调整Innodb参数来提升MySQL性能
 Innodb中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能;而IO Thread的工作主要是负责这些IO请求的回调callback。本文梳理了大部分相关的配置参数,以期在调整的过程中提高性能。
Innodb中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能;而IO Thread的工作主要是负责这些IO请求的回调callback。本文梳理了大部分相关的配置参数,以期在调整的过程中提高性能。innodb_read_io_threads
设置read thread(读线程个数,默认是4个)
innodb_write_io_threads
设置write thread(写线程个数,默认是4个)
事务被提交后,其所使用的undolog撤销日志可能不再需要,因此需要Purge Thread清理线程来回收已经使用并分配的undo页。
innodb1.1版本之前,purge操作仅在innodb引擎中的Master Thread中完成。而从innodb1.1版本开始,purge操作可以独立到单独的线程中进行。以此来减轻Master Thread的工作,提高cpu使用率以及提升存储引擎性能。
innodb_purge_thread = 1
注意:在innodb1.1版本中,即使该值设置大于1,innodb启动时也会将其设置为1。并在错误文件中给出警告。
innodb1.2支持多个Pugre Thread线程。
innodb_buffer_pool_instances = 2
设置多个缓冲池实例,每个页根据哈希值平均分配到不同缓冲池实例中。好处在于减少数据库内部资源竞争。增加数据库并发处理能力。
innodb_old_blocks_pct
LRU算法,默认值是37,插入到LRU列表端的37%,差不多3/8的位置。innodb把midpoint之后的列表称为old列表,之前的列表称为new列表,可以理解为new列表中的页都是最为活跃的热点数据。
innodb_old_blocks_time
当第一次读取到的新页,innodb会根据innodb_old_blocks_pct设置的值将读取到的页插入LRU列表指定的midpoint中间点位置,如果没有修改,默认是37%,3/8的位置。防止将真正的new列表中的热点数据刷出。当再次读取到old列表中的页时也就是midpoint之后的页,innodb_old_blocks_time用于读取到old列表中的页时需要等待多久才会被加入到LRU列表的首部。防止new列中的热点数据被刷出。innodb_old_blocks_time默认值是0,没有等待。
innodb_log_buffer_size
默认是8M,用来缓冲日志数据的缓冲区的大小,当此值快满时,InnoDB将必须刷新数据到磁盘上。由于基本上每秒都会刷新一次,所以没有必要将此值设置的太大(甚至对于长事务而言) 。
innodb_max_dirty_pages_pct = 75
在InnoDB缓冲池中最大允许的脏页面的比例,当缓冲池中脏页的数量占据75%时,强制进行checkpoin,刷新一部分的脏页到磁盘。
innodb_io_capacity
表示磁盘io的吞吐量,默认值是200.对于刷新到磁盘页的数量,会按照inodb_io_capacity的百分比来进行控制。
规则如下:
在合并插入缓冲时,合并插入缓冲数量为innodb_io_capacity 值的5%。
在从缓冲池刷新脏页时,刷新脏页的数量为innodb_io_capacity的值,也就是默认值200。
如果使用了ssd,或者raid磁盘时,磁盘拥有更高的io速度,可以适当增加该参数的值。
innodb_adaptive_flushing
自适应刷新脏页,默认已经开启。
innodb_purge_batch_size
在进行full purge时,回收Undo页的个数,默认是20,可以适当加大。
innodb_fast_shutdown
在关闭时,该参数影响表innodb存储引擎行为。参数可取值为0,1,2,默认值是1。
0:表示在mysql数据库关闭时,innodb需要完成所有的full purge,merge insert buffer,并且将所有脏页刷新回磁盘。如果在innodb进行升级时,必须将这个参数设为0.然后在关闭数据库.
