.1:6379> GET result "HYLL\x01\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00Lo\x80JH\x80GD\x84_;\x80B\xc1" |
1.3.4、Geospatial
现在的App,很多都会利用用户的地理位置,做一些实用的功能,比如,查找附近的人,查找附近的车,查找附近的餐厅等。
Redis 3.2开始提供的一种高级功能:Geospatial(地理空间),基于GeoHash和有序集合实现的地理位置相关的功能。
如果叫你实现一个这样的功能,你会如何实现呢?
用户的地理位置,即地理坐标系统中的一个坐标,我们的问题可以转化为:在坐标系统的某个坐标上,查找附近的坐标。
而Redis中的Geo是基于已有的数据结构实现的,已有的数据结构中,能够实现数值对比的就只有ZSET了,但是坐标是有两个值组成的,怎么做比较呢?
**核心思想:**将二维的坐标转换为一维的数据,就可以通过ZSET,B树等数据结构进行对比查找附近的坐标了。
我们可以基于GeoHash编码,把坐标转换为一个具体的可比较的值,再基于ZSET去存储获取。
GeoHash编码
GeoHash编码的大致原理:将地球理解为一个二维平面,将平面递归分解为子块,每个子块在一定的经纬度范围有相同的编码。
总结来说就是利用二分法分区间,再给区间编码,随着区块切分的越来越细,编码长度也不断追加,变得更精确。
为了能够直观的对GeoHash编码有个认识,我们来拿我们的贝吉塔行星来分析,如下图,我们把行星按照地理位置系统展开,得到如下图所示的坐标系统:
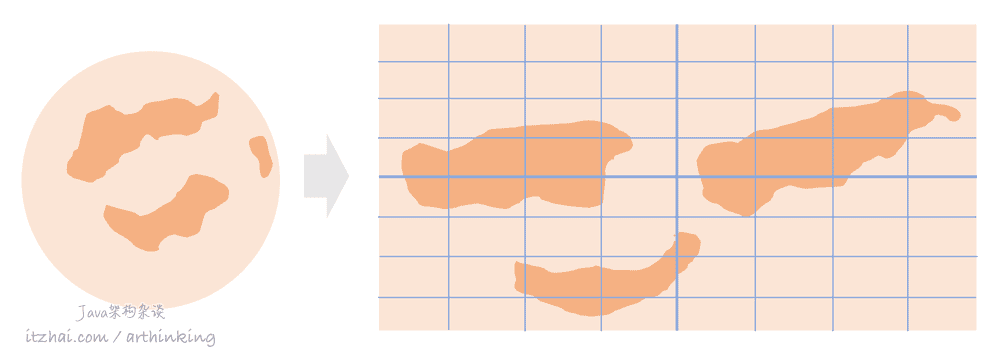
我们可以给坐标系统上面的区块进行分块标识,规则如下:
- 把纬度二等分:左边用0表示,右边用1表示;
- 把经度二等分:左边用0表示,右边用1表示。
偶数位放经度,奇数位放维度,划分后可以得到下图:
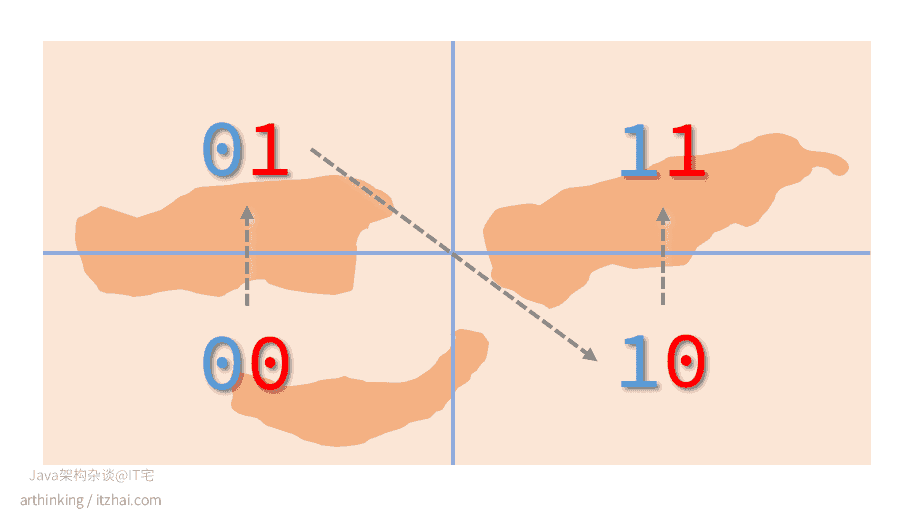
其中,箭头为数值递增方向。上图可以映射为一维空间上的连续编码: 00 01 10 11,相邻的编码一般距离比较接近。
我们进一步递归划分,划分的左边或者下边用0表示,右边或者上边用1表示,可以得到下图:
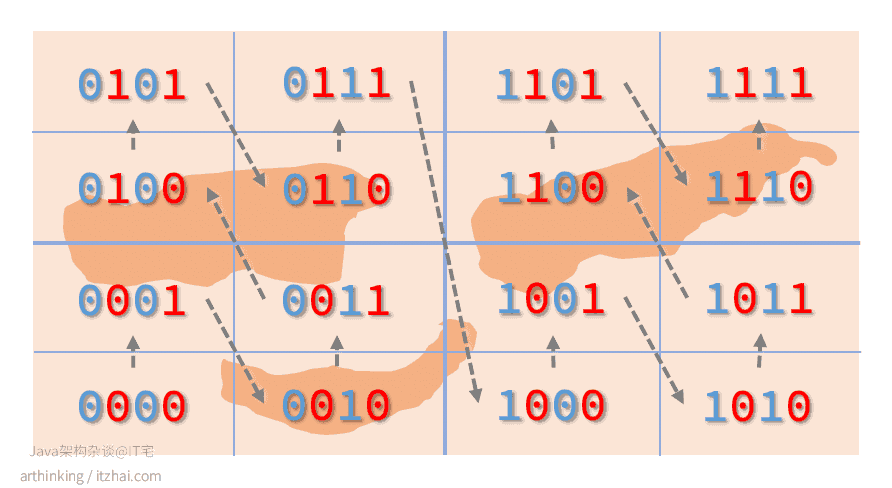
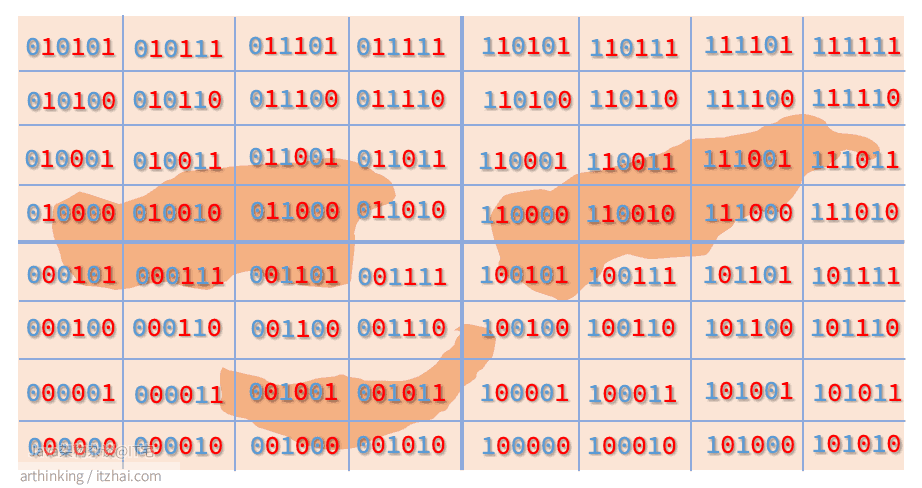
GeoHash Base32编码
最后,使用以下32个字符对以上区块的经纬度编码进行base 32编码,最终得到区块的GeoHash Base32编码。
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| Decimal | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Base 32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
同一个区块内,编码是相同的。可以发现:
- 编码长度越长,那么编码代表的区块就越精确;
- 字符串相似编码所代表的区块距离相近,但有特殊情况;
根据Geohash[12]可知,当GeoHash Base32编码长度为8的时候,距离精度在19米左右。
关于区块距离的误差
基于GeoHash产生的空间填充曲线最大缺点是突变性:有些编码相邻但是距离却相差很远,如下图:
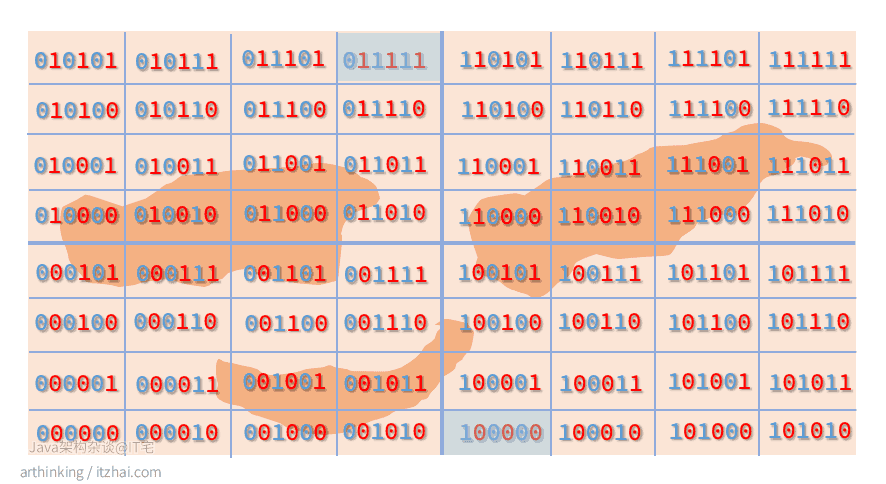
因此,为了避免曲突变造成的影响,在查找附近的坐标的时候,首先筛选出GeoHash编码相近的点,然后进行实际的距离计算。
Redis中的Geo
Redis中的Geo正是基于GeoHasn编码,把地理坐标的编码值存入ZSET中,进行查找的。
下面我们演示一下相关API的用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | # 添加国内的6个旅游地点 127.0.0.1:6379> GEOADD destinations 100.26764 25.60648 大理 1 127.0.0.1:6379> GEOADD destinations 99.74317 27.84254 香格里拉 1 127.0.0.1:6379> GEOADD destinations 100.29829 29.03704 稻城 1 127.0.0.1:6379> GEOADD destinations 119.73572 49.21336 呼伦贝尔 1 127.0.0.1:6379> GEOADD destinations 117.37836 49.59655 满洲里 1 127.0.0.1:6379> GEOADD destinations 116.23128 40.22077 北京 1 # 查找坐标 116.23128 40.22077 1500公里范围内的旅游地点 127.0.0.1:6379> GEORADIUS destinations 116.23128 40.22077 1500 km ASC COUNT 10 北京 呼伦贝尔 满洲里 # 查找坐标 116.23128 40.22077 2000公里范围内的旅游地点 127.0.0.1:6379> GEORADIUS destinations 116.23128 40.22077 2000 km ASC COUNT 10 北京 呼伦贝尔 满洲里 稻城 # 查找坐标 116.23128 40.22077 3000公里范围内的旅游地点 127.0.0.1:6379> GEORADIUS destinations 116.23128 40.22077 3000 km ASC COUNT 10 北京 呼伦贝尔 满洲里 稻城 香格里拉 大理 |
正是因为命令执行完全是在内存中处理的,所以redis执行速度非常快,但是为了数据的持久化,我们就不能离开磁盘了,因为一旦断点,内存的数据就都丢失了。
下面再来讲讲Redis是怎么通过磁盘来提供数据持久化,和宕机后的数据恢复的。
2、磁盘
Redis是一个内存的键值对数据库,但是要是服务进程挂了,如何恢复数据呢?这个时候我们就要来讲讲Redis的持久化了。
Redis的持久化有两种方式:RDB和AOF。
2.1、RDB
RDB是Redis持久化存储内存中的数据的文件格式。RDB,即Redis Database的简写。也称为内存快照。
2.1.1、如何创建RDB文件?
触发生成RDB文件命令是SAVE和BGSAVE。从命名的命名就可以知道,BGSAVE是在后台运行的:
SAVE:执行SAVE命令创建RDB文件的过程中,会阻塞Redis服务进程,此时服务器不能处理任何命令;BGSAVE:BGSAVE会派生出一个子进程来创建RDB文件,Redis父进程可以继续处理命令请求。
BGSAVE执行流程
BGSAVE执行流程如下:
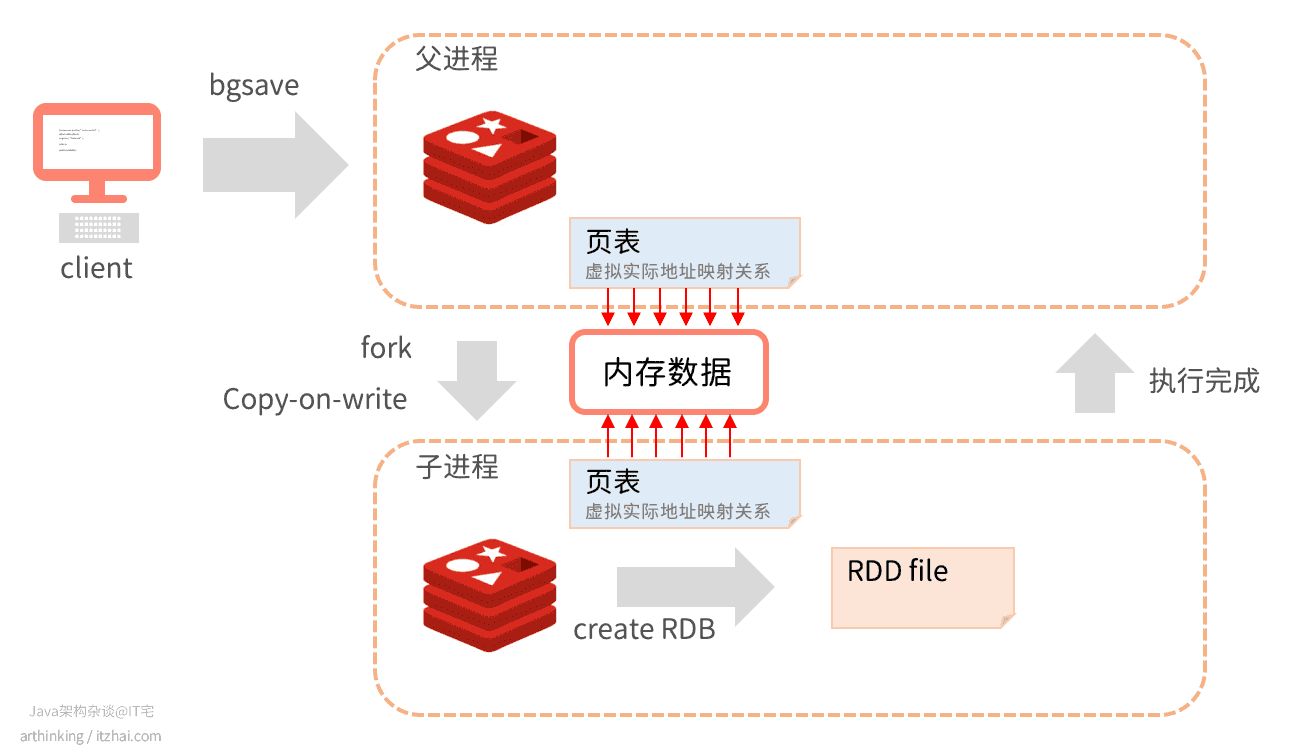
在发起BGSAVE命令之后,Redis会fork出一个子进程用于执行生成RDB文件。fork的时候采用的是写时复制(Copy-on-write)技术。不会立刻复制所有的内存,只是复制了页表,保证了fork执行足够快。如上图,Redis父进程和执行BGSAVE的子进程的页表都指向了相同的内存,也就是说,内存并没有立刻复制。
然后子进程开始执行生成RDB。
在生成RDB过程中,如果父进程有执行新的操作命令,那么会复制需要操作的键值对,父子进程之间的内存开始分离:
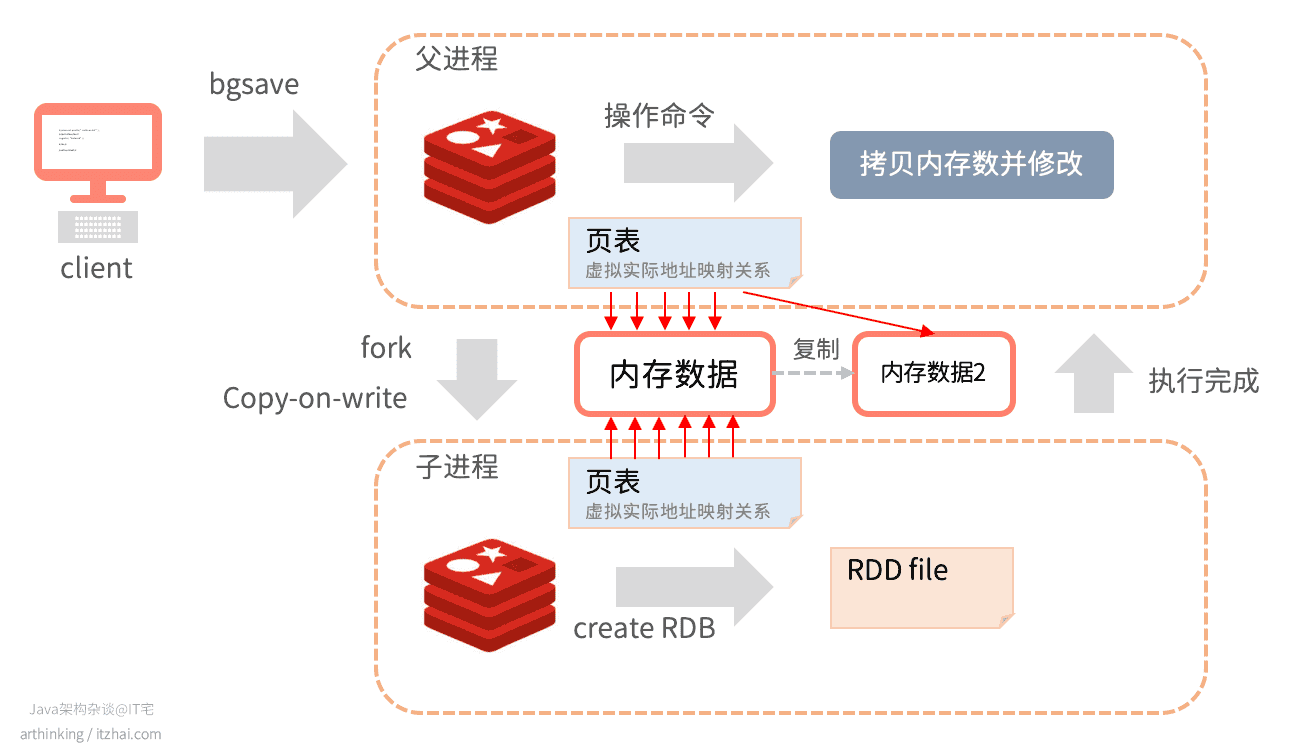
如上图,父进程执行命令修改了一些键值对的时候,该部分键值对实际上会复制一份进行修改,修改完成之后,父进程中的该内存数据的指针会指向被复制的的内存。而子进程继续指向原来的数据,原来的数据内容是不会被修改的。
在生成RDB文件过程中,父进程中对数据的修改操作不会被持久化。
执行BGSAVE会消耗很多内存吗?
由上面描述可知,BGSAVE并不会立刻复制内存数据,而是采用了写时复制技术,所以并不会立刻消耗很多内存。
但是如果Redis实例写比读的执行频率高很多,那么势必会导致执行BGSAVE过程中大量复制内存数据,并且消耗大量CPU资源,如果内存不足,并且机器开启了Swap机制,把部分数据从内存swap到磁盘上,那么性能就会进一步下降了。
服务端什么时候会触发BGSAVE?
Redis怎么知道什么时候应该创建RDB文件呢?我们得来看看redisServer中的几个关键属性了,如下图:
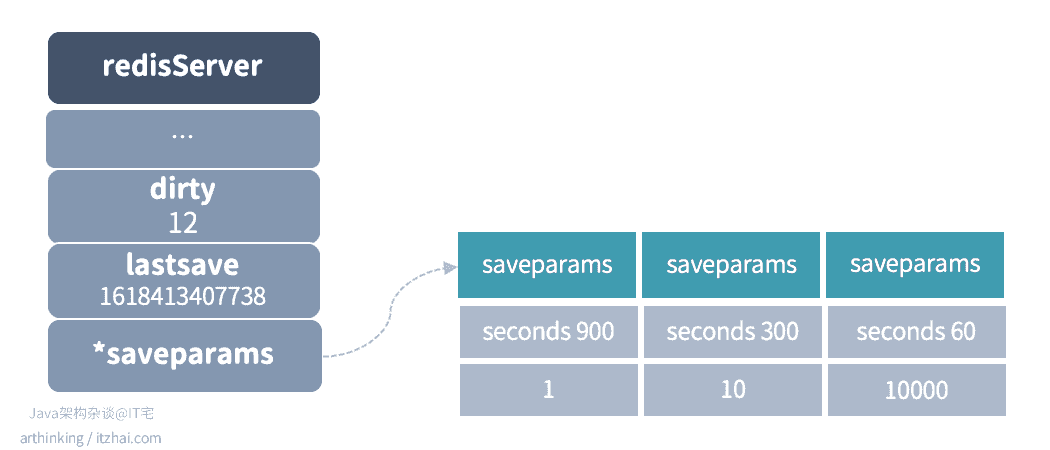
- dirty计数器:记录距离上一次成功执行SAVE或者BGSAVE命令之后,服务器数据库进行了多少次修改操作(添加、修改、删除了多少个元素);
- lastsave时间:一个Unix时间戳,记录服务器上一次成功执行SAVE或者BGSAVE命令的时间;
- saveparams配置:触发BGSAVE命令的条件配置信息,如果没有手动设置,那么服务器默认设置如上图所示:
- 服务器在900秒内对数据库进行了至少1次修改,那么执行BGSAVE命令;
- 服务器在300秒内对数据库进行了至少10次修改,那么执行BGSAVE命令;
- 服务器在60秒内对数据库进行了至少10000次修改,那么只需BGSAVE命令。
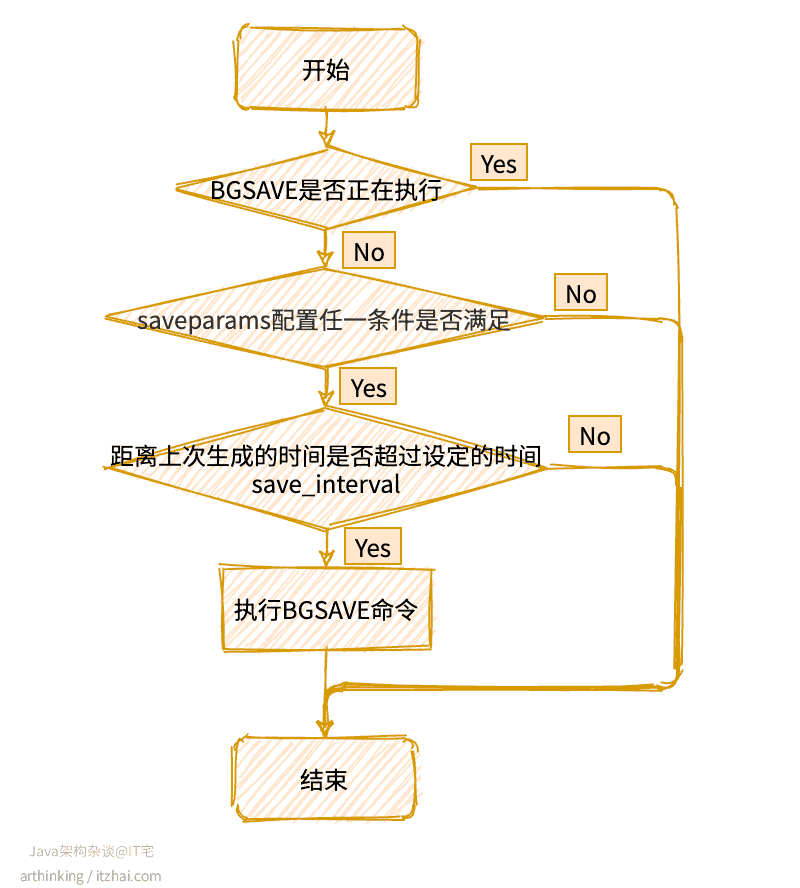
Redis默认的每隔100毫秒会执行一次serverCron函数,检查并执行BGSAVE命令,大致的处理流程如下图所示:
2.1.2、如何从RDB文件恢复?
Redis只会在启动的时候尝试加载RDB文件,但不是一定会加载RDB文件的,关键处理流程如下图:
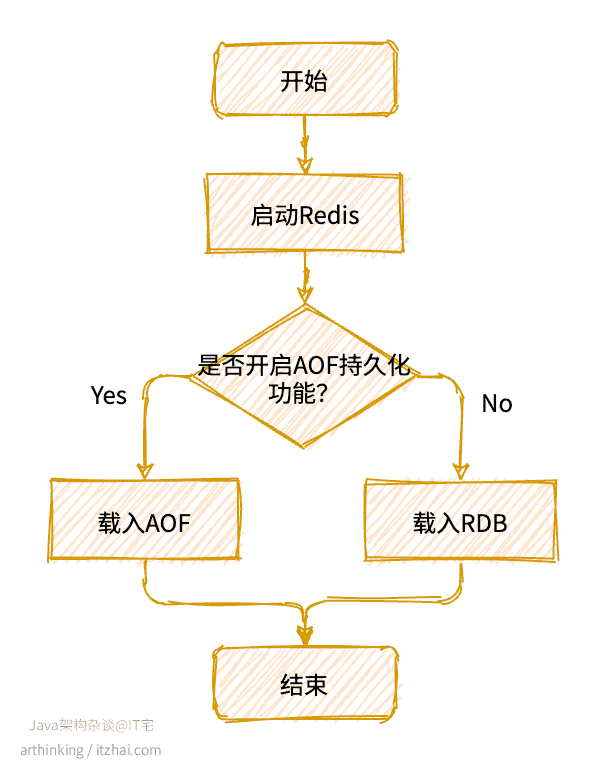
服务器在载入RDB文件期间,一直处于阻塞状态。
2.1.3、RDB文件结构是怎样的?
我们用一张图来大致了解下RDB文件的结构,如下图所示:
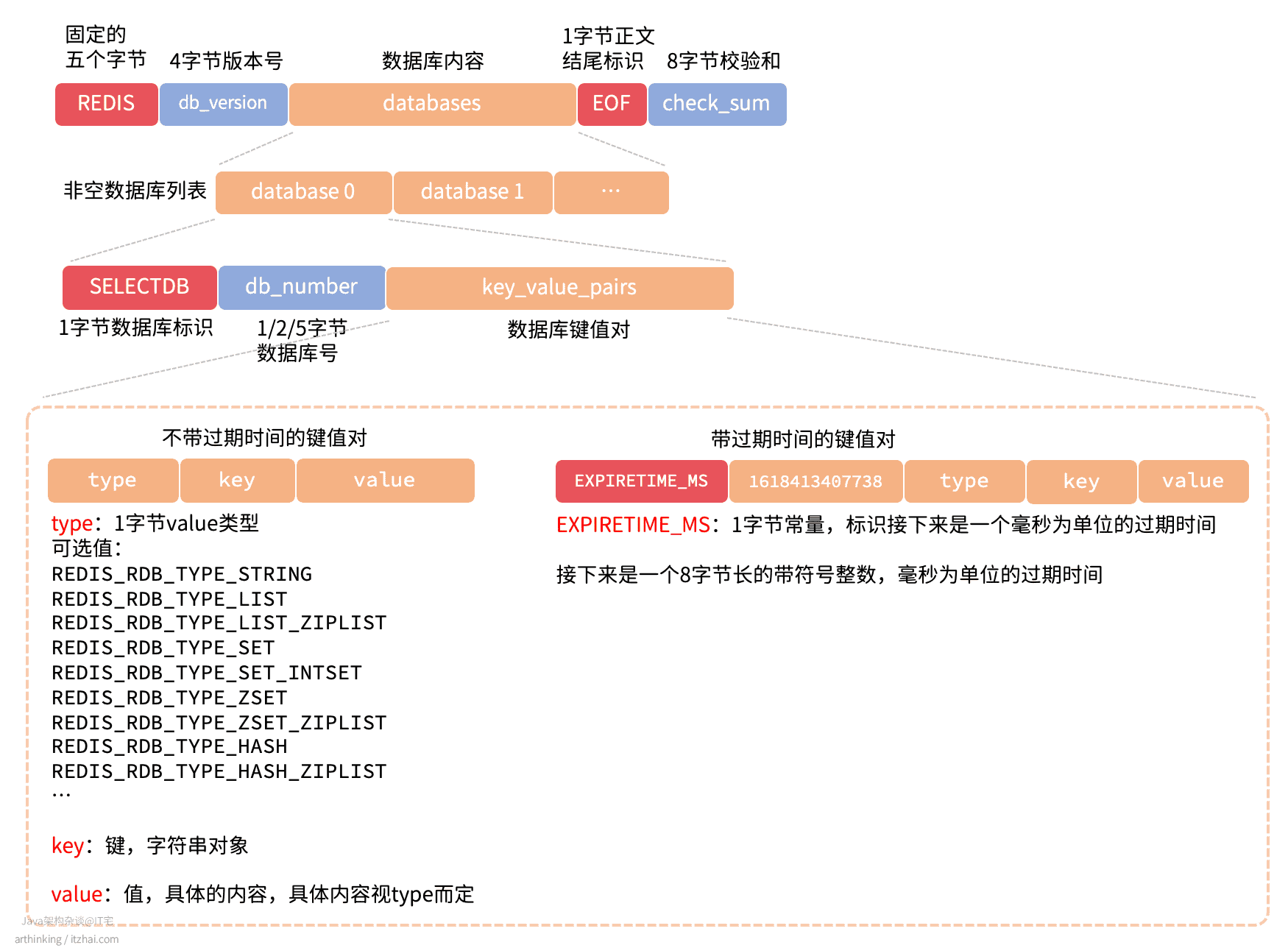
具体格式以及格式说明参考上图以及图中的描述。
而具体的value,根据不同的编码有不同的格式,都是按照约定的格式,紧凑的存储起来。
2.2、AOF
从上一节的内容可知,RDB是把整个内存的数据按照约定的格式,输出成一个文件存储到磁盘中的。
而AOF(Append Only File)则有所不同,是保存了Redis执行过的命令。
AOF,即Append Only File的简写。
我们先来看看,执行命令过程中是如何生成AOF日志的:
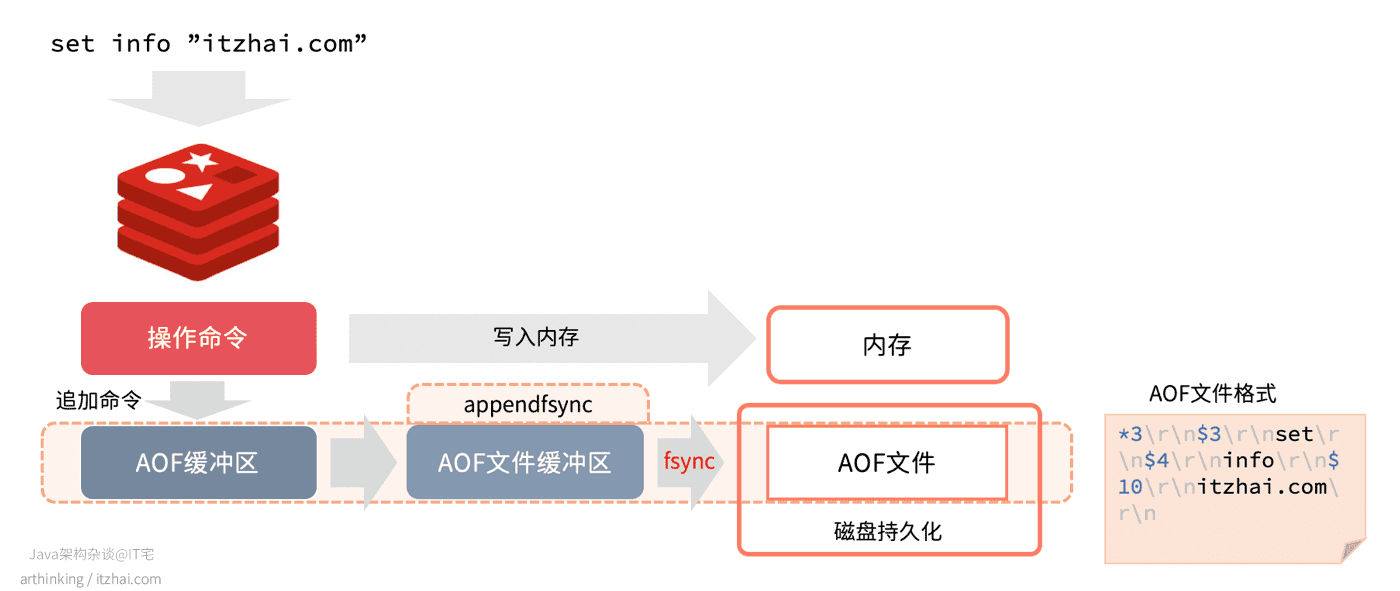
如上图,是Redis执行命令过程中,产生AOF日志的一个过程:
- 执行完命令之后,相关数据立刻写入内存;
- 追加命令到AOF缓冲区(对应redisServer中的aof_buf属性),该缓冲区用于把AOF日志追写回到磁盘的AOF文件中,有三种不同的写回策略,由
appendfsync参数控制:- Always:同步写回,每个写命令执行完毕之后,立刻将AOF缓冲区的内容写入到AOF文件缓冲区,并写回磁盘;
- Everysec:每秒写回,每个写命令执行完后,将AOF缓冲区所有内容写入到AOF文件缓冲区,如果AOF文件上次同步时间距离现在超过了一秒,那么将再次执行AOF文件同步,将AOF文件写回磁盘;
- No:操作系统控制写回,每个写命令执行完毕之后,将AOF缓冲区的内容写入到AOF文件缓冲区,具体写回磁盘的时间,由操作系统的机制来决定。
2.2.1、AOF文件格式
AOF文件格式如上图最右边所示:
*3:表示当前命令有三部分;$3:每个部分以$ + 数字打头,数字表示这部分有多少字节;- 字符串:该部分具体的命令内容。
2.2.2、应该用哪种AOF写回策略?
