 HBase 为用户提供了一个非常方便的使用方式:“HBase Shell”。HBase Shell 提供了大多数的 HBase 命令,通过它用户可以方便地创建、删除及修改表,还可以向表中添加数据、列出表中的相关信息等。下面这张指令简述图来自的他人的博客,感谢原作者。
HBase 为用户提供了一个非常方便的使用方式:“HBase Shell”。HBase Shell 提供了大多数的 HBase 命令,通过它用户可以方便地创建、删除及修改表,还可以向表中添加数据、列出表中的相关信息等。下面这张指令简述图来自的他人的博客,感谢原作者。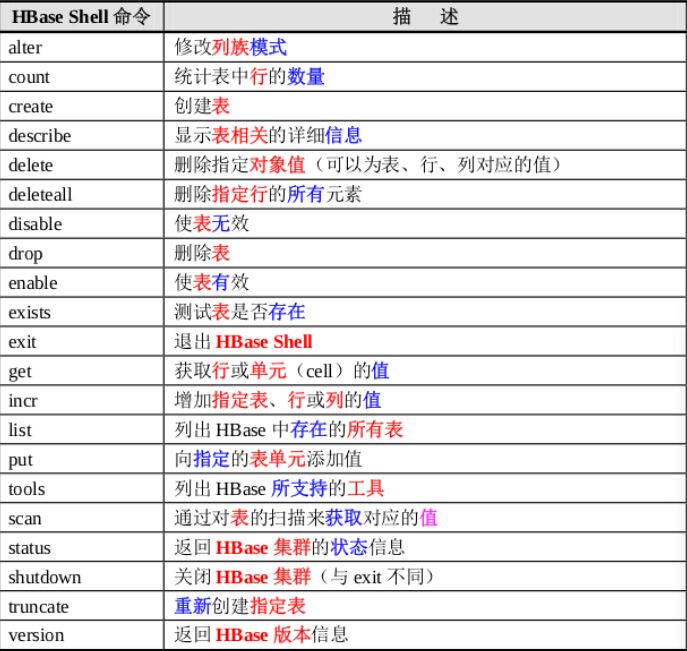
备注:写错 HBase Shell 命令时用键盘上的“Delete”进行删除,“Backspace”不起作用。它的使用并不难,而且提供即时的帮助:进入hbase shell console
$HBASE_HOME/bin/hbase shell
使用hbase shell进入可以使用whoami命令可查看当前用户
hbase(main)> whoami
使用'help cmd',可以看到关于'cmd'的帮助介绍和救命用法。
hbase shell中的指令分组
组名: general
指令: status, version
组名: ddl
指令: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, is_disabled, is_enabled, list, show_filters
组名: dml
指令: count, delete, deleteall, get, get_counter, incr, put, scan, truncate
组名: tools
指令: assign, balance_switch, balancer, close_region, compact, flush, hlog_roll, major_compact,move, split, unassign, zk_dump
组名: replication
指令: add_peer, disable_peer, enable_peer, list_peers, remove_peer, start_replication, stop_replication
组名: security
指令: grant, revoke, user_permission
表的管理
1)查看有哪些表
hbase(main)> list
2)创建表
# 语法:create <table>, {NAME=><family>, VERSIONS=><VERSIONS>}
# 例如:创建表t1,有两个family name:f1,f2,且版本数均为2
hbase(main)> create 't1',{NAME=>'f1', VERSIONS=>2},{NAME=>'f2', VERSIONS=>2}
3)删除表
分两步:首先disable,然后drop
例如:删除表t1
hbase(main)> disable 't1'
hbase(main)> drop 't1'
4)查看表的结构
# 语法:describe <table>
# 例如:查看表t1的结构
hbase(main)> describe 't1'
5)修改表结构
修改表结构必须先disable
# 语法:alter 't1', {NAME=>'f1'}, {NAME=>'f2', METHOD=>'delete'}
# 例如:修改表test1的cf的TTL为180天
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'
alter命令使用如下需要先将用表disable:
a、改变或添加一个列族:
hbase> alter 't1', NAME => 'f1', VERSIONS => 5
b、删除一个列族:
hbase> alter 't1', NAME => 'f1', METHOD => 'delete'
hbase> alter 't1', 'delete' => 'f1'
c、也可以修改表属性如MAX_FILESIZE
MEMSTORE_FLUSHSIZE, READONLY,和 DEFERRED_LOG_FLUSH:
hbase> alter 't1', METHOD => 'table_att', MAX_FILESIZE => '134217728'
d、可以添加一个表协同处理器
hbase> alter 't1', METHOD => 'table_att', 'coprocessor'=> 'hdfs:///foo.jar|com.foo.FooRegionObserver|1001|arg1=1,arg2=2'
一个表上可以配置多个协同处理器,一个序列会自动增长进行标识。加载协同处理器可以说是过滤程序需要符合以下规则:
[coprocessor jar file location] | class name | [priority] | [arguments]
e、移除coprocessor如下:
hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE'
hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
f、可以一次执行多个alter命令:
