MySQL 8 vs PostgreSQL 10
 既然 MySQL 8 和 PostgreSQL 10 已经发布了,现在是时候回顾一下这两大开源关系型数据库是如何彼此竞争的。在这些版本之前,人们普遍认为,Postgres 在功能集表现更出色,也因其“学院派”风格而备受称赞,MySQL 则更善长大规模并发读/写。
既然 MySQL 8 和 PostgreSQL 10 已经发布了,现在是时候回顾一下这两大开源关系型数据库是如何彼此竞争的。在这些版本之前,人们普遍认为,Postgres 在功能集表现更出色,也因其“学院派”风格而备受称赞,MySQL 则更善长大规模并发读/写。但是随着它们最新版本的发布,两者之间的差距明显变小了。
特性比较
让我们来看看我们都喜欢谈论的“时髦”功能。
| 特性 | MySQL 8 | PostgreSQL 10 |
|---|---|---|
| 查询 & 分析 | ||
| 公用表表达式 (CTEs) | ✔ New | ✔ |
| 窗口函数 | ✔ New | ✔ |
| 数据类型 | ||
| JSON 支持 | ✔ Improved | ✔ |
| GIS / SRS | ✔ Improved | ✔ |
| 全文检索 | ✔ | ✔ |
| 可扩展性 | ||
| 逻辑复制 | ✔ | ✔ New |
| 半同步复制 | ✔ | ✔ New |
| 声明式分区 | ✔ | ✔ New |
过去经常会说 MySQL 最适合在线事务,PostgreSQL 最适合分析流程。但现在不是了。
