 info以一种易于解释且易于阅读的格式,返回关于Redis服务器的各种信息和统计数值,命令如下:
info以一种易于解释且易于阅读的格式,返回关于Redis服务器的各种信息和统计数值,命令如下:redis-cli -h x.x.x.x -p nn -a password info all
当不带参数直接调用 info 命令时,使用 default 作为默认参数。
info命令的使用方法有以下三种:
info:部分默认的Redis系统状态统计信息。
info default:返回默认选择的信息。
info all:全部Redis系统状态统计信息。
info section:某一块的系统状态统计信息,其中section可以忽略大小写。
相关的监控条目
Server: General information about the Redis server
Stats: General statistics
Memory: Memory consumption information
Clients: Client connections section
Persistence: RDB and AOF information
Replication: Master/slave replication information
CPU: CPU consumption statistics
Commandstats: Redis command statistics
Cluster: Redis Cluster information
Keyspace: Database related statistics
Key metrics
We mentioned several Redis metrics worth monitoring. Here’s where to find them with the info command:
Section Metric
Stats
instantaneous_ops_per_sec
hit rate*
evicted_keys
rejected_connections
keyspace_misses
Memory
used_memory
mem_fragmentation_ratio
Clients
blocked_clients
connected_clients
Persistence
rdb_last_save_time
rdb_changes_since_last_save
Replication
master_link_down_since
connected_slaves
master_last_io_seconds_ago
Keyspace
keyspace size
The only exception is the hit rate, which must be calculated using the keyspace_hits and keyspace_misses metrics from the Stats section like this:
HitRate=keyspace_hits/(keyspace_hits+keyspace_misses)
redis 基本信息查看
INFO [section]
以一种易于解释(parse)且易于阅读的格式,返回关于 Redis 服务器的各种信息和统计数值。通过给定可选的参数 section,可以让命令只返回某一部分的信息:
server 部分记录了 Redis 服务器的信息,它包含了Redis服务本身的一些信息,例如版本号、运行模式、操作系统的版本、TCP端口等:
redis_version : Redis 服务器版本
redis_git_sha1 : Git SHA1
redis_git_dirty : Git dirty flag
os : Redis 服务器的宿主操作系统
arch_bits : 架构(32或64位)
multiplexing_api : Redis 所使用的事件处理机制
gcc_version : 编译 Redis 时所使用的 GCC 版本
process_id : 服务器进程的 PID
run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
tcp_port : TCP/IP 监听端口
uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
uptime_in_days : 自 Redis 服务器启动以来,经过的天数
lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
clients 部分记录了已连接客户端的信息,它包含了连接数、阻塞命令连接数、输入输出缓冲区等相关统计信息:
connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端)
client_longest_output_list : 当前连接的客户端当中,最长的输出列表
client_longest_input_buf : 当前连接的客户端当中,最大输入缓存
blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
memory 部分记录了服务器的内存信息,它包含Redis内存使用、系统内存使用、碎片率、内存分配器等相关统计信息:
used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps等命令的输出一致。
used_memory_peak : Redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值
used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位)
mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率
mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
在理想情况下,used_memory_rss 的值应该只比 used_memory 稍微高一点,当 rss > used,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。
Because Redis does not have control over how its allocations are mapped to memory pages, high used_memory_rss is often the result of a spike in memory usage.当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致,可查看 used_memory_peak 的值可以验证这种情况是否发生。