hbase> alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
权限管理
1)分配权限
# 语法 : grant <user> <permissions> <table> <column family> <column qualifier> 参数后面用逗号分隔
# 权限用五个字母表示: "RWXCA".
# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
# 例如,给用户'test'分配对表t1有读写的权限,
hbase(main)> grant 'test','RW','t1'
2)查看权限
# 语法:user_permission <table>
# 例如,查看表t1的权限列表
hbase(main)> user_permission 't1'
3)收回权限
# 与分配权限类似,语法:revoke <user> <table> <column family> <column qualifier>
# 例如,收回test用户在表t1上的权限
hbase(main)> revoke 'test','t1'
表数据的增删改查
1)添加数据
# 语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 例如:给表t1的添加一行记录:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系统默认
hbase(main)> put 't1','rowkey001','f1:col1','value01'
用法比较单一。
2)查询数据
a)查询某行记录
# 语法:get <table>,<rowkey>,[<family:column>,....]
# 例如:查询表t1,rowkey001中的f1下的col1的值
hbase(main)> get 't1','rowkey001', 'f1:col1'
# 或者:
hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}
# 查询表t1,rowke002中的f1下的所有列值
hbase(main)> get 't1','rowkey001'
get用法:
hbase> get 't1', 'r1'
hbase> get 't1', 'r1', {TIMERANGE => [ts1, ts2]}
hbase> get 't1', 'r1', {COLUMN => 'c1'}
hbase> get 't1', 'r1', {COLUMN => ['c1', 'c2', 'c3']}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2], VERSIONS => 4}
hbase> get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1, VERSIONS => 4}
hbase> get 't1', 'r1', 'c1'
hbase> get 't1', 'r1', 'c1', 'c2'
hbase> get 't1', 'r1', ['c1', 'c2']
b)扫描表
# 语法:scan <table>, {COLUMNS=>[ <family:column>,.... ], LIMIT=>num}
# 另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能
# 例如:扫描表t1的前5条数据
hbase(main)> scan 't1',{LIMIT=>5}
scan数据的用法:
scan 'scores'
也可以指定一些修饰词:TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH,or COLUMNS。没任何修饰词,就是上边例句,就会显示所有数据行。
hbase> scan '.META.'
hbase> scan '.META.', {COLUMNS => 'info:regioninfo'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1333668804, 1333668904]}
hbase> scan 't1', {FILTER => “(PrefixFilter ('row2') AND (QualifierFilter (>=, 'binary:xyz'))) AND (TimestampsFilter (123, 456))”}
hbase> scan 't1', {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
过滤器filter有两种方法指出:
a. Using a filterString – more information on this is available in the Filter Language document attached to the HBASE-4176 JIRA
b. Using the entire package name of the filter.