公共表表达式(CTEs) 和窗口函数是选择 PostgreSQL 的主要原因。但是现在,通过引用同一个表中的 boss_id 来递归地遍历一张雇员表,或者在一个排序的结果中找到一个中值(或 50%),这在 MySQL 上不再是问题。
在 PostgreSQL 中进行复制缺乏配置灵活性,这就是 Uber 转向 MySQL 的原因。但是现在,有了逻辑复制特性,就可以通过创建一个新版本的 Postgres 并切换到它来实现零停机升级。在一个巨大的时间序列事件表中截断一个陈旧的分区也要容易得多。
就特性而言,这两个数据库现在都是一致的。
有哪些不同之处呢?
现在,我们只剩下一个问题 —— 那么,选择一个而不选另一个的原因是什么呢?
生态系统是其中一个因素。MySQL 有一个充满活力的生态系统,包括 MariaDB、Percona、Galera 等等,以及除 InnoDB 以外的存储引擎,但这也可能是和令人困惑的。Postgres 的高端选择有限,但随着最新版本引入的新功能,这会有所改变。
治理是另一个因素。当 Oracle(或最初的 SUN)收购 MySQL时,每个人都担心他们会毁掉这个产品,但在过去的十年里,这并不是事实。事实上,在收购之后,发展反倒加速了。而 Postgres 在工作管理和协作社区方面有着丰富的经验。
基础架构不会经常改变,虽然近来没有对这方面的详细讨论,这也是值得再次考虑的。
来复习下:
| 特性 | MySQL 8 | PostgreSQL 10 |
|---|---|---|
| 架构 | 单进程 | 多进程 |
| 并发 | 多线程 | fork(2) |
| 表结构 | 聚簇索引 | 堆 |
| 页压缩 | Transparent | TOAST |
