MySQL JOIN 的用法
 (一):用法
(一):用法JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接。这里描述先给出一张用烂了的图,然后创建测试数据。
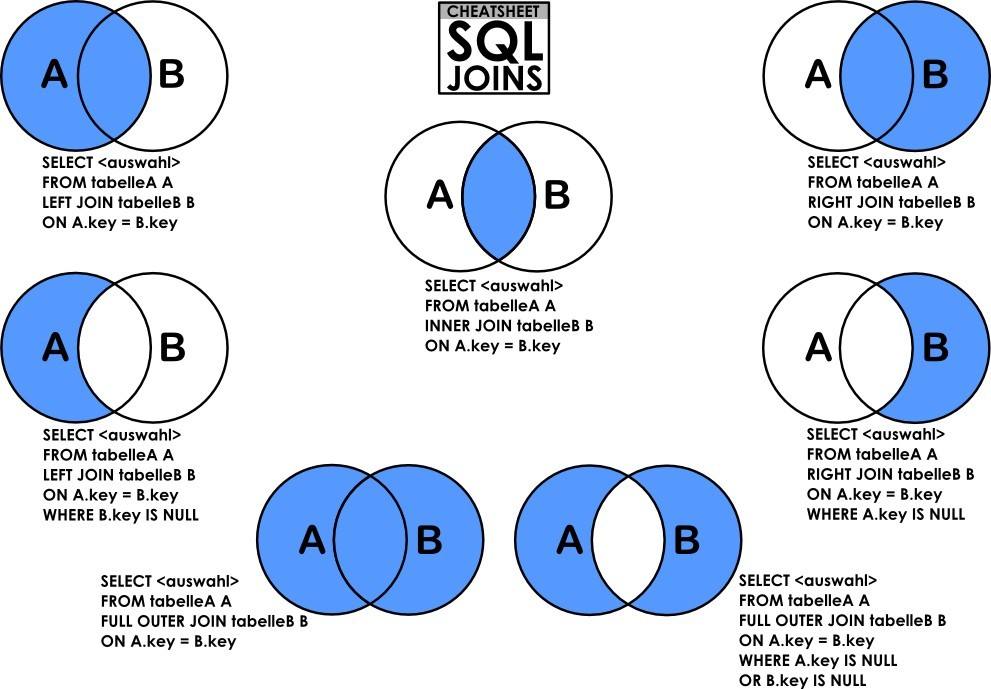
测试数据表:
CREATE TABLE t_blog(
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(50),
typeId INT
);
INSERT INTO t_blog VALUES(NULL,'aaa',1),
(NULL,'bbb',2),(NULL,'ccc',3),(NULL,'ddd',4),(NULL,'eee',4),
(NULL,'fff',3),(NULL,'ggg',2),(NULL,'hhh',NULL),(NULL,'iii',NULL),(NULL,'jjj',NULL);
CREATE TABLE t_type(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
INSERT INTO t_type VALUES (NULL,'C++'),
(NULL,'C'),(NULL,'JAVA'),(NULL,'Perl'),(NULL,'JVASCRIPT');
SELECT * FROM t_blog;
+----+-------+--------+
| id | title | typeId |
+----+-------+--------+
| 1 | aaa | 1 |
| 2 | bbb | 2 |
| 3 | ccc | 3 |
| 4 | ddd | 4 |
| 5 | eee | 4 |
| 6 | fff | 3 |
| 7 | ggg | 2 |
| 8 | hhh | NULL |
| 9 | iii | NULL |
| 10 | jjj | NULL |
+----+-------+--------+
SELECT * FROM t_type;
+----+------------+
| id | name |
+----+------------+
| 1 | C++|
| 2 | C |
| 3 | Java |
| 4 | Perl |
| 5 | Javascript |
+----+------------+
笛卡尔积:CROSS JOIN
要理解各种JOIN首先要理解笛卡尔积。笛卡尔积就是将A表的每一条记录与B表的每一条记录强行拼在一起。所以,如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录。下面的例子,t_blog有10条记录,t_type有5条记录,所有他们俩的笛卡尔积有50条记录。有五种产生笛卡尔积的方式如下。
SELECT * FROM t_blog CROSS JOIN t_type;
SELECT * FROM t_blog INNER JOIN t_type;
SELECT * FROM t_blog,t_type;
SELECT * FROM t_blog NATURE JOIN t_type;
内连接:INNER JOIN
内连接INNER JOIN是最常用的连接操作。从数学的角度讲就是求两个表的交集,从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录。有INNER JOIN,WHERE(等值连接),STRAIGHT_JOIN,JOIN(省略INNER)四种写法。至于哪种好会在后面的(二):优化讲述中介绍,示例如下。
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId=t_type.id;
SELECT * FROM t_blog,t_type WHERE t_blog.typeId=t_type.id;
SELECT * FROM t_blog STRAIGHT_JOIN t_type ON t_blog.typeId=t_type.id; --注意STRIGHT_JOIN有个下划线
SELECT * FROM t_blog JOIN t_type ON t_blog.typeId=t_type.id;
+----+-------+--------+----+------+
| id | title | typeId | id | name |
+----+-------+--------+----+------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | Perl |
| 5 | eee | 4 | 4 | Perl |
+----+-------+--------+----+------+
左连接:LEFT JOIN
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据。依旧从笛卡尔积的角度讲,就是先从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录(见最后三条):
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id;
+----+-------+--------+------+------+
| id | title | typeId | id | name |
+----+-------+--------+------+------+
| 1 | aaa | 1 |1 | C++ |
| 2 | bbb | 2 |2 | C |
| 7 | ggg | 2 |2 | C |
| 3 | ccc | 3 |3 | Java |
| 6 | fff | 3 |3 | Java |
| 4 | ddd | 4 |4 | Perl |
| 5 | eee | 4 |4 | Perl |
| 8 | hhh | NULL | NULL | NULL |