persistence 部分记录了跟 RDB 持久化和 AOF 持久化有关的信息,它包含以下域:
loading : 一个标志值,记录了服务器是否正在载入持久化文件。
rdb_changes_since_last_save : 距离最近一次成功创建持久化文件之后,经过了多少秒。
rdb_bgsave_in_progress : 一个标志值,记录了服务器是否正在创建 RDB 文件。
rdb_last_save_time : 最近一次成功创建 RDB 文件的 UNIX 时间戳。
rdb_last_bgsave_status : 一个标志值,记录了最近一次创建 RDB 文件的结果是成功还是失败。
rdb_last_bgsave_time_sec : 记录了最近一次创建 RDB 文件耗费的秒数。
rdb_current_bgsave_time_sec : 如果服务器正在创建 RDB 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。
aof_enabled : 一个标志值,记录了 AOF 是否处于打开状态。
aof_rewrite_in_progress : 一个标志值,记录了服务器是否正在创建 AOF 文件。
aof_rewrite_scheduled : 一个标志值,记录了在 RDB 文件创建完毕之后,是否需要执行预约的 AOF 重写操作。
aof_last_rewrite_time_sec : 最近一次创建 AOF 文件耗费的时长。
aof_current_rewrite_time_sec : 如果服务器正在创建 AOF 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。
aof_last_bgrewrite_status : 一个标志值,记录了最近一次创建 AOF 文件的结果是成功还是失败。
如果 AOF 持久化功能处于开启状态,那么这个部分还会加上以下域:
aof_current_size : AOF 文件目前的大小。
aof_base_size : 服务器启动时或者 AOF 重写最近一次执行之后,AOF 文件的大小。
aof_pending_rewrite : 一个标志值,记录了是否有 AOF 重写操作在等待 RDB 文件创建完毕之后执行。
aof_buffer_length : AOF 缓冲区的大小。
aof_rewrite_buffer_length : AOF 重写缓冲区的大小。
aof_pending_bio_fsync : 后台 I/O 队列里面,等待执行的 fsync 调用数量。
aof_delayed_fsync : 被延迟的 fsync 调用数量。
stats 部分记录了一般统计信息,它包含了Redis的基础统计信息:连接、命令、网络、过期、同步等很多统计信息:
total_connections_received : 服务器已接受的连接请求数量。
total_commands_processed : 服务器已执行的命令数量。
instantaneous_ops_per_sec : 服务器每秒钟执行的命令数量。
rejected_connections : 因为最大客户端数量限制而被拒绝的连接请求数量。
expired_keys : 因为过期而被自动删除的数据库键数量。
evicted_keys : 因为最大内存容量限制而被驱逐(evict)的键数量。
keyspace_hits : 查找数据库键成功的次数。
keyspace_misses : 查找数据库键失败的次数。
pubsub_channels : 目前被订阅的频道数量。
pubsub_patterns : 目前被订阅的模式数量。
latest_fork_usec : 最近一次 fork()操作耗费的毫秒数。
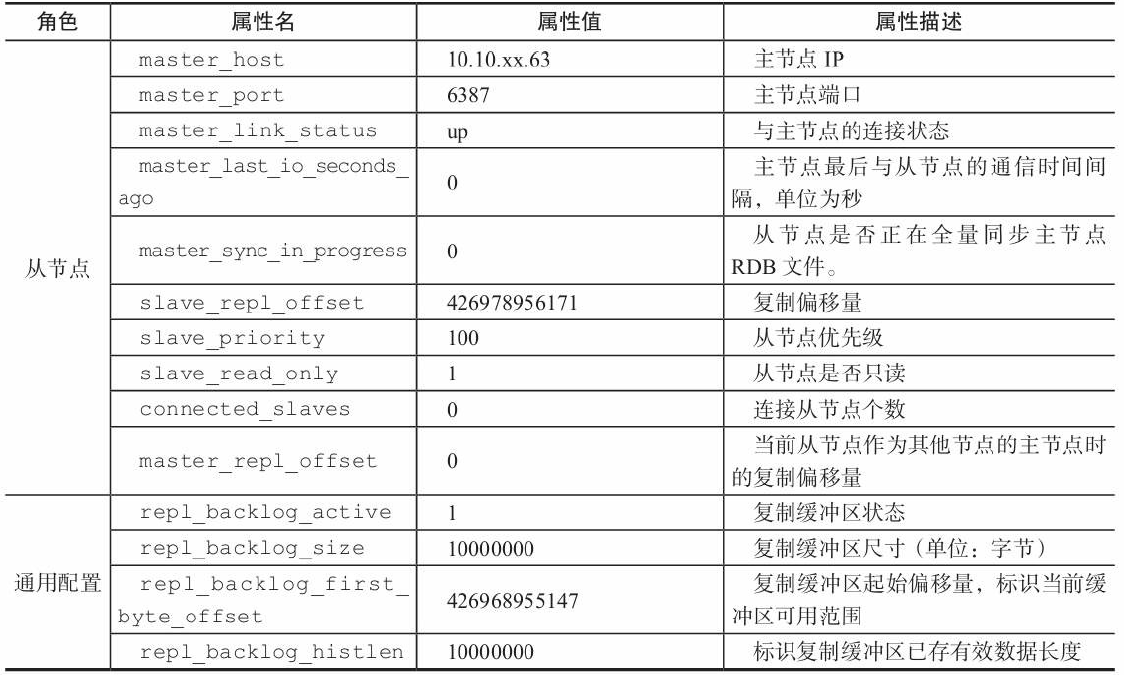
replication : Redis主从复制的一些统计信息,根据主从节点,统计信息也略有不同:
role : 如果当前服务器没有在复制任何其他服务器,那么这个域的值就是master;否则的话,这个域的值就是slave。注意,在创建复制链的时候,一个从服务器也可能是另一个服务器的主服务器。
如果当前服务器是一个从服务器的话,那么这个部分还会加上以下域:
master_host : 主服务器的 IP 地址。
master_port : 主服务器的 TCP 监听端口号。
master_link_status : 复制连接当前的状态, up 表示连接正常, down 表示连接断开。
master_last_io_seconds_ago : 距离最近一次与主服务器进行通信已经过去了多少秒钟。
master_sync_in_progress : 一个标志值,记录了主服务器是否正在与这个从服务器进行同步。
如果同步操作正在进行,那么这个部分还会加上以下域:
master_sync_left_bytes : 距离同步完成还缺少多少字节数据。
master_sync_last_io_seconds_ago : 距离最近一次因为 SYNC 操作而进行 I/O 已经过去了多少秒。
如果主从服务器之间的连接处于断线状态,那么这个部分还会加上以下域:
master_link_down_since_seconds : 主从服务器连接断开了多少秒。
以下是一些总会出现的域:
connected_slaves : 已连接的从服务器数量。
对于每个从服务器,都会添加以下一行信息:
slaveXXX : ID、IP 地址、端口号、连接状态

cpu 部分记录了 CPU 的计算量消耗统计信息,它包含以下域:
used_cpu_sys : Redis 服务器耗费的系统 CPU 。
used_cpu_user : Redis 服务器耗费的用户 CPU 。
used_cpu_sys_children : 后台进程耗费的系统 CPU 。
used_cpu_user_children : 后台进程耗费的用户 CPU 。
commandstats 部分记录了各种不同类型的命令的执行统计信息,比如命令执行的次数、命令耗费的 CPU 时间、执行每个命令耗费的平均 CPU 时间等等。对于每种类型的命令,这个部分都会添加一行以下格式的信息:
cmdstat_XXX:calls=XXX,usec=XXX,usecpercall=XXX
cluster 部分记录了和集群有关的信息,它包含以下域:
cluster_enabled : 一个标志值,记录集群功能是否已经开启。
keyspace 部分记录了数据库相关的统计信息,比如数据库的键数量、数据库已经被删除的过期键数量等。对于每个数据库,这个部分都会添加一行以下格式的信息:
dbXXX:keys=XXX,expires=XXX
当不带参数直接调用 INFO 命令时,使用 default 作为默认参数。不同版本的 Redis 可能对返回的一些域进行了增加或删减。因此一个健壮的客户端程序在对 INFO 命令的输出进行分析时,应该能够跳过不认识的域,并且妥善地处理丢失不见的域。