| 更新 | In-Place / Rollback Segments | Append Only /HOT |
| 垃圾回收 | 清除线程 | 自动清空进程 |
| 事务日志 | REDO Log (WAL) | WAL |
| 复制日志 | Separate (Binlog) | WAL |
进程vs线程
当 Postgres 派生出一个子进程来建立连接时,每个连接最多可以占用 10MB。与 MySQL 的线程连接模型相比,它的内存压力更大,在 64 位平台上,线程的默认堆栈大小为 256KB。(当然,线程本地排序缓冲区等使这种开销变得不那么重要,即使在不可以忽略的情况下,仍然如此。)
尽管“写时复制”保存了一些与父进程共享的、不可变的内存状态,但是当您有 1000 多个并发连接时,基于进程的架构的基本开销是很繁重的,而且它可能是容量规划的最重要的因素之一。
也就是说,如果你在 30 台服务器上运行一个 Rails 应用,每个服务器都有 16 个 CPU 核心 32 线程,那么你有 960 个连接。可能只有不到 0.1% 的应用会超出这个范围,但这是需要记住的。
聚簇索引 vs 堆表
聚簇索引是一种表结构,其中的行直接嵌入其主键的 b 树结构中。一个(非聚集)堆是一个常规的表结构,它与索引分别填充数据行。
有了聚簇索引,当您通过主键查找记录时,单次 I/O 就可以检索到整行,而非集群则总是需要查找引用,至少需要两次 I/O。由于外键引用和 JOIN 将触发主键查找,所以影响可能非常大,这将导致大量查询。
聚簇索引的一个理论上的缺点是,当您使用二级索引进行查询时,它需要遍历两倍的树节点,第一次扫描二级索引,然后遍历聚集索引,这也是一棵树。
