君子黎讲解的PostgreSQL体系架构
 本文摘抄整理于君子黎的微信空间,感谢原作者。
本文摘抄整理于君子黎的微信空间,感谢原作者。目录
体系架构入门
postmaster.pid文件
pg_control文件
为何postmaster辅助进程均带有前缀"postgres:"
libpq库
PostgreSQL中的文件描述符
堆表文件底层结构布局分析
---------------------------------------------------------------
体系架构入门
PostgreSQL使用多进程模式的客户端/服务器体系结构。客户端将请求发送到PostgreSQL服务器,之后PostgreSQL服务器解析客户端下发的具体请求内容,并进行处理、响应。在这种情况下,典型的应用程序客户端和服务器位于不同的主机上。在客户端与服务器之间使用TCP/IP协议或是Linux套接字(AF_UNIX)进行通行。在数据库的内部,主要是由一些后台进程、共享内存和数据文件组成。其系统的基本架构原理如下图所示:
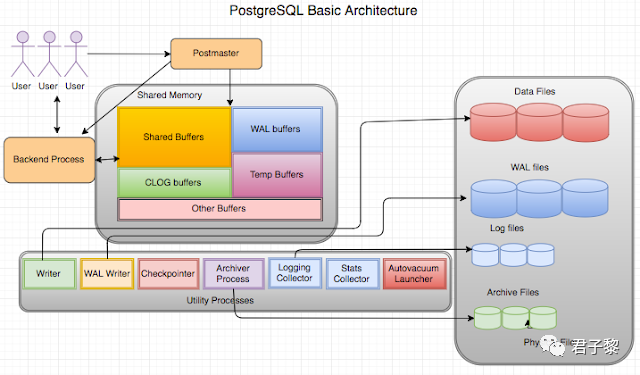
1.1 C/S通信模式
它通过C/S的模式提供服务,通常PostgreSQL数据库会话由以下两个进程(程序)组成。
服务端进程:该进程管理数据库的库文件,包括视图、索引、表、日志等等,并且它接收客户端的连接,并代表客户端来操作数据库,这个服务进程是postgres。
客户端(前端)应用程序:即PostgreSQL数据库操作的客户端应用程序,它可能是:libpq封装的应用程序、字符界面工具(psql)、图形界面(pgAdmin)或通过网页访问数据库的Web程序等等。总之,客户端应用程序是多种多样的。
1.2 PostgreSQL服务器进程类型
通常情况下,对协作管理一个数据库集群的多个进程的集称为“PostgreSQL服务器”。在PostgreSQL中,进程类型大致上可分为以下三类,分别是:
Postmaster(守护进程)
Background Process(后台进程)
Backend Process(后端进程)
1.2.1 postmaster守护进程
当执行附加-start选项参数的pg_ctl程序命令时,postgres服务器将启动,它是PostgreSQL服务启动过程中的第一个进程。同时它也是PostgreSQL数据库服务器中所有进程的父进程,在早期的PostgreSQL版本中,该父进程称为“postmaster”(备注:除非特殊声明,否则后序所有文章中都将该父进程称呼为postmaster)。当该进程启动后,将执行一系列的初始化操作,比如初始化环境变量、全局遍历、安装信号捕捉函数、在内存中分配一个共享内存区域、fork()各种辅助后台进程(checkpointer、logger),并负责后台进程的管理。
同时它将等待客户端的连接请求。默认配置下,PostgreSQL服务器监听5432的端口。对于一台服务器,可以在上面同时运行多个PostgreSQL数据库服务器,此时应该将各PostgreSQL服务器修改为监听不同的端口号。
当客户端向postmaster服务器发起TCP连接请求时候,首先它会发起身份认证消息,postmaster守护进程会根据配置(pg_hba.conf)的认证方法对该客户端请求进行相应的检验,当身份认证校验通过之后,会新fork()一个后端进程(postgres),之后该postgres将负责处理对应的连接客户端的所有查询以及其他操作。其请求连接详细过程如下所示:
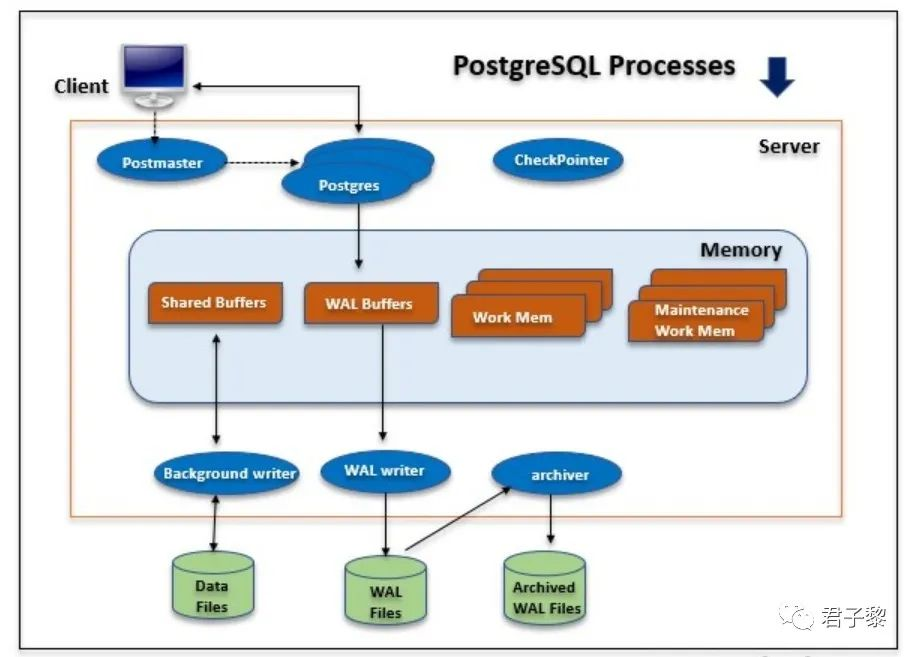
1.2.2 Background Process 后台进程
PostgreSQL的后台进程有check pointer、background write、walwriter、autovacuum launcher、stats collector和logical replication launcher。每个后台进程负责完成自己专属的逻辑业务处理,下面将详细说明每个后台进程的功能。
check pointer
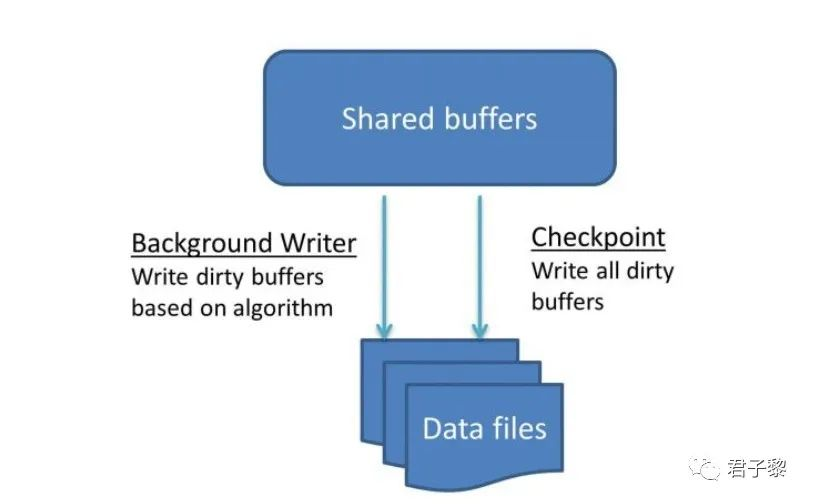
检查点是一个强制性的过程。一旦用户更改了数据(这些数据已经在缓冲区中可用),该缓冲区就是脏的。用户提交的更改并不意味着该更改已经写入到数据文件中,真正更改写入到磁盘数据文件中的任务是由check pointer后台进程完成的。如下图所示:

它将所有脏页从内存写入到磁盘上的表和索引文件,并清除shared_buffers区域,将页面标记为干净的。此外,它还将到目前为止的预写日志标记为已应用。和check pointer主要相关联的两个参数分别是checkpoint_segments 、checkpoint_timeout 。如果将checkpoint_segments 设置得过低,会导致可用的段很快被填充满,并且check pointer也会运行很频繁;同样,若将checkpoint_timeout 参数设置的过低,也会导致check pointer进程频繁地工作运行。参数过低的设置将带来的最直接影响就是磁盘吞吐量过大。另一方面,如果我们将这checkpoint_timeout 、checkpoint_segments 参数的值设置得过大,则会出现check pointer进程运行频率很低的情况。这在某些写操作较多的系统中,可能会导致检查点期间出现异常的高I/O峰值,从而影响其他查询等操作的性能。
check pointer将会发生在以下几种情形中出现:pg_start_backup、CREATE DATABASE、pg_ctl stop|restart、pg_stop_backup、issue of commit、pages is dirty等。
background write
background write后台写进程的功能是根据算法将shared_buffers中的特定脏(新的或是修改过的)数据写入到磁盘文件中。备:check pointer检查点进程则是将缓冲区中的所有脏数据写入到磁盘文件中去。由于有专门的进程负责写缓冲区脏数据,因此,处理客户端查询的服务器(postgres)进程很少或从不需要去等等写操作的发生。不过,后台写进程确实会导致I/O负载的整体净增加,因为虽然重复写入的页面可能每个检查点间隔只能写入一次,但是background write进程可能会多次写入它,因为在同一时间间隔中,它被弄脏了。
walwriter
前面提到过,当我们提交修改数据的请求时候,这些修改并不会立即被写入到磁盘文件。PostgreSQL对共享缓冲区中的数据块进行这些修改,然后将这些修改写入到WAL缓冲区。当(每次)提交事务时,更改(WAL缓冲区)会被刷新到WAL段。
与WAL相关的几个参数有:fsync、max_wal_size、wal_writer_delay。
其中fsync设置强制每个事务在每次提交之后写入磁盘。关闭此功能将提高性能,特别是针对一些批量上传操作;禁用fsync可能会导致严重的问题,比如电源断电或服务器奔溃时,数据一致性问题。
在写操作较为频繁的系统中,过小的设置max_wal_size可能会导致性能损失、下降;而设置过高的max_wal_size将会显著地增加恢复时间。wal_writer_delay是walwriter进程活动轮之间的延迟,在每一个回合中,都将会把WAL写入到磁盘文件中。然后它休息wal_writer_delay毫秒,并不断重复此过程。注意:在许多系统中,将wal_writer_delay设置为10ms是个不错的选择。
logical replication launcher
日志收集器进程,它捕获发送到stderr的日志消息,并将他们重定向到日志文件中。所有的后台进程、后端进程(postgres)以及postmaster守护进程所产生的活动信息都将被logical进程给记录下来。
autovacuum launcher
和logger日志收集器进程一样,autovacuum进程是一个支持手动关闭/打开的后台进程,不过autovacuum进程默认是开启的,而logger日志收集器进程默认是关闭的。autovacuum进程将以前删除(或更新)的记录(行,元组)所使用的空间标记为可在表中重用的空间。它还有一个vacuum命令可以手动执行此操作。vacuum进程操作不会锁住表。
然而VACUUM FULL除了将空间标记为可重用外,还会删除之前已删除或更新的记录,并重新排序表数据,这需要使用独占锁。PostgreSQL服务会在服务处于非高峰、负载情况下,自动开启vacuum,vacuum会更新规划器使用的数据统计信息。
stats collector
统计收集器进程支持收集和报告有关服务器活动的消息,然后将这些信息更新给优化器(pg_catalog),优化器使用pg_catalog生成查询计划。收集器可以计算磁盘块和单行项中对表和索引的访问次数。它还跟踪每个表中的总函数,以及关于每个表的vacuum和analyze操作的信息。
它还可以计算对用户定义函数的调用以及每次调用所花费的时间。它还支持报告其他服务器进程当前正在指向的确切命令。stats collector状态统计器通过临时文件将收集到的信息传递给其他PostgreSQL进程。默认情况下,这些文件存储在由stats_temp_directory参数命名的目录中,即pg_stat_tmp。为了获取更好的性能,可将stats_temp_directory指向基于RAM的文件系统中,从而降低物理I/O需求。
当服务器完全关闭时候,统计数据的永久副本存储在pg_stat子目录中,这样在服务器重启时统计数据可以保留。在服务器启动时执行恢复(例如,在立即关机、服务器奔溃和时间点恢复点之后),所有统计计数器都将重置。
1.2.3 Backend Process 后端进程
在1.3.1节中关于postmaster守护进程如何接收客户端的连接请求,作了比较详细的说明。简言之就是客户端的每个请求连接,postgmaster都会fork()一个postgres后端进程来进行处理。可打开的后端进程最大数目由postgresql.conf配置文件中的max_connections参数进行控制,默认值是100个。该参数可以通过修改postgresql.conf配置文件修改,也可通过执行系统命令ALTER SYSTEM来进行修改,详细修改过程请阅读彻底搞清postgresql.auto.conf 与 postgresql.conf 之间的差异 。
---------------------------------------------------------------
postmaster.pid文件
1. postmaster.pid是什么文件?
postmaster.pid文件是一个描述数据蔟目录的锁文件(lock file)。这里数据蔟目录为initdb命令中参数-D所指定的目录位置。
1.1 postmaster.pid文件位于哪?
postmaster.pid锁文件位于指定数据蔟目录下。比如我的数据目录是/home/ssd/PG132, 那么postmaster.pid文件在/home/ssd/PG132/目录下。
1.2 postmaster.pid文件中都有什么数据?
根据文件名后缀,大家第一时间想到的是,该文件存储了辅助进程postmaster的进程PID,没错,该文件确实存储了postmaster进程的PID, 但是实际上,该文件还存储有其他多项数据,下面一起来看看存储了什么项,每一项分别代表什么。
在不去阅读源码时候,有一个文件可以快速帮你了解postmaster.pid锁文件中的各项数据的内容。该文件是pidfile.h(位于src/include/utils/pidfile.h)。在postmaster.pid文件中,每项数据存储为一行,从PostgreSQL 10.0开始,该锁文件中的内容共有8行(每行为一项),如下图所示:

其中每行的含义如下:
LINE 1:postmaster守护进程的PID,或独立后端PID的负数。对于PostgreSQL数据库,其postgres的启动方式有两种,一种是多用户模式,即PostmasterMain()函数分支;另外一种是不经过postmaster的单用户模式。走PostgresMain()分支。
LINE 2:数据蔟目录路径。
LINE 3:postmaster守护进程的启动时间. 以秒(s)为单位。
LINE 4:postmaster进程监听的端口。默认5432.
LINE 5:第一个Unix套接字目录路径(如果没有则为空)。
LINE 6:第一个监听地址(它可以是IP地址或"*", 如果没有TCP端口则为空)。
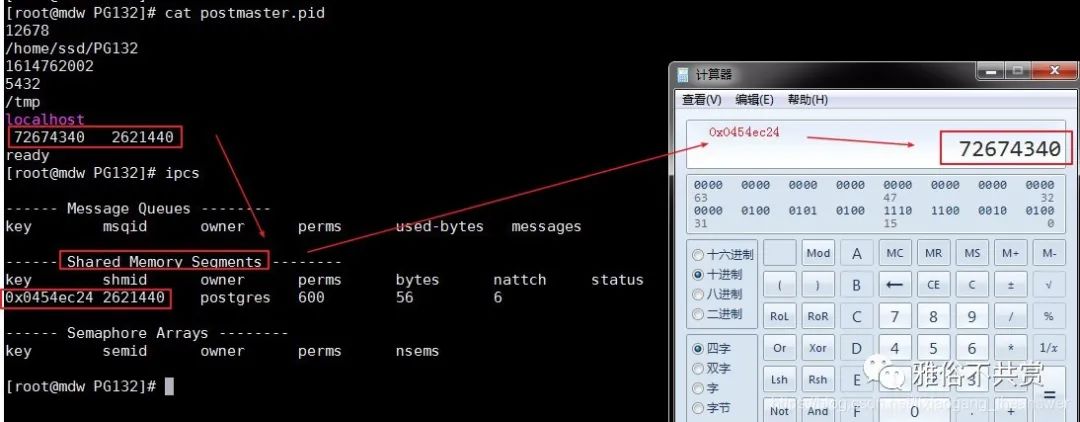
LINE 7:共享内存键(在Windows上面为空)
在类Unix系统上,可以使用ipcs命令看到共享内存键值信息如下图所示,其中0x0454ec24(十六进制)所对应的十进制数据刚好是72674340。和postmaster.pid文件中的第7行对应上。
LINE 8:postmaster守护进程的状态。对于postmaster,可能出现的状态有以下几种:
#define PM_STATUS_STARTING "starting" /* 仍在启动*/
#define PM_STATUS_STOPPING "stopping" /* 在顺序关机汇总 */
#define PM_STATUS_READY "ready " /* 准备好连接,只有postmaster启动成功,postmaster.pid文件中的第8行就是"read",参考上图 */
#define PM_STATUS_STANDBY "standby " /* 不接受连接*/
注意:第6行及以上是在初始文件创建后通过AddToDataDirLockFile()添加的,另外第5行最初是空的(看下面的代码,最初socketDir初始化为空,CreateLockFile()函数第3个参数),并在第一个Unix套接字打开后更改。旁观者不应该认为第4行及以上是按照任何特定的顺序填写的。
void CreateDataDirLockFile(bool amPostmaster){
CreateLockFile(DIRECTORY_LOCK_FILE, amPostmaster, "", true, DataDir);
}
snprintf(buffer, sizeof(buffer), "%d\n%s\n%ld\n%d\n%s\n", amPostmaster ? (int) my_pid : -((int) my_pid),DataDir,(long) MyStartTime,PostPortNumber,socketDir);
1.2.1 套接字锁定文件目录路径
在1.2节中详细描述了postmaster.pid文件中各行(项)内容及其含义,其中第5行是第一个Unix套接字目录路径(若有的前提下。不过一般都有,因为一个不能监听端口的数据库没有实际应用)。这里第一个套接字即为postmaster所监听的端口,默认是5432,这里手动配置为了5566。
套接字目录路径默认在/tmp目录下,因此postmaster.pid锁文件中的第5行为"/tmp"。除此之外,postmaster还会在/tmp目录下创建一个“套接字锁文件(Socket lock files.)”。该文件中的内容共有5行,这5行数据与postmaster.pid锁文件中的前面5行内容是相同的。套接字锁文件是一个隐藏文件,其文件名的格式为 .s.PGSQL.5432和 .s.PGSQL.5432.lock(这里5432是指定的postmaster监听端口),其初始化代码如下:
#define UNIXSOCK_PATH(path, port, sockdir) \
(AssertMacro(sockdir), \
AssertMacro(*(sockdir) != '\0'), \
snprintf(path, sizeof(path), "%s/.s.PGSQL.%d", (sockdir), (port)))
void CreateSocketLockFile(const char *socketfile, bool amPostmaster,const char *socketDir){
char lockfile[MAXPGPATH];
snprintf(lockfile, sizeof(lockfile), "%s.lock", socketfile);
CreateLockFile(lockfile, amPostmaster, socketDir, false, socketfile);
}
文件.s.PGSQL.5432.lock是Unix套接字锁文件,.s.PGSQL.5432是socket套接字文件,如下图所示:
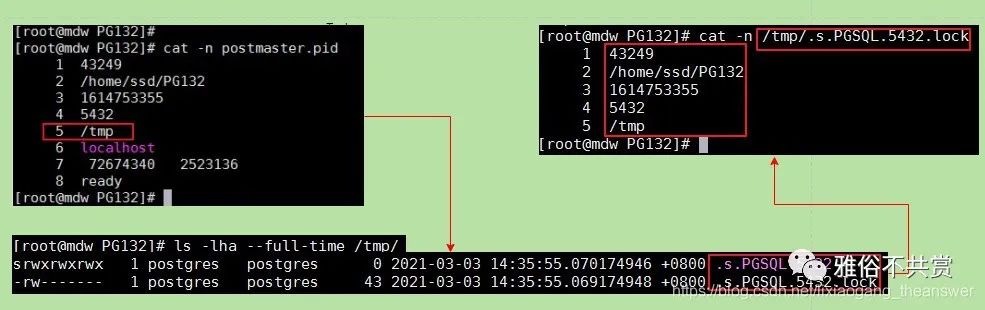
2. postmaster.pid锁文件底层源码
2.1 postmaster.pid文件入口
postmaster.pid文件的创建入口是函数CreateDataDirLockFile(true)。该函数的作为CreateLockFile()的一层封装,真正的文件创建逻辑是由CreateLockFile()函数完成。
static void CreateLockFile(const char *filename, bool amPostmaster,const char *socketDir,bool isDDLock, const char *refName){
//省略
}
void CreateDataDirLockFile(bool amPostmaster){
CreateLockFile(DIRECTORY_LOCK_FILE, amPostmaster, "", true, DataDir);
}
对于CreateLockFile()函数,共有5个参数,分别是:filename、amPostmaster、socketDir、isDDLock、refName。 它们所代表的意义分别如下:
filename:要创建的锁文件名, 即postmaster.pid。它由预定义宏DIRECTORY_LOCK_FILE表示,位于src/backend/utils/init/miscinit.c文件中,如下:
#define DIRECTORY_LOCK_FILE "postmaster.pid"
amPostmaster:用于确定如何对输出的PID进行编码,即如果它为true,则于postmaster.pid文件中写入当前守护进程postmaster的PID(getpid()),反之则向该文件写入“-PID”,即在进程的PID数字的前面追加一个“-”符号。实测:为了验证该结果将CreateDataDirLockFile(true);函数中的参数置为false。如下:
CreateDataDirLockFile(false); //该入口位于 src/backend/postmaster/postmaster.c line:982
修改之后重新启动PostgreSQL服务进程,再来看postmaster.pid文件的第1行数据,可以看到在进程PID的前面多了一个横杆字符“-”(因此,这里的所谓编码并不是常见的例如MD5等算法编码)。如下图所示:

socketDir:Unix套接字目录路径,它可能为空。
isDDLock:用于说明是否为创建postmaster.pid锁文件。
refName:指明当前要创建的文件的绝对路径目录位置,同时isDDLock和refName这两个参数也用于确定生成什么错误的日志消息。
2.2 postmaster.pid创建逻辑图
postmaster.pid文件的底层创建逻辑流程图如下所示:

2.3.1 postmaster.pid创建过程代码分析
首先获取当前运行环境中的进程PID、父进程PPID。一方面是因为postmaster.pid文件中需要写入进程PID值,另外一方面是在打开文件失败时候用获取到的PID、PPID进行一些列的业务逻辑处理判断。考虑到postgres服务在启动过程中,会有若干的外界环境因素(比如存在竞争条件,同一时间多个用户同时启动等)影响,在打开文件的时候需要有一个循环,但是又不能永远循环下去(比如一个不可写的数据蔟目录可能会导致永远的失败),因此,当前策略是循环100次尝试。若100次都无法成功打开文件或是创建文件,则结束任务。
以可读写的方式来打开指定的postmaster.pid文件,并附加上O_CREAT | O_EXCL标志,若文件不存在则,则创建该锁文件。反之若指定了O_CREAT标志且文件已经存在在报错。并对open返回的错误码进行相应的判断处理, 若错误码errno不为EEXIST(文件已经存在)且同时不为EACCES(对文件请求访问不允许), 又或者尝试次数(ntries > 100)大于指定的100次,则打印报错信息,继续向下处理。
若文件打开且错误码不为上面两个,那么继续尝试打开该文件,若文件打开仍然失败,但错误码errno为ENOENT,那么继续打开文件。则继续往下走。
if (errno == ENOENT)
continue; /* race condition; try again */
之后便读取该文件的所有内容,读取到文件的末尾之后则关闭该文件句柄fd。若读取出来的文件内容大小为0字节,那么有两种可能:
另外一个服务器正在启动。
该锁定文件是上一个服务器启动时候奔溃时留下的残余。
若文件内容长度(len != 0)大于0,则获取该文件中的进程PID(正如前面所说,postmaster.pid文件的第一行为postmaster进程的PID)。
#define MAXPGPATH 1024
char buffer[MAXPGPATH * 2 + 256];
buffer[len] = '\0';
encoded_pid = atoi(buffer);
若果文件中的PID小于0, 那么这个进程PID值是postgres进程而非postmaster进程的。很显然这是一个不正常的现象,则打印错误提示信息。
/* if pid < 0, the pid is for postgres, not postmaster */
other_pid = (pid_t) (encoded_pid < 0 ? -encoded_pid : encoded_pid);
if (other_pid <= 0)
elog(FATAL, "bogus data in lock file \"%s\": \"%s\"",filename, buffer);
现在我们需要去检查另外一个进程是否仍然存在的情况,使用从文件中读取出来的PID(other_pid)和当前进程PID、父进程PPID的值进行比较,若other_pid同时不等于进程PID和父进程PPID,则kill掉other_pid进程。若kill信号发送成功,同时错误码不等于ESRCH和EPERM,那么表名当前的postmaster.pid锁文件属于以下进程之一。
if (other_pid != my_pid && other_pid != my_p_pid && other_pid != my_gp_pid){
if (kill(other_pid, 0) == 0 ||
(errno != ESRCH && errno != EPERM)){
/* lockfile belongs to a live process */
ereport(FATAL,
(errcode(ERRCODE_LOCK_FILE_EXISTS),
errmsg("lock file \"%s\" already exists",
filename),
isDDLock ?
(encoded_pid < 0 ?
errhint("Is another postgres (PID %d) running in data directory \"%s\"?",
(int) other_pid, refName) :
errhint("Is another postmaster (PID %d) running in data directory \"%s\"?",
(int) other_pid, refName)) :
(encoded_pid < 0 ?
errhint("Is another postgres (PID %d) using socket file \"%s\"?",
(int) other_pid, refName) :
errhint("Is another postmaster (PID %d) using socket file \"%s\"?",
(int) other_pid, refName))));
}
}
EPERM与ESRCH信号所代表的含义分别如下:
EPERM:进程没有向任何目标进程发送信息的权限。
ESRCH:进程PID或进程组PGID不存在。注意,现有的进程可能是僵尸进程,虽已经提交终止请求,但是还没有被(wait)回收。
实测:lsof先查看监听端口为5432的postmaster进程情况,如下图所示,可看到进程已经存在且PID是4451,现在使用pg_ctl命令尝试新启动一个postmaster服务,可看到pg_ctl命令报错,并提示或许有另一个进程在跑。而指定的1.log文件中,则可以清楚地看到上面的代码中指定的信息打印。即
errmsg("lock file \"%s\" already exists", filename) //filename这里是"postmaster.pid"
isDDLock ?
(encoded_pid < 0 ?
errhint("Is another postgres (PID %d) running in data directory \"%s\"?",(int) other_pid, refName) :
//因为isDDLock = true 且 other_pid大于0, 所以走下面这条打印。和下图的截图能够相匹配。
errhint("Is another postmaster (PID %d) running in data directory \"%s\"?",
(int) other_pid, refName)) :
(encoded_pid < 0 ?
errhint("Is another postgres (PID %d) using socket file \"%s\"?",
(int) other_pid, refName) :
errhint("Is another postmaster (PID %d) using socket file \"%s\"?",
(int) other_pid, refName))));
终端日志报错提示信息如下图所示:

继续一些其他逻辑处理判断,若满足条件则跳转到写postmaster.pid文件的业务分支,反之则结束本次处理流程。当postmaster.pid锁文件成功打开之后,返回对应的文件句柄fd,之后按照约定的格式构造5行数据,写入该文件句柄fd中。构造写入数据的完整代码如下:
snprintf(buffer, sizeof(buffer), "%d\n%s\n%ld\n%d\n%s\n",
amPostmaster ? (int) my_pid : -((int) my_pid), //getpid()
DataDir,//数据目录
(long) MyStartTime,//postmaster启动时间
PostPortNumber,//postmaster监听端口,默认5432
socketDir);//第一个Unix套接字目录路径,这个一开始为空
其中 MyStartTime(第3行)是一个全局变量,位于src/backend/utils/init/globals.c文件中,其类型是双长整型(long long int)。
#ifndef HAVE_INT64
typedef long long int int64;
#endif
typedef int64 pg_time_t;
pg_time_t MyStartTime; //
MyStartTime变量是在PostmasterMain()函数入口处进行初始化的,这样能够更加精确地去表示postmaster守护进程的启动时间。
void InitProcessGlobals(void){
unsigned int rseed;
MyProcPid = getpid();
MyStartTimestamp = GetCurrentTimestamp();
MyStartTime = timestamptz_to_time_t(MyStartTimestamp);
. . . . . . //省略若干
}
void PostmasterMain(int argc, char *argv[]){
int opt;
int status;
char *userDoption = NULL;
bool listen_addr_saved = false;
int i;
char *output_config_variable = NULL;
InitProcessGlobals();
. . . . . . //省略若干
}
当数据(buffer)格式化之后,便写入到postmaster.pid锁文件中,同时调用fsync同步刷新数据到磁盘文件中去。之后再对文件句柄fd设置一些其他高级属性,然后关闭该文件句柄fd。到这里时候,整个锁文件从创建到写数据等过程就已经详细讲解完成了。
3. 小结
上文详细的讲解了PostgreSQL数据库中postmaster.pid文件的作用以及文件中的内容。比较深入地分析了该文件创建过程中的底层内核源码,图文并茂地进行了剖析。同时本文还附加说明了什么是套接字锁文件,以及套接字锁文件的位置和文件中的数据内容。
---------------------------------------------------------------
pg_control文件
pg_control是一个8KB大小的二进制文件,该文件中记录了PostgreSQL服务器内部信息状态的各方面信息,比如最新检查点(checkpoint)、系统状态、当前运行的postgres服务版本、CRC校验,以及initdb初始化PostgreSQL数据库蔟时设置的某些基本参数。它是在PostgreSQL的7.1版本中新引入的。实际上,该文件中的有效字段值内容仅有几百字节,即sizeof(ControlFileData)。剩下的数据全用零填充。这个在1.3.1小节会详细介绍。
从PostgreSQL的9.6版本开始,以下几个函数也可以用于从该文件(pg_control)中提取相应的数据信息。
pg_control_checkpoint()
有关当前检查点状态的信息,如下图所示:

pg_control_system()
pg_control控制文件状态信息。比如当前运行的postgres版本号、目录版本号、系统标识和该控制文件的最后一次修改时间。详情如下图所示:

pg_control_init()
该函数将查询出有关集群初始化状态信息。详情如下图所示:

pg_control_recovery()
关于恢复状态信息。如下图所示:

pg_control控制文件的格式可以进行变更,即从一个发行包变更为另一个发行版。
1.1 pg_control文件位于何处?
该文件位于PostgreSQL数据蔟的global目录下,即PGDATA/global下,如下图所示:

1.2 pg_control文件数据内容
不同的PostgreSQL数据库版本,pg_control文件中的内容会有些许差异,因为每次版本的迭代都意味着修复了某些已知缺陷,或是优化了某些性能瓶颈。因此,本次文件中内容相比于其他版本的控制文件,可能多增加了一些字段,也可能移除了一些字段。比如:PostgreSQL 12版本中,新增了:int max_wal_sender,同时又删除了:uint32 nextXidEpoch, TransactionnextXid; PostgreSQL 11版本中,删除了字段: XLogRecPtr prevCheckPoint; PostgreSQL 10版本中,添加了字段:char mock_authentication_nonce[MOCK_AUTH_NONCE_LEN]等等。
对于PostgreSQL 13.2版本,pg_control文件中的内容即为ControlFileData结构体变量值。该结构体类型声明如下(共35个成员变量):
typedef struct ControlFileData{
uint64 system_identifier; //系统唯一标识
uint32 pg_control_version; //pg的控制版本号. 在13.2版本中,#define PG_CONTROL_VERSION 1300
uint32 catalog_version_no; //目录版本号. 在13.2版本中, #define CATALOG_VERSION_NO 202007201
DBState state; //系统状态数据.
pg_time_t time;
XLogRecPtr checkPoint;
CheckPoint checkPointCopy;
XLogRecPtr unloggedLSN;
XLogRecPtr minRecoveryPoint;
TimeLineID minRecoveryPointTLI;
XLogRecPtr backupStartPoint;
XLogRecPtr backupEndPoint;
bool backupEndRequired;
int wal_level;
bool wal_log_hints;
int MaxConnections;
int max_worker_processes;
int max_wal_senders;
int max_prepared_xacts;
int max_locks_per_xact;
bool track_commit_timestamp;
uint32 maxAlign;
double floatFormat;
#define FLOATFORMAT_VALUE 1234567.0
uint32 blcksz;
uint32 relseg_size;
uint32 xlog_blcksz;
uint32 xlog_seg_size;
uint32 nameDataLen;
uint32 indexMaxKeys;
uint32 toast_max_chunk_size;
uint32 loblksize;
bool float8ByVal;
uint32 data_checksum_version;
char mock_authentication_nonce[MOCK_AUTH_NONCE_LEN];
pg_crc32c crc;
} ControlFileData;
由于ControlFileData结构体类型中的成员数量较多,因此这里仅对其中部分成员做详细说明。
state 系统状态
成员state表示当前系统的状态,其类型为DBState。在PostgreSQL 13.2版本中,PostgreSQL数据库管理系统的状态信息有以下几种:
typedef enum DBState{
DB_STARTUP = 0, //启动
DB_SHUTDOWNED, //关机
DB_SHUTDOWNED_IN_RECOVERY, //关机恢复
DB_SHUTDOWNING, //关机中
DB_IN_CRASH_RECOVERY, //奔溃恢复
DB_IN_ARCHIVE_RECOVERY, //存档恢复
DB_IN_PRODUCTION //生产(正确启动成功的PostgreSQL服务器状态码)
} DBState;
当执行附加选项-start的pg_ctl程序命令时候,若PostgreSQL服务正常启动,那么系统状态值为“DB_IN_PRODUCTION”。对于以上几个系统状态枚举值,有对应的可视化字符串表示,分别对应如下:
static const char *dbState(DBState state){
switch (state){
case DB_STARTUP:
return _("starting up");
case DB_SHUTDOWNED:
return _("shut down");
case DB_SHUTDOWNED_IN_RECOVERY:
return _("shut down in recovery");
case DB_SHUTDOWNING:
return _("shutting down");
case DB_IN_CRASH_RECOVERY:
return _("in crash recovery");
case DB_IN_ARCHIVE_RECOVERY:
return _("in archive recovery");
case DB_IN_PRODUCTION:
return _("in production");
}
return _("unrecognized status code");
}
当然,控制文件(pg_control)中的数据均为二进制,并没有写入系统枚举值对应的可视化字符串。这里终端展示的数据信息是使用了PostgreSQL提供的客户端命令工具读取转换展示的,该工具下面会详细介绍。

catalog_version_no 目录版本号
目录版本号用于标记PostgreSQL系统目录中不兼容的更改。每当有人更改系统目录关系的格式,如添加、删除或修改标准目录条目时,更新的后端将无法与旧数据库一起工作(反之亦然),目录版本号也应该更改。initdb将存储在pg_control中的版本号与启动时编译到后端的版本号进行检查,这样后端就可以拒绝在不兼容的数据库中运行。
如果开发人员提交了init的更改,则同时也应该更新目录版本号。对于目录版本号的命名,使用的格式是:“YYYYMMDDN”。其中YYYY-代表年份、 MM-代表月、 DD-代表某天,N则代表当天更改的编号,该编号从1开始(备注:希望永远不要再同一天提交10次独立的目录更改请求)。该版本号用宏CATALOG_VERSION_NO表示,该宏位于/src/include/catalog/目录中的catversion.h文件中。
time pg_control文件最后一次更新的时间戳
PostgreSQL数据库的每次启动、关闭、重启等等都会对文件中的该字段进行实时更新。
该结构体类型中的其他一些成员是用于确保此数据库的配置与后端进程可执行程序的相兼容。还有一些参数用于归档或是热备用的参数设置。可与1.2.1节中pg_controldata命令所展示的数据相结合进行阅读。
1.2.1 借助工具查看pg_control中的数据
由于pg_control控制文件中的内容是二进制,所以你无法使用类似strings等命令之间来查看文件中的数据。不过好在PostgreSQL数据库提供了用来查看该文件的程序命令pg_controldata,该命令的使用方式如下:
su postgres -c ‘/usr/local/postgresql_13_2/bin/pg_controldata -D /home/ssd/PGSQL132’
使用该命令可以直接看到pg_control文件中的数据,如下所示(以下展示的数据来自PostgreSQL 13.2版本):
pg_control version number: 1300
Catalog version number: 202007201
Database system identifier: 6937939388570580870
Database cluster state: in production
pg_control last modified: Wed 17 Mar 2021 05:34:45 PM CST
Latest checkpoint location: 0/15C1FF8
Latest checkpoint's REDO location: 0/15C1FC0
Latest checkpoint's REDO WAL file: 000000010000000000000001
Latest checkpoint's TimeLineID: 1
Latest checkpoint's PrevTimeLineID: 1
Latest checkpoint's full_page_writes: on
Latest checkpoint's NextXID: 0:486
Latest checkpoint's NextOID: 16385
Latest checkpoint's NextMultiXactId: 1
Latest checkpoint's NextMultiOffset: 0
Latest checkpoint's oldestXID: 478
Latest checkpoint's oldestXID's DB: 1
Latest checkpoint's oldestActiveXID: 486
Latest checkpoint's oldestMultiXid: 1
Latest checkpoint's oldestMulti's DB: 1
Latest checkpoint's oldestCommitTsXid:0
Latest checkpoint's newestCommitTsXid:0
Time of latest checkpoint: Wed 17 Mar 2021 05:34:45 PM CST
Fake LSN counter for unlogged rels: 0/3E8
Minimum recovery ending location: 0/0
Min recovery ending loc's timeline: 0
Backup start location: 0/0
Backup end location: 0/0
End-of-backup record required: no
wal_level setting: replica
wal_log_hints setting: off
max_connections setting: 100
max_worker_processes setting: 8
max_wal_senders setting: 10
max_prepared_xacts setting: 0
max_locks_per_xact setting: 64
track_commit_timestamp setting: off
Maximum data alignment: 8
Database block size: 8192
Blocks per segment of large relation: 131072
WAL block size: 8192
Bytes per WAL segment: 16777216
Maximum length of identifiers: 64
Maximum columns in an index: 32
Maximum size of a TOAST chunk: 1996
Size of a large-object chunk: 2048
Date/time type storage: 64-bit integers
Float8 argument passing: by value
Data page checksum version: 0
Mock authentication nonce: e260837100cb356118c5ad1463cac97906e35a660f52ce1953e2b28df2f815d4
1.3 pg_control文件创建原理
pg_control控制文件是在系统安装时创建的(即initdb),此外,系统安装时候还会初始化XLOG段。对于pg_control文件的创建与初始化主要由函数BootStrapXLOG()负责完成。其内部创建流程如下图所示:
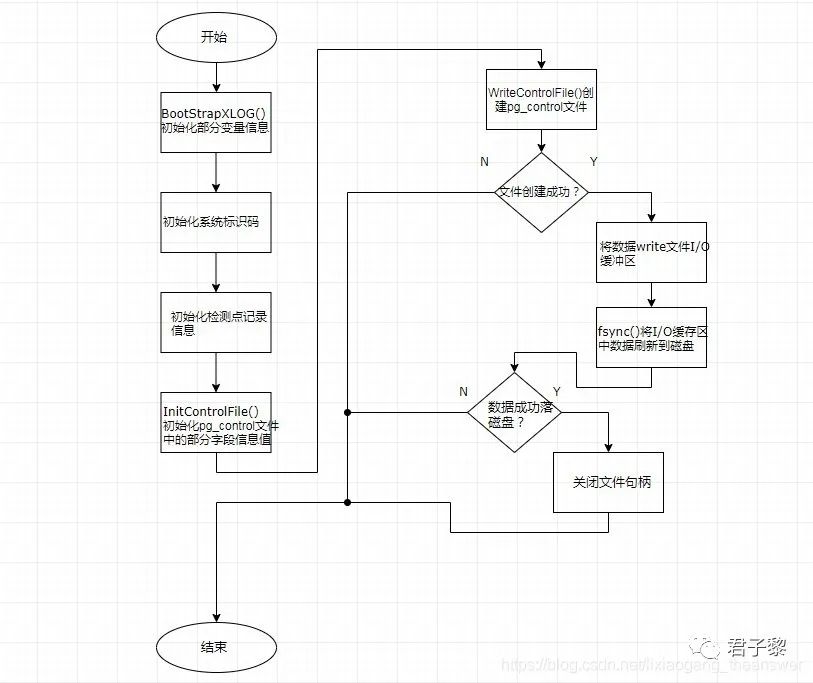
系统首先初始化一些相关的变量数据,比如对于系统唯一标识码system_identifier(该系统唯一标识码确保我们将xlog文件与生成它们的安装相匹配),将根据gettimeofday()函数获取到的时间戳值,再加上当前进程PID,结合位运算,将得到的结果值用于初始化该成员变量。代码如下:
gettimeofday(&tv, NULL);
sysidentifier = ((uint64) tv.tv_sec) << 32;
sysidentifier |= ((uint64) tv.tv_usec) << 12;
sysidentifier |= getpid() & 0xFFF;
在完成了待写入pg_control文件中的所有成员字段值之后,将创建pg_control文件,并将这些字段值写入该文件中,对于pg_control文件,默认大小是8KB(#define PG_CONTROL_FILE_SIZE 8192),但是该文件该文件中的有效内容字段值为几百字节左右(即sizeof(ControlFileData)),然后多余部分空间将用零来进行填充。这样做减少了在读取pg_control文件时候发生过早的EOF错误的几率。当我们去检查该文件的内容时,我们仍然会失败,但是希望有一个比“无法读取pg_control”更加具体的错误提示。
对于pg_control文件大小为8KB,其源码中有注释到(位于src/include/catalog/pg_control.h文件中):
#define PG_CONTROL_FILE_SIZE 8192
pg_control文件的物理大小。注意,这比实际使用的大小要大得多(例如,sizeof(ControlFileData))。其思想是保持物理大小恒定,不受格式变化的影响,这样ReadControlFile在查看不兼容的文件时就会传递一个合适的错误版本消息,而不是一个读取错误。
当所有字段成功写入文件I/O缓存区中之后,将立刻调用fysnc()函数同步将文件句柄I/O缓存区中的数据刷新到磁盘文件上,持久化存储。若刷新磁盘成功,则关闭句柄,继续postmaster的其他初始化流程;反之,则结束本次的数据库操作。
2. pg_control文件功能
pg_control控制文件可以看做是PostgreSQL数据库的一层保护罩,它可以保证数据库不会被不满足数据蔟相同版本其他程序命令进行读取修改操作。这样就间接有效地保护了数据库系统的安全。比如你不能用PostgreSQL 9.0版本的程序命令pg_ctl去启动由PostgreSQL13.2版本初始化的数据蔟服务器,因为不同版本中,底层细节的某些实现都作了微调,这样冒然地允许混合版本进行数据库操作,那将是很危险的信号。
2.1 pg_control文件对系统的影响
提到pg_control文件对PostgreSQL数据库的影响,可分为两种情形进行讨论。第一种是pg_control文件缺失,即PGDATA/global目录根本不存在该文件;第二种是PGDATA/global目录下存在pg_control文件,但是该文件中没有数据,或者是数据内容和当前启动服务的postmaster服务版本不匹配。
首先可以肯定的是,无论出现以上两种情形中的任何一种,PostgreSQL服务都不会正常启动。因为这两种情形的出现都明显表名当前环境上的PostgreSQL服务出现了未知的问题,是不正常的现象。
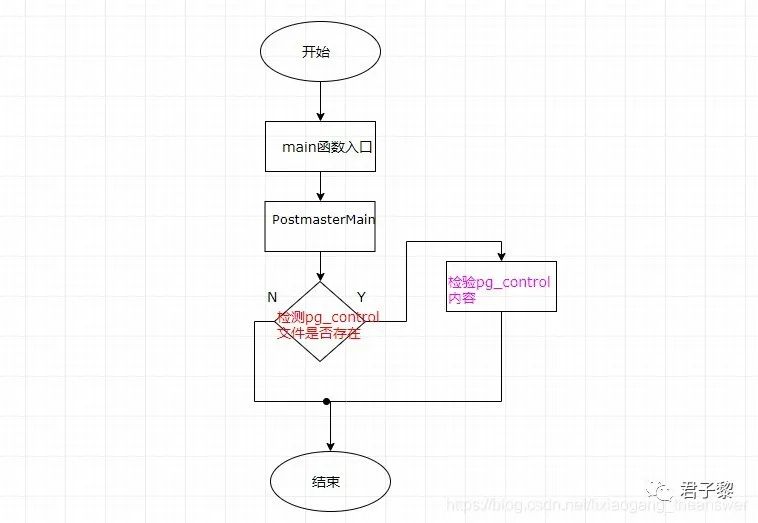
当初始化postmaster守护进程的(PostmasterMain()函数)时候,会对pg_control文件进行两次的读取操作(红色字体表示第一次读取pg_contrl文件,紫色字体表示第二次读取pg_control文件)。如下流程图所示:
2.1.1 pg_control文件不存在
第一次读取pg_control控制文件时,不对该文件中的内容进行读操作,以及其他的数据逻辑判断,仅仅用于检查该文件(pg_control)是否存在。该功能由函数checkControlFile()完成。
static void checkControlFile(void){
char path[MAXPGPATH];
FILE *fp;
snprintf(path, sizeof(path), "%s/global/pg_control", DataDir); //$PGDATA
fp = AllocateFile(path, PG_BINARY_R);
if (fp == NULL){
write_stderr("%s: could not find the database system\n"
"Expected to find it in the directory \"%s\",\n"
"but could not open file \"%s\": %s\n",
progname, DataDir, path, strerror(errno));
ExitPostmaster(2);
}
FreeFile(fp);
}
若文件存在,则继续下面其他初始化流程,反之,则打印日志信息并结束当前的postmaster服务启动操作。比如这里我特意删除了PGDATA/global目录下的pg_control文件,然后使用pg_ctl启动postmaster服务时候,报错提示并结束。终端打印的日志信息和代码匹配上。

