Perl IO操作之文件句柄
文件句柄
文件句柄用来对应要操作的文件系统中的文件,这么说不太严谨,但比较容易理解。首先为要打开的文件绑定文件句柄(称为打开文件句柄),然后在后续的操作中都通过文件句柄来操作对应的文件,最后关闭文件句柄。
如不理解文件句柄的概念,可将文件句柄看作Linux中文件描述符的概念(当然,它们是不同的,Perl的文件句柄在层次上对应于Linux中的标准IO流)。例如特殊的STDIN、STDOUT、STDERR就是perl中预定义好的文件句柄,分别表示标准输入、标准输出、标准错误,要将它们对应到Linux上的话,它们是默认的文件描述符fd=0、fd=1和fd=2的字符串描述形式,而这几个文件描述符分别对应文件系统中的/dev/stdin、/dev/stdout和/dev/stderr设备文件。也就是说,Linux上的perl中的文件句柄STDIN、STDOUT和STDERR默认关联的文件是/dev/stdin、/dev/stdout和/dev/stderr。
如果还不理解文件句柄,就把它想象成通道:perl程序中IO操作和磁盘上文件的通道。例如,print语句将数据通过某个通道输出到对应的文件中。
文件句柄和文件描述符
实际上,文件句柄和文件描述符是有区别的。文件描述符是一个数值,代表操作系统所使用的裸数据流,文件描述符是文件句柄的核心,文件句柄可以看作是文件描述符的更高一层次的封装,比如提供了和描述符有关数据流的输入、输出的buffer缓冲。也就是说,文件句柄比文件描述符多一些额外的功能。
可以为任意要操作的文件定义一个文件句柄。通常使用大写字母作为文件句柄的名称。例如,下面打开一个文件句柄LOG,这个文件句柄对应的文件是/tmp/a.log,操作模式是追加写入(和shell中的追加重定向是相同的意思)。然后向LOG文件句柄中输入一段数据,最后关闭文件句柄。
open LOG,">>/tmp/a.log";
print LOG "haha, hello world";
close LOG;
一般来说,打开了文件句柄后,在操作完成后要关闭文件句柄以便节省操作系统"打开文件数量限制"的资源。但perl有时候比较智能,会在某些时候自动帮我们关掉文件句柄。而且,当打开一个文件句柄后,再次去打开这个文件句柄时,perl会先关闭这个文件句柄再打开这个文件句柄,这称为"文件句柄的reopen",它只是隐式地关闭并重新打开,perl并不认为中间涉及了关闭操作(例如reopen时行号不会重置)。
打开文件句柄
要打开文件句柄,使用open函数。open函数的功能其实很丰富,如有需要,可去官方手册查看:http://perldoc.perl.org/functions/open.html
打开(open)文件是有目的的:为了读取?为了写入?为了追加写入?这是操作模式。在open文件时,需要指明操作模式。此外,还要给定要关联的文件路径,路径可以是绝对路径,也可以是相对当前perl程序的相对路径。另外注意文件句柄需唯一,不能出现重名。例如:
open LOG1,">","/tmp/a.log"; # 以覆盖写入的方式打开文件/tmp/a.log
open LOG2,">>","/tmp/a.log"; # 以追加写入的方式打开文件/tmp/a.log
open LOG3,"<","/tmp/a.log"; # 打开/tmp/a.log文件,以提供输入源
open LOG4,"/tmp/a.log"; # 等价于上面的输入,默认的模式就是输入
另一种写法是将模式符号和目标文件放在一起:
open LOG1,">/tmp/a.log";
open LOG2,">>/tmp/a.log";
open LOG3,"</tmp/a.log";
中间还可以有空格:
open LOG1,"> /tmp/a.log";
open LOG2,">> /tmp/a.log";
open LOG3,"< /tmp/a.log";
可以将目标文件赋值给一个变量,然后在open函数中使用变量名替换。
my $tmp_file = "/tmp/a.log";
open LOG1,">","$tmp_file";
如果要指明输入、输出的文件编码,则使用上面将"模式和路径分开"的方式。例如:
open LOG1,">:encoding(UTF-8)","/tmp/a.log"; # 以UTF-8编码方式写入数据
open LOG1,">>:encoding(UTF-8)","/tmp/a.log";
open LOG1,"<:encoding(UTF-8)","/tmp/a.log"; # 以UTF-8编码方式读入数据
需要注意,perl自身是无法打开外部文件的,它需要请求操作系统内核,让操作系统来打开文件。所以打开文件正确、错误时,操作系统都会有相应的回馈信息。对于perl来说,open函数的返回值就表示正确、错误打开文件。所以通过以下方式可以判断是否正确打开:
my $success = open LOG,">","/tmp/a.log";
if(!success){
exit 1;
}
更好、更常用的方式是使用die:
open LOG,">","/tmp/a.log" or die "open file wrong: $!";
或者使用autodie功能,当捕获到某些错误时,会自动调用die结束程序:
use autodie;
open LOG,">","/tmp/a.log";
无法打开文件的可能原因有很多,比如读取时文件不存在,比如上级目录不存在,比如无权限等等。操作系统会向perl报告这些错误,使用"$!"可以引用操作系统向perl报告的错误,例如die "can't open file: $!";被触发时的消息如下:
can't open file: No such file or directory at myperl.plx line 5.
上面的"No such file or directory at myperl.plx line 5."就是$!收集和整理后的错误信息。
同理,关闭文件句柄错误也可以捕捉:
close DATA or die "Couldn't close file properly";
使用文件句柄:读取文件数据
例如要从test.log文件中读取所有数据行,一般的流程如下:
#!/usr/bin/perl
use 5.010;
open LOG,"<","test.log" or die "open file wrong: $!"
while(<LOG>){
chomp;
say $_;
}
另外,从特殊文件句柄<STDIN>、<>、<ARGV>中读取数据时,由于它们是预定义好的,所以不需要先open。
使用文件句柄:写入数据到文件
要向文件中写入数据,可以使用输出语句,如print/say和printf,要写多行的时候,可以使用heredoc的方式。
在使用print/say/printf的时候,在这几个关键字后面接上文件句柄即表示本输出语句写入到此文件句柄中。其实,当它们不指定文件句柄的时候,所采用的就是默认的文件句柄STDOUT。
例如,以追加模式写入一行数据到test.log中。
#!/usr/bin/perl
use 5.010;
open LOG,">>","test.log" or die "Can't open file: $!";
say LOG "NEW LINE!";
再例如,向标准输出、标准错误中输出信息:
say STDOUT "NEW LINE!";
say STDERR "NEW LINE!";
选一个默认的输出文件句柄
注意是选择默认的输出文件句柄,不适用于输入的文件句柄。
默认情况下的默认输出文件句柄就是STDOUT,但是可以使用select关键字自己选一个默认的输出文件句柄。只是需要注意的是,再将内容输出到自选的默认输出文件句柄结束后,应该重新选回STDOUT。
例如读取某个文件的内容,追加重定向输出到另一个文件中:
#!/usr/bin/perl
open LOG,">>","test1.log" or die "Can't open file: $!";
select LOG;
while(<>){
print "Line $. from $ARGV: $_";
}
select STDOUT;
print "restored default filehandler: STDOUT\n";
然后执行该perl程序(程序名:15.plx),并传递a.log作为命令行参数。作为运行结果,会将a.log中的数据追加到test1.log文件中,并输出一行内容到终端屏幕上。
$ perl 15.plx a.log
restored default filehandler: STDOUT
选择默认的文件句柄后,上面while循环中的print,等价于print LOG ...。
通常,选择默认的文件句柄更常用于设置文件句柄是否要缓冲。例如,输出到下面三个文件句柄(LOG/STDERR/STDOUT)的数据不会缓冲,而是直接输出到文件句柄。
select LOG; $| = 1; # make unbuffered
select STDERR; $| = 1; # make unbuffered
select STDOUT; $| = 1; # make unbuffered
其中,控制输出的缓冲变量为$|,通常在使用管道、套接字的时候,可能不需要甚至不应该对数据进行缓冲,而是直接暴露给其它进程。
一般来说,在超过一个文件句柄需要关闭缓冲时,不会使用这种select XXX; $|=1的方式,而是导入IO::Handle模块,然后使用它的autoflush(1)函数来实现关闭IO缓冲。
use IO::Handle;
FH1->autoflush(1);
FH2->autoflush(2);
FH3->autoflush(3);
autoflush(1)的功能等价于:
select( (select(NEWOUT), $| = 1 )[0] );
因为select()的返回值是当前标准输出的文件句柄,然后内层的select的结果和$| = 1的结果构成一个匿名列表,选择列表的第一个元素即之前标准输出的文件句柄,将其作为外层select的参数,即表示恢复了之前的文件句柄。(如果目前看不懂,请忽略)
关于IO Buffer
分为两种IO缓冲模式:block buffer、line buffer。
block buffer是表示先积累一定数据量(比如通常是几K大小)之后再输出。line buffer是表示只有读取到了换行符的时候才输出。$|=1或者autoflush(1)都表示从block buffer(默认)切换成line buffer,而不是禁用(或关闭)buffer。
如果真要禁用buffer,可以使用syswrite(),它会直接绕过buffer,也就是禁用buffer。
文件句柄变量
除了使用大写字母(一般情况下文件句柄都如此命名,称为裸句柄)的文件句柄,还可以使用变量来命名文件句柄。例如使用变量代表的文件句柄:
my $rock_fh;
open $rock_fh,"<","/tmp/a.log" or die "Can't open file: $!";
或者:
open my $rock_fh,"<","/tmp/a.log" or die "Can't open file: $!";
使用变量文件句柄时:
while(<$rock_fh>){
chomp;
...