还有一个CACHE_BLOCKS修饰词,开关scan的缓存的,默认是开启的CACHE_BLOCKS=>true,可以选择关闭CACHE_BLOCKS=>false。
c)查询表中的数据行数
# 语法:count <table>, {INTERVAL=>intervalNum, CACHE=>cacheNum}
# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
# 例如,查询表t1中的行数,每100条显示一次,缓存区为500
hbase(main)> count 't1', {INTERVAL=>100, CACHE=>500}
统计行数:
hbase> count 't1'
hbase> count 't1', INTERVAL => 100000
hbase> count 't1', CACHE => 1000
hbase> count 't1', INTERVAL => 10, CACHE => 1000
count一般会比较耗时,使用mapreduce进行统计,统计结果会缓存,默认是10行。统计间隔默认的是1000行INTERVAL。
3)删除数据
a )删除行中的某个列值
# 语法:delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名
# 例如:删除表t1,rowkey001中的f1:col1的数据
hbase(main)> delete 't1','rowkey001','f1:col1'
注:将删除改行f1:col1列所有版本的数据
b )删除行
# 语法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据
# 例如:删除表t1,rowk001的数据
hbase(main)> deleteall 't1','rowkey001'
c)删除表中的所有数据
# 语法: truncate <table>
# 其具体过程是:disable table -> drop table -> create table
# 例如:删除表t1的所有数据
hbase(main)> truncate 't1'
Region管理
1)移动region
# 语法:move 'encodeRegionName', 'ServerName'
# encodeRegionName指的regioName后面的编码,ServerName指的是master-status的Region Servers列表
#示例
hbase(main)>move '4343995a58be8e5bbc739af1e91cd72d', 'db-41.xxx.xxx.org,60020,1390274516739'
2)开启/关闭region
# 语法:balance_switch true|false
hbase(main)> balance_switch
3)手动split
# 语法:split 'regionName', 'splitKey'
4)手动触发major compaction
语法:
#Compact all regions in a table:
hbase> major_compact 't1'
#Compact an entire region:
hbase> major_compact 'r1'
#Compact a single column family within a region:
hbase> major_compact 'r1', 'c1'
#Compact a single column family within a table:
hbase> major_compact 't1', 'c1'
配置管理及节点重启
1)修改hdfs配置
hdfs配置位置:/etc/hadoop/conf
# 同步hdfs配置
#关闭:
sbin/hadoop-daemon.sh --config /etc/hadoop/conf stop datanode"
#启动:
sbin/hadoop-daemon.sh --config /etc/hadoop/conf start datanode"
2)修改hbase配置
hbase配置位置:
# 同步hbase配置
# graceful重启
cd ~/hbase
bin/graceful_stop.sh --restart --reload --debug
Hbase自身信息查询
1)status命令
hbase(main)> status
2)version命令
hbase(main)> version
下面我们将以“一个学生成绩表”的例子来详细介绍常用的 HBase 命令及其使用方法。
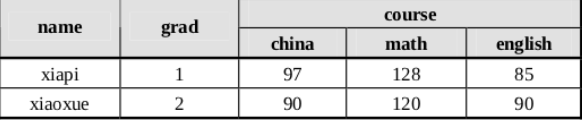
这里 grad 对于表来说是一个列,course 对于表来说是一个列族,这个列族由三个列组成 china、math 和 english,当然我们可以根据我们的需要在 course 中建立更多的列族,如computer、physics等相应的列添加入 course 列族(注意:列族下面的列也是可以没有名字的)。
1). create 命令
创建一个具有两个列族“grad”和“course”的表“scores”。其中表名、行和列都要用单引号括起来,并以逗号隔开。
hbase(main):012:0> create 'scores', 'name', 'grad', 'course'
2). list 命令
查看当前 HBase 中具有哪些表。
hbase(main):012:0> list
3). describe 命令
查看表“scores”的构造。
hbase(main):012:0> describe 'scores'
4). put 命令
使用put命令向表中插入数据,参数分别为表名、行名、列名和值,其中列名前需要列族最为前缀,时间戳由系统自动生成。
格式:put 表名,行名,列名([列族:列名]),值
例子:
a. 加入一行数据,行名称为“xiapi”,列族“grad”的列名为”(空字符串)”,值位 1。
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '1'
hbase(main):012:0> put 'scores', 'xiapi', 'grad:', '2' --修改操作(update)