但是,如果按照现代表设计的约定,将一个自动增量整数作为主键——它被称为代理键——那么拥有一个聚集索引几乎总是可取的。更重要的是,如果您做了大量的 ORDER BY id 来检索最近的(或最老的)N 个记录的操作,我认为这是很适用的。
Postgres 不支持聚集索引,而 MySQL(InnoDB)不支持堆。但不管怎样,如果你有大量的内存,差别应该是很小的。
页结构和压缩
Postgres 和 MySQL 都有基于页面的物理存储。(8KB vs 16KB)
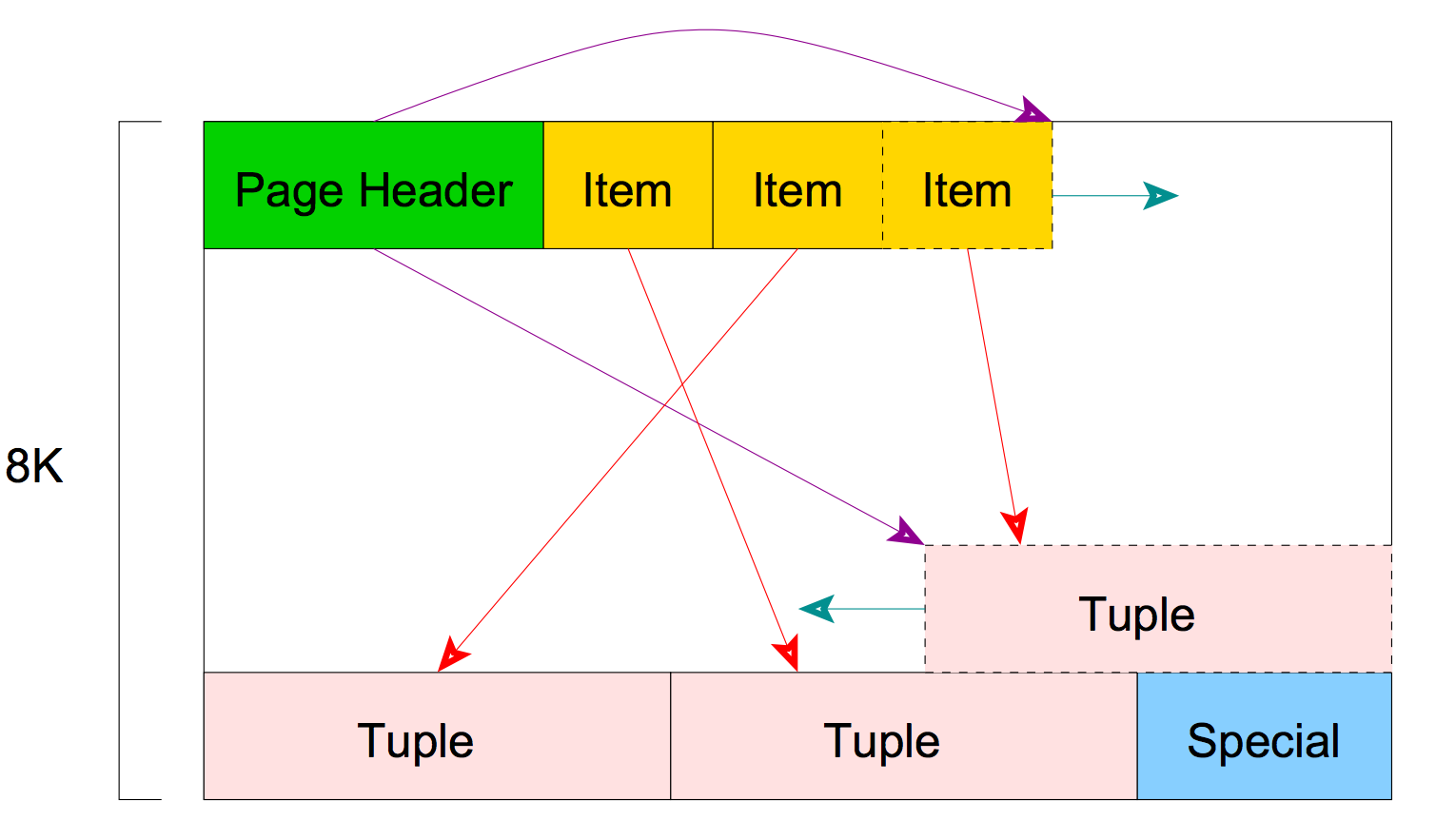
PostgreSQL 物理存储的介绍
页结构看起来就像右边的图。它包含一些我们不打算在这里讨论的条目,但是它们包含关于页的元数据。条目后面的项是一个数组标识符,由指向元组或数据行的(偏移、长度)对组成。在 Postgres 中,相同记录的多个版本可以以这种方式存储在同一页面中。
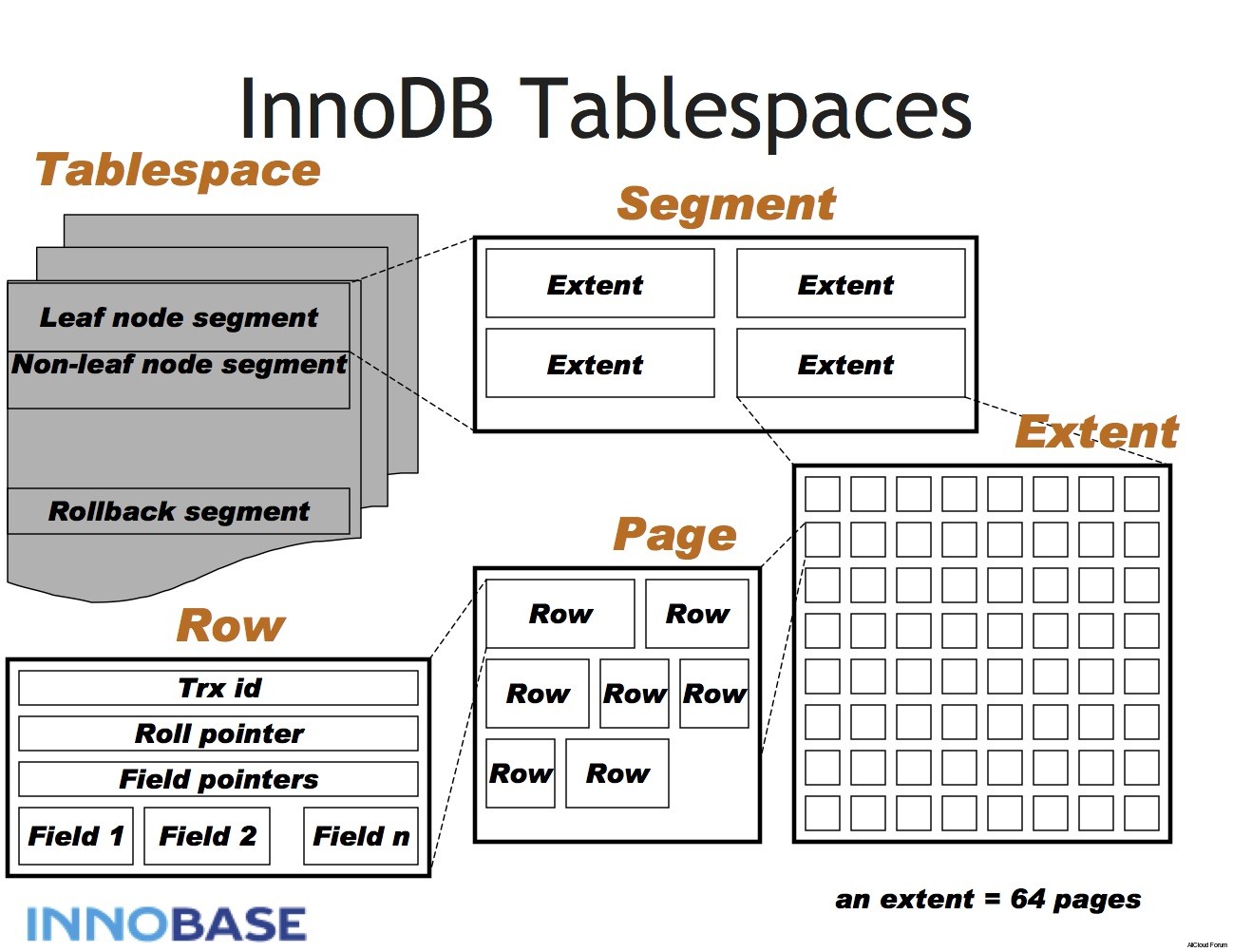
MySQL 的表空间结构与 Oracle 相似,它有多个层次,包括层、区段、页面和行层。
此外,它还有一个用于撤销的单独段,称为“回滚段”。与 Postgres 不同的是,MySQL 将在一个单独的区域中保存同一记录的多个版本。
如果存在一行必须适合两个数据库的单个页面,,这意味着一行必须小于 8KB。(至少有 2 行必须适合 MySQL 的页面,恰巧是 16KB/2 = 8KB)
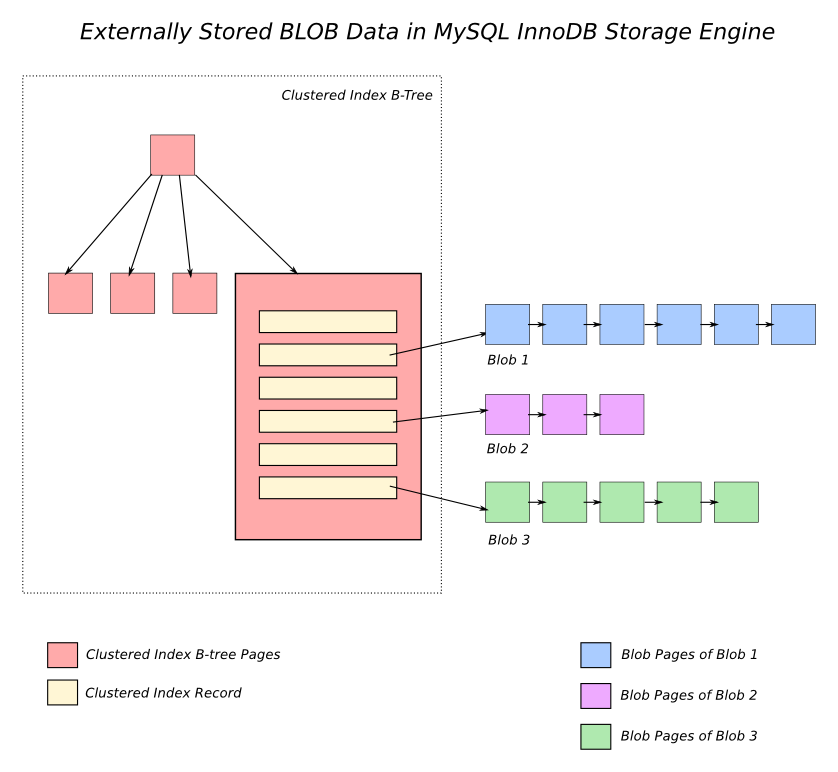
那么当你在一个列中有一个大型 JSON 对象时会发生什么呢?