}
不过有时候,使用文件句柄变量会产生歧义。例如下面的语句:
print $rock_fh;
perl并不知道$rock_fh是要输出的列表数据还是输出的目标文件句柄。如果是目标文件句柄,这意味着print将$_写入到文件句柄$rock_fh中。如果是要输出的列表数据,由于$rock_fh是一个已定义好的文件句柄,print将输出它的引用(类似于:GLOB(oxABCDEF12))。
这时可以使用大括号包围文件句柄变量。
print {$rock_fh};
print {$rock_fh} "hello world";
最后需要注意的是,裸句柄是包变量,在整个文件内都是有效的,而变量方式的文件句柄只在代码块范围内有效,出了自己的作用域范围就失效(自动关闭)。
目录句柄
目录句柄和文件句柄类似,可以打开它,并读取其中的文件列表。只不过需要使用:
opendir替换open函数
使用readdir来替换readline,readdir返回一个列表
readdir不会递归到子目录中
使用closedir来替代close
注意每个Unix的目录下都包含两个特殊目录.和..
opendir JAVAHOME,"/usr/local/java" or die "Can't open dir handler: $!";
foreach $file (readdir JAVAHOME){
print "Filename: $file\n";
}
closedir JAVAHOME;
更多文件句柄模式
open函数除了> >> <这三种最基本的文件句柄模式,还支持更丰富的操作模式,例如管道。其实bash shell支持的重定向模式,perl都支持,即使是2>&1这种高级重定向模式,perl也有对应的模式。
打开管道文件句柄
perl程序内部也支持管道,以便和操作系统进行交互。例如将perl的输出在程序内部就输出给操作系统的命令,或者将操作系统的命令执行结果输出给perl程序内部。所以,perl有2种管道模式:句柄到管道、管道到句柄。
例如将perl print语句的输出,交给操作系统的cat -n命令来输出行号。也就是说,下面的perl程序和cat -n命令的效果是一样的。
#!/usr/bin/perl
open LOG,"| cat -n" or die "Can't open file: $!";
while(<LOG>){
print $_;
}
再例如,将操作系统命令的执行结果通过管道交给perl文件句柄:
#!/usr/bin/perl
open LOG,"cat -n test.log |" or die "Can't open file: $!";
while(<LOG>){
print "from pipe: $_";
}
虽然只有两种管道模式,但有3种写法:
管道输出到文件句柄模式:-|
文件句柄输出到管道模式:|-
|写在左边,表示句柄到管道,等价于|-,|写在右边,等价于管道到句柄,等价于-|,可以认为"-"代表的就是外部命令
上面第三点|的写法见上面的例子便可理解。而|-和-|是作为open函数的模式参数的,以下几种写法是等价的:
open LOG, "|tr '[a-z]' '[A-Z]'";
open LOG, "|-", "tr '[a-z]' '[A-Z]'";
open LOG, "|-", "tr", '[a-z]', '[A-Z]';
open LOG, "cat -n '$file'|";
open LOG, "-|", "cat -n '$file'";
open LOG, "-|", "cat", "-n", $file;
而且,管道还可以继续传递给管道:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n";
但是涉及到两个管道的时候,输出到终端屏幕上时可能不太合意:
[root@xuexi perlapp]# perl 15.plx test.log
[root@xuexi perlapp]# 1 A
2 B
3 C
如何让输出不附加在shell提示符后,暂时也不知道如何做。但输出到文件中不会出现这样的问题:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n >test2.log";
# perl 15.plx test.log
# cat test2.log
1 A
2 B
3 C
更多关于open和管道的解释参见:Perl进程间通信。
以读写模式打开
默认情况下:
以>模式打开文件句柄时,会先截断文件,也就是说无法从此文件句柄关联的文件中读取原有数据,且还会清空原有数据。
以>>模式打开文件句柄时,首先会将指针指向文件的末尾以便追加数据,但无法读取该文件句柄对应的文件数据。
如何以"既可写又可读"的模式打开文件句柄?在Perl中可以在模式前使用+符号来实现。
结合"+"的模式有3种,都用来实现读写更新操作。它们的意义如下:
+<:read-update,如open FH, "+<$file",可以提供读写行为。如果文件不存在,则open失败(以read为主,写为辅),如果文件存在,则文件内容保留,但IO的指针放在文件开头,也就是说无论读写操作,都从开头开始,写操作会从指针位置开始覆盖同字节数的数据。
+>:write-update,如open FH, "+>$file",可以提供读写行为。如果文件不存在,则创建文件(以write为主,read为辅)。如果文件存在,则截断整个文件,因此这种方式是先将文件清空然后写数据,再从中读数据。
+>>:append-update,如open FH, "+>>$file",提供读写行为。如果文件不存在,则创建(以append为主,read为辅),如果文件存在,则将IO指针放到文件尾部。一般情况下,每一次读操作之前都需要通过seek将指针移动到文件的某个位置,而写操作则总是追加到文件尾部并自动移动指针到结尾。
一般来说,要同时提供读写操作,+<是最可能需要的模式。
1.打开可供读、写、更新的文件句柄,但不截断文件
open LOG,"+<","/tmp/test.log" or die "Couldn't open file: $!";
如下面的例子,say语句会将数据写入到test.log的尾部,因为遍历完test.log后,指针在文件的尾部。
#!/usr/bin/perl
use 5.010;
open LOG,"+<","test.log" or die "Couldn't open file: $!";
while(<LOG>){
print $_;
}
say LOG "from hello world";
但注意,如果将上面的say语句放进while循环,则会出现读、写错乱的问题,因为+<模式打开文件句柄时IO指针默认在文件的开头:
use 5.010;
open LOG,"+<","test.log" or die "Couldn't open file: $!";
while(<LOG>){
print $_;
say LOG "from hello world";
}
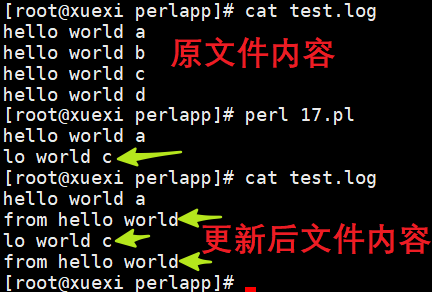
分析下这个错乱:当读取了第一行后,放置好指针位置,然后赋值给$_并被print输出,然后再写入"from hello world",写入的位置是指针的后面,它会直接更新后面对应数量的字符数。数一数"from hello world"的字符数量和替换掉的字符数量,会发现正好相等。
2.打开可供读、写、更新的文件句柄,但首先截断文件
open LOG,"+>","/tmp/test.log" or die "Couldn't open file: $!";
因为首先会截断文件,无法直接去读取内容。所以这种操作模式,需要首先向文件中写入数据,再去读取数据。
use 5.010;
open LOG,"+>","test.log" or die "Couldn't open file: $!";
say LOG "from hello world1";
say LOG "from hello world2";
say LOG "from hello world3";
while(<LOG>){
say $_;
}
3.打开可供读、追加写的文件句柄,它不会截断文件。
open LOG,"+>>","/tmp/test.log" or die "Couldn't open file: $!";
因为追加写模式会将指针放置在文件尾部,如果不将指针移动到文件的某个位置(可通过seek来移动),将无法读出数据来。例如:
use 5.012;
open LOG,"+>>","test.log" or die "Couldn't open file: $!";
say LOG "from hello world1";
say LOG "from hello world2";
say LOG "from hello world3";
while(<LOG>){
print "First: ", $_; # 啥也不输出
}
seek(LOG, 0, 0); # 将读指针移动到文件开头
while(<LOG>){
print "Second: ", $_; # 正常输出
}
open打开STDOUT和STDIN
如果想要打开标准输入、标准输出,那么可以使用二参数格式的open,并将"-"指定为文件名。例如:
open LOG, "-"; # 打开标准输入
open LOG, "<-"; # 打开标准输入
open LOG, ">-"; # 打开标准输出
没有类似的直接打开标准错误输出的方式。如果有一个文件名就是"-",这时想要打开这个文件而不是标准输入或标准输出,那么需要将"-"文件名作为open的第三个参数:
open LOG, "<", "-";
创建临时文件
如果将open()函数打开文件句柄时的文件名指定为undef,则表示创建一个匿名文件句柄,即临时文件。这个临时文件将创建在/tmp目录下,创建完成后将立即被删除,但是却一直持有并打开这个文件句柄直到文件句柄关闭。这样,这个文件就成了看不到却仍被进程占用的临时文件。
什么时候才能用上打开就立即删除的临时文件?只读或只写的临时文件都是没有意义的,只有同时能读写的文件句柄才是有意义的,所以open的模式需要指定为+<或+>。显然,+<是更为通用的读、写模式。例如:
use v5.12;
# 创建临时文件
open my $tmp_file, '+<', undef or die "open filed: $!";
# 设置自动flush
select $tmp_file; $| = 1;;
# 这个临时文件已经被删除了
system("lsof -n -p $$ | grep 'deleted'");
# 写入一点数据
say {$tmp_file} "Hello World1";
say {$tmp_file} "Hello World2";
say {$tmp_file} "Hello World3";
say {$tmp_file} "Hello World4";
# 指针移动到临时文件的头部来读取数据
seek($tmp_file, 0, 0);
select STDOUT;
while(<$tmp_file>){
print "Reading from tmpfile: $_";
}
执行结果:
perl 22685 root 3u REG 0,2 0 108086391056997277 /tmp/PerlIO_JHnTx1 (deleted)