1:默认值,表示不需要完成full purge和merge insert buffer,但是在缓冲池中的一些数据脏页还是会刷新回磁盘。
2:表示不完成full purge和merge inser buffer操作,也不将缓冲池中的数据脏页刷新回磁盘,而是将日志写入日志文件,这样不会有事务丢失,但是下次数据库启动时,会进行恢复操作recovery
innodb_force_recovery
该参数影响了整个innodb存储引擎的恢复状况。该参数默认值为0,代表发生需要恢复时,进行所有的恢复操作,当不能进行有效恢复时,如数据页发生了损坏,把错误写入错误日志。还可以设置为6个非零值:1-6,大的数字包含了前面所有小数字的影响。具体如下:
1:忽略检查到的corrupt页
2:阻止master thread线程运行。如master thred需要进行full purge操作,会导致crash。
3:不进行事务的回滚。
4:不进行插入缓冲的合并操作
5:不查看撤销日志undo log,innodb存储引擎会将未提交的事务视为已提交。
6:不进行回滚的操作
注意:当该参数设置大于0以后,用户可以对表进行select,create,drop,但是innsert,update,delete这类DML操作却是不允许的。
以下参数影响着二进制日志记录信息的行为:
max_binlog_size
binlog_cache_szie
sync_binlog
binlog-do-db
binlog-ignore-db
log-slave-update
master==>slave==>slave 架构必须开启此参数slave端开启
binlog_format
其中比较重要的是sync_binlog参数,如果想让replication得到最大的可用性。最好将该值设置为1,表示采用同步写磁盘的方式来写二进制日志。不过有一点是会给IO带来一定压力。
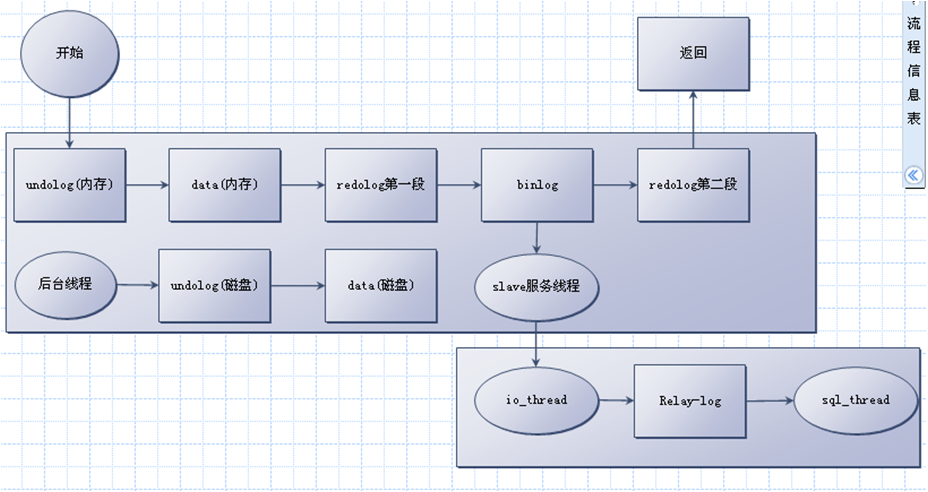
MySQL文件访问流程
当sysnc_binlog设置为1以后,还有一个参数需要设置。innodb_support_xa也需要将该值设置为1,避免事务不能被回滚的问题。当进行replication时,最好将二进制格式改为row,避免master使用了rand,uuid等函数,或者触发器,导致主从服务器数据不一致。通常将binlog_format设置为row格式。
innodb_data_file_path
表空间的设置,默认配置下有一个初始大小为10MB,名为ibdata1的文件,自动增长。用户可以通过多个文件组成一个表空间,同时定制文件属性,设置如下:
innodb_data_file_path= /db/ibdata1:2000M;/db2/ibdata2:2000M:autoextend
若这两个文件位于不同磁盘上,磁盘的负载可能被平均。因此可以提高数据库整体性能。
innodb_file_per_table
默认没有开启,将每个基于innodb引擎的表使用独立的表空间。
以下参数影响重做日志文件属性:
innodb_log_file_size
重做日志文件的大小。innodb1.2以前,大小不得超过4G。1.2x以后可以最大到512G。
innodb_log_files_in_group
指定了日志文件组中重做日志文件的数量,默认为2。
innodb_mirrored_log_groups
指定了日志镜像文件组的数量,默认为1.表示只有一个文件组,没有使用镜像。若磁盘使用了类似磁盘阵列,可以不开启重做日志镜像功能。
innodb_log_group_home_dir
指定日志文件组所在路径。默认为./,表示在mysql数据库目录下。
注意:重做日志文件不能设置的太大,否则在恢复时可能需要很长的时间;如果设置的太小,可能导致一个事务日志需要多次切换重做日志文件。此外,重做日志文件太小会导致频繁的发生async checkpoint,导致性能抖动。
innodb_flush_log_at_trx_commit
该参数表示在提交操作时commit,处理重做日志的方式。有效值有0,1,2。
0:代表当提交事务时,并不将事务的重做日志写入磁盘上的日志文件,而是等待主线程master thread每秒刷新。
1,2不同的地方在于:
1:表示在执行commit时将重做日志缓冲同步到写到磁盘。既有fsync的调度。
2:表示将重做日志异步写到磁盘,既写到文件系统的缓冲中。因此不能完全保证在执行commit时肯定会写入重做日志文件,只是有这个动作发生。