可用版本:>= 1.0.0
时间复杂度:O(1)
返回值:具体请参见下面的返回示例。
这里参考的redis版本是v3.0,返回参数如下:
Server 服务器的信息
# Server
redis_version:3.0.8 ## redis 服务器版本
redis_git_sha1:00000000 ## Git SHA1
redis_git_dirty:0 ## Git dirty flag
redis_build_id:d811223d6cb3a727 ##
redis_mode:standalone ## 运行模式,可分为:Cluster、Sentinel、Standalone
os:Linux 2.6.32-573.18.2.el6.x86_64 x86_64 ## redis 服务器的宿主操作系统
arch_bits:64 ## 架构(32 或 64 位)
multiplexing_api:epoll ## redis 所使用的事件处理机制
gcc_version:4.8 ## 编译 Redis 时所使用的 GCC 版本
process_id:2100 ## 服务器进程的 PID
run_id:80c1113082d87bae5c828cf51f3875bcf4d6fccc ##redis 服务器的随机标识符(用于 Sentinel 和集群)
tcp_port:4601 ## TCP/IP 监听端口
uptime_in_seconds:1904575 ## 自 redis 服务器启动以来,经过的秒数
uptime_in_days:22 ## 自 Redis 服务器启动以来,经过的天数
hz:10 ## serverCron每秒运行次数
lru_clock:1524258 ## 以分钟为单位进行自增的时钟,用于 LRU 管理
config_file:/freeoa/redis/redis.conf ## 启动 redis 的配置文件
Clients 部分记录了已连接客户端的信息
# Clients
connected_clients:19 ## 已连接客户端的数量(不包括通过从属服务器连接的客户端),Redis默认允许客户端连接的最大数量是10000。若是看到连接数超过5000以上,那可能会影响Redis的性能
client_longest_output_list:0 ## 当前连接的客户端当中,最长的输出列表
client_biggest_input_buf:0 ## 当前连接的客户端当中,最大输入缓存
blocked_clients:0 ## 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
Memory 部分记录了服务器的内存信息
# Memory
used_memory:5502288 ## 由 redis 分配器分配的内存总量,以字节(byte)为单位,也就是内部存储的所有数据内存占用量
used_memory_human:5.25M ## 以人类可读的格式返回 redis 分配的内存总量
used_memory_rss:7254016 ## 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top、ps 等命令的输出一致。
used_memory_peak:11285384 ## redis 的内存消耗峰值(以字节为单位)
used_memory_peak_human:10.76M ## 以人类可读的格式返回 redis 的内存消耗峰值
used_memory_lua:36894 ## Lua 引擎所使用的内存大小(以字节为单位)
mem_fragmentation_ratio:1.32 ## used_memory_rss 和 used_memory 之间的比率
mem_allocator:jemalloc-3.6.0 ## 在编译时指定的,Redis 所使用的内存分配器,可以是 libc 、 jemalloc 或者 tcmalloc
备注:在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点。
1、当 rss > used 时,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过 mem_fragmentation_ratio的值看出。
2、当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。
当 Redis 释放内存时,分配器可能将内存返还给操作系统。如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致,可查看 used_memory_peak 的值可以验证这种情况是否发生。
# Memory
#实际缓存占用的内存和Redis自身运行所占用的内存(如元数据、lua)。
#它是由Redis使用内存分配器分配的内存,所以这个数据并没有把内存碎片浪费掉的内存给统计进去
#如果used_memory > 可用最大内存,那么操作系统开始进行内存与swap空间交换
#当 rss > used,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。
#内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。
#当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。
#从操作系统上显示已经分配的内存总量, 包括碎片
# the RSS will stay more near to the peak
# the memory consumed by rss is not released to the OS by redis, but will be reused for additional data
# 比如在某时刻过期了大量数据, used降低, rss不会降低, peak不变, 会是的mem_fragmentation_ratio增大
# redis 释放的内存, (短期内)不返回给系统,以便重用
#内存碎片率
#内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低,也说明redis没有发生内存交换。
#但如果内存碎片率超过1.5,那就说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率
#若是内存碎片率低于1的话,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。内存交换会引起非常明显的响应延迟
mem_fragmentation_ratio:1.13
Persistence 部分记录了跟 RDB 持久化和 AOF 持久化有关的信息
# Persistence
loading:0 ## 一个标志值,记录了服务器是否正在载入持久化文件