Reading from tmpfile: Hello World1
Reading from tmpfile: Hello World2
Reading from tmpfile: Hello World3
Reading from tmpfile: Hello World4
内存文件
如果将open()函数打开文件句柄时的文件名参数指定为一个标量变量(的引用,即下面示例中标量前加上了反斜线),也就是不再读写具体的文件,而是读写内存中的变量,这样就实现了一个内存IO的模式。
$text = "Hello World1\nHello World2\n";
# 打开内存文件以便读取操作
open MEMFILE, "<", \$text or die "open failed: $!";
print scalar <MEMFILE>;
# 提供内存文件以供写入操作
$log = ""
open MEMWRITE, ">", \$log;
pritn MEMWRITE "abcdefg\n";
pritn MEMWRITE "ABCDEFG\n";
print $log;
如果内存文件操作的是STDOUT和STDERR这两个特殊的文件句柄,如果需要重新打开它们,一定要先关闭它们再重新打开,因为内存文件不依赖于文件描述符,再次打开文件句柄不会覆盖文件句柄。例如:
close STDOUT;
open(STDOUT, ">", \$variable) or die "Can't open STDOUT: $!";
perl的高级重定向
在shell中可以通过>&和<&实现文件描述符的复制(duplicate)从而实现更高级的重定向。在perl中也同样能实现,符号也一样,只不过复制对象是文件句柄。例如:
open LOG,">&STDOUT"
表示将写入LOG文件句柄的数据重定向到STDOUT中。
shell中很常用的一个符号是>&FILENAME或>FILENAME 2>&1,它们都表示标准错误和标准输出都输出到FILENAME中。在perl中实现这种功能的方式为:(注意dup目标使用\*的方式,且不加引号)
open LOG,">","/dev/null" or die "Can't open filehandle: $!";
open STDOUT,">&",\*LOG or die "Can't dup LOG:$!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
或者简写一下:
open STDOUT,">","/dev/null" or die "Can't dup LOG:$!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
测试下:
use 5.010;
open LOG,">>","/tmp/test.log" or die "Can't open filehandle: $!";
open STDOUT,">&",\*LOG or die "Can't dup LOG: $!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
say "hello world stdout default";
say STDOUT "hello world stdout";
say STDERR "hello world stderr";
会发现所有到STDOUT和STDERR的内容都追加到/tmp/test.log文件中。
如果在同一perl程序中,STDOUT和STDERR有多个输出方向,那么dup这两个文件句柄之前,需要先将它们保存起来。需要的时候再还原回来:
# 保存STDOUT和STDERR到$oldout和OLDERR
open(my $oldout, ">&STDOUT") or die "Can't dup STDOUT: $!";
open(OLDERR, ">&", \*STDERR) or die "Can't dup STDERR: $!";
# 实现标准错误、标准输出都重定向到foo.out的功能,即"&>foo.out"
open(STDOUT, '>', "foo.out") or die "Can't redirect STDOUT: $!";
open(STDERR, ">&STDOUT") or die "Can't dup STDOUT: $!";
# 还原回STDOUT和STDERR
open(STDOUT, ">&", $oldout) or die "Can't dup \$oldout: $!";
open(STDERR, ">&OLDERR") or die "Can't dup OLDERR: $!";
因为这种高级重定向用的很少,所以不多做解释。如需理解,可参考shell关于高级重定向的文章:Linux重定向命令介绍,或者直接参考下文的Perl的高级重定向章节:Perl IO之IO重定向。
Perl文件句柄相关常量变量
文件句柄相关变量
对应的官方手册。
默认情况下:
$/:输入行的分隔符以换行符为单位,可以使用$/指定
$\:print输出行的分隔符为undef,可以使用$\指定,例如指定换行符"\n"
$,:print输出列表(也就是每个逗号分隔的部分)的字段分隔符为undef,可以使用$,指定,例如指定空格
$":默认在双引号上下文中,数组被输出的时候是使用空格作为分隔符的,可以使用$"指定列表分隔符
$.:当前处理到的行号$.。它是一个行号计数器。文件句柄关闭时会重置行号
由于读取文件的输入符号<>从不会显式关闭文件句柄,所以从命令行ARGV读取的文件行号会不断增加
$ARGV:表示当前处理的命令行参数中的文件,注意区分:
@ARGV表示命令行参数
$ARGV[N]表示的是@ARGV数组中的某个元素
$ARGV是命令行参数中各文件列表,perl当前正在处理的文件
$|:控制写入或输出数据时是否先放进缓冲再刷入文件句柄
值为0时,表示先缓存,缓冲了一段数据之后再刷入文件句柄通道
值为非0时,表示直接刷入文件句柄通道
在使用管道、套接字的时候,建议设置为非0值,以便数据能立刻被处理
该变量只对写数据或输出有效,对读取操作无效
注意:输出的分隔符只适用于print,不适用say。例如:
1.指定输出行分隔符$\。这样每次输出的时候,会自动在输出语句的尾部加上这个分隔符。可以指定多个字符作为分隔符。
{
$\ = "\n";
print "new line1";
print "new line2";
print "new line3";
# 可以指定多个字符:$\ = "YYY"
}
上面将换行输出各行。
2.指定输出字段分隔符$,。这样print语句中每个逗号隔开的地方都会按照指定的分隔符输出。
{
my $,="-";
print "new field1","new field2","new field3","\n";
# 可以指定多个字符:$, = "YYY"
}
上面将输出:new field1-new field2-new field3
3.数组输出字段分隔符$"。当print的输出列表中有数组,且数组使用双引号包围的时候(即双引号上下文中数组替换),默认数组元素是使用空格分隔的,该分隔符指定元素之间的分隔符。
{
$"="x";
@arr=qw{perl python shell};
print "@arr","\n";
}
上面将输出:"perlxpythonxshell"。
4.$.表示当前处理到的行号。文件句柄关闭时会重置行号,但重新打开文件句柄时不会重置。但由于读取文件的输入符号<>从不会显式关闭文件句柄,所以ARGV读取的文件行号会不断增加。
# 打开文件,看行号
open LOG1,"<","test.log";
while(<LOG1>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG1;
# 关闭上面的文件句柄后,再打开一次文件句柄,行号重置
open LOG2,"<","test.log";
while(<LOG2>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG2;
# 从<>读内容,行号一直变大
while(<>){
print "Line $. from $ARGV: $_";
}
5.$/控制的是输入行分隔符。在读取文件的时候,通过该特殊变量可以控制如何分行。例如以下是test1.log文件的内容:
a
b
x
c
d
x
e
以下是15.plx的源代码:
$/="x";
while(<>){
print "Line $.: $_","\n";
}
# perl 15.pl test1.log
执行的结果:
Line 1: a
b
x
Line 2:
c
d
x
Line 3:
e
注意换行符"x"也会保留在行中。
伪文件句柄DATA
经常地,想要在源码文件里读取一些文件数据来进行测试,这时可以直接使用一个预定义的伪文件句柄DATA。
... some code ...
从__DATA__或__END__开始的数据都将被DATA文件句柄读取,直到文件结尾
__DATA__
...一些待读取数据...
当perl编译器遇到__DATA__或__END__了,就意味着代码到此结束,下面的数据都将作为当前文件内有效的DATA文件句柄的数据流。例如:
#!/usr/bin/perl
while(<DATA>){
chomp;
print "read from DATA: $_\n";
}
__DATA__
first line in DATA
second line in DATA
third line in DATA
last line in DATA
Inline::Files
DATA伪文件句柄的一个缺点是从遇到__DATA__或__END__起直到文件的尾部,都属于DATA文件句柄的内容,也就是说在源代码文件中只能定义一个伪文件句柄。在CPAN上有一个Inline::Files模块,它可以在同一个源代码文件中定义多个伪文件句柄。需要先安装:cpan install Inline::Files
例如:
use 5.010;
use Inline::Files;
say "@main::FILE1";
say "@main::FILE2";
while(<FILE1>){
say "$_";
}
while(<FILE2>){
say "$_";
}
__FILE1__
first line in FILE1
second line in FILE1
third line in FILE1
__FILE2__
first line in FILE2
second line in FILE2
third line in FILE2
它像ARGV一样,在运行程序初始阶段就打开这些虚拟文件句柄,并将每个虚拟文件句柄保存到@<PACKNAME>::<HANDLE>中。例如上面的是示例是在main包中定义了FILE1和FILE2两个文件句柄,那么这两个文件句柄将保存到@main::FILE1和@main::FILE2中,并在处理某个文件句柄的时候,将其保存到标量$main::FILE1或$main::FILE2中。
可以同时定义多个名称相同的虚拟文件系统,例如:
__FILE1__
...
__FILE2__
...
__FILE1__
...