| 9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
+----+-------+--------+------+------+
右连接:RIGHT JOIN
同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。再次从笛卡尔积的角度描述,右连接就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上右表中剩余的记录(见最后一条):
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+----+------------+
| id | title | typeId | id | name |
+------+-------+--------+----+------------+
|1 | aaa | 1 | 1 | C++|
|2 | bbb | 2 | 2 | C |
|3 | ccc | 3 | 3 | Java |
|4 | ddd | 4 | 4 | Perl |
|5 | eee | 4 | 4 | Perl |
|6 | fff | 3 | 3 | Java |
|7 | ggg | 2 | 2 | C |
| NULL | NULL | NULL | 5 | Javascript |
+------+-------+--------+----+------------+
外连接:OUTER JOIN
外连接就是求两个集合的并集。从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录,最后加上右表中剩余的记录。另外MySQL不支持OUTER JOIN,但是我们可以对左连接和右连接的结果做UNION操作来实现。
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id
UNION
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+------+------------+
| id | title | typeId | id | name |
+------+-------+--------+------+------------+
|1 | aaa | 1 |1 | C++|
|2 | bbb | 2 |2 | C |
|7 | ggg | 2 |2 | C |
|3 | ccc | 3 |3 | Java |
|6 | fff | 3 |3 | Java |
|4 | ddd | 4 |4 | Perl |
|5 | eee | 4 |4 | Perl |
|8 | hhh | NULL | NULL | NULL |
|9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
| NULL | NULL | NULL |5 | Javascript |
+------+-------+--------+------+------------+
USING子句
MySQL中连接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name。当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。
所以,USING的功能相当于ON,区别在于USING指定一个属性名用于连接两个表,而ON指定一个条件。另外,SELECT *时,USING会去除USING指定的列,而ON不会。实例如下:
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId =t_type.id;
+----+-------+--------+----+------+
| id | title | typeId | id | name |
+----+-------+--------+----+------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | Perl |
| 5 | eee | 4 | 4 | Perl |
+----+-------+--------+----+------+
SELECT * FROM t_blog INNER JOIN t_type USING(typeId);
ERROR 1054 (42S22): Unknown column 'typeId' in 'from clause'
-- 这里t_blog的typeId与t_type的id不同名,无法用Using,这里用id代替下。
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.id = t_type.id;
+----+-------+--------+----+-----------+
| id | title | typeId | id | name |
+----+-------+--------+----+-----------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 3 | ccc | 3 | 3 | JAVA |
| 4 | ddd | 4 | 4 | Perl|
| 5 | eee | 4 | 5 | JVASCRIPT |
+----+-------+--------+----+-----------+
SELECT * FROM t_blog INNER JOIN t_type USING(id);
+----+-------+--------+------------+
| id | title | typeId | name |
+----+-------+--------+------------+
| 1 | aaa | 1 | C++|
| 2 | bbb | 2 | C |
| 3 | ccc | 3 | Java |