可以看到appendfsync是实现数据持久化的关键技术了,哪种写回策略最好呢?
这里,我们通过一个表格来对比下:
| 写回策略 | 写回时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步写回 | 数据基本不丢失 | 每次写数据都要同步,性能较差 |
| Everysec | 每秒写回 | 性能与可靠性的平衡 | 宕机将丢失一秒的数据 |
| No | 操作系统控制写回 | 性能好 | 宕机将丢失上一次同步以来的数据 |
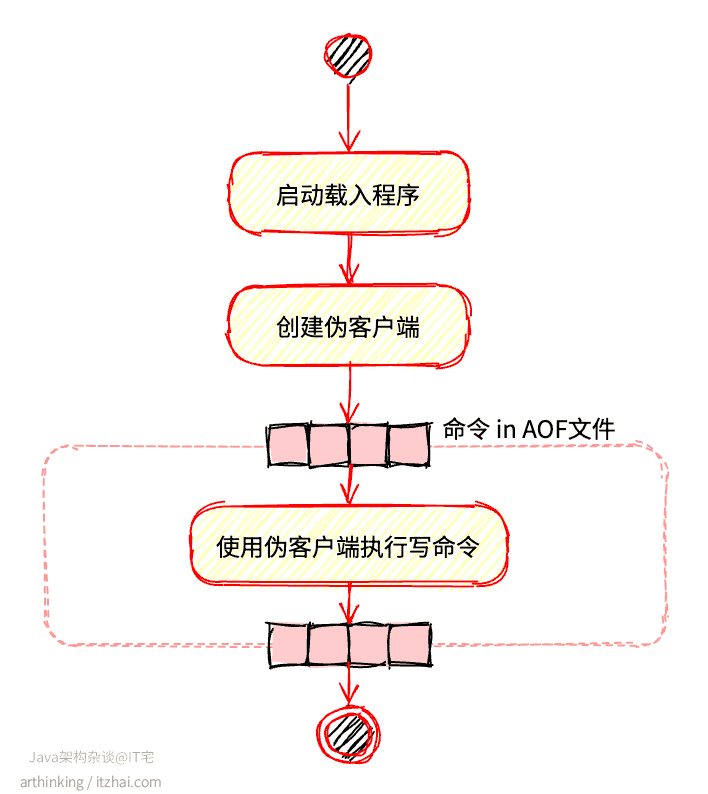
2.2.3、如何通过AOF实现数据还原?
为了实现数据还原,需要把AOF日志中的所有命令执行一遍,而Redis命令只能在客户端上下文中执行,所以会先创建一个不带网络套接字的伪客户端进行执行命令,大致流程如下:
2.2.4、AOF文件太大了,影响载入速度怎么办?
如果AOF文件太大,需要执行的命令就很多,载入速度回变慢,为了避免这种问题,Redis中提供了AOF重写机制,把原来的多个命令压缩成一个,从而减小AOF文件的大小和AOF文件中的命令数量,加快AOF文件的载入速度。
Redis中触发AOF重写的是bgrewriteaof命令。
要注意的是,AOF重写并不是读取原来的AOF文件的内容进行重写,而是根据系统键值对的最新状态,生成对应的写入命令。
重写效果
比如执行了以下命令:
1 2 3 4 5 6 | RPUSH list "a RPUSH list "b" "c" RPOP list HMSET map "site" "itzhai.com" HMSET map "author" "arthinking" HMSET map "wechat" "Java架构杂谈" |
那么,理想的情况,执行AOF重写之后,生成的AOF文件的内容会变为如下所示:
1 2 | RPUSH list "a" "b" HMSET map "site" "itzhai.com" "author" "arthinking" "wechat" "Java架构杂谈" |
最终,每个键,都压缩成了一个命令。
如果集合中的元素太多了,如何生成命令?
为了避免命令太长,导致客户端输入缓冲区溢出,重写生成命令的时候,会检查元素个数,如果超过了
redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD(64),那么将拆分为多条命令。
AOF重写运行原理
重写运行原理如下图所示:
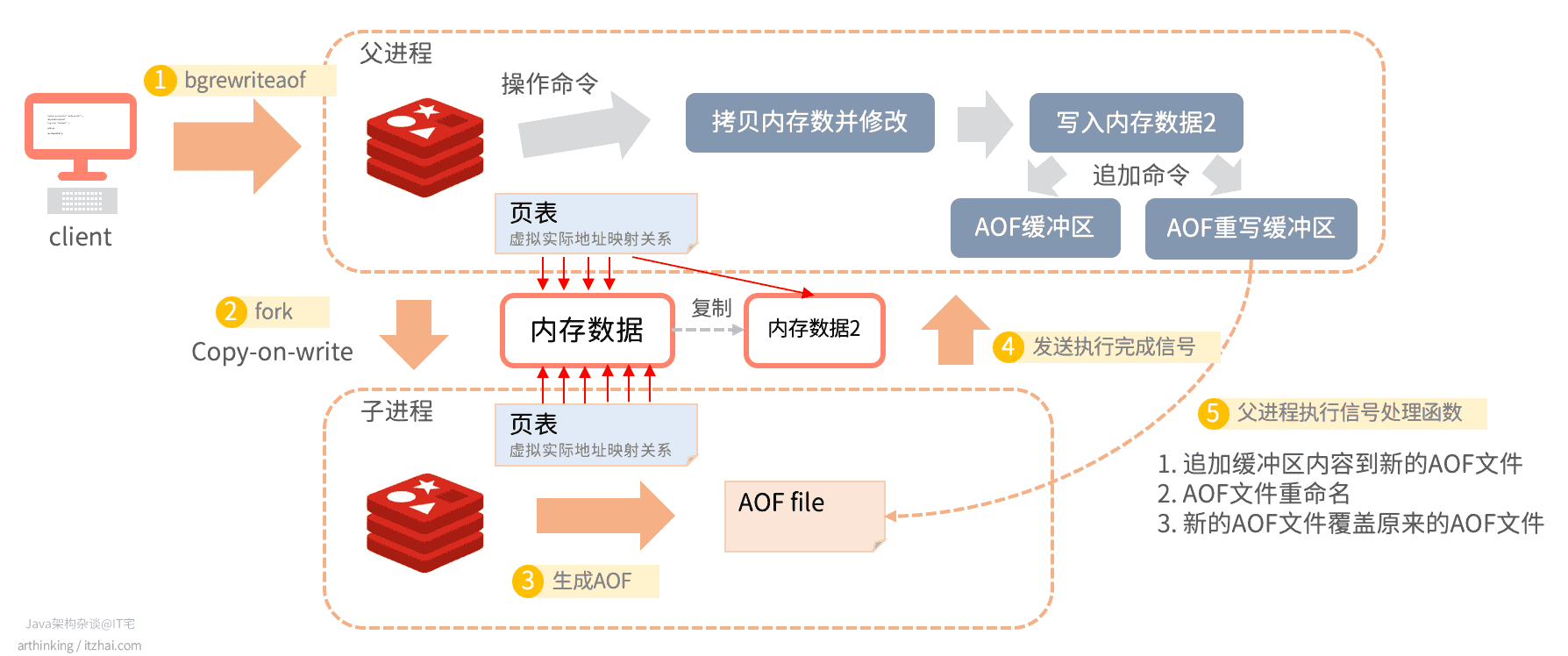
- 1、触发bgrewriteaof命令;
- 2、fork子进程,采用写时复制,复制页表;
- 如果此时父进程还需要执行操作命令,则会拷贝内存数据并修改,同时追加命令到AOF缓冲区和AOF重写缓冲区中;
- 3、根据内存数据生成AOF文件;
- 4、生成完成之后,向父进程发送信号;
- 5、父进程执行信号处理函数,这一步会把AOF重写缓冲区中的数据追加到新生成的AOF文件中,最终替换掉旧的AOF文件。
AOF重写涉及到哪些关键设计点?
不停服:所谓的不停服,指的是父进程可以继续执行命令;双写:因为重写不一定会成功,所以在重写过程中执行的操作命令,需要同时写到AOF缓冲区和AOF重写缓冲区中。这样一来:- 即使重写失败了,也可以继续使用AOF缓冲区,把数据回写到AOF文件;
- 如果重写成功了,那么就把AOF重写缓冲区的数据追加到新的AOF文件即可;
内存优化:这里采用的是写时复制技术,保证fork效率,以及尽可能少的占用过多的内存。
2.3、有没有那种快速恢复、开销小、数据不丢失的持久化方案?
Redis 4.0开始提供了RDB+AOF的混合持久化方式,结合了两者的优点。对应的配置项开关为:aof-use-rdb-preamble。
开启了混合持久化之后,serverCron定时任务以及BGREWRITEAOF命令会触发生成RDB文件,在两次生成RDB文件之间执行的操作命令,使用AOF日志记录下来。
最终生成的RDB和AOF都存储在一个文件中。
通过这种方案,基本保证了数据的不丢失,但是在分布式主从集群系统中,一旦发生了故障导致主从切换或者脑裂问题,就不可避免的导致主从数据不一致,可能导致数据丢失。有没有修复主从数据不一致问题的方法决定了数据会不会丢失,很可惜,Redis不管怎么做,都是有可能丢失消息的,我们在分布式章节会详细介绍这类问题。
2.4、RDB、AOF仍然不够快?
虽然RDB文件生成,或者AOF重写都用上了写时复制技术,但是如果内存中的数据实在太多了,那也是会造成Redis实例阻塞的。
有没有更好的方案呢?有,可以实现的思路:让内存中的数据不能保存太多,内存只存储热点数据,对于冷数据,可以写入到SSD硬盘中,再把未写入SSD硬盘的数据通过某种方式记录下来,可以参考MySQL的binlog,这样不用RDB或者AOF,就实现了数据的持久化。
比如,360开源的Pika。
不过该方案也是有缺点的,如果要频繁的从SSD中加载数据,那么查询的性能就会低很多。另外SSD硬盘的使用寿命也和擦写次数有关,频繁的改写,SSD硬盘成本也是一个问题。
这种方案适合需要大容量存储、访问延迟没有严格要求低业务场景中使用。
Part Ⅱ. 内存数据库
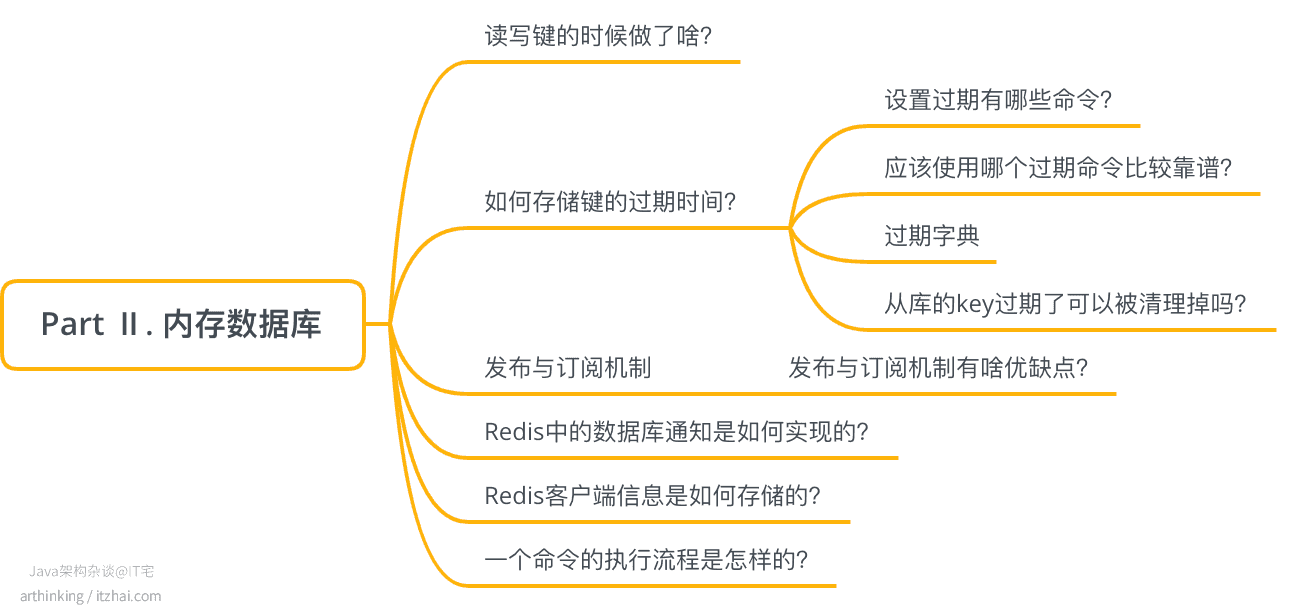
接下来,我们来看看Redis是如何组织这些数据类型,来构建一个内存数据库的。
以下是Redis数据库的结构:
Redis服务器程序所有的数据库都保存在redisService结构体中,其中有个db数组,为redisDb类型,每个元素为一个数据库。
db数组可配置,默认为16个,redisDb中保存了一个字典,该字典保存了数据库中所有的键值对,我们也称该字典为键空间(key space)。
字典的key为String类型,字典的value就是我们上一节提到的各种数据类型了,这些数据类型让Redis可以存储多样化的数据,利用特定的数据结构实现一些业务场景,我们后面在应用场景小节具体介绍。
客户端连接哪个数据库?
默认情况下,Redis客户端会连接0号数据库,可以通过SELECT命令切换数据库。
1 2 3 4 5 6 7 8 | 127.0.0.1:6379> SET name arthinking OK 127.0.0.1:6379> GET name "arthinking" 127.0.0.1:6379> DEL name (integer) 1 127.0.0.1:6379> GET name (nil) |
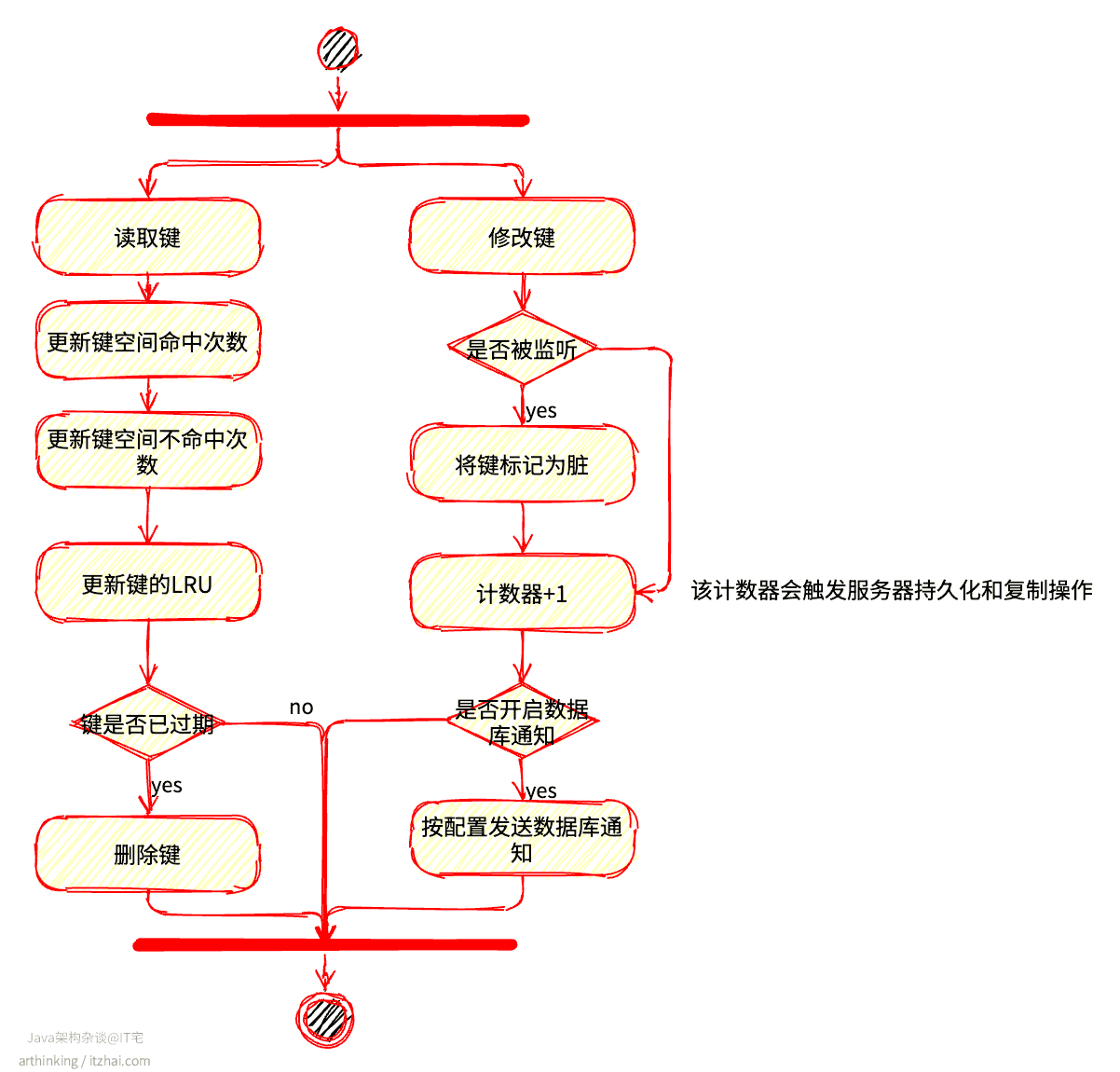
3、读写键的时候做了啥
当通过命令对数据库进行了读写之后,Redis同时会做一些维护工作:
4、如何存储键的过期时间
4.1、过期相关命令
- EXPIRE key seconds,设置key的生存秒数;
- PEXPIRE key milliseconds,设置key的生存毫秒数;
- EXPIREAT key timestamp,设置key的过期时间戳(秒);
- PEXPIREAT key timestamp,设置key的过期时间戳(毫秒)
- SETEX,设置一个字符串的过期时间;
- TTL与PTTL,接收一个带有生存时间的键,返回键的剩余生成时间。
这些设置过期时间命令,本质上都会转成PEXPIREAT命令来执行,数据库中存储的是键的过期时间点。
4.2、应该使用哪个过期命令比较靠谱?
注意:建议直接使用EXPIREAT命令来设置过期时间,避免主从同步延迟,导致从库实际的EXPIREAT时间比主库的晚,最终客户端在从库上读取到了过期的数据(主库已过期,从库未过期)。
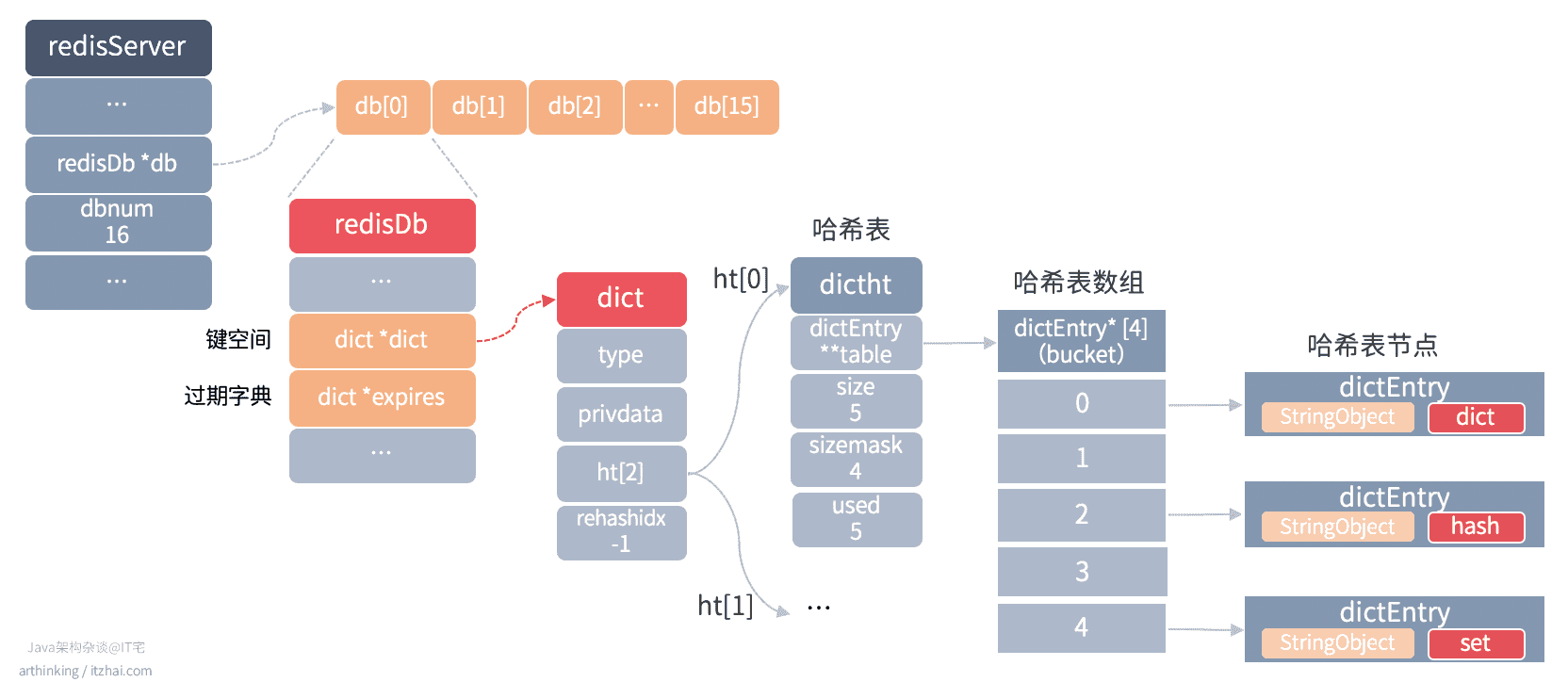
4.3、过期字典
我们注意到,上面的数据库结构图中,包含了一个expires过期字典,该字典的键是一个纸指向键空间中某个数据库键的指针,值是一个long long类型的整数,保存数据库键的过期时间(毫秒时间戳)。
5、如何删除过期键
在一般程序设计中,我们也会用三种策略来实现数据的过期删除:
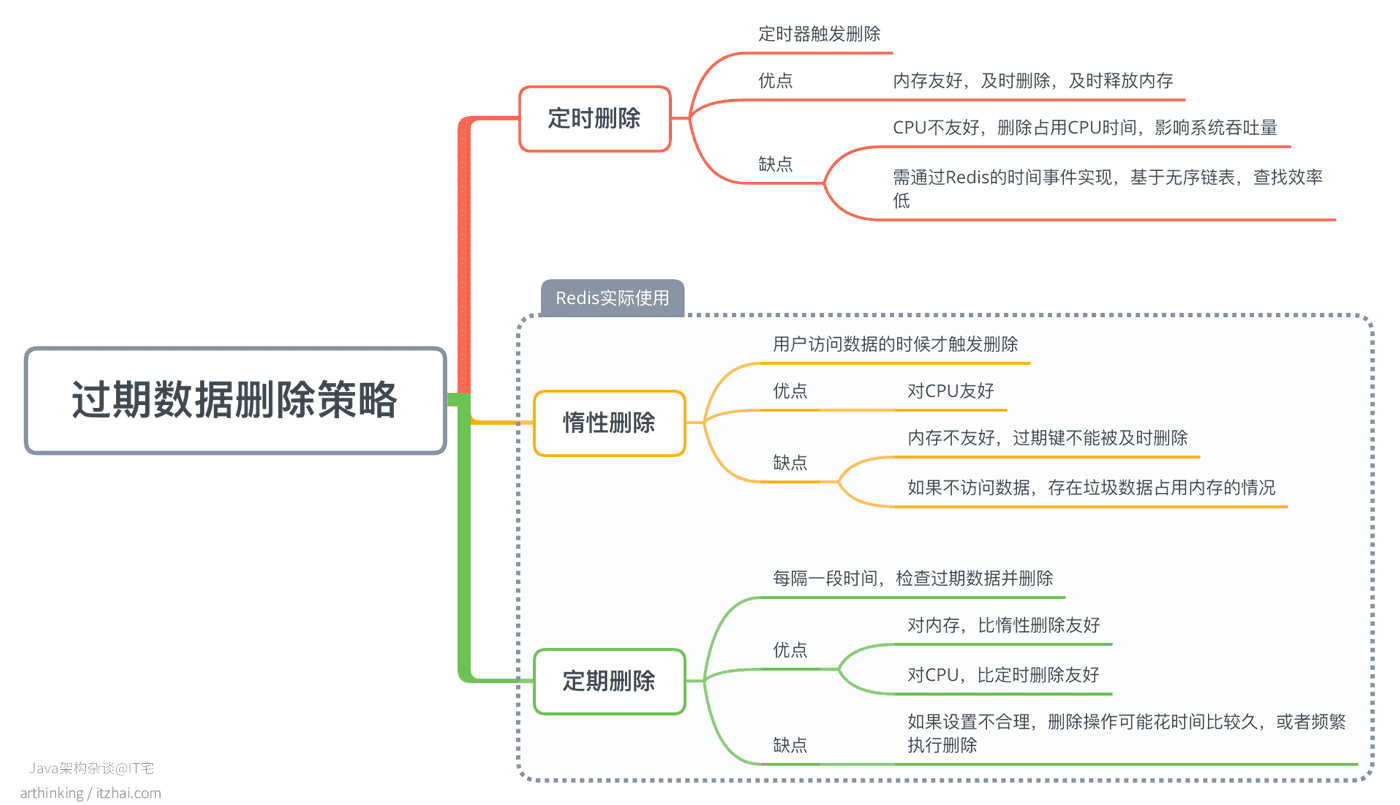
定时删除策略是一种方案,但是如果设置的不合理,就会即浪费CPU,或者内存及时删除。为此,Redis采用了惰性删除和定期删除配合工作的方式。
- Redis中的惰性删除:接收读写数据库命令,判断是否已过期,如果过期则删除并返回空回复,否则执行实际的命令流程;
- Redis中的定期删除:每次运行,从一定量数据库中取出一定量随机键进行检查,然后把过期的键删除掉,通过一个全局表示current_db记录处理进度,确保所有数据库都可以被处理。
5.1、从库的key过期了可以被清理掉吗?
当主库键key过期时时,会同步一个DEL操作到从库,从库不会自己删除过期key,只会应用从主库同步过来的DEL操作,这样就避免了缓存一致性的错误。
这样就会有一个问题,如果从库在同步DEL操作之前,就有客户端请求从库获取key,那么就有可能读取到主库已经删除,但是从库还未删除的key。
好在从Redis 3.2开始,对从库读取key做了优化:在从库发起读请求的时候,会先判断这个key是否过期,如果过期了,就直接返回nil,从而避免了在从库中读取到了过期的key的问题。
另外:建议直接使用EXPIREAT命令来设置过期时间,避免主从同步延迟,导致从库实际的EXPIREAT时间比主库的晚,最终客户端在从库上读取到了过期的数据(主库已过期,从库未过期)。
6、Redis中的发布订阅机制
Redis的发布订阅功能有以下命令组成:
SUBSCRIBE channel [channel ...]订阅给定的一个或多个频道的信息;
SUBSCRIBE channel
UNSUBSCRIBE [channel [channel ...]]退订给定的频道
UNSUBSCRIBE channel
PUBLISH channel message用于将信息发送到指定的频道;
PUBLISH channel itzhai.com
PUBSUB subcommand [argument [argument ...\]]查看订阅与发布系统状态
PUBSUB CHANNELS
PSUBSCRIBE pattern [pattern ...]订阅一个或多个符合给定模式的频道
PSUBSCRIBE site.*
PUNSUBSCRIBE [pattern [pattern ...\]]退订给定模式的频道
UNSUBSCRIBE site.*
如下,通过给定的模式频道进行订阅和发布消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # 客户端A订阅模式频道 127.0.0.1:6379> PSUBSCRIBE site.* psubscribe site.* 1 # 客户端B向模式频道发布消息 127.0.0.1:6379> PUBLISH site.itzhai "hello world!!!" 1 # 客户端A输出 pmessage site.* site.itzhai hello world!!! |
Redis在服务端通过链表的形式维护了每个频道的客户端的订阅记录,每次发布消息的时候,都从链表中找到所有相关的客户端的socket连接,并发送订阅消息给各个客户端。Redis中存放客户端订阅关系的相关数据结构:
1 2 3 4 5 6 | struct redisServer { // ... dict *pubsub_channels; // 保存所有频道订阅关系 list *pubsub_patterns; // 保存所有模式订阅关系 // ... }; |
具体结构如下图所示:
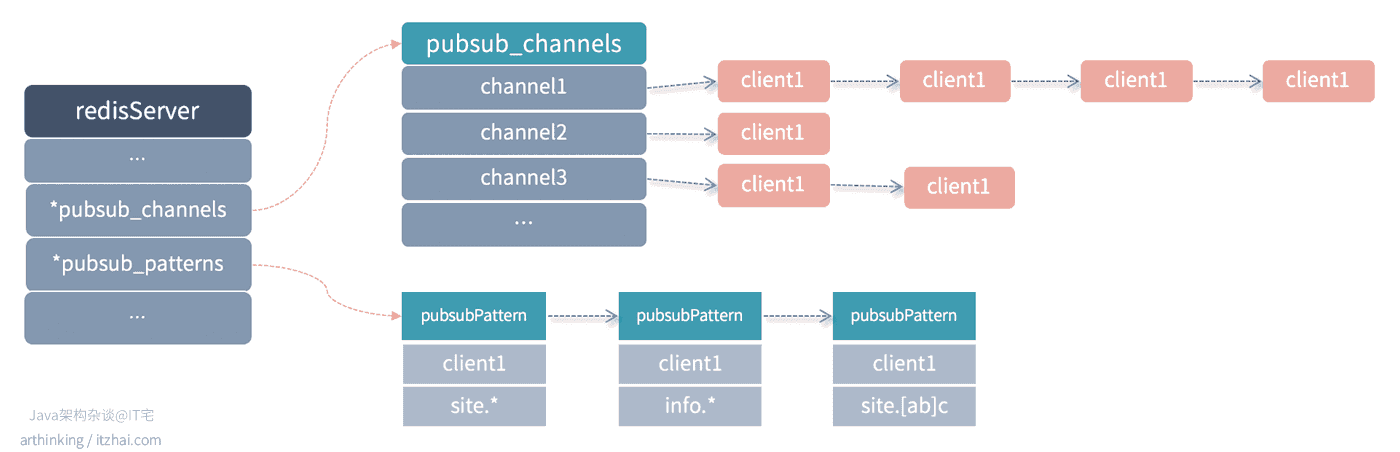
在dict字典中,每个键值对存储一个频道的订阅关系,key为频道名称,value为链表结构,存储该频道所有订阅的客户端。
每当执行SUBSCRIBE命令的时候,执行把客户端追加到字典中对应频道的key的values链表中即可。
每当执行PUBLISH命令的时候,从字典中找到对应的频道键值对,依次遍历values中所有的客户端进行发送消息即可。
在list链表中,保存了所有的模式频道订阅关系。
每当执行PUBLISH命令的时候,除了在pubsub_channels寻找频道订阅关系,发给具体的频道的所有客户端之外,同时,Redis会遍历pubsub_patterns中的所有订阅模式频道,找到与当前发布消息频道匹配的模式频道,将消息发送给该模式频道的客户端。
6.1、发布订阅的优缺点
通过使用Redis的发布订阅机制,很容易实现消息的订阅与通知,可以快速实现一个消息队列。
但是,该消息队列的缺点也比较明显,请大家慎用:
- 发布的消息不支持持久化,如果Redis挂了,那么发布的消息也就丢失了;或者消息发送给了一半的订阅者,Redis就挂了,那么剩下的一般订阅者也就不会收到消息了;或者准备发送消息给其中一个订阅者的时候,该订阅者失去连接了,消息也会丢失;
- 消息发送缺少ACK机制,不能保证消息一定会被消费...