rdb_changes_since_last_save:80219051 ## 距离最近一次成功创建持久化文件之后,经过了多少秒
rdb_bgsave_in_progress:0 ## 一个标志值,记录了服务器是否正在创建 RDB 文件
rdb_last_save_time:1459237977 ## 最近一次成功创建 RDB 文件的 UNIX 时间戳
rdb_last_bgsave_status:ok ## 一个标志值,记录了最近一次创建 RDB 文件的结果是成功还是失败
rdb_last_bgsave_time_sec:0 ## 记录了最近一次创建 RDB 文件耗费的秒数
rdb_current_bgsave_time_sec:-1 ## 如果服务器正在创建 RDB 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
aof_enabled:0 ## 一个标志值,记录了 AOF 是否处于打开状态
aof_rewrite_in_progress:0 ## 一个标志值,记录了服务器是否正在创建 AOF 文件
aof_rewrite_scheduled:0 ## 一个标志值,记录了在 RDB 文件创建完毕之后,是否需要执行预约的 AOF 重写操作
aof_last_rewrite_time_sec:-1 ## 最近一次创建 AOF 文件耗费的时长
aof_current_rewrite_time_sec:-1 ## 如果服务器正在创建 AOF 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数
aof_last_bgrewrite_status:ok ## 一个标志值,记录了最近一次创建 AOF 文件的结果是成功还是失败
aof_last_write_status:ok
备注:
如果 AOF 持久化功能处于开启状态,那么这个部分还会加上以下域:
aof_current_size ## AOF 文件目前的大小
aof_base_size ## 服务器启动时或者 AOF 重写最近一次执行之后,AOF 文件的大小
aof_pending_rewrite ## 一个标志值,记录了是否有 AOF 重写操作在等待 RDB 文件创建完毕之后执行
aof_buffer_length ## AOF 缓冲区的大小
aof_rewrite_buffer_length ## AOF 重写缓冲区的大小
aof_pending_bio_fsync ## 后台 I/O 队列里面,等待执行的 fsync 调用数量
aof_delayed_fsync ## 被延迟的 fsync 调用数量
Stats 部分记录了一般统计信息
# Stats
total_connections_received:6703 ## 服务器已接受的连接请求数量
total_commands_processed:102444866 ## 服务器已执行的命令数量
instantaneous_ops_per_sec:10 ## 服务器每秒钟执行的命令数量
total_net_input_bytes:156252763413 ## 自 redis 服务器启动以来,流入的流量,以字节(byte)为单位
total_net_output_bytes:965371342363 ## 自 redis 服务器启动以来,流出的流量,以字节(byte)为单位
instantaneous_input_kbps:0.53 ## 接收输入的速率(每秒)
instantaneous_output_kbps:2.74 ## 输出的速率(每秒)
rejected_connections:0 ## 因为最大客户端数量限制而被拒绝的连接请求数量
sync_full:1 ## 主从完全同步成功次数
sync_partial_ok:0 ## 主从部分同步成功次数
sync_partial_err:0 ## 主从部分同步失败次数
expired_keys:40982 ## 因为过期而被自动删除的数据库键数量
evicted_keys:0 ## 因为最大内存容量限制而被驱逐(evict)的键数量
keyspace_hits:510132 ## 查找数据库键成功的次数
keyspace_misses:337627 ## 查找数据库键失败的次数
pubsub_channels:1 ## 目前被订阅的频道数量
pubsub_patterns:0 ## 目前被订阅的模式数量
latest_fork_usec:201 ## 最近一次 fork() 操作耗费的毫秒数
migrate_cached_sockets:0 ## 记录当前Redis正在进行migrate操作的目录Redis个数。如Redis A分别向Redis B和C执行migrate操作,那么该值为2
Replication 主/从复制信息
# Replication
role:master ## 如果当前服务器没有在复制任何其他服务器,那么这个域的值就是master;否则的话,这个域的值就是slave。注意在创建复制链的时候,一个从服务器也可能是另一个服务器的主服务器
connected_slaves:1
slave0:ip=10.68.111.196,port=4601,state=online,offset=155899191338,lag=0
master_repl_offset:155899191651
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:155898143076
repl_backlog_histlen:1048576
CPU 部分记录了 CPU 的计算量统计信息
# CPU
used_cpu_sys:5727.55 ## 服务器耗费的系统 CPU
used_cpu_user:2277.16 ## 服务器耗费的用户 CPU
used_cpu_sys_children:0.00 ## 后台进程耗费的系统 CPU
used_cpu_user_children:0.00 ## 后台进程耗费的用户 CPU
Commandstats 部分记录了各种不同类型的命令的执行统计信息
比如命令执行的次数、命令耗费的 CPU 时间、执行每个命令耗费的平均 CPU 时间等等。对于每种类型的命令,这个部分都会添加一行以下格式的信息
cmdstat_XXX:calls=XXX,usec=XXX,usecpercall=XXX
# Commandstats
cmdstat_select:calls=605,usec=1097,usec_per_call=1.81
cmdstat_ttl:calls=375,usec=1764,usec_per_call=4.70
cmdstat_get:calls=172590,usec=1566516,usec_per_call=9.08
cmdstat_setex:calls=11930,usec=308273,usec_per_call=25.84