| 4 | ddd | 4 | Perl |
| 5 | eee | 4 | Javascript |
+----+-------+--------+------------+
自然连接:NATURE JOIN
自然连接就是USING子句的简化版,它找出两个表中相同的列作为连接条件进行连接。有左自然连接,右自然连接和普通自然连接之分。在t_blog和t_type示例中,两个表相同的列是id,所以会拿id作为连接条件。
另外千万分清下面三条语句的区别。
自然连接:SELECT * FROM t_blog NATURAL JOIN t_type; //NATURAL 为关键字,表示自然连接
笛卡尔积:SELECT * FROM t_blog NATURA JOIN t_type; //NATURA 为表的别名
SELECT * FROM t_blog NATURAL JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog,t_type WHERE t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type USING(id);
+----+-------+--------+------------+
| id | title | typeId | name |
+----+-------+--------+------------+
| 1 | aaa | 1 | C++|
| 2 | bbb | 2 | C |
| 3 | ccc | 3 | Java |
| 4 | ddd | 4 | Perl |
| 5 | eee | 4 | Javascript |
+----+-------+--------+------------+
SELECT * FROM t_blog NATURAL LEFT JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog LEFT JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog LEFT JOIN t_type USING(id);
+----+-------+--------+------------+
| id | title | typeId | name |
+----+-------+--------+------------+
| 1 | aaa | 1 | C++|
| 2 | bbb | 2 | C |
| 3 | ccc | 3 | Java |
| 4 | ddd | 4 | Perl |
| 5 | eee | 4 | Javascript |
| 6 | fff | 3 | NULL |
| 7 | ggg | 2 | NULL |
| 8 | hhh | NULL | NULL |
| 9 | iii | NULL | NULL |
| 10 | jjj | NULL | NULL |
+----+-------+--------+------------+
SELECT * FROM t_blog NATURAL RIGHT JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog RIGHT JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog RIGHT JOIN t_type USING(id);
+----+------------+-------+--------+
| id | name | title | typeId |
+----+------------+-------+--------+
| 1 | C++| aaa | 1 |
| 2 | C | bbb | 2 |
| 3 | Java | ccc | 3 |
| 4 | Perl | ddd | 4 |
| 5 | Javascript | eee | 4 |
+----+------------+-------+--------+
文章开头给出的第一张图除去讲了的内连接、左连接、右连接、外连接。
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id WHERE t_type.id IS NULL;
+----+-------+--------+------+------+
| id | title | typeId | id | name |
+----+-------+--------+------+------+
| 8 | hhh | NULL | NULL | NULL |
| 9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
+----+-------+--------+------+------+
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id WHERE t_blog.id IS NULL;
+------+-------+--------+----+------------+
| id | title | typeId | id | name |
+------+-------+--------+----+------------+
| NULL | NULL | NULL | 5 | Javascript |
+------+-------+--------+----+------------+
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id WHERE t_type.id IS NULL
UNION
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id WHERE t_blog.id IS NULL;
+------+-------+--------+------+------------+