Postgres 使用 TOAST,这是一个专用的影子表(shadow table)存储。当行和列被选中时,大型对象就会被拉出。换句话说,大量的黑盒不会污染你宝贵的缓存。它还支持对 TOAST 对象的压缩。
MySQL 有一个更复杂的特性,叫做透明页压缩,这要归功于高端 SSD 存储供应商 Fusio-io 的贡献。它设计目的是为了更好地使用 SSD,在 SSD 中,写入量与设备的寿命直接相关。
对 MySQL 的压缩不仅适用于页面外的大型对象,而且适用于所有页面。它通过在稀疏文件中使用打孔来实现这一点,这是被 ext4 或 btrfs 等现代文件系统支持的。
有关更多细节,请参见:在 FusionIO 上使用新 MariaDB 页压缩获得显著的性能提升。
更新的开销
另一个经常被忽略的特性,但是对性能有很大的影响,并且可能是最具争议的话题,是更新。
这也是Uber放弃Postgres的另一个原因,这激起了许多Postgres的支持者来反驳它。
MySQL对Uber可能是合适的,但是未必对你合适
一篇PostgreSQL对Uber的回应(PDF)
两者都是MVCC数据库,它们可以隔离多个版本的数据。
为了做到这一点,Postgres将旧数据保存在堆中,直到被清空,而MySQL将旧数据移动到一个名为回滚段的单独区域。
在Postgres中,当您尝试更新时,整个行必须被复制,以及指向它的索引条目也被复制。这在一定程度上是因为Postgres不支持聚集索引,所以从索引中引用的一行的物理位置不是由逻辑键抽象出来的。
为了解决这个问题,Postgres使用了堆上元组(HOT),在可能的情况下不更新索引。但是,如果更新足够频繁(或者如果一个元组比较大),元组的历史可以很容易地超过8 KB的页面大小,跨越多个页面并限制该特性的有效性。修剪和/或碎片整理的时间取决于启发式解决方案。另外,设置不超过100的填充参数会降低空间效率——这是一种很难在创建表时考虑的折衷方案。
这种限制更深入; 因为索引元组没有关于事务的任何信息,所以直到9.2之前一直不能支持仅索引扫描。 它是所有主要数据库(包括MySQL,Oracle,IBM DB2和Microsoft SQL Server)支持的最古老,最重要的优化方法之一。但即使使用最新版本,当有许多UPDATE在可见性映射中设置脏位时,Postgres也不能完全支持仅索引扫描,并且在我们不需要时经常选择Seq扫描。
在MySQL上,更新发生在原地,旧的行数据被封存在一个称为回滚段的独立区域中。结果是你不需要VACUUM,并且提交非常快,而回滚相对较慢,这对于大多数用例来说是一个可取的折衷。
它也足够聪明,尽快清除历史。 如果事务的隔离级别设置为READ-COMMITTED或更低,则在语句完成时清除历史记录。
事务记录的大小不会影响主页面。 碎片化是一个伪命题。 因此,在MySQL上能更好,更可预测整体性能。
Garbage Collection 垃圾回收
在Postgres中VACUUM上开销很高,因为它在主要工作在堆区,造成了直接的资源竞争。它感觉就像是编程语言中的垃圾回收 - 它会挡在路上,并随时让你停下来。
为具有数十亿记录的表配置autovacuum仍然是一项挑战。
在MySQL上清除(Purge)也可能相当繁重,但由于它是在单独的回滚段中使用专用线程运行的,因此它不会以任何方式影响读取的并发性。即使使用默认配置,变膨胀的回滚段使你执行速度减慢的可能性也是很低的。
拥有数十亿记录的繁忙表不会导致MySQL上的历史数据膨胀,诸如存储上的文件大小和查询性能等事情上几乎是可以预测的并且很稳定。
日志与副本
Postgres 拥有被称作 预写日志(WAL)的单信源事务历史。它一直被用于副本,并且称为逻辑复制的新功能可将二进制内容快速解码为更易消化的逻辑语句,从而可对数据进行细粒度控制。
MySQL维护两个单独的日志:1.用于崩溃恢复的InnoDB特定的重做日志,以及 2. 用于复制和增量备份的二进制日志。
InnoDB 上的重做日志与 Oracle 一致,它是一个免维护的循环缓冲区,不会随着时间的推移而增长,只在启动时以固定大小创建。 这种设计保证在物理设备上保留一个连续的连续区域,从而提高性能。 更大的重做日志产生更高的性能,但要以崩溃恢复时间为代价。
随着新的复制功能添加到Postgres,我觉得他们不分伯仲。
前面文章太长不想读的话,请看后面的总结
令人惊讶的是,它证明了普遍的观点依然存在;MySQL最适合在线交易,而PostgreSQL最适合仅用于append only模式,像数据仓库一样分析过程。
正如我们在这篇文章中看到的,Postgres的绝大多数难题都来自于append only模式,过于冗余的堆结构。