针对可靠性要求低的业务,为了简单快速实现,可以使用Redis的发布订阅机制来实现消息通知。而对于可靠性要求比较高的,则可以尝试Redis 5.0的新数据结构Stream,具体用法和原理,参考Part I部分相关内容。
7、实现数据库通知
基于Redis的发布订阅机制,我们就可以实现数据库通知功能了。该功能常常用于作为对数据或者命令的监控。
因为开启数据库通知需要消耗一定的CPU,所以默认配置下,是关闭状态的。为了开启这个功能更,我们可以修改redis.conf文件:
1
| notify-keyspace-events KElg
|
如上,我们开启了:
- K:键空间通知,所有通知以
__keyspace@<db>__为前缀; - E:键事件通知,所有通知以
__keyevent@<db>__为前缀; - l:列表命令通知;
- g:
DEL、EXPIRE、RENAME等类型无关的通用命令的通知。
更多关于notify-keyspace-events的配置,请参考官方文档:Redis Keyspace Notifications[13]
现在我们启动Redis服务器,就支持数据库通知了。
现在我们在一个客户端1订阅一个键空间通知,监听我的钱包my_money:
1 2 3 4 5 | 127.0.0.1:6379> SUBSCRIBE __keyspace@0__:my_money Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "__keyspace@0__:my_money" 3) (integer) 1 |
在另一个客户端2,给我的钱包打100块钱看看:
1 2 | 127.0.0.1:6379> SET my_money 100 OK |
结果我们在客户端1可以收到以下到账通知:
1 2 3 | 1) "message" 2) "__keyspace@0__:my_money" 3) "set" |
另外,我们也可以监听某一个命令:
1
| 127.0.0.1:6379> SUBSCRIBE __keyevent@0__:del
|
8、Redis客户服务程序设计
Redis在传输层,使用的是TCP协议,每当有客户端连接到服务器的时候,都会创建一个Socket连接,对应一个套接字文件描述符fd。
而在Redis服务器中,是如何维护这些网络连接的呢,接下来我们就来看看。
8.1、客户端信息
当客户端与Redis服务器连接之后,redisServer结构中会存储一个客户端的链表,该链表节点用来记录与客户端通信的各种信息:
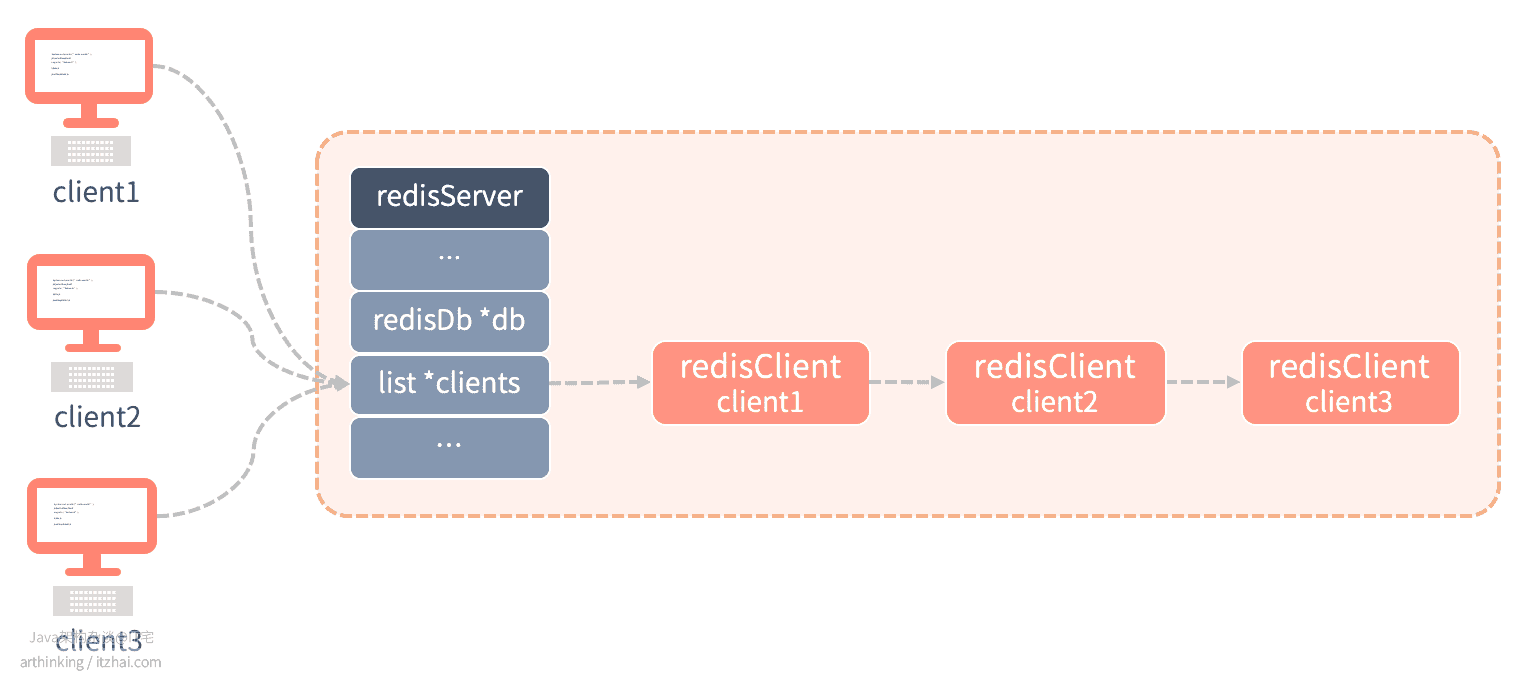
我们重点来关注redisClient以下信息:
int fd:文件描述符,-1代表伪客户端;robj * name:客户端名字;int flags:客户端标志,flags可以是单个标志,或者多个标志的二进制或,常见的标志:- REDIS_LUA_CLIENT:表示客户端是用于处理Lua脚本的伪户端;
- REDIS_MONITOR:客户端正在执行MONITOR命令;
- REDIS_UNIX_SOCKET:服务器使用UNIX套接字来连接客户端;
- REDIS_BLOCKED:客户端正在被BRPOP、BLPOP等命令阻塞;
- REDIS_UNBOKCKED:表示客户端已从阻塞状态中脱离出来,该标志只能在REDIS_BLOCKED标志已经打开的情况下使用;
- REDIS_MULTI:客户端正在执行事务
- REDIS_FORCE_AOF:强制将执行的命令写入到AOF文件里面,一般情况,Redis只会对数据库进行了修改的命令写入到AOF文件中,而对于PUBSUB和SCRIPT LOAD命令,则需要通过该标志,强制将这个命令写入到AOF文件中,另外,为了让主从服务器可以正确载入SCRIPT LOAD命令指定的脚本,需要使用REDIS_FORCE_REPL标志,强制将SCRIPT LOAD命令复制给所有从服务器;
sds querybuf:客户端输入缓冲区,命令请求字符串,最大大小不能超过1G,否则客户端将被服务器关闭;robj **argv:要执行的命令,以及所有参赛构成的数组;int argc:argv数组的长度;struct redisCommand *cmd:客户端请求对应的命令,从字典结构的命令表中查找得到;char buf[REDIS_REPLY_CHUNK_BYTES]:固定大小缓冲区,REDIS_REPLY_CHUNK_BYTES值默认为16KB;int bufpos:固定大小缓冲区易用字节数量;list *reply:可变大小缓冲区由链表组成,每个节点为一个字符串对象;int authenticated:客户端身份验证状态,1表示验证通过,如果Redis启用了身份验证功能,则需要用到该字段;time_t ctime:客户端连接创建时间;time_t lastinteraction:客户端与服务器最后一次通信时间;time_t obuf_soft_limit_reached_time:输出缓冲区第一次达到软性限制的时间;
8.2、命令执行流程
一个命令执行的完整流程如下图所示:
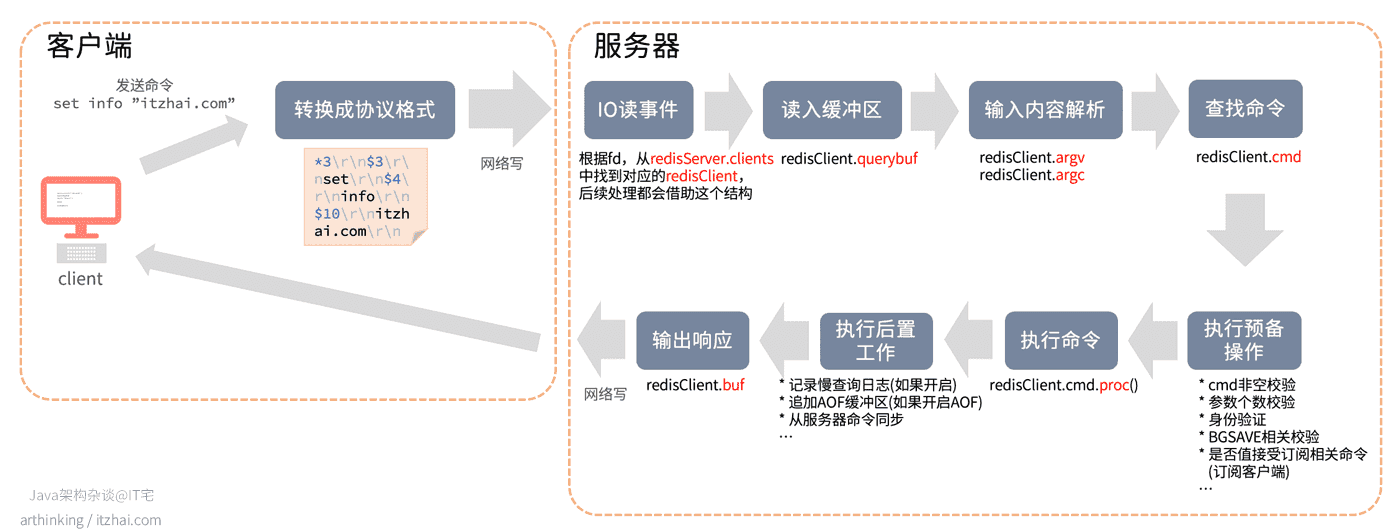
可以发现,Redis执行命令的整个过程,相关的中间信息都存储在redisClient中。
而整个执行过程中,线程模型是怎样的,我们在后面小节会详细介绍。
Part Ⅲ. 网络处理与线程模型
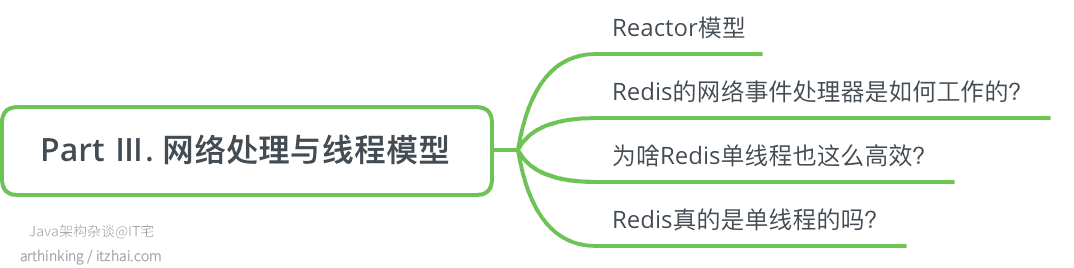
9、Redis网络处理与线程模型
相信大家已经听过无数遍“Redis是单线程的”这句话了,Redis真的是单线程的吗,又是如何支撑那么大的并发量,并且运用到了这么多的互联网应用中的呢?
其实,Redis的单线程指的是Redis内部会有一个主处理线程,充分利用了非阻塞、IO多路复用模型,实现的一个Reactor架构。但是在某些情况下,Redis会生成线程或者子进程来执行某些比较繁重的任务。
Redis包含了一个称为AE事件模型的强大的异步事件库来包装不同操作系统的IO复用技术,如epoll、kqueue、select等。
关于Redis的网络处理与线程模型,我在Java架构杂谈公众号以及IT宅(itzhai.com)中的这篇文章有详细的介绍了:性能追击:万字长文30+图揭秘8大主流服务器程序线程模型,感兴趣的朋友可以进一步阅读。
Part Ⅳ. 性能
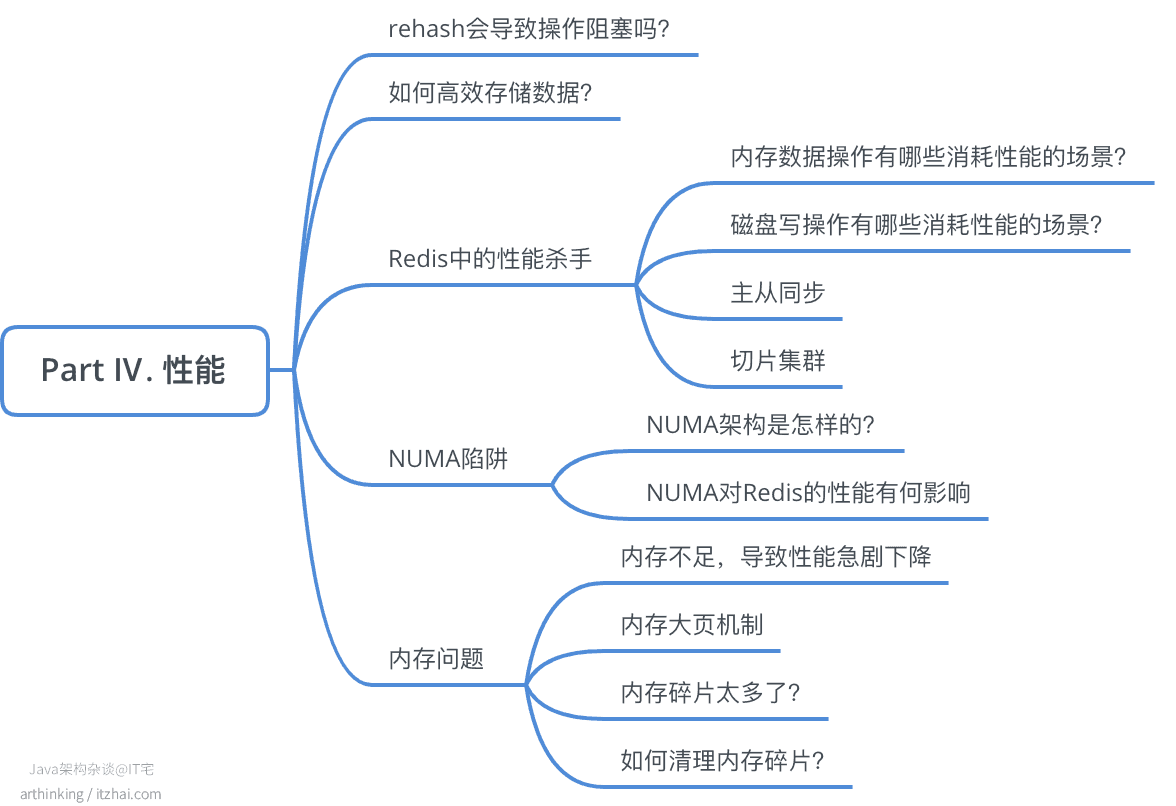
10、rehash会导致操作阻塞吗?
如下图,Redis的字典结构中包含了两个哈希表:
默认是往ht[0]写数据的,随着数据主键增多,Redis就会触发执行rehash操作了,主要步骤如下:
- 给ht[1]分配更大的空间;
- 将ht[0]的数据拷贝到ht[1];
- 释放ht[0]的空间。
如果直接拷贝数据,肯定是会花很长时间的,进一步会导致阻塞Redis。
为了避免这个问题,Redis中使用的是渐进式的rehash,进一步了解,可以阅读Part I中Hash字典小节内容。
11、如何高效存储数据
为了节省存储空间,针对不同的数据类型,优先采用更加紧凑型的编码格式。通过特定条件,可以让Redis选择紧凑型的编码:
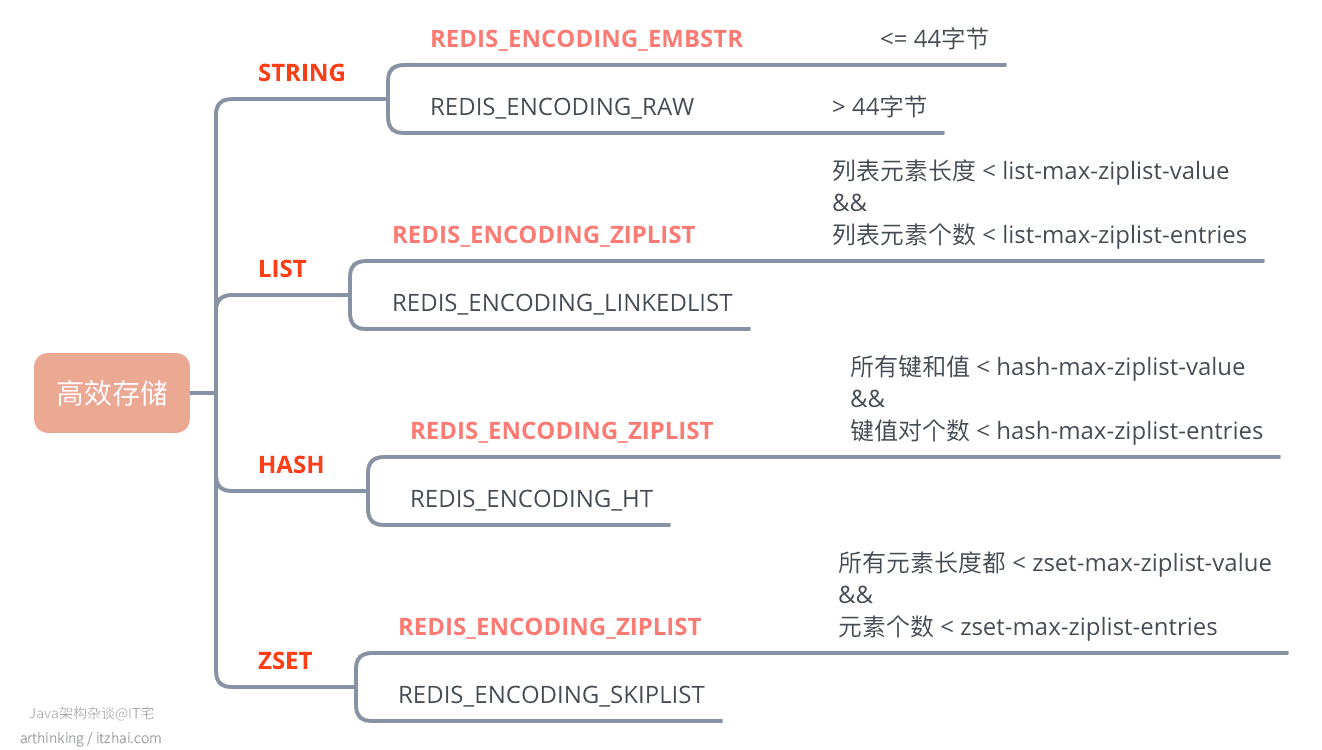
比如我们有一个很大集合的数据需要存储,如果数据有一定规律,并且键值大小都小于 hash-max-ziplist-value,并且可以划分成若干份,每份都可以保持在 hash-max-ziplist-entries以内,那么我们就可以分开来存储成多个Hash,这样就可以保证每个Hash都是用上ZIPLIST编码,极大的节省了空间。
但这是用时间换空间的做法:使用了压缩列表,也就意味着查询需要遍历ziplist,降低了查询的性能。在时间和空间之间,我们需要根据具体场景做出合理的抉择。
12、Redis中的性能杀手
Part III 部分,我们已经了解到,接收客户端网络执行命令的网络请求,网络开销对Redis的开销影响很小,那么在Redis中,究竟有哪些影响性能的点呢?这节,我们详细来探讨下。
不像线上性能分析,可以根据各种参数指标去挖掘定位性能点,为了摸底Redis的性能,那么就得从Redis的方法面面入手,我们将从以下各个维度去解析性能影响点。
12.1、内存数据操作
读操作
每当客户端请求数据的时候,都需要等待命令执行完,获取到执行的结果,所以执行命令的复杂度决定了性能的好坏,我们在实际操作中,要尽量使用复杂度低的命令,少用复杂度低的命令,控制一次读取的数据量。
以下是复杂度比较高的命令:
集合统计排序:
SINTER交集,复杂度O(N*M),其中 N 是最小集合的基数,M 是集合的数量;SUNION并集,复杂度O(N),其中 N 是所有给定集合中元素的总数;SDIFF差集,复杂度O(N) ,其中 N 是所有给定集合中元素的总数;SORT排序,复杂度O(N+M*log(M)),其中 N 是列表或集合中要排序的元素数,M 是返回元素的数量。
大数据量查询:
- HGETALL 返回存储在字典中所有的键值对,时间复杂度O(N),其中 N 是字典的大小;
- SMEMBERS 返回集合中的所有成员key,时间复杂度O(N),其中N是设置的基数。
如果实在要执行此类操作,而数据量又比较大,建议将此类操作放到单独的从库中执行。
删除操作
如果我们删除了bigkey,那么就可能导致阻塞主线程。为什么呢?
因为删除操作除了会释放内存空间,还会把空闲空间插入操作系统的空闲内存块链表中,删除的key越大,那么就越耗时。
为了避免删除bigkey对主线程的阻塞,Redis 4.0开始新增了UNLINK命令实现惰性删除。删除bigkey,建议都使用UNLINK命令。
UNLINK命令是先释放掉字典和过期字典中的键值对引用,然后在符合以下任一条件的情况,决定是否需要放到lazyfree队列中进行异步删除:
- Hash、Set底层采用哈希,并且元素个数超过64;
- ZSET底层采用跳跃表,并且元素个数超过64;
- List节点数量超过64。
否则,还是会直接删除。
可见惰性删除也不一定会起效,所以为了杜绝此类性能问题,最好避免在Redis中存储bigkey。
另外,如果我们执行FLUSHALL或者FLUSHDB,也会阻塞线程。为了避免此种情况,可以通过向FLUSHALL/FLUSHDB添加async异步清理选项,redis在清理整个实例或db时会以异步运行。
12.2、磁盘写
AOF日志落盘
如果我们的AOF写回策略是Always同步写,那么每次写数据的过程中,都会因写磁盘而阻塞住了。
如果可以容忍一秒钟的数据丢失,那么,我们可以把AOF写回策略设置为Everysec,这样就会通过异步线程去落盘了,从而避免阻塞主线程。
如果我们使用了Always策略,那么就需要注意了,如果刚好Redis在执行AOF重新,会导致大量的磁盘IO,最终导致操作系统fsync被阻塞,最终导致主线程也被fsync调用阻塞住了。
为了进一步减小重写AOF被阻塞的风险,可以设置为AOF重写是,不进行fsync:
1
| no-appendfsync-on-rewrite yes
|
12.3、主从同步
当我们要进行主从同步的时候,首先,主库会生成一份完整的RDB,传给从库,从库首先执行FLUSHDB清空原来数据库,然后从库在载入RDB文件,这个过程会导致从库被阻塞。
12.4、切片集群
在切片集群场景,如果刚好有big key需要迁移到其他节点,那么就会导致主线程阻塞,因为Redis Cluster是用的同步迁移。迁移过程中会同时阻塞源节点和目标节点。
而如果使用Codis进行集群,则可以利用其异步迁移的特性减少big key迁移对集群性能的影响。
13、NUMA陷阱
Redis的性能跟CPU也有关?没错。接下来看看NUMA陷阱对Redis性能的影响。
13.1、NUMA
NUMA(Non-Uniform Memory Access),非统一内存访问架构,为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。
在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
诞生背景
现代 CPU 的运行速度比它们使用的主内存快得多。在计算和数据处理的早期,CPU 通常比自己的内存运行得慢。
随着第一台超级计算机的出现,处理器和内存的性能线在 1960 年代出现了转折点。从那时起,CPU 越来越多地发现自己“数据匮乏”,不得不在等待数据从内存中到达时停止运行。1980 年代和 1990 年代的许多超级计算机设计专注于提供高速内存访问,而不是更快的处理器,使计算机能够以其他系统无法接近的速度处理大型数据集。
NUMA 尝试通过为每个处理器提供单独的内存来解决这个问题,避免在多个处理器尝试寻址同一内存。
NUMA架构解析
以下是NUMA架构图示:(图片来源:NUMA Deep Dive Part 2: System Architecture[14])
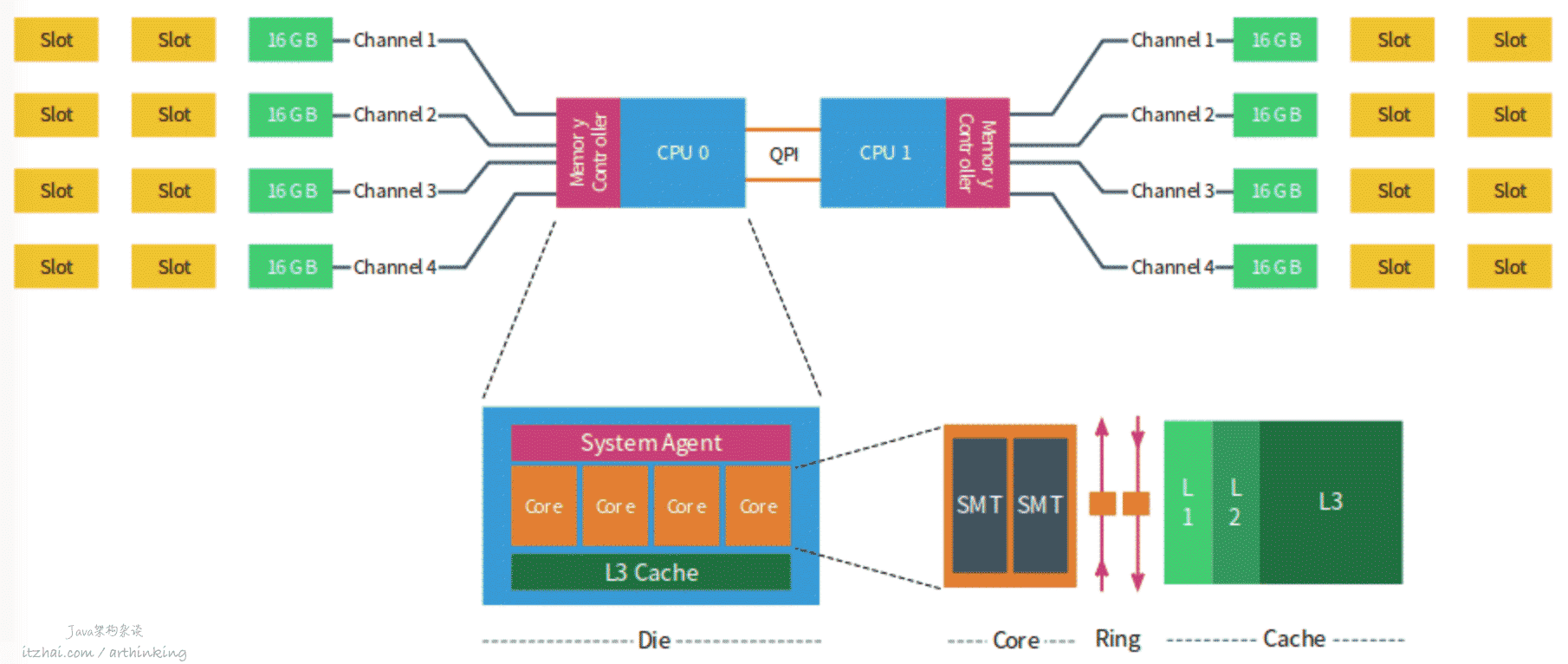
每个CPU有自己的物理核、L3缓存,以及连接的内存,每个物理核包括L1、L2缓存。不同处理器之间通过QPI总线连接。
每个CPU可以访问本地内存和系统中其他CPU控制的内存,由其他CPU管理的内存被视为远程内存,远程内存通过QPI访问。
在上图中,包含两个CPU,每个CPU包含4个核,每个CPU包含4个通道,每个通道最多3个DIMM,每个通道都填充了一个16 GB的内存,每个CPU用64GB内存,系统总共有128GB内存。
13.2、NUMA对Redis性能有何影响?
读取远程内存导致的问题
在NUMA架构上,程序可以在不同的CPU上运行,假设一个程序现在CPU 0上面运行,并把数据保存到了CPU 0的内存中,然后继续在CPU 1上面运行,这个时候需要通过QPI访问远程内存,导致增加数据读取的时间,从而导致性能变差。
另外,每次切换CPU,就需要从L3缓存重新加载相关的指令和数据到L1、L2缓存中,如果L3缓存也找不到,则会从内存中加载,导致增加CPU的处理时间。
如何解决?
linux 操作系统提供了一个名为 NUMACTL 的函数,NUMACTL 提供了控制的能力:
- NUMA 调度策略,例如,我想在哪些内核上运行这些任务
- 内存放置策略,在哪里分配数据
为了解决这个问题,我们可以把我们的程序绑定到某一个CPU上面来调度执行,相关命令:
1 2 3 4 5 | # 查看CPU信息 numactl --hardware # 指定进程在某个CPU上运行 taskset -c 1 ./redis-server numactl --cpubind=0 --membind=0 ./redis-server |
当然,也可以通过Taskset,进行设置,更详细的相关操作说明,参考:NUMACTL, taskset and other tools for controlling NUMA accesses notes[15]
如果我们的网络中断处理程序也做了绑核操作,建议把Redis和网络中断成本绑定到同一个CPU上。
切记:Redis是需要用到多线程能力的(RDB、AOF文件生成、惰性删除...),我们不能把Redis只绑定到某一个内核中,否则就失去了多线程的能力。
14、内存问题
14.1、内存不足,性能急剧下降
在内存不足的情况下,操作系统会启用swap机制,这个时候,Redis主线程会导致大量磁盘IO,极大的增加Redis响应时间,导致Redis性能急剧下降。
为此,我们除了要给Redis服务设置最大内存之外,还需要监控Redis服务器的内存使用情况,避免与其他内存需求大的应用一起运行。
如何监控swap情况
1 2 3 | # 找到Redis的进程号,进入/proc目录,进行查看 cd /proc/进程号 cat smaps | egrep '^(Swap|Size)' |
如果发现很多几百MB或者上GB的swap,就说明实例的内存压力很大,需要排查是否内存不足导致Redis性能变慢。
14.2、内存大页机制
在发起BGSAVE命令之后,Redis会fork出一个子进程用于执行生成RDB文件。fork的时候采用的是写时复制(Copy-on-write)技术。不会立刻复制所有的内存,只是复制了页表,保证了fork执行足够快。
如果此时正好开启了内存大页机制,即使客户端请求的数据只有几k,也会拷贝2MB的大页,最终导致大量的内存拷贝,从而影响Redis的访问速度。
为了避免这种情况,可以关闭内存大页机制:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | [root@VM_0_14_centos ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled [root@VM_0_14_centos ~]# echo never > /sys/kernel/mm/transparent_hugepage/defrag [root@VM_0_14_centos ~]# cat /sys/kernel/mm/transparent_hugepage/defrag [always] madvise never [root@VM_0_14_centos ~]# cat /sys/kernel/mm/transparent_hugepage/enabled [always] madvise never # 验证是否生效 [root@VM_0_14_centos ~]# grep Huge /proc/meminfo AnonHugePages: 18432 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB [root@VM_0_14_centos ~]# cat /proc/sys/vm/nr_hugepages 0 |
14.3、碎片
Redis并没有实现自己的内存池,也没有基于标准的系统内存分配器进行扩展。因此,系统内存分配器的性能和碎片率会对Redis产生一定的性能影响。向jemalloc这类的分配策略,是以一系列固定大小来进行内存空间的划分的,如8bit、16bit、32bit...这无形之中会导致一些分配的内存用不上,导致内存碎片的出现。
而内存碎片的出现,会导致内存空间利用率不高,导致无法分配新的空间。
如,在Redis中,SDS的空间预分配策略就很容易造成内存碎片。另外,频繁的删改操作、键值对大小不一致,也是造成内存碎片的原因之一。
为了监控Redis是否存在内存碎片,可以执行以下命令:
1 2 3 4 | 127.0.0.1:6379> INFO memory ... mem_fragmentation_ratio:2.64 ... |
2.64,这个值大不大呢?