| id | title | typeId | id | name |
+------+-------+--------+------+------------+
|8 | hhh | NULL | NULL | NULL |
|9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
| NULL | NULL | NULL |5 | Javascript |
+------+-------+--------+------+------------+
(二):JOIN原理
表连接算法
Nested Loop Join(NLJ)算法:
首先介绍一种基础算法:NLJ,嵌套循环算法。循环外层是驱动表,循坏内层是被驱动表。驱动表会驱动被驱动表进行连接操作。首先驱动表找到第一条记录,然后从头扫描被驱动表,逐一查找与驱动表第一条记录匹配的记录然后连接起来形成结果表中的一条记。被驱动表查找完后,再从驱动表中取出第二个记录,然后从头扫描被驱动表,逐一查找与驱动表第二条记录匹配的记录,连接起来形成结果表中的一条记录。重复上述操作,直到驱动表的全部记录都处理完毕为止。这就是嵌套循环连接算法的基本思想,伪代码如下:
foreach row1 from t1
foreach row2 from t2
if row2 match row1 //row2与row1匹配,满足连接条件
join row1 and row2 into result //连接row1和row2加入结果集
首先加载t1,然后从t1中取出第一条记录,之后加载t2表,与t2表中的记录逐个匹配,连接匹配的记录。
Block Nested Loop Join(BNLJ)算法:
再介绍一种高级算法:BNLJ,块嵌套循环算法,可以看作对NLJ的优化。大致思想就是建立一个缓存区,一次从驱动表中取多条记录,然后扫描被驱动表,被驱动表的每一条记录都尝试与缓冲区中的多条记录匹配,如果匹配则连接并加入结果集。缓冲区越大,驱动表一次取出的记录就越多。这个算法的优化思路就是减少内循环的次数从而提高表连接效率。
影响性能的因素
1.内循环的次数:现在考虑这么一个场景,当t1有100条记录,t2有10000条记录。那么,t1驱动t2与t2驱动t1,他们之间在效率上孰优孰劣?如果是单纯的分析指令执行次数,他们都是100*10000,但是考虑到加载表的次数呢。首先分析t1驱动t2,t1表加载1次,t2表需要加载100次。然后分析t2驱动t1,t2表首先加载1次,但是t1表要加载10000次。所以,t1驱动t2的效率要优于t2驱动t1的效率。由此得出,小表驱动大表能够减少内循环的次数从而提高连接效率。
另外,如果使用Block Nested Loop Join算法的话,通过扩大一次缓存区的大小也能减小内循环的次数。由此又可得,设置合理的缓冲区大小能够提高连接效率。
2.快速匹配:扫描被驱动表寻找合适的记录可以看做一个查询操作,如何提高查询的效率呢?当然是建索引,由此还可得出,在被驱动表建立索引能够提高连接效率
3.排序:假设t1表驱动t2表进行连接操作,连接条件是t1.id=t2.id,而且要求查询结果对id排序。现在有两种选择:
方式一[...ORDER BY t1.id],
方式二[...ORDER BY t2.id]。
如果我们使用方式一的话,可以先对t1进行排序然后执行表连接算法,如果我们使用方式二的话,只能在执行表连接算法后,对结果集进行排序(Using temporary),效率自然低下。由此最后可得出,优先选择驱动表的属性进行排序能够提高连接效率。
(三):JOIN优化实践之内循环的次数
这节讲述如何优化内循环的次数。内循环的次数受驱动表的记录数所影响,驱动表记录数越多,内循环就越多,连接效率就越低下,所以尽量用小表驱动大表,先插入测试数据。
CREATE TABLE t1 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t1;
+----------+
| COUNT(*) |
+----------+
|10000 |
+----------+
CREATE TABLE t2 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t2;
+----------+
| COUNT(*) |
+----------+
| 100 |
+----------+
内连接谁当驱动表
实际业务场景中,左连接、右连接可以根据业务需求认定谁是驱动表,谁是被驱动表。但是内连接不同,根据嵌套循环算法的思想,t1内连接t2和t2内连接t1所得结果集是相同的。那么到底是谁连接谁呢?谨记一句话即可,小表驱动大表可以减小内循环的次数。
下面用STRAIGHT_JOIN强制左表连接右表。顺便说一下,STRIGHT_JOIN比较冷门,其作用相当于内连接,不过强制规定了左表驱动右边。
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.type=t2.type;
+----+-------+------+------+-------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+-------+----------------------------------------------------+
| 1 | t1| ALL | NULL | 10000 | NULL |
| 1 | t2| ALL | NULL | 100 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+-------+----------------------------------------------------+
EXPLAIN SELECT * FROM t2 STRAIGHT_JOIN t1 ON t2.type=t1.type;