cmdstat_scan:calls=123,usec=26822,usec_per_call=218.07
cmdstat_ping:calls=54261,usec=70864,usec_per_call=1.31
cmdstat_keys:calls=199,usec=11120,usec_per_call=55.88
cmdstat_auth:calls=202467,usec=666260,usec_per_call=3.29
cmdstat_del:calls=471,usec=3416,usec_per_call=7.25
cmdstat_type:calls=402,usec=2076,usec_per_call=5.16
cmdstat_info:calls=17851,usec=1691110,usec_per_call=94.73
cmdstat_command:calls=2,usec=2116,usec_per_call=1058.00
Cluster 部分记录了和集群有关的信息
# Cluster
cluster_enabled:0 ## 一个标志值,记录集群功能是否开启
Keyspace 部分记录了数据库相关的统计信息
比如数据库的键数量、数据库已经被删除的过期键数量等。对于每个数据库,这个部分都会添加一行以下格式的信息
dbXXX:keys=XXX,expires=XXX
# Keyspace
db0:keys=5370,expires=1643,avg_ttl=45157331
Redis Info信息包括Server、Clients、Memory、Persistence、Stats、Replication、CPU、Commandstats、Cluster、Keyspace等,下边我们以表格的形式来详细介绍各部分对应信息。
Server:
redis_version | Redis 服务器版本 |
redis_git_sha1 | Git SHA1 |
redis_git_dirty | Git dirty flag |
redis_build_id | Git dirty flag |
redis_mode | 运行模式,单机或者集群 |
os | 服务器的宿主操作系统 |
arch_bits | 架构(32 或 64 位) |
multiplexing_api | Redis 所使用的事件处理机制 |
atomicvar_api | 原子处理api |
gcc_version | 编译 Redis 时所使用的 GCC 版本 |
process_id | 服务器进程的 PID |
run_id | Redis 服务器的随机标识符(用于 Sentinel 和集群) |
tcp_port | TCP/IP 监听端口 |
uptime_in_seconds | 自 Redis 服务器启动以来,经过的秒数 |
uptime_in_days | 自 Redis 服务器启动以来,经过的天数 |
hz | edis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次。 |
lru_clock | 自增的时钟,用于LRU管理,该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次。 |
executable | 执行文件 |
config_file | 配置文件路径 |
Clients:
connected_clients | 已连接客户端的数量(不包括通过从属服务器连接的客户端) |
client_longest_output_list | 当前连接的客户端当中,最长的输出列表 |
client_biggest_input_buf | 当前连接的客户端当中,最大输入缓存 |
blocked_clients | 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 |
Memory:
| 指标 | 含义 |
|---|---|
| used_memory | 由 Redis 分配器分配的内存总量,包含了redis进程内部的开销和数据占用的内存,以字节(byte)为单位,即当前redis使用内存大小。 |
| used_memory_human | 已更直观的单位展示分配的内存总量。 |
| used_memory_rss | 向操作系统申请的内存大小,与 top 、 ps等命令的输出一致,即redis使用的物理内存大小。 |
| used_memory_rss_human | 已更直观的单位展示向操作系统申请的内存大小。 |
| used_memory_peak | redis的内存消耗峰值(以字节为单位),即历史使用记录中redis使用内存峰值。 |
| used_memory_peak_human | 以更直观的格式返回redis的内存消耗峰值 |
| used_memory_peak_perc | 使用内存达到峰值内存的百分比,used_memory/ used_memory_peak) *100%,即当前redis使用内存/历史使用记录中redis使用内存峰值*100% |
| used_memory_overhead | Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。 |
| used_memory_startup | Redis服务器启动时消耗的内存 |
| used_memory_dataset | 数据实际占用的内存大小,即used_memory-used_memory_overhead |
| used_memory_dataset_perc | 数据占用的内存大小的百分比,100%*(used_memory_dataset/(used_memory-used_memory_startup)) |
| total_system_memory | 整个系统内存 |
| total_system_memory_human | 以更直观的格式显示整个系统内存 |
| used_memory_lua | Lua脚本存储占用的内存 |
| used_memory_lua_human | 以更直观的格式显示Lua脚本存储占用的内存 |
| maxmemory | Redis实例的最大内存配置 |
| maxmemory_human | 以更直观的格式显示Redis实例的最大内存配置 |
| maxmemory_policy | 当达到maxmemory时的淘汰策略 |
| mem_fragmentation_ratio | 碎片率,used_memory_rss/ used_memory。ratio指数>1表明有内存碎片,越大表明越多,<1表明正在使用虚拟内存,虚拟内存其实就是硬盘,性能比内存低得多,这是应该增强机器的内存以提高性能。一般来说,mem_fragmentation_ratio的数值在1 ~ 1.5之间是比较健康的。 |
| mem_allocator | 内存分配器 |