这个值的计算公式:
mem_fragmentation_ratio = used_memory_rss/ used_memory
used_memory_rss:操作系统分配给Redis实例的内存大小,表示Redis进程占用的物理内存大小;
used_memory:Redis使用其分配器分配的内存大小;
mem_fragmentation_ratio < 1 表示Redis内存分配超出了物理内存,操作系统正在进行内存交换;
mem_fragmentation_ratio > 1 合理的指标值;
mem_fragmentation_ratio > 1.5 表示Redis消耗了实际需要物理内存的150%以上,其中50%是内存碎片率。
如果这个值超过1.5(50%)了,说明碎片化还是比较严重的,需要进行优化了。
内存碎片清理方法
在Redis 4.0之前,解决内存碎片问题的唯一方法就是重启Redis了,从Redis 4.0开始,提供了主动内存碎片整理的方式。
通过以下配置,来让Redis触发自动内存清理:
1 2 3 4 5 6 7 8 9 10 | # 启用主动碎片整理 activedefrag yes # 启动活动碎片整理的最小碎片浪费量 active-defrag-ignore-bytes 100mb # 启动活动碎片整理的最小碎片百分比 active-defrag-threshold-lower 10 # 主动碎片整理所用CPU时间最小占比,保证能够正常展开清理 active-defrag-cycle-min 25 # 主动碎片整理所用CPU时间最大占比,超过这个值,就停止清理,避免因为清理导致阻塞Redis active-defrag-cycle-max 75 |
您可以在不用重启Redis的情况下,通过以下方式启用碎片整理:
1
| redis-cli config set activedefrag "yes"
|
Part Ⅴ. 分布式
所谓分布式系统,就是把多台机器通过特定约定组合连接起来,构成一个集群,让他们共同完成一件任务,可以是计算任务,也可以是存储任务。
而Redis则可以用于构建实现存储任务的分布式系统。一般在构建分布式系统的时候,为了保证系统的可靠性,除了通过RDB+AOF实现数据的持久化和恢复之外,还需要保证服务持续运行,都需要搭建主从集群。而为了实现存储更多的数据,需要做切片集群,让数据分散到分布式系统的各个节点中,均摊计算和存储压力。
首先我们从主从集群说起,看看Redis是如何通过主从集群构建高可靠的系统的。
几年前我写了一系列的技术文章,发布到了
IT宅(itzhai.com),但是由于服务器出了一些问题,而我的又没有做备份,导致我的那两年的文章都丢失了,可见备份有多么重要。同样的,我们也应该给Redis实例备份,避免出现故障导致服务无法访问。
15、主从集群
Redis搭建主从集群还是比较简单的,只需要通过
replicaof 主库IP 主库端口
命令就可以了。如下图,我们分别在101和102机器上执行命令:
1
| replicaof 192.168.0.1 6379
|
我们就构建了一个主从集群:
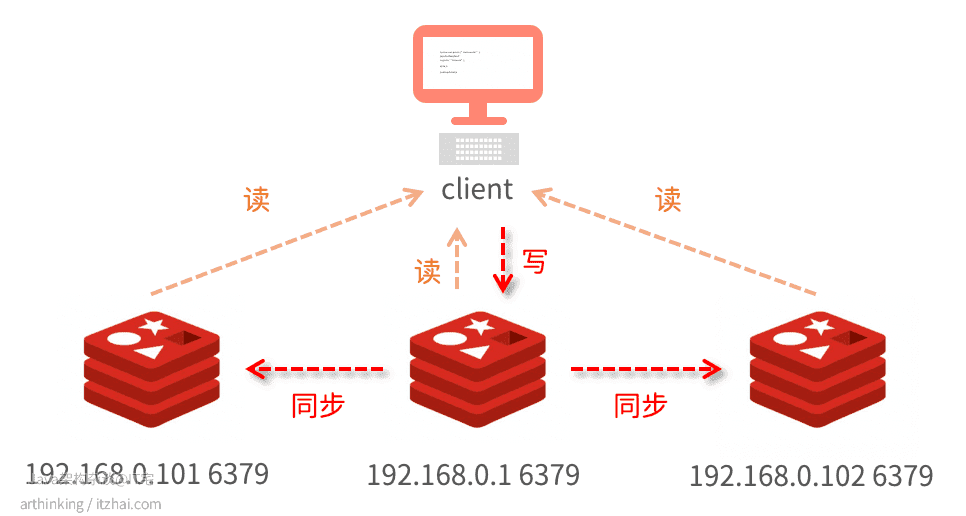
为了保证主从数据的一致性,主从节点采用读写分离的方式:主库负责写,同步给从库,主从均可负责读。
那么,我们搭建好了主从集群之后,他们是如何实现数据同步的呢?
15.1、主从集群数据如何同步?
当从库和主库第一次做数据同步的时候,会先进行全量数据复制,大致流程如下图所示:
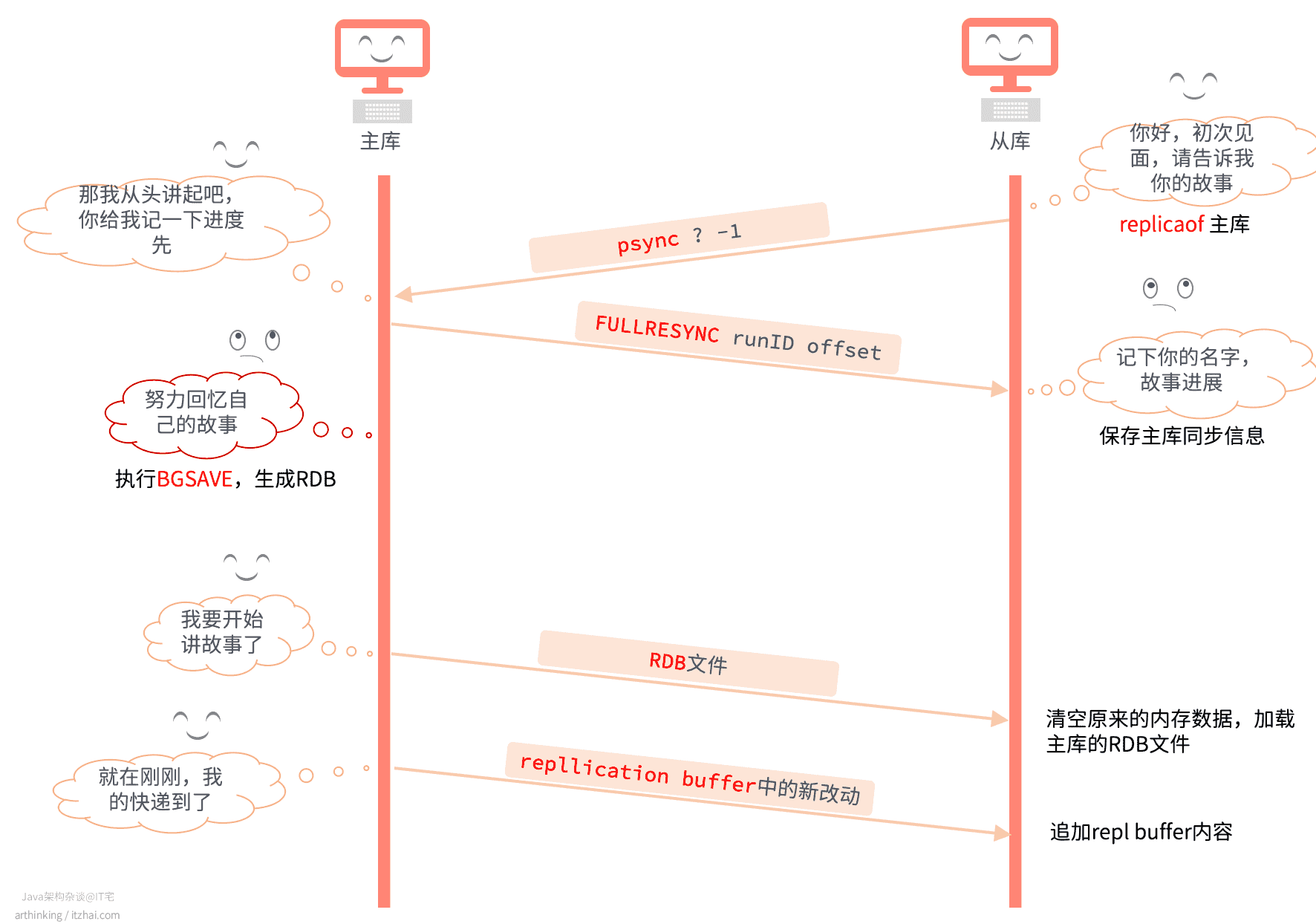
- 从库执行replicaof命令,与主库建立连接,发送psync命令,请求同步,刚开始从库不认识主库,也还不知道他的故事,所以说了一句:那谁,请开始讲你的故事(psync ? -1);
- 主库收到从库的打招呼,于是告诉了从库它的名字(runId),要给他讲整个人生的经历(FULLRESYNC,全量复制),以及讲故事的进度(offset);
- 主库努力回忆自己的故事(通过BGSAVE命令,生成RDB文件);
- 主库开始跟从库讲故事(发送RDB文件);
- 从库摒弃主观偏见,重新开始从主库的故事中认识了解主库;
- 主库讲故事过程中,又有新的故事发生了(收快递),于是继续讲给从库听(repl buffer)。
15.1.1、主从复制过程中,新产生的改动如何同步?
从上面的流程图中,我们也可以知道,主库会在复制过程中,把新的修改操作追加到replication buffer中,当发送完RDB文件后,再把replication buffer中的修改操作继续发送给从库:
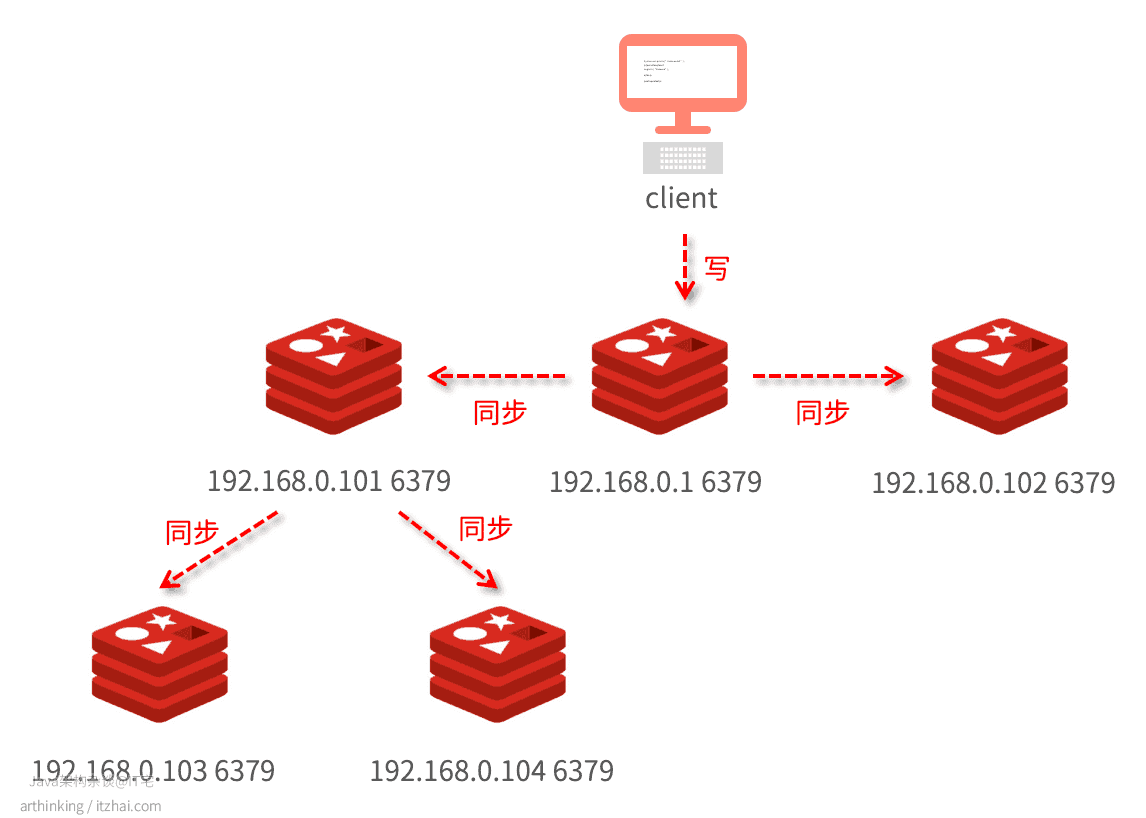
15.1.2、从库太多了,主库如何高效同步?
当我们要同步的从库越多,主库就会执行多次BGSAVE进行数据全量同步,为了减小主库的压力,可以做如下的集群配置,通过选择一个硬件配置比较高的从库作为其他从库的同步源,把压力分担给从库:
15.1.3、首次同步完成之后,如何继续同步增量数据?
主从同步完成之后,主库会继续使用当前创建的网络长连接,以命令传播的方式进行同步增量数据。
15.1.4、主从断开了,如何继续同步?
当主从断开重连之后,从库会采用增量复制的方式进行同步。
为了实现增量复制,需要借助于repl_backlog_buffer缓冲区。
如下图:
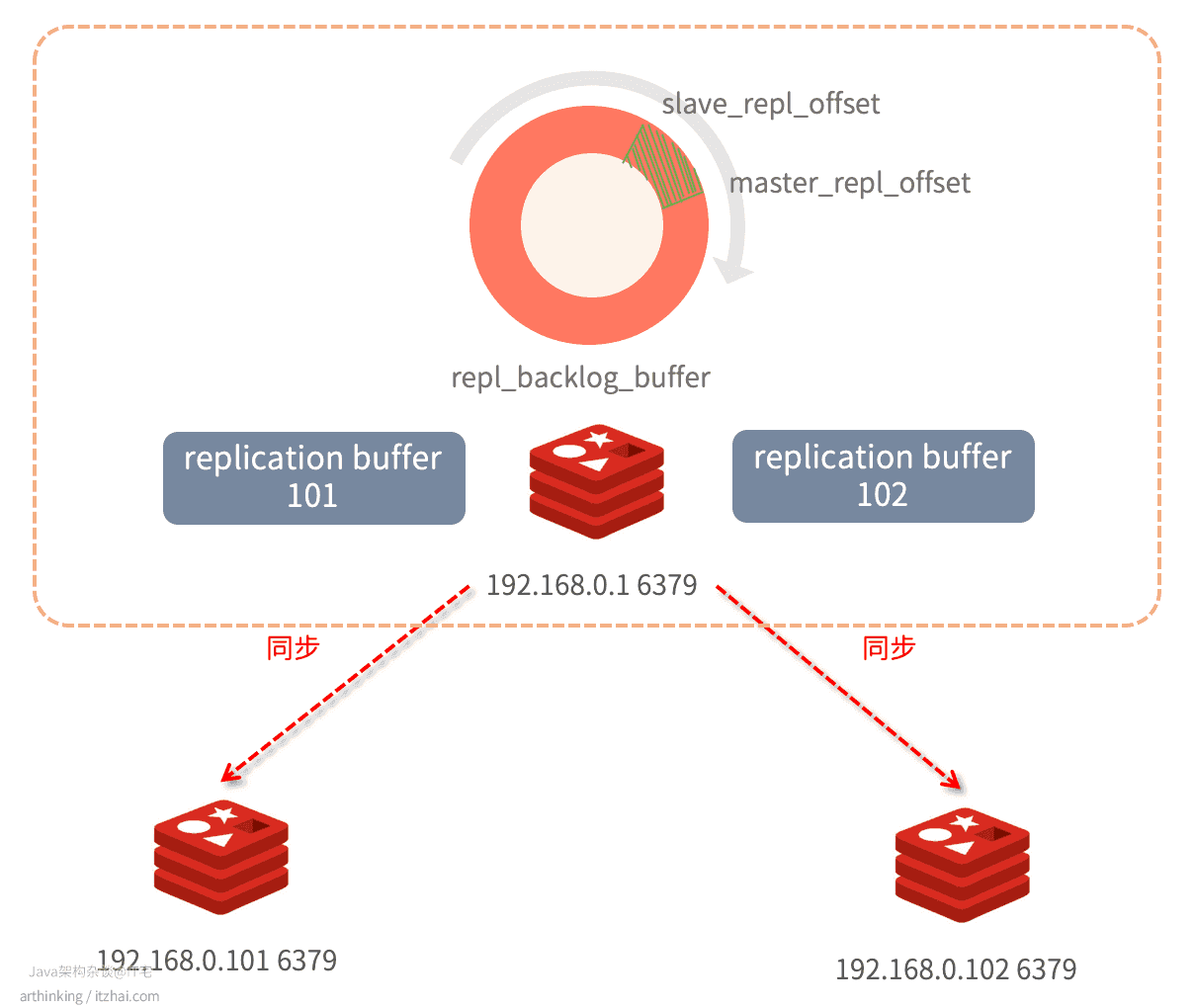
Redis主库会给每一个从库分别创建一个replication buffer,这个buffer正是用于辅助传播操作命令到各个从库的。
同时,Redis还持有一个环形缓冲 repl_backlog_buffer,主库会把操作命令同时存储到这个环形缓冲区中,每当有从库断开连接的时候,就会向主库重新发送命令:
psync runID offset
主库获取都这个命令,到repl_backlog_buffer中获取已经落后的数据,重新发送给从库。
注意:由于repl_backlog_buffer是一个环形缓冲区,如果主库进度落后太多,导致要同步的offset都被重写覆盖掉了,那么只能重新进行全量同步了。
所以,为了保证repl_backlog_buffer有足够的空间,要设置好该缓冲区的大小。
计算公式:repl_backlog_buffer = second * write_size_per_second
- second:从服务器断开连接并重新连接到主服务器所需的平均时间;
- write_size_per_second:主库每秒平均生成的命令数据量(写命令和数据大小的总和)。
为了应对突然压力,一般要对这个计算值乘于一个适当的倍数。
更多关于集群数据复制的说明和配置,参考:https://redis.io/topics/replication[16]
15.2、主库挂了,怎么办?
一个Redis主从集群中,如果主库挂了?怎么办?首先,我们怎么知道主库挂了?不可能让运维人员隔一段时间去检查检查机器状况吧?
所以,我们的第一个问题是:怎么知道主库挂了?
15.2.1、怎么知道主库下线了?
既然不能让运维同事盯着电脑去监控主库状态,那么我们是不是可以安排一个机器人来做这件事情呢?
很庆幸,Redis中提供了一个这样的角色:哨兵(Sentinel),专门来帮忙监控主库状态。除此之外,监控到主库下线了,它还会帮忙重新选主,以及切换主库。
Redis的哨兵是一个运行在特殊模式下的Redis进程。
Redis安装目录中有一个sentinel.conf文件,里面可以进行哨兵的配置:
| > sentinel monitor itzhaimaster 192.168.0.1 6379 2 # 指定监控的master节点> sentinel down-after-milliseconds itzhaimaster 30000 # 主观下线时间,在此时间内实例不回复哨兵的PING,或者回复错误> sentinel parallel-syncs itzhaimaster 1 # 指定在发生failover主备切换时最大的同步Master从库数量,值越小,完成failover所需的时间就越长;值越大,越多的slave因为replication不可用> sentinel failover-timeout mymaster 180000 # 指定内给宕掉的Master预留的恢复时间,如果超过了这个时间,还没恢复,那哨兵认为这是一次真正的宕机。在下一次选取时会排除掉该宕掉的Master作为可用的节点,然后等待一定的设定值的毫秒数后再来检测该节点是否恢复,如果恢复就把它作为一台从库加入哨兵监测节点群,并在下一次切换时为他分配一个”选取号”。默认是3分钟> protected-mode no # 指定当前哨兵是仅限被localhost本地网络的哨兵访问,默认为yes,表示只能被部署在本地的哨兵访问,如果要设置为no,请确保实例已经通过防火墙等措施保证不会受到外网的攻击> bind # > ...> |
然后执行命令启动哨兵进程即可:
./redis-sentinel ../sentinel.conf
**注意:**如果哨兵是部署在不同的服务器上,需要确保将protected-mode设置为no,否则哨兵将不能正常工作。
为啥要哨兵集群?
即使是安排运维同事去帮忙盯着屏幕,也可能眼花看错了,走神了,或者上厕所了,或者Redis主库刚好负载比较高,需要处理一下,或者运维同事的网络不好等导致错误的认为主库下线了。同样的,我们使用哨兵也会存在这个问题。
为了避免出现这种问题,我们多安排几个哨兵,来协商确认主库是否下线了。
以下是三个哨兵组成的集群,在监控着主从Redis集群:
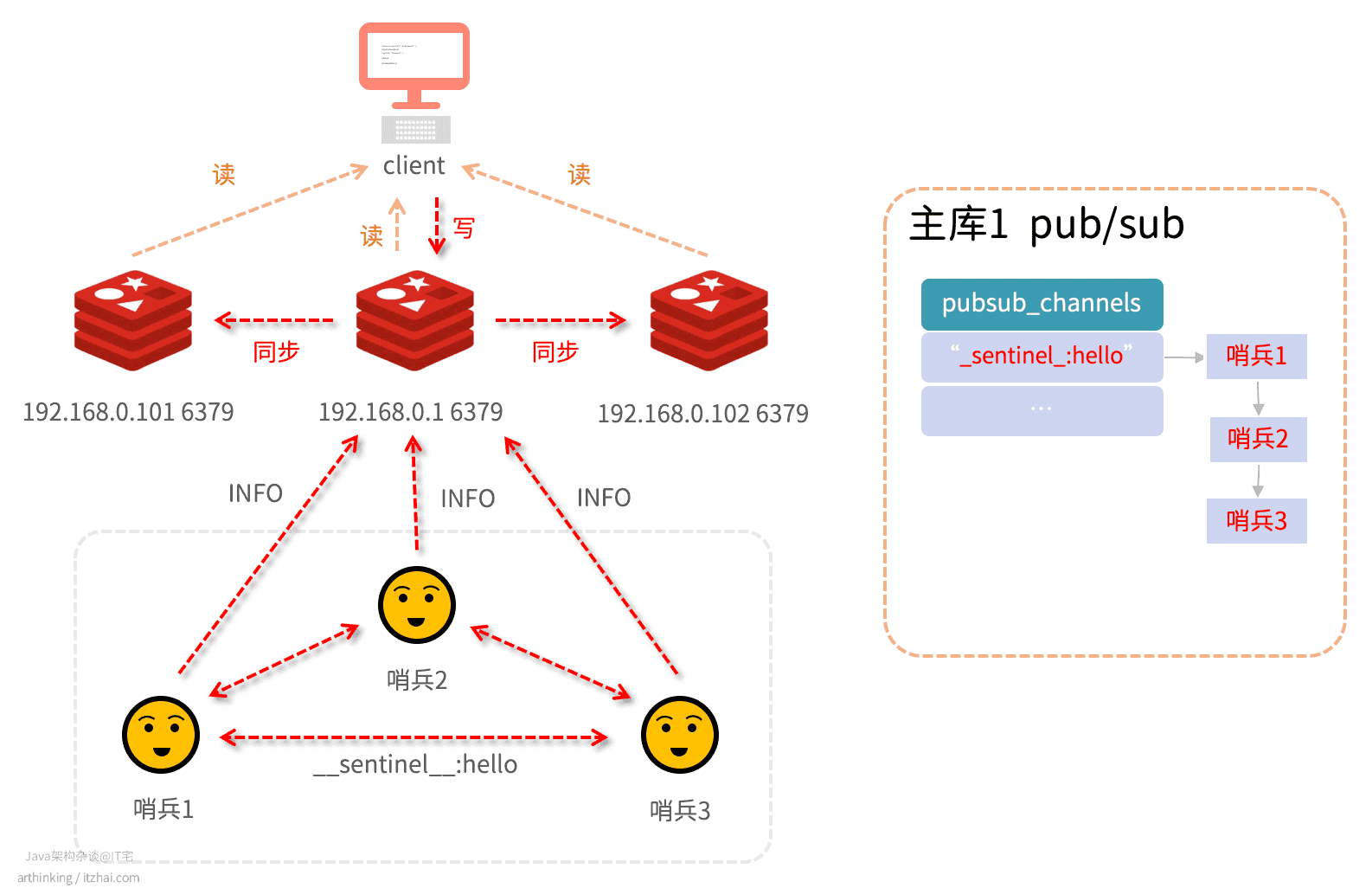
如上图,哨兵除了要监控Redis集群,还需要与哨兵之间交换信息。哨兵集群的监控主要有三个关键任务组成:
_sentinel_:hello:哨兵之间每2秒通过主库上面的_sentinel_:hello频道交换信息:- 发现其他哨兵,并建立连接;
- 交换对节点的看法,以及自身信息;
INFO:每个哨兵每10秒向主库发送INFO命令,获取从库列表,发现从节点,确认主从关系,并与从库建立连接;ping:每个哨兵每1秒对其他哨兵和Redis执行ping命令,判断对方在线状态。
这样,哨兵进去之间就可以开会讨论主库是不是真正的下线了。
如何确认主库是真的下线了?
当一个哨兵发现主库连不上的时候,并且超过了设置的down-after-milliseconds主观下线时间,就会把主库标记为主观下线,这个时候还不能真正的任务主库是下线了,还需要跟其他哨兵进行沟通确认,因为,也许是自己眼花了呢?
比如哨兵2把主库标记为客观下线了,这个时候还需要跟其他哨兵进行沟通确认,如下图所示:
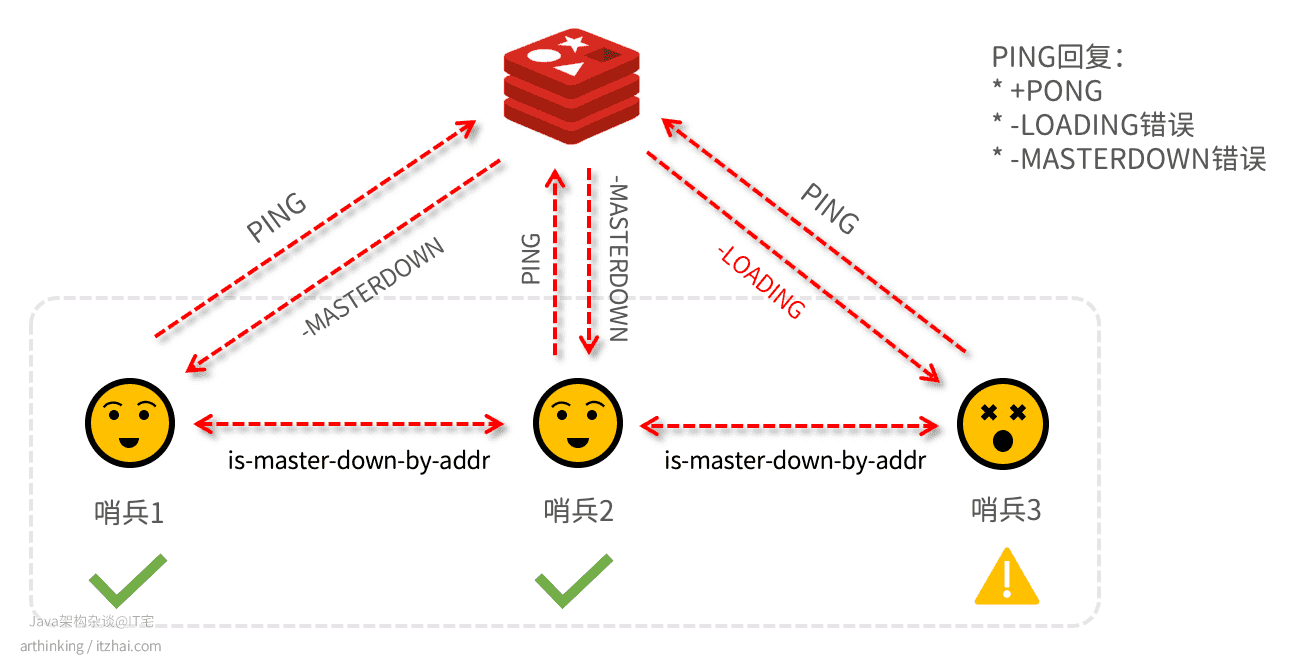
哨兵2判断到主库下线了,于是请求哨兵集群的其他哨兵,确认是否其他哨兵也认为主库下线了,结果收到了哨兵1的下线确认票,但是哨兵3却不清楚主库的状况。
只有哨兵2拿到的确认票数超过了quorum配置的数量之后,才可以任务是客观下线。这里哨兵2已经拿到两个确认票,quorum=2,此时,哨兵2可以把主库标识为客观下线状态了。
关于quorum:建议三个节点设置为2,超过3个节点设置为 节点数/2+1。
15.2.2、主库下线了,怎么办?
主库挂了,当然是要执行主从切换了,首先,我们就要选出一位哨兵来帮我们执行主从切换。
如何选举主从切换的哨兵?
一个哨兵要想被哨兵集群选举为Leader进行主从切换,必须符合两个条件:
- 拿到票数要大于等于哨兵配置文件的quorum值;
- 拿到整个集群半数以上的哨兵票数。
注意:与判断客观下线不太一样的,这里多了一个条件。
如果一轮投票下来,发现没有哨兵胜出,那么会等待一段时间之后再尝试进行投票,等待时间为:哨兵故障转移超时时间failover_timeout * 2,这样就能够争取有足够的时间让集群网络好转。
15.2.3、切换完主库之后,怎么办?
切换完成之后,哨兵会自动重写配置文件,让其监控新的主库。
15.2.4、客户端怎么知道主从正在切换?
哨兵之间可以通过主库上面的_sentinel_:hello进行交换信息。同样的,客户端也可以从哨兵上面的各个订阅频道获取各种主从切换的信息,来判断当前集群的状态。
以下是常见的订阅频道:
- 主库下线:
+sdown <instance details>:哨兵实例进入主观下线(Subjectively Down)状态;-sdown <instance details>:哨兵实例退出主观下线(Objectively Down)状态;+odown <instance details>:进入客观下线状态;-odown <instance details>:退出客观下线状态;
- 主从切换:
failover-end <instance details>:故障转移操作顺利完成。所有从服务器都开始复制新的主服务器了;+switch-master <master name> <oldip> <oldport> <newip> <newport>:配置变更,主服务器的 IP 和地址已经改变。 这是绝大多数外部用户都关心的信息。
有了这些信息之后,客户端就可以知道主从切换进度,并且获取到新的主库IP,并使用新的主库IP和端口进行通信,执行写操作了。
更多关于Redis哨兵机制的说明和配置方法,参考文档:Redis Sentinel Documentation[17]
通过主从集群,保证了Redis的高可靠,但是随着Redis存储的数据量越来越多,势必会导致占用内存越来越大,内存太大产生问题:
- 重启,从磁盘恢复数据的时间会变长;
- Redis在做持久化的时候,需要fork子进程,虽然是通过写时复制进行fork,拷贝的只是页表数据,也是会导致拷贝时间变长,导致阻塞主线程,最终影响到服务的可用性。
为此,我们需要保证单个节点的数据量不能太大,于是引入了切片集群。下面就来详解介绍切片集群的实现技术。
15.2.5、如何避免主库脑裂导致的数据丢失问题?
我们直接看一下这个场景。
假设quorum=2,由于网络问题,两个哨兵都主观判断到master下线了,最终master被判断为客观下线:
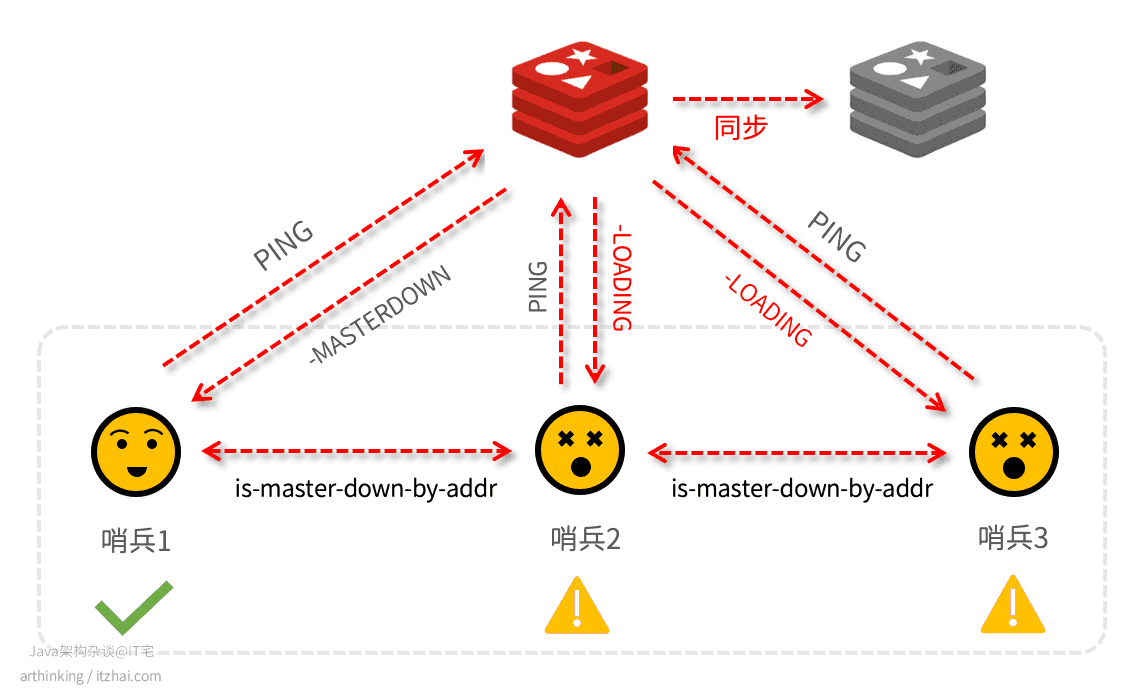
于是进行主从切换,但是在切换期间,原master又恢复正常了,可以正常接收客户端请求,现在就有两个master都可以同时接收客户端的请求了。这个时候,集群里面会有两个master。原本只有一个大脑的分布式系统,分裂成了两个,所以称为脑裂现象。
这个时候如果有写请求到达原来的主库,新的主库就没有这部分数据了。等到主从切换完成之后,哨兵会让原来的主库会执行slave of命令,进而触发和新主库的全量同步,最终导致主从切换期间源主库接收的数据丢失了。
如何避免脑裂问题?