+----+-------+------+------+-------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+-------+----------------------------------------------------+
| 1 | t2| ALL | NULL | 100 | NULL |
| 1 | t1| ALL | NULL | 10000 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+-------+----------------------------------------------------+
对于第一条查询语句,t1是驱动表,其有10000条记录,内循环也就有10000次,这还得了?
对于第二条查询语句,t2是驱动表,其有100条记录,内循环100次,感觉不错!
这些SQL语句的执行时间也说明了,当内连接时,务必用小表驱动大表。
最佳实践:直接让MySQL去判断
但是,表的记录数是会变化的,有没有一劳永逸的写法?当然有啦,MySQL自带的Optimizer会优化内连接,优化策略就是上面讲的小表驱动大表。所以,以后写内连接不要纠结谁内连接谁了,直接让MySQL去判断吧。
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.type=t2.type;
EXPLAIN SELECT * FROM t2 INNER JOIN t1 ON t1.type=t2.type;
EXPLAIN SELECT * FROM t1 JOIN t2 ON t1.type=t2.type;
EXPLAIN SELECT * FROM t2 JOIN t1 ON t1.type=t2.type;
EXPLAIN SELECT * FROM t1,t2 WHERE t1.type=t2.type;
EXPLAIN SELECT * FROM t2,t1 WHERE t1.type=t2.type;
+----+-------+------+------+--------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+--------+----------------------------------------------------+
| 1 | t2| ALL | NULL|100 | NULL |
| 1 | t1| ALL | NULL | 110428 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+--------+----------------------------------------------------+
上面6条内连接SQL,MySQL的Optimizer都会进行优化。
(四):JOIN优化实践之快速匹配
这节讲述如何优化扫描速度。通过(二):JOIN原理得知了两张表的JOIN操作就是不断从驱动表中取出记录,然后查找出被驱动表中与之匹配的记录并连接。这个过程的实质就是查询操作,想要优化查询操作,建索引是最常用的方式。那索引怎么建呢?我们来讨论下,首先插入测试数据:
CREATE TABLE t1 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t1;
+----------+
| COUNT(*) |
+----------+
| 110000 |
+----------+
CREATE TABLE t2 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t2;
+----------+
| COUNT(*) |
+----------+
| 100 |
+----------+
左连接
左连接中,左表是驱动表,右表是被驱动表。想要快速查找被驱动表中匹配的记录,所以我们可以在右表建索引,从而提高连接性能。
-- 首先两个表都没建索引
EXPLAIN SELECT * FROM t1 LEFT JOIN t2 ON t1.type=t2.type;
+----+-------+------+------+--------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+--------+----------------------------------------------------+
| 1 | t1| ALL | NULL | 110428 | NULL |
| 1 | t2| ALL | NULL |100 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+--------+----------------------------------------------------+
-- 尝试在左表建立索引,改进不大
CREATE INDEX idx_type ON t1(type);
EXPLAIN SELECT * FROM t1 LEFT JOIN t2 ON t1.type=t2.type;
+----+-------+-------+----------+--------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+-------+----------+--------+----------------------------------------------------+
| 1 | t1| index | idx_type | 110428 | Using index|
| 1 | t2| ALL | NULL |100 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+-------+----------+--------+----------------------------------------------------+
-- 尝试在右表建立索引,出现了Using index!