Postgres的未来版本可能需要对其存储引擎进行重大改进。您不必为接受我说的——实际上在官方wiki上已经有对它的讨论,这表明现在是时候从InnoDB身上学回来一些好的想法了。
人们一次又一次的说MySQL正在追赶Postgres,但是这一次,潮流已经改变。
1.UUID作为主键是一个可怕的想法,顺便说一句——密码随机性完全是为了杀死引用的局部性而设计,因此性能会损失。
2.当我说Postgres特别适合分析时,我是认真的:万一你不知道TimescaleDB,它是PostgreSQL上边的一个封装,允许你每秒插入100万条数据,每台服务器又1000亿行。多么疯狂的事情。难怪Amazon会选择PostgreSQL作为Redshift的基础。
本文转自:“王者对战”之 MySQL 8 vs PostgreSQL 10,感谢作者。
MySQL8.0 自带工具集合

服务类
mysql 客户端工具,本地链接远程链接都支持。
mysqld 服务启动。
mysqld_safe 守护进程启动服务。
mysqld_safe 是Unix上启动mysqld服务器的推荐方法,其增加了一些安全特性,比如在发生错误时重新启动服务器,并将运行时信息记录到错误日志中。
mysqld_multi 多个实例启动服务,基本很少使用。mysqld_multi用于管理多个mysqld进程,这些进程监听不同Unix套接字文件和TCP/IP端口上的连接。
mysql_upgrade 更新数据词典,也会更新表结构。8.0版本已弃用。
运维类
1.mysqladmin命令
用于执行管理操作的客户端。可以使用它来检查服务器的配置和当前状态,创建和删除数据库等等。主要体现在不需要登录mysql命令行里边,可以直接执行命令。
##1)使用mysqladmin extended-status命令获得的MySQL的性能指标
## 进行差值计算;加上参数 --relative(-r)
## --sleep(-i)就可以指定刷新的频率。
shell> mysqladmin -uroot -p123456 extended-status --relative --sleep=1
2.mysqlslap压测
自带的性能压力测试工具,比较单一,可以使用模拟数据。
shell> mysqlslap --delimiter=";" --create=“CREATE TABLE a (b int);INSERT INTO a VALUES (23)” --query=“SELECT * FROM a” --concurrency=50 --iterations=200
3.mysqlbinlog
以用户可视的方式展示出二进制日志中的内容,同时也可以将其中的内容读取出来。非常使用,日常运维离不开。
4.mysqlcheck
执行表维护:检查、维修、优化或分析表,执行期间读锁 。延伸下去还可以改成mysqlrepair,mysqlanalyze,mysqloptimize。实际环境也很少用,容易锁住表,或者修复中丢数据。
5.mysqldumpslow
解析MySQL慢查询日志文件并总结其内容。目前最大问题是没有时间范围指定。
6.mysqlshow
可用于快速查看存在哪些数据库、它们的表、表的列或索引。是命令行show的简版。实际环境基本不使用。
7.mysqlimport
为LOAD DATA SQL语句提供了一个命令行。实际环境基本不使用。
8.mysqldump&mysqlpump
执行逻辑备份,生成一组SQL语句,可以执行这些SQL语句来重新生成原始的数据库对象定义和表数据。它转储一个或多个MySQL数据库以备备份或传输到另一个SQL服务器。也可以进行压缩。两个工具最大的区别在于单线程与多线程。比较常用的用户导出功能,推荐使用:
shell> mysqlpump --exclude-databases=% --users
8.myisam支持工具
针对MyISAM引擎的,基本不使用:
myisamchk:表或检查、修复或优化
myisampack:压缩MyISAM表
myisamlog:显示日志文件内容
myisam_ftdump:全文索引
配置类
1.mysql_secure_installation
安全配置向导
a)为root用户设置密码
b)删除匿名账号
c)取消root用户远程登录
d)删除test库和对test库的访问权限
e)刷新授权表使修改生效
2.mysql_config_editor
login-path方式免密码登录,不能明文看到密码。加密的登录路径文件.mylogin.cnf中存储审核身份信息,需要控制好操作系统的用户权限。
3.my_print_defaults