为了避免以上问题,最关键的就是避免客户端同时对两个主库进行写。
Redis通过配置,可以支持这样的功能:如果响应主库的消息延迟小于或等于M秒的从库的数量至少有N个,那么主从才会继续接写入。如果响应主库的消息延迟小于或等于 M 秒的从库数量少于 N 个,则主库会停止接受写入。相关配置:
- min-slaves-to-write:N 至少要连接的从库数;
- min-slaves-max-lag:M 主库向从库ping的ACK最大延迟不能超过的秒数
当然,这样不能保证避免脑裂问题。
场景1
以下场景则可以避免脑裂问题,假设从节点为一个,主观下线时间和客观下线时间相差无几,如下图:
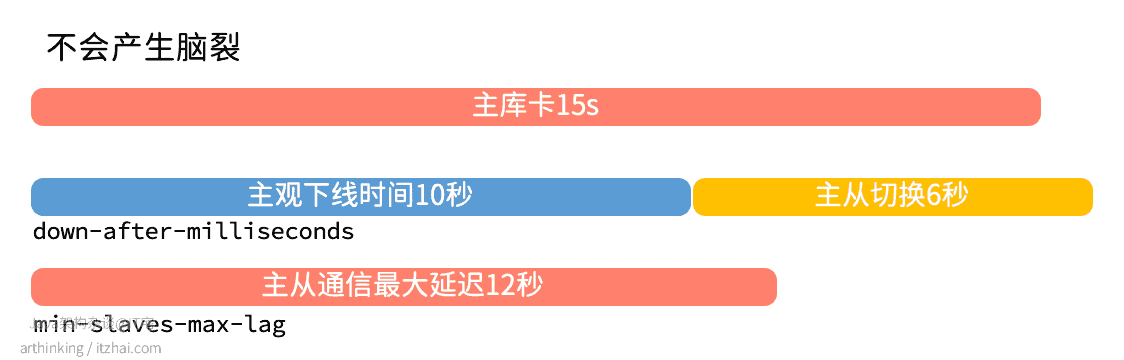
虽然主库恢复正常之后,还在进行主从切换,由于只有一个从库,并且延迟超过了min-slaves-max-lag,所以主库被限制停止接受消息了
场景2
以下场景则不可以避免脑裂问题,假设从节点为一个,主观下线时间和客观下线时间相差无几,如下图:
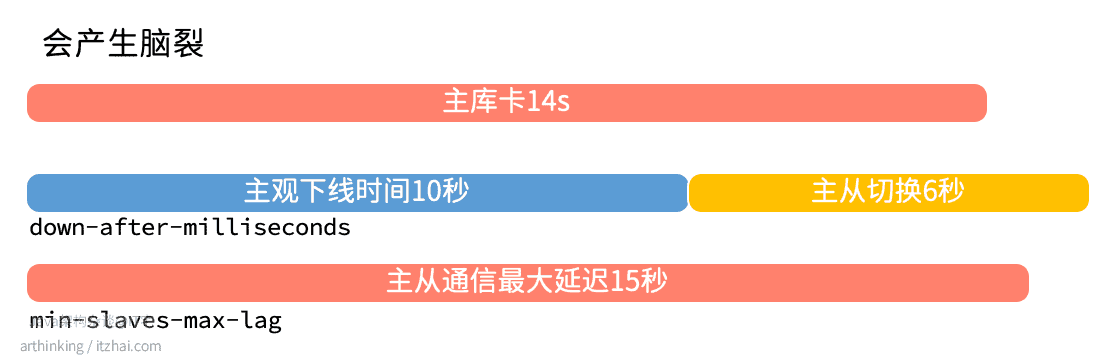
虽然主库恢复正常后,还在进行主从切换,由于只有一个从库,但是延迟还没有超过min-slaves-max-lag,所以原主库可以继续接收消息,最终导致主从切换完之后,数据丢失。
也就是说,min-slaves-to-write 和 min-slaves-max-lag也不一定能够避免脑裂问题,只是降低了脑裂的风险。
进一步探讨问题的本质?
作为一个分布式系统,节点之间的数据如果要保持强一致性,那么就需要通过某种分布式一致性协调算法来实现,而Redis中没有。
而类似Zookeeper则要求大多数节点都写成功之后,才能算成功,避免脑裂导致的集群数据不一致。
注意:如果只有一个从库,设置min-slaves-to-write=1有一定的风险,如果从库因为某些原因需要暂停服务,那么主库也就没法提供服务了。如果是手工运维导致需要暂停从库,那么可以先开启另一台从库。
16、切片集群
集群的扩容可以通过垂直扩容(增加集群硬件配置),或者通过水平扩容(分散数据到各个节点)来实现。切片集群属于水平扩容。
16.1、Redis Cluster方案
从Redis 3.0开始引入了Redis Cluster方案来搭建切片集群。
16.1.2、Redis Cluster原理
Redis Cluster集群的实现原理如下图所示:
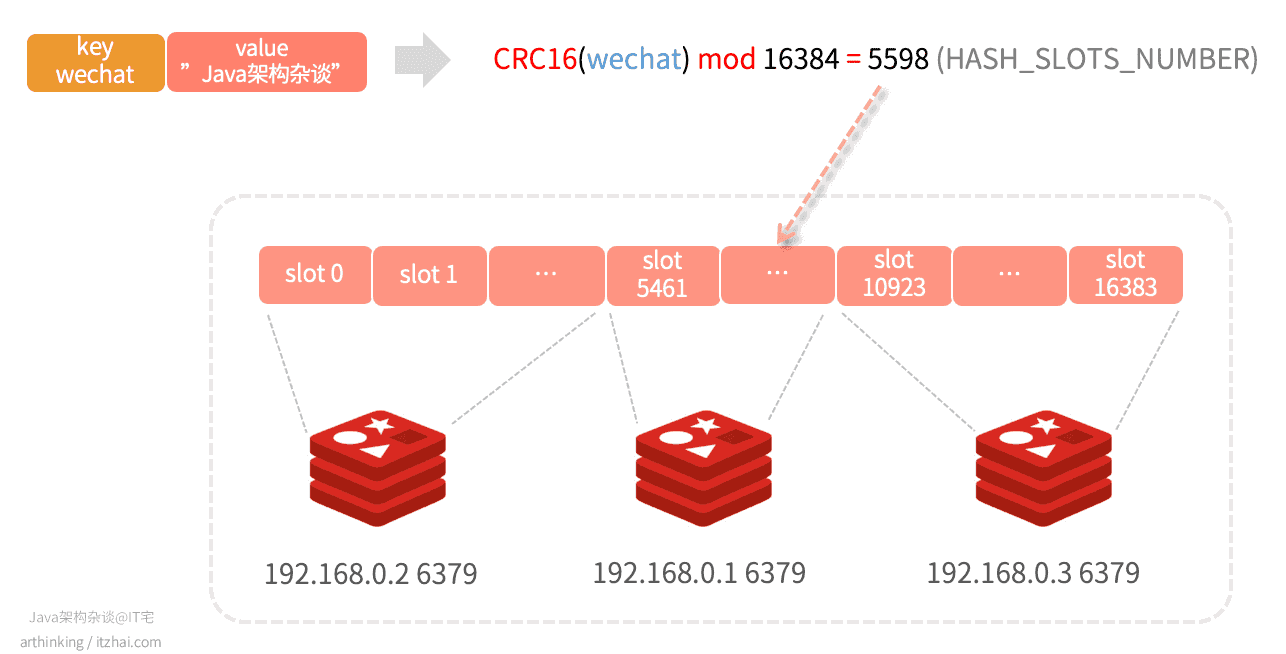
Redis Cluster不使用一致哈希,而是使用一种不同形式的分片,其中每个key从概念上讲都是我们称为哈希槽的一部分。
Redis集群中有16384个哈希槽,要计算给定key的哈希槽,我们只需对key的CRC16取模16384就可以了。
如上图,key为wechat,value为”Java架构杂谈“的键值对,经过计算后,最终得到5598,那么就会把数据落在编号为5598的这个slot,对应为 192.168.0.1 这个节点。
16.1.3、可以按预期工作的最小集群配置
以下是redis.conf最小的Redis群集配置:
1 2 3 4 5 | port 7000 # Redis实例端口 cluster-enabled yes # 启用集群模式 cluster-config-file nodes.conf # 该节点配置存储位置的文件路径,它不是用户可编辑的配置文件,而是Redis Cluster节点每次发生更改时都会自动持久保存集群配置的文件 cluster-node-timeout 5000 # Redis群集节点不可用的最长时间,如果主节点无法访问的时间超过指定的时间长度,则其主节点将对其进行故障转移 appendonly yes # 开启AOF |
除此之外,最少需要配置3个Redis主节点,最少3个Redis从节点,每个主节点一个从节点,以实现最小的故障转移机制。
Redis的
utils/create-cluster文件是一个Bash脚本,可以运行直接帮我们在本地启动具有3个主节点和3个从节点的6节点群集。
注意:如果cluster-node-timeout设置的过小,每次主从切换的时候花的时间又比较长,那么就会导致主从切换不过来,最终导致集群挂掉。为此,cluster-node-timeout不能设置的过小。
如下图,是一个最小切片集群:
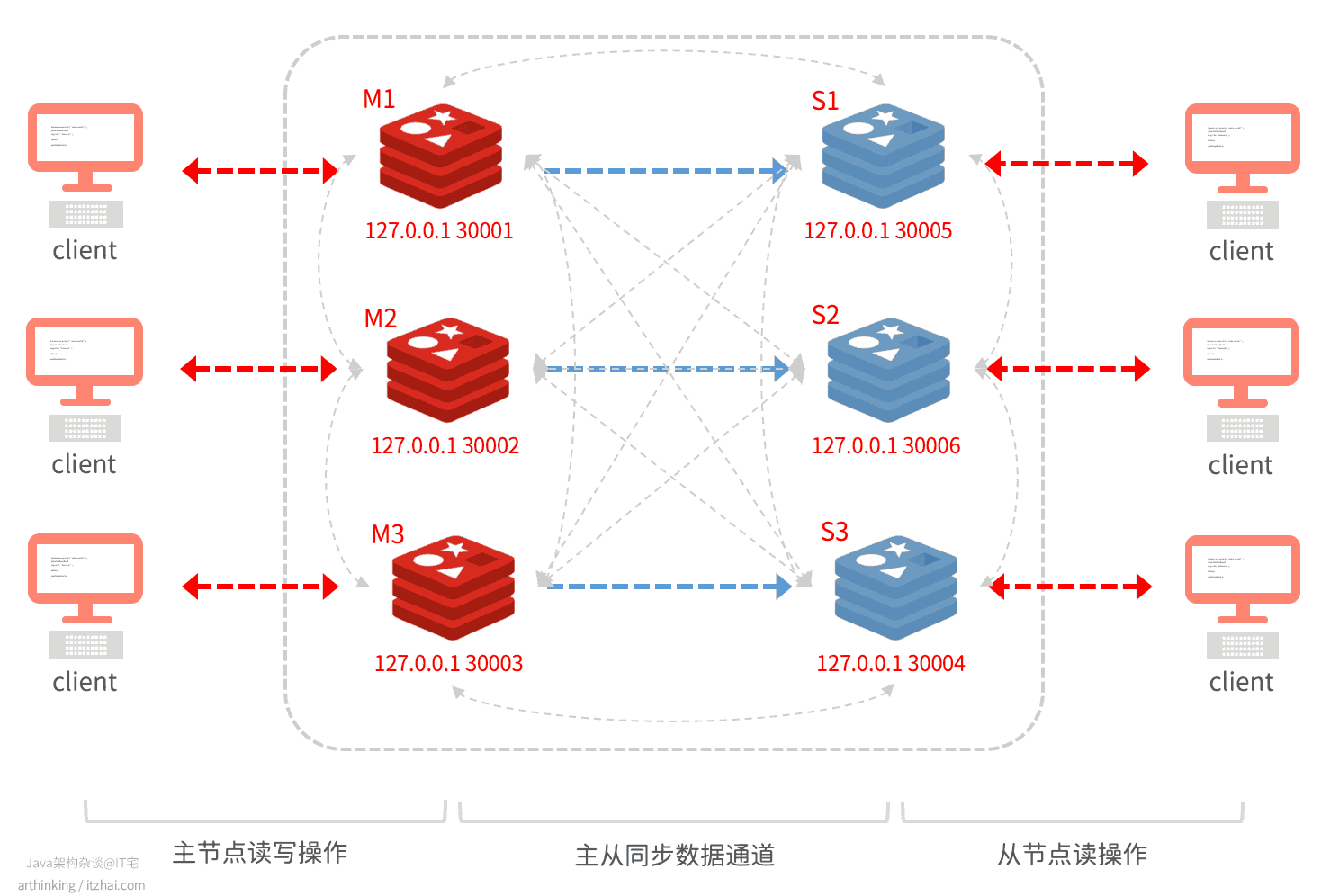
有三个主节点,三个从节点。
其中灰色虚线为节点间的通信,采用gossip协议。
可以通过create-cluster脚本在本地创建一个这样的集群:
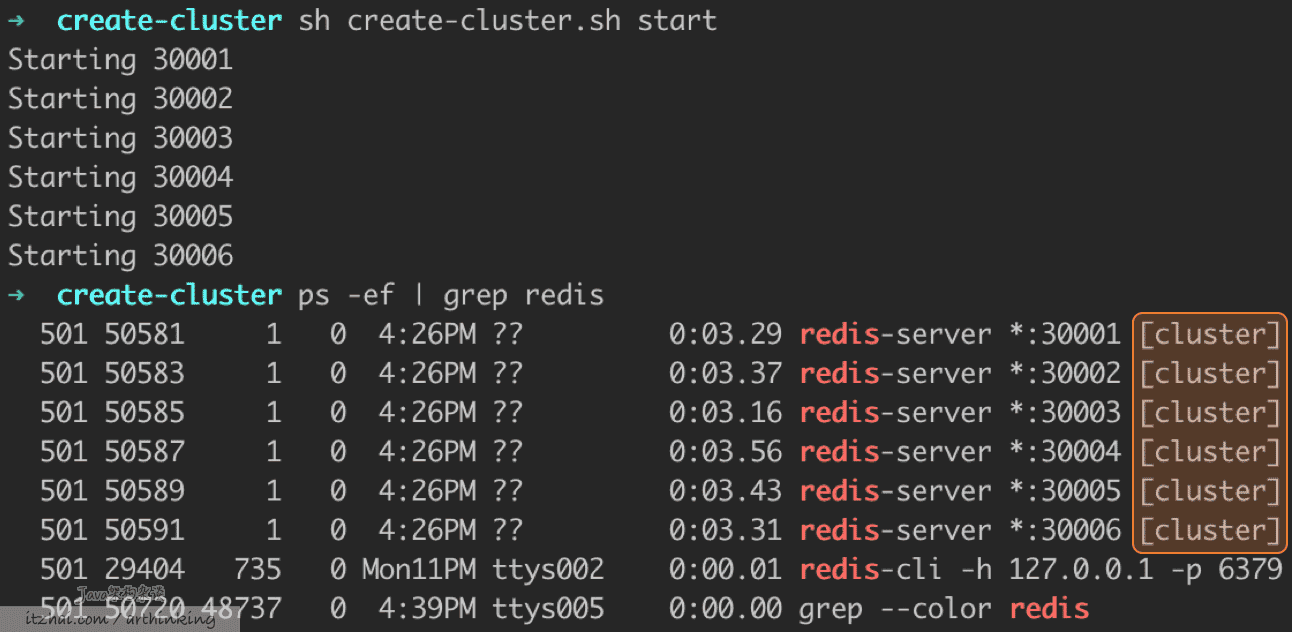
如上图,已经创建了6个以集群模式运行的节点。

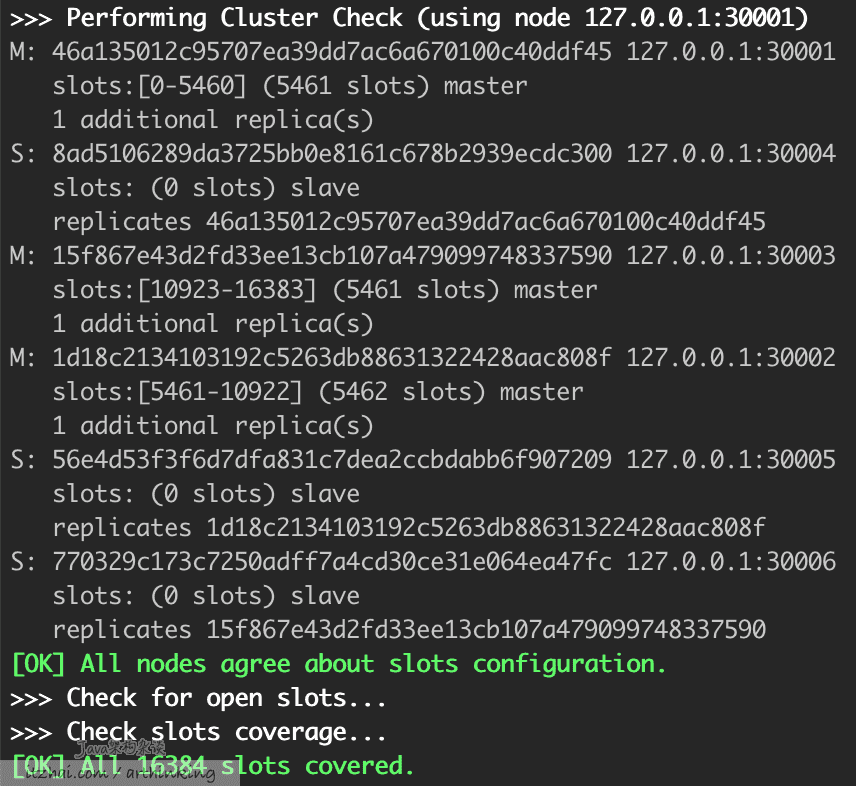
继续输入yes,就会按照配置信息进行集群的构建分配:
一切准备就绪,现在客户端就可以连上集群进行数据读写了:
1 2 3 4 5 6 7 8 9 10 11 12 | ➜ create-cluster redis-cli -p 30001 -c --raw # 连接到Redis集群 127.0.0.1:30001> set wechat "Java架构杂谈" # 添加键值对 OK 127.0.0.1:30001> set qq "Java架构杂谈" # 添加键值对 -> Redirected to slot [5598] located at 127.0.0.1:30002 # slot不在当前节点,重定向到目标节点 OK 127.0.0.1:30002> get wechat -> Redirected to slot [410] located at 127.0.0.1:30001 Java架构杂谈 127.0.0.1:30001> get qq -> Redirected to slot [5598] located at 127.0.0.1:30002 Java架构杂谈 |
注意:-c,开启reidis cluster模式,连接redis cluster节点时候使用。
为了能让客户端能够在检索数据时通过Redis服务器返回的提示,跳转到正确的的节点,需要在redis-cli命令中添加-c参数。
16.1.4、客户端获取集群数据?
上一节的实例,可以知道,我们在客户端只是连接到了集群中的某一个Redis节点,然后就可以通信了。
但是想要访问的key,可能并不在当前连接的节点,于是,Redis提供了两个用于实现客户端定位数据的命令:
MOVED和ASK命令
这两个命令都实现了重定向功能,告知客户端要访问的key在哪个Redis节点,客户端可以通过命令信息进行重定向访问。
MOVED命令
我们先来看看MOVED命令,我们做如下操作:
1 2 3 | ➜ create-cluster redis-cli -p 30001--raw 127.0.0.1:30001> set qq "Java架构杂谈" (error) MOVED 5598 127.0.0.1:30002 |
可以发现,终端打印了MOVED命令,比提供了重定向的IP和端口,这个是key对应的slot所在的Redis节点地址。我们只要通过集群模式连接Redis服务器,就可以看到重定向信息了:
1 2 3 | 127.0.0.1:30001> set qq "Java架构杂谈" -> Redirected to slot [5598] located at 127.0.0.1:30002 OK |
MOVED命令的重定向流程如下:
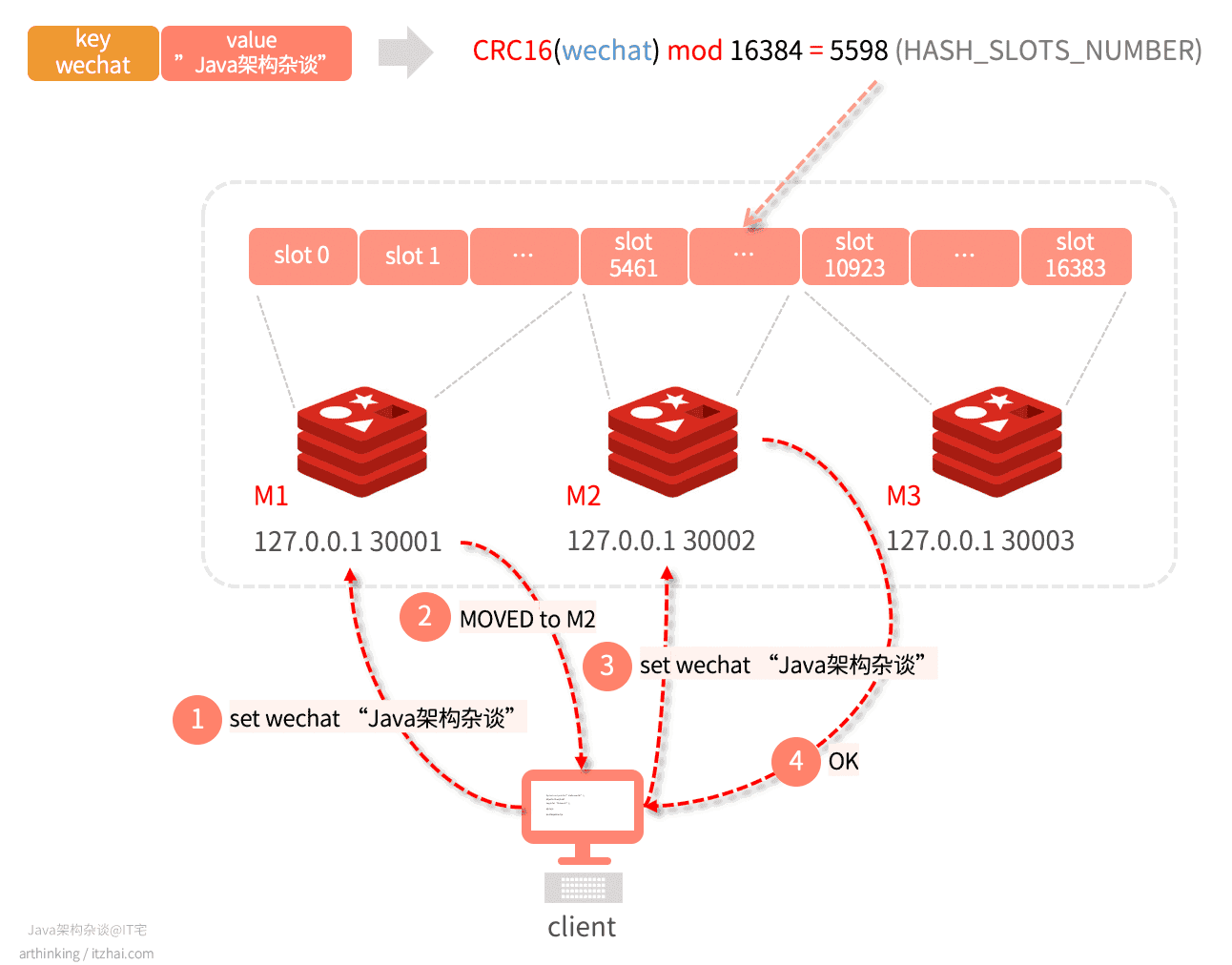
- 客户端连接到M1,准备执行:
set wechat "Java架构杂谈"; - wechat key执行CRC16取模后,为5598,M1响应MOVED命令,告知客户端,对应的slot在M2节点;
- 客户端拿到MOVED信息之后,可以重定向连接到M2节点,在发起set写命令;
- M2写成功,返回OK。
如果我们使用客户端的集群模式,就可以看到这个重定向过程了:
1 2 3 | 127.0.0.1:30001> set qq "Java架构杂谈" -> Redirected to slot [5598] located at 127.0.0.1:30002 OK |
一般在实现客户端的时候,可以在客户端缓存slot与Redis节点的映射关系,当收到MOVED响应的时候,修改缓存中的映射关系。这样,客户端就可以基于已保存的映射关系,把请求发送到正确的节点上了,避免了重定向,提升请求效率。
ASK命令
如果M2节点的slot a中的key正在迁移到M1节点的slot中,但是还没有迁移完,这个时候我们的客户端连接M2节点,请求已经迁移到了M1节点部分的key,M2节点就会响应ASK命令,告知我们这些key已经移走了。如下图:
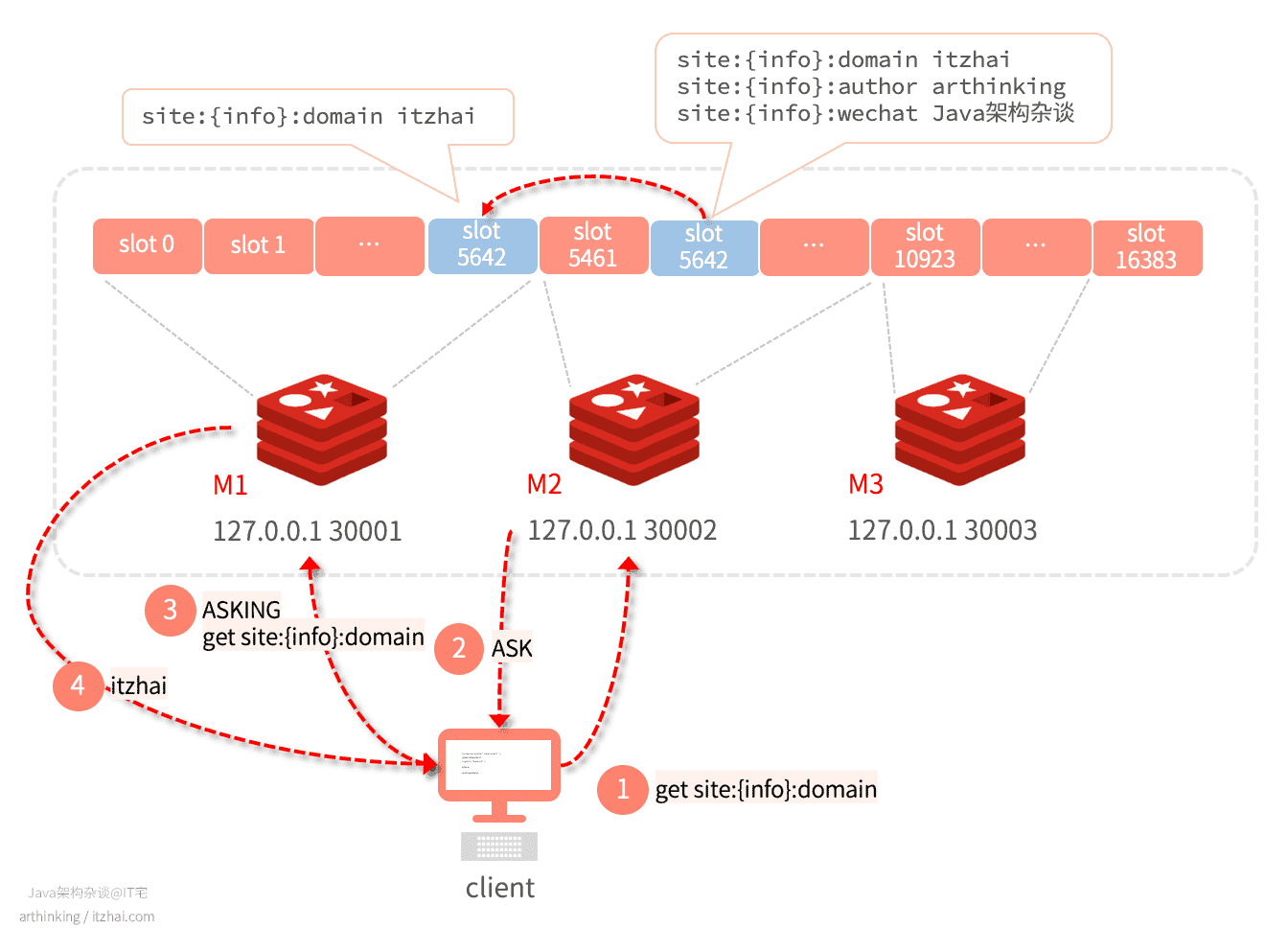
- slot 5642 正在从M2迁移到M1,其中
site:{info}:domain已经迁移到M1了; - 这个时候连接M2,尝试执行
get site:{info}:domain,则响应ASK,并提示key已经迁移到了M1; - 客户端收到ASK,则连接M1,尝试获取数据。
下面可以通过 hash_tag 演示一下迁移一个slot过程中,尝试get迁移的key,Redis服务器的响应内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | # 先通过hash_tag往M2节点的5642 slot写入三个key 127.0.0.1:30002> set site:{info}:domain itzhai OK 127.0.0.1:30002> set site:{info}:author arthinking OK 127.0.0.1:30002> set site:{info}:wechat Java架构杂谈 OK 127.0.0.1:30002> keys *{info}* site:{info}:author site:{info}:wechat site:{info}:domain 127.0.0.1:30002> cluster keyslot *{info}* 5642 # 三个key都在M2节点的5642 slot中 # 查看节点情况 127.0.0.1:30001> cluster nodes 56e4d53f3f6d7dfa831c7dea2ccbdabb6f907209 127.0.0.1:30005@40005 slave 1d18c2134103192c5263db88631322428aac808f 0 1619363985000 2 connected 1d18c2134103192c5263db88631322428aac808f 127.0.0.1:30002@40002 master - 0 1619363984913 2 connected 5461-10922 46a135012c95707ea39dd7ac6a670100c40ddf45 127.0.0.1:30001@40001 myself,master - 0 1619363984000 1 connected 0-5460 [5642-<-1d18c2134103192c5263db88631322428aac808f] 8ad5106289da3725bb0e8161c678b2939ecdc300 127.0.0.1:30004@40004 slave 46a135012c95707ea39dd7ac6a670100c40ddf45 0 1619363985114 1 connected 15f867e43d2fd33ee13cb107a479099748337590 127.0.0.1:30003@40003 master - 0 1619363985215 3 connected 10923-16383 770329c173c7250adff7a4cd30ce31e064ea47fc 127.0.0.1:30006@40006 slave 15f867e43d2fd33ee13cb107a479099748337590 0 1619363985315 3 connected # M1节点执行importing,准备接受迁移过来的slot,hash值为M2节点 127.0.0.1:30001> cluster setslot 5642 importing 1d18c2134103192c5263db88631322428aac808f OK # M2节点执行migrating,准备把slot迁移出去,hash值为M1节点 127.0.0.1:30002> cluster setslot 5642 migrating 46a135012c95707ea39dd7ac6a670100c40ddf45 OK # 迁移5642的site:{info}:domain到M1节点 127.0.0.1:30002> migrate 127.0.0.1 30001 site:{info}:domain 0 10000 OK # 这个时候,再从M2节点请求site:{info}:domain,则响应ASK命令 127.0.0.1:30002> get site:{info}:domain ASK 5642 127.0.0.1:30001 # 迁移slot中剩余的key 127.0.0.1:30002> migrate 127.0.0.1 30001 site:{info}:wechat 0 10000 OK 127.0.0.1:30002> migrate 127.0.0.1 30001 site:{info}:author 0 10000 OK # 通知所有主节点,槽已迁移完成 127.0.0.1:30002> cluster setslot 5642 node 46a135012c95707ea39dd7ac6a670100c40ddf45 OK 127.0.0.1:30002> ➜ create-cluster redis-cli -p 30001 -c --raw 127.0.0.1:30001> cluster setslot 5642 node 46a135012c95707ea39dd7ac6a670100c40ddf45 OK 127.0.0.1:30001> ➜ create-cluster redis-cli -p 30003 -c --raw 127.0.0.1:30003> cluster setslot 5642 node 46a135012c95707ea39dd7ac6a670100c40ddf45 OK # 再次在M1节点指向get命令,已经迁移完成,响应MOVED命令 ➜ create-cluster redis-cli -p 30002 --raw 127.0.0.1:30002> get site:{info}:domain MOVED 5642 127.0.0.1:30001 # 再次查看,发现5642节点已经在M1节点中 127.0.0.1:30001> cluster nodes 56e4d53f3f6d7dfa831c7dea2ccbdabb6f907209 127.0.0.1:30005@40005 slave 1d18c2134103192c5263db88631322428aac808f 0 1619365718115 2 connected 1d18c2134103192c5263db88631322428aac808f 127.0.0.1:30002@40002 master - 0 1619365718115 2 connected 5461-5641 5643-10922 46a135012c95707ea39dd7ac6a670100c40ddf45 127.0.0.1:30001@40001 myself,master - 0 1619365718000 7 connected 0-5460 5642 8ad5106289da3725bb0e8161c678b2939ecdc300 127.0.0.1:30004@40004 slave 46a135012c95707ea39dd7ac6a670100c40ddf45 0 1619365718015 7 connected 15f867e43d2fd33ee13cb107a479099748337590 127.0.0.1:30003@40003 master - 0 1619365718115 3 connected 10923-16383 770329c173c7250adff7a4cd30ce31e064ea47fc 127.0.0.1:30006@40006 slave 15f867e43d2fd33ee13cb107a479099748337590 0 1619365718115 3 connected |
hash_tag:如果键中包含{},那么集群在计算哈希槽的时候只会使用{}中的内容,而不是整个键,{}内的内容称为hash_tag,这样就保证了不同的键都映射到相同的solot中,这通常用于Redis IO优化。
MOVED和ASK的区别
- MOVED相当于永久重定向,表示槽已经从一个节点转移到了另一个节点;
- ASK表示临时重定向,表示槽还在迁移过程中,但是要找的key已经迁移到了新节点,可以尝试到ASK提示的新节点中获取键值对。
16.1.5、Redis Cluster是如何实现故障转移的
Redis单机模式下是不支持自动故障转移的,需要Sentinel辅助。而Redis Cluster提供了内置的高可用支持,这一节我们就来看看Redis Cluster是如何通过内置的高可用特性来实现故障转移的。
我们再来回顾下这张图:
Redis节点之间的通信是通过Gossip算法实现的,Gossip是一个带冗余的容错,最终一致性的算法。节点之间完全对等,去中心化,而冗余通信会对网络带宽和CPU造成负载,所以也是有一定限制的。如上图的集群图灰色线条所示,各个节点都可以互相发送信息。
Redis在启动之后,会每间隔100ms执行一次集群的周期性函数clusterCron(),该函数里面又会调用clusterSendPing函数,用于将随机选择的节点信息加入到ping消息体中并发送出去。
如何判断主库下线了?