DROP INDEX idx_type ON t1;
CREATE INDEX idx_type ON t2(type);
EXPLAIN SELECT * FROM t1 LEFT JOIN t2 ON t1.type=t2.type;
+----+-------+------+---------------+----------+--------+-------------+
| id | table | type | possible_keys | key | rows | Extra |
+----+-------+------+---------------+----------+--------+-------------+
| 1 | t1| ALL | NULL | NULL | 110428 | NULL|
| 1 | t2| ref | idx_type | idx_type | 1 | Using index |
+----+-------+------+---------------+----------+--------+-------------+
右连接
右连接中,右表是驱动表,左表是被驱动表,想要快速查找被驱动表中匹配的记录,所以我们可以在左表建索引,从而提高连接性能。
DROP INDEX idx_type ON t2;
-- 两个表都没有索引
EXPLAIN SELECT * FROM t1 RIGHT JOIN t2 ON t1.type=t2.type;
+----+-------+------+------+--------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+--------+----------------------------------------------------+
| 1 | t2| ALL | NULL |100 | NULL |
| 1 | t1| ALL | NULL | 110428 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+--------+----------------------------------------------------+
-- 在右边建立索引,改进不大
CREATE INDEX idx_type ON t2(type);
EXPLAIN SELECT * FROM t1 RIGHT JOIN t2 ON t1.type=t2.type;
+----+-------+-------+---------------+----------+--------+----------------------------------------------------+
| id | table | type | possible_keys | key | rows | Extra |
+----+-------+-------+---------------+----------+--------+----------------------------------------------------+
| 1 | t2| index | NULL | idx_type |100 | Using index|
| 1 | t1| ALL | NULL | NULL | 110428 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+-------+---------------+----------+--------+----------------------------------------------------+
-- 尝试在左边建立索引,效果立即显现。
DROP INDEX idx_type ON t2;
CREATE INDEX idx_type ON t1(type);
EXPLAIN SELECT * FROM t1 RIGHT JOIN t2 ON t1.type=t2.type;
+----+-------+------+---------------+--------------+------+-------------+
| id | table | type | possible_keys | ref | rows | Extra |
+----+-------+------+---------------+--------------+------+-------------+
| 1 | t2| ALL | NULL | NULL | 100 | NULL|
| 1 | t1| ref | idx_type | test.t2.type |5 | Using index |
+----+-------+------+---------------+--------------+------+-------------+
内连接
我们知道,MySQL Optimizer会对内连接做优化,不管谁内连接谁,都是用小表驱动大表,所以如果要优化内连接,可以在大表上建立索引,以提高连接性能。
另外注意一点,在小表上建立索引时,MySQL Optimizer会认为用大表驱动小表效率更快,转而用大表驱动小表。对内连接小表驱动大表的优化策略不清楚的话,可以看(三):JOIN优化实践之内循环的次数。
DROP INDEX idx_type ON t1;
-- 两个表都没有索引,t2驱动t1
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.type=t2.type;
+----+-------+------+------+--------+----------------------------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+------+------+--------+----------------------------------------------------+
| 1 | t2| ALL | NULL |100 | NULL |
| 1 | t1| ALL | NULL | 110428 | Using where; Using join buffer (Block Nested Loop) |
+----+-------+------+------+--------+----------------------------------------------------+