这时在@<packname>::FILE1数组中就保存了两个元素,当处理第二个FILE1的时候,将自动重新打开这个文件句柄。
一般来说,这些就够了,更多详细的用法请参见官方手册:Inline::Files。
Perl IO之IO重定向
文件句柄和文件描述符的关系
文件描述符是操作系统的资源,对于实体文件来说,每打开一次文件,操作系统都会为该进程分配一个文件描述符来关联(指向)这个文件,以后操作文件数据都根据这个文件描述符来操作,而不是文件名。就像对文件句柄的操作一样。实际上,文件句柄、文件描述符和实体文件的关系存在层次上的关系。文件句柄指向文件描述符,文件描述符指向实体文件结构。如下图:
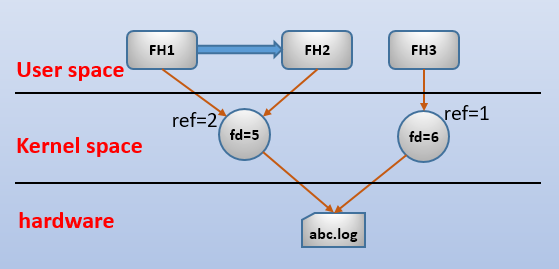
正如上图中所示,文件句柄是文件描述符的更上层封装,文件句柄指向文件描述符,且多个文件句柄还可以指向同一个文件描述符。同样地,多个文件描述符可以指向同一个实体文件。实际上,从文件到文件描述符,是采用引用计数的方式的,表示有多少个文件描述符还关联在这个文件上。同理,文件描述符到文件句柄,也是使用引用计数方式的,表示有多少文件句柄指向这个文件描述符。
使用引用计数的特点之一就是只有引用数为0之后才表示关闭/删除/释放行为。例如,关闭文件句柄只是在文件描述符上引用数减一,而不是真的关闭文件描述符,直到文件描述符上的文件句柄引用数为0之后,这个文件描述符才会被关闭。同理,关闭文件描述符只是对文件结构的引用计数减1,直到这个文件结构的所有文件描述符都关闭了,才表示释放这个文件结构。
因为文件句柄是文件描述符的上层封装,所以文件句柄比文件描述符的功能多一些。实际上,从文件描述符到实体文件,中间的数据传输是纯裸数据流,不会有缓冲行为(当然,从操作系统的角度上看,有文件系统层的IO缓冲或操作系统层的缓冲,如page cache、buffer cache)。而文件句柄到文件描述符,中间有好几个IO层次,例如编码层(utf8)、换行符层(raw/crlf)、标准IO库层(stdio/perlio)、最底层(unix)。如下图:
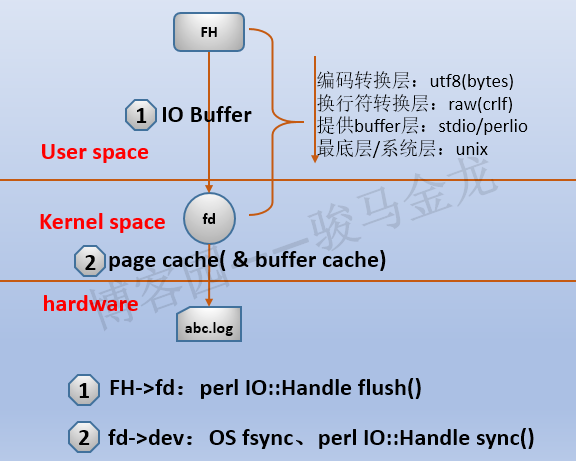
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构。但page cache是内核空间的)
其中标准IO库层用来提供IO buffer层,stdio是操作系统提供的标准IO库,perlio是Perl提供的标准IO库,在Perl中可以选择使用哪种IO库提供buffer。unix是perl io的最底层(就算是在win下也是unix层),它几乎等价于直接操作文件描述符,相当于是纯裸数据,没有IO buffer。
模块PerlIO::Layers提供了Perl在文件描述符到文件句柄的IO层次上的一些检测功能,例如检测文件句柄是否已打开,是否设置了autoflush,是否使用缓冲等等。
另外,从文件句柄到文件描述符中间的IO Buffer中的数据,可以通过perl IO::Handle->flush()来刷,flush时,io buffer中未读数据被丢弃,未写数据将写入到文件描述符。从文件描述符到设备文件(如磁盘上的abc.log)中间的缓冲(如page cache),可以通过操作系统的fsync()系统调用或perl IO::Handle->sync()来刷盘。
文件句柄、文件描述符的duplicate
在bash shell中经常见到的>file 2>&1,它表示将标准错误、标准输出都重定向到file文件中。这里的过程是将标准输入重定向到file文件,然后duplicate文件描述符fd=1得到fd=2,使得fd=2也指向fd=1对应的文件(即file),从而使得标准错误、标准输出都输出到file中。除了重定向、文件描述符的duplicate,bash shell还支持文件描述符的手动打开(分配文件描述符)、移动、关闭。
Perl当然也支持类似的重定向和duplcate,而且不仅支持文件描述符级别的,还支持更上层别文件句柄级,无论是duplicate文件句柄还是duplicate文件描述符,都会生成新的文件描述符。另外,duplicate的对象是文件句柄时,不会将IO Buffer中的内容也duplicate,也就是说新的文件句柄中没有缓冲任何数据。
在Perl中,可以在open时在>、>>、<、+>、+>>、+<的后面加上符号&,这就表示文件句柄或文件描述符的duplicate。给文件句柄就是文件句柄的duplicate,给数值就是文件描述符的duplicate。open可以是两参数的或三参数的,三参数时,可以是文件句柄、文件句柄的引用(即\*FILEHANDLE格式),可以是文件描述符数值。如果需要获取文件句柄指向的文件描述符,可以使用fileno FILEHANDLE函数来获取。
例如下面将STDOUT文件句柄duplicate一份得到NEWOUT,使得NEWOUT也指向标准输出,即向NEWOUT写入数据时也会出现在屏幕上(默认)。
# 两参数或三参数的文件句柄duplicate
open NEWOUT, ">&STDOUT";
open NEWOUT, ">&", "STDOUT";
open NEWOUT, ">&", "\*STDOUT";
# 三参数的文件描述符duplicate
open NEWOUT, ">&", fileno STDOUT;
按照上面的duplicate过程,结果如下图:
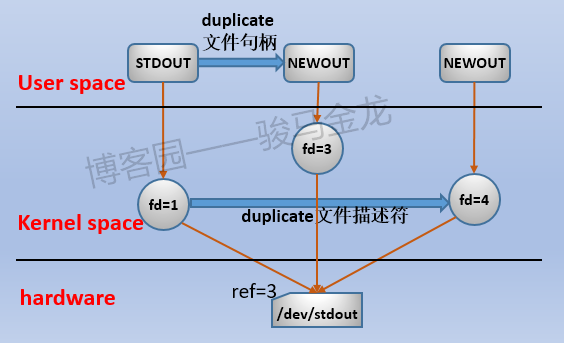
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构)
在duplicate时,所选的模式一定要匹配源文件句柄的模式。例如STDOUT是可写不可读(write-only)的文件句柄,在duplicate STDOUT时,就必须只能选择可写不可读的>&模式。duplicate后,新的文件句柄或文件描述符和源文件句柄/文件描述符的读、写模式是完全一样的。
下面是将STDOUT复制多份的示例:
use strict;
use warnings;
use 5.010;
open NEWOUT, ">&STDOUT" or die "duplicate1 failed: $!";
say NEWOUT "hello world1, fd=", fileno NEWOUT;
open NEWOUT1, ">&", "NEWOUT" or die "duplicate2 failed: $!";
say NEWOUT1 "hello world2, fd=", fileno NEWOUT1;
open NEWOUT2, ">&", "\*NEWOUT" or die "duplicate3 failed: $!";
say NEWOUT2 "hello world3, fd=", fileno NEWOUT2;
open NEWOUT3, ">&", fileno NEWOUT or die "duplicate4 failed: $!";
say NEWOUT3 "hello world4, fd=", fileno NEWOUT3;
close NEWOUT;
close NEWOUT1;
close NEWOUT2;
close NEWOUT3;
执行后输出结果:
hello world1, fd=3
hello world2, fd=4
hello world3, fd=5
hello world4, fd=6
文件描述符重用:句柄别名
duplicate文件句柄或文件描述符时,都会自动新建一个新的文件描述符,并自动新建指向这个文件描述符的文件句柄。也就是说,只要duplicate一次,就至少有2个描述符,两个句柄。
如果想要重用文件描述符,只新建文件句柄,Perl中可以使用&=符号(<&=、>&=、>>&=、+<&=、+>&=、+>>&=),这表示创建一个文件句柄别名,使这个文件句柄也指向同一个文件描述符。也支持直接对文件描述符设置别名句柄,它会新建一个句柄指向这个文件描述符。例如:
open(ALIAS, ">&=HANDLE");
open ALIAS, ">&=", fileno HANDLE;
这表示创建HANDLE句柄的一个别名,使得它两指向同一个文件描述符。如下:
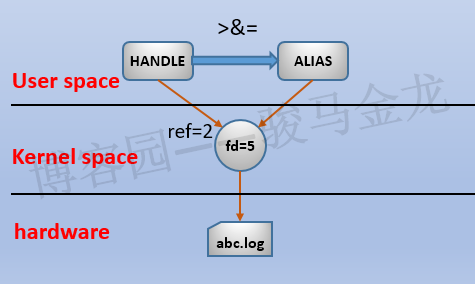
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构)
因为两个句柄指向同一个文件描述符,所以这两个文件句柄共享了这个文件描述符,包括这个描述符上的锁。另外,从任一句柄更改描述符状态,都会直接反映到另一个文件句柄上,比如从一个文件句柄上加一把flock锁,因为flock锁是直接文件描述符上的,所以另一个文件句柄别名也会持有这把锁。
重定向
在bash中重定向非常的简单,在Perl中重定向直接使用> < >> +> +>> +<即可,只不过open的第一个参数是一个已存在的文件句柄,其无非是将输入自或输出到的某个文件句柄/文件描述符的数据转向另一个方向。
例如将输出到标准输出的数据重定向到某个文件中,就像使用select FILEHANDLE一样。
open STDOUT, "> abc.log";
say "hello world"; # 将输出到abc.log文件中
再例如输入重定向,STDIN本该是从标准输入中读取数据的,但是现在改从一个文件中读取数据。
open STDIN, "< abc.log";
while(<STDIN>){
chomp;
print "$_\n";
}
但是这样使用重定向功能会有一个问题,STDOUT或STDIN或其它重定向句柄没法还原回原始的目标了。例如STDOUT原本是输出到终端的,将其重定向到某个文件后就没法找回输出到终端的方法了。所以在程序中使用重定向时,经常会将重定向配合duplicate使用,在重定向之前,先将重定向句柄dup保存一份,然后重定向,重定向结束后再使用保存的句柄恢复回来。
例如:
# 1.dup,OLDOUT和STDOUT都将指向同一个底层文件结构:终端设备文件
open OLDOUT, ">&", STDOUT or die "duplicate failed: $!";
# 2.redirect,OLDOUT仍然指向终端设备文件,但是STDOUT指向新文件结构
open STDOUT, "> $newfile" or die "redirect failed: $!";
... do something to STDOUT ...