所以当为了保证事务的ACID中的持久性,必须将该值设置为1 。也就是每当有事务提交时,就必须确保事务都已经写入重做日志文件。
上面介绍了所有与innodb相关的参数,我们再来分类介绍一些,方便针对性的调优。
内存相关
innodb_buffer_pool_size 缓冲池,会缓冲索引页、数据页、undo页、插入缓冲、自适应哈希索引、innodb存储的锁信息、数字字典信息等
innodb_buffer_pool_instances 允许多个缓冲池实例,每页根据哈希平均分配到不同缓冲池实例中,减少数据库内部资源竞争,增加数据库并发处理能力
innodb_old_blocks_pct 确定modpoint位置,默认37,modpoint指新读取到的页放入LRU最近最少使用算法列表中的位置,modpoint之后的列表称为old列表,之前的称为new列表
innodb_old_blocks_time 表示页读入mid位置后需要等待多久才会被加入到LRU列表的热端
innodb_purge_batch_size 控制每次full purge回收的undo页的数量
innodb_change_buffer_max_size 控制change buffer最大使用内存数量
IO相关
MySQL 5.6 开始支持 Multi-Range Read (MRR),减少磁盘随机访问,将随机访问转化为较为顺序的访问,适用于 range, ref, eq_ref 类型的查询
查看是否开启 show variables like '%optimizer_switch%' mrr=on,mrr_cost_based=off,off为不判断,总是开启
read_rnd_buffer_size控制键值的缓冲区大小,当大于该值时,执行器对已经缓存的数据根据RowID进行排序,并通过RowID来取得行数据,默认256k
5.6 开始支持Index Condition Pushdown(ICP),取出索引的同时,判断是否可以进行条件过滤,过滤后再去获取记录,可以大大减少上层SQL对记录的索取,支持range,ref,eq_ref,ref_or_null类型的查询
innodb_flush_log_at_trx_commit 用来控制重做日志刷新到磁盘的策略
默认值为1,事务提交时必须调用一次fsync,将日志刷新到磁盘
0:事务提交时不写入重做日志,这个操作仅在master thread中完成,master thread每1秒会进行一次重做日志文件的fsync操作
2:事务提交时将重做日志写入重做日志文件,但仅写入文件系统的缓存中,不进行fsync操作
优缺点,#1数据有保障但是依赖于磁盘的性能;#2在操作系统宕机时会造成事务丢失。#0 &#2的设置都会使事务丧失ACID特性
innodb_purge_batch_size
innodb_max_purge_lag & innodb_max_purge_lag_delay
binlog_max_flush_queue_time
innodb_read_io_threads & innodb_write_io_threads,多核cpu可以通过这两个参数更有效的利用cpu性能
innodb_io_capacity 可以充分利用固态硬盘带来的高IOPS特性
innodb_purge_threads 将purge线程从master线程分离出来,提高cpu使用率提升存储引擎性能,innodb1.2之后可以设置多个purge线程
innodb_flush_neighbors 刷新邻接页,对于高iops的磁盘,建议关闭此特性
系统相关
innodb_fast_shutdown 0表示完成所有full purge和merge insert buffer,并将所有脏页刷新回磁盘;1表示不需要完成full purge和merge insert buffer,但要刷新脏页;2表示不执行以上所有操作,但将日志全部写入日志文件,下次启动时需要恢复recovery
innodb_force_recovery
SLOW QUERY 查询相关
long_query_time
log_slow_queries
log_queries_not_useing_indexes 开启后,没有用到索引的查询也会记录到slowlog里
log_throttle_queries_not_using_indexes 5.6.5新增,表示每分钟允许记录到slow log的未使用索引的sql语句次数