| active_defrag_running | 表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理) |
| lazyfree_pending_objects | 0表示不存在延迟释放的挂起对象 |
Persistence:
loading | 服务器是否正在载入持久化文件 |
rdb_changes_since_last_save | 离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化 |
rdb_bgsave_in_progress | 服务器是否正在创建rdb文件 |
rdb_last_save_time | 离最近一次成功创建rdb文件的时间戳。当前时间戳 - rdb_last_save_time=多少秒未成功生成rdb文件 |
rdb_last_bgsave_status | 最近一次rdb持久化是否成功 |
rdb_last_bgsave_time_sec | 最近一次成功生成rdb文件耗时秒数 |
rdb_current_bgsave_time_sec | 如果服务器正在创建rdb文件,那么这个域记录的就是当前的创建操作已经耗费的秒数 |
rdb_last_cow_size | RDB过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等)。 |
aof_enabled | 是否开启了aof |
aof_rewrite_in_progress | 标识aof的rewrite操作是否在进行中 |
aof_rewrite_scheduled | rewrite任务计划,当客户端发送bgrewriteaof指令,如果当前rewrite子进程正在执行,那么将客户端请求的bgrewriteaof变为计划任务,待aof子进程结束后执行rewrite |
aof_last_rewrite_time_sec | 最近一次aof rewrite耗费的时长 |
aof_current_rewrite_time_sec | 如果rewrite操作正在进行,则记录所使用的时间,单位秒 |
aof_last_bgrewrite_status | 上次bgrewriteaof操作的状态 |
aof_last_write_status | 上次aof写入状态 |
aof_last_cow_size | AOF过程中父进程与子进程相比执行了多少修改(包括读缓冲区,写缓冲区,数据修改等)。 |
Stats:
total_connections_received | 新创建连接个数,如果新创建连接过多,过度地创建和销毁连接对性能有影响,说明短连接严重或连接池使用有问题,需调研代码的连接设置 |
total_commands_processed | redis处理的命令数 |
instantaneous_ops_per_sec | redis当前的qps,redis内部较实时的每秒执行的命令数 |
total_net_input_bytes | redis网络入口流量字节数 |
total_net_output_bytes | redis网络出口流量字节数 |
instantaneous_input_kbps | redis网络入口kps |
instantaneous_output_kbps | redis网络出口kps |
rejected_connections | 拒绝的连接个数,redis连接个数达到maxclients限制,拒绝新连接的个数 |
sync_full | 主从完全同步成功次数 |
sync_partial_ok | 主从部分同步成功次数 |
sync_partial_err | 主从部分同步失败次数 |
expired_keys | 运行以来过期的key的数量 |
expired_stale_perc | 过期的比率 |
expired_time_cap_reached_count | 过期计数 |
evicted_keys | 运行以来剔除(超过了maxmemory后)的key的数量 |
keyspace_hits | 命中次数 |
keyspace_misses | 没命中次数 |
pubsub_channels | 当前使用中的频道数量 |
pubsub_patterns | 当前使用的模式的数量 |
latest_fork_usec | 最近一次fork操作阻塞redis进程的耗时数,单位微秒 |
migrate_cached_sockets | 是否已经缓存了到该地址的连接 |
slave_expires_tracked_keys | 从实例到期key数量 |
active_defrag_hits | 主动碎片整理命中次数 |
active_defrag_misses | 主动碎片整理未命中次数 |
active_defrag_key_hits | 主动碎片整理key命中次数 |
active_defrag_key_misses | 主动碎片整理key未命中次数 |
Replication:
role | 实例的角色,是master or slave |
connected_slaves | 连接的slave实例个数 |
master_replid | 主实例启动随机字符串 |
master_replid2 | 主实例启动随机字符串2 |
master_repl_offset | 主从同步偏移量,此值如果和上面的offset相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置。 |
second_repl_offset | 主从同步偏移量2,此值如果和上面的offset相同说明主从一致没延迟 |
repl_backlog_active | 复制积压缓冲区是否开启 |
repl_backlog_size | 复制积压缓冲大小 |
repl_backlog_first_byte_offset | 复制缓冲区里偏移量的大小 |
repl_backlog_histlen | 此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小 |
CPU:
used_cpu_sys | 将所有redis主进程在核心态所占用的CPU时求和累计起来 |
used_cpu_user | 将所有redis主进程在用户态所占用的CPU时求和累计起来 |
used_cpu_sys_children | 将后台进程在核心态所占用的CPU时求和累计起来 |
used_cpu_user_children | 将后台进程在用户态所占用的CPU时求和累计起来 |
Commandstats命令使用统计快照:
cmdstat_set | Set 命令统计 |
cmdstat_ping | Ping 命令统计 |
cmdstat_del | Del命令统计 |
cmdstat_psync | Psync命令统计 |
cmdstat_keys | Keys命令统计 |