b. 给“xiapi”这一行的数据的列族“course”添加一列“<china,97>”。
hbase(main):012:0> put 'scores', 'xiapi', 'course:china', '97'
hbase(main):012:0> put 'scores', 'xiapi', 'course:math', '128'
hbase(main):012:0> put 'scores', 'xiapi', 'course:english', '85'
5). get 命令
a.查看表“scores”中的行“xiapi”的相关数据。
hbase(main):012:0> get 'scores', 'xiapi'
b.查看表“scores”中行“xiapi”列“course :math”的值。
hbase(main):012:0> get 'scores', 'xiapi', 'course :math'
或者
hbase(main):012:0> get 'scores', 'xiapi', {COLUMN=>'course:math'}
hbase(main):012:0> get 'scores', 'xiapi', {COLUMNS=>'course:math'}
备注:COLUMN 和 COLUMNS 是不同的,scan 操作中的 COLUMNS 指定的是表的列族, get操作中的 COLUMN 指定的是特定的列,COLUMNS 的值实质上为“列族:列修饰符”。COLUMN 和 COLUMNS 必须为大写。
6). scan 命令
a. 查看表“scores”中的所有数据。
hbase(main):012:0> scan 'scores'
注意:scan 命令可以指定 startrow,stoprow 来 scan 多个 row。例如:
scan 'user_test',{COLUMNS =>'info:username',LIMIT =>10, STARTROW=>'test', STOPROW=>'test2'}
b.查看表“scores”中列族“course”的所有数据。
hbase(main):012:0> scan 'scores', {COLUMN=>'grad'}
hbase(main):012:0> scan 'scores', {COLUMN=>'course:math'}
hbase(main):012:0> scan 'scores', {COLUMNS=>'course'}
hbase(main):012:0> scan 'scores', {COLUMNS=>'course'}
7). count 命令
hbase(main):068:0> count 'scores'
8). exists 命令
hbase(main):071:0> exists 'scores'
9). incr 命令(赋值)
10). delete 命令
删除表“scores”中行为“xiaoxue”, 列族“course”中的“math”。
hbase(main):012:0> delete 'scores', 'xiapi', 'course:math'
11). truncate 命令
hbase(main):012:0> truncate 'scores'
12). disbale、drop 命令
通过“disable”和“drop”命令删除“scores”表,在删除表之前必须将其"disable"。
hbase(main):012:0> disable 'scores' --enable 'scores'
hbase(main):012:0> drop 'scores'
另外在 shell 中,常量不需要用引号引起来,但二进制的值需要双引号引起来,而其他值则用单引号引起来。hbase shell常用的操作命令有create,describe,disable,drop,list,scan,put,get,delete,deleteall,count,status等,通过help可以看到详细的用法。
HBase中timerange和version的使用
hb在创建表时,如果不指定版本(version)的话则直接默认为1,这样该记录第二写入时,之前的数据将被覆盖。只有指定其数目大于1时,才能读出历史数据,当然还要配合相应的时间区间,否则只会读出最近写入的数据列。
create 'freeoa',{NAME=>'cf',VERSIONS=>2}
HBase默认scan出来的结果是最后一条时间戳的记录,可以加入VERSIONS这个约束条件把这两条都scan出来:
scan 'freeoa',{VERSIONS=>2}
ROW COLUMN+CELL
Tom column=cf:math, timestamp=1445848653570, value=100
Tom column=cf:math, timestamp=1445848639911, value=97
1 row(s) in 0.0110 seconds
查找最先写入的那条记录:
scan 'freeoa',{TIMERANGE=>[1445848639911,1445848653570],VERSIONS=>2}
ROW COLUMN+CELL
column=cf:math, timestamp=1445848639911, value=97
1 row(s) in 0.0130 seconds
timerange表示的是">=开始时间 and <结束时间"的。
要取得多个版本时,必须指定version,即使指定了两条记录的时间区间。
scan 'freeoa',{TIMERANGE=>[1445848630911,1445848659570],VERSIONS=>2}
scan 'freeoa',{TIMERANGE=>[1445848630911,1445848659570]}
versions指定时必须再创建表的时候加上versions,否则无效。如果想开启多个版本的功能而不必重建数据,可以立刻修改表:
alter 'freeoa',{NAME=>'cf','VERSIONS'=>2}
HBase启动脚本解析
HBase安装好的控制脚本位于:$HBASE_HOME/bin/,其下有诸多脚本,用于控制HBase各个功能块,具体介绍如下:
开启集群:start-hbase.sh
关闭集群:stop-hbase.sh