# 3.restore,通过dup的方式从OLDOUT恢复STDOUT
close STDOUT or die "close failed: $!";
open STDOUT, ">&", OLDOUT or die "duplicate failed: $!";
注意:上面第三步中恢复之前,记得先关闭STDOUT,如果不关闭STDOUT,在第二步过程中STDOUT中的缓冲不会flush。
本文总结自骏马金龙的个人博客,感谢原作者。
文件句柄用来对应要操作的文件系统中的文件,这么说不太严谨,但比较容易理解。首先为要打开的文件绑定文件句柄(称为打开文件句柄),然后在后续的操作中都通过文件句柄来操作对应的文件,最后关闭文件句柄。
如不理解文件句柄的概念,可将文件句柄看作Linux中文件描述符的概念(当然,它们是不同的,Perl的文件句柄在层次上对应于Linux中的标准IO流)。例如特殊的STDIN、STDOUT、STDERR就是perl中预定义好的文件句柄,分别表示标准输入、标准输出、标准错误,要将它们对应到Linux上的话,它们是默认的文件描述符fd=0、fd=1和fd=2的字符串描述形式,而这几个文件描述符分别对应文件系统中的/dev/stdin、/dev/stdout和/dev/stderr设备文件。也就是说,Linux上的perl中的文件句柄STDIN、STDOUT和STDERR默认关联的文件是/dev/stdin、/dev/stdout和/dev/stderr。
如果还不理解文件句柄,就把它想象成通道:perl程序中IO操作和磁盘上文件的通道。例如,print语句将数据通过某个通道输出到对应的文件中。
文件句柄和文件描述符
实际上,文件句柄和文件描述符是有区别的。文件描述符是一个数值,代表操作系统所使用的裸数据流,文件描述符是文件句柄的核心,文件句柄可以看作是文件描述符的更高一层次的封装,比如提供了和描述符有关数据流的输入、输出的buffer缓冲。也就是说,文件句柄比文件描述符多一些额外的功能。
可以为任意要操作的文件定义一个文件句柄。通常使用大写字母作为文件句柄的名称。例如,下面打开一个文件句柄LOG,这个文件句柄对应的文件是/tmp/a.log,操作模式是追加写入(和shell中的追加重定向是相同的意思)。然后向LOG文件句柄中输入一段数据,最后关闭文件句柄。
open LOG,">>/tmp/a.log";
print LOG "haha, hello world";
close LOG;
一般来说,打开了文件句柄后,在操作完成后要关闭文件句柄以便节省操作系统"打开文件数量限制"的资源。但perl有时候比较智能,会在某些时候自动帮我们关掉文件句柄。而且,当打开一个文件句柄后,再次去打开这个文件句柄时,perl会先关闭这个文件句柄再打开这个文件句柄,这称为"文件句柄的reopen",它只是隐式地关闭并重新打开,perl并不认为中间涉及了关闭操作(例如reopen时行号不会重置)。
打开文件句柄
要打开文件句柄,使用open函数。open函数的功能其实很丰富,如有需要,可去官方手册查看:http://perldoc.perl.org/functions/open.html
打开(open)文件是有目的的:为了读取?为了写入?为了追加写入?这是操作模式。在open文件时,需要指明操作模式。此外,还要给定要关联的文件路径,路径可以是绝对路径,也可以是相对当前perl程序的相对路径。另外注意文件句柄需唯一,不能出现重名。例如:
open LOG1,">","/tmp/a.log"; # 以覆盖写入的方式打开文件/tmp/a.log
open LOG2,">>","/tmp/a.log"; # 以追加写入的方式打开文件/tmp/a.log
open LOG3,"<","/tmp/a.log"; # 打开/tmp/a.log文件,以提供输入源
open LOG4,"/tmp/a.log"; # 等价于上面的输入,默认的模式就是输入
另一种写法是将模式符号和目标文件放在一起:
open LOG1,">/tmp/a.log";
open LOG2,">>/tmp/a.log";
open LOG3,"</tmp/a.log";
中间还可以有空格:
open LOG1,"> /tmp/a.log";
open LOG2,">> /tmp/a.log";
open LOG3,"< /tmp/a.log";
可以将目标文件赋值给一个变量,然后在open函数中使用变量名替换。
my $tmp_file = "/tmp/a.log";
open LOG1,">","$tmp_file";
如果要指明输入、输出的文件编码,则使用上面将"模式和路径分开"的方式。例如:
open LOG1,">:encoding(UTF-8)","/tmp/a.log"; # 以UTF-8编码方式写入数据
open LOG1,">>:encoding(UTF-8)","/tmp/a.log";
open LOG1,"<:encoding(UTF-8)","/tmp/a.log"; # 以UTF-8编码方式读入数据
需要注意,perl自身是无法打开外部文件的,它需要请求操作系统内核,让操作系统来打开文件。所以打开文件正确、错误时,操作系统都会有相应的回馈信息。对于perl来说,open函数的返回值就表示正确、错误打开文件。所以通过以下方式可以判断是否正确打开:
my $success = open LOG,">","/tmp/a.log";
if(!success){
exit 1;
}
更好、更常用的方式是使用die:
open LOG,">","/tmp/a.log" or die "open file wrong: $!";
或者使用autodie功能,当捕获到某些错误时,会自动调用die结束程序:
use autodie;
open LOG,">","/tmp/a.log";
无法打开文件的可能原因有很多,比如读取时文件不存在,比如上级目录不存在,比如无权限等等。操作系统会向perl报告这些错误,使用"$!"可以引用操作系统向perl报告的错误,例如die "can't open file: $!";被触发时的消息如下:
can't open file: No such file or directory at myperl.plx line 5.
上面的"No such file or directory at myperl.plx line 5."就是$!收集和整理后的错误信息。
同理,关闭文件句柄错误也可以捕捉:
close DATA or die "Couldn't close file properly";
使用文件句柄:读取文件数据
例如要从test.log文件中读取所有数据行,一般的流程如下:
#!/usr/bin/perl
use 5.010;
open LOG,"<","test.log" or die "open file wrong: $!"
while(<LOG>){
chomp;
say $_;
}
另外,从特殊文件句柄<STDIN>、<>、<ARGV>中读取数据时,由于它们是预定义好的,所以不需要先open。
使用文件句柄:写入数据到文件
要向文件中写入数据,可以使用输出语句,如print/say和printf,要写多行的时候,可以使用heredoc的方式。
在使用print/say/printf的时候,在这几个关键字后面接上文件句柄即表示本输出语句写入到此文件句柄中。其实,当它们不指定文件句柄的时候,所采用的就是默认的文件句柄STDOUT。
例如,以追加模式写入一行数据到test.log中。
#!/usr/bin/perl
use 5.010;
open LOG,">>","test.log" or die "Can't open file: $!";
say LOG "NEW LINE!";
再例如,向标准输出、标准错误中输出信息:
say STDOUT "NEW LINE!";
say STDERR "NEW LINE!";
选一个默认的输出文件句柄
注意是选择默认的输出文件句柄,不适用于输入的文件句柄。
默认情况下的默认输出文件句柄就是STDOUT,但是可以使用select关键字自己选一个默认的输出文件句柄。只是需要注意的是,再将内容输出到自选的默认输出文件句柄结束后,应该重新选回STDOUT。
例如读取某个文件的内容,追加重定向输出到另一个文件中:
#!/usr/bin/perl
open LOG,">>","test1.log" or die "Can't open file: $!";
select LOG;
while(<>){
print "Line $. from $ARGV: $_";
}
select STDOUT;
print "restored default filehandler: STDOUT\n";
然后执行该perl程序(程序名:15.plx),并传递a.log作为命令行参数。作为运行结果,会将a.log中的数据追加到test1.log文件中,并输出一行内容到终端屏幕上。
$ perl 15.plx a.log
restored default filehandler: STDOUT
选择默认的文件句柄后,上面while循环中的print,等价于print LOG ...。
通常,选择默认的文件句柄更常用于设置文件句柄是否要缓冲。例如,输出到下面三个文件句柄(LOG/STDERR/STDOUT)的数据不会缓冲,而是直接输出到文件句柄。
select LOG; $| = 1; # make unbuffered
select STDERR; $| = 1; # make unbuffered
select STDOUT; $| = 1; # make unbuffered
其中,控制输出的缓冲变量为$|,通常在使用管道、套接字的时候,可能不需要甚至不应该对数据进行缓冲,而是直接暴露给其它进程。
一般来说,在超过一个文件句柄需要关闭缓冲时,不会使用这种select XXX; $|=1的方式,而是导入IO::Handle模块,然后使用它的autoflush(1)函数来实现关闭IO缓冲。
use IO::Handle;
FH1->autoflush(1);
FH2->autoflush(2);
FH3->autoflush(3);
autoflush(1)的功能等价于:
select( (select(NEWOUT), $| = 1 )[0] );
因为select()的返回值是当前标准输出的文件句柄,然后内层的select的结果和$| = 1的结果构成一个匿名列表,选择列表的第一个元素即之前标准输出的文件句柄,将其作为外层select的参数,即表示恢复了之前的文件句柄。(如果目前看不懂,请忽略)
关于IO Buffer
分为两种IO缓冲模式:block buffer、line buffer。
block buffer是表示先积累一定数据量(比如通常是几K大小)之后再输出。line buffer是表示只有读取到了换行符的时候才输出。$|=1或者autoflush(1)都表示从block buffer(默认)切换成line buffer,而不是禁用(或关闭)buffer。
如果真要禁用buffer,可以使用syswrite(),它会直接绕过buffer,也就是禁用buffer。
文件句柄变量
除了使用大写字母(一般情况下文件句柄都如此命名,称为裸句柄)的文件句柄,还可以使用变量来命名文件句柄。例如使用变量代表的文件句柄:
my $rock_fh;
open $rock_fh,"<","/tmp/a.log" or die "Can't open file: $!";
或者:
open my $rock_fh,"<","/tmp/a.log" or die "Can't open file: $!";
使用变量文件句柄时:
while(<$rock_fh>){
chomp;
...