-- 在t2表上建立索引,MySQL的Optimizer发现后,用大表驱动了小表
CREATE INDEX idx_type ON t2(type);
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.type=t2.type;
+----+-------+------+----------+--------+-------------+
| id | table | type | key | rows | Extra |
+----+-------+------+----------+--------+-------------+
| 1 | t1| ALL | NULL | 110428 | Using where |
| 1 | t2| ref | idx_type | 1 | Using index |
+----+-------+------+----------+--------+-------------+
-- 在t1表上建立索引,再加上t1是大表,符合“小表驱动大表”的原则,性能比上面的语句要好
DROP INDEX idx_type ON t2;
CREATE INDEX idx_type ON t1(type);
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.type=t2.type;
+----+-------+------+---------------+----------+------+-------------+
| id | table | type | possible_keys | key | rows | Extra |
+----+-------+------+---------------+----------+------+-------------+
| 1 | t2| ALL | NULL | NULL | 100 | Using where |
| 1 | t1| ref | idx_type | idx_type |5 | Using index |
+----+-------+------+---------------+----------+------+-------------+
三表连接
上面都是两表连接,三表连接也是一样的,找出驱动表和被驱动表,在被驱动表上建立索引,即可提高连接性能。
总结
想要从快速匹配的角度优化JOIN,首先就是找出谁是驱动表,谁是被驱动表,然后在被驱动表上建立索引即可。
(五):JOIN优化实践之排序
这节讲述如何优化JOIN查询带有排序的情况,大致分为对连接属性排序和对非连接属性排序两种情况,插入测试数据:
CREATE TABLE t1 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t1;
+----------+
| COUNT(*) |
+----------+
| 10000 |
+----------+
CREATE TABLE t2 (
id INT PRIMARY KEY AUTO_INCREMENT,
type INT
);
SELECT COUNT(*) FROM t2;
+----------+
| COUNT(*) |
+----------+
| 100 |
+----------+
对连接属性进行排序
现要求对t1和t2做内连接,连接条件是t1.id=t2.id,并对连接属性id属性进行排序(MySQL为主键id建立了索引)。
有两种选择:方式一[...ORDER BY t1.id],方式二[...ORDER BY t2.id],选哪种呢?
首先我们找出驱动表和被驱动表,按照小表驱动大表的原则,大表是t1,小表是t2,所以t2是驱动表,t1是非驱动表,t2驱动t1。然后进行分析,如果我们使用方式一的话,MySQL会先对t1进行排序然后执行表连接算法,如果我们使用方式二的话,只能执行表连接算法后对结果集进行排序(extra:using temporary),效率必然低下。所以,当对连接属性进行排序时,应当选择驱动表的属性作为排序表中的条件。
-- 对被驱动表字段进行排序
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.id =t2.id ORDER BY t1.id;
+----+-------+--------+---------+------+---------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+--------+---------+------+---------------------------------+
| 1 | t2| ALL| NULL| 100 | Using temporary; Using filesort |
| 1 | t1| eq_ref | PRIMARY |1 | NULL|
+----+-------+--------+---------+------+---------------------------------+
-- 对驱动表字段进行排序,没有Using temporary,也没有Using filesort
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.id =t2.id ORDER BY t2.id;
+----+-------+--------+---------+------+-------+
| id | table | type | key | rows | Extra |
+----+-------+--------+---------+------+-------+
| 1 | t2| index | PRIMARY | 100 | NULL |
| 1 | t1| eq_ref | PRIMARY |1 | NULL |
+----+-------+--------+---------+------+-------+
对非连接属性进行排序
现要求对t1和t2做内连接,连接条件是t1.id=t2.id,并对非连接属性t1的type属性进行排序,[...ORDER BY t1.type]。
首先我们找出驱动表和被驱动表,按照小表驱动大表的原则,大表是t1,小表是t2,所以MySQL Optimizer会用t2驱动t1。现在我们要对t1的type属性进行排序,t1是被驱动表,必然导致对连接后结果集进行排序Using temporary(比Using filesort更严重)。所以能不能不用MySQL Optimizer,用大表驱动小表呢?