集群内部使用Gossip协议进行信息交换,常用的Gossip消息如下:
- MEET:用于邀请新节点加入集群,接收消息的节点会加入集群,然后新节点就会与集群中的其他节点进行周期性的ping pong消息交换;
- PING:每个节点都会频繁的给其他节点发送ping消息,其中包含了自己的状态和自己维护的集群元数据,和部分其他节点的元数据信息,用于检测节点是否在线,以及交换彼此状态信息;
- PONG:接收到meet和ping消息之后,则响应pong消息,结构类似PING消息;节点也可以向集群广播自己的pong消息,来通知整个集群自身运行状况;
- FAIL:节点PING不通某个节点,并且超过规定的时间后,会向集群广播一个fail消息,告知其他节点。
**疑似下线:**当节发现某个节没有在规定的时间内向发送PING消息的节点响应PONG,发送PING消息的节点就会把接收PING消息的节点标注为疑似下线状态(Probable Fail,Pfail)。
交换信息,判断下线状态:集群节点交换各自掌握的节点状态信息,交换之后,如果判断到超过半数的主节点都将某个主节点A判断为疑似下线,那么该主节点A就会标记为下线状态,并广播出去,所有接收到广播消息的节点都会立刻将主节点标记为fail。
疑似下线状态是有时效性的,如果超过了cluster-node-timeout *2的时间,疑似下线状态就会被忽略。
如何进行主从切换?
**拉票:**从节点发现自己所属的主节点已经下线时,就会向集群广播消息,请求其他具有投票权的主节点给自己投票;
最终,如果某个节点获得超过半数主节点的投票,就成功当选为新的主节点,这个时候会开始进行主从切换,
16.1.6、Redis Cluster能支持多大的集群?
我们知道Redis节点之间是通过Gossip来实现通信的,随着集群越来越大,内部的通信开销也会越来越大。Redis官方给出的Redis Cluster规模上限是1000个实例。更多关于Redis的集群规范:Redis Cluster Specification[18]
而在实际的业务场景中,建议根据业务模块不同,单独部署不同的Redis分片集群,方便管理。
如果我们把slot映射信息存储到第三方存储系统中,那么就可以避免Redis Cluster这样的集群内部网络通信开销了,而接下来介绍的Codis方案,则是采用这样的思路。
16.2、Codis方案
与Redis Cluster不同,Codis是一种中心化的Redis集群解决方案。
Codis是豌豆荚公司使用Go语言开发的一个分布式Redis解决方案。选用Go语言,同时保证了开发效率和应用性能。
对于Redis客户端来说,连接到Codis Proxy和连接原生的Redis没有太大的区别,Redis客户端请求统一由Codis Proxy转发给实际的Redis实例。
Codis实现了在线动态节点扩容缩容,不停机数据迁移,以及故障自动恢复功能。
中心化:通过一个中间层来访问目标节点
去中心化:客户端直接与目标节点进行访问。
以下是Codis的架构图:
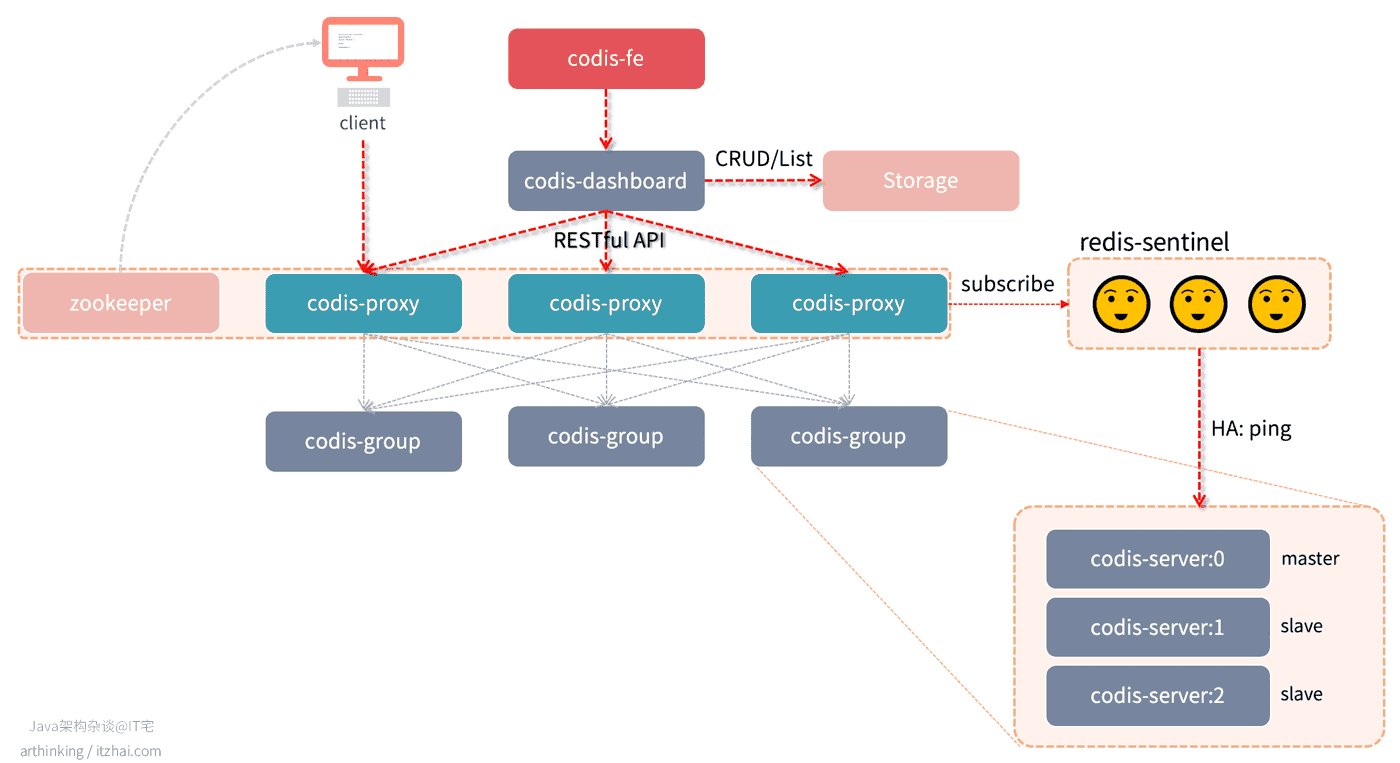
( 以下各个组件说明来自于Codis官方文档:Codis 使用文档[19] )
- Codis Server:基于 redis-3.2.8 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
- Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 客户端访问codis proxy时,和访问原生的Redis实例没有什么区别,方便原单机Redis快速迁移至Codis。除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。
- 对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;
- 不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
- Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。
- 对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;
- 所有对集群的修改都必须通过 codis-dashboard 完成。
- Codis Admin:集群管理的命令行工具。
- 可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
- Codis FE:集群管理界面。
- 多个集群实例共享可以共享同一个前端展示页面;
- 通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
- Storage:为集群状态提供外部存储。
- 提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;
- 目前仅提供了 Zookeeper、Etcd、Fs 三种实现,但是提供了抽象的 interface 可自行扩展。
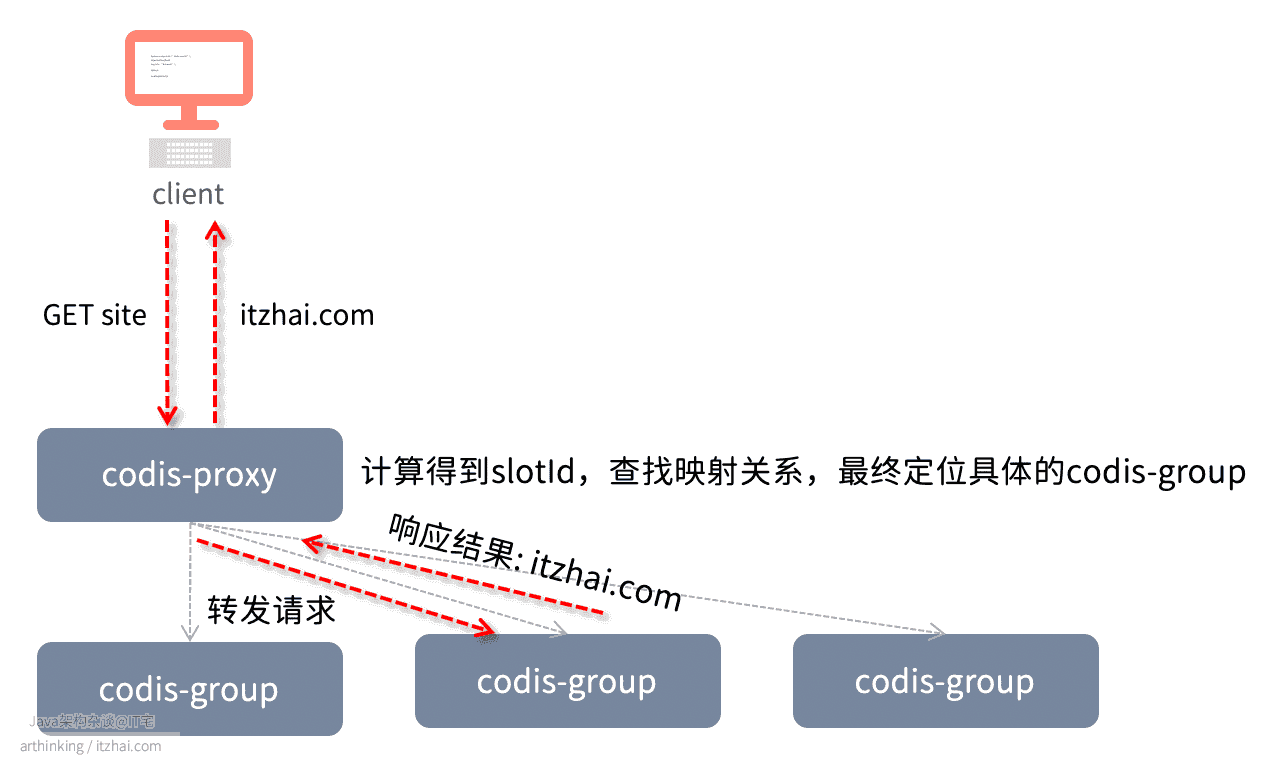
16.2.1、Codis如何分布与读写数据?
Codis采用Pre-sharding技术实现数据分片,默认分为1024个slot,通过crc32算法计算key的hash,然后对hash进行1024取模,得到slot,最终定位到具体的codis-server:
1
| slotId = crc32(key) % 1024
|
我们可以让dashboard自动分配这些slot到各个codis-server中,也可以手动分配。
slot和codis-server的映射关系最终会存储到Storage中,同时也会缓存在codis-proxy中。
以下是Codis执行一个GET请求的处理流程:
16.2.2、Codis如何保证可靠性
从以上架构图可以看出,codis-group中使用主从集群来保证codis-server的可靠性,通过哨兵监听,实现codis-server在codis-group内部的主从切换。
16.2.3、Codis如何实现在线扩容
扩容codis-proxy
我们直接启动新的codis-proxy,然后在codis-dashboard中把proxy加入集群就可以了。每当增加codis-proxy之后,zookeeper上就会有新的访问列表。客户端可以从zookeeper中读取proxy列表,通过特定的负载均衡算法,把请求发给proxy。
扩容codis-server
首先,启动新的codis-server,将新的server加入集群,然后把部分数据迁移到新的codis-server。
Codis会逐个迁移slot中的数据。
codis 2.0版本同步迁移性能差,不支持大key迁移。
不过codis 3.x版本中,做了优化,支持slot同步迁移、异步迁移和并发迁移,对key大小无任何限制,迁移性能大幅度提升。
同步迁移与异步迁移
同步迁移:数据从源server发送到目标server过程中,源server是阻塞的,无法处理新请求。
异步迁移:数据发送到目标server之后,就可以处理其他的请求了,并且迁移的数据会被设置为只读。
当目标server收到数据并保存到本地之后,会发送一个ACK给源server,此时源server才会把迁移的数据删除掉。
Part Ⅵ. 缓存常见问题
17、如何同步缓存和数据库的数据?
技术的出现都是有特定的背景的,我们摸清了技术的发展脉络,也就能更好的掌握这门技术,也能理解未来的发展趋势。所以我在Java架构杂谈公众号以及IT宅(itzhai.com)中写的一些技术文章有可能会顺便梳理一下发展脉络。如:架构演变之路:为何要搞微服务架构?, 三万长文50+趣图带你领悟web编程的内功心法
为了同步缓存和数据库的数据,我们也先来看看传统的缓存策略。常见的有以下几种更新策略:
17.1、Cache-Aside策略
我们学过操作系统的缓存之后,知道无论是LLC还是page cache,我们都不会显示的去维护它,而是在操作系统内部直接集成了这些缓存。
而Redis的缓存是独立于应用程序的,我们要使用Redis缓存,必须手动在程序中添加缓存操作代码,所以我们把这种使用缓存的方式叫旁路缓存(Cache-Aside)[^20] (把Redis和数据库数据同步逻辑封装好下沉到持久层的此类场景不算是Cache-Aside)。
以下是Cache-Aside的查询数据的图示:
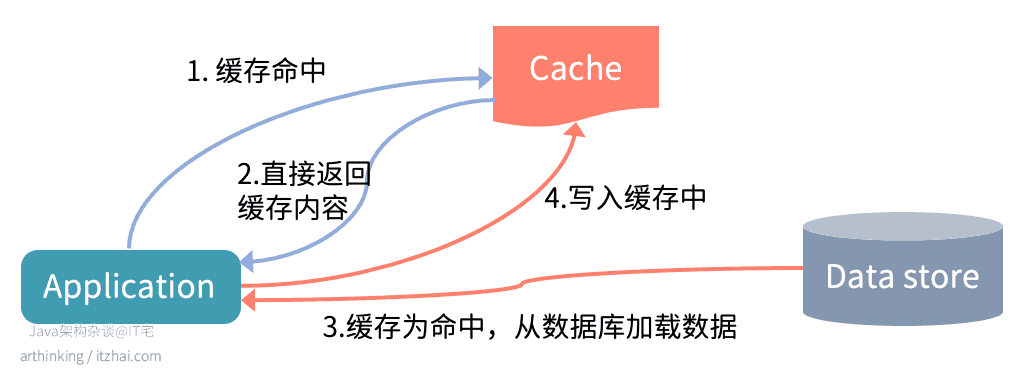
这也是最常用的缓存方法,缓存位于侧面(Aside),应用程序直接与缓存和数据库通信。具体交互:
- 应用程序首先检查缓存
- 如果缓存命中,直接返回数据给客户端
- 如果缓存没有命中,则查询数据库以读取数据,并将其返回给客户端以及存储在缓存中。
一般写数据流程如下图:
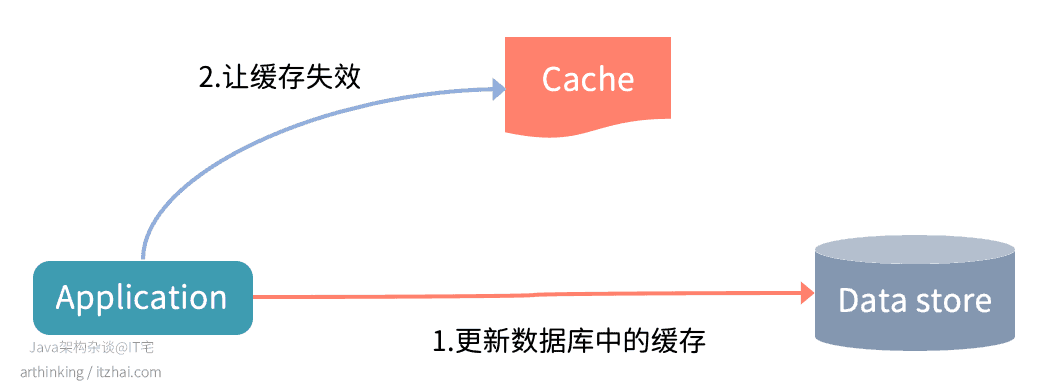
- 更新数据库中的缓存
- 让缓存失效
17.1.1、优缺点
优点:
- Cache-Aside很适合读取繁重的场景,使用Cache-Aside使系统对缓存故障具有弹性,如果缓存集群宕机了,系统仍然可以通过直接访问数据库来运行。不过响应时间可能变得很慢,在最坏的情况下,数据库可能会停止工作;
- 这种方式,缓存的数据模型和数据库中的数据模型可以不同,比如,把数据库中多张表的数据组合加工之后,再放入缓存。
缺点:
- 使用Cache-Aside的时候,写数据之后,很容易导致数据不一致。可以给缓存设置一个TTL,让其自动过期,如果要保证数据的实时性,那么必须手动清除缓存。
17.1.2、数据不一致问题
并发写导致的脏数据
有些写缓存的代码会按如下逻辑编写:
- 更新数据
- 更新缓存
这种方案,可能会因为并发写导致脏数据,如下图:
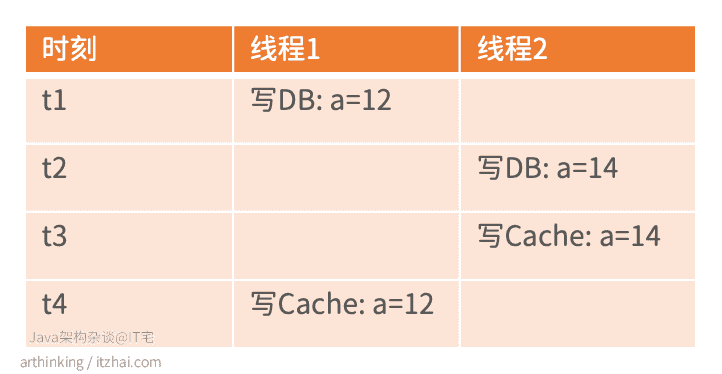
线程1设置a为12,线程2设置a为14,由于执行顺序问题。最终,数据库中的值是14,而缓存中的值是12,导致缓存数据和数据库中的数据不一致。
为此,我们一般不写完数据库之后立刻更新缓存。
读写并发导致的脏数据
即使是写完数据之后,我们直接删掉缓存,也是有可能导致缓存中出现脏数据的,如下图:

数据库被线程2更新为了12,但是缓存最终又加载到了老的值10。
不过这个场景概率很低,因为一方面一般读操作比写操作只需快得多,并且另一方面还需要读操作必须在写操作之前就进入数据库查询,才能导致这种场景的出现。
**我们最常用的兜底策略是设置一个缓存过期时间,好让这种极端场景产生的脏数据能够定时被淘汰。**当然,用2PC或者Paxos协议来保证一致性也可以,不过实现起来太复杂了。
17.2、Read/Write Through策略
前面的Cache-Aside需要应用程序参与整个缓存和数据库的同步过程,而Read/Write Throught策略则不需要应用程序参与,而是让缓存自己来代理缓存和数据的同步,在应用层看来,后端就是一个单一的存储介质,至于存储内部的缓存机制,应用层无需关注。
就像操作系统的缓存,无论是LLC还是page cache,我们都不会显示的去维护它,而是在操作系统内部直接集成了这些缓存。
接下来看看这个策略。
Read-Through
Read-Through,缓存与数据库保持一致,当缓存未命中的时候,从数据库中加载丢失的缓存,填充缓存,并将其返回给应用程序。加载缓存过程对应用透明:

这种策略要保证数据库和缓存中的数据模型必须相同。
Write-Through
Write-Through,当更新数据的时候,如果没有命中缓存,则直接更新数据库,然后返回。如果命中了缓存,则直接更新缓存,缓存内部触发自动更新数据库,都更新完成之后,再返回。
缓存和数据库保持一致,写入总是通过缓存到达数据库。如下图:

Write-Back
Write-Back,更新数据的时候,只更新缓存,不立刻更新数据库,而是异步的批量更新数据到数据库中。
这个策略与Write-Through相比,写入的时候,避免了要同步写数据库,让写入的速度有了很大的提高,但是确定也很明显:缓存和数据库中的数据不是强一致性的,还有可能会导致数据丢失。

Write-Back策略适用于写入繁重的场景,通过与Read-Through配合使用,可以很好的适用于读写都和频繁的场景。
我们可以稍微来总结一下缓存策略的选用:
| 缓存策略 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| Read-Through | 读效率高 | 缓存和数据库的数据可能不一致 | 适合读取繁重的场景 |
| Write-Through | 保证数据一致性,避免缓存失效,保证缓存数据是最新的 | 写效率低 | 写入不是很频繁,对数据一致性要求比较高的场景,如资讯网站,博客 |
| Write-Back | 写效率高,保证缓存数据是最新的 | 数据库可能丢数据 | 适合写入繁重但是数据可靠性要求不是很严格的场景,如评论系统,消息通知系统 |
| Cache-Aside | 缓存和数据库的数据模型不要求一致,可根据业务灵活组织,应用不强依赖缓存,缓存实时性高 | 编码复杂,缓存与数据库可能不一致 | 数据模型复杂的业务系统 |
Read-Through的缓存和数据库数据不一致解决方案在于写入策略,只要我们配合合理的写入策略,就更好的保证缓存和数据库数据的一致性。
在实际的使用场景中,我们会关注使用的缓存要不要求实时更新。根据实时性,Redis缓存更新可以分为两种策略:实时策略,异步策略。这两种策略都是离不开以上介绍的几种的缓存策略的思想。
实时策略
实时策略,是最常用的缓存策略。
类似Cache-Aside策略的实现就是实时策略,
**读取:**先从缓存读取数据,如果缓存没有命中,则从数据库中读取,读取到了则放到缓存中。如果缓存命中,则直接从缓存中读取数据。
**写入:**写入的时候,先把数据写入到数据库中,然后在让缓存失效,缓存下次读取的时候,从数据库中加载数据。
这种方案会存在数据不一致问题,在Cache-Aside策略小节已经有讲过了。
对于缓存与数据库的数据一致性要求高的场景,建议使用实时策略;如果对缓存与数据库一致性要求不高,则可以使用异步策略。接下来讲讲异步策略。
异步策略
所谓的异步,我们可以做成读写都是异步的:
**读取:**当从缓存中读取不到数据的时候,不直接从数据库加载,而是返回一个fallback数据,然后往消息队列中放入一个加载数据的消息,通过异步消费消息去加载数据。可以避免因为缓存失效,导致高并发大流量一起请求到数据库,从而对数据库造成压力。
**写入:**总是先写入数据库或者缓存,然后异步更新另一个:
- 先更新数据库:生成消息异步更新缓存,优点:数据持久性可以得到保证,缺点:缓存实时性差
- 先更新缓存:异步刷新缓存到数据库,相当于把缓存当成了数据库在用,优点:完全使用缓存,IO效率高,缺点:可能丢数据
定时策略
针对读写并发量过大的场景,我们可以进一步降级,定时的把缓存中的数据刷到数据库,可以在缓存中对数据进行整合,然后在刷新到数据库中。
优点:IO效率高,比异步策略更高,缺点:可能丢数据。
其实MySQL的Change Buffer就是采用异步策略,同时又使用Redo Log来实现数据的不丢失。进一步阅读:洞悉MySQL底层架构:游走在缓冲与磁盘之间[20]
来总结对比下这几种方案:
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 实时策略 | 实时性高 | 缓存更新困难,容易导致数据不一致 | 金融,交易系统等业务数据实时性要求高,数据可靠性要求高的场景 |
| 异步策略-先更新数据库 | 数据持久性可以得到保证 | 缓存实时性差 | 产品详情,文章详情等不要求实时展现,但要求不丢数据 |
| 异步策略-先更新缓存 | 完全使用缓存,IO效率高 | 可能丢数据 | 评论系统,消息通知 |
| 定时策略 | IO效率高,比异步策略更高 | 比异步策略-先更新缓存更容易丢数据 | 评论系统,消息通知 |
其实,在使用实时策略的时候,我们关注的是如何进一步降低丢数据的风险,有两种处理方式:
- 用2PC或者Paxos协议来保证一致性也可以,不过实现起来太复杂了;
- 通过各种其他五花八门的骚操作,来进一步降低实时策略丢数据的概率。
降低丢数据的概率的常用措施有哪些?
实时策略场景:
- 缓存双删,可以在第二次删除之前休眠一小段时间。进一步降低了数据不一致的概率,但是也不能避免数据不一致;
- 增加组件订阅binglog,完成缓存的更新,适合缓存结构和数据库结构一致的场景。如果缓存结构复杂,也不好写成通用的组件;
- 通过分布式事务,把缓存操作和数据库操作通过一个事务完成,但由于Redis并不支持类似MySQL的事务,所以在分布式处理过程中,还是可能导致其他客户端读取到中间数据,导致脏读问题。
异步策略场景:
- 优先修改缓存数据,通过队列异步写到请求到数据库中;(异步直写),如果消息队列可靠,则可以保证数据最终写入数据库,
18、缓存雪崩
当大量缓存数据同时过期,或者Redis实例突然宕机的时候,就会有大量的请求打到DB,这种场景我们称为缓存雪崩。
雪崩这个词,很形象。想象一下,当缓存都挡不住了,一大堆流量涌向数据库 的场景,像极了当山坡积雪内部的内聚力抗拒不了它所受到的重力拉引,导致向下滑动,引起大量雪体崩塌的场景...
为了应对缓存雪崩,建议系统做如下设计。
18.1、服务降级
当Redis宕机的时候,让非核心的业务暂时返回空数据或者错误信息,从而避免大量请求直接访问到数据库。
对于核心业务,我们则可以考虑熔断限流。
18.2、熔断限流
基于现有的业务规划,我们可以做基准测试和容量测试,得到系统在没有缓存的情况下能够支撑的并发数,这个参数可以作为缓存不可用场景下的限流值。
另外,一般在系统出现雪崩的情况,请求响应速度回立刻降下来,通过设置响应的阈值来触发熔断,从而避免系统被源源不断的流量压垮。可以采用Hystrix或者Sentinel等熔断限流组件来实现该需求。
18.3、搭建可靠集群
如果我们只有一个主节点,那么当主节点宕机之后,缓存服务就再也不可用使用了,从而导致缓存雪崩问题。
如果我们搭建了主从集群,假设主节点宕机了,还可以通过切换主从节点,继续提供缓存服务,而在主从切换期间,可以暂时让服务降级,从而避免了因缓存雪崩导致数据库面临过大压力。
18.4、尽量避免让key同时过期
如果不是Redis宕机,那么产生缓存雪崩的原因就是大量的key同时过期了,为了避免这种情况发生,建议不要设置大量key在同一时间过期。如果不可以避免,则可以尝试在过期时间添加合理的随机数,让过期时间尽量错开。
19、缓存击穿
缓存击穿,指的是缓存中访问率很高的的key,因为过期了或者被淘汰了等原因,导致无法从缓存中读取,进而导致大量请求直接打到数据库,给数据库带来巨大的压力。

我们可以通过如下的措施,避免缓存击穿:
- 不给此类热点key设置过期时间,并且淘汰策略设置为volatile,然后通过异步刷新策略或者定时刷新策略进行更新缓存;
- 在缓存快要过期之前,通过分布式锁,限制放一个线程请求后端数据库进行更新缓存。
20、缓存穿透
缓存穿透则指的是由于缓存和数据库都不存在数据,导致请求永远不会止步于缓存,每次都会打到DB,缓存就跟透明的一样。
- 这可能会被不怀好意的人利用,大量请求不存在的key频繁攻击我们的数据库;
- 或者在高并发场景,我们要查询的数据刚好不在数据库中,缓存中也没有,也会导致DB压力增加。比如大促场景,商品突然被误删了,或者用户注册场景校验用户名是否存在的时候,如果缓存设计不合理,很可能导致大量请求查库。
我们可以通过如下的措施,避免缓存穿透:
- 使用Bloom Filter校验数据是否存在,从而阻挡大部分流量。例如用户注册用户名校验场景,可以把用户名存在的状态在Bloom Filter中 设置为1,这样就可以快速判断用户名是否存在了。
- 要注意的是:Bloom Filter判定不在的数据一定不存在,存在的数据不一定存在。对于不存在的数据误判为存在的情况,需要评估业务是否接受这种结果,对于注册业务来说影响不大。
- 缓存空结果。如果我们要读取的不仅仅是二状值,而是一个完整的数据,那么就可以把空结果也缓存起来,从而让不存在的数据也走缓存;
- 对于恶意请求,我们则可以多从网关层下功夫,比如设置限流避免同一个IP大量请求到服务器,入参合法性校验等。
21、缓存何时淘汰
当我们的缓存空间不够的时候,还想加载新的数据怎么办呢?要么就加载不了了,要么就得删掉一些使用率比较低的缓存,腾出空间来加载新的数据到缓存中。
那么,我们的缓存应该设置多大比较合理?
21.1、缓存应该设置多大?
Wired杂志的Chris Anderson,创造了术语“长尾”来指代电子商务系统中少量的商品可以构成大部分的销售额,少量的博客可以获得大部分的点击量,还有一些是不太受欢迎的“长尾巴”,如下图所示(来源 Hello, Ehcache[21] ):
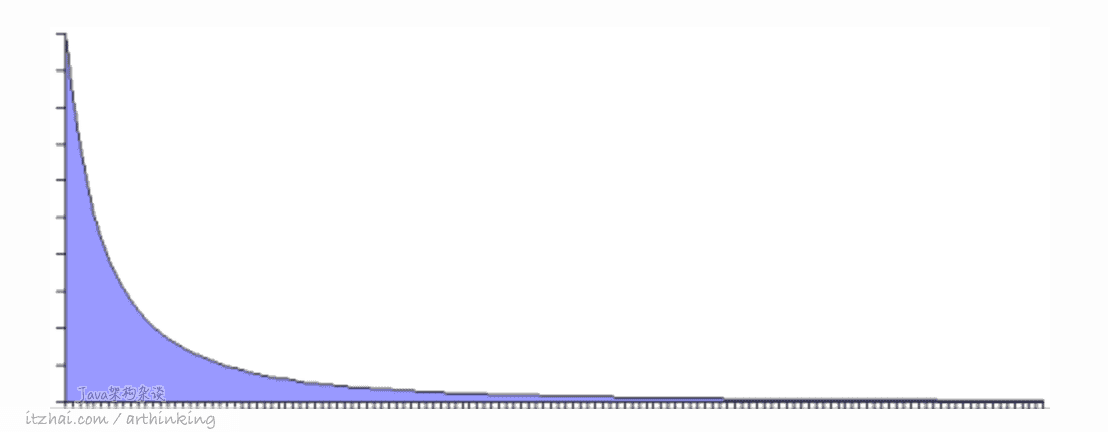
长尾是幂律分布(Power Law)的一个示例,还有帕累托分布或八二法则(80:20 rule)。
基于八二法则,我们可以分析缓存使用效率的一般规律:20% 的对象在 80% 的时间内被使用,剩余的数据量虽然很大,但是只有20%的访问量。
我们可以基于八二法则,加上对业务的访问特征评估,来预估要分配的缓存的大小。
一旦确定下来之后,就可以到redis.conf中进行配置了:
1 2 | # maxmemory <bytes> maxmemory 1G |
21.2、缓存何时淘汰?