可以使用mysqldumpslow命令分析slow log
log_output,有FILE和TABLE两种,动态修改且是全局的
数据安全性相关
sync_binlog=[N]表示每写缓冲多少次就同步到磁盘,1表示同步写磁盘的方式写二进制日志。默认为0,由操作系统决定同步
innodb_support_xa=1,可以保证二进制日志和InnoDB存储引擎数据文件的同步
innodb_log_file_size 指每个重做日志文件的大小,innodb1.2之前必须小于4G,之后扩大到512G
innodb_log_files_in_group 指定了日志文件组中重做日志文件的数量,默认为2
innodb_mirrored_log_groups 指定了日志镜像文件组的数量,默认为1
在线DDL相关
innodb_online_alter_log_max_size Online DDL 原理是在执行创建或删除操作的同时,将INSERT、UPDATE、DELETE 这类 DML 操作日志写入到一个缓存中,此参数控制缓存大小,默认128M
影响IO/内存的一些参数
1、innodb_flush_log_at_trx_commit 设置为2
这参数是指 事务logib_logfile0、ib_logfile1以怎样的方式写入到log buffer
=0 mysql crash 就丢失了,性能最好
buffer pool -> log buffer 每秒 wirte os cache & flush磁盘
=1 不会丢失,效率低
buffer pool -> log buffer 每次 write os cache & flush磁盘
=2 即使mysql崩溃也不会丢数据
buffer pool -> os cache 每秒flush 磁盘
注意:由于进程调度策略问题,这个"每秒执行一次 flush(刷到磁盘)操作"并不是保证100%的"每秒
2、sync_binlog
二进制日志binary log同步到磁盘的频率。binary log 每写入sync_binlog 次后,刷写到磁盘。如果 autocommit 开启,每个语句都写一次 binary log,否则每次事务写一次。
默认值是 0,不主动同步,而依赖操作系统本身不定期把文件内容 flush 到磁盘,设为 1 最安全,在每个语句或事务后同步一次 binary log,即使在崩溃时也最多丢失一个语句或事务的日志,但因此也最慢。大多数情况下,对数据的一致性并没有很严格的要求,所以并不会把 sync_binlog 配置成 1,为了追求高并发,提升性能,可以设置为 100 或直接用 0
3、write/read thread
异步IO线程数
innodb_write_io_threads=16
innodb_read_io_threads=16
(该参数需要在配置文件中添加,重启mysql实例生效)脏页写的线程数,加大该参数可以提升写入性能
4、innodb_max_dirty_pages_pct
最大脏页百分数,当系统中脏页所占百分比超过这个值,INNODB就会进行写操作以把页中的已更新数据写入到磁盘文件中。默认75,一般现在流行的SSD硬盘很难达到这个比例。可依据实际情况在75-80之间调节
5、innodb_io_capacity=5000
从缓冲区刷新脏页时,一次刷新脏页的数量。根据磁盘IOPS的能力一般建议设置如下:
SAS 200
SSD 5000
PCI-E 10000-50000
6、innodb_flush_method=O_DIRECT(该参数需要重启mysql实例起效)
控制innodb 数据文件和redo log的打开、刷写模式。有三个值:fdatasync(默认),O_DSYNC,O_DIRECT。
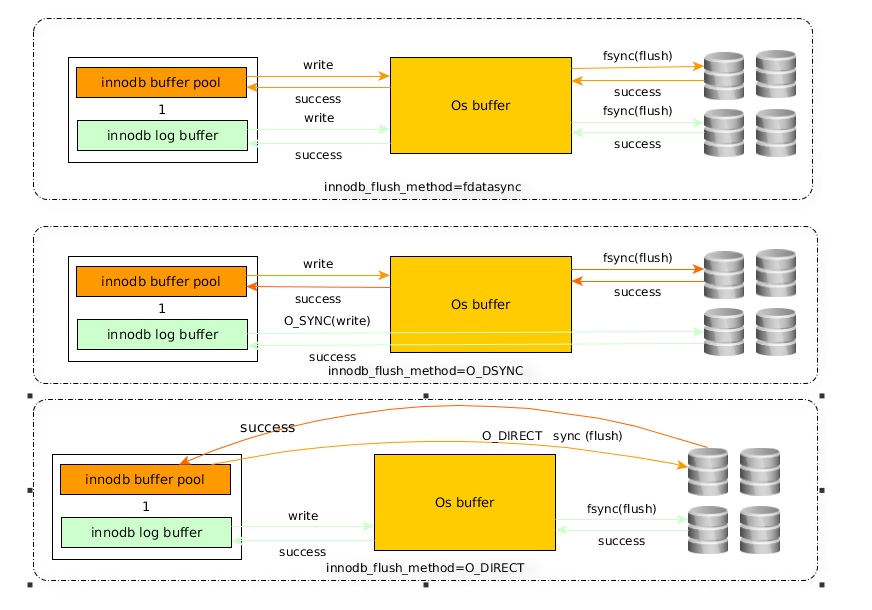
fdatasync模式:写数据时,write这一步并不需要真正写到磁盘才算完成可能写入到操作系统buffer中就会返回完成,真正完成是flush操作,buffer交给操作系统去flush,并且文件的元数据信息也都需要更新到磁盘。
O_DSYNC模式:写日志操作是在write这步完成,而数据文件的写入是在flush这步通过fsync完成。
O_DIRECT模式:数据文件的写入操作是直接从mysql innodb buffer到磁盘的,并不用通过操作系统的缓冲,而真正的完成也是在flush这步,日志还是要经过OS缓冲。