开启/关闭所有的regionserver、zookeeper:hbase-daemons.sh start/stop regionserver/zookeeper
开启/关闭单个regionserver、zookeeper:hbase-daemon.sh start/stop regionserver/zookeeper
开启/关闭master:hbase-daemon.sh start/stop master, 是否成为active master取决于当前是否有active master
用来逐个重启:rolling-restart.sh
具体细节:
hbase-daemon.sh start master 与 hbase-daemon.sh start master --backup,这2个命令的作用一样的,是否成为backup或active是由master的内部逻辑来控制的
stop-hbase.sh 不会调用hbase-daemons.sh stop regionserver 来关闭regionserver, 但是会调用hbase-daemons.sh stop zookeeper/master-backup来关闭zk和backup master,关闭regionserver实际调用的是hbaseAdmin的shutdown接口
通过$HBASE_HOME/bin/hbase stop master关闭的是整个集群而非单个master,只关闭单个master的话使用$HBASE_HOME/bin/hbase-daemon.sh stop master
$HBASE_HOME/bin/hbase stop regionserver/zookeeper 不能这么调,调了也会出错,也没有路径会调用这个命令,但是可以通过$HBASE_HOME/bin/hbase start regionserver/zookeeper 来启动rs或者zk,hbase-daemon.sh调用的就是这个命令
核心控制脚本:hbase-daemon.sh
$HBASE_HOME/bin/hbase-daemons.sh start|stop
启动或停止,所有的regionserver或zookeeper或backup-master
它也会调用hbase-config.sh、hbase-env.sh来调整一些控制参数。
hbase-config.sh:
装载相关配置,如HBASE_HOME目录,conf目录,regionserver机器列表,JAVA_HOME目录等,它会调用$HBASE_HOME/conf/hbase-env.sh
hbase-env.sh:
主要是配置JVM及其GC参数,还可以配置log目录及参数,配置是否需要hbase管理ZK,配置进程id目录等
hbase-daemons.sh:
根据需要启动的进程
如为zookeeper,则调用zookeepers.sh
如为regionserver,则调用regionservers.sh
如为master-backup,则调用master-backup.sh
1、zookeepers.sh:
如果hbase-env.sh中的HBASE_MANAGES_ZK" ="true",那么通过ZKServerTool这个类解析xml配置文件,获取ZK节点列表(即hbase.zookeeper.quorum的配置值),然后通过SSH向这些节点发送远程命令:
cd ${HBASE_HOME};
bin/hbase-daemon.sh --config ${HBASE_CONF_DIR} start/stop zookeeper
2、regionservers.sh:
与zookeepers.sh类似,通过${HBASE_CONF_DIR}/regionservers配置文件,获取regionserver机器列表,然后SSH向这些机器发送远程命令:
cd ${HBASE_HOME};
bin/hbase-daemon.sh --config ${HBASE_CONF_DIR} start/stop regionserver
3、master-backup.sh:
通过${HBASE_CONF_DIR}/backup-masters这个配置文件,获取backup-masters机器列表(默认配置中,这个配置文件并不存在,所以不会启动backup-master),然后SSH向这些机器发送远程命令:
cd ${HBASE_HOME};
bin/hbase-daemon.sh --config ${HBASE_CONF_DIR} start/stop master --backup
hbase-daemon.sh:
无论是zookeepers.sh还是regionservers.sh或是master-backup.sh,最终都会调用本地的hbase-daemon.sh,其执行过程如下:
1.运行hbase-config.sh,装载各种配置(java环境、log配置、进程ID目录等)
2.如果是start命令
滚动out输出文件,滚动gc日志文件,日志文件中输出启动时间+ulimit -a信息,如
“Mon Nov 26 10:31:42 CST 2012 Starting master on dwxx.yy.freeoa”
"..open files (-n) 65536.."
3.调用$HBASE_HOME/bin/hbase start master/regionserver/zookeeper
4.执行wait,等待3中开启的进程结束
5.执行cleanZNode,将regionserver在zk上登记的节点删除,这样做的目的是:在regionserver进程意外退出的情况下,可以免去3分钟的ZK心跳超时等待,直接由master进行宕机恢复
6.如果是stop命令
根据进程ID,检查进程是否存在;调用kill命令,然后等待到进程不存在为止
HBase shell commands
As told in HBase introduction, HBase provides Extensible jruby-based (JIRB) shell as a feature to execute some commands(each command represents one functionality).
HBase shell commands are mainly categorized into 6 parts.