当Redis占用的内存超过了设置的maxmemory的值的时,Redis将启用缓存淘汰策略来删除缓存中的key,设置淘汰策略配置参数:
1
| maxmemory-policy noeviction # 默认的淘汰策略,不删除任何key,内存不足的时候写入返回错误
|
当内存到达上限之后,Redis会选择什么数据进行淘汰呢?这个跟设置的淘汰策略有关。可选的淘汰策略:
volatile,只针对设置了过期时间的key的淘汰策略volatile-lru:使用近似 LRU(Least Recently Used, 最近最少使用) 驱逐,淘汰带有过期时间的键值对volatile-lfu:使用近似的 LFU(Least Frequently Used, 最不经常使用) 驱逐,淘汰带有过期时间的键值对volatile-random:随机驱除,淘汰带有过期时间的键值对volatile-ttl:删除过期时间最近的键值对(最小TTL)
allkeys,对所有范围的key有效的淘汰策略allkeys-lru:使用近似 LRU 驱逐,淘汰任何键值对allkeys-lfu:使用近似 LFU 驱逐,淘汰任何键值对allkeys-random:删除随机键值对
noeviction:不要驱逐任何东西,只是在写操作时返回一个错误。
在内存不足的时候,如果一个键值对被删除策略选中了,即使还没有过期,也会被删掉。
LRU, Least Recently Used, 最近最少使用淘汰算法,淘汰最长时间没有被使用的缓存;
LFU, Least Frequently Used, 最不经常使用淘汰算法,淘汰一段时间内,使用次数最少的缓存。
注意:使用上述任何一种策略,当没有合适的键可以驱逐时,Redis 将在需要更多内存的写操作时返回错误。
出于效率的考虑,LRU、LFU 和 volatile-ttl 都不是精确算法,而是使用近似随机算法实现的。
Redis中的LRU,LFU算法是如何实现的?我应该是用哪种策略?
Redis中的LRU算法
为了实现一个LRU,我们需要一个链表,每访问了链表中的某个元素之后,该元素都需要往链表表头移动。
使用链表存储的缺点:
- 想象一下,假如Redis的key也放入一个这样的链表,大量的key同时被访问,导致链表内部频繁移动,这极大的降低了Redis的访问性能;
- 我们需要存储链表的前继指针prev,后继指针next,至少占用16个字节,消耗空间比较大。
为此,Redis并没有按照链表的方式实现LRU算法。
我们在介绍RedisObject的时候,有提到其中有一个lru字段:
1 2 3 4 5 6 7 | typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj; |
该字段用于记录最近一次的访问时钟。这个字段只使用改了24位(3个字节)来存储。
Redis通过随机采样获取取一组数据,放入驱逐池(实际上是一个链表)中,池中的key按照空闲时间从小到大排列,最终从池末尾选一个键进行删除,从而把lru值最小的数据淘汰掉;不断重复这个过程,直到内存使用量低于限制。
Redis中的LRU算法会有什么问题?
Redis中每次读取新的数据到内存中,都会更新该缓存的lru字段,如果我们一次性读取了大量不会再被读取的数据到缓存中,而此时刚好要执行缓存数据淘汰,那么这些一次性的数据就会把其他lru字段比较小,但是使用很频繁的缓存给淘汰掉了,这也称为缓存污染。
举个例子,有家中餐店,里面有8个顾客正在吃饭,这个时候,突然来了四个不得不接待的顾客,需要腾出4个位置,该如何选择呢?
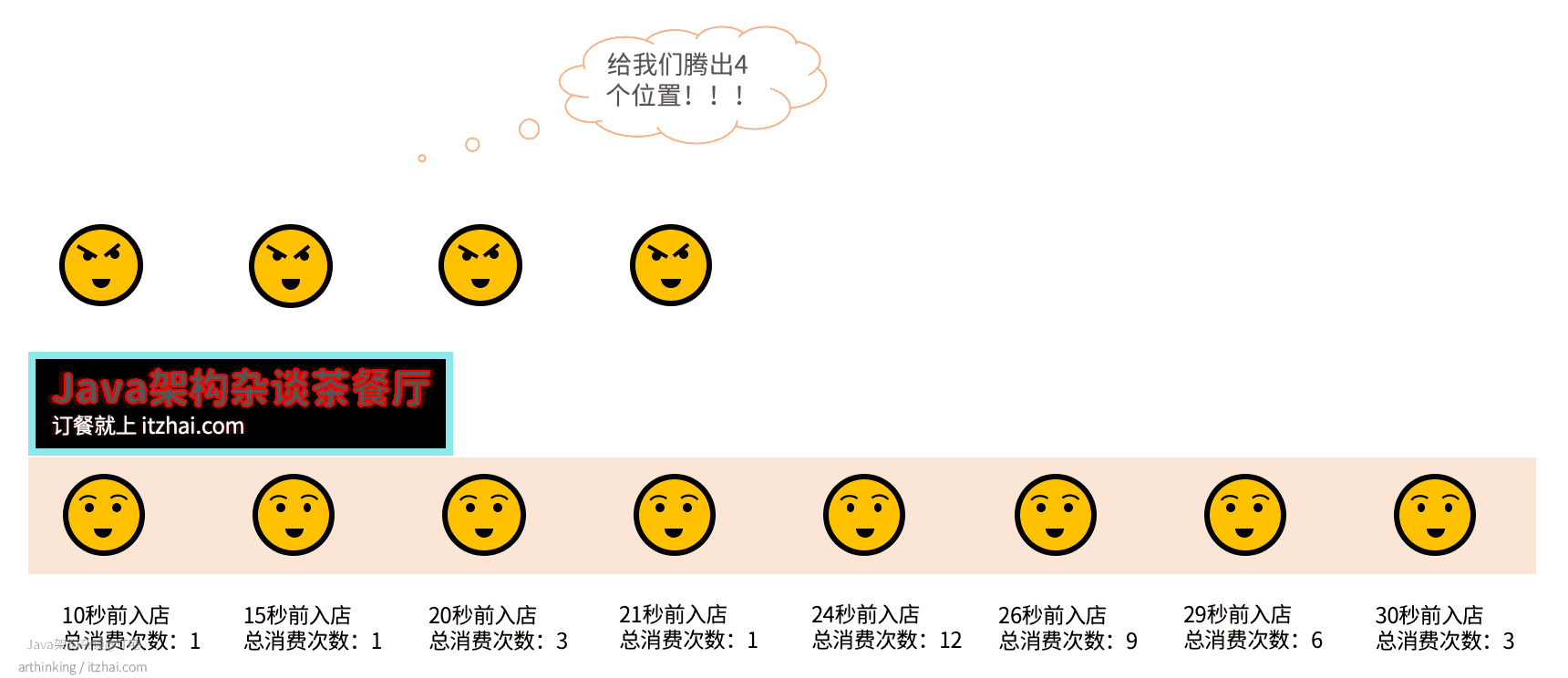
在Redis中,则会直接把入店时间最久的4个给淘汰掉,可以发现,我们直接把熟客给打发走了,最终导致丢失了常客,得不偿失:
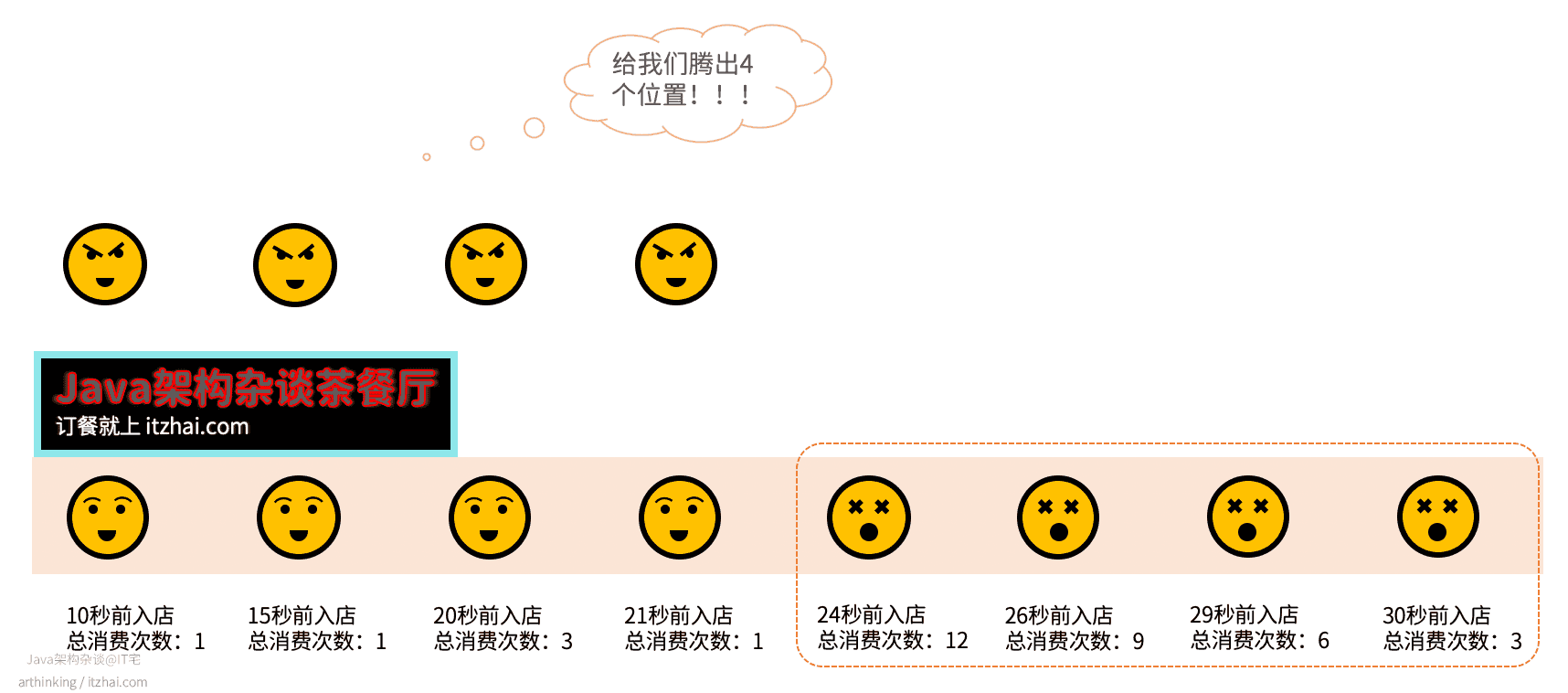
为了避免LRU队列的缓存污染问题,在Redis 4.0版本开始,提供了一种新的淘汰策略:LFU,下面简单介绍下。
MySQL如何避免LRU队列被冲刷掉?
MySQL也会有类似的全表扫描导致读取一次性的数据冲刷LRU队列的问题。为此,MySQL实现了一种改进版本的LRU算法,避免全表扫描导致LRU队列中的最近频繁使用的数据被冲刷掉。参考:洞悉MySQL底层架构:游走在缓冲与磁盘之间#3.1.1、缓冲池LRU算法[20:1]
Redis中的LFU算法
在Redis中LFU策略中,会记录每个键值对的访问次数。当进行淘汰数据的时候,首先会把访问次数最低的数据淘汰出缓存,如果淘汰过程中发现两个键值对访问次数一样,那么再把上一次访问时间更久的键值对给淘汰掉:
访问次数低的先淘汰,次数相同则淘汰lru比较小的。
举个例子,还是那个Java架构杂谈茶餐厅,来了4个得罪不起的顾客,需要腾出4个位置,使用了Redis的LFU算法之后,则是腾出这四个:
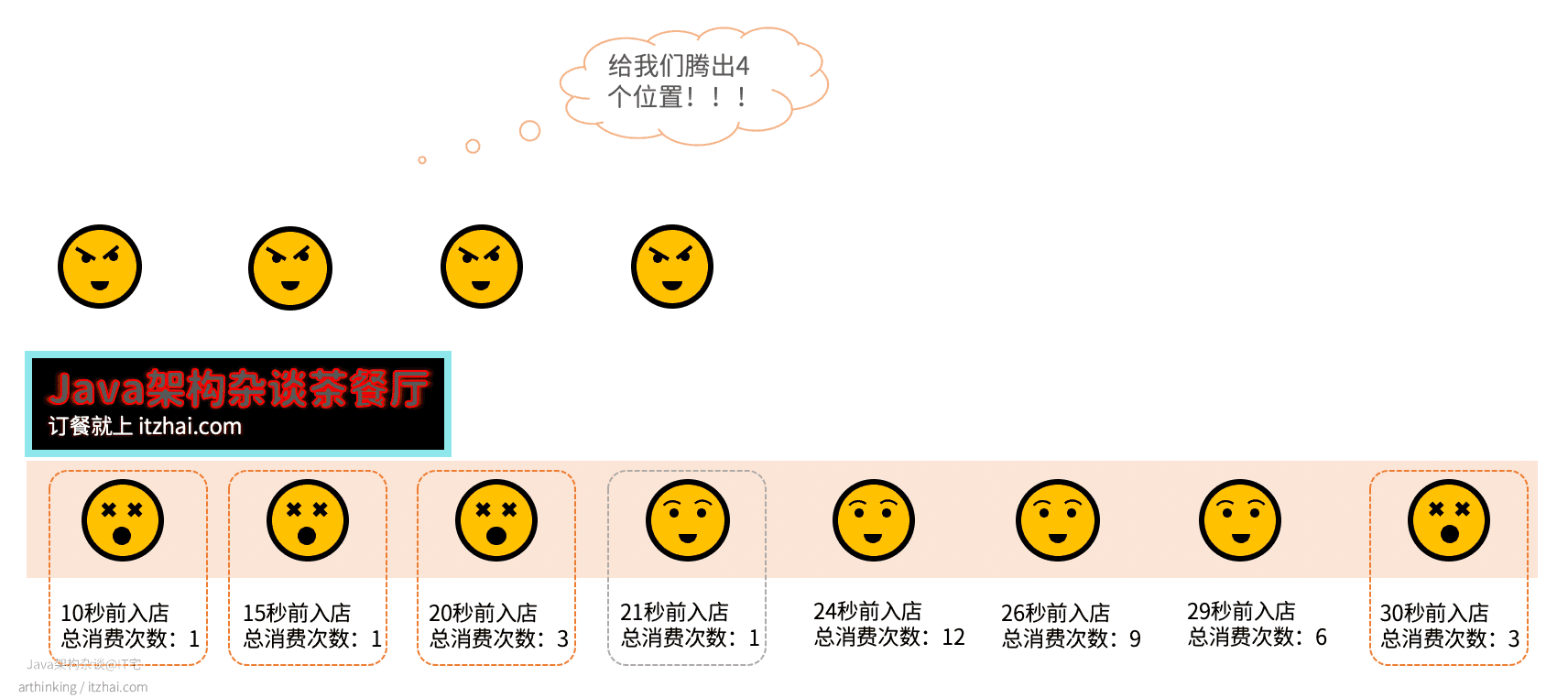
可以发现,我们优先把总消费次数比较低的顾客给打发走了,3号和8号顾客总消费次数一样,所以我们把那个进店比较久的8号顾客打发走了。
这样就可以最大程度的优先保证了熟客的用餐体验,至于我们在3号和8号顾客之间,选择打发走8号顾客,是因为可能8号顾客只点了几个咖喱鱼蛋,30秒狼吞虎咽就吃完了呢?也不是没可能,所以就让他先出去了。
LFU算法如何记录访问次数?
Redis中的LFU算法是基于LRU算法改进的,而Redis 的惊人之处在于它只是重用了 24 位 LRU 时钟空间,也就是 3 个八位字节中存储了访问计数器和最近一次衰减时间。
在key超过一定时间没被访问之后,Redis就会衰减counter的值,这是必要的,否则计数器将收敛到 255 并且永远不会回归,这势必会影响内存驱逐机制,具体确定要衰减的方法:
衰减值:
- 距离上一次衰减分钟数 = 当前时间 - 最近衰减时间
- 衰减值 = 距离上一次衰减分钟数 / lfu_decay_time
其中控制衰减周期的参数:
lfu_decay_time,单位为分钟。可见,如果要让key衰减的快点,可以把lfu_decay_time设置的小点。
Redis将这24位分成两部分,最高两个字节用于存储衰减时间,最低一个字节用于存储访问计数器。
1 2 3 | +----------------+----------------+----------------+ | last decay time | counter | +----------------+----------------+----------------+ |
只有8bit来存储访问次数,所以里面存储的并不是精确数据,而是一个大概的数据。
下面是计数器增加的关键代码:
1 2 3 4 5 6 7 8 9 10 11 | /* Logarithmically increment a counter. The greater is the current counter value * the less likely is that it gets really implemented. Saturate it at 255. */ uint8_t LFULogIncr(uint8_t counter) { if (counter == 255) return 255; double r = (double)rand()/RAND_MAX; double baseval = counter - LFU_INIT_VAL; if (baseval < 0) baseval = 0; double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++; return counter; } |
可以看出,随着计数器越来越大,计数器增加的概率越来越小。
为什么没有设置过期时间的key被删除了?
使用了allkeys策略,导致对所有范围内的key进行淘汰。
Part Ⅶ. 应用场景

既然Redis给我提供了这么丰富的数据类型,那么我们就在各种业务场景中用起来吧,接下来我们介绍常见的应用场景。
22、App DAU统计,留存统计 - SET
App每日活跃用户数,每日留存统计,是一个很常见的需求。在Redis中,我们刚好可以通过SET来记录所有的用户,并通过SET提供的各种操作API来实现对比统计。
每日DAU统计例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | # 记录20210525这天的活跃用户 127.0.0.1:6379> SADD user:20210525 10010 10011 2 127.0.0.1:6379> SADD user:20210525 10010 10086 10090 2 127.0.0.1:6379> SADD user:20210525 10086 12345 999900 100000 3 # 可以看到没有重复的内容 127.0.0.1:6379> SMEMBERS user:20210525 10010 10011 10086 10090 12345 100000 999900 # 记录20210526这天的活跃用户 127.0.0.1:6379> SADD user:20210526 10010 10086 2 # 通过交集获取26号的留存 127.0.0.1:6379> SINTERSTORE result user:20210525 user:20210526 2 127.0.0.1:6379> SMEMBERS result 10010 10086 |
注意:SET数据类型的并集和交集计算复杂度比较高,如果SET数据量过大,可能会导致操作阻塞,建议此类操作放到单独的从库中进行。
23、评论分页 - ZSET
我们在给具有分页的评论列表添加缓存的时候,由于新的评论一直在入库,所以分页的界限也会在变化。如果按照以下得到的分页结果进行缓存:
1
| select * from t_user order by id desc limit 10 offset 15;
|
那么,每当有新的记录插入表的时候,所有分页内容都将产生变化,导致所有分页缓存都会失效。
如何避免大量分页缓存失效?
如果是写评率比较少的场景,那么我们可以把读取评率比较高的前几页内容给缓存起来,每次只触发更新这几页缓存即可。
但是如果写的很频繁,那么就需要频繁的更新这几页的内容了,会导致写操作变重。或者业务需要,前几十页的访问评论都是比较高的场景,有什么比较好的缓存方法呢?
这个时候我们就可以使用Redis中的有序集合来实现分页缓存了:
- 我们可以给每个评论设置一个权重值,可以是当前时间戳,通过ZADD添加到ZSET中;
- 然后通过 ZRANGEBYSCORE 按照score进行分页查找
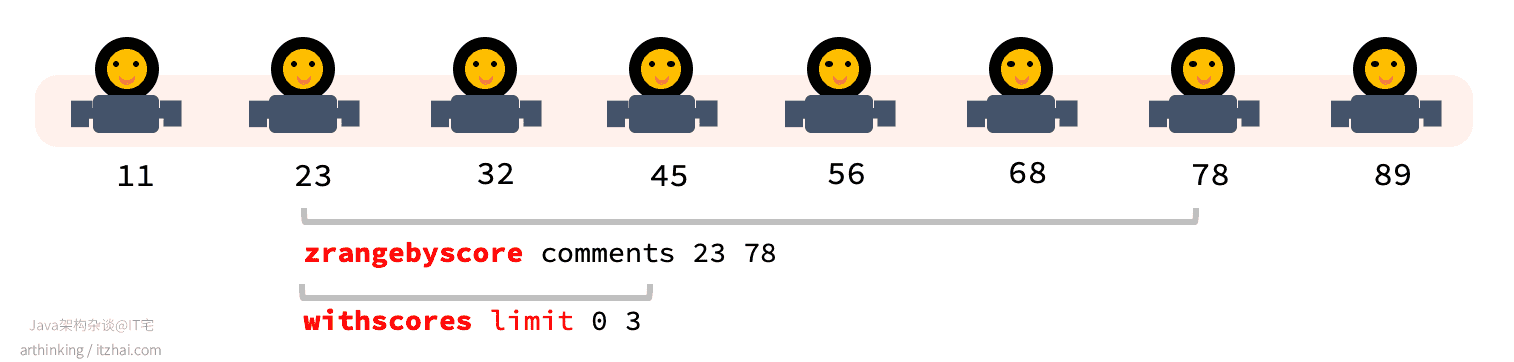
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count][22]
Available since 1.0.5.
时间复杂度:O(log(N)+ M),其中N是排序集中的元素数,M是要返回的元素数。如果M为常数(例如,始终要求使用LIMIT限制前10个元素),则可以将其视为O(log(N))。
以下是具体的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # 按照评论时间微秒设置每条评论的score 127.0.0.1:6379> ZADD comments 1621900305499398 '沙发' 127.0.0.1:6379> ZADD comments 1621900588459950 '板凳' 127.0.0.1:6379> ZADD comments 1621900628104233 '牛逼' 127.0.0.1:6379> ZADD comments 1621900661283904 'itzhai.com' # 按照score排序进行范围查找,实现分页效果,查找第一页 127.0.0.1:6379> zrangebyscore comments 0 1621901132532229 withscores limit 0 3 沙发 1621900305499398 板凳 1621900588459950 牛逼 1621900628104233 # 查找第二页,使用上一页返回的最后一个微秒时间戳作为查找的min参数 127.0.0.1:6379> zrangebyscore comments (1621900628104233 1621901132532229 withscores limit 0 3 itzhai.com 1621900661283904 |
另外,对于更新非常频繁需要排序的列表,都可以考虑使用ZSET。
24、每日签到统计 - BitMap
很多网站为了保持用户的活跃,都会搞签到活动,每日签到一次送金币啥的。
也许你会想到把签到状态放到一个HashMap中,标识用户已签到,但是随着用户数越来越多,我们就要寻找更加节省内存的存储结构了,这个时候,BitMap就派上用场了。
以下是记录某一天签到记录的例子:
1 2 3 4 5 6 7 8 9 10 | # 通过 sign:20210525 记录5月25日的签到的用户记录 127.0.0.1:6379> SETBIT sign:20210525 10010 1 0 127.0.0.1:6379> SETBIT sign:20210525 10086 1 0 127.0.0.1:6379> SETBIT sign:20210525 99980 1 0 # 统计5月25日的前导记录 127.0.0.1:6379> BITCOUNT sign:20210525 3 |
以下是统计连续两天签到的用户记录数:
1 2 3 4 5 6 7 | 127.0.0.1:6379> SETBIT sign:20210526 10010 1 0 # 通过与操作获取连续两天都签到的用户数 127.0.0.1:6379> BITOP AND result sign:20210525 sign:20210526 12498 127.0.0.1:6379> BITCOUNT result 1 |
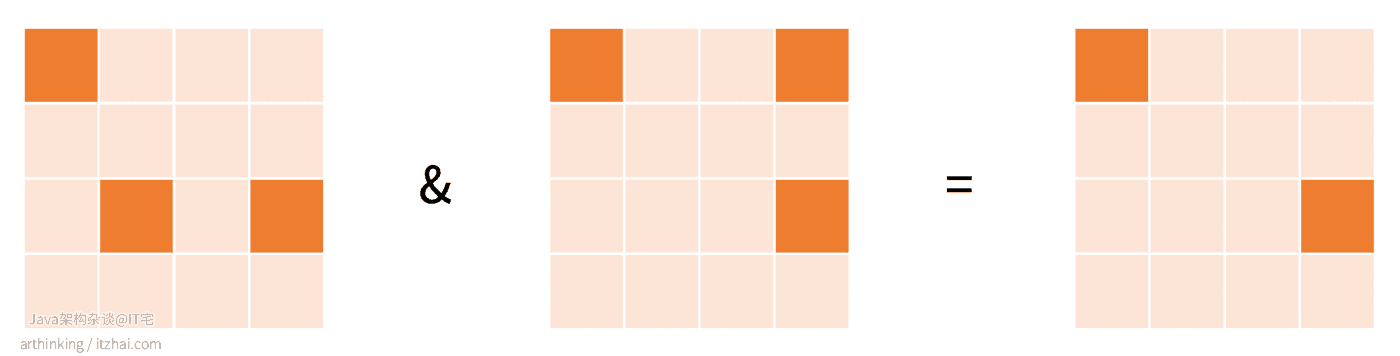
如果用户的标识比较复杂,不能直接作为BitMap的偏移量,或者用户标识已经超过了Redis的BitMap能够存储的范围,我们可以进一步使用BloomFilter,通过哈希函数去做映射,当然这意味着你需要接受一定范围内的偏差。
254、查找附近的景点 - Geospatial
这种场景,我们很自让的想到了要用Geospatial功能了。
下面我们初始化一些景点的坐标:
1 2 3 4 5 6 7 8 9 10 | 127.0.0.1:6379> GEOADD inner-mongolia 119.933018 50.829028 恩和俄罗斯民族乡 127.0.0.1:6379> GEOADD inner-mongolia 117.95893 49.493591 呼伦贝尔大草原 127.0.0.1:6379> GEOADD inner-mongolia 119.766941 49.219447 卢布里西餐厅 127.0.0.1:6379> GEOADD inner-mongolia 120.346281 47.208699 阿尔山国家森林公园 127.0.0.1:6379> GEOADD inner-mongolia 120.133019 50.536113 白桦林景区 127.0.0.1:6379> GEOADD inner-mongolia 117.684185 49.5045 猛犸公园旅游景区 127.0.0.1:6379> GEOADD inner-mongolia 119.752034 49.216568 呼伦贝尔古城 127.0.0.1:6379> GEOADD inner-mongolia 117.671052 49.339278 呼伦湖 127.0.0.1:6379> GEOADD inner-mongolia 121.481696 50.785409 敖鲁古雅使鹿部落景区 127.0.0.1:6379> GEOADD inner-mongolia 101.087036 41.967675 额济纳胡杨林 |
现在我们刚从海拉尔机场出来,坐标:119.83751,49.214948,查找附近150公里的景点:
1 2 3 4 5 6 7 8 9 | 127.0.0.1:6379> GEORADIUS inner-mongolia 119.83751 49.214948 150 km ASC COUNT 10 WITHDIST 卢布里西餐厅 5.1516 呼伦贝尔古城 6.2127 呼伦贝尔大草原 139.5841 白桦林景区 148.4668 |
走,玩去~ ????
26、消息队列 - LIST、STREAM
如果要实现一个消息队列,在Redis 5.0之前,我们可能会想到LIST。在前面我们也提到,通过LPUSH,LPOP,RPUSH,RPOP操作,可以把List当成队列或者栈来使用。
26.1、使用LIST
使用List实现的一个最简单的消息队列模型如下:
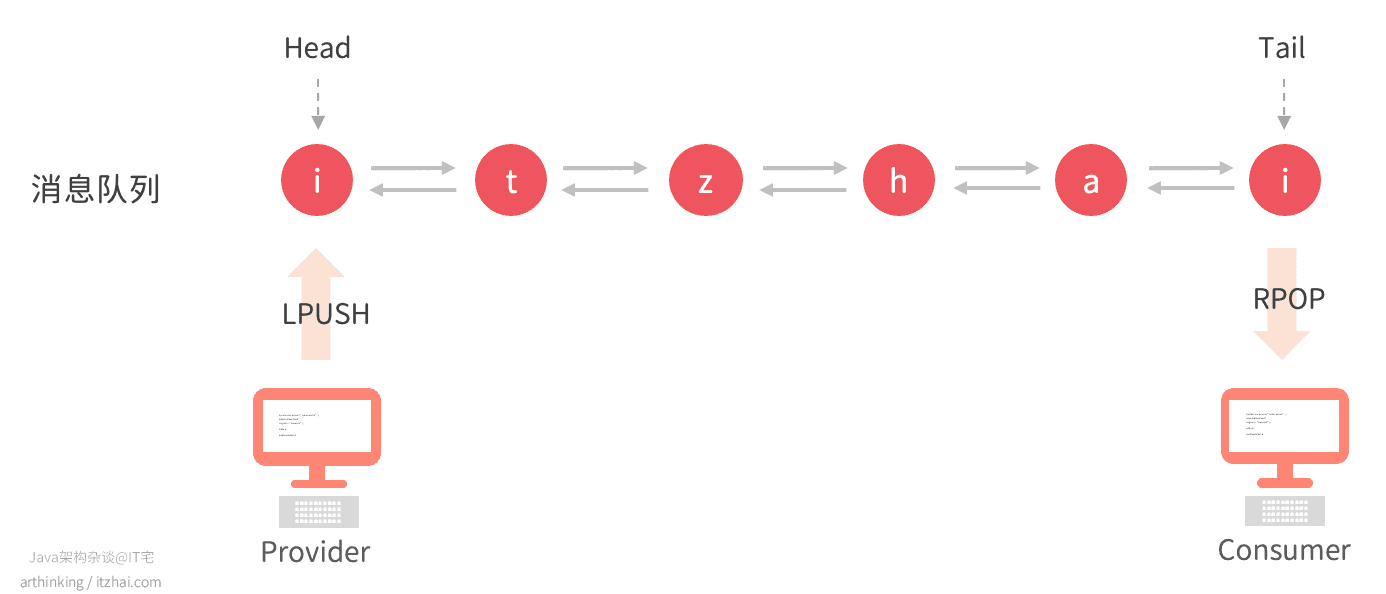
消息队列由Redis的List充当,Provider使用LPUSH命令往消息队列中推送消息,Consumer使用RPOP从消息队列中拉取消息。
当然,可以支持多个消费者:
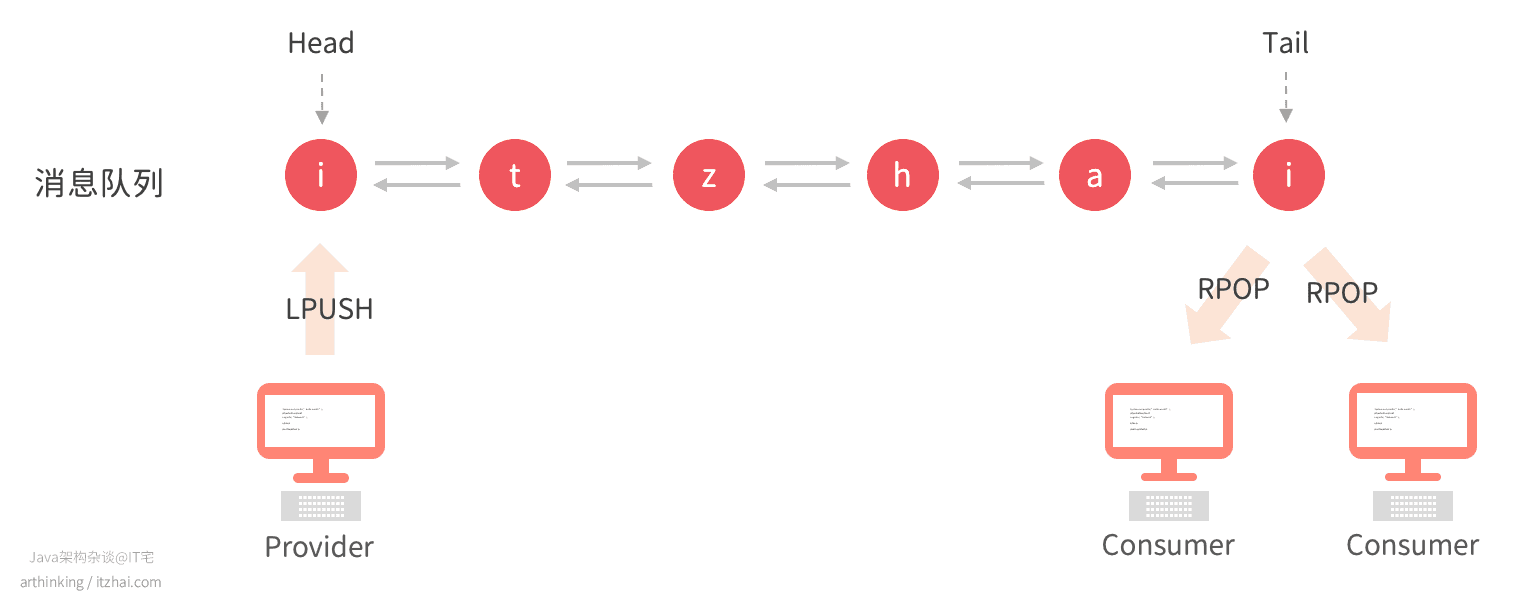
List中的元素一旦出队列之后,就再也找不到了这会导致消息一旦消费失败,就会导致消息丢失。为了保证消息的可靠性,我们可以引入多一个备份消息列表。每当执行POP的时候,顺便把消息写入到备份消息队列中,等待消费者真正的处理完消息之后,再从备份的消息队列中删除掉消息:
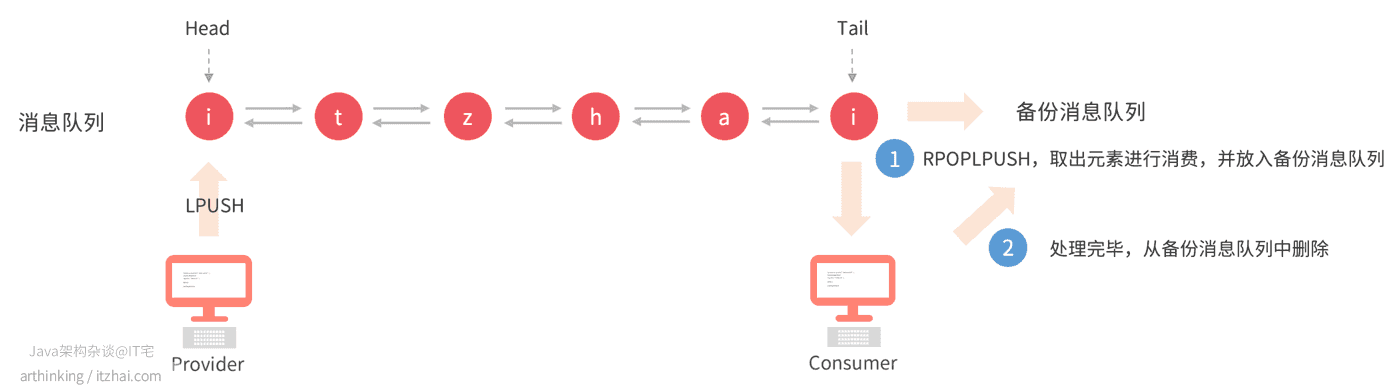
当然,也可以引入ACK机制,在消息消费完毕之后,再让消息从队列中POP出来,但这样会导致消息不能多个消费者并行消费,必须等到上一个消息处理完,并且发送了ACK之后,才会从List中取出,才能得继续读取下一条消息。
但是,使用List作为消息队列会存在以下问题:
- ID由客户端自己生成,需要客户端另外准备一个唯一ID生成器组件;
- 不支持消息分组:虽然可以支持多个消费者同时消费同一个消息队列,但是list这个结构不支持一条消息被多个消费者重复消费;
- 消息可靠性无法保证,消息可能会丢失,导致未被消费到,虽然可以通过备份消息队列处理。
为此,在Redis 5.0中,引入了Stream数据类型,非常适合用作消息队列。
为了进一步提高CPU效率,我们可以使用阻塞式的API,如
BRPOP、BRPOPLPUSH,这样可以挂起线程,让线程进入等待,避免在队列还没有元素的时候反复的进行网络请求,减少系统资源消耗。
26.2、使用Stream
Stream,抽象日志类型,存储起来的数据,不会立刻删除掉,而是可以传入一个偏移量进行反复读取。
Stream支持一下特性:
- 自动生成ID,ID顺序增长,保证有序性;
- 支持消息的分组消费,这个特性借鉴了kafka;
- 支持消息的ACK机制,支持重复读取消息,不像List中的消息,POP出来之后,就再也找不到了。
使用Stream实现消息队列的关键命令如下:
- XADD:添加日志消息
- XREAD:读取日志消息
- XGROUP:创建分组
- XREADGROUP:按分组读取消息
- XPENDING:检查待处理消息列表,即每个消费组内消费者已读取,但是尚未得到确认的消息
- XACK:用于消费完之后,发送ACK消息给Stream,这个时候消息将从XPENDING中移除
- XCLAIM:如果某一个客户端挂了,可以使用此命令,让其他Consumer主动接管它的pending msg
具体命令使用,参考Part I中的相关内容。
使用Stream实现的消息队列,我们在讲Stream数据类型的时候已经讲过了,我们再来回顾一下这张图:
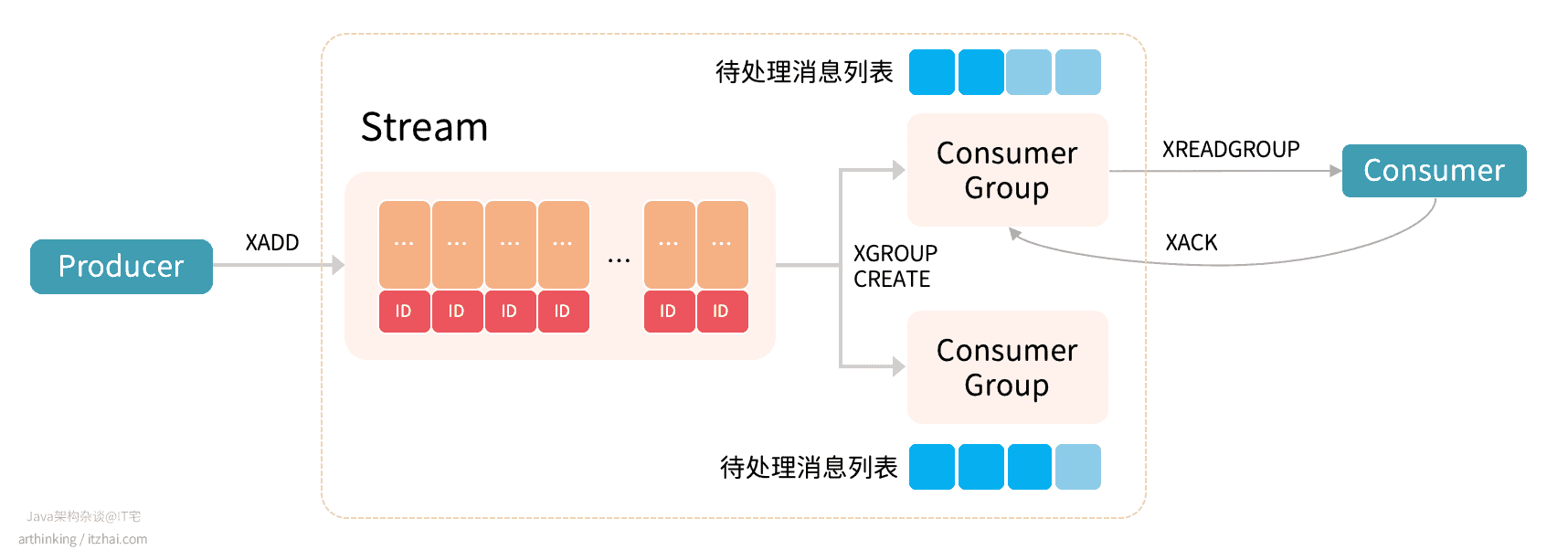
- 生产者通过XADD命令往Stream中添加消息:
1
| XADD articles * title redis author arthinking
|
默认的,会为每条消息生成一个唯一ID;
通过XGROUP CREATE创建Group分组;
消费者通过XREADGROUP命令消费分组中的消息,一条消息只会被同一个消费分组下的一个消费者消费,不同消费分组可以消费相同的消息
如果XREADGROUP命令没有指定NOACK选项,那么默认的会把每个消费分组中被消费者取出的消息放入待处理消息列表中;
消费者消费完消息后,执行XACK命令,把消息从待处理消息列表中删除。
使用消息队列需要注意什么
一般的,我们在使用消息队列的时候,业务实现尽量不要依赖消息的顺序,业务本身做好幂等,最后,要考虑消息可靠性,我们是否需要确保消息不能丢失,如果不能丢失,那么就要考虑装满的消息队列中间件了。
26.3、可以使用Stream代替消息队列中间件吗?