通过图可以看出O_DIRECT相比fdatasync的优点是避免了双缓冲,本身innodb buffer pool就是一个缓冲区,不需要再写入到系统的buffer,但是有个缺点是由于是直接写入到磁盘,所以相比fdatasync的顺序读写的效率要低些。
在大量随机写的环境中O_DIRECT要比fdatasync效率更高些,顺序写多的话,还是默认的fdatasync更高效。更多可详见《sync、fsync与fdatasync》。
7、innodb_adaptive_flushing 设置为 ON 使刷新脏页更智能
影响每秒刷新脏页的数目,规则由原来的"大于innodb_max_dirty_pages_pct时刷新100个脏页到磁盘"变为 "通过buf_flush_get_desired_flush_reate函数判断重做日志产生速度确定需要刷新脏页的最合适数目",即使脏页比例小于 innodb_max_dirty_pages_pct时也会刷新一定量的脏页。
8、innodb_adaptive_flushing_method 设置为 keep_average
影响checkpoint,更平均的计算调整刷脏页的速度,进行必要的flush.该变量为mysql衍生版本Percona Server下的一个变量,原生mysql不存在
9、innodb_stats_on_metadata=OFF
关掉一些访问information_schema库下表而产生的索引统计。当重启mysql实例后,mysql会随机的io取数据遍历所有的表来取样来统计数据,这个实际使用中用的不多,建议关闭.
10、innodb_change_buffering=all
当更新/插入的非聚集索引的数据所对应的页不在内存中时对非聚集索引的更新操作通常会带来随机IO,会将其放到一个insert buffer中,当随后页面被读到内存中时,会将这些变化的记录merge到页中。当服务器比较空闲时,后台线程也会做merge操作。
由于主要用到merge的优势来降低io,但对于一些场景并不会对固定的数据进行多次修改,此处则并不需要把更新/插入操作开启change_buffering,如果开启只是多余占用了buffer_pool的空间和处理能力。这个参数要依据实际业务环境来配置。
11、innodb_old_blocks_time=1000
使Block在old sublist中停留时间长为1s,不会被转移到new sublist中,避免了Buffer Pool被污染BP可以被认为是一条长链表。被分成young 和 old两个部分,其中old默认占37%的大小由innodb_old_blocks_pct 配置。靠近顶端的Page表示最近被访问。靠近尾端的Page表示长时间未被访问。而这两个部分的交汇处成为midpoint。每当有新的Page需要加载到BP时,该page都会被插入到midpoint的位置,并声明为old-page。当old部分的page,被访问到时,该page会被提升到链表的顶端,标识为young。
由于table scan的操作是先load page,然后立即触发一次访问。所以当innodb_old_blocks_time =0 时,会导致table scan所需要的page不读的作为young page被添加到链表顶端。而一些使用较为不频繁的page就会被挤出BP,使得之后的SQL会产生磁盘IO,从而导致响应速度变慢。
这时虽然mysqldump访问的page会不断加载在LRU顶端,但是高频度的热点数据访问会以更快的速度把page再次抢占到LRU顶端。从而导致mysqldump加载入的page会被迅速刷下,并立即被evict淘汰。因此,time=0或1000对这种压力环境下的访问不会造成很大影响,因为dump的数据根本抢占不过热点数据。不只dump,当大数据操作的时候也是如此。
12、binlog_cache_size
二进制日志缓冲大小:一个事务,在没有提交uncommitted的时候,产生的日志,记录到Cache中;等到事务提交committed需要提交的时候,则把日志持久化到磁盘。
设置太大的话,会比较消耗内存资源Cache本质就是内存,更加需要注意的是:binlog_cache是不是全局的,是按SESSION为单位独享分配的,也就是说当一个线程开始一个事务的时候,Mysql就会为这个SESSION分配一个binlog_cache。怎么判断我们当前的binlog_cache_size设置的没问题呢?