2.1.2 pg_control文件存在但内容不正确
若pg_control文件存在,那么至少可以说明该我们正在查看一个真正的数据库目录。通俗地说,就是pg_ctl参数-D后面的选项是真正使用过initdb初始化的数据蔟目录,而非任意指定的一个目录位置。之后,我们将当前工作目录切换至PGDATA中。该功能由函数ChangeToDataDir()完成。
void ChangeToDataDir(void){
AssertState(DataDir);
if (chdir(DataDir) < 0)
ereport(FATAL,
(errcode_for_file_access(),
errmsg("could not change directory to \"%s\": %m",
DataDir)));
}
将当前工作目录切换至PGDATA中的原因是因为,大多数的postmaster守护进程和后端进程都是假定我们在PGDATA目录下,因为它们可以使用相对路径来访问数据目录中或是数据目录下的内容。接着校验GUC中的一些无效组合参数,然后开始创建PGDATA数据蔟目录锁文件,即postmaster.pid文件。当数据目录锁文件postmaster.pid文件创建成功之后,再次打开pg_control锁文件。本次将读取该文件的二进制数据,并对该文件中的内容进行校验处理,此部分的功能主要由函数ReadControlFile()完成。该函数的部分逻辑代码如下:
static void
ReadControlFile(void){
pg_crc32c crc;
int fd;
static char wal_segsz_str[20];
int r;
/*
* Read data...
*/
fd = BasicOpenFile(XLOG_CONTROL_FILE,O_RDWR | PG_BINARY);
if (fd < 0)
ereport(PANIC,
(errcode_for_file_access(),
errmsg("could not open file \"%s\": %m",
XLOG_CONTROL_FILE)));
pgstat_report_wait_start(WAIT_EVENT_CONTROL_FILE_READ);
r = read(fd, ControlFile, sizeof(ControlFileData));
if (r != sizeof(ControlFileData)){
if (r < 0)
ereport(PANIC,
(errcode_for_file_access(),
errmsg("could not read file \"%s\": %m",
XLOG_CONTROL_FILE)));
else
ereport(PANIC,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("could not read file \"%s\": read %d of %zu",
XLOG_CONTROL_FILE, r, sizeof(ControlFileData))));
}
pgstat_report_wait_end();
close(fd);
. . . . . . //省略若干
}
pg_control_version成员标识了pg_control本身的格式,而catalog_version_no则负责标识系统目录(PGDATA)的格式。对pg_control文件中读出来的内容,着重判断catlog_version_no字段值,进行兼容性检查,若当前数据库与后端可执行文件不兼容,则在可能造成任何损坏之前立即终止数据库。每个版本的PostgreSQL数据库,都有着唯一的catalog_version_no标识符,对于PostgreSQL 13.2版本,该值为:202007201 。
当pg_control文件中的某个内容不正确时候,立即终止数据库的初始化和运行。比如本次测试中,我特意移除pg_control文件,并重新创建一个同名文件,然后尝试启动数据库,最终报错如下:

3. pg_control文件损坏恢复措施
若由于某些因素导致pg_control控制文件被损坏,这是可以使用pg_resetwal程序命令来进行恢复。在9.6以及9.6更早之前的版本中,使用pg_resetxlog。
---------------------------------------------------------------
postmaster.pid与pg_control文件
可以肯定的是,这两个文件对于PostgreSQL数据库来说,都是至关重要的。但是它们之间还是有着很大的差异,即各自负责的功能不同,所谓各司其职。对于pg_control,它是PostgreSQL数据库的控制文件,是在第一次安装数据库(initdb)时候生成的,文件中存储的是当前数据库目录(PGDATA)的版本、初始化配置参数、系统唯一标识、CRC校验码等等,该文件是在initdb之后就一直存在的,PostgreSQL服务的启停不影响该文件的存在状态,也就是说这个文件只要该PGDATA数据蔟目录是有效的,那么就会一直存在。如果这个文件被删除,那么PostgreSQL数据库服务就永远起不来了。它保证了数据库的安全,同时通过读取该文件内容并进行逻辑校验,能保证不同版本的程序命令无法进行非法操作。
而postmaster.pid文件则不一样,它是随着PostgreSQL数据库服务的每次启动而创建,停止而被删除,也就是说,该文件的存在与否永远受到服务状态的影响。该文件的读取是在pg_control文件之后,而且该文件中存储的数据和系统的配置参数这些没有关系,它只记录当前启动的postmaster服务的进行PID、进程启动时间戳、数据蔟目录位置、socket套接字目录位置、共享内存key等信息,当PostgreSQL被停止后,该文件将立刻被删除,从而保证下一次的PostgreSQL服务能够正常启动。
pg_control是PostgreSQL服务能够启动的必要条件。
PostgreSQL服务的正常运行离不开postmaster.pid文件
当PostgreSQL服务正常启动之后,会在ServerLoop()函数中负责管理各后端辅助进程、后台进程以及和系统有关的控制文件pg_control、锁文件postmaster.pid,以及等待接收客户端的连接处理等等。该函数内部是死循环,只要PostgreSQL服务运行正常,则该函数将永远不会返回;若返回则表明当前服务出现了异常情况,默认采取的措施是立刻停止当前的PostgreSQL服务。
在ServerLoop()函数中,会每隔1分钟去检测一次postmaster.pid文件的状态,以确认该文件没有被覆盖或是被删除。
#define SECS_PER_MINUTE 60
for( ; ; ){
// . . . . . . 省略其余部分代码
if (now - last_lockfile_recheck_time >= 1 * SECS_PER_MINUTE){
if (!RecheckDataDirLockFile()){
ereport(LOG,
(errmsg("performing immediate shutdown because data directory lock file is invalid")));
kill(MyProcPid, SIGQUIT);
}
last_lockfile_recheck_time = now;
}
//. . . . . . 省略其余部分代码
}
如果有,则立刻强制关闭服务。这样就避免了postmaster守护进程和子进程在它们的数据库消失之后仍然挂起的问题。如果在相同的地方创建(initdb)新的数据库集群,可能会导致该问题。同时还提供了一些保护,即防止数据库管理员(Database Administrator, DBA)不理智地去删除postmaster.pid文件并手动启动一个新的postmaster。
那么这里会有两种情况,第一种是直接删除postmaster.pid文件;第二种是修改该文件中的内容,但是文件依然存在。下面将分别详细进行讲解这两种情形下的PostgreSQL数据库服务的采取措施是什么。
1、postmaster.pid文件被删除
对应postmaster.pid文件的检测,主要由RecheckDataDirLockFile()函数负责处理。首先函数尝试打开该文件,若成功,则继续下面的流程判断处理;反之,若文件打开失败,则对open()函数返回的错误码进行判断, 若该错误码是ENOTDIR,则立刻停止该数据库服务。若为其他错误码,则继续下一次的检测逻辑。其部分代码如下:
bool RecheckDataDirLockFile(void){
int fd;
int len;
long file_pid;
char buffer[BLCKSZ];
fd = open(DIRECTORY_LOCK_FILE, O_RDWR | PG_BINARY, 0);
if (fd < 0){
switch (errno){
case ENOENT:
case ENOTDIR:
/* disaster */
ereport(LOG,
(errcode_for_file_access(),
errmsg("could not open file \"%s\": %m",
DIRECTORY_LOCK_FILE)));
return false;
default:
/* non-fatal, at least for now */
ereport(LOG,
(errcode_for_file_access(),
errmsg("could not open file \"%s\": %m; continuing anyway",
DIRECTORY_LOCK_FILE)));
return true;
}
}
// . . . . . . 省略若干业务代码
附:open()函数的错误码ENOTDIR,表示“给定的路径虽然存在,但不是一个目录。”
其具体内部业务逻辑处理流程图如下所示:

结论:若运行中的PostgreSQL服务,当检测到postmaster.pid文件不存在时,则立刻停止服务。如下图所示:

2、postmaster.pid文件内容被修改
从第1节中知道,若postmaster.pid文件被删除掉,则服务将在本次检测时候,立刻停止运行中的postmaster服务。那么postmaster.pid文件不被删除,但是修改了其中的内容又会怎样呢?下面我们将继续分析这个问题。
这部分的业务代码如下所示:
bool RecheckDataDirLockFile(void){
// . . . . . . 省略若干业务代码
len = read(fd, buffer, sizeof(buffer) - 1);
pgstat_report_wait_end();
if (len < 0){
ereport(LOG,
(errcode_for_file_access(),
errmsg("could not read from file \"%s\": %m",
DIRECTORY_LOCK_FILE)));
close(fd);
return true; /* treat read failure as nonfatal */
}
buffer[len] = '\0';
close(fd);
file_pid = atol(buffer);
if (file_pid == getpid())
return true; /* all is well */
/* Trouble: someone's overwritten the lock file */
ereport(LOG,
(errmsg("lock file \"%s\" contains wrong PID: %ld instead of %ld",
DIRECTORY_LOCK_FILE, file_pid, (long) getpid())));
return false;
}
当文件成功打开之后,将返回一个指向当前内核中可用的最小文件描述符fd。然后从中读取一行数据,postmaster.pid文件中的第一行数据是当前运行的postmaster守护进程的PID。

因此通过判断该PID的值和getpid()函数获取的结果进行比对即可得知这个PostgreSQL服务是否正常。若正常,则getpid()和从postmaster.pid文件中获取的PID值相同,反之,则不相同。所以若该文件中,除第一行数据外,其余行数据被修改或是删除时,PostgreSQL服务仍然能够运行;反之若第一行数据被修改,那么服务也会立刻停止运行。其内部逻辑处理流程图如下所示:
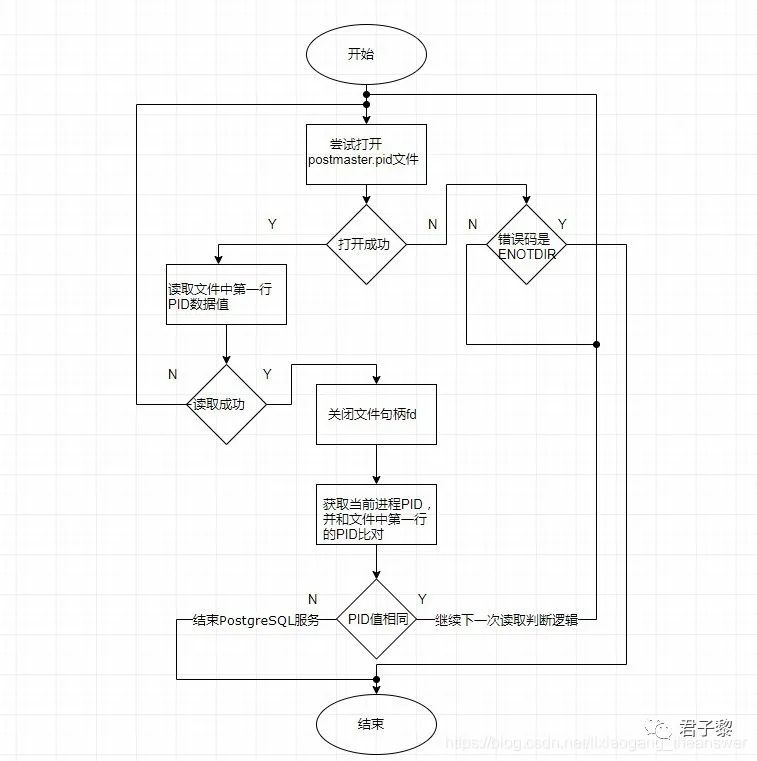
当修改了第一行数据之后,PostgreSQL服务立刻停止并打印相关的日志信息。

小结
上文比较详细地介绍了pg_control控制文件与postmaster.pid锁文件两者之间的区别,包括但不限于文件的生成时间、生命周期、规则以及文件大致中大致内容。同时对postmaster.pid锁文件的存在与否,以及文件中内容修改、怎么修改对PostgreSQL服务造成的不同影响进行了详细分析说明。
---------------------------------------------------------------
为何postmaster辅助进程均带有前缀"postgres:"
PostgreSQL内核中为每个辅助进程创建进程名的原理过程:首先它在初始化每个进程的入口函数中,对应初始化 MyBackendType 变量,然后调用函数GetBackendTypeDesc()来获取对应的进程名。之后启动postmaster进程,得到的所有辅助进程名前面均带有“postmaster: ”前缀,如下图所示:

1.1 编译不带“postgres: ”前缀的辅助进程
PostgreSQL内核源码中的init_ps_display()函数,会对运行的辅助进程添加了前缀操作,如下:
#if defined(PS_USE_SETPROCTITLE) || defined(PS_USE_SETPROCTITLE_FAST)
#define PROGRAM_NAME_PREFIX ""
#else
#define PROGRAM_NAME_PREFIX "postgres: "
#endif
if (*cluster_name == '\0'){
snprintf(ps_buffer, ps_buffer_size,
PROGRAM_NAME_PREFIX "%s ",
fixed_part);
}
else{
snprintf(ps_buffer, ps_buffer_size,
PROGRAM_NAME_PREFIX "%s: %s ",
cluster_name, fixed_part);
}
fixed_part是每个辅助进程的名字,通过snprintf指定的格式化之后,ps_buffer缓存中的数据即为: postgres: process_name。比如是初始化logger日志辅助进程,则ps_buffer中的结果为 postgres: logger。若想运行的postmaster服务中的辅助进程不带postgres前缀,则需要修改PostgreSQL内核源码中的ps_status.c文件。该文件位于src/backend/misc/ps_status.c。具体修改位置是init_ps_display()函数中的宏PROGRAM_NAME_PREFIX。修改之后,重新编译安装PostgreSQL。即指向以下三步骤:
./configure
(备注:若最初选择了参数–prefix指定安装的位置,则这里也需要保持一致)
make -j
make install
之后再重新启动postmaster进程,就可以看到辅助进程已经没有前缀了。如下图所示:

2. 为postmaster辅助进程添加自定义前缀
默认的postmaster中所有辅助进程名都带有“postgres:”前缀,除此之外,你还可以在具体进程名,“postgres:”前缀之后添加自定义的前缀名字。直接上图看效果:

2.1 postgresql.conf配置文件中两个重要参数
若想要为辅助进程名添加名字前缀,则需要同时开启以下两个配置参数,分别是:
(1) update_process_title,配置为on,则表示开启该功能,反之off,则不停用。
(2) cluster_name 自定义辅助进程前缀名,此处填写为: cluster_name = 'lixiaogang5'。默认为空,即cluster_name = ''。
##################################### postgresql.conf配置文件 #####################
#------------------------------------------------------------------------------
# PROCESS TITLE
#------------------------------------------------------------------------------
#cluster_name = '' # added to process titles if nonempty
cluster_name = 'lixiaogang5' # (change requires restart)
update_process_title = on
当postmaster服务运行时修改,则需要重启生效。
---------------------------------------------------------------
libpq库
libpq是一套使用C语言编写的以供(C)程序员访问PostgreSQL后端服务器的库函数集合。通过使用libpq库函数,使客户端能够像psql程序命令一样登录PostgreSQL数据库,并进行相关的系列操作,比如登录、验证、创建表、插入表数据、删除表、向服务端发送查询请求、接收响应请求等等。同时,libpq也是其他几个postgres应用程序接口的底层引擎,包括libpq++(C++)、libpgtcl(Tcl)、Perl和ecpg。
libpq库函数嵌套在PostgreSQL源码发行包中。因此,首先需要从PostgreSQL的官方网站下载你所需要的对应发行版本,然后进行解压、编译。当解压发行包过后,则可得到该PostgreSQL版本对应的libpq库,其位于src/interfaces/ 目录下。libpq目录下的文件列表即为libpq的各库函数集合定义与实现。通过libpq同级目录的 Makefile文件,可编译得到libpq的客户端程序所必须链接到的libpq动态库(libpq.so)文件。
对于PostgreSQL 13.2版本,libpq目录下的共有34个文件,其中两个是目录文件,另外32个是常规文件。
libpq目录各文件的作用
该目录下的各文件,其具体功能如下所示:
fe-auth.h , fe-auth.c:
这两个文件是“前端(客户端)网络身份验证、授权的”的相关定义与实现。
fe-connect.c
该文件主要实现了“与建立到后端(PostgreSQL服务器)连接”相关的函数的实现。
fe-exec.c
该文件主要实现了“与向后端(PostgreSQL服务器)发送查询相关的函数”的实现。
fe-gssapi-common.h, fe-gssapi-common.c
这两个文件主要实现了“前端(客户端)GSSAPI公共例行程序”的定义和实现。
fe-lobj.c
该文件实现了“前端(客户端)大对象”操作的接口。
fe-misc.c
该文件提供了与“后端(PostgreSQL服务器)常规通信例行程序”不同的细节实现,这里使用了非阻塞模式的套接字,而不是stdout流,这样可以避免不必要的应用程序的阻塞。
fe-print.c
该文件提供了“用于优美地打印查询结果的函数”。如果你使用过Mongodb的终端pretty()查询命令(eg: db.a.find().pretty()),想必你一定不陌生,它会使终端展示的数据格式更加符合阅读。
fe-protocol2.c, fe-protocol3.c
这两个文件实现了“特定于前端/后端协议版本2/3的函数”的相关实现。
fe-secure-* 开头的5个函数
这5个函数提供并实现了SSL的支持和实现。
legacy-pqsignal.c
该文件内部使用sigaction函数完成了相关信号集的安装、登记。对于sigacton()函数的功能,请阅读 Linux信号函数之sigaction系统调用 。
libpq-events.h, libpq-events.c
这两个文件实现了应用程序调用“libpq事件API的相关定义与实现”。
libpq-fe.h
该文件包含了“前端postgres应用程序使用函数的结果和扩展的定义”。
libpq-int.h
该文件包含了“仅供前端libpq库使用的内部定义。” 不提供给调用它的应用程序使用。
pqexpbuffer.h, pqexpbuffer.c
这两个文件实现了“一种无限扩展的字符串数据类型”。更通俗点说,就是C++中的string STL的封装实现。
pthread-win32.c
该文件实现了Win32下的pthread线程的封装、实现。
使用libpq的客户端程序,需要(必须)包含libpq-fe.h头文件,并且必须链接到libpq.so动态库。将libpq函数库集合应用到实际项目中,需要包含libpq-fe.h文件,其实该文件内还包含了另外两个头文件,分别是:pg_config_ext.h、postgres_ext.h。所以实际上共需要包含3个头文件。
在postgresql-13.2/src/test/examples/目录下,有几个libpq库函数的使用用例,其中包括如何创建一个客户端连接句柄、如何使用查询、获取数据库中表记录(元组)数、列数、销毁PostgreSQL返回的报文缓存变量、释放客户端连接句柄等等。所以看完该目录下的几个用例之后,对libpq库函数的使用便有了清晰的感念。
---------------------------------------------------------------
PostgreSQL中的文件描述符
文件描述符(file descriptor)是唯一标识计算机操作系统中打开文件的数字(非负整数),它描述了数据资源,以及如何访问该资源。当进程需要打开一个文件(网络套接字、字符设备等)时,内核授予访问权限,并在其全局文件表中创建一个条目,然后向进程提供该条目的位置。也就是说,类UNIX内核使用fd引用所有打开的文件。对于文件描述符,它具有以下两个属性:
1)、每个进程都有自己的增量fd空间。被关闭的fd占用的正整数可以被重复利用。单个进程可以同时打开的文件句柄数量受到系统limit设置的限制的数量。
2)、按照约定,所以shell在启动一个新应用程序时候,总是打开了这三个文件描述符,它们分别是:0(标准输入)、1(标准输出)、2(标准错误)。
由于操作系统内核对每个进程同时刻所能打开的文件句柄数量作了限制,因此PostgreSQL数据库在进程起来的时,会对可打开的文件句柄数量作一个评估,然后初始化一个可打开文件句柄数量的安全值。
PostgreSQL评估可打开的fd数量
在初始化postmaster守护进程时,当设置了信号量之后,便开始统计、评估当前系统环境上可打开文件句柄的数量。之所以要在初始化信号量之后,是因为在某些平台上,信号量会被视为打开的文件。
该评估过程主要由函数 set_max_safe_fds() 完成。具体统计过程如下:
1、获取当前系统允许打开的文件句柄个数,以及有多少文件句柄已经打开(被使用)。
这里主要使用了类UNIX的系统函数getrlimit(),该函数的功能是获取操作系统的资源限制。操作系统内核默认会对系统资源做一些默认值的限制,比如允许打开的文件句柄个数、最大用户进程数、文件大小等等:
# ulimit -a
getrlimit()函数的格式声明为:
int getrlimit(int resource, struct rlimit *rlim);
该函数接收两个参数,参数resource指定想要获取对应类型的资源限制,比如:RLIMIT_NOFILE(每个进程可以打开的最大文件数)、RLIMIT_AS(进程可用存储区的最大总长度-字节)等等。struct rlimit是一个结构体类型声明,该类型包括两个结构体成员,如下:
struct rlimit {
rlim_t rlim_cur; /* Soft limit */
rlim_t rlim_max; /* Hard limit (ceiling for rlim_cur) */
};
其中rlim_cur表示软限制;rlim_max表示硬件限制。软限制是内核对相应资源强制执行的值,而硬限制充当软限制的上限:非特权进程只能将软限制设置为从0到硬限制的范围的值,并(不可逆地)降低其硬限制。特权进程(在Linux下:具有CAP_SYS_RESOURCE功能的进程)可以对任意一个限制值进行更改。值RLIM_INFINITY表示对资源没有限制(无论是在getrlimit()返回的结构中还是传递给setrlimit()的结构中)。
PostgreSQL数据库中默认每个进程能够打开的最大文件描述符数量是:1000。该值的定义是在fd.c文件中(fd.c文件位于src/backend/storage/file/fd.c)。
int max_files_per_process = 1000;
如果getrlimit()函数执行成功,那么一直调用dup(0)系统函数,直到循环次数大于等于max_files_per_process,或者是dup(0)返回的最小可用文件描述符大于等于rlim.rlim_cur(资源软限制,默认是1024)时,则结束循环。
当跳出循环之后,一 一释放fd指针变量中打开的文件句柄。默认申请了1024个文件句柄空间,并且max_files_per_process最大值是1000,所以后面的24个索引是0,无文件句柄。
int *fd = NULL;
size = 1024;
fd = (int *) palloc(size * sizeof(int));
最终释放fd指针变量申请的内存空间,并且统计出当前系统可用的文件句柄个数(usable_fds,这个句柄数量并不是真正的可打开的文件句柄数,它仅仅代表dup成功的数量),并且计算当前系统已经打开的文件句柄数(默认0、1、2是已经打开),其计算方法是: 当前最小的可用文件描述符 + 1 - 成功打开的文件句柄数。
*usable_fds = used;
*already_open = highestfd + 1 - used;
如下图所示,可以计算得知当前已经打开了3个文件句柄(记住:0是一个合法的fd数)。
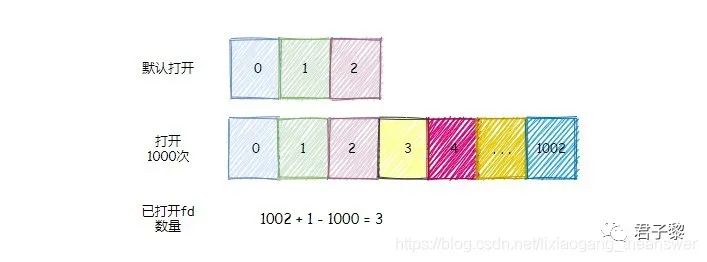
对于统计系统资源的以使用句柄数,其完整的流程图如下:
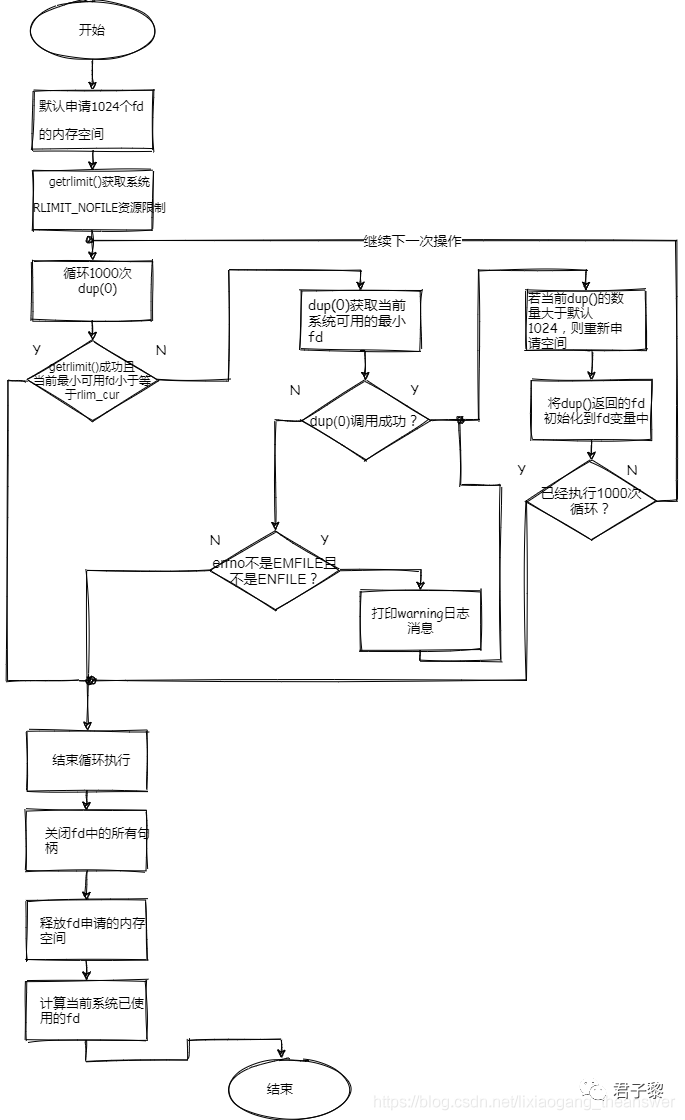
2、计算PostgreSQL可以安全使用的文件句柄个数
在1中得出准确的已打开文件句柄数,尽管也返回了可使用的文件句柄个数(usable_fds),但是这个数是有些风险的,因为它只是默认的1000。为了降低风险以及减去不用咨询fd.c(fd.c实现了VFD机制,对外提供虚拟的经过封装了的FD,后面会专门出一篇博文讲解PostgreSQL的VFD)就打开的倾斜系数。PostgreSQL采取的保证系统可安全使用的最大fd计算方式是:
取 max_safe_fds = Min(usable_fds, max_files_per_process - already_open)的最小值。
#define Min(x, y) ((x) < (y) ? (x) : (y))
其中usable_fds等于max_files_per_process(1000),already_open(3)。所以可用的是 997个。此外,fd.c文件中特意说明了,我们还必须为system()、动态加载程序和其他试图在不咨询fd.c的情况下打开文件的代码保留一些文件描述符 。这里保留的文件描述符个数是:10个。
#define NUM_RESERVED_FDS 10
最终系统可安全使用的最大文件描述符个数是:max_safe_fds -= NUM_RESERVED_FDS。
max_safe_fds = Min(usable_fds, max_files_per_process - already_open);
/*
* Take off the FDs reserved for system() etc.
*/
max_safe_fds -= NUM_RESERVED_FDS;
3、当PostgreSQL可使用的fd数量小于48,则进程启动失败
如果最终PostgreSQL可使用的文件描述符数量小于48个,那么将不允许postmaster服务起来。(选择FD_MINFREE(64)这个值是为了使用" ulimit -n 64", 但也不能比这个小太多。注意,这个值确保numExternalFDs可以至少为16;PostgreSQL作者在编写这些代码是,contrib/postgres_fdw回溯测试将不能通过,除非它能增长到至少14个)
#define FD_MINFREE 48
/*
* Make sure we still have enough to get by.
*/
if (max_safe_fds < FD_MINFREE)
ereport(FATAL,
(errcode(ERRCODE_INSUFFICIENT_RESOURCES),
errmsg("insufficient file descriptors available to start server process"),
errdetail("System allows %d, we need at least %d.",
max_safe_fds + NUM_RESERVED_FDS,
FD_MINFREE + NUM_RESERVED_FDS)));
若可安全使用的最大文件描述符个数大于48,那么初始化全局变量 max_safe_fds 。这个变量非常重要,本文前面提到过,PostgreSQL内部使用了VFD机制,对外提供的是虚拟的文件fd,内部对真实的文件句柄fd进行了封装,每次底层去获取fd时候,都会使用这个全局变量 max_safe_fds来进行判断。以达到安全使用fd以及确保进程不会因为超出系统的文件描述符个数限制而产生一些内核级别的bug。
4、成功获可安全使用的最大文件描述符数量
成功初始化max_safe_fds变量之后,便日志打印告知当前的相关变量值信息。
elog(DEBUG2, "max_safe_fds = %d, usable_fds = %d, already_open = %d", max_safe_fds, usable_fds, already_open);
出于各种原因,PostgreSQL服务器会打开许多文件描述符。包括基表、临时文件(例如排序和哈希散列spool文件等)以及对libpq C常规库(如system(3))的随机调用。一个进程可以拥有的打开文件的数量很容易超过系统限制(在许多现代操作系统上,默认这个值约为1024,但在其他操作系统上可能会更低)。
为了统一管理、使用文件句柄,于是乎PostgreSQL引进了VFD机制,所谓VFD即指虚拟文件描述符(Virtual File Descriptors(VFDs))。VFD作为LRU池进行维护管理,根据需要打开和关闭实际的操作系统(内核)分配的文件描述符。当进程需要打开文件时候,VFD总是能够返回一个有效且可用的文件描述符。对于进程而言,VFD像是一个黑盒,它对外屏蔽掉了内部的实现细节,以及相应的逻辑判断处理。
本质上,PostgreSQL所能够使用的文件描述符数量仍然是操作系统规定的最大值,只不过因为VFD内部特殊实现机制,给进程一种表象,即文件描述符数量是无穷尽的。进程在操作系列文件(UNIX宗旨,一切皆文件,因此这里包括文件包括目录等)时,不是直接通过调用系统函数(比如open、read、write、lseek、sync等)去处理,而是通过VFD。VFD内部会进行系列的逻辑判断处理,并最终给出一个待处理文件的对应内核中的文件句柄fd。不过反馈给进程的fd不是内核分配的那个真实fd,而是一个虚拟的,即经过VFD内部一层映射后的虚拟文件句柄vfd。实际上,该vfd是VFD缓存池VfdCache中的真实文件句柄fd所对应的VFD索引,即数组下标。
从Linux内核架构图来看,VFD位于应用层的系统调用(即open、read等)函数上方,如下图示所示:
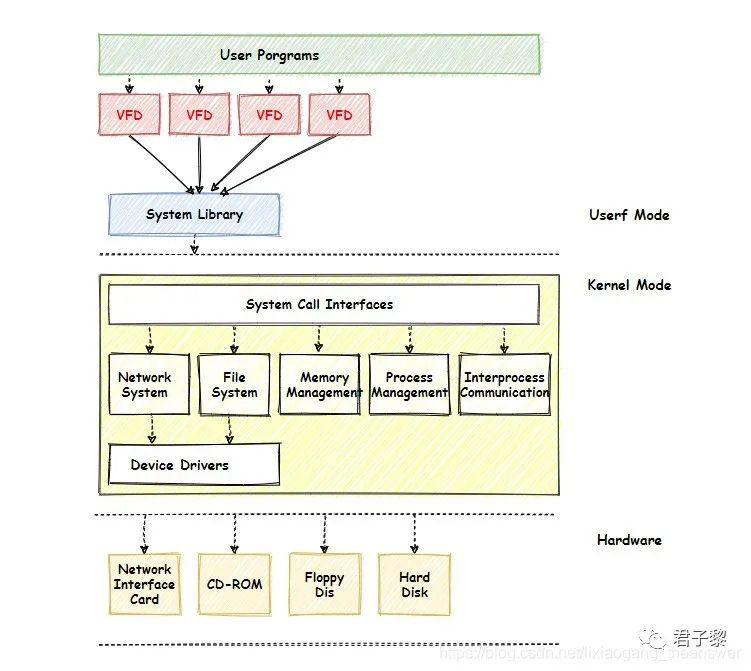
其顺序是:PostgreSQL进程直接调用VFD,VFD内部封装了系统函数。当进程要获取文件相关数据信息时候直接调用VFD的系列封装函数即可。
VFD数据结构
PostgreSQL是通过声明一个名为Vfd的结构体数据类型来实现VFD的LRU(Last Recently Used,最近最少使用)缓存池管理的。因此,在进入LRU池管理之前,让我们先对Vfd的结构类型声明有个熟悉的概念。
对于PostgreSQL中的进程,每当打开一个文件时候,均会返回一个Vfd结构体变量。对于Vfd的类型声明,位于src/backend/storage/file/fd.c文件中,其格式如下所示:
typedef struct vfd{
int fd; /* current FD, or VFD_CLOSED if none */
unsigned short fdstate; /* bitflags for VFD's state */
ResourceOwner resowner; /* owner, for automatic cleanup */
File nextFree; /* link to next free VFD, if in freelist */
File lruMoreRecently; /* doubly linked recency-of-use list */
File lruLessRecently;
off_t fileSize; /* current size of file (0 if not temporary) */
char *fileName; /* name of file, or NULL for unused VFD */
/* NB: fileName is malloc'd, and must be free'd when closing the VFD */
int fileFlags; /* open(2) flags for (re)opening the file */
mode_t fileMode; /* mode to pass to open(2) */
} Vfd;
在PostgreSQL 13.2版本中,该结构体数据类型中共有10个数据成员。下面分别对各成员所充当的功能进行描述,这将有助于接下来的对LRU池逻辑的理解。
fd
fd是当前VFD所对应的内核分配的真实文件描述符fd。如果VFD没有打开文件(即没有文件描述符),则其初始值是VFD_CLOSED,即-1。其宏名声明如下:
#define VFD_CLOSED (-1)
fdstate
记录该VFD的状态标记位。在13.2版本中,该状态标记位共有以下三种,分别是:FD_DELETE_AT_CLOSE、FD_CLOSE_AT_EOXACT 以及FD_TEMP_FILE_LIMIT。其声明如下:
#define FD_DELETE_AT_CLOSE (1 << 0) /* T = delete when closed */
#define FD_CLOSE_AT_EOXACT (1 << 1) /* T = close at eoXact */
#define FD_TEMP_FILE_LIMIT (1 << 2) /* T = respect temp_file_limit */
这里之所以强调PostgreSQL版本,是因为不同版本间该成员的标记位值差异比较大。比如在V9.6.7中,该标记位的值声明如下:
/* these are the assigned bits in fdstate below: */
#define FD_TEMPORARY (1 << 0) /* T = delete when closed */
#define FD_XACT_TEMPORARY (1 << 1) /* T = delete at eoXact */
不但宏名改变,其值也有所差异:
FD_DELETE_AT_CLOSE
若fdstate第1位置1,则表示文件关闭时应该删除掉。
FD_TEMP_FILE_LIMIT
若fdstate第2位置1,则遵守临时文件限制。
FD_CLOSE_AT_EOXACT
若fdstate第3位置1,则在eoXact关闭。
resowner
记录资源所有者,用于自动清理。该成员所属的结构体类型如下:
typedef struct ResourceOwnerData{
ResourceOwner parent; /* NULL if no parent (toplevel owner) */
ResourceOwner firstchild; /* head of linked list of children */
ResourceOwner nextchild; /* next child of same parent */
const char *name; /* name (just for debugging) */
/* We have built-in support for remembering: */
ResourceArray bufferarr; /* owned buffers */
ResourceArray catrefarr; /* catcache references */
ResourceArray catlistrefarr; /* catcache-list pins */
ResourceArray relrefarr; /* relcache references */
ResourceArray planrefarr; /* plancache references */
ResourceArray tupdescarr; /* tupdesc references */
ResourceArray snapshotarr; /* snapshot references */
ResourceArray filearr; /* open temporary files */
ResourceArray dsmarr; /* dynamic shmem segments */
ResourceArray jitarr; /* JIT contexts */
/* We can remember up to MAX_RESOWNER_LOCKS references to local locks. */
int nlocks; /* number of owned locks */
LOCALLOCK *locks[MAX_RESOWNER_LOCKS]; /* list of owned locks */
} ResourceOwnerData;
该结构体内部成员列表中分别记录了快照、动态shmem段、所分配的缓存资源等等。
nextFree
指向下一个空闲的VFD。其中nextFree成员的数据类型是FILE。注意,Vfd中的FILE并不是C库中的文件流FILE数据类型。在Vfd中,其FILE类型是int整型的别名,它表示该VFD位于VfdCache数组中的下标。如下所示:
typedef int File;
而对于C库中的FILE类型,其结构体类型声明如下(该结构类型声明来自glibc V2.31)。
typedef struct _IO_FILE FILE;
struct _IO_FILE{
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
/* The following pointers correspond to the C++ streambuf protocol. */
char *_IO_read_ptr; /* Current read pointer */
char *_IO_read_end; /* End of get area. */
char *_IO_read_base; /* Start of putback+get area. */
char *_IO_write_base; /* Start of put area. */
char *_IO_write_ptr; /* Current put pointer. */
char *_IO_write_end; /* End of put area. */
char *_IO_buf_base; /* Start of reserve area. */
char *_IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
int _flags2;
__off_t _old_offset; /* This used to be _offset but it's too small. */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
如何理解上面提到的“指向下一个空闲的VFD?” 请在后面的内容是找到。
lruMoreRecently
该成员指向比该VFD最近更常使用的虚拟文件描述符。
lruLessRecently
指向此LRU虚拟句柄池中比该VFD最近更不常用的虚拟文件描述符。
fileSize
如果当前VFD是指向文件不是临时文件,则表示当前文件的大小。
fileName
文件名,对于未使用的VFD,则其值为NULL。注意,这里的fileName是动态malloc的内存空间,在关闭该VFD虚拟文件描述符时候,需要free掉指针的内存空间。
fileFlags
文件权限标记,比如当该文件不存在且open()的第二个标记参数或上O_CREATE时,则该参数设置文件的所有者、所属组、其他用户的文件读、写和执行权限。
fileMode
用于打开/重打开(open())文件的标记。比如O_RDONLY (只读)、O_WRONLY(只写)或O_RDWR(读写)等模式。如下所示:
#define PG_MODE_MASK_OWNER (S_IRWXG | S_IRWXO)
/*
* Mode mask for data directory permissions that also allows group read/execute.
*/
#define PG_MODE_MASK_GROUP (S_IWGRP | S_IRWXO)
/* Default mode for creating directories */
#define PG_DIR_MODE_OWNER S_IRWXU
/* Mode for creating directories that allows group read/execute */
#define PG_DIR_MODE_GROUP (S_IRWXU | S_IRGRP | S_IXGRP)
/* Default mode for creating files */
#define PG_FILE_MODE_OWNER (S_IRUSR | S_IWUSR)
/* Mode for creating files that allows group read */
#define PG_FILE_MODE_GROUP (S_IRUSR | S_IWUSR | S_IRGRP)
在介绍完Vfd结构类型的成员列表之后,接下来重点剖析PostgreSQL是如何使用Vfd数据结构来实现LRU句柄资源池的。
LRU虚拟文件描述符池
对于PostgreSQL,每个后台进程(更多关于后台进程的概念,请阅读 PostgreSQL数据库体系架构)都使用一个所谓的LRU(Last Recently Use,最近最少使用)池来管理所有已打开的虚拟文件描述符VFD。对于该LRU池中的每一个VFD,都分别一一对应磁盘上已打开的文件。每个进程都拥有者自己私有的LRU池和文件描述符VFD。当进程需要打开文件中,直接从自己的LRU池中申请VFD,当不需要时释放VFD(包括对应的内存段、缓存资源、快照等)。
1、VfdCache全局数组
PostgreSQL通过在fd.c文件中定义一个指向Vfd数据类型的全局指针变量VfdCache来开始管理LRU池。它是虚拟文件描述符数组指针,它在需要时动态增长。VfdCache作为LRU池的头部(类似于链表中的头指针)。
对于VfdCache指针变量的定义如下所示:
static Vfd *VfdCache;
static Size SizeVfdCache = 0;
/*
* Number of file descriptors known to be in use by VFD entries.
*/
static int nfile = 0;
这里有3个重要的变量,分别是:VfdCache、SizeVfdCache 和nfile。VfdCache指向LRU池头部,SizeVfdCache 表示当前LRU池的大小。nfile表示当前LRU池中已使用的VFD虚拟文件描述符句柄数量。
2、VfdCache数组初始化
VfdCache数组指针变量在postmanster进程起来之前,会进行初始化操作。并且置fd成员的值为VFD_CLOSED, 表示该文件描述符fd不可用。该初始化过程由函数InitFileAccess()完成。
Assert(SizeVfdCache == 0); /* call me only once */
/* initialize cache header entry */
VfdCache = (Vfd *) malloc(sizeof(Vfd));
if (VfdCache == NULL)
ereport(FATAL,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of memory")));
MemSet((char *) &(VfdCache[0]), 0, sizeof(Vfd));
VfdCache->fd = VFD_CLOSED;
注意,VfdCache[0]不是一个可用的VFD,它是整个LRU池的头节点(即头指针)。当初始化完成之后,VfdCache指向堆空间中的某个地址,示意图如下:
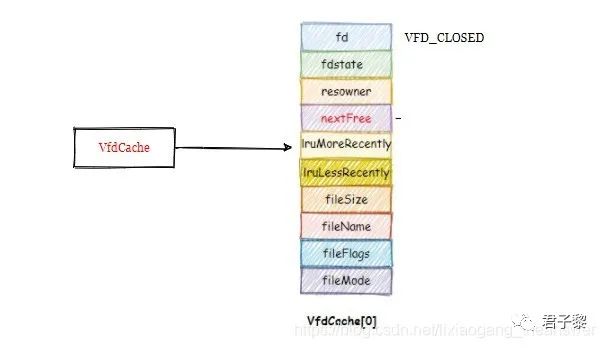
因为全局变量SizeVfdCache 动态记录着VfdCache池的大小,所以这里SizeVfdCache将会被置为1。因为此时VfdCache指向LRU池的头部。虽然VFD[0]不是一个可用的VFD,但它是唯一指向该LRU池,充当头节点的作用。
{
. . . //省略若干
SizeVfdCache = 1;
/* register proc-exit hook to ensure temp files are dropped at exit
*/
on_proc_exit(AtProcExit_Files, 0);
}
同时on_proc_exit()将注册一个回调函数,用于确保临时文件在进程退出时候能被删除。每当打开一个文件时,内部会根据打开文件的类型初始化Vfd结构体数据类型中的数据成员fdstate。在进程退出时候会根据fdstate成员的不同值,分别调用对应的函数进行情理操作。如下代码所示:
switch (desc->kind){
case AllocateDescFile:
result = fclose(desc->desc.file);
break;
case AllocateDescPipe:
result = pclose(desc->desc.file);
break;
case AllocateDescDir:
result = closedir(desc->desc.dir);
break;
case AllocateDescRawFD:
result = close(desc->desc.fd);
break;
default:
elog(ERROR, "AllocateDesc kind not recognized");
result = 0; /* keep compiler quiet */
break;
}
3、LRU池结构图
LRU池是一个双向链表,开始和结束于元素VfdCache[0],元素0是特殊节点,它不代表一个文件,其中fd字段总是等于VFD_CLOSED。元素0是一个头节点,它标明了LRU池的开始/结束。只有当前真正打开(分配了FD)的VFD元素在LRU池中。
虽然LRU池是双向链表,但是Vfd结构中并没有指针,而是通过lruMoreRecently、lruLessRecently这两个int类型的成员变量实现了双向链表中的next和prev指针的功能。
对于LRU池中的每个VFD,均使用成员lruMoreRecently、lruLessRecently链接两个VFD变量,通过lruMoreRecently成员数组下标链接最近更常使用的VFD;而通过lruLessRecently成员数组下标链接最近不常用的VFD。如下图所示:

其中VfdCache[0]充当该链接池的头节点(特殊VFD);另外该LRU池的尾元素VfdCache[0]通过lruLessRecently成员链接到VfdCache[0]头部,而VfdCache[0]头节点通过lruMoreRecently成员链接到VfdCache[n]。这样就能够很方便地通过VfdCache[0]头节点找到该池中最近最少使用的VFD。
当然,这个LRU池的大小同样是受到操作系统对进程打开文件描述符数据的限制是一样的。在PostgreSQL中,与max_safe_fds变量的值极其相关。
从LRU池获取VFD
在第1节中说过,postmaster进程起来时候,会对VfdCache指针变量分配一个Vfd类型大小内存空间。但是此时,还没有可使用的VfdCache虚拟文件句柄,正如前面提到的,VfdCache[0]充当双向链表头节点的功能,所以它是不会存储有效的VFD的。因此,在第一次尝试获取VFD时候,进程会先走AllocateVfd()函数以分配有效的可用的VFD变量。
VfdCache在分配VFD时候,其采取的方案是成倍的申请(最小的VFD申请数量是32)。比如在第一次初始化VfdCache内存空间时候,在成功申请内存空间的情况下,会将SizeVfdCache变量置为1。该变量记录着当前VfdCache申请的VFD个数。首次调用AllocateVfd()时,因为SizeVfdCache = 1,所以小于32,则本次申请32个VFD变量内存空间。VFD申请示意图如下所示:

其对应的代码参考如下:
Size newCacheSize = SizeVfdCache * 2; //InitFileAccess之后,置为1
Vfd *newVfdCache;
if (newCacheSize < 32)
newCacheSize = 32;
/*
* Be careful not to clobber VfdCache ptr if realloc fails.
*/
newVfdCache = (Vfd *) realloc(VfdCache, sizeof(Vfd) * newCacheSize);
if (newVfdCache == NULL)
ereport(ERROR,
(errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("out of memory")));
VfdCache = newVfdCache;
当VFD内存空间申请成功之后,便依次对VFD变量中的成员nextFree进行初始化,使其依次指向下一个VFD。因为SizeVfdCache等于1,所以从VfdCache[1]开始进行初始化。
for (i = SizeVfdCache; i < newCacheSize; i++){
MemSet((char *) &(VfdCache[i]), 0, sizeof(Vfd));
VfdCache[i].nextFree = i + 1; //31 next--> 32
VfdCache[i].fd = VFD_CLOSED;
}
VfdCache[newCacheSize - 1].nextFree = 0;
VfdCache[0].nextFree = SizeVfdCache;
/*
* Record the new size
*/
SizeVfdCache = newCacheSize; //1, 32, 64, 128, 256 . . .
当nextFree成员初始化之后,重置SizeVfdCache 全局变量的值为当前申请的VFD个数(依次是32、64、128、256、512知道满足不超过操作系统对进程可打开文件描述符的限制为止)。
file = VfdCache[0].nextFree;
VfdCache[0].nextFree = VfdCache[file].nextFree;
return file;
然后返回可用的VfdCache,即VFD。这里file即为VFD位于VfdCache数组的下标。因为是第一次申请VFD,所以从VfdCache[0]开始依次使用VFD,这里file分别是:1、2、3、4、5、6 . . . ,知道可使用的VFD小于本次所申请的32个时候,继续重新申请VFD,这时候是申请64个。如下图所示,获取LRU池中的VfdCache[1]变量。