有请STRAIGHT_JOIN!
EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t1.id =t2.id ORDER BY t1.type;
+----+-------+--------+---------+------+---------------------------------+
| id | table | type | key | rows | Extra |
+----+-------+--------+---------+------+---------------------------------+
| 1 | t2| ALL| NULL| 100 | Using temporary; Using filesort |
| 1 | t1| eq_ref | PRIMARY |1 | NULL|
+----+-------+--------+---------+------+---------------------------------+
-- Using temporary没有了,但是大表驱动小表,导致内循环次数增加,实际开发中要从实际出发对此作出权衡。
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.id =t2.id ORDER BY t1.type;
+----+-------+--------+---------+-------+----------------+
| id | table | type | key | rows | Extra |
+----+-------+--------+---------+-------+----------------+
| 1 | t1| ALL| NULL| 10000 | Using filesort |
| 1 | t2| eq_ref | PRIMARY | 1 | NULL |
+----+-------+--------+---------+-------+----------------+
最后在(一):用法那里挖了个坑,现在填上:INNER JOIN、JOIN、WHERE等值连接和STRAIGHT_JOIN都能表示内连接,那平时如何选择呢?一般情况下用INNER JOIN、JOIN或者WHERE等值连接,因为MySQL Optimizer会按照“小表驱动大表的策略”进行优化。当出现上述问题时,才考虑用STRAIGHT_JOIN。
全文到此为止。
本文总结自:文文1的个人工作日志,感谢原作者。
多表联查
* 数据表的别名
select * from 表名 as 别名; // as 可省略
* 交叉连接(笛卡尔积)
//显示两张表的乘积
select * from 表1 cross join 表2 on 连接条件 where 查询条件; //cross join on 可省略
select * from 表1,表2 where 查询条件; //默认就是交叉连接,如果 where 条件中有等值判断则称为等值连接
* 内连接
//显示两张表的交集
select * from 表1 inner join 表2 on 连接条件 where 查询条件; //inner 可省略
* 左外连接
//左表显示全集,右表显示交集
select * from 表1 left outer join 表2 on 连接条件 where 查询条件; //outer 可省略
* 右外连接
//左表显示交集,右表显示全集
select * from 表1 right outer join 表2 on 连接条件 where 查询条件; //outer 可省略
* 联合查询
//显示两张表的并集,要求两张表的查询字段名必须保持一致
select id,name from 表1 union select id,name from 表2;
* 全外连接(MySQL不支持)
//显示两张表的并集
select * from 表1 full outer join 表2 on 连接条件 where 查询条件; //outer 可省略
//可以通过左外连接和右外连接的联合查询来实现
select * from 表1 left join 表2 on 连接条件 where 查询条件 union select * from 表1 right join 表2 on 连接条件 where 查询条件;
嵌套查询
select * from 表名 where 字段名 = (select 字段名 from 表名 where 字段名=?);
* 当子查询返回的值只有一个时,才可以直接使用 =,>,< 等运算符;
* 当子查询返回的值是一个结果集时,需要使用 in,not in,any,some,all 等操作符;
* all : 匹配结果集中的所有结果, 例如 > all 表示比所有结果都大;
* any : 匹配结果信中任意一个结果, 例如 < any 表示只要比其中任意一个小就符合条件;
* in : 查询的数据在子查询的结果集中,相当于 = any;
* not in : 查询的数据不在子查询结果集中,相当于 <> all;
* some : 匹配结果集中的部分结果,基本等同于 any,不常用;
* 子查询通常只用于返回单个字段的结果集,如果需要匹配多个字段,可以使用多表联查(后面讲);
示例:
select * from 表名 where 字段名 > all (select 字段名 from 表名);