1) General HBase shell commands
| status | Show cluster status. Can be 'summary', 'simple', or 'detailed'. The default is 'summary'. hbase> status |
| version | Output this HBase versionUsage: hbase> version |
| whoami | Show the current hbase user.Usage: hbase> whoami |
2) Tables Management commands
| alter | Alter column family schema; pass table name and a dictionary specifying new column family schema. Dictionaries are described on the main help command output. Dictionary must include name of column family to alter.For example, to change or add the 'f1' column family in table 't1' from current value to keep a maximum of 5 cell VERSIONS, do: hbase> alter 't1', NAME => 'f1', VERSIONS => 5 You can operate on several column families: hbase> alter 't1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5} To delete the 'f1' column family in table 't1', use one of:hbase> alter 't1', NAME => 'f1', METHOD => 'delete' You can also change table-scope attributes like MAX_FILESIZE, READONLY, hbase> alter 't1', MAX_FILESIZE => '134217728' You can add a table coprocessor by setting a table coprocessor attribute: hbase> alter 't1', Since you can have multiple coprocessors configured for a table, a The coprocessor attribute must match the pattern below in order for [coprocessor jar file location] | class name | [priority] | [arguments] You can also set configuration settings specific to this table or column family: hbase> alter 't1', CONFIGURATION => {'hbase.hregion.scan.loadColumnFamiliesOnDemand' => 'true'} You can also remove a table-scope attribute: hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE' hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'coprocessor$1' There could be more than one alteration in one command: hbase> alter 't1', { NAME => 'f1', VERSIONS => 3 }, |
| create | Create table; pass table name, a dictionary of specifications per column family, and optionally a dictionary of table configuration. hbase> create 't1', {NAME => 'f1', VERSIONS => 5} Table configuration options can be put at the end. |
| describe | Describe the named table. hbase> describe 't1' |
| disable | Start disable of named table hbase> disable 't1' |
| disable_all | Disable all of tables matching the given regex hbase> disable_all 't.*' |
| is_disabled | verifies Is named table disabled hbase> is_disabled 't1' |
| drop | Drop the named table. Table must first be disabled hbase> drop 't1' |
| drop_all | Drop all of the tables matching the given regex hbase> drop_all 't.*' |
| enable | Start enable of named table hbase> enable 't1' |
| enable_all | Enable all of the tables matching the given regex hbase> enable_all 't.*' |
| is_enabled | verifies Is named table enabled hbase> is_enabled 't1' |
| exists | Does the named table exist hbase> exists 't1' |
| list | List all tables in hbase. Optional regular expression parameter could be used to filter the output hbase> list |
| show_filters | Show all the filters in hbase. hbase> show_filters |
| alter_status | Get the status of the alter command. Indicates the number of regions of the table that have received the updated schema Pass table name. hbase> alter_status 't1' |
| alter_async | Alter column family schema, does not wait for all regions to receive the schema changes. Pass table name and a dictionary specifying new column family schema. Dictionaries are described on the main help command output. Dictionary must include name of column family to alter. To change or add the 'f1' column family in table 't1' from defaults hbase> alter_async 't1', NAME => 'f1', METHOD => 'delete'or a shorter version:hbase> alter_async 't1', 'delete' => 'f1' You can also change table-scope attributes like MAX_FILESIZE For example, to change the max size of a family to 128MB, do: hbase> alter 't1', METHOD => 'table_att', MAX_FILESIZE => '134217728' There could be more than one alteration in one command: hbase> alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'} To check if all the regions have been updated, use alter_status <table_name> |
3) Data Manipulation commands
| count | Count the number of rows in a table. Return value is the number of rows. This operation may take a LONG time (Run '$HADOOP_HOME/bin/hadoop jar hbase.jar rowcount' to run a counting mapreduce job). Current count is shown every 1000 rows by default. Count interval may be optionally specified. Scan caching is enabled on count scans by default. Default cache size is 10 rows. If your rows are small in size, you may want to increase this parameter. Examples:hbase> count 't1' hbase> count 't1', INTERVAL => 100000 hbase> count 't1', CACHE => 1000 hbase> count 't1', INTERVAL => 10, CACHE => 1000 The same commands also can be run on a table reference. Suppose you had a reference |
| delete | Put a delete cell value at specified table/row/column and optionally timestamp coordinates. Deletes must match the deleted cell's coordinates exactly. When scanning, a delete cell suppresses older versions. To delete a cell from 't1' at row 'r1' under column 'c1' marked with the time 'ts1', do: hbase> delete 't1', 'r1', 'c1', ts1 The same command can also be run on a table reference. Suppose you had a reference |
| deleteall | Delete all cells in a given row; pass a table name, row, and optionally a column and timestamp. Examples:hbase> deleteall 't1', 'r1' hbase> deleteall 't1', 'r1', 'c1' hbase> deleteall 't1', 'r1', 'c1', ts1 The same commands also can be run on a table reference. Suppose you had a reference |
| get | Get row or cell contents; pass table name, row, and optionally a dictionary of column(s), timestamp, timerange and versions. Examples: hbase> get 't1', 'r1' Besides the default 'toStringBinary' format, 'get' also supports custom formatting by Note that you can specify a FORMATTER by column only (cf:qualifer). You cannot specify hbase> t.get 'r1' |
| get_counter | Return a counter cell value at specified table/row/column coordinates. A cell cell should be managed with atomic increment function oh HBase and the data should be binary encoded. Example: hbase> get_counter 't1', 'r1', 'c1' The same commands also can be run on a table reference. Suppose you had a reference hbase> t.get_counter 'r1', 'c1' |
| incr | Increments a cell 'value' at specified table/row/column coordinates. To increment a cell value in table 't1' at row 'r1' under column 'c1' by 1 (can be omitted) or 10 do: hbase> incr 't1', 'r1', 'c1' The same commands also can be run on a table reference. Suppose you had a reference |
| put | Put a cell 'value' at specified table/row/column and optionally timestamp coordinates. To put a cell value into table 't1' at row 'r1' under column 'c1' marked with the time 'ts1', do: hbase> put 't1', 'r1', 'c1', 'value', ts1 The same commands also can be run on a table reference. Suppose you had a reference hbase> t.put 'r1', 'c1', 'value', ts1 |
| scan | Scan a table; pass table name and optionally a dictionary of scanner specifications. Scanner specifications may include one or more of: TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH, or COLUMNS, CACHEIf no columns are specified, all columns will be scanned. To scan all members of a column family, leave the qualifier empty as in 'col_family:'.The filter can be specified in two ways: 1. Using a filterString – more information on this is available in the Filter Language document attached to the HBASE-4176 JIRA 2. Using the entire package name of the filter.Some examples:hbase> scan '.META.' hbase> scan '.META.', {COLUMNS => 'info:regioninfo'} hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'} hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]} hbase> scan 't1', {FILTER => “(PrefixFilter ('row2') AND (QualifierFilter (>=, 'binary:xyz'))) AND (TimestampsFilter ( 123, 456))”} hbase> scan 't1', {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)} For experts, there is an additional option — CACHE_BLOCKS — which Also for experts, there is an advanced option — RAW — which instructs the hbase> scan 't1', {RAW => true, VERSIONS => 10} Besides the default 'toStringBinary' format, 'scan' supports custom formatting 1. either as a org.apache.hadoop.hbase.util.Bytes method name (e.g, toInt, toString) Example formatting cf:qualifier1 and cf:qualifier2 both as Integers: Note that you can specify a FORMATTER by column only (cf:qualifer). You cannot Scan can also be used directly from a table, by first getting a reference to a hbase> t = get_table 't' Note in the above situation, you can still provide all the filtering, columns, |
| truncate | Disables, drops and recreates the specified table. Examples: hbase>truncate 't1' |
4) HBase surgery tools
| assign | Assign a region. Use with caution. If region already assigned, this command will do a force reassign. For experts only. Examples: hbase> assign 'REGION_NAME' |
| balancer | Trigger the cluster balancer. Returns true if balancer ran and was able to tell the region servers to unassign all the regions to balance (the re-assignment itself is async). Otherwise false (Will not run if regions in transition). Examples: hbase> balancer |
| balance_switch | Enable/Disable balancer. Returns previous balancer state. Examples: hbase> balance_switch true |
| close_region | Close a single region. Ask the master to close a region out on the cluster or if 'SERVER_NAME' is supplied, ask the designated hosting regionserver to close the region directly. Closing a region, the master expects 'REGIONNAME' to be a fully qualified region name. When asking the hosting regionserver to directly close a region, you pass the regions' encoded name only. A region name looks like this:TestTable,0094429456,1289497600452.527db22f95c8a9e0116f0cc13c680396.The trailing period is part of the regionserver name. A region's encoded name is the hash at the end of a region name; e.g. 527db22f95c8a9e0116f0cc13c680396 (without the period). A 'SERVER_NAME' is its host, port plus startcode. For example: host187.example.com,60020,1289493121758 (find servername in master ui or when you do detailed status in shell). This command will end up running close on the region hosting regionserver. The close is done without the master's involvement (It will not know of the close). Once closed, region will stay closed. Use assign to reopen/reassign. Use unassign or move to assign the region elsewhere on cluster. Use with caution. For experts only. Examples:hbase> close_region 'REGIONNAME' hbase> close_region 'REGIONNAME', 'SERVER_NAME' |