当获取到可用的VFD数组元素之后,接下来就开始调用系统函数来打开所指定的文件,然后将open()系统函数返回的文件描述符fd初始化给VFD中的fd成员变量。同时分别将本次打开文件的模式以及文件权限(若是创建文件的话)初始化给VFD中的成员fileFlags和fileMode。并将其他的成员根据实际情况进行初始化。
file = AllocateVfd();
vfdP = &VfdCache[file];
/* Close excess kernel FDs.
* 关闭多余的内核fd.
*/
ReleaseLruFiles();
vfdP->fd = BasicOpenFilePerm(fileName, fileFlags, fileMode);
if (vfdP->fd < 0){
int save_errno = errno;
FreeVfd(file);
free(fnamecopy);
errno = save_errno;
return -1;
}
++nfile;
DO_DB(elog(LOG, "PathNameOpenFile: success %d",vfdP->fd));
vfdP->fileName = fnamecopy;
/* Saved flags are adjusted to be OK for re-opening file */
vfdP->fileFlags = fileFlags & ~(O_CREAT | O_TRUNC | O_EXCL);
vfdP->fileMode = fileMode;
vfdP->fileSize = 0;
vfdP->fdstate = 0x0;
vfdP->resowner = NULL;
到这里时,VFD已经是一个可提供给进程使用的虚拟文件描述符了。给上层的是该VFD位于LRU池中的数组下标nextFree,而不会对外提供VFD中的成员fd值。接下来的最后一个任务就是初始化VFD中的两个数组下标成员lruMoreRecently和lruMoreRecently。使它们分别指向VfdCache头节点。以便于快速从VfdCache[0]找到该LRU池中最近常使用、不常使用的VFD。以便于在LRU池超出操作系统文件描述符限制时根据LRU策略删除不常用的VFD。对应代码如下:
vfdP = &VfdCache[file];
vfdP->lruMoreRecently = 0;
vfdP->lruLessRecently = VfdCache[0].lruLessRecently;
VfdCache[0].lruLessRecently = file;
VfdCache[vfdP->lruLessRecently].lruMoreRecently = file;
小结
上文通过结合源码,详细地分析了PostgreSQL数据库分配、管理文件描述符的内部原理。因为操作系统对进程同时能够打开的fd数量是强烈有限制,并且在超过限制后会触发一些内核级别的问题,所以如何使用、管理文件描述符就成了PostgreSQL数据库中的一个急切重要的功能点。通过使用VFD虚拟文件描述符映射的方式,可以给进程一种假象是文件描述符fd是数量用之不竭,这样的好处是进程不必过多地去担心、判断fd的细节处理问题。要打开文件,直接调用VFD,便可得到文件的fd(当然这里是VfdCache LRU池中的VFD数组下标)。然后调用相应的系列位于fd.c文件中封装的函数接口即可,屏蔽掉了系统函数调用返回错误码的逻辑判断处理。
---------------------------------------------------------------
堆表文件底层结构布局分析
1. 表文件
PostgreSQL提供了可靠、稳定、有序的数据存储、检索管理。即使在不知道其背后运行原理的情况下,也没有多大关系,因为我们只需要按部就班地执行建库、建表然后插入数据结构这几个流程,就可以如愿以偿地实现将我们的数据持久化于PostgreSQL数据库中。于是我们不得不好奇,这些数据最终落盘于磁盘上的哪个位置?又是以什么样的形式存储?存储的格式又是什么?在这几个疑问的驱动下,本文将通过源码结合数据入库实践操作的方式,来详细地对PostgreSQL底层数据的存储方式进行详细的解读。
PostgreSQL中的每个表(TABLE)都将由一个或多个堆文件表示。默认情况下,表的每个1GB块(Block)存储在一个单独的(堆)文件中。当该表文件已经达到1GB之后,用户再次插入数据时,postgres会重新创建一个新的堆文件,新文件名格式是:表Oid +“.” + 序号id(序号id从1开始一次递增)。示意图如下所示,其中student为CREATE TABLE创建的表名,该student表对应的堆文件名是16387。

在PostgreSQL中,数据库名和表文件名都是使用Oid来进行命名。该Oid是一个无符号整型(unsigned int),定义在postgres_ext.h文件中。如下:
/*
* Object ID is a fundamental type in Postgres.
*/
typedef unsigned int Oid;
当我们将数据存储在PostgreSQL中时,PostgreSQL会将用户插入(INSERT INTO)的数据依次存储于文件系统的常规文件中。对于这样的文件,我们称之为“堆文件(Heap File)”。在PostgreSQL中,可以将堆文件分为四种类型:“普通堆文件(Ordinary Cataloged Heap)、“临时堆文件(Temporary Heap File)、“序列堆文件(Sequence File)和“TOAST表堆文件(TOAST FILE)”。上面说的常规文件,即指普通堆文件。TOAST文件专门用于存储变长数据,本质上它也是属于普通堆文件。对于上面的这四种堆文件,虽然底层组织方式细节不大一样,但是结构上是相似的,所以我们这里将着中分析普通堆文件。
1.1 数据簇目录位置
在研究表文件之前,我们先要知道postgres的数据蔟目录位置。因为所有的数据库、表、索引、配置文件等等都是存储在数据蔟目录下的,即PGDATA。如果你不确定当前环境上面PostgreSQL的数据蔟目录位置,没关系,你仅需要psql登录终端,然后执行 SHOW DATA_DIRECTORY;命令即可得到。如下图所示,当前环境的数据蔟目录是:/home/lixiaogang5/DB。
test=# SHOW DATA_DIRECTORY;
data_directory
----------------------
/home/lixiaogang5/DB
1. 2 表文件位置
对于关系型数据库,所有的表都是以库为维度进行管理,即某个表总是属于某个库。因此,我们还需要找到我们创建的数据库(CREATE DATABASE;)以及该库下的所有表(CREATE TABLE)。PostgreSQL为我们提供了pg_relation_filepath,用于查找指定表名的相对($PGDATA)文件路径。
test=#
test=# SELECT pg_relation_filepath('student');
pg_relation_filepath
----------------------
base/16384/16387
其中16384是数据库(test)的Oid名;16387是student数据表名。其数据库和数据表的创建过程如下:
postgres=# CREATE DATABASE test;
CREATE DATABASE
test=#
test=# CREATE TABLE student(id SERIAL PRIMARY KEY, name VARCHAR, age INT NOT NULL);
CREATE TABLE
2. 表文件的内部布局
前面创建了名为student的数据表,到此为止,还没有向该表中插入(INSERT INTO)过数据。因此student表的总行数是0。
test=# SELECT COUNT(*) FROM student;
count
-------
0
注:关系数据表中的行数据称为记录(record),又称之为元组(tuple),即行、记录、元组都是同一个概念。在表中没有数据时,很显然此时文件大小是0字节(ls -lha --full-time)。
现在我们向该表中插入一条数据,如下:
test=# SELECT COUNT(*) FROM student;
count
-------
0
test=# INSERT INTO student(name,age) VALUES ('lixiaogang5', 27);
INSERT 0 1
test=# SELECT *FROM student;
id | name | age
----+-------------+-----
1 | lixiaogang5 | 27
此时再次查看该student数据表文件时,可看到其文件大小是8KB(8192Byte)。很显然,我们刚插入的这条数据并没有这么大。因此可知,postgres在向表中插入数据时候是以8KB为单位进行数据存储管理的。第一次数据进来,无论数据多少,postgres都会在该文件中分配8KB的空间 。
[root@Thor 16384]# ls -lh --full-time 16387
-rw------- 1 postgres postgres 8.0K 2021-05-22 15:05:55.223806439 +0800 16387
2.1 表文件由页组成
对于PostgreSQL数据库,在每个数据文件(堆文件、索引文件、FSM文件、VM文件等)内部,它分为固定长度的页(或块)。换言之,即一个1GB大小的表文件内部是有若干个固定的页组成。页的默认大小为8192字节(8KB)。单个表文件中的这些页(Page)从0开始进行顺序编号,这些编号也称为“块编号(Block Numbers)”。如果第一页空间已经被数据填满,则postgres会立刻重新在文件末尾(即已填满页的后面)添加一个新的空白页,用于继续存储数据,一直持续这个过程,直到当前表文件大小达到1GB位置。若文件达到1GB,则重新创建一个新的表文件,然后重复上面的这个过程。
然后每个页的内部又由一个页文件头(Page Header)、若干行指针(Line Pointer)、若干个元组数据(Heaple Tuple)组成。单个文件大小1GB(默认,可以修改其大小),因为堆(重点将普通堆)文件是由页组成,所以可知一个堆文件中有:1GB = (1024 * 1024) KB / 8KB(Page) = 131072个页。
2.1.1 页的内部布局
堆表文件的内部页布局示意图如下:
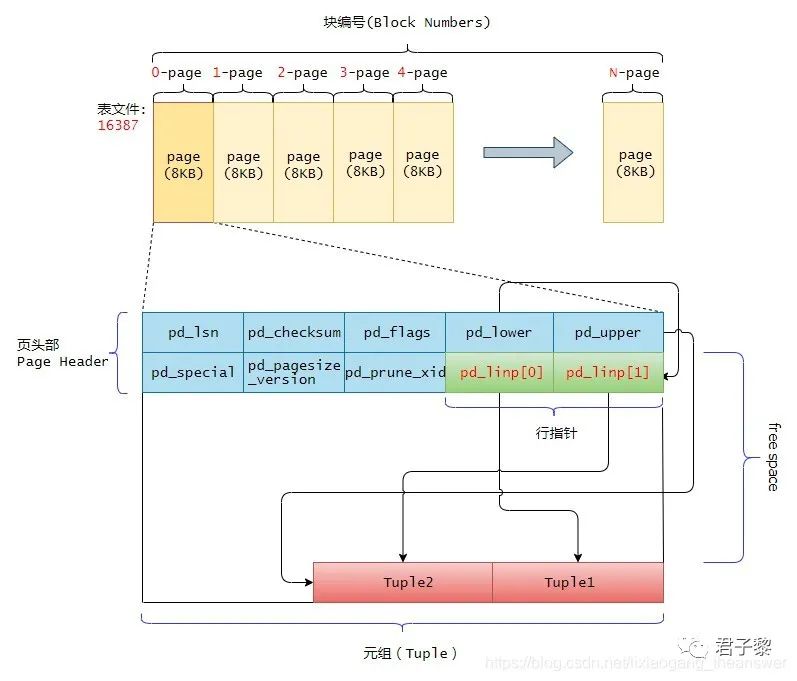
下面分别对页中的“页头、行指针和堆元组”这三个重要数据进行介绍。
2.1.1.1 页的头部数据结构
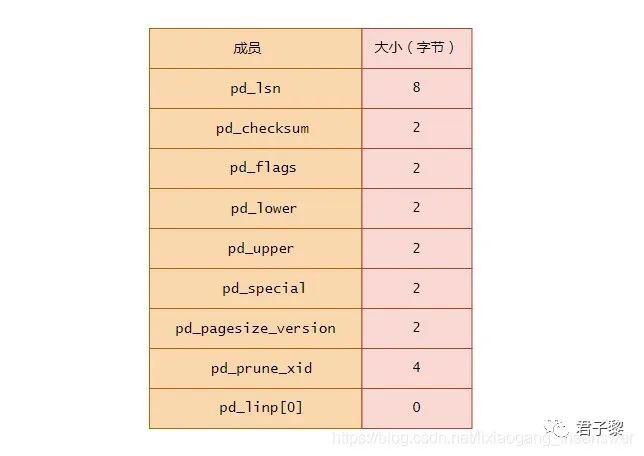
页头数据结构(PageHeaderData)声明于文件bufpage.h中,它包含了当前页的常规信息。其大小是24字节(byte),且分配在页的开头位置。其声明格式如下:
typedef struct PageHeaderData{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array [行指针数组]*/
} PageHeaderData;
以下是该数据结构中各成员成员的功能描述:
pd_lsn
pd_lsn变量存储由本页最后一次更改所写入的XLOG记录的LSN(即当前WAL位置)。它是一个8字节的无符号整数,与WAL (Write-Ahead Logging)机制有关。其中PageXLogRecPtr 数据类型的声明如下:
typedef unsigned int uint32; /* == 32 bits */
typedef struct{
uint32 xlogid; /* high bits */
uint32 xrecoff; /* low bits */
} PageXLogRecPtr;
pd_checksum
此变量存储此页的校验和值(请注意,9.3或更高版本支持此变量;在早期版本中,此部分存储了页面的timelineId)。如果checksum已启用,则为每个数据页计算校验和。检测到校验和失败将导致读取数据时出错,并将中止当前正在运行的事务。因此,这为直接在数据库服务器级别检测I/O或硬件问题带来了额外的控制。
pd_flags
该成员用以设置位标志。对于PostgreSQL 13.2版本,共支持以下几种标志:
//是否有未使用的行指针?
#define PD_HAS_FREE_LINES 0x0001
//没有足够的空间容纳新元组?
#define PD_PAGE_FULL 0x0002
//页面上的所有元组对每个人都可见?
#define PD_ALL_VISIBLE 0x0004
//所有有效pd_flags位的OR
#define PD_VALID_FLAG_BITS 0x0007
pd_lower
指向空闲空间的开始位置。
pd_upper
指向空闲空间的结尾。
当向表中插入数据时,postgres会分配8KB(BLCKSZ)的内存空间。此时的8KB,除了页的头部数据占用的24字节外,其余的空间都是可用于存储元组的(当然行指针也有占用空间)。如下图所示,该图是刚好分配好8KB大小的内存空间和页头占用的结构示意图。由于此时没有元组插入表文件中,所以pd_upper指向可用空间的末尾,而pd_lower指向页头(PageHeaderData)之后的第一个空闲空间的起始位置。pd_upper - pd_lower是该页中剩余可用的空闲空间(下图粉红色的区间为可用的空闲空间),随着元素的不断插入,pd_upper和pd_lower变量会不断地随着更新。

pd_special
指向特殊空间的起始偏移量。该变量主要用于索引文件,对于表文件中的页,它指向页的末尾(因为对于普通的表文件,这个字段没有使用)。在索引文件的页中,它指向特殊空间的开始,这是仅有索引持有的数据区域,根据索引类型,如B-tree、GiST、GiN等,它包含特定的数据。
pd_pagesize_version
页面大小及页面版本号。页面大小和页面版本号被打包成一个大一的uint16字段。这是由于历史原因,在PostgreSQL 7.3之前,没有页面版本号的概念,这样可以让我们假设7.3之前的数据库页面版本号是0。我们将页面版本号的大小限制为256的倍数,并将低8位留给版本号。
pd_prune_xid
可删除的旧XID,如果没有则为零。
pd_linp
pd_linp是极为重要的成员变量,它是一个零长度数组(Arrays of Length Zero)。当页中没有插入数据时候,它的数组元素个数是0,因此这个pd_linp也就是上图中所谓的“行指针”数组。它指向该页中的元组(也就是表记录)。其pd_linp的数据类型是:
typedef struct ItemIdData{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
更多pd_linp成员的描述将在下面2.1.1.2小节中进行更加详细的描述。
注:PostgreSQL中,最小的页大小是64B,以适应页头、不透明空间和最小元组;最大只能支持32KB的页面大小。
2.1.1.2 行指针
行指针的长度为4个字节,它形成一个简单的(ItemId,行指针)数组,该数组起着元组索引的作用。每个索引编号从1开始,称为“偏移数”。当将一个新的元组添加到页的时候,新的行指针也被添加到pd_linp数组中,以指向其对应的元组。
typedef struct ItemIdData{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
typedef ItemIdData *ItemId;
当不断向页中插入数据时候,其元组、行指针以及可用空间的变化如下图所示:

2.1.1.3 元组结构
在2.1.1.1和2.1.1.2两个小节中分别对页(page)中的页头数据结构和行指针的功能细节进行了较为详细的描述,接下来会对页中的元组数据结构以及其内部布局等进行分析。
对于表文件页中的元组可细分为“普通数据元组和TOAST元组”。TOAST(The Oversized-Attribute Storage Technique,超大属性存储技术)主要用于存储变长数据,当待插入元组的大小大于约为2KB(即页的1/4)时候,会自动启动TOAST技术来存储该元组。TOAST较普通元组稍加复杂些,这里主要针对普通元组文件进行说明。
元组内部可以分为三部分,分别是:堆元组头部、位图和用户存储的数据。示意图如下所示:

其中堆元组头部的结构定义如下:
struct HeapTupleHeaderData{
union{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
其中t_choice成员变量是一个共用体数据类型。对于t_choice中的t_heap成员,它描述了当前元组的事务id、事务id等信息,如下:
typedef struct HeapTupleFields{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
该数据类型中,t_xmin成员保存的是插入该元组的事务txid。t_xmax报错删除或是更新该元组的txid。如果尚未删除或更新过该元组,则t_xmax将设置为0,即INVALID。t_cid保留命令id(cid)。这表示了从0开始到当前事务中共执行了多少个SQL命令。比如我们在一个事务中查询了2个INSERT INTO命令,即:
'BEGIN;
INSERT INTO ... ;
INSERT INTO ... ;
COMMIT;'
那么第一次插入该元组时候,t_cid初始化为0.第二次插入次元组时候,该t_cid将被设置为1,依次类推。
t_ctid保存指向自身或是新元组的元组表示符。当该元组被更新时,该元组的t_ctid指向新的元组;否则,t_ctid指向自身。注:为了标识数据表中的元组,在元组内部使用了元组标识符(Tuple Identifile, TID), tid包含一对值,类似tid(key1,key2)。其中key1表示包含元组的页的块号,key2表示指向元组的行指针的偏移量。如下所示:
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 604154 | 0 | 0 | (0,1) | 3 | 2050 | 24 | | | \x01000000174c495849414f47414e47001c000000
成员t_infomask2用来表示当前元组的属性个数。t_infomask用于标识元组的当前状态,比如是否空属性、是否具有对象id、是否具有外部存储属性等等,PostgreSQL 13.2版本中,t_infomask成员具有以下状态信息:
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID_OLD 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0
* VACUUM FULL; kept for binary upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0
* VACUUM FULL; kept for binary upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
成员t_hoff标识该元组头的大小。成员t_bits数组用于标识当前元组哪些字段是空。
在读写元组头HeapTupleHeaderData 时候,我们往往直接使用其HeapTupleHeader指针来进行操作。其声明如下:
/* typedefs and forward declarations for structs defined in htup_details.h */
typedef struct HeapTupleHeaderData HeapTupleHeaderData;
typedef HeapTupleHeaderData *HeapTupleHeader;
堆元组的整体数据类型声明如下,它嵌套了元组头部结构信息,另外新增了几个附加成员字段,用以描述当前元组的用户数据长度等。如下:
typedef struct HeapTupleData{
uint32 t_len; /* length of *t_data */
ItemPointerData t_self; /* SelfItemPointer */
Oid t_tableOid; /* table the tuple came from */
#define FIELDNO_HEAPTUPLEDATA_DATA 3
HeapTupleHeader t_data; /* -> tuple header and data */
} HeapTupleData;
typedef HeapTupleData *HeapTuple;
2.1.2 pageinspect扩展查看页内容
PostgreSQL提供了一些扩展的功能,这些扩展功能的想要sql脚本都放在了share/extension/目录下,如下图示所示:
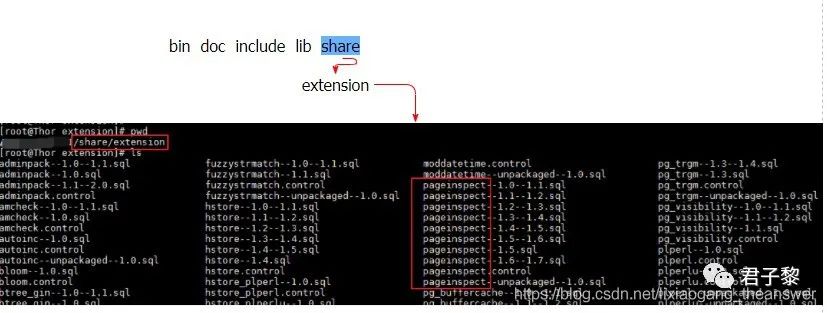
可以看到,除了pageinspect外,该目录下还有其他的附属功能脚本,比如pg_freespace(用于查看当前表或索引的页中可用的剩余空间)等。这些扩展功能使用之前需要使用SQL命令先创建:
CREATE EXTENSION pageinspect; //pageinspect --扩展功能名
若使用CREATE EXTENSION 创建扩展功能时候,对应的share/extension/目录下没有该扩展功能的SQL脚本,则会报错提示当前目录没有对应的文件,如下:
ERROR: could not open extension control file "/usr/local/pg132/share/postgresql/extension/pageinspect.control": No such file or directory
2.1.2.1 查看表文件页头信息
使用page_header()函数和get_raw_page()函数结合可得到指定页的头部信息。如下所示,其中数字0表示指定表的页数。
test=# select *from page_header(get_raw_page('student', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
------------+----------+-------+-------+-------+---------+----------+---------+-----------
0/39620C78 | 0 | 0 | 28 | 8144 | 8192 | 8192 | 4 | 0
使用heap_page_items和get_raw_page可得到表元组的头部信息和数据信息,如下:
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 604154 | 0 | 0 | (0,1) | 3 | 2050 | 24 | | | \x01000000174c495849414f47414e47001c000000
2.2 使用工具读堆文件表内容
因为表文件中的数据都是二进制,所以在不借助工具的情况下,是无法直接查看的。因此我们需要借助工具来查看表文件中的数据内容,结合上面的介绍进行分析。在类UNIX环境上,可以使用hexdump、od命令对堆文件表中的数据进行十六进制转存,然后进行分析。当前student表中的数据仅有一条,如下:
test=# \d+ student;
Table "public.student"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+-------------------------------------+----------+--------------+-------------
id | integer | | not null | nextval('student_id_seq'::regclass) | plain | |
name | character varying(10) | | | | extended | |
age | integer | | | | plain | |
Indexes:
"student_pkey" PRIMARY KEY, btree (id)
test=# SELECT *FROM student;
id | name | age
----+----------+-----
1 | XIAOGANG | 27
hexdump命令主要用来查看二进制文件的十六进制编码(当然,也可以直接vim,然后 :%!xxd将其二进制数据转换为十六进制),如下所示:
[root@Thor 163898]# hexdump 16387
0000000 0000 0000 aab8 40a1 0000 0000 001c 1fd0
0000010 2000 2004 0000 0000 9fd0 0058 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
* //省略若干字节内容(全是0000, free space,未使用的内存空间)
0001fd0 b4cb 0009 0000 0000 0000 0000 0000 0000
0001fe0 0001 0003 0902 0018 0001 0000 5813 4149
0001ff0 474f 4e41 0047 0000 001b 0000 0000 0000
0002000
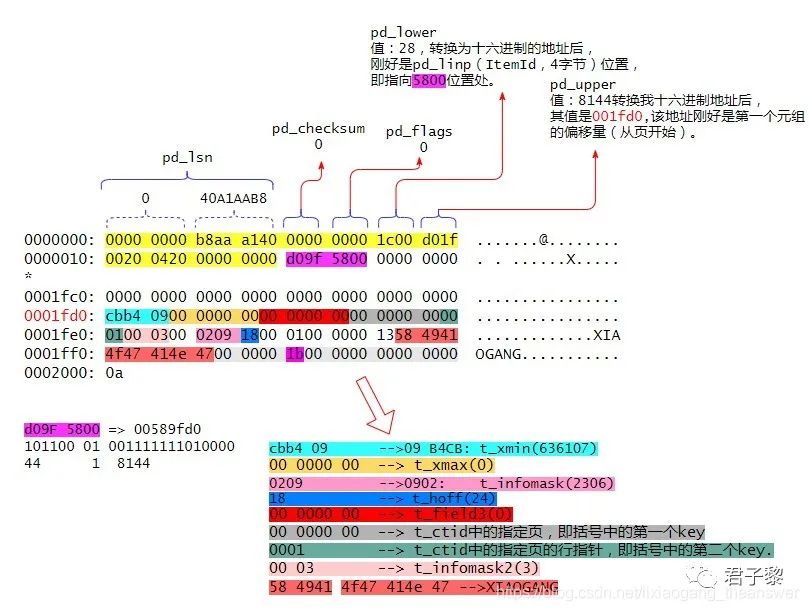
注:堆表文件的元组数据是从页的尾部开始存储,直到pd_upper - pd_lower的空间不足以存储元组为止。如下图中的Tuple1、Tuple2、Tuple3、Tuple4等等。

现在我们将上面hexdump显示的十六进制数据结合页头数据结构(PageHeaderData)成员列表来进行详细分析。如下图所示:
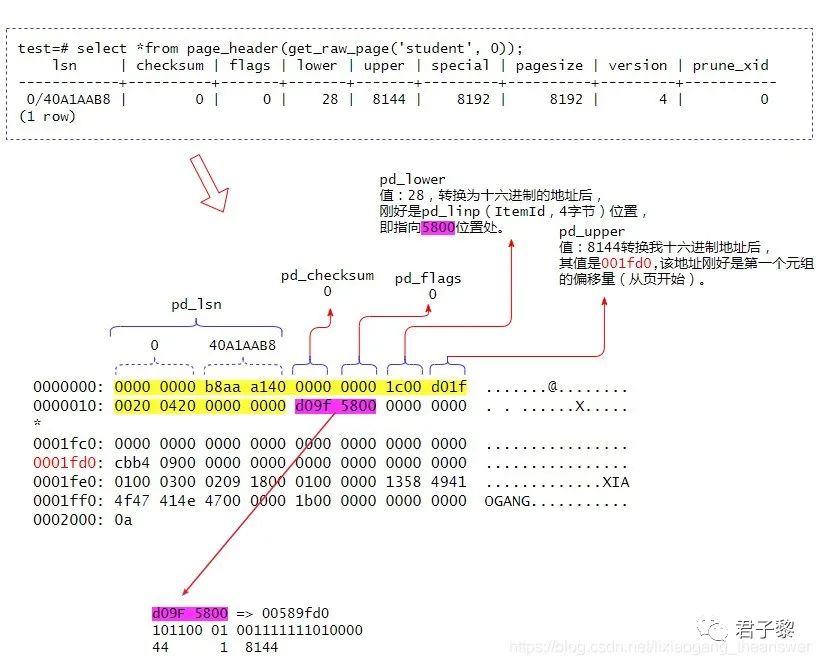
堆表文件中的页头部信息可以通过系统表page_header获取得到,其查询出来的结果和hexdump显示的十六进制数据是能够一一对应的。上图中黄色标注的24字节是页的头部(PageHeaderData),其中各成员的大小如下图所示:
上图中2000 2004 0000 0000依次对应这页头中的m_special、m_pagesize_version、pd_prune_xid。
紫色表示的4字节(d09F 5800)是指向元组的行指针pd_linp(也称为 ItemId)。行指针的结构声明如下:
typedef struct ItemIdData{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
第1至15位指向该元组的偏移量(从页开始)、15至17位声明当前元组的状态,这个前面有说过、17至32声明该元组的长度大小。这里之所以将hexdump展示的十六进制反过来书写是因为我当前系统架构是小端模式。经转换过后,其各值能够和pg_header表查出来的结果相吻合。说明分析是正确的。
pd_linp[0] ==== 00589FD0 //转换为二进制后是:10110001001111111010000
101100 01 001111111010000
44(字节) 1 8144(字节)
上面对页中元组的头部信息、行指针进行了详细的分析。接下来重点剖析页中行指针所指向的对应的元组数据信息。
在分析元组的结构信息时候,我们需要借助heap_page_items()函数,该函数会将元组在页内存中的分布信息详细展示出来。
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 636107 | 0 | 0 | (0,1) | 3 | 2306 | 24 | | | \x01000000135849414f47414e470000001b000000
test=# select *from student;
id | name | age
----+----------+-----
1 | XIAOGANG | 27
由于元组中字段占用的大小有严格的内存对齐要求,所以实际上可以看到各成员之间会存在一些“填充”字节数据。其对齐(必须始终是平台的MAXALIGN距离的倍数。)要求如下:
#define MAXALIGN(LEN) TYPEALIGN(MAXIMUM_ALIGNOF, (LEN))
#define TYPEALIGN(ALIGNVAL,LEN) (((uintptr_t) (LEN) + ((ALIGNVAL) - 1)) & ~((uintptr_t) ((ALIGNVAL) - 1)))
通过heap_page_items()函数得到结果与hexdump命令得到的数据,最终可得到该元组在页为0内存中布局详情如下图所示。下图中紫色标注的1b其值是age字段中的值27。该字段周边的0000是填充字节数据,用于保证内存对齐。
2.2.1 hexdump分析堆表文件
由于这两个命令显示的结果在不手动转换情况下,无法直接看出(需要转换)该文件中的表头结构、行指针和元组结构等数据信息。因此,出于方便,还需使用其他工具,分别是:pg_filedump和pg_hexedit。pg_filedump 和pg_hexedit 两个工具并没有附加在PostgreSQL源码中,所以源码安装的PostgreSQL中,bin目录下是没有这两个工具命令的。这两个工具有专门的pg团队在进行维护,所以你可以在github上面找到其源码,然后进行源码安装。
由于pg_hexedit工具显示的结果需要借助 wxHexEditor工具来进行展示,所以这里使用pg_filedump工具来进行分析。
2.2.2 pg_filedump工具
pg_filedump命令提供许多供选的参数,具体详情可使用 pg_filedump --help。该工具得到的数据比较直观,因为结果中直接给出了当前文件中的页数、行指针的起始位置,以及各页中分别指向空闲空间起始、结束位置的地址等。如下所示:
[root@Thor bin]# ./pg_filedump -i /var/lib/pgsql/11/data/base/163898/16387
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: /var/lib/pgsql/11/data/base/163898/164056
* Options used: -i
*******************************************************************
Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 28 (0x001c)
Block: Size 8192 Version 4 Upper 8144 (0x1fd0)
LSN: logid 0 recoff 0x40a1aab8 Special 8192 (0x2000)
Items: 1 Free Space: 8116
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()
Length (including item array): 28
<Data> -----
Item 1 -- Length: 44 Offset: 8144 (0x1fd0) Flags: NORMAL
XMIN: 636107 XMAX: 0 CID|XVAC: 0
Block Id: 0 linp Index: 1 Attributes: 3 Size: 24
infomask: 0x0902 (HASVARWIDTH|XMIN_COMMITTED|XMAX_INVALID)
---------------------------------------------------------------
---------------------------------------------------------------