mysql> show status like 'binlog_%';
+----------------------------+------------+
| Variable_name | Value |
+----------------------------+------------+
| Binlog_cache_disk_use | 24506 |
| Binlog_cache_use | 1208714674 |
| Binlog_stmt_cache_disk_use | 423459 |
| Binlog_stmt_cache_use | 453218580 |
+----------------------------+------------+
mysql> select @@binlog_cache_size;
+---------------------+
| @@binlog_cache_size |
+---------------------+
| 32768 |
+---------------------+
1 row in set (0.00 sec)
运行情况binlog_cache_use表示binlog_cache内存方式被用上了多少次,binlog_cache_disk_use表示binlog_cache临时文件方式被用上了多少次。
13、innodb_file_per_table
innodb_file_per_table=1
独立表空间
优点:
每个表的数据和索引都会存在自已的表空间中
可以实现单表在不同的数据库中移动
空间可以回收除drop table操作
删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间
使用turncate table也会使空间收缩
对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能
缺点:
单表增加过大
结论:共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整一 下:innodb_open_files ,InnoDB Hot Backup冷备的表空间cp不会面对很多无用的copy了。而且利用innodb hot backup及表空间的管理命令可以实现单现移动。
调整innodb_read_io_threads和innodb_write_io_threads参数来充分利用CPU多核的处理能力
在MySQL5.1.X版本中,innodb_file_io_threads参数默认是4,该参数在Linux系统上是不可更改的,但Windows系统上可以调整。这个参数的作用是:InnoDB使用后台线程处理数据页上读写I/O输入输出请求的数量。
在MySQL5.5.X版本中,或者说是在InnoDB Plugin1.0.4以后,就用两个新的参数,即innodb_read_io_threads和innodb_write_io_threads,取代了innodb_file_io_threads如此调整后,在Linux平台上就可以根据CPU核数来更改相应的参数值了,默认是4。
假如CPU是2颗8核的,那么可以设置:
innodb_read_io_threads = 8
innodb_write_io_threads = 8
如果数据库的读操作比写操作多,那么可以设置:
innodb_read_io_threads = 10
innodb_write_io_threads = 6
可以根据情况加以设置。
注意:这两个参数不支持动态改变,需要把该参数加入my.cnf里,修改完后重启MySQL服务,允许值的范围是1~64。调整完成后,你可以用命令"show engine innodb status\G"来查看调整结果,如下所示:
show engine innodb status
Innodb buffer pool内存:undo page /insert buffer page/adaptive hash index/index page/lock info/data dictionary
IO线程分别是insert buffer thread、log thread、read thread、write thread。
在MySQL 5.6.10之后,默认线程处理模型使用执行每个客户端连接一个线程语句。随着越来越多的客户端连接到服务器和执行语句,整体性能降低。线程池插件的提供旨在减少开销,提高性能的其他线程的处理模式。该插件实现了通过有效地管理语句执行线程的大量客户端连接的提高服务器性能的线程池。
InnoDB Plugin版本开始增加了默认IO thread的数量,默认的read thread和write thread分别增大到了4个,并且不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_threads和innodb_write_io_threads参数。
线程池解决每个连接模型解决单线程的几个问题
Too many thread stacks make CPU caches almost useless in highly parallel execution workloads. The thread pool promotes thread stack reuse to minimize the CPU cache footprint.
With too many threads executing in parallel, context switching overhead is high. This also presents a challenging task to the operating system scheduler. The thread pool controls the number of active threads to keep the parallelism within the MySQL server at a level that it can handle and that is appropriate for the server host on which MySQL is executing.
Too many transactions executing in parallel increases resource contention. In InnoDB, this increases the time spent holding central mutexes. The thread pool controls when transactions start to ensure that not too many execute in parallel.