| compact | Compact all regions in passed table or pass a region row to compact an individual region. You can also compact a single column family within a region. Examples: Compact all regions in a table: hbase> compact 't1' Compact an entire region: hbase> compact 'r1' Compact only a column family within a region: hbase> compact 'r1', 'c1' Compact a column family within a table: hbase> compact 't1', 'c1' |
| flush | Flush all regions in passed table or pass a region row to flush an individual region. For example:hbase> flush 'TABLENAME' hbase> flush 'REGIONNAME' |
| major_compact | Run major compaction on passed table or pass a region row to major compact an individual region. To compact a single column family within a region specify the region name followed by the column family name. Examples: Compact all regions in a table: hbase> major_compact 't1' Compact an entire region: hbase> major_compact 'r1' Compact a single column family within a region: hbase> major_compact 'r1', 'c1' Compact a single column family within a table: hbase> major_compact 't1', 'c1' |
| move | Move a region. Optionally specify target regionserver else we choose one at random. NOTE: You pass the encoded region name, not the region name so this command is a little different to the others. The encoded region name is the hash suffix on region names: e.g. if the region name were TestTable,0094429456,1289497600452.527db22f95c8a9e0116f0cc13c680396. then the encoded region name portion is 527db22f95c8a9e0116f0cc13c680396 A server name is its host, port plus startcode. For example: host187.example.com,60020,1289493121758 Examples:hbase> move 'ENCODED_REGIONNAME' hbase> move 'ENCODED_REGIONNAME', 'SERVER_NAME' |
| split | Split entire table or pass a region to split individual region. With the second parameter, you can specify an explicit split key for the region. Examples: split 'tableName' split 'regionName' # format: 'tableName,startKey,id' split 'tableName', 'splitKey' split 'regionName', 'splitKey' |
| unassign | Unassign a region. Unassign will close region in current location and then reopen it again. Pass 'true' to force the unassignment ('force' will clear all in-memory state in master before the reassign. If results in double assignment use hbck -fix to resolve. To be used by experts). Use with caution. For expert use only. Examples:hbase> unassign 'REGIONNAME' hbase> unassign 'REGIONNAME', true |
| hlog_roll | Roll the log writer. That is, start writing log messages to a new file. The name of the regionserver should be given as the parameter. A 'server_name' is the host, port plus startcode of a regionserver. For example: host187.example.com,60020,1289493121758 (find servername in master ui or when you do detailed status in shell) hbase>hlog_roll |
| zk_dump | Dump status of HBase cluster as seen by ZooKeeper. Example: hbase>zk_dump |
5) Cluster replication tools
| add_peer | Add a peer cluster to replicate to, the id must be a short and the cluster key is composed like this: hbase.zookeeper.quorum:hbase.zookeeper.property.clientPort:zookeeper.znode.parent This gives a full path for HBase to connect to another cluster. Examples:hbase> add_peer '1', “server1.cie.com:2181:/hbase” hbase> add_peer '2', “zk1,zk2,zk3:2182:/hbase-prod” |
| remove_peer | Stops the specified replication stream and deletes all the meta information kept about it. Examples: hbase> remove_peer '1' |
| list_peers | List all replication peer clusters. hbase> list_peers |
| enable_peer | Restarts the replication to the specified peer cluster, continuing from where it was disabled.Examples: hbase> enable_peer '1' |
| disable_peer | Stops the replication stream to the specified cluster, but still keeps track of new edits to replicate.Examples: hbase> disable_peer '1' |
| start_replication | Restarts all the replication features. The state in which each stream starts in is undetermined. WARNING: start/stop replication is only meant to be used in critical load situations. Examples: hbase> start_replication |
| stop_replication | Stops all the replication features. The state in which each stream stops in is undetermined. WARNING: start/stop replication is only meant to be used in critical load situations. Examples: hbase> stop_replication |
6) Security tools
| grant | Grant users specific rights. Syntax : grantpermissions is either zero or more letters from the set “RWXCA”. READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')For example:hbase> grant 'bobsmith', 'RWXCA' hbase> grant 'bobsmith', 'RW', 't1', 'f1', 'col1' |
| revoke | Revoke a user's access rights. Syntax : revoke For example: hbase> revoke 'bobsmith', 't1', 'f1', 'col1' |
| user_permission | Show all permissions for the particular user. Syntax : user_permission For example:hbase> user_permission hbase> user_permission 'table1' |