cmdstat_hmset | Hmset命令统计 |
cmdstat_command | Command命令统计 |
cmdstat_info | Info命令统计 |
cmdstat_replconf | Replconf命令统计 |
cmdstat_client | Client命令统计 |
cmdstat_hgetall | Hgetall命令统计 |
Cluster:
cluster_enabled | 实例是否启用集群模式 |
Keyspace:
db0 | db0的key的数量,以及带有生存期的key的数,平均存活时间 |
Redis内存使用详细分析
Redis的高性能表现,除了由于其完全基于内存进行数据操作,另一方面也在于作者超强的架构能力,代码极其简洁短小精悍且运行效率非常高,内存的使用方法决定了它的效率。
used_memory: redis当前数据使用的内存,有可能包括SWAP虚拟内存。
used_memory_rss: redis当前占用的物理内存,包括内存碎片。此值和用top命令查看的进程占用内存一致。
mem_fragmentation_ratio:used_memory_rss/used_memory , 此值很重要,当mem_fragmentation_ratio <1 时,说明used_memory > used_memory_rss,这时Redis已经在使用SWAP,运行性能会受很大影响。通常在正常情况下,该值比1大一些。
如何避免mem_fragmentation_ratio <1?我们需要在redis.conf文件中正确配置Redis内存管理的三个参数:maxmemory、maxmemory-policy、maxmemory-samples。
maxmemory:默认为0,被注释掉。在这种情况下,Redis会尽可能地使用物理内容,用完后尽可能使用虚拟内存SWAP。当使用SWAP时,性能会急剧下降,极限情况下,Redis服务会撑不住就会宕掉。这可能是运行环境下Redis服务宕掉的主要原因。因此在运行环境中一定要给该参数设置一个合理值。实际使用时会根据机器物理内存情况,设置一个阈值,如物理内存的70%等。当内存使用耗尽达到阈值时,Redis会使用清除策略腾出内存,如清除策略失效,就直接返回写异常。这里就涉及到第二个参数,maxmemory-policy清除策略的定义。
对于Redis的最大内存需要进行设置,否则操作系统为Redis内存分配过小,会导致Redis使用SWAP,过大,会使机器内存使用率上升,出现问题,因此在运行环境中一定要给该参数设置一个合理值。结合used_memory_peak,即Redis使用内存峰值,来去酌情配置内存分配。
maxmemory-policy:清除策略的定义,共有6种策略:
1)volatile-lru 对设置了时间期限的键值集合采用LRU近期最少使用算法。
2)allkeys-lru 对所有键值,采用LRU算法。
3)volatile-random 对设置了时间期限的键值集合采取随机选取策略。
4)allkeys-random 对所有键值采取随机选取策略。
5)volatile-ttl 对设置了时间期限的键值采用TTL算法,快过期的先删除。
6)noeviction 不删除,直接返回写异常。
为了提高效率,Redis的LRU和TTL算法,并不是严格意义的精确算法,而是采用一种近似算法,这是在效率和精确性方面所做的权衡。这就涉及到第三个参数,maxmemory-samples,Redis会设置一个采样值,在采样值范围内,使用LRU和TTL。maxmemory-samples就是采样值的定义,缺省是5,作者的建议已是最佳。
限制客户端连接数: maxclients 配置可以配置客户端连接的最大数,这个数字应该设置为预期连接数峰值的110%到150之间,若是连接数超出这个数字后,Redis会拒绝并立刻关闭新来的连接。
Redis的内存碎片率
内存碎片率是Redis的一个很重要的性能指标:mem_fragmentation_ratio(内存碎片率),它是通过以下的公式计算出来的:
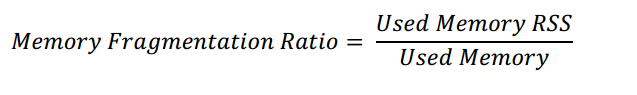
计算公式
used_memory和used_memory_rss数字都包含的内存分配有:
用户定义的数据:内存被用来存储key-value值。
内部开销: 存储内部Redis信息用来表示不同的数据类型。
used_memory_rss的rss是Resident Set Size的缩写,表示该进程所占物理内存的大小,是操作系统分配给Redis实例的内存大小。除了用户定义的数据和内部开销以外,used_memory_rss指标还包含了内存碎片的开销,内存碎片是由操作系统低效的分配/回收物理内存导致的。操作系统负责分配物理内存给各个应用进程,Redis使用的内存与物理内存的映射是由操作系统上虚拟内存管理分配器完成的。内存分配器另一个复杂的层面是,它经常会预先分配一些内存块给引用,这样做会使加快应用程序的运行。
举个例子来说,Redis需要分配连续内存块来存储1G的数据集,这样的话更有利,但可能物理内存上没有超过1G的连续内存块,那操作系统就不得不使用多个不连续的小内存块来分配并存储这1G数据,也就会导致内存碎片的产生。
可以直接以下命令查看得到
# redis-cli -h localhost -p 6379 info
mem_fragmentation_ratio:4.76
可以看到内存碎片率已经达到了4.76,内存碎片率略高于1是属于正常,但超出1.5的时候就说明redis的内存管理变差了。分析实际环境,因为该redis主要是存储频繁更新的数据,每次更新数据之前,redis会删除旧的数据,实际上由于Redis释放了内存块,但内存分配器并没有返回内存给操作系统;这个内存分配器是在编译时指定的,可以是libc、jemalloc或者tcmalloc。used_memory_rss会越来越大,导致mem_fragmentation_ratio越来越高。
解决方法
重启Redis服务器可以让额外产生的内存碎片失效并重新作为新内存来使用,使操作系统恢复高效的内存管理。修改内存分配器,Redis支持glibc's malloc、jemalloc11、tcmalloc几种不同的内存分配器,每个分配器在内存分配和碎片上都有不同的实现,更改时要重新编译Redis。
used_memory:104430120
used_memory_rss:2633490432
mem_fragmentation_ratio:25.22
used_memory_human的值很小,表示redis实际使用的内存很小,used_memory_rss为操作系统分配给redis的内存很大,说明redis并没用把内存返还给操作系统,看来需要重启redis。可执行如下命令:
127.0.0.1:6379> shutdown save
(1.50s)
not connected>
127.0.0.1:6379> info memory
# Memory
...