使用Redis的Stream做消息队列的优势是,部署简单,不需要依赖其他第三方组件。
需要注意的是,由于Redis持久化机制会导致丢数据的问题,Stream也可能丢消息。如果需要更加强大的消息队列,比如,金融业务场景,不允许丢失消息的场景,那么就得用上专业的消息队列组件了。
而Redis的Stream则更适用于发短信、消息推送等对可靠性要求不高的业务场景。
27、统计不重复的访客 - HyperLogLog
当然,我们也可以使用BitMap进行统计,但是有没有一种更加节省内存,统计效率更高的方式呢?如果你允许支持一定范围内的误差,那么HyperLogLog就派上用场了。
关于HyperLogLog的原理,我在 Part 1部分已经做了介绍了,如果要用HyperLogLog统计不重复访客,操作起来很简单:
1 2 3 4 5 6 | # 往HyperLogLog中记录访客信息 127.0.0.1:6379> PFADD visitors 10010 10086 itzhai.com arthinking itzhai.com 10010 1 # 获取不重复的访客 127.0.0.1:6379> PFCOUNT visitors 4 |
28、如何实现多个Redis命令原子操作
想象以下,我们要执行以下的操作:
1 2 3 | a = GET test; a ++; SET test a |
有没有办法保证原子性呢?如果直接这样顺序执行,多线程场景下,可能会导致数据错误。
为了实现这个功能更,Redis实现了原子操作命令:DECR, INCR
7.1、DECR, INCR
DECR key
时间复杂度: O(1),将存储在 key 中的数字减一。如果该键不存在,则在执行操作前将其设置为 0。如果键包含错误类型的值或包含不能表示为整数的字符串,则返回错误。此操作仅限于 64 位有符号整数。
返回:递减后key的值。
INCR key
时间复杂度: O(1),将存储在 key 中的数字增加 1。如果该键不存在,则在执行操作前将其设置为 0。如果键包含错误类型的值或包含不能表示为整数的字符串,则返回错误。此操作仅限于 64 位有符号整数。
注意:这是一个字符串操作,因为 Redis 没有专用的整数类型。存储在键中的字符串被转换为64 位有符号10进制整数来执行操作。
返回:递增后key的值。
通过这两个命令,可以保证整数的原子递增和递减。
如果我们要原子执行的是多个Redis命令,那么如何实现呢。这对这种场景,可以使用Lua脚本来实现。
7.2、Redis中执行Lua脚本实现原子操作
我们先来举个需要原子执行多个Redis命令的例子,可能例子不是很恰当,不过足以说明没有原子性执行一批Redis命令导致的问题。
我们需要在Redis中分别记录4个商品的最后购买人,而在业务逻辑中,4个商品是批量下单更新的,更新完之后,再分别设置了商品的购买人,逻辑如下:
1 2 3 4 5 | update product set buyer = Jack where id in(1, 2, 3, 4); HSET prod:1 BUYER Jack; HSET prod:2 BUYER Jack; HSET prod:3 BUYER Jack; HSET prod:4 BUYER Jack; |
如果此时,有多个线程同时对这些商品执行了库存扣减操作,如果这几行代码不是原子性执行,那么就可能导致4个商品的最后购买人和product表里面的不一致了,如下图:

为了避免这个问题,我们可以通过Lua脚本写一个批量更新商品最近购买人的脚本:
1 2 3 4 | local name = ARGV[1]; for k, v in ipairs(KEYS) do redis.call("hset", v, "BUYER", name); end; |
然后直接执行即可
redis-cli -p 6379 -c --eval batch_update.lua prod:1 prod:2 prod:3 prod:4 , arthinking
最终,可以发现,4个商品的BUYER字段都同时更新了:
1 2 3 4 5 6 7 8 9 | ➜ script redis-cli -p 6379 -c --raw 127.0.0.1:6379> HGET prod:1 BUYER arthinking 127.0.0.1:6379> HGET prod:2 BUYER arthinking 127.0.0.1:6379> HGET prod:3 BUYER arthinking 127.0.0.1:6379> HGET prod:4 BUYER arthinking |
为了避免每次执行lua脚本,都需要通过网络传递脚本到Redis服务器,我们可以通过SCRIPT LOAD命令把lua脚本加载到Redis中,然后通过EVALSHA命令执行:
1 2 3 4 5 6 7 8 9 | 127.0.0.1:6379> script load 'local name = ARGV[1];for k, v in ipairs(KEYS) do redis.call("hset", v, "BUYER", name); end;' 526b107ee608d0695e33f34f9358d5a18858400d 127.0.0.1:6379> EVALSHA 526b107ee608d0695e33f34f9358d5a18858400d 2 prod:1 prod:2 itzhai 127.0.0.1:6379> hget prod:1 BUYER itzhai 127.0.0.1:6379> hget prod:2 BUYER itzhai |
**SCRIPT LOAD:**将脚本加载到脚本缓存中,但不执行它,并返回脚本的SHA1摘要。除非调用SCRIPT FLUSH,否则脚本会一直存在缓存中。
**EVALSHA:**使用该命令,通过脚本的SHA1进行调用脚本。
除了Redis命令的原子操作的场景,我们面临更多的问题是,在分布式系统中,对业务代码中的一组业务需要保证原子性。这个时候,就只能使用分布式锁了。
29、分布式锁:如何实现业务原子操作
在一个JVM,如果一组业务操作要确保原子性,我们可以通过JDK提供的各种锁,如synchronized和ReentrantLock等。
而在一个分布式如果一个业务操作必须要确保原子性,单靠JDK的锁是无法锁住的。此时,我们就需要借助一个共享存储系统来实现一个分布式锁。
29.1、可否直接使用数据库锁实现分布式锁?
在并发度不高的场景中,我们可以使用数据库的行锁或者间隙锁来作为分布式锁,只有获取到了数据库锁的节点才可以继续往下执行。这数据库行锁是悲观锁,在其他线程获取不到锁的情况下,会进入阻塞状态,如果这种并发竞争度高的话,那么就会对数据库性能有开销了。
总结下数据库悲观锁的优缺点:
优点:
- 部署成本低,除了数据库,无需依赖其他组件;
- 数据库保证了持久化,可靠性高。
缺点:
- 如果并发度高,数据库锁的性能开销会增加,并且导致占用大量数据库连接,可能导致数据库连接池耗尽。
为了避免对数据库连接池造成影响,我们可以通过其他方式实现分布式锁,Redis就可以用来实现分布式锁。
29.2、如何用Redis实现一把单机版的分布式锁
Redis中的SETNX命令可以在设置key的时候,同时返回key是否已经存在,这有点像上锁,判断锁是否已经存在的场景。
SETNX命令
如果不存在,则设置key为保持字符串,并返回1;
当已经持有一个值时,不执行任何操作,并返回0。
在Redis 2.6.12之前,可以通过这个命令实现分布式锁
不过从Redis2.6.12版本开始,可以使用以下更简单的锁定原语:
SET key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]
- NX:仅在不存在的情况下设置key;
- XX:仅设置已存在的key;
- GET:返回存储在key中的旧值,或者当key不存在时,返回nil。
如果是实现单Redis实例的分布式锁,则可以通过使用SET命令来实现。
获取锁
1 2 | // 客户端client_01尝试获取分布式锁distributed_lock,锁的过期时间为10秒 SET distributed_lock client_01 PX 10000 NX |
释放锁
释放锁的时候,为了避免勿删其他客户端的锁,我们需要先判断当前锁的持有者,如果当前锁的持有者为当前客户端,才可以发起释放锁,我们为了保证执行的原子性,这里用lua脚本来实现,release_lock.lua:
1 2 3 4 5 | if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end |
执行如下命令进行释放锁:
1 2 | ➜ script redis-cli -p 6379 -c --eval release_lock.lua distributed_lock , client_01 (integer) 1 |
如果我们这个时候,在另一个客户端client_02执行释放锁,那么将返回0,表示没有释放掉锁,因为该锁不属于client_02:
1 2 3 4 5 6 7 8 9 | # 获取锁 ➜ script redis-cli -p 6379 -c --raw 127.0.0.1:6379> SET distributed_lock client_01 PX 1000000 NX OK # 尝试用另一个客户端释放锁 127.0.0.1:6379> ➜ script redis-cli -p 6379 -c --eval del_lock.lua distributed_lock , client_03 (integer) 0 |
续命锁
细心的同学应该会看到,我在上面的例子中,给锁设置了10秒的过期时间。
那么问题来了:要是10秒内,业务没有执行完毕,而此时,锁有过期了,不是会被其他线程获取到锁就立刻开始执行业务了吗?
为了避免这种情况,我们需要给即将过期的锁进行续命。
如果我们的锁超时时间为10秒,那么我们可以在获取到锁之后,开启一个异步线程,设置一个间隔时间(10秒内)定时重新给锁过期时间为10秒后,直到业务执行完毕,然后再异步线程终止操作,再释放锁。这样就可以保证业务执行过程中,锁都不会过期了。
以上是实现单Redis实例的分布式锁。不过单Redis实例的分布式锁具有单点故障的风险,为了增加分布式锁的可靠性,我们需要实现多Redis节点的分布式锁。
29.3、如何用Redis实现一把集群版的分布式锁
Redis的作者设计了用于实现多节点的Redis分布式锁算法:Redlock,并推荐使用该算法实现分布式。
该算法的关键思路是:让客户端依次向多个Redis节点请求加锁,如果能够获得半数以上的实例的锁,那么就表示获取锁成功。否则表示加锁失败。
加锁失败的情况下,需要向所有Redis节点发起释放锁的请求。
如果获取锁的过程消耗的时间超过了锁的有效时间,那么也算加锁失败。
可用的Redis分布式实现:
- Redlock-rb Ruby 实现
- Redlock-py Python 实现
- Pottery Python 实现
- Aioredlock Asyncio Python 实现
- Redlock-php PHP 实现
- PHPRedisMutex 进一步的PHP实现
- cheprasov/php-redis-lock 用于锁的 PHP 库
- rtckit/react-redlock 异步 PHP 实现
- Redsync Go 实现
- Redisson Java 实现
- Redis::DistLock Perl 实现
- Redlock-cpp C++ 实现
- Redlock-cs C#/.NET 实现
- RedLock.net C#/.NET 实现)。包括异步和锁定扩展支持
- ScarletLock 具有可配置数据存储的 C# .NET 实现
- Redlock4Net C# .NET 实现
- node-redlock NodeJS实现
更多关于Redis分布式锁的相关内容,参考:Distributed locks with Redis[23]
29.4、通过lua脚本执行多个Redis命令,原子性一定可以得到保证吗?
Redis作为内存数据库,其“事务”与大多数人认为的经典 DBMS 中的事务完全不同。
29.4.1、Redis事务与MySQL事务有何不同?
Redis并没有类似MySQL的redolog基于WAL机制去实现原子性和持久性,通过undolog的MVCC支持隔离性,从而避免幻读。
虽然Redis有MULTI和EXEC命令配合使用来实现多个操作的事务块,但并不能实现MySQL那样的ACID事务特性。为了保证原子性,MULTI/EXEC 块将 Redis 命令的执行延迟到 EXEC。所以客户端只会把命令命令堆在内存的一个指令队列里,直到执行EXEC的时候,一起执行所有的命令,从而实现原子性。

把指令记录到指令队列过程中,如果检测出语法有错误的命令,这种情况下执行EXEC命令会丢弃事务,原子性可以得到保证。
如果Redis事务块执行过程中部分命令报错报错之后,数据是不会回滚的。此时原子性得不到保证
例如,如果指令语法没问题,只是操作的类型不匹配,是检测不出来的,实际执行EXEC的时候,会正确执行没问题的指令,有问题的指令报错,导致事务块的原子性不能得到保证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | 127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> SET str1 itzhai QUEUED # 这里实际执行的时候应该报错 127.0.0.1:6379(TX)> LPUSH str1 com QUEUED 127.0.0.1:6379(TX)> SET str2 arthinking QUEUED 127.0.0.1:6379(TX)> EXEC OK WRONGTYPE Operation against a key holding the wrong kind of value OK 127.0.0.1:6379> GET str1 itzhai # 可以发现虽然执行过程中报错了,但是str2也成功设置了值 127.0.0.1:6379> GET str2 arthinking |
另外,执行事务块的过程中,是不会触发执行RDB的,所以事务命令操作不会保存到RDB中。但是会记录到AOF文件中。
如果事务执行过程中异常停机,导致AOF文件出错,此时可以**使用redis-check-aof对原来的 AOF 文件进行修复,清除事务中已完成的操作,进而再启动redis。**这种情况,原子性是可以得到保证的。
既然谈到了原子性,我们再来看看Redis事务如何才能实现隔离性。
29.4.2、如何保证Redis的隔离性?
**隔离性:**不同事务先后提交,最终的执行效果是串行的,也就是在执行过程中,事务能感知到数据的变化只有是自己操作引起的,不会因为其他事务操作导致感知到数据变化。
在MySQL的InnoDB引擎的可重复读隔离级别中,为了避免幻读,引入了间隙锁,为了避免不可重复读,引入了MVCC。
当需要修改数据的时候,会采用当前读模式,锁定需要修改的记录,从而避免多个事务同时更新同一条记录导致的并发过程中数据被覆盖,不能得到预期的执行结果。
而Redis中修改数据是不会锁定需要修改的记录的,并没有MySQL的当前读机制。
当前读和快照读
当前读:读取记录的最新版本,并且读取时要保证其他并发事务不能修改当前记录,为此会对读取的记录进行加锁。
可以使用**SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE、UPDATE、DELETE、INSERT、**操作实现当前读。本质上都是在这些操作的过程中,先请求获取锁。
快照度:读取的是快照版本,也就是历史版本,通过MVCC + undo log实现。
为了保证隔离性,就需要通过其他方式来实现了。Redis是通过WATCH命令来实现MySQL的当前读机制的。
与MySQL的事前锁定记录不同,Redis采用的是事后通知记录变更进而取消需要当前读的操作。
WATCH命令:
Redis Watch 命令用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
以下是通过WATCH命令保证隔离性的例子:

Part Ⅷ. 好用的Redis性能分析与监控工具
30、Redis性能分析与监控工具
30.1、Redis监控工具
info命令
最常用的就是Redis内置的info命令了。通过info命令,可以打印有关Redis服务器的指标和信息。
输出的信息分为以下10组:server, client, memory, persistence, stats, replication, cpu, commandstats, cluster, keyspace。
启用慢日志[24]
Redis 慢日志是一种记录超过指定执行时间的查询的系统。执行时间不包括与客户端通信、发送回复等 I/O 操作,而只是实际执行命令所需的时间(这是命令执行的唯一阶段,该阶段Redis线程会被阻塞)。
可以通过编辑redis.conf或在服务器运行时使用 CONFIG GET 和 CONFIG SET 命令来完成配置。
如,可以通过以下命令设置慢日志监控参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # 命令执行超过5毫秒则记录为慢日志,注意,设置为负数会禁用慢日志,设置为0会强制记录每个命令 127.0.0.1:6379> CONFIG SET slowlog-log-slower-than 5000 OK # 只保留最近1000条慢日志 127.0.0.1:6379> CONFIG SET slowlog-max-len 1000 OK # 查看慢日志 127.0.0.1:6379> slowlog get 2 1) 1) (integer) 14 2) (integer) 1309448221 3) (integer) 15 4) 1) "ping" 2) 1) (integer) 13 2) (integer) 1309448128 3) (integer) 30 4) 1) "slowlog" 2) "get" 3) "100" |
redis-stat
Redis-stat是一个Redis指标可视化监控工具,采用ruby开发,基于Redis的info命令来统计,不影响Redis性能。
RedisLive
RedisLive是一个采用Python开发的Redis可视化及查询分析工具。
redis_exporter
如果您正在使用Prometheus,则可以使用这个工具。redis_exporter是为Prometheus提供的Redis指标监控exporter,支持Redis 2.x, 3.x, 4.x, 5.x, and 6.x。
redmon
简单的基于 sinatra 的 redis 仪表板,提供了用于管理 redis 的 Web 界面:cli、admin,同时能够实时监控Redis。
接下来介绍其中最常用的性能指标[25]。
30.2、Redis性能监控常用指标
30.2.1、used_memory
used_memory:给Redis分配的内存总字节数
used_memory_human:以更易读懂的格式给出相同的值
用于判断是否由于内存交换引起的性能问题
如果used_memory超过了操作系统总可用内存,操作系统将开始进行内存交换,旧的内存部分将被写入磁盘,从磁盘写读写数据的速度比从内存中读写数据的速度慢了5个数量级,如果内存交换发生在Redis进程上,Redis的性能以及依赖Redis的任何应用程序性能将受到严重的影响。
跟踪内存使用情况,以解决性能问题
如果没有开启RDB,那么Redis可以使用的内存总量超过可用内存的95%。
如果开启了RDB,那么如果Redis使用超过45%的可用内存,就会变得有风险了。当然,这个比例也不是绝对的,如果Redis实例写比读的执行频率高很多,则需要尽可能保证这个比例。如果读比写频率高很多,那可以适当调高这个比例。
如何减少Redis内存占用?
- 如果规划要存储的数据小于4GB,请使用32位的Redis实例,因为32位的指针大小是64位的一半,其内存占用小多了;
- 为键设置过期时间;
- 通过将maxmemory设置为可用内存的45%(未开启RDB则为95%),并通过选择volatile-ttl或者allkey-lru等作为驱逐策略,如非必要,避免使用noeviction,可用严格限制Redis的内存使用,以确保不会产生内存交换。
30.2.2、total_commands_processed
处理的命令数,可以通过该指标来诊断延迟。
例如,如果处理的命令激增,并且导致Redis处理不过来,那么就会导致Redis响应变慢,该指标值突然增加;或者如果正在执行一个复杂度很高的命令,导致Redis被阻塞住,那么同样会导致Redis响应变慢,该指标值下降或者停滞了。
可以设置一个脚本来定期记录total_commands_processed指标,并测量延迟。如果观测到指标相比之前有所增加,可能是突然接受了一大批命令,并且在排队等待执行,此时可能导致Redis处理不过来导致响应延迟;如果观测到指标相比之前有所减少,可能是有几个阻塞系统的慢命令在执行。
如何解决大批命令排队或者慢命令导致的延迟问题?
- 通过使用多参数命令,如MGET,MSET,LPUSH, RPUSH等,把一批数据一次性传递给Redis,而不是循环一个一个命令的传递,这可以减少命令数量;
- 使用pipeline,将多个命令一起发送给Redis,这样可以减少由于网络开销导致的延迟;
- 避免使用bigkey,避免使用复杂度高的命令;
30.2.3、Latency
Latency,延迟,衡量Redis服务器响应所需的平均时间,次指标无法通过Redis info命令获得,可以通过以下命令得到:
1 2 | ➜ ~ redis-cli -p 6379 --latency min: 0, max: 2, avg: 0.20 (8293 samples) |
如何诊断和解决Redis延迟问题?
一旦您确定延迟是一个问题,可以采用以下措施来诊断和解决相关性能问题:
**使用慢日志识别慢命令:**通过查看Redis慢日志,可以快速识别超过用户指定执行时间的命令;
1 2 3 4 5 6
➜ ~ redis-cli -p 6379 127.0.0.1:6379> slowlog get (empty array) # 通过以下命令设置慢日志的阈值 127.0.0.1:6379> config set slowlog-log-slower-than 5000 OK
**监控客户端连接:**由于Redis是单线程的,随着客户端连接数量增加,分配给每个客户端的资源百分比就会减少,导致每个客户端花费越来越多的时间等待Redis服务器执行操作和响应。监控客户端连接数很重要,因为应用程序可能无法有效关闭未使用的连接:
1 2 3 4 5 6 7 8 9 10
127.0.0.1:6379> info clients # Clients connected_clients:3 cluster_connections:0 maxclients:10000 client_recent_max_input_buffer:48 client_recent_max_output_buffer:0 blocked_clients:0 tracking_clients:0 clients_in_timeout_table:0
**限制客户端连接:**Redis 2.6以及更高版本可以在redis.conf中或者redis-cli中配置Redis服务器的最大连接数maxclients,你应该设置maxclients为预期峰值的110~150%;
**改善内存管理:**需要重点监控内存是否够用。
30.2.4、Fragmentation Ratio
碎片率,可以通过mem_fragmentation_ratio指标得到内存碎片率。
mem_fragmentation_ratio = used memory rss / used memory
used_memory_rss:操作系统分配给Redis实例的内存大小,表示Redis进程占用的物理内存大小;
used_memory:Redis使用其分配器分配的内存大小。
什么时候碎片化严重?
mem_fragmentation_ratio < 1 表示Redis内存分配超出了物理内存,操作系统正在进行内存交换;
mem_fragmentation_ratio > 1 合理的指标值;
mem_fragmentation_ratio > 1.5 表示Redis消耗了实际需要物理内存的150%以上,其中50%是内存碎片率。
如果这个值超过1.5(50%)了,说明碎片化还是比较严重的,需要进行优化了。
30.2.5、Evictions
evicted_keys 指标给出了已被驱逐(删除)的key数量。
如果evicted_keys增长比较快,说明部分CPU用来回收key了。
您可以通过将 maxmemory-policy 设置为 volatile-lru 或 volatile-ttl 等选择不同的驱逐算法。
如果您的 evicted_keys 始终高于0,可能会导致命令延迟的增加,因为此时Redis除了处理客户端命令请求之外,还需要处理频繁的驱逐工作。但是驱逐并不像内存交换那样对性能具有更大的杀伤力。
如何减少Redis驱逐的影响?
这里有两种方法可以减少Redis的驱逐次数:
- 增加maxmemory限制,但是要注意,不要让内存不足导致进行内存交换;
- 对您的实例进行分区。
30.2.6、其他更多指标[26]
- keyspace_misses:key值查找未命中缓存的次数,如果出现次数太多,则要考虑是否有缓存穿透问题,或者是否被恶意攻击;
- blocked_clients:等待阻塞调用的客户端数量(BLPOP、BRPOP、BRPOPLPUSH、BLMOVE、BZPOPMIN、BZPOPMAX);
- instantaneous_ops_per_sec:每秒处理的命令数;
- total_commands_processed:服务器处理的命令总数;
- total_connections_received:服务器接受的链接总数;
- expired_stale_perc:可能已过期的key的百分比;
- used_cpu_sys:Redis服务器消耗的系统CPU,是服务进程所有线程的消耗系统CPU之和;
- used_cpu_sys_main_thread:Redis服务器主线程消耗的系统CPU;
- used_cpu_user_main_thread:Redis服务器主线程消耗的用户CPU...
如何快速得到Redis服务器的性能?
Redis 包含redis-benchmark[27]模拟 N 个客户端同时发送 M 个查询执行的运行命令的实用程序。
可以通过redis-benchmark命令对Redis进行性能测试:
./redis-benchmark -c 100 -n 5000
对应为100个连接,执行5000次请求的性能结果。
以上就是Redis相关的内容,由于Redis的思维导图比较大,所以没有在文章中放完整的截图,感兴趣的朋友可以到Java架构杂谈公众号回复 Redis 获取思维导图文件。本文转自Java技术栈的空间,感谢原作者。
References
antirez / sds. Retrieved from https://github.com/antirez/sds ↩︎
Redis - Strings. Retrieved from https://www.tutorialspoint.com/redis/redis_strings.htm ↩︎
Redis Modules: an introduction to the API. Retrieved from https://redis.io/topics/modules-intro ↩︎
RPC11.md | Redis Change Proposals. Retrieved from https://github.com/redis/redis-rcp/blob/master/RCP11.md ↩︎
Bloom Filter Calculator. Retrieved from https://hur.st/bloomfilter ↩︎
RedisBloom Bloom Filter Command Documentation. Retrieved from https://oss.redislabs.com/redisbloom/Bloom_Commands/ ↩︎
Redis 中 HyperLogLog 讲解. Retrieved from https://www.huaweicloud.com/articles/4318da1b4433ab32b21e385dde2247d6.html ↩︎
HyperLogLog: A Simple but Powerful Algorithm for Data Scientists. Retrieved from https://towardsdatascience.com/hyperloglog-a-simple-but-powerful-algorithm-for-data-scientists-aed50fe47869 ↩︎
Redis 中 HyperLogLog 的使用场景. Retrieved from https://www.cnblogs.com/54chensongxia/p/13803465.html ↩︎
Geohash. Retrieved from https://en.wikipedia.org/wiki/Geohash ↩︎
Redis Keyspace Notifications. Retrieved from https://redis.io/topics/notifications ↩︎
NUMA Deep Dive Part 2: System Architecture. Retrieved from http://www.staroceans.org/system_architecture.htm ↩︎
NUMACTL, taskset and other tools for controlling NUMA accesses notes. Retrieved from https://yunmingzhang.wordpress.com/2015/07/22/numactl-notes-and-tutorialnumactl-localalloc-physcpubind04812162024283236404448525660646872768084889296100104108112116120124/
[^ 20]: Caching Strategies and How to Choose the Right One. Retrieved from https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/ ↩︎Replication. Retrieved from https://redis.io/topics/replication ↩︎
Redis Sentinel Documentation. Retrieved from https://redis.io/topics/sentinel ↩︎
Redis Cluster Specification. Retrieved from https://redis.io/topics/cluster-spec ↩︎
Codis 使用文档. Retrieved from https://github.com/CodisLabs/codis/blob/release3.2/doc/tutorial_zh.md ↩︎
洞悉MySQL底层架构:游走在缓冲与磁盘之间. Retrieved from ttps://www.itzhai.com/articles/insight-into-the-underlying-architecture-of-mysql-buffer-and-disk.html ↩︎ ↩︎
Hello, Ehcache. Retrieved from https://www.ehcache.org/documentation/2.8/get-started/introduction.html ↩︎
ZRANGEBYSCORE. Retrieved from https://redis.io/commands/ZRANGEBYSCORE ↩︎
Distributed locks with Redis. Retrieved from https://redis.io/topics/distlock ↩︎
SLOWLOG subcommand [argument]. Retrieved from https://redis.io/commands/slowlog ↩︎
Understanding the Top 5 Redis Performance Metrics. Retrieved from https://www.datadoghq.com/pdf/Understanding-the-Top-5-Redis-Performance-Metrics.pdf ↩︎
INFO [section]. Retrieved from https://redis.io/commands/INFO ↩︎
How fast is Redis?. Retrieved from https://redis.io/topics/benchmarks ↩︎
黄健宏. Redis设计与实现. 机械工业出版社 ↩︎
蒋德钧. Redis核心技术与实战. 极客时间 ↩︎
redis.io/documentation. Retrieved from https://redis.io/documentation ↩︎