}
不过有时候,使用文件句柄变量会产生歧义。例如下面的语句:
print $rock_fh;
perl并不知道$rock_fh是要输出的列表数据还是输出的目标文件句柄。如果是目标文件句柄,这意味着print将$_写入到文件句柄$rock_fh中。如果是要输出的列表数据,由于$rock_fh是一个已定义好的文件句柄,print将输出它的引用(类似于:GLOB(oxABCDEF12))。
这时可以使用大括号包围文件句柄变量。
print {$rock_fh};
print {$rock_fh} "hello world";
最后需要注意的是,裸句柄是包变量,在整个文件内都是有效的,而变量方式的文件句柄只在代码块范围内有效,出了自己的作用域范围就失效(自动关闭)。
目录句柄
目录句柄和文件句柄类似,可以打开它,并读取其中的文件列表。只不过需要使用:
opendir替换open函数
使用readdir来替换readline,readdir返回一个列表
readdir不会递归到子目录中
使用closedir来替代close
注意每个Unix的目录下都包含两个特殊目录.和..
opendir JAVAHOME,"/usr/local/java" or die "Can't open dir handler: $!";
foreach $file (readdir JAVAHOME){
print "Filename: $file\n";
}
closedir JAVAHOME;
更多文件句柄模式
open函数除了> >> <这三种最基本的文件句柄模式,还支持更丰富的操作模式,例如管道。其实bash shell支持的重定向模式,perl都支持,即使是2>&1这种高级重定向模式,perl也有对应的模式。
打开管道文件句柄
perl程序内部也支持管道,以便和操作系统进行交互。例如将perl的输出在程序内部就输出给操作系统的命令,或者将操作系统的命令执行结果输出给perl程序内部。所以,perl有2种管道模式:句柄到管道、管道到句柄。
例如将perl print语句的输出,交给操作系统的cat -n命令来输出行号。也就是说,下面的perl程序和cat -n命令的效果是一样的。
#!/usr/bin/perl
open LOG,"| cat -n" or die "Can't open file: $!";
while(<LOG>){
print $_;
}
再例如,将操作系统命令的执行结果通过管道交给perl文件句柄:
#!/usr/bin/perl
open LOG,"cat -n test.log |" or die "Can't open file: $!";
while(<LOG>){
print "from pipe: $_";
}
虽然只有两种管道模式,但有3种写法:
管道输出到文件句柄模式:-|
文件句柄输出到管道模式:|-
|写在左边,表示句柄到管道,等价于|-,|写在右边,等价于管道到句柄,等价于-|,可以认为"-"代表的就是外部命令
上面第三点|的写法见上面的例子便可理解。而|-和-|是作为open函数的模式参数的,以下几种写法是等价的:
open LOG, "|tr '[a-z]' '[A-Z]'";
open LOG, "|-", "tr '[a-z]' '[A-Z]'";
open LOG, "|-", "tr", '[a-z]', '[A-Z]';
open LOG, "cat -n '$file'|";
open LOG, "-|", "cat -n '$file'";
open LOG, "-|", "cat", "-n", $file;
而且,管道还可以继续传递给管道:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n";
但是涉及到两个管道的时候,输出到终端屏幕上时可能不太合意:
[root@xuexi perlapp]# perl 15.plx test.log
[root@xuexi perlapp]# 1 A
2 B
3 C
如何让输出不附加在shell提示符后,暂时也不知道如何做。但输出到文件中不会出现这样的问题:
open LOG, "|tr '[a-z]' '[A-Z]' | cat -n >test2.log";
# perl 15.plx test.log
# cat test2.log
1 A
2 B
3 C
更多关于open和管道的解释参见:Perl进程间通信。
以读写模式打开
默认情况下:
以>模式打开文件句柄时,会先截断文件,也就是说无法从此文件句柄关联的文件中读取原有数据,且还会清空原有数据。
以>>模式打开文件句柄时,首先会将指针指向文件的末尾以便追加数据,但无法读取该文件句柄对应的文件数据。
如何以"既可写又可读"的模式打开文件句柄?在Perl中可以在模式前使用+符号来实现。
结合"+"的模式有3种,都用来实现读写更新操作。它们的意义如下:
+<:read-update,如open FH, "+<$file",可以提供读写行为。如果文件不存在,则open失败(以read为主,写为辅),如果文件存在,则文件内容保留,但IO的指针放在文件开头,也就是说无论读写操作,都从开头开始,写操作会从指针位置开始覆盖同字节数的数据。
+>:write-update,如open FH, "+>$file",可以提供读写行为。如果文件不存在,则创建文件(以write为主,read为辅)。如果文件存在,则截断整个文件,因此这种方式是先将文件清空然后写数据,再从中读数据。
+>>:append-update,如open FH, "+>>$file",提供读写行为。如果文件不存在,则创建(以append为主,read为辅),如果文件存在,则将IO指针放到文件尾部。一般情况下,每一次读操作之前都需要通过seek将指针移动到文件的某个位置,而写操作则总是追加到文件尾部并自动移动指针到结尾。
一般来说,要同时提供读写操作,+<是最可能需要的模式。
1.打开可供读、写、更新的文件句柄,但不截断文件
open LOG,"+<","/tmp/test.log" or die "Couldn't open file: $!";
如下面的例子,say语句会将数据写入到test.log的尾部,因为遍历完test.log后,指针在文件的尾部。
#!/usr/bin/perl
use 5.010;
open LOG,"+<","test.log" or die "Couldn't open file: $!";
while(<LOG>){
print $_;
}
say LOG "from hello world";
但注意,如果将上面的say语句放进while循环,则会出现读、写错乱的问题,因为+<模式打开文件句柄时IO指针默认在文件的开头:
use 5.010;
open LOG,"+<","test.log" or die "Couldn't open file: $!";
while(<LOG>){
print $_;
say LOG "from hello world";
}
分析下这个错乱:当读取了第一行后,放置好指针位置,然后赋值给$_并被print输出,然后再写入"from hello world",写入的位置是指针的后面,它会直接更新后面对应数量的字符数。数一数"from hello world"的字符数量和替换掉的字符数量,会发现正好相等。
2.打开可供读、写、更新的文件句柄,但首先截断文件
open LOG,"+>","/tmp/test.log" or die "Couldn't open file: $!";
因为首先会截断文件,无法直接去读取内容。所以这种操作模式,需要首先向文件中写入数据,再去读取数据。
use 5.010;
open LOG,"+>","test.log" or die "Couldn't open file: $!";
say LOG "from hello world1";
say LOG "from hello world2";
say LOG "from hello world3";
while(<LOG>){
say $_;
}
3.打开可供读、追加写的文件句柄,它不会截断文件。
open LOG,"+>>","/tmp/test.log" or die "Couldn't open file: $!";
因为追加写模式会将指针放置在文件尾部,如果不将指针移动到文件的某个位置(可通过seek来移动),将无法读出数据来。例如:
use 5.012;
open LOG,"+>>","test.log" or die "Couldn't open file: $!";
say LOG "from hello world1";
say LOG "from hello world2";
say LOG "from hello world3";
while(<LOG>){
print "First: ", $_; # 啥也不输出
}
seek(LOG, 0, 0); # 将读指针移动到文件开头
while(<LOG>){
print "Second: ", $_; # 正常输出
}
open打开STDOUT和STDIN
如果想要打开标准输入、标准输出,那么可以使用二参数格式的open,并将"-"指定为文件名。例如:
open LOG, "-"; # 打开标准输入
open LOG, "<-"; # 打开标准输入
open LOG, ">-"; # 打开标准输出
没有类似的直接打开标准错误输出的方式。如果有一个文件名就是"-",这时想要打开这个文件而不是标准输入或标准输出,那么需要将"-"文件名作为open的第三个参数:
open LOG, "<", "-";
创建临时文件
如果将open()函数打开文件句柄时的文件名指定为undef,则表示创建一个匿名文件句柄,即临时文件。这个临时文件将创建在/tmp目录下,创建完成后将立即被删除,但是却一直持有并打开这个文件句柄直到文件句柄关闭。这样,这个文件就成了看不到却仍被进程占用的临时文件。
什么时候才能用上打开就立即删除的临时文件?只读或只写的临时文件都是没有意义的,只有同时能读写的文件句柄才是有意义的,所以open的模式需要指定为+<或+>。显然,+<是更为通用的读、写模式。例如:
use v5.12;
# 创建临时文件
open my $tmp_file, '+<', undef or die "open filed: $!";
# 设置自动flush
select $tmp_file; $| = 1;;
# 这个临时文件已经被删除了
system("lsof -n -p $$ | grep 'deleted'");
# 写入一点数据
say {$tmp_file} "Hello World1";
say {$tmp_file} "Hello World2";
say {$tmp_file} "Hello World3";
say {$tmp_file} "Hello World4";
# 指针移动到临时文件的头部来读取数据
seek($tmp_file, 0, 0);
select STDOUT;
while(<$tmp_file>){
print "Reading from tmpfile: $_";
}
执行结果:
perl 22685 root 3u REG 0,2 0 108086391056997277 /tmp/PerlIO_JHnTx1 (deleted)