程序是用来解析my.cnf文件的,将其中的参数打印到终端。
shell> my_print_defaults mysqlcheck client
--socket=/opt/data5.7/data/mysql.sock
--port=3306
shell> my_print_defaults mysqld server mysql_server mysql.server
4.mysql_ssl_rsa_setup
创建SSL证书和密钥文件和RSA密钥对文件。
shell> mysql_ssl_rsa_setup
其他
1.ibd2sdi
ibd2sdi是一个用于从InnoDB表空间文件中提取序列化字典信息(SDI)的实用程序,导出格式为JSON。所有的InnoDB表空间文件都存在SDI数据。
2.zlib_decompress & lz4_decompress
mysqlpump这是使用压缩创建的输出。zlib和lz4都在压缩50%以上,因为本身数据是语句,压手比率更,lz4优势在于速度更快。
shell> mysqlpump --compress -output=ZLIB > dump.zlib
shell> zlib_decompress dump.zlib dump.txt
# 或
shell> mysqlpump --compress-output=LZ4 > dump.lz4
shell> lz4_decompress dump.lz4 dump.txt
3.innnchecksum
一个用于校验innodb表空间文件完整性的工具,必须关闭mysqld进程;也只有在mysqld进程异常退出,或者服务器宕机的时候用于快速检查表空间文件的完整性。进一步也可以分析page。
shell> innochecksum --count ./t11.ibd
Number of pages:7
shell> innochecksum --page-type-summary ./t11.ibd
shell> innochecksum --page-type-dump=/tmp/ibd.log ./t11.ibd
Filename::./t11.ibd
==============================================================================
PAGE_NO | PAGE_TYPE | EXTRA INFO
==============================================================================
#:: 0 | File Space Header | -
#:: 1 | Insert Buffer Bitmap | -
#:: 2 | Inode page | -
#:: 3 | SDI Index page | index id=18446744073709551615, page level=0, No. of records=2, garbage=0, -
#:: 4 | Index page | index id=181, page level=0, No. of records=1, garbage=0, -
#:: 5 | Freshly allocated page | -
#:: 6 | Freshly allocated page | -
4.perror
显示MySQL错误信息,补助作用。
shell> perror 1032
MySQL error code MY-001032 (ER_KEY_NOT_FOUND): Can't find record in '%-.192s'
5.mysqld-debug
调试mysql显示信息。
shell> mysqld-debug --defaults-file=/etc/my8.0.cnf --user=mysql &
可以在/tmp/mysqld.trace 下看到调试的信息。如出现问题,可以作为参考。
6.mysql_tzinfo_to_sql
mysql_tzinfo_to_sql工具导入时区值
shell> mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root mysql
7.mysql_config
mysql_config为编译MySQL客户端并将其连接到MySQL提供了有用的信息。它是一个shell脚本,因此仅在Unix和类Unix系统上可用。
工具就是替代一部分功能,提高效率的。MySQL运维中需要引入这些工具,也需要使用得当;理解,熟悉用法才是运维之道。