mem_fragmentation_ratio:1.09
mem_fragmentation_ratio代表着used_memory_rss/used_memory , 此值很重要,当mem_fragmentation_ratio <1 时,说明used_memory 大于used_memory_rss,这时Redis已经在使用虚拟内存SWAP,运行性能会受很大影响。极限情况下,Redis服务撑不住了,就会宕掉。这可能也是运行环境下Redis服务宕掉的主要原因,通常在正常情况下,该值比1大一些。
回收策略相关配置:
maxmemory
CONFIG SET/GET maxmemory 100mb 读/写最大内存配置
maxmemory 100mb redis.conf 配置
如果为0表示没有限制
maxmemory-policy 回收策略(当内存达到maxmemory限制)
CONFIG SET/GET maxmemory-policy
maxmemory-samples 回收样本大小
maxmemory-policy 六种方式
volatile-lru:(默认值)从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
noeviction:禁止驱逐数据,永不过期,返回错误
如果数据分布符合幂定律分布, 如果你不确定选择什么,allkeys-lru是个很好的选择,volatile-ttl 样本同样受maxmemory_samples控制。
LRU:
lru属性
redisObject 结果包括一个lru属性, 记录了对象最后一次被命令程序访问的时间
OBJECT IDLETIME 输出对象的空转时间, 是将当前时间减去对象lru, 该命令是特殊实现, 不会修改对象的lru属性
lru 属性用于配合实现maxmemory-policy中volatile-lru和allkeys-lru回收策略
lru算法
在Redis中LRU算法是一个近似算法,默认情况下,Redis随机挑选maxmemory-samples个键,并且从中选取一个最近最久未使用的key进行淘汰,在配置文件中可以通过maxmemory-samples的值来设置redis需要检查key的个数,但是栓查的越多,耗费的时间也就越久,但是结构越精确(也就是Redis从内存中淘汰的对象未使用的时间也就越久)
性能分析
延迟检测
Redis-cli --latency -h 127.0.0.1 -p 6379 结果单位是ms。
诊断响应延迟
跟踪info stats total_commands_processed的变化。
定期记录total_commands_processed的值,当客户端明显发现响应时间过慢时,可以通过记录的total_commands_processed历史数据值来判断命理处理总数是上升趋势还是下降趋势。延迟的可能原因:命令队列里的命令数量过多,后面命令一直在等待中;或有几个慢命令阻塞Redis。
解决方案:
使用多参数命令
管道命令
避免操作大集合的慢命令
Redis基准测试工具
Redis本身提供了基准测试命令redis-benchmark,使用redis-benchmark可以进行压力测试,了解当前Redis环境下的性能表现。redis-benchmark命令自身的帮助很详细,这里列举几个常用参数:
-h <hostname> 主机名 (缺省 127.0.0.1)
-p <port> 端口号 (缺省 6379)
-a <password> 登录口令(如Redis设置,缺省无)
-c <clients> 并发连接数 (缺省 50)
-n <requests> 总请求数 (缺省 100000)
-d <size> SET/GET操作数据值字节大小(缺省 2)
-r <keyspacelen> SET/GET/INCR操作键值以及SADD操作数据值的随机选择范围。
-t <tests> 测试的操作集,用逗号分隔,缺省都执行
下面这条命令就是1000个客户端并发,进行set操作请求,key值是16位固定长度,其低位在0-100000之间随机选择,value的大小是1024个字节,在37.44秒内完成了1000000次请求。
redis-cli monitor 命令
实时监视redis操作情况,该命令实时监视Redis被访问详情,包括来源、时间、操作命令等,注意该命令对Redis实时性能会造成一些影响。
参考来源
Redis INFO
Redis Info 命令
How to Monitor Redis
Redis性能问题排查解决手册