Reading from tmpfile: Hello World1
Reading from tmpfile: Hello World2
Reading from tmpfile: Hello World3
Reading from tmpfile: Hello World4
内存文件
如果将open()函数打开文件句柄时的文件名参数指定为一个标量变量(的引用,即下面示例中标量前加上了反斜线),也就是不再读写具体的文件,而是读写内存中的变量,这样就实现了一个内存IO的模式。
$text = "Hello World1\nHello World2\n";
# 打开内存文件以便读取操作
open MEMFILE, "<", \$text or die "open failed: $!";
print scalar <MEMFILE>;
# 提供内存文件以供写入操作
$log = ""
open MEMWRITE, ">", \$log;
pritn MEMWRITE "abcdefg\n";
pritn MEMWRITE "ABCDEFG\n";
print $log;
如果内存文件操作的是STDOUT和STDERR这两个特殊的文件句柄,如果需要重新打开它们,一定要先关闭它们再重新打开,因为内存文件不依赖于文件描述符,再次打开文件句柄不会覆盖文件句柄。例如:
close STDOUT;
open(STDOUT, ">", \$variable) or die "Can't open STDOUT: $!";
perl的高级重定向
在shell中可以通过>&和<&实现文件描述符的复制(duplicate)从而实现更高级的重定向。在perl中也同样能实现,符号也一样,只不过复制对象是文件句柄。例如:
open LOG,">&STDOUT"
表示将写入LOG文件句柄的数据重定向到STDOUT中。
shell中很常用的一个符号是>&FILENAME或>FILENAME 2>&1,它们都表示标准错误和标准输出都输出到FILENAME中。在perl中实现这种功能的方式为:(注意dup目标使用\*的方式,且不加引号)
open LOG,">","/dev/null" or die "Can't open filehandle: $!";
open STDOUT,">&",\*LOG or die "Can't dup LOG:$!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
或者简写一下:
open STDOUT,">","/dev/null" or die "Can't dup LOG:$!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
测试下:
use 5.010;
open LOG,">>","/tmp/test.log" or die "Can't open filehandle: $!";
open STDOUT,">&",\*LOG or die "Can't dup LOG: $!";
open STDERR,">&",\*STDOUT or die "Can't dup STDOUT: $!";
say "hello world stdout default";
say STDOUT "hello world stdout";
say STDERR "hello world stderr";
会发现所有到STDOUT和STDERR的内容都追加到/tmp/test.log文件中。
如果在同一perl程序中,STDOUT和STDERR有多个输出方向,那么dup这两个文件句柄之前,需要先将它们保存起来。需要的时候再还原回来:
# 保存STDOUT和STDERR到$oldout和OLDERR
open(my $oldout, ">&STDOUT") or die "Can't dup STDOUT: $!";
open(OLDERR, ">&", \*STDERR) or die "Can't dup STDERR: $!";
# 实现标准错误、标准输出都重定向到foo.out的功能,即"&>foo.out"
open(STDOUT, '>', "foo.out") or die "Can't redirect STDOUT: $!";
open(STDERR, ">&STDOUT") or die "Can't dup STDOUT: $!";
# 还原回STDOUT和STDERR
open(STDOUT, ">&", $oldout) or die "Can't dup \$oldout: $!";
open(STDERR, ">&OLDERR") or die "Can't dup OLDERR: $!";
因为这种高级重定向用的很少,所以不多做解释。如需理解,可参考shell关于高级重定向的文章:Linux重定向命令介绍,或者直接参考下文的Perl的高级重定向章节:Perl IO之IO重定向。
Perl文件句柄相关常量变量
文件句柄相关变量
对应的官方手册。
默认情况下:
$/:输入行的分隔符以换行符为单位,可以使用$/指定
$\:print输出行的分隔符为undef,可以使用$\指定,例如指定换行符"\n"
$,:print输出列表(也就是每个逗号分隔的部分)的字段分隔符为undef,可以使用$,指定,例如指定空格
$":默认在双引号上下文中,数组被输出的时候是使用空格作为分隔符的,可以使用$"指定列表分隔符
$.:当前处理到的行号$.。它是一个行号计数器。文件句柄关闭时会重置行号
由于读取文件的输入符号<>从不会显式关闭文件句柄,所以从命令行ARGV读取的文件行号会不断增加
$ARGV:表示当前处理的命令行参数中的文件,注意区分:
@ARGV表示命令行参数
$ARGV[N]表示的是@ARGV数组中的某个元素
$ARGV是命令行参数中各文件列表,perl当前正在处理的文件
$|:控制写入或输出数据时是否先放进缓冲再刷入文件句柄
值为0时,表示先缓存,缓冲了一段数据之后再刷入文件句柄通道
值为非0时,表示直接刷入文件句柄通道
在使用管道、套接字的时候,建议设置为非0值,以便数据能立刻被处理
该变量只对写数据或输出有效,对读取操作无效
注意:输出的分隔符只适用于print,不适用say。例如:
1.指定输出行分隔符$\。这样每次输出的时候,会自动在输出语句的尾部加上这个分隔符。可以指定多个字符作为分隔符。
{
$\ = "\n";
print "new line1";
print "new line2";
print "new line3";
# 可以指定多个字符:$\ = "YYY"
}
上面将换行输出各行。
2.指定输出字段分隔符$,。这样print语句中每个逗号隔开的地方都会按照指定的分隔符输出。
{
my $,="-";
print "new field1","new field2","new field3","\n";
# 可以指定多个字符:$, = "YYY"
}
上面将输出:new field1-new field2-new field3
3.数组输出字段分隔符$"。当print的输出列表中有数组,且数组使用双引号包围的时候(即双引号上下文中数组替换),默认数组元素是使用空格分隔的,该分隔符指定元素之间的分隔符。
{
$"="x";
@arr=qw{perl python shell};
print "@arr","\n";
}
上面将输出:"perlxpythonxshell"。
4.$.表示当前处理到的行号。文件句柄关闭时会重置行号,但重新打开文件句柄时不会重置。但由于读取文件的输入符号<>从不会显式关闭文件句柄,所以ARGV读取的文件行号会不断增加。
# 打开文件,看行号
open LOG1,"<","test.log";
while(<LOG1>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG1;
# 关闭上面的文件句柄后,再打开一次文件句柄,行号重置
open LOG2,"<","test.log";
while(<LOG2>){
print "Line $.: $_";
}
print "---------------------\n";
close LOG2;
# 从<>读内容,行号一直变大
while(<>){
print "Line $. from $ARGV: $_";
}
5.$/控制的是输入行分隔符。在读取文件的时候,通过该特殊变量可以控制如何分行。例如以下是test1.log文件的内容:
a
b
x
c
d
x
e
以下是15.plx的源代码:
$/="x";
while(<>){
print "Line $.: $_","\n";
}
# perl 15.pl test1.log
执行的结果:
Line 1: a
b
x
Line 2:
c
d
x
Line 3:
e
注意换行符"x"也会保留在行中。
伪文件句柄DATA
经常地,想要在源码文件里读取一些文件数据来进行测试,这时可以直接使用一个预定义的伪文件句柄DATA。
... some code ...
从__DATA__或__END__开始的数据都将被DATA文件句柄读取,直到文件结尾
__DATA__
...一些待读取数据...
当perl编译器遇到__DATA__或__END__了,就意味着代码到此结束,下面的数据都将作为当前文件内有效的DATA文件句柄的数据流。例如:
#!/usr/bin/perl
while(<DATA>){
chomp;
print "read from DATA: $_\n";
}
__DATA__
first line in DATA
second line in DATA
third line in DATA
last line in DATA
Inline::Files
DATA伪文件句柄的一个缺点是从遇到__DATA__或__END__起直到文件的尾部,都属于DATA文件句柄的内容,也就是说在源代码文件中只能定义一个伪文件句柄。在CPAN上有一个Inline::Files模块,它可以在同一个源代码文件中定义多个伪文件句柄。需要先安装:cpan install Inline::Files
例如:
use 5.010;
use Inline::Files;
say "@main::FILE1";
say "@main::FILE2";
while(<FILE1>){
say "$_";
}
while(<FILE2>){
say "$_";
}
__FILE1__
first line in FILE1
second line in FILE1
third line in FILE1
__FILE2__
first line in FILE2
second line in FILE2
third line in FILE2
它像ARGV一样,在运行程序初始阶段就打开这些虚拟文件句柄,并将每个虚拟文件句柄保存到@<PACKNAME>::<HANDLE>中。例如上面的是示例是在main包中定义了FILE1和FILE2两个文件句柄,那么这两个文件句柄将保存到@main::FILE1和@main::FILE2中,并在处理某个文件句柄的时候,将其保存到标量$main::FILE1或$main::FILE2中。
可以同时定义多个名称相同的虚拟文件系统,例如:
__FILE1__
...
__FILE2__
...
__FILE1__
...
这时在@<packname>::FILE1数组中就保存了两个元素,当处理第二个FILE1的时候,将自动重新打开这个文件句柄。
一般来说,这些就够了,更多详细的用法请参见官方手册:Inline::Files。
Perl IO之IO重定向
文件句柄和文件描述符的关系
文件描述符是操作系统的资源,对于实体文件来说,每打开一次文件,操作系统都会为该进程分配一个文件描述符来关联(指向)这个文件,以后操作文件数据都根据这个文件描述符来操作,而不是文件名。就像对文件句柄的操作一样。实际上,文件句柄、文件描述符和实体文件的关系存在层次上的关系。文件句柄指向文件描述符,文件描述符指向实体文件结构。如下图:
正如上图中所示,文件句柄是文件描述符的更上层封装,文件句柄指向文件描述符,且多个文件句柄还可以指向同一个文件描述符。同样地,多个文件描述符可以指向同一个实体文件。实际上,从文件到文件描述符,是采用引用计数的方式的,表示有多少个文件描述符还关联在这个文件上。同理,文件描述符到文件句柄,也是使用引用计数方式的,表示有多少文件句柄指向这个文件描述符。
使用引用计数的特点之一就是只有引用数为0之后才表示关闭/删除/释放行为。例如,关闭文件句柄只是在文件描述符上引用数减一,而不是真的关闭文件描述符,直到文件描述符上的文件句柄引用数为0之后,这个文件描述符才会被关闭。同理,关闭文件描述符只是对文件结构的引用计数减1,直到这个文件结构的所有文件描述符都关闭了,才表示释放这个文件结构。
因为文件句柄是文件描述符的上层封装,所以文件句柄比文件描述符的功能多一些。实际上,从文件描述符到实体文件,中间的数据传输是纯裸数据流,不会有缓冲行为(当然,从操作系统的角度上看,有文件系统层的IO缓冲或操作系统层的缓冲,如page cache、buffer cache)。而文件句柄到文件描述符,中间有好几个IO层次,例如编码层(utf8)、换行符层(raw/crlf)、标准IO库层(stdio/perlio)、最底层(unix)。如下图:
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构。但page cache是内核空间的)
其中标准IO库层用来提供IO buffer层,stdio是操作系统提供的标准IO库,perlio是Perl提供的标准IO库,在Perl中可以选择使用哪种IO库提供buffer。unix是perl io的最底层(就算是在win下也是unix层),它几乎等价于直接操作文件描述符,相当于是纯裸数据,没有IO buffer。
模块PerlIO::Layers提供了Perl在文件描述符到文件句柄的IO层次上的一些检测功能,例如检测文件句柄是否已打开,是否设置了autoflush,是否使用缓冲等等。
另外,从文件句柄到文件描述符中间的IO Buffer中的数据,可以通过perl IO::Handle->flush()来刷,flush时,io buffer中未读数据被丢弃,未写数据将写入到文件描述符。从文件描述符到设备文件(如磁盘上的abc.log)中间的缓冲(如page cache),可以通过操作系统的fsync()系统调用或perl IO::Handle->sync()来刷盘。
文件句柄、文件描述符的duplicate
在bash shell中经常见到的>file 2>&1,它表示将标准错误、标准输出都重定向到file文件中。这里的过程是将标准输入重定向到file文件,然后duplicate文件描述符fd=1得到fd=2,使得fd=2也指向fd=1对应的文件(即file),从而使得标准错误、标准输出都输出到file中。除了重定向、文件描述符的duplicate,bash shell还支持文件描述符的手动打开(分配文件描述符)、移动、关闭。
Perl当然也支持类似的重定向和duplcate,而且不仅支持文件描述符级别的,还支持更上层别文件句柄级,无论是duplicate文件句柄还是duplicate文件描述符,都会生成新的文件描述符。另外,duplicate的对象是文件句柄时,不会将IO Buffer中的内容也duplicate,也就是说新的文件句柄中没有缓冲任何数据。
在Perl中,可以在open时在>、>>、<、+>、+>>、+<的后面加上符号&,这就表示文件句柄或文件描述符的duplicate。给文件句柄就是文件句柄的duplicate,给数值就是文件描述符的duplicate。open可以是两参数的或三参数的,三参数时,可以是文件句柄、文件句柄的引用(即\*FILEHANDLE格式),可以是文件描述符数值。如果需要获取文件句柄指向的文件描述符,可以使用fileno FILEHANDLE函数来获取。
例如下面将STDOUT文件句柄duplicate一份得到NEWOUT,使得NEWOUT也指向标准输出,即向NEWOUT写入数据时也会出现在屏幕上(默认)。
# 两参数或三参数的文件句柄duplicate
open NEWOUT, ">&STDOUT";
open NEWOUT, ">&", "STDOUT";
open NEWOUT, ">&", "\*STDOUT";
# 三参数的文件描述符duplicate
open NEWOUT, ">&", fileno STDOUT;
按照上面的duplicate过程,结果如下图:
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构)
在duplicate时,所选的模式一定要匹配源文件句柄的模式。例如STDOUT是可写不可读(write-only)的文件句柄,在duplicate STDOUT时,就必须只能选择可写不可读的>&模式。duplicate后,新的文件句柄或文件描述符和源文件句柄/文件描述符的读、写模式是完全一样的。
下面是将STDOUT复制多份的示例:
use strict;
use warnings;
use 5.010;
open NEWOUT, ">&STDOUT" or die "duplicate1 failed: $!";
say NEWOUT "hello world1, fd=", fileno NEWOUT;
open NEWOUT1, ">&", "NEWOUT" or die "duplicate2 failed: $!";
say NEWOUT1 "hello world2, fd=", fileno NEWOUT1;
open NEWOUT2, ">&", "\*NEWOUT" or die "duplicate3 failed: $!";
say NEWOUT2 "hello world3, fd=", fileno NEWOUT2;
open NEWOUT3, ">&", fileno NEWOUT or die "duplicate4 failed: $!";
say NEWOUT3 "hello world4, fd=", fileno NEWOUT3;
close NEWOUT;
close NEWOUT1;
close NEWOUT2;
close NEWOUT3;
执行后输出结果:
hello world1, fd=3
hello world2, fd=4
hello world3, fd=5
hello world4, fd=6
文件描述符重用:句柄别名
duplicate文件句柄或文件描述符时,都会自动新建一个新的文件描述符,并自动新建指向这个文件描述符的文件句柄。也就是说,只要duplicate一次,就至少有2个描述符,两个句柄。
如果想要重用文件描述符,只新建文件句柄,Perl中可以使用&=符号(<&=、>&=、>>&=、+<&=、+>&=、+>>&=),这表示创建一个文件句柄别名,使这个文件句柄也指向同一个文件描述符。也支持直接对文件描述符设置别名句柄,它会新建一个句柄指向这个文件描述符。例如:
open(ALIAS, ">&=HANDLE");
open ALIAS, ">&=", fileno HANDLE;
这表示创建HANDLE句柄的一个别名,使得它两指向同一个文件描述符。如下:
(图注:fd是用户空间的内容,图中放在内核层是为了概括与之关联的内核层的几个结构:fd对应内核层的这几个结构)
因为两个句柄指向同一个文件描述符,所以这两个文件句柄共享了这个文件描述符,包括这个描述符上的锁。另外,从任一句柄更改描述符状态,都会直接反映到另一个文件句柄上,比如从一个文件句柄上加一把flock锁,因为flock锁是直接文件描述符上的,所以另一个文件句柄别名也会持有这把锁。
重定向
在bash中重定向非常的简单,在Perl中重定向直接使用> < >> +> +>> +<即可,只不过open的第一个参数是一个已存在的文件句柄,其无非是将输入自或输出到的某个文件句柄/文件描述符的数据转向另一个方向。
例如将输出到标准输出的数据重定向到某个文件中,就像使用select FILEHANDLE一样。
open STDOUT, "> abc.log";
say "hello world"; # 将输出到abc.log文件中
再例如输入重定向,STDIN本该是从标准输入中读取数据的,但是现在改从一个文件中读取数据。
open STDIN, "< abc.log";
while(<STDIN>){
chomp;
print "$_\n";
}
但是这样使用重定向功能会有一个问题,STDOUT或STDIN或其它重定向句柄没法还原回原始的目标了。例如STDOUT原本是输出到终端的,将其重定向到某个文件后就没法找回输出到终端的方法了。所以在程序中使用重定向时,经常会将重定向配合duplicate使用,在重定向之前,先将重定向句柄dup保存一份,然后重定向,重定向结束后再使用保存的句柄恢复回来。
例如:
# 1.dup,OLDOUT和STDOUT都将指向同一个底层文件结构:终端设备文件
open OLDOUT, ">&", STDOUT or die "duplicate failed: $!";
# 2.redirect,OLDOUT仍然指向终端设备文件,但是STDOUT指向新文件结构
open STDOUT, "> $newfile" or die "redirect failed: $!";
... do something to STDOUT ...
# 3.restore,通过dup的方式从OLDOUT恢复STDOUT
close STDOUT or die "close failed: $!";
open STDOUT, ">&", OLDOUT or die "duplicate failed: $!";
注意:上面第三步中恢复之前,记得先关闭STDOUT,如果不关闭STDOUT,在第二步过程中STDOUT中的缓冲不会flush。
本文总结自骏马金龙的个人博客,